【大模型理论篇】关于生成式模型中联合分布概率学习必要性以及GPT是生成式模型的讨论
1. 背景
之前我们在《生成式模型与判别式模型对比(涉及VAE、CRF的数学原理详述)》以及《生成式模型算法原理深入浅出(涉及Stable Diffusion、生成对抗网络、高斯混合模型、隐马尔可夫模型、朴素贝叶斯等算法原理分析及生成式模型解释)》中,我们对一些常见的算法做了分析。刚好最近和同事聊天,聊起生成式模型,这里做一些额外信息的补充。
生成式模型可以通过学习数据本身的分布 p(x),而不直接涉及联合分布 p(x,y),这取决于具体的模型设计和任务目标,可以参考前述文章链接中的算法原理讲解。
2. 生成式模型的核心目标
2.1 无监督学习场景
生成式模型的本质是学习数据的分布 p(x),从而能够生成与训练数据相似的新样本。在无监督学习场景中(如生成图像、文本等任务),模型的目标是直接建模 p(x),而无需依赖标签 y。常见的模型包括:
自编码器(Autoencoders):通过压缩与重建数据学习 p(x)。
生成对抗网络(GANs):通过对抗训练生成与真实数据分布 p(x) 匹配的样本。
变分自编码器(VAEs):通过概率框架建模 p(x),并引入隐变量进行生成。
这些模型不需要标签 y,仅通过学习 p(x)完成任务。
2.2. 监督学习中的生成式模型
在监督学习任务中(如分类),传统的生成式模型(如朴素贝叶斯、高斯混合模型)通常会建模联合分布 p(x,y)=p(y)p(x∣y),然后通过贝叶斯定理计算 p(y∣x) 进行分类。但此时,模型仍然需要标签 y 的信息。
3. 是否可以不学 p(x,y)
是否可以不学 p(x,y),仅通过 p(x) 完成监督任务?
直接分类不可行:如果目标是分类(即预测 y),则必须建模 p(y∣x),而生成式方法通常需要先学习 p(x,y)。
间接辅助:如果仅学习 p(x),可以通过无监督预训练提取特征,再结合少量标签数据微调分类器(半监督学习)。例如:
用VAE或GAN预训练模型提取数据特征,再用逻辑回归分类。
生成数据增强样本(基于 p(x))以提升监督模型的泛化性。
关键区别:任务目标决定建模方式
无监督生成任务:只需学习 p(x),无需标签。
监督分类任务:若使用生成式方法,通常需建模 p(x,y);但 p(x) 的学习可作为辅助手段。
实例说明:
GAN生成图像:GAN直接学习 p(x)(如图像分布),生成新图像时不需要标签。
朴素贝叶斯分类:需学习 p(x,y),通过 p(x∣y) 和 p(y) 进行分类。
因此结论如下:
可以仅学习 p(x):在无监督生成任务中,模型完全不需要标签 y,直接建模 p(x)。
无法绕过 p(x,y) 的直接监督任务:若目标是分类或回归,生成式方法通常需联合分布,但 p(x)的学习可作为特征提取或数据增强的辅助手段。
生成式模型是否学习 p(x) 或 p(x,y) 取决于具体任务类型,两者均有其适用场景。
4. 生成新数据
在生成式模型中,一旦学习到了数据分布 p(x),生成新数据的关键是从这个分布中采样(Sampling)。以下是不同生成模型的采样方法及其核心原理:
4.1 直接显式建模 p(x) 的模型
这类模型直接定义了概率密度 p(x),并可通过解析或数值方法采样。
示例模型:
自回归模型(Autoregressive Models)
原理:将 p(x) 分解为条件概率的链式乘积,例如 p(x)=p(x1)p(x2∣x1)⋯p(xn∣x1,x2,…,xn−1)
采样方法:逐次生成每个维度(如像素或单词),每一步基于已生成的部分采样下一个值。
例子:PixelCNN(生成图像)、GPT(生成文本)。
归一化流(Normalizing Flows)
原理:通过可逆变换将简单分布(如高斯分布)映射到复杂分布 p(x)。
采样方法:从简单分布采样 z∼p(z),然后通过变换 x=f−1(z) 得到样本。
例子:Glow、RealNVP。
采样步骤:
选择一个简单分布(如高斯分布)作为基分布。
通过可逆变换的逆函数 f−1 将基分布的样本转换为数据空间的样本。
4.2 隐变量模型(Latent Variable Models)
这类模型引入隐变量 z 来间接建模 p(x),即 p(x)=∫p(x∣z)p(z)dz。
示例模型:
变分自编码器(VAE)
原理:通过编码器学习隐变量 zz 的后验分布 q(z∣x),解码器生成 p(x∣z)。
采样方法:
从先验分布 p(z)(通常为标准高斯分布)采样 z。
通过解码器网络 p(x∣z) 生成样本 x。
扩散模型(Diffusion Models)
原理:通过逐步添加噪声破坏数据,再学习逆向去噪过程。
采样方法:
从纯噪声 xT∼N(0,I)开始。
逐步应用训练好的去噪网络 pθ(xt−1∣xt),迭代生成 xT−1,xT−2,…,x0。
隐变量模型的通用采样流程:
采样隐变量:从隐变量分布 p(z) 中随机抽取 z(如高斯噪声)。
生成数据:通过生成器网络 p(x∣z) 将 z 映射到数据空间 x。
3. 隐式生成模型(Implicit Generative Models)
这类模型不显式定义 p(x),而是通过生成器直接生成样本。
示例模型:
-
生成对抗网络(GAN)
-
原理:生成器 G(z) 将噪声 z 映射到数据空间,判别器 D(x) 区分真实数据与生成数据。
-
采样方法:
-
从简单分布(如均匀分布或高斯分布)采样噪声 z。
-
通过生成器 G(z) 直接输出样本 x。
-
-
特点:
-
生成过程无需显式概率密度计算,直接通过神经网络映射实现。
5. 为什么说GPT是生成模型
GPT(Generative Pre-trained Transformer)被归类为生成式模型,是因为它的核心设计目标、训练方法以及应用场景均围绕生成新数据(如文本、代码等)展开。以下是具体原因和分析:
5.1 GPT 的生成式特性
(1) 自回归生成机制
GPT 通过自回归方式生成文本,即逐个预测下一个词(token),并基于已生成的上下文生成后续内容。这与生成式模型(如 PixelCNN)的链式分解完全一致。
示例:
输入提示“中国的首都是”,GPT 逐步生成“北”→“京”→“。”,最终输出“中国的首都是北京。”
(2) 预训练目标的生成式性质
GPT 的预训练任务是语言建模(Language Modeling),即最大化训练语料中文本序列的似然概率。这一目标直接对应生成式模型的核心任务——学习数据分布 p(x)。
(3) 生成新数据的能力
GPT 能够生成全新的、未见过的文本,例如:
创作故事、诗歌。
生成代码、对话回复。
续写或补全不完整的输入。
这种能力是生成式模型的标志性特征,而判别式模型(如分类器)仅能对已有输入进行预测,无法创造新内容。
5.2 GPT 与其他生成式模型的对比
| 模型类型 | 生成方式 | 应用场景 | 代表模型 |
|---|---|---|---|
| 自回归模型 | 逐词生成,依赖上文 | 文本、代码生成 | GPT、PixelCNN |
| 隐变量模型 | 通过隐变量映射生成 | 图像、语音合成 | VAE、扩散模型 |
| 隐式生成模型 | 对抗训练生成 | 图像生成 | GAN |
| GPT | Transformer 自回归生成 | 文本、多模态生成 | GPT-3、GPT-4 |
5.3 可能存在的疑问
Q1:GPT 也能用于分类任务,为什么不是判别式模型?
-
生成式模型的条件生成能力:
GPT 可以通过在输入中附加任务描述(如“情感分类:这句话是正面还是负面?xxx”),生成“正面”或“负面”作为答案。这种能力本质上是条件生成(生成答案的条件概率 p(y∣x)),而非直接学习判别边界。 -
底层架构仍是生成式:
即使微调用于分类,GPT 的核心架构(自回归生成)和预训练目标(语言建模)始终基于生成式框架。
Q2:生成式模型必须显式定义概率分布吗?
-
隐式生成模型(如 GAN)无需显式建模 p(x),而是通过生成器隐式匹配数据分布。
-
GPT 的隐式概率建模:
GPT 虽然通过自回归分解显式建模了 p(x),但其概率分布的具体形式(如神经网络的参数化表示)是隐式的。
相关文章:

【大模型理论篇】关于生成式模型中联合分布概率学习必要性以及GPT是生成式模型的讨论
1. 背景 之前我们在《生成式模型与判别式模型对比(涉及VAE、CRF的数学原理详述)》以及《生成式模型算法原理深入浅出(涉及Stable Diffusion、生成对抗网络、高斯混合模型、隐马尔可夫模型、朴素贝叶斯等算法原理分析及生成式模型解释)》中,我…...

tailwindcss 4 使用的一些注意点
目录 一、tailwindcss 4 官网地址变更了 二、自定义颜色的使用方式 三、安装的时候可能的报错 一、tailwindcss 4 官网地址变更了 之前的官网地址是:Tailwind CSS 中文网 现在的官网地址是:Tailwind CSS - Rapidly build modern websites without e…...

案例分析:东华新径,拉动式生产的智造之路
目录 文章目录 目录南京东华智能转向系统有限公司是一家什么公司?背景知识:新能源汽车生产制造流程简介东华遇见了什么问题?东华希望如何解决?解决思路:从 “推动式生产” 到 “拉动式生产”,从 “冗余式思…...
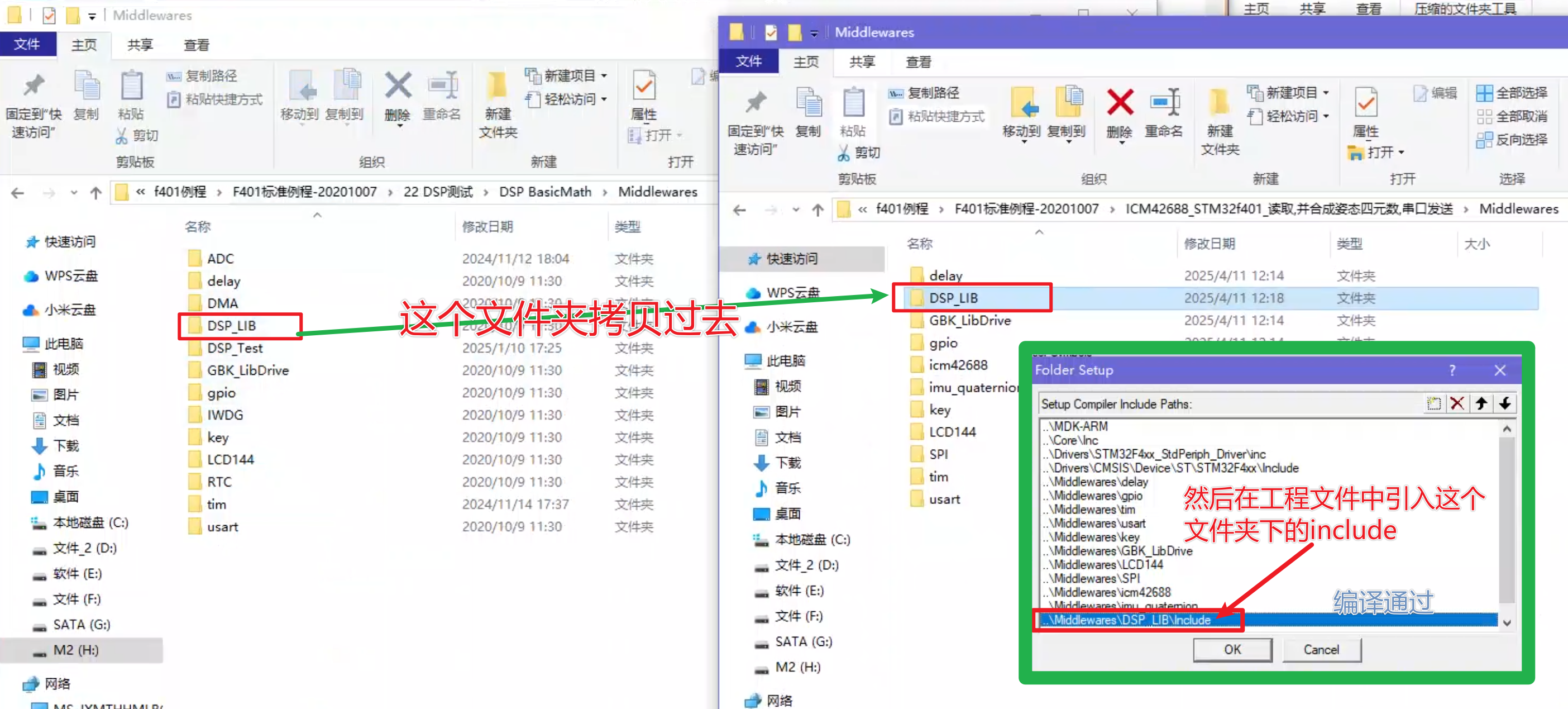
stm32工程,拷贝到另一台电脑编译,错误提示头文件找不到cannot open source input file “core_cm4.h”
提示 cannot open source input file “core_cm4.h” ,找不到 [ core_cm4.h ] 这个头文件 . 于是我在原电脑工程文件里找也没有找到这个头文件 接下来查看原电脑keil的头文件引入配置,发现只引入了工程文件下的头文件, 那么core_cm4.h到底哪里来的? (到现在我也不清楚怎…...

无锡东亭无人机培训机构电话
无锡东亭无人机培训机构电话,随着科技的迅猛发展,无人机逐渐走入我们的生活和工作领域,成为多种行业中不可或缺的工具。而在其广泛的应用中,如何正确、熟练地操控无人机成为了关键。因此,找到一家专业的无人机培训机构…...

Linux操作系统的计算机体系结构与网络安全的深度关联
在当今数字化时代,Linux操作系统因其开源、稳定和安全性而被广泛应用于服务器、嵌入式系统和云计算等领域。本文将深入探讨Linux的计算机体系结构,并分析其在网络安全中的关键作用。 一、Linux的计算机体系结构 (一)基于冯诺依曼…...

大厂文章阅读
1.异步任务处理系统,如何解决业务长耗时、高并发难题? 1)任务失败如何处理(CAS失败也可用):1.指数退避,匹配下游任务执行系统的处理能力。比如收到下游任务执行系统的流控错误,或者感知到任务执行成为瓶颈,需要指数退…...
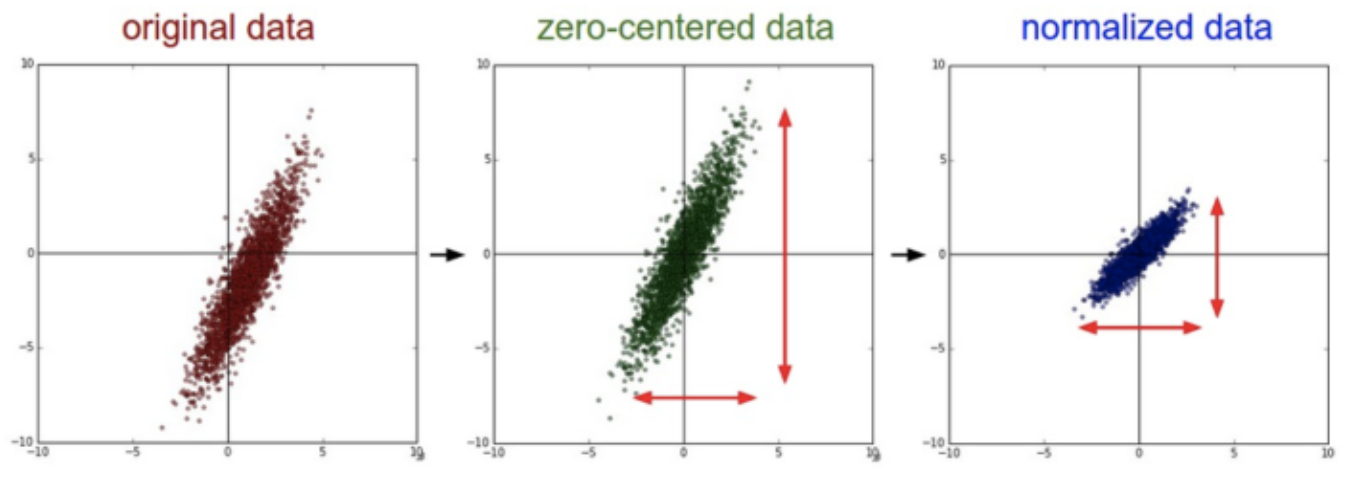
卷积神经网络 CNN 系列总结(二)---数据预处理、激活函数、梯度、损失函数、优化方法等
数据预处理 零中心化、归一化 关于数据预处理我们有3个常用的符号,数据矩阵X,假设其尺寸是[N x D](N是数据样本的数量,D是数据的维度)。 均值减法(Mean subtraction)是预处理最常用的形式。它对数据中每个独立特征减去平均值,从几何上可以理解为在每个维度上都将数据…...
速学Android 16新功能:带有进度的通知类型
前言 在当前已公布的Android 16版本中新增了一系列的功能特性和API,如: 动态壁纸的内容处理,提供新的 content API 预测性返回更新,添加了finishAndRemoveTaskCallback() 和 moveTaskToBackCallback等API 健康数据共享更新&…...

微信小程序开发:微信小程序上线发布与后续维护
微信小程序上线发布与后续维护研究 摘要 微信小程序作为移动互联网的重要组成部分,其上线发布与后续维护是确保其稳定运行和持续优化的关键环节。本文从研究学者的角度出发,详细探讨了微信小程序的上线发布流程、后续维护策略以及数据分析与用户反馈处理的方法。通过结合实…...

深度学习基础--CNN经典网络之分组卷积与ResNext网络实验探究(pytorch复现)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 ResNext是分组卷积的开始之作,这里本文将学习ResNext网络;本文复现了ResNext50神经网络,并用其进行了猴痘病分类实验…...

AutoGen深度解析:从核心架构到多智能体协作的完整指南
AutoGen是微软推出的一个革命性多智能体(Multi-Agent)框架,它通过模块化设计和灵活的对话机制,极大地简化了基于大型语言模型(LLM)的智能体系统开发。本文将深入剖析AutoGen的两个核心模块——core基础架构和agentchat多智能体对话系统,带您全…...
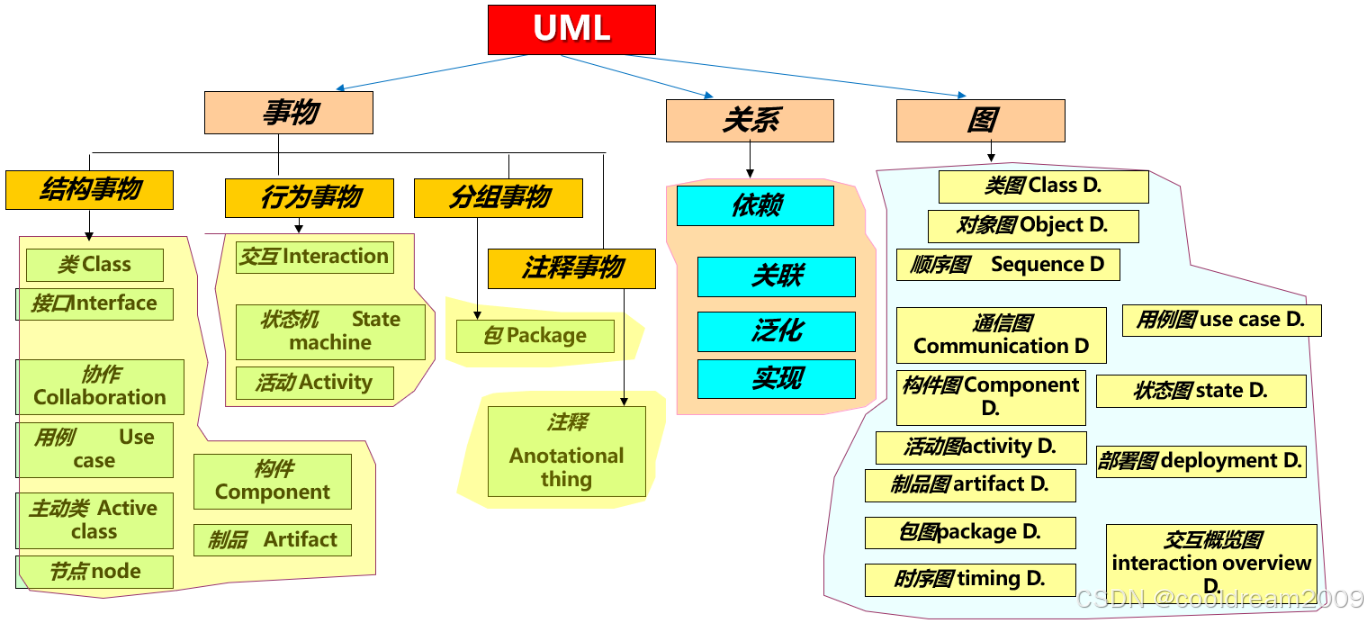
面向对象的需求分析与UML构造块详解
目录 前言1 面向对象的需求分析概述2 UML构造块概述3 UML事物详解3.1 结构事物(Structural Things)3.2 行为事物(Behavioral Things)3.3 分组事物(Grouping Things)3.4 解释事物(Annotational T…...

计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比
计算机视觉色彩空间全解析:RGB、HSV与Lab的实战对比 一、前言二、RGB 色彩空间2.1 RGB 色彩空间原理2.1.1 基本概念2.1.2 颜色混合机制 2.2 RGB 在计算机视觉中的应用2.2.1 图像读取与显示2.2.2 颜色识别2.2.3 RGB 色彩空间的局限性 三、HSV 色彩空…...

使用Docker安装Gogs
1、拉取镜像 docker pull gogs/gogs 2、运行容器 # 创建/var/gogs目录 mkdir -p /var/gogs# 运行容器 # -d,后台运行 # -p,端口映射:(宿主机端口:容器端口)->(10022:22)和(10880:3000) # -v,数据卷映射:(宿主机目…...

【Web API系列】XMLHttpRequest API和Fetch API深入理解与应用指南
前言 在现代Web开发中,客户端与服务器之间的异步通信是构建动态应用的核心能力。无论是传统的AJAX技术(基于XMLHttpRequest)还是现代的Fetch API,它们都为实现这一目标提供了关键支持。本文将从底层原理、核心功能、代码实践到实…...
)
Spring Boot 自定义 Redis Starter 开发指南(附动态 TTL 实现)
一、功能概述 本 Starter 基于 Spring Boot 2.7 实现以下核心能力: Redis 增强:标准化 RedisTemplate 配置(JSON 序列化 LocalDateTime 支持)缓存扩展:支持 Cacheable(value “key#60s”) 语法动态设置 TTL配置集中…...
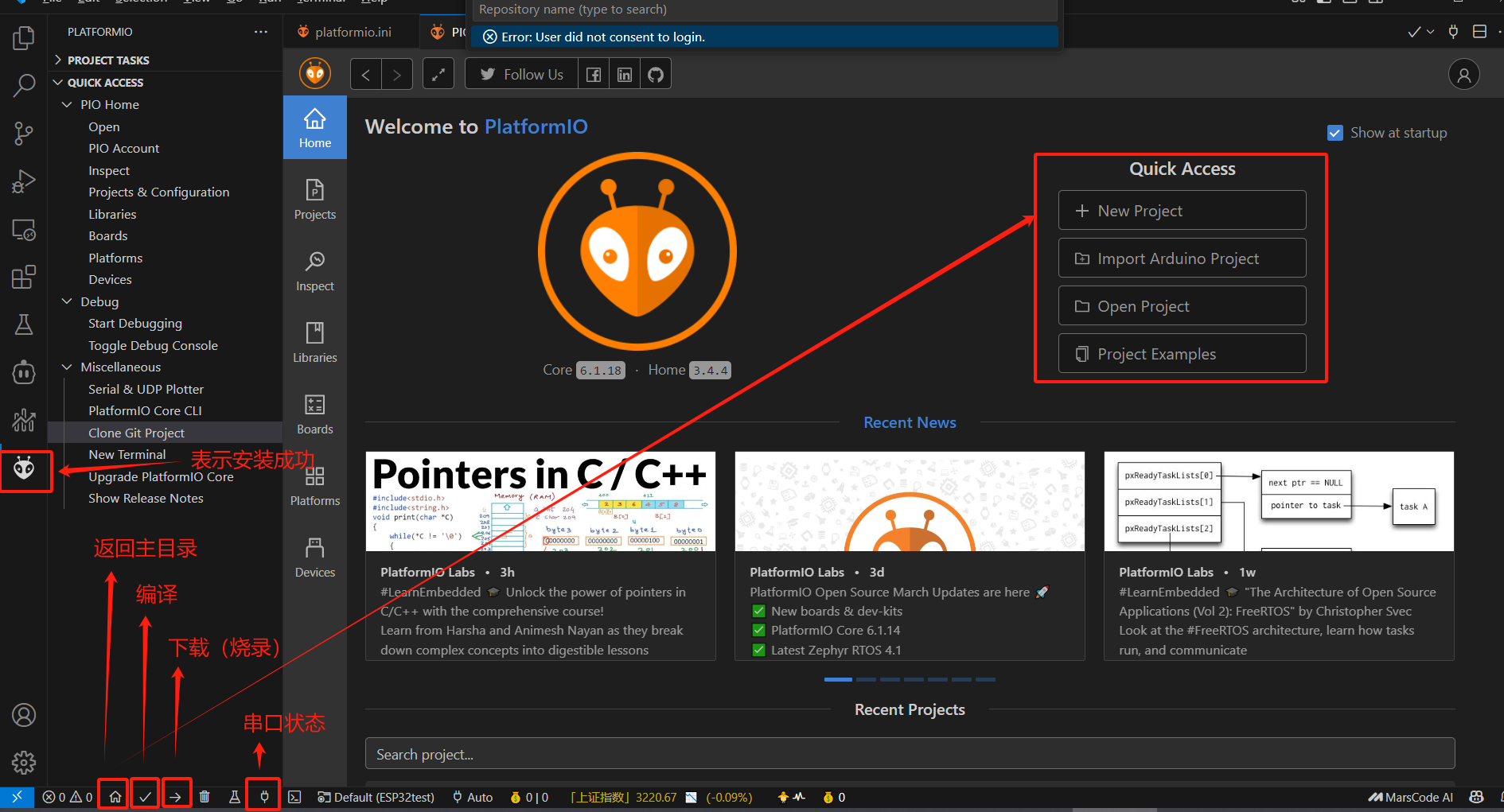
ESP32开发入门:基于VSCode+PlatformIO环境搭建指南
前言 ESP32作为一款功能强大的物联网开发芯片,结合PlatformIO这一现代化嵌入式开发平台,可以大幅提升开发效率。本文将详细介绍如何在VSCode中搭建ESP32开发环境,并分享实用开发技巧。 一、环境安装(Windows/macOS/Linux…...

2025.4.13机器学习笔记:文献阅读
2025.4.13周报 题目信息摘要创新点网络架构实验结论不足以及展望 题目信息 题目: Physics-informed neural networks for inversion of river flow and geometry with shallow water model期刊: Physics of Fluids作者: Y. Ohara; D. Moteki…...

Quartz修仙指南:从定时任务萌新到调度大能的终极奥义
各位被Thread.sleep()和ScheduledExecutorService折磨的道友们!今天要解锁的是Java界任务调度至尊法宝——Quartz!这货能让你像玉皇大帝安排天庭日程一样,精确控制每个任务的执行时机!准备好告别蹩脚的手动定时器了吗?…...

如何免费使用Meta Llama 4?
周六, Meta发布了全新开源的Llama 4系列模型。 架构介绍查看上篇文章。 作为开源模型,Llama 4存在一个重大限制——庞大的体积。该系列最小的Llama 4 Scout模型就拥有1090亿参数,如此庞大的规模根本无法在本地系统运行。 不过别担心!即使你没有GPU,我们也找到了通过网页…...

编程助手fitten code使用说明(超详细)(vscode)
这两年 AI 发展迅猛,作为开发人员,我们总是追求更快、更高效的工作方式,AI 的出现可以说改变了很多人的编程方式。 AI 对我们来说就是一个可靠的编程助手,给我们提供了实时的建议和解决方,无论是快速修复错误、提升代…...

Python自动化爬虫:Scrapy+APScheduler定时任务
在数据采集领域,定时爬取网页数据是一项常见需求。例如,新闻网站每日更新、电商价格监控、社交媒体舆情分析等场景,都需要定时执行爬虫任务。Python的Scrapy框架是强大的爬虫工具,而APScheduler则提供了灵活的任务调度功能。 一、…...

技术分享|iTOP-RK3588开发板Ubuntu20系统旋转屏幕方案
iTOP-3588开发板采用瑞芯微RK3588处理器,是全新一代AloT高端应用芯片,采用8nmLP制程,搭载八核64位CPU,四核Cortex-A76和四核Cortex-A55架构,主频高达2.4GHz。是一款可用于互联网设备和其它数字多媒体的高性能产品。 在…...

Java中的参数是值传递还是引用传递?
在java中, 参数传递只有值传递 ,不论是基本类型还是引用类型。 其中的区别在于: 基本数据类型(如byte,short,int等):传递的参数是值的副本,即基本类型的数值本身。因此在方法中&am…...
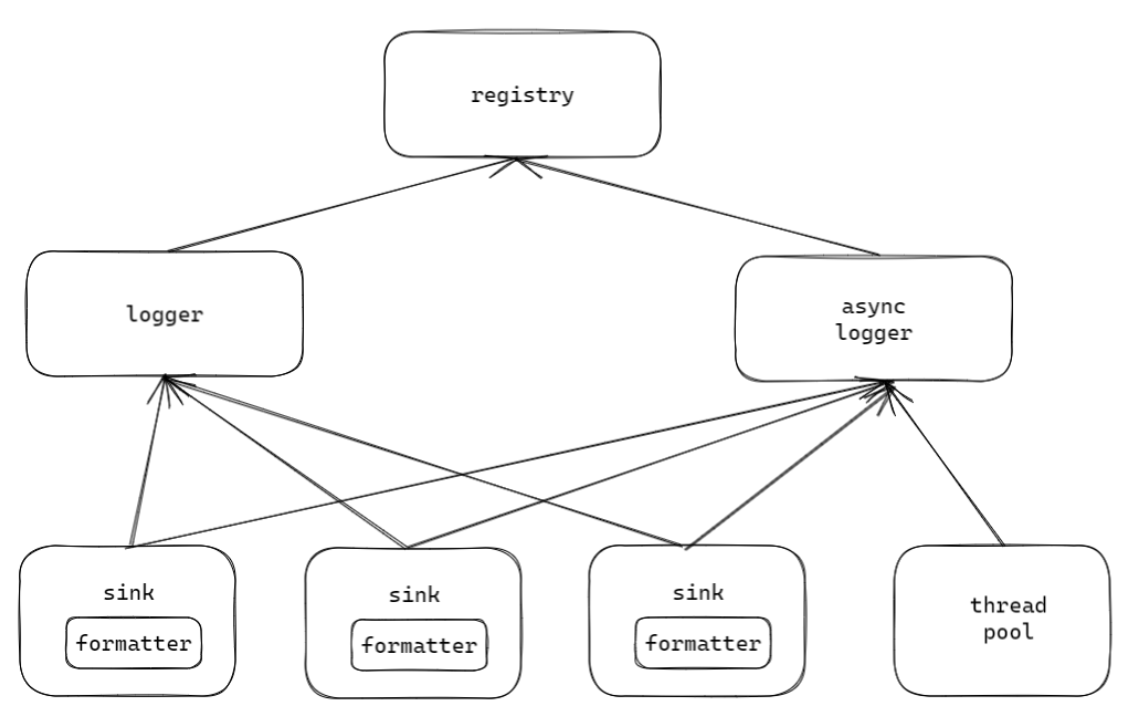
3.3.1 spdlog异步日志
文章目录 3.3.1 spdlog异步日志1. spdlog1. 日志作用2 .同步日志和异步日志区别 2. spdlog是什么下载命令:2. spdlog为什么高效3. spdlog特征5. spdlog输出控制6. 处理流程7. 文件io8.问题 2. 如何创建logger3. 如何创建sink4. 如何自定义格式化5. 如何创建异步日志…...

SSRF漏洞公开报告分析
文章目录 1. SSRF | 获取元数据 | 账户接管2. AppStore | 版本上传表单 | Blind SSRF3. HOST SSRF一、为什么HOST修改不会影响正常访问二、案例 4. Turbonomic 的 终端节点 | SSRF 获取元密钥一、介绍二、漏洞分析 5. POST | Blind SSRF6. CVE-2024-40898利用 | SSRF 泄露 NTL…...

生物化学笔记:医学免疫学原理14 感染免疫 感染免疫的机制+病原体的免疫逃逸机制
感染免疫的基本概念 感染免疫的机制 病原体的免疫逃逸机制...

RocketMQ深度百科全书式解析
一、核心架构与设计哲学 1. 设计目标 海量消息堆积:单机支持百万级消息堆积,适合大数据场景(如日志采集)。严格顺序性:通过队列分区(Queue)和消费锁机制保证局部顺序。事务…...

谈谈模板方法模式,模板方法模式的应用场景是什么?
一、模式核心理解 模板方法模式是一种行为设计模式,通过定义算法骨架并允许子类重写特定步骤来实现代码复用。 如同建筑图纸规定房屋结构,具体装修由业主决定,该模式适用于固定流程中需要灵活扩展的场景。 // 基础请求处理…...