JVM常见问题与调优
目录
一、内存管理问题
1、内存泄漏(Memory Leak)
2、内存溢出(OOM, OutOfMemoryError)
2.1 堆内存溢出(OutOfMemoryError: Java heap space)
2.2 元空间溢出(OutOfMemoryError: Metaspace)
2.3 栈溢出(StackOverflowError)或 栈内存不足(OutOfMemoryError: Unable to create native thread)
二、垃圾回收(GC)问题
1、频繁垃圾回收
1.1 频繁YoungGC
1.2 频繁FullGC
2、GC算法选择不当
三、类加载问题
1、ClassNotFoundException
2、NoClassDefFoundError
3、依赖冲突:NoSuchMethodError / NoSuchFieldError
4、元空间溢出
5、类重复加载
四、线程和锁问题
1、死锁(Deadlock)
2、线程数过多
3、CPU飙升(热点代码)
五、其他问题
1、未启用压缩指针
2、JIT编译问题
一、内存管理问题
1、内存泄漏(Memory Leak)
表现:对象不再使用但无法被GC回收,导致内存逐渐耗尽。
原因:静态集合持有对象、未关闭资源(如数据库连接)、监听器未注销等。
排查工具:jmap生成堆转储,通过MAT(Memory Analyzer Tool)分析对象引用链。
jps -l # 显示进程id、主类全名或 JAR 路径
jmap -dump:live,format=b,file=heap.hprof <pid> # 生成存活对象的堆转储文件MAT的使用参照:MAT
通过Dominator Tree,显示占用内存最多的对象及其引用关系,查找未释放的引用
2、内存溢出(OOM, OutOfMemoryError)
2.1 堆内存溢出(OutOfMemoryError: Java heap space)
本质:对象占用的堆内存超过了 JVM 最大堆容量(-Xmx)
原因:内存泄漏(代码逻辑问题导致对象无法被GC回收);数据规模过大(没有分页或分批处理);JVM堆设计不合理(-Xmx最大堆内存设计过小);高并发场景(对象创建超过GC回收,频繁创建大对象,未复用线程池资源)
特征:抛出异常java.lang.OutOfMemoryError: Java heap space;FullGC频繁触发且快速占满(通过 jstat -gcutil 观察);堆内存使用率持续高位(接近100%,老年代空间不足);服务响应变慢甚至进程崩溃。
解决:
1> 应急处理
临时扩容:增大 JVM 堆参数(-Xmx 和 -Xms),但需结合物理机内存。
重启服务:快速恢复业务,但需后续根因分析。
2> 原因及对应问题解决
内存泄漏:生成堆转储文件,用MAT定位泄漏对象
数据规模过大:避免全量加载,分页处理数据
缓存设计:限制缓存容量和过期时间,使用分布式缓存替代本地缓存
代码设计:优化大对象创建(如复用对象、使用对象池);避免在循环中创建无意义临时对象(如字符串拼接改用StringBuilder)
JVM参数:根据业务负载调整-Xmx 和-Xms(建议初始值=最大值,避免动态扩容开销);合理设置新生代与老年代比例(增大新生代比例(-XX:NewRatio=2),避免过早晋升对象到老年代;调整Survivor区大小(-XX:SurvivorRatio=8),减少对象复制次数);限制大对象分配:通过-XX:PretenureSizeThreshold直接分配大对象到老年代,减少新生代压力
监控:
1> 在OOM时自动生成Heap Dump
在启动应用时添加参数:
java -XX:+HeapDumpOnOutOfMemoryError \-XX:HeapDumpPath=/logs/heapdumps/-%p-%t.hprof \-XX:OnOutOfMemoryError="sh /scripts/restart_service.sh" \-jar your-app.jar-XX:+HeapDumpOnOutOfMemoryError
启用 OOM 时自动生成堆转储的功能
-XX:HeapDumpPath=/path/to/dump/directory/-%p-%t.hprof
指定堆转储文件的保存路径(需确保目录存在且有写入权限),按进程ID和时间戳生成唯一文件名
-XX:OnOutOfMemoryError="sh /scripts/restart_service.sh"
在 OOM 时触发自定义命令(如发送告警、重启服务)
2> 设置JVM的告警阈值并生成堆转储文件
使用jstat查看堆内存
# 实时监控堆内存使用率(间隔 1 秒)
jstat -gcutil <PID> 1000# 输出示例
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 99.80 10.00 80.50 95.20 92.10 15 0.250 3 0.450 0.700编写 Shell 脚本触发告警并生成堆转储文件:老年代超过80%
#!/bin/bash
PID=$(jps | grep YourAppName | awk '{print $1}')
THRESHOLD=80
DUMP_DIR="/data/heapdumps"while true; do# 获取老年代使用率O_USAGE=$(jstat -gcutil $PID | tail -1 | awk '{print $4}')# 判断是否超过阈值if (( $(echo "$O_USAGE > $THRESHOLD" | bc -l) )); thenecho "警告:堆内存使用率超过 ${THRESHOLD}% (当前: ${O_USAGE}%)" | mail -s "JVM 告警" admin@example.com# 生成堆转储文件(按时间戳命名)DUMP_FILE="$DUMP_DIR/heapdump_$(date +%Y%m%d%H%M%S).hprof"jmap -dump:live,format=b,file=$DUMP_FILE $PIDecho "堆转储已生成: $DUMP_FILE"fisleep 60 # 每分钟检查一次
done3> 定期分析历史内存使用数据,调整 -Xmx 和 -Xms
2.2 元空间溢出(OutOfMemoryError: Metaspace)
原因:动态生成大量类(类加载过多)
例如:Spring AOP默认使用CGLIB生成代理类,若频繁生成且未回收,导致元空间膨胀;某些ORM框架(如Hibernate)动态生成代理类未回收
问题排查:
1> 查看元空间使用情况
jcmd <PID> VM.metaspace # 查看元空间统计信息
jstat -gcmetacapacity <PID> # 监控元空间容量变化可以使用JConsole查看元空间使用情况
2> 启用JVM参数
-XX:NativeMemoryTracking=summary -XX:+UnlockDiagnosticVMOptions-XX:+UnlockDiagnosticVMOptions
作用:解锁JVM的诊断选项。许多高级诊断和调试功能(如内存跟踪、JVM内部状态监控等)默认被锁定,此参数允许启用这些功能。
-XX:NativeMemoryTracking=summary
作用:启用本地内存跟踪(NMT)的概要模式,监控JVM内部组件的本地(非堆)内存使用情况。
通过jcmd <PID> VM.native_memory summary命令查看实时内存报告,分析本地内存分配
jcmd <PID> VM.native_memory summary3> 生成和分析堆转储
生成堆转储:
jmap -dump:live,format=b,file=heapdump.hprof <PID> # 手动生成
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path # OOM时自动生成通过分析工具MAT检查ClassLoader对象和加载的类数量
4> 类加载器泄漏定位
在堆转储中搜索ClassLoader实例,检查是否残留未回收的自定义类加载器
重点关注以下场景:
-
Web应用卸载后仍被引用(如静态变量持有
ClassLoader)。 -
动态代理类未释放(如CGLIB生成的
$$EnhancerByCGLIB$$类)。 -
线程上下文类加载器(TCCL)未重置。
解决方案:
1> 限制元空间大小:显式设置元空间上限,避免无限增长
-XX:MaxMetaspaceSize=256m # 根据应用需求调整提高初始元空间大小(-XX:MetaspaceSize),减少动态扩容次数
2> 代码方面
避免静态变量持有ClassLoader或动态生成的类
确保自定义类加载器的生命周期管理(如Web应用关闭时调用close()方法)
优化反射、动态代理、字节码增强(如ASM)的使用频率,避免滥用反射和动态代理(如限制CGLIB生成类数量)
缓存重复使用的动态类(如使用ClassValue或第三方缓存库)
3> 框架设置
Spring:优先使用JDK动态代理(proxyTargetClass=false)代替CGLIB
Tomcat:检查Context.reload逻辑,确保旧类加载器被GC回收
2.3 栈溢出(StackOverflowError)或 栈内存不足(OutOfMemoryError: Unable to create native thread)
原因:递归过深或栈帧过大(单个线程的栈大小默认1MB,-Xss1m)
问题排查:
1> 定位栈溢出位置
异常堆栈的日志会显示调用链,如:
Exception in thread "main" java.lang.StackOverflowErrorat com.example.MyClass.recursiveMethod(MyClass.java:10)at com.example.MyClass.recursiveMethod(MyClass.java:10)...(重复上千次)通过堆栈末尾的重复行快速定位问题方法
添加 -XX:+PrintGCDetails -XX:+PrintStackAtOverflowError,在溢出时打印更详细的栈信息
2> 线程栈分析
使用 jstack 查看线程栈:
jstack <PID> > thread_dump.txt检查所有线程的调用栈,寻找异常调用链。
3> 代码静态分析
-
检查递归方法:确认递归终止条件是否正确。
-
检查循环调用:查找方法间相互调用的逻辑。
-
检查大局部变量:避免在方法内定义过大的数组或对象。
解决方案:
1> 调整 JVM 参数:增大线程栈大小
-Xss2m # 将栈大小调整为 2MB注意:
-
增大栈空间可能掩盖代码问题,需优先优化代码逻辑。
-
高并发场景下,过大的栈空间会导致总内存消耗激增(总内存 ≈ 线程数 × 栈大小)。
2> 优化代码逻辑
递归改写为迭代;减少方法调用深度;避免大局部变量(将大对象移到堆内存中,如通过 new 创建而非局部定义)
3> 控制线程数量
-
限制线程池大小(如使用
ThreadPoolExecutor时合理设置核心线程数)。 -
避免无限制创建线程(如使用异步框架需配置并发度)。
二、垃圾回收(GC)问题
1、频繁垃圾回收
1.1 频繁YoungGC
现象:Young GC触发频率高(如每秒多次),且每次回收后Eden区很快再次填满
原因:短时间创建大量短生命周期对象;年轻代-Xmn设置国小,无法容纳正常对象分配;内存泄漏,某些短命对象被意外长期引用导致无法被回收
问题定位:
1> 确认Young GC频率
查看GC日志(需启用日志记录):
-Xlog:gc*,gc+heap=debug:file=gc.log:time,uptime:filecount=10,filesize=10M关键信息:GC触发间隔、每次回收后的Eden/Survivor使用量。
GC日志:[GC (Allocation Failure) [PSYoungGen: ...] 频繁出现。
2> 使用jstat监控内存变化
jstat -gcutil <PID> 1000 # 每秒输出一次各区域使用率关注列:E(Eden使用率)、S0/S1(Survivor区)、YGC(Young GC次数)
3> 分析对象分配热点
使用Profiler工具(如async-profiler、Arthas的profiler)生成分配火焰图,定位高频分配代码
Arthas命令:
profiler start -e alloc -d 60 # 监控60秒内的对象分配4> 检查Survivor区对象晋升
GC日志分析:观察每次Young GC后进入老年代的对象大小(-XX:+PrintTenuringDistribution)
-XX:+PrintTenuringDistribution # 输出年龄分布信息解决方案:
1> 减少临时对象创建(如重用对象、使用基本类型替代包装类),避免在循环内频繁创建大对象(如JSON解析结果)
2> 调整年轻代大小
增大Eden区:通过调整-XX:SurvivorRatio或直接设置-Xmn(年轻代总大小)
-XX:SurvivorRatio=4 # Eden:S0:S1=4:1:1(增大Eden)
-Xmn2g # 年轻代设为2G(根据堆总大小调整)注意:如果survivor区过小,Young GC后存活的对象无法进入Survivor区,会直接晋升老年代,频繁触发Full GC
3> 避免内存泄漏
-
检查代码:确保集合缓存、监听器、线程局部变量(
ThreadLocal)及时清理。 -
工具验证:通过堆转储分析Eden区中“本应回收”的对象为何存活。
1.2 频繁FullGC
现象:Gang Worker线程CPU高,伴随Full GC日志
原因:内存泄漏(FullGC后释放内存极少);堆内存分配不合理(年轻代过小导致对象过早晋升老年代、老年代过小导致频繁GC);大对象阈值设置不当,直接分配到老年代;代码显式调用System.gc();元空间(Metaspace)溢出(类加载元数据占用过多内存,间接影响堆内存稳定性);GC算法选择不当(G1 Humongous对象分配:大对象分配导致Region碎片化)
问题定位:
1> 分析GC日志
-
启用GC日志:
-Xlog:gc*,gc+heap=debug:file=gc.log:time:filecount=10,filesize=100M关键指标:
-
Full GC频率、耗时、回收前后内存变化。
-
老年代占用率是否持续增长(内存泄漏特征)。
2> 监控工具
jstat实时监控:
jstat -gcutil <pid> 1000 # 每秒输出一次内存区域利用率关注 FGC(Full GC次数)、FGCT(Full GC总耗时)、OU(老年代使用率)
jmap生成堆转储
jmap -dump:live,format=b,file=heap.hprof <pid>3>堆转储分析:MAT
步骤:
- 查看支配树(Dominator Tree)找到占用内存最大的对象。
- 检查集合类(如
HashMap、ArrayList)是否持有大量无用对象。 - 追踪对象引用链,定位泄漏代码位置。
4> 检查显式GC调用
代码搜索System.gc()或Runtime.getRuntime().gc()
5> 元空间监控
-
使用
jstat -gcutil查看MU(Metaspace使用率)。 -
检查是否动态生成大量类(如反射、CGLIB代理)。
解决:
1> 调整堆内存分布
调整大对象阈值:避免频繁分配大对象(如拆分大文件读取为分块处理)
-XX:PretenureSizeThreshold=1M # 对象超过1MB直接进入老年代优化分代比例:
-
年轻代与老年代比例(
-XX:NewRatio=2,即老年代占2/3)。
-Xmx4g -Xms4g # 增大堆总大小
-XX:NewRatio=2 # 老年代与新生代比例为2:1-
增大Survivor区,避免年轻代过小导致对象过早晋升老年代(
-XX:SurvivorRatio=8,Eden:Survivor=8:1:1)。 -
调整晋升阈值
-XX:MaxTenuringThreshold=15 # 提高对象在Survivor区的存活次数阈值(默认15)2> 禁用显式GC
-XX:+DisableExplicitGC # 阻止System.gc()触发Full GC3> 修复内存泄漏
4> 调整GC算法
G1 GC调优(适用于大堆内存):
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200 # 目标最大停顿时间
-XX:InitiatingHeapOccupancyPercent=45 # 触发并发标记的堆占用阈值切换为ZGC/Shenandoah(超低延迟场景):
-XX:+UseZGC # JDK 11+
-XX:+UseShenandoahGC # OpenJDK 12+5> 元空间优化
限制元空间大小:
-XX:MaxMetaspaceSize=256m减少动态类生成:避免滥用反射或动态代理。
2、GC算法选择不当
GC算法的选择
| GC 算法 | 适用场景 | 核心参数 |
|---|---|---|
| Parallel GC | 高吞吐量,容忍较长停顿(后台计算) | -XX:+UseParallelGC |
| CMS | 低停顿,老年代回收(已废弃) | -XX:+UseConcMarkSweepGC |
| G1 GC | 平衡吞吐量和停顿时间(默认 JDK 9+) | -XX:+UseG1GC |
| ZGC | 超低停顿(10ms 以下),大堆内存 | -XX:+UseZGC |
| Shenandoah | 低停顿,与 ZGC 类似(非 Oracle JDK) | -XX:+UseShenandoahGC |
三、类加载问题
1、ClassNotFoundException
现象:运行时找不到指定类
原因:
-
类路径(Classpath)未正确配置,缺少依赖的 JAR 包。
-
动态加载类时路径错误(如反射加载类名拼写错误)。
-
类加载器未正确传递委托(如自定义类加载器未遵循双亲委派)。
问题定位:类加载日志、检查类路径
1> 启用类加载日志:添加 JVM 参数,追踪类加载过程,观察日志中缺失的类或重复加载的类
-verbose:class # 打印加载的类信息
-XX:+TraceClassLoading # 更详细的类加载日志(JDK 8+)2> 检查类路径:确认 -classpath 或 CLASSPATH 环境变量包含所有依赖,使用命令检查 JAR 包内容
jar -tvf mylib.jar | grep "ClassName.class"解决方法:添加
缺失依赖或修正类名
2、NoClassDefFoundError
现象:编译时存在类,但运行时找不到类定义
原因:
-
类初始化失败(如静态代码块抛出异常)。
-
类文件被修改或损坏。
-
类加载后又被卸载(如热部署场景)。
问题定位:堆转储分析、检查类初始化逻辑
解决方法:修复静态代码块异常或类文件损坏
3、依赖冲突:NoSuchMethodError / NoSuchFieldError
现象:调用方法或字段时找不到。
原因:
-
依赖冲突:多个 JAR 包包含同名但版本不同的类。
-
编译环境和运行环境的类版本不一致。
问题定位:Maven/Gradle 依赖树分析
Maven:
mvn dependency:tree # 生成依赖树,检查重复或冲突版本Gradle:
gradle dependencies # 查看依赖关系解决方法:排除冲突版本或强制指定版本
Maven 排除冲突依赖:
<dependency><groupId>com.example</groupId><artifactId>lib-a</artifactId><version>1.0</version><exclusions><exclusion><groupId>com.conflict</groupId><artifactId>lib-b</artifactId></exclusion></exclusions>
</dependency>Gradle 强制指定版本:
configurations.all {resolutionStrategy.force 'com.example:lib-b:2.0'
}4、元空间溢出
现象:java.lang.OutOfMemoryError: Metaspace
原因:
-
动态生成大量类(如频繁使用反射、CGLIB 代理)。
-
未设置元空间上限(默认无限扩展)。
问题定位:jstat、堆转储分析
使用 jstat 监控元空间使用情况:
jstat -gcutil <PID> 1000 # 关注 MU(Metaspace Utilization) 生成堆转储(jmap -dump),使用 Eclipse MAT 分析加载的类数量及来源
解决方法:限制元空间大小,减少动态类生成
-XX:MaxMetaspaceSize=256m # 设置元空间上限5、类重复加载
现象:同一类被不同类加载器多次加载,导致 instanceof 判断失效
原因:自定义类加载器未正确隔离类(如 OSGi、Tomcat 的 WebApp 类加载器)
问题定位:jcmd VM.classloaders 分析
使用 jcmd 或 jstack 查看线程上下文类加载器
jcmd <PID> VM.classloaders # 打印类加载器层次(JDK 8+)解决方法:遵循双亲委派,隔离类加载器(如 Tomcat 为每个 WebApp 使用独立的 WebAppClassLoader)
四、线程和锁问题
1、死锁(Deadlock)
现象:线程互相等待锁(阻塞:BLOCKED),应用无响应,CPU使用率低
原因:线程持有一个锁,同时请求其他线程的锁,并且不放弃已持有的锁,形成环形等待链
问题定位:jstack获取线程转储,分析锁持有情况。
1> 生成线程转储
jstack <PID> > thread_dump.txt # 生成线程转储文件
或
jcmd <PID> Thread.print # 效果同 jstack2> 分析线程转储
-
查找
BLOCKED状态的线程:
在转储文件中搜索java.lang.Thread.State: BLOCKED。 -
检查锁持有关系:
查看线程的堆栈跟踪,确定其持有的锁和等待的锁。 -
识别循环等待链:
多个线程互相等待对方持有的锁,形成环路。
示例输出:
"Thread-1" #12 prio=5 os_prio=0 tid=0x00007f48740d2000 nid=0x5d4 waiting for monitor entry [0x00007f486b7f6000]java.lang.Thread.State: BLOCKED (on object monitor at 0x000000076abb88b0)at com.example.DeadlockDemo$2.run(DeadlockDemo.java:30)- waiting to lock <0x000000076abb88c0> (a java.lang.Object)- locked <0x000000076abb88b0> (a java.lang.Object)"Thread-0" #11 prio=5 os_prio=0 tid=0x00007f48740d0000 nid=0x5d3 waiting for monitor entry [0x00007f486b8f7000]java.lang.Thread.State: BLOCKED (on object monitor at 0x000000076abb88c0)at com.example.DeadlockDemo$1.run(DeadlockDemo.java:20)- waiting to lock <0x000000076abb88b0> (a java.lang.Object)- locked <0x000000076abb88c0> (a java.lang.Object)3> 工具辅助分析
Arthas(阿里开源工具):实时监控线程和锁状态。
thread -b # 自动检测死锁并显示阻塞线程解决方法:
1> 代码层面
避免嵌套锁;按固定顺序获取锁;减少锁粒度:使用细粒度锁(如 ConcurrentHashMap 分段锁)代替全局锁;通过 ReentrantLock.tryLock(timeout) 避免无限等待
Lock lockA = new ReentrantLock();
Lock lockB = new ReentrantLock();if (lockA.tryLock(1, TimeUnit.SECONDS)) {try {if (lockB.tryLock(1, TimeUnit.SECONDS)) {try { ... } finally { lockB.unlock(); }}} finally { lockA.unlock(); }
}2> 资源管理
-
限制资源池大小:
避免线程池或连接池资源耗尽导致死锁。 -
使用无锁数据结构:
如AtomicInteger、Disruptor环形队列。
2、线程数过多
现象:应用响应变慢或卡死;内存占用过高,大量线程可能触发OutOfMemoryError: unable to create new native thread;频繁Full GC;线程创建失败,抛出java.lang.OutOfMemoryError或java.lang.Error: unable to create new native thread
原因:
1> 线程泄漏(Thread Leak):线程未正确关闭(如未调用ThreadPoolExecutor.shutdown())。
2> 线程池配置不合理:
-
核心线程数(
corePoolSize)或最大线程数(maxPoolSize)设置过高。 -
任务队列(
workQueue)无界,导致任务堆积后线程数激增。
3> 业务代码问题:
-
循环/递归中无节制地创建线程。
-
同步代码块设计不合理(如死锁、长时间阻塞)。
4> 第三方库或框架缺陷:某些库(如Netty、gRPC)可能因配置不当或Bug导致线程数失控。
5> 操作系统限制:超过用户进程最大线程数限制(可通过ulimit -u查看)。
问题定位:
1> 查看线程数统计
# 查看JVM进程ID
jps -l
# 统计线程数
ps -T <pid> | wc -l2> 分析线程堆栈
# 生成线程快照
jstack <pid> > thread_dump.txt
# 或使用Arthas的`thread`命令实时分析
thread -n 10 # 查看最活跃的10个线程3> 跟踪线程数变化
JConsole:连接目标 JVM 后,进入 线程 标签页,实时查看活动线程数及状态分布。
4> 分析线程状态
-
BLOCKED/WATING:可能因锁竞争或I/O阻塞。
-
RUNNABLE:高CPU线程可能是业务热点。
5> 代码审查
-
检查线程池使用是否规范(如是否调用
shutdown())。 -
搜索代码中
new Thread()或ExecutorService的创建点。
解决方法:优化线程池配置,减少线程创建(如使用异步非阻塞模型)。
1> 修复线程泄漏
-
确保线程池正确关闭(使用
shutdown()或shutdownNow())。 -
使用
try-finally或try-with-resources管理线程资源。
案例:线程池未关闭导致线程数持续增长
-
定位:Arthas的
thread --state WAITING显示大量线程处于等待任务状态。 -
解决:添加
Runtime.getRuntime().addShutdownHook()确保线程池关闭。
2> 优化线程池配置
-
设置合理的
corePoolSize和maxPoolSize(根据CPU核数和任务类型)。 -
使用有界队列(如
ArrayBlockingQueue)避免任务堆积。 -
配置拒绝策略(如
ThreadPoolExecutor.CallerRunsPolicy)。
案例:日志中频繁出现OutOfMemoryError: unable to create new native thread
-
定位:通过
jstack发现大量线程卡在第三方HTTP客户端的连接池等待。 -
解决:调低连接池最大线程数,或改用连接复用(如HTTP/2)。
3> 减少线程竞争
-
优化锁粒度(使用分段锁或
ReadWriteLock)。 -
替换为无锁数据结构(如
ConcurrentHashMap)。
4> 调整JVM参数
-
减少线程栈大小(
-Xss256k,需权衡栈溢出风险)。 -
调整系统级限制(如
ulimit -u 65535)。
5> 异步化改造
-
使用响应式框架(如Reactor、RxJava)替代阻塞式多线程。
-
采用协程(如Kotlin协程或Project Loom的虚拟线程)。
6> 第三方库调优
-
检查Netty的
EventLoopGroup线程数配置。 -
调整Tomcat的
maxThreads(针对Web应用)。
3、CPU飙升(热点代码)
常见原因:
1> 无限循环或高CPU消耗的代码逻辑
解决:增加合理的休眠(Thread.sleep())或退出条件,避免死循环或无阻塞的密集计算
2> 线程竞争或锁争用:大量线程处于BLOCKED状态(如synchronized锁竞争),或自旋锁(CAS操作)未成功
示例:ConcurrentHashMap的高并发扩容竞争、ReentrantLock未合理释放。
解决:优化并发策略(如减少竞争粒度、改用LongAdder),减少锁竞争(如用并发容器、读写锁、分段锁)
3> 外部资源调用阻塞:大量线程因IO或网络请求阻塞,但未正确释放CPU(如非阻塞模式未生效)
示例:数据库查询未设置超时,线程长期阻塞等待响应。
4> 频繁的垃圾回收(GC)
解决:合理设置堆大小(避免GC频繁触发),选择低延迟GC算法(如G1、ZGC)
5> 大量线程创建与销毁:线程频繁启动/停止(如不合理的线程池配置),线程调度开销大
排查:检查线程池配置(核心线程数、队列容量等)
6> JIT编译或代码优化问题:JIT编译器(C1/C2线程)在热点代码编译期间占用CPU。
示例:高频方法被反复编译/去优化(如OnStackReplacement)。
解决:调整JIT编译参数(如-XX:CompileThreshold)
排查步骤:
1> 定位高CPU进程/线程
Step 1:使用top命令找到占用CPU高的Java进程(PID)。
Step 2:通过top -Hp <PID>查看该进程内各线程的CPU占用,记录高CPU线程的ID(转为16进制,如printf "%x\n" 12345)。
2> 分析线程堆栈
Step 3:使用jstack <PID> > jstack.log导出线程堆栈。
Step 4:在堆栈日志中搜索高CPU线程的16进制ID(如nid=0x3039),查看其执行代码逻辑。
关键状态:
RUNNABLE:正在执行CPU密集型操作(如循环计算)。
BLOCKED:等待锁(检查锁竞争)。
WAITING/TIMED_WAITING:通常不占CPU,但需结合代码逻辑判断。
3> 结合其他工具验证
GC问题:使用jstat -gcutil <PID> 1000观察GC频率和内存区域变化。
锁竞争:使用jstack或arthas的thread -b命令检测死锁。
代码热点:使用async-profiler或Arthas的profiler生成火焰图,定位CPU热点方法。
五、其他问题
1、未启用压缩指针
未启用压缩指针(-XX:+UseCompressedOops)导致64位环境内存浪费。
在 64 位 JVM 中,未压缩的指针(对象引用)占 8 字节,而开启压缩后指针仅占 4 字节。启用 -XX:+UseCompressedOops 时,默认同时开启 -XX:+UseCompressedClassPointers,压缩类元数据指针(类型指针),进一步减少对象头大小(64 位下对象头从 16 字节压缩至 12 字节)
优点:减少内存占用;提升缓存效率;支持更大堆内存;降低GC开销
压缩范围限制:当堆内存超过 32GB 时,压缩指针无法覆盖全部地址空间,JVM 会自动关闭压缩功能。
适用场景:
- 64 位 JVM 且堆内存 ≤32GB(默认开启)。
- 内存敏感型应用(如大数据处理、高并发服务)。
验证:
通过 java -XX:+PrintFlagsFinal -version 可验证参数是否启用
2、JIT编译问题
JVM 在运行时会将频繁执行的热点代码(HotSpot Code)通过 JIT 编译器转换为本地机器码,这些编译后的代码会存储在 Code Cache 中。ReservedCodeCacheSize 直接控制该缓存区的最大容量,确保编译后的代码能够被高效存储和复用,避免重复编译带来的性能损耗。
表现:方法编译耗时高或代码缓存不足(CodeCache满)。
调优:调整-XX:ReservedCodeCacheSize(为即时编译器(JIT)生成的本地机器代码预留内存空间),避免频繁去优化。可结合 -XX:+UseCodeCacheFlushing 参数启用缓存刷新机制,缓解空间不足问题
注意:缓存区过小,可能导致频繁垃圾回收(即已编译的代码被清除)。当Code Cache被填满时,JVM 会停止进一步的编译优化,甚至禁用 JIT 功能,导致应用性能急剧下降
参数调整依据:
- 监控工具(如
jconsole、jstat)观察 Code Cache 使用率,若频繁达到阈值(如 90% 以上)需增大该值。 - 建议初始设置为 256MB,并根据实际负载动态调整,一般不超过堆内存(
-Xmx)的 10%-20%
相关文章:

JVM常见问题与调优
目录 一、内存管理问题 1、内存泄漏(Memory Leak) 2、内存溢出(OOM, OutOfMemoryError) 2.1 堆内存溢出(OutOfMemoryError: Java heap space) 2.2 元空间溢出(OutOfMemoryError: Metaspace…...

汽车售后诊断 ODX 和 OTX 对比分析报告
一、引言 在汽车行业不断发展的当下,汽车售后诊断技术对于保障车辆性能、维护车主权益以及提升汽车品牌服务质量起着至关重要的作用。随着汽车电子化程度的不断提高,售后诊断所涉及的数据和流程愈发复杂,这就促使行业需要更加标准化、高效化…...
》)
AI重构农业:从“面朝黄土“到“数字原野“的产业跃迁—读中共中央 国务院印发《加快建设农业强国规划(2024-2035年)》
在东北黑土地的万亩良田上,无人机编队正在执行精准施肥作业;在山东寿光的智慧大棚里,传感器网络实时调控着番茄生长的微环境;在云南的咖啡种植园中,区块链溯源系统记录着每粒咖啡豆的旅程。这场静默的农业革命…...

go游戏后端开发33:解散房间
接下来,我们来实现房间的解散功能。因为在调试过程中,如果不能取消房间,就需要频繁重启程序,这非常不方便。所以,我们先来实现这个解散功能。 房间解散的流程其实很简单。当发起解散请求后,我们会向所有用…...
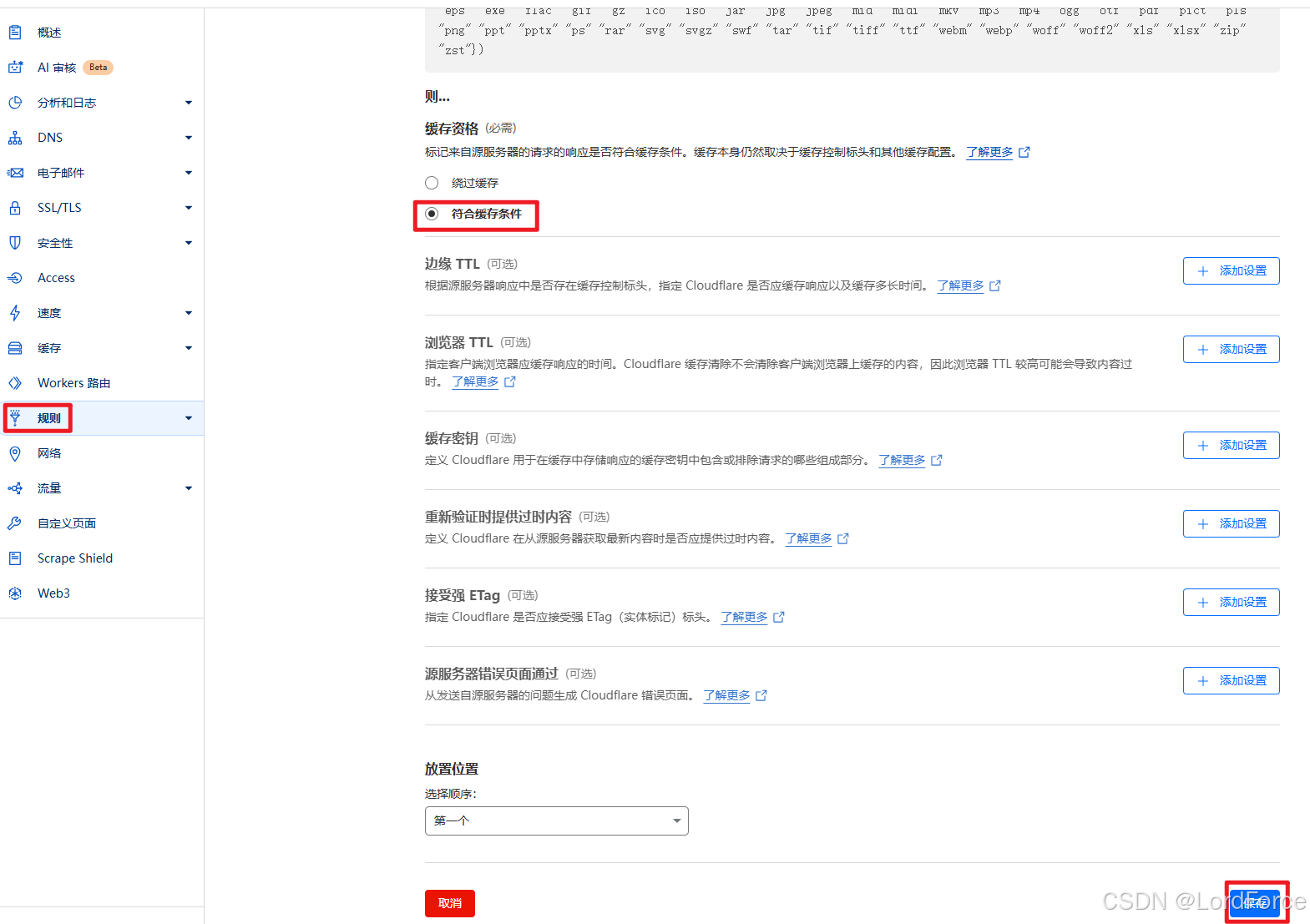
Cloudflare教程:免费优化CDN加速配置,提升网站访问速度 | 域名访问缓存压缩视频图片媒体文件优化配置
1、启用 Tiered Cache 缓存开关:通过选择缓存拓扑,可以控制源服务器与 Cloudflare 数据中心的连接方式,以确保缓存命中率更高、源服务器连接数更少,并且 Internet 延迟更短。 2、增加浏览器缓存时间TTL:在此期间&#…...

Python设计模式:策略模式
1. 什么是策略模式 策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,将每个算法封装起来,并使它们可以互换。策略模式使得算法的变化独立于使用算法的客户。换句话说,策略模式允许在运…...
)
JavaScript(JS进阶)
目录 00闭包 01函数进阶 02解构赋值 03通过forEach方法遍历数组 04深入对象 05内置构造函数 06原型 00闭包 <!-- 闭包 --><html><body><script>// 定义:闭包内层函数(匿名函数)外层函数的变量(s&…...

C/C++共有的类型转换与c++特有的四种强制类型转换
前言 C 语言和 C 共有的类型转换: 自动类型转换(隐式类型转换): 编译器在某些情况下会自动进行的类型转换。强制类型转换(显示类型转换): 使用 (type)expression 或 type(expression) 语法进行…...

Nginx 负载均衡案例配置
负载均衡案例 基于 docker 进行 案例测试 1、创建三个 Nginx 实例 创建目录结构 为每个 Nginx 实例创建单独的目录,用于存储 HTML 文件和配置文件 mkdir -p data/nginx1/html mkdir -p data/nginx2/html mkdir -p data/nginx3/html添加自定义 HTML 文件 在每个…...
【蓝桥杯】贪心算法
1. 区间调度 1.1. 题目 给定个区间,每个区间由开始时间start和结束时间end表示。请选择最多的互不重叠的区间,返回可以选择的区间的最大数量。 输入格式: 第一行包含一个整数n,表示区间的数量 接下来n行,每行包含两个整数,分别表示区间的开始时间和结束时间 输出格式:…...

LLaMA-Factory 数据集成从入门到精通
一、框架概述 LLaMA-Factory 框架通过Alpaca/Sharegpt双格式体系实现多任务适配,其中Alpaca专注结构化指令微调(含SFT/DPO/预训练),Sharegpt支持多角色对话及多模态数据集成。核心配置依托 dataset_info.json 实现数据源映射、格…...

数据库架构
常见数据库架构类型及其优势解析 1. 集中式架构(Centralized Architecture) 定义:所有数据存储在单个服务器或主机上,由中央处理器统一管理。核心优势: ✅ 数据一致性:单一数据源避免数据冗余和不一致。 …...
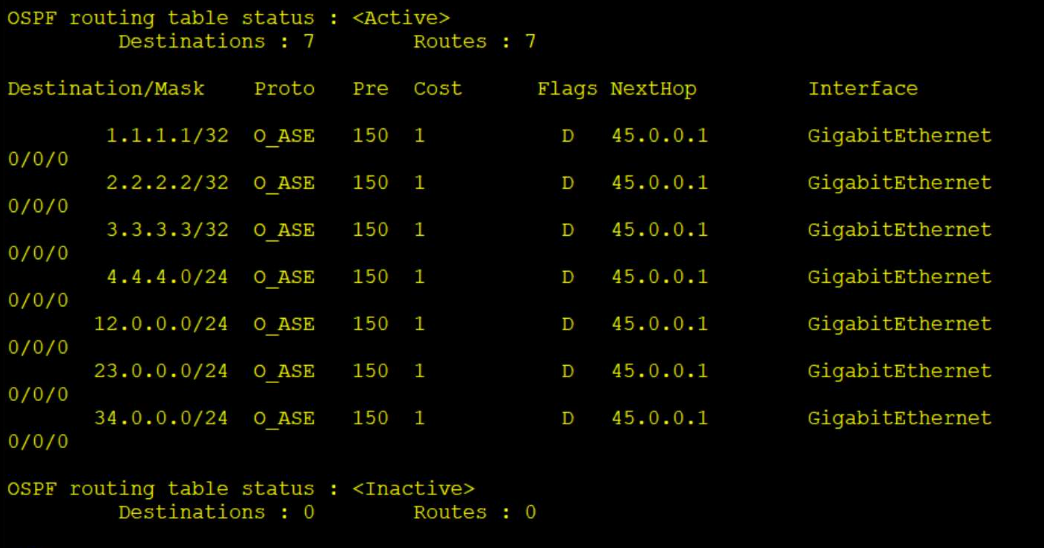
OSPF接口的网络类型和不规则区域
网络类型(数据链路层所使用的协议所构建的二层网络类型) 1、MA --- 多点接入网络 BMA --- 支持广播的多点接入网络 NBMA --- 不支持广播的多点接入网络 2、P2P --- 点到点网络 以太网 --- 以太网最主要的特点是需要基于MAC地址进行物理寻址,主要是因为以太网接口所连…...

MySQL SQL Mode
SQL Mode 是 MySQL 中一个重要的系统变量,它决定了 MySQL 应遵循的 SQL 语法规则和数据验证规则。 什么是 SQL Mode SQL Mode 定义了 MySQL 应该支持的 SQL 语法以及执行数据验证的方式。通过设置不同的 SQL Mode,可以让 MySQL 在不同程度上兼容其他数据…...

Mysql备忘记录
1、简介 Mysql操作经常忘记命令,本文将持续记录Mysql一些常用操作。 2、常见问题 2.1、忘记密码 # 1、首先停止Mysql服务 systemctl stop mysqld # windows 从任务管理器里面停 # 2、更改配置文件 my.cnf (windows是 ini文件) vim /etc/my.cnf 在[mysqld]下面添…...
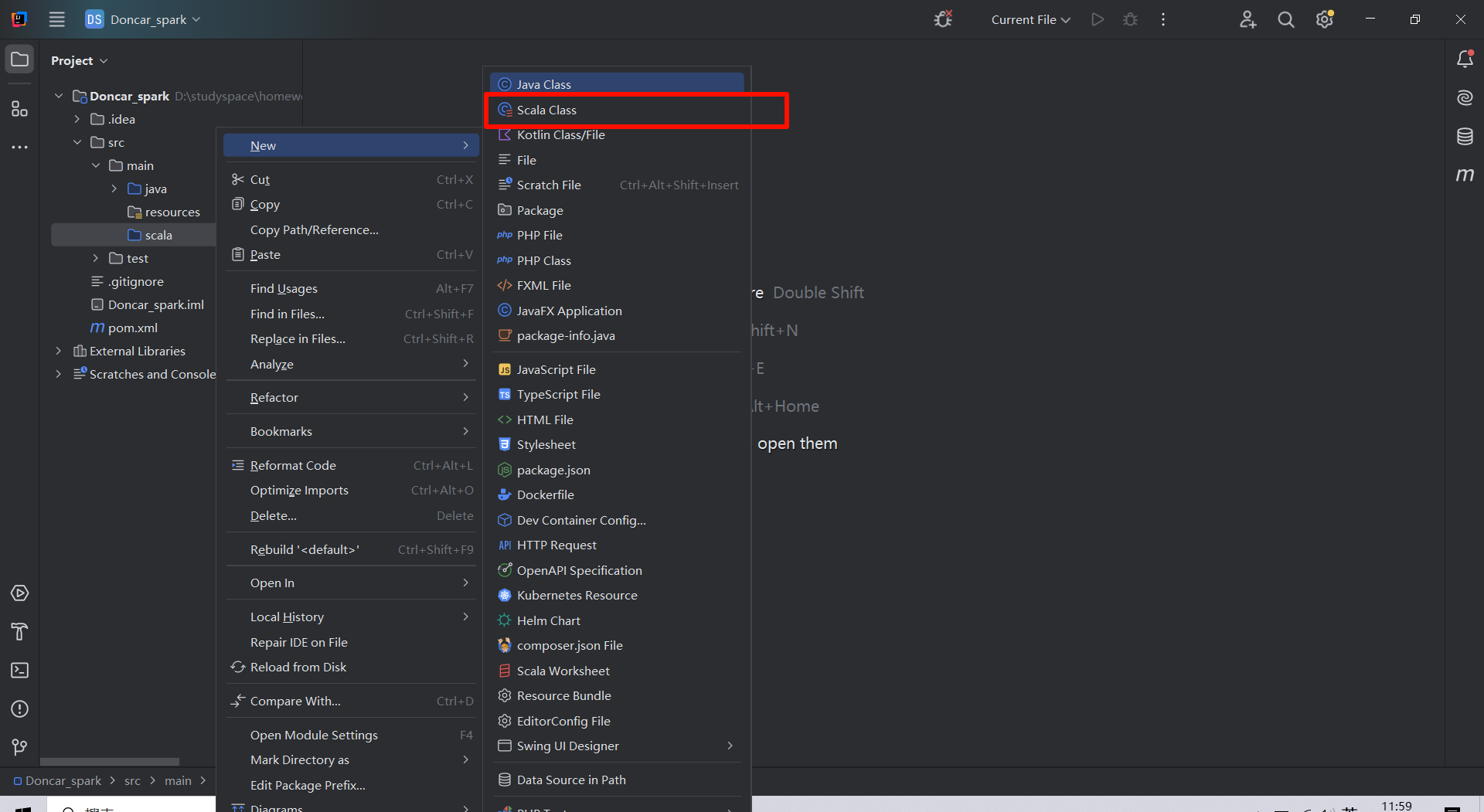
idea 创建 maven-scala项目
文章目录 idea 创建 maven-scala项目1、创建普通maven项目并且配置pom.xml文件2、修改项目结构1)创建scala目录并标记成【源目录】2)导入scala环境3)测试环境 idea 创建 maven-scala项目 1、创建普通maven项目并且配置pom.xml文件 maven依赖…...
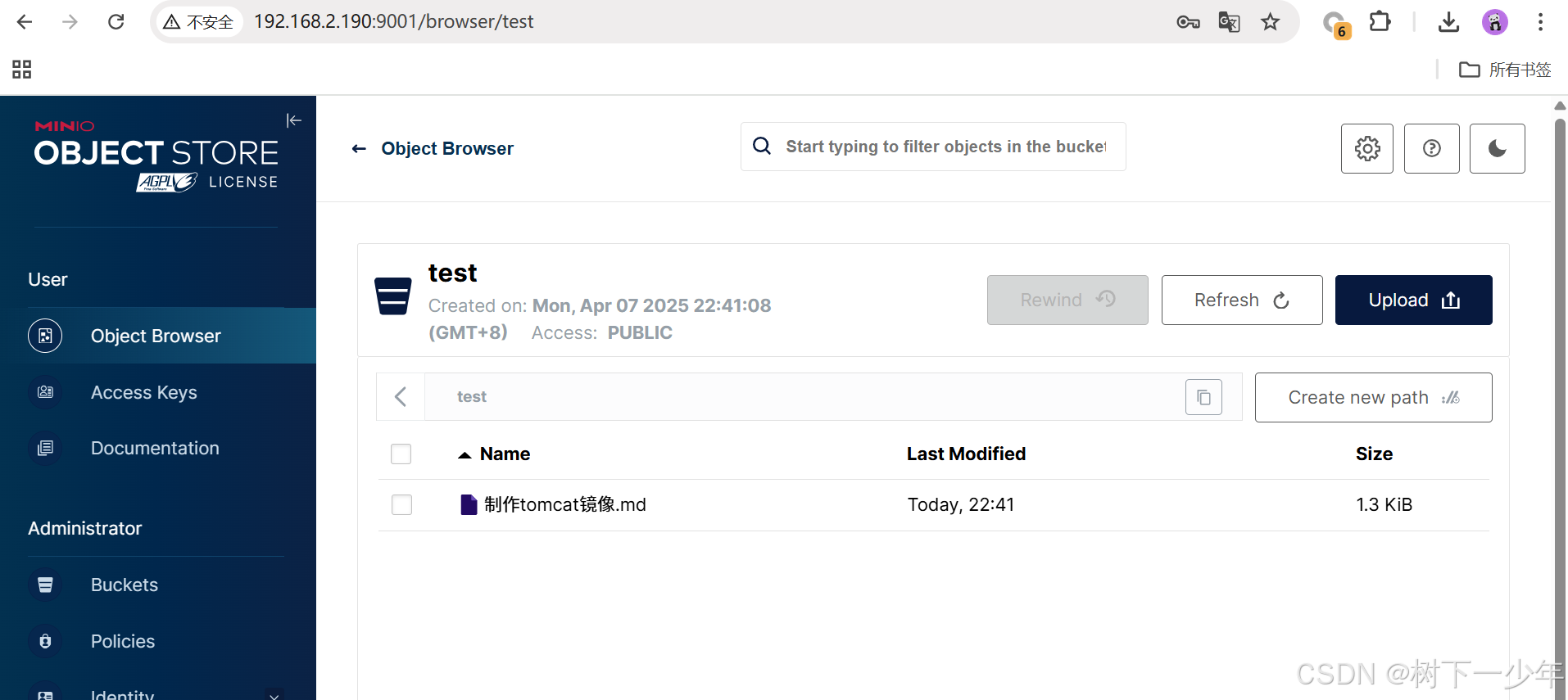
ansible+docker+docker-compose快速部署4节点高可用minio集群
目录 github项目地址 示例服务器列表 安装前 修改变量文件group_vars/all.yml 修改ansible主机清单 修改setup.sh安装脚本 用法演示 安装后验证 github项目地址 https://github.com/sulibao/ansible_minio_cluster.git 示例服务器列表 安装前 修改变量文件group_var…...

使用libcurl编写爬虫程序指南
用户想知道用Curl库编写的爬虫程序是什么样的。首先,我需要明确Curl本身是一个命令行工具和库,用于传输数据,支持多种协议。而用户提到的“Curl库”可能指的是libcurl,这是一个客户端URL传输库,可以用在C、C等编程语言…...

K8S学习之基础七十五:istio实现灰度发布
istio实现灰度发布 上传镜像到harbor 创建两个版本的pod vi deployment-v1.yaml apiVersion: apps/v1 kind: Deployment metadata:name: appv1labels:app: v1 spec:replicas: 1selector:matchLabels:app: v1apply: canarytemplate:metadata:labels:app: v1apply: canaryspec…...
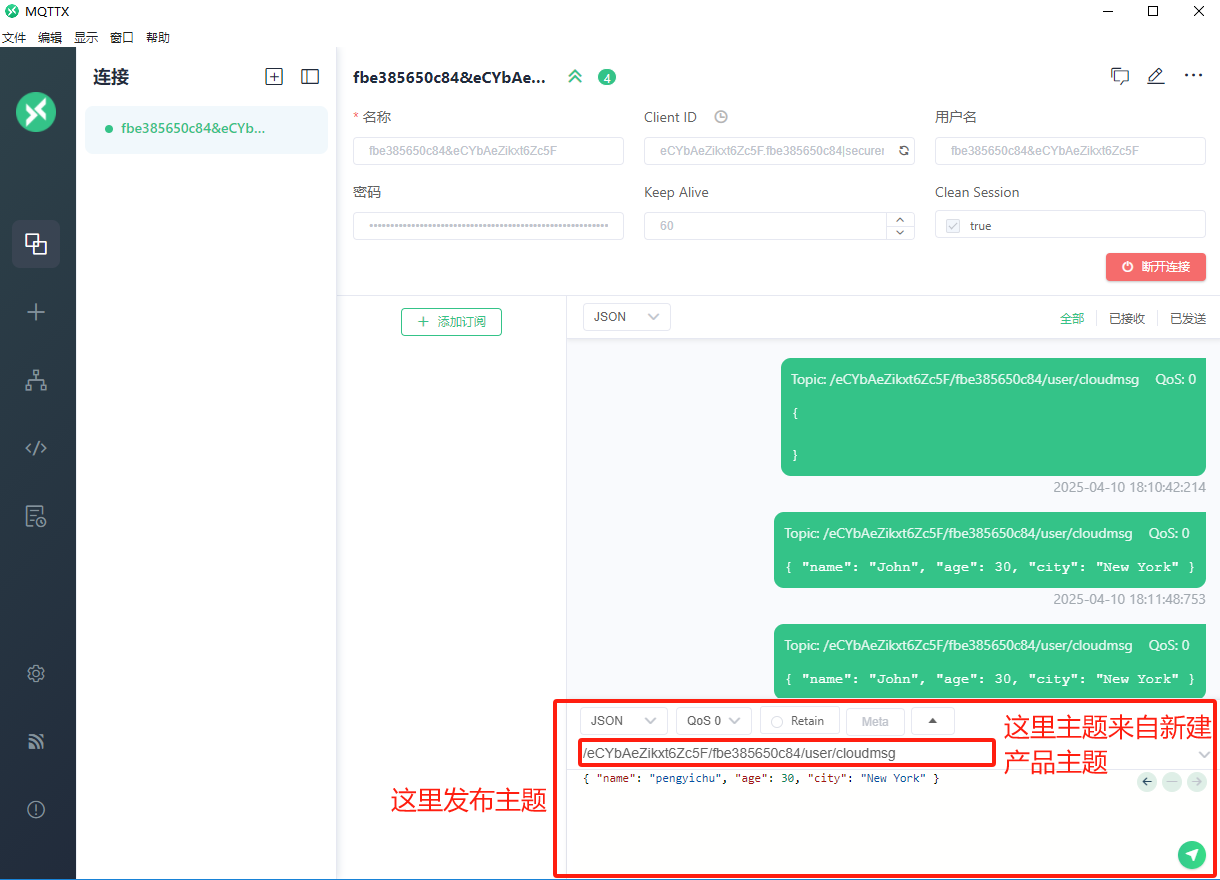
【设备连接涂鸦阿里云】
设备连接涂鸦阿里云 ■ Tuya IoT on Alibaba Cloud■ 控制台操作步骤■ 1. 创建产品■ 2. 添加设备■ 3. 添加设备■ 4. 获取设备MQTT连接参数 ■ MQTTX使用教程■ 1,先在 Tuya IoT on Alibaba Cloud 新建产品和设备■ 2,MQTTX 设置■ 3,MQTT…...
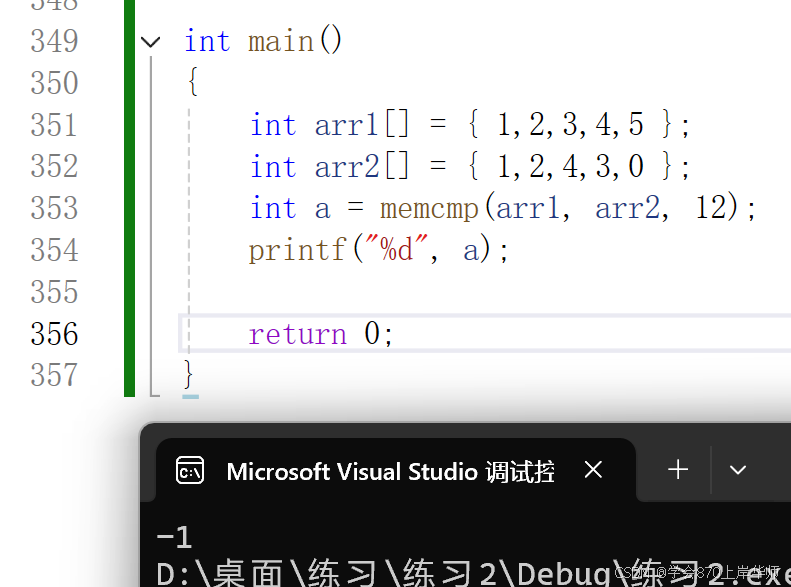
c语言学习16——内存函数
内存函数 一、memcpy使用和模拟实现1.1参数1.2 使用1.3 模拟实现 二、memmove使用和模拟实现2.1 参数2.2 使用2.3 模拟实现 三、memset使用3.1 参数3.2 使用 四、memcmp使用4.1 参数4.2 使用 一、memcpy使用和模拟实现 1.1参数 因为内存中不知道存的是什么类型的地址ÿ…...

渗透测试实战:使用Hydra破解MySQL弱口令(附合法授权流程+防御方案)
渗透测试实战:使用Hydra破解MySQL弱口令(附合法授权流程防御方案) 郑重声明:本文仅供安全学习研究,任何未经授权的网络攻击行为均属违法。实操需获得目标系统书面授权,请遵守《网络安全法》相关规定。 一、…...

一文了解亿级数据检索:RedisSearch
文章目录 1.什么是Redis Search2.为什么要使用Redis Search3.RedisSearch 的核心特性4.RedisSearch 的原理4.1 倒排索引4.2 索引创建与数据存储4.3 数据模型4.4 搜索查询处理4.5 高性能与可扩展性: 5.有了ES为什么还需要RedisSearch5.RedisSearch的安装6.RedisSearc…...
uniApp开发微信小程序-连接蓝牙连接打印机上岸!
历经波折三次成功上岸! 三次经历简单絮叨一下:使用uniAppvue开发的微信小程序,使用蓝牙连接打印机,蓝牙所有的接口都是插件中封装的,用的插件市场中的这个: dothan-lpapi-ble ;所以,…...

Spring Boot 线程池配置详解
Spring Boot 线程池配置详解 一、核心配置参数及作用 基础参数核心线程数 (corePoolSize) 作用:线程池中始终保持存活的线程数量,即使空闲也不回收。 建议:根据任务类型设定(如 I/O 密集型任务可设为 CPU 核心数 2)。 最大线程数 (maxPoolSize) 作用:…...
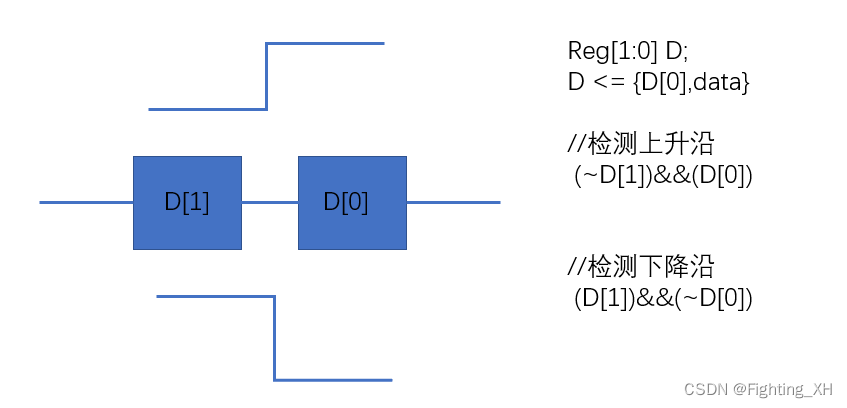
【特权FPGA】之按键消抖
完整代码如下所示: timescale 1ns / 1ps// Company: // Engineer: 特权 // // Create Date: // Design Name: // Module Name: // Project Name: // Target Device: // Tool versions: // Description: // // Dependencies: // // Revision: // …...
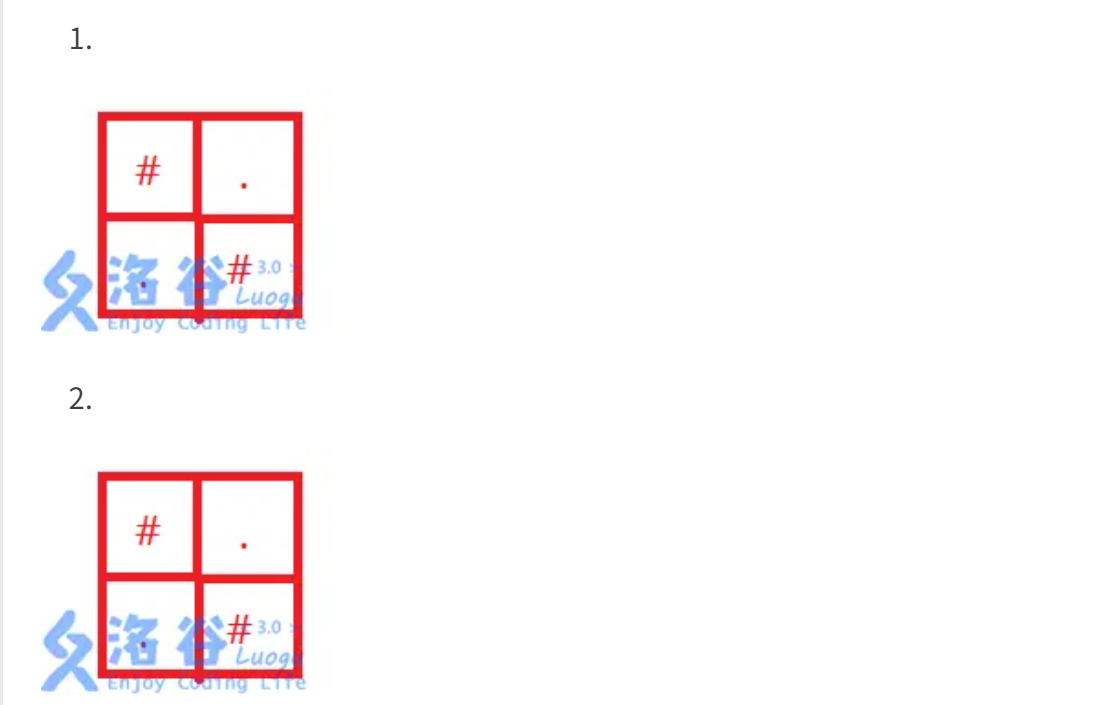
P1331 洛谷 海战
题目描述 思路 这个题需要读懂题意,即“什么样的形式表示两只船相撞?” ----> 上下相邻或左右相邻 如果图是不和法的,一定存在如下结构: # # . # 或 # # # . 或 # . # # 或 . # # #即四个格子里有三个#,一个"…...
)
Python 实现的运筹优化系统数学建模详解(最大最小化模型)
一、引言 在数学建模的实际应用里,最大最小化模型是一种极为关键的优化模型。它的核心目标是找出一组决策变量,让多个目标函数值里的最大值尽可能小。该模型在诸多领域,如资源分配、选址规划等,都有广泛的应用。本文将深入剖析最大…...

网络安全·第二天·ARP协议安全分析
今天我们来考虑考虑计算机网络中的一类很重要的协议-------ARP协议,介绍他用途的同时,分析分析ARP协议存在的一些漏洞及其相关的协议问题。 一、物理地址与IP地址 1、举例 在计算机网络中,有两类地址十分关键,一类称为物理地址&a…...

Python设计模式:命令模式
1. 什么是命令模式? 命令模式是一种行为设计模式,它将请求封装为一个对象,从而使您能够使用不同的请求、队列或日志请求,以及支持可撤销操作。 命令模式的核心思想是将请求的发送者与请求的接收者解耦,使得两者之间的…...