【图像生成之21】融合了Transformer与Diffusion,Meta新作Transfusion实现图像与语言大一统
论文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
地址:https://arxiv.org/abs/2408.11039
类型:理解与生成
Transfusion模型是一种将Transformer和Diffusion模型融合的多模态模型,旨在同时处理离散数据(如文本)和连续数据(如图像)。该模型由Meta公司开发,能够在单个模型中预测离散文本token并生成连续图像,从而实现了语言建模和图像生成的一体化。
Transfusion模型的核心特点
-
统一的Transformer架构:Transfusion使用单一的Transformer模型来处理文本和图像数据,通过不同的损失函数和注意力机制来实现多模态建模。
-
双重训练目标:对于文本,采用经典的语言建模目标(LM loss),即预测序列中的下一个token;对于图像,则引入扩散模型的目标(DDPM loss),通过预测加噪过程中的噪声分量来逐步生成图像12。
-
模态混合序列:Transfusion将文本和图像数据整合成单一输入序列,使用特殊标记分隔不同模态,确保模型能区分处理对象2。
-
注意力机制的创新:对于文本,保持因果注意力;对于图像patch,引入双向注意力,捕捉空间关系,提升生成质量2。
-
联合损失函数:训练时,将语言建模损失和扩散模型损失加权组合为一个总损失函数
一、摘要
我们介绍了Transfusion,这是一种在离散和连续数据上训练多模态模型的方法。Transfusion将语言建模损失函数(下一个token预测)与扩散相结合,在混合模态序列上训练单个Transformer。我们在文本和图像数据的混合上从头开始预训练多达7B个参数的多个Transfusion模型,建立了关于各种单模态和跨模态基准的缩放规律。我们的实验表明,Transfusion的缩放效果明显优于量化图像和在离散图像标记上训练语言模型。通过引入特定于模态的编码和解码层,我们可以进一步提高Transfusion模型的性能,甚至将每张图像压缩到只有16个patch。我们进一步证明,将我们的Transfusion配方扩展到7B参数和2T多模态令牌可以产生一个模型,该模型可以生成与类似规模的扩散模型和语言模型相当的图像和文本,从而获得两个世界的好处。
二、介绍
多模态生成模型需要能够感知、处理和生成离散元素(如文本或代码)和连续元素(如图像、音频和视频数据)。虽然在下一个令牌预测目标上训练的语言模型主导了离散模态,但扩散模型及其推广Flow matching是生成连续模态的最新技术。已经做出了许多努力来结合这些方法,包括扩展语言模型以使用扩散模型作为工具,无论是明确地还是将预训练的扩散模型移植到语言模型上。在这项工作中,我们表明,通过训练一个模型来预测离散文本标记和扩散连续图像,可以在不损失信息的情况下完全整合这两种模式。
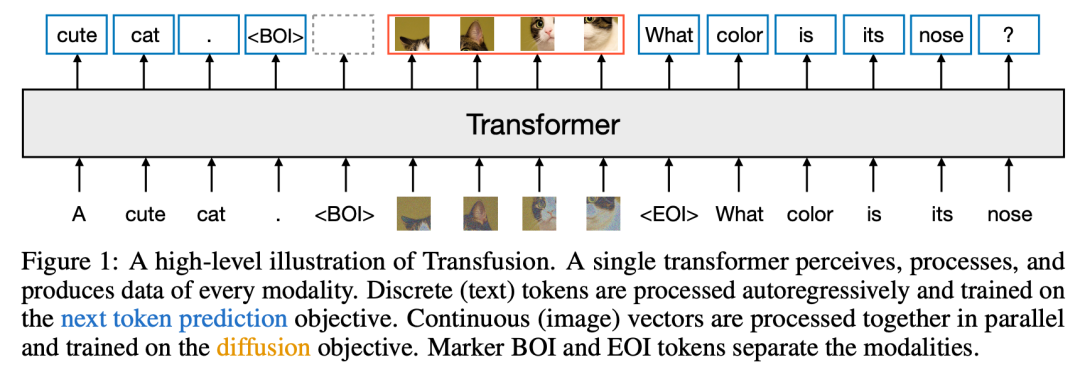
我们介绍了Transfusion,这是一种训练模型的方法,可以无缝生成离散和连续的模态。我们通过在50%的文本和50%的图像数据上预训练一个transformer模型来演示Transfusion,为每种模态使用不同的目标:文本的下一个标记预测和图像的扩散。该模型在每个训练步骤中都暴露于模态和损失函数。Standard embedding layers将文本标记转换为向量,而patchification layer则表示每个图像作为补丁矢量序列。我们对文本标记应用 causal attention,对image patches应用bidirectional attention。为了进行推理,我们引入了一种解码算法,该算法结合了从语言模型生成文本和从扩散模型生成图像的标准实践。图1显示了Transfusion。
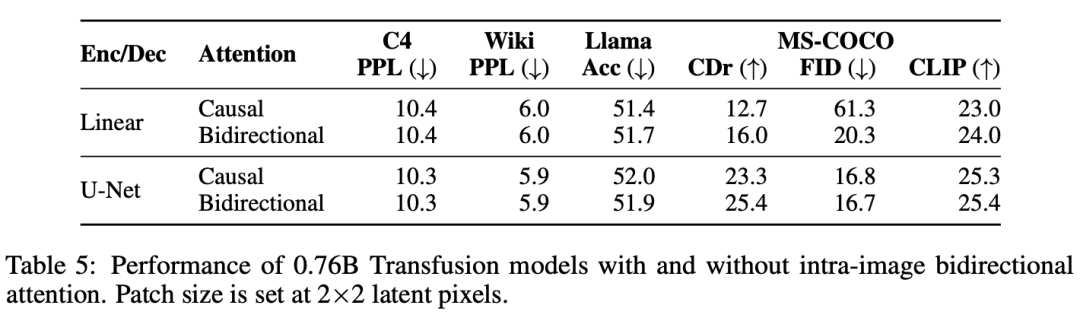
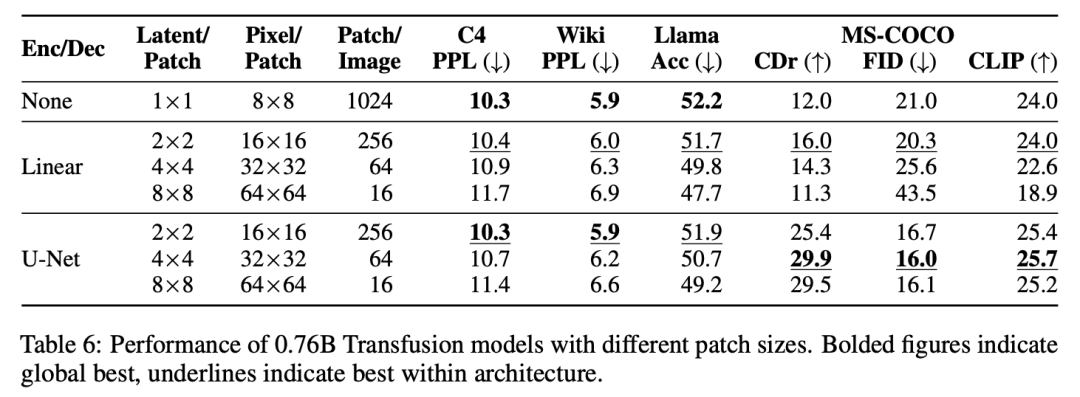
消融实验揭示了Transfusion的关键组成部分和潜在的改进。我们观察到,图像内双向注意力很重要,用因果注意力代替它会损害文本到图像的生成。我们还发现,添加U-Net上下块来编码和解码图像,使Transfusion能够以相对较小的性能损失压缩较大的图像块,从而可能将服务成本降低64倍。

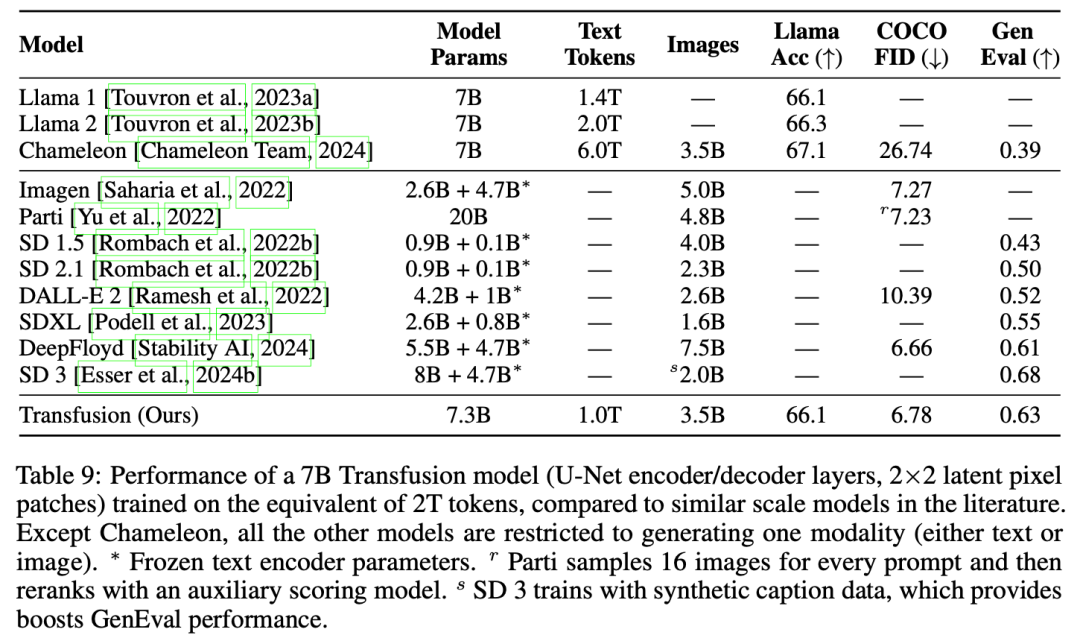
最后,我们证明了Transfusion可以生成与其他扩散模型质量相似的图像。我们从头开始训练一个7B转换器,该转换器在2T令牌上增强了U-Net down/up(0.27B参数):1T文本令牌,以及大约5个epochs 692M图像及其captions迭代,总计1T patches/tokens。图2显示了从模型中采样的一些生成图像。在GenEval基准测试中,我们的模型优于其他流行模型,如DALL-E 2和SDXL;与那些图像生成模型不同,它可以生成文本,在文本基准测试中达到与Llama 1相同的性能水平。因此,我们的实验表明,Transfusion是一种训练真正多模态模型的有前景的方法。
GenEval是专门评估生成式AI模型(如文本到图像生成)性能的基准测试,它定义明确,通过标准化的测试流程,对模型在图像生成质量、指令遵循度、多模态理解等关键指标上进行量化评估。例如,在开源模型Janus-Pro与DALL-E 3、Stable Diffusion的对比中,GenEval的测试结果显示Janus-Pro-7B的准确率高达80%,显著优于竞品。
GenEval的框架设计包含多维度评估体系,覆盖图像生成质量(如分辨率、色彩准确性)、指令响应能力(如地标识别、文字生成)、多模态任务处理(如视觉问答、图像标注)等核心模块。其测试方法结合了自动化指标(如FID分数、CLIP匹配度)与人工评审,确保评估的全面性与可靠性。
三、背景
Transfusion是一个单一的模型,有两个目标:语言建模和扩散(language modeling and diffusion)。这些目标分别代表了离散和连续数据建模的最新技术。本节简要定义了这些目标,以及潜在表示的背景。
3.1 Language Modeling
给定离散令牌序列y=y1...yn,语言模型预测序列P(y)的概率。标准语言模型将P(y)分解为条件概率的乘积如下公式,这创建了一个自回归分类任务,其中每个令牌yi的概率分布是在序列y<i的前缀的条件下,使用由θ参数化的单个分布Pθ进行预测的。该模型可以通过最小化Pθ和数据经验分布之间的交叉熵来优化,从而产生标准的下一个令牌预测目标,俗称LM损失:
![]()
![]()
一旦经过训练,语言模型还可以通过从模型分布Pθ中逐个采样来生成文本,通常使用温度和top-P截断。
温度参数用于控制生成文本的随机性,其值通常介于0.1到2.0之间;
Top-P截断是一种动态限制采样范围的方法,仅考虑概率最高的前P%的词汇
3.2 Diffusion
去噪扩散概率模型(也称为DDPM或扩散模型)的工作原理是学习如何逆转逐渐增加噪声的过程。与通常使用离散标记(y)的语言模型不同,扩散模型在连续向量(x)上运行,使其特别适合涉及图像等连续数据的任务。扩散框架涉及两个过程:一个描述原始数据如何转化为噪声的正向过程,以及模型学习执行的去噪反向过程。
Forward Process。从数学的角度来看,正向过程定义了如何创建噪声数据(作为模型输入)。给定一个数据点x0,Ho等人定义了一个马尔可夫链,该链在T步上逐渐增加高斯噪声,从而产生一个噪声越来越大的序列x1, x2, ..., xT,这个过程的每一步都由
![]()
其中βt根据预定义的噪声时间表随时间增加(见下文)。该过程可以重新参数化,使我们能够使用高斯噪声ε∼N(0,I)的单个样本直接从x0中采样xt:
![]()
![]()
它提供了对原始马尔可夫链的有用抽象。事实上,训练目标和噪声调度器最终都以这些术语表示(和实现)。
Reverse Process。对扩散模型进行训练,以执行逆过程pθ(xt−1|xt),学习逐步对数据进行去噪。有几种方法可以做到这一点;在这项工作中,我们遵循Ho等人的方法,将方程2中的高斯噪声ε建模为步骤t处累积噪声的代理。具体来说,在给定噪声数据xt和时间步长t的情况下,训练一个具有参数θ的模型εθ(·)来估计噪声ε。在实践中,该模型通常在生成图像时以附加的上下文信息c为条件,例如caption。因此,通过最小化均方误差损失来优化噪声预测模型的参数:
![]()
Noise Schedule。在创建有噪声的示例xt时,ᾱt确定了时间步长t的噪声方差。在这项工作中,我们采用了常用的余弦调度器,该调度器在很大程度上遵循sqrt(αt)≈cos(t/T·π/2),并进行了一些调整。
Inference。解码是迭代完成的,每一步都会消除一些噪声。从xT处的纯高斯噪声开始,模型εθ(xT,t,c)预测时间步长t处累积的噪声。然后根据噪声调度对预测的噪声进行缩放,并从xT中去除预测噪声的比例量以产生xT-1。在实践中,推理的时间步比训练少。无分类器引导(CFG)通常用于通过对比基于上下文c的模型预测和无条件预测来改进生成,代价是计算量加倍。
3.3 Latent Image Representation
早期的扩散模型直接在像素空间pixel-space中工作,但这被证明计算成本很高。变分自编码器(VAEs)可以通过将图像编码到低维潜在空间来节省计算。作为深度卷积神经网络实现,现代VAE在重建和正则化损失的组合上进行训练,允许潜在扩散模型(LDM)等下游模型在紧凑的图像块嵌入上高效运行;例如,将每个8×8像素的补丁表示为8维向量。对于自回归语言建模方法,必须对图像进行离散化。离散自编码器,如矢量量化VAE(VQ-VAE),通过引入将连续潜在嵌入映射到离散标记的量化层(和相关的正则化损失)来实现这一点。
四、方法
Transfusion是一种训练单个统一模型以理解和生成离散和连续模态的方法。我们的主要创新是证明,我们可以对不同的模态使用单独的损失——文本的语言建模、图像的扩散——而不是共享的数据和参数。图1显示了Transfusion。
Data Representation。我们实验了两种模式的数据:离散文本和连续图像。每个文本字符串都被标记为来自固定词汇表的离散标记序列,其中每个标记都表示为整数。使用VAE将每个图像编码为潜在patch,其中每个patch表示为连续向量;patch从左到右从上到下排序,以从每张图像中创建patch向量序列。对于混合模态示例,我们在将每个图像序列插入文本序列之前,用特殊的图像开始(BOI)和图像结束(EOI)标记包围每个图像序列;因此,我们得到一个可能包含离散元素(表示文本标记的整数)和连续元素(表示图像块的向量)的单一序列。
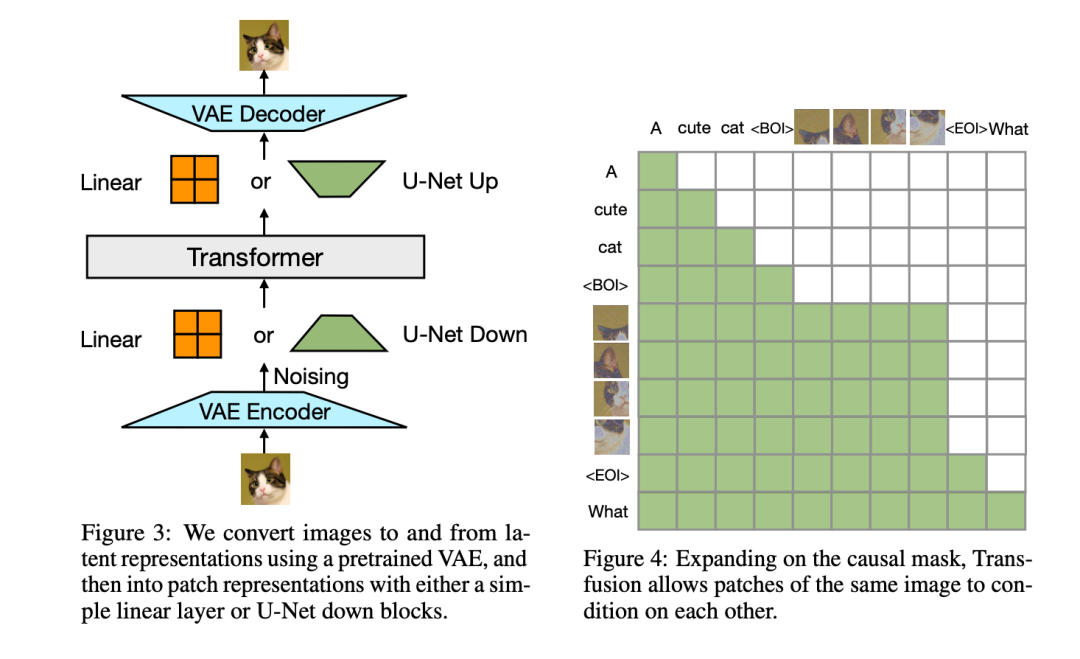
Model Architecture。模型的绝大多数参数属于一个Transformer,该Transformer处理每个序列,而不管模态如何。Transformer将R^d中的一系列高维向量作为输入,并产生相似的向量作为输出。为了将我们的数据转换到这个空间,我们使用具有非共享参数的轻量级模态特定组件。对于文本,这些是嵌入矩阵,将每个输入整数转换为向量空间,将每个输出向量转换为词汇表上的离散分布。对于图像,我们尝试了两种将k×k个patch向量的局部窗口压缩为 single transformer vector的替代方案:(1)简单线性层;(2)UNet上下块,图3显示了整体架构。
Transfusion Attention。语言模型通常使用causal masking来有效地计算单个前向后向传递中整个序列的损失和梯度,而不会从未来的token中泄露信息。虽然文本是自然顺序的,但图像不是,并且通常以不受限制的(双向)注意力进行建模。Transfusion通过对序列中的每个元素应用因果注意力,以及在每个单独图像的元素内应用双向注意力,将两种注意力模式结合在一起。这允许每个图像补丁处理同一图像中的其他补丁,但只处理序列中之前出现的其他图像的文本或补丁。我们发现,启用图像内注意力可以显著提高模型性能。图4显示了 Transfusion attention mask。
Training Objective。为了训练我们的模型,我们将语言建模目标L-LM应用于文本标记的预测,将扩散目标L-DDPM应用于图像块的预测。LM损失按每个标记计算,而扩散损失按每个图像计算,这可能跨越序列中的多个元素(图像块)。具体来说,我们根据扩散过程将噪声ε添加到每个输入的潜像x0中,以在diffusion之前产生xt,然后计算图像级扩散损失。我们通过简单地将每种模态上计算的损失与平衡系数λ相加,将这两种损失结合起来:
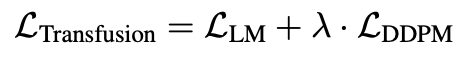
这个公式是一个更广泛想法的具体实例:将离散分布损失与连续分布损失相结合,以优化同一模型。我们将对这一领域的进一步探索,例如用flow matching取代扩散,留给未来的工作。
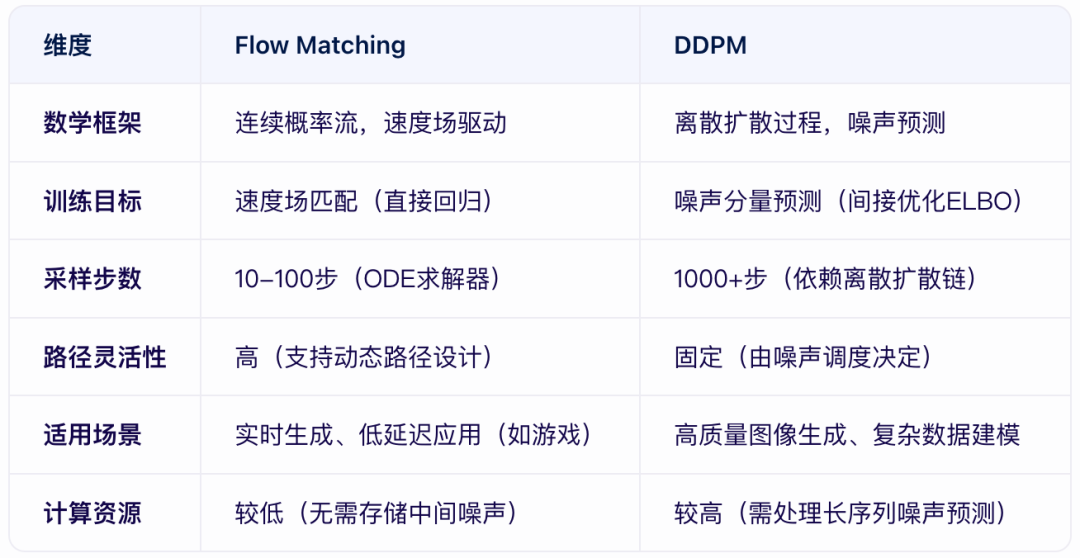
一、Flow Matching的核心原理与应用
1. 数学本质:连续概率流的“路径规划”
类比理解:如同用黏土塑形,Flow Matching通过构建一个连续的速度场(Velocity Field),将随机噪声(先验分布)逐步“引导”至目标图像分布。
技术实现:定义从噪声到数据的平滑路径(如线性插值或动态学习路径)。通过神经网络直接预测每个时空点的速度向量(而非噪声),形成确定性轨迹。满足概率质量守恒(连续性方程),确保转换过程中信息不丢失。
2. 训练与采样优势
模板函数:直接优化速度场与预定义路径的匹配度(均方误差MSE),无需马尔可夫链假设。
采样效率:采用高阶ODE求解器(如RK45),10-100步即可生成高质量图像,支持实时应用(如直播、游戏场景)。
灵活性:允许自定义路径(直线、曲线或动态路径),适合复杂分布建模。二、DDPM的核心原理与应用
1. 数学本质:离散扩散的“噪声逆转”
- 类比理解
:类似沙堡被侵蚀后重建,DDPM通过逐步添加高斯噪声破坏图像,再学习逆转此过程的去噪步骤。
- 技术实现:
前向过程:按固定噪声调度(如线性β_t)将图像逐步转化为纯噪声。
反向过程:用U-Net预测每一步的噪声分量,通过迭代去噪还原图像。2. 训练与采样特点
- 目标函数
:间接优化变分下界(ELBO),依赖马尔可夫链分解。
- 采样效率
:需1000步以上(即使通过DDIM加速仍受限于离散步数)。
- 生成质量
:擅长建模复杂数据(如高分辨率图像),与U-Net结合可捕捉细节。
Flow Matching:
优势场景:需要快速生成(如实时互动、低延迟应用)或路径可控的场景(如风格迁移中的渐变控制)。
案例:条件Flow Matching(CFM)在文本到图像生成中,通过定义噪声与数据间的连续路径,提升生成速度。
DDPM:
优势场景:追求高质量图像生成(如艺术画作、超分辨率重建)或复杂数据分布建模。
案例:Stable Diffusion通过潜在空间扩散生成高分辨率图像,支持文本引导和图像修复。
Inference。为了反映训练目标,我们的解码算法还可以在两种模式之间切换:LM和diffusion。在LM模式下,我们遵循从预测分布中逐个采样的标准做法。当我们对BOI令牌进行采样时,解码算法会切换到扩散模式,在那里我们遵循从扩散模型解码的标准过程。具体来说,我们以n个图像块的形式将纯噪声xT附加到输入序列中(取决于所需的图像大小),并在T步内进行降噪。在每个步骤t,我们进行噪声预测并使用它来产生xt-1,然后覆盖序列中的xt;即,该模型总是以噪声图像的最后一个时间步长为条件,而不能关注之前的时间步长。一旦扩散过程结束,我们将EOI令牌附加到预测图像中,并切换回LM模式。该算法能够生成文本和图像模态的任何混合。
五、实验
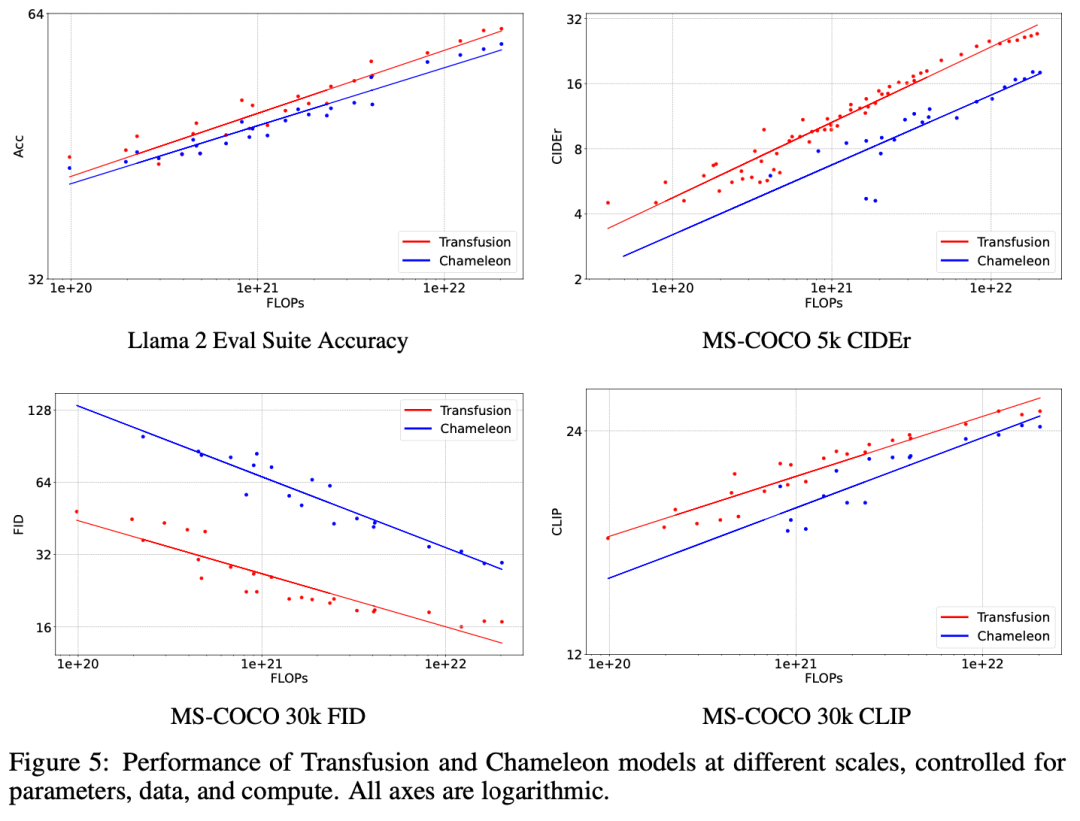
我们在一系列对照实验中证明,transfusion是一种可行的、可扩展的训练统一多模态模型的方法。
Evaluation。我们在一系列标准uni-modal\cross-modal benchmarks基准上评估模型性能,如表1所示。包括Wikipedia\MS-COCO,覆盖文生图、与文本生成。指标包括FID、CLIP、Perplexity等。
Baseline。Chameleon和Transfusion之间的关键区别在于,虽然Chameleon将图像离散化并将其作为token进行处理,但Transfusion将图像保持在连续空间中,消除了量化信息瓶颈。
Data。对于我们几乎所有的实验,我们以1:1的token比率从两个数据集中采样0.5T令牌(补丁)。对于文本,我们使用Llama 2标记器和语料库,其中包含跨不同域分布的2T标记。对于图像,我们使用一组3.8亿张获得许可的Shutterstock图像和字幕。每幅图像都经过中心裁剪和调整大小,以产生256×256像素的图像。我们随机排列图像和字幕,80%的时间先排列字幕。
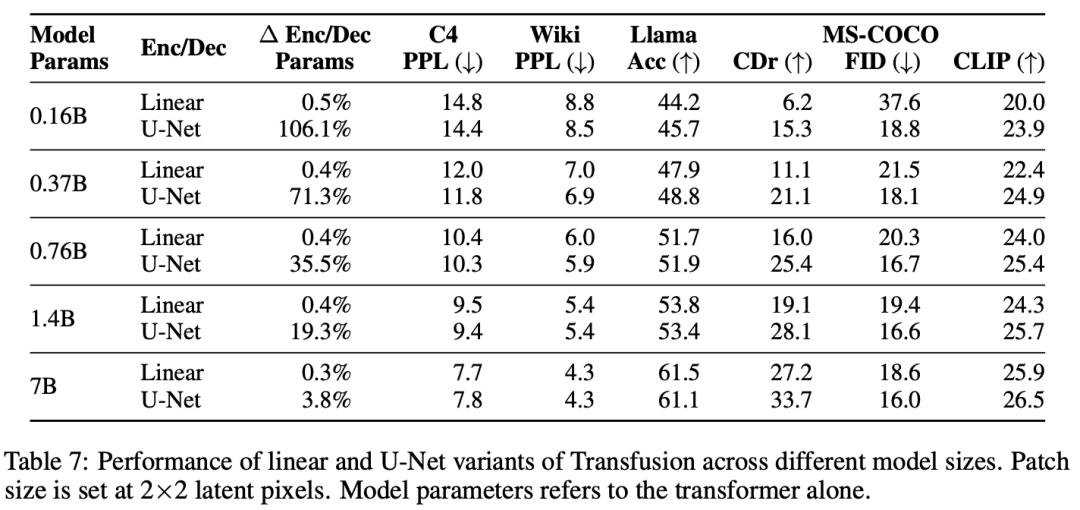
Model Configuration。为了研究缩放趋势,我们按照Llama的标准设置,以五种不同的尺寸(0.16B、0.37B、0.76B、1.4B和7B参数)训练模型。表2详细描述了每种设置。在使用线性补丁编码的配置中,附加参数的数量微不足道,在每个配置中占总参数的不到0.5%。当使用U-Net补丁编码时,这些参数在所有配置中加起来总共为0.27B的额外参数;虽然这是对较小模型的大量参数添加,但这些层仅比7B配置增加了3.8%,几乎与嵌入层中的参数数量相同。
Optimization。我们随机初始化所有模型参数,并使用学习率为3e-4的AdamW(β1=0.9,β2=0.95,ε=1e-8)对其进行优化,warmed up 4000步,使用cosine scheduler衰减到1.5e-5。我们在4096个token的序列上进行训练,每批2M个token,每次250k步,总共达到0.5T个令牌。在我们的大规模实验中,我们在500k步内使用4M令牌的批量进行训练,总共2T令牌。
实验主要探索了Controlled Comparison with Chameleon, Architecture Ablations(Attention Masking,Patch Size,Patch Encoding/Decoding Architecture, Image Noising), Comparison with Image Generation Literature, Image Editing等,具体实验结果如下表分析所示。
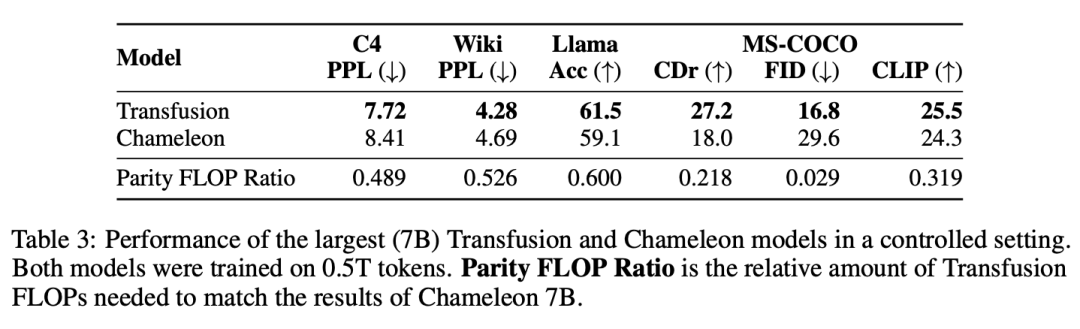
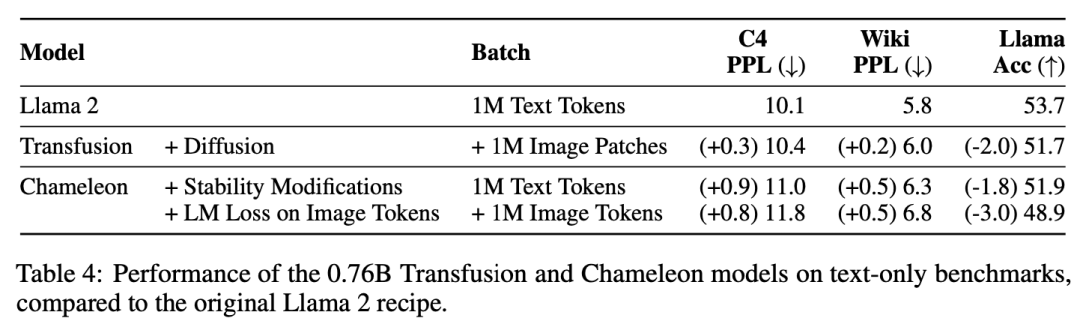

这项工作探讨了如何缩小离散序列建模(下一个token预测)和连续媒体生成(扩散)之间的差距。我们提出了一个简单但以前未被探索的解决方案:在两个目标上训练一个联合模型,将每种模式与其首选目标联系起来。我们的实验表明,Transfusion可以有效地扩展,几乎不产生参数共享成本,同时能够生成任何模态。
相关文章:
【图像生成之21】融合了Transformer与Diffusion,Meta新作Transfusion实现图像与语言大一统
论文:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model 地址:https://arxiv.org/abs/2408.11039 类型:理解与生成 Transfusion模型是一种将Transformer和Diffusion模型融合的多模态模型,旨…...
Microsoft Office 如何启用和正常播放 Flash 控件
对于新安装的 Office 默认是不支持启用 Flash 组件的,Flash 组件会无法播放或者黑屏。 本片文章就带你解决这个问题,相关资料都在下方连接内。前提概要,教程对应的版本是 mso16,即 Office 2016 及更新版本,以及 365 等…...

深入浅出:信号灯与系统V信号灯的实现与应用
深入浅出:信号灯与系统V信号灯的实现与应用 信号灯(Semaphore)是一种同步机制,用于控制对共享资源的访问。在多线程或多进程环境下,信号灯能够帮助协调多个执行单元对共享资源的访问,确保数据一致性与程序…...

定位改了IP属地没变怎么回事?一文解析
明明用虚拟定位软件将手机位置改到了“三亚”,为何某某应用评论区显示的IP属地还是“北京”?为什么切换了代理IP,平台却似乎“无视”这一变化? 在“IP属地显示”功能普及后,许多用户尝试通过技术手段隐藏真实位置&…...

Cygwin中使用其它平台生成的动态库
在 Cygwin 环境下链接 VC 生成的 DLL 库需解决符号导出格式和调用约定的兼容性问题,以下是具体操作步骤: 一、VC 生成 DLL 的配置要点 声明 C 风格导出函数 在 VC 中使用 extern "C" 和 __declspec(dllexport) 避免 C 名称修饰,…...

《深入理解生命周期与作用域:以C语言为例》
🚀个人主页:BabyZZの秘密日记 📖收入专栏:C语言 🌍文章目入 一、生命周期:变量的存在时间(一)生命周期的定义(二)C语言中的生命周期类型(三&#…...

算法魅力揭秘:螺旋矩阵 II 的模拟填充与规则总结
算法魅力揭秘:螺旋矩阵 II 的模拟填充与规则总结 作为一个算法人,我们经常在竞赛和面试中遇到各种“矩阵类”问题,而螺旋矩阵 II 是其中一颗耀眼的明星。今天我将带大家从直观理解到实战代码,全面拆解螺旋矩阵 II 的规律与实现。…...

一个插件,免费使用所有顶级大模型(Deepseek,Gpt,Grok,Gemini)
DeepSider是一款集成于浏览器侧边栏的AI对话工具,可免费使用所有顶级大模型 包括GPT-4o,Grok3,Claude 3.5 Sonnet,Claude 3.7,Gemini 2.0,Deepseek R1满血版等 以极简交互与超快的响应速度,完成AI搜索、实时问答、内容创作、翻译、…...

springboot Filter实现请求响应全链路拦截!完整日志监控方案
一、为什么你需要这个过滤器? 日志痛点: 🚨 请求参数散落在各处? 🚨 响应数据无法统一记录? 🚨 日志与业务代码严重耦合? 解决方案: 一个Filter同时拦截请…...
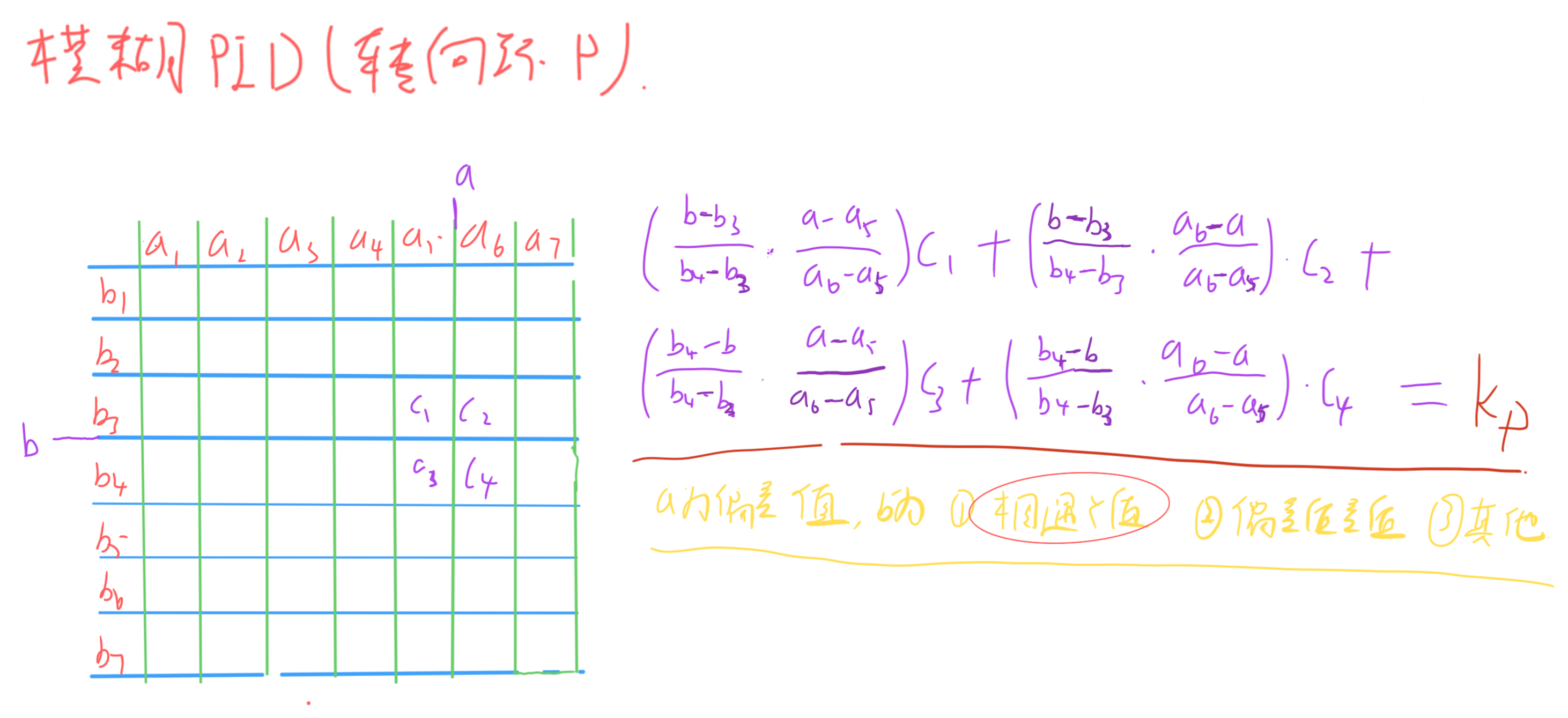
智能车摄像头开源—9 动态权、模糊PID、速度决策、路径优化
目录 一、前言 二、动态权 1.概述 2.偏差值加动态权 三、模糊PID 四、速度决策 1.曲率计算 2.速度拟合 3.速度控制 五、路径 六、国赛视频 一、前言 在前中期通过识别直道、弯道等元素可进行加减速操作实现速度的控制,可进一步缩减一圈的运行速度ÿ…...

《2025蓝桥杯C++B组:D:产值调整》
**作者的个人gitee** 作者的算法讲解主页▶️ 每日一言:“泪眼问花花不语,乱红飞过秋千去🌸🌸” 题目 二.解题策略 本题比较简单,我的思路是写三个函数分别计算黄金白银铜一次新产值,通过k次循环即可获…...

蓝队技能-Web入侵-入口查杀攻击链
Web攻击事件 分析思路: 1、利用时间节点筛选日志行为 2、利用对漏洞进行筛选日志行为 3、利用后门查杀进行筛选日志行为 4、利用文件修改时间筛选日志行为 Web日志分析 明确存储路径以及查看细节 常见中间件存储路径 IIS、Apache、Tomcat 等中间件的日志存放目…...

Android11车载WiFi热点默认名称及密码配置
一、背景 基于车厂信息安全要求,车载热点默认名称不能使用统一的名称,以及默认密码不能为简单的1~9。 基于旧项目经验,组装工厂自动化测试及客户整车组装的时候均存在多台设备同时打开,亦不太推荐使用统一的热点名称,连接无法区分。 二、需求 根据客户的要求,默认名称…...

对于GAI虚假信息对舆论观察分析
摘要 生成式人工智能(Generative Artificial Intelligence, GAI)的技术革新重构了信息生产机制,但也加剧了虚假信息对舆论生态的异化风险。 关键词:生成式人工智能、虚假信息、舆论异化、智能治理 一、生成式人工智能虚假信息下…...

问题 | 对于初学者来说,esp32和stm32哪个比较适合?
对于初学者选择ESP32还是STM32入门嵌入式开发,需综合考虑学习目标、兴趣方向及未来职业规划。以下是两者的对比分析及建议: 1. 适合初学者的关键因素 ESP32的优势 内置无线通信:集成Wi-Fi和蓝牙功能,无需额外模块即可开发物联网…...

grafana/loki 部署搜集 k8s 集群日志
grafana/loki 和 grafana/loki-stack 的区别 Grafana 提供了多个 Helm Chart 用于在 Kubernetes 集群中部署 Loki 及相关组件,其中主要包括 grafana/loki 和 grafana/loki-stack。它们的主要区别如下: 1.grafana/loki Helm Chart: 专注于 Loki 部署: 该 Chart 专门…...

EN控制同步整流WD1020 ,3.0V-21V 的宽 VIN 输入范围,0.9V-20V 的宽输出电压范围
WD1020 是一款功能强大且性能卓越的电源管理芯片,凭借其独特的特点在众多电子设备领域中展现出广泛的应用前景。以下是对其特点和应用电路的详细阐述: 集成式功率 MOSFET:WD1020 集成了低 RDS(开)功率 MOSFETÿ…...

asm汇编语言源代码之-获取环境变量
提供1个子程序: 1. 读取环境变量 GETENVSTR 具体功能及参数描述如下 GETENVSTR PROC FAR ;IN: DSPSP SEG. ; ES:BX -> ENV VAR NAME ;OUT: DS:DX -> ENV VAR VALUE; IF DX0FFFFH, NOT FOUND ; more source code at http://www.ahjoe.com/source/srcdown.aspPU…...

2025认证杯一阶段各题需要使用的模型或算法(冲刺阶段)
A题(小行星轨迹预测) 问题一:三角测量法、最小二乘法、空间几何算法、最优化方法 问题二:Gauss/Laplace轨道确定方法、差分校正法、数值积分算法(如Runge-Kutta法)、卡尔曼滤波器 B题(谣言在…...
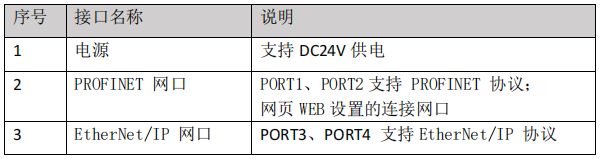
①(PROFINET 转 EtherNet/IP)EtherCAT/Ethernet/IP/Profinet/ModbusTCP协议互转工业串口网关
型号 协议转换通信网关 PROFINET 转 EtherNet/IP MS-GW32 概述 MS-GW32 是 PROFINET 和 EtherNet/IP 协议转换网关,为用户提供两种不同通讯协议的 PLC 进行数据交互的解决方案,可以轻松容易将 EtherNet/IP 网络接入 PROFINET 网络中,方便…...

LeetCode 3272.统计好整数的数目:枚举+排列组合+哈希表
【LetMeFly】3272.统计好整数的数目:枚举排列组合哈希表 力扣题目链接:https://leetcode.cn/problems/find-the-count-of-good-integers/ 给你两个 正 整数 n 和 k 。 如果一个整数 x 满足以下条件,那么它被称为 k 回文 整数 。 x 是一个…...

Linux中的tar -P选项
tar -P选项 Linux中的tar命令可用于文件和目录的归档以及压缩解压缩。而其中的-P选项是什么含义呢?下面我们就来看一看 1、不添加-P选项 对于如下压缩命令: tar -czvf pkg.tar.gz /opt/software执行该命名,控制台首行输出将会提示…...

Linux目录探秘:文件系统的核心架构
引言 Linux文件系统就像一棵精心设计的大树🌳,每个分支都有其特定的用途和规范。与Windows不同,Linux采用单一的目录结构,所有设备、分区和网络资源都挂载在这个统一的目录树下。本文将带你深入探索Linux目录结构的奥秘ÿ…...
国标GB28181视频平台EasyCVR如何搭建汽车修理厂远程视频网络监控方案
一、背景分析 近年我国汽车保有量持续攀升,与之相伴的汽车保养维修需求也逐渐提高。随着社会经济的发展,消费者对汽车维修服务质量的要求越来越高,这使得汽车维修店的安全防范与人员管理问题面临着巨大挑战。 多数汽车维修店分布分散&#…...

python【标准库】multiprocessing
文章目录 介绍多进程Process 创建子进程共享内存数据多进程通信Pool创建子进程多进程案例多进程注意事项介绍 python3.10.17版本multiprocessing 是一个多进程标准模块,使用类似于threading模块的API创建子进程,充分利用多核CPU来并行处理任务。提供本地、远程的并发,高效避…...

南墙WAF非标端口防护实战解析——指定端口安全策略深度剖析
本文系统解析非标端口DDoS攻击防护难点,重点阐述南墙WAF在指定端口防御中的技术突破。通过某金融机构真实攻防案例,结合Gartner最新防御架构模型,揭示如何构建基于智能流量建模的精准防护体系,为金融、政务等关键领域提供可落地的…...
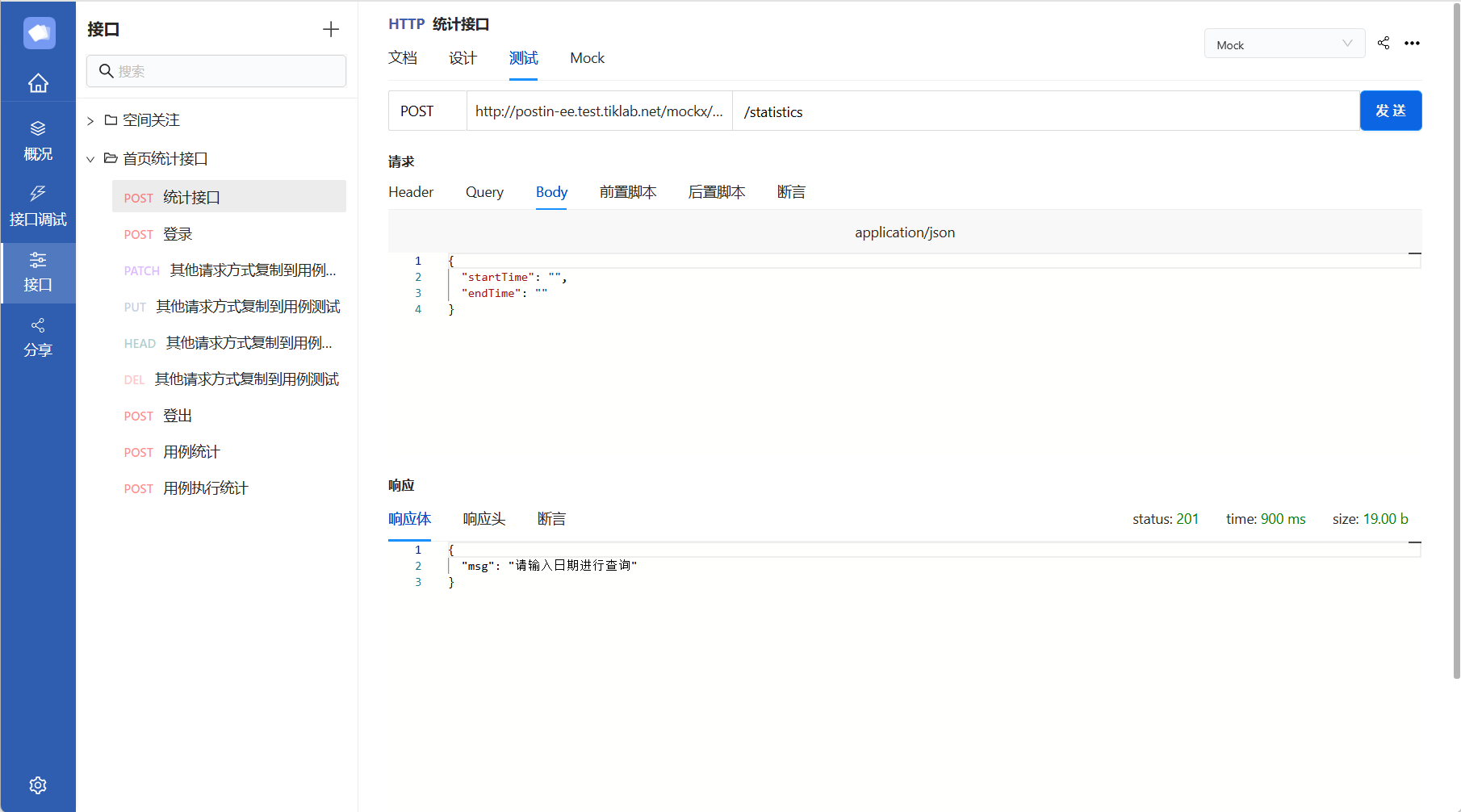
PostIn安装及入门教程
PostIn是一款国产开源免费的接口管理工具,包含项目管理、接口调试、接口文档设计、接口数据MOCK等模块,支持常见的HTTP协议、websocket协议等,支持免登陆本地接口调试,本文将介绍如何快速安装配置及入门使用教程。 1、安装 私有…...
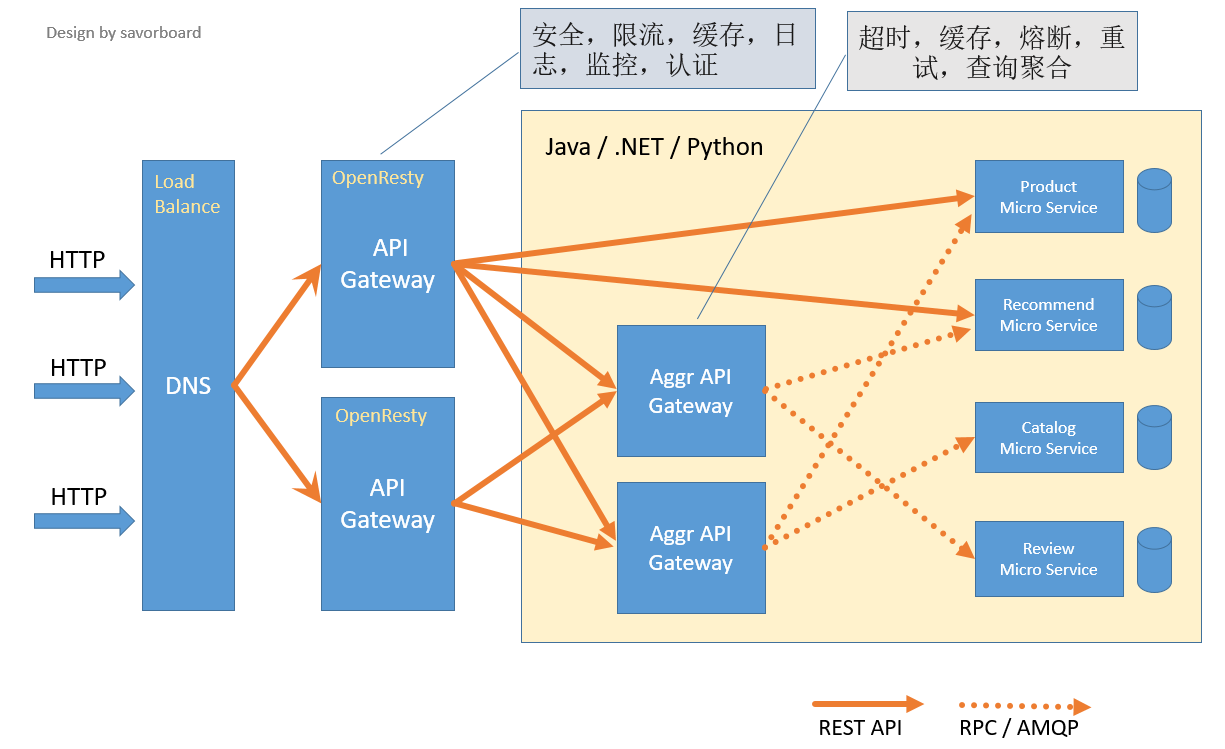
spring cloud微服务API网关详解及各种解决方案详解
微服务API网关详解 1. 核心概念 定义:API网关作为微服务的统一入口,负责请求路由、认证、限流、监控等功能,简化客户端与后端服务的交互。核心功能: 路由与转发:将请求分发到对应服务。协议转换:HTTP/HTTP…...
最新版PhpStorm超详细图文安装教程,带补丁包(2025最新版保姆级教程)
目录 前言 一、PhpStorm最新版下载 二、PhpStorm安装 三、PhpStorm补丁 四、运行PhpStorm 前言 PhpStorm 是 JetBrains 公司推出的 专业 PHP 集成开发环境(IDE),专为提升 PHP 开发效率设计。其核心功能包括智能代码补全、实时语法错误检…...

FileInputStream 详解与记忆方法
FileInputStream 详解与记忆方法 一、FileInputStream 核心概念 FileInputStream 是 Java 中用于从文件读取原始字节的类,继承自 InputStream 抽象类。 1. 核心特点 特性说明继承关系InputStream → FileInputStream数据单位字节(8bit)用…...