python学智能算法(九)|决策树深入理解
【1】引言
前序学习进程中,初步理解了决策树的各个组成部分,此时将对决策树做整体解读,以期实现深入理解。
各个部分的解读文章链接为:
python学智能算法(八)|决策树-CSDN博客
【2】代码
【2.1】完整代码
这里直接给出完整代码:
import numpy as np
from math import log # 引入log()函数求对数
import operator# 定义一个嵌套列表
def creatDataset():# dataset是一个嵌套列表dataset = [[1, 1, 'yes'],[1, 1, 'yes'],[1, 0, 'no'],[0, 1, 'no'],[0, 1, 'no']]# lables也是一个列表labels = ['no surfacing', 'flippers']return dataset, labels# calcShannonEnt是具体的香农熵求解函数
def calcShannonEnt(dataset):# numEntries获得了dataset列表的行数numEntries = len(dataset)# labelcounts是一个空的字典labelcounts = {}# for函数的意义是,对于dataset里面的每一行都会执行循环操作for feature in dataset:# currentlabel 取到了feature的最后一个元素currentlabel = feature[-1]# 由于labelcounts是一个空字典,labelcounts.keys()在第一次运行的时候不会指向任何标签,所以会被直接添加# currentlabel是每一行dataset的最后一列,也就是最后一个元素# if函数实际上进行了同类项合并工作if currentlabel not in labelcounts.keys():# 给以currentlabel为标签的项目赋值0labelcounts[currentlabel] = 0# 只要currentlabel和labelcounts.keys()存储的元素一致,就给以currentlabel为标签的项目赋值加1labelcounts[currentlabel] += 1# 定义香农熵的初始值=0ShannonEnt = 0.0# 由于labelcounts是字典,所以可以用key访问字典的项目for key in labelcounts:# 计算值为浮点数# 用key指向的项目对应的数量比上总数prob = float(labelcounts[key]) / numEntries# 香农熵就是频数乘以以2为底的频数的对数,然后还要取负值# 取负值是因为,频数小于1,所以对数小于0,一旦取负值就获得了正数ShannonEnt -= prob * log(prob, 2)return ShannonEntdataset, labels = creatDataset()
ShannonEnt = calcShannonEnt(dataset)
print('ShannonEnt=', ShannonEnt)# splitdataset把一些列因素直接删除后输出
def splitdataset(dataset, axis, value):# 创建一个新的列表retdataset = []# 对于dataset的每一行for featvec in dataset:# if第axis列的数据刚好和value相等if featvec[axis] == value:# reducedfeature先获取索引从第0个到axis-1的元素,一共axis个reducedfeatvec = featvec[:axis]# reducedfeature继续获取索引从第axis+1开始的所有元素# reducedfeature后面再获取从第axis+2个开始一直到最后一个元素reducedfeatvec.extend(featvec[axis + 1:])# retdataset存储了reducedfeature# retdataset中刚好没有位置索引为axis的元素retdataset.append(reducedfeatvec)return retdatasetdef choosebestfeaturetosplit(dataset):# 对dataset第0行求长度,获得列数,然后再减去1numfeatures = len(dataset[0]) - 1# 调用函数calcShannonEnt获得dataset的香农熵baseentroy = calcShannonEnt(dataset)# 定义一个常数bestinfogain = 0.0# 定义一个常数bestfeature = -1# 对于numfeatures中的每一个数# numfeatures比dataset的列数少一个for i in range(numfeatures):# 对于每一个在dataset中的元素,按照位置索引为i的形式提取featlist = [example[i] for example in dataset]# set是一个内置函数,将featlist这个列表转化为集合# 集合具有合并同类项的作用,重复的元素只会保留一个uniquevals = set(featlist)# 定义一个常数newentropy = 0.0# 对于uniquevals中的每一个值for value in uniquevals:# 调用splitdataset进行子集划分subdataset = splitdataset(dataset, i, value)# 获取每一个元素的香农熵prob = len(subdataset) / float(len(dataset))# 更新香农熵newentropy += prob * calcShannonEnt(subdataset)# 获得香农熵的变化量infogain = baseentroy - newentropy# 如果变化量查过阈值if (infogain > bestinfogain):# 新变化=变化量bestinfogain = infogain# 给bestfeature赋值ibestfeature = ireturn bestfeaturedef majoritycnt(classlist):# classcount是一个空字典classcount = {}for vote in classlist:# classlist是一个外部导入的参数# 从if条件来看,classlist也是一个字典# 对于classlist字典里的每一个键if vote not in classcount.keys():# 如果classlist里的键和clssscount里的键不一样# classcount字典里的vote键赋值0classcount[vote] = 0# 如果classlist里的键和clssscount里的键一样# classcount字典里的vote键值+1classcount[vote] += 1# Python 3中字典的iteritems()方法已被items()方法取代sortedclasscount = sorted(classcount.items(), key=operator.itemgetter(1), reverse=True)return sortedclasscount[0][0]def creattree(dataset, labels):# 对dataset中的最后一列取值# classlist是一个列元素列表classlist = [example[-1] for example in dataset]# 修正判断条件的括号# classlist.count(classlist[0])获得的是classlist列元素的第一个元素出现的次数# len(classlist)是classlist的行数,等于dataset中样本的数量if classlist.count(classlist[0]) == len(classlist):return classlist[0]# dataset[0]代表的是列数,如果列数=1,就直接返回classlist代入majoritycnt()函数的值if len(dataset[0]) == 1:return majoritycnt(classlist)# bestfeat通过choosebestfeaturetosplit(dataset)函数取值bestfeat = choosebestfeaturetosplit(dataset)# bestfeatlabel通过labels[bestfeat]函数取值bestfeatlabel = labels[bestfeat]# mytree是一个空字典,字典的键为bestfeatlabel,键值暂时是一个空字典mytree = {bestfeatlabel: {}}# 从特征标签中删除bestfeaturedel (labels[bestfeat])# featvalues的取值是dataset中位置索引为bestfeat的行featvalues = [example[bestfeat] for example in dataset]# 合并同类项uniquevals = set(featvalues)# 对于每一项for value in uniquevals:# sublabels是一个lables的副本sublabels = labels[:]# 获得决策树mytree[bestfeatlabel][value] = creattree(splitdataset(dataset, bestfeat, value), sublabels)return mytree# 测试代码
dataset, labels = creatDataset()
tree = creattree(dataset, labels.copy())
print("决策树:", tree)如此长的代码如果不看上一篇文章会有些费力。如果确实不想看,可以先一起看最后构建决策树的部分。
【2.2】构建决策树代码
这里直接给出构建决策树代码:
# 新定义的creattree函数有dataset和labels两个参数
def creattree(dataset,labels):# classlist是从dataset中的每一行取出的最后一个数据classlist=[example[-1] for example in dataset]# classlist[0]表示classlist列表中的第一个元素# classlist.count(classlist[0])表示classlist列表中的第一个元素出现的次数# len(classlist)表示classlist的长度,就是这个列表中有几个元素的意思if classlist.count(classlist[0])==len(classlist):# 如果classlist第一个元素的数量就和len(classlisi)相等# 直接返回classlist[0]return classlist[0]# 如果dataset的第一行只有1个数据,表明所有的特征也都只有一个# 没有其他特征,也就是特征划分完毕if len(dataset[0])==1:# 调用majority()函数return majoritycnt(classlist)# bestfeat从choosebestfeaturetosplit()函数获取bestfeat=choosebestfeaturetosplit(dataset)# bestfeatlabel从labels中按照bestfeat位置索引获取bestfeatlabel=labels[bestfeat]# mytree是一个嵌套列表# bestfeatlabel是一个键,但它的值是一个空字典mytree={bestfeatlabel:{}}# del是一个删除函数,删除了labels中,bestfeat为位置索引的标签名del(labels[bestfeat])# featvalues是对dataset逐行取bestfeat对应的值featvalues=[example[bestfeat] for example in dataset]# uniquevals是对featvalues进行合并同类项uniquevals=set(featvalues)# 对于uniquevals中的每一个取值,构建一个子树for value in uniquevals:# labels[:]是一个切片操作sublabels=labels[:]# 绘制决策树mytree[bestfeatlabel][value]=creattree(splitdataset(dataset,bestfeat,value),sublabels)return mytree其实这里也可以理解为主函数,因为在这里对子函数进行了调用。
【2.2.1】前置操作
首先看前三行:
# 新定义的creattree函数有dataset和labels两个参数
def creattree(dataset,labels):# classlist是从dataset中的每一行取出的最后一个数据classlist=[example[-1] for example in dataset]# classlist[0]表示classlist列表中的第一个元素# classlist.count(classlist[0])表示classlist列表中的第一个元素出现的次数# len(classlist)表示classlist的长度,就是这个列表中有几个元素的意思if classlist.count(classlist[0])==len(classlist):# 如果classlist第一个元素的数量就和len(classlisi)相等# 直接返回classlist[0]return classlist[0]这是一个自定义函数,有两个参数引入:dataset和labels。
classlist=[],先不考虑方括号“[]”里面的内容,表明classlist是一个列表,内部可以不断存储新的元素。
classlist=[example[-1] for example in dataset]
实际的代码定义过程表明classlist使用了嵌套for循环遍历方法:
- for example in dataset,对于dataset,要遍历其中的每一行;
- axample[-1],提取最后一列数据;
- classlist实际上存储了dataset的最后一列数据。
然后使用了列表函数的自动计数功能classlist.count(),它计算了classlist[0] 也就是classlist第一个元素的出现次数,如果这个次数和classlist内部的元素数量相等,就会直接返回这个元素。
实际上这是一个结束操作,如果classlist内的所有元素都一样,已经没有继续分类的必要。
【2.2.2】调用函数
调用函数的部分相对复杂,拆开来看:
if len(dataset[0])==1:# 调用majority()函数return majoritycnt(classlist)# bestfeat从choosebestfeaturetosplit()函数获取bestfeat=choosebestfeaturetosplit(dataset)# bestfeatlabel从labels中按照bestfeat位置索引获取bestfeatlabel=labels[bestfeat]首先判断dataset[0]是否只剩下一个元素,如果是,就调用majority()函数。
借此机会回忆一下majority函数:
# majoritycnt是一个新函数,调用参数为classlist
def majoritycnt(classlist):# classcount是一个空列表classcount={}# 定义一个for循环来遍历外部输入参数classlistfor vote in classlist:# 如果vote不在clsaacount的键值中# 定义一个新的键vote,并赋值0if vote not in classcount.keys():classcount[vote]=0# if not in 是完成对首次出现的值进行键定义的操作# 但实际上只有出现它的次数就至少为1,所以这里会有一个自动加1的操作classcount[vote]+=1# sorted函数函数会对classcount中的字典进行键值对取值后排列# operator.itemgetter(1)是一个函数,会自动统计每个键值出现的次数# reverse则要求按照从大到小的顺序排列sortedclasscount=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)# sortedclssscount作为列表,内部有很多元组# 每个元组的第一个元素代表统计出来的类别,第二个元素代表这个类别的数量return sortedclasscount[0][0]majority()函数的外部输入参数是classlist,前述学习已知这是一个列表。
然后定义了一个空的字典classcount备用。
对于列表classlist,对其中的每一个元素都进行遍历,如果某个元素不在classcount中,就新增这个元素为字典classcount的键,然后赋键值为1,如果本来就是classcount中的键,将对应键值+1。
然后使用sorted()函数将classcount这个字典里面的项目进行排序:
- classcount.items()是获取classcount这个字典中所有项目的意思;
- key=operator.itemgetter(1)决定了排序的依据是python语言认为的第1个元素(第0个,第1个,常规认知里面的第2个);
- reverse=True表明排序后的数据将从大到小排列。
排序后的sortedclasscount是一个由元组组成的列表数组,每个元组都是由字典形式直接转换,第一个元素是字典的键,第二个元素是字典的值。
最后输出的sortedclasscount[0][0]是字典classcount中键值最大的一组键和值。
然后回到为何要调用majority()函数:需要先判断dataset[0]是否只剩下一个元素,如果是,就调用majority()函数。dataset[0]是一行数据,剩下一个元素时表明已经无法再细分。这个时候已经可以进行最后的判断,也就是找出classlist中各类别的数量极大值。
然后面对dataset[0]剩下不止一个元素的情况,此时需要通过调用choosebestfeaturetosplit()函数获得一个最佳的特征值:bestfeat = choosebestfeaturetosplit(dataset)。
借此机会回忆choosebestfeaturetosplit()函数:
from 划分数据集 import splitdataset
from 香农熵 import calcShannEntdef choosebestfeaturetosplit(dataset):# 取dataset的第0行,获取列数后减去1numfeature=len(dataset[0])-1# 直接调用calcShannEnt(dataset)函数获得数据集的原始香农熵baseentrop=calcShannEnt(dataset)# 定义bestinfogain的初始值为0.0bestinfogain=0.0# 定义bestfeature的初始值为-1bestfeature=-1# 定义一个for循环for i in range(numfeature):# feature是一个嵌套列表# for axample indataset的意思是对于dataset的每一行# example[i]是指每一行数据中的每一列featlist=[example[i] for example in dataset]# set()函数具有合并同类型的作用uniquevalues=set(featlist)# 定义newentropy初始值为0.0newentropy=0.0# 在一个新的for循环中# 调用splitdataset函数来进行数据划分for value in uniquevalues:# 参数i是取到的列数据# 逐列进行了数据同类合并操作# value就代表了每一列中的数据可能取值subdataset=splitdataset(dataset,i,value)# subdataset是按照i和value划分的集合# prob是划分的子集合和原来的数据集比例prob= len(subdataset)/float(len(dataset))# 新的熵是新子集比例和原来香农熵的乘积newentropy+=prob*calcShannEnt(subdataset)# 整个for循环是按照每列的形式,提取该列所有可能的取值,重新对数据及进行划分# newentropy是按照列进行数据集划分之后,获得的新熵值# infogain代表了数据集的原始熵值和新熵值的变化量,也就是信息增益infogain=baseentrop-newentropy# if判断信息增益超过最佳增益# 取信息增益为最佳增益# 取当前i为最佳的列划分依据if (infogain>bestinfogain):bestinfogain=infogainbestfeature=i# 在整个for循环中,按照列的形式提取数据后划分数据集# 然后计算这种划分方式产生的信息增益return bestfeature
choosebestfeaturetosplit()函数需要和香农熵定义函数以及数据集划分函数共同使用。
先看数据提取和初始定义部分:
# 取dataset的第0行,获取列数后减去1numfeature=len(dataset[0])-1# 直接调用calcShannEnt(dataset)函数获得数据集的原始香农熵baseentrop=calcShannEnt(dataset)# 定义bestinfogain的初始值为0.0bestinfogain=0.0# 定义bestfeature的初始值为-1bestfeature=-1choosebestfeaturetosplit()函数的参数是dataset,提取dataset列数据然后减1得到numfeature。
baseentropy是对初始数据集香农熵的直接提取。
bestinfogain初始化定义为0.0。
bestfeature初始化定义为-1。
然后定义一个for循环:
# 定义一个for循环for i in range(numfeature):# feature是一个嵌套列表# for axample indataset的意思是对于dataset的每一行# example[i]是指每一行数据中的每一列featlist=[example[i] for example in dataset]# set()函数具有合并同类型的作用uniquevalues=set(featlist)# 定义newentropy初始值为0.0newentropy=0.0这个for循环里面用到了numfeature,依据这个数据进行遍历:
featlist是一个列表,提取了dataset中的每一行数据的第i列,可以理解为featlist是一个取列的操作。
uniquevalues是一个集合,是通过调用set()函数合并同类项后的结果。
uniquevalues是set()函数对第i列数据进行同类项合并以后的结果。
然后在for循环内部定义了一个新的for循环,也就是依然对提取到的第i列数据进行操作。为便于说清楚,将对numfeature的遍历for循环定义为外循环,对uniquevalues的for循环定义为内循环。
# 在一个新的for循环中# 调用splitdataset函数来进行数据划分for value in uniquevalues:# 参数i是取到的列数据# 逐列进行了数据同类合并操作# value就代表了每一列中的数据可能取值subdataset=splitdataset(dataset,i,value)# subdataset是按照i和value划分的集合# prob是划分的子集合和原来的数据集比例prob= len(subdataset)/float(len(dataset))# 新的熵是新子集比例和原来香农熵的乘积newentropy+=prob*calcShannEnt(subdataset)在这个for循环中,对uniquevalues中的每个元素进行遍历 :
调用splitdataset()函数进行数据集划分获得subdataset。
然后将获得的subdataset长度和原始数据集长度进行对比,获得比例数据prob,prob和subdataset的香农熵相乘,据此获得新的熵。
最后需要判断是否获得了最大的信息增益(熵增),这个判断是在外层的for循环进行。
# 整个for循环是按照每列的形式,提取该列所有可能的取值,重新对数据及进行划分# newentropy是按照列进行数据集划分之后,获得的新熵值# infogain代表了数据集的原始熵值和新熵值的变化量,也就是信息增益infogain=baseentrop-newentropy# if判断信息增益超过最佳增益# 取信息增益为最佳增益# 取当前i为最佳的列划分依据if (infogain>bestinfogain):bestinfogain=infogainbestfeature=i# 在整个for循环中,按照列的形式提取数据后划分数据集# 然后计算这种划分方式产生的信息增益return bestfeature最后输出的bestfeature是对比了所有列数据之后获得的。
choosebestfeaturetosplit()函数一共调用了两个子函数,分别是香农熵计算函数calcShannEnt()和
数据集划分函数splitdataset()。
此处先回忆香农熵计算函数calcShannEnt():
# 定义香农熵计算函数
def calcShannEnt(dataset):# 取dataset数据集的行数numEntries=len(dataset)# 定义一个空字典# 字典包括键和键值两部分labelCounts={}# 定义一个循环,去除每一类数据的数量for featVec in dataset:# currentLabel取dataset的最后一列currentLabel=featVec[-1]# labelCounts.keys()取出了labelCounts这个字典里面的所有键值if currentLabel not in labelCounts.keys():# 如果currentLabel不在labelCounts的键值里面# 对labelCounts这个字典进行赋值# currentLabel是字典里面的键,0是对应的键值labelCounts[currentLabel]=0# 如果currentLabel在labelCounts的键值里面# 对labelCounts这个字典进行赋值# currentLabel是字典里面的键,对应的键值增加1labelCounts[currentLabel]+=1# 定义初始香农熵=0shannonEnt=0# 使用for循环# 对于字典labelCounts进行遍历for key in labelCounts:# 计算每一个键值在所有键中的比例# 这里计算的就是每一种类别的比例prob =float(labelCounts[key])/numEntries# 对数计算香农熵shannonEnt-=prob*log(prob,2)# 香农熵的计算值返回return shannonEnt相对来说,香农熵计算函数最好理解,但需要注意的是,它以dataset数组的最后一列为依据,计算了每一种类别的比例,然后得到原始数据集的香农熵。
然后是分数据集划分函数splitdataset():
def splitdataset(dataset,axis,value):# 定义一个空列表retdataset=[]# 定义一个for循环for featvec in dataset:# axis是外部输入的参数# 对于dataset的每一行,会按照axis的位置索引进行判断# 如果预设值value被发现,会提取删除value后的行数据if featvec[axis]==value:# 获取第0到axis-1个数据reducedfeatvec=featvec[:axis]# 获取第axis+1到最后一个数据reducedfeatvec.extend(featvec[axis+1:])# 把获取到的数据放到空列表中# 空列表中存储的数据,刚好不包含value所在的行# 这还重反向剔除,找出这个值,然后取不包含这个值的部分retdataset.append(reducedfeatvec)return retdataset这里的代码更加简短,主要使用了外部传入的dataset、axis和value参数来对第axis列的数据进行判断,如果该列有这个数据,取这行数据中这一列之外的所有数据。
现在我们再次回到主函数:
if len(dataset[0])==1:# 调用majority()函数return majoritycnt(classlist)# bestfeat从choosebestfeaturetosplit()函数获取bestfeat=choosebestfeaturetosplit(dataset)# bestfeatlabel从labels中按照bestfeat位置索引获取bestfeatlabel=labels[bestfeat]bestfeat是通过调用choosebestfeaturetosolit()函数获得的参数,这个参数将用于定位labels[bestfeature]。
labels是外部传入的参数:def creattree(dataset, labels)。
labels的来源则是creatdataset函数:
# 定义一个嵌套列表
def creatDataset():# dataset是一个嵌套列表dataset = [[1, 1, 'yes'],[1, 1, 'yes'],[1, 0, 'no'],[0, 1, 'no'],[0, 1, 'no']]# lables也是一个列表labels = ['no surfacing', 'flippers']return dataset, labels删除labels[bestfeat]:
# 从特征标签中删除bestfeaturedel (labels[bestfeat])之后定义了一个空字典:
# mytree是一个空字典,字典的键为bestfeatlabel,键值暂时是一个空字典mytree = {bestfeatlabel: {}}取dataset中每一行的最佳特征:
# featvalues的取值是dataset中位置索引为bestfeat的行featvalues = [example[bestfeat] for example in dataset]bestfeature是从choosebestfeaturetosolit()函数获得的参数,此时定位到了最大信息增益对应的列,所以就直接从dataset中提取这一列数据,存储到featvalues列表中。
然后需要进行合并同类项操作:
# 合并同类项uniquevals = set(featvalues)之后就是获得决策树的操作:
# 对于每一项for value in uniquevals:# sublabels是一个lables的副本sublabels = labels[:]# 获得决策树mytree[bestfeatlabel][value] = creattree(splitdataset(dataset, bestfeat, value), sublabels)return mytree最难理解的部分其实是源于creattree(splitdataset(dataset, bestfeat, value), sublabels)。
首先splitdataset对原始数据集dataset依据bestfeat列和最佳特征值value进行了划分,然后使用sublabels获得bestfeature。这是一个递归过程,在函数内自己调用自己,最后实现决策树绘制。
【3】总结
对决策树程序进一步思考,深入理解内涵。
相关文章:
|决策树深入理解)
python学智能算法(九)|决策树深入理解
【1】引言 前序学习进程中,初步理解了决策树的各个组成部分,此时将对决策树做整体解读,以期实现深入理解。 各个部分的解读文章链接为: python学智能算法(八)|决策树-CSDN博客 【2】代码 【2.1】完整代…...

蓝桥杯 C/C++ 组历届真题合集速刷(一)
一、1.单词分析 - 蓝桥云课 (模拟、枚举)算法代码: #include <bits/stdc.h> using namespace std;int main() {string s;cin>>s;unordered_map<char,int> mp;for(auto ch:s){mp[ch];}char result_charz;int max_count0;fo…...

多类型医疗自助终端智能化升级路径(代码版.上)
大型医疗自助终端的智能化升级是医疗信息化发展的重要方向,其思维链一体化路径需要围绕技术架构、数据流协同、算法优化和用户体验展开: 一、技术架构层:分布式边缘计算与云端协同 以下针对技术架构层的分布式边缘计算与云端协同模块,提供具体编程实现方案: 一、边缘节点…...

区间 DP 详解
文章目录 区间 DP分割型合并型环形合并 区间 DP 区间 DP,就是在对一段区间进行了若干次操作后的最小代价,一般是合并和拆分类型。 分割型 分割型,指把一个区间内的几项分开拆成一份一份的,再全部合起来就是当前答案,…...

如何在多线程中安全地使用 PyAudio
1. 背景介绍 在多线程环境下使用 PyAudio 可能会导致段错误(Segmentation Fault)或其他不可预期的行为。这是因为 PyAudio 在多线程环境下可能会出现资源冲突或线程安全问题。 PyAudio 是一个用于音频输入输出的 Python 库,它依赖于 PortAu…...
QAM 信号的距离以及能量归一化
QAM星座图平均功率能量_星座图功率计算-CSDN博客 正交幅度调制(QAM) - Vinson88 - 博客园 不同阶QAM调制星座图中,符号能量的归一化计算原理_qpsk的星座图归一化-CSDN博客 https://zhuanlan.zhihu.com/p/690157236...

Reactive编程框架与工具
文章目录 6.2 后端 Reactive 框架6.2.1 Spring WebFlux核心架构核心组件实际应用高级特性性能优化适用场景与限制 6.2.2 Akka(Actor模型)Actor模型基础基本用法高级特性响应式特性实现性能优化实际应用场景优势与挑战 6.2.3 Vert.x(事件驱动&…...

五子棋游戏开发:静态资源的重要性与设计思路
以下是以CSDN博客的形式整理的关于五子棋游戏静态资源需求的文章,基于我们之前的讨论,内容结构清晰,适合开发者阅读和参考。我尽量保持技术性、实用性,同时加入一些吸引读者的亮点。 五子棋游戏开发:静态资源的重要性与…...

Python爬虫第7节-requests库的高级用法
目录 前言 一、文件上传 二、Cookies 三、会话维持 四、SSL证书验证 五、代理设置 六、超时设置 七、身份认证 八、Prepared Request 前言 上一节,我们认识了requests库的基本用法,像发起GET、POST请求,以及了解Response对象是什么。…...

Maven的安装配置-项目管理工具
各位看官,大家早安午安晚安呀~~~ 如果您觉得这篇文章对您有帮助的话 欢迎您一键三连,小编尽全力做到更好 欢迎您分享给更多人哦 今天我们来学习:Maven的安装配置-项目管理工具 目录 1.什么是Maven?Maven用来干什么的?…...
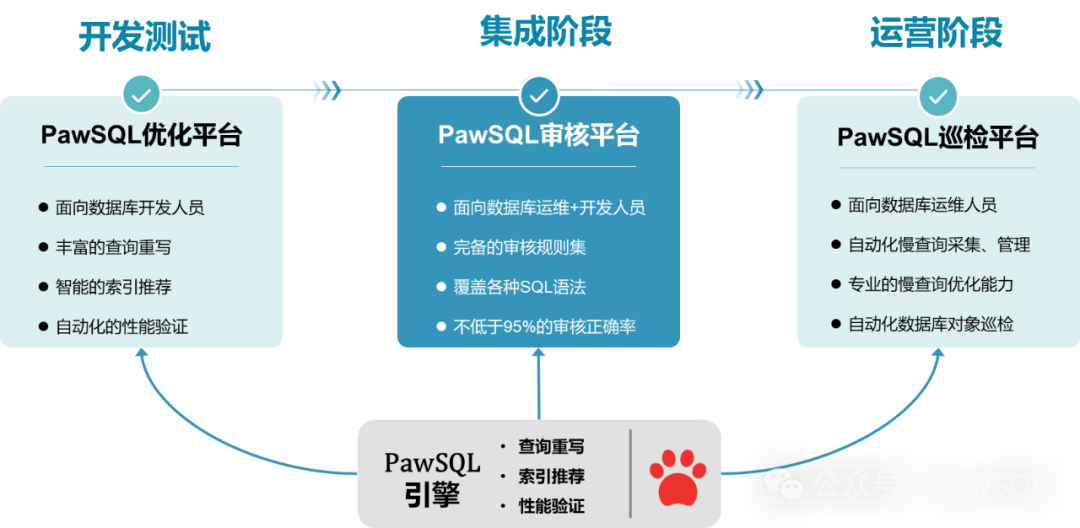
智能 SQL 优化工具 PawSQL 月度更新 | 2025年3月
📌 更新速览 本月更新包含 21项功能增强 和 9项问题修复,重点提升SQL解析精度与优化建议覆盖率。 一、SQL解析能力扩展 ✨ 新增SQL语法解析支持 SELECT...INTO TABLE 语法解析(3/26) ALTER INDEX RENAME/VISIBLE 语句解析&#…...
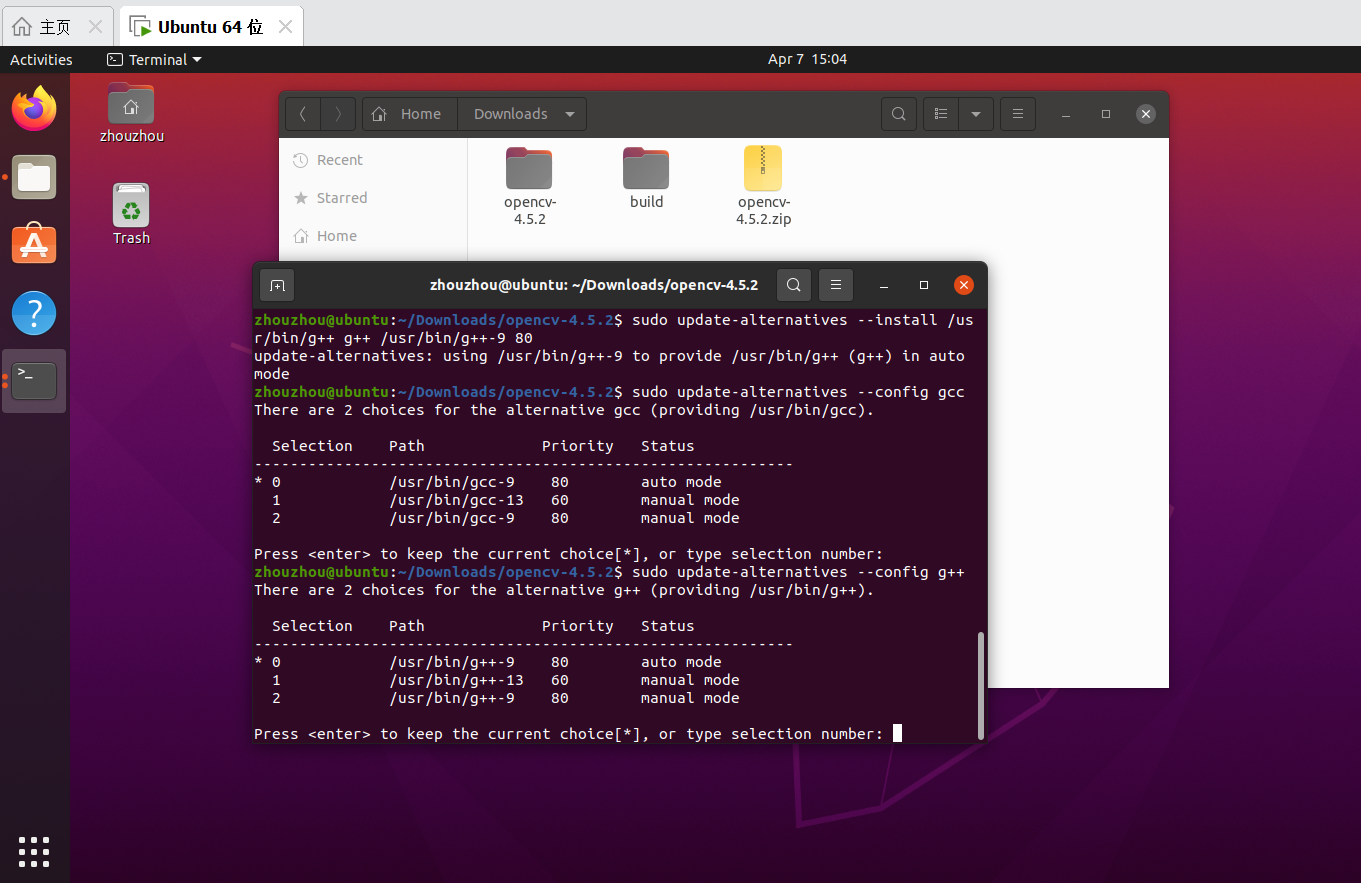
Ubuntu虚拟机编译安装部分OpenCV模块方法实现——保姆级教程
Ubuntu虚拟机的安装过程可以查看另一篇文章:VMware安装Ubuntu虚拟机实现COpenCV代码在虚拟机下运行教程-CSDN博客 目前我们已经下载好了OpenCV,这里以OpenCV4.5.2为例。 在内存要求尽可能小的情况下,可以尝试只编译安装代码中使用到的OpenC…...

find指令中使用正则表达式
linux查找命令能结合正则表达式吗 find命令要使用正则表达式需要结合-regex参数 另,-type参数可以指定查找类型(f为文件,d为文件夹) rootlocalhost:~/regular_expression# ls -alh 总计 8.0K drwxr-xr-x. 5 root root 66 4月 8日 16:26 . dr-xr-…...
)
Java Web从入门到精通:全面探索与实战(二)
Java Web从入门到精通:全面探索与实战(一)-CSDN博客 目录 四、Java Web 开发中的数据库操作:以 MySQL 为例 4.1 MySQL 数据库基础操作 4.2 JDBC 技术深度解析 4.3 数据库连接池的应用 五、Java Web 中的会话技术ÿ…...

基于大模型的阵发性室上性心动过速风险预测与治疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与目标 1.3 研究方法与数据来源 二、阵发性室上性心动过速概述 2.1 定义与分类 2.2 发病机制与流行病学 2.3 临床表现与诊断方法 三、大模型在阵发性室上性心动过速预测中的应用 3.1 大模型技术原理与特点 3.2 模型构…...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
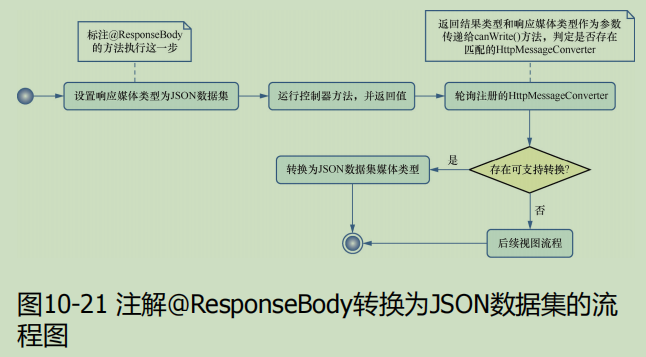
spring mvc @ResponseBody 注解转换为 JSON 的原理与实现详解
ResponseBody 注解转换为 JSON 的原理与实现详解 1. 核心作用 ResponseBody 是 Spring MVC 的一个注解,用于将方法返回的对象直接序列化为 HTTP 响应体(如 JSON 或 XML),而不是通过视图解析器渲染为视图(如 HTML&…...

TDengine.C/C++ 连接器
简介 C/C 开发人员可以使用 TDengine 的客户端驱动,即 C/C 连接器(以下都用 TDengine 客户端驱动表示),开发自己的应用来连接 TDengine 集群完成数据存储、查询以及其他功能。TDengine 客户端驱动的 API 类似于 MySQL 的 C API。…...

[docker] 简单操作场景
Docker的简单操作场景 1 安装 暂时没空写~ 2 登陆 一共4步: ~$ sudo docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d765d4c1eb5f ubuntu:24.04 "/bin/bash" …...

skynet.rawcall使用详解及应用场景
目录 核心特性函数原型使用场景场景 1:高性能二进制传输(如文件转发)场景 2:自定义序列化协议(如 Protocol Buffers)场景 3:跨服务共享内存(避免拷贝) 配套接收方实现与 …...
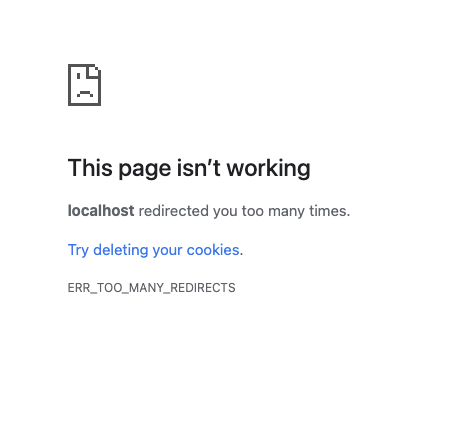
使用SpringSecurity下,发生重定向异常
使用SpringSecurity下,发生空转异常 环境信息: Spring Boot 3.4.4 , jdk 17 , springSecurity 6.4.4 问题背景: 没有自定义controller ,改写了login 页面,并且进行了成功后的跳转处理…...
)
gbase8s之逻辑导出导入脚本(完美版本)
该脚本dbexport.sh用于快速导出库和导入库(使用多并发unload,和多并发dbload的方式) #!/bin/sh #脚本功能:将数据导出成文本,迁移至其他实例 #最后更新时间:2023-12-19 #使用方法: #1.执行该脚…...
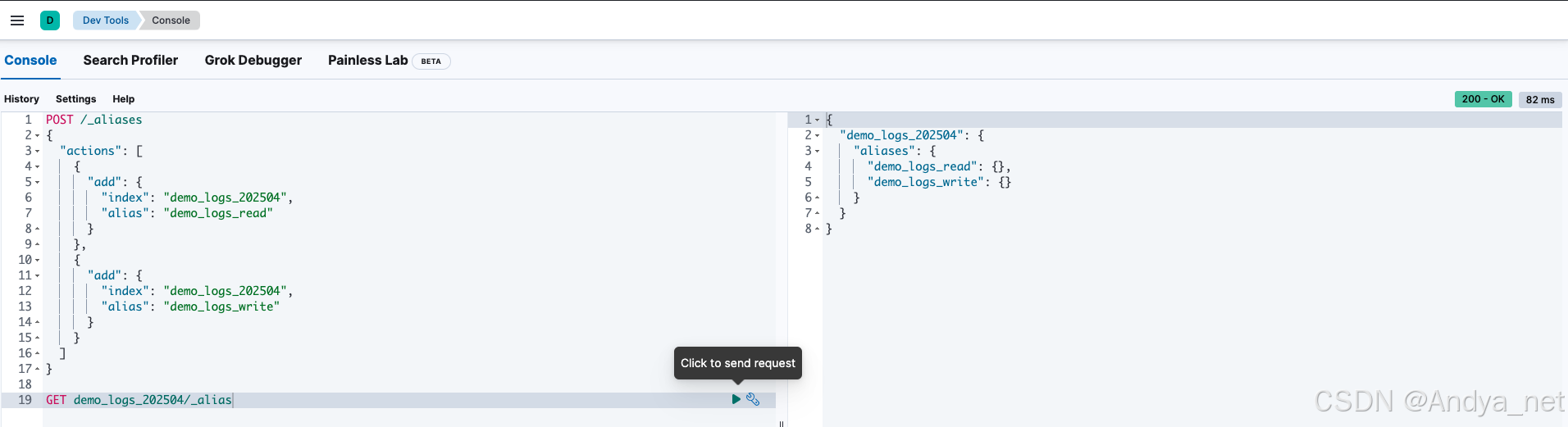
Elasticsearch | ES索引模板、索引和索引别名的创建与管理
关注:CodingTechWork 引言 在使用 Elasticsearch (ES) 和 Kibana 构建数据存储和分析系统时,索引模板、索引和索引别名的管理是关键步骤。本文将详细介绍如何通过 RESTful API 和 Kibana Dev Tools 创建索引模板、索引以及索引别名,并提供具…...

【Easylive】视频删除方法详解:重点分析异步线程池使用
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 方法整体功能 这个deleteVideo方法是一个综合性的视频删除操作,主要完成以下功能: 权限验证:检查视频是否存在及用户是否有权限删除核心数据删除&…...
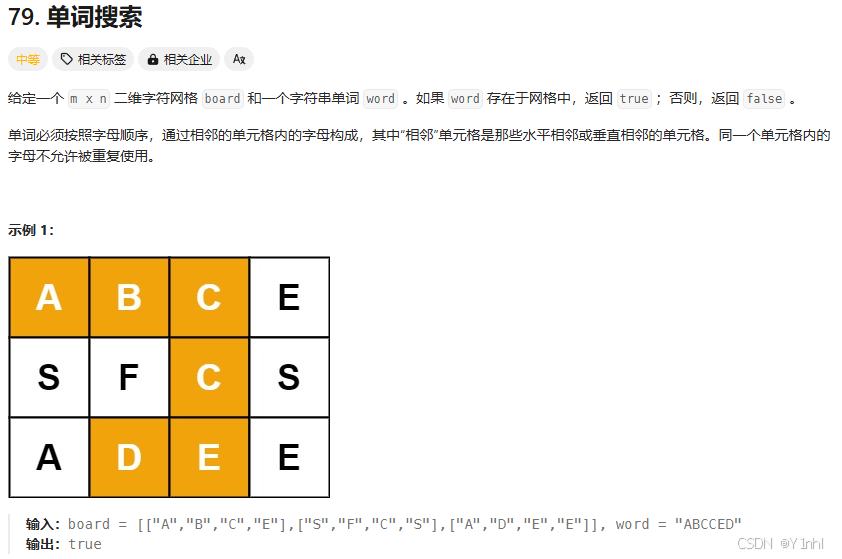
力扣hot100_回溯(2)_python版本
一、39. 组合总和(中等) 代码: class Solution:def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:ans []path []def dfs(i: int, left: int) -> None:if left 0:# 找到一个合法组合ans.append(pa…...

SGLang实战:从KV缓存复用到底层优化,解锁大模型高效推理的全栈方案
在当今快速发展的人工智能领域,大型语言模型(LLM)的应用已从简单对话扩展到需要复杂逻辑控制、多轮交互和结构化输出的高级任务。面对这一趋势,如何高效地微调并部署这些大模型成为开发者面临的核心挑战。本文将深入探讨SGLang——这一专为大模型设计的高…...
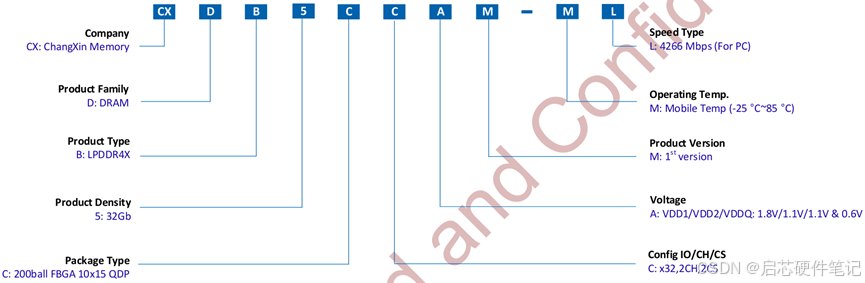
LPDDR4内存颗粒命名规则全解析:三星、镁光、海力士、南亚、长鑫等厂商型号解码与选型指南
由于之前DDR的系列选型文章有很好的反馈,所以补充LPDDR4低功耗内存的选型和命名规则,总结了目前市面上常用的内存,供硬件工程师及数码爱好者参考。 在智能手机、平板电脑和低功耗设备中,LPDDR4 SDRAM凭借其高带宽、低功耗特性成为…...

特权FPGA之Johnson移位
完整代码: module johnson(clk,rst_n,led,sw1_n,sw2_n,sw3_n);input clk; //时钟信号,50MHz input rst_n; //复位信号,低电平有效 output[3:0] led; //LED控制,1--灭…...
)
网络安全小知识课堂(最终完结版)
网络安全入门 :从 “小白” 到 “守护者” 的蜕变之旅 写在完结之际 历经 13 篇的深度探索,我们从 DDoS 攻击的 “流量洪水” 一路闯关到 HTTPS 的 “加密堡垒”,揭开了网络安全世界的层层面纱。感谢每一位读者的陪伴与互动,你们…...

2025年AI生成引擎搜索发展现状与趋势总结
2025年AI生成引擎搜索发展现状与趋势总结 一、国内外AI生成引擎搜索发展现状 1. 国内动态 社交搜索崛起:小红书2024年Q4日均搜索量达6亿次,用户更依赖社交平台UGC内容进行决策(如购物、旅游场景)&#…...