机器学习 Day10 逻辑回归
1.简介

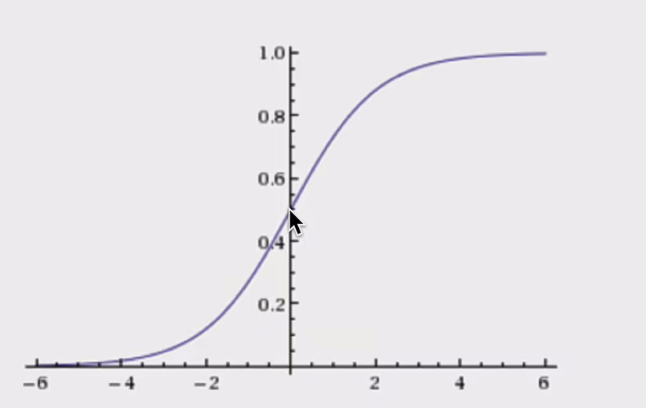
流程就是:



就是我们希望回归后激活函数给出的概率越是1和0.
2.API介绍
sklearn.linear_model.LogisticRegression 是 scikit-learn 库中用于实现逻辑回归算法的类,主要用于二分类或多分类问题。以下是对其重要参数的详细介绍:
2.1. API函数
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty='l2', C = 1.0)
因为逻辑回归是先回归再使用激活函数,所以也涉及过拟合问题,所以后边会有正则化以及处罚力度。
2.2. 参数说明
- solver:用于优化问题的算法,可选参数为
{'liblinear', 'sag', 'saga', 'newton - cg', 'lbfgs'}。- 默认值:
'liblinear'。对于小数据集,'liblinear'是不错的选择 。 - 大数据集适用:
'sag'和'saga'对于大型数据集计算速度更快。 - 多类问题处理:对于多类问题,只有
'newton - cg'、'sag'、'saga'和'lbfgs'可以处理多项损失;'liblinear'仅限于 “one - versus - rest”(一对多)分类 。
- 默认值:
- penalty:指定正则化的种类 。通过对模型参数进行约束,防止模型过拟合。常见的正则化类型如
'l1'(lasso回归)、'l2'等(岭回归),不同类型对参数的约束方式有差异。 - C:正则化力度的倒数 。默认值:
1.0。C 值越小,正则化力度越强,模型越倾向于简单化,防止过拟合;C 值越大,正则化力度越弱,模型复杂度可能更高 。
2.3. 其他特性
- 默认将类别数量少的当做正例。
LogisticRegression方法相当于SGDClassifier(loss="log", penalty=" "),即损失函数是对数似然损失的回归,(这个api是回归里的api,默认是最小二乘法,是Day09里的)SGDClassifier实现了普通的随机梯度下降学习,而LogisticRegression(实现了SAG,随机平均梯度法 )在一些情况下能更高效地收敛,尤其对于大规模数据。
3.肿瘤预测案例


import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import ssl# 解决SSL验证问题
ssl._create_default_https_context = ssl._create_unverified_context# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)# 2.基本数据处理
# 2.1 缺失值处理
data = data.replace(to_replace="?", value=np.NaN)
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:, 1:10]
y = data["Class"]
# 2.3 分割数据
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)# 3.特征工程(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4.机器学习(逻辑回归)
estimator = LogisticRegression()
estimator.fit(x_train, y_train)# 5.模型评估
y_predict = estimator.predict(x_test)
print("预测结果:", y_predict)
score = estimator.score(x_test, y_test)
print("模型得分:", score)names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class'] data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",names=names)从提供的链接读取数据集时,若不指定
names,默认会将文件第一行数据当作列名,但该数据集可能无此默认列名信息,通过手动指定names列表,能准确对应各列含义,方便后续基于列名进行数据处理、特征提取等操作 。
提出疑问: 我们仅仅考虑准确率是不行的,我们相比准确率更加关注的是在所有样本中,是否能把所有是癌症患者检测出来,这是我们很关注的,所以评估分类模型还有一下评估办法也很重要(KNN也可以用)
4.分类模型评估方法

labels和target_names对应是为了让结果显示的更加容易观察。
但是有如下问题:如果我们有99个癌症,1个非癌症,不管如何预测为癌症,这样的话预测准确率就是99%,这样好吗,这个模型如果在其他数据上会出大错,因为全部预测为了癌症哈哈哈,这就是样本不均衡问题,一会我们会讲样本不均衡数据该怎么样做到样本均衡但是现在我们要看其他的评估指标来用于样本不均衡问题:
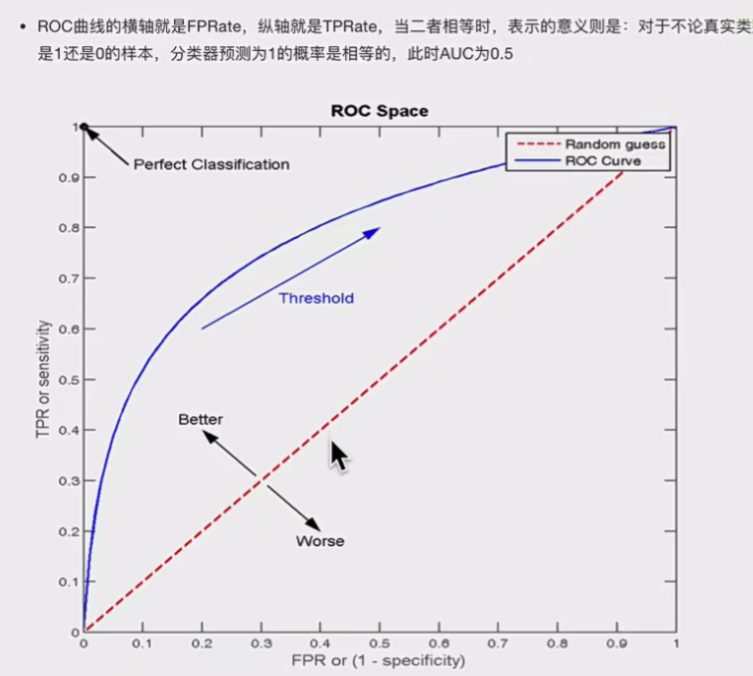
TPR就是召回率,就是模型识别正确能力,FPR就是模型识别错误的能力,下一节会详解ROC曲线是如何绘制的。

即AUC=0.5,模型就是瞎蒙
总结:

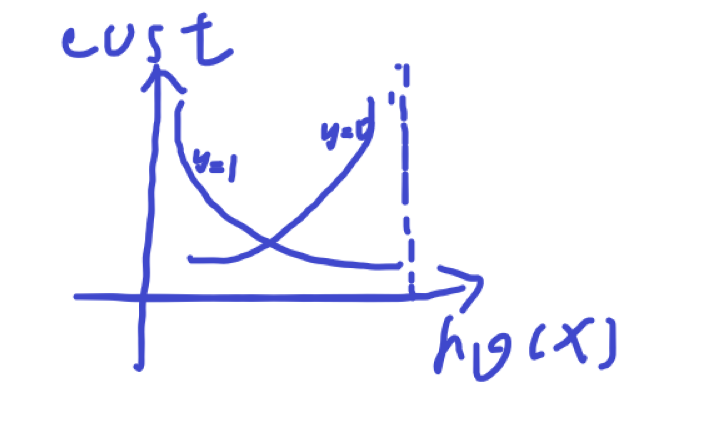
5.AUC如何绘制
就是你给我传入真实值(y_test)和预测值(y_pre),让它们一一对应起来,逻辑回归其实会转化概率,即每个预测值都会带有一个概率,我们让这些成对数据按照概率排序(概率仅用来排序,而具体的概率数值并不直接影响TPR和FPR的计算)
然后从第一个开始,我们将每个对预测结果都视为正(其实不一定为正),将原本的正/0进行比对,带入混淆矩阵,计算TRP与FRP作为一对,依次绘图即可:
比如原始真实数据是:![]()
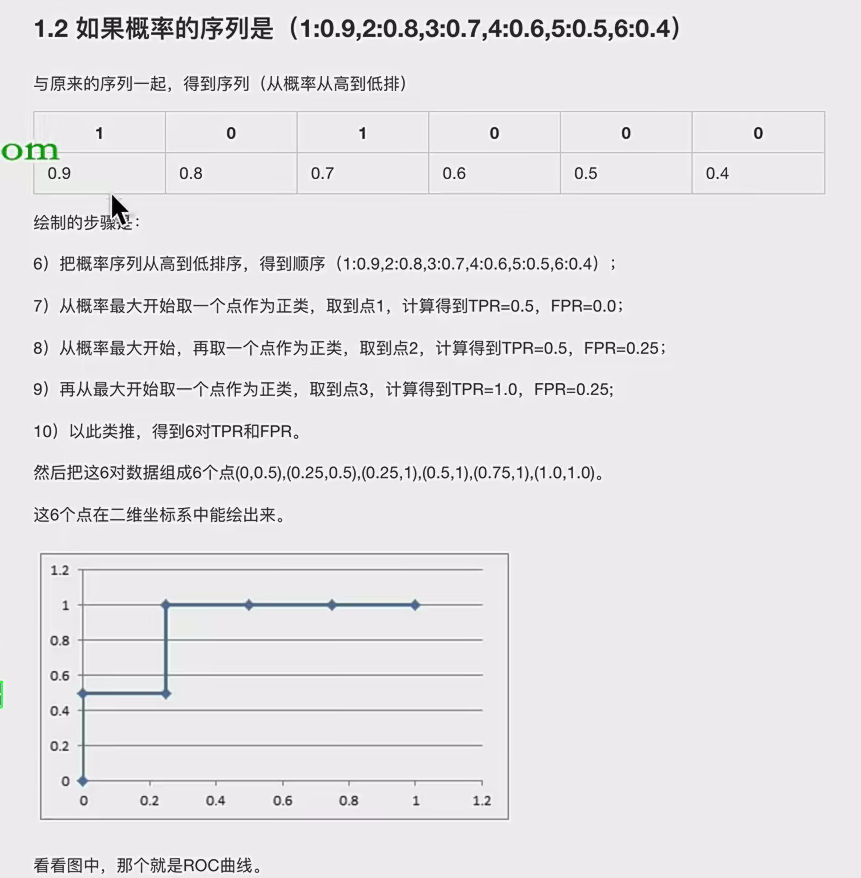
可以看到概率仅仅是排序作用,你正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),这就是为什么ROC越靠左上越好。概率对ROC曲线的影响。而且每次计算都是将预测值视为正值,带入混淆矩阵,即:
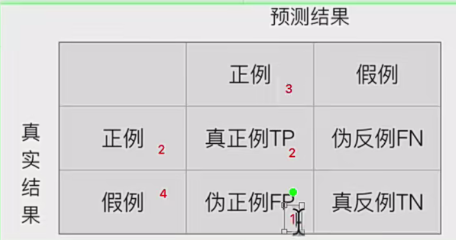
每次选取总是会填在预测结果的第一列(均视为正例),实际是什么决定天真第几行。
看我想到的一些深远的问题:
1.概率问题:正值概率越高,就会越排在前面,这样的话计算的TRP就会越接近1,而FPR就是0,这样的话ROC曲线就越靠近左上,效果越好,模型做的越好,因为损失小(正值概率越高,假值概率越低),所以ROC看重的是排序能力。
2.阈值不影响ROC绘制:

6.对于类别不平衡数据处理
6.1准备:
python中lmblearn库专门用来处理类别不平衡问题 。
1. 类别不平衡问题概述
类别不平衡是指数据集中不同类别的样本数量差异很大的情况。一个三分类问题,其中:
类别0: 64个样本(1.28%)
类别1: 262个样本(5.24%)
类别2: 4674个样本(93.48%)
这种极端不平衡会导致模型偏向多数类,忽视少数类。
2. 创建不平衡数据集
使用datasets库里的
make_classification函数创建人工不平衡数据集:from sklearn.datasets import make_classification import matplotlib.pyplot as plt# 创建5000个样本,2个特征,3个类别的不平衡数据集 X, y = make_classification(n_samples=5000,n_features=2, # 特征总数n_informative=2, # 有意义的特征数n_redundant=0, # 冗余特征数n_repeated=0, # 重复特征数n_classes=3, # 类别数n_clusters_per_class=1, # 每个类别的簇数weights=[0.01, 0.05, 0.94], # 各类别比例random_state=0 # 随机种子 )特征总数需要等于后面的有意义,冗余,重复特征数3. 查看类别分布
使用
Counter函数可以查看各类别样本数量:from collections import Counter print(Counter(y)) # 输出: Counter({2: 4674, 1: 262, 0: 64})
6.2处理办法

相关文章:
机器学习 Day10 逻辑回归
1.简介 流程就是: 就是我们希望回归后激活函数给出的概率越是1和0. 2.API介绍 sklearn.linear_model.LogisticRegression 是 scikit-learn 库中用于实现逻辑回归算法的类,主要用于二分类或多分类问题。以下是对其重要参数的详细介绍: 2.1.…...

即时通讯软件BeeWorks,企业如何实现细粒度的权限控制?
BeeWorks作为一款专为企业设计的即时通讯平台,高度重视用户隐私安全,采取了多种措施来保障数据的保密性、完整性和可用性。 首先,BeeWorks采用私有化部署模式,企业可以将服务器架设在自己的网络环境中,所有通讯数据&a…...
Seq2Seq - Dataset 类
本节代码定义了一个 CMN 类,它继承自 PyTorch 的 Dataset 类,用于处理英文和中文的平行语料库。这个类的主要作用是将文本数据转换为模型可以处理的格式,并进行必要的填充操作,以确保所有序列的长度一致。 ⭐重写Dataset类是模型训…...

学习OpenCV C++版
OpenCV C 1 数据载入、显示与保存1.1 概念1.2 Mat 类构造与赋值1.3 Mat 类的赋值1.4 Mat 类支持的运算1.5 图像的读取与显示1.6 视频加载与摄像头调用1.7 数据保存 参考:《OpenCV4快速入门》作者冯 振 郭延宁 吕跃勇 1 数据载入、显示与保存 1.1 概念 Mat 类 : Ma…...
echarts图表相关
echarts图表相关 echarts官网折线图实际开发场景一: echarts官网 echarts官网 折线图 实际开发场景一: 只有一条折线,一半实线,一半虚线。 option {tooltip: {trigger: "axis",formatter: (params: any) > {const …...
idea自动部署jar包到服务器Alibaba Cloud Toolkit
安装插件:Alibaba Cloud Toolkit 配置服务器: 服务器配置: 项目启动Shell脚本命令: projectpd-otb.jar echo 根据项目名称查询对应的pid pid$(pgrep -f $project); echo $pid echo 杀掉对应的进程,如果pid不存在,则不执行 if [ …...

奥利司他
https://m.baidu.com/bh/m/detail/ar_9900965142893895938 奥利司他(四氢脂抑素)是一种众所周知的胰腺和胃脂肪酶不可逆抑制剂 生物活性:奥利司他(四氢脂抑素)是一种众所周知的胰腺和胃脂肪酶不可逆抑制剂。奥利司…...
Element Plus 图标使用方式整理
Element Plus 图标使用方式整理 以下是 Element Plus 图标的所有使用方式,包含完整代码示例和总结表格: 1. 按需引入图标组件 适用场景:仅需少量图标时,按需导入减少打包体积 示例代码: <template><div>…...

链路聚合+vrrp
1.链路聚合 作用注意事项将多个物理接口(线路)逻辑上绑定在一起形成一条逻辑链路,起到叠加带宽的作用1.聚合接口必须转发速率一致。2.聚合设备两端必须一致 配置命令 方法一 [Huawei]interface Eth-Trunk 0----先创建聚合接口,…...
Dynamics 365 Business Central Register Customer Payment 客户付款登记
#Dynamics 365 BC ERP# #D365 ERP# #Navision 前言 在实施过程,经常给客户介绍的 给客户付款一般用Payment Journal. 在客户熟悉系统运行后,往往会推荐客户使用Register Customer Payment.用这个function 工作会快很多,但出错的机会也比较大…...

Odoo免费开源ERP:企业销售过程中出现的问题
在企业未上线Odoo免费开源ERP时,企业销售过程中会存在失误。比如,许多销售订单都有如下问题:不当的定价、向客户过多地询问、处理订单延误、错过发货日期等。这些问题源于企业三个未集成的信息系统:销售管理系统、库存系统和财务系…...

手撕unique_ptr 和 shareed_ptr
文章目录 unique_ptrshared_ptr unique_ptr template<class T> class Unique_ptr { private:T* ptrNULL; public://1、删除默认的拷贝构造函数Unique_ptr(Unique_ptr& u) delete;//2、删除默认的复制构造Unique_ptr& operator(Unique_ptr& u) delete; …...

工会考试的重点内容是什么
工会考试的内容通常涵盖以下几个方面: 1、政治理论: 主要考查考生对马克思主义基本原理、中国特色社会主义理论体系、党的基本路线、方针、政策等方面的掌握程度。题型通常包括选择题、判断题和论述题。 2、法律法规: 这部分主要涉及国家…...
网络稳定性--LCA+最大生成树+bfs1/dfs1找最小边
1.最大生成树去除重边,只要最大的边成树 2.LCA查最近公共祖先,然后询问的lca(x,y)ff,分别从x,y向上找最小边 3.bfs1/dfs1就是2.中向上找的具体实现 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typede…...

混合并行技术在医疗AI领域的应用分析(代码版)
混合并行技术(专家并行/张量并行/数据并行)通过多维度的计算资源分配策略,显著提升了医疗AI大模型的训练效率与推理性能。以下结合技术原理与医疗场景实践,从策略分解、技术对比、编排优化及典型案例等维度展开分析: 一、混合并行技术:突破单卡算力限制 1. 并行策略三维分…...

【C++面向对象】封装(上):探寻构造函数的幽微之境
每文一诗 💪🏼 我本将心向明月,奈何明月照沟渠 —— 元/高明《琵琶记》 译文:我本是以真诚的心来对待你,就像明月一样纯洁无瑕;然而,你却像沟渠里的污水一样,对这份心意无动于衷&a…...

每日算法-250409
这是我今天的算法学习记录。 2187. 完成旅途的最少时间 题目描述 思路 二分查找 解题过程 为什么可以使用二分查找? 问题的关键在于寻找一个最小的时间 t,使得在时间 t 内所有公交车完成的总旅途次数 sum 大于等于 totalTrips。 我们可以观察到时间的单…...

如何实现文本回复Ai ChatGPT DeepSeek 式文字渐显效果?前端技术详解(附完整代码)
个人开发的塔罗牌占卜小程序:【问问塔罗牌】 快来瞧瞧吧! 一、核心实现原理 我们通过三步实现这个效果: 逐字渲染:通过 JavaScript 定时添加字符 透明度动画:CSS 实现淡入效果 光标动画:伪元素 CSS 动画…...

CompletableFuture高级模式详解
目录 CompletableFuture高级模式详解 1. CompletableFuture基础概念 1.1 什么是CompletableFuture? 1.2 异步编程基础 1.3 CompletableFuture与Future的对比 2. 创建CompletableFuture 2.1 基本创建方法 2.2 使用异步方法创建 2.3 指定执行器 3. 转换和链式操作 3.…...

【AI开源大模型工具链ModelEngine】【01】应用框架-源码编译运行
ModelEngine提供从数据处理、知识生成,到模型微调和部署,以及RAG(Retrieval Augmented Generation)应用开发的AI训推全流程工具链。 GitCode开源地址:https://gitcode.com/ModelEngineGitee开源地址:https…...
linux下截图工具的选择
方案一 gnome插件Screenshot Tool(截屏) ksnip(图片标注) gnome setting设置图片的默认打开方式为ksnip就可以快捷的将Screenshot Tool截屏的图片打开进行标记了。 但是最近我发现Screenshot Tool的延迟截图功能是有问题的&…...

每天记录一道Java面试题---day36
事务的基本特性和隔离级别 回答重点 事务基本特性ACID分别是: - 原子性指的是一个事务中的操作要么全部成功,要么全部失败。 - 一致性指的是数据库总是一个一致性的状态转换到另一个一致性的状态。比如A转账给B100块钱,假设A只有 90块&…...

Qt音频采集:QAudioInput详解与示例
1. 简介 QAudioInput是Qt Multimedia模块中用于音频采集的核心类,能够从麦克风等输入设备实时获取原始音频数据(PCM格式)。本文将通过原理讲解和代码示例,帮助开发者快速掌握音频采集的核心技术。 2. 核心功能 支持多种音频格式&…...
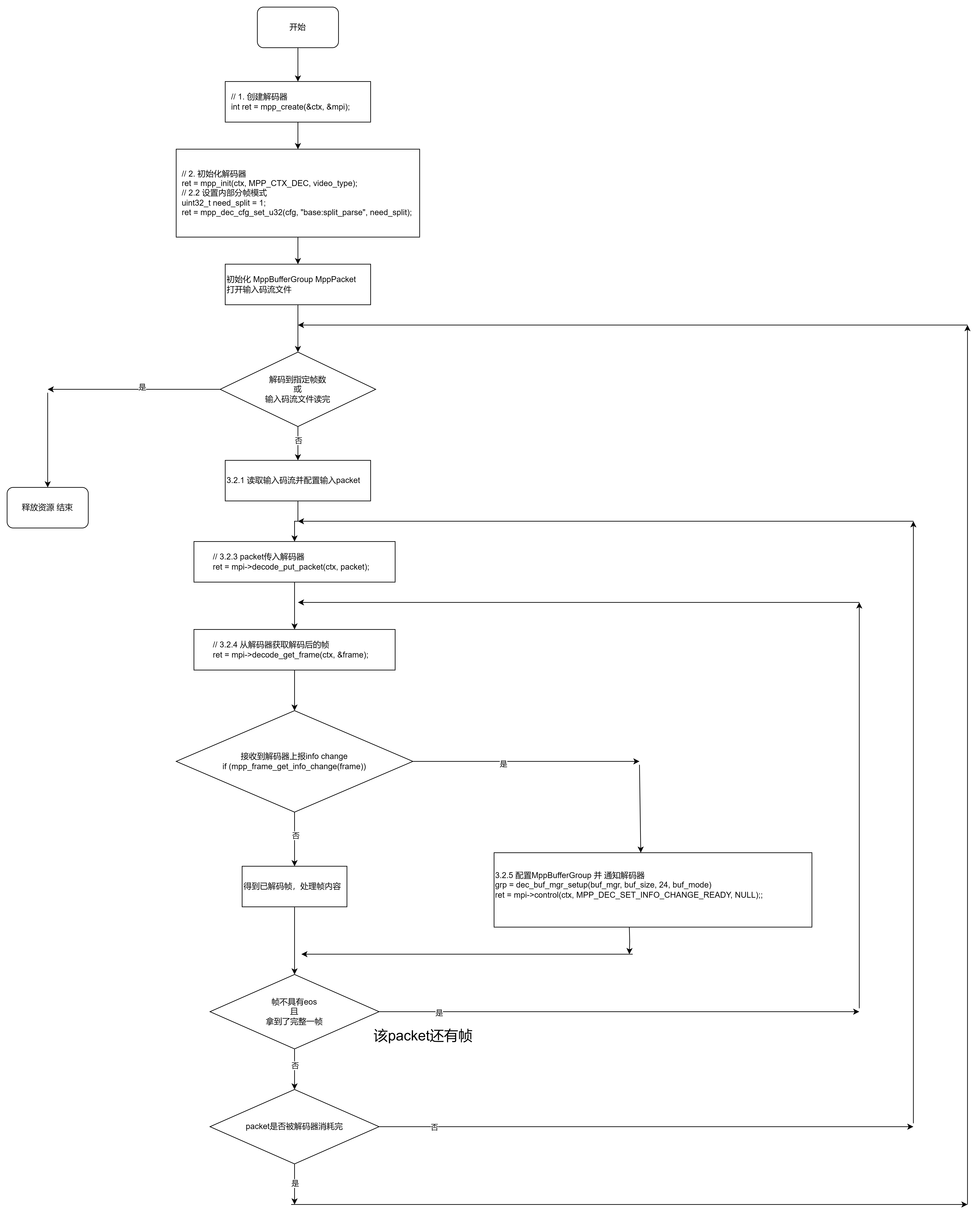
rkmpp 解码 精简mpi_dec_test.c例程
rkmpp 解码流程(除 MPP_VIDEO_CodingMJPEG 之外) 源码 输入h264码流 输出nv12文件 /** Copyright 2015 Rockchip Electronics Co. LTD** Licensed under the Apache License, Version 2.0 (the "License");* you may not use this file exce…...

怎么构造思维链数据?思维链提示工程的五大原则
我来为您翻译这篇关于思维链提示工程的文章,采用通俗易懂的中文表达: 思维链(CoT)提示工程是生成式AI(GenAI)中一种强大的方法,它能让模型通过逐步推理来解决复杂任务。通过构建引导模型思考过程的提示,思维链能提高输出的准确性…...
网络安全之-信息收集
域名收集 域名注册信息 站长之家 https://whois.chinaz.com/ whois 查询的相关网站有:中国万网域名WHOIS信息查询地址: https://whois.aliyun.com/西部数码域名WHOIS信息查询地址: https://whois.west.cn/新网域名WHOIS信息查询地址: http://whois.xinnet.com/domain/whois/in…...
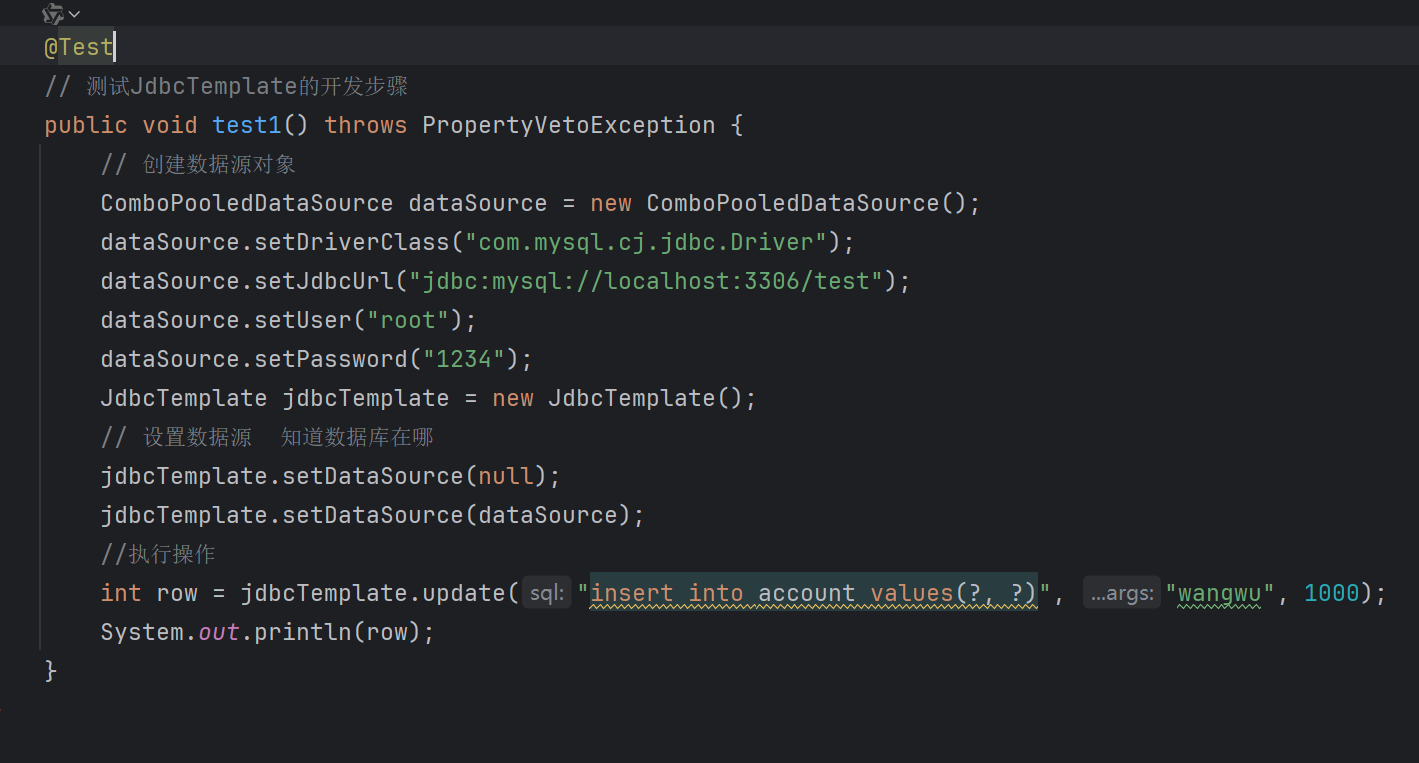
JdbcTemplate基本使用
JdbcTemplate概述 它是spring框架中提供的一个对象,是对原始繁琐的JdbcAPI对象的简单封装。spring框架为我们提供了很多的操作模板类。例如:操作关系型数据的JdbcTemplate和MbernateTemplate,操作nosql数据库的RedisTemplate,操作消息队列的…...

pnpm 中 Next.js 模块无法找到问题解决
问题概述 项目在使用 pnpm 管理依赖时,出现了 “Cannot find module ‘next/link’ or its corresponding type declarations” 的错误。这是因为 pnpm 的软链接机制在某些情况下可能导致模块路径解析问题。 问题诊断 通过命令 pnpm list next 确认项目已安装 Next.js 15.2.…...
openEuler24.03 LTS下安装Spark
目录 安装模式介绍 下载Spark 安装Local模式 前提条件 解压安装包 简单使用 安装Standalone模式 前提条件 集群规划 解压安装包 配置Spark 配置Spark-env.sh 配置workers 分发到其他机器 启动集群 简单使用 关闭集群 安装YARN模式 前提条件 解压安装包 配…...

蓝桥杯真题——接龙序列
蓝桥杯2023年第十四届省赛真题-接龙数列 题目描述 对于一个长度为 K 的整数数列:A1, A2, . . . , AK,我们称之为接龙数列当且仅当 Ai 的首位数字恰好等于 Ai−1 的末位数字 (2 ≤ i ≤ K)。 例如 12, 23, 35, 56, 61, 11 是接龙数列;12, 2…...