python应用之使用pdfplumber 解析pdf文件内容
目录标题
- 一. 通过 pdfplumber.open() 解析复杂PDF:
- 1-2. 报错:
- V2 :
- 1-3. v3 使用tk 库,弹框选择文件
- 运行环境准备
- 完整代码保存
- 运行测试步骤
- 方式二:命令行方式(适用于自动化)
- 测试用例示例
- 常见问题排查
- 1. 无文件选择对话框弹出:
- 2. No such file or directory错误:
- 3. 提取内容为空:
- 4. 内存不足错误:
- 扩展测试建议
- 1-10 总结:
- 二. PDF中包含表格,table = first_page.extract_table() 只能提取到 PDF文件中的表头如下:
- 1. 表格结构识别问题
- 解决办法
- 2. 文本布局问题
- 解决办法
- 3. 字体和颜色问题
- 解决办法
一. 通过 pdfplumber.open() 解析复杂PDF:
这段 Python 代码使用了 pdfplumber 库来读取 PDF 文件中的文本内容,下面是逐行解释:
import pdfplumber
- 引入
pdfplumber模块,这是一个用于从 PDF 文件中提取文本、表格等内容的第三方库。
# 打开 PDF 文件, 这里写死了,看下面的V2版本,用弹框选择文件
with pdfplumber.open("example.pdf") as pdf:
- 使用
pdfplumber.open()方法打开名为"example.pdf"的 PDF 文件。 - 使用
with语句可以确保文件使用完后会自动关闭,避免资源泄露。
# 获取第一页page = pdf.pages[0]
- 获取 PDF 文件的第一页内容,
pdf.pages是一个页面对象的列表,索引从 0 开始。
# 提取文本text = page.extract_text()
- 调用
extract_text()方法从第一页中提取文本内容。 - 这个方法返回一个字符串,包含该页的所有可提取文本(按照排版顺序)。
print(text)
- 将提取到的文本打印出来。
1-2. 报错:
ImportError: DLL load failed while importing _rust: 找不到指定的程序。
Traceback:
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\ltjt_ai_seek_app\com\szkj\test_pdf\pdf_parser.py", line 2, in <module>import pdfplumber
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfplumber\__init__.py", line 15, in <module>from .pdf import PDF
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfplumber\pdf.py", line 8, in <module>from pdfminer.layout import LAParams
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\layout.py", line 21, in <module>from pdfminer.pdfinterp import Color, PDFGraphicState
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfinterp.py", line 10, in <module>from pdfminer.pdfdevice import PDFDevice, PDFTextSeq
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfdevice.py", line 16, in <module>from pdfminer.pdfpage import PDFPage
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfpage.py", line 6, in <module>from pdfminer.pdfdocument import (
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfdocument.py", line 23, in <module>from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\cryptography\hazmat\primitives\ciphers\__init__.py", line 11, in <module>from cryptography.hazmat.primitives.ciphers.base import (
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\cryptography\hazmat\primitives\ciphers\base.py", line 10, in <module>from cryptography.hazmat.bindings._rust import openssl as rust_openssl
你遇到的 ImportError: DLL load failed while importing _rust: 找不到指定的程序 错误通常是由于缺少某些依赖项或环境配置问题导致的。以下是一些可能的解决方案:
- 确保安装了所有必要的依赖项
确保你已经安装了所有必要的依赖项,特别是 cryptography 和 pdfplumber。你可以使用以下命令来安装这些库:
pip install pdfplumber cryptography
- 安装 Visual C++ Redistributable
有时,这个错误是由于缺少 Microsoft Visual C++ Redistributable 包引起的。你可以从微软官方网站下载并安装最新版本的 Visual C++ Redistributable for Visual Studio 2015, 2017, 2019 或 2022。
Visual C++ Redistributable for Visual Studio 2015, 2017, and 2019
Visual C++ Redistributable for Visual Studio 2022
- 检查 Python 和 pip 的版本
确保你使用的是兼容的 Python 和 pip 版本。你可以使用以下命令来检查和升级它们:
python --version
pip --version
pip install --upgrade pip
- 重新安装 cryptography 库
有时,重新安装 cryptography 库可以解决问题。你可以使用以下命令来卸载并重新安装它:
pip uninstall cryptography
pip install cryptography
如果都安装了,还是报错,那就是python版本的问题:
从3.9 -> 3.12 ,换完之后 ,成功
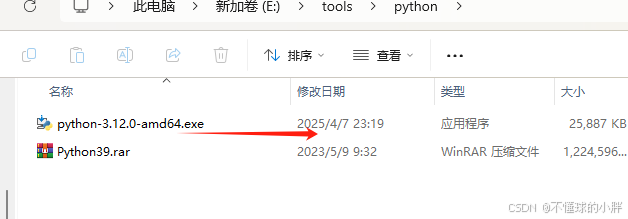


验证 安装成功
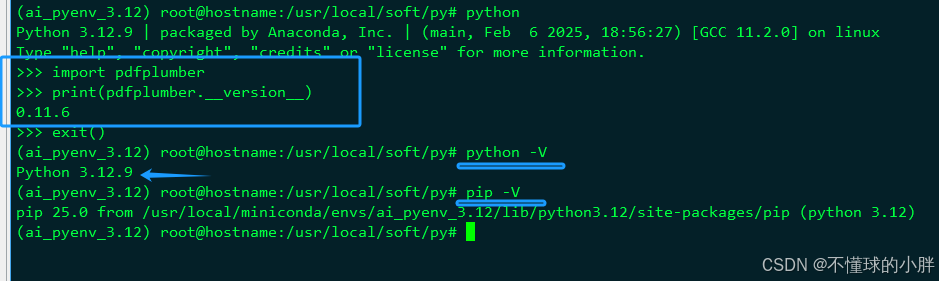
pip show pdfplumber
linux下 一样,pdfplumber 好像需要python3.12 版本:
V2 :
代码如下:
import streamlit as st
import pdfplumber
import io# 设置页面标题
st.title("PDF 文本提取工具")# 创建文件上传组件
uploaded_file = st.file_uploader("请选择一个 PDF 文件", type=["pdf"])if uploaded_file is not None:# 读取上传的文件file_bytes = uploaded_file.read()# 转换为类文件对象file_stream = io.BytesIO(file_bytes)# 使用 pdfplumber 打开 PDF 文件with pdfplumber.open(file_stream) as pdf:# 获取第一页page = pdf.pages[0]# 提取文本text = page.extract_text()# 显示提取的文本if text:st.subheader("提取的文本内容:")st.write(text)else:st.warning("未能从该页提取到任何文本。")
else:st.info("请上传一个 PDF 文件以开始提取文本。")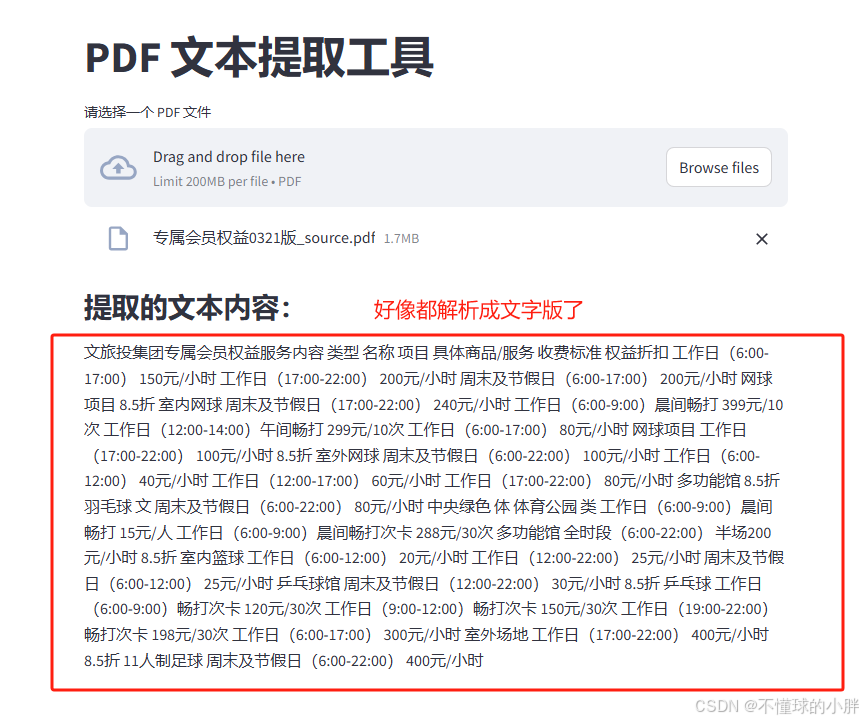
提取的文本内容:
文旅投集团专属会员权益服务内容 类型 名称 项目 具体商品/服务 收费标准 权益折扣 工作日(6:00-17:00) 150元/小时 工作日(17:00-22:00) 200元/小时 周末及节假日(6:00-17:00) 200元/小时 网球项目 8.5折 室内网球 周末及节假日(17:00-22:00) 240元/小时 工作日(6:00-9:00)晨间畅打 399元/10次 工作日(12:00-14:00)午间畅打 299元/10次 工作日(6:00-17:00) 80元/小时 网球项目 工作日(17:00-22:00) 100元/小时 8.5折 室外网球 周末及节假日(6:00-22:00) 100元/小时 工作日(6:00-12:00) 40元/小时 工作日(12:00-17:00) 60元/小时 工作日(17:00-22:00) 80元/小时 多功能馆 8.5折 羽毛球 文 周末及节假日(6:00-22:00) 80元/小时 中央绿色 体 体育公园 类 工作日(6:00-9:00)晨间畅打 15元/人 工作日(6:00-9:00)晨间畅打次卡 288元/30次 多功能馆 全时段(6:00-22:00) 半场200元/小时 8.5折 室内篮球 工作日(6:00-12:00) 20元/小时 工作日(12:00-22:00) 25元/小时 周末及节假日(6:00-12:00) 25元/小时 乒乓球馆 周末及节假日(12:00-22:00) 30元/小时 8.5折 乒乓球 工作日(6:00-9:00)畅打次卡 120元/30次 工作日(9:00-12:00)畅打次卡 150元/30次 工作日(19:00-22:00)畅打次卡 198元/30次 工作日(6:00-17:00) 300元/小时 室外场地 工作日(17:00-22:00) 400元/小时 8.5折 11人制足球 周末及节假日(6:00-22:00) 400元/小时

1-3. v3 使用tk 库,弹框选择文件
以下是运行完整示例程序并进行测试的详细步骤说明:
运行环境准备
- 安装依赖库:
pip install pdfplumber tk
-
pdfplumber:用于PDF解析
-
tk:用于图形界面(Python自带,但部分Linux系统可能需要单独安装)
-
准备测试文件:
-
准备一个测试用的PDF文件(建议同时准备正常PDF和错误文件用于测试异常处理)
完整代码保存
新建一个.py文件(如pdf_extractor.py),粘贴以下代码:
import pdfplumber
import io
import tkinter as tk
from tkinter import filedialog# 创建隐藏的根窗口
root = tk.Tk()
root.withdraw()# 打开文件选择对话框
file_path = filedialog.askopenfilename(title="选择PDF文件",filetypes=[("PDF文件", "*.pdf")]
)if not file_path:print("未选择文件")exit()try:# 先读取为字节数据with open(file_path, "rb") as f:file_bytes = f.read()# 转换为类文件对象file_stream = io.BytesIO(file_bytes)# 解析PDFwith pdfplumber.open(file_stream) as pdf:first_page = pdf.pages[0]print("="*30 + "\n提取的文本内容:\n" + "="*30)print(first_page.extract_text() or "未检测到文本内容")except Exception as e:print(f"处理文件时出错:{str(e)}")
运行测试步骤
####. 方式一:图形界面方式(推荐)
启动程序:
python pdf_extractor.py
- 选择文件:
- 将自动弹出文件选择对话框
- 选择准备好的测试PDF文件(建议选择包含可识别文本的简单PDF)
- 查看输出:
==============================
提取的文本内容:
==============================
这里是PDF第一页的文本内容...
方式二:命令行方式(适用于自动化)
python pdf_extractor.py "/path/to/your/file.pdf"
测试用例示例
| 测试场景 | 预期结果 | 验证点 |
|---|---|---|
| -------- | -------- | ----- |
| 选择正常PDF文件 | 正确输出第一页文本 | 文本提取功能正常 |
| 取消文件选择 | 输出"未选择文件"并退出 | 异常处理逻辑正常 |
| 选择非PDF文件(如.jpg) | 弹出错误提示 | 文件类型过滤有效 |
| 选择加密的PDF文件 | 抛出解密错误 | 异常处理机制有效 |
| 选择损坏的PDF文件 | 显示解析错误信息 | 健壮性验证 |
常见问题排查
1. 无文件选择对话框弹出:
- 检查是否安装了图形界面支持
- 在Linux服务器环境可使用以下命令安装基础GUI支持:
sudo apt-get install python3-tk
2. No such file or directory错误:
- 确认文件路径是否正确
- 检查文件权限设置
3. 提取内容为空:
- 测试文件是否是扫描版图片PDF(需要OCR处理)
- 尝试使用官方测试文件:
# 测试代码
import pdfplumber
with pdfplumber.open("https://www.w3.org/WAI/ER/tests/xhtml/testfiles/resources/pdf/dummy.pdf") as pdf:print(pdf.pages[0].extract_text())
4. 内存不足错误:
对于超大PDF文件(>100MB),改用文件路径方式打开:
# 替代BytesIO的方式
with pdfplumber.open(file_path) as pdf:# 处理逻辑
扩展测试建议
- 多页测试:
# 修改代码遍历所有页面
for i, page in enumerate(pdf.pages):print(f"第 {i+1} 页内容:")print(page.extract_text())
- 表格提取测试: TODO 看看能不能 弥补上面 V2 解析结果错乱的问题
# 在with语句中添加
table = first_page.extract_table()
if table:print("\n检测到表格:")for row in table:print(row)
- 性能测试:
import time
start = time.time()
# 处理代码
print(f"处理耗时:{time.time()-start:.2f}秒")
通过以上步骤可以完整验证PDF文本提取功能的可用性和健壮性。
1-10 总结:
这段代码实现了从一个名为 example.pdf 的 PDF 文件中提取第一页的文本,并将其输出到控制台。它适合用于快速查看或处理 PDF 中的文本信息。
如果你有 PDF 文件想解析或提取特定内容,也可以告诉我,我可以帮你构建更复杂的提取逻辑。
二. PDF中包含表格,table = first_page.extract_table() 只能提取到 PDF文件中的表头如下:
提取的文本内容:
==============================
['类型', '名称', '项目', '具体商品/服务', '收费标准', '权益折扣']表格里的单元格数据 提取不到
1. 表格结构识别问题
pdfplumber 是基于规则来识别表格的,若表格的结构较为复杂或者不规则,它可能无法正确识别表格的边界,进而导致只能提取到表头。
解决办法
调整表格检测参数:可以通过修改 table_settings 参数来调整表格检测的规则。例如,修改 vertical_strategy 和 horizontal_strategy 参数,让其能更精准地识别表格的边界。
import pdfplumberpdf_path = 'your_pdf_file.pdf'
with pdfplumber.open(pdf_path) as pdf:first_page = pdf.pages[0]# 调整表格检测参数table_settings = {"vertical_strategy": "text","horizontal_strategy": "text"}table = first_page.extract_table(table_settings)for row in table:print(row)效果:

有单元格内容,也能成行成行打印了,但是对于前2列 是合并行的单元格,还不友好。
2. 文本布局问题
若表格中的文本布局比较特殊,例如存在合并单元格、跨页表格等情况,pdfplumber 可能难以正确识别表格的结构。
解决办法
- 手动指定表格区域:可以通过指定表格的坐标区域来精确提取表格数据。你可以使用 pdfplumber 的 crop() 方法来裁剪页面,只保留表格所在的区域。
生成 pdf_table_extraction_manual.py。 未测试验证
import pdfplumberpdf_path = 'your_pdf_file.pdf'
with pdfplumber.open(pdf_path) as pdf:first_page = pdf.pages[0]# 手动指定表格区域的坐标(x0, top, x1, bottom)table_bbox = (100, 200, 500, 400)cropped_page = first_page.crop(table_bbox)table = cropped_page.extract_table()for row in table:print(row)
3. 字体和颜色问题
如果表格中的文本使用了特殊的字体或者颜色,pdfplumber 在识别文本时可能会出现问题。
解决办法
- 检查 PDF 文件:尝试使用 PDF 阅读器打开文件,查看表格中的文本是否能够正常显示。若文本显示存在问题,可以尝试重新生成 PDF 文件。
相关文章:
python应用之使用pdfplumber 解析pdf文件内容
目录标题 一. 通过 pdfplumber.open() 解析复杂PDF:1-2. 报错:V2 : 1-3. v3 使用tk 库,弹框选择文件运行环境准备完整代码保存运行测试步骤方式二:命令行方式(适用于自动化) 测试用例示例常见问…...

laravel update报In PackageManifest.php line 122:Undefined index: name 错误的解决办法
用 composer 更新 laravel依赖包时报错 > Illuminate\Foundation\ComposerScripts::postAutoloadDump > Illuminate\Foundation\ComposerScripts::postAutoloadDump > php artisan package:discover --ansiIn PackageManifest.php line 122:Undefined index: nameScr…...

Vue中使用antd-table组件实现数据选择、禁用、已选择禁用-demo
实现案例 实现过程 表格代码 关键代码 :row-selection="rowSelection" <div><div class="flex items-center justify-between pt-[24px] pb-[16px]"><p>已选:{{ keysNum }}</p><a-input-search v-model:value="productN…...
C语言--统计输入字符串中的单词个数
输入 输入:大小写字母以及空格,单词以空格分隔 输出:单词个数 代码 如果不是空格且inWord0说明是进入单词的第一个字母,则单词总数加一。 如果是空格,证明离开单词,inWord 0。 #include <stdio.h&g…...
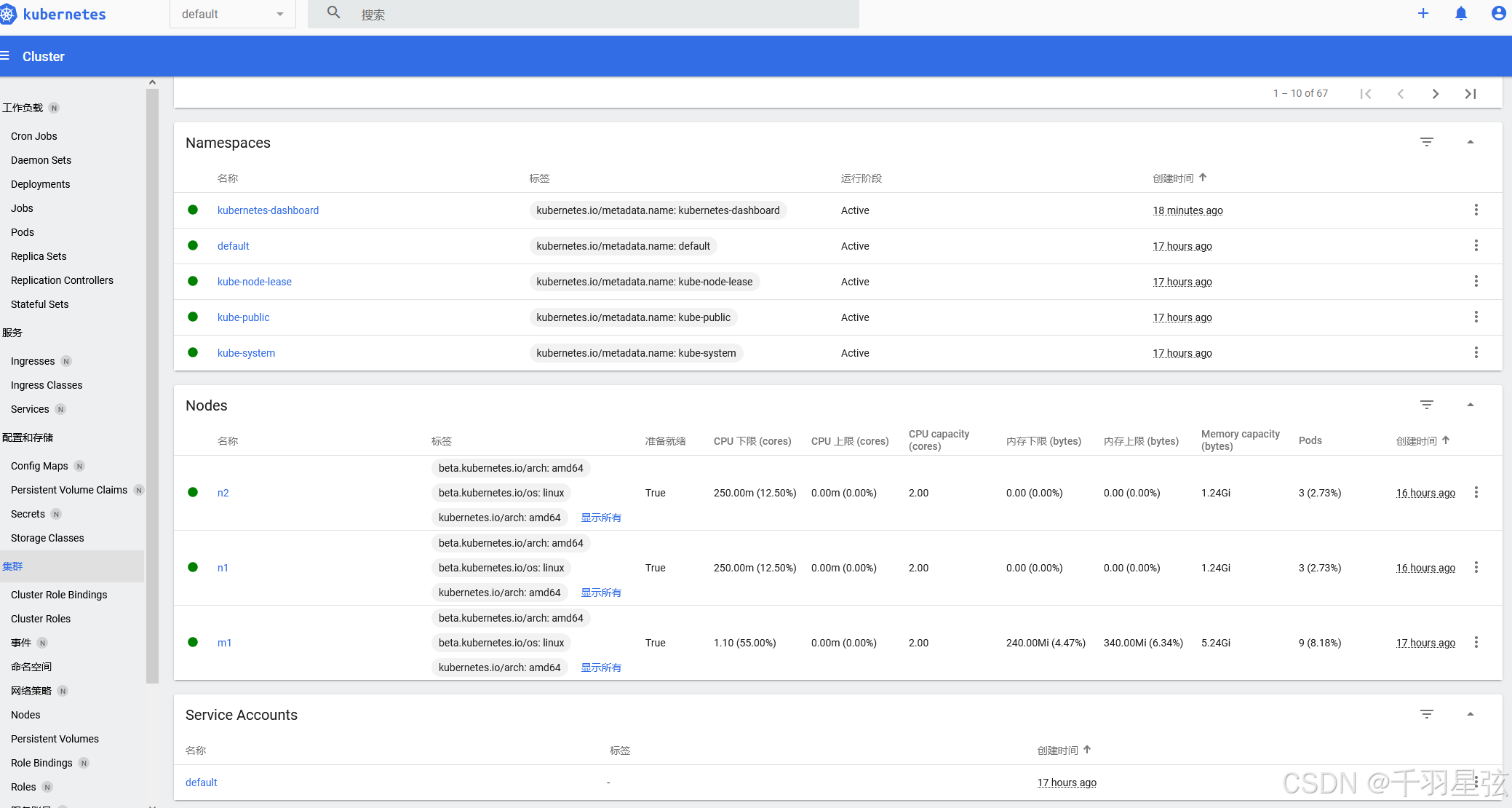
Kubernetes 集群搭建(三):使用dashboard用户界面(需要访问外网获取yaml)
(一)简介 K8s Dashboard是Kubernetes提供的一种基于Web的用户界面工具,用于可视化地管理和监控Kubernetes集群 主要功能: 资源查看与管理: 查看Kubernetes集群中的各种资源,如节点、Pod、服务、部署等。 对…...
Debian 12 服务器搭建Beego环境
一、Debian 12系统准备 1.更新系统 #apt update && apt upgrade -y 2.安装基础工具 #apt install -y git curl wget make gcc 二、安装Go环境 Go语言的镜像官网:https://golang.google.cn/ 1.下载go最新版 #cd /usr/local/src #wget -o https://golang.go…...

游戏引擎学习第208天
运行游戏并回顾我们的情况 今天,我们将继续完成之前中断的调试输出工作。最近的工作偏离了一些,展示了如何进行元编程的实践,主要涉及了一个小的解析器。尽管这个解析器本身是一个玩具,但它展示了如何完成一个完整的循环…...

【在校课堂笔记】Python 第 7 节课 总结
- 第 85 篇 - Date: 2025 - 04 - 06 Author: 郑龙浩/仟墨 【Python 在校课堂笔记】 南山-第 7 节课 上课时间: 2025-03-27 文章目录 南山-第 7 节课一 99乘法表 –> 三角二 函数1 已接触的函数,部分举例2 自定函数的定义与使用自定义函数:举例 3 带参数的4 阶乘…...

评价区动态加载是怎么实现的?
淘宝商品评价区的动态加载是通过一系列前端技术和后端接口实现的,其核心目的是提升用户体验和页面性能。以下是其实现原理和关键技术的详细解析: 1. 前端实现:AJAX 和 JavaScript 淘宝利用 AJAX(Asynchronous JavaScript and XM…...
【 <二> 丹方改良:Spring 时代的 JavaWeb】之 Spring Boot 中的监控:使用 Actuator 实现健康检查
<前文回顾> 点击此处查看 合集 https://blog.csdn.net/foyodesigner/category_12907601.html?fromshareblogcolumn&sharetypeblogcolumn&sharerId12907601&sharereferPC&sharesourceFoyoDesigner&sharefromfrom_link <今日更新> 一、引子&…...
蓝桥杯—数字接龙(dfs+减枝)
一.题目 二.思路 一看就是迷宫问题的变种,从左上角到达右下角,要解决 1.8个方向的方向向量,用dx,dy数组代表方向向量 2.要按照一个规律的数值串进行搜索0,1,2,k-1,0,1…...
Docker与VNC的使用
https://hub.docker.com/r/dorowu/ubuntu-desktop-lxde-vnc 下载nvc 客户端 https://downloads.realvnc.com/download/file/viewer.files/VNC-Viewer-7.12.0-Windows.exe 服务端 docker pull dorowu/ubuntu-desktop-lxde-vnc#下载成功 docker pull dorowu/ubuntu-desktop-l…...
C++——清明
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory> #include <ctime>using namespace std;class Weapon; // 前置声明class Hero{ pr…...

Unity ViewportConstraint
一、组件功能概述 ViewportConstraint是一个基于世界坐标的UI边界约束组件,主要功能包括: 将UI元素限制在父容器范围内支持自定义内边距(padding)可独立控制水平和垂直方向的约束 二、实现原理 1. 边界计算(世界坐…...

Gin、Echo 和 Beego三个 Go 语言 Web 框架的核心区别及各自的优缺点分析,结合其设计目标、功能特性与适用场景
1. Gin 核心特点 高性能:基于 Radix 树路由,无反射设计,性能接近原生 net/http,适合高并发场景。轻量级:仅提供路由、中间件、请求响应处理等基础功能,依赖少。易用性:API 设计简洁直观&#…...

ffmpeg视频转码相关
ffmpeg视频转码相关 简介参数 实战举栗子获取视频时长视频转码mp4文件转为hls m3u8 ts等文件图片转视频抽取视频第一帧获取基本信息 转码日志输出详解转码耗时测试 简介 FFmpeg 是领先的多媒体框架,能够解码、编码、 转码、复用、解复用、流、过滤和播放 几乎所有人…...

手搓多模态-06 数据预处理
前情回顾 我们目前实现了视觉模型的编码器部分,然而,我们所做的是把一张图片编码嵌入成了许多个上下文相关的嵌入向量,然而我们期望的是一张图片用一个向量来表示,从而与文字的向量做点积形成相似度(参考手搓多模态-01…...
HCIP【路由过滤技术(详解)】
目录 1 简介 2 路由过滤方法 3 路由过滤工具 3.1 静默接口 3.2 ACL 3.3 地址前缀列表 3.4 filter-policy 3.4.1 filter-policy过滤接收路由(以RIP为例) 3.4.2 filter-policy过滤接收路由(以OSPF为例) 1 简介 路由过滤技术…...
)
【Kafka基础】topics命令行操作大全:高级命令解析(2)
1 强制删除主题 /export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-topics.sh --delete \--zookeeper 192.168.10.33:2181 \--topic mytopic \--if-exists 参数说明: --zookeeper:直接连接Zookeeper删除(旧版本方式)--if-exists&…...

【AI插件开发】Notepad++ AI插件开发实践(代码篇):从Dock窗口集成到功能菜单实现
一、引言 上篇文章已经在Notepad的插件开发中集成了选中即问AI的功能,这一篇文章将在此基础上进一步集成,支持AI对话窗口以及常见的代码功能菜单: 显示AI的Dock窗口,可以用自然语言向 AI 提问或要求执行任务选中代码后使用&…...

Vue3在ZKmall开源商城前端的应用实践与技术创新
ZKmall开源商城作为一款企业级电商解决方案,其前端架构基于Vue3实现了高效、灵活的开发模式,结合响应式设计、组件化开发与全链路性能优化,为多端协同和复杂业务场景提供了先进的技术支持。以下从技术架构、核心特性、性能优化等维度解析Vue3…...
SpringAI+MCP协议 实战
文章目录 前言快速实战Spring AISpring AI 集成 MCP 协议Spring Mcp Client 示例Spring Mcp Server 示例 前言 尽管Python最近成为了编程语言的首选,但是Java在人工智能领域的地位同样不可撼动,得益于强大的Spring框架。随着人工智能技术的快速发展&…...

[数据结构]图krusakl算法实现
目录 Kruskal算法 Kruskal算法 我们要在连通图中去找生成树 连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。 生成树:一个连通图的最小…...

SQL122 删除索引
alter table examination_info drop index uniq_idx_exam_id; alter table examination_info drop index full_idx_tag; 描述 请删除examination_info表上的唯一索引uniq_idx_exam_id和全文索引full_idx_tag。 后台会通过 SHOW INDEX FROM examination_info 来对比输出结果。…...
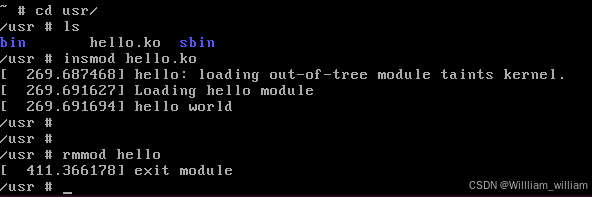
QEMU学习之路(5)— 从0到1构建Linux系统镜像
QEMU学习之路(5)— 从0到1构建Linux系统镜像 一、前言 参考:从内核到可启动镜像:0到1构建你的极简Linux系统 二、linux源码获取 安装编译依赖 sudo apt install -y build-essential libncurses-dev flex bison libssl-dev li…...
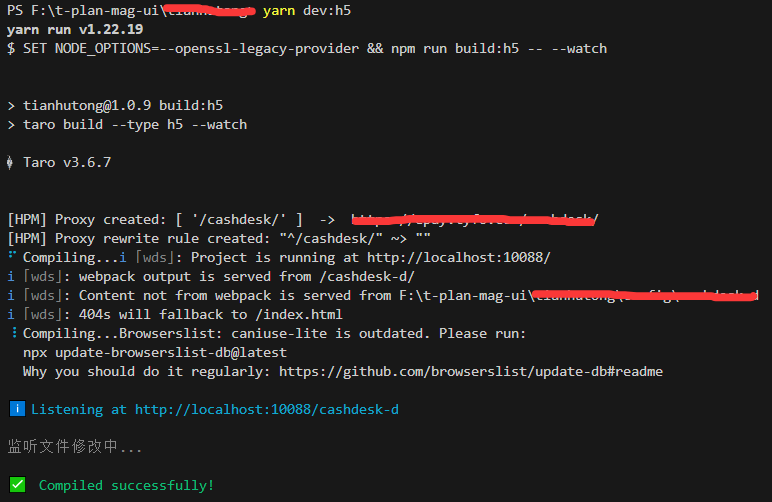
node ---- 解决错误【Error: error:0308010C:digital envelope routines::unsupported】
1. 报错 在 Node.js 18.18.0 的版本中,遇到以下错误: this[kHandle] new _Hash(algorithm, xofLen);^ Error: error:0308010C:digital envelope routines::unsupported这个错误通常发生在运行项目或构建时,尤其是在使用 Webpack、Vite 或其他…...

蓝桥杯——走迷宫问题(BFS)
这是一个经典的BFS算法 1. BFS算法保证最短路径 核心机制:广度优先搜索按层遍历所有可能的路径,首次到达终点的路径长度即为最短步数。这是BFS的核心优势。队列的作用:通过队列按先进先出的顺序处理节点,确保每一步探索的都是当…...
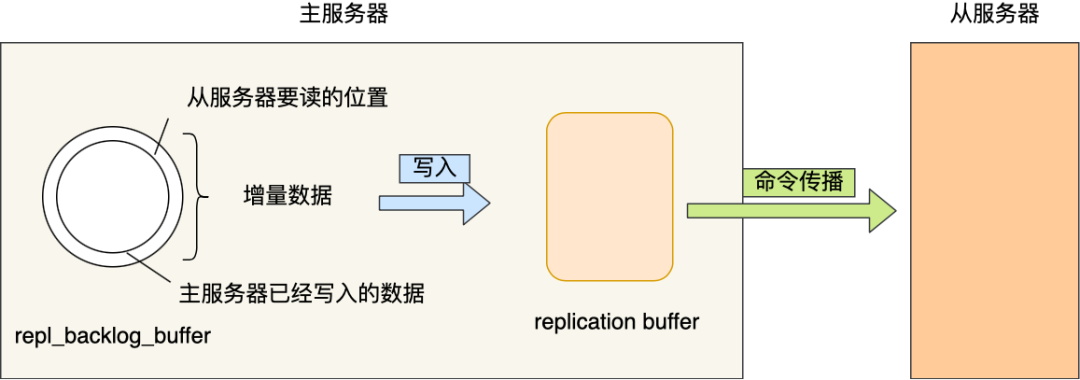
详解 Redis repl_backlog_buffer(如何判断增量同步)
一、repl_backlog_buffer 复制积压缓冲区(Replication Backlog Buffer) 是一个环形内存区域(Ring Buffer),用于临时保存主节点最近写入的写命令,以支持从节点断线重连后的增量同步。 1.1 三个复制偏移量 …...

服务器虚拟化技术深度解析:医药流通行业IT架构优化指南
一、服务器虚拟化的定义与原理 (一)技术定义:从物理到虚拟的资源重构 服务器虚拟化是通过软件层(Hypervisor)将物理服务器的CPU、内存、存储、网络等硬件资源抽象为逻辑资源池,分割成多个相互隔离的虚拟机…...
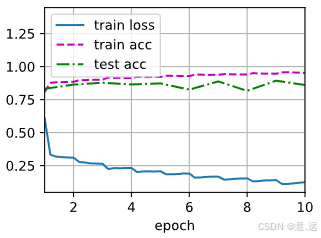
使用PyTorch实现ResNet:从残差块到完整模型训练
ResNet(残差网络)是深度学习中的经典模型,通过引入残差连接解决了深层网络训练中的梯度消失问题。本文将从残差块的定义开始,逐步实现一个ResNet模型,并在Fashion MNIST数据集上进行训练和测试。 1. 残差块(…...