【数据结构】排序算法(下篇·开端)·深剖数据难点


前引:前面我们通过层层学习,了解了Hoare大佬的排序精髓,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,借此分享一下:【用1520分钟去调试】,如果我们遇到了任何问题,必须先学会自己能不能解决,调试是每次代码找错的一个途径。通过每次调试,看它的数据变化是否达到了目前应该的预期,然后我们找到了错误,应该如何改进!下面小编通过拆分思想,一步步带你深解这些算法思想的奥妙!
目录
快排(双指针·递归)
算法思想:
实现步骤:
复杂度分析:
代码实现:
单趟实现:
递归实现:
代码优化:
优缺点分析:
快排(双指针·非递归)
算法思想:
实现步骤:
代码实现:
左区间:
右区间:
整体代码展示:
优缺点分析:
小编寄语
快排(双指针·递归)
大家在写部分题目的时候,是否有在评论区看见这样的评论:“双指针秒了”,小编当时见的很多,当时我不知道双指针是哈,但是现在领悟了!双指针是通过两个指针完成!这里的“指针”并非真正是指针,也可以是下标,因为arr【i】=*(p+i),它们都是指元素,下面我们看看哈是双指针!
算法思想:
双指针排序是利用两个指针协助操作来完成排序的任务,它们通常同向移动或者相向移动,典型的运用场景如下面两方面:
(1)快速排序:通过分区操作将数组分为小于/大于基准值的两部分进行递归(当前主讲)
(2)归并排序:合并两个有序子数组时,通过双指针比较元素大小
为了方便接下来思路拆分比较好理解,我先总结2个指针的原理(cur是前指针,prev是后指针):
(1)cur找小,找到小之后,prev再找大,然后二者交换对应的元素,cur再向前移动
(2)prev找大,找到大之后,与cur所指的值进行交换
实现步骤:
在进行正式的学习之前,我们先来看一下它的动图,好好感悟一下,然后我们进行思路拆分讲解:

1:老套路,我们先来实现单趟。我们发现,在开始前,数据的初始化是如下图这样的:
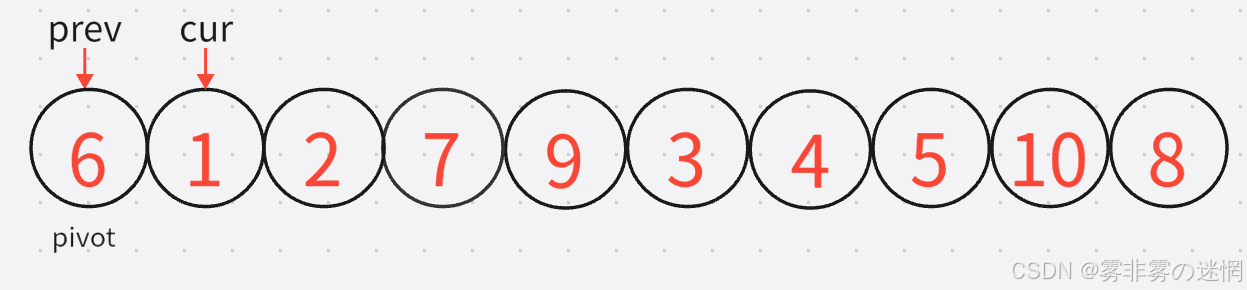
2:然后重点来了!为了清晰对比,我对这两个指针功能进行了拆分,为什么找小、找大?
cur :找小(对于基准值而言),因为我们需要与prev所指向的进行交换,小的交换到左边去
prev :找大(对于基准值而言)因为我们需要将其与cur所指的内容进行交换,大的要到右边去
3:既然是前后指针法,cur是要先动,cur找到小之后,prev再动,直到找到较大的元素:【注意:prev不能跑到cur的前面去】
这里cur所指的元素刚好就是满足条件的,因此再移动prev就行了,如图:
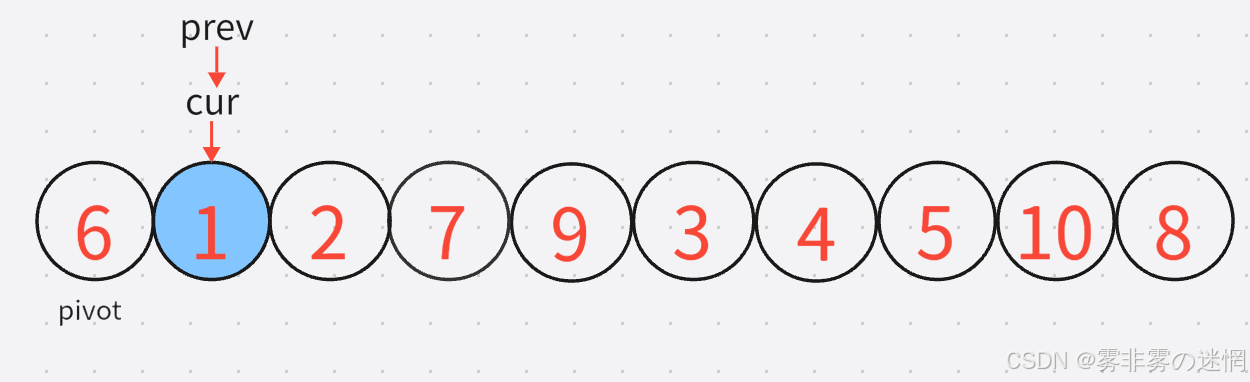
此时prev与cur重合了, 那么就进行交换,交换之后1还是在原来的地方,交换完之后cur再加加,进入新一轮的判断,这是第一轮结束的情况:
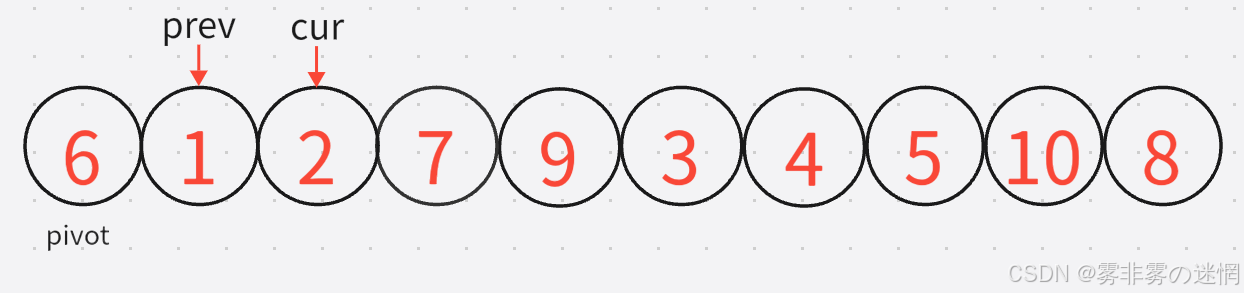
4:下面进行第二轮 。这里还是跟刚才情况一样,cur刚好满足情况,二者重合了,所以第二轮结尾的状况就是:
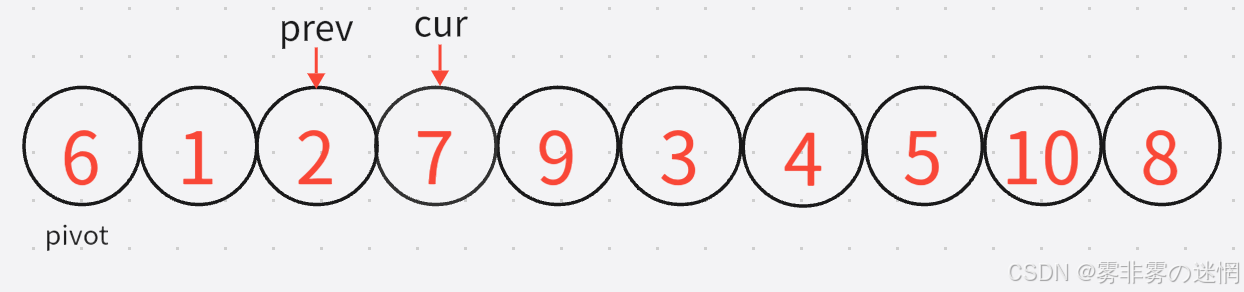
5: 第三轮:cur所指的元素是较大的,因此经过几轮循环加加,直到找到小于基准值所指的元素
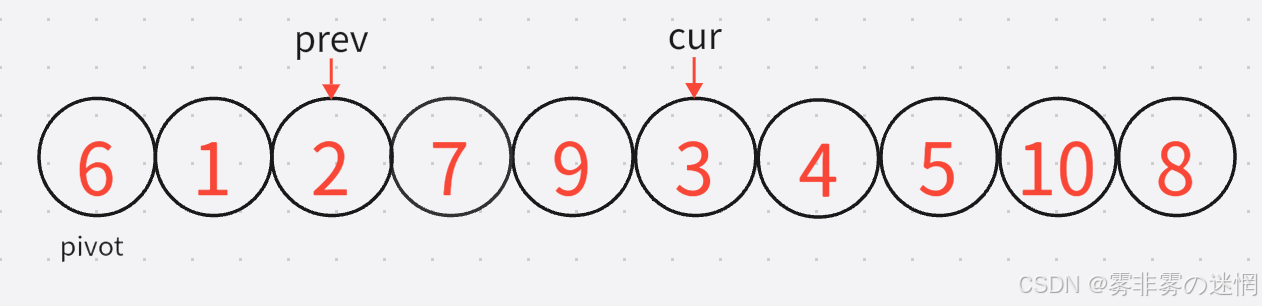
现在找到了较小的元素3,然后prev加加,直到找到较大的元素,二者再进行交换:
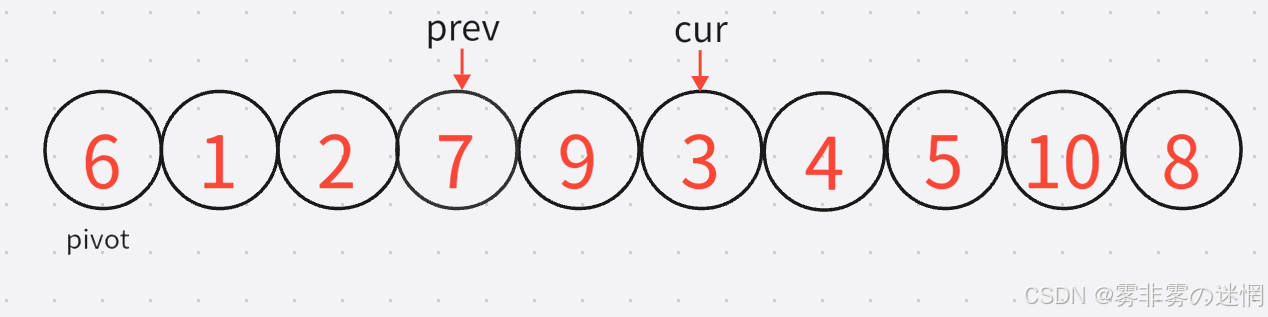
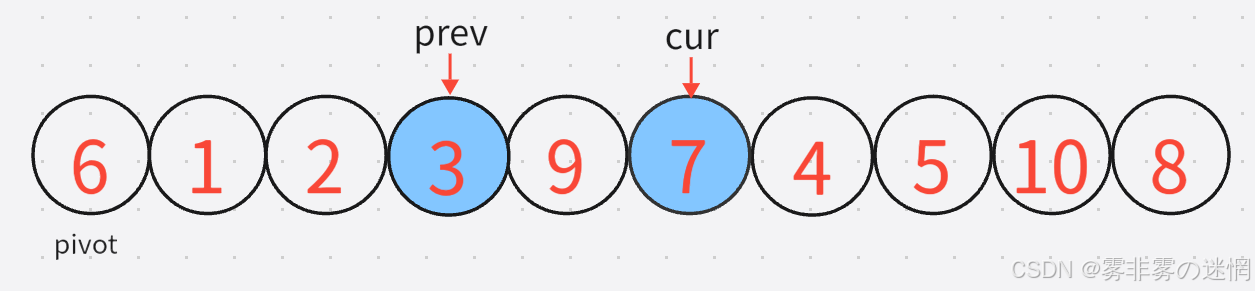
6:然后按照cur再加加,直到找到较小的元素,prev再找到较大的元素,进行交换:
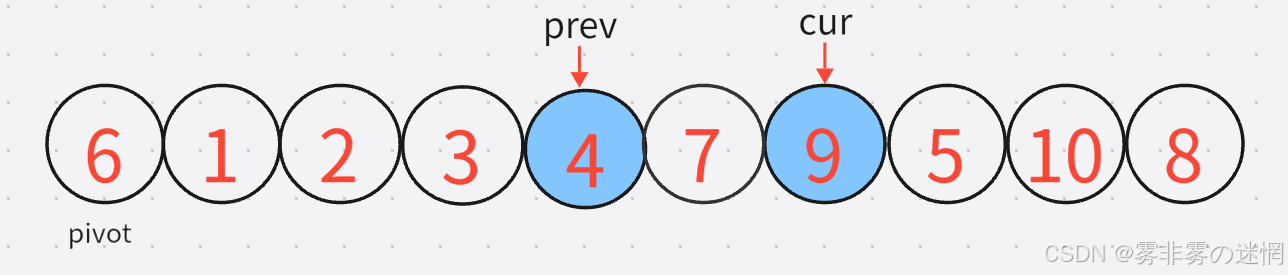
7:下一轮还是同理,先找小,再找大,再交换:
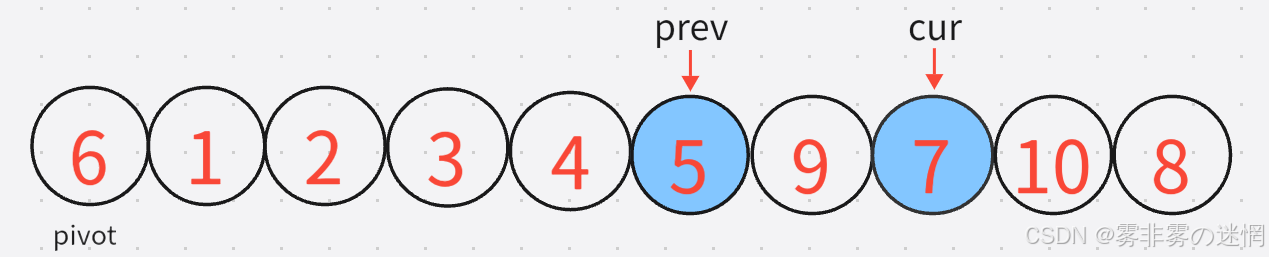
那么cur再出了数组界限,最后再将prev所指的与pivot位置进行交换,更新pivot,单趟就结束了

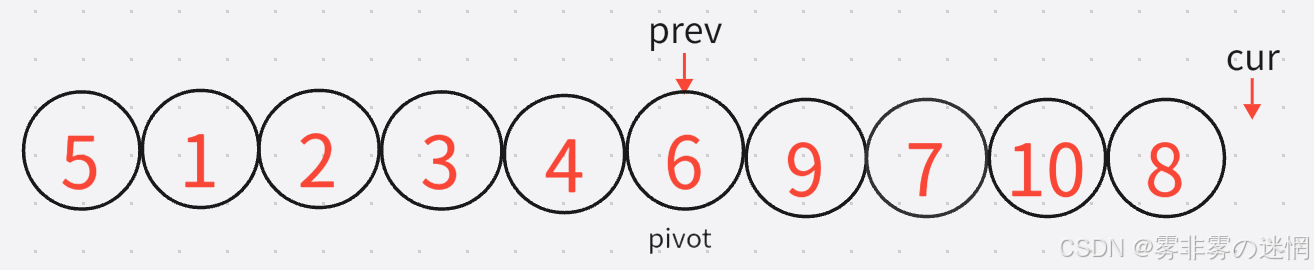
接下来这么将基准值为界限,分为左右2组进行递归就可以了!
复杂度分析:
最好时间复杂度、平均时间复杂度:
每次分区操作的时间复杂度为O(n),递归树的深度为 log n,总操作次数为O(n logn)
最坏时间复杂度:
每次分区之后,一个子数组为空,另一个子数组包含剩余的所有元素,时间复杂度为O(n^2)
空间复杂度:
递归树的深度为log n
代码实现:
单趟实现:
按照上面的原理,我们先实现单趟:
cur找小,找到之后prev再找大【prev不能超过cur】,交换之后,cur++
prev找大,找到之后交换
while (cur <= right)
{//找小if (arr[cur] < arr[pivot]){prev++;//交换Exchange(&arr[prev], &arr[cur]);cur++;}if (arr[cur] > arr[pivot]){cur++;}
}
//此时right=size,交换left与pivot下标的元素
Exchange(&arr[pivot], &arr[prev]);
//更改pivot的位置
pivot = prev;如果单趟有问题的小伙伴们可以去看看实现步骤,这里是重点讲解了单趟的实现的!
递归实现:
对于递归,我觉得很有必要强调一下思路,下面我们借助代码来分析:
int left = 0;
int right = size-1;void QuickSort(int* arr, int left, int right)
{//递归结束条件if(left >= right){return;}//找基准值int pivot= Pointer(arr, left, right);//左区间QuickSort(arr, left, pivot - 1);//右区间QuickSort(arr, pivot + 1, right);
}首先咱们的left初始位置是数组下标为0的位置,right是数组下标末尾的位置,不满足递归结束条件。我们第一次找基准值得到6,通过基准值来划分区间,也就是这里的单趟,如图划分区间:
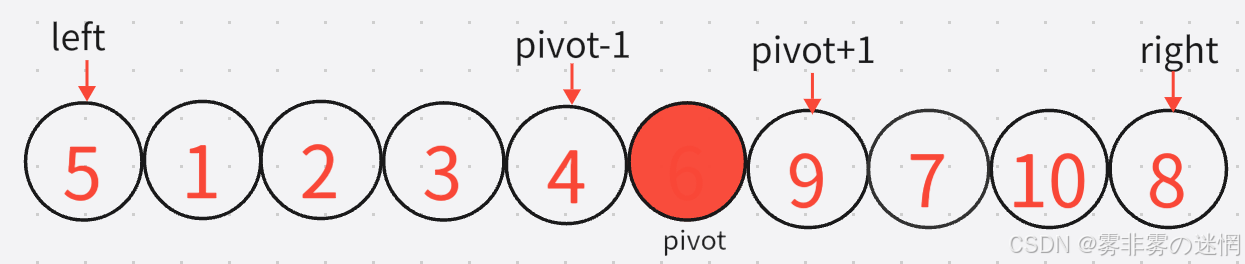
这里以左区间为例,QuickSort函数拿到的区间是【arr,left,pivot-1】 现在进入了单趟函数:
进入单趟函数Pointer之后,此时单趟函数的参数也就是【arr,left,pivot-1】,这里为什么要设置这么多的参数呢?如下面的代码
//设置基准值
int pivot = left;
//记录参数
int prev = left;
int cur = left + 1;因为我们拿到的是区间,只有左右两个端点,首先cur prev是必须要设置的,因为是新变量。
既然传过来的只是形参,我为什么要设置一个一模一样的变量prev去代替left,这是为了方便统一,避免混淆,其实不换也是可以的, 大家可以看演示效果(标红点的地方是把prev->left的):
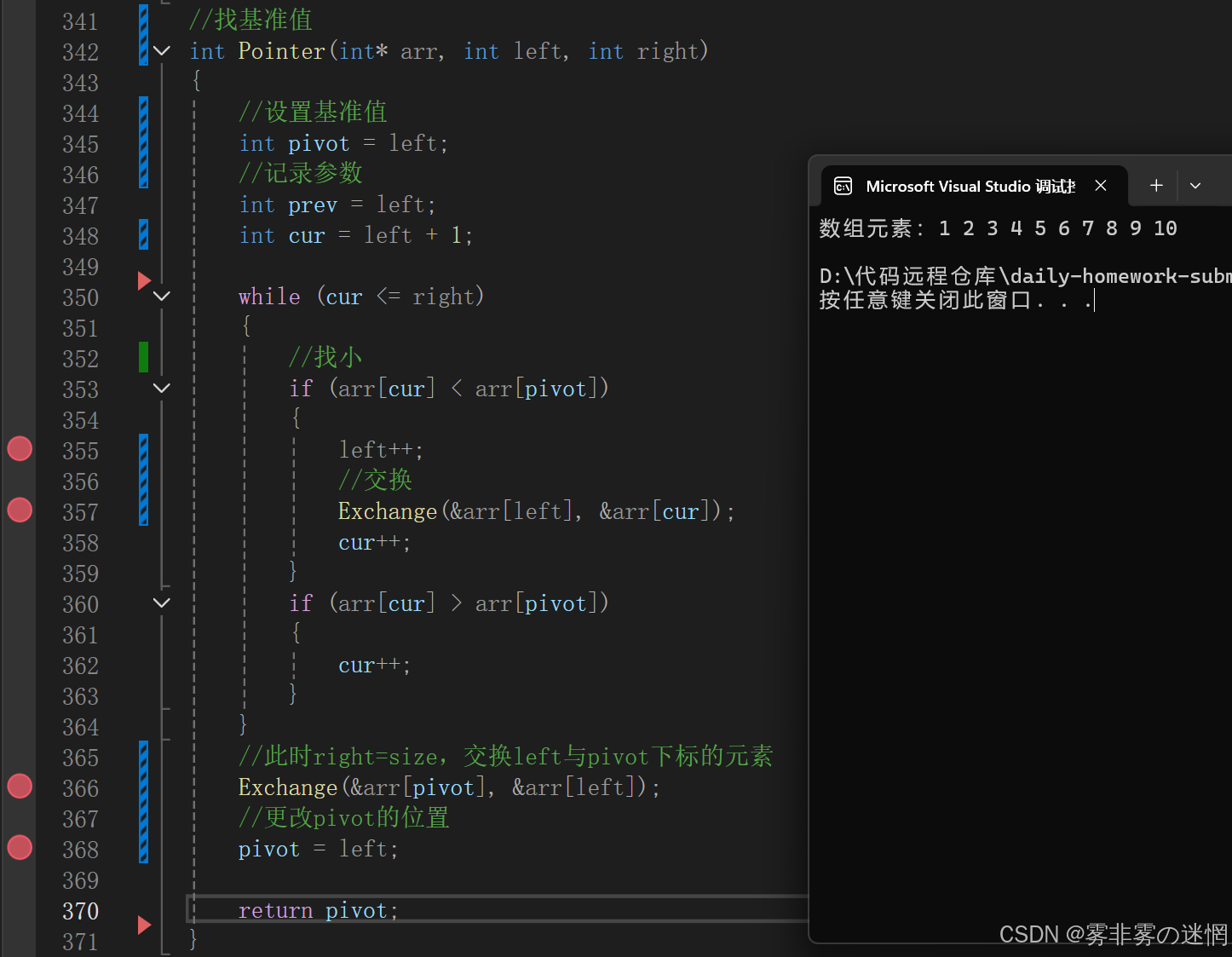
经过这个函数我们得到了新的基准值5,然后再次调用递归函数,得到新的区间是【left,pivot-1】
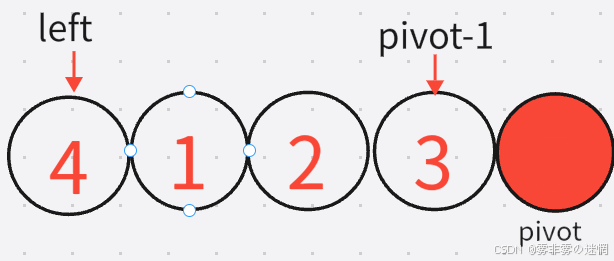
再就这样一直循环找基准值进行排序就可以了,递归结束的条件又是如何更改left 、right的?
这是第一次进入递归函数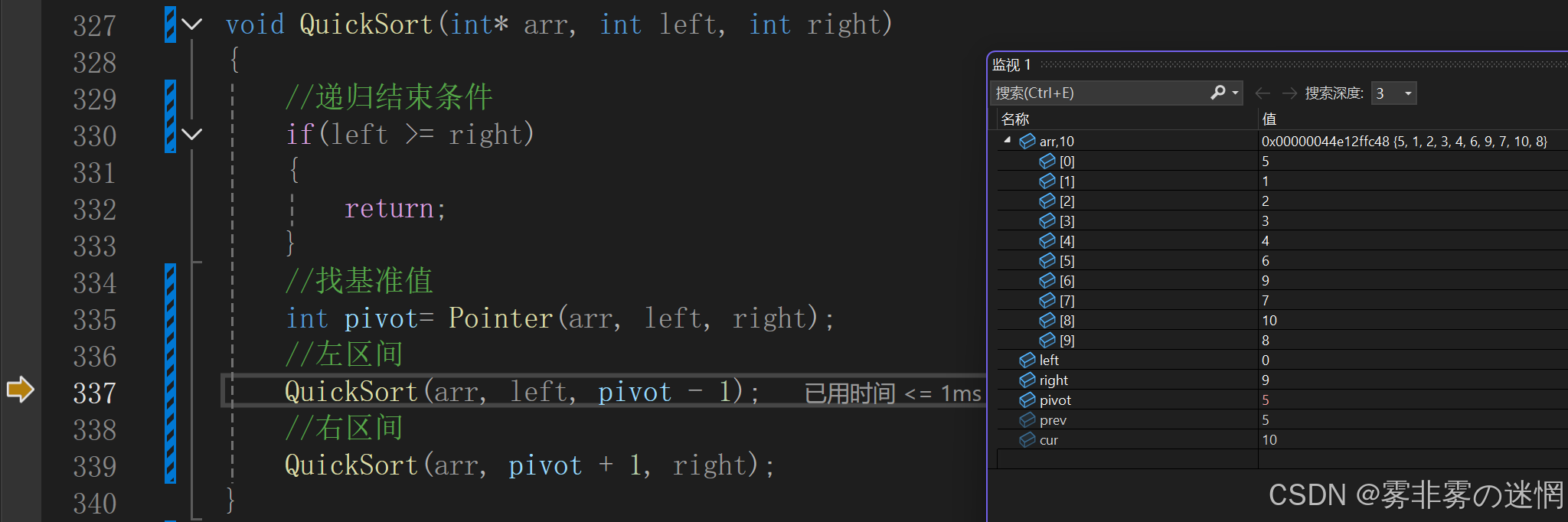
这是第二次进行递归函数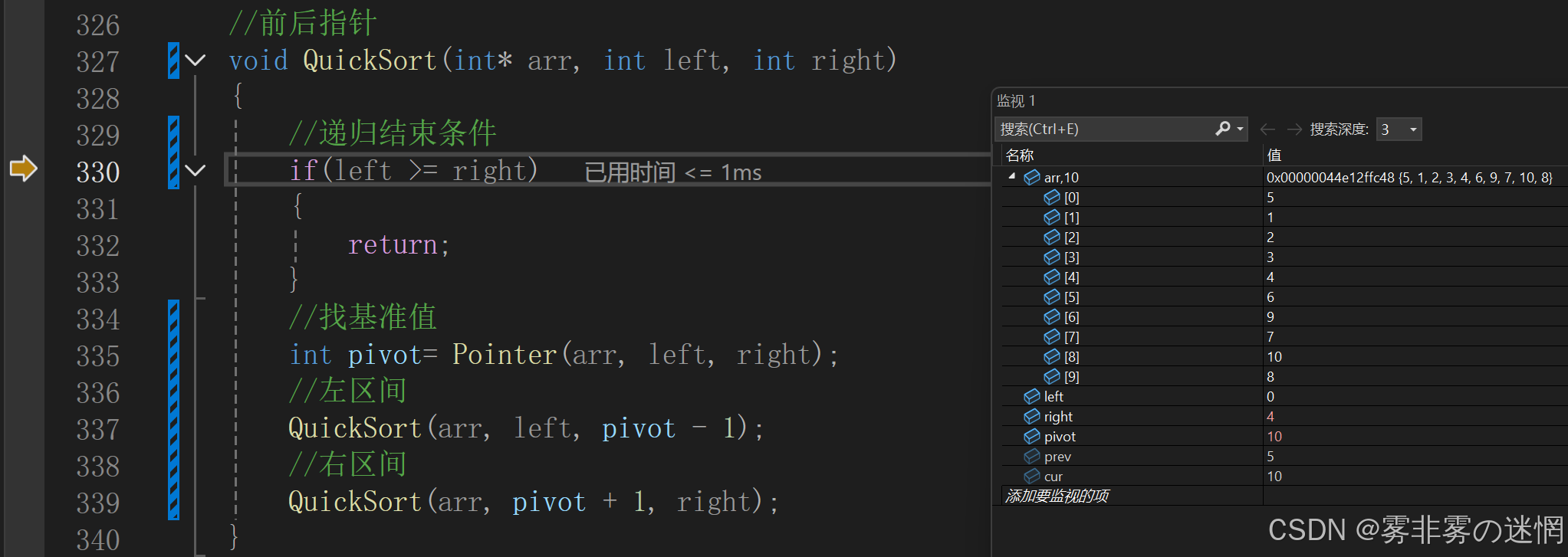
我们很明显的看到right的值发生了变化,请看下面这幅图,你就明白了,右区间递归函数同理:
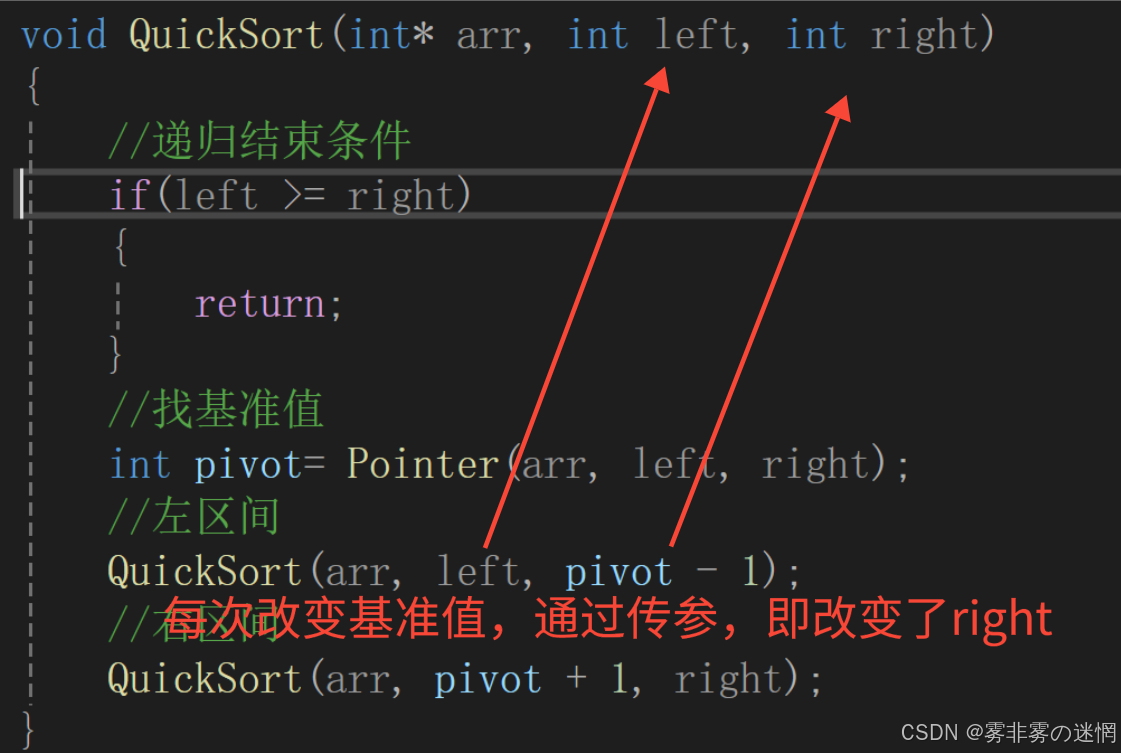
代码优化:
双指针:我们知道分组递归可以想象成【树】那样,一组变两组,两组变四组,这么循环下去,当最后一层时,它的分组是相当多的,双指针排序虽然平均时间复杂度达到O(n logn),但是它主要的开销还是在后面的分组,越往后分的越多。
插入排序:而插入排序虽然整体来说时间复杂度达到O(n^2),但是它对几乎有序的子数组来说效率很高,所以我们如果将二者结合,取一个界线,当剩余的元素到达某个阈值时,切换为插入排序,这是很常见的一种优化。
我们一般取10左右的数字为阈值。这里只需要看剩余数组元素个数即可,用分支判断:
我们总共的数组元素个数是right+1,那么剩余的元素个数不就是right+1-left吗!(如下图)
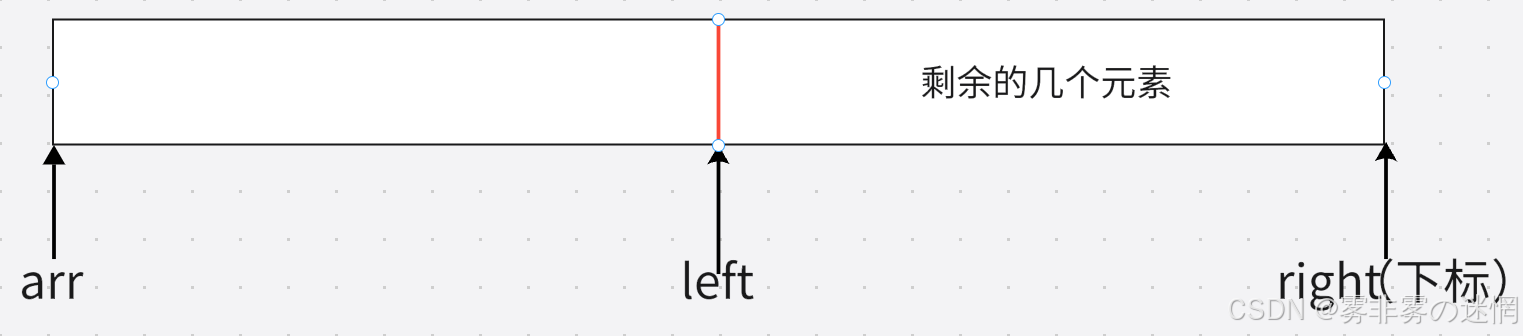
下面我来解释这个区间的开始位置应该如何表示:
首先我们的arr是数组名,如果我们直接传数组名过去是错误的,因为我们不能保证剩余的元素一定是从数组的起始位置开始的,如下图我们得到剩余元素的开始应该是arr+left
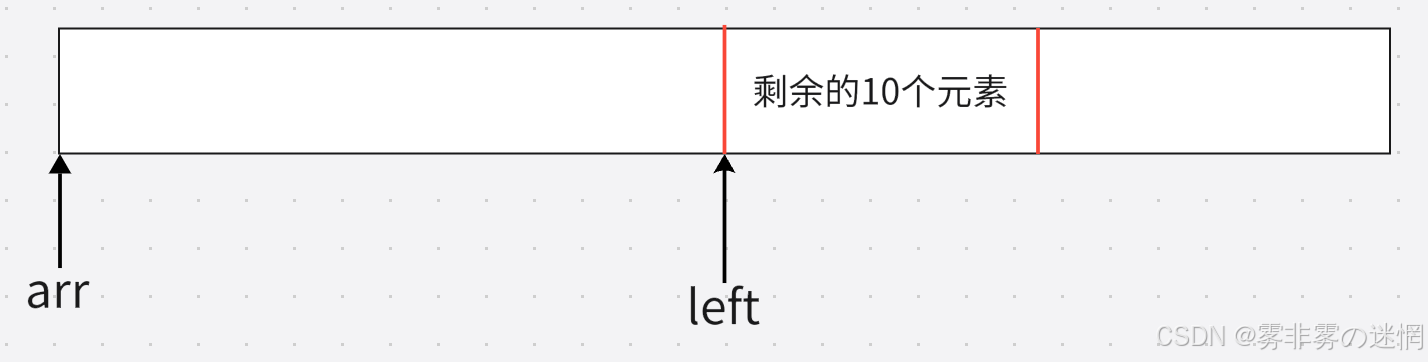
下面是优化代码
void QuickSort(int* arr, int left, int right)
{//递归结束条件if(left >= right){return;}if ((right - left + 1) > 10){//找基准值int pivot = Pointer(arr, left, right);//左区间QuickSort(arr, left, pivot - 1);//右区间QuickSort(arr, pivot + 1, right);}else//到达阈值时选用直接插入排序Insert(arr+left, right - left + 1);}
优缺点分析:
首先是时间复杂度,双指针排序的时间复杂度均为O(n logn),这是一个很大的优化,双指针可以在单次遍历中实现快速排序,减少了冗杂的操作,适用范围广,是比较推荐的一种快排方法,当然需要先理解哈。并且双指针还可以应用在两数之和、去重、合并区间等不同的其它问题,点赞!
快排(双指针·非递归)
首先我们已经学会了递归的形式去走快排,为什么还要去学习非递归?
我们平时写递归代码,数据还比较少,如果我们将递归放在几百万、上千万的数据里面呢?在上面我们只用了10个数据去走递归,每一层是上一层的两倍,呈现倍数的增长,那么它在实际应用中是不推荐的,数据如果太多太多,递归深度也就越深,容易发生栈溢出,因此递归方式我们能不用就不要用,在以后工作时,一般递归的代码会让我们改成非递归的,这也是在避免以后出现隐患
算法思想:
我们知道快排双指针的方式是通过 基准值 来实现对数组的分组,通过递归一步步调用函数来完成分组排序,那么它的本质是什么?
我们每次调用函数,改变的是它的参数,也就是改变它的区间,每个组一直通过基准值分下去:
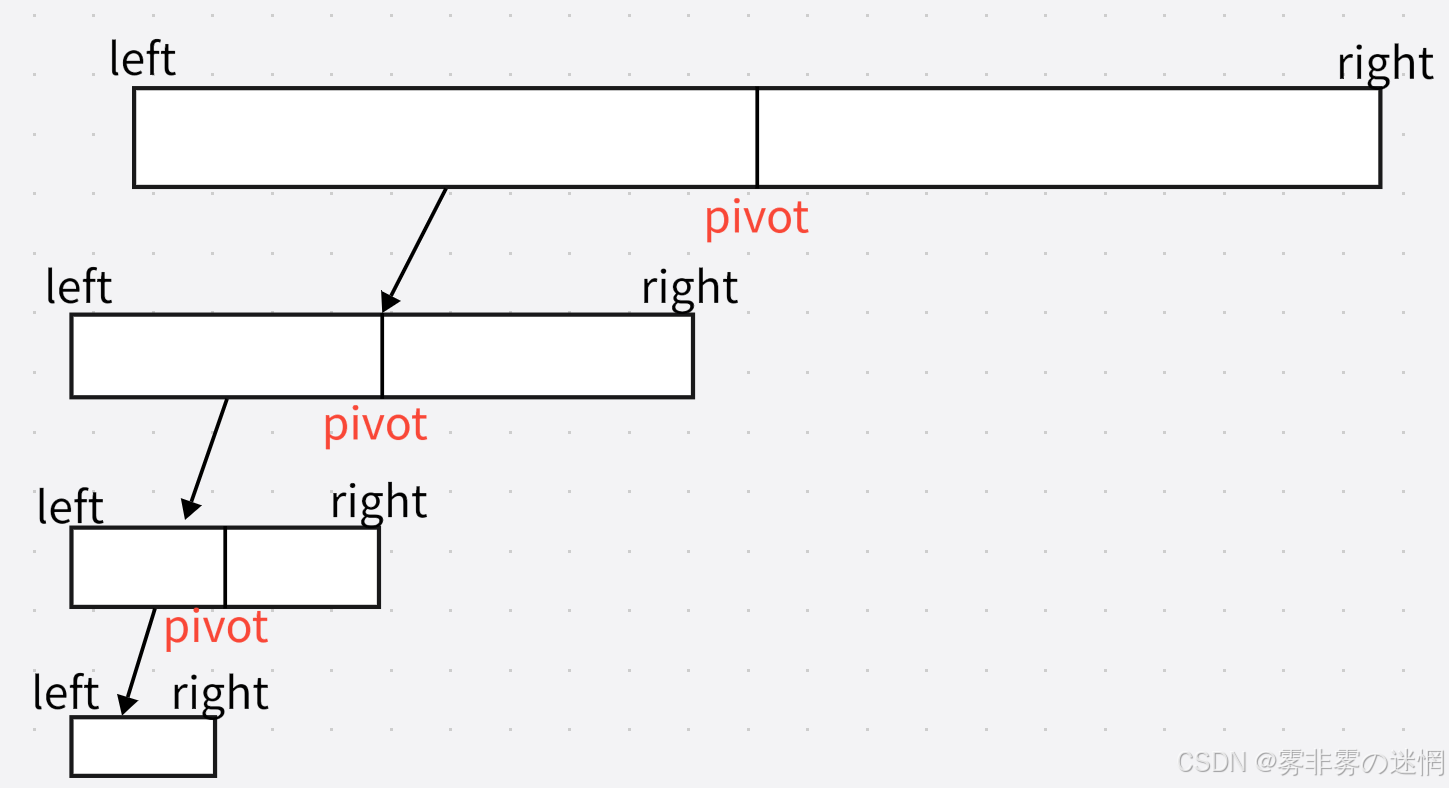
我们把它的区间存起来,每次改变获取不一样的区间,再传参给排序函数就达到了非递归的效果!
我们可以通过栈和队列来存储分组的区间,每次调用栈和队列的元素来进行传参给排序函数
在这里我推荐栈来实现,原因:
首先用队列也是可以的,这样就是一层一层的去排序了(层序遍历),如果我们换栈去实现,就是先将左边的分组分完了,再去分组右边(前序遍历),且栈的应用比较广泛,因此我们在这里选择栈去存储分组区间
实现步骤:
栈的存储特点:先进后出,就像将数据一个个放进容器
按照上面的思路,我们先从左边的分组开始:

我们发现左区间的left是不变的,变的只有pivot-1,也就是基准值在不断变化,因此我们可以通过每计算一个基准值,就存入栈里面,再拿出来,然后再通过出栈的值去做左区间的参数
右边的区间是只改变left,即右边区间是将基准值pivot+1作为每次参数的改变,如图:

代码实现:
左区间:
按照原理,先找基准值,再来实现对基准值的入栈,再出栈作为参数:
//找基准值
int pivot = Pointer(arr, left, cur);
//左区间的基准值入栈
Enter(s, pivot);
//再出栈,cur作为右边不断变化的区间
cur = Out(s);
//出栈元素作为左区间参数
Pointer(arr, left, cur - 1);需要注意:我们此时已经获得了基准值,就不需要递归函数了,注意切换函数。这样我们就完成了单趟,我们外面再套一个循环,就完成了左边分组的排序,循环的条件就是当区间剩余一个元素时就停下【因为一个元素表示它已经是正确位置了】即right-left+1==0 注意:左边排序我们需要记录right,因为我们的参数是不断变化的,需要用一个变量去代替right,效果展示如下:
//标记
int cur = right;
while ( ( cur - left + 1) > 1 )
{//找基准值int pivot = Pointer(arr, left, cur);//左区间的基准值入栈Enter(s, pivot);//再出栈,cur作为右边不断变化的区间cur = Out(s);//出栈元素作为左区间参数Pointer(arr, left, cur - 1);
}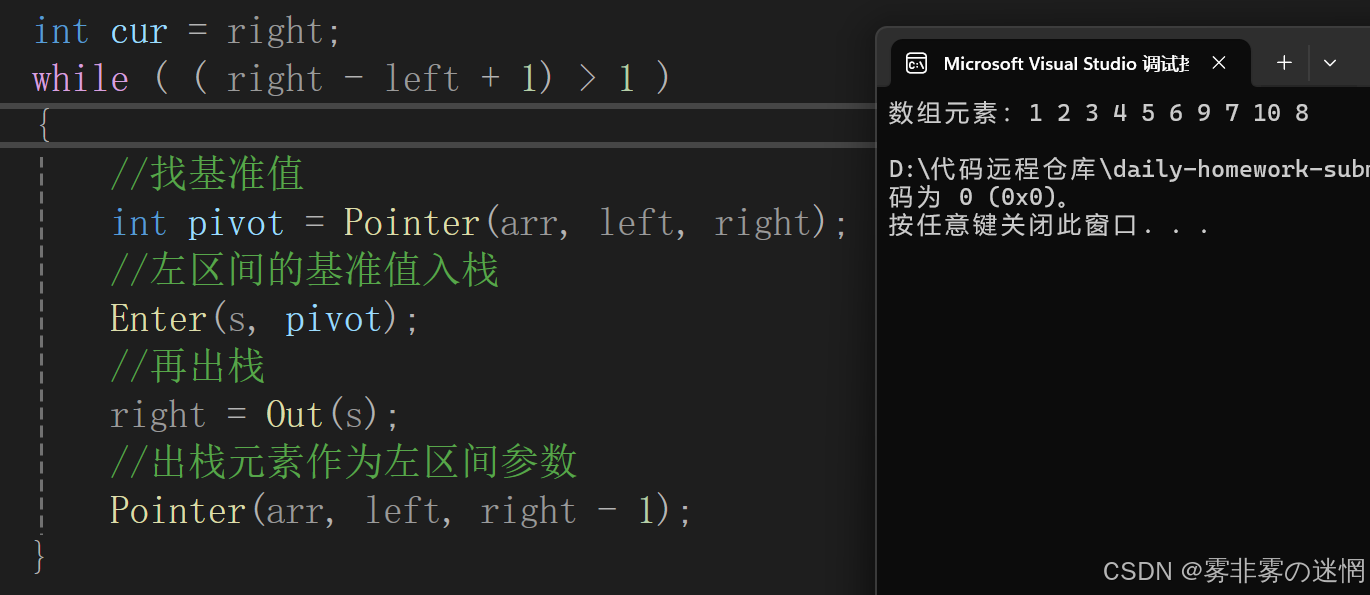
此时数组左边的数据通过非递归的方式已经完成排序了,如下图展示: 
右区间:
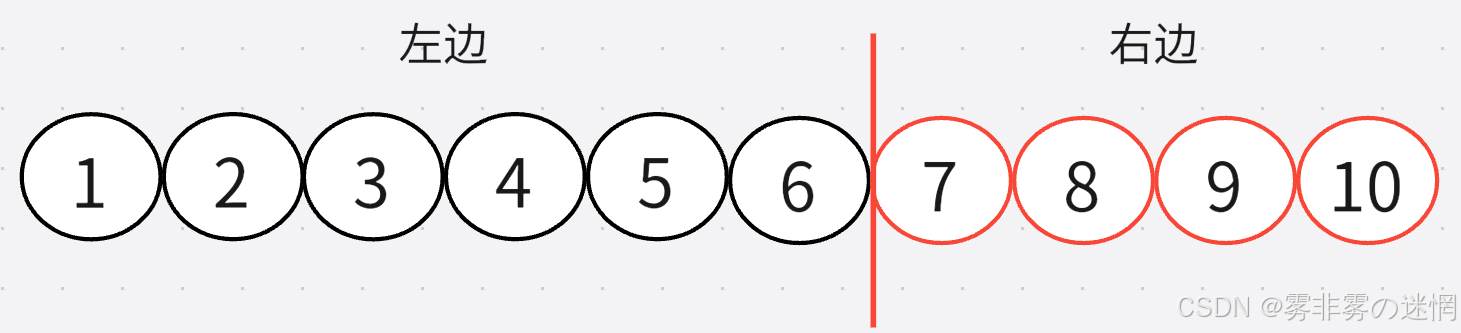
完成了左边,我们直接复制一下代码,稍微改动就行了【注意右边是改变left】,如下代码展示:
//标记
int prev = left;
while ((right - prev + 1) > 1)
{//找基准值int pivot = Pointer(arr, prev, right);//左区间的基准值入栈Enter(s, pivot);//再出栈prev = Out(s);//出栈元素作为左区间参数Pointer(arr, prev + 1, right);
}
整体代码展示:
void QuickSort(int* arr, Stack* s, int left, int right)
{//标记int cur = right;while ( ( cur - left + 1) > 1 ){//找基准值int pivot = Pointer(arr, left, cur);//左区间的基准值入栈Enter(s, pivot);//再出栈cur = Out(s);//出栈元素作为左区间参数Pointer(arr, left, cur - 1);}//标记int prev = left;while ((right - prev + 1) > 1){//找基准值int pivot = Pointer(arr, prev, right);//左区间的基准值入栈Enter(s, pivot);//再出栈prev = Out(s);//出栈元素作为左区间参数Pointer(arr, prev + 1, right);}
}int Pointer(int* arr, int left, int right)
{//设置基准值int pivot = left;//记录参数int prev = left;int cur = left + 1;while (cur <= right){//找小if (arr[cur] < arr[pivot]){prev++;//交换Exchange(&arr[prev], &arr[cur]);cur++;}if (arr[cur] > arr[pivot]){cur++;}}//此时right=size,交换left与pivot下标的元素Exchange(&arr[pivot], &arr[prev]);//更改pivot的位置pivot = prev;return pivot;
}优缺点分析:
我们最大的成功就是将递归改成了非递归,通过循环去实现整体的排序,这里避免了栈溢出,在未来我们去工作时,能不写递归就尽量不要写递归,出现递归能改则改。对于数据大的环境下,递归的深度很可怕的!而循环则不同,它不会出现栈溢出,只需要控制循环的条件即可
小编寄语
见证了Hoare大佬的排序思想,又衍生出了双指针的方式,感叹如此精妙的改进!排序的道路没有结束,此篇是难点的第一篇,领教双指针的魅力,快排和归并作为效率很高的两种排序,能够随时手撕代码是对这些思想的真正领悟,让排序算法成为技术世界里不停歇的实验场,预知归并如何,详见下篇!
相关文章:
【数据结构】排序算法(下篇·开端)·深剖数据难点
前引:前面我们通过层层学习,了解了Hoare大佬的排序精髓,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,借此分享一下:【用1520分钟去调试】,如果我们遇到了任…...
山东大学软件学院创新项目实训开发日志(9)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...

【VUE3】Eslint 与 Prettier 的配置
目录 0 前言 1 VSCode 中的 Eslint 与 prettier 插件 2 两种方案 3 eslint.config.js 4 eslint-plugin-prettier 插件 5 eslint-config-prettier 插件 6 安装插件命令 7 其他配置 8 参考资料 0 前言 黑马程序员视频地址:160-Vue3大事件项目-ESlint配合P…...

蓝桥杯C++组算法知识点整理 · 考前突击(上)【小白适用】
【背景说明】本文的作者是一名算法竞赛小白,在第一次参加蓝桥杯之前希望整理一下自己会了哪些算法,于是有了本文的诞生。分享在这里也希望与众多学子共勉。如果时间允许的话,这一系列会分为上中下三部分和大家见面,祝大家竞赛顺利…...

springboot调用python文件,python文件使用其他dat文件,适配windows和linux,以及docker环境的方案
介绍 后台是用springboot技术,其他同事做的算法是python,现在的需求是springboot调用python,python又需要调用其他的数据文件,比如dat文件,这个文件是app通过蓝牙获取智能戒指数据以后,保存到后台…...
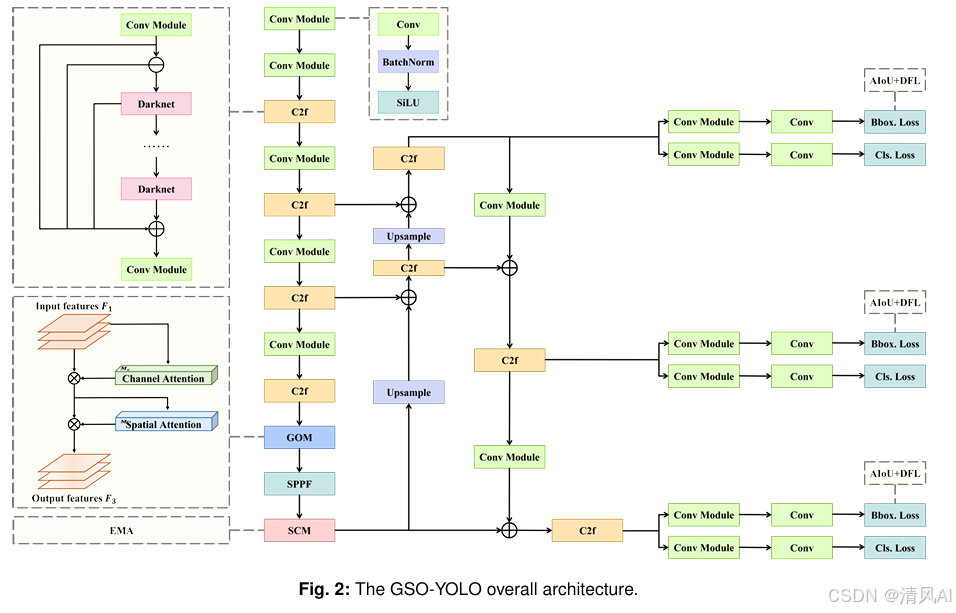
GSO-YOLO:基于全局稳定性优化的建筑工地目标检测算法解析
论文地址:https://arxiv.org/pdf/2407.00906 1. 论文概述 《GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection》提出了一种针对建筑工地复杂场景优化的目标检测模型。通过融合全局优化模块(GOM)、稳定捕捉模块(SCM)和创新的AIoU损失函…...

Python 中使用单例模式
有这么一种场景,Web服务中有一个全局资源池,在需要使用的地方就自然而言引用该全局资源池即可,此时可以将该资源池以单例模式实现。随后,需要为某一特殊业务场景专门准备一个全局资源池,于是额外复制一份代码新建了一个…...

系统思考—提升解决动态性复杂问题能力
感谢合作伙伴的信任推荐! 客户今年的人才发展重点之一,是提升管理者应对动态性、复杂性问题的能力。 在深入交流后,系统思考作为关键能力模块,最终被纳入轮训项目——这不仅是一次培训合作,更是一场共同认知的跃迁&am…...
)
Java基础 - 反射(2)
文章目录 示例5. 通过反射获得类的private、 protected、 默认访问修饰符的属性值。6. 通过反射获得类的private方法。7. 通过反射实现一个工具BeanUtils, 可以将一个对象属性相同的值赋值给另一个对象 接上篇: 示例 5. 通过反射获得类的private、 pro…...

Python proteinflow 库介绍
ProteinFlow是一个开源的Python库,旨在简化蛋白质结构数据在深度学习应用中的预处理过程。以下是其详细介绍: 功能 数据处理:支持处理单链和多链蛋白质结构,包括二级结构特征、扭转角等特征化选项。 数据获取:能够从Protein Data Bank (PDB)和Structural Antibody Databa…...

P1162 洛谷 填涂颜色
题目描述 思考 看数据量 30 而且是个二维的,很像走迷宫 直接深搜! 而且这个就是搜连通块 代码 一开始的15分代码,想的很简单,对dfs进行分类,如果是在边界上,就直接递归,不让其赋值,…...
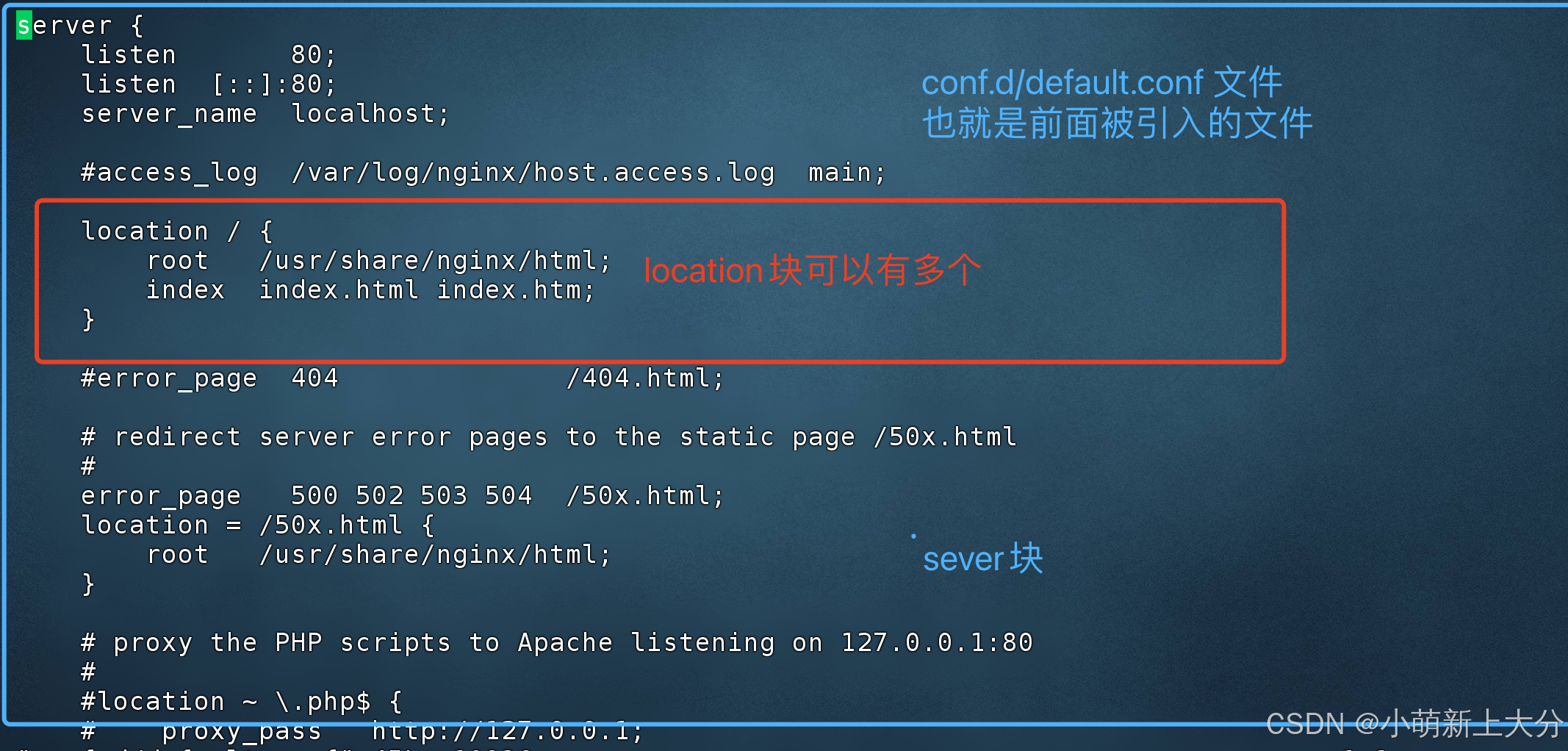
docker安装nginx,基础命令,目录结构,配置文件结构
Nginx简介 Nginx是一款轻量级的Web服务器(动静分离)/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强. 🔗官网 docker安装Nginx 🐳 一、前提条件 • 已安装 Docker(dock…...

SQLI漏洞公开报告分析
文章目录 1. 闭合 )2. 邀请码|POST参数|时间盲注 | **PostgreSQL**3. POST|order by参数|布尔盲注|Oracle4. SOAP请求|MSSQL|布尔盲注5. MySQL 时间盲注漏洞6. GET|普通回显注入7. ImpressCMS 1.4.2 | CVE | POST | 布尔盲注8. Mysql | post | 布尔/时间盲注9. 登录口 | post |…...

SpringBoot项目部署之启动脚本
一、启动脚本方案 1. 基础启动方式 1.1 直接运行JAR java -jar your-app.jar --spring.profiles.activeprod优点:简单直接,适合快速测试缺点:终端关闭即终止进程 1.2 后台运行 nohup java -jar your-app.jar > app.log 2>&1 &…...
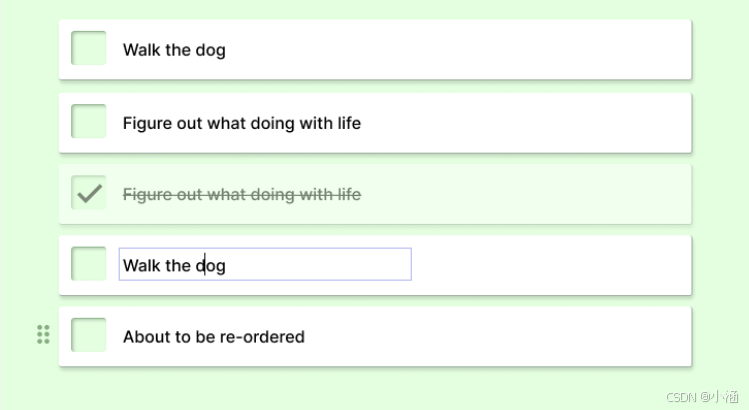
用Django和AJAX创建一个待办事项应用
用Django和AJAX创建一个待办事项应用 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 用Django和AJAX创建一个待办事项应用让我们创建一个简单的 Django 项目,其中包含不同类型的 A…...

JavaScript:游戏开发的利器
在近年来的科技迅速发展中,JavaScript 已逐渐成为游戏开发领域中最受欢迎的编程语言之一。它的跨平台特性、广泛的社区支持、丰富的库和框架使得开发者能够快速、有效地创建各种类型的游戏。本文将深入探讨 JavaScript 在游戏开发中的优势。 一、跨平台支持 JavaSc…...
C语言今天开始了学习
好多年没有弄了,还是捡起来弄下吧 用的vscode 建议大家参考这个配置 c语言vscode配置 c语言这个语言简单,但是今天听到了一个消息说python 不知道怎么debug。人才真多啊...

Elasticsearch 系列专题 - 第五篇:集群与性能优化
随着数据量和访问量的增长,单节点 Elasticsearch 已无法满足需求。本篇将介绍集群架构、性能优化方法以及常见故障排查,帮助你应对生产环境中的挑战。 1. 集群架构 1.1 节点角色(Master、Data、Ingest 等) Elasticsearch 集群由多个节点组成,每个节点可扮演不同角色: M…...
)
鸿蒙NEXT开发Preferences工具类(ArkTs)
import { AppUtil } from ./AppUtil; import dataPreferences from ohos.data.preferences; export const DEFAULT_PREFERENCE_NAME: string "SP_HARMONY_UTILS_PREFERENCES"; // Preferences实例的名称。/*** Preferences工具类* author CSDN-鸿蒙布道师* since 20…...
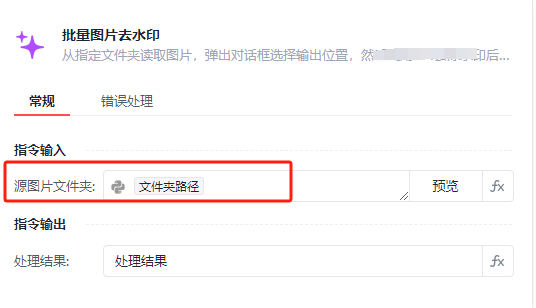
电商素材革命:影刀RPA魔法指令3.0驱动批量去水印,实现秒级素材净化
本文 去除水印实操视频展示电商图片水印处理的困境影刀 RPA 魔法指令 3.0 强势登场利用魔法指令3.0两步实现去除水印操作关于影刀RPA 去除水印实操视频展示 我们这里选择了4张小红书里面比较帅气的图片,但凡用过小红书的都知道,小红书右下角是会有小…...
:什么是vuex,请解释一下它在Vue中的作用)
前端面试题(七):什么是vuex,请解释一下它在Vue中的作用
Vuex 是一个专门为 Vue.js 应用程序开发的状态管理库。它可以集中管理应用的所有状态,并保证状态以一种可预测的方式发生变化。简单来说,Vuex 用来管理 Vue 应用中的数据(即状态),使得数据的传递和共享更加清晰和可靠&…...

笔记:头文件与静态库的使用及组织方式
笔记:头文件与静态库的使用及组织方式 1. 头文件的作用 接口声明:提供函数、类、变量等标识符的声明,供其他模块调用。编译依赖:编译器需要头文件来验证函数调用和类型匹配。避免重复定义:通过包含保护(如…...
)
ubuntu,react的学习(1)
在此目录下,开启命令行 /home/kt/react 如下操作 tkt4028:~/react$ npm create vitelatest task-manager -- --template react Need to install the following packages: create-vite6.3.1 Ok to proceed? (y) y> npx > cva task-manager --template react…...

【QT】QTreeWidgetItem的checkState/setCheckState函数和isSelected/setSelected函数
目录 1、函数原型1.1 checkState/setCheckState1.2 isSelected/setSelected2、功能用途3、示例QTreeWidget的checkState/setCheckState函数和isSelected/setSelected这两组函数有着不同的用途,下面具体说明: 1、函数原型 1.1 checkState/setCheckState Qt::CheckState QTr…...
 join() get() 使用经验)
CompletableFuture 和 List<CompletableFuture> allOf() join() get() 使用经验
CompletableFuture<Map<Menu, Map<IntentDetail, Double>>> xxx CompletableFuture.supplyAsync(() -> {Map<Menu, Map<IntentDetail, Double>> scores new ConcurrentHashMap<>();// 存储结果scores.computeIfAbsent(menu, k -> n…...

CExercise_09_结构体和枚举_2VS的Debug模式查看它的内存布局,采用结构体数组的方式存储信息,调用函数打印结构体数组.
题目: 下面结构体类型的变量的内存布局是怎样的?请使用VS的Debug模式查看它的内存布局 typedef struct stundent_s {int number;char name[25];char gender;int chinese;int math;int english; } Student;// 结构体对象的声明和初始化 Student s1 { 1, …...

SSRF漏洞技术解析与实战防御指南
一、SSRF漏洞简介 服务端请求伪造(Server-Side Request Forgery, SSRF) 是一种攻击者通过操控服务端发起非预期网络请求的安全漏洞。攻击者利用目标服务器的权限,构造恶意请求访问内网资源、本地系统文件或第三方服务,可能导致…...
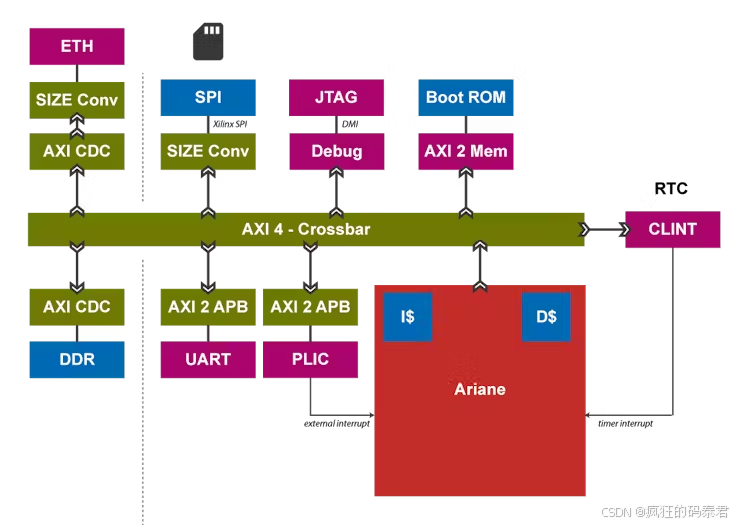
CVA6:支持 Linux 的 RISC-V CPU CORE-V
RISC-V 是一种开源的可扩展指令集架构 (ISA),在过去几年中广受欢迎。RISC-V 的主要特性之一是它采用整体架构中性设计,支持浮点运算、加载存储架构、符号扩展加速和多路复用器简化。这使得 RISC-V 成为 FPGA 上软处理器的经济实惠的选择。自 RISC-V ISA …...

水文-用 Coze 工作流打造你的自媒体写作工厂
零代码水文神器:用 Coze 工作流打造你的自媒体写作工厂 作为一个每天被 KPI 追着跑的自媒体运营人,你是不是也常常在想: “这篇文章换个标题就能发第二遍,能不能自动来?” 现在,用 Coze 工作流,…...

轻奢宅家|约克VRF带你畅享舒适居家体验
下班回到家最期待什么?当然是一阵阵沁人心脾的舒适感扑面而来啦! 想要从头到脚都舒服自在?答案就在眼前——就是它!约克VRF中央空调! 约克VRF中央空调独特的臻静降噪技术,让空调运行音轻…...