LLaMA-Factory 数据集成从入门到精通
一、框架概述
LLaMA-Factory 框架通过Alpaca/Sharegpt双格式体系实现多任务适配,其中Alpaca专注结构化指令微调(含SFT/DPO/预训练),Sharegpt支持多角色对话及多模态数据集成。核心配置依托 dataset_info.json 实现数据源映射、格式定义(formatting)、列名绑定(columns)及角色标签(tags)设置,需特别注意多模态路径与文本标记的严格匹配。优先级规则遵循:云端仓库 > 本地脚本 > 文件直读,配置时须规避角色标签冲突和路径验证疏漏等常见误区。
二、数据集配置规范
dataset_info.json 包含了所有可用的数据集。如果您希望使用自定义数据集,请务必在 dataset_info.json 文件中添加数据集描述,并通过修改 dataset: 数据集名称 配置来使用数据集。
目前我们支持 alpaca 格式和 sharegpt 格式的数据集。
"数据集名称": {"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)","ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)","script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)","file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必需)","formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)","ranking": "是否为偏好数据集(可选,默认:False)","subset": "数据集子集的名称(可选,默认:None)","split": "所使用的数据集切分(可选,默认:train)","folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)","num_samples": "该数据集所使用的样本数量。(可选,默认:None)","columns(可选)": {"prompt": "数据集代表提示词的表头名称(默认:instruction)","query": "数据集代表请求的表头名称(默认:input)","response": "数据集代表回答的表头名称(默认:output)","history": "数据集代表历史对话的表头名称(默认:None)","messages": "数据集代表消息列表的表头名称(默认:conversations)","system": "数据集代表系统提示的表头名称(默认:None)","tools": "数据集代表工具描述的表头名称(默认:None)","images": "数据集代表图像输入的表头名称(默认:None)","videos": "数据集代表视频输入的表头名称(默认:None)","audios": "数据集代表音频输入的表头名称(默认:None)","chosen": "数据集代表更优回答的表头名称(默认:None)","rejected": "数据集代表更差回答的表头名称(默认:None)","kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"},"tags(可选,用于 sharegpt 格式)": {"role_tag": "消息中代表发送者身份的键名(默认:from)","content_tag": "消息中代表文本内容的键名(默认:value)","user_tag": "消息中代表用户的 role_tag(默认:human)","assistant_tag": "消息中代表助手的 role_tag(默认:gpt)","observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)","function_tag": "消息中代表工具调用的 role_tag(默认:function_call)","system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"}
}
Alpaca 格式
指令监督微调数据集
- 样例数据集
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
预训练数据集
- 样例数据集
在预训练时,只有 text 列中的内容会用于模型学习。
[{"text": "document"},{"text": "document"}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "text"}
}
偏好数据集
偏好数据集用于奖励模型训练、DPO 训练、ORPO 训练和 SimPO 训练。
它需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答。
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","chosen": "优质回答(必填)","rejected": "劣质回答(必填)"}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","ranking": true,"columns": {"prompt": "instruction","query": "input","chosen": "chosen","rejected": "rejected"}
}
KTO 数据集
KTO 数据集需要提供额外的 kto_tag 列。详情请参阅 sharegpt。
多模态图像数据集
多模态图像数据集需要提供额外的 images 列。详情请参阅 sharegpt。
多模态视频数据集
多模态视频数据集需要提供额外的 videos 列。详情请参阅 sharegpt。
多模态音频数据集
多模态音频数据集需要提供额外的 audios 列。详情请参阅 sharegpt。
Sharegpt 格式
指令监督微调数据集
- 样例数据集
相比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "function_call","value": "工具参数"},{"from": "observation","value": "工具结果"},{"from": "gpt","value": "模型回答"}],"system": "系统提示词(选填)","tools": "工具描述(选填)"}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system","tools": "tools"}
}
预训练数据集
尚不支持,请使用 alpaca 格式。
偏好数据集
- 样例数据集
Sharegpt 格式的偏好数据集同样需要在 chosen 列中提供更优的消息,并在 rejected 列中提供更差的消息。
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "gpt","value": "模型回答"},{"from": "human","value": "人类指令"}],"chosen": {"from": "gpt","value": "优质回答"},"rejected": {"from": "gpt","value": "劣质回答"}}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","ranking": true,"columns": {"messages": "conversations","chosen": "chosen","rejected": "rejected"}
}
KTO 数据集
- 样例数据集
KTO 数据集需要额外添加一个 kto_tag 列,包含 bool 类型的人类反馈。
[{"conversations": [{"from": "human","value": "人类指令"},{"from": "gpt","value": "模型回答"}],"kto_tag": "人类反馈 [true/false](必填)"}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","kto_tag": "kto_tag"}
}
多模态图像数据集
- 样例数据集
多模态图像数据集需要额外添加一个 images 列,包含输入图像的路径。
注意图片的数量必须与文本中所有 <image> 标记的数量严格一致。
[{"conversations": [{"from": "human","value": "<image>人类指令"},{"from": "gpt","value": "模型回答"}],"images": ["图像路径(必填)"]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","images": "images"}
}
多模态视频数据集
- 样例数据集
多模态视频数据集需要额外添加一个 videos 列,包含输入视频的路径。
注意视频的数量必须与文本中所有 <video> 标记的数量严格一致。
[{"conversations": [{"from": "human","value": "<video>人类指令"},{"from": "gpt","value": "模型回答"}],"videos": ["视频路径(必填)"]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","videos": "videos"}
}
多模态音频数据集
- 样例数据集
多模态音频数据集需要额外添加一个 audios 列,包含输入音频的路径。
注意音频的数量必须与文本中所有 <audio> 标记的数量严格一致。
[{"conversations": [{"from": "human","value": "<audio>人类指令"},{"from": "gpt","value": "模型回答"}],"audios": ["音频路径(必填)"]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","audios": "audios"}
}
OpenAI 格式
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词。
[{"messages": [{"role": "system","content": "系统提示词(选填)"},{"role": "user","content": "人类指令"},{"role": "assistant","content": "模型回答"}]}
]
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
"数据集名称": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "messages"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant","system_tag": "system"}
}
三、常见问题排查
问题:dataset_info.json 中 hf_hub_url、ms_hub_url、script_url、file_name 的优先级关系是什么?
答案:
优先级为 hf_hub_url/ms_hub_url > script_url > file_name。若指定了 hf_hub_url 或 ms_hub_url,系统会直接从 Hugging Face 或 ModelScope 加载数据集,忽略 script_url 和 file_name;若未指定,则依次检查 script_url 和 file_name。
误区举例:用户可能同时填写多个字段(如同时指定 hf_hub_url 和 file_name),导致实际加载数据集时忽略本地文件,引发数据路径错误。
问题:偏好数据集(DPO/ORPO)的配置中,Alpaca 格式和 Sharegpt 格式的 columns 字段有何差异?
答案:
- Alpaca 格式需指定
chosen和rejected列,对应优质和劣质回答,并设置"ranking": true。 - Sharegpt 格式需将
chosen和rejected配置为消息对象(如{"from": "gpt", "value": "回答"}),并同样设置"ranking": true。
误区举例:用户可能误将 Sharegpt 格式的 chosen/rejected 配置为纯文本(而非消息对象),导致解析失败;或在 Alpaca 格式中遗漏 "ranking": true,导致数据集未被识别为偏好类型。
问题:多模态数据集(如图像)的配置中,images 列与文本中的 <image> 标记为何需严格数量一致?
答案:
images 列中的文件路径数量必须与文本中 <image> 标记的数量完全一致,以确保模型能正确关联图像输入与文本指令。例如,若文本中有 2 个 <image> 标记,则 images 列必须包含 2 个路径。
误区举例:用户可能在数据预处理时未检查标记数量与文件路径的匹配性,导致训练时因数据格式错误而中断。
问题:Sharegpt 格式的 tags 字段(如 role_tag、user_tag)有何作用?如何适配 OpenAI 格式数据?
答案:
tags字段用于自定义消息中角色和内容的键名。例如,OpenAI 格式的role和content需通过tags映射为role_tag: "role"和content_tag: "content"。- 适配 OpenAI 格式需额外设置
user_tag: "user"、assistant_tag: "assistant"、system_tag: "system"。
误区举例:用户可能未正确配置 tags,导致无法解析第三方格式(如 OpenAI)的消息结构,或因角色标签冲突(如 system 覆盖系统列)引发错误。
问题:KTO 数据集的 kto_tag 列在配置时需要注意什么?
答案:
kto_tag 列需包含布尔类型(True/False)的标签,表示人类对回答的反馈。在 dataset_info.json 中需显式声明 "kto_tag": "列名",且数据集格式必须为 Sharegpt。
误区举例:用户可能误将 kto_tag 配置为字符串(如 "true" 而非布尔值 true),或忘记设置 "formatting": "sharegpt",导致数据加载失败。
问题:在 Alpaca 格式中,history 列的作用是什么?如何正确配置它?
答案:
- 作用:
history列存储历史对话的指令和回答(二元组列表),用于多轮对话场景。模型会学习历史对话内容,而不仅是当前指令和回答。 - 配置: 需在
dataset_info.json中明确指定"history": "列名",且数据格式应为[["指令1", "回答1"], ["指令2", "回答2"]]。
误区举例: 用户可能忽略 history 列的存在,导致多轮对话数据未被利用;或错误配置为单字符串(如 "instruction,answer"),引发解析错误。
问题:预训练数据集的 Alpaca 格式为何只需 text 列?如何与指令微调数据集区分?
答案:
- 原因: 预训练目标是学习通用文本表示,因此仅需原始文本(
text列),无需指令或回答结构。 - 区分: 指令微调需
instruction/output等列,而预训练只需"columns": {"prompt": "text"}。若误用指令数据配置预训练,会导致模型忽略关键字段。
误区举例: 用户可能混淆预训练和微调的数据格式,错误地将指令数据用于预训练,浪费计算资源。
问题:Sharegpt 格式中,tools 列的作用是什么?是否必须与 function_call 角色配合使用?
答案:
- 作用:
tools列定义工具的描述(如 API 文档),供模型生成工具调用参数(function_call角色)。 - 配合要求: 是。若数据包含
function_call消息,则需提供tools列;若无工具调用,可省略。
误区举例: 用户可能遗漏 tools 列但保留 function_call 消息,导致模型无法理解工具定义;或反向误配,引发训练错误。
问题:如何正确处理多模态数据(如图像、视频)中的路径问题?
答案:
- 要求: 文件路径需为绝对路径或相对于数据集根目录的相对路径,且确保文件实际存在。
- 验证: 在加载数据集前,应检查
images/videos/audios列中的路径是否有效,避免因路径错误导致训练中断。
误区举例: 用户可能使用错误路径格式(如未处理系统路径分隔符差异),或未验证文件是否存在,导致多模态数据加载失败。
问题:subset 和 split 字段在 dataset_info.json 中有何区别?
答案:
subset: 指定 Hugging Face/ModelScope 数据集的子集名称(如"zh"表示中文子集)。split: 定义数据切分(如train、test),默认为train。两者可同时使用(如"subset": "zh", "split": "test")。
误区举例: 用户可能误将 subset 当作数据切分,或混淆两者优先级,导致加载错误的数据子集。
问题:如何为自定义数据集选择正确的 formatting 值(alpaca 或 sharegpt)?
答案:
- 关键判断点:
- 角色多样性: 若需多角色(如
human/gpt/function),选sharegpt。 - 工具/多模态支持: 涉及工具调用或媒体输入时,必须用
sharegpt。 - 结构简化性: 若仅需
instruction-output结构,用alpaca。
- 角色多样性: 若需多角色(如
误区举例: 用户可能因未全面评估数据复杂度而选错格式,导致后续配置无法适配。
相关文章:

LLaMA-Factory 数据集成从入门到精通
一、框架概述 LLaMA-Factory 框架通过Alpaca/Sharegpt双格式体系实现多任务适配,其中Alpaca专注结构化指令微调(含SFT/DPO/预训练),Sharegpt支持多角色对话及多模态数据集成。核心配置依托 dataset_info.json 实现数据源映射、格…...

数据库架构
常见数据库架构类型及其优势解析 1. 集中式架构(Centralized Architecture) 定义:所有数据存储在单个服务器或主机上,由中央处理器统一管理。核心优势: ✅ 数据一致性:单一数据源避免数据冗余和不一致。 …...
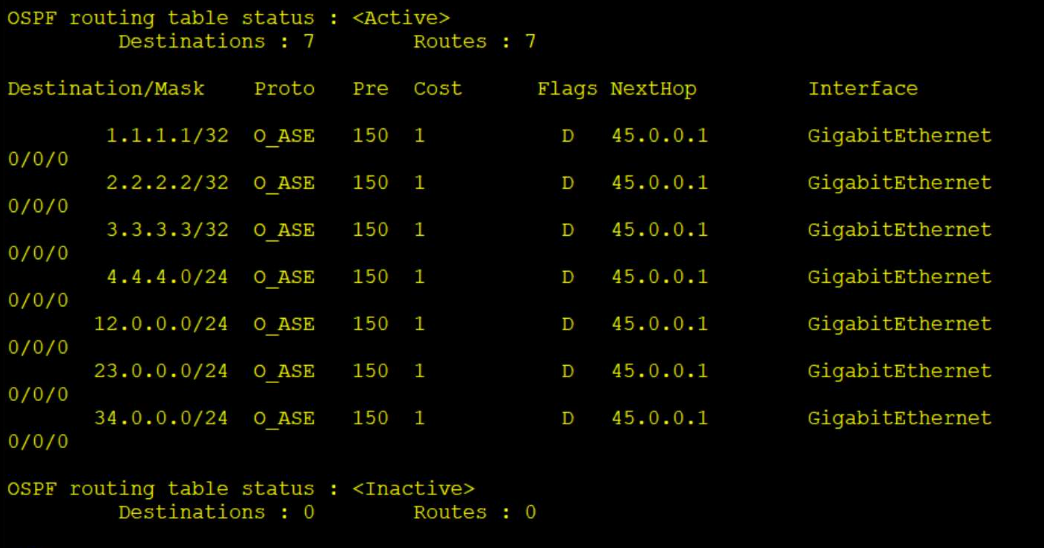
OSPF接口的网络类型和不规则区域
网络类型(数据链路层所使用的协议所构建的二层网络类型) 1、MA --- 多点接入网络 BMA --- 支持广播的多点接入网络 NBMA --- 不支持广播的多点接入网络 2、P2P --- 点到点网络 以太网 --- 以太网最主要的特点是需要基于MAC地址进行物理寻址,主要是因为以太网接口所连…...

MySQL SQL Mode
SQL Mode 是 MySQL 中一个重要的系统变量,它决定了 MySQL 应遵循的 SQL 语法规则和数据验证规则。 什么是 SQL Mode SQL Mode 定义了 MySQL 应该支持的 SQL 语法以及执行数据验证的方式。通过设置不同的 SQL Mode,可以让 MySQL 在不同程度上兼容其他数据…...

Mysql备忘记录
1、简介 Mysql操作经常忘记命令,本文将持续记录Mysql一些常用操作。 2、常见问题 2.1、忘记密码 # 1、首先停止Mysql服务 systemctl stop mysqld # windows 从任务管理器里面停 # 2、更改配置文件 my.cnf (windows是 ini文件) vim /etc/my.cnf 在[mysqld]下面添…...
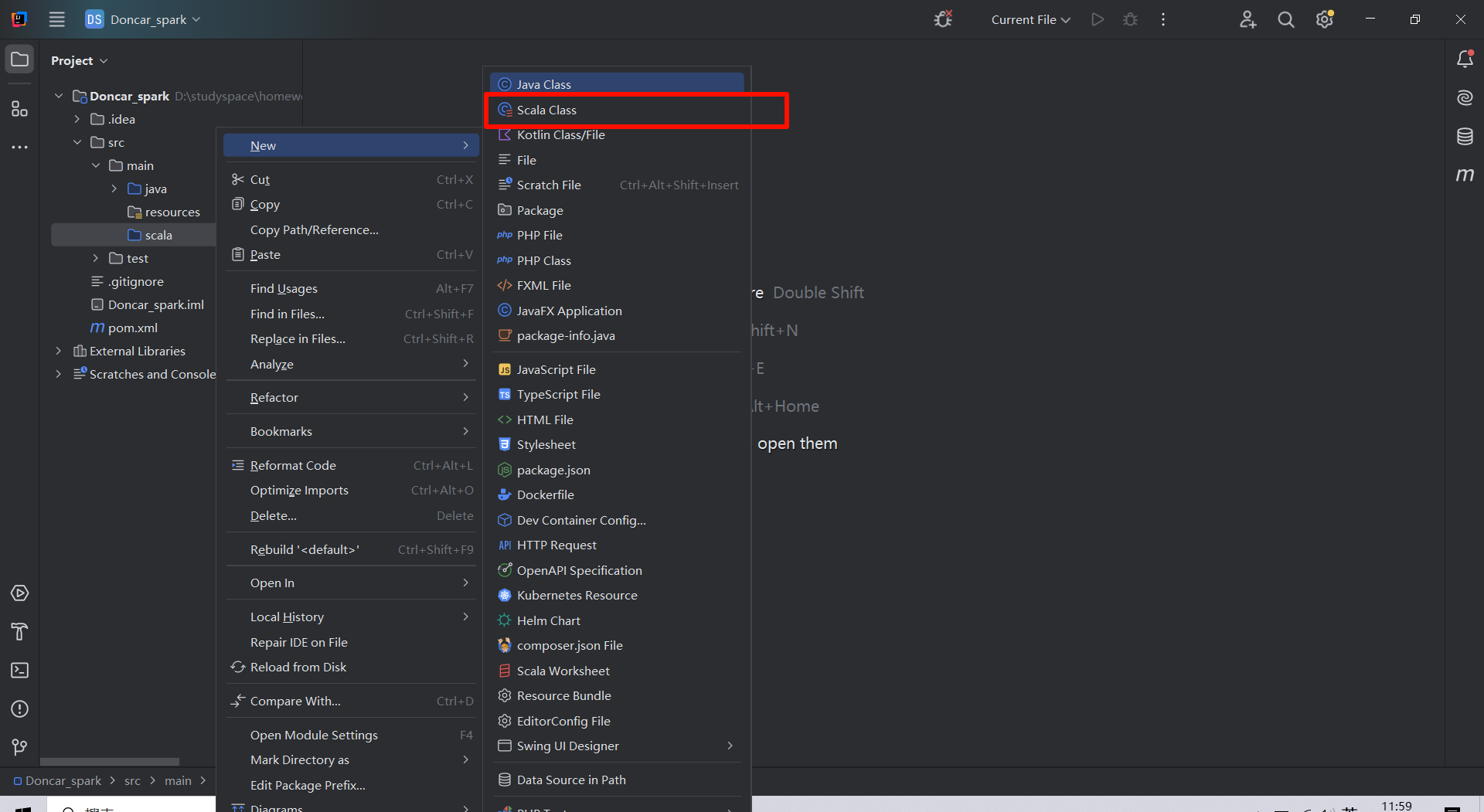
idea 创建 maven-scala项目
文章目录 idea 创建 maven-scala项目1、创建普通maven项目并且配置pom.xml文件2、修改项目结构1)创建scala目录并标记成【源目录】2)导入scala环境3)测试环境 idea 创建 maven-scala项目 1、创建普通maven项目并且配置pom.xml文件 maven依赖…...
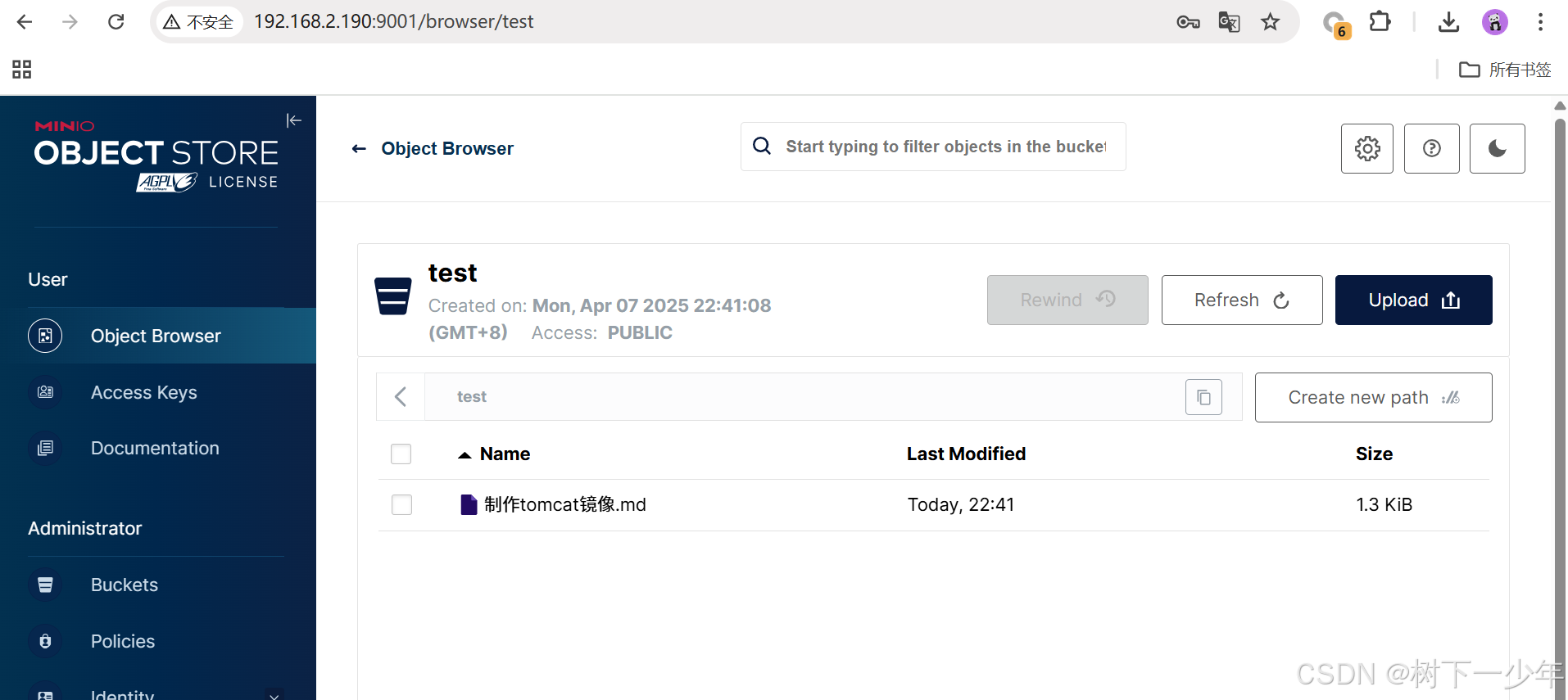
ansible+docker+docker-compose快速部署4节点高可用minio集群
目录 github项目地址 示例服务器列表 安装前 修改变量文件group_vars/all.yml 修改ansible主机清单 修改setup.sh安装脚本 用法演示 安装后验证 github项目地址 https://github.com/sulibao/ansible_minio_cluster.git 示例服务器列表 安装前 修改变量文件group_var…...

使用libcurl编写爬虫程序指南
用户想知道用Curl库编写的爬虫程序是什么样的。首先,我需要明确Curl本身是一个命令行工具和库,用于传输数据,支持多种协议。而用户提到的“Curl库”可能指的是libcurl,这是一个客户端URL传输库,可以用在C、C等编程语言…...

K8S学习之基础七十五:istio实现灰度发布
istio实现灰度发布 上传镜像到harbor 创建两个版本的pod vi deployment-v1.yaml apiVersion: apps/v1 kind: Deployment metadata:name: appv1labels:app: v1 spec:replicas: 1selector:matchLabels:app: v1apply: canarytemplate:metadata:labels:app: v1apply: canaryspec…...
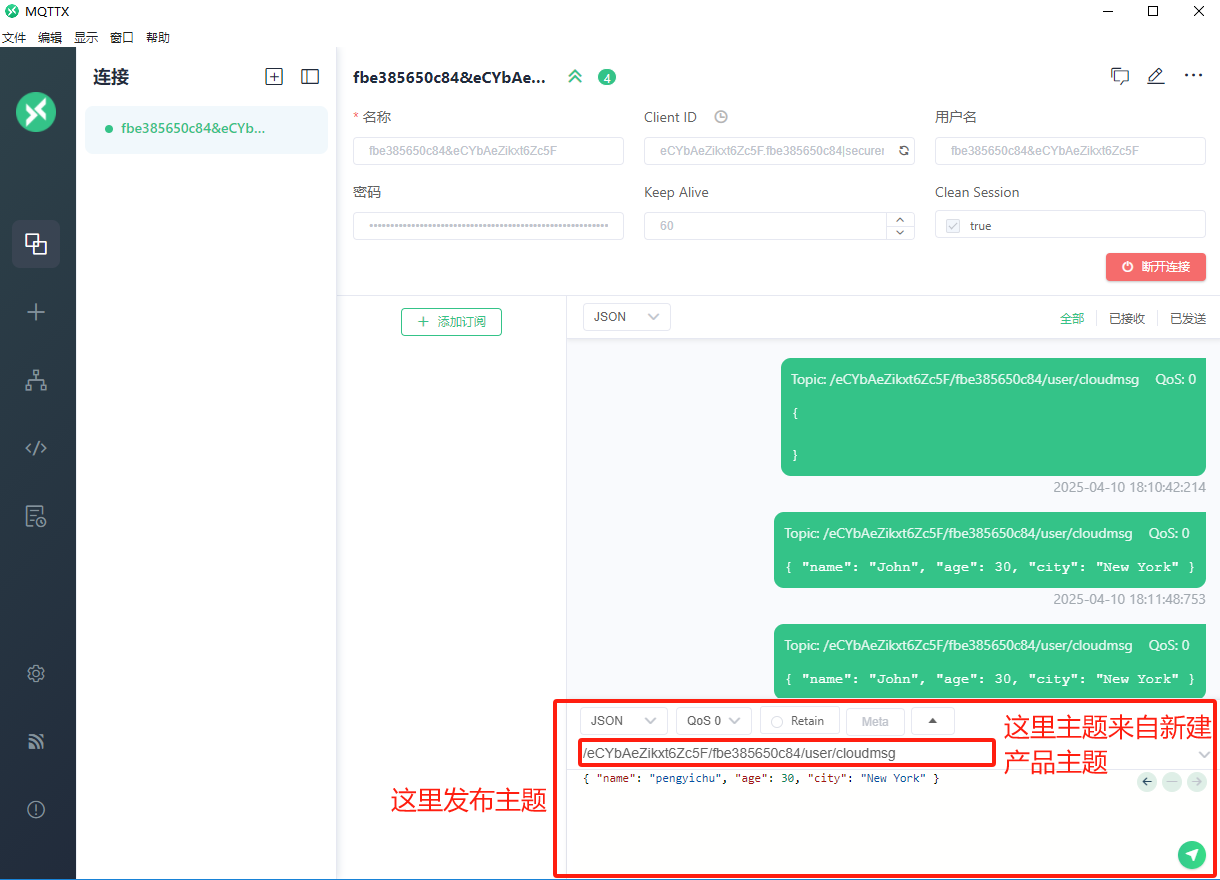
【设备连接涂鸦阿里云】
设备连接涂鸦阿里云 ■ Tuya IoT on Alibaba Cloud■ 控制台操作步骤■ 1. 创建产品■ 2. 添加设备■ 3. 添加设备■ 4. 获取设备MQTT连接参数 ■ MQTTX使用教程■ 1,先在 Tuya IoT on Alibaba Cloud 新建产品和设备■ 2,MQTTX 设置■ 3,MQTT…...
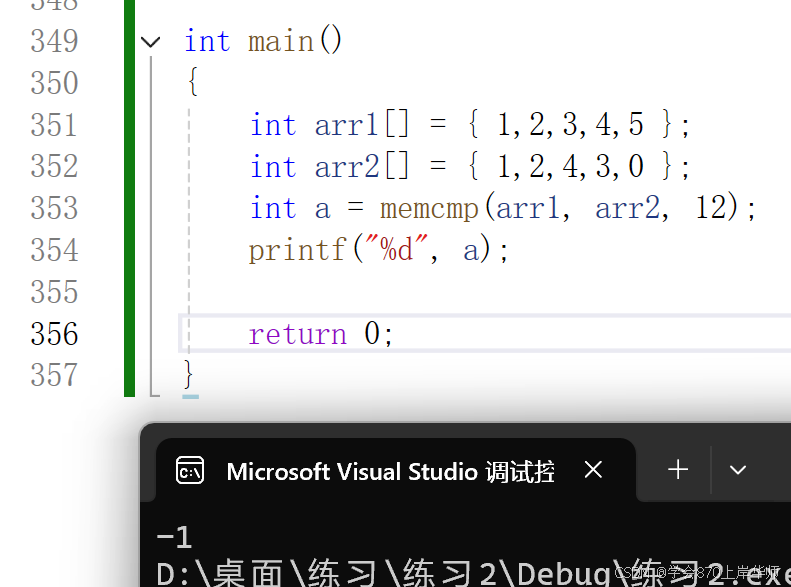
c语言学习16——内存函数
内存函数 一、memcpy使用和模拟实现1.1参数1.2 使用1.3 模拟实现 二、memmove使用和模拟实现2.1 参数2.2 使用2.3 模拟实现 三、memset使用3.1 参数3.2 使用 四、memcmp使用4.1 参数4.2 使用 一、memcpy使用和模拟实现 1.1参数 因为内存中不知道存的是什么类型的地址ÿ…...

渗透测试实战:使用Hydra破解MySQL弱口令(附合法授权流程+防御方案)
渗透测试实战:使用Hydra破解MySQL弱口令(附合法授权流程防御方案) 郑重声明:本文仅供安全学习研究,任何未经授权的网络攻击行为均属违法。实操需获得目标系统书面授权,请遵守《网络安全法》相关规定。 一、…...

一文了解亿级数据检索:RedisSearch
文章目录 1.什么是Redis Search2.为什么要使用Redis Search3.RedisSearch 的核心特性4.RedisSearch 的原理4.1 倒排索引4.2 索引创建与数据存储4.3 数据模型4.4 搜索查询处理4.5 高性能与可扩展性: 5.有了ES为什么还需要RedisSearch5.RedisSearch的安装6.RedisSearc…...
uniApp开发微信小程序-连接蓝牙连接打印机上岸!
历经波折三次成功上岸! 三次经历简单絮叨一下:使用uniAppvue开发的微信小程序,使用蓝牙连接打印机,蓝牙所有的接口都是插件中封装的,用的插件市场中的这个: dothan-lpapi-ble ;所以,…...

Spring Boot 线程池配置详解
Spring Boot 线程池配置详解 一、核心配置参数及作用 基础参数核心线程数 (corePoolSize) 作用:线程池中始终保持存活的线程数量,即使空闲也不回收。 建议:根据任务类型设定(如 I/O 密集型任务可设为 CPU 核心数 2)。 最大线程数 (maxPoolSize) 作用:…...
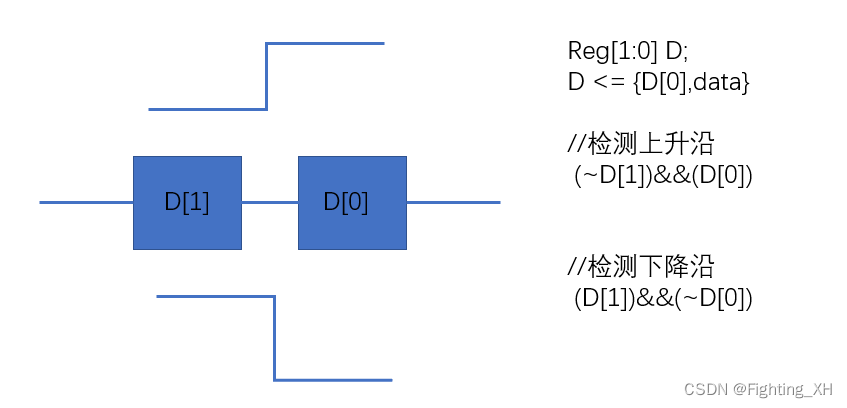
【特权FPGA】之按键消抖
完整代码如下所示: timescale 1ns / 1ps// Company: // Engineer: 特权 // // Create Date: // Design Name: // Module Name: // Project Name: // Target Device: // Tool versions: // Description: // // Dependencies: // // Revision: // …...
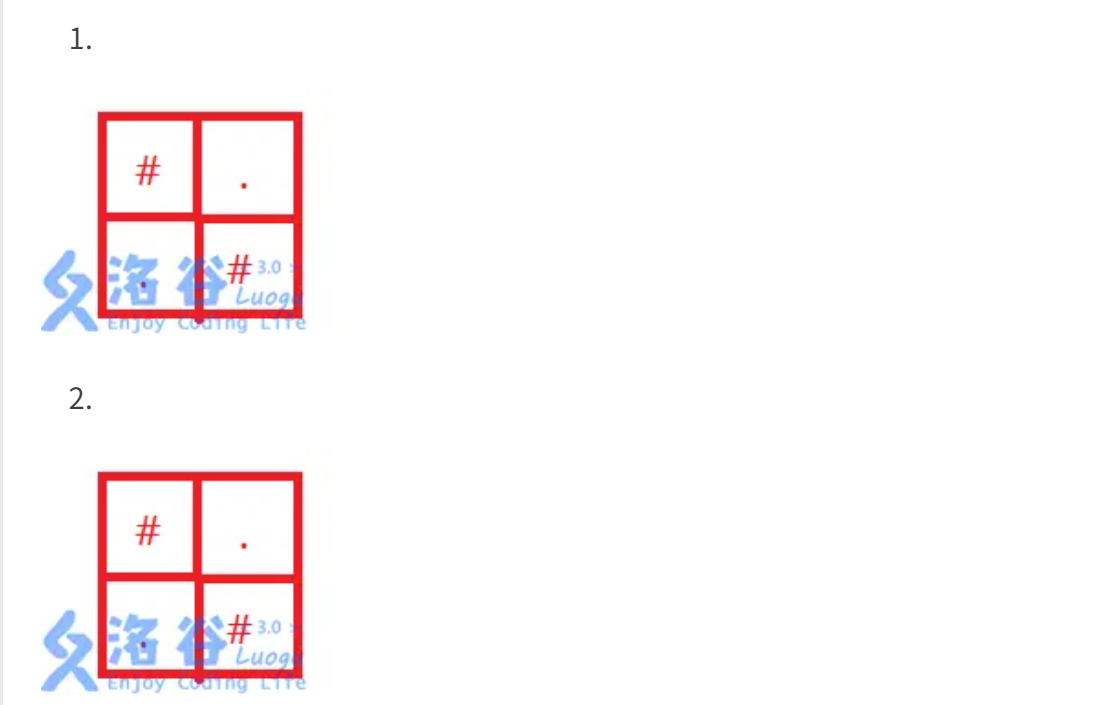
P1331 洛谷 海战
题目描述 思路 这个题需要读懂题意,即“什么样的形式表示两只船相撞?” ----> 上下相邻或左右相邻 如果图是不和法的,一定存在如下结构: # # . # 或 # # # . 或 # . # # 或 . # # #即四个格子里有三个#,一个"…...
)
Python 实现的运筹优化系统数学建模详解(最大最小化模型)
一、引言 在数学建模的实际应用里,最大最小化模型是一种极为关键的优化模型。它的核心目标是找出一组决策变量,让多个目标函数值里的最大值尽可能小。该模型在诸多领域,如资源分配、选址规划等,都有广泛的应用。本文将深入剖析最大…...

网络安全·第二天·ARP协议安全分析
今天我们来考虑考虑计算机网络中的一类很重要的协议-------ARP协议,介绍他用途的同时,分析分析ARP协议存在的一些漏洞及其相关的协议问题。 一、物理地址与IP地址 1、举例 在计算机网络中,有两类地址十分关键,一类称为物理地址&a…...

Python设计模式:命令模式
1. 什么是命令模式? 命令模式是一种行为设计模式,它将请求封装为一个对象,从而使您能够使用不同的请求、队列或日志请求,以及支持可撤销操作。 命令模式的核心思想是将请求的发送者与请求的接收者解耦,使得两者之间的…...
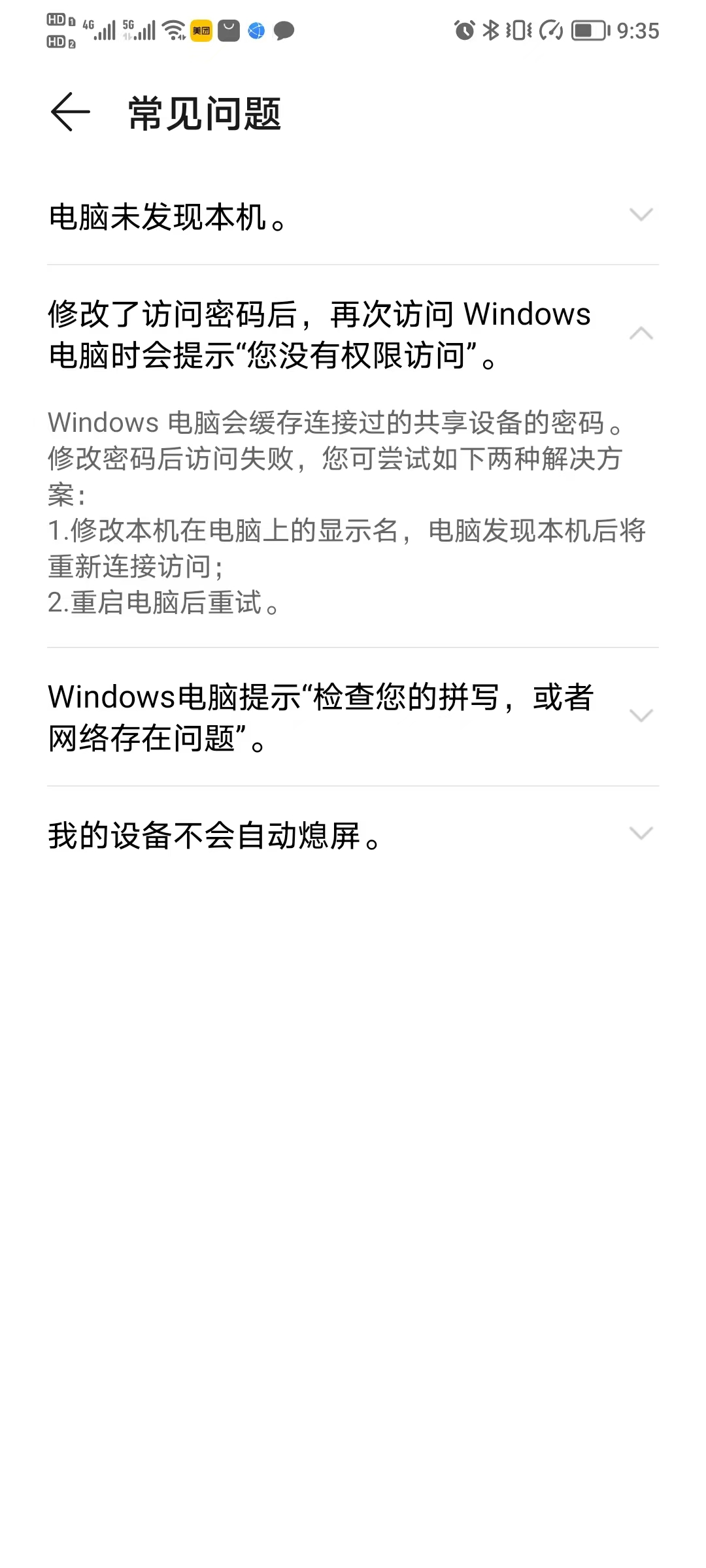
华为手机或平板与电脑实现文件共享
1.手机或平板与电脑在同一个网络 2.打开手机或平板端,设置---更多连接----快分享或华为分享打开此功能-----开启共享至电脑 3.打开电脑,网络中就可看到手机端分享的用户名称 4. 登陆就可访问手机 5.常见问题 5.1 电脑未发现本机 5.2 修改了访问密码后再…...
幻兽帕鲁(Palworld)在线工具集:让游戏体验更轻松!
幻兽帕鲁(Palworld)在线工具集:让游戏体验更轻松! 🎮 工具介绍 为了帮助广大幻兽帕鲁玩家更好地享受游戏,我开发了这个全面的在线工具集。无需下载安装,打开网页即可使用,完全免费! …...
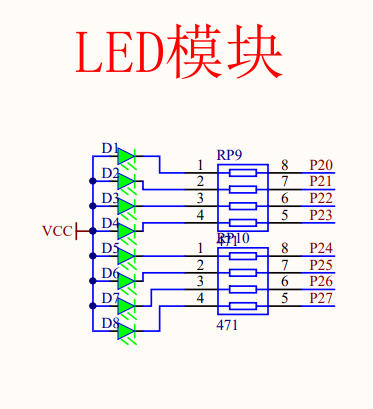
学习51单片机Day02---实验:点亮一个LED灯
目录 1.先看原理图 2.思考一下(sbit的使用): 3.给0是要让这个LED亮(LED端口设置为低电平) 4.完成的代码 1.先看原理图 比如我们要让LED3亮起来,对应的是P2^2。 2.思考一下(sbit的使用&…...

【Kubernetes】Kubernetes 如何进行日志管理?Fluentd / Loki / ELK 适用于什么场景?
由于 Kubernetes 运行在容器化的环境中,应用程序和系统日志通常分布在多个容器和节点上,传统的日志管理方法(例如直接访问每个节点的日志文件)在 Kubernetes 中不适用。 因此,Kubernetes 引入了集中式日志管理方案&am…...
如何使用通义灵码学习JavaScript和DOM
如果你看到了本手册的页面数量,你就会发现JavaScript的API真的非常丰富,在MDN上专门有一大分类用于介绍JavaScript的API,但软件工程行业有一个著名法则叫2-8法则,意思是只有20%的内容会经常使用到,而80%的内容只在一些…...

Elasticsearch8.x集成SpringBoot3.x
Elasticsearch8.x集成SpringBoot3.x 配置项目引入依赖添加配置文件导入ca证书到项目中添加配置 实战操作创建mapping创建文档查询更新全量更新删除数据批量操作(bulk)基本搜索复杂布尔搜索嵌套(nested)搜索分页查询滚动分页查询After分页查询词条(terms)聚合日期聚合 配置项目 …...

基于labview的多功能数据采集系统
基于labview的多功能数据采集系统(可定制功能) 包含基于NI温度采集卡。电流采集卡。电压采集卡的数据采集功能 数据存储 报表存储 数据处理与分析 生产者消费者架构 有需要可联系...

250410异常记事
今天遇到一件极坑的事情,关于uni.setStorageSync: Invalid args: type check failed for args “key”. Expected String, got Boolean with value true. 项目是网上下的一个element-plus、uniapp 混搭的框架https://ext.dcloud.net.cn/plugin?id16396 异常代码如…...

小程序租赁系统源码功能分享
系统架构图解:技术栈与业务流程 设备租赁系统的架构可以分为三个主要部分:后台服务(SpringBoot MyBatisPlus MySQL)、用户端与师傅端(UniApp)、以及管理后台(Vue ElementUI)。下…...

30天学Java第八天——设计模式
装饰器模式 Decorator Pattern 装饰器模式(Decorator Pattern)是一种结构型设计模式,它允许通过动态地添加功能来扩展对象的行为,而不需要修改原有的类。 这种模式通常用于增强对象的功能,与继承相比,使用…...