大厂文章阅读
1.异步任务处理系统,如何解决业务长耗时、高并发难题?
1)任务失败如何处理(CAS失败也可用):1.指数退避,匹配下游任务执行系统的处理能力。比如收到下游任务执行系统的流控错误,或者感知到任务执行成为瓶颈,需要指数退避重试。不能因为重试反而加大了下游系统的压力,压垮下游。反压控制,或者类似于flink基于credit 双向同步 的流空机制2.重试的策略要简单清晰,易于用户理解和配置。首先要对错误进行分类,区分不可重试错误,可重试错误,流控错误。不可重试错误是指确定性失败的错误,重试没有意义,比如参数错误,权限问题等等。可重试错误是指导致任务失败的因素具有偶然性,通过重试任务最终会成功,比如网络超时等系统内部错误。流控错误是一种比较特殊的可重试错误,通常意味着下游已经满负荷,重试需要采用退避模式,控制发送给下游的请求量。
2)任务的负载均衡:任务的执行时间变化很大,短的几百毫秒,长的数十小时。简单的 round-robin 方式分发任务,会导致执行节点负载不均。实践中常见的模式是将任务放置到队列中,执行节点根据自身任务执行情况主动拉取任务。如果DAG任务的话,由master下发,而对于没有依赖的任务,worker节点有更多的信息,主动拉去更好。单点问题
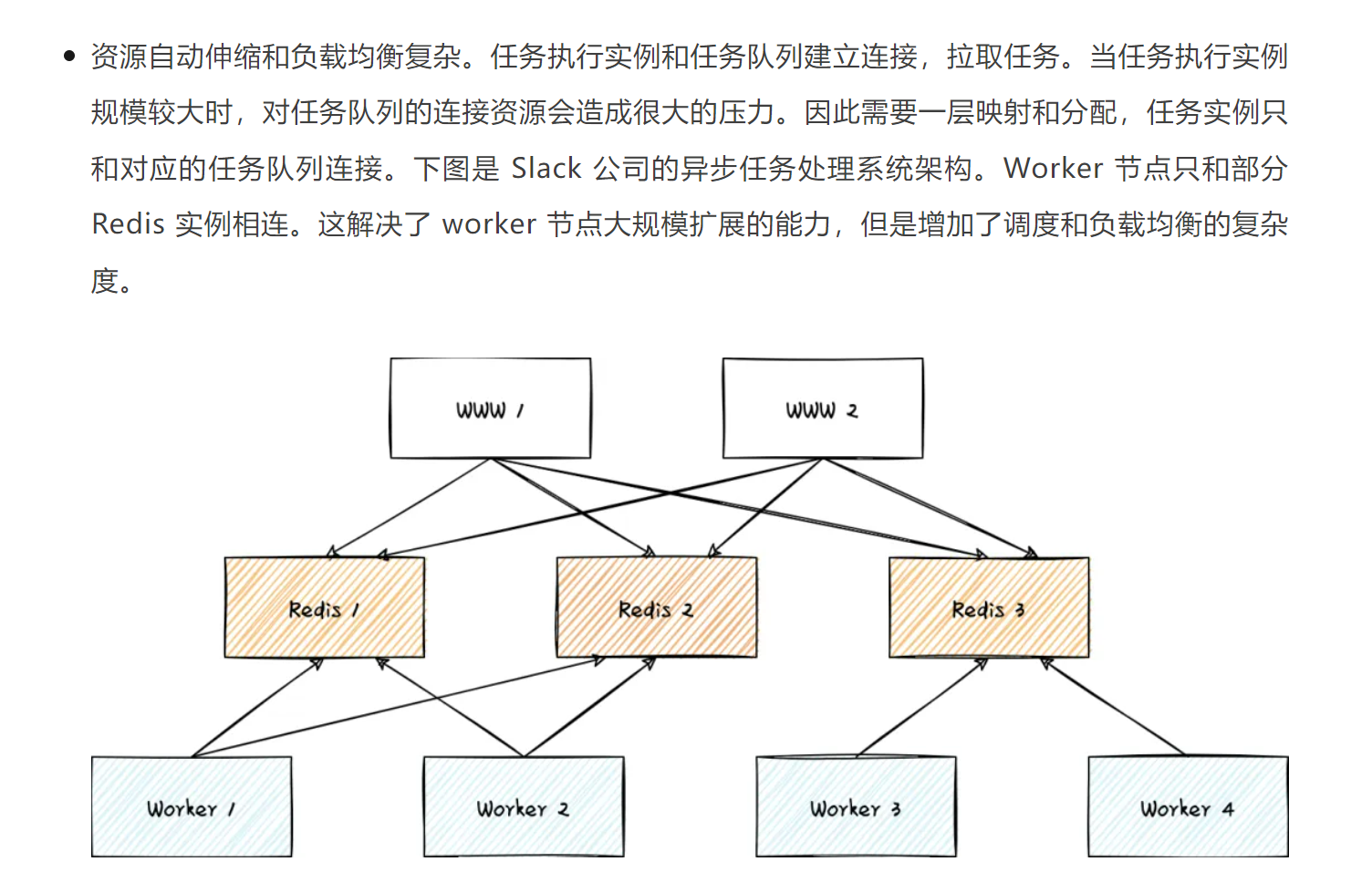
-
从支持任务优先级,隔离和流控等需求的角度考虑,最好能使用不同的队列。但队列过多,又增加了管理和连接资源消耗,如何平衡很有挑战。
3)防止机器爆炸: 任何用户的流量最多路由到2台服务器上,即使造成两台服务器宕机,绿色用户的请求仍然不受影响。这种将用户的负载映射到部分而非全部服务器的负载分片模式,能够很好的实现负载隔离,降低服务不可用的风险。代价则是系统需要准备更多的冗余资源。
2.分布式链路追踪在字节跳动的实践
可观测性的三大基础数据是 Metrics / Log / Trace。说到这三大件,可能大家会想到当需要监控变化趋势和配置告警时就去用 Metrics;当需要细查问题时去查 log;对于微服务数量较多的系统,还得有 Trace,Trace 也可以看做一种标准结构化的 log,记录了很多固定字段,例如上下游调用关系和耗时,查看上下游调用关系或者请求耗时在链路各节点上的分布可以查看 Trace。
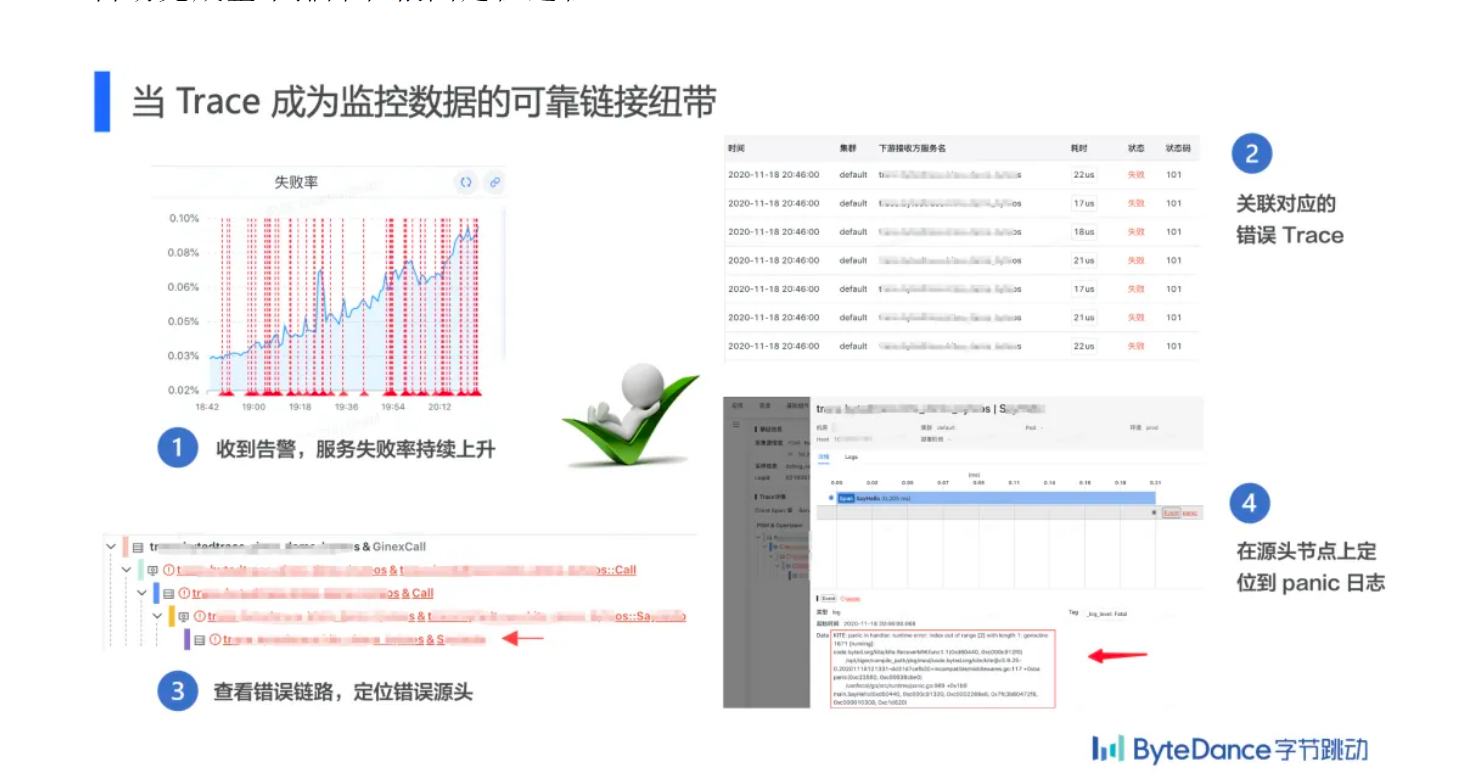
统一的数据模型是 Trace 的基础,字节链路追踪系统的数据模型设计借鉴了 opentracing 和 CAT 等优秀的开源解决方案,结合字节内部实际生态和使用习惯,使用如下数据模型:
-
Span: 一个有时间跨度的事件,例如一次 RPC 调用,一个函数执行。
-
Event: 一个没有时间跨度的事件,例如一条 log,一次 panic。
-
Metric: 一个带多维 tag 的数值,例如一个消息体的大小,一个订单的价格。
-
Trace: 一个请求上下文在多个分布式微服务节点的完整执行链路。
-
Transaction: 一条 Trace 在单个服务节点上的所有 Span / Event / Metric 对象构成的树形结构消息体。Transaction 是 Trace 数据的处理和存储的最小单位,紧凑的数据结构有利于节约成本和提高检索性能。
春节钱包大流量奖励系统入账及展示的设计与实现
后面还需要继续研读
如何应该百万并发?
分为下面的几个问题
稳定性保障:在大流量的入账场景下,保证钱包核心路径稳定性与完善,通过常用稳定性保障手段如资源扩容、限流、熔断、降级、兜底、资源隔离等方式保证用户奖励方向的核心体验。
资金安全:在大流量的入账场景下,通过幂等、对账、监控与报警等机制,保证资金安全,保证用户资产应发尽发,不少发。
活动隔离:实现内部测试活动、灰度放量活动和正式春节活动三个阶段的奖励入账与展示的数据隔离,不互相影响。
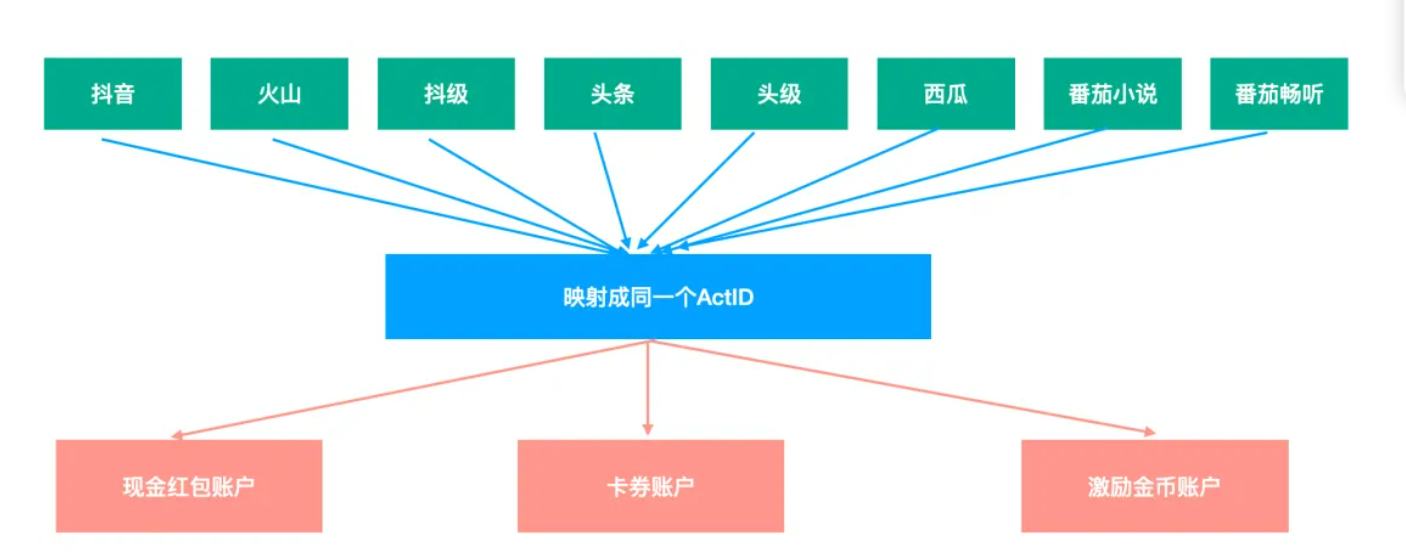
支持八端奖励数据互通,多端登入 手机号优先级最高,如果不同端登录的手机号一样,在不同端的 actID 是一致的,构建中间层
高并发挑战

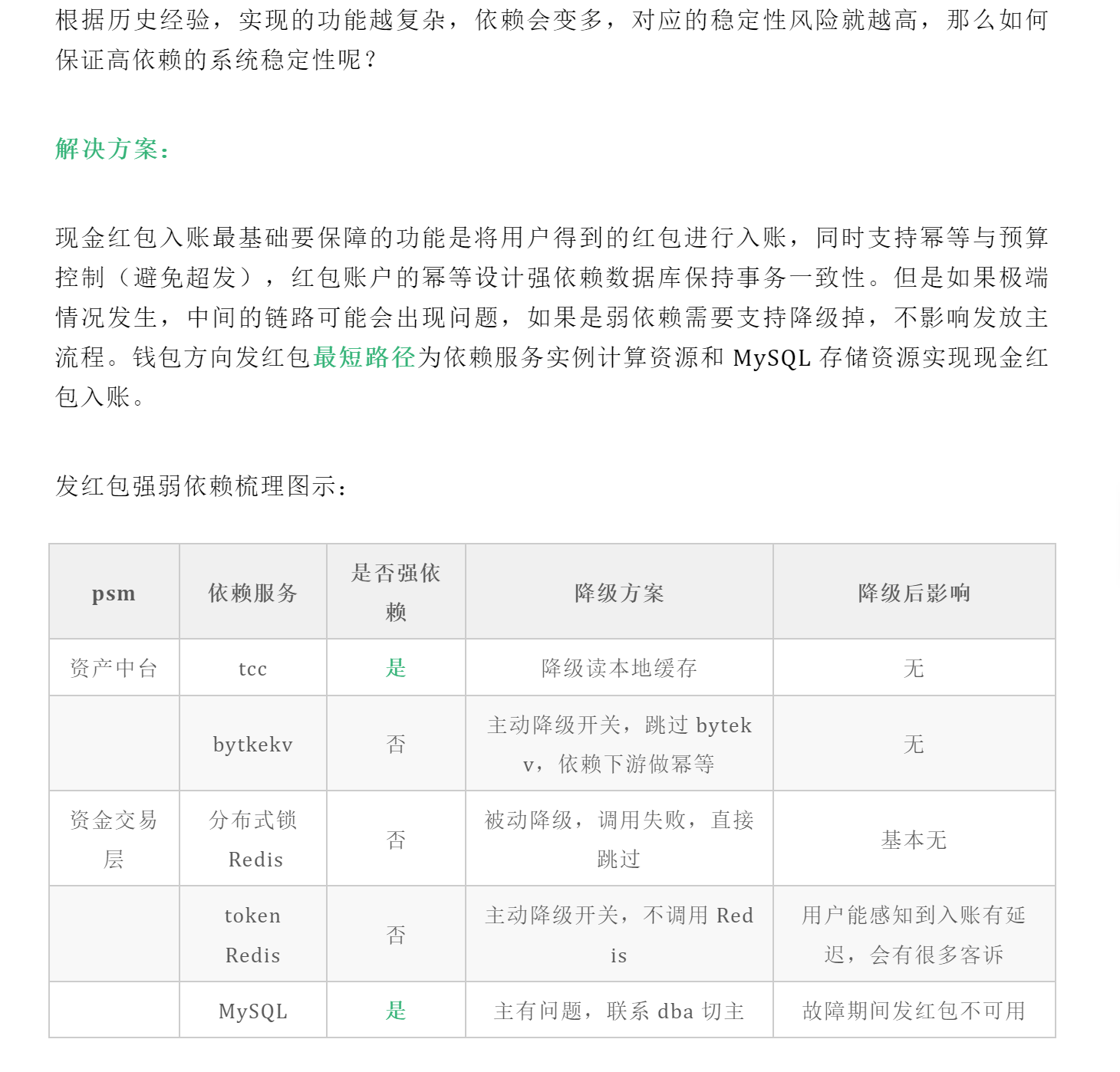

在经历过春节超大流量活动后的设计与实现后,有一些总结和经验与大家一起分享一下。
5.1 容灾降级层面
大流量场景,为了保证活动最终上线效果,容灾是一定要做好的。参考业界通用实现方案,如降级、限流、熔断、资源隔离,根据预估活动参与人数和效果进行使用存储预估等。
5.1.1 限流层面
(1)限流方面应用了 api 层 nginx 入流量限流,分布式入流量限流,分布式出流量限流。这几个限流器都是字节跳动公司层面公共的中间件,经过大流量的验证。
(2)首先进行了实际单实例压测,根据单实例扛住的流量与本次春节活动预估流量打到该服务的流量进行扩容,并结合下游能抗住的情况,在 tlb 入流量、入流量限流以及出流量限流分别做好了详细完整的配置并同。
限流目标:
保证自身服务稳定性,防止外部预期外流量把本身服务打垮,防止造成雪崩效应,保证核心业务和用户核心体验。
简单集群限流是实例维度的限流,每个实例限流的 QPS=总配置限流 QPS/实例数,对于多机器低 QPS 可能会有不准的情况,要经过实际压测并且及时调整配置值。
对于分布式入流量和出流量限流,两种使用方式如下,每种方式都支持高低 QPS,区别只是 SDK 使用方式和功能不同。一般低 QPS 精度要求高,采用 redis 计数方式,使用方提供自己的 redis 集群。高 QPS 精度要求低,退化为总 QPS/tce 实例数的单实例限流。
5.1.2 降级层面
对于高流量场景,每个核心功能都要有对应的降级方案来保证突发情况核心链路的稳定性。
(1)本次春节奖励入账与活动活动钱包页方向做好了充分的操作预案,一共有 26 个降级开关,关键时刻弃车保帅,防止有单点问题影响核心链路。
(2)以发现金红包链路举例,钱包方向最后完全降级的方案是只依赖 docker 和 MySQL,其他依赖都是可以降级掉的,MySQL 主有问题可以紧急联系切主,虽说最后一个都没用上,但是前提要设计好保证活动的万无一失。
5.1.3 资源隔离层面
(1)提升开发效率不重复造轮子。因为钱包资产中台也日常支持抖音资产发放的需求,本次春节活动也复用了现有的接口和代码流程支持发奖。
(2)同时针对本次春节活动,服务层面做了集群隔离,创建专用活动集群,底层存储资源隔离,活动流量和常规流量互不影响。
5.1.4 存储预估
(1)不但要考虑和验证了 Redis 或者 MySQL 存储能抗住对应的流量,同时也要按照实际的获取参与和发放数据等预估存储资源是否足够。
(2)对于字节跳动公司的 Redis 组件来讲,可以进行垂直扩容(每个实例增加存储,最大 10G),也可以进行水平扩容(单机房上限是 500 个实例),因为 Redis 是三机房同步的,所以计算存储时只考虑一个机房的存储上限即可。要留足 buffer,因为水平扩容是很慢的一个过程,突发情况遇到存储资源不足只能通过配置开关提前下掉依赖存储,需要提前设计好。
5.1.5 压测层面
本次春节活动,钱包奖励入账和活动钱包页做了充分的全链路压测验证,下面是一些经验总结。
-
在压测前要建立好压测整条链路的监控大盘,在压测过程当中及时和方便的发现问题。
-
对于 MySQL 数据库,在红包雨等大流量正式活动开始前,进行小流量压测预热数据库,峰值流量前提前建链,减少正式活动时的大量建链耗时,保证发红包链路数据库层面的稳定性。
-
压测过程当中一定要传压测标,支持全链路识别压测流量做特殊逻辑处理,与线上正常业务互不干扰。
-
针对压测流量不做特殊处理,压测流量处理流程保持和线上流量一致。
-
压测中要验证计算资源与存储资源是否能抗住预估流量
-
梳理好压测计划,基于历史经验,设置合理初始流量,渐进提升压测流量,实时观察各项压测指标。
-
存储资源压测数据要与线上数据隔离,对于 MySQL 和 Bytekv 这种来讲是建压测表,对于 Redis 和 Abase 这种来讲是压测 key 在线上 key 基础加一下压测前缀标识 。
-
压测数据要及时清理,Redis 和 Abase 这种加短时间的过期时间,过期机制处理比较方便,如果忘记设置过期时间,可以根据写脚本识别压测标前缀去删除。
-
压测后也要关注存储资源各项指标是否符合预期。
5.2 微服务思考
在日常技术设计中,大家都会遵守微服务设计原则和规范,根据系统职责和核心数据模型拆分不同模块,提升开发迭代效率并不互相影响。但是微服务也有它的弊端,对于超大流量的场景功能也比较复杂,会经过多个链路,这样是极其消耗计算资源的。本次春节活动资产中台提供了 sdk 包代替 rpc 进行微服务链路聚合对外提供基础能力,如查询余额、判断用户是否获取过奖励,强制入账等功能。访问流量最高上千万,与使用微服务架构对比节约了上万核 CPU 的计算资源。
抖音支付十万级 TPS 流量发券实践
跟新redis 合并请求,降级,本地缓存。
为了使 Redis 集群流量均匀,不同券批次的库存数据被打散到了不同的 Redis 分片上,但是当在一段时间内集中发放某一券批次时,流量仍然会大量偏移到一个分片内,造成 Redis 数据热点问题。如果想办法能将某个券批次多次零散扣减库存的操作合并到一起,那么数据热点问题就可以会得到较大的缓解
优雅正常退出,捕获信号,在退出前做处理
使用本地队列进行数据处理的一大弊端是内存易失性会使数据无法持久性地存储,在应用重新发布或升级时,本地队列中的发券数据有可能会丢失,用户发券请求无法得到正常处理。
为了内存中的数据不丢失,我们需要能够感知到应用退出的信号,在应用退出前将内存中的数据处理掉。因此我们调研了字节云应用实例的生命周期,在实例终止时,首先会将当前应用实例从服务注册中心中摘除,此操作执行后意味着当前实例不再接收新的外部流量;之后会发送 SIGINT 退出信号给业务进程。应用收到 SIGINT 信号后,不再消费队列中剩余的发券请求数据,而是将这些数据发送到远程队列中,由当前仍存活的其他应用实例来消费这些数据。
多队列模式

字节跳动基于Flink的MQ-Hive实时数据集成
TODO
相关文章:
大厂文章阅读
1.异步任务处理系统,如何解决业务长耗时、高并发难题? 1)任务失败如何处理(CAS失败也可用):1.指数退避,匹配下游任务执行系统的处理能力。比如收到下游任务执行系统的流控错误,或者感知到任务执行成为瓶颈,需要指数退…...
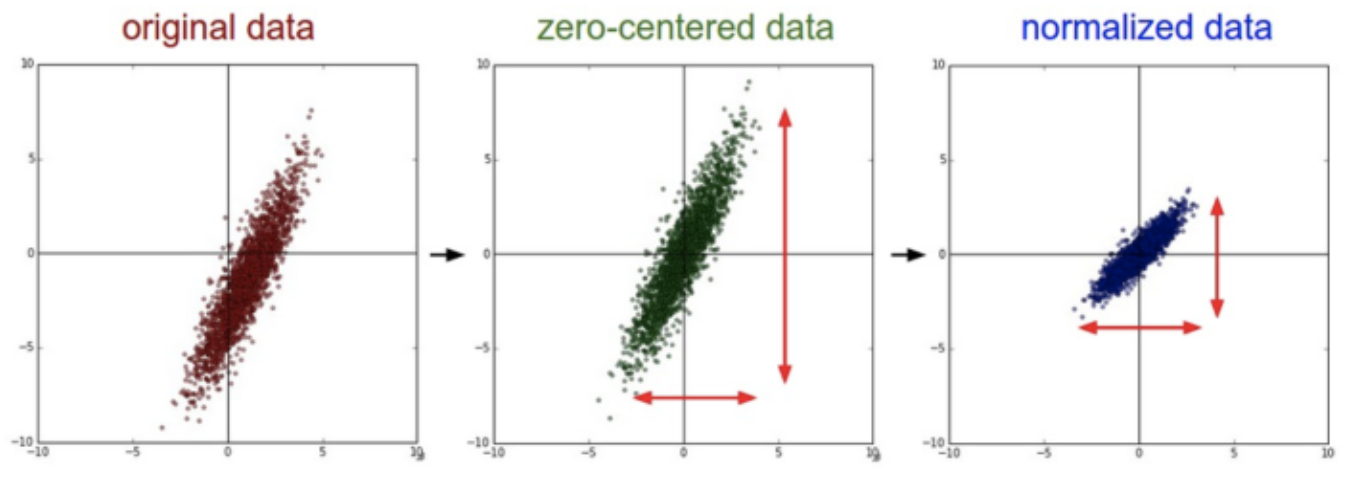
卷积神经网络 CNN 系列总结(二)---数据预处理、激活函数、梯度、损失函数、优化方法等
数据预处理 零中心化、归一化 关于数据预处理我们有3个常用的符号,数据矩阵X,假设其尺寸是[N x D](N是数据样本的数量,D是数据的维度)。 均值减法(Mean subtraction)是预处理最常用的形式。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据…...
速学Android 16新功能:带有进度的通知类型
前言 在当前已公布的Android 16版本中新增了一系列的功能特性和API,如: 动态壁纸的内容处理,提供新的 content API 预测性返回更新,添加了finishAndRemoveTaskCallback() 和 moveTaskToBackCallback等API 健康数据共享更新&…...

微信小程序开发:微信小程序上线发布与后续维护
微信小程序上线发布与后续维护研究 摘要 微信小程序作为移动互联网的重要组成部分,其上线发布与后续维护是确保其稳定运行和持续优化的关键环节。本文从研究学者的角度出发,详细探讨了微信小程序的上线发布流程、后续维护策略以及数据分析与用户反馈处理的方法。通过结合实…...

深度学习基础--CNN经典网络之分组卷积与ResNext网络实验探究(pytorch复现)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 ResNext是分组卷积的开始之作,这里本文将学习ResNext网络;本文复现了ResNext50神经网络,并用其进行了猴痘病分类实验…...

AutoGen深度解析:从核心架构到多智能体协作的完整指南
AutoGen是微软推出的一个革命性多智能体(Multi-Agent)框架,它通过模块化设计和灵活的对话机制,极大地简化了基于大型语言模型(LLM)的智能体系统开发。本文将深入剖析AutoGen的两个核心模块——core基础架构和agentchat多智能体对话系统,带您全…...
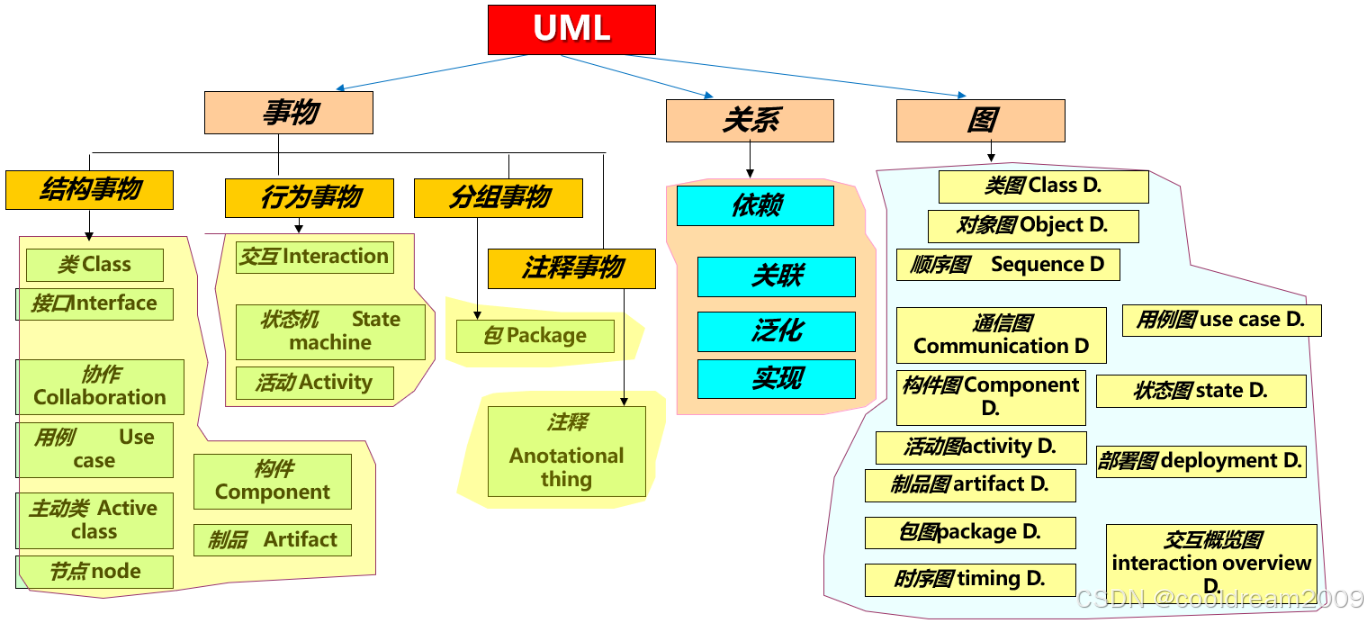
面向对象的需求分析与UML构造块详解
目录 前言1 面向对象的需求分析概述2 UML构造块概述3 UML事物详解3.1 结构事物(Structural Things)3.2 行为事物(Behavioral Things)3.3 分组事物(Grouping Things)3.4 解释事物(Annotational T…...

计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比
计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比 一、前言二、RGB 色彩空间2.1 RGB 色彩空间原理2.1.1 基本概念2.1.2 颜色混合机制 2.2 RGB 在计算机视觉中的应用2.2.1 图像读取与显示2.2.2 颜色识别2.2.3 RGB 色彩空间的局限性 三、HSV 色彩空…...

使用Docker安装Gogs
1、拉取镜像 docker pull gogs/gogs 2、运行容器 # 创建/var/gogs目录 mkdir -p /var/gogs# 运行容器 # -d,后台运行 # -p,端口映射:(宿主机端口:容器端口)->(10022:22)和(10880:3000) # -v,数据卷映射:(宿主机目…...

【Web API系列】XMLHttpRequest API和Fetch API深入理解与应用指南
前言 在现代Web开发中,客户端与服务器之间的异步通信是构建动态应用的核心能力。无论是传统的AJAX技术(基于XMLHttpRequest)还是现代的Fetch API,它们都为实现这一目标提供了关键支持。本文将从底层原理、核心功能、代码实践到实…...
)
Spring Boot 自定义 Redis Starter 开发指南(附动态 TTL 实现)
一、功能概述 本 Starter 基于 Spring Boot 2.7 实现以下核心能力: Redis 增强:标准化 RedisTemplate 配置(JSON 序列化 LocalDateTime 支持)缓存扩展:支持 Cacheable(value “key#60s”) 语法动态设置 TTL配置集中…...
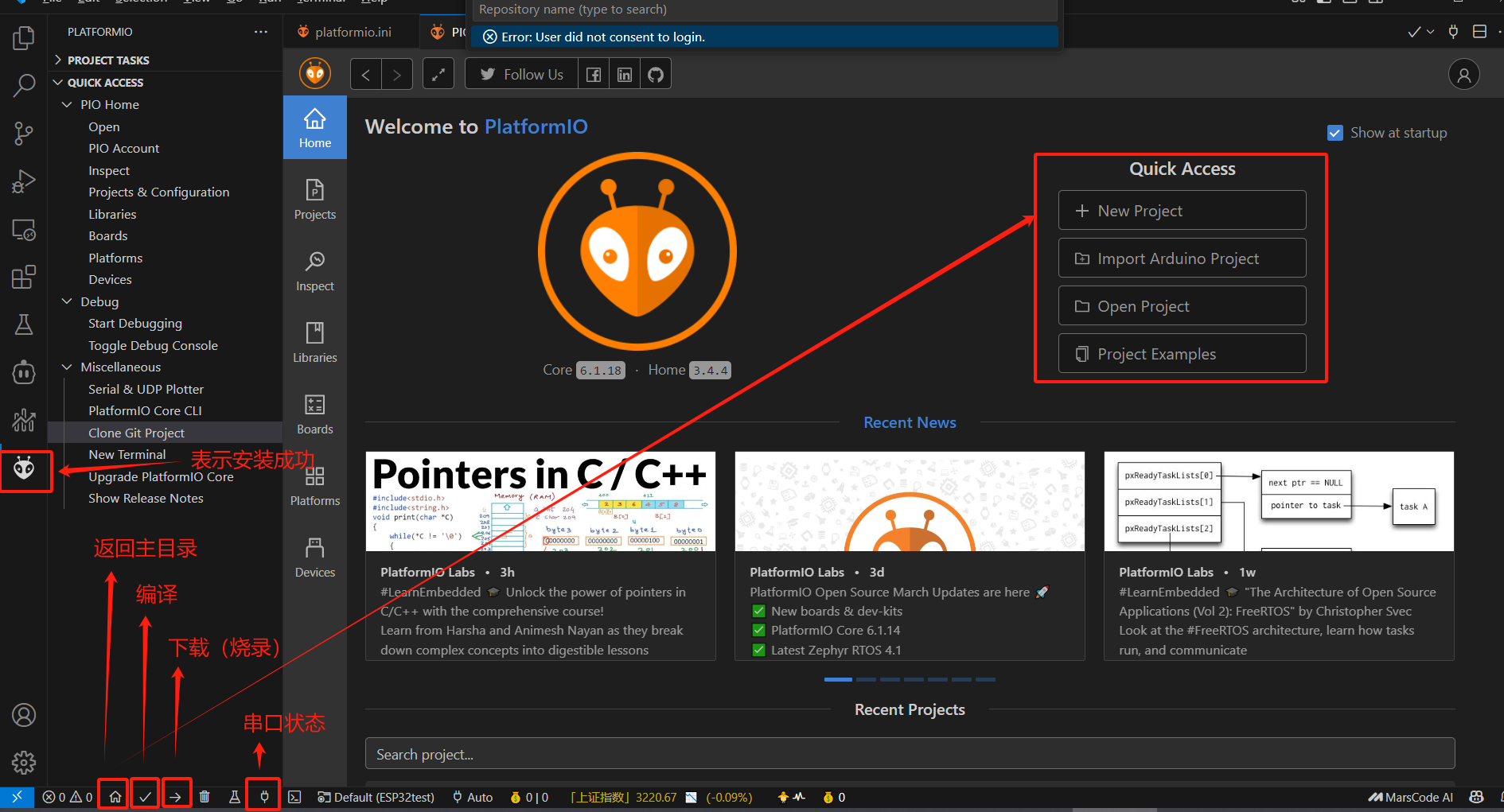
ESP32开发入门:基于VSCode+PlatformIO环境搭建指南
前言 ESP32作为一款功能强大的物联网开发芯片,结合PlatformIO这一现代化嵌入式开发平台,可以大幅提升开发效率。本文将详细介绍如何在VSCode中搭建ESP32开发环境,并分享实用开发技巧。 一、环境安装(Windows/macOS/Linux…...

2025.4.13机器学习笔记:文献阅读
2025.4.13周报 题目信息摘要创新点网络架构实验结论不足以及展望 题目信息 题目: Physics-informed neural networks for inversion of river flow and geometry with shallow water model期刊: Physics of Fluids作者: Y. Ohara; D. Moteki…...

Quartz修仙指南:从定时任务萌新到调度大能的终极奥义
各位被Thread.sleep()和ScheduledExecutorService折磨的道友们!今天要解锁的是Java界任务调度至尊法宝——Quartz!这货能让你像玉皇大帝安排天庭日程一样,精确控制每个任务的执行时机!准备好告别蹩脚的手动定时器了吗?…...

如何免费使用Meta Llama 4?
周六, Meta发布了全新开源的Llama 4系列模型。 架构介绍查看上篇文章。 作为开源模型,Llama 4存在一个重大限制——庞大的体积。该系列最小的Llama 4 Scout模型就拥有1090亿参数,如此庞大的规模根本无法在本地系统运行。 不过别担心!即使你没有GPU,我们也找到了通过网页…...

编程助手fitten code使用说明(超详细)(vscode)
这两年 AI 发展迅猛,作为开发人员,我们总是追求更快、更高效的工作方式,AI 的出现可以说改变了很多人的编程方式。 AI 对我们来说就是一个可靠的编程助手,给我们提供了实时的建议和解决方,无论是快速修复错误、提升代…...

Python自动化爬虫:Scrapy+APScheduler定时任务
在数据采集领域,定时爬取网页数据是一项常见需求。例如,新闻网站每日更新、电商价格监控、社交媒体舆情分析等场景,都需要定时执行爬虫任务。Python的Scrapy框架是强大的爬虫工具,而APScheduler则提供了灵活的任务调度功能。 一、…...

技术分享|iTOP-RK3588开发板Ubuntu20系统旋转屏幕方案
iTOP-3588开发板采用瑞芯微RK3588处理器,是全新一代AloT高端应用芯片,采用8nmLP制程,搭载八核64位CPU,四核Cortex-A76和四核Cortex-A55架构,主频高达2.4GHz。是一款可用于互联网设备和其它数字多媒体的高性能产品。 在…...

Java中的参数是值传递还是引用传递?
在java中, 参数传递只有值传递 ,不论是基本类型还是引用类型。 其中的区别在于: 基本数据类型(如byte,short,int等):传递的参数是值的副本,即基本类型的数值本身。因此在方法中&am…...
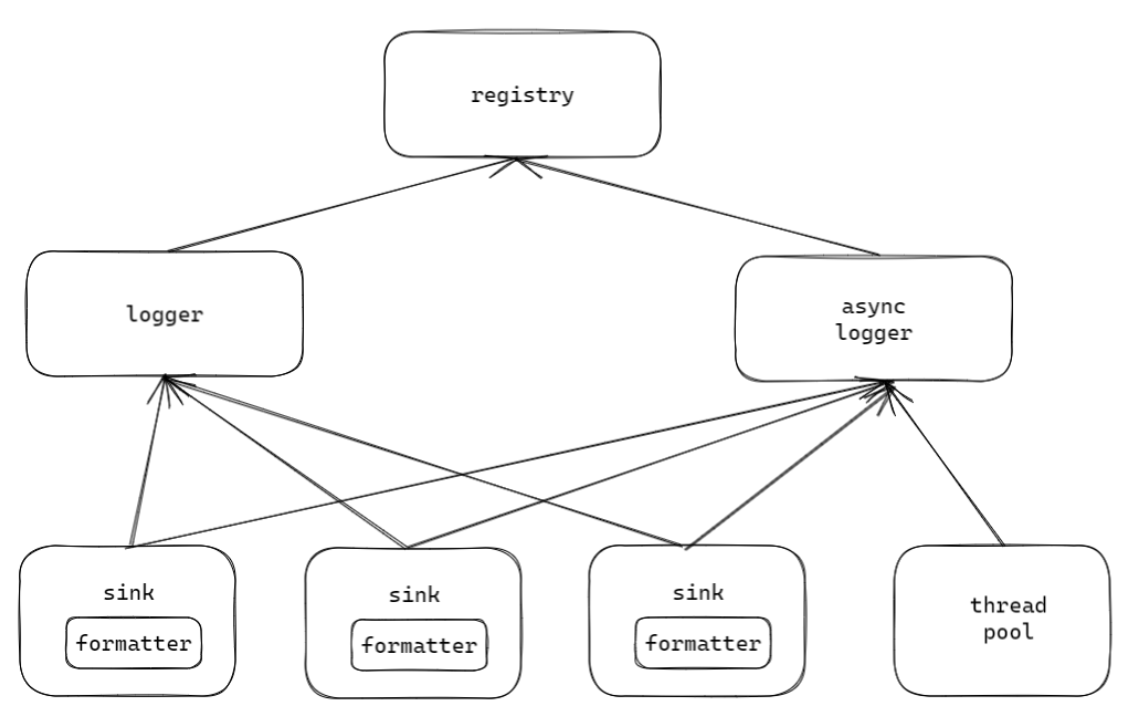
3.3.1 spdlog异步日志
文章目录 3.3.1 spdlog异步日志1. spdlog1. 日志作用2 .同步日志和异步日志区别 2. spdlog是什么下载命令:2. spdlog为什么高效3. spdlog特征5. spdlog输出控制6. 处理流程7. 文件io8.问题 2. 如何创建logger3. 如何创建sink4. 如何自定义格式化5. 如何创建异步日志…...

SSRF漏洞公开报告分析
文章目录 1. SSRF | 获取元数据 | 账户接管2. AppStore | 版本上传表单 | Blind SSRF3. HOST SSRF一、为什么HOST修改不会影响正常访问二、案例 4. Turbonomic 的 终端节点 | SSRF 获取元密钥一、介绍二、漏洞分析 5. POST | Blind SSRF6. CVE-2024-40898利用 | SSRF 泄露 NTL…...

生物化学笔记:医学免疫学原理14 感染免疫 感染免疫的机制+病原体的免疫逃逸机制
感染免疫的基本概念 感染免疫的机制 病原体的免疫逃逸机制...

RocketMQ深度百科全书式解析
一、核心架构与设计哲学 1. 设计目标 海量消息堆积:单机支持百万级消息堆积,适合大数据场景(如日志采集)。严格顺序性:通过队列分区(Queue)和消费锁机制保证局部顺序。事务…...

谈谈模板方法模式,模板方法模式的应用场景是什么?
一、模式核心理解 模板方法模式是一种行为设计模式,通过定义算法骨架并允许子类重写特定步骤来实现代码复用。 如同建筑图纸规定房屋结构,具体装修由业主决定,该模式适用于固定流程中需要灵活扩展的场景。 // 基础请求处理…...

电脑的usb端口电压会大于开发板需要的电压吗
电脑的USB端口电压通常不会大于开发板所需的电压,以下是详细解释: 1. USB端口电压标准 根据USB规范,USB接口的标称输出电压为5V。实际测量时,USB接口的输出电压会略有偏差,通常在4.75V到5.25V之间。USB 2.0和USB 3.0…...

DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用
DeepSeek-V3与DeepSeek-R1全面解析:从架构原理到实战应用 DeepSeek作为中国人工智能领域的新锐力量,其推出的DeepSeek-V3和DeepSeek-R1系列模型在开源社区和商业应用中引起了广泛关注。本指南将系统介绍这两款模型的架构特点、安装部署方法以及实际应用…...
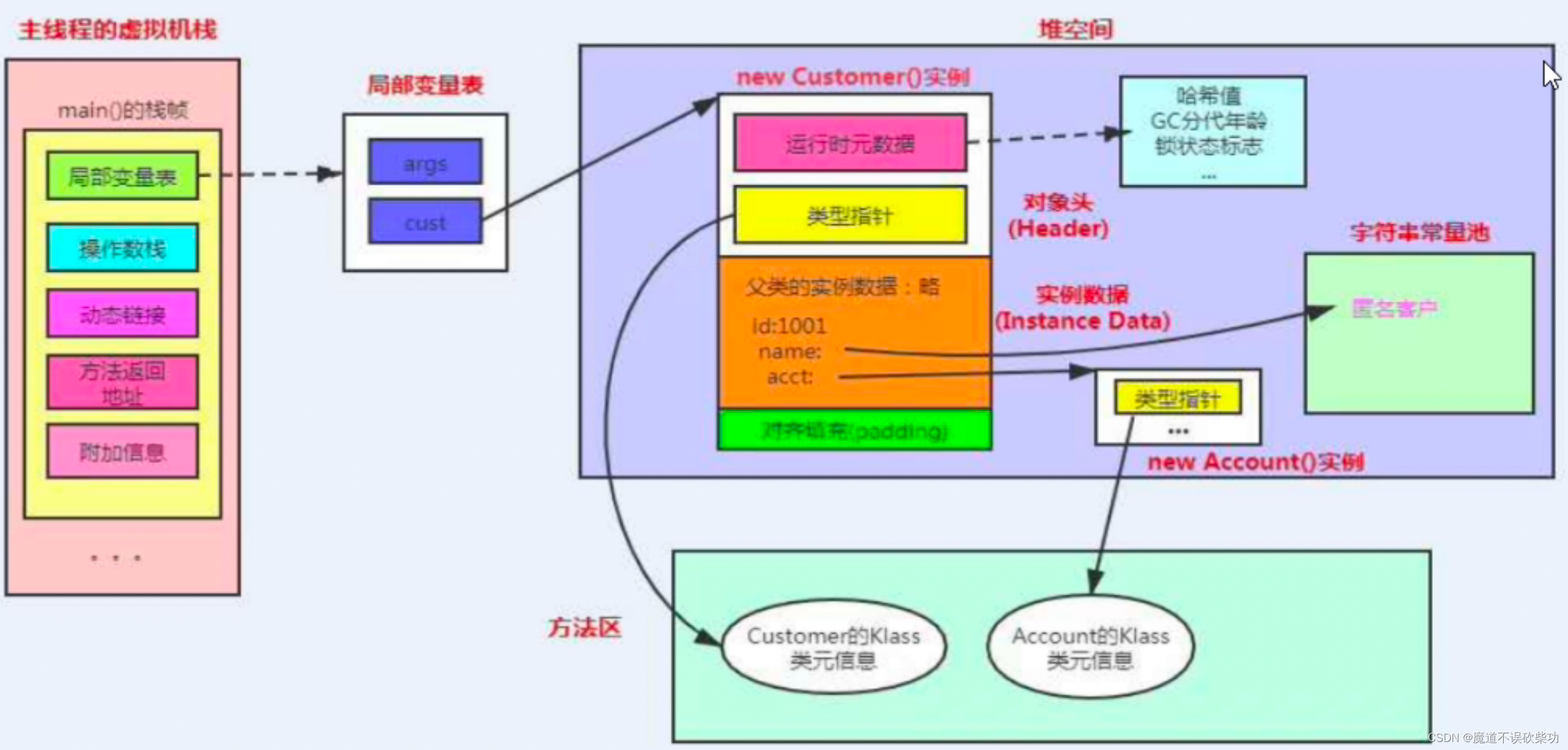
Java 基础(4)—Java 对象布局及偏向锁、轻量锁、重量锁介绍
一、Java 对象内存布局 1、对象内存布局 一个对象在 Java 底层布局(右半部分是数组连续的地址空间),如下图示: 总共有三部分总成: 1. 对象头:储对象的元数据,如哈希码、GC 分代年龄、锁状态…...

Flink回撤流详解 代码实例
一、概念介绍 1. 回撤流的定义 在 Flink 中,回撤流主要出现在使用 Table API 或 SQL 进行聚合或更新操作时。对于那些结果并非单纯追加(append-only)的查询,Flink 会采用“回撤流”模式来表达更新。 回撤流的数据格式ÿ…...
工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明)
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,具体的应用及优势进行分析说明
Glowroot 是一个开源的 Java 应用性能监控(APM)工具,专为 低开销、易用性 设计,适用于开发和生产环境。它可以帮助你实时监控 Java 应用的性能指标(如响应时间、SQL 查询、JVM 状态等),无需复杂配置即可快速定位性能瓶颈。 1. 核心功能 功能说明请求性能分析记录 HTTP 请…...

台式电脑插入耳机没有声音或麦克风不管用
目录 一、如何确定插孔对应功能1.常见音频插孔颜色及功能2.如何确认电脑插孔?3.常见问题二、 解决方案1. 检查耳机连接和设备选择2. 检查音量设置和静音状态3. 更新或重新安装声卡驱动4. 检查默认音频格式5. 禁用音频增强功能6. 排查硬件问题7. 检查系统服务8. BIOS设置(可选…...