力扣第444场周赛
这次力扣周赛对我来说难度确实大, 只做出两题, 但还是想分享一下的做题经验和感受
1. 移除最小数对使数组有序 I
题目链接:力扣
给你一个数组
nums,你可以执行以下操作任意次数:
- 选择 相邻 元素对中 和最小 的一对。如果存在多个这样的对,选择最左边的一个。
- 用它们的和替换这对元素。
返回将数组变为 非递减 所需的 最小操作次数 。
如果一个数组中每个元素都大于或等于它前一个元素(如果存在的话),则称该数组为非递减。
示例 1:
输入: nums = [5,2,3,1]
输出: 2
解释:
- 元素对
(3,1)的和最小,为 4。替换后nums = [5,2,4]。- 元素对
(2,4)的和为 6。替换后nums = [5,6]。数组
nums在两次操作后变为非递减。示例 2:
输入: nums = [1,2,2]
输出: 0
解释:
数组
nums已经是非递减的。
提示:
1 <= nums.length <= 50-1000 <= nums[i] <= 1000
解题思路:按题目进行模拟就行, 第一题一般不会卡你时间复杂度的, 找到相邻和最小, 然后用相邻和去替换这个数对
class Solution {
public:bool judge(vector<int>& arr){for(int i=1;i<arr.size();i++){if(arr[i-1]>arr[i]){return false;}}return true;}void solve(vector<int>& nums){int index=-1; int maxNum=INT_MAX;for(int i=1;i<nums.size();i++){if(nums[i]+nums[i-1]<maxNum){maxNum=nums[i]+nums[i-1];index=i;// cout<<index<<endl;}}vector<int>::iterator a=nums.begin()+index; nums[index-1]=maxNum;// cout<<nums[index-1];nums.erase(a);}void print(vector<int>& nums){for(int i=0;i<nums.size();i++){cout<<nums[i];}cout<<endl;}int minimumPairRemoval(vector<int>& nums) {int count=0;while(!judge(nums)){// cout<<count<<endl;solve(nums);// print(nums);count++;}return count;}
};2.设计路由器
题目链接:力扣
请你设计一个数据结构来高效管理网络路由器中的数据包。每个数据包包含以下属性:
source:生成该数据包的机器的唯一标识符。destination:目标机器的唯一标识符。timestamp:该数据包到达路由器的时间戳。实现
Router类:
Router(int memoryLimit):初始化路由器对象,并设置固定的内存限制。
memoryLimit是路由器在任意时间点可以存储的 最大 数据包数量。- 如果添加一个新数据包会超过这个限制,则必须移除 最旧的 数据包以腾出空间。
bool addPacket(int source, int destination, int timestamp):将具有给定属性的数据包添加到路由器。
- 如果路由器中已经存在一个具有相同
source、destination和timestamp的数据包,则视为重复数据包。- 如果数据包成功添加(即不是重复数据包),返回
true;否则返回false。
int[] forwardPacket():以 FIFO(先进先出)顺序转发下一个数据包。
- 从存储中移除该数据包。
- 以数组
[source, destination, timestamp]的形式返回该数据包。- 如果没有数据包可以转发,则返回空数组。
int getCount(int destination, int startTime, int endTime):
- 返回当前存储在路由器中(即尚未转发)的,且目标地址为指定
destination且时间戳在范围[startTime, endTime](包括两端)内的数据包数量。注意:对于
addPacket的查询会按照timestamp的递增顺序进行。
示例 1:
输入:
["Router", "addPacket", "addPacket", "addPacket", "addPacket", "addPacket", "forwardPacket", "addPacket", "getCount"]
[[3], [1, 4, 90], [2, 5, 90], [1, 4, 90], [3, 5, 95], [4, 5, 105], [], [5, 2, 110], [5, 100, 110]]输出:
[null, true, true, false, true, true, [2, 5, 90], true, 1]解释:
Router router = new Router(3);// 初始化路由器,内存限制为 3。
router.addPacket(1, 4, 90);// 数据包被添加,返回 True。
router.addPacket(2, 5, 90);// 数据包被添加,返回 True。
router.addPacket(1, 4, 90);// 这是一个重复数据包,返回 False。
router.addPacket(3, 5, 95);// 数据包被添加,返回 True。
router.addPacket(4, 5, 105);// 数据包被添加,[1, 4, 90]被移除,因为数据包数量超过限制,返回 True。
router.forwardPacket();// 转发数据包[2, 5, 90]并将其从路由器中移除。
router.addPacket(5, 2, 110);// 数据包被添加,返回 True。
router.getCount(5, 100, 110);// 唯一目标地址为 5 且时间在[100, 110]范围内的数据包是[4, 5, 105],返回 1。示例 2:
输入:
["Router", "addPacket", "forwardPacket", "forwardPacket"]
[[2], [7, 4, 90], [], []]输出:
[null, true, [7, 4, 90], []]解释:
Router router = new Router(2);// 初始化路由器,内存限制为 2。
router.addPacket(7, 4, 90);// 返回 True。
router.forwardPacket();// 返回[7, 4, 90]。
router.forwardPacket();// 没有数据包可以转发,返回[]。
提示:
2 <= memoryLimit <= 1051 <= source, destination <= 2 * 1051 <= timestamp <= 1091 <= startTime <= endTime <= 109addPacket、forwardPacket和getCount方法的总调用次数最多为105。- 对于
addPacket的查询,timestamp按递增顺序给出。
解题思路:
forwardPacket()方法要求先进先出, 就写个队列, addPacket()方法就用set去维护, 当你insert一个[source、destination和timestamp]相同的元素时候,insert插入失败(insert的返回值是pair<iterator, bool> p)取出p.second的false即可,getCount()方法返回指定destination, 时间戳范围[startTime, endTime](包括两端)内的数据包数量. 怎么实现呢?用一个邻接表即可, key:destination, value: timestamp
class Router {
public:int memory_limit;set<tuple<int,int,int>> p_set;queue<tuple<int,int,int>> p_que;unordered_map<int, pair<vector<int>, int>> dest_to_timestamps; //destination -> [[timestamp], head]Router(int memoryLimit) {this->memory_limit=memoryLimit;}bool addPacket(int source, int destination, int timestamp) {auto p=make_tuple(source,destination,timestamp);if(!p_set.insert(p).second){return false;}//重复包if(p_que.size()==memory_limit){// return false;forwardPacket();}//包超了p_que.push(p);dest_to_timestamps[destination].first.push_back(timestamp);return true;}vector<int> forwardPacket() {if(p_que.empty()){return {};}auto p=p_que.front();p_que.pop();p_set.erase(p);auto [source, destination, timestamp] = p;dest_to_timestamps[destination].second++;return {source, destination, timestamp};}int getCount(int destination, int startTime, int endTime) {auto& [timestamps, head] = dest_to_timestamps[destination];auto left = lower_bound(timestamps.begin() + head, timestamps.end(), startTime);auto right = upper_bound(timestamps.begin() + head, timestamps.end(), endTime);return right - left;}
};
// 0 1 2 3 4
// 2 4
// 4-2=2
// [2,3]=2
/*** Your Router object will be instantiated and called as such:* Router* obj = new Router(memoryLimit);* bool param_1 = obj->addPacket(source,destination,timestamp);* vector<int> param_2 = obj->forwardPacket();* int param_3 = obj->getCount(destination,startTime,endTime);*/3.最大化交错和为 K 的子序列乘积
题目链接:力扣
给你一个整数数组
nums和两个整数k与limit,你的任务是找到一个非空的 子序列,满足以下条件:
- 它的 交错和 等于
k。- 在乘积 不超过
limit的前提下,最大化 其所有数字的乘积。返回满足条件的子序列的 乘积 。如果不存在这样的子序列,则返回 -1。
子序列 是指可以通过删除原数组中的某些(或不删除)元素并保持剩余元素顺序得到的新数组。
交错和 是指一个 从下标 0 开始 的数组中,偶数下标 的元素之和减去 奇数下标 的元素之和。
示例 1:
输入: nums = [1,2,3], k = 2, limit = 10
输出: 6
解释:
交错和为 2 的子序列有:
[1, 2, 3]
- 交错和:
1 - 2 + 3 = 2- 乘积:
1 * 2 * 3 = 6[2]
- 交错和:2
- 乘积:2
在 limit 内的最大乘积是 6。
示例 2:
输入: nums = [0,2,3], k = -5, limit = 12
输出: -1
解释:
不存在交错和恰好为 -5 的子序列。
示例 3:
输入: nums = [2,2,3,3], k = 0, limit = 9
输出: 9
解释:
交错和为 0 的子序列包括:
[2, 2]
- 交错和:
2 - 2 = 0- 乘积:
2 * 2 = 4[3, 3]
- 交错和:
3 - 3 = 0- 乘积:
3 * 3 = 9[2, 2, 3, 3]
- 交错和:
2 - 2 + 3 - 3 = 0- 乘积:
2 * 2 * 3 * 3 = 36子序列
[2, 2, 3, 3]虽然交错和为k且乘积最大,但36 > 9,超出 limit 。下一个最大且在 limit 范围内的乘积是 9。
提示:
1 <= nums.length <= 1500 <= nums[i] <= 12-105 <= k <= 1051 <= limit <= 5000
代码思路: 我最初用的是, 选或不选的思路, 根据题意, 我们可能需要维护交错和要等于k, 乘积不能超过limit, 还要维护当前子序列长度是奇数还是偶数。每个交错和下, 都保存着最大的乘积。但是,477 / 664 个通过的测试用例。
class Solution {
public:int maxProduct(vector<int>& nums, int k, int limit) {unordered_map<int,int> a;unordered_map<int,int> b;a[0]=1;for(int num:nums){unordered_map<int,int> new_a,new_b;for(auto& [x,y]:a){if(new_a.count(x)==0||y>new_a[x]){new_a[x]=y;}}for(auto& [x,y]:b){if(new_b.count(x)==0||y>new_b[x]){new_b[x]=y;}}for(auto& [x,y]:a){int new_x=x+num;int new_y=y*num;if(new_y<=limit){if(new_a.count(new_x)==0||new_y>new_b[new_x]){new_b[new_x]=new_y;}}}for(auto& [x,y]:b){int new_x=x-num;int new_y=y*num;if(new_x<=limit){if(new_a.count(new_x)==0||new_y>new_a[new_x]){new_a[new_x]=new_y;}}}int only_x=num;int only_y=num;if(only_x<=limit){if(new_b.count(only_x)==0){new_b[only_x]=num;}}a=move(new_a);b=move(new_b);}int maxNum=-1;if(a.count(k)){maxNum=max(maxNum,a[k]);}if(b.count(k)){maxNum=max(maxNum,b[k]);}return maxNum>0?maxNum:-1;}
};但是其实本题是可以直接进行暴力搜索的, 详细解释如下:
3509. 最大化交错和为 K 的子序列乘积 - 力扣(LeetCode)
我解释一下, 你在阅读中可能遇到的疑问:
1. 在本题的数据范围下,L≤12
注:2^12=4096<5000, 选2最多选12个,同理最多选7个3, 对1是的选择是没有限制的
2. 在两个大于 1 的数之间的连续的 1,其交错和 1−1+1−1+⋯ 的绝对值 ≤1。所以子序列中的所有 1 的交错和的绝对值 ≤L+1
注:
1的影响:如果有一堆
1,比如1 -1 +1 -1...,总和要么是0,要么是1或-1(来回摇摆)。所以
1不会让总和变得特别大。但是在一个序列中可能有L个大于1的数, L个数将序列分成L+1个只包含1的小块儿
eg: [1, 1, 2, 1, 3, 1, 1]
每一段的最大贡献为1, L+1段自然最多贡献L+1
3. 如果大于 1 的数都是 2,交错和的绝对值 ≤2L+(L+1)=3L+1≤37
注:如果选了
L个2,最坏情况是+2 -2 +2 -2...,总和最大是2L(比如2 + 2 + 2...)1*L*2=2*L
所以, 由于“较大的数”的数量有限,且乘积不能太大,实际有效的“乘积”状态非常少。
3. 定义dfs(i,s,m,odd,empty)
参数:x=nums[i]选还是不选, s: 当前子序列的交错和, m: 子序列的元素乘积
odd: 如果选x, 减x/加x empty: 子序列是否为空
递归入口:dfs(0,0,1,false,true)
代码如下:
class Solution {
public:int maxProduct(vector<int>& nums, int k, int limit) {int total = reduce(nums.begin(), nums.end());if (total < abs(k)) { return -1;}int n = nums.size(), ans = -1;unordered_set<long long> vis;dfs(0, 0, 1, false, true, nums, k, limit, n, total, ans, vis);return ans;}private:void dfs(int i, int s, int m, bool odd, bool empty, const vector<int>& nums, int k, int limit, int n, int total, int& ans,unordered_set<long long>& vis) {if (ans == limit) {return;}if (i == n) {if (!empty && s == k && m <= limit) { ans = max(ans, m);}return;}long long mask = (long long) i << 32 | (s + total) << 14 | m << 2 | odd << 1 | empty;if (!vis.insert(mask).second) {return;}dfs(i + 1, s, m, odd, empty, nums, k, limit, n, total, ans, vis);int x = nums[i];dfs(i + 1, s + (odd ? -x : x), min(m * x, limit + 1), !odd, false, nums, k, limit, n, total, ans, vis);}
};水平有限, 有疑问可以发布到评论区, 感谢!
相关文章:

力扣第444场周赛
这次力扣周赛对我来说难度确实大, 只做出两题, 但还是想分享一下的做题经验和感受 1. 移除最小数对使数组有序 I 题目链接:力扣 给你一个数组 nums,你可以执行以下操作任意次数: 选择 相邻 元素对中 和最小 的一对。如果存在多个这样的对&a…...

Redis 持久化机制详解:RDB/AOF 过程、优缺点及配置。Redis持久化中的Fork与Copy-on-Write技术解析。
Redis 持久化机制详解:RDB/AOF 过程、优缺点及配置 一、RDB 持久化过程及特性 核心机制 生成快照:通过 fork 子进程生成内存数据的二进制快照文件(.rdb),父进程继续处理请求。写时复制(Copy-On-Write&…...

Go并发背后的双引擎:CSP通信模型与GMP调度|Go语言进阶(4)
为什么需要理解CSP与GMP? 当我们启动一个Go程序时,可能会创建成千上万个goroutine,它们是如何被调度到有限的CPU核心上的?为什么Go能够如此轻松地处理高并发场景?为什么有时候我们的并发程序会出现奇怪的性能瓶颈&…...

docker内安装达梦8数据库
1. 其他机器上实现挂载ISO # 1. 确保挂载点目录存在(你已经创建了dm8目录) ls -ld dm8# 2. 使用正确的mount命令挂载ISO sudo mount -o loop dm8_20250117_HWarm920_kylin10_sp1_64.iso dm8# 3. 验证是否挂载成功 mount | grep dm8 ls dm82. docker内运…...

UDP怎么样实现可靠传输?
如果需要在基于UDP的应用中实现可靠传输(例如确保数据不丢失、按顺序到达等),通常需要在应用层实现相应的机制。 1. 确认应答机制 应用层可以使用确认应答机制来确保数据的可靠传输。当发送方发送一个数据包时,接收方收到数据包…...

代码随想录算法训练营Day25
一、力扣93.复原IP地址【medium】 题目链接:力扣93.复原IP地址 left x300 视频链接:代码随想录 1、思路 时间复杂度: O ( n ) O(n) O(n) 2、代码 class Solution:def restoreIpAddresses(self, s: str) -> List[str]:n len(s)ans []…...

Linux服务器——Samba服务器
简介 Samba 是一个开源的跨平台文件共享服务,允许 Linux/Unix 系统与 Windows 系统实现文件和打印机的共享与互操作。其核心协议为 SMB/CIFS(Server Message Block / Common Internet File System),是 Windows 网络中…...
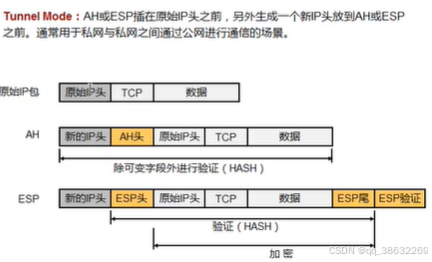
华为网路设备学习-17
目录 一、加密算法 二、验证算法 三、IPsec协议 1.IKE协议(密钥交换协议) ①ISAKMP(Internet Security Association and Key Management Protocol)互联网安全关联和密钥管理协议 ②安全关联(SA) ③…...

各开源协议一览
在 GitHub 上,开源项目通常会使用一些常见的开源协议来定义项目的使用、修改和分发规则。以下是目前 GitHub 上最常见的几种开源协议及其差异和示例说明: TL;DR 协议宽松程度是否强制开源专利保护适用场景MIT最宽松否无希望代码被广泛使用Apache 2.0宽松…...

解决python manage.py shell ModuleNotFoundError: No module named xxx
报错如下: python manage.py shellTraceback (most recent call last):File "/Users/z/Documents/project/c/manage.py", line 10, in <module>execute_from_command_line(sys.argv)File "/Users/z/.virtualenvs/c/lib/python3.12/site-packa…...
机器学习12-集成学习-案例
参考 【数据挖掘】基于XGBoost的垃圾短信分类与预测 【分类】使用XGBoost算法对信用卡交易进行诈骗预测 银行卡电信诈骗危险预测(LightGBM版本) 【数据挖掘】基于XGBoost的垃圾短信分类与预测 基于XGBoost的垃圾短信分类与预测 我分享了一个项目给你《【数据挖掘】基于XG…...

使用Ubuntu18恢复群晖nas硬盘数据外接usb
使用Ubuntu18恢复群晖nas硬盘数据外接usb 1. 接入硬盘2.使用Ubuntu183.查看nas硬盘信息3. 挂载nas3.1 挂载损坏nas硬盘(USB)3.2 挂载当前运行的nas 4. 拷贝数据分批传输 5. 新旧数据对比 Synology NAS 出现故障,DS DiskStation损坏,则可以使用计算机和 U…...

微服务系统记录
记录下曾经工作涉及到微服务的相关知识。 1. 架构设计与服务划分 关键内容 领域驱动设计(DDD): 利用领域模型和限界上下文(Bounded Context)拆分业务,明确服务边界。通过事件风暴(Event Storm…...
【数据库原理及安全实验】实验二 数据库的语句操作
目录 指导书原文 实操备注 指导书原文 【实验目的】 1) 掌握使用SQL语言进行数据操纵的方法。 【实验原理】 1) 面对三个关系表student,course,sc。利用SQL语句向表中插入数据(insert),然后对数据进行delete&…...

python 微信小程序支付、查询、退款使用wechatpy库
首先使用 wechatpy 库,执行以下命令进行安装 pip install wechatpy 1、 直连商户支付 import logging from django.http import JsonResponse from django.views.decorators.http import require_http_methods from wechatpy.pay import WeChatPay from wechatpy.…...
)
蓝桥杯备赛学习笔记:高频考点与真题预测(C++/Java/python版)
2025蓝桥杯备赛学习笔记 ——高频考点与真题预测 一、考察趋势分析 通过对第13-15届蓝桥杯真题的分析,可以发现题目主要围绕基础算法、数据结构、数学问题、字符串处理、编程语言基础展开,且近年逐渐增加动态规划、图论、贪心算法等较难题目。 1. 基…...
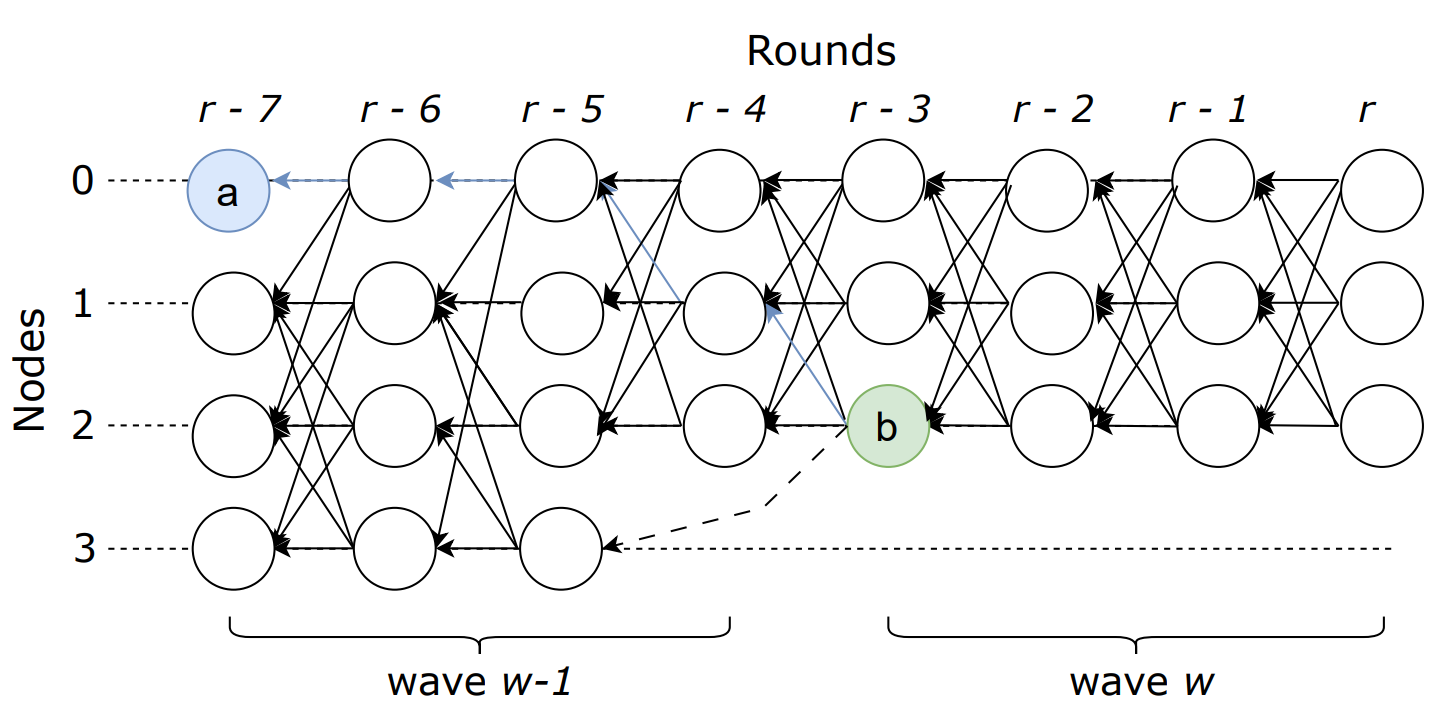
【BFT帝国】20250409更新PBFT总结
2411 2411 2411 Zhang G R, Pan F, Mao Y H, et al. Reaching Consensus in the Byzantine Empire: A Comprehensive Review of BFT Consensus Algorithms[J]. ACM COMPUTING SURVEYS, 2024,56(5).出版时间: MAY 2024 索引时间(可被引用): 240412 被引:…...
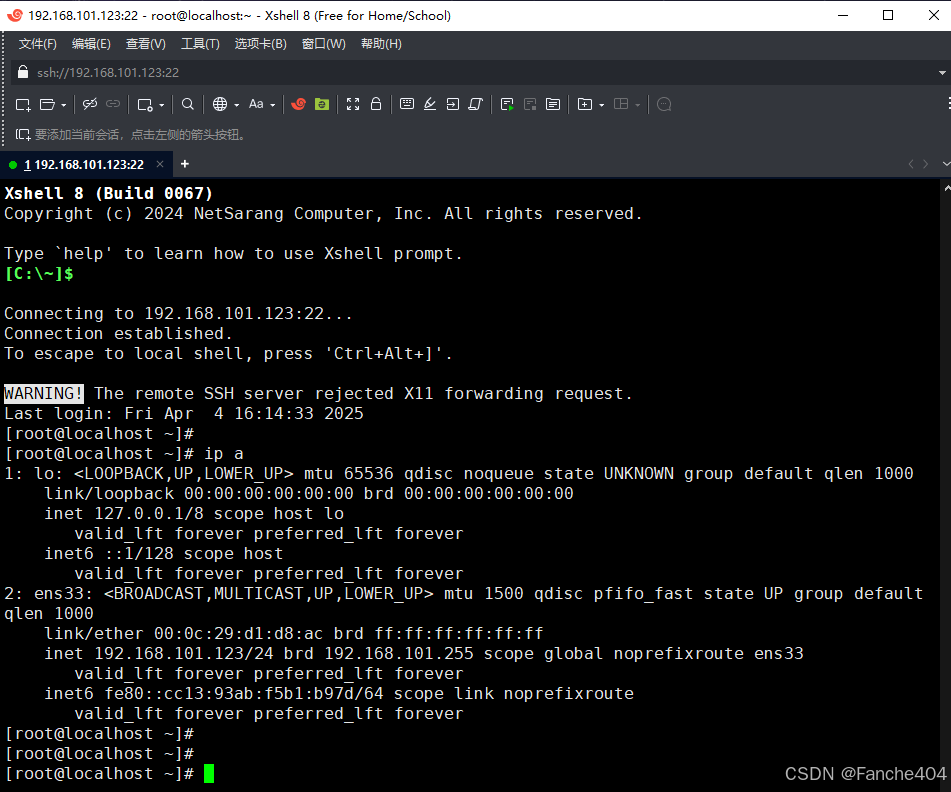
Linux-CentOS-7—— 配置静态IP地址
文章目录 CentOS-7——配置静态IP地址VMware workstation的三种网络模式配置静态IP地址1. 编辑虚拟网络2. 确定网络接口名称3. 切换到网卡所在的目录4. 编辑网卡配置文件5. 查看网卡文件信息6. 重启网络服务7. 测试能否通网8. 远程虚拟主机(可选) 其他补…...

Jupyter Lab 无法启动 Kernel 问题排查与解决总结
📄 Jupyter Lab 无法启动 Kernel 问题排查与解决总结 一、问题概述 🚨 现象描述: 用户通过浏览器访问远程服务器的 Jupyter Lab 页面(http://xx.xx.xx.xx:8891/lab)后,.ipynb 文件可以打开,但无…...

算法训练之位运算
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

linux入门三:Linux 编辑器
一、轻量级编辑器:快速上手的首选 1.1 Leafpad:极简主义的轻量之选 核心特点 轻量快速:体积小、启动快,资源占用极低,适合低配设备或快速编辑简单文件。 无复杂功能:仅支持基础文本编辑,界面…...
C++设计模式+异常处理
#include <iostream> #include <cstring> #include <cstdlib> #include <unistd.h> #include <sstream> #include <vector> #include <memory> #include <stdexcept> // 包含异常类using namespace std;// 该作业要求各位写一…...

HttpServletRequest是什么
HttpServletRequest 是 Java Servlet API 中的一个接口,表示 HTTP 请求对象。它封装了客户端(如浏览器)发送到服务器的请求信息,并提供了访问这些信息的方法。 1. 基本概念 作用: HttpServletRequest 提供了一种机制&…...
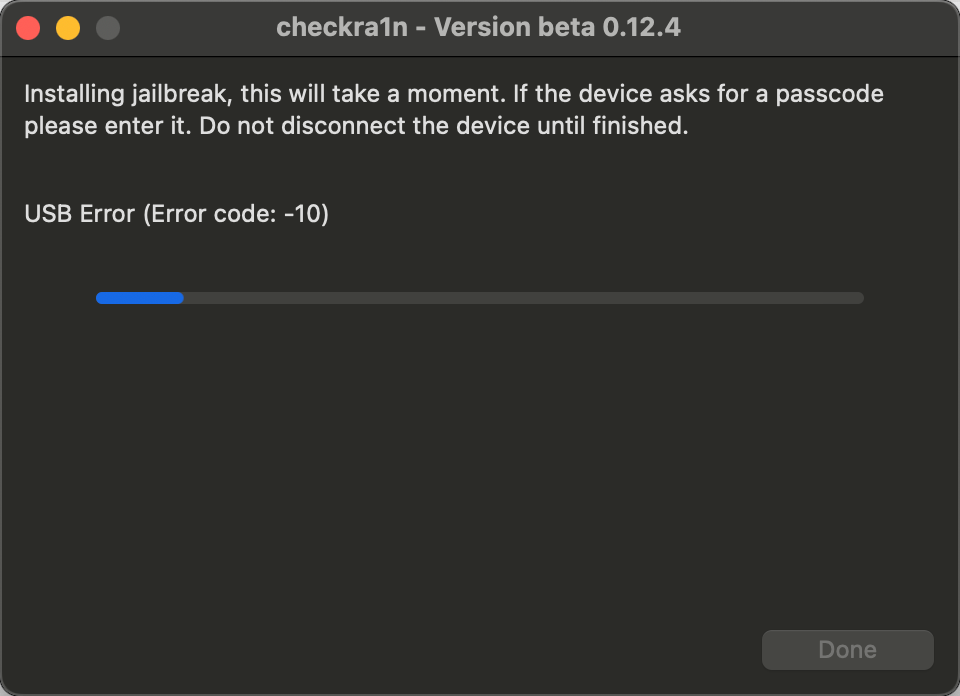
checkra1n越狱出现的USB error -10问题解决
使用checkra1n进行越狱是出现: 解决办法(使用命令行进行越狱): 1. cd /Applications/checkra1n.app/Contents/MacOS 2. ./checkra1n -cv 3. 先进入恢复模式 a .可使用爱思助手 b. 或者长按home,出现关机的滑条,同时按住home和电源键&#…...

golang-defer延迟机制
defer延迟机制 defer是什么 defer是go中一种延迟调用机制。 执行时机 defer后面的函数只有在当前函数执行完毕后才能执行。 执行顺序 将延迟的语句按defer的逆序进行执行,也就是说先被defer的语句最后被执行,最后被defer的语句,最先被执…...

【小沐学Web3D】three.js 加载三维模型(Angular)
文章目录 1、简介1.1 three.js1.2 angular.js 2、three.js Angular.js结语 1、简介 1.1 three.js Three.js 是一款 webGL(3D绘图标准)引擎,可以运行于所有支持 webGL 的浏览器。Three.js 封装了 webGL 底层的 API ,为我们提供了…...

一种替代DOORS在WORD中进行需求管理的方法 (二)
一、前景 参考: 一种替代DOORS在WORD中进行需求管理的方法(基于WORD插件的应用)_doors aspice-CSDN博客 二、界面和资源 WORD2013/WORD2016 插件 【已使用该工具通过第三方功能安全产品认证】: 1、 核心功能 1、需求编号和跟…...

一个基于ragflow的工业文档智能解析和问答系统
工业复杂文档解析系统 一个基于ragflow的工业文档智能解析和问答系统,支持多种文档格式的解析、知识库管理和智能问答功能。 系统功能 1. 文档管理 支持多种格式文档上传(PDF、Word、Excel、PPT、图片等)文档自动解析和分块处理实时处理进度显示文档解析结果预览批量文档…...

23种设计模式-行为型模式-访问者
文章目录 简介场景解决完整代码核心实现 总结 简介 访问者是一种行为设计模式,它能把算法跟他所作用的对象隔离开来。 场景 假如你的团队开发了一款能够使用图像里地理信息的应用程序。图像中的每个节点既能代表复杂实体(例如一座城市)&am…...

WebView2最低支持.NET frame4.5,win7系统
WebView2最低支持.NET frame什么版本 WebView2 对 .NET Framework 的最低版本要求 基础支持范围 WebView2 官方支持的 .NET Framework 最低版本为 4.5,同时兼容 .NET Core 3.0 及以上版本18。对于 WPF、WinForms 等桌面应用开发,需确…...