BERT-DDP
DDP 代码执行流程详解
这份代码执行的是一个典型的数据并行分布式训练流程,利用多个 GPU(可能分布在多个节点上)来加速模型训练。核心思想是每个 GPU 处理一部分数据,计算梯度,然后同步梯度并更新模型。
假设你使用 torchrun 启动了 N 个进程 (World Size = N),每个进程对应一个 GPU。
阶段一:初始化 (所有进程并行执行,但需要协调)
- 进入
main()函数。 setup_distributed()被调用:- 读取环境变量: 每个进程从启动器 (
torchrun) 设置的环境变量中读取MASTER_ADDR,MASTER_PORT,RANK,WORLD_SIZE,LOCAL_RANK。 dist.init_process_group(backend="nccl", ...): 这是关键的同步点。- 所有
N个进程都会尝试连接到MASTER_ADDR:MASTER_PORT这个地址。 - 主进程 (Rank 0) 会在这里建立一个
TCPStore服务进行监听。 - 其他进程连接到这个服务。
- 所有进程通过
TCPStore交换彼此的连接信息(例如,NCCL 需要知道其他 GPU 的地址和端口来进行直接通信)。 - 当所有
N个进程都成功连接并完成信息交换后,分布式通信组才算建立成功。NCCL 后端也会在此期间完成初始化。 - 如果任何一个进程连接失败或超时,所有进程都会卡住或报错。
- 所有
- 获取 Rank 和 World Size: 进程从环境变量或初始化结果中明确自己的全局排名 (
rank) 和总进程数 (world_size)。 - 设置设备: 每个进程根据自己的
local_rank(它在自己节点内的 GPU 编号) 调用torch.cuda.set_device(local_rank),确保后续的 Tensor 和模型都放在正确的 GPU 上。 - 打印初始化信息: 每个进程打印自己的 Rank、World Size、Local Rank 和使用的设备。
- 返回信息: 函数返回
rank,world_size,local_rank,device给main函数。
- 读取环境变量: 每个进程从启动器 (
- 判断主进程:
is_main_process = (rank == 0)变量被设置,用于后续控制哪些操作只由 Rank 0 执行(如打印、保存模型)。 - 配置参数加载: 所有进程都会加载配置参数,但只有主进程会打印它们。
- 加载 Tokenizer: 所有进程都加载 Tokenizer(从本地路径加载很快)。只有主进程打印加载信息。
- 加载模型: 所有进程都从本地路径加载相同的模型结构和预训练权重 (
AutoModelForSequenceClassification.from_pretrained(...))。 - 模型移动到设备: 每个进程将自己加载的模型副本移动到自己对应的 GPU 上 (
model.to(device))。 - 包装模型 (DDP):
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank): 所有进程都使用 DDP 包装自己的模型副本。device_ids=[local_rank]: 告诉 DDP 这个进程的模型在哪个 GPU 上。output_device=local_rank: 指定梯度聚合和可能的前向输出汇总到哪个设备(通常设为当前 GPU)。- DDP 内部操作:
- 它会确保所有进程的模型参数在开始时是完全一致的(通过一次广播同步)。
- 它会注册钩子 (hooks) 到模型参数上,用于在
backward()时自动触发梯度同步。
- 加载和预处理数据集:
- 所有进程都从磁盘加载数据集 (
load_from_disk)。 - 所有进程都执行
map(tokenize_function, ...)对数据进行 Tokenize 和格式化。datasets库的map可能会并行处理,每个进程都会看到进度条。 set_format("torch")将数据集转换为 PyTorch Tensor 格式。
- 所有进程都从磁盘加载数据集 (
- 创建
DistributedSampler:train_sampler = DistributedSampler(...): 为训练集创建分布式采样器。它会根据world_size和rank,确保每个进程在每个 epoch 中只获取到整个数据集的一个不重复子集。shuffle=True表示在每个 epoch 开始时打乱数据的顺序(但在进程间仍然是不重复的)。eval_sampler = DistributedSampler(...): 为评估集创建采样器,shuffle=False通常用于评估。
- 创建
DataLoader:train_dataloader = DataLoader(..., sampler=train_sampler, ...): 创建训练数据加载器,必须传入train_sampler,并且shuffle参数必须是False(因为sampler已经处理了 shuffle)。DataLoader 现在只会迭代当前进程负责的那部分数据。eval_dataloader = DataLoader(..., sampler=eval_sampler, ...): 创建评估数据加载器。
- 定义优化器和学习率调度器:
optimizer = AdamW(model.parameters(), ...): 所有进程都为自己的模型副本创建优化器。传入model.parameters()(即使是被 DDP 包装后) 会正确获取到底层模型的参数。lr_scheduler = get_scheduler(...): 所有进程都创建学习率调度器。
阶段二:训练循环 (并行执行,穿插同步)
- 进入 Epoch 循环:
for epoch in range(NUM_EPOCHS):(所有进程同步进行)。 - 设置训练模式:
model.train()(所有进程设置自己的模型副本)。 - 设置 Sampler 的 Epoch:
train_sampler.set_epoch(epoch)。非常重要! 这确保了每个 epoch 的数据 shuffle 方式不同,否则每个 epoch 加载的数据顺序将完全一样。 - 进入 Batch 循环:
for i, batch in enumerate(train_dataloader):(所有进程并行迭代自己数据子集的 batch)。 - 数据移动到设备:
batch = {k: v.to(device) for k, v in batch.items()}(每个进程将自己的 batch 移到自己的 GPU)。 - 前向传播:
outputs = model(**batch)(每个进程在自己的 GPU 上,用自己的模型副本和自己的 batch 数据独立执行前向计算)。 - 计算损失:
loss = outputs.loss(每个进程计算自己的损失)。 - 反向传播:
loss.backward()(这是 DDP 发挥作用的关键点):- 每个进程独立计算自己 batch 数据的梯度。
- DDP 自动触发: 在计算过程中,一旦某层(或某个梯度桶)的梯度计算完成,DDP 会自动在后台启动 AllReduce 操作,将这个梯度在所有
N个进程之间进行求和或平均(取决于 DDP 设置,默认为平均)。 - 计算与通信重叠: 这个 AllReduce 通信过程会尝试与剩余层梯度的计算过程并行进行,以隐藏通信延迟。
- 最终结果: 当
loss.backward()执行完毕时,所有进程的模型参数都拥有了完全相同的、基于全局批次数据计算出的平均梯度。
- 优化器更新:
optimizer.step()(每个进程使用相同的平均梯度独立更新自己的模型副本参数)。由于梯度相同,所有进程的模型参数在更新后保持一致。 - 学习率更新:
lr_scheduler.step()(所有进程独立更新自己的学习率)。 - 梯度清零:
optimizer.zero_grad()(所有进程清零自己的梯度)。 - 主进程更新进度条:
if is_main_process: progress_bar.update(1)...。 - 重复 Batch 循环 直到当前 epoch 结束。
- 主进程打印 Epoch 损失: 计算并打印平均损失。
- 重复 Epoch 循环。
阶段三:评估循环 (并行执行,结果收集)
- 主进程打印信息:
if is_main_process: print(...)。 - 设置评估模式:
model.eval()(所有进程设置)。 - 禁用梯度:
with torch.no_grad():(所有进程执行)。 - 进入评估 Batch 循环:
for batch in eval_dataloader:(所有进程并行迭代评估集的不重复子集)。 - 数据移动和前向传播: 与训练类似,每个进程处理自己的 batch。
- 获取预测:
predictions = torch.argmax(logits, dim=-1)(每个进程得到自己那部分数据的预测)。 - 本地收集: 每个进程将自己处理的预测
predictions和真实标签batch["labels"]收集到本地列表all_predictions_proc和all_references_proc中。 - 同步点:
dist.barrier()确保所有进程都完成了各自的评估循环。 - 收集结果:
- 每个进程将本地收集的列表转换为 Tensor (
pred_tensor,ref_tensor)。 - 主进程 (Rank 0) 准备好接收列表
gathered_preds_list,gathered_refs_list。 - 调用
dist.gather(...):- 非主进程将其
pred_tensor和ref_tensor发送给主进程 (dst=0)。 - 主进程从所有进程(包括自己)接收 Tensor,并按 Rank 顺序填充到
gathered_preds_list和gathered_refs_list中。
- 非主进程将其
- 每个进程将本地收集的列表转换为 Tensor (
- 同步点:
dist.barrier()确保gather操作完成。 - 主进程计算指标:
- 只有主进程 (
if is_main_process:) 执行后续代码。 - 合并从所有进程收集到的预测和标签列表。
- (可选) 处理
DistributedSampler可能引入的重复样本,截断到原始数据集大小。 - 调用
accuracy_score计算最终的准确率。 - 打印评估结果。
- 只有主进程 (
阶段四:保存与清理 (主进程执行)
- 主进程保存模型:
if is_main_process:确保只有 Rank 0 执行。- 获取 DDP 包装下的原始模型:
model.module。 - 调用
model_to_save.save_pretrained(OUTPUT_DIR)保存模型权重和配置。 - 调用
tokenizer.save_pretrained(OUTPUT_DIR)保存 Tokenizer。
- 清理分布式环境:
- 所有进程 调用
cleanup_distributed()中的dist.destroy_process_group()来释放资源并断开连接。
- 所有进程 调用
- 脚本结束。
解释 torchrun 脚本中的 Rendezvous 参数:
torchrun \...--rdzv_id=bert_job_n1n3_01 \--rdzv_backend=c10d \--rdzv_endpoint="$MASTER_ADDR:$MASTER_PORT" \...
这些参数共同定义了进程集合点 (Rendezvous),这是让所有分布式进程能够互相发现并加入同一个训练作业的关键机制。
--rdzv_backend=c10d: 指定使用 PyTorch 内置的 C10d 后端来进行集合。c10d是 PyTorch 分布式库的核心组件。这个后端通常依赖于一个外部(或由 rank 0 进程创建的)键值存储(Key-Value Store)来让进程交换信息。--rdzv_endpoint="$MASTER_ADDR:$MASTER_PORT": 当rdzv_backend为c10d时,这个参数指定了 C10d 后端使用的键值存储的地址和端口。在这种设置下,torchrun会让 Rank 0 进程在$MASTER_ADDR:$MASTER_PORT上启动一个临时的TCPStore作为这个键值存储。所有其他进程会连接到这个地址和端口,通过TCPStore进行注册和信息交换。这就是为什么MASTER_ADDR和MASTER_PORT如此重要。--rdzv_id=bert_job_n1n3_01: 一个唯一的作业标识符。它确保只有属于同一个训练作业的进程才会加入同一个集合点。如果你同时运行多个不同的分布式作业,它们需要有不同的rdzv_id以免互相干扰。你可以把它看作是这次特定训练任务的“房间号”。
总的来说,这些参数告诉 torchrun 如何组织和协调所有启动的进程,让它们能够找到彼此并形成一个可以进行分布式通信的整体。
相关代码
finetune_bert_imdb_ddp.py
import torch
import torch.nn as nn
import torch.distributed as dist # <--- 导入分布式库
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler # <--- 导入分布式采样器
from torch.optim import AdamW
from transformers import (AutoTokenizer,AutoModelForSequenceClassification,get_scheduler
)
from datasets import load_from_disk
from tqdm.auto import tqdm
from sklearn.metrics import accuracy_score
import time
import os
import argparse # <--- 使用 argparse 获取 local_rank (虽然 torchrun 会设环境变量)
import datetime# --- 函数:初始化分布式环境 ---
def setup_distributed():# torchrun 会自动设置 MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE, LOCAL_RANK# 初始化进程组dist.init_process_group(backend="nccl", timeout=datetime.timedelta(minutes=5))# 获取 rank 和 world_sizerank = int(os.environ['RANK'])world_size = int(os.environ['WORLD_SIZE'])local_rank = int(os.environ['LOCAL_RANK']) # 当前节点上的 GPU 索引# 将当前进程绑定到指定的 GPUtorch.cuda.set_device(local_rank)device = torch.device("cuda", local_rank)print(f"[Rank {rank}/{world_size}, LocalRank {local_rank}] Process initialized on device: {device}")return rank, world_size, local_rank, device# --- 函数:清理分布式环境 ---
def cleanup_distributed():dist.destroy_process_group()print("Distributed process group destroyed.")def main():# --- 初始化分布式环境 ---rank, world_size, local_rank, device = setup_distributed()is_main_process = (rank == 0) # 判断是否是主进程# --- 1. 配置参数 ---# 注意:路径必须是所有节点都能访问的共享路径,或者在每个节点上都存在LOCAL_MODEL_PATH = '/lihongliang/fangzl/BERT/model'MODEL_NAME = 'bert-base-uncased'DATASET_NAME = '/lihongliang/fangzl/BERT/imdb_local'NUM_EPOCHS = 4# BATCH_SIZE 现在是 *每个 GPU* 的批量大小PER_GPU_BATCH_SIZE = 8 # <--- 修改变量名,明确含义 (根据单 GPU 显存调整)EFFECTIVE_BATCH_SIZE = PER_GPU_BATCH_SIZE * world_sizeif is_main_process:print(f"Per GPU Batch Size: {PER_GPU_BATCH_SIZE}")print(f"World Size: {world_size}")print(f"Effective Global Batch Size: {EFFECTIVE_BATCH_SIZE}")MAX_LENGTH = 512LEARNING_RATE = 2e-5LOCAL_DATA_PATH = '/lihongliang/fangzl/BERT/imdb_local'OUTPUT_DIR = "./bert_imdb_finetuned_ddp" # 区分输出目录# --- 3. 加载 Tokenizer 和 模型 ---# Tokenizer 只需要主进程加载一次即可,因为它不包含需要同步的参数# 但为了简单起见,让每个进程都加载也无妨,因为它很快if is_main_process:print(f"Loading Tokenizer from: {LOCAL_MODEL_PATH}")tokenizer = AutoTokenizer.from_pretrained(LOCAL_MODEL_PATH)if is_main_process:print(f"Loading Model from: {LOCAL_MODEL_PATH}")# 每个进程都需要加载模型结构model = AutoModelForSequenceClassification.from_pretrained(LOCAL_MODEL_PATH, num_labels=2)# 将模型移动到当前进程对应的 GPU 设备model.to(device)# ===> 修改点:使用 DistributedDataParallel 包装模型 <===if is_main_process:print(f"Wrapping model with nn.parallel.DistributedDataParallel.")# device_ids 指定当前进程使用的 GPU# output_device 指定梯度和输出汇总到哪个设备 (通常等于 local_rank)model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)if is_main_process:print("Model and Tokenizer loaded and wrapped successfully.")# --- 4. 加载和预处理数据集 ---# 数据集加载和预处理通常可以在每个进程独立完成# (如果数据集很大,可以考虑只在主进程处理然后广播,但 load_from_disk 很快)if is_main_process:print(f"Loading Dataset from disk: {LOCAL_DATA_PATH}")raw_datasets = load_from_disk(LOCAL_DATA_PATH)if is_main_process:print("Dataset structure:", raw_datasets)def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=MAX_LENGTH)if is_main_process:print("Tokenizing dataset...")tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)tokenized_datasets = tokenized_datasets.remove_columns(["text"])tokenized_datasets = tokenized_datasets.rename_column("label", "labels")tokenized_datasets.set_format("torch")train_dataset = tokenized_datasets["train"]eval_dataset = tokenized_datasets["test"]# ===> 修改点:使用 DistributedSampler <===# 创建分布式采样器,它会确保每个进程拿到不重复的数据子集train_sampler = DistributedSampler(train_dataset, num_replicas=world_size, rank=rank, shuffle=True)# 评估时通常不需要打乱,但仍需确保每个进程处理不同部分eval_sampler = DistributedSampler(eval_dataset, num_replicas=world_size, rank=rank, shuffle=False)# 创建 DataLoader 时传入 sampler,并且 shuffle 必须为 Falsetrain_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=PER_GPU_BATCH_SIZE)eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=PER_GPU_BATCH_SIZE)if is_main_process:print(f"DataLoaders created. Train batches per process: {len(train_dataloader)}, Eval batches per process: {len(eval_dataloader)}")# --- 5. 定义优化器和学习率调度器 ---# DDP 包装后,仍可通过 model.parameters() 或 model.module.parameters() 获取参数optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)# 总训练步数应该基于单个进程的 dataloader 长度num_training_steps_per_epoch = len(train_dataloader)num_training_steps = NUM_EPOCHS * num_training_steps_per_epochlr_scheduler = get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)if is_main_process:print(f"Optimizer and LR scheduler configured. Total training steps: {num_training_steps}")# --- 6. 训练循环 ---if is_main_process:print("Starting training...")start_time = time.time()# 总进度条只在主进程显示progress_bar = tqdm(range(num_training_steps), desc="Total Training Progress")for epoch in range(NUM_EPOCHS):model.train()# ===> 修改点:设置 sampler 的 epoch <===# 每个 epoch 开始前设置 sampler 的 epoch,确保 shuffle 在不同 epoch 不同train_sampler.set_epoch(epoch)epoch_loss = 0.0# 内部循环进度条也只在主进程显示 (或者完全去掉)# train_progress_bar = tqdm(train_dataloader, desc=f"Epoch {epoch+1}/{NUM_EPOCHS}", disable=not is_main_process, leave=False)for i, batch in enumerate(train_dataloader): # DDP 每个进程迭代自己的数据# 将数据移动到当前进程的设备batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.loss # DDP 会自动处理损失的同步(如果需要)# DDP 会自动在 backward() 过程中平均梯度loss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()# 累加损失用于日志记录# dist.all_reduce(loss, op=dist.ReduceOp.SUM) # 可以选择同步所有进程的 loss# loss /= world_sizeepoch_loss += loss.item()if is_main_process:progress_bar.update(1)progress_bar.set_postfix(epoch=f"{epoch+1}", loss=loss.item())# 计算并打印平均损失 (只在主进程)avg_epoch_loss = epoch_loss / num_training_steps_per_epochif is_main_process:tqdm.write(f"--- Epoch {epoch+1} Average Training Loss: {avg_epoch_loss:.4f} ---")if is_main_process:progress_bar.close()training_time = time.time() - start_timeprint(f"\nTraining finished. Total time: {training_time:.2f} seconds")# --- 同步点:确保所有进程完成训练 ---dist.barrier()if is_main_process:print("All processes finished training.")# --- 7. 评估循环 ---if is_main_process:print("\nStarting evaluation...")eval_start_time = time.time()model.eval()all_predictions_list = [None] * world_size # 用于收集所有进程的预测all_references_list = [None] * world_size # 用于收集所有进程的标签all_predictions_proc = []all_references_proc = []with torch.no_grad():# eval_progress_bar = tqdm(eval_dataloader, desc="Evaluating", disable=not is_main_process, leave=True)for batch in eval_dataloader: # 每个进程处理自己的评估子集batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)all_predictions_proc.extend(predictions.cpu().tolist())all_references_proc.extend(batch["labels"].cpu().tolist())# ===> 修改点:收集所有进程的评估结果 <===# 使用 dist.gather 或 dist.all_gather 将每个进程的结果汇总到主进程# dist.all_gather_object 需要 Python 对象列表dist.barrier() # 确保所有进程完成评估# 将列表转换为 tensor 以便使用 dist.gatherpred_tensor = torch.tensor(all_predictions_proc).to(device)ref_tensor = torch.tensor(all_references_proc).to(device)# 创建用于接收 gather 结果的 tensor 列表gathered_preds_list = [torch.zeros_like(pred_tensor) for _ in range(world_size)]gathered_refs_list = [torch.zeros_like(ref_tensor) for _ in range(world_size)]if rank == 0: # 主进程接收dist.gather(pred_tensor, gather_list=gathered_preds_list, dst=0)dist.gather(ref_tensor, gather_list=gathered_refs_list, dst=0)else: # 其他进程发送dist.gather(pred_tensor, gather_list=[], dst=0)dist.gather(ref_tensor, gather_list=[], dst=0)dist.barrier() # 确保 gather 完成# 在主进程计算最终指标if is_main_process:# 合并所有进程的结果final_predictions = []final_references = []for preds in gathered_preds_list:final_predictions.extend(preds.cpu().tolist())for refs in gathered_refs_list:final_references.extend(refs.cpu().tolist())# 注意:由于 DistributedSampler 可能添加重复样本以使数据均匀分布,# 最终收集到的样本总数可能略多于原始数据集大小。# 对于 accuracy 计算通常影响不大,但对于精确指标可能需要处理。# 这里假设评估数据集大小能被 world_size 整除,或者忽略少量重复。# 截断到原始评估集大小(如果需要精确匹配)original_eval_size = len(eval_dataset)final_predictions = final_predictions[:original_eval_size]final_references = final_references[:original_eval_size]accuracy = accuracy_score(y_true=final_references, y_pred=final_predictions)eval_metric = {"accuracy": accuracy}eval_time = time.time() - eval_start_timeprint(f"\nEvaluation finished. Time: {eval_time:.2f} seconds")print(f"Accuracy on evaluation set: {eval_metric['accuracy']:.4f}")# --- 8. (可选) 保存模型 ---# ===> 修改点:只有主进程保存 <===if is_main_process:print(f"\nSaving model to {OUTPUT_DIR}...")if not os.path.exists(OUTPUT_DIR):os.makedirs(OUTPUT_DIR)# 获取 DDP 包装下的原始模型model_to_save = model.module if isinstance(model, nn.parallel.DistributedDataParallel) else modelmodel_to_save.save_pretrained(OUTPUT_DIR)# Tokenizer 通常只需要保存一次tokenizer.save_pretrained(OUTPUT_DIR)print("Model and tokenizer saved successfully by main process.")# --- 清理分布式环境 ---cleanup_distributed()if __name__ == "__main__":main()
node1.sh(类似的三个其他脚本就不写了)
#!/bin/bash
export MASTER_ADDR=x.x.x.x
export MASTER_PORT=xxxxxtorchrun \--nnodes=4 \--nproc_per_node=1 \--node_rank=0 \--rdzv_id=bert_job_n1n3_01 \--rdzv_backend=c10d \--rdzv_endpoint="$MASTER_ADDR:$MASTER_PORT" \finetune_bert_imdb_ddp.py # 你的 Python 训练脚本
运行遇到的问题
获取服务器的ip地址
hostname -i
编辑节点的主机名与ip地址映射,加入“ip 对应主机名”,Ctrl+O保存,Enter,Ctrl+X退出
nano /etc/hosts
相关文章:

BERT-DDP
DDP 代码执行流程详解 这份代码执行的是一个典型的数据并行分布式训练流程,利用多个 GPU(可能分布在多个节点上)来加速模型训练。核心思想是每个 GPU 处理一部分数据,计算梯度,然后同步梯度并更新模型。 假设你使用 …...

【MySQL】002.MySQL数据库基础
文章目录 数据库基础1.1 什么是数据库1.2 基本使用创建数据库创建数据表表中插入数据查询表中的数据 1.3 主流数据库1.4 服务器,数据库,表关系1.5 MySQL架构1.6 SQL分类1.7 存储引擎1.7.1 存储引擎1.7.2 查看存储引擎1.7.3 存储引擎对比 前言:…...

02-redis-源码下载
1、进入到官网 redis官网地址https://redis.io/ 2 进入到download页面 官网页面往最底下滑动,找到如下页面 点击【download】跳转如下页面,直接访问:【https://redis.io/downloads/#stack】到如下页面 3 找到对应版本的源码 https…...

大模型上下文协议MCP详解(1)—技术架构与核心机制
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl1. MCP概述 1.1 定义与目标 MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的开放标准协议。它旨在解决AI大模型与外部工具、数据源及API之间的标准化交互问题…...
Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...
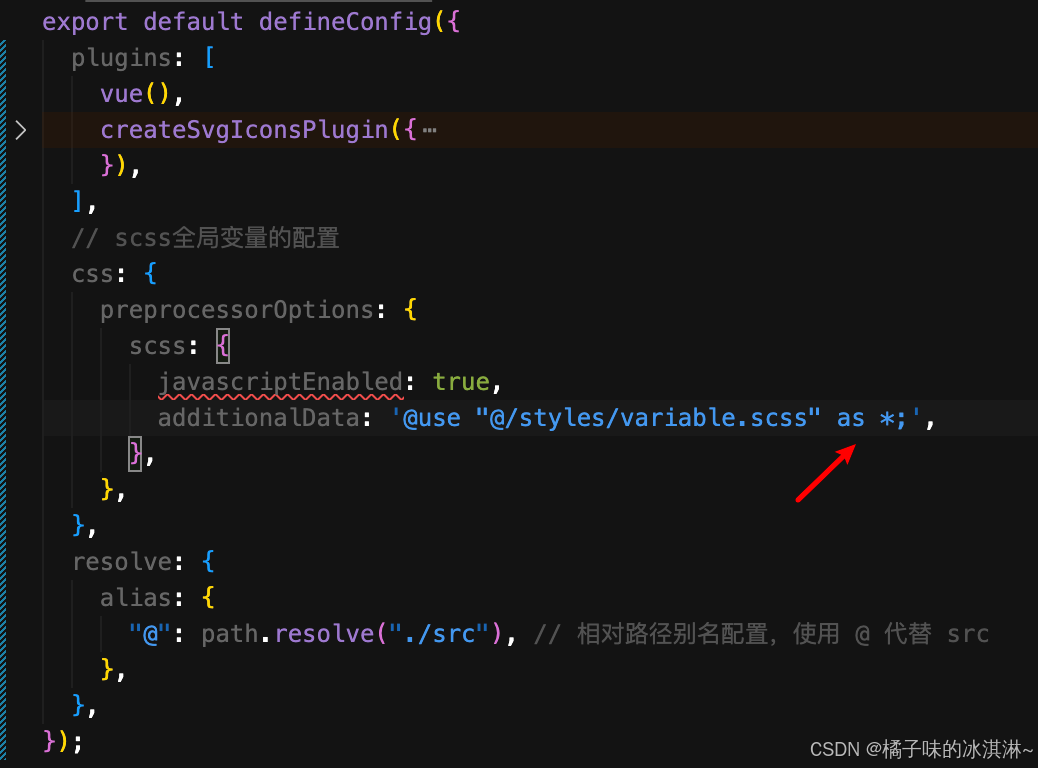
解决 vite.config.ts 引入scss 预处理报错
版本号: "sass": "^1.86.3","sass-loader": "^16.0.5","vite": "^6.2.0" 报错1:[plugin:vite:css] [SASS] Error:Cant find stylesheet to import vite.config.ts 开始文件错…...

MySQL学习笔记7【InnoDB】
Innodb 1. 架构 1.1 内存部分 buffer pool 缓冲池是主存中的第一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删查改操作时,先操作缓冲池中的数据,然后以一定频率刷新到磁盘,这样操作明显提升了速度。 …...

分布式锁和事务注解结合使用
在分布式系统中,事务注解(如 Transactional)与分布式锁的结合使用是保障数据一致性和高并发安全的核心手段。以下是两者的协同使用场景及技术实现要点: 一、事务注解的局限性及分布式锁的互补性 维度事务注解(Transac…...

全国产压力传感器常见的故障有哪些?
全国产压力传感器常见的故障如哪些呢?来和武汉利又德的小编一起了解一下,主要包括以下几类: 零点漂移 表现:在没有施加压力或处于初始状态时,传感器的输出值偏离了设定的零点。例如,压力为零时,…...
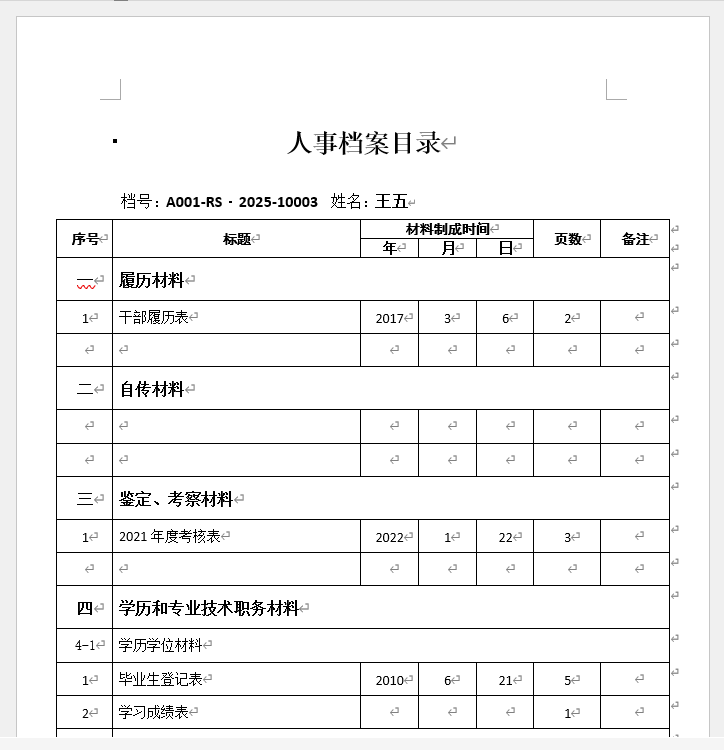
使用nhdeep档案目录打印工具生成干部人事档案目录打印文件
打开nhdeep档案目录打印工具,在左侧的模版列表中选中"干部人事档案目录"模版。 然后点击右下角“批量导入行”按钮,选择事先准备好的人事目录数据excel文件完成导入。 人事目录数据excel文件的结构和内容如下: 导入完成后…...
工作记录 2015-08-24
工作记录 2015-08-24 序号 工作 相关人员 1 更新76.19的D:\FNEHRRD,更新的差不多了,还在测试中。具体情况见附件。 郝 识别引擎监控 Ps (iCDA LOG :剔除了204篇ASG_BLANK之后的结果): LOG_File 20150823.txt BLANK_CDA/ALL 102/947 (10.8%) TIME…...

在 Dev-C++中编译运行GUI 程序介绍(三)有趣示例一组
在 Dev-C中编译运行GUI程序介绍(三)有趣示例一组 前期见 在 Dev-C中编译运行GUI 程序介绍(一)基础 https://blog.csdn.net/cnds123/article/details/147019078 在 Dev-C中编译运行GUI 程序介绍(二)示例&a…...
Compose 适配 - 响应式排版 自适应布局
一、概念 基于可用空间而非设备类型来设计自适应布局,实现设备无关性和动态适配性,避免硬编码,以不同形态布局更好的展示内容。 二、区分可用空间 WindowSizeClasses 传统根据屏幕大小和方向做适配的方式已不再适用,APP的显示方式…...
光储充智能协调控制系统的设计与应用研究
摘要 随着化石能源枯竭与环境污染问题加剧,构建高效、稳定的新能源系统成为能源转型的关键。本文针对光伏发电间歇性、储能系统充放电效率及充电桩动态负荷分配等技术挑战,提出一种基于智能协调管理的光储充一体化解决方案。通过多源数据融合与优化控制算…...
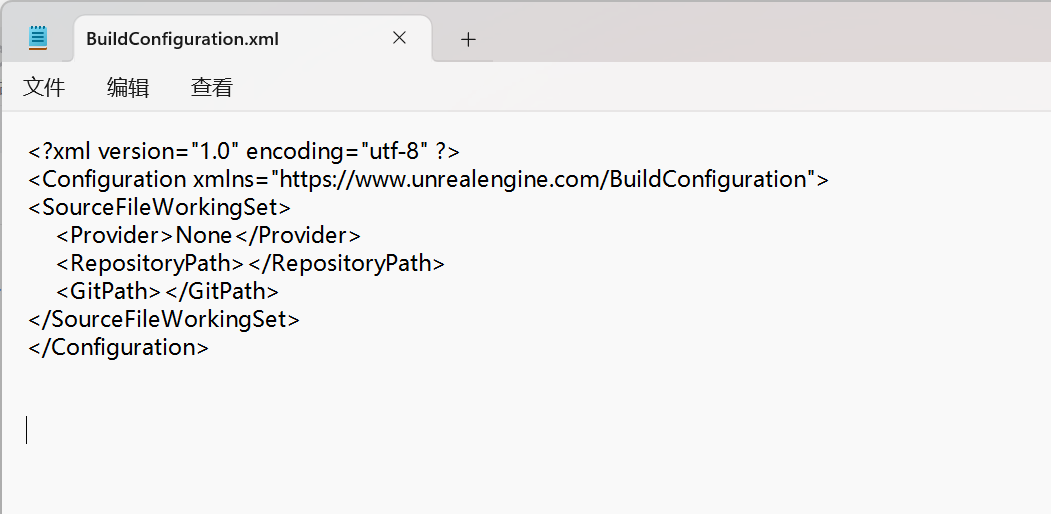
UE4 踩坑记录
1、Using git status to determine working set for adaptive non-unity build 我删除了一个没用的资源,结果就报这个错,原因就是这条命令导致的, 如果这个项目是git项目, ue编译时会优先通过 git status检查哪些文件被修改&#…...
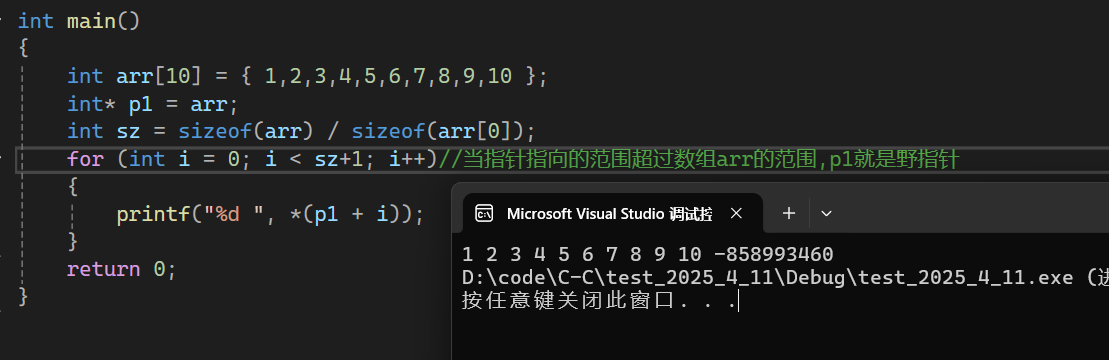
C语言超详细指针知识(一)
通过前面一段学习C语言的学习,我们了解了数组,函数,操作符等相关知识,今天我们将要进行指针学习,这是C语言中较难的一个部分,我将带你由浅入深慢慢学习。 1.内存与地址 在正式学习指针前,我们首…...
《算法笔记》3.3小节——入门模拟->图形输出
1036 跟奥巴马一起编程 #include <iostream> #include <cmath> using namespace std;int main() {int n,m;char c;cin>>n>>c;for (int i 0; i < n; i) {cout<<c;}cout<<endl;m round(1.0*n/2)-2;//round里面不能直接写n/2,…...
【深入浅出 Git】:从入门到精通
这篇文章介绍下版本控制器。 【深入浅出 Git】:从入门到精通 Git是什么Git的安装Git的基本操作建立本地仓库配置本地仓库认识工作区、暂存区、版本库的概念添加文件添加文件到暂存区提交文件到版本库提交文件演示 理解.git目录中的文件HEAD指针与暂存区objects对象 …...
在gitee上创建仓库——拉取到本地---添加文件---提交
2025/04/11/yrx0203 1-创建仓库 2-填写信息 3-创建完成后把仓库地址复制下来 4-在电脑上创建1个空的文件夹,进入这个文件夹,鼠标右击打开git bash 5-粘贴刚才复制的仓库的地址,回车 这样仓库就被拉取完成了 6-把本地的这个文件夹初始化…...

小刚说C语言刷题——第21讲 一维数组
在日常生活中,我们经常输入一组数据。例如输入一个班30名学生的语文成绩,或者输入一组商品的价格。这个时候,我们如何输入一组类型相同的数据呢?这里我们就要用到数组。 1.数组的概念 所谓数组就是一组相同类型数据的集合。数组中…...
芯片同时具备Wi-Fi、蓝牙、Zigbee,MAC地址会打架吗?
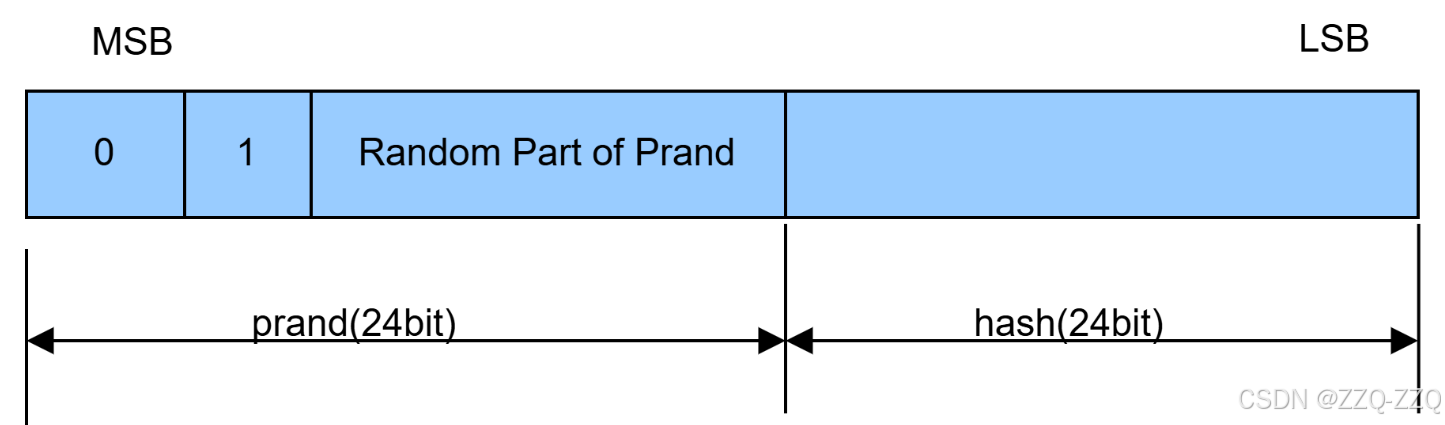
目录 【MAC 地址简介】 【MAC、Wi-Fi MAC、Bluetooth MAC的关系】 【以乐鑫ESP32-C6为例分析MAC】 【MAC 地址简介】 MAC(Media Access Control)地址是设备的物理地址,在全球范围内唯一标识每个网络接口。它是一个 48 比特(6 字…...

Kotlin 学习-方法和参数类型
/*** kotlin 的方法有三种* */fun main() {/*** 方法一* 1.普通类的成员方法申明与调用* (1)需要先构建出实例对象,才能访问成员方法* (2)实例对象的构建只需要在类名后面加上()* */Person().test()/*** 方法二&#x…...

基于风力水力和蓄电池的低频率差联合发电系统simulink建模与仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 4.1 风力发电 4.2 风力发电 4.3 蓄电池原理 4.4 蓄电池对系统稳定性分析 5.完整工程文件 1.课题概述 基于风力水力和蓄电池的低频率差联合发电系统simulink建模与仿真。模型包括风力发电模块…...

Harmony实战之简易计算器
前言 臭宝们,在学会上一节的基础知识之后,我们来实战一下。 预备知识 我们需要用到的知识点有: Column组件Row组件Link装饰器button组件TextInput组件State装饰器 最终效果图 代码实现 index页面(首页) /** * program: * * descriptio…...

【Ansible自动化运维】四、ansible应用部署:加速开发到生产的流程
在软件开发的生命周期中,从开发到生产的应用部署过程往往是复杂且容易出错的。手动部署不仅效率低下,还可能引入人为错误,导致系统故障。Ansible 作为一款强大的自动化工具,能够显著简化应用部署流程,提高部署的准确性…...
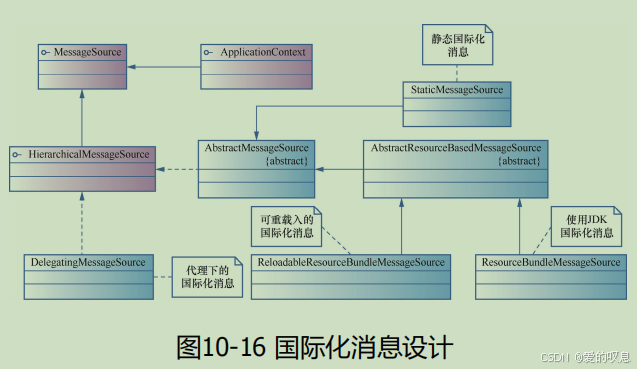
Spring MVC 国际化机制详解(MessageSource 接口体系)
Spring MVC 国际化机制详解(MessageSource 接口体系) 1. 核心接口与实现类详解 接口/类名描述功能特性适用场景MessageSource核心接口,定义消息解析能力支持参数化消息(如{0}占位符)所有国际化场景的基础接口Resource…...
安卓开发中不同类型的view之间继承关系详解)
(十五)安卓开发中不同类型的view之间继承关系详解
在安卓开发中,View 是所有 UI 组件的基类,不同类别的 View 通过继承关系扩展和特化功能,以满足多样化的界面需求。以下将详细讲解常见 View 类别的继承关系,并结合代码示例和使用场景进行说明。 1. View 继承关系: java.lang.Obj…...

美团Leaf分布式ID生成器:雪花算法原理与应用
📖 前言 在分布式系统中,全局唯一ID生成是保证数据一致性的核心技术之一。传统方案(如数据库自增ID、UUID)存在性能瓶颈或无序性问题,而美团开源的Leaf框架提供了高可用、高性能的分布式ID解决方案。本文重点解析Leaf…...
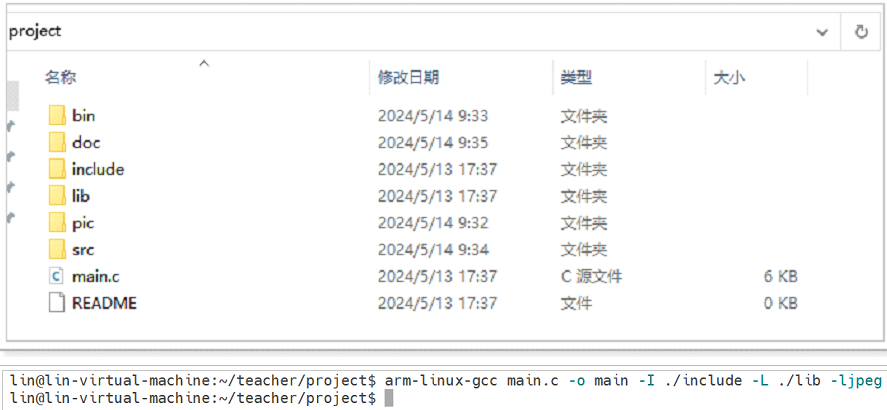
文件IO5(JPEG图像原理与应用)
JPEG图像原理与应用 ⦁ 基本概念 JPEG(Joint Photographic Experts Group)指的是联合图像专家组,是国际标准化组织ISO制订并于1992年发布的一种面向连续色调静止图像的压缩编码标准,所以也被称为JPEG标准。 同样,JP…...
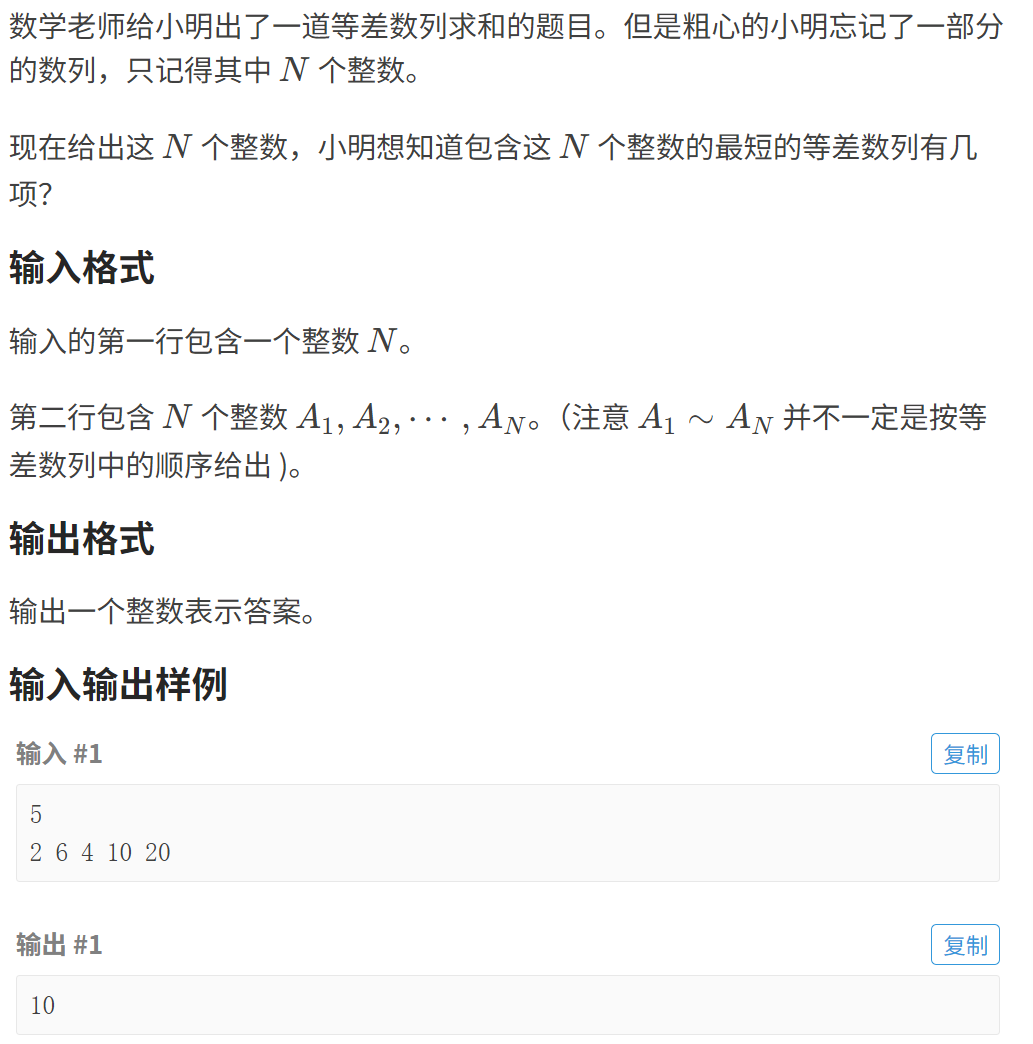
P8682 [蓝桥杯 2019 省 B] 等差数列
题目描述 思路 让求包含这n个整数的最短等差数列,既让包含这几个数,项数最少,若项数最少,肯定不能添加小于最小的和大于最大的,而且让项数最小,公差得大 等差数列的公差aj - ai / j - i; 这又是一个等差数…...