从PDF中提取表格:以GB/T2260—2007为例
文章目录
- 先说结论
- 前因后果
- 思路
- 1、PDF2CSV
- 2、PDF2MD → MD2CSV
- 3、针对不同表格的两种思路
- 1) 竖形三线表
- 2)五元素为一组
- 还没结束
- 批量处理
- 1、分割markdown文档
- 2、跳过另一种格式的文档
- 总结一下
先说结论
结论就是,博主用了一天的时间去研究如何把PDF的表格内容,转换为csv文件,下面放图。
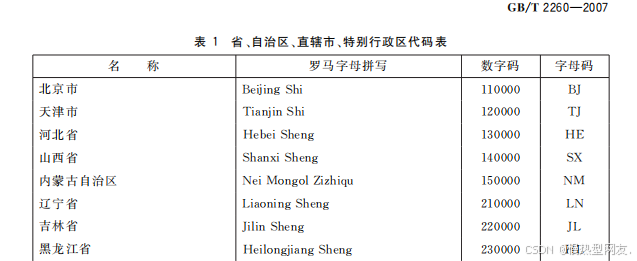
这次转换的文档是国标GB/T2260—2007,GB/T2260《中华人民共和国行政区划代码》自1980年发布以来,已广泛应用于我国计划、统计、人口普查、经济普查、农业普查、社会保障、信息化、教育、人事管理、组织机构管理等诸多领域。
转换为👇

请注意:本篇不太赘述太多代码,主要讲解决思路。
前因后果
因为博主的课题是知识图谱方向,所以想找一些内容来测试一下图谱构建,图谱构建的第一步就是去构建实体和关系,所以我想到一个关系性很强的内容,就是今天测试的内容,我国的行政区,包含省市县区,他们中间的关系也很明确。
那么好,回到文档,起初拿到这个文档的时候,我想着要不就手动复制,反正现在各种OCR技术都这么强,结果发现正片文档整整247页,就以我需要整理的内容来说也有130页左右,这样手动构建肯定是不合适的,费时费力。
所以,我就想到能不能搞点代码来解决,其实目前大模型技术发展很迅速了,各种单模态的,多模态的,专门处理表格的,其实把这些交给大模型让它们生成结构化的文档也很方便,不过博主还是喜欢去探究一下本质,所以选择用传统方法。
思路
1、PDF2CSV
前期的思路是,直接PDF转CSV,目前有很多第三方库也都支持,Camelot、Tabula-py、pdf2csv,都不错,但是回归到根源,从文档本身出发,可以看到这是一个算是竖形的三线表格式的,这些第三方库去处理的时候都会把第一列的所有内容放在一个单元格中,等于说白干,那么我想能不能用另一种格式做一个过渡呢,这种格式还得是普遍被接收了,那么想到了一种符合当前要求的——markdown。
2、PDF2MD → MD2CSV
PDF识别表格转成markdown格式也是一种思路,再用markdown的特点,有固定的表格格式,方便分割,思路有了,开始实操。
这次选择的是pdfplumber,它有一个extract_tables()方法,可以提取PDF中的表格。
def extract_tables(self, table_settings: Optional[T_table_settings] = None) -> List[List[List[Optional[str]]]]:tset = TableSettings.resolve(table_settings)tables = self.find_tables(tset)return [table.extract(**(tset.text_settings or {})) for table in tables]def extract_table(self, table_settings: Optional[T_table_settings] = None) -> Optional[List[List[Optional[str]]]]:tset = TableSettings.resolve(table_settings)table = self.find_table(tset)if table is None:return Noneelse:return table.extract(**(tset.text_settings or {}))
提取后转为markdown格式,内容如下:
#篇幅有限取前六个元素作为示例
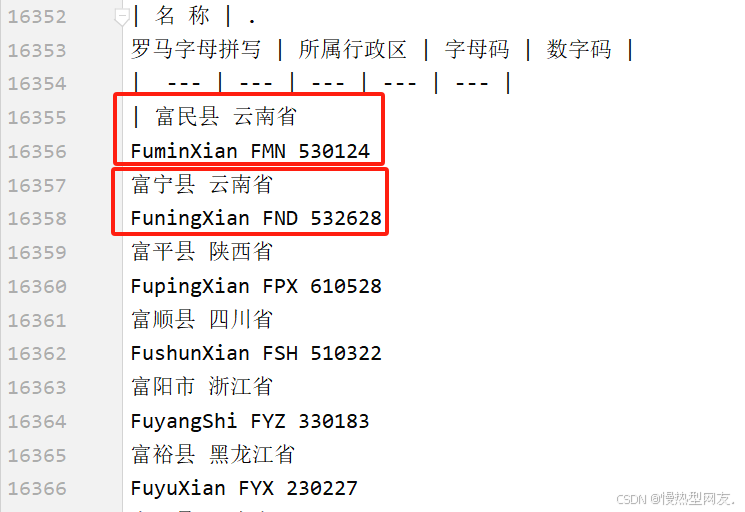
| 名 称 | 罗马字母拼写 | 数字码 | 字母码 |
| --- | --- | --- | --- |
| 北京市
天津市
河北省
山西省
内蒙古自治区
辽宁省| BeijingShi
TianjinShi
HebeiSheng
ShanxiSheng
NeiMongolZizhiqu
LiaoningSheng | 110000
120000
130000
140000
150000
210000| BJ
TJ
HE
SX
NM
LN|
从转换的文档看,因为markdown表格格式限制,各个元素中存在换行符,没法变为表格。
不过,博主灵机一动,那我把它们全部转为字符串,再以“|”为分割,把第一个单元格的的第一个元素作为表格里第一列的第一个,第二个单元格的第一个作为第二列的第二个,以此类推…
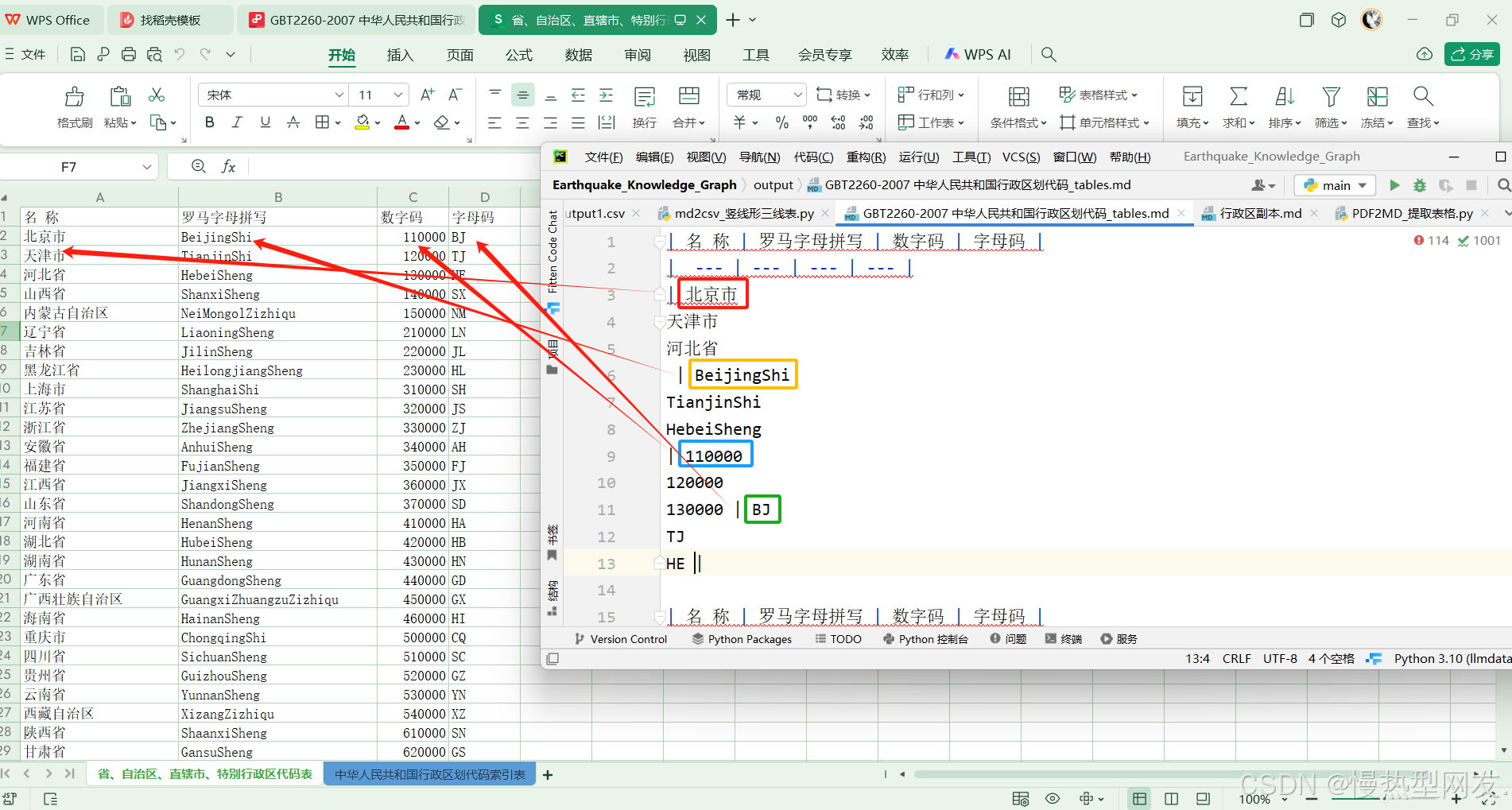
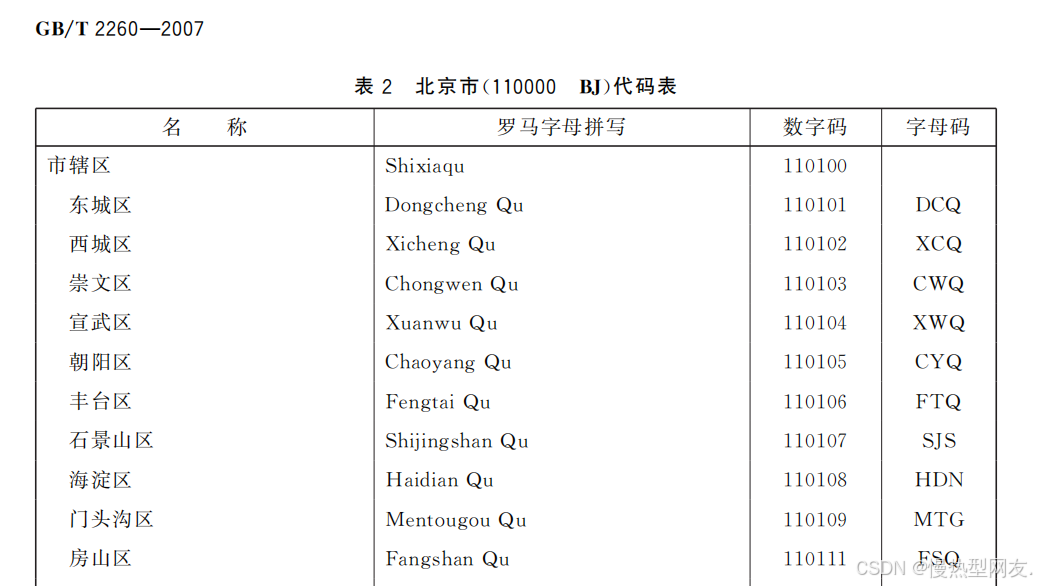
观察生成的md文件,发现总共有两种形式的md文档
第一种是刚才讲的这种,第二种是下图这样的,所有元素都在同一个单元格中,中间以空格隔开
3、针对不同表格的两种思路
那么针对这两种的表格,有了下面两个思路
1) 竖形三线表
这种思路参照刚才讲的把第一个单元格的的第一个元素作为表格里第一列的第一个,第二个单元格的第一个作为第二列的第二个,讲关键步骤:
1、将数据行转换为一个长字符串,保留原始的换行符
| 北京市 天津市 河北省 山西省 内蒙古自治区 辽宁省 吉林省 黑龙江省 上海市 江苏省 浙江省 安徽省 福建省 江西省 山东省 河南省 湖北省 湖南省 广东省 广西壮族自治区 海南省 重庆市 四川省 贵州省 云南省 西藏自治区 陕西省 甘肃省 青海省 宁夏回族自治区 新疆维吾尔自治区 台湾省 香港特别行政区 澳门特别行政区 | BeijingShi TianjinShi HebeiSheng ShanxiSheng NeiMongolZizhiqu LiaoningSheng JilinSheng HeilongjiangSheng ShanghaiShi JiangsuSheng ZhejiangSheng AnhuiSheng FujianSheng JiangxiSheng ShandongSheng HenanSheng HubeiSheng HunanSheng GuangdongSheng GuangxiZhuangzuZizhiqu HainanSheng ChongqingShi SichuanSheng GuizhouSheng YunnanSheng XizangZizhiqu ShaanxiSheng GansuSheng QinghaiSheng NingxiaHuizuZizhiqu XinjiangUygurZizhiqu TaiwanSheng HongkongTebiexingzhengqu | 110000 120000 130000 140000 150000 210000 220000 230000 310000 320000 330000 340000 350000 360000 370000 410000 420000 430000 440000 450000 460000 500000 510000 520000 530000 540000 610000 620000 630000 640000 650000 710000 810000 | BJ TJ HE SX NM LN JL HL SH JS ZJ AH FJ JX SD HA HB HN GD GX HI CQ SC GZ YN XZ SN GS QH NX XJ TW HK |
2、使用正则表达式在每个 | 符号的前后都加上换行符
呈现的结果是这样的,那么可以看到每一列都被完美的隔离开,并且每个元素中间都有空格

3、按行分割清洗后的内容
['|', ' 北京市 天津市 河北省 山西省 内蒙古自治区 辽宁省 吉林省 黑龙江省 上海市 江苏省 浙江省 安徽省 福建省 江西省 山东省 河南省 湖北省 湖南省 广东省 广西壮族自治区 海南省 重庆市 四川省 贵州省 云南省 西藏自治区 陕西省 甘肃省 青海省 宁夏回族自治区 新疆维吾尔自治区 台湾省 香港特别行政区 澳门特别行政区 ', '|', ' BeijingShi TianjinShi HebeiSheng ShanxiSheng NeiMongolZizhiqu LiaoningSheng JilinSheng HeilongjiangSheng ShanghaiShi JiangsuSheng ZhejiangSheng AnhuiSheng FujianSheng JiangxiSheng ShandongSheng HenanSheng HubeiSheng HunanSheng GuangdongSheng GuangxiZhuangzuZizhiqu HainanSheng ChongqingShi SichuanSheng GuizhouSheng YunnanSheng XizangZizhiqu ShaanxiSheng GansuSheng QinghaiSheng NingxiaHuizuZizhiqu XinjiangUygurZizhiqu TaiwanSheng HongkongTebiexingzhengqu ', '|', ' 110000 120000 130000 140000 150000 210000 220000 230000 310000 320000 330000 340000 350000 360000 370000 410000 420000 430000 440000 450000 460000 500000 510000 520000 530000 540000 610000 620000 630000 640000 650000 710000 810000 ', '|', ' BJ TJ HE SX NM LN JL HL SH JS ZJ AH FJ JX SD HA HB HN GD GX HI CQ SC GZ YN XZ SN GS QH NX XJ TW HK ', '|']
4、构造两个数组,分别遍历
这里定义了两个数组,大的数组存储每一组数据,小数组放每一组数据的具体信息,遍历后结果如下:
[
['北京市', 'BeijingShi', '110000', 'BJ'],
['天津市', 'TianjinShi', '120000', 'TJ'],
['河北省', 'HebeiSheng', '130000', 'HE'],
['山西省', 'ShanxiSheng', '140000', 'SX'],
['内蒙古自治区', 'NeiMongolZizhiqu', '150000', 'NM'],
['辽宁省', 'LiaoningSheng', '210000', 'LN'],
['吉林省', 'JilinSheng', '220000', 'JL']
]
那么后面转csv就不讲了,逐行遍历逗号隔开即可。
2)五元素为一组
那么有了上一个处理的思路,这个处理思路更快的就想出来了,还是转换为字符串,但是这次就不要“|”为分割了,所以处理字符串的时候直接删掉,只留元素和空格,每五个元素为一行。
1、将数据行转换为一个长字符串,保留空格
越西县 四川省 YuexiXian YXC 513434 越秀区 广东省广州市 YuexiuQu YXU 440104 云县 云南省 YunXian YXP 530922 云安县 广东省 Yun’anXian YUA 445323 云城区 广东省云浮市 YunchengQu YYF 445302 云浮市 广东省 YunfuShi YFS 445300 云和县 浙江省 YunheXian YNH 331125 云龙区 江苏省徐州市 YunlongQu YLF 320303 云龙县 云南省 YunlongXian YLO 532929 云梦县 湖北省 YunmengXian YMX 420923 云南省 YunnanSheng YN 530000 云溪区 湖南省岳阳市 YunxiQu YXI 430603 云霄县 福建省 YunxiaoXian YXO 350622 云岩区 贵州省贵阳市 YunyanQu YYQ 520103 云阳县 重庆市 YunyangXian YNY 500235 郧县 湖北省 YunXian YUN 420321 郧西县 湖北省 YunxiXian YNX 420322 运城市 山西省 YunchengShi YCE 140800 运河区 河北省沧州市 YunheQu YHC 130903 郓城县 山东省 YunchengXian YCR 371725 杂多县 青海省 ZadoiXian ZAD 632722 赞皇县 河北省 ZanhuangXian ZHG 130129 枣强县 河北省 ZaoqiangXian ZQJ 131121 枣阳市 湖北省 ZaoyangShi ZOY 420683 枣庄市 山东省 ZaozhuangShi ZZG 370400 泽库县 青海省 ZêkogXian ZEK 632323 泽普县 新疆维吾尔自治区 Zepu(Poskam)Xian ZEP 653124 泽州县 山西省 ZezhouXian ZEZ 140525 曾都区 湖北省随州市 ZengduQu ZDU 421302 增城市 广东省 ZengchengShi ZEC 440183 扎赉特旗 内蒙古自治区 JalaidQi JAL 152223 扎兰屯市 内蒙古自治区 ZalantunShi ZLT 150783 扎鲁特旗 内蒙古自治区 JarudQi JAR 150526 扎囊县 西藏自治区 Chanang(Chatang)Xian CNG 542222 札达县 西藏自治区
2、遍历列表,按固定数量进行分组
# 初始化一个列表来存储分组后的数据groups = []current_group = []# 遍历列表,按固定数量进行分组for item in data_content.split():item = item.strip() # 去除元素前后的空格if item: # 忽略空字符串current_group.append(item)print(current_group)# 每五个元素换行if len(current_group) == 5:groups.append(current_group)current_group = []
最后的效果是这样的:

还没结束
批量处理
这两个代码固然可以提速,但我处理的md格式的文档有30929行,每一个表格大概是130行,那么我就要处理三百余次,虽然手动处理可以,但是还是觉得效率低,在处理了差不多100个的时候就觉得有点累了,所以我就在想如何可以让他批量处理
1、分割markdown文档
因为前面也讲了,我这个markdown文档里发现识别了两种表格,那么我一次处理全部的当然不合适,所以我的思路是先根据文档特点去分割markdown文档为不同的文件,再根据不同的文件结构用不同的方法。
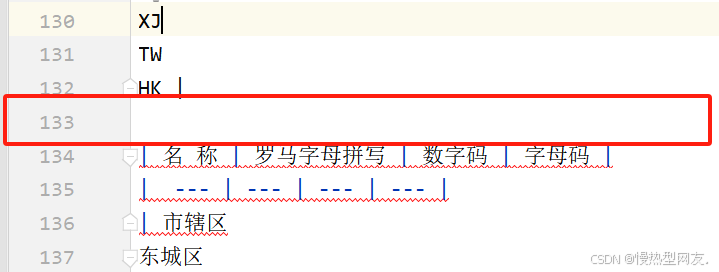
文档里每个表格之间都有一行空白行,那么就以它为标识符去分割,最后在剩余的文档里分出来了56个文档

2、跳过另一种格式的文档
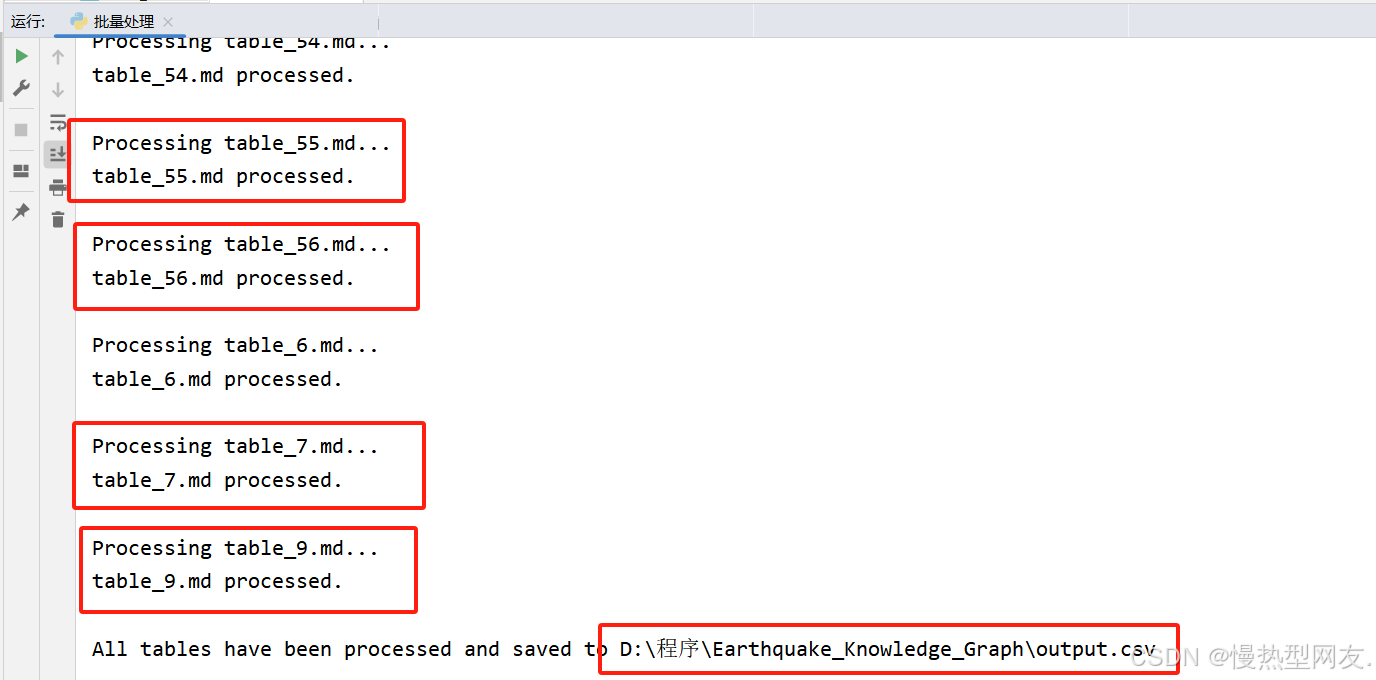
经过看每个文档发现,第二种类的文档还是比较少,有以下这几个,那么我在处理的时候跳过这些即可,去批量处理。
skip_tables = {8, 11, 14, 16, 20, 21, 28, 33,37, 44, 52}
总结一下
在当今时代,AI 的强大能力确实为我们的学习和生活带来了极大的便利,但过度依赖它却可能削弱我们的思维能力。我们应将 AI 视为助力而非拐杖,在借助其高效处理数据和执行任务的同时,积极锻炼自己的思维,尤其是代码思维。这种严谨的逻辑思维不仅能帮助我们更好地与 AI 沟通协作,还能在复杂多变的现实中发挥独特价值,从而在人机合作中提升效率,实现优势互补。
相关文章:
从PDF中提取表格:以GB/T2260—2007为例
文章目录 先说结论前因后果思路1、PDF2CSV2、PDF2MD → MD2CSV3、针对不同表格的两种思路1) 竖形三线表2)五元素为一组 还没结束批量处理1、分割markdown文档2、跳过另一种格式的文档 总结一下 先说结论 结论就是,博主用了一天的时间去研究如…...

初识MySQL · 复合查询(内外连接)
目录 前言: 基本查询回顾 笛卡尔积和子查询 笛卡尔积 内外连接 子查询 单行子查询 多行子查询 多列子查询 from中使用子查询 合并查询 前言: 在前文我们学习了MySQL的基本查询,就是简单的套用了select语句,最多不过是…...

电视剧角色扮演AI Agent中的大模型操作流程
电视剧角色扮演AI Agent中的大模型操作流程 在您描述的 “电视剧角色扮演 + 挑战任务” 的AI Agent场景中,大模型(如GPT-4、Claude等)需要完成多个关键操作,以下是详细的技术流程分解: 1. 用户输入处理阶段 操作:文本向量化(Embedding) 技术实现: 使用 文本嵌入模型…...

Android学习总结之数据结构篇
Java 的集合体系 Java 的集合框架主要分为两大接口体系:Collection 和 Map。以下是对这两大体系下常见集合类的介绍: Collection 体系 Collection 是单列集合的根接口,它有三个主要的子接口:List、Set 和 Queue。 List 接口&a…...

OpenCV--图像平滑处理
在数字图像处理领域,图像平滑处理是一项极为重要的技术,广泛应用于计算机视觉、医学影像分析、安防监控等多个领域。在 OpenCV 这一强大的计算机视觉库的助力下,我们能便捷地实现多种图像平滑算法。本文将深入探讨图像平滑的原理,…...

8. git branch
基本概述 git branch 的作用是:查看、创建、删除、重命名和跟踪分支等。 查看分支 1.查看本地分支 git branch当前分支前会标记 * 2.查看远程分支 git branch -r3.查看所有分支 git branch -a4.查看分支信息 git branch -v会显示分支的最新提交信息 5.查看…...

辛格迪客户案例 | 北京舒曼德医药实施电子合约系统(eSign)
01 北京舒曼德医药科技开发有限公司:医药科技的数字化先锋 北京舒曼德医药科技开发有限公司(以下简称“舒曼德医药”)作为国内医药科技领域的领军企业,致力于创新药物的研发、临床试验和市场推广。公司以“科技兴药、质量为先、服…...

Python面向对象-开闭原则(OCP)
1. 什么是开闭原则? 开闭原则(Open-Closed Principle, OCP) 是面向对象设计的五大SOLID原则之一,由Bertrand Meyer提出。其核心定义是: “软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。” 对扩展开放:当需求…...
 1-0 等级保护制度公安部前期发文总结)
网络安全-等级保护(等保) 1-0 等级保护制度公安部前期发文总结
################################################################################ 等级保护从1994年开始已经有相关文件下发,进行建设,后续今年多年制度完善,现在已进入等保2.0时代,相关政策已运行多年。 前期等保相关发文,目前还在使用的包括:《中华人民共和国计算…...

Class 文件和类加载机制
一、Class 文件 与 类加载机制 概述 什么是 Class 文件? Java 源码(.java)经过 javac 编译器 编译生成的字节码文件(.class);由 JVM 识别执行,包含类的完整结构信息(如字段、方法、…...

Vue3+Vite+TypeScript+Element Plus开发-07.Mockjs引用与Axios封装
系列文档目录 Vue3ViteTypeScript安装 Element Plus安装与配置 主页设计与router配置 静态菜单设计 Pinia引入 Header响应式菜单缩展 Mockjs引用与Axios封装 登录设计 登录成功跳转主页 多用户动态加载菜单 Pinia持久化 动态路由-配置 文章目录 目录 系列文档目…...

安全理念和安全产品发展史
从安全理念的发展历史来看,技术与产品的演进始终围绕 “威胁对抗” 与 “业务适配” 两大核心展开。以下从七个关键阶段解析安全技术与产品的发展脉络,并结合最新实践与未来趋势提供深度洞察: 一、密码学奠基阶段(1970s 前) 安全理念:以 “信息保密” 为核心,防御手段…...
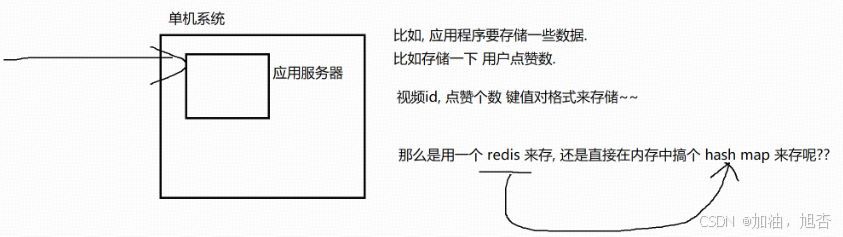
【Redis】背景知识
一、Redis的特性 Redis是一种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的是,Redis中的值可以是由string(字符串),hash(哈希),list…...
)
Spring MVC 返回 JSON 视图的方式及对比(6种)
Spring MVC 返回 JSON 视图的方式及对比(新增 MappingJackson2JsonView) 1. 方式一:ResponseBody 注解 作用:直接返回对象,由消息转换器(如 Jackson)序列化为 JSON。 适用场景:简单…...

【Kafka基础】消费者命令行完全指南:从基础到高级消费
Kafka消费者是消息系统的关键组成部分,掌握/export/home/kafka_zk/kafka_2.13-2.7.1/bin/kafka-console-consumer.sh工具的使用对于调试、测试和监控都至关重要。本文将全面介绍该工具的各种用法,帮助您高效地从Kafka消费消息。 1 基础消费模式 1.1 从最…...
。)
在 Vue 中监听常用按键事件(回车,ESC 键,空格等)。
一、Vue 原生按键修饰符(推荐) html <!-- 常用按键监听 --> <input keyup.enter"submit" <!-- 回车键 -->keydown.esc"cancel" <!-- ESC 键 -->keyup.space"togglePlay" <!-- 空格键…...

航电系统的任务载荷集成技术要点概述!
一、任务载荷集成技术难点 1. 接口标准化与兼容性 异构设备协议冲突:不同厂商的载荷设备(如光学相机、雷达、电子战模块)采用不同的通信协议(如1553B、RS422、以太网),需设计统一的总线接口标准以支持即…...

OceanBase V4.3.5 上线全文索引功能,让数据检索更高效
近日,OceanBase 4.3.5 BP1 版本正式推出了企业级全文索引功能。该版本在中文分词、查询效率及混合检索能力上进行了全面提升。经过自然语言模式和布尔模式在不同场景下的对比测试,OceanBase 的全文索引性能明显优于 MySQL。 点击下载 OceanBase 社区版…...
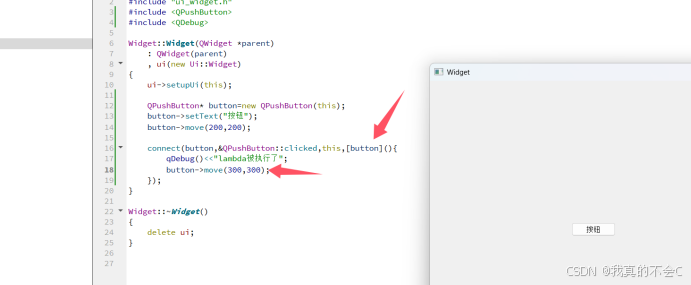
Qt中的信号与槽及其自定义
信号源:哪个控件发的信号 信号的类型:用户进行不同的操作就会触发不同的信号 如点击按钮,在输入框移动光标,勾选一个复选框,选 择一个下拉框 信号的处理方式:槽(slot)----也就是函数,Qt中用con…...

【PFPGA学习】状态机思想编程HDLbitsFPGA练习
目录 一、用状态机实现LED流水灯 1.1状态机思想 1.2状态机思想LED流水灯 1.3 modesim仿真 1.4 FPGA烧录实现 二、CPLD和FPGA芯片 1. 核心结构与技术原理 2. 性能与容量 3. 适用场景 4. 选型建议 三、HDLbitsFPGA练习记录(combinational logic…...
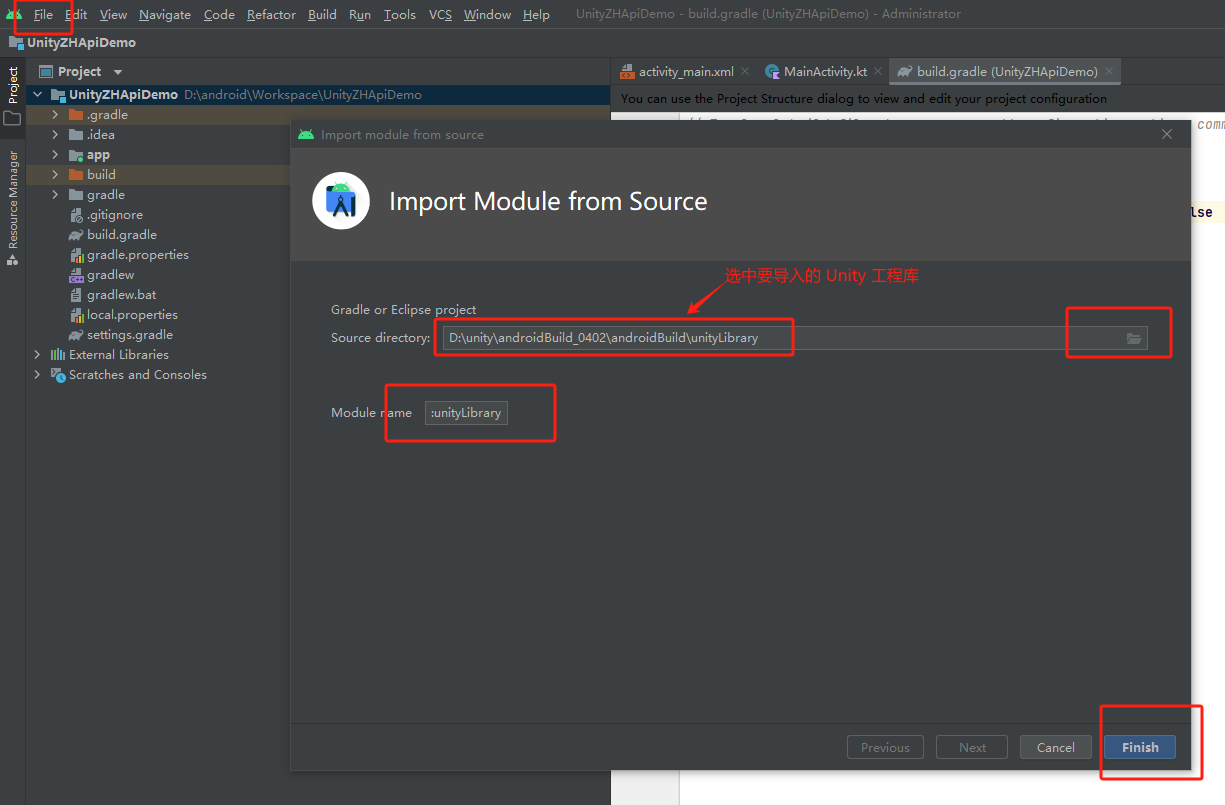
Android 中集成 Unity 工程的步骤
在 Adroid 项目中集成 Unity 工程,主要步骤如下: 一、前提条件 1、已有一个 Android 工程项目; 2、Unity 工程已导出为 Android 工程,目录大概如下: 二、集成步骤 1、在 Android 工程中导入 Unity 工程的 unityLibrary 模块。 在 Android Studio 中,点击菜单栏 Fil…...

Python从入门到精通全套视频教程免费
概述 📢 所有想学Python的小伙伴看过来!作为深耕编程领域的技术分享者,最新整理了一份Python从0到1的视频教程。 💡亮点 ✅ 保姆级系统路线:从环境搭建、语法精讲,到爬虫/数据分析/AI/Web全栈开发&#…...

关于Spring MVC中@RequestMapping注解的详细解析,涵盖其核心功能、属性、使用场景及最佳实践
以下是关于Spring MVC中RequestMapping注解的详细解析,涵盖其核心功能、属性、使用场景及最佳实践: 1. 基础概念 RequestMapping是Spring MVC的核心注解,用于将HTTP请求映射到控制器(Controller)的方法上。它支持类级…...
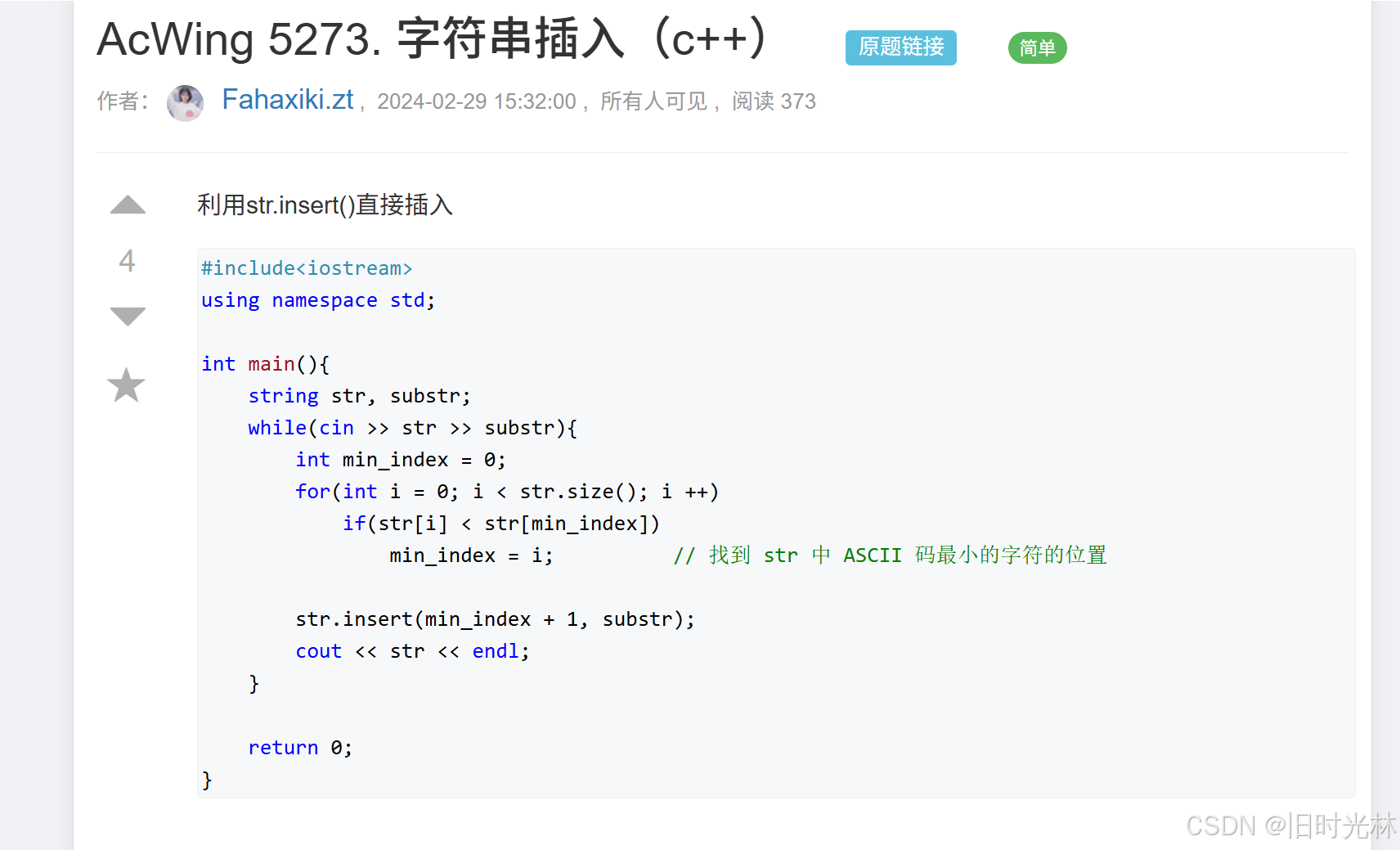
蓝桥杯:对字符串处理常用知识笔记
一、前面四个是计算带有空格字符串的的长度计算 C语言代码 #include<string.h> #include<stdio.h> int main() { char s[105]; gets(s); printf("%d", strlen(s)); return 0; } 算法2 C 代码(常用) #include <iostream> #in…...

实现一个 Markdown 编辑器组件:Vue 3 + Vite + Highlight.js
文章目录 一、项目背景与需求分析二、搭建基础项目1. 初始化 Vue 3 项目2. 安装依赖 三、实现 Markdown 编辑器组件1. 创建 Markdown 编辑器组件2. 组件说明 四、优化与拓展1. 自动保存功能2. 文件上传功能 五、总结 一、项目背景与需求分析 在现代前端开发中,Mark…...
进程间通讯 之 信号量)
【回眸】Linux 内核 (十四)进程间通讯 之 信号量
前言 信号量概念 信号量常用API 1.创建/获取一个信号量 2.改变信号量的值 3. 控制信号量 信号量函数调用 运行结果展示 前言 上一篇文章介绍的共享内存有局限性,如:同步与互斥问题、内存管理复杂性问题、数据结构限制问题、可移植性差问题、调试困难问题。本篇博文介…...

Redis的used_memory_peak_perc和used_memory_dataset_perc超过90%会怎么样
当Redis的used_memory_peak_perc(当前内存占历史峰值的百分比)和used_memory_dataset_perc(数据集内存占比)均超过90%时,可能引发以下问题及风险: 一、used_memory_peak_perc > 90% 的影响 内存交换风险…...
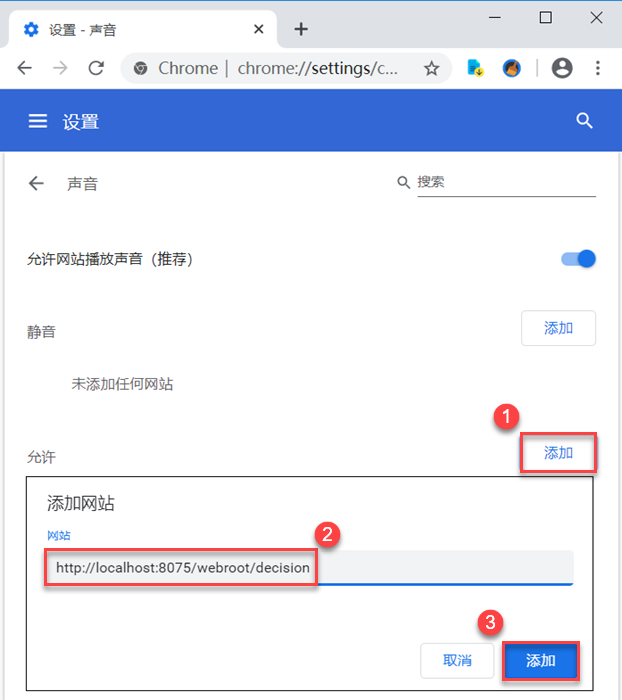
帆软fvs文件中某表格新增数据来声提醒
1.上传音频文件到帆软安装目录的指定环境 准备一个音频文件(如 mp3 格式),并将其放置在合适的目录。 例如:%FR_HOME%\webapps\webroot\help 2.点击 FVS 模板左上角「模板>页面加载结束事件」,输入以下 JavaScript …...
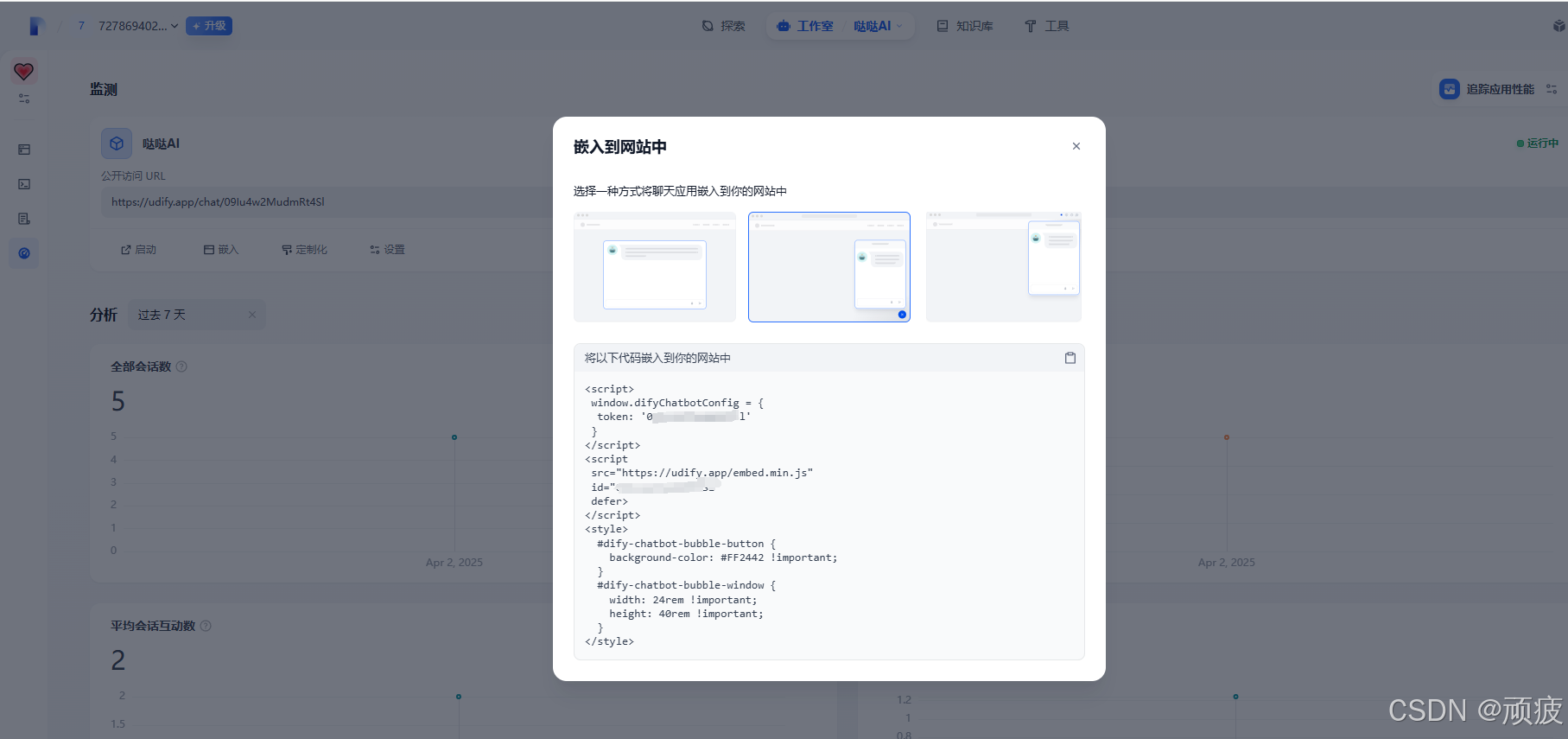
从零用java实现 小红书 springboot vue uniapp (11)集成AI聊天机器人
前言 移动端演示 http://8.146.211.120:8081/#/ 管理端演示 http://8.146.211.120:8088/#/ 项目整体介绍及演示 前面的文章我们主要完成了基础模块的开发 这次我们跟一下热点 创建AI聊天机器人 并嵌入到我们的uniapp中 首先需要了解dify我已经完成了搭建win10 VMware安装ubuntu…...

Redis中AOF的实现方式和AOF重写
一、AOF 的实现方式 核心原理 AOF 通过将写操作命令以追加方式记录到日志文件中,重启时通过重放命令恢复数据。与 RDB 的快照机制不同,AOF 是增量记录,更适用于数据一致性要求较高的场景。写入流程 命令执行:客户端发送写命令&am…...