LangChain-记忆系统 (Memory)
记忆系统是LangChain的核心组件之一,允许应用程序记住和使用过去的交互信息。本文档详细介绍了LangChain中的记忆组件类型、工作原理和使用场景。
概述
在构建对话式AI应用时,能够记住上下文和之前的交互至关重要。LangChain的记忆组件负责:
- 存储对话历史:保存之前的消息交换
- 管理上下文窗口:控制传递给模型的上下文量
- 提取相关信息:从历史中选择重要信息
- 处理长期记忆:管理超出上下文窗口的信息
基础记忆类型
1. 对话缓冲记忆 (ConversationBufferMemory)
最简单的记忆类型,存储所有之前的对话:
from langchain_community.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI# 创建记忆组件
memory = ConversationBufferMemory(return_messages=True, memory_key="history")# 创建带记忆的提示模板
prompt = ChatPromptTemplate.from_messages([("system", "你是一位友好的AI助手。"),MessagesPlaceholder(variable_name="history"),("human", "{input}")
])# 创建模型和链
model = ChatOpenAI()
chain = prompt | model# 首次交互
input_1 = {"input": "你好!我叫李明。"}
memory.chat_memory.add_user_message(input_1["input"])
response_1 = chain.invoke({"history": memory.load_memory_variables({})["history"], **input_1})
memory.chat_memory.add_ai_message(response_1.content)# 第二次交互,记忆中已经有之前的对话
input_2 = {"input": "你还记得我的名字吗?"}
response_2 = chain.invoke({"history": memory.load_memory_variables({})["history"], **input_2})
特点:
- 简单易用
- 存储完整对话历史
- 随着对话增长可能超出上下文窗口
2. 对话摘要记忆 (ConversationSummaryMemory)
通过总结之前的对话来节省上下文空间:
from langchain_community.memory import ConversationSummaryMemory# 创建摘要记忆
summary_memory = ConversationSummaryMemory(llm=ChatOpenAI(), # 用于生成摘要的模型return_messages=True,memory_key="history"
)# 使用摘要记忆
summary_memory.chat_memory.add_user_message("你好!我叫李明,我是一名软件工程师。")
summary_memory.chat_memory.add_ai_message("你好李明!很高兴认识你。作为软件工程师,你主要负责什么技术领域?")
summary_memory.chat_memory.add_user_message("我主要做后端开发,使用Python和Go语言,专注于微服务架构。")# 加载记忆变量(内部会生成摘要)
summarized_history = summary_memory.load_memory_variables({})["history"]
特点:
- 通过总结节省上下文空间
- 适合长对话
- 可能丢失细节信息
3. 对话摘要缓冲记忆 (ConversationSummaryBufferMemory)
结合缓冲和摘要的混合方法:
from langchain_community.memory import ConversationSummaryBufferMemory# 创建摘要缓冲记忆
buffer_memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(),max_token_limit=100, # 设置最大token数return_messages=True,memory_key="history"
)# 添加一些消息
for i in range(5):buffer_memory.chat_memory.add_user_message(f"这是用户消息 {i}")buffer_memory.chat_memory.add_ai_message(f"这是AI回复 {i}")# 当消息超过max_token_limit时,旧消息会被总结
history = buffer_memory.load_memory_variables({})["history"]
特点:
- 结合了缓冲和摘要的优点
- 自动管理上下文长度
- 保留最近消息的详细信息,总结旧消息
4. 向量存储记忆 (VectorStoreRetrieverMemory)
基于语义相关性检索历史消息:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.memory import VectorStoreRetrieverMemory# 创建向量存储
embedding = OpenAIEmbeddings()
vector_store = Chroma(embedding_function=embedding)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})# 创建向量存储记忆
vector_memory = VectorStoreRetrieverMemory(retriever=retriever,memory_key="relevant_history"
)# 添加记忆
vector_memory.save_context({"input": "人工智能的主要应用领域有哪些?"}, {"output": "主要应用领域包括自然语言处理、计算机视觉、机器人学、医疗健康、金融分析等。"})# 之后可以检索相关信息
relevant_memories = vector_memory.load_memory_variables({"input": "医疗AI的具体应用是什么?"}) # 会检索与医疗相关的之前对话
特点:
- 基于语义相似性检索相关历史
- 适合非线性对话
- 可以处理大量历史信息
5. 实体记忆 (EntityMemory)
追踪对话中提到的实体信息:
from langchain_community.memory import ConversationEntityMemory# 创建实体记忆
entity_memory = ConversationEntityMemory(llm=ChatOpenAI(),return_messages=True
)# 对话中会提取实体
entity_memory.save_context({"input": "我的名字是张伟,我住在上海。"},{"output": "你好张伟!上海是一个美丽的城市。"}
)# 提取实体信息
entities = entity_memory.load_memory_variables({})["entities"]
# 包含"张伟"和"上海"的实体信息
特点:
- 自动提取和跟踪重要实体
- 构建关于特定实体的知识库
- 适合需要记住用户具体信息的应用
高级用法
记忆链集成
使用新的RunnableWithMessageHistory接口将记忆组件集成到链中:
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory# 创建基本链
prompt = ChatPromptTemplate.from_messages([("system", "你是一位友好的AI助手。"),MessagesPlaceholder(variable_name="history"),("human", "{input}")
])
chain = prompt | ChatOpenAI() | StrOutputParser()# 创建存储对话历史的字典
store = {}# 添加记忆到链
chain_with_history = RunnableWithMessageHistory(chain,lambda session_id: store.get(session_id, ChatMessageHistory()),input_messages_key="input",history_messages_key="history"
)# 使用带记忆的链
for i in range(3):response = chain_with_history.invoke({"input": f"这是第{i+1}轮对话"},config={"configurable": {"session_id": "user-123"}})print(response)# 历史会自动更新在store字典中
记忆过滤和转换
控制记忆内容的处理:
from langchain_community.memory import ConversationTokenBufferMemory
from langchain_openai import OpenAI# 创建基于token数的缓冲记忆
token_memory = ConversationTokenBufferMemory(llm=OpenAI(), # 用于计算tokenmax_token_limit=200, # 最大token数return_messages=True,memory_key="history"
)# 添加消息直到超过限制
for i in range(10):token_memory.chat_memory.add_user_message(f"这是一个较长的用户消息 {i} " * 5)token_memory.chat_memory.add_ai_message(f"这是一个AI回复 {i} " * 5)# 获取记忆,只会包含最近的几条消息,使总token数保持在限制之内
history = token_memory.load_memory_variables({})["history"]
自定义记忆组件
创建自定义记忆系统:
from langchain_core.memory import BaseMemory
from typing import Dict, Any, List
from langchain_core.messages import BaseMessage, HumanMessage, AIMessageclass TimeAwareMemory(BaseMemory):"""一个记录对话时间的记忆组件"""chat_memory: List[Dict] = [] # 存储消息及其时间戳memory_key: str = "history" # 输出变量名input_key: str = "input" # 输入变量名def clear(self):"""清除所有记忆"""self.chat_memory = []@propertydef memory_variables(self) -> List[str]:"""定义这个记忆组件输出的变量"""return [self.memory_key]def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:"""加载记忆变量"""messages = []for entry in self.chat_memory:if entry["role"] == "human":messages.append(HumanMessage(content=entry["content"]))else:messages.append(AIMessage(content=entry["content"]))return {self.memory_key: messages}def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:"""保存当前对话上下文"""import time# 保存用户输入及时间self.chat_memory.append({"role": "human","content": inputs[self.input_key],"timestamp": time.time()})# 保存AI输出及时间self.chat_memory.append({"role": "ai","content": outputs["output"],"timestamp": time.time()})
分布式持久化记忆
实现跨会话的持久化记忆存储:
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_community.memory import ConversationBufferMemory# 使用Redis存储对话历史
message_history = RedisChatMessageHistory(url="redis://localhost:6379/0",session_id="user-123"
)# 使用持久化的历史创建记忆
redis_memory = ConversationBufferMemory(chat_memory=message_history,return_messages=True,memory_key="history"
)# 添加消息(会持久化到Redis)
redis_memory.chat_memory.add_user_message("你好,AI助手!")
redis_memory.chat_memory.add_ai_message("你好!有什么可以帮助你的?")# 即使程序重启,历史信息也会保留
history = redis_memory.load_memory_variables({})["history"]
常见记忆模式
1. 默认对话记忆
适用于简单聊天机器人:
from langchain.chains import ConversationChain
from langchain_community.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI# 创建对话链
conversation = ConversationChain(llm=ChatOpenAI(),memory=ConversationBufferMemory(),verbose=True
)# 进行对话
response1 = conversation.predict(input="你好!")
response2 = conversation.predict(input="今天天气怎么样?")
response3 = conversation.predict(input="我们之前聊了什么?")
2. 长期记忆与短期记忆结合
适用于需要长期保持用户信息的应用:
from langchain_community.memory import CombinedMemory, ConversationSummaryMemory# 创建短期记忆(详细近期消息)
short_term_memory = ConversationBufferMemory(memory_key="short_term_memory",return_messages=True
)# 创建长期记忆(摘要形式)
long_term_memory = ConversationSummaryMemory(llm=ChatOpenAI(),memory_key="long_term_memory",return_messages=True
)# 组合记忆
combined_memory = CombinedMemory(memories=[short_term_memory, long_term_memory]
)# 创建提示模板
combined_prompt = ChatPromptTemplate.from_messages([("system", "你是一位助手,有短期和长期记忆。\n\n长期记忆摘要:\n{long_term_memory}\n\n最近对话:\n{short_term_memory}"),("human", "{input}")
])# 创建链
chain = combined_prompt | ChatOpenAI() | StrOutputParser()# 使用示例
def chat_with_combined_memory(user_input):result = chain.invoke({"input": user_input, **combined_memory.load_memory_variables({})})combined_memory.save_context({"input": user_input}, {"output": result})return result
3. 记忆库模式
为多个用户或会话管理记忆:
from langchain_community.chat_message_histories import SQLChatMessageHistory# 用户会话管理
class SessionManager:def __init__(self, connection_string):self.connection_string = connection_stringdef get_session_memory(self, session_id):# 从数据库获取特定会话的历史message_history = SQLChatMessageHistory(session_id=session_id,connection_string=self.connection_string)memory = ConversationBufferMemory(chat_memory=message_history,return_messages=True,memory_key="history")return memory# 使用示例
session_manager = SessionManager("sqlite:///chat_history.db")# 用户1的会话
user1_memory = session_manager.get_session_memory("user-1")
user1_chain = RunnableWithMessageHistory(chain,lambda session_id: session_manager.get_session_memory(session_id).chat_memory,input_messages_key="input",history_messages_key="history"
)# 使用特定用户的记忆
response = user1_chain.invoke({"input": "你好!"},config={"configurable": {"session_id": "user-1"}}
)
最佳实践
-
根据应用场景选择记忆类型
- 简短对话:
ConversationBufferMemory - 长对话:
ConversationSummaryMemory或ConversationSummaryBufferMemory - 多主题对话:
VectorStoreRetrieverMemory - 需要追踪特定信息:
EntityMemory
- 简短对话:
-
管理上下文窗口
- 使用token限制或自动摘要防止超出模型上下文窗口
- 对于长对话,定期总结并清理老旧信息
-
结合多种记忆类型
- 使用
CombinedMemory混合不同记忆策略 - 为不同数据类型使用专门的记忆组件
- 使用
-
持久化考虑
- 对于生产应用,实现记忆持久化
- 使用数据库或Redis等存储对话历史
-
注意隐私和安全
- 实现记忆清理和过期机制
- 对敏感信息考虑加密存储
常见问题与解决方案
-
记忆过长导致模型上下文溢出
- 解决方案:使用摘要记忆或设置token限制
-
记忆不连贯或丢失信息
- 解决方案:调整摘要提示或使用缓冲+摘要混合方法
-
跨会话记忆丢失
- 解决方案:实现持久化存储(Redis、SQL等)
-
记忆检索效率低下
- 解决方案:使用向量存储和语义检索
高级记忆架构
对于复杂应用,可以构建分层记忆架构:
工作记忆(最近几轮对话)↑↓
短期记忆(当前会话重要信息)↑↓
长期记忆(跨会话持久信息)↑↓
知识库(向量存储的相关信息)
总结
记忆系统是构建有效对话应用的关键组件。LangChain提供了多种记忆类型,从简单的缓冲记忆到复杂的向量和实体记忆,可以根据应用需求灵活选择和组合。通过正确设计记忆策略,可以显著提升模型的上下文理解能力,创造更自然、连贯的对话体验。
后续学习
- 提示模板 - 学习如何在提示中有效使用记忆
- 链 - 了解如何在复杂流程中集成记忆
- 检索系统 - 探索基于检索的外部记忆系统
相关文章:
)
LangChain-记忆系统 (Memory)
记忆系统是LangChain的核心组件之一,允许应用程序记住和使用过去的交互信息。本文档详细介绍了LangChain中的记忆组件类型、工作原理和使用场景。 概述 在构建对话式AI应用时,能够记住上下文和之前的交互至关重要。LangChain的记忆组件负责:…...
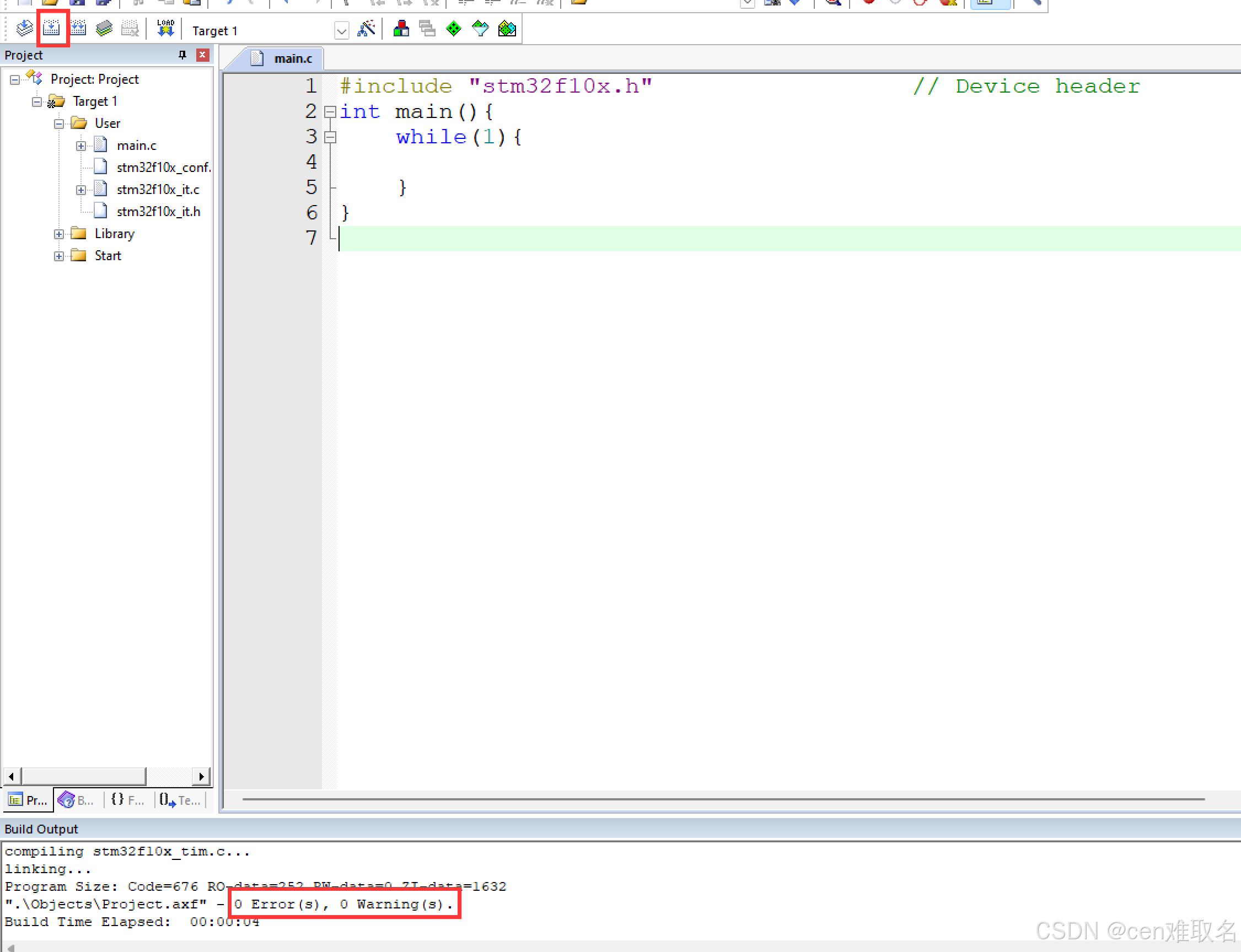
stm32开发(一)之创建工程与第一个程序
ps: 开发模式 1.基于库函数(标准库) 推荐 2.基于HAL库 图形化 3.基于寄存器 最直接 一、创建工程 1、打开keil5 new Project->路径->命名->保存 2、选择型号:stm32f103c8 初始创建工程我们不使用快捷项目建设 …...
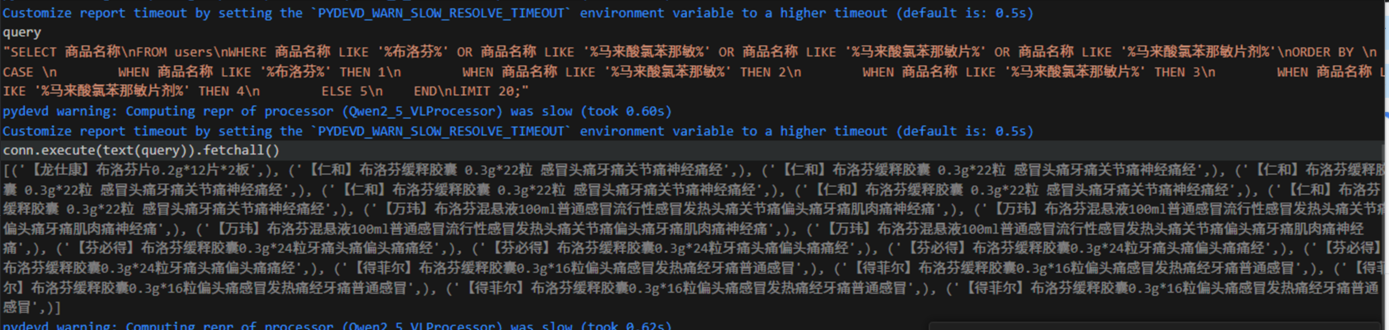
【电商】基于LangChain框架将多模态大模型连接数据库实现精准识别
1. LangChain框架 LangChain是一个用于构建基于大语言模型的应用框架,通过模块化设计简化了LLM与外部工具,数据源和复杂逻辑的集成。 连接能力 将多个LLM调用,工具调用或者数据处理步骤串联成工作流 数据感知 外部数据集成 支持连接数据…...

鸿蒙HarmonyOS埋点SDK,ClkLog适配鸿蒙埋点分析
ClkLog埋点分析系统,是一种全新的、开源的洞察方案,它能够帮助您捕捉每一个关键数据点,确保您的决策基于最准确的用户行为分析。技术人员可快速搭建私有的分析系统。 ClkLog鸿蒙埋点SDK通过手动埋点的方式实现HarmonyOS 原生应用的前端数据采…...

详解 kotlin 相对 Java 特有的关键字及使用
文章目录 1. val 和 var2. fun3. when4. is 和 !is5. lateinit6. by7. reified8. companion 本文首发地址:https://h89.cn/archives/366.html 最新更新地址:https://gitee.com/chenjim/chenjimblog Kotlin 在兼容Java的基础上,引入了许多特有…...

湘西的未来交响曲
故事摘要 在中国湖南湘西的未来,苗族文化与高科技完美融合,构建出一个既传统又现代的世界。晨曦中的沱江,悬浮的吊脚楼面带着品位独特的织锦纹样,展示了令人惊叹的未来建筑美学。独特的工坊技术使得每件首饰都能感知佩戴者的情感&…...

STM32_HAL库提高中断执行效率
目录 中断流程分析我的解决办法优缺点 大家都在说STM32 HAL 库中断效率低下。具体哪里不行?如何优化? 我手里的项目要用到多个定时器TIM6、TIM7、TIM9、TIM10、TIM11、TIM12、TIM13,在处理这些定时器中断的时候,也发现了这个问题。…...

软件系统安全设计方案,信息化安全建设方案(Word原件)
1.1 总体设计 1.1.1 设计原则 1.2 物理层安全 1.2.1 机房建设安全 1.2.2 电气安全特性 1.2.3 设备安全 1.2.4 介质安全措施 1.3 网络层安全 1.3.1 网络结构安全 1.3.2 划分子网络 1.3.3 异常流量管理 1.3.4 网络安全审计 1.3.5 网络访问控制 1.3.6 完…...

什么是微前端?有什么好处?有哪一些方案?
微前端(Micro Frontends) 微前端是一种架构理念,借鉴了微服务的思想,将一个大型的前端应用拆分为多个独立、自治的子应用,每个子应用可以由不同团队、使用不同技术栈独立开发和部署,最终聚合为一个整体产品…...

电机 断路器选型
一、断路器额定电流计算基础 电机额定电流估算 三相380V电机额定电流可按经验公式快速计算: I电机≈2P(P为功率/kW)I电机≈2P(P为功率/kW) 例如:7.5kW电机额定电流约15A。 断路器倍数选择范围 通用标准:1.2~2.5倍电机额定电…...

Web前端之Vue+Element实现表格动态不同列合并多行、localeCompare、forEach、table、push、sort、Map
MENU 效果图公共数据数据未排序时(需要合并的行数据未处于相邻位置)固定合并行(写死)动态合并行方法(函数)执行 效果图 公共数据 Html <el-table :data"tableData" :span-method"chang…...
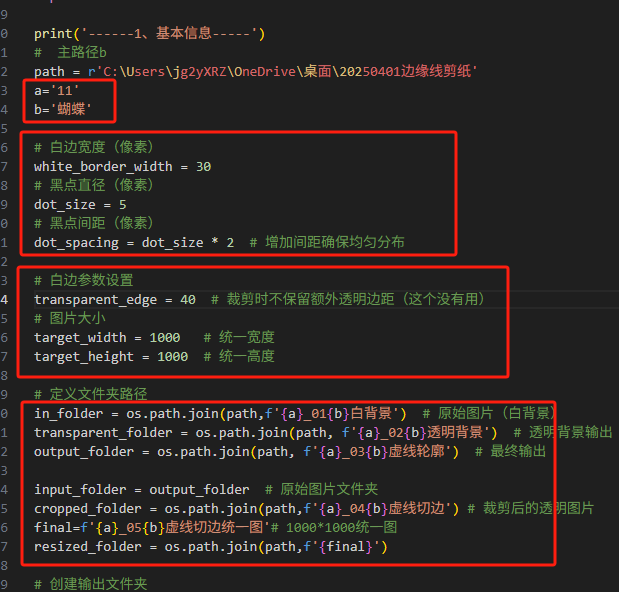
【教学类-102-07】剪纸图案全套代码07——Python点状虚线优化版本+制作1图2图6图
背景需求: 我觉得这个代码里面的输入信息分离太远(42行和241行),想重新优化一下 【教学类-102-05】蛋糕剪纸图案(留白边、沿线剪)04——Python白色(255)图片转为透明png再制作“点状边框和虚线边框”-CSDN博客文章浏览阅读864次,点赞14次,收藏27次。【教学类-102-0…...

Redis与Lua原子操作深度解析及案例分析
一、Redis原子操作概述 Redis作为高性能的键值存储系统,其原子性操作是保证数据一致性的核心机制。在Redis中,原子性指的是一个操作要么完全执行,要么完全不执行,不会出现部分执行的情况。 Redis原子性的实现原理 单线程模型&a…...

QT中怎么隐藏或显示最大化、最小化、关闭按钮
文章目录 方法一:通过代码动态设置1、隐藏最大化按钮2、隐藏最小化按钮3、隐藏关闭按钮方法 1:移除 WindowCloseButtonHint方法 2:使用 Qt::CustomizeWindowHint 并手动控制按钮 4、同时隐藏最大化和最小化按钮5、同时隐藏最大化和关闭按钮6、…...

OpenSceneGraph相机系统
一、相机的核心原理 Open Scene Graph(OSG)中相机的核心原理围绕视图变换和投影变换展开,结合场景图的层次化结构实现三维空间的动态渲染。 1、视图变换(View Transformation) )视图矩阵的作用…...
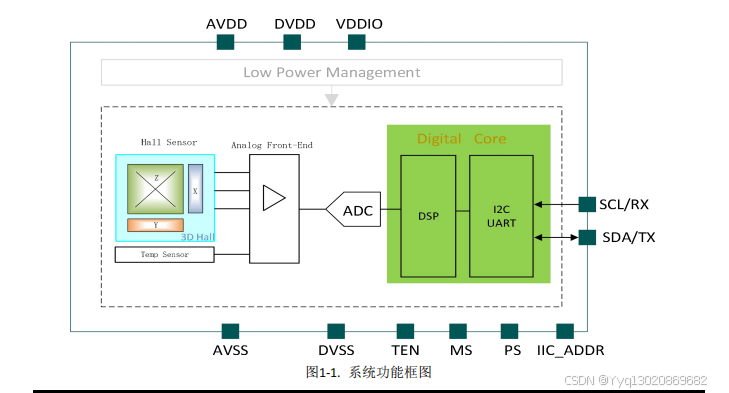
KTH5772 系列游戏手柄摇杆专用3D 霍尔位置传感器
产品概述 KTH5772是一款专为游戏手柄上的摇杆应用而设计的3D霍尔磁感应芯片,主要面向对线性度、回报率、灵敏度、功耗要求严格的摇杆应用。KTH5772基于3D霍尔技术,内部分别集成了X轴、Y轴和Z轴三个独立的霍尔元件,能够通过测量和处理磁通密度…...

Soybean Admin 使用tv-focusable兼容电视TV端支持遥控器移动焦点
环境 window10 pnpm 8.15.4 node 8.15.4 vite 5.1.4 soybean admin: 1.0.0 native-ui: 2.38.0 vue-tv-focusable: 2.0.1 小米电视 MIUI TV版本:MiTV OS 2.7.1886(稳定版) 飞视浏览器:https://www.fenxm.com/1220.html这里必须使用飞视浏览器,…...

经济金融最优化:从理论到MATLAB实践——最大利润问题全解析
内容摘要 本文聚焦经济金融领域的最大利润问题,深入探讨不考虑销售影响和考虑销售影响两种情形下的利润最大化模型柯布 - 道格拉斯生产函数等理论构建与求解。 关键词:经济金融;最大利润问题;柯布-道格拉斯生产函数 1. 引言 在…...
大模型学习七:小米8闲置,直接安装ubuntu,并安装VNC远程连接手机,使劲造
一、说明 对于咱们技术人来说,就没有闲的蛋疼的时候,那不是现在机会来了 二、刷机器准备 1、申请解锁手机 申请解锁小米手机https://www.miui.com/unlock/download.html 下载工具,安装下面的步骤来,官网不欺人吧 打开开发者工…...
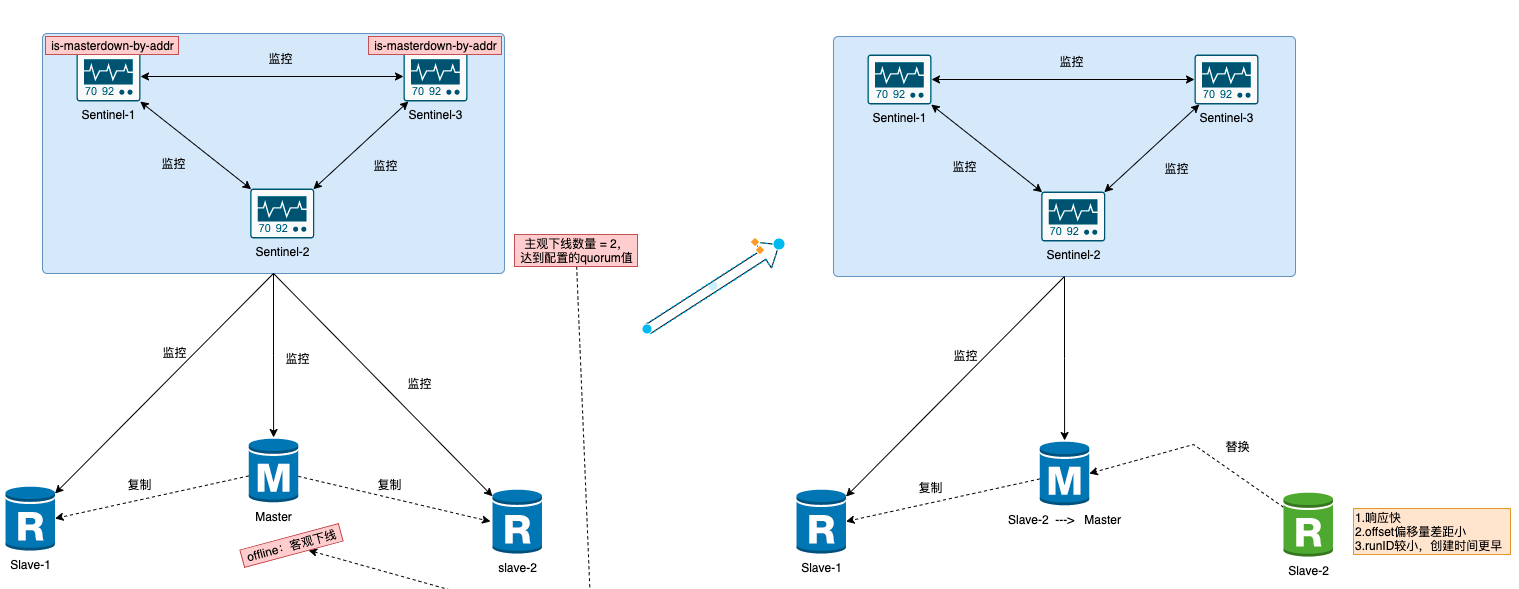
高可用之战:Redis Sentinal(哨兵模式)
参考:Redis系列24:Redis使用规范 - Hello-Brand - 博客园 1 背景 在我们的《Redis高可用之战:主从架构》篇章中,介绍了Redis的主从架构模式,可以有效的提升Redis服务的可用性,减少甚至避免Redis服务发生完…...

简单括号匹配_栈
课程笔记 10:数据结构(清华) 栈_opnd push-CSDN博客 括号匹配。对于一个表达式,要想确认其中所使用的括号是否匹配,可以采用减而治之的思路,将每对邻近括号消去,则剩下的达式括号匹配当且仅当…...

CSS Grid布局:从入门到放弃再到真香
Flexbox 与 Grid 布局:基础概念与特点 Flexbox Flexbox(Flexible Box Layout),即弹性盒布局模型,主要用于创建一维布局,能够轻松实现元素在一行或一列中的排列、对齐与分布。通过display: flex属性启用 Fl…...

Springboot把外部jar包打包进最终的jar包,并实现上传服务器
1、创建lib目录,把jar包放进这个目录下,然后标记lib目录为“资源根路径”(鼠标右键lib目录->将目录标记为->资源根路径。之后lib文件夹会有如下的图标变化) 文件结构如下: 2、pom文件添加依赖 <dependency…...

仿照管理系统布局配置
1.vue仿照snowy 配置,如下图: 2.代码实现 <template><div class"theme-settings"><!-- 导航栏 --><div class"nav-bar"><el-breadcrumb separator"/"><el-breadcrumb-item>导航设置…...

A2L文件解析
目录 1 摘要2 A2L文件介绍2.1 A2L文件作用2.2 A2L文件格式详解2.2.1 A2L文件基本结构2.2.2 关键元素与声明2.2.3 完整A2L文件示例 3 总结 1 摘要 A2L文件(也称为ASAP2文件)是ECU开发的核心接口文件,用于标定、测量和诊断的关键配置文件&…...
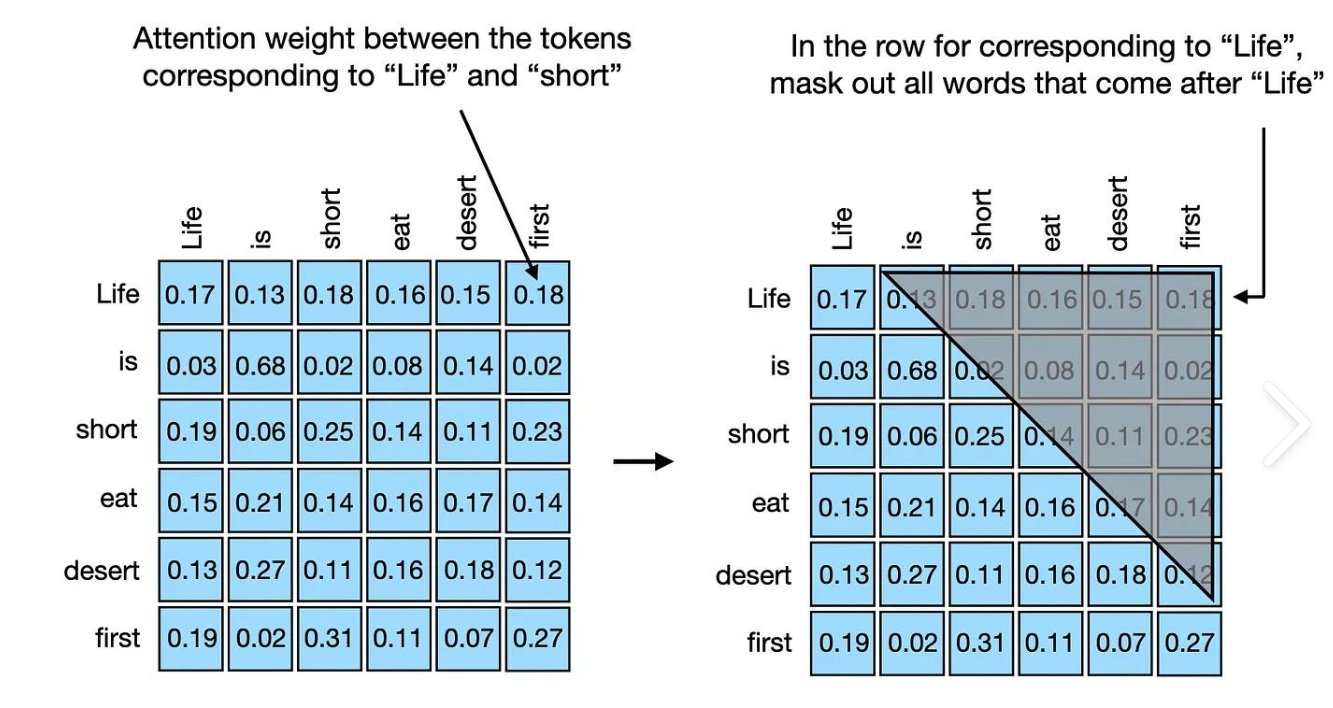
GPT - 因果掩码(Causal Mask)
本节代码定义了一个函数 causal_mask,用于生成因果掩码(Causal Mask)。因果掩码通常用于自注意力机制中,以确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。这种掩码在自然语言处理任务(如…...

SpringBoot 数据库MySql的读写分离 多数据源 Shardingsphere高并发优化
介绍 传统的 MySQL 架构中,所有的数据库操作(包括读操作和写操作)都在同一个数据库实例上进行。随着应用程序的规模增长,单一数据库实例可能会成为瓶颈,无法满足高并发的需求。为了优化性能,可以将数据库的…...

适合工程建筑行业的OA系统有什么推荐?
工程行业具有项目周期长、协作链条复杂等特性,传统管理模式下的 “人治”“纸质化” 弊端日益凸显。OA 系统作为数字化管理的核心载体,通过流程标准化、数据可视化,精准解决工程行业项目管理核心痛点。 泛微 e-office 深度聚焦工程场景&#…...

如何使用 DeepSeek 帮助自己的工作?
1. 信息检索 信息检索是获取特定信息的过程,尤其是在大量数据或文本中查找相关内容。这个过程应用广泛,从网页搜索引擎到数据库查询,再到企业内部信息系统。在使用 DeepSeek 或其它类似工具进行信息检索时,可以考虑以下几个重要方…...

python对mysql数据库的操作
现在遇到一个问题如何将数据批量的插入mysql数据库中 基础操作 import asyncio from config import config from mysql_pool import MysqlPoolclass MysqlLoop(object):def __init__(self):self.logger config.loggerself.pool MysqlPool()def loop_query(self, queries):lo…...