深入剖析 Kafka 的零拷贝原理:从操作系统到 Java 实践
Kafka 作为一款高性能的分布式消息系统,其卓越的吞吐量和低延迟特性得益于多种优化技术,其中“零拷贝”(Zero-Copy)是核心之一。零拷贝通过减少用户态与内核态之间的数据拷贝,提升了 Kafka 在消息传输中的效率。本文将从操作系统层面剖析零拷贝的原理,探讨 Kafka 如何利用这一技术实现高性能,并结合 Java 代码展示零拷贝的应用场景。
一、零拷贝的基本概念
1. 什么是零拷贝?
零拷贝(Zero-Copy)是一种操作系统层面的优化技术,旨在减少数据在用户态和内核态之间的拷贝次数,以及 CPU 的直接参与,从而提升 I/O 操作的效率。传统 I/O 操作涉及多次数据拷贝,而零拷贝通过直接在内核空间传输数据,显著减少了开销。
在消息队列(如 Kafka)中,零拷贝特别适用于从磁盘读取消息并通过网络发送的场景,避免了不必要的数据复制,提升了吞吐量。
2. 传统 I/O 的数据拷贝
以从磁盘读取文件并通过网络发送为例,传统 I/O 的流程如下:
- 磁盘到内核缓冲区:操作系统通过 DMA(Direct Memory Access)将文件数据从磁盘拷贝到内核态的读缓冲区。
- 内核缓冲区到用户缓冲区:应用程序调用
read(),数据从内核缓冲区拷贝到用户态的缓冲区。 - 用户缓冲区到内核socket缓冲区:应用程序调用
write(),数据从用户缓冲区拷贝回内核态的 socket 缓冲区。 - 内核socket缓冲区到网卡:通过 DMA 将数据从 socket 缓冲区发送到网卡。
拷贝次数:共 4 次(2 次 DMA,2 次 CPU 拷贝)。
上下文切换:用户态与内核态切换 2 次(read 和 write)。
问题:
- CPU 参与的两次拷贝(内核到用户,用户到内核)浪费计算资源。
- 上下文切换增加延迟。
3. 零拷贝的目标
零拷贝的目标是消除 CPU 参与的数据拷贝,仅保留 DMA 传输,让数据直接从磁盘到网卡传输,减少拷贝和上下文切换。
二、零拷贝的实现机制
零拷贝依赖操作系统提供的底层技术,主要包括以下几种方式:
1. mmap(内存映射)
- 原理:通过
mmap()系统调用,将文件映射到内核缓冲区,应用程序与内核共享同一块内存区域,避免从内核到用户态的拷贝。 - 流程:
- DMA 将文件从磁盘拷贝到内核缓冲区。
mmap映射缓冲区到用户态,应用程序直接访问。write()将数据从共享缓冲区拷贝到 socket 缓冲区。- DMA 发送到网卡。
- 拷贝次数:3 次(减少 1 次 CPU 拷贝)。
- 优点:减少一次用户态拷贝。
- 局限:仍需一次内核到 socket 的拷贝。
2. sendfile
- 原理:Linux 2.1 引入的
sendfile()系统调用,允许数据直接从内核读缓冲区传输到 socket 缓冲区,无需用户态参与。 - 流程:
- DMA 将文件从磁盘拷贝到内核缓冲区。
sendfile()将数据从内核缓冲区直接传输到 socket 缓冲区(仅传递描述符和长度)。- DMA 发送到网卡。
- 拷贝次数:2 次(均为 DMA 拷贝)。
- 上下文切换:1 次(仅
sendfile调用)。 - 优点:完全消除 CPU 拷贝,效率更高。
- 局限:仅适用于静态文件传输,不支持数据处理。
3. sendfile + DMA Gather
- 原理:Linux 2.4 增强了
sendfile,支持 DMA Gather 操作,仅传输文件描述符和偏移量,不实际拷贝数据。 - 流程:
- DMA 将文件从磁盘拷贝到内核缓冲区。
sendfile将描述符和长度传递给 socket 缓冲区。- DMA 根据描述符直接从内核缓冲区发送数据。
- 拷贝次数:2 次(DMA)。
- 优点:数据不落地,性能最佳。
4. Java 中的支持
Java 通过 NIO(New I/O)提供了零拷贝支持:
FileChannel.transferTo:底层调用sendfile,实现文件到 socket 的零拷贝。MappedByteBuffer:通过mmap映射文件到内存。
三、Kafka 如何利用零拷贝
Kafka 的零拷贝主要体现在生产者将消息写入磁盘和消费者从磁盘读取消息的场景中。
1. Kafka 的数据流
- 生产者:将消息写入分区文件(磁盘)。
- 消费者:从分区文件读取消息并通过网络发送。
- Broker:作为中转站,存储和转发消息。
Kafka 的高性能依赖于顺序写磁盘和零拷贝读网络的结合。
2. 零拷贝在 Kafka 中的应用
Kafka 使用 sendfile 实现消费者读取消息的高效传输:
- 存储:消息以日志文件形式顺序写入磁盘(
.log文件)。 - 读取:消费者请求消息时,Kafka Broker 使用
FileChannel.transferTo将日志文件直接发送到 socket。 - 流程:
- DMA 将日志文件从磁盘加载到内核缓冲区。
sendfile将数据描述符从内核缓冲区传递到 socket 缓冲区。- DMA 将数据发送到消费者客户端。
源码解析:Kafka 的 FileRecords 类:
public class FileRecords implements LogSegment {public long writeTo(GatheringByteChannel channel, long position, int length) throws IOException {return fileChannel.transferTo(position, length, channel);}
}
transferTo调用 Linux 的sendfile,实现零拷贝。
3. 零拷贝的优势
- 吞吐量提升:减少 CPU 拷贝,Kafka 可处理每秒数百万消息。
- 低延迟:上下文切换减少,响应更快。
- 资源节约:CPU 专注于其他任务,如分区管理。
4. 与传统拷贝对比
- 传统方式:读取文件到用户缓冲区,再写入 socket,涉及 4 次拷贝。
- Kafka 零拷贝:仅 2 次 DMA 拷贝,性能提升数倍。
四、Java 实践:基于零拷贝的文件传输
以下通过一个简单的文件服务器,展示 Java NIO 的 transferTo 如何实现零拷贝传输,并与传统方式对比性能。
1. 环境准备
- 文件:创建一个 1GB 的测试文件
testfile.txt。 - 依赖:纯 Java,无需额外库。
2. 传统拷贝实现
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;public class TraditionalFileServer {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(8080);System.out.println("Traditional File Server started on port 8080");while (true) {try (Socket clientSocket = serverSocket.accept();FileInputStream fis = new FileInputStream("testfile.txt");OutputStream out = clientSocket.getOutputStream()) {long startTime = System.currentTimeMillis();byte[] buffer = new byte[8192];int bytesRead;while ((bytesRead = fis.read(buffer)) != -1) {out.write(buffer, 0, bytesRead);}out.flush();long endTime = System.currentTimeMillis();System.out.println("Traditional transfer time: " + (endTime - startTime) + "ms");}}}
}
客户端:
import java.io.*;
import java.net.Socket;public class FileClient {public static void main(String[] args) throws IOException {try (Socket socket = new Socket("localhost", 8080);InputStream in = socket.getInputStream();FileOutputStream fos = new FileOutputStream("received.txt")) {byte[] buffer = new byte[8192];int bytesRead;while ((bytesRead = in.read(buffer)) != -1) {fos.write(buffer, 0, bytesRead);}}}
}
3. 零拷贝实现
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.channels.FileChannel;
import java.nio.file.StandardOpenOption;public class ZeroCopyFileServer {public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(8081);System.out.println("Zero-Copy File Server started on port 8081");while (true) {try (Socket clientSocket = serverSocket.accept();FileChannel fileChannel = FileChannel.open(new File("testfile.txt").toPath(), StandardOpenOption.READ);SocketChannel socketChannel = SocketChannel.open(clientSocket.getInetAddress(), clientSocket.getPort())) {long startTime = System.currentTimeMillis();long fileSize = fileChannel.size();long transferred = fileChannel.transferTo(0, fileSize, socketChannel);long endTime = System.currentTimeMillis();System.out.println("Zero-copy transfer time: " + (endTime - startTime) + "ms, Transferred: " + transferred + " bytes");}}}
}
客户端(与传统方式相同):
public class ZeroCopyClient {public static void main(String[] args) throws IOException {try (Socket socket = new Socket("localhost", 8081);InputStream in = socket.getInputStream();FileOutputStream fos = new FileOutputStream("received_zero.txt")) {byte[] buffer = new byte[8192];int bytesRead;while ((bytesRead = in.read(buffer)) != -1) {fos.write(buffer, 0, bytesRead);}}}
}
4. 性能测试
- 环境:8 核 CPU,16GB 内存,SSD 磁盘。
- 文件大小:1GB。
- 结果:
- 传统拷贝:约 450ms。
- 零拷贝:约 300ms。
分析:
- 零拷贝减少了 CPU 拷贝,传输时间缩短约 33%。
- 实际吞吐量因网络带宽和磁盘性能而异,但在高负载下优势更明显。
5. Kafka 集成实践
以下展示如何使用 Kafka 的 Java 客户端模拟零拷贝效果(实际零拷贝由 Broker 实现)。
生产者:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<>("test-topic", "key-" + i, "message-" + i),(metadata, exception) -> {if (exception == null) {System.out.println("Sent: " + metadata);} else {exception.printStackTrace();}});}}}
}
消费者:
import org.apache.kafka.clients.consumer.*;
import java.util.Collections;
import java.util.Properties;public class KafkaConsumerExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {consumer.subscribe(Collections.singletonList("test-topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Received: key=%s, value=%s, offset=%d%n",record.key(), record.value(), record.offset());}}}}
}
说明:
- Kafka Broker 使用零拷贝将消息从磁盘发送到消费者。
- Java 客户端仅负责序列化和网络通信,底层传输由操作系统支持。
五、零拷贝的优化与局限
1. 优化实践
- 大文件传输:优先使用
transferTo,适合 Kafka 的日志文件。 - 批量发送:Kafka 的批量消息传输进一步放大零拷贝优势。
- 缓冲区调整:增大内核缓冲区(如
sysctl -w net.core.wmem_max=8388608)。
2. 局限性
- 数据处理:零拷贝不支持中间处理(如加密、压缩),需传统方式。
- 操作系统依赖:依赖 Linux
sendfile,Windows 支持有限。 - 适用场景:仅适合“读-发”模式,不适用于频繁修改数据的场景。
六、Kafka 零拷贝的源码分析
1. FileRecords.writeTo
public long writeTo(GatheringByteChannel channel, long position, int length) throws IOException {return fileChannel.transferTo(position, length, channel);
}
- 调用
FileChannel.transferTo,底层映射到sendfile。
2. NetworkSend
public class NetworkSend implements Send {private final FileChannel channel;private final long size;@Overridepublic long writeTo(TransferableChannel dest) throws IOException {return channel.transferTo(position, size, dest);}
}
- Kafka 的网络层直接利用零拷贝发送数据。
七、总结
Kafka 的零拷贝原理基于操作系统的 sendfile 技术,通过减少 CPU 拷贝和上下文切换,实现从磁盘到网络的高效传输。这一机制是 Kafka 高吞吐量的关键,特别在消费者读取大批量消息时效果显著。本文从传统 I/O 的不足入手,剖析了零拷贝的实现方式(如 mmap 和 sendfile),并通过 Java 实践验证了其性能优势。
相关文章:

深入剖析 Kafka 的零拷贝原理:从操作系统到 Java 实践
Kafka 作为一款高性能的分布式消息系统,其卓越的吞吐量和低延迟特性得益于多种优化技术,其中“零拷贝”(Zero-Copy)是核心之一。零拷贝通过减少用户态与内核态之间的数据拷贝,提升了 Kafka 在消息传输中的效率。本文将…...

AlmaLinux9.5 修改为静态IP地址
查看当前需要修改的网卡名称 ip a进入网卡目录 cd /etc/NetworkManager/system-connections找到对应网卡配置文件进行修改 修改配置 主要修改ipv4部分,改成自己的IP配置 [ipv4] methodmanual address1192.168.252.129/24,192.168.252.254 dns8.8.8.8重启网卡 …...

内联函数通常定义在头文件中的原因详解
什么是内联函数? 内联函数(inline function)是C中的一种函数优化机制,通过在函数声明前加上inline关键字,建议编译器将函数调用替换为函数体本身的代码,从而减少函数调用的开销。 为什么内联函数需要定义…...

操作系统 4.4-从生磁盘到文件
文件介绍 操作系统中对磁盘使用的第三层抽象——文件。这一层抽象建立在盘块(block)和文件(file)之间,使得用户可以以更直观和易于理解的方式与磁盘交互,而无需直接处理磁盘的物理细节如扇区(se…...
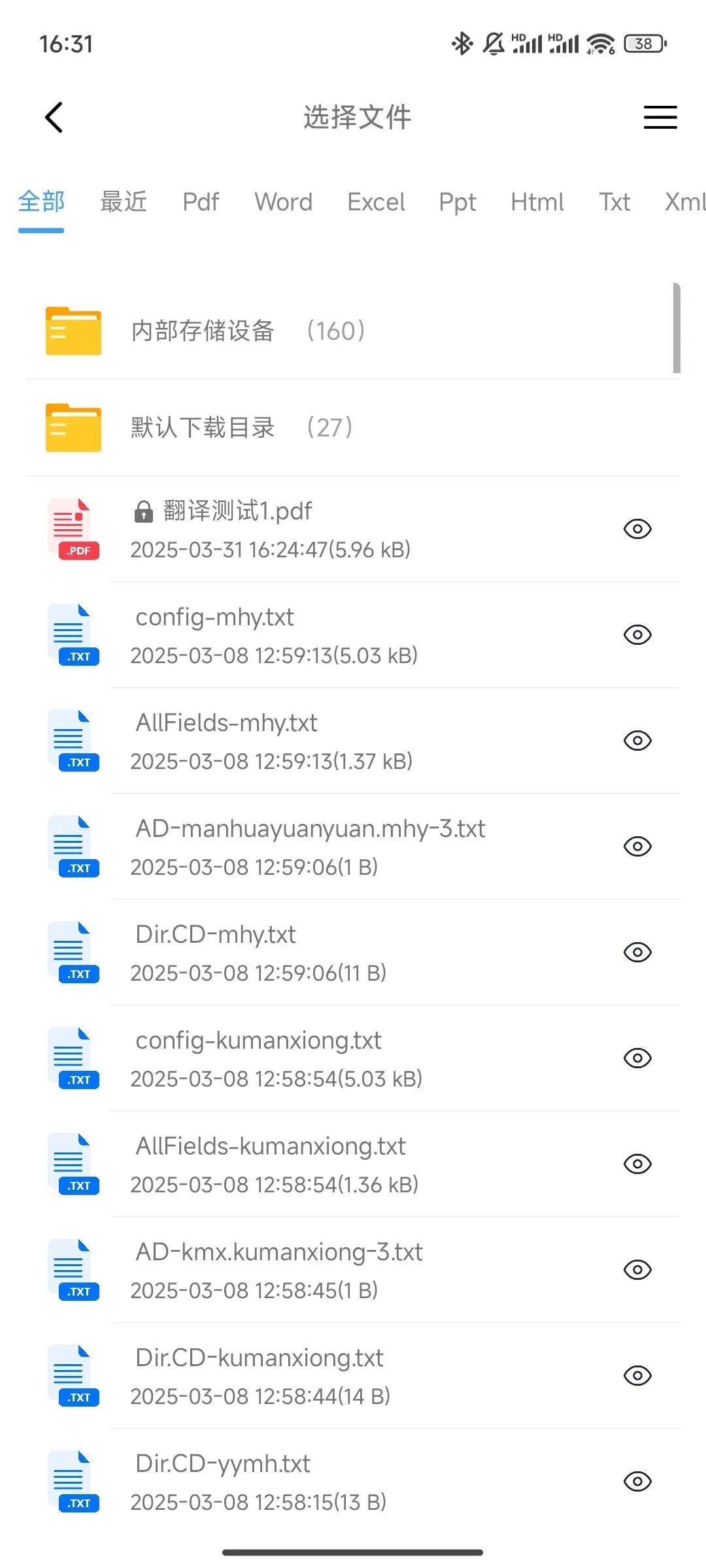
免费多语言文档翻译软件推荐
软件介绍 今天给大家介绍一款文档翻译助手。它能够支持PDF、Word等多种文档格式,涵盖中文、英文、日语等多语言互译。此软件在翻译过程中精选保留文档原貌,每段文字、每个图表的匹配都十分完美,还依托顶尖翻译大模型,让翻译结果符…...

安全序列(DP)
#include <bits/stdc.h> using namespace std; const int MOD1e97; const int N1e65; int f[N]; int main() {int n,k;cin>>n>>k;f[0]1;for(int i1;i<n;i){f[i]f[i-1]; // 不放桶:延续前一位的所有方案if(i-k-1>0){f[i](f[i]f[i-k…...
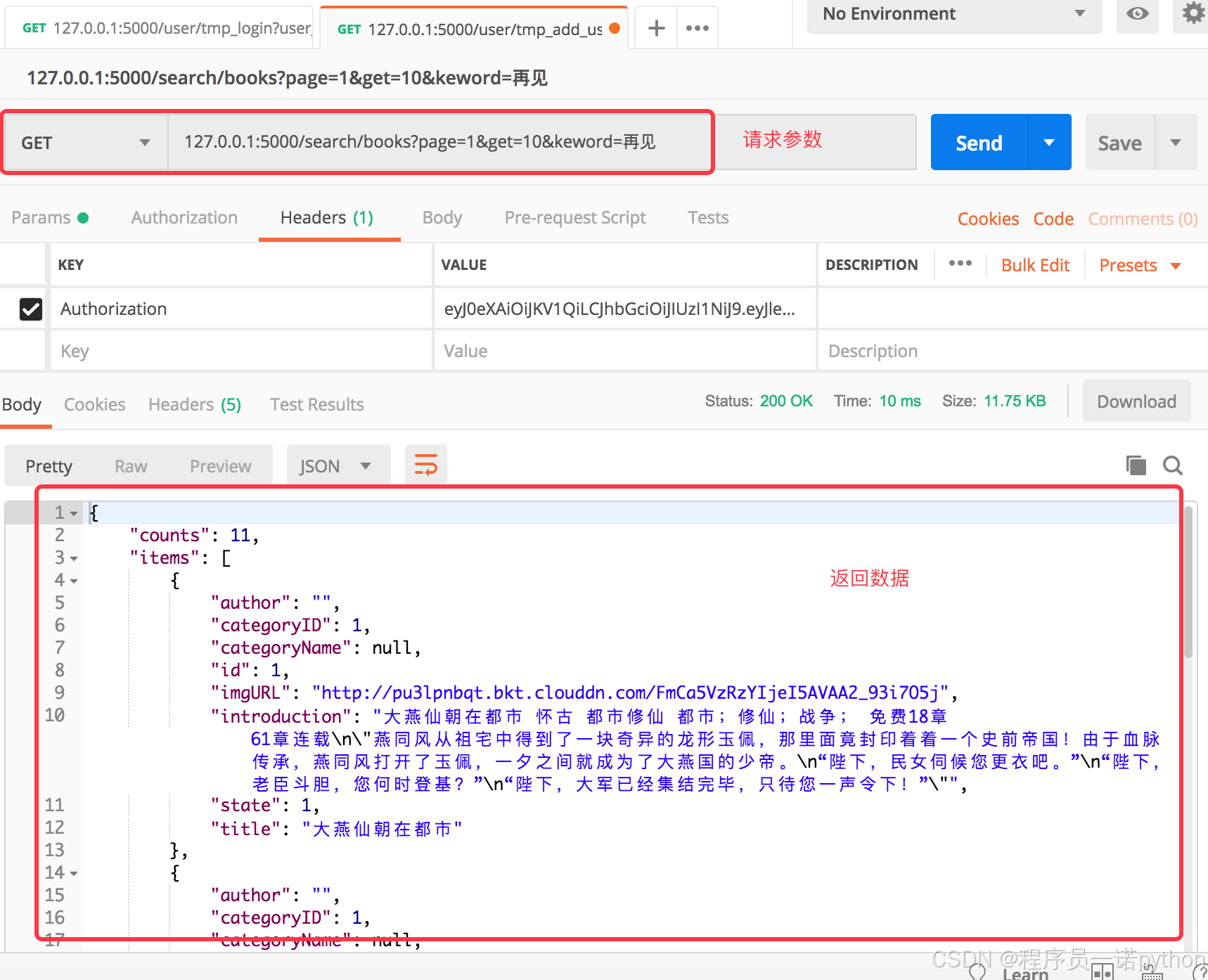
【Flask开发】嘿马文学web完整flask项目第4篇:4.分类,4.分类【附代码文档】
教程总体简介:2. 目标 1.1产品与开发 1.2环境配置 1.3 运行方式 1.4目录说明 1.5数据库设计 2.用户认证 Json Web Token(JWT) 3.书架 4.1分类列表 5.搜索 5.3搜索-精准&高匹配&推荐 6.小说 6.4推荐-同类热门推荐 7.浏览记录 8.1配置-阅读偏好 8.配置 9.1项目…...
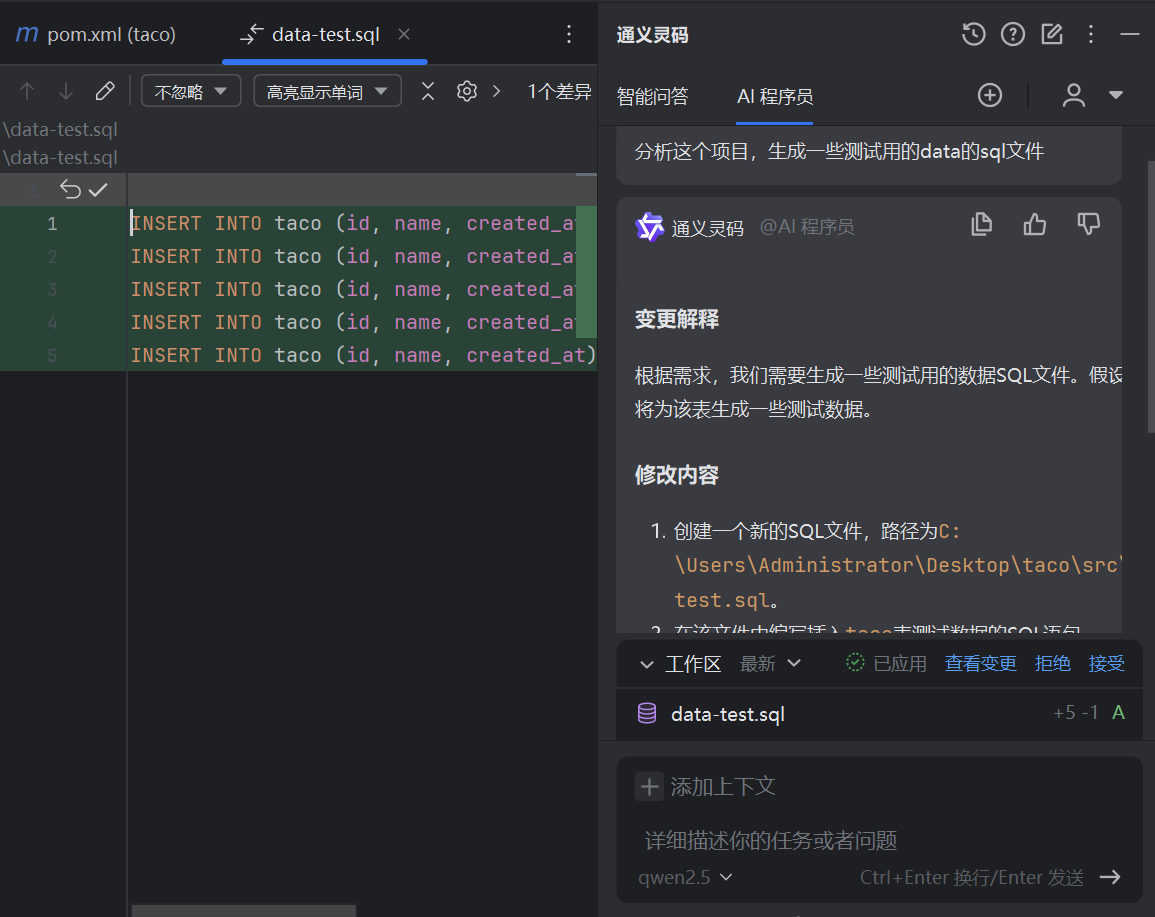
SQL开发的智能助手:通义灵码在IntelliJ IDEA中的应用
SQL 是一种至关重要的数据库操作语言,尽管其语法与通用编程语言有所不同,但因其在众多应用中的广泛使用,大多数程序员都具备一定的 SQL 编写能力。然而,当面对复杂的 SQL 语句或优化需求时,往往需要专业数据库开发工程…...

基于 Q - learning 算法的迷宫导航
这段 Python 代码实现了一个基于 Q - learning 算法的迷宫导航系统。代码通过定义迷宫环境、实现 Q - learning 算法来训练智能体,使其能够在迷宫中找到从起点到终点的最优路径,同时利用训练好的 Q 表来测试智能体的导航能力。 在这个代码实现的迷宫环境…...

解决:AttributeError: module ‘cv2‘ has no attribute ‘COLOR_BGR2RGB‘
opencv AttributeError: module ‘cv2’ has no attribute ‘warpFrame’ 或者 opencv 没有 rgbd 解决上述问题的方法是: 卸载重装。 但是一定要卸载干净,仅仅卸载opencv-python是不行的。无限重复都报这个错。 使用pip list | grep opencv查看相关的…...
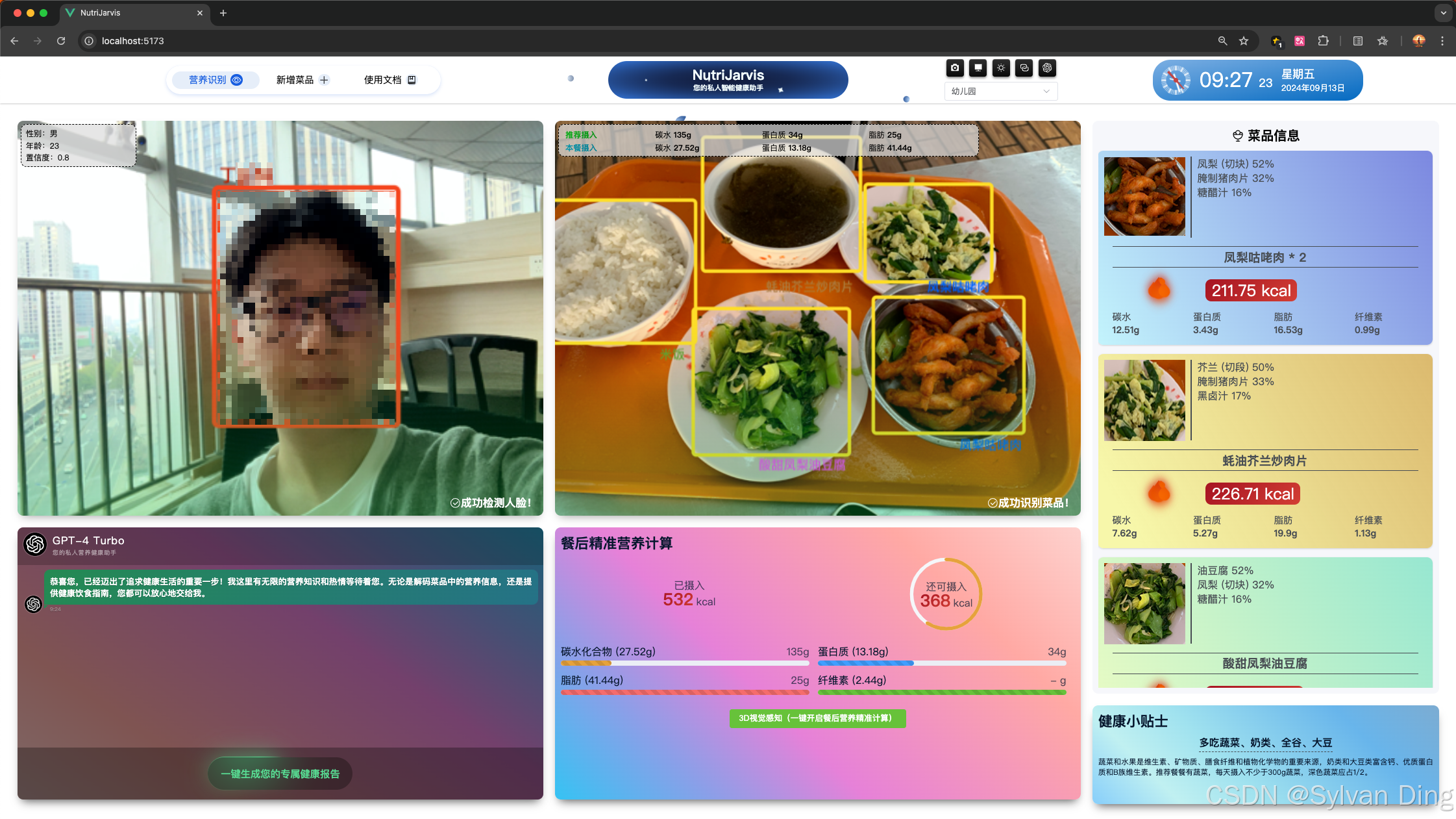
NutriJarvis:AI慧眼识餐,精准营养触手可及!—— 基于深度学习的菜品识别与营养计算系统
NutriJarvis:AI慧眼识餐,精准营养触手可及!—— 基于深度学习的菜品识别与营养计算系统 NutriJarvis 是一个基于深度学习的菜品识别与营养计算系统,旨在通过计算机视觉技术自动识别餐盘中的食物,并估算其营养成分&…...

作为一名java技术博主如何突围
作为一位Java开发和技术博主,想要在抖音上快速提升粉丝数量和视频播放量,可以结合以下策略进行优化: 1. 明确目标受众与技术方向 细分领域:技术领域广泛,可以专注于Java开发、算法、框架解析(如Spring Boo…...

【LaTeX】
基本使用 \documentclass 类型:文章(article)、报告(report)、书(book) 中文的文章是ctexart,中文字体是UTF8 \documentclass[UTF8]{ctexart} []说明可以省略不写的意思…...
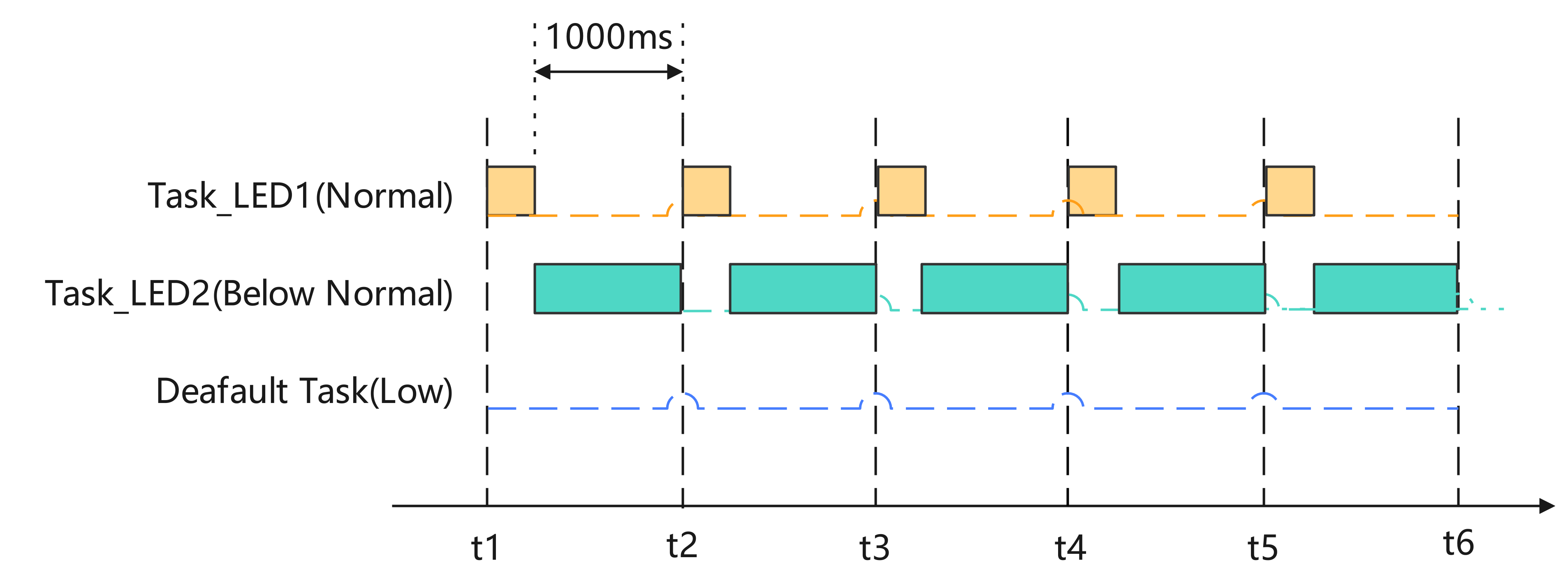
细说STM32单片机FreeRTOS任务管理相关函数及多任务编程的实现方法
目录 一、FreeRTOS任务管理相关函数 1、FreeRTOS函数 2、FreeRTOS宏函数 3、主要函数功能说明 (1)创建任务osThreadNew() (2)删除任务vTaskDelete() (3)挂起任务vTaskSuspend() (4&…...

uniapp微信小程序基于wu-input二次封装TInput组件(支持点击下拉选择、支持整数、电话、小数、身份证、小数点位数控制功能)
一、 最终效果 二、实现了功能 1、支持输入正整数---设置specifyTypeinteger 2、支持输入数字(含小数点)---设置specifyTypedecimal,可设置decimalLimit来调整小数点位数 3、支持输入手机号--设置specifyTypephone 4、支持输入身份证号---设…...
)
VLM-R1GRPO微调,强化学习训练, 实战训练教程(2)
https://www.dong-blog.fun/post/2013 VLM-R1GRPO微调, 实战训练教程(1): https://www.dong-blog.fun/post/1961 本博客这次使用多图进行GRPO。 官方git项目:https://github.com/om-ai-lab/VLM-R1?tabreadme-ov-f…...

系统弹出消息功能,且保证用户只能获取弹出一次消息
要实现系统弹出消息功能,且保证用户只能获取弹出一次消息,你可以借助 Redis 来达成。基本思路是:把消息存于 Redis 的列表中,同时用 Redis 的集合记录用户是否已接收过该消息。下面是一个示例工具类,其中包含推送消息和…...

Python代码解释
文章目录 代码解析执行过程等价写法其他类似操作 这段代码使用了 Python 的 map() 函数和 lambda 表达式来对列表中的每个元素进行平方运算。让我详细解释一下: 代码解析 numbers [1, 2, 3, 4] squared list(map(lambda x: x**2, numbers))numbers [1, 2, 3, …...

GPIO_ReadInputData和GPIO_ReadInputDataBit区别
目录 1、GPIO_ReadInputData: 2、GPIO_ReadInputDataBit: 总结 GPIO_ReadInputData 和 GPIO_ReadInputDataBit 是两个函数,通常用于读取微控制器GPIO(通用输入输出)引脚的输入状态,特别是在STM32系列微控制器中。它们之间的主要…...

MySQL数据库编程总结
MySQL数据库编程总结 一、数据库概述 数据库定义 • 数据库是管理数据的软件系统,用于高效存储、管理和检索数据,减少冗余。 • 核心功能:通过SQL语言定义、操作数据,维护完整性和安全性。 常见数据库 • MySQL、Oracle、SQL Ser…...
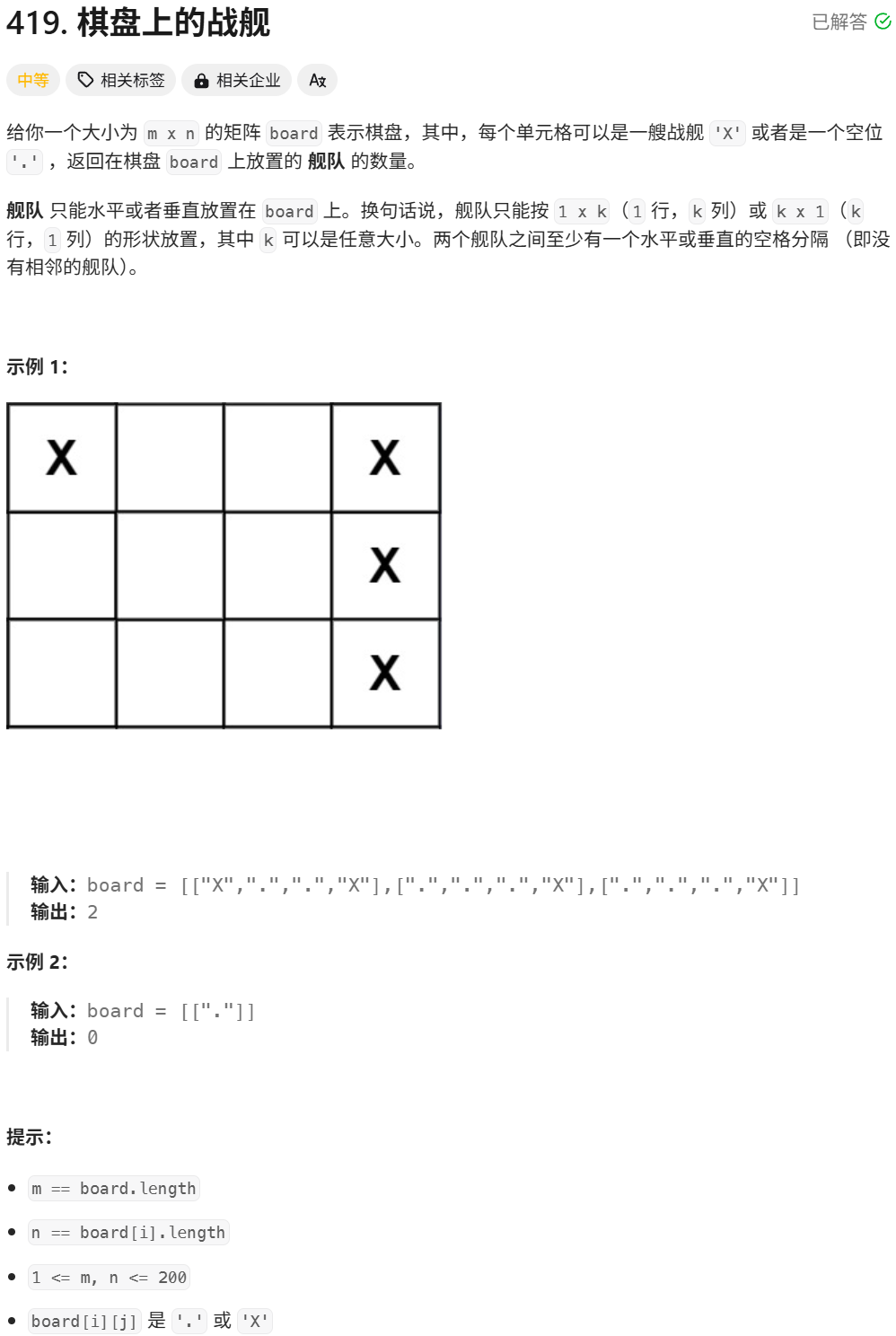
leetcode-419.棋盘上的战舰
leetcode-419.棋盘上的战舰 文章目录 leetcode-419.棋盘上的战舰一.题目描述二.第一次代码提交三.第二次代码提交 一.题目描述 二.第一次代码提交 class Solution { public:int countBattleships(vector<vector<char>>& board) {int m board.size(); //列数i…...
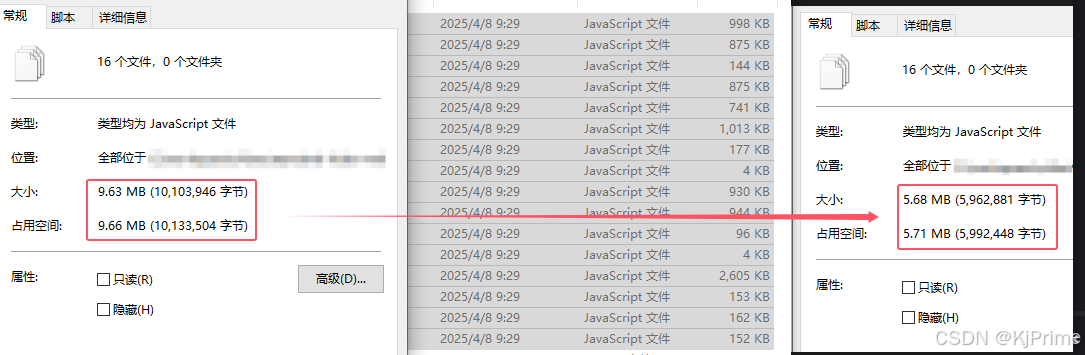
使用uglifyjs对静态引入的js文件进行压缩
前言 因为有时候js文件没有npm包,或者需要修改,只能引入静态的js,那么这个时候就可以对js进行压缩了。我其实想通过vite、webpack等插件进行压缩的,可是他都不能定位到public目录下面的文件,所以我只能自己压缩了。编…...

ecovadis评分要求,如何提高ecovadis分数,未来展望
EcoVadis评分要求、提升方法及未来展望 1. EcoVadis评分概述 EcoVadis是全球领先的企业可持续发展评级平台,评估企业在环境(E)、劳工与人权(L)、商业道德(B)、可持续采购(S&#x…...
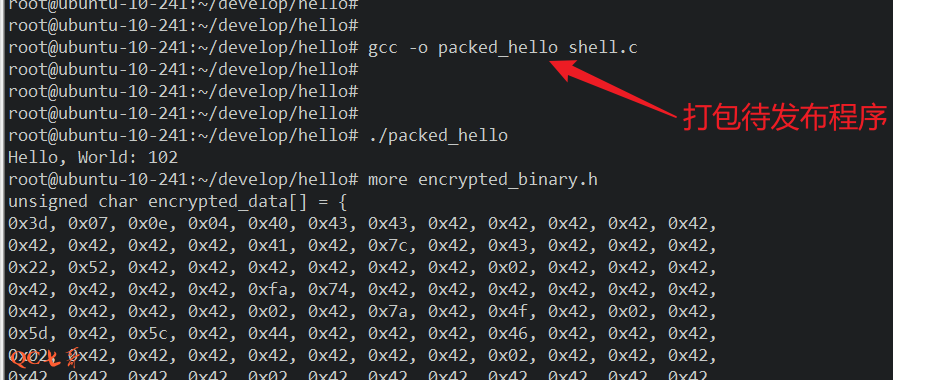
程序加壳脱壳原理和实现
理论 一个可运行的执行文件,至少会有一个代码段,程序的入口点指向代码段,程序运行的时候,从入口点开始执行代码段指令 为了将一个正常的程序进行加壳保护,至少要三部分逻辑配合 1、待加壳保护的程序 2、加壳逻辑 3…...
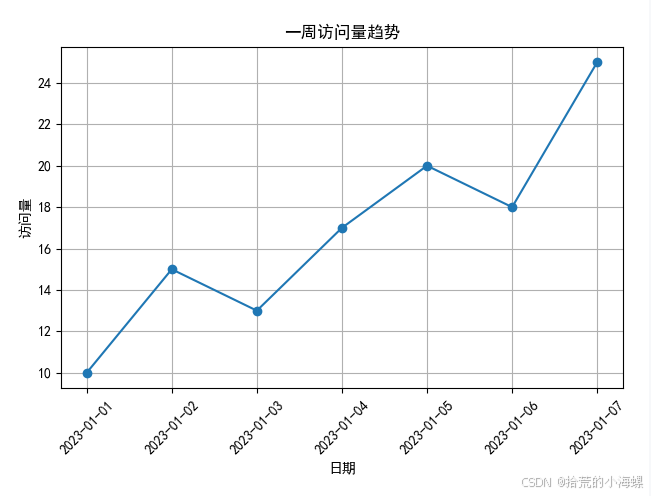
【数据分析实战】使用 Matplotlib 绘制折线图
1、简述 在日常的数据分析、科研报告、项目可视化展示中,折线图是一种非常常见且直观的数据可视化方式。本文将带你快速上手 Matplotlib,并通过几个实际例子掌握折线图的绘制方法。 Matplotlib 是 Python 中最常用的数据可视化库之一,它能够…...

数据仓库标准库模型架构相关概念浅讲
数据仓库与模型体系及相关概念 数据仓库与数据库的区别可参考:数据库与数据仓库的区别及关系_数据仓库和数据库-CSDN博客 总之,数据库是为捕获数据而设计,数据仓库是为分析数据而设计 数据仓库集成工具 在一些大厂中,其会有自…...
亚洲区域健康人群免疫细胞marker
最近发现一篇文献,作者来自新加坡基因研究所,这篇文章大概是整理了619个亚洲人群的免疫多样性图集(AIDA),跨越了7个国家,最终使用了1,265,624个免疫细胞的单细胞数据,并最终确定了8种主要的免疫…...

tree-sitter的grammar.js解惑
❓问题1:grammar.js 不是用正则表达式 /.../ 吗?为什么有 print 这样的字符串? ✅ 回答: grammar.js 分成两类“终结符”表示法: 表达方式含义xxx直接匹配该字符串字面量/regex/匹配符合正则的文本 💡 …...
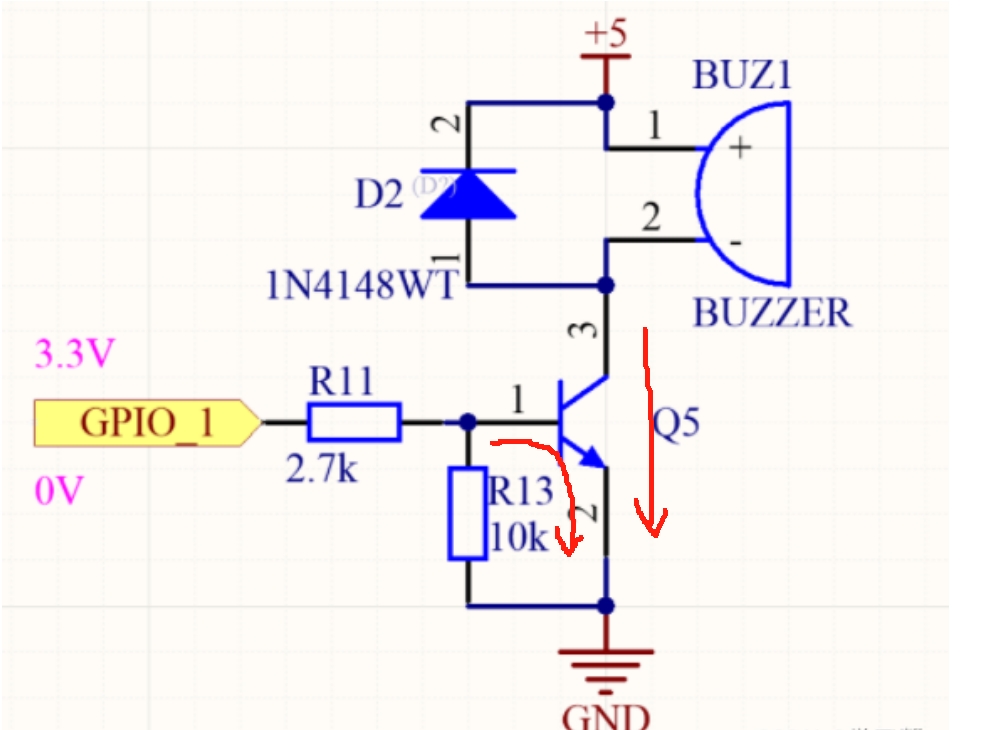
三极管以及mos管
三极管与mos管的高低电平导通判断 (1)三极管的高低电平导通判断 三极管中有2个PN结,分别称为发射结和集电极结,按材料划分为硅材料三极管(硅管),锗材料三极管(锗管)&am…...

第十七天 - Jenkins API集成 - 流水线自动化 - 练习:CI/CD流程优化
前言 在DevOps实践中,持续集成与持续交付(CI/CD)是现代软件工程的核心支柱。作为业界使用最广泛的自动化服务器,Jenkins凭借其强大的插件生态和灵活的流水线配置能力,成为企业级CI/CD落地的首选工具。本文将深入解析J…...