openEuler24.03 LTS下安装Spark
目录
安装模式介绍
下载Spark
安装Local模式
前提条件
解压安装包
简单使用
安装Standalone模式
前提条件
集群规划
解压安装包
配置Spark
配置Spark-env.sh
配置workers
分发到其他机器
启动集群
简单使用
关闭集群
安装YARN模式
前提条件
解压安装包
配置Spark
配置spark-env.sh
配置历史服务器
配置spark-env.sh
启动服务
简单使用
关闭服务
安装模式介绍
Spark常见的部署模式
(1)Local模式:在本地部署单个Spark服务,使用本地资源调度。(测试用)
(2)Standalone模式:构建一个由Master + Worker构成的Spark集群,使用Spark自带的资源调度执行任务,不需要借助Yarn或Mesos等其他框架资源。(不常用)
(3)YARN模式:Spark作为客户端,Spark直接使用Hadoop的YARN组件进行资源与任务调度。(常用)
(4)Mesos模式:和YARN模式类似。Spark直接使用Mesos进行资源与任务调度。
(5)K8S模式:和YARN模式类似。Spark直接使用K8S进行资源与任务调度。
这里介绍前面三种模式,安装模式对比如下
| 模式 | Spark安装机器数 | 需启动的进程 |
|---|---|---|
| Local模式 | 1 | 无 |
| Standalone模式 | 3 | Master、Worker |
| YARN模式 | 1 | YARN、HDFS |
下载Spark
下载Spark
https://archive.apache.org/dist/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3.tgz
上传安装包到Linux /opt/software目录下
安装Local模式
解压安装包就完成Local模式安装,不需要任何配置,也不需要启动任何进程。
在node2机器操作。
前提条件
Linux机器安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-local简单使用
使用Local模式计算pi
$ cd spark-local$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10命令参数介绍
--class 表示要执行程序的主类 --master 表示使用本地的多少核线程来计算 xxx.jar 表示程序所在的jar包 10 表示程序计算的次数
命令行查看结果
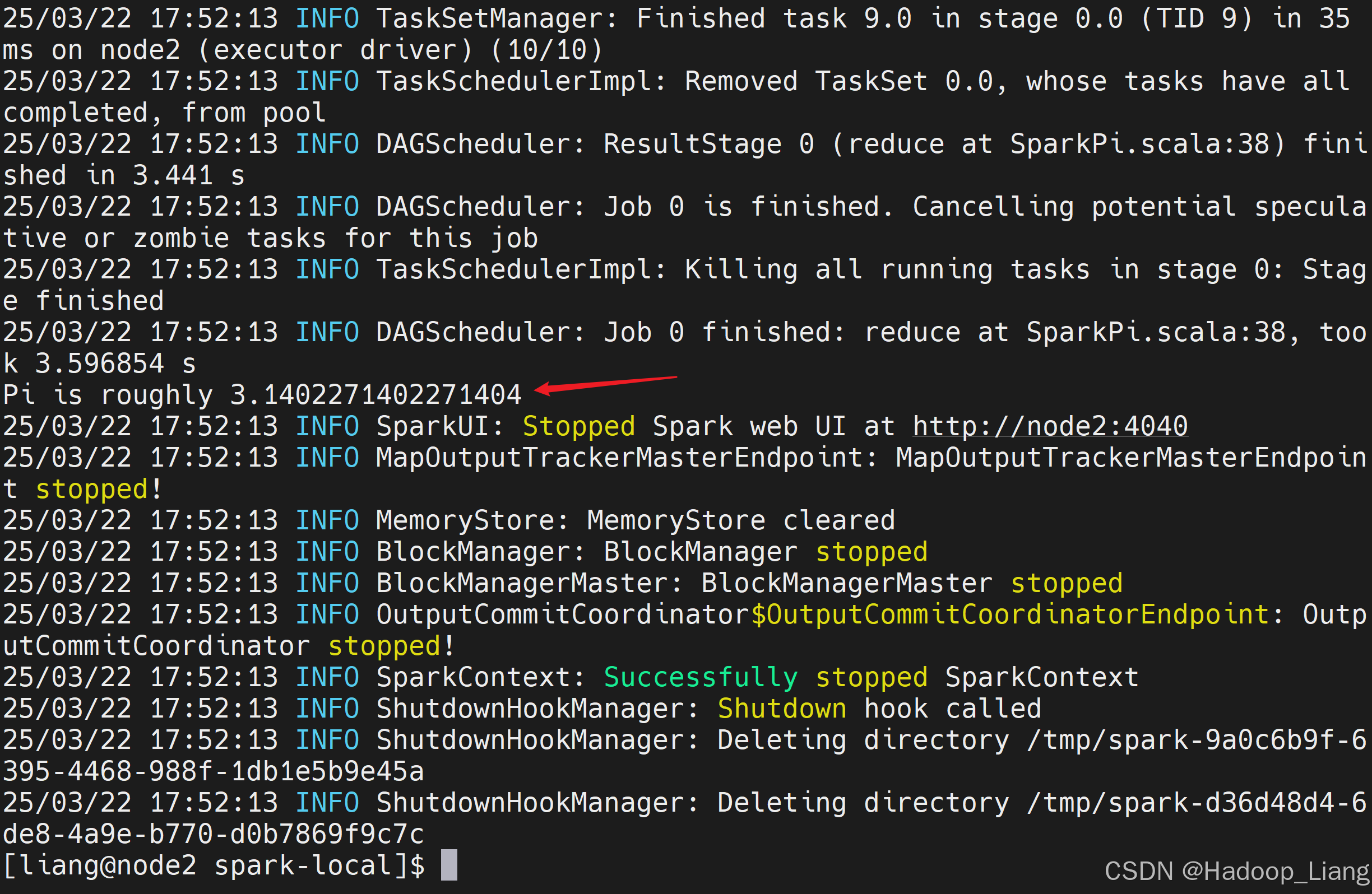
Web UI监控执行过程,浏览器访问如下地址
node2:4040
如果Web UI看不到,调大计算次数,再次查看Web UI
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
100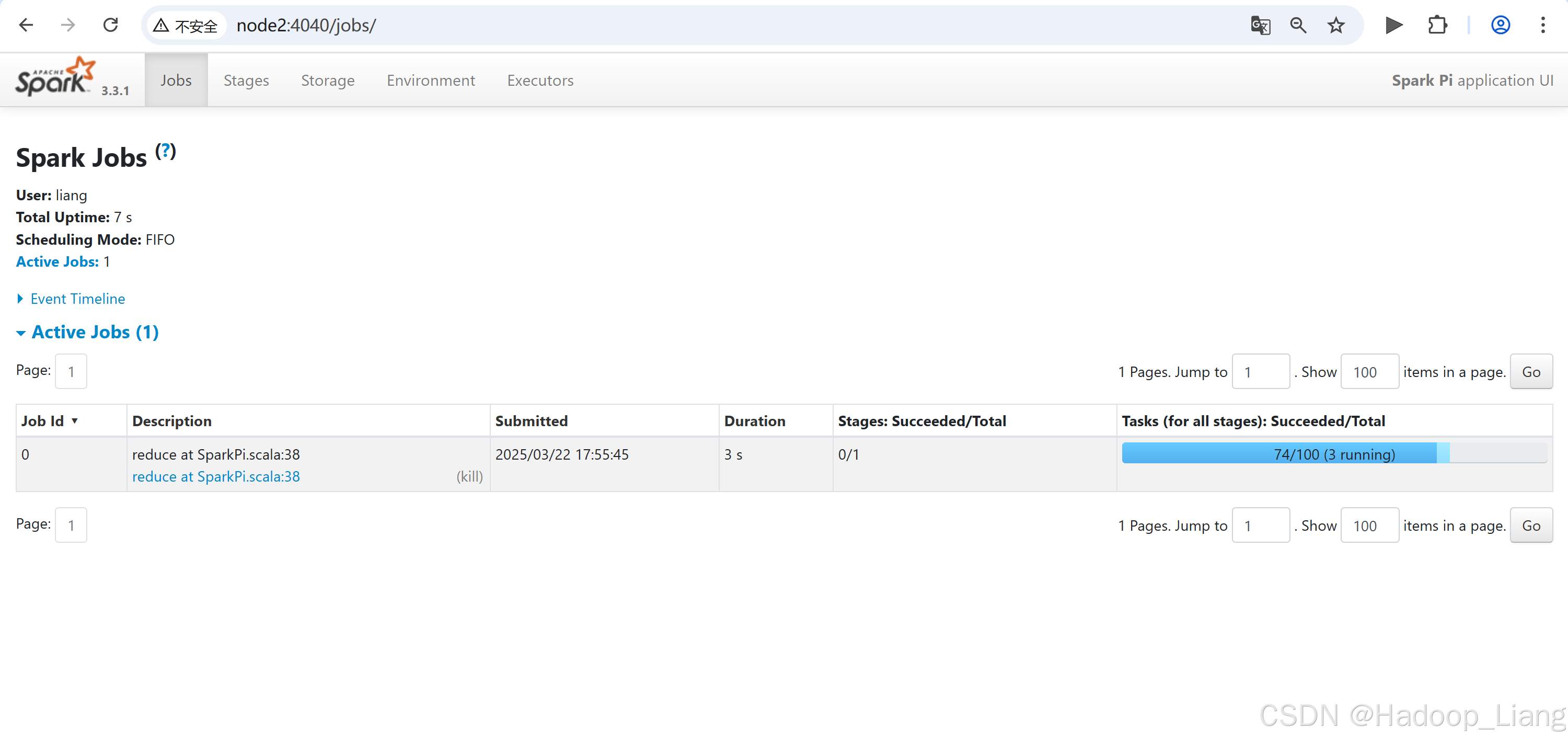
安装Standalone模式
前提条件
有三台Linux机器,都安装好Java,可参考:openEuler24.03 LTS下安装Hadoop3完全分布式-安装Java
集群规划
Spark Standalone集群规划
| node2 | node3 | node4 |
|---|---|---|
| Master | ||
| Woker | Worker | Worker |
解压安装包
解压安装包及重命名
[liang@node2 sorfware]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-standalone配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-standalone/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置Spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加以下内容
export SPARK_MASTER_HOST=node2配置workers
[liang@node2 conf]$ mv workers.template workers
[liang@node2 conf]$ vim workers删除原有localhost,添加如下内容
node2
node3
node4分发到其他机器
$ xsync /opt/module/spark-standalone启动集群
启动集群
[liang@node2 conf]$ cd /opt/module/spark-standalone
[liang@node2 spark-standalone]$ sbin/start-all.sh执行输出
[liang@node2 spark-standalone]$ sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.master.Master-1-node2.out node2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node2.out node3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node3.out node4: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-standalone/logs/spark-liang-org.apache.spark.deploy.worker.Worker-1-node4.out
jps查看进程
$ jpsall执行输出
[liang@node2 spark-standalone]$ jpsall =============== node2 =============== 2839 Worker 2921 Jps 2701 Master =============== node3 =============== 2092 Jps 2030 Worker =============== node4 =============== 2096 Jps 2034 Worker
简单使用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node2:7077 \
--deploy-mode client \
--driver-memory 1G \
--executor-memory 1G \
--total-executor-cores 2 \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10查看Web UI
node2:8080
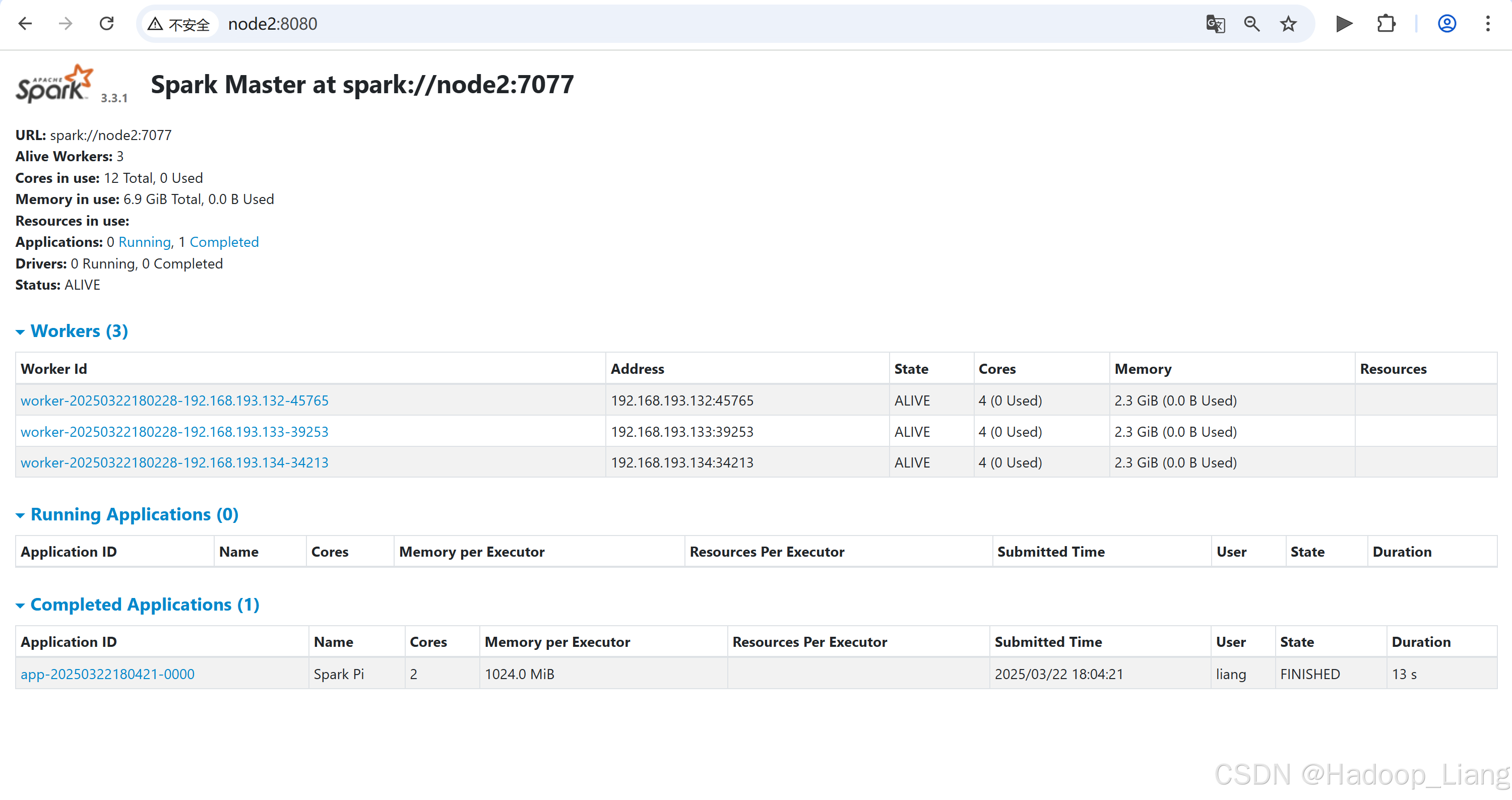
delploy-mode 为client运行,结果直接在客户端显示

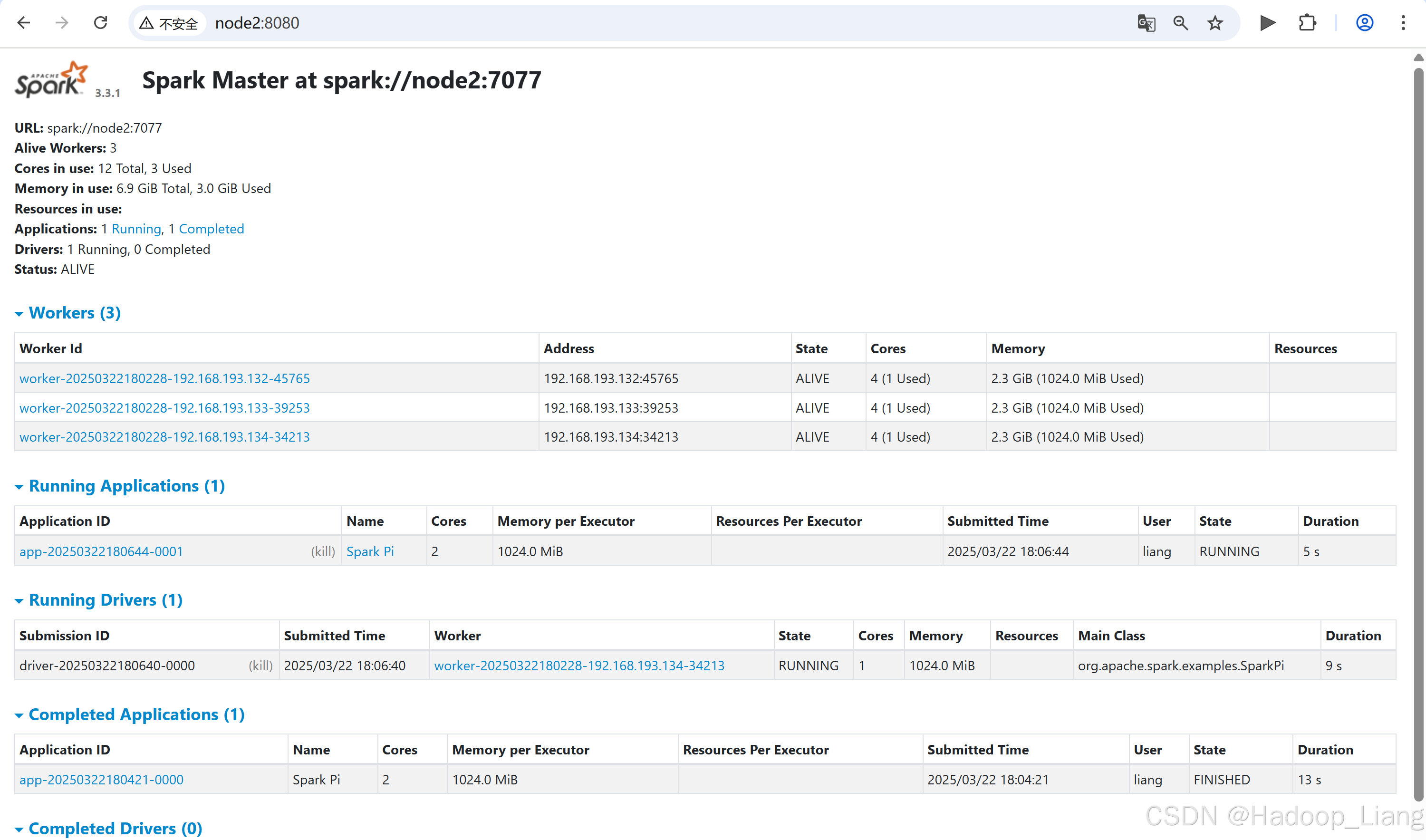
deploy-mode 可以改为 cluster ,测试看看效果,运行结果需要登录Web页面的driver 日志查看。
[liang@node2 spark-standalone]$ bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node2:7077 --deploy-mode cluster --driver-memory 1G --executor-memory 1G --total-executor-cores 2 --executor-cores 1 ./examples/jars/spark-examples_2.12-3.3.1.jar 10如果访问速度较块,可以看到并点击Running Drivers下Worker的超链接


如果运行完成,过一定的时间后,可以在Completed Drivers的Worker去找结果
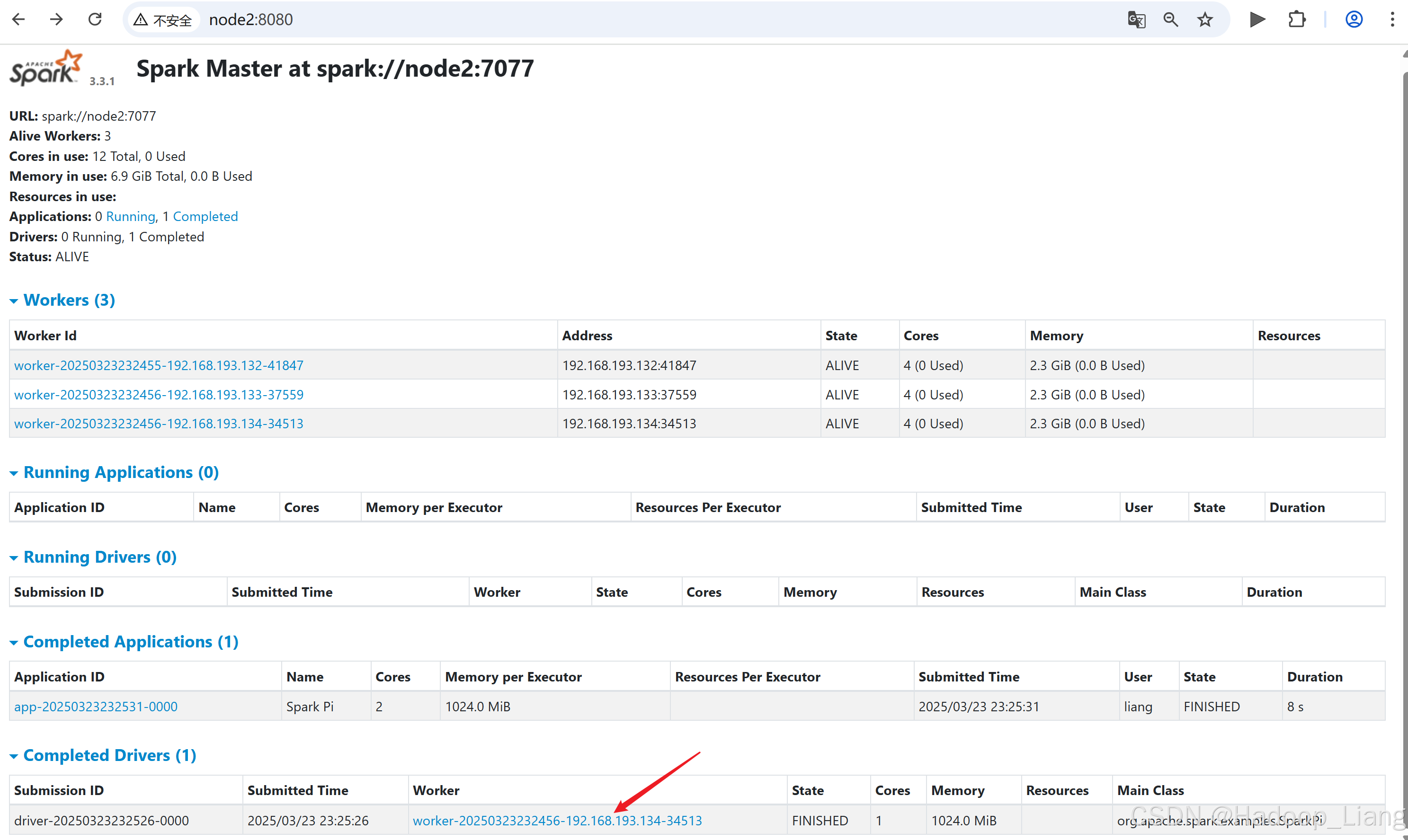
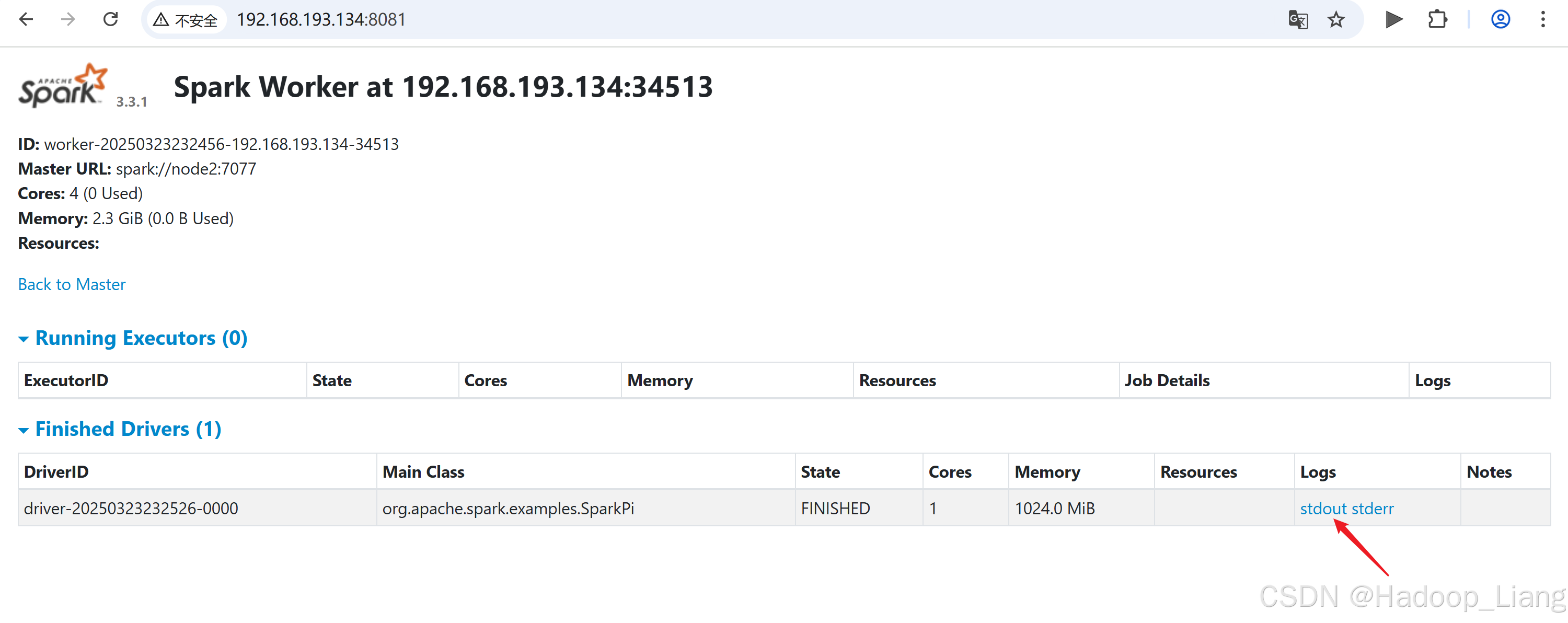
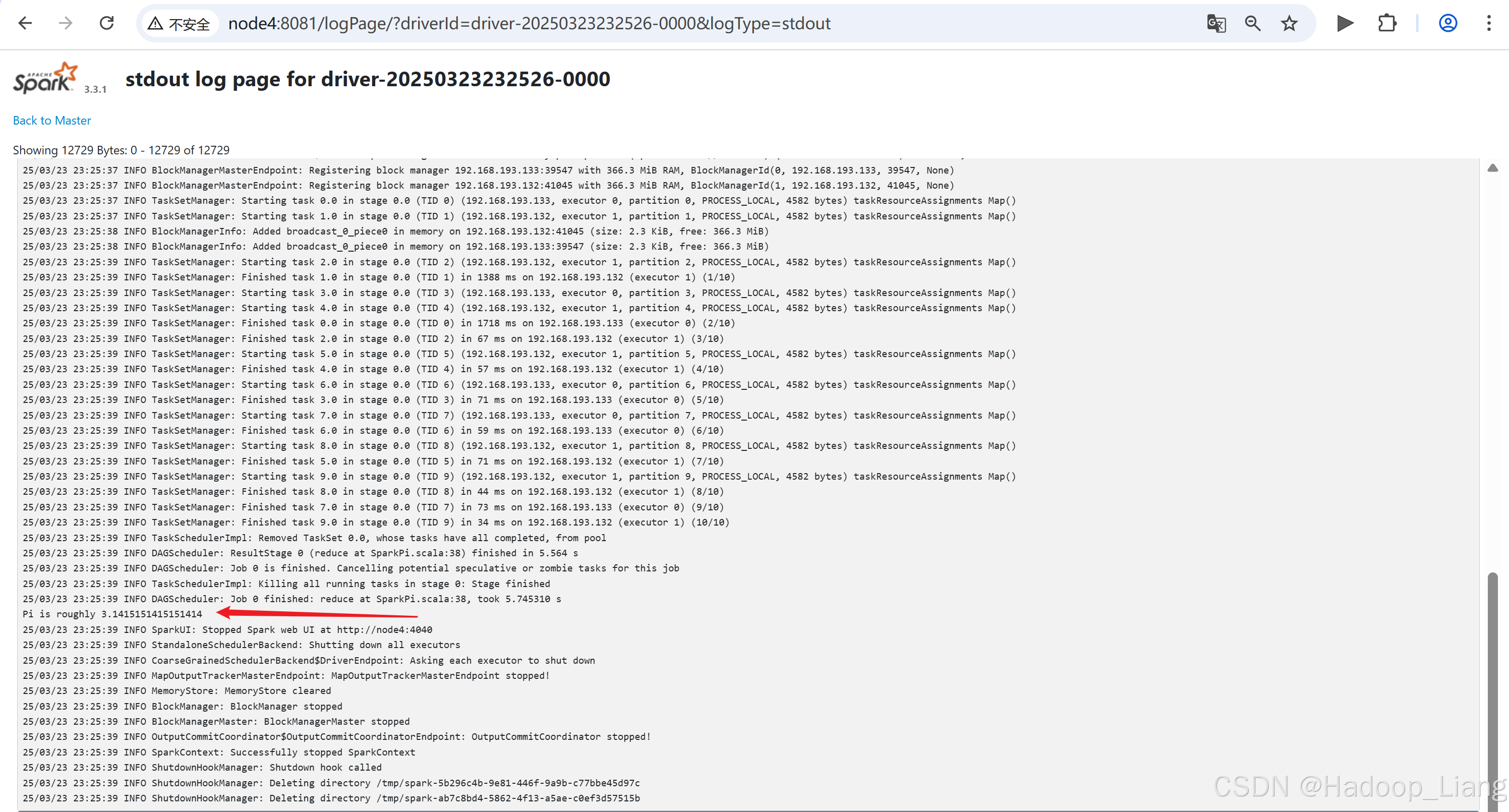
关闭集群
关闭集群
./sbin/stop-all.shjps查看进程
jpsall操作过程
[liang@node2 spark-standalone]$ sbin/stop-all.sh node3: stopping org.apache.spark.deploy.worker.Worker node2: stopping org.apache.spark.deploy.worker.Worker node4: stopping org.apache.spark.deploy.worker.Worker stopping org.apache.spark.deploy.master.Master [liang@node2 spark-standalone]$ jpsall =============== node2 =============== 3404 Jps =============== node3 =============== 2365 Jps =============== node4 =============== 2371 Jps
安装YARN模式
在node2机器操作
前提条件
安装好Hadoop完全分布式集群, 可参考:openEuler24.03 LTS下安装Hadoop3完全分布式
解压安装包
[liang@node2 ~]$ cd /opt/software
[liang@node2 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module
[liang@node2 sorfware]$ cd /opt/module
[liang@node2 sorfware]$ mv spark-3.3.1-bin-hadoop3 spark-yarn配置Spark
进入Spark配置目录
[liang@node2 conf]$ cd spark-yarn/conf
[liang@node2 conf]$ ls
fairscheduler.xml.template metrics.properties.template spark-env.sh.template
log4j2.properties.template spark-defaults.conf.template workers.template配置spark-env.sh
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh添加如下内容
YARN_CONF_DIR=/opt/module/hadoop-3.3.4/etc/hadoop配置含义:告诉Spark yarn的配置哪里,yarn-site.xml配置了yarn相关信息。
配置历史服务器
配置spark-defaults.conf
$ mv spark-defaults.conf.template spark-defaults.conf
$ vim spark-defaults.conf末尾添加如下内容
# 打开记录事件日志
spark.eventLog.enabled true
# 事件记录保存地址,需要提前手动创建
spark.eventLog.dir hdfs://node2:8020/spark-evenlog-directory
# yarn关联跳转到spark历史服务器地址
spark.yarn.historyServer.address=node2:18080
# spark历史服务器地址
spark.history.ui.port=18080配置spark-env.sh
$ vim spark-env.sh添加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node2:8020/spark-evenlog-directory
-Dspark.history.retainedApplications=30"启动服务
启动Hadoop
$ hdp.sh start创建历史服务的存储目录
$ hdfs dfs -mkdir /spark-evenlog-directory启动Spark历史服务
$ cd ../
$ sbin/start-history-server.sh jps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 4706 NameNode 5650 JobHistoryServer 4916 DataNode 5349 NodeManager 6070 Jps 5997 HistoryServer =============== node3 =============== 3888 Jps 3016 DataNode 3275 ResourceManager 3420 NodeManager =============== node4 =============== 3203 SecondaryNameNode 3654 Jps 3415 NodeManager 3032 DataNode
在node2能看到Spark的HistoryServer进程
简单使用
使用Spark YARN模式计算pi
$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10计算完成后,控制台结果如下
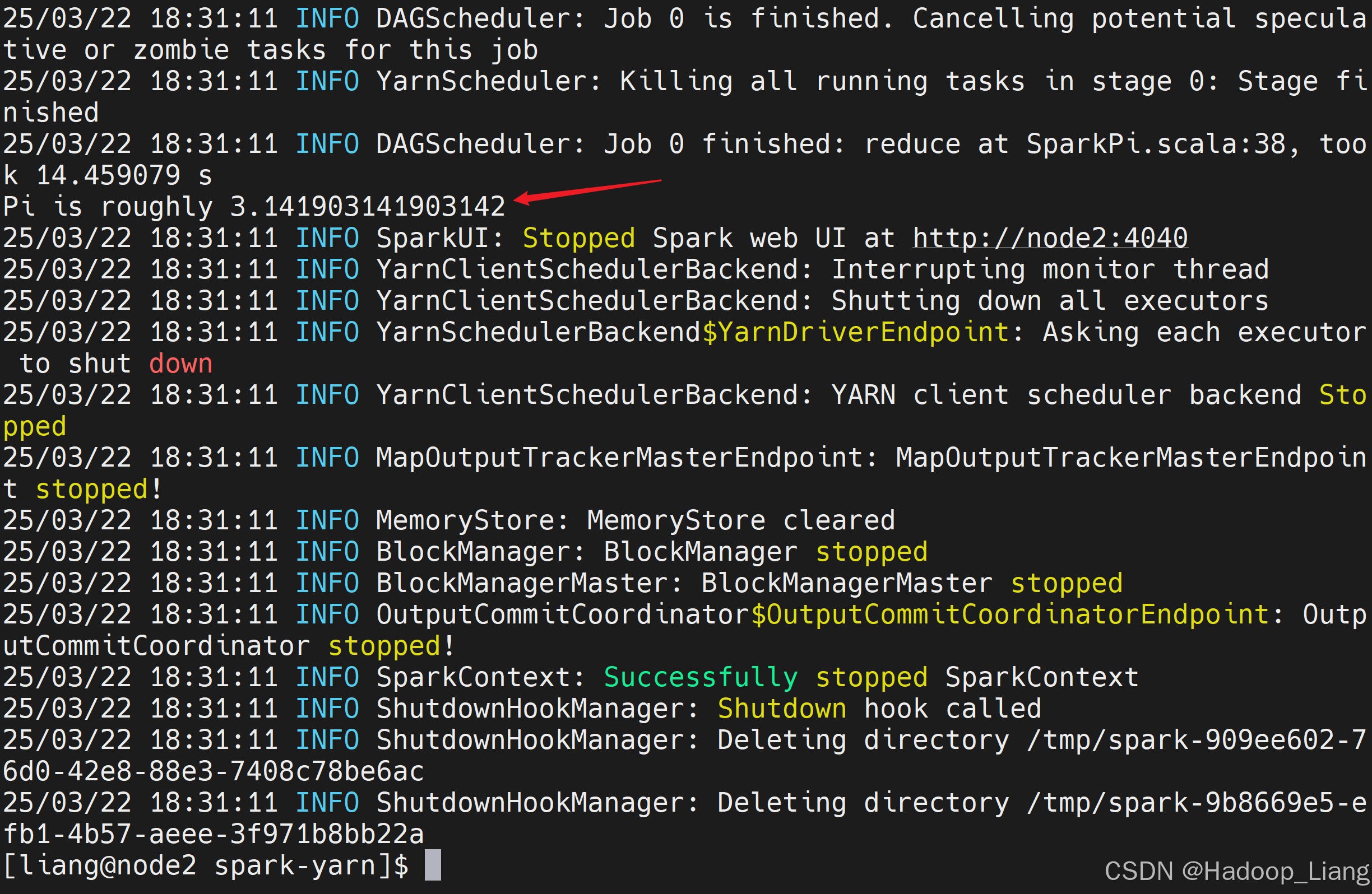
Web UI查看日志
node3:8088
点击具体作业的History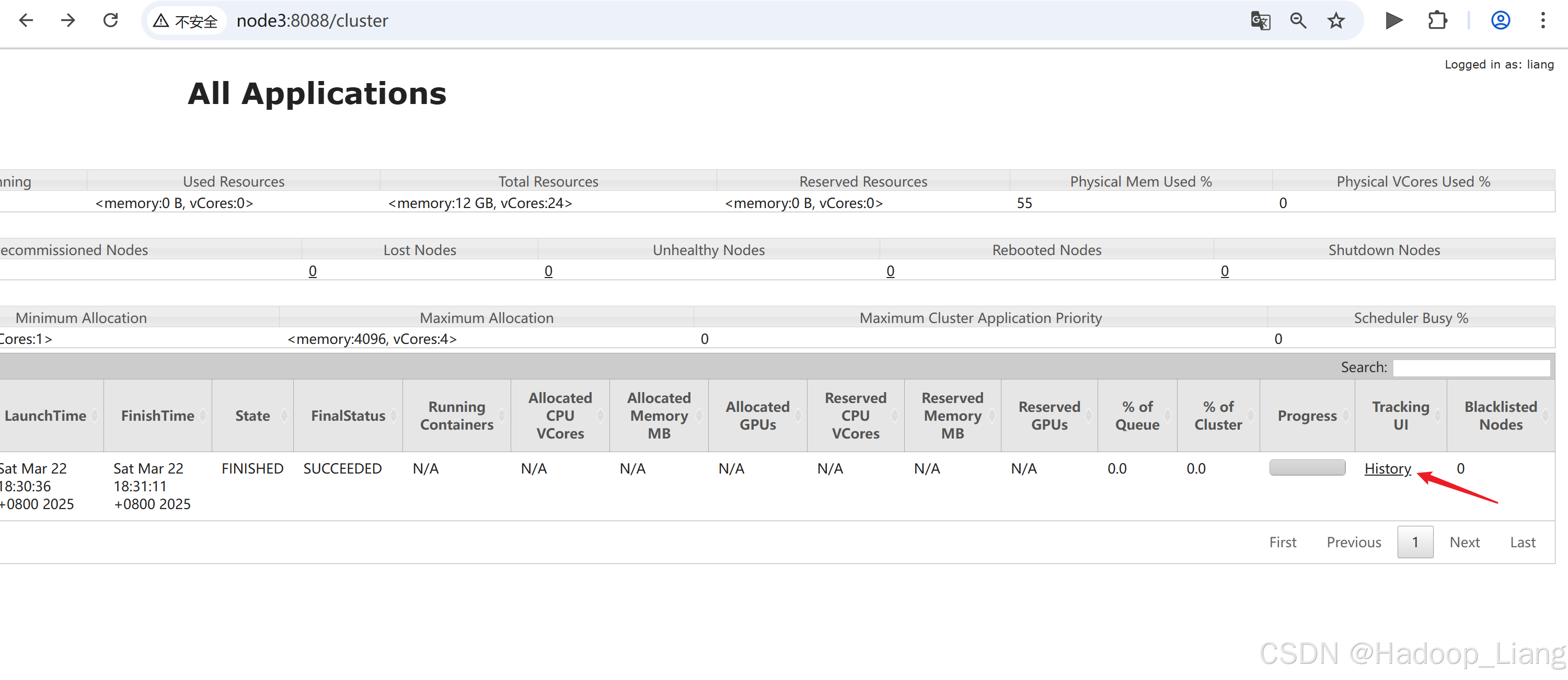 跳转到了Spark的历史服务
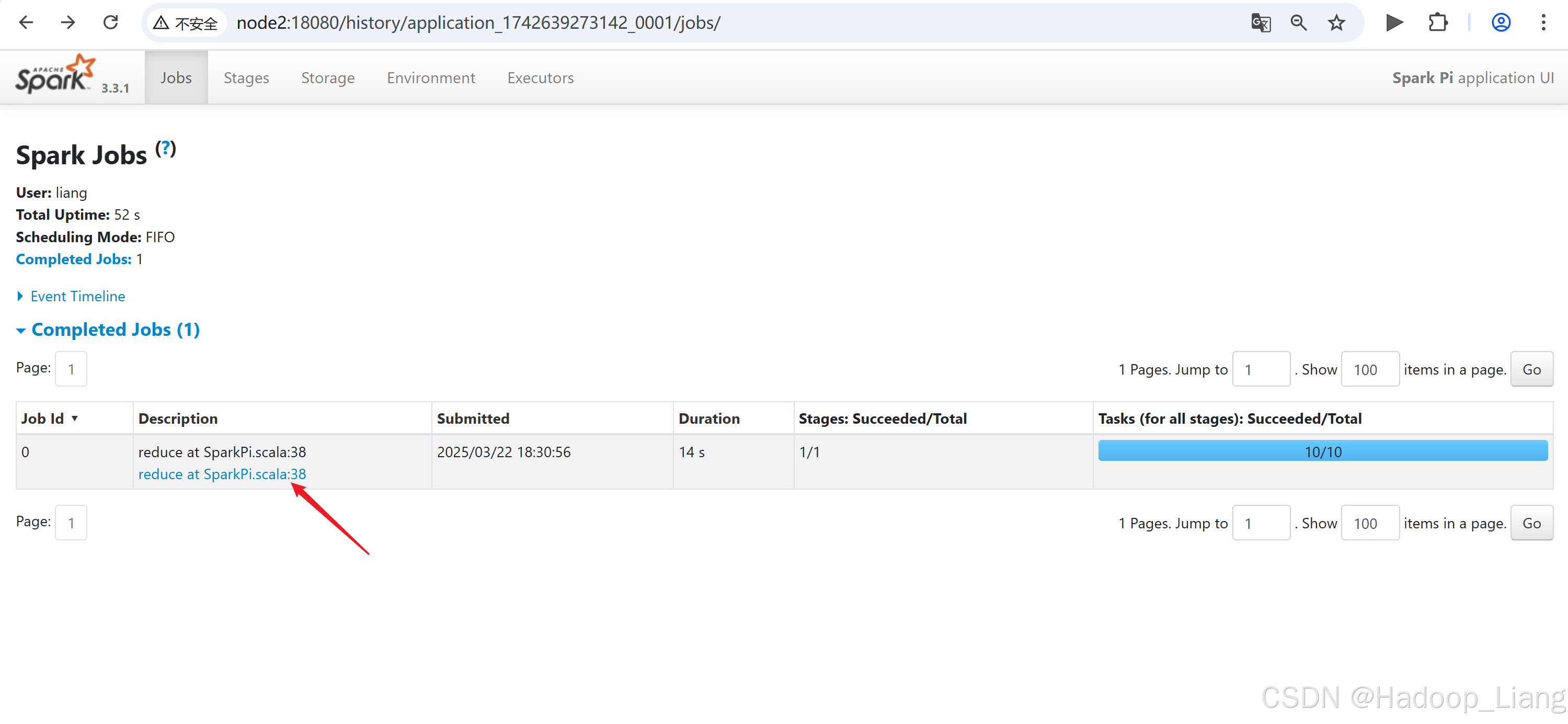
跳转到了Spark的历史服务node2:18080

点击Description下的链接
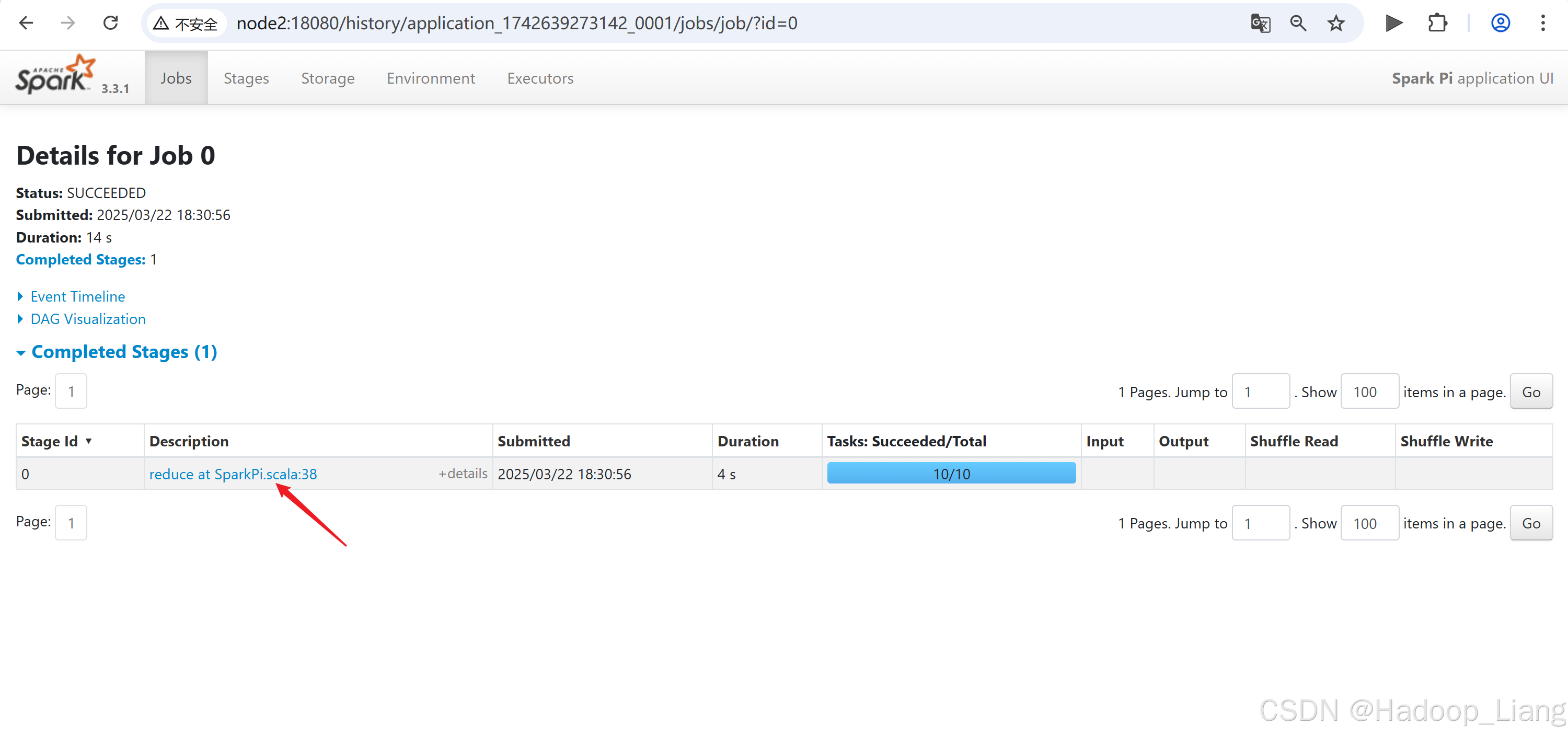
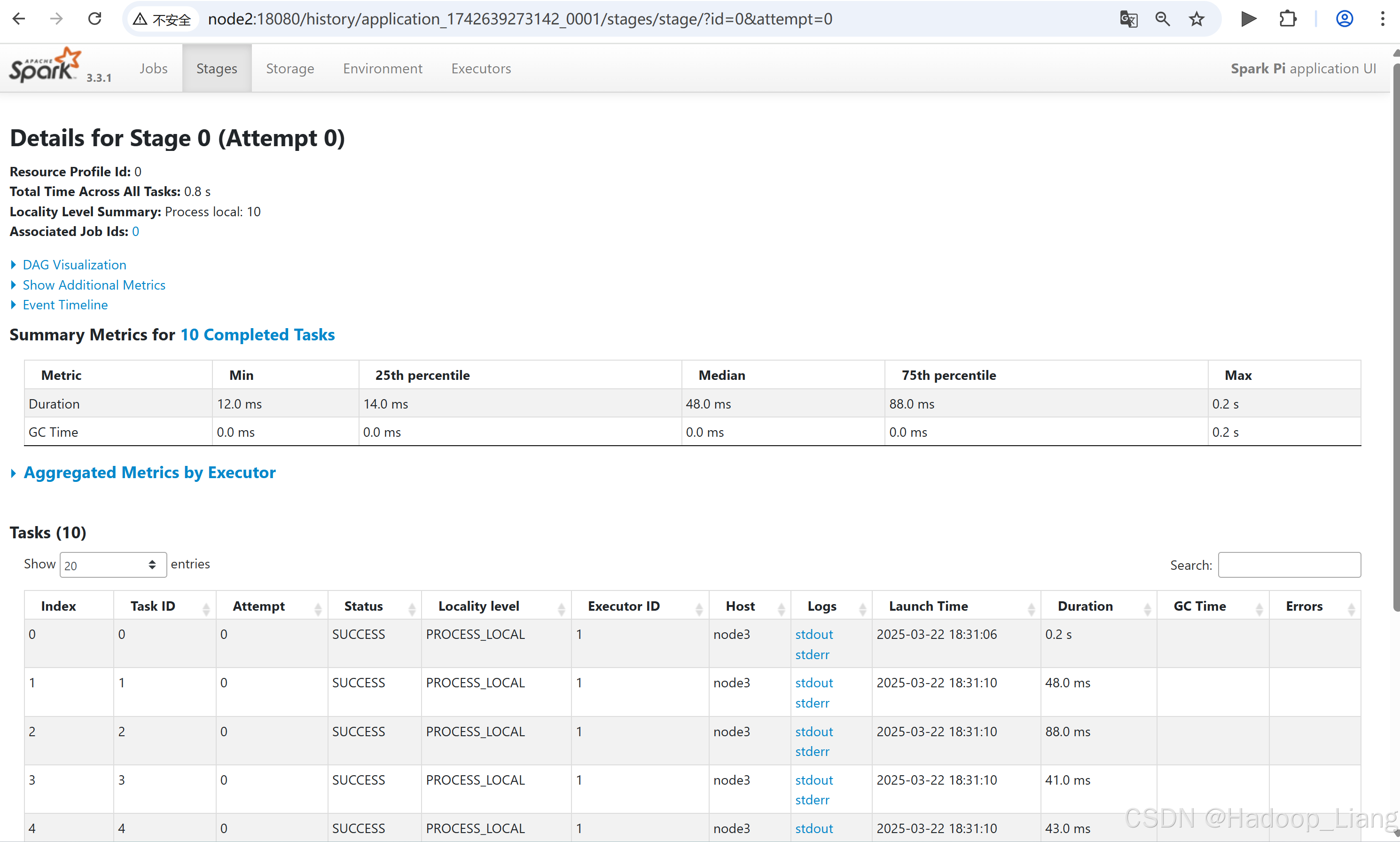
点击需要查看的日志,例如:查看最后一次Index的stdout日志
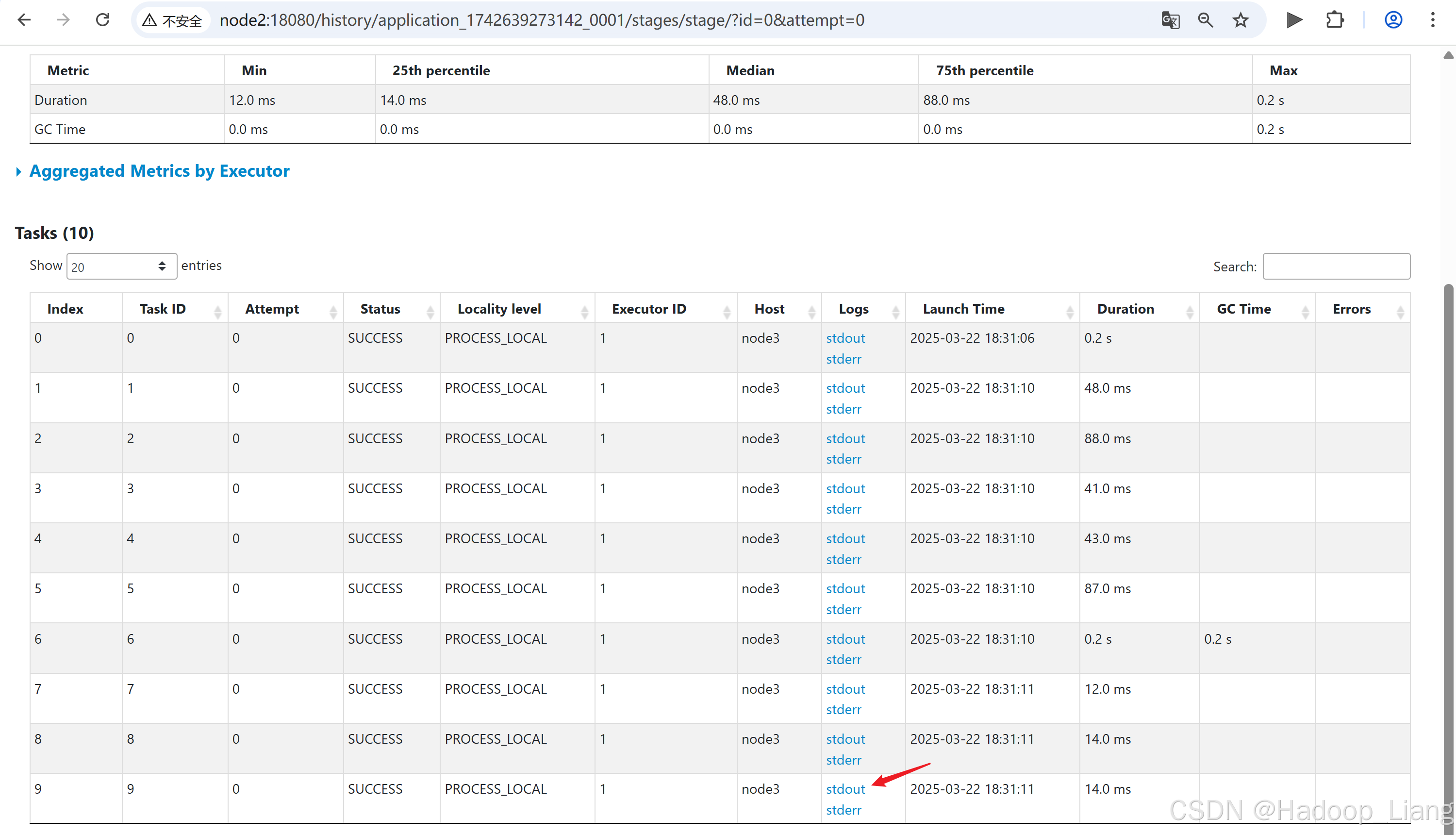
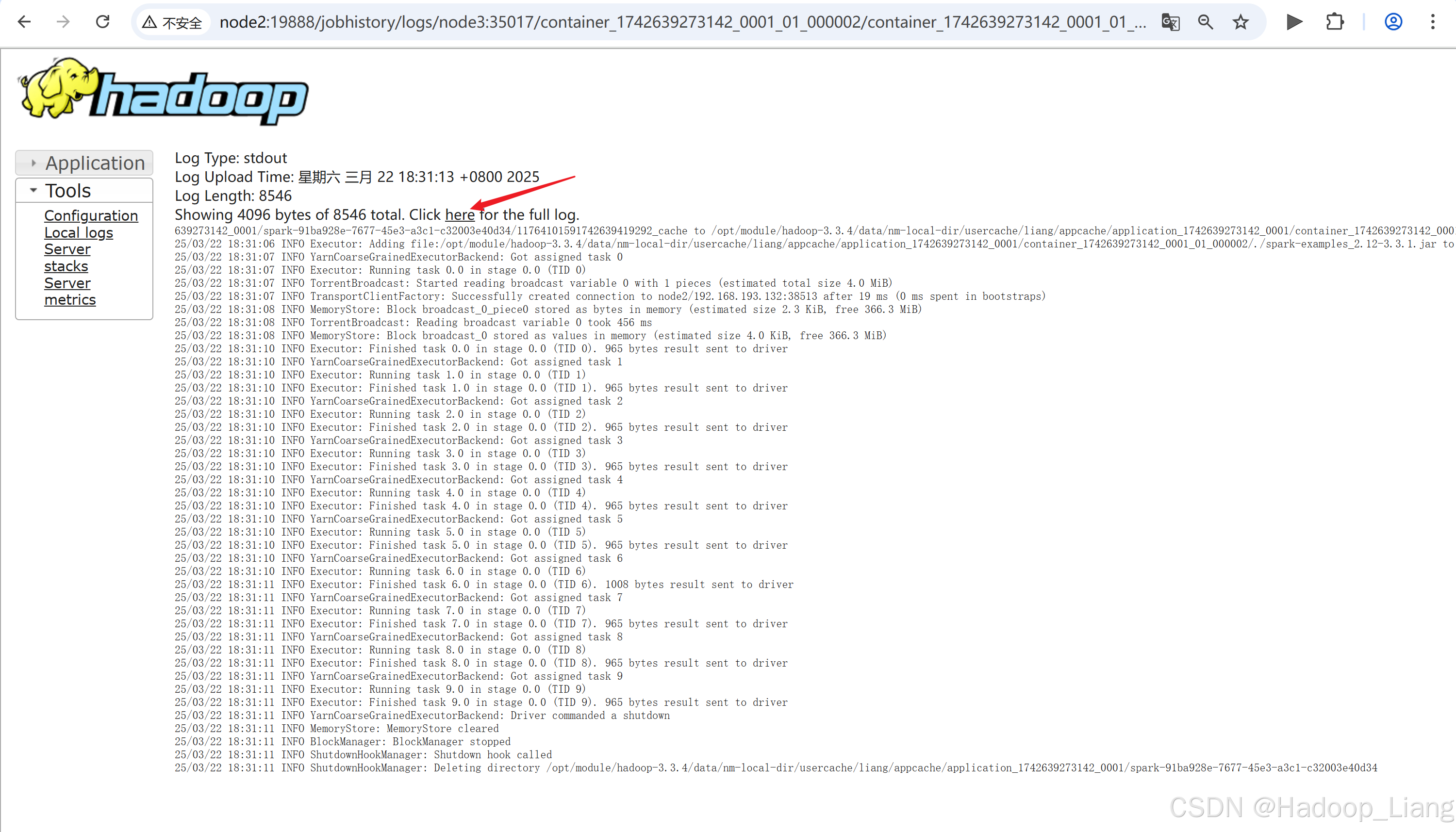
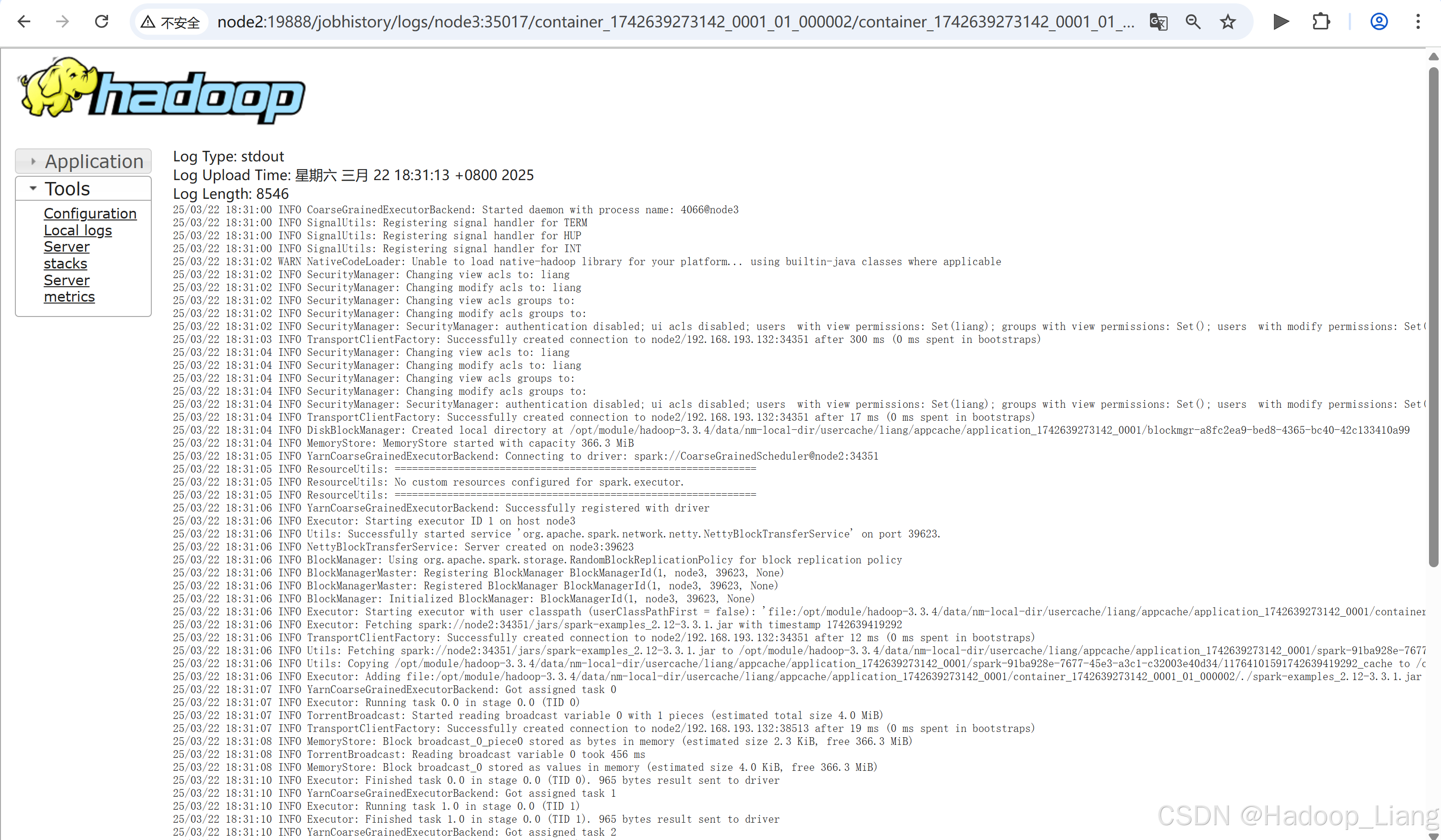
关闭服务
$ sbin/stop-history-server.sh
$ hdp.sh stopjps查看进程
[liang@node2 spark-yarn]$ jpsall =============== node2 =============== 24703 Jps =============== node3 =============== 16513 Jps =============== node4 =============== 14598 Jps
如有需要,可点击查看:配套视频教程
完成!enjoy it!
相关文章:
openEuler24.03 LTS下安装Spark
目录 安装模式介绍 下载Spark 安装Local模式 前提条件 解压安装包 简单使用 安装Standalone模式 前提条件 集群规划 解压安装包 配置Spark 配置Spark-env.sh 配置workers 分发到其他机器 启动集群 简单使用 关闭集群 安装YARN模式 前提条件 解压安装包 配…...

蓝桥杯真题——接龙序列
蓝桥杯2023年第十四届省赛真题-接龙数列 题目描述 对于一个长度为 K 的整数数列:A1, A2, . . . , AK,我们称之为接龙数列当且仅当 Ai 的首位数字恰好等于 Ai−1 的末位数字 (2 ≤ i ≤ K)。 例如 12, 23, 35, 56, 61, 11 是接龙数列;12, 2…...
使用 DeepSeek API 实现新闻文章地理位置检测与地图可视化
使用 DeepSeek API 实现新闻文章地理位置检测与地图可视化 | Implementing News Article Location Detection and Map Visualization with DeepSeek API 作者:zhutoutoutousan | Author: zhutoutoutousan 发布时间:2025-04-08 | Published: 2025-04-08 标…...
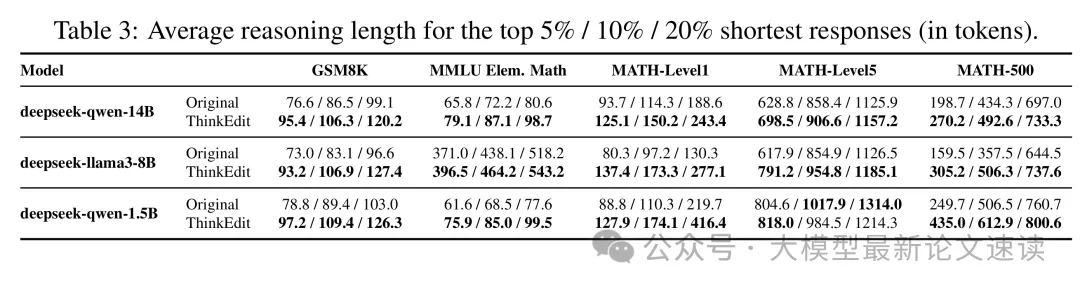
如何精准控制大模型的推理深度
论文标题 ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models 论文地址 https://arxiv.org/pdf/2503.22048 代码地址 https://github.com/Trustworthy-ML-Lab/ThinkEdit 作者背景 加州大学圣迭戈分校 动机 链式推理能显…...

【力扣hot100题】(078)跳跃游戏Ⅱ
好难啊,我愿称之为跳崖游戏。 依旧用了两种方法,一种是我一开始想到的,一种是看答案学会的。 我自己用的方法是动态规划,维护一个数组记录到该位置的最少步长,每遍历到一个位置就嵌套循环遍历这个位置能到达的位置&a…...

Leetcode 34.在排序数组中查找元素的第一个和最后一个位置
题目描述 给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。 考察二…...

LangChain入门指南:调用DeepSeek api
文章目录 1. 什么是LangChain?2. 核心组件3. 为什么选择LangChain?4. 实战案例安装简单chat案例流式交互Prompt模板 5. 简单总结 1. 什么是LangChain? 定义:LangChain是一个用于构建大语言模型(LLM)应用的…...
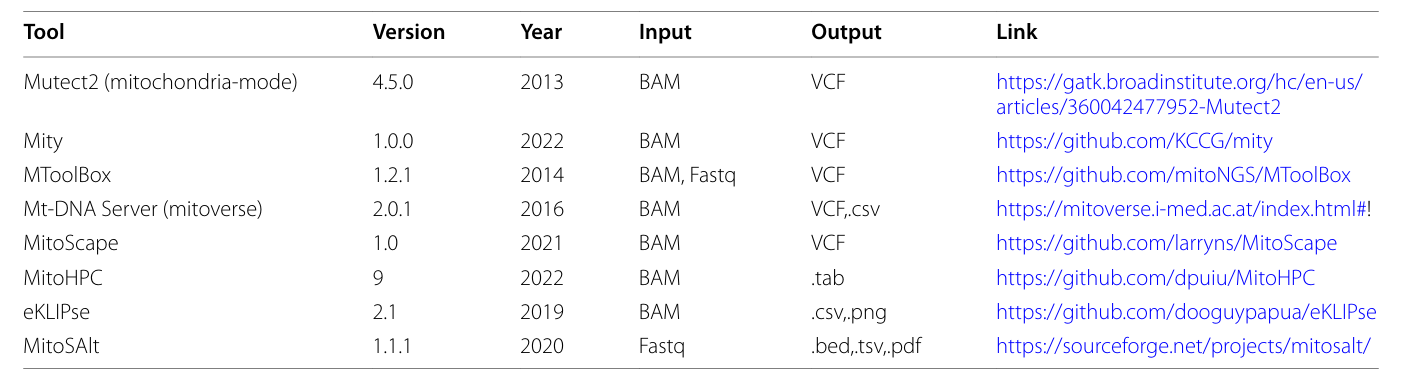
WES与WGS数据线粒体DNA数据分析及检测工具
1. 线粒体DNA的异质性 传统的全外显子组测序(WES)和全基因组测序(WGS)的二代测序(SGS) 数据分析流程,能够识别多种类型的基因改变。但大多数用于基因变异分析和注释的工具,在输出文…...
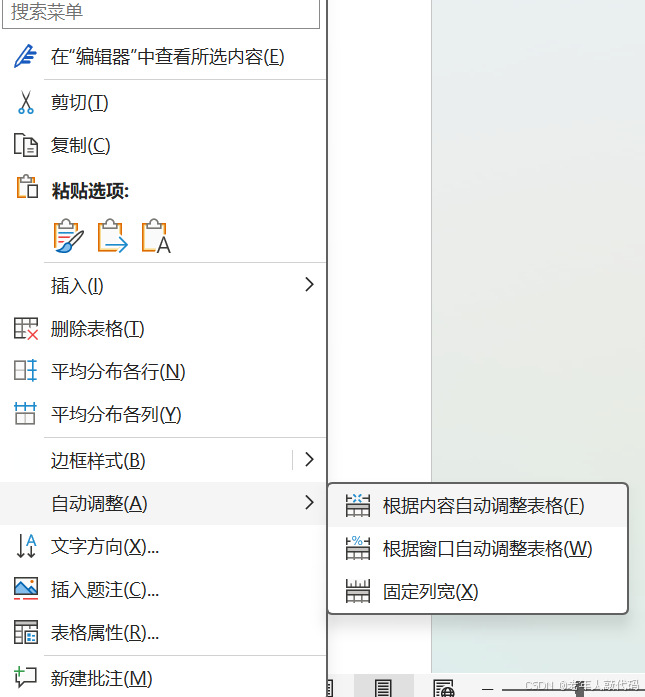
word表格间隔设置
1.怎么解决word表格间隔达不到我们想要的要求 其实很简单, 我们直接在word表格里面, 全选表格中里面的内容。接着,我们选择自动调整---->根据内容自动调整表格,即可达到我们想要的要求...
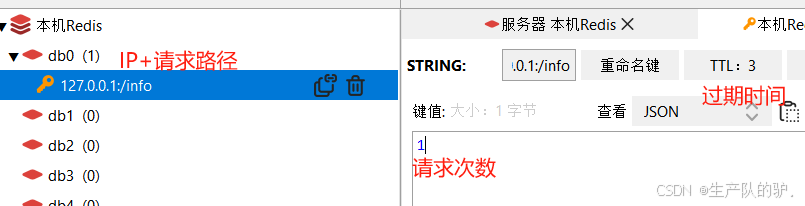
SpringBoot 接口限流Lua脚本接合Redis 服务熔断 自定义注解 接口保护
介绍 Spring Boot 接口限流是防止接口被频繁请求而导致服务器负载过重或服务崩溃的一种策略。通过限流,我们可以控制单位时间内允许的请求次数,确保系统的稳定性。限流可以帮助防止恶意请求、保护系统资源,并优化 API 的可用性,避…...

设计模式 --- 观察者模式
设计模式 --- 观察者模式 什么是观察者模式观察者模式典型应用 --- C#中的事件使用观察者模式实现事件处理机制 什么是观察者模式 观察者模式(Observer Pattern)是一种行为型设计模式,用于在对象之间建立一对多的依赖关系。当一个对象&#x…...

电商核心指标解析与行业趋势:数据驱动的增长策略【大模型总结】
电商核心指标解析与行业趋势:数据驱动的增长策略 在电商领域,数据是决策的核心。从流量监测到用户行为分析,从价格策略到技术赋能,每一个环节的优化都离不开对核心指标的深度理解。本文结合行业最新趋势与头部平台实践࿰…...
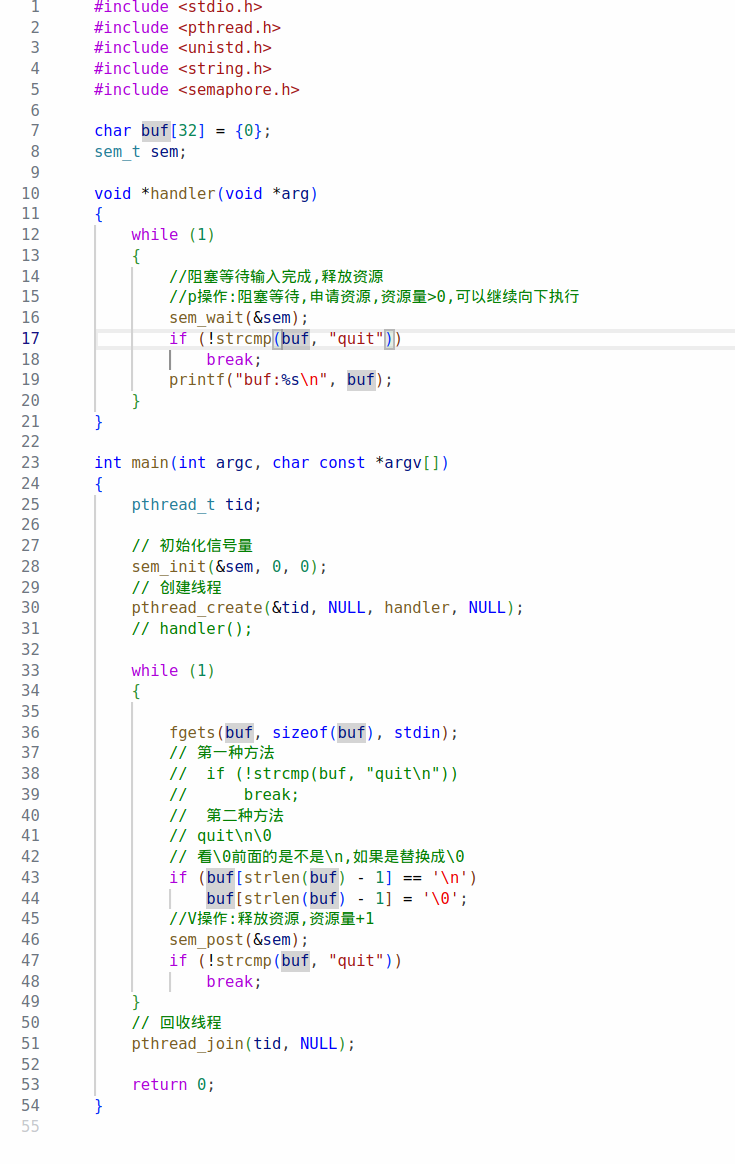
I/O进程4
day4 九、信号灯集 1.概念 信号灯(semaphore),也叫信号量。它是不同进程间或一个给定进程内部不同线程间同步的机制;System V的信号灯是一个或者多个信号灯的一个集合。其中的每一个都是单独的计数信号灯。 通过信号灯集实现共享内存的同步操作。 2.编程…...
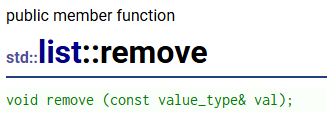
【语法】C++的list
目录 为什么会有list? 迭代器失效: list和vector的迭代器不同的地方: list的大部分用法和vector都很像,例如push_back,构造,析构,赋值重载这些就不再废话了,本篇主要讲的是和vecto…...

【算法笔记】并查集详解
🚀 并查集(Union-Find)详解:原理、实现与优化 并查集(Union-Find)是一种非常高效的数据结构,用于处理动态连通性问题,即判断若干个元素是否属于同一个集合,并支持集合合…...
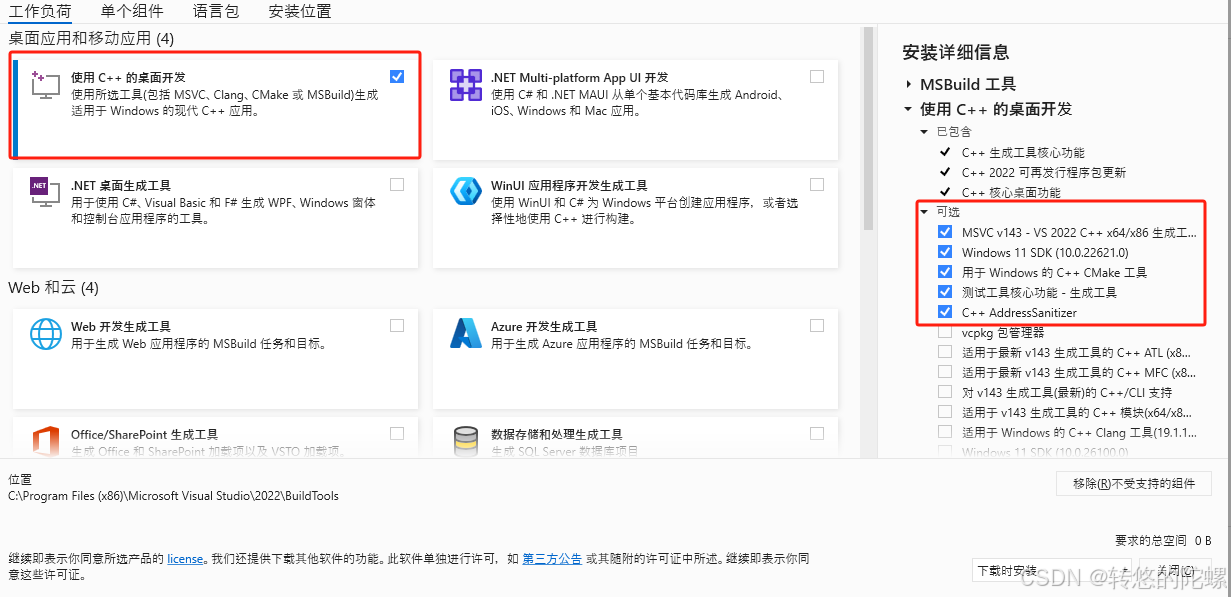
【Ai/Agent】Windows11中安装CrewAI过程中的错误解决记录
CrewAi是什么,可以看之下之前写的 《初识CrewAI多智能代理团队协框架》 (注:这篇是基于linux系统下安装实践的) 基于以下记录解决问题后,可以再回到之前的文章继续进行CrewAI的安装 遇到问题 在windows系统中安装 CrewAi 不管是使用 pip 或者…...

OSPF的数据报文格式【复习篇】
OSPF协议是跨层封装的协议(跨四层封装),直接将应用层的数据封装在网络层协议之后,IP协议包中协议号字段对应的数值为89 OSPF的头部信息: 所有的数据共有的信息字段 字段名描述版本当前OSPF进程使用的版本(…...

[leetcode]查询区间内的所有素数
一.暴力求解 #include<iostream> #include<vector> using namespace std; vector<int> result; bool isPrime(int i) { if (i < 2) return false; for (int j 2;j * j < i;j) { if (i % j 0) { …...

【力扣刷题实战】Z字形变换
大家好,我是小卡皮巴拉 文章目录 目录 力扣题目:Z字形变换 题目描述 解题思路 问题理解 算法选择 具体思路 解题要点 完整代码(C) 兄弟们共勉 !!! 每篇前言 博客主页:小卡…...

【RK3588 嵌入式图形编程】-SDL2-扫雷游戏-添加地雷到网格
添加地雷到网格 文章目录 添加地雷到网格1、概述2、更新Globals.h3、在随机单元格中放置地雷4、更新单元格以接收地雷5、渲染地雷图像6、开发助手7、完整代码8、总结在本文中,我们将更新游戏以在网格中随机放置地雷,并在单元格被清除时渲染它们。 1、概述 在我们扫雷游戏教程…...

Fortran 中读取 MATLAB 生成的数据文件
在 Fortran 中读取 MATLAB 生成的数据文件,可以通过以下几种方法实现,包括使用开源工具和手动解析: 1. 使用开源工具:MATFOR MATFOR 是一个商业/开源混合工具(部分功能免费),提供 Fortran 与 M…...

Kubernetes 入门篇之网络插件 calico 部署与安装
在运行kubeadm init 和 join 命令部署好master和node节点后,kubectl get nodes 看到节点都是NotReady状态,这是因为没有安装CNI网络插件。 kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master Not…...
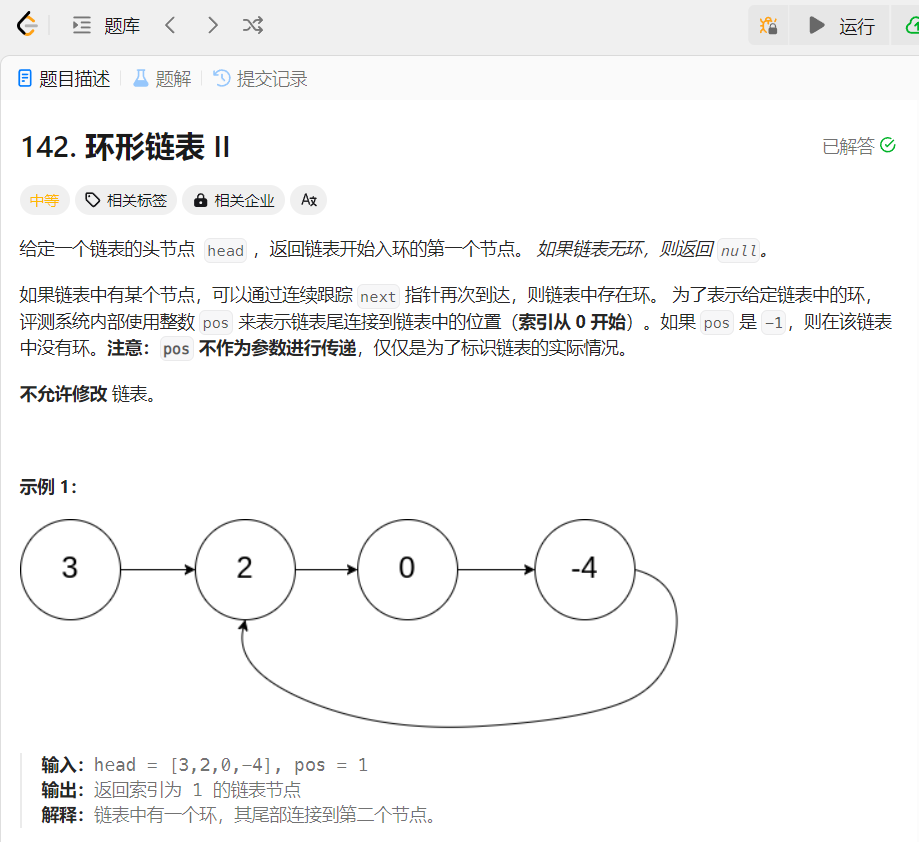
力扣题解:142. 环形链表 II
在链表学习中,我们已经了解了单链表和双链表,两者的最后一个结点都会指向NULL;今天我们介绍的循环列表则不同,其末尾结点指向的这是链表中的一个结点。 循环链表是一种特殊类型的链表,其尾节点的指针指向头节点&#…...

latex模板文件
LaTeX 是一款广泛应用于学术领域的文档排版系统,尤其以其在数学公式、科学符号和复杂技术文档排版中的强大能力著称。虽然它本身并非专门的“数学软件”,但在处理数学相关内容时表现尤为出色。 1. LaTeX 的核心特点 数学公式支持ÿ…...

BLE 协议栈事件驱动机制详解
在 BlueNRG-LP 等 BLE 系统中,事件驱动是控制状态转移、数据交互和外设协作的基础。本文将深入讲解 BLE 协议栈中事件的来源、分发流程、处理结构与实际工程实践策略,帮助你构建稳定、可维护的 BLE 系统。 📦 一、BLE 事件的来源分类 BLE 协议栈中的事件严格来自协议栈本身…...
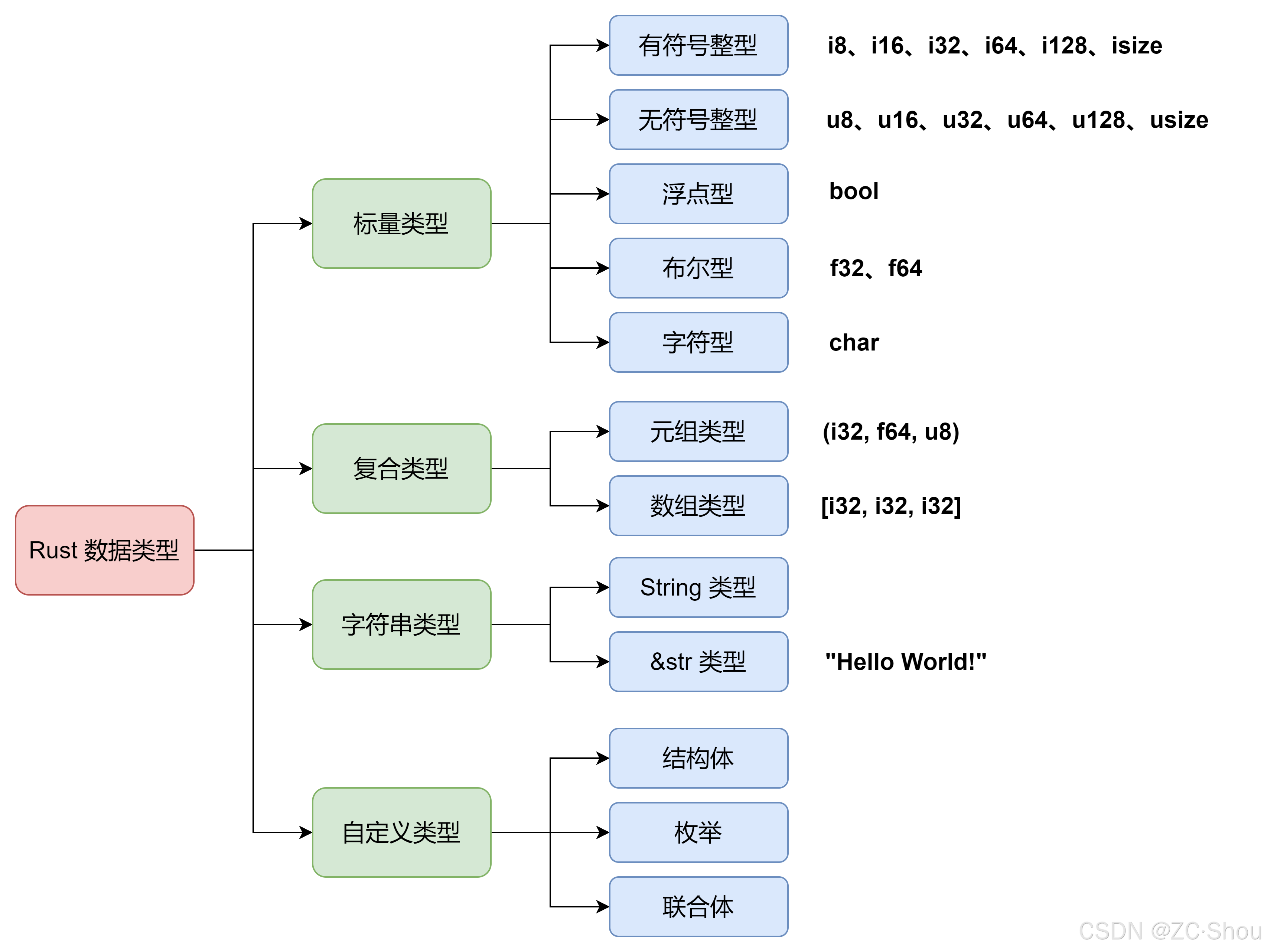
Rust 之四 运算符、标量、元组、数组、字符串、结构体、枚举
概述 Rust 的基本语法对于从事底层 C/C 开发的人来说多少有些难以理解,虽然官方有详细的文档来介绍,不过内容是相当的多,看起来也费劲。本文通过将每个知识点简化为 一个 DEMO 每种特性各用一句话描述的形式来简化学习过程,提高学…...

fuse-python使用fuse来挂载fs
winfsp 安装winfsp,https://winfsp.dev/ fusepy python安装fusepy #!/usr/bin/env python3 import os import stat from fuse import FUSE, FuseOSError, Operationsclass Passthrough(Operations):def __init__(self, root):self.root root# 辅助函数:将挂载点…...
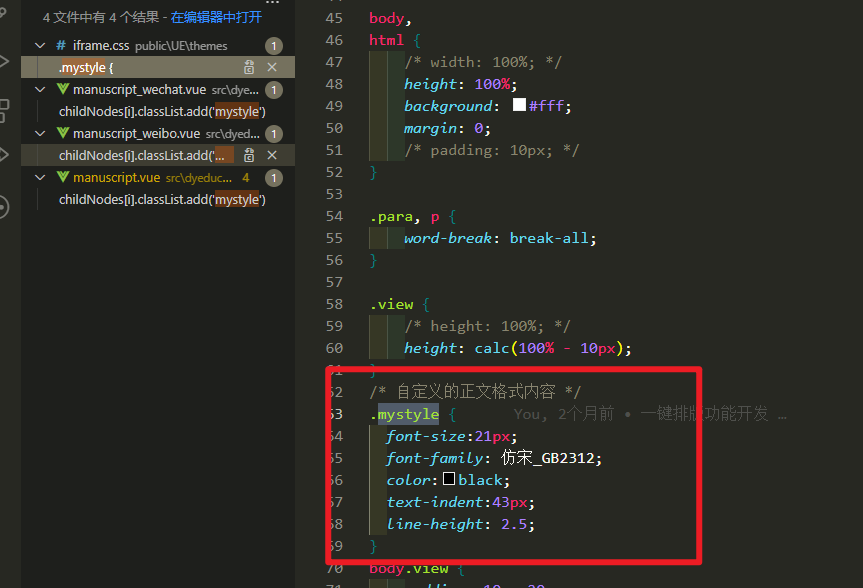
基于ueditor编辑器的功能开发之增加自定义一键排版功能
用户有自己的文章格式,要求复制或者粘贴进来的文章能够一键排版,不需要手动调试 这个需求的话咱们就需要自己去注册一个事件啦,这里我没有修改源码,而是在编辑器初始化之后给他注册了一个事件 我的工具列表变量 vue组件中data中…...

内核态切换到用户态
内核态切换到用户态 是操作系统中 CPU 执行模式的一种切换过程,涉及从高权限的内核态(Kernel Mode)切换到低权限的用户态(User Mode)。以下是详细解释: 1. 什么是内核态和用户态? 内核态&#…...

win10离线环境下配置wsl2和vscode远程开发环境
win10离线环境下配置wsl2和vscode远程开发环境 环境文件准备wsl文件准备vscode文件准备 内网环境部署wsl环境部署vscode环境部署 迁移后Ubuntu中的程序无法启动 环境 内网机:win10、wsl1 文件准备 wsl文件准备 在外网机上的wsl安装Ubuntu24.04,直接在…...