python三大库之---pandas(二)
python三大库之—pandas(二)
文章目录
- python三大库之---pandas(二)
- 六,函数
- 6.1、常用的统计学函数
- 6.2重置索引
- 6.3 遍历
- 6.3.1DataFrame 遍历
- 6.3.2 itertuples()
- 6.3.3 使用属性遍历
- 6.4 排序
- 6.4.1 sort_index
- 6.4.2 sort_values
- 6.5 去重
- 6.6 分组
- 6.6.1 groupby
- 6.6.2 filter
- 6.7 合并
- 6.8 随机抽样
- 6.9空值处理
- 6.9.1 检测空值
- 6.9.2 填充空值
- 6.9.3 删除空值
- 七,读取CSV文件
- 7.1 to_csv()
- 7.2 read_csv()
- 八,绘图
六,函数
6.1、常用的统计学函数
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积 |
numpy的方差默认为总体方差,pandas默认为样本方差
#常用的统计学函数
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
print(df.mean())#计算均值
print(df.median())#计算中位数
print(df.mode())#计算众数
print(df.var())#计算方差
print(df.std())#计算标准差
print(df.sum())#计算总和
print(df.min())#计算最小值
print(df.max())#计算最大值
print(df.count())#计算非空值的个数
print(df.prod())#计算乘积
print(df.abs())#计算绝对值
A 2.5
B 6.5
C 10.5
dtype: float64
A 2.5
B 6.5
C 10.5
dtype: float64A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
A 1.666667
B 1.666667
C 1.666667
dtype: float64
A 1.290994
B 1.290994
C 1.290994
dtype: float64
A 10
B 26
C 42
dtype: int64
A 1
B 5
C 9
dtype: int64
A 4
B 8
C 12
dtype: int64
A 4
B 4
C 4
dtype: int64
A 24
B 1680
C 11880
dtype: int64A B C
0 1 5 9
1 2 6 10
2 3 7 11
3 4 8 12
6.2重置索引
重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 对象。重新索引意味着根据新的索引标签重新排列数据,并填充缺失值。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
- 语法
DataFrame.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=np.nan, limit=None, tolerance=None)
参数:
- labels:
- 类型:数组或列表,默认为 None。
- 描述:新的索引标签。
- index:
- 类型:数组或列表,默认为 None。
- 描述:新的行索引标签。
- columns:
- 类型:数组或列表,默认为 None。
- 描述:新的列索引标签。
- axis:
- 类型:整数或字符串,默认为 None。
- 描述:指定重新索引的轴。0 或 ‘index’ 表示行,1 或 ‘columns’ 表示列。
- method:
- 类型:字符串,默认为 None。
- 描述:用于填充缺失值的方法。可选值包括 ‘ffill’(前向填充)、‘bfill’(后向填充)等。
- copy:
- 类型:布尔值,默认为 True。
- 描述:是否返回新的 DataFrame 或 Series。
- level:
- 类型:整数或级别名称,默认为 None。
- 描述:用于多级索引(MultiIndex),指定要重新索引的级别。
- fill_value:
- 类型:标量,默认为 np.nan。
- 描述:用于填充缺失值的值。
- limit:
- 类型:整数,默认为 None。
- 描述:指定连续填充的最大数量。
- tolerance:
- 类型:标量或字典,默认为 None。
- 描述:指定重新索引时的容差。
- 重置索引行
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行
new_index = ['a','b','c','d','e']
print(df.reindex(new_index))#重置索引 A B C
a 1.0 5.0 9.0
b 2.0 6.0 10.0
c 3.0 7.0 11.0
d 4.0 8.0 12.0
e NaN NaN NaN
- 重置索引列
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引列
new_columns = ['A','B','C','D']
print(df.reindex(columns=new_columns))
A B C D
a 1 5 9 NaN
b 2 6 10 NaN
c 3 7 11 NaN
d 4 8 12 NaN
- 重置索引行,并使用向前填充
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行,并使用向前填充
new_index = ['a','b','c','d','e']
print(df.reindex(new_index,method='ffill')) A B C
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
e 4 8 12
- 重置索引行,并使用指定值填充
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data,index=['a','b','c','d'])
#重置索引行,并使用指定值填充
new_index = ['a','b','c','d','e']
print(df.reindex(new_index,method='ffill',fill_value=0)) A B C
a 1 5 9
b 2 6 10
c 3 7 11
d 4 8 12
e 4 8 12
6.3 遍历
6.3.1DataFrame 遍历
# DataFrame 的遍历
data = pd.DataFrame({'A': pd.Series([1, 2, 3],index=['a','b','c']),'B': pd.Series([5, 6, 7, 8],index=['a','b','c','d']),
})
df = pd.DataFrame(data)
print(df)
for i in df:print(i) A B
a 1.0 5
b 2.0 6
c 3.0 7
d NaN 8
A
B
6.3.2 itertuples()
#使用 itertuples() 遍历行
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
#如果index为False,则打印出的元组过滤掉行索引信息
for i in df.itertuples(index=False):print(i)for j in i:print(j)
Pandas(A=1, B=4, C=7)
1
4
7
Pandas(A=2, B=5, C=8)
2
5
8
Pandas(A=3, B=6, C=9)
3
6
6.3.3 使用属性遍历
#使用属性遍历
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
#使用属性遍历
for inx in df.index:for col in df.columns:print(df.loc[inx,col])
1
4
7
2
5
8
3
6
9
6.4 排序
6.4.1 sort_index
sort_index 方法用于对 DataFrame 或 Series 的索引进行排序。
DataFrame.sort_index(axis=0, ascending=True, inplace=False)
Series.sort_index(axis=0, ascending=True, inplace=False)
参数:
- axis:指定要排序的轴。默认为 0,表示按行索引排序。如果设置为 1,将按列索引排序。
- ascending:布尔值,指定是升序排序(True)还是降序排序(False)。
- inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
6.4.2 sort_values
sort_values 方法用于根据一个或多个列的值对 DataFrame 进行排序。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数:
- by:列的标签或列的标签列表。指定要排序的列。
- axis:指定沿着哪个轴排序。默认为 0,表示按行排序。如果设置为 1,将按列排序。
- ascending:布尔值或布尔值列表,指定是升序排序(True)还是降序排序(False)。可以为每个列指定不同的排序方向。
- inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
- kind:排序算法。默认为 ‘quicksort’,也可以选择 ‘mergesort’(归并排序) 或 ‘heapsort’(堆排序)。
- na_position:指定缺失值(NaN)的位置。可以是 ‘first’ 或 ‘last’。
#sort_values排序
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 25, 35, 30],'Score': [85, 90, 80, 95, 88]
}
df = pd.DataFrame(data)
print(df)print(df.sort_values(by='Age'))
print(df.sort_values(by=['Age','Score']))
print(df.sort_values(by=['Age','Score'],ascending=[True,False])) Name Age Score
0 Alice 25 85
1 Bob 30 90
2 Charlie 25 80
3 David 35 95
4 Eve 30 88Name Age Score
0 Alice 25 85
2 Charlie 25 80
1 Bob 30 90
4 Eve 30 88
3 David 35 95Name Age Score
2 Charlie 25 80
0 Alice 25 85
4 Eve 30 88
1 Bob 30 90
3 David 35 95Name Age Score
0 Alice 25 85
2 Charlie 25 80
1 Bob 30 90
4 Eve 30 88
3 David 35 95
6.5 去重
drop_duplicates 方法用于删除 DataFrame 或 Series 中的重复行或元素。
- 语法
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)
参数:
-
by:用于标识重复项的列名或列名列表。如果未指定,则使用所有列。
-
subset:与 by 类似,但用于指定列的子集。
-
keep:指定如何处理重复项。可以是:
- ‘first’:保留第一个出现的重复项(默认值)。
- ‘last’:保留最后一个出现的重复项。
- False:删除所有重复项。
-
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的删除重复项后的对象。
#去重
data = {'A':[1,2,2,3],'B':[4,5,5,6],'C':[7,8,8,9],
}
df = pd.DataFrame(data)#按照所有列去重
print(df.drop_duplicates())
#按照指定列去重
print(df.drop_duplicates(subset='A'))
print(df.drop_duplicates(keep='last'))
A B C
0 1 4 7
1 2 5 8
3 3 6 9A B C
0 1 4 7
1 2 5 8
3 3 6 9A B C
0 1 4 7
2 2 5 8
3 3 6 9
6.6 分组
6.6.1 groupby
groupby 方法用于对数据进行分组操作,这是数据分析中非常常见的一个步骤。通过 groupby,你可以将数据集按照某个列(或多个列)的值分组,然后对每个组应用聚合函数,比如求和、平均值、最大值等。
- 语法
groupby 方法用于对数据进行分组操作,这是数据分析中非常常见的一个步骤。通过 groupby,你可以将数据集按照某个列(或多个列)的值分组,然后对每个组应用聚合函数,比如求和、平均值、最大值等。
参数**:
- by:用于分组的列名或列名列表。
- axis:指定沿着哪个轴进行分组。默认为 0,表示按行分组。
- level:用于分组的 MultiIndex 的级别。
- as_index:布尔值,指定分组后索引是否保留。如果为 True,则分组列将成为结果的索引;如果为 False,则返回一个列包含分组信息的 DataFrame。
- sort:布尔值,指定在分组操作中是否对数据进行排序。默认为 True。
- group_keys:布尔值,指定是否在结果中添加组键。
- squeeze:布尔值,如果为 True,并且分组结果返回一个元素,则返回该元素而不是单列 DataFrame。
- observed:布尔值,如果为 True,则只考虑数据中出现的标签。
#分组
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}
df = pd.DataFrame(data)
print(df)#按A分组
# 查看分组结果
grouped = df.groupby('A')
print(list(grouped))# 按Af分组,然后计算每个分组的C的平均值
grouped = df.groupby('A')['C']
print(grouped.mean())#按A分组,计算所有列(如果报错使有非数字类型的值)
grouped = df.groupby(['A'])
print(grouped.mean)#通过transform()函数对分组进行操作,保存到DataFrame中
grouped = df.groupby('A')['C'].transform('mean')
df['C_mean'] = grouped
print(df)#可以使用匿名函数来对分组进行操作,比如正态分布的标准化
grouped = df.groupby('A')['C'].transform(lambda x: (x - x.mean()) / x.std())
df['C_norm'] = grouped
print(df)
A B C D
0 foo one 1 10
1 bar one 2 20
2 foo two 3 30
3 bar three 4 40
4 foo two 5 50
5 bar two 6 60
6 foo one 7 70
7 foo three 8 80
[('bar', A B C D
1 bar one 2 20
3 bar three 4 40
5 bar two 6 60), ('foo', A B C D
0 foo one 1 10
2 foo two 3 30
4 foo two 5 50
6 foo one 7 70
7 foo three 8 80)]
A
bar 4.0
foo 4.8
Name: C, dtype: float64A B C D C_mean
0 foo one 1 10 4.8
1 bar one 2 20 4.0
2 foo two 3 30 4.8
3 bar three 4 40 4.0
4 foo two 5 50 4.8
5 bar two 6 60 4.0
6 foo one 7 70 4.8
7 foo three 8 80 4.8A B C D C_mean C_norm
0 foo one 1 10 4.8 -1.327018
1 bar one 2 20 4.0 -1.000000
2 foo two 3 30 4.8 -0.628587
3 bar three 4 40 4.0 0.000000
4 foo two 5 50 4.8 0.069843
5 bar two 6 60 4.0 1.000000
6 foo one 7 70 4.8 0.768273
7 foo three 8 80 4.8 1.117488
6.6.2 filter
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集
# # 按列 'A' 分组,并过滤掉列 'C' 的平均值小于 4 的组
# filter
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
filtered_df = df.groupby('A').filter(lambda x: x['C'].mean() > 4)
print(filtered_df) A B C D
0 foo one 1 10
2 foo two 3 30
4 foo two 5 50
6 foo one 7 70
7 foo three 8 80
6.7 合并
merge 函数用于将两个 DataFrame 对象根据一个或多个键进行合并,类似于 SQL 中的 JOIN 操作。这个方法非常适合用来基于某些共同字段将不同数据源的数据组合在一起,最后拼接成一个新的 DataFrame 数据表。
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
-
left:左侧的 DataFrame 对象。
-
right:右侧的 DataFrame 对象。
-
how:合并方式,可以是 ‘inner’、‘outer’、‘left’ 或 ‘right’。默认为 ‘inner’。
- ‘inner’:内连接,返回两个 DataFrame 共有的键。
- ‘outer’:外连接,返回两个 DataFrame 的所有键。
- ‘left’:左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
- ‘right’:右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
-
on:用于连接的列名。如果未指定,则使用两个 DataFrame 中相同的列名。
-
left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
-
left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
-
sort:布尔值,指定是否在合并后对结果进行排序。
-
suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
-
copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
-
indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
-
validate:验证合并是否符合特定的模式。
#合并
# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})# 内连接,只连接key相同的行
df = pd.merge(left, right, on='key', how='inner')
print(df)# 左连接,连接所有左边的行,右边没有的用NaN填充
df = pd.merge(left, right, on='key', how='left')
print(df)# 右连接,连接所有右边的行,左边没有的用NaN填充
df = pd.merge(left, right, on='key', how='right')
print(df)# 外连接,连接所有行,没有的用NaN填充
df = pd.merge(left, right, on='key', how='outer')
print(df)
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaNkey A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K4 NaN NaN C3 D3key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN
4 K4 NaN NaN C3 D3
6.8 随机抽样
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
参数:
- n:要抽取的行数
- frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
- replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
- weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
- random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
- axis:表示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
# 随机抽样
def sample_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000, 24000, 40000],"age": [25, 35, 49]})print(df.sample(frac=0.4))#随机抽取40%,4舍五入print(df.sample(n=2,axis=0))#随机抽取2条数据print(df.sample(n=1,axis=1))#随机抽取1列数据print(df.sample(n=2,axis=0,random_state=1))#随机抽取2条数据,并指定随机种子print(df.sample(frac=0.5, replace=True))#随机抽取50%,允许重复sample_test() company salary age
1 阿里 24000 35company salary age
2 腾讯 40000 49
1 阿里 24000 35age
0 25
1 35
2 49company salary age
0 百度 43000 25
2 腾讯 40000 49company salary age
0 百度 43000 25
0 百度 43000 25
6.9空值处理
6.9.1 检测空值
isnull()用于检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()用于检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
#空值检测
#isnull,检测DataFrame中的空值,返回一个布尔值矩阵,True表示空值,False表示非空值
def isnull_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.isnull())print(df.isnull().sum())#统计空值print(df.isnull().sum().sum())#统计空值总数isnull_test()
#notnull,检测DataFrame中的非空值,返回一个布尔值矩阵,True表示非空值,False表示空值
def notnull_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.notnull())print(df.notnull().sum())#统计非空值print(df.notnull().sum().sum())#统计非空值总数
company salary age
0 False False False
1 False True False
2 False False False
company 0
salary 1
age 0
dtype: int64
1
6.9.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
#空值填充
def fillna_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.fillna(0))#填充0print(df.fillna(method='ffill'))#填充前一个值fillna_test()
company salary age
0 百度 43000.0 25
1 阿里 0.0 35
2 腾讯 40000.0 49
6.9.3 删除空值
dropna() 方法用于删除 DataFrame 或 Series 中的空值。
#删除空值
def dropna_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})print(df.dropna())#删除空值print(df.dropna(axis=1))#删除空值所在列dropna_test()
company salary age
0 百度 43000.0 25
2 腾讯 40000.0 49company age
0 百度 25
1 阿里 35
2 腾讯 49
七,读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本);
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
7.1 to_csv()
to_csv() 方法将 DataFrame 存储为 csv 文件
#存csv文件
#to_csv()
def to_csv_test():df = pd.DataFrame({"company": ['百度', '阿里', '腾讯'],"salary": [43000,np.nan, 40000],"age": [25, 35, 49]})df.to_csv('test.csv',index=False)#index=False表示不保存索引to_csv_test()
7.2 read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
#读取csv文件
def read_csv_test():df = pd.read_csv('test.csv')print(df)read_csv_test()
company salary age
0 百度 43000.0 25
1 阿里 NaN 35
2 腾讯 40000.0 49
八,绘图
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#绘图
import matplotlib.pyplot as plt
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 25, 30, 40]
}
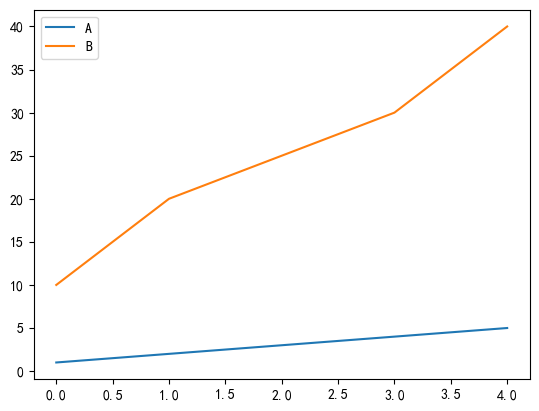
df = pd.DataFrame(data)# 折线图
df.plot(kind='line')
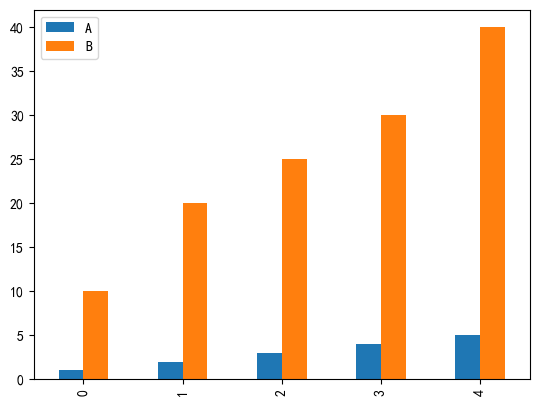
plt.show()# 柱状图
df.plot(kind='bar')
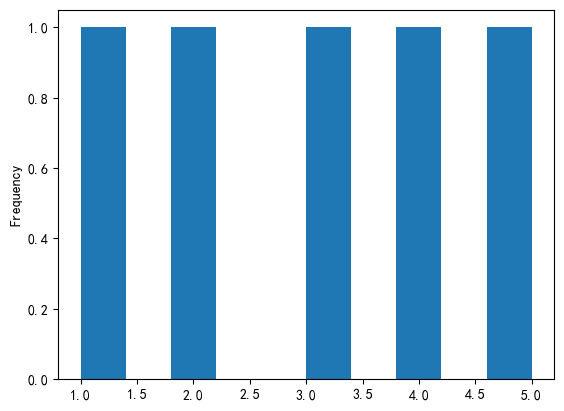
plt.show()#直方图
df['A'].plot(kind='hist')
plt.show()#散点图
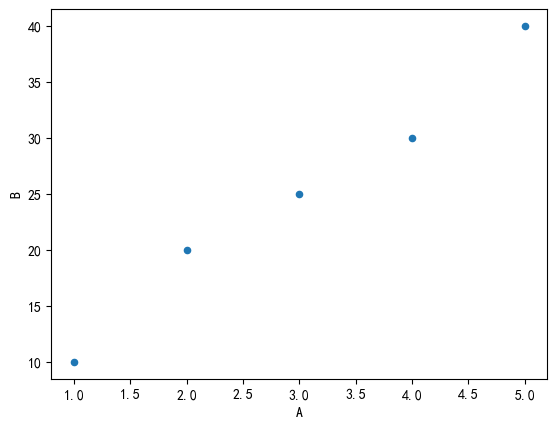
df.plot(kind='scatter',x='A',y='B')
plt.show()# 饼图
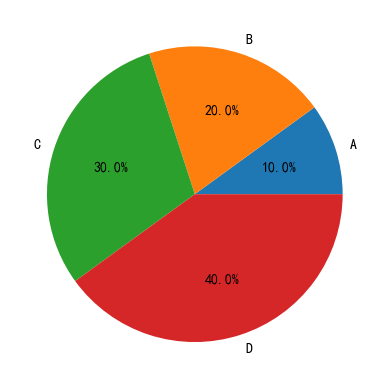
# 创建一个示例
data = {'A': 10,'B': 20,'C': 30,'D': 40
}
pd = pd.Series(data)
# 绘制饼图
pd.plot(kind='pie', autopct='%1.1f%%')
# 显示图表
plt.show()
相关文章:
python三大库之---pandas(二)
python三大库之—pandas(二) 文章目录 python三大库之---pandas(二)六,函数6.1、常用的统计学函数6.2重置索引6.3 遍历6.3.1DataFrame 遍历6.3.2 itertuples()6.3.3 使用属性遍历 6.4 排序6.4.1 sort_index6.4.2 sort_…...
php7.4.3连接MSsql server方法
需要下载安装Microsoft Drivers for PHP for SQL Server驱动, https://download.csdn.net/download/tjsoft/90568178 实操Win2008IISphp7.4.3连接SqlServer2008数据库所有安装包资源-CSDN文库 适用于 SQL Server 的 PHP 的 Microsoft 驱动程序支持与 SQL Server …...

Flask返回文件方法详解
在 Flask 中返回文件可以通过 send_file 或 send_from_directory 方法实现。以下是详细方法和示例: 1. 使用 send_file 返回文件 这是最直接的方法,适用于返回任意路径的文件。 from flask import Flask, send_fileapp = Flask(__name__)@app.route("/download")…...

JS中的Promise对象
基本概念 Promise 是 JavaScript 中用于处理异步操作的对象。它代表一个异步操作的最终完成及其结果值。Promise 提供了一种更优雅的方式来处理异步代码,避免了传统的回调地狱。 Promise 有三种状态 Pending(等待中):初始状态&…...
macOS设置定时播放眼保健操
文章目录 1. ✅方法一:直接基于日历2. 方法二:基于脚本2.1 音乐文件获取(ncm转mp3)2.2 创建播放音乐任务2.3 脚本实现定时播放 1. ✅方法一:直接基于日历 左侧新建一个日历,不然会和其他日历混淆,看起来会有点乱 然后…...

Python 小练习系列 | Vol.14:掌握偏函数 partial,用函数更丝滑!
🧩 Python 小练习系列 | Vol.14:掌握偏函数 partial,用函数更丝滑! 本节的 Python 小练习系列我们将聚焦一个 冷门但高能 的工具 —— functools.partial。它的作用类似于“函数的预设模板”,能帮你写出更加灵活、优雅…...
记录学习的第二十三天
老样子,每日一题开胃。 我一开始还想着暴力解一下试试呢,结果不太行😂 接着两道动态规划。 这道题我本来是想用最长递增子序列来做的,不过实在是太麻烦了,实在做不下去了。 然后看了题解,发现可以倒着数。 …...

Web品质 - 重要的HTML元素
Web品质 - 重要的HTML元素 在构建一个优秀的Web页面时,HTML元素的选择和运用至关重要。这些元素不仅影响页面的结构,还直接关系到页面的可用性、可访问性和SEO表现。本文将深入探讨一些关键的HTML元素,并解释它们在提升Web品质方面的重要性。 1. <html> 根元素 HTM…...

SpringBoot整合sa-token,Redis:解决重启项目丢失登录态问题
SpringBoot整合sa-token,Redis:解决重启项目丢失登录态问题 🔥1. 痛点直击:为什么登录状态会消失?2.实现方案2.1.导入依赖2.2.新增yml配置文件 3.效果图4.结语 😀大家好!我是向阳🌞&…...
)
Python 字典和集合(子类化UserDict)
本章内容的大纲如下: 常见的字典方法 如何处理查找不到的键 标准库中 dict 类型的变种set 和 frozenset 类型 散列表的工作原理 散列表带来的潜在影响(什么样的数据类型可作为键、不可预知的 顺序,等等) 子类化UserDict 就创造自…...

npm fund 命令的作用
运行别人的项目遇到这个问题: npm fund 命令的作用 npm fund 是 npm 提供的命令,用于显示项目依赖中哪些包需要资金支持。这些信息来自包的 package.json 中定义的 funding 字段,目的是帮助开发者了解如何支持开源维护者。 典型场景示例 假…...

ES:账号、索引、ILM
目录 笔记1:账号权限查看、查看账号、创建账号等查看所有用户查看特定用户验证权限修改用户权限删除用户 笔记2:索引状态和内容的查看等查看所有索引查看特定索引内容查看索引映射查看索引设置查看索引统计信息查看ILM策略 笔记1:账号权限查看…...
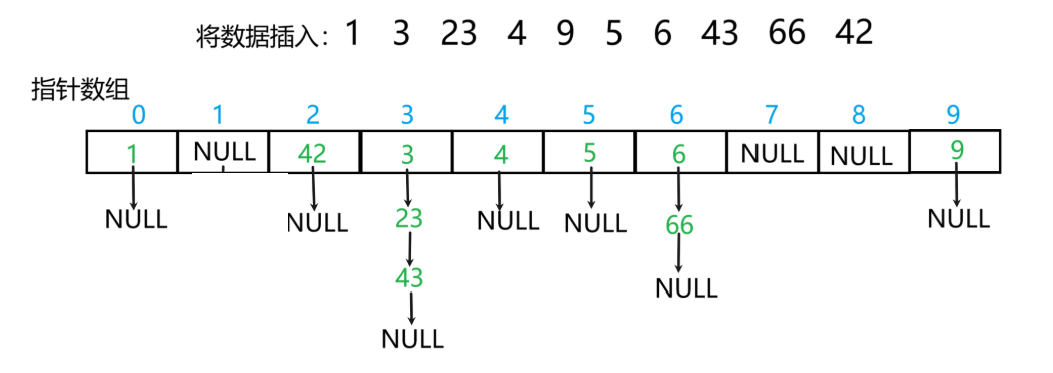
哈希表(开散列)的实现
目录 引入 开散列的底层实现 哈希表的定义 哈希表的扩容 哈希表的插入 哈希表查找 哈希表的删除 引入 接上一篇,我们使用了闭散列的方法解决了哈希冲突,此篇文章将会使用开散列的方式解决哈希冲突,后面对unordered_set和unordered_map的…...

#在docker中启动mysql之类的容器时,没有挂载的数据...在后期怎么把数据导出外部
如果要导出 Docker 容器内的 整个目录(包含所有文件及子目录),可以使用以下几种方法: 方法 1:使用 docker cp 直接复制目录到宿主机 适用场景:容器正在运行或已停止(但未删除)。 命…...
[蓝桥杯] 挖矿(CC++双语版)
题目链接 P10904 [蓝桥杯 2024 省 C] 挖矿 - 洛谷 题目理解 我们可以将这道题中矿洞的位置理解成为一个坐标轴,以题目样例绘出坐标轴: 样例: 输入的5为矿洞数量,4为可走的步数。第二行输入是5个矿洞的坐标。输出结果为在要求步数…...

Johnson算法 流水线问题 java实现
某印刷厂有 6项加工任务J1,J2,J3,J4,J5,J6,需要在两台机器Mi和M2上完 成。 在机器Mi上各任务所需时间为5,1,8,5,3,4单位; 在机器M2上各任务所需时间为7,2,2,4,7,4单位。 即时间矩阵为: T1 {5, …...
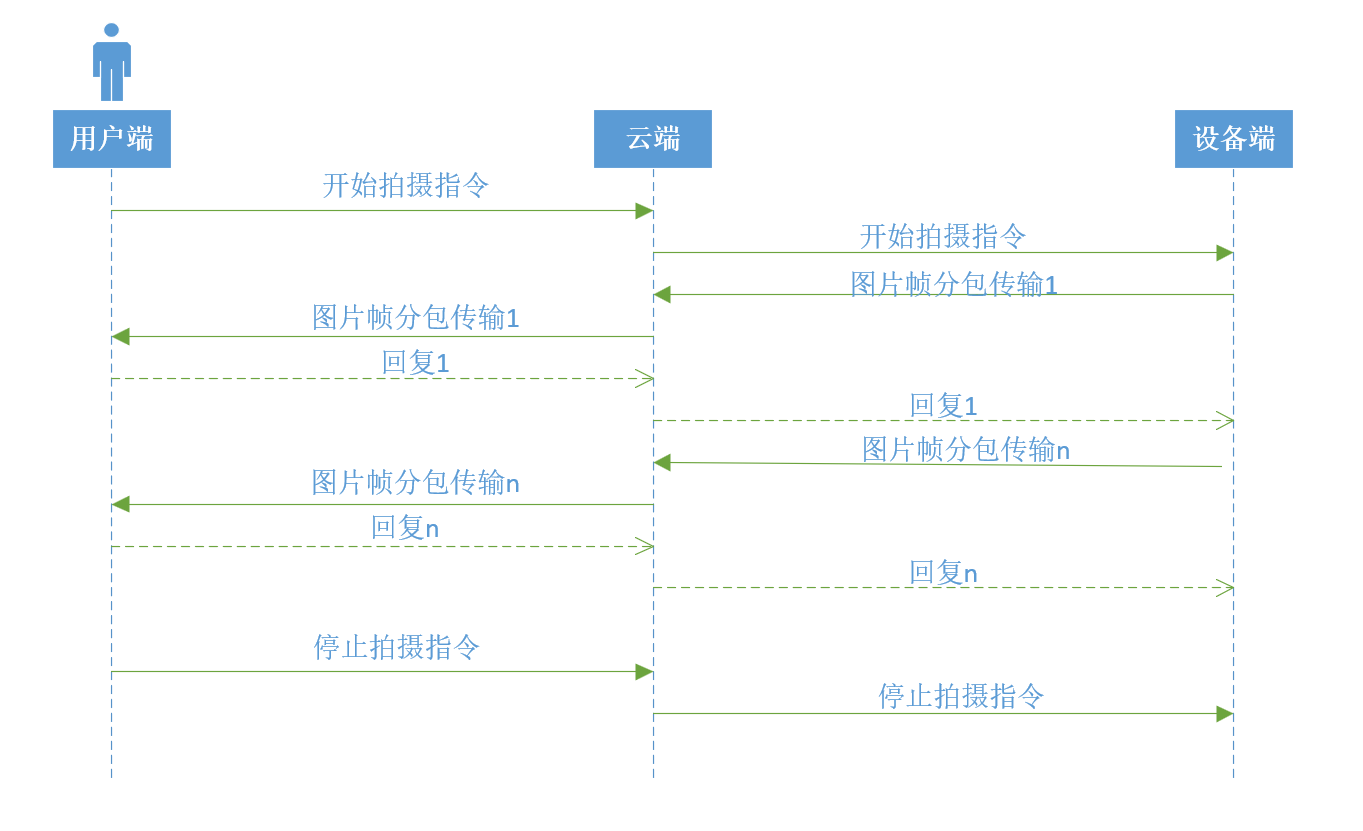
远程监控系统项目里练习
1、项目目标 设备端: (1)基于stm32mp157开发板,裁剪linux5.10.10,完成ov5640摄像头移植; (2)完成用户层程序,完成对摄像头的控制及与云端服务的数据交互。 云端&…...
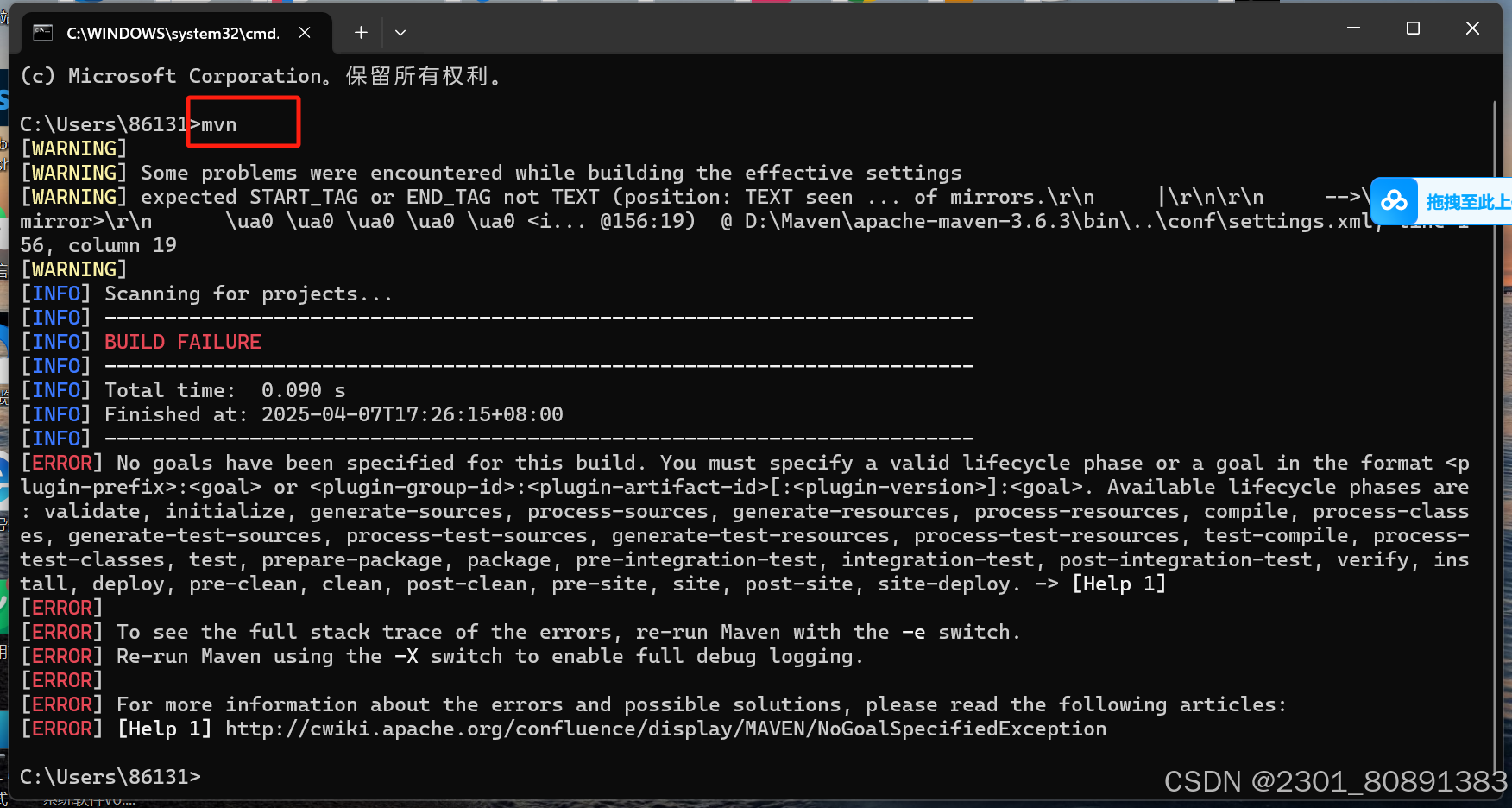
安装并配置Maven
如图所示,解压安装包,配置环境变量,在bin目录那个界面新建文件夹repository,写上安装路径的坐标,修改Maven仓库镜像,输入cmd验证是否安装成功 <mirror><id>alimaven</id><mirrorOf>…...

PlatformIO 自定义脚本选择编译库源文件 - 设置只用于C++ 的编译选项
PlatformIO 只支持以文件夹为单位选择要编译的源文件,不像Keil 或者CMake,可以手动控制每一个源文件。而且默认只会将库的src 文件夹下的源文件全部加入编译。比如,某个库的文件结构如下: libx src include mem| a.c| b.c| c.c…...
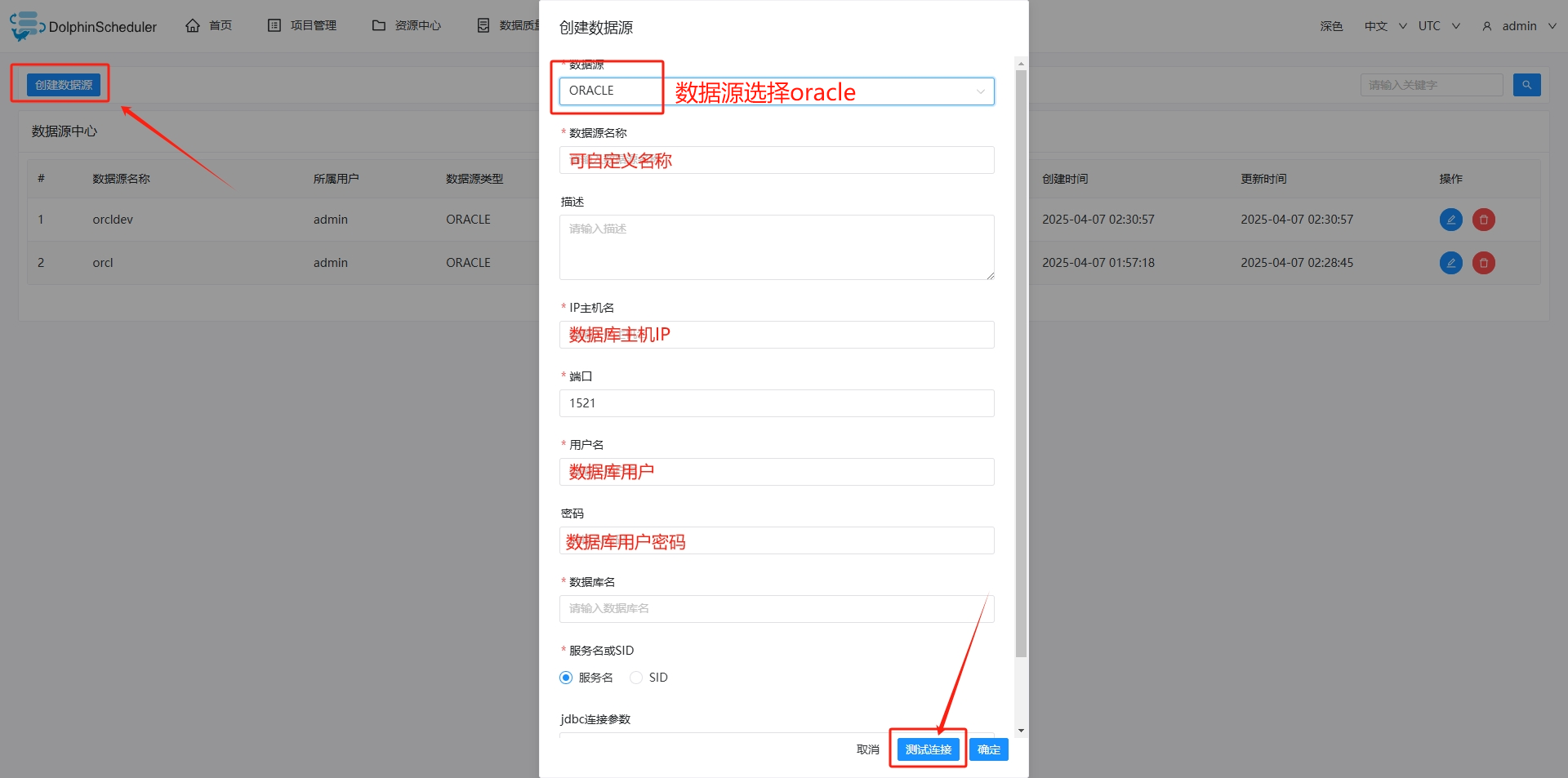
dolphinscheduler单机部署链接oracle
部署成功请给小编一个赞或者收藏激励小编 1、安装准备 JDK版本:1.8或者1.8oracle版本:19Coracle驱动版本:8 2、安装jdk 下载地址:https://www.oracle.com/java/technologies/downloads/#java8 下载后上传到/tmp目录下。 然后执行下面命…...
MongoDB常见面试题总结(上)
MongoDB 基础 MongoDB 是什么? MongoDB 是一个基于 分布式文件存储 的开源 NoSQL 数据库系统,由 C 编写的。MongoDB 提供了 面向文档 的存储方式,操作起来比较简单和容易,支持“无模式”的数据建模,可以存储比较复杂…...

java基础 迭代Iterable接口以及迭代器Iterator
Itera迭代 Iterable < T>迭代接口(1) Iterator iterator()(2) forEach(Consumer<? super T> action)forEach结合Consumer常见场景forEach使用注意细节 (3)Spliterator spliterator() Iterator< T>迭代器接口如何“接收” Iterator<T>核心方法迭代器的…...

CentOS禁用nouveau驱动
1、验证 nouveau 是否在运行 lsmod | grep nouveau如果命令返回结果,说明 nouveau 驱动正在运行。 2、编辑黑名单文件 通过编辑黑名单配置文件来禁用 nouveau 驱动,这样在系统启动时不会加载它。 vi /etc/modprobe.d/blacklist-nouveau.conf修改以下…...

Linux 时间同步工具 Chrony 简介与使用
一、Chrony 是什么? chrony 是一个开源的网络时间同步工具,主要由两个组件组成: chronyd:后台服务进程,负责与时间服务器交互,同步系统时钟。chronyc:命令行工具,用于手动查看或修…...

C语言:字符串处理函数strstr分析
在 C 语言中,strstr 函数用于查找一个字符串中是否存在另一个字符串。它的主要功能是搜索指定的子字符串,并返回该子字符串在目标字符串中第一次出现的位置的指针。如果没有找到子字符串,则返回 NULL。 详细说明: 头文件…...

28--当路由器开始“宫斗“:设备控制面安全配置全解
当路由器开始"宫斗":设备控制面安全配置全解 引言:路由器的"大脑保卫战" 如果把网络世界比作一座繁忙的城市,那么路由器就是路口执勤的交通警察。而控制面(Control Plane)就是警察的大脑…...
-- 动画)
Vue知识点(5)-- 动画
CSS 动画是 Vue3 中实现组件动画效果的高效方式,主要通过 CSS transitions 和 keyframes 动画 CSS Keyframes(关键帧动画) 用来创建复杂的动画序列,可以精确控制动画的各个阶段。 核心语法: keyframes animationNa…...
MATLAB2024a超详细图文安装教程(2025最新版保姆级教程)附安装钥
目录 前言 一、MATLAB下载 二、MATLAB安装 二、MATLAB启动 前言 MATLAB(Matrix Laboratory)是由MathWorks公司开发的一款高性能的编程语言和交互式环境,主要用于数值计算、数据分析和算法开发。内置数学函数和工具箱丰富,开发…...
基于 Spring Boot 瑞吉外卖系统开发(二)
基于 Spring Boot 瑞吉外卖系统开发(二) 员工登录功能实现 员工登录页面login.html存放在/resources/backend/page/login目录下。 启动项目,在浏览器中通过地址“http://localhost:8080/backend/page/login/login.html”访问员工登录页面。…...

软考系统架构设计师之大数据与人工智能笔记
一、大数据架构设计 1. 核心概念与挑战 大数据特征:体量大(Volume)、多样性(Variety)、高速性(Velocity)、价值密度低(Value)。传统数据库问题:数据过载、性…...