制造一只电子喵 (qwen2.5:0.5b 微调 LoRA 使用 llama-factory)
AI (神经网络模型) 可以认为是计算机的一种新的 “编程” 方式. 为了充分利用计算机, 只学习传统的编程 (编程语言/代码) 是不够的, 我们还要掌握 AI.
本文以 qwen2.5 和 llama-factory 举栗, 介绍语言模型 (LLM) 的微调 (LoRA SFT). 为了方便上手, 此处选择使用小模型 (qwen2.5:0.5b). 不需要很高的硬件配置, 基本上找台机器就能跑.
微调就是对已有模型进行再训练 (改变模型参数), 从而改变模型的输出和功能. 微调有很多种不同的方式, 此处使用 SFT (监督微调), 也就是提供多组输入/输出数据, 让模型来学习.
LoRA (低秩适配) 的原理也很简单: 我们知道, qwen2.5 是基于 transformer 的语言模型, 而 transformer 的核心是矩阵运算 (矩阵相乘). 也就是说, 输入模型的是矩阵数据, 模型的参数也是许多矩阵, 模型输出的也是矩阵. 如果对模型的全量参数进行微调, 就要对整个参数矩阵进行修改, 计算量很大.
LoRA 的做法就是, 用两个小矩阵相乘来代替一个大矩阵. 比如 100x2 (100 行 2 列) 的矩阵和 2x100 的矩阵相乘, 就能得到一个 100x100 的大矩阵. 大矩阵里面一共有 10000 个数字, 两个小矩阵只有 400 个数字. LoRA 只对小矩阵进行微调, 微调结束后加到原来的大矩阵上即可. 由于显著减少了微调参数的数量, LoRA 可以减少计算量, 减少对硬件配置 (显存) 的要求, 更快的微调模型.
这里是 穷人小水滴, 专注于 穷人友好型 低成本技术. (本文为 68 号作品. )
相关文章:
- 《本地运行 AI 有多慢 ? 大模型推理测速 (llama.cpp, Intel GPU A770)》 https://blog.csdn.net/secext2022/article/details/141563659
- 《低功耗低成本 PC (可更换内存条) 推荐 (笔记本, 小主机)》 https://blog.csdn.net/secext2022/article/details/146135064
参考资料:
- https://qwen.readthedocs.io/zh-cn/latest/training/SFT/llama_factory.html
- https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
- https://docs.astral.sh/uv/
- https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
- https://github.com/hiyouga/LLaMA-Factory
目录
- 1 安装 llama-factory
- 1.1 安装 uv
- 1.2 下载并安装 llama-factory
- 2 下载 qwen2.5:0.5b 模型
- 3 准备数据并进行 LoRA 微调
- 4 测试结果
- 5 总结与展望
1 安装 llama-factory
类似于大部分 AI 相关的项目, llama-factory 也是 python 编写的. 然而 python 嘛 … . 有点麻烦, 特别是安装. 所以:
重点: 安装 llama-factory 可能是本文中最困难的一步了, 各种报错, 令人头大 !!
1.1 安装 uv
首先, 安装 python 包管理器 uv: https://docs.astral.sh/uv/
此处以 ArchLinux 操作系统举栗:
sudo pacman -S uv
验证安装:
> uv --version
uv 0.6.10 (f2a2d982b 2025-03-25)
然后安装几个常用版本的 python:
> uv python install 3.10 3.11 3.12 3.13
Installed 4 versions in 17.82s+ cpython-3.10.16-linux-x86_64-gnu+ cpython-3.11.11-linux-x86_64-gnu+ cpython-3.12.9-linux-x86_64-gnu+ cpython-3.13.2-linux-x86_64-gnu
设置 pypi 镜像 (比如):
> cat ~/.config/uv/uv.toml
[[index]]
url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple"
default = true
1.2 下载并安装 llama-factory
从 github release 页面下载 llama-factory 的源代码: https://github.com/hiyouga/LLaMA-Factory/releases/tag/v0.9.2
注意不要直接下载主分支, 可能会安装失败 ! (python 依赖错误)
下载 llamafactory-0.9.2.tar.gz 并解压.
> cd llamafactory-0.9.2> uv venv --python=3.10
Using CPython 3.10.16
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate.fish> uv pip install torch setuptools> uv sync --no-build-isolation --extra torch --extra metrics --prerelease=allow
安装完毕, 检查一下能否正常运行:
> uv run --prerelease=allow llamafactory-cli version----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.9.2 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
2 下载 qwen2.5:0.5b 模型
我们从国内网站下载模型, 这样下载速度快, 比较方便: https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
创建一个新目录并初始化 venv:
> cd dl-model> uv venv
Using CPython 3.13.2
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate.fish
安装下载工具:
uv pip install modelscope setuptools
然后下载模型:
> uv run modelscope download --model Qwen/Qwen2.5-0.5B-Instruct
Downloading Model from https://www.modelscope.cn to directory: /home/s2/.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instruct
查看下载好的模型:
> cd ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instruct
> ls -l
总计 976196
-rw-r--r-- 1 s2 s2 659 4月12日 13:26 config.json
-rw-r--r-- 1 s2 s2 2 4月12日 13:26 configuration.json
-rw-r--r-- 1 s2 s2 242 4月12日 13:26 generation_config.json
-rw-r--r-- 1 s2 s2 11343 4月12日 13:26 LICENSE
-rw-r--r-- 1 s2 s2 1671839 4月12日 13:26 merges.txt
-rw-r--r-- 1 s2 s2 988097824 4月12日 13:28 model.safetensors
-rw-r--r-- 1 s2 s2 4917 4月12日 13:26 README.md
-rw-r--r-- 1 s2 s2 7305 4月12日 13:26 tokenizer_config.json
-rw-r--r-- 1 s2 s2 7031645 4月12日 13:26 tokenizer.json
-rw-r--r-- 1 s2 s2 2776833 4月12日 13:26 vocab.json
3 准备数据并进行 LoRA 微调
微调过程参考: https://qwen.readthedocs.io/zh-cn/latest/training/SFT/llama_factory.html
-
(1) 准备数据文件:
llamafactory-0.9.2/data/dataset_info.json{"miao1": {"file_name": "miao1.json","columns": {"prompt": "instruction","response": "output","system": "system"}} }注意这个文件的位置是固定的.
其中
miao1是数据集名称, 可以自己随意指定.
文件:
llamafactory-0.9.2/data/miao1.json[{"instruction": "你是谁 ?","output": "我是一只小猫呀, 喵 ~","system": "你是一只可爱的小猫, 喵 ~"} ]这是数据集的具体内容, 此处有一条数据. 其中
instruction是输入,output是模型的输出,system是系统消息. -
(2) 准备训练参数文件:
test_sft_lora/train.yamlmodel_name_or_path: /home/s2/.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instructstage: sft do_train: true finetuning_type: lora lora_rank: 8 lora_target: q_proj,v_projdataset: miao1 template: qwen cutoff_len: 1024 max_samples: 1000 overwrite_cache: true preprocessing_num_workers: 1 dataloader_num_workers: 0output_dir: ./out_cp logging_steps: 1 save_steps: 20 plot_loss: true overwrite_output_dir: true save_only_model: falseper_device_train_batch_size: 1 gradient_accumulation_steps: 4 learning_rate: 5.0e-5 num_train_epochs: 200 lr_scheduler_type: cosine warmup_steps: 10 bf16: true ddp_timeout: 9000 resume_from_checkpoint: true这个文件的位置和名称随意. 其中
model_name_or_path指定原始模型的完整路径,dataset指定使用的数据集,output_dir指定输出目录.其余训练参数可根据需要适当调节.
-
(3) 准备完毕, 开始训练:
uv run --prerelease=allow llamafactory-cli train test_sft_lora/train.yaml好, 开始炼丹 ! 期间会有类似这样的输出:
{'loss': 2.0416, 'grad_norm': 5.902700424194336, 'learning_rate': 4e-05, 'epoch': 8.0} {'loss': 2.0027, 'grad_norm': 5.895074844360352, 'learning_rate': 4.5e-05, 'epoch': 9.0} {'loss': 1.9685, 'grad_norm': 5.861382007598877, 'learning_rate': 5e-05, 'epoch': 10.0} {'loss': 1.9394, 'grad_norm': 5.852997303009033, 'learning_rate': 4.9996582624811725e-05, 'epoch': 11.0} {'loss': 1.9005, 'grad_norm': 5.758986473083496, 'learning_rate': 4.9986331433523156e-05, 'epoch': 12.0} {'loss': 1.8258, 'grad_norm': 5.6334004402160645, 'learning_rate': 4.996924922870762e-05, 'epoch': 13.0} {'loss': 1.7746, 'grad_norm': 5.594630718231201, 'learning_rate': 4.994534068046937e-05, 'epoch': 14.0} 7%|███████▍ | 14/200 [10:34<2:20:09, 45.21s/it]
***** train metrics *****epoch = 200.0total_flos = 16023GFtrain_loss = 0.0004train_runtime = 1:17:01.72train_samples_per_second = 0.043train_steps_per_second = 0.043
Figure saved at: ./out_cp/training_loss.png
炼丹完毕 !
> cd out_cp/checkpoint-100/
> ls -l
总计 22008
-rw-r--r-- 1 s2 s2 696 4月12日 15:11 adapter_config.json
-rw-r--r-- 1 s2 s2 2175168 4月12日 15:11 adapter_model.safetensors
-rw-r--r-- 1 s2 s2 605 4月12日 15:11 added_tokens.json
-rw-r--r-- 1 s2 s2 1671853 4月12日 15:11 merges.txt
-rw-r--r-- 1 s2 s2 4403514 4月12日 15:11 optimizer.pt
-rw-r--r-- 1 s2 s2 5146 4月12日 15:11 README.md
-rw-r--r-- 1 s2 s2 13990 4月12日 15:11 rng_state.pth
-rw-r--r-- 1 s2 s2 1064 4月12日 15:11 scheduler.pt
-rw-r--r-- 1 s2 s2 613 4月12日 15:11 special_tokens_map.json
-rw-r--r-- 1 s2 s2 7361 4月12日 15:11 tokenizer_config.json
-rw-r--r-- 1 s2 s2 11421896 4月12日 15:11 tokenizer.json
-rw-r--r-- 1 s2 s2 16383 4月12日 15:11 trainer_state.json
-rw-r--r-- 1 s2 s2 5624 4月12日 15:11 training_args.bin
-rw-r--r-- 1 s2 s2 2776833 4月12日 15:11 vocab.json
像 out_cp/checkpoint-100 就是保存的检查点, 也就是训练结果.
打开文件: llamafactory-0.9.2/out_cp/training_loss.png

可以看到训练过程中的损失 (loss). 大约 75 步 (step) 的时候, 看起来已经收敛了 (也就是训练好了).
可以先尝试运行一下, 首先准备参数文件: test_sft_lora/chat.yaml
model_name_or_path: /home/s2/.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instructadapter_name_or_path: ./out_cp/checkpoint-100template: qwen
infer_backend: huggingfacedefault_system: 你是一只可爱的小猫, 喵 ~
其中 adapter_name_or_path 指定使用的检查点, default_system 是系统消息, 应该和训练时的保持一致.
然后:
> uv run --prerelease=allow llamafactory-cli chat test_sft_lora/chat.yaml此处省略[INFO|2025-04-12 19:14:05] llamafactory.model.model_utils.attention:157 >> Using torch SDPA for faster training and inference.
[INFO|2025-04-12 19:14:05] llamafactory.model.adapter:157 >> Merged 1 adapter(s).
[INFO|2025-04-12 19:14:05] llamafactory.model.adapter:157 >> Loaded adapter(s): ./out_cp/checkpoint-100
[INFO|2025-04-12 19:14:06] llamafactory.model.loader:157 >> all params: 494,032,768
Welcome to the CLI application, use `clear` to remove the history, use `exit` to exit the application.
User: 你是谁 ?
Assistant: 我是一只小猫呀, 喵 ~
User:
输出符合预期, 模型训练成功 !
4 测试结果
为了方便运行, 可以合并 LoRA 导出模型, 然后用 ollama 运行: https://ollama.com/
ArchLinux 安装 ollama:
sudo pacman -S ollama
启动 ollama:
> sudo systemctl start ollama
> ollama --version
ollama version is 0.6.5
准备参数文件: test_sft_lora/export.yaml
model_name_or_path: /home/s2/.cache/modelscope/hub/models/Qwen/Qwen2.5-0.5B-Instructadapter_name_or_path: ./out_cp/checkpoint-100template: qwen
finetuning_type: loraexport_dir: ./export1
export_size: 2
export_legacy_format: false
然后:
> uv run --prerelease=allow llamafactory-cli export test_sft_lora/export.yaml此处省略[INFO|2025-04-12 19:32:19] llamafactory.model.model_utils.attention:157 >> Using torch SDPA for faster training and inference.
[INFO|2025-04-12 19:32:19] llamafactory.model.adapter:157 >> Merged 1 adapter(s).
[INFO|2025-04-12 19:32:19] llamafactory.model.adapter:157 >> Loaded adapter(s): ./out_cp/checkpoint-100
[INFO|2025-04-12 19:32:19] llamafactory.model.loader:157 >> all params: 494,032,768
[INFO|2025-04-12 19:32:19] llamafactory.train.tuner:157 >> Convert model dtype to: torch.bfloat16.
[INFO|configuration_utils.py:423] 2025-04-12 19:32:19,801 >> Configuration saved in ./export1/config.json
[INFO|configuration_utils.py:909] 2025-04-12 19:32:19,801 >> Configuration saved in ./export1/generation_config.json
[INFO|modeling_utils.py:3040] 2025-04-12 19:32:20,597 >> Model weights saved in ./export1/model.safetensors
[INFO|tokenization_utils_base.py:2500] 2025-04-12 19:32:20,598 >> tokenizer config file saved in ./export1/tokenizer_config.json
[INFO|tokenization_utils_base.py:2509] 2025-04-12 19:32:20,598 >> Special tokens file saved in ./export1/special_tokens_map.json
[INFO|2025-04-12 19:32:20] llamafactory.train.tuner:157 >> Ollama modelfile saved in ./export1/Modelfile
查看导出的模型:
> cd export1/
> ls -l
总计 980472
-rw-r--r-- 1 s2 s2 605 4月12日 19:32 added_tokens.json
-rw-r--r-- 1 s2 s2 778 4月12日 19:32 config.json
-rw-r--r-- 1 s2 s2 242 4月12日 19:32 generation_config.json
-rw-r--r-- 1 s2 s2 1671853 4月12日 19:32 merges.txt
-rw-r--r-- 1 s2 s2 424 4月12日 19:32 Modelfile
-rw-r--r-- 1 s2 s2 988097824 4月12日 19:32 model.safetensors
-rw-r--r-- 1 s2 s2 613 4月12日 19:32 special_tokens_map.json
-rw-r--r-- 1 s2 s2 7362 4月12日 19:32 tokenizer_config.json
-rw-r--r-- 1 s2 s2 11421896 4月12日 19:32 tokenizer.json
-rw-r--r-- 1 s2 s2 2776833 4月12日 19:32 vocab.json
其中 Modelfile: (手动修改为如下内容)
# ollama modelfile auto-generated by llamafactoryFROM .TEMPLATE """{{ if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ range .Messages }}{{ if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
<|im_start|>assistant
{{ else if eq .Role "assistant" }}{{ .Content }}<|im_end|>
{{ end }}{{ end }}"""SYSTEM """你是一只可爱的小猫, 喵 ~"""PARAMETER stop "<|im_end|>"
PARAMETER num_ctx 4096
导入 ollama:
ollama create miao-100 -f Modelfile
导入的模型:
> ollama list
NAME ID SIZE MODIFIED
miao-100:latest e6bad20de2f7 994 MB 30 seconds ago
运行:
> ollama run --verbose miao-100
>>> /show system
你是一只可爱的小猫, 喵 ~>>> 你是谁 ?
我是一只小猫呀, 喵 ~total duration: 452.998361ms
load duration: 23.522214ms
prompt eval count: 27 token(s)
prompt eval duration: 88.381273ms
prompt eval rate: 305.49 tokens/s
eval count: 12 token(s)
eval duration: 337.489268ms
eval rate: 35.56 tokens/s
>>>
使用 CPU 运行:
> ollama ps
NAME ID SIZE PROCESSOR UNTIL
miao-100:latest e6bad20de2f7 1.7 GB 100% CPU 3 minutes from now
多说几句:
> ollama run miao-100
>>> 你是谁 ?
我是一只小猫呀, 喵 ~>>> 你喜欢什么 ?
我最喜欢玩捉迷藏了, 喵 ~>>> 你喜欢吃什么 ?
我喜欢吃米饭和面包, 喵 ~>>> 你喜欢去哪里 ?
我喜欢在树上玩耍, 喵 ~>>> 喵喵喵
你好啊~ 喵 ~
电子喵制造大成功 !!
5 总结与展望
使用 llama-factory 工具可以对 AI 语言模型 (LLM) 进行微调 (LoRA SFT), 只需准备数据集即可.
可以看到, AI 具有一定的泛化能力, 也就是训练数据集中没有的问题, 模型也可以给出比较合理的回答.
此处使用的丹炉不好, 炼不了上品仙丹, 只能用个小模型意思意思. 但原理和操作步骤都是一样的, 只要换上更好的硬件, 准备更多数据, 就能炼制更好更大的仙丹啦 ~
AI 并不复杂神秘, 模型只是大 (烧钱) 而已. 大力出奇迹, 力大砖飞.
本文使用 CC-BY-SA 4.0 许可发布.
相关文章:
制造一只电子喵 (qwen2.5:0.5b 微调 LoRA 使用 llama-factory)
AI (神经网络模型) 可以认为是计算机的一种新的 “编程” 方式. 为了充分利用计算机, 只学习传统的编程 (编程语言/代码) 是不够的, 我们还要掌握 AI. 本文以 qwen2.5 和 llama-factory 举栗, 介绍语言模型 (LLM) 的微调 (LoRA SFT). 为了方便上手, 此处选择使用小模型 (qwen2…...

如何查询node inode上限是多少?
在 Linux 系统中,inode 上限由文件系统的类型和格式化时的参数决定。不同文件系统(如 ext4、XFS)有不同的查询方法。以下是详细操作步骤: 1. 确认文件系统类型 首先确定目标磁盘分区的文件系统类型(如 ext4、XFS&…...
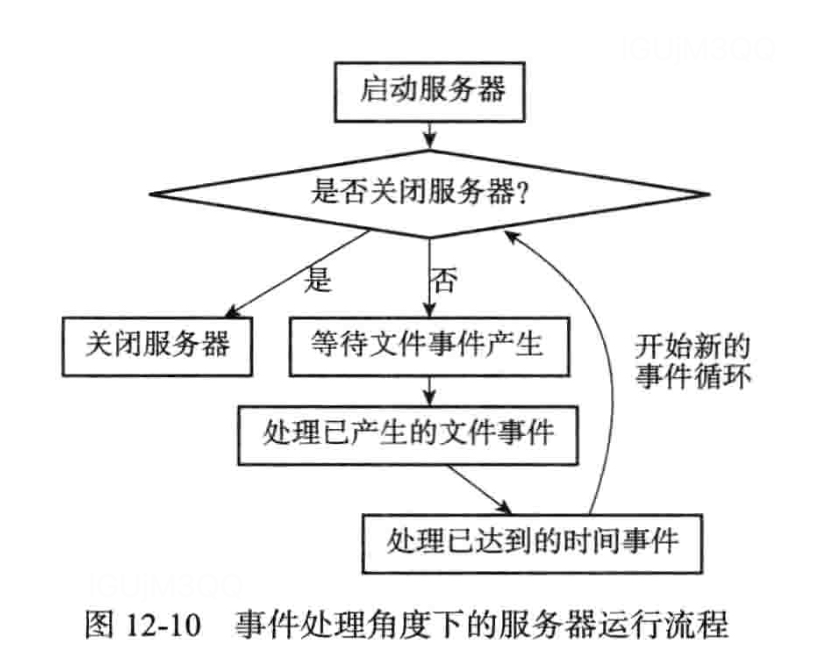
Redis核心功能实现
前言 学习是个输入的过程,在进行输入之后再进行一些输出,比如写写文章,笔记,或者做一些技术串讲,虽然需要花费不少时间,但是好处很多,首先是能通过输出给自己的输入带来一些动力,然…...

驱动学习专栏--字符设备驱动篇--1_chrdevbase
字符设备驱动简介 字符设备是 Linux 驱动中最基本的一类设备驱动,字符设备就是一个一个字节,按照字节 流进行读写操作的设备,读写数据是分先后顺序的。比如我们最常见的点灯、按键、 IIC 、 SPI , LCD 等等都是字符设备&…...

Python及C++中的列表
一、Python中的列表(List) Python的列表是动态数组,内置于语言中,功能强大且易用,非常适合算法竞赛。 1. 基本概念 定义:列表是一个有序、可变的序列,可以存储任意类型的元素(整数…...

Oracle DROP、TRUNCATE 和 DELETE 原理
在 Oracle 11g 中,DROP、TRUNCATE 和 DELETE 是三种不同的数据清理操作,它们的底层原理和适用场景有显著差异 1. DELETE 的原理 类型:DML(数据操作语言) 功能:逐行删除表中符合条件的数据,保留…...

ida 使用记录
文章目录 伪代码-汇编hexstring快捷键 伪代码-汇编 流程图界面——F5——伪代码界面——再点Tab——流程图界面——再按空格——汇编界面流程图界面——空格——汇编界面 hex view - open subviews - hex dump string view - open subviews - string快捷键: sh…...
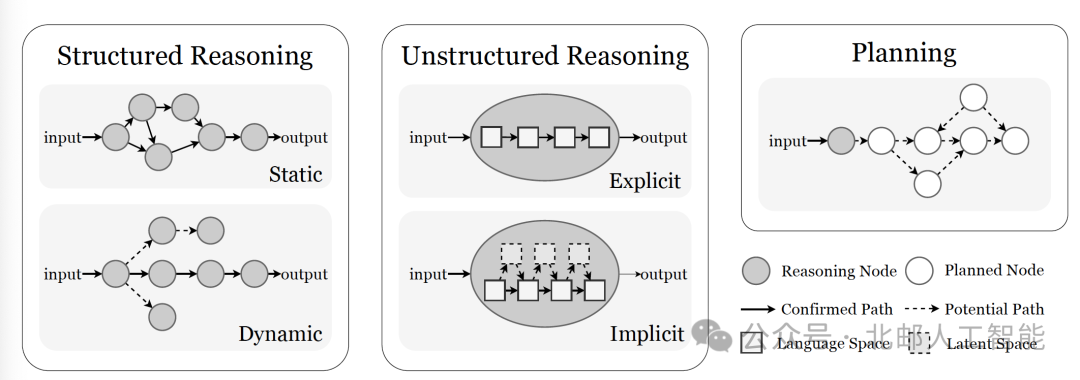
【连载3】基础智能体的进展与挑战综述
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 2. 认知 人类认知是一种复杂的信息处理系统,它通过多个专门的神经回路协调运行…...

MacOs java环境配置+maven环境配置踩坑实录
oracl官网下载jdk 1.8的安装包 注意可能需要注册!!! 下载链接:下载地址点击 注意晚上就不要下载了 报错400 !!! 1.点击安装嘛 2.配置环境变量 export JAVA_HOME/Library/Java/Java…...
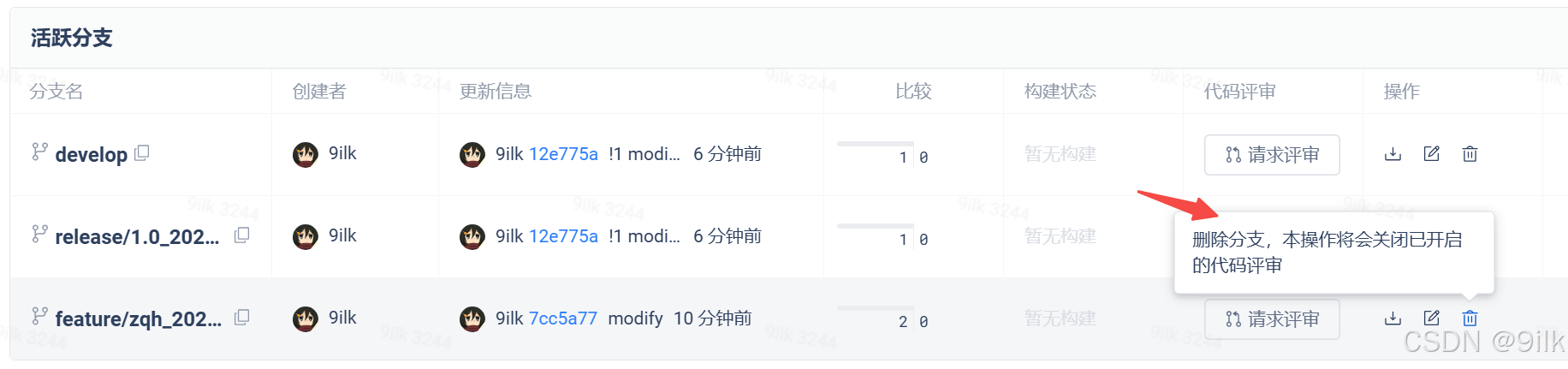
【Git】--- 企业级开发流程
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: Git 本篇博客我们讲解Git在企业开发中的整体流程,理解Git在实际企业开发中的高效设计。 🏠 企业级开发流程 一个软件从零开始到最…...

SAP系统客户可回收包材库存管理
问题:客户可回收包材库存管理 现象:回收瓶无库存管理,在库数量以及在客户的库存数量没有统计,管理混乱。 解决方法: 客户可回收包装材料在SAP有标准的解决方案,在集团尚未启用该业务,首先…...
蓝桥杯嵌入式历年省赛客观题
一.第十五届客观题 第十四届省赛 十三届 十二届...

JDK的卸载与安装
卸载JDK 删除java的1安装目录 卸载JAVA_HOME 删除path下关于java的路径 java -version查看 安装JDK 百度搜索JDK,找到下载地址 同意协议 下载电脑对应版本 双击安装 记住安装路径 配置环境变量 我的电脑–>右键–>属性–>高级系统设置 环境变…...
持续更新!)
八股系列(分布式与微服务)持续更新!
八股系列(分布式与微服务) 分布式系统的概念 分布式系统是由多个节点组成,节点之间通过网络协议传递数据,对外表现为一个统一的整体,一个节点可以是一台机器或一个进程;分布式系统的核心功能 资源共享&…...

【源码】Mybatis源码
引言 MyBatis 作为 Java 开发中广泛使用的持久层框架,其高效且灵活的数据库操作能力备受开发者青睐。在日常开发中,我们熟练运用 MyBatis 的各种功能来实现数据持久化,但深入探究其源码,能让我们更透彻地理解它的工作原理&#…...
解决2080Ti使用节点ComfyUI-PuLID-Flux-Enhanced中遇到的问题
使用蓝大的工作流《一键同时换头、换脸、发型、发色之双pulid技巧》 刚开始遇到的是不支持bf16的错误 根据《bf16 is only supported on A100 GPUs #33》中提到,修改pulidflux.py中的dtype 为 dtype torch.float16 后,出现新的错误,这个…...
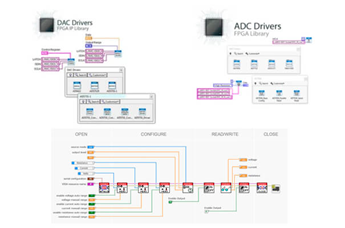
LabVIEW驱动开发的解决思路
在科研项目中,常面临将其他语言开发的定制采集设备驱动转换为 LabVIEW 适用形式的难题。特别是当原驱动支持匮乏、开发人员技术支持不足时,如何抉择解决路径成为关键。以下提供具体解决思路,助力高效解决问题。 一、评估现有驱动死磕的可…...

[英语] abominable、detestable、despicable、odious、contemptible的区别
关于 abominable 与其他近义词的辨析 abominable 的核心含义是“因极端恶劣或违背道德而令人憎恶”,其情感强度较高,常带有道德批判意味。以下是其与常见近义词的区别及典型用法: 1. abominable vs. detestable abominable:强调…...
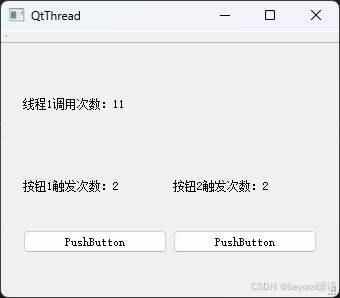
七、Qt框架编写的多线程应用程序
一、大纲 学习内容:使用两个线程,分别点击两个按钮,触发两个不同的效果 所需控件:两个button、三个label 涉及知识点:多线程、Qt的connect机制、定时器、互斥锁 需求: 1,多线程定时计数&#x…...
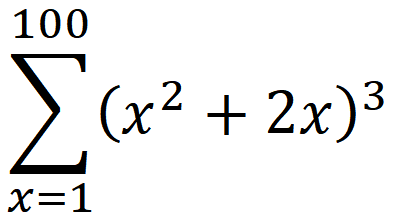
MATLAB求和∑怎么用?
MATLAB求和∑怎么用? 一:题目:求下列方程的和 二、代码如下 1.syms函数 (方法一) 代码如下(示例): 1. syms x 2. symsum((x.^22*x).^3,1,100) 3. 2.直接用循环 (方法二) 代码如下&am…...
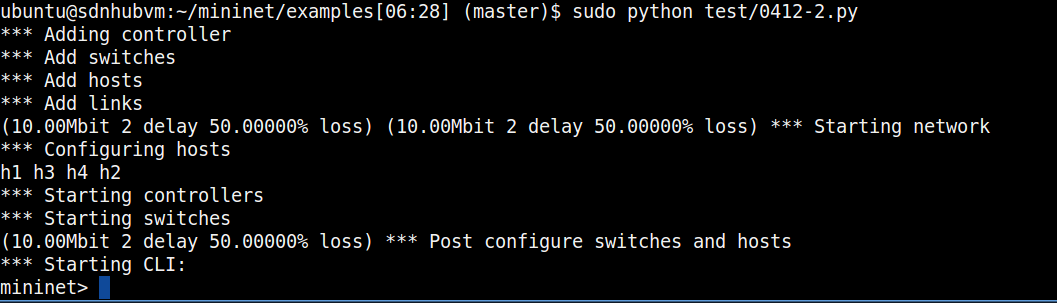
项目二 使用miniedit创建拓扑
一、项目需求分析: 1. 在ubuntu的桌面环境中运行Mininet的图形化界面2. Mininet图形化界面中搭建拓扑并设置相关的设备和链路属性3. Floodlight中查看拓扑4. 完成Mininet的测试 二、项目实施步骤 1. 运行Mininet图形化界面 在“~/mininet/examples”目录下有一m…...
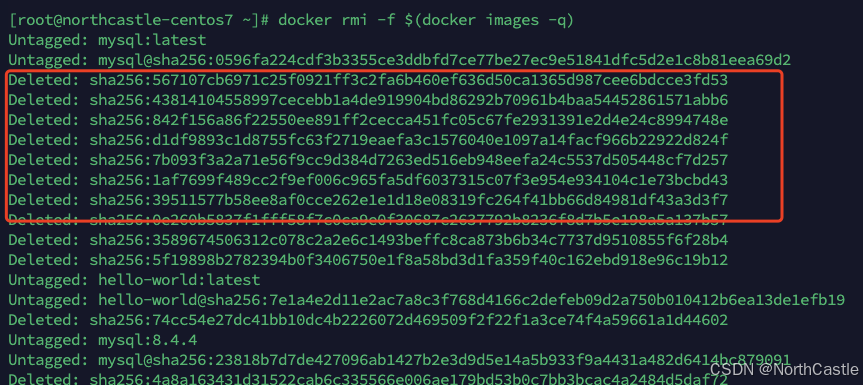
Docker 镜像 的常用命令介绍
拉取镜像 $ docker pull imageName[:tag][:tag] tag 不写时,拉取的 是 latest 的镜像查看镜像 查看所有本地镜像 docker images or docker images -a查看完整的镜像的数字签名 docker images --digests查看完整的镜像ID docker images --no-trunc只查看所有的…...
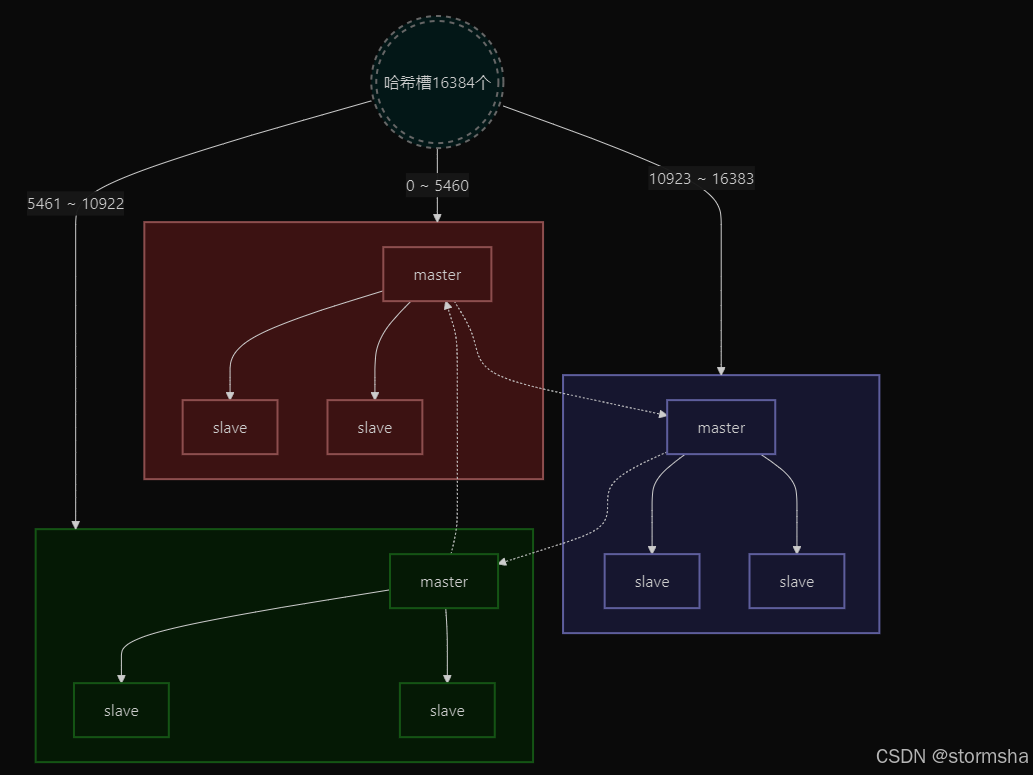
0x02.Redis 集群的实现原理是什么?
回答重点 Redis 集群(Redis cluster)是通过多个 Redis 实例组成的,每个主节点实例负责存储部分的数据,并且可以有一个或多个从节点作为备份。 具体是采用哈希槽(Hash Slot)机制来分配数据,将整…...
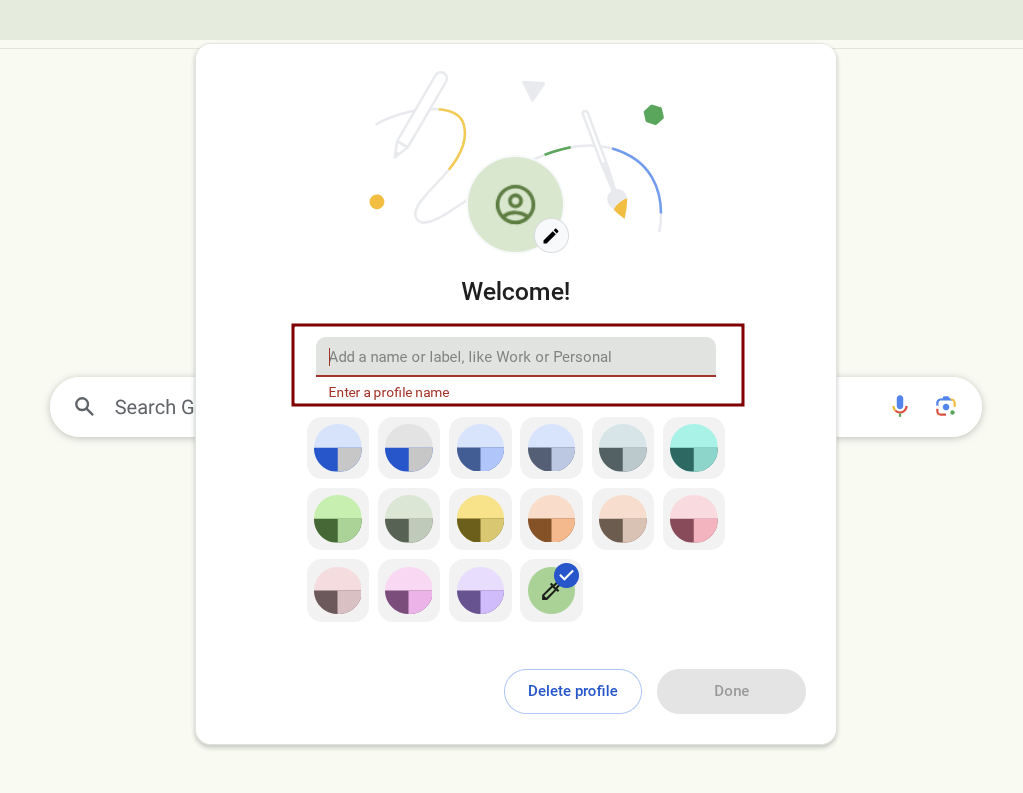
浏览器多开
使用浏览器的用户功能,创建多个用户即可完成浏览器多开的需求,插件等相对独立 需要命名 然后就可以通过多个用户切换来实现多开了,不同任务选择不同用户...

Python中NumPy的逻辑和比较
在数据科学和科学计算领域,NumPy是一个不可或缺的Python库。它提供了高效的多维数组对象以及丰富的数组操作函数,其中逻辑和比较操作是NumPy的核心功能之一。通过灵活运用这些操作,我们可以轻松实现数据筛选、条件判断和复杂的数据处理任务。…...

20250412_代码笔记_CVRProblemDef
文章目录 前言一、get_random_problems 函数分析二、augment_xy_data_by_8_fold 函数分析代码 前言 该笔记分析代码的功能是生成随机VRP问题的数据,包含仓库坐标、节点坐标和节点需求。 对该代码进行改进 20250412-代码改进-拟蒙特卡洛 一、get_random_problems 函…...
——决策树)
机器学习(3)——决策树
文章目录 1. 决策树基本原理1.1. 什么是决策树?1.2. 决策树的基本构成:1.3. 核心思想 2. 决策树的构建过程2.1. 特征选择2.1.1. 信息增益(ID3)2.1.2. 基尼不纯度(CART)2.1.3. 均方误差(MSE&…...

Redis常用数据结构和应用场景
一、前言 Redis提供了多种数据结构,每种结构对应不同的应用场景。本文对部分常用的核心数据结构和典型使用场景作出介绍。 二、String(字符串) 特点:二进制安全,可存储文本、数字、序列化对象等。场景: 缓…...
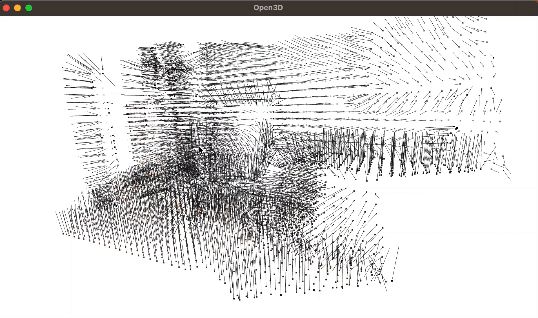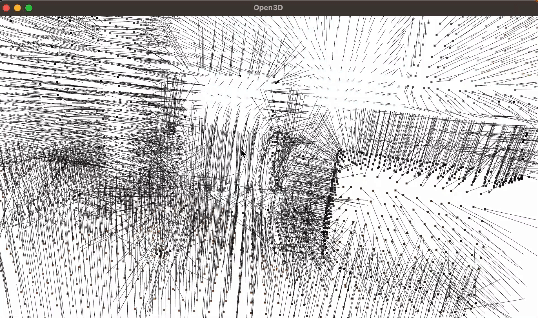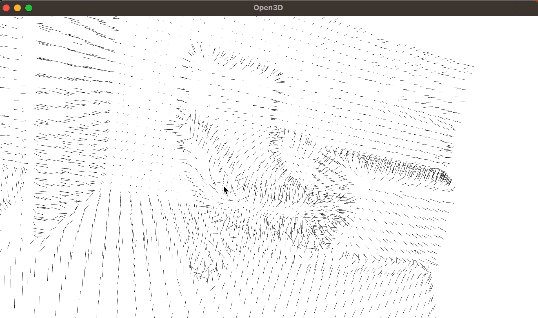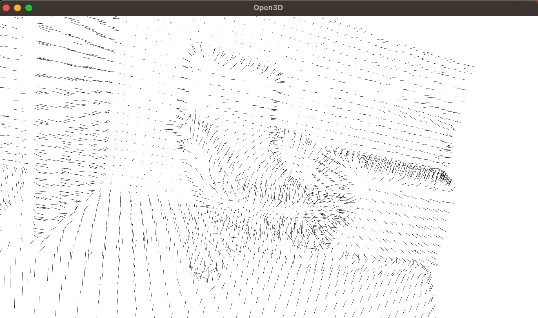
【转载翻译】使用Open3D和Python进行点云处理
转自个人博客:【转载翻译】使用Open3D和Python进行点云处理 转载自:Point Cloud Processing with Open3D and Python 本文由 Carlos Melo 发布于2024年2月12日 本文很适合初学者对三维处理、点云处理以及Open3D库进行初步了解 另外,本文是基于…...
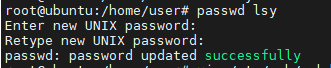
用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...