Python常用排序算法
1. 冒泡排序
冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较相邻的元素,如果他们的顺序错误就交换他们。
def bubble_sort(arr):# 遍历所有数组元素for i in range(len(arr)):# 最后i个元素是已经排序好的for j in range(0, len(arr)-i-1):# 如果当前元素大于下一个元素,则交换位置if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j]return arrarr = [11, 32, 21, 67, 54, 19]
sorted_arr = bubble_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(完全逆序)
- 最好情况:O(n)
- 平均情况:O(n2)
- 空间复杂度:O(1)(原地排序)
2. 选择排序
选择排序是一种简单直观的排序算法,它的工作原理是每次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排序完毕。
def select_sort(arr):# 遍历所有数组元素for i in range(len(arr)):# 找到剩余未排序部分的最小元素索引min_index = ifor j in range(i+1, len(arr)):if arr[j] < arr[min_index]:min_index = j# 将找到的最小元素与第i个位置的元素交换arr[i], arr[min_index] = arr[min_index], arr[i]return arrarr = [11, 32, 21, 67, 54, 19]
sorted_arr = select_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:O(n2)
- 空间复杂度:O(1)(原地排序)
3. 插入排序
插入排序是一种简单直观的排序算法,它的工作原理是通过构建有序序列,在已排序序列中从后向前扫描,找到相应位置并插入。
def insert_sort(arr):# 遍历从1到倒数第二个元素for i in range(1, len(arr)):# 当前需要插入的元素key = arr[i]# 已排序部分的最后一个元素索引j = i - 1# 将arr[i]与已排序部分的元素逐个比较,如果比key大则后移一位while j >= 0 and key < arr[j]:arr[j + 1] = arr[j]j -= 1# 找到合适位置,插入keyarr[j + 1] = keyreturn arrarr = [11, 32, 21, 67, 54, 19]
sorted_arr = insert_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(当数组是逆序时)
- 最好情况:O(n)(当数组已经有序时)
- 平均情况:O(n2)
- 空间复杂度:O(1)(原地排序)
4. 快速排序
快速排序是一种高效的排序算法,采用分治法策略。首先任意选取一个元素作为基准数据,将待排序列表中的数据分割成独立的两部分,比基准数据小的放在它左边,比基准数据大的放在它右边,此时第一轮数据排序完成。然后再按照此方法对两边的数据分别进行分割,直至被分割的数据只有一个或者零个时,递归结束。
def quick_sort(arr):if len(arr) <= 1:return arr# 选择中间元素作为基准值pivot = arr[len(arr)//2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)arr = [11, 32, 21, 67, 54, 19]
sorted_arr = quick_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [11, 19, 21, 32, 54, 67]
复杂度分析
- 时间复杂度:
- 最坏情况:O(n2)(当分区极度不平衡时)
- 最好情况:O(n log n)
- 平均情况:O(n log n)
- 空间复杂度:O(n)(创建了新的列表)
5. 归并排序
归并排序是一种基于分治策略的高效排序算法,将数组不断地分成两半,然后递归地对两半进行排序,最后将排序好的两半合并在一起。
def merge_sort(arr):if len(arr) <= 1:return arr# 分割阶段mid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])# 合并阶段return merge(left, right)def merge(left, right):"""合并两个已排序的列表"""result = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1# 添加剩余元素result.extend(left[i:])result.extend(right[j:])return resultarr = [38, 27, 43, 3, 9, 82, 10]
sorted_arr = merge_sort(arr)
print("排序后为:", sorted_arr)输出结果:
排序后为: [3, 9, 10, 27, 38, 43, 82]
复杂度分析
- 时间复杂度:O(n log n)
- 空间复杂度: O(n)(需要额外空间存储临时数组)
6. 堆排序
堆排序是一种基于二叉堆数据结构的高效排序算法。堆是一种特殊的完全二叉树,其中每个父节点的值都大于或等于其子节点的值(称为最大堆)或每个父节点的值都小于或等于其子节点的值(称为最小堆)。
import heapqdef heap_sort(arr):# 构建最小堆heapq.heapify(arr)return [heapq.heappop(arr) for _ in range(len(arr))]arr = [12, 11, 15, 3, 21, 9]
sorted_arr = heap_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [3, 9, 11, 12, 15, 21]
复杂度分析
- 时间复杂度:
- 建堆过程:O(n)
- 每次堆化:O(log n)
- 总体时间复杂度:O(n log n)
- 空间复杂度: O(1)(原地排序)
7. 计数排序
计数排序是一种非比较排序算法,适用于对一定范围内的整数进行排序。它统计数组中每个元素出现的次数,然后根据统计结果将元素放回正确的位置。
def count_sort(arr):if len(arr) == 0:return arr# 找到数组中的最大值和最小值max_val = max(arr)min_val = min(arr)# 创建计数数组,初始化为0count = [0] * (max_val - min_val + 1)# 统计每个元素出现的次数for num in arr:count[num - min_val] += 1# 重建排序后的数组sorted_arr = []for i in range(len(count)):sorted_arr.extend([i + min_val] * count[i])return sorted_arrarr = [4, 2, 5, 1, 8]
sorted_arr = count_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [1, 2, 4, 5, 8]
复杂度分析
- 时间复杂度:O(n+k),其中n是元素数量,k是数据范围
- 空间复杂度:O(n+k)
8. 基数排序
基数排序是一种非比较型整数排序算法,它通过将整数按位切割成不同的数字,然后按每个位数分别比较排序。基数排序可以采用最低位优先(LSD)或最高位优先(MSD)两种方式。
def radix_sort(arr):# 找到数组中的最大数,确定排序的轮数max_num = max(arr)# 从个位开始exp = 1while max_num // exp > 0:counting_sort_by_digit(arr, exp)exp *= 10return arrdef counting_sort_by_digit(arr, exp):n = len(arr)output = [0] * ncount = [0] * 10# 统计当前位数的数字出现次数for num in arr:digit = (num // exp) % 10count[digit] += 1# 计算累加计数for i in range(1, 10):count[i] += count[i-1]# 反向填充输出数组(保证稳定性)for i in range(n-1, -1, -1):digit = (arr[i] // exp) % 10output[count[digit] - 1] = arr[i]count[digit] -= 1# 将排序结果复制回原数组for i in range(n):arr[i] = output[i]arr = [170, 45, 75, 90, 802, 24, 2, 66]
sorted_arr = radix_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [2, 24, 45, 66, 75, 90, 170, 802]
复杂度分析
- 时间复杂度:O(d*(n+k)),其中d是最大数字的位数,n是元素数量,k是基数
- 空间复杂度:O(n+k)
9. 桶排序
桶排序是一种分布式排序算法,它将元素分到有限数量的桶里,每个桶再分别排序。
def bucket_sort(arr, bucket_size=5):if len(arr) == 0:return arr# 找到最大值和最小值max_val = max(arr)min_val = min(arr)# 计算桶的数量bucket_count = (max_val - min_val) // bucket_size + 1buckets = [[] for _ in range(bucket_count)]# 将元素分配到各个桶中for num in arr:index = (num - min_val) // bucket_sizebuckets[index].append(num)# 对每个桶进行排序sorted_arr = []for bucket in buckets:# 使用内置的sorted函数sorted_arr.extend(sorted(bucket))return sorted_arrarr = [29 ,25, 13, 21, 8, 43]
sorted_arr = bucket_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [8, 13, 21, 25, 29, 43]
复杂度分析
- 时间复杂度:
- 平均情况:O(n+k),其中k是桶的数量
- 最坏情况:O(n2)(当所有元素都分配到同一个桶中)
- 空间复杂度:O(n+k)
10. 希尔排序
希尔排序是插入排序的一种高效改进版本,也称为缩小增量排序。它通过将原始列表分割成多个子列表来进行插入排序,随着算法的进行,子列表的长度逐渐增大,最终整个列表变为一个子列表完成排序。
def shell_sort(arr):n = len(arr)# 初始间隔(gap)设置为数组长度的一半gap = n // 2while gap > 0:# 对各个间隔分组进行插入排序for i in range(gap, n):temp = arr[i]j = i# 对子列表进行插入排序while j >= gap and arr[j - gap] > temp:arr[j] = arr[j - gap]j -= gaparr[j] = temp# 缩小间隔gap = gap // 2return arrarr = [9 , 8, 3, 6, 5, 7, 1]
sorted_arr = shell_sort(arr)
print("排序后为:", sorted_arr)
输出结果:
排序后为: [1, 3, 5, 6, 7, 8, 9]
复杂度分析
- 时间复杂度:
- 平均情况:O(n1.3)到O(n1.5)
- 最坏情况:O(n*n)
- 最好情况:O(n log n)
- 空间复杂度:O(1)(原地排序)
11. 拓扑排序
拓扑排序是针对有向无环图的线性排序算法,使得对于图中的每一条有向边(u, v),u在排序中总是位于v的前面。
from collections import dequedef topo_sort_kahn(graph):# 计算所有节点的入度in_degree = {node: 0 for node in graph}for node in graph:for neighbor in graph[node]:in_degree[neighbor] += 1# 初始化队列,将所有入度为0的节点加入队列queue = deque([node for node in graph if in_degree[node] == 0])topo_order = []while queue:current = queue.popleft()topo_order.append(current)# 减少所有邻居的入度for neighbor in graph[current]:in_degree[neighbor] -= 1# 如果邻居的入度变为0,加入队列if in_degree[neighbor] == 0:queue.append(neighbor)# 检查是否所有节点都被排序(无环)if len(topo_order) == len(graph):return topo_orderelse:return [] # 图中存在环,无法进行拓扑排序
# 定义有向无环图(邻接表表示)
graph = {'A': ['B', 'C'],'B': ['D', 'E'],'C': ['F'],'D': [],'E': ['F'],'F': []
}print("Kahn算法拓扑排序结果:", topo_sort_kahn(graph))
输出结果:
Kahn算法拓扑排序结果: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’]
复杂度分析
- 时间复杂度:O(V+E),其中V是顶点数,E是边数
- 空间复杂度:O(V)(存储入度或递归栈)
相关文章:

Python常用排序算法
1. 冒泡排序 冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较相邻的元素,如果他们的顺序错误就交换他们。 def bubble_sort(arr):# 遍历所有数组元素for i in range(len(arr)):# 最后i个元素是已经排序好的for j in range(0, …...
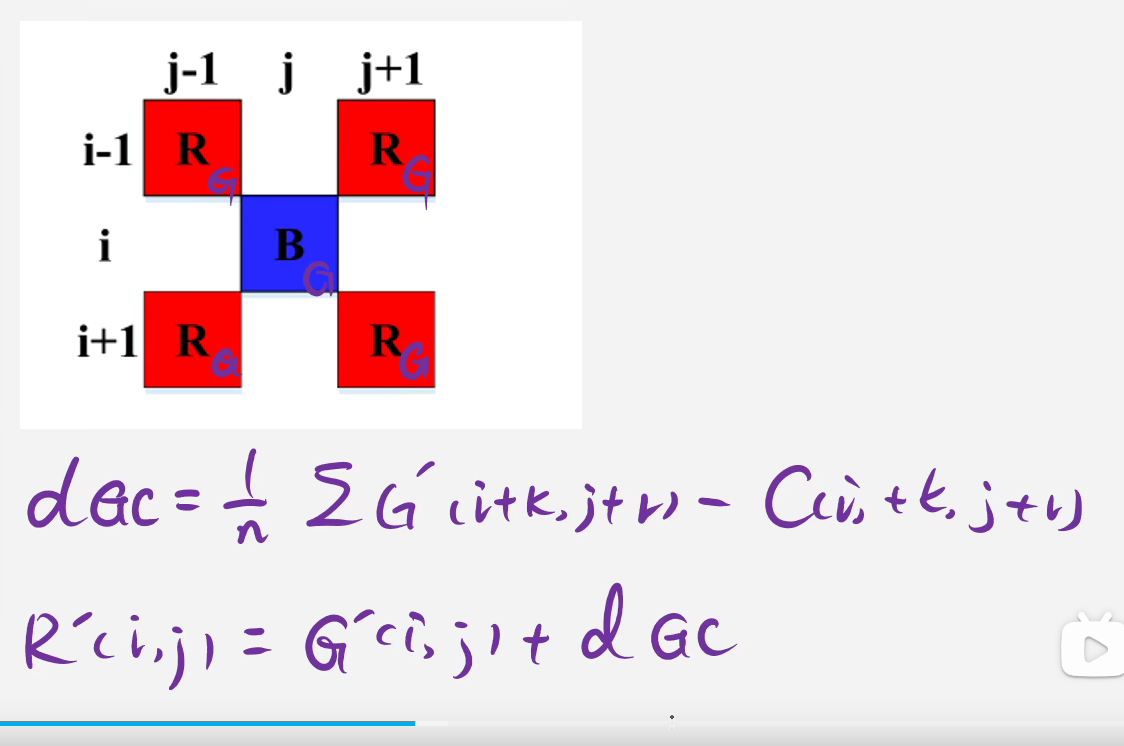
ISP--Demosaicking
文章目录 前言算法解释简单的线性插值代码实现 色差法和色比法基于方向加权的方法RB缺失的G通道的插值RB缺失的BR的插值G缺失的BR的插值代码实现 基于边缘检测的方法计算缺失的G计算缺失的RB值/计算缺失的G值 前言 人眼之所以有能感受到自然界的颜色,是因为人眼的感…...
国标GB28181协议EasyCVR视频融合平台:5G时代远程监控赋能通信基站安全管理
一、背景介绍 随着移动通信行业的迅速发展,无人值守的通信基站建设规模不断扩大。这些基站大多建于偏远地区,周边人迹罕至、交通不便,给日常的维护带来了极大挑战。其中,位于空旷地带的基站设备,如空调、蓄电池等&…...

vue watch 和 watchEffect的区别和用法
在 Vue.js 里,watch 和 watchEffect 都用于响应式地追踪数据变化并执行相应操作,不过它们在使用方式、应用场景等方面存在差异。 1. watch watch 是 Vue 提供的一个选项,用于监听特定数据的变化。当监听的数据发生变化时,会触发…...

SQL 不走索引的常见情况
在 SQL 查询中,即使表上有索引,某些情况下数据库优化器也可能决定不使用索引。以下是常见的不走索引的情况: 1. 使用否定操作符 NOT IN ! 或 <> NOT EXISTS NOT LIKE 2. 对索引列使用函数或运算 -- 不走索引 SELECT * FROM user…...

git配置 gitcode -- windows 系统
版本 $ git --version git version 2.49.0.windows.1检查现有的 SSH 密钥 打开git-bash终端,执行以下命令查看是否已经生成过 SSH 密钥: ls -al ~/.ssh如果看到类似 id_rsa 和 id_rsa.pub(或者其他命名的密钥对)文件࿰…...

基于Kubeadm实现K8S集群扩缩容指南
一、集群缩容操作流程 1.1 缩容核心步骤 驱逐节点上的Pod 执行kubectl drain命令驱逐节点上的Pod,并忽略DaemonSet管理的Pod: kubectl drain <节点名> --ignore-daemonsets # 示例:驱逐worker233节点 kubectl drain worker233 --ignor…...

模拟-与-现实协同训练:基于视觉机器人操控的简单方法
25年3月来自 UT Austin、Nvidia、UC Berkeley 和纽约大学的论文“Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation”。 大型现实世界机器人数据集在训练通才机器人模型方面拥有巨大潜力,但扩展现实世界人类数据收集既耗时又耗资…...

WRS-PHM电机智能安康系统:为浙江某橡胶厂构筑坚实的生产防线
以行业工况为背景 一、顾客工厂的背景 浙江某橡胶厂以电机为中心生产设备必须连续平稳运行。但由于缺乏有效的故障预警体系,电机故障就像潜伏着的“不定时炸弹”,不但不时地造成生产流程的中断,也使对生产进行管理异常艰难,对持续安全生产提…...

将 CrewAI 与 Elasticsearch 结合使用
作者:来自 Elastic Jeffrey Rengifo 学习如何使用 CrewAI 为你的代理团队创建一个 Elasticsearch 代理,并执行市场调研任务。 CrewAI 是一个用于编排代理的框架,它通过角色扮演的方式让多个代理协同完成复杂任务。 如果你想了解更多关于代理…...

wait 和notify ,notifyAll,sleep
wait 使线程进入阻塞状态,释放CPU,以及锁 sleep 使线程进入睡眠状态,sleep方法不会释放CPU资源和锁资源,而是让出CPU的使用权。操作系统会将CPU分配给其他就绪线程,但当前线程依然存在,不会释放其占用的…...
)
ECMAScript 6 新特性(二)
ECMAScript 6 新特性(二) ECMAScript 6 新特性(一) ECMAScript 6 新特性(二)(本文) ECMAScript 7~10 新特性 1. 生成器 生成器函数是 ES6 提供的一种解决异步编程方案,一…...

SpringBoot接口覆盖上一次调用的实现方案
调用springboot接口时,如何实现覆盖上一次调用 Spring Boot 接口覆盖上一次调用的实现方案 以下是多种实现覆盖上一次接口调用的方案,适用于不同场景。 方案一:同步锁控制(单机环境) 适用场景:单实例…...

Spring 的 IoC 和 DI 详解:从零开始理解与实践
Spring 的 IoC和 DI 详解:从零开始理解与实践 一、IoC(控制反转) 1、什么是 IoC? IoC 是一种设计思想,它的核心是将对象的创建和管理权从开发者手中转移到外部容器(如 Spring 容器)。通过这种…...

Python Cookbook-5.12 检查序列的成员
任务 你需要对一个列表执行很频繁的成员资格检査。而in操作符的 O(n)时间复杂度对性能的影响很大,你也不能将序列转化为一个字典或者集合,因为你还需要保留原序列的元素顺序。 解决方案 假设需要给列表添加一个在该列表中不存在的元素。一个可行的方法…...

签名过期怎么办?
1无论是证书到期还是被封停,只需要找到签名服务商,重新签名就可以了,但签名经常性过期会造成app用户流失,所以我们在选择签名时需要注意,在资金充足的情况下,优先选择独立、稳定签名,接下来我们…...

ZYNQ笔记(四):AXI GPIO
版本:Vivado2020.2(Vitis) 任务:使用 AXI GPIO IP 核实现按键 KEY 控制 LED 亮灭(两个都在PL端) 一、介绍 AXI GPIO (Advanced eXtensible Interface General Purpose Input/Output) 是 Xilinx 提供的一个可…...

实操(环境变量)Linux
环境变量概念 我们用语言写的文件编好后变成了程序,./ 运行的时候他就会变成一个进程被操作系统调度并运行,运行完毕进程相关资源被释放,因为它是一个bash的子进程,所以它退出之后进入僵尸状态,bash回收他的退出结果&…...

【补题】P9423 [蓝桥杯 2023 国 B] 数三角
题意:小明在二维坐标系中放置了 n 个点,他想在其中选出一个包含三个点的子集,这三个点能组成三角形。然而这样的方案太多了,他决定只选择那些可以组成等腰三角形的方案。请帮他计算出一共有多少种选法可以组成等腰三角形ÿ…...

Word / WPS 页面顶部标题 段前间距 失效 / 不起作用 / 不显示,标题紧贴页眉 问题及解决
问题描述: 在 Word 或者 WPS 里面,如果不是新的一节,而是位于新的一页首行时,不管怎么设置段前间距,始终是失效的,实际段前间距一直是零。 解决方案: 查询了很多方案均无法解决问题ÿ…...
)
Mysql自动增长数据的操作(修改增长最大值)
在MySQL中,如果你想要修改一个表的自增长(auto-increment)属性的起始值,可以使用ALTER TABLE语句。这对于初始化新环境或修复损坏的自增长计数器特别有用。下面是如何操作的一些步骤: 查看当前自增长值 首先ÿ…...
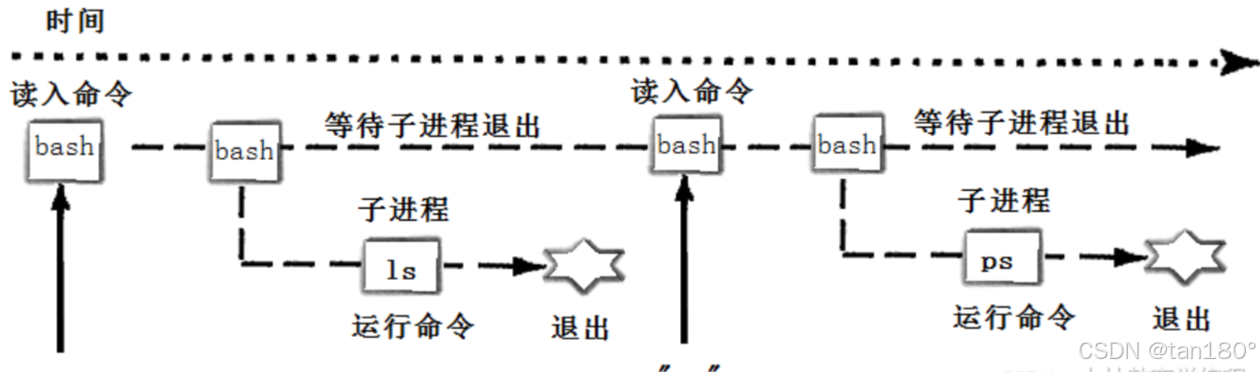
Linux自行实现的一个Shell(15)
文章目录 前言一、头文件和全局变量头文件全局变量 二、辅助函数获取用户名获取主机名获取当前工作目录获取最后一级目录名生成命令行提示符打印命令行提示符 三、命令处理获取用户输入解析命令行执行外部命令 四、内建命令添加环境变量检查和执行内建命令 五、初始化初始化环境…...
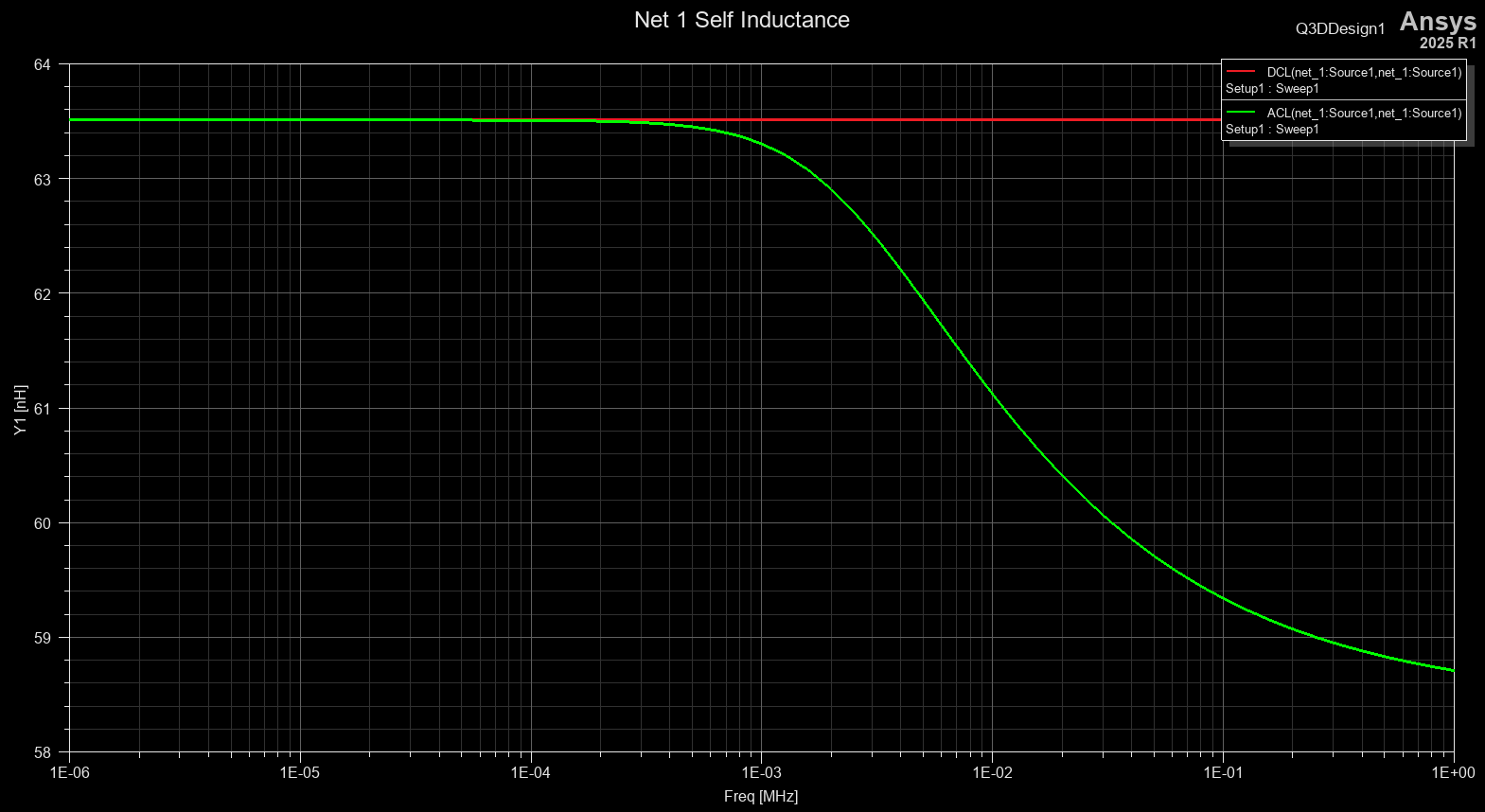
在 Q3D 中提取汇流条电感
汇流条排简介和设计注意事项 汇流条排是用于配电的金属导体,在许多应用中与传统布线相比具有设计优势。在设计母线排时,必须考虑几个重要的因素: 低电感:高频开关内容会导致无功损耗,从而降低效率电容:管…...

MySQL:事务的理解
一、CURD不加控制,会有什么问题 (1)因为,MySQL里面存的是数据,所以很有可能会被多个客户访问,所以mysqld可能一次会接受到多个关于CURD的请求。(2)且mysql内部是采用多线程来完成数…...

[raspberrypi 0w and respeaker 2mic]实时音频波形
0. 环境 ubuntu22主机, 192.168.8.162, raspberry 0w, 192.168.8.220 路由器 1. 树莓派 # rpi - send.py # 或者命令行:arecord -D plughw:1,0 -t wav -f cd -r 16000 -c 2 | nc 192.168.8.162 12345import socket imp…...

python 基础:句子缩写
n int(input()) for _ in range(n):words input().split()result ""for word in words:result word[0].upper()print(result)知识点讲解 input()函数 用于从标准输入(通常是键盘)读取用户输入的内容。它返回的是字符串类型。例如在代码中…...
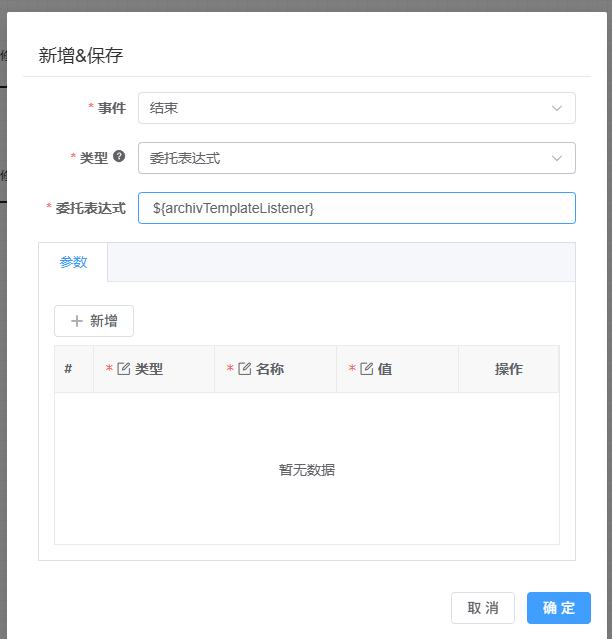
Ruoyi-vue plus 5.2.2 flowble 结束节点异常错误
因业务要求, 我在结束节点的结束事件中,制作了一个归档的事件,来执行一个业务。 始终都会报错, 错误信息 ${archivTemplateListener} did not resolve to an implementation of interface org.flowable.engine.delegate.Execution…...

Sublime Text使用教程(用Sublime Text编写C语言程序)
Sublime Text 是一款当下非常流行的文本编辑器,其功能强大(提供有众多的插件)、界面简洁、还支持跨平台使用(包括 Mac OS X、Linux 和 Windows)。 在程序员眼中,Sublime Text 不仅仅是一个文本编辑器&…...

【1】k8s集群管理系列--包应用管理器之helm
一、helm概述 Helm核心是模板,即模板化K8s YAML文件。 通过模板实现Chart高效复用,当部署多个应用时,可以将差异化的字段进行模板化,在部署时使用-f或 者–set动态覆盖默认值,从而适配多个应用 helm工作流程…...

【书籍】DeepSeek谈《持续交付2.0》
目录 一、深入理解1. 核心理念升级:从"自动化"到"双环模型"2. 数字化转型的五大核心能力3. 关键实践与案例4. 组织与文化变革5. 与其它框架的关系6. 实际应用建议 二、对于开发实习生的帮助1. 立刻提升你的代码交付质量(技术验证环实…...