智能医疗辅助诊断:深度解析与实战教程
引言:医疗领域的新革命
在医疗资源紧张、诊断效率亟待提升的今天,智能医疗辅助诊断技术正以前所未有的速度改变医疗行业的面貌。通过结合人工智能与医学专业知识,智能医疗辅助诊断系统能够为医生提供精准的诊断建议和决策支持,显著提高诊断的准确性和效率。本文将带您深入探索这一领域,从理论到实践,手把手教您如何构建一个基于医学影像的智能辅助诊断系统。
一、技术概述:智能医疗辅助诊断的核心
1.1 什么是智能医疗辅助诊断?
智能医疗辅助诊断是人工智能与医疗领域深度融合的产物,它利用机器学习、深度学习等算法,对医疗数据(如医学影像、电子病历等)进行分析,为医生提供诊断建议。这种技术不仅能够提高诊断的准确性,还能缩短诊断时间,优化医疗资源配置。
1.2 技术栈选择
- 编程语言:Python(以其丰富的库和易用性成为首选);
- 深度学习框架:PyTorch(动态计算图、强大的社区支持);
- 医学影像库:SimpleITK(专业的医学影像处理工具)。
二、实战教程:构建智能医疗辅助诊断系统
2.1 数据预处理
数据是智能医疗辅助诊断的基石。以医学影像(如X光片)为例,数据预处理包括以下步骤:
2.1.1 数据收集
- 来源:公开数据集(如Kaggle、NIH Chest X-ray数据集)或与医疗机构合作获取。
- 格式:DICOM、PNG等,需统一转换为模型可处理的格式。
2.1.2 数据清洗
import SimpleITK as sitk
import numpy as np
import matplotlib.pyplot as pltdef load_image(image_path):"""加载医学影像"""image = sitk.ReadImage(image_path)image_array = sitk.GetArrayFromImage(image)return image_arraydef preprocess_image(image_array):"""预处理图像:归一化、调整大小等"""image_array = image_array.astype(np.float32)image_array = (image_array - np.min(image_array)) / (np.max(image_array) - np.min(image_array))image_array = np.resize(image_array, (224, 224)) # 调整到模型输入尺寸return image_array# 示例:加载并预处理图像
image_path = "path/to/xray.png"
image_array = load_image(image_path)
preprocessed_image = preprocess_image(image_array)plt.imshow(preprocessed_image, cmap='gray')
plt.title("Preprocessed X-ray Image")
plt.show()
2.1.3 数据增强
- 目的:增加数据多样性,提高模型泛化能力。
- 方法:旋转、翻转、缩放、添加噪声等。
from torchvision.transforms import functional as Fdef augment_image(image):"""数据增强:随机旋转、翻转"""angle = np.random.uniform(-10, 10)image = F.rotate(image, angle)if np.random.rand() > 0.5:image = F.hflip(image)return image# 示例:增强图像
augmented_image = augment_image(preprocessed_image)
plt.imshow(augmented_image, cmap='gray')
plt.title("Augmented X-ray Image")
plt.show()
2.2 模型构建
我们将构建一个基于卷积神经网络(CNN)的分类模型,用于判断X光片中是否存在病变。
2.2.1 模型定义
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MedicalImageClassifier(nn.Module):def __init__(self):super(MedicalImageClassifier, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout(0.25)self.dropout2 = nn.Dropout(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 2) # 二分类:正常/病变def forward(self, x):x = self.conv1(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = torch.flatten(x, 1)x = self.dropout1(x)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)output = F.softmax(x, dim=1)return output# 示例:初始化模型
model = MedicalImageClassifier()
print(model)
2.2.2 模型编译
import torch.optim as optim# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
2.3 模型训练
2.3.1 数据加载
from torch.utils.data import Dataset, DataLoaderclass MedicalImageDataset(Dataset):def __init__(self, image_paths, labels, transform=None):self.image_paths = image_pathsself.labels = labelsself.transform = transformdef __len__(self):return len(self.image_paths)def __getitem__(self, idx):image_path = self.image_paths[idx]image = load_image(image_path)image = preprocess_image(image)if self.transform:image = self.transform(image)label = self.labels[idx]return image, label# 示例:创建数据集和数据加载器
image_paths = ["path/to/xray1.png", "path/to/xray2.png"] # 替换为实际路径
labels = [0, 1] # 0: 正常, 1: 病变
dataset = MedicalImageDataset(image_paths, labels)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
2.3.2 训练循环
def train_model(model, dataloader, criterion, optimizer, num_epochs=10):model.train()for epoch in range(num_epochs):running_loss = 0.0for images, labels in dataloader:images = images.unsqueeze(1) # 增加通道维度images = images.float()labels = labels.long()optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader):.4f}")# 示例:训练模型
train_model(model, dataloader, criterion, optimizer, num_epochs=5)
2.4 模型评估
2.4.1 评估指标
- 准确率:正确分类的样本数占总样本数的比例。
- 灵敏度:正确识别出病变样本的能力。
- 特异性:正确识别出正常样本的能力。
2.4.2 评估代码
from sklearn.metrics import accuracy_score, confusion_matrix, classification_reportdef evaluate_model(model, dataloader):model.eval()all_preds = []all_labels = []with torch.no_grad():for images, labels in dataloader:images = images.unsqueeze(1)images = images.float()labels = labels.long()outputs = model(images)_, preds = torch.max(outputs, 1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.numpy())print("Confusion Matrix:\n", confusion_matrix(all_labels, all_preds))print("Classification Report:\n", classification_report(all_labels, all_preds))return accuracy_score(all_labels, all_preds)# 示例:评估模型
accuracy = evaluate_model(model, dataloader)
print(f"Model Accuracy: {accuracy:.4f}")
2.5 模型部署
将训练好的模型部署到实际应用中,可以通过以下步骤实现:
-
保存模型:
python复制代码torch.save(model.state_dict(), "medical_image_classifier.pth") -
构建API:使用Flask或FastAPI构建RESTful API,接收患者数据并返回诊断结果。
-
集成到医疗系统:将API与医院信息系统(HIS)或电子病历(EMR)系统集成,实现无缝对接。
三、案例分析:智能医疗辅助诊断的应用
3.1 案例背景
某三甲医院引入智能医疗辅助诊断系统,用于辅助医生诊断肺结节。该系统基于大量胸部X光片训练,能够准确识别肺结节的位置和大小。
3.2 实施效果
- 诊断准确性:系统辅助诊断的准确率高达92%,显著高于人工诊断的85%。
- 诊断效率:系统能够在几秒钟内完成一张X光片的诊断,而人工诊断需要几分钟。
- 医疗资源优化:医生可以将更多时间用于复杂病例的分析,提高整体医疗服务质量。
3.3 技术挑战与解决方案
- 数据质量:部分X光片存在噪声或伪影。解决方案:采用数据增强和图像去噪算法。
- 模型可解释性:深度学习模型的黑盒特性影响医生信任度。解决方案:采用可视化技术(如Grad-CAM)展示模型关注的区域。
四、挑战与展望
4.1 当前挑战
- 数据隐私与安全:医疗数据涉及患者隐私,需严格遵守相关法律法规。
- 模型泛化能力:不同医院的数据分布差异影响模型性能。解决方案:采用迁移学习和多中心数据训练。
- 法规政策:监管政策不完善,责任界定不清晰。需加强政策研究和行业合作。
4.2 未来展望
- 多模态数据融合:结合影像、病历、基因等多源数据,提高诊断准确性。
- 个性化医疗:根据患者个体差异,提供定制化的诊断和治疗方案。
- 远程医疗:利用5G和物联网技术,实现远程诊断和治疗,提高医疗服务可及性。
五、结论
智能医疗辅助诊断技术作为人工智能与医疗领域深度融合的产物,具有广阔的应用前景。通过本文的实战教程,您已经掌握了从数据预处理、模型构建到训练和评估的完整流程。未来,随着技术的不断进步和法规政策的逐步完善,智能医疗辅助诊断技术将在提高医疗服务质量、优化医疗资源配置等方面发挥更加重要的作用。
附录:代码完整示例
# 完整代码示例
import SimpleITK as sitk
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 数据预处理
def load_image(image_path):image = sitk.ReadImage(image_path)image_array = sitk.GetArrayFromImage(image)return image_arraydef preprocess_image(image_array):image_array = image_array.astype(np.float32)image_array = (image_array - np.min(image_array)) / (np.max(image_array) - np.min(image_array))image_array = np.resize(image_array, (224, 224))return image_array# 模型定义
class MedicalImageClassifier(nn.Module):def __init__(self):super(MedicalImageClassifier, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout(0.25)self.dropout2 = nn.Dropout(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 2)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = torch.flatten(x, 1)x = self.dropout1(x)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)output = F.softmax(x, dim=1)return output# 数据集类
class MedicalImageDataset(Dataset):def __init__(self, image_paths, labels, transform=None):self.image_paths = image_pathsself.labels = labelsself.transform = transformdef __len__(self):return len(self.image_paths)def __getitem__(self, idx):image_path = self.image_paths[idx]image = load_image(image_path)image = preprocess_image(image)if self.transform:image = self.transform(image)label = self.labels[idx]return image, label# 训练函数
def train_model(model, dataloader, criterion, optimizer, num_epochs=10):model.train()for epoch in range(num_epochs):running_loss = 0.0for images, labels in dataloader:images = images.unsqueeze(1)images = images.float()labels = labels.long()optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader):.4f}")# 评估函数
def evaluate_model(model, dataloader):model.eval()all_preds = []all_labels = []with torch.no_grad():for images, labels in dataloader:images = images.unsqueeze(1)images = images.float()labels = labels.long()outputs = model(images)_, preds = torch.max(outputs, 1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.numpy())print("Confusion Matrix:\n", confusion_matrix(all_labels, all_preds))print("Classification Report:\n", classification_report(all_labels, all_preds))return accuracy_score(all_labels, all_preds)# 主程序
if __name__ == "__main__":# 示例数据(替换为实际数据)image_paths = ["path/to/xray1.png", "path/to/xray2.png"]labels = [0, 1]# 创建数据集和数据加载器dataset = MedicalImageDataset(image_paths, labels)dataloader = DataLoader(dataset, batch_size=2, shuffle=True)# 初始化模型、损失函数和优化器model = MedicalImageClassifier()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型train_model(model, dataloader, criterion, optimizer, num_epochs=5)# 评估模型accuracy = evaluate_model(model, dataloader)print(f"Model Accuracy: {accuracy:.4f}")# 保存模型torch.save(model.state_dict(), "medical_image_classifier.pth")
注意事项:
- 替换
image_paths为实际医学影像路径。 - 根据数据量调整
batch_size和num_epochs。 - 可根据需要修改模型结构(如增加层数、调整超参数)。
- 部署时需考虑数据隐私和安全,建议采用加密传输和访问控制。
相关文章:

智能医疗辅助诊断:深度解析与实战教程
引言:医疗领域的新革命 在医疗资源紧张、诊断效率亟待提升的今天,智能医疗辅助诊断技术正以前所未有的速度改变医疗行业的面貌。通过结合人工智能与医学专业知识,智能医疗辅助诊断系统能够为医生提供精准的诊断建议和决策支持,显…...
(已解决)如何安装python离线包及其依赖包 2025最新
字数 305,阅读大约需 2 分钟 没有网络的Linux服务器上,如何安装完整的、离线的python包 1. 写入待安装的包 新建requirement.txt, 写入待安装的包 和 包的版本 如 flwr1.13.0 2.使用命令行直接下载 pip download -d flwr_packages -r requirements.tx…...

Java如何获取文件的编码格式?
Java获取文件的编码格式 在计算机中,文件编码是指将文件内容转换成二进制形式以便存储和传输的过程。常见的文件编码格式包括UTF-8、GBK等。不同的编码使用不同的字符集和字节序列,因此在读取文件时需要正确地确定文件的编码格式 Java提供了多种方式以获…...

豪越赋能消防安全管控,解锁一体化内管“安全密码”
在消防安全保障体系中,内部管理的高效运作是迅速、有效应对火灾及各类灾害事故的重要基础。豪越科技凭借在消防领域的深耕细作与持续创新,深入剖析消防体系内部管理的痛点,以自主研发的消防一体化安全管控平台,为行业发展提供了创…...

Python实现链接KS3,并批量下载KS3文件数据到本地
前言 本文是该专栏的第56篇,后面会持续分享python的各种干货知识,值得关注。 在本专栏的上篇文章《Python实现链接KS3,并将文件数据批量上传到KS3》中,笔者有详细介绍基于Python,实现链接KS3并将文件数据批量上传。而本文,笔者将基于在上一篇文章的基础之上,实现链接KS…...

状态机 XState
以下是关于 状态机(XState) 基本知识的梳理,涵盖核心概念、高级特性、实际应用场景及最佳实践,帮助我们掌握这一强大的状态管理工具: 一、状态机核心概念 1. 有限状态机(Finite State Machine, FSM)基础 定义:系统在有限状态集合中流转,由事件触发状态转换核心要素:…...

Python及C++中的排序
一、Python中的排序 (一)内置排序函数sorted() 基本用法 sorted()函数可以对所有可迭代对象进行排序操作,返回一个新的列表,原列表不会被修改。例如,对于一个简单的数字列表nums [3, 1, 4, 1, 5, 9, 2, 6]ÿ…...

拓扑排序 —— 2. 力扣刷题207. 课程表
题目链接:https://leetcode.cn/problems/course-schedule/description/ 题目难度:中等 相关标签:拓扑排序 / 广度优先搜搜 BFS / 深度优先搜索 DFS 2.1 问题与分析 2.1.1 原题截图 2.1.2 题目分析 首先,理解题目后必须马上意识到…...

从入门到进阶:React 图片轮播 Carousel 的奇妙世界!
全文目录: 开篇语🖐 前言✨ 目录🎯 什么是图片轮播组件?🔨 初识 React 中的轮播实现示例代码分析 📦 基于第三方库快速实现轮播示例:用 react-slick优势局限性 🛠️ 自己动手实现一个…...
【STM32】ST7789屏幕驱动
目录 CubeMX配置 配置SPI 开DMA 时钟树 堆栈大小 Keil工程配置 添加两个group 添加文件包含路径 驱动编写 写单字节函数 写字函数 写多字节函数 初始化函数 设置窗口函数 情况一:正常的0度旋转 情况二:顺时针90度旋转 情况三࿱…...

深入理解 PyTorch 的 nn.Embedding:词向量映射及变量 weight 的更新机制
文章目录 前言一、直接使用 nn.Embedding 获得变量1、典型场景2、示例代码:3、特点 二、使用 iou_token nn.Embedding(1, transformer_dim) 并访问 iou_token.weight1、典型场景2、示例代码:3、特点 三、第一种方法在模型更新中会更新其值吗?…...

10min速通Linux文件传输
实验环境 在Linux中传输文件需要借助网络以及sshd,我们可通过systemctl status sshd来查看sshd状态 若服务未开启我们可通过systemctl enable --now sshd来开启sshd服务 将/etc/ssh/sshd_config中的PermitRootLogin 状态修改为yes 传输文件 scp scp (Sec…...
dify windos,linux下载安装部署,提供百度云盘地址
dify1.0.1 windos安装包百度云盘地址 通过网盘分享的文件:dify-1.0.1.zip 链接: 百度网盘 请输入提取码 提取码: 1234 dify安装包 linux安装包百度云盘地址 通过网盘分享的文件:dify-1.0.1.tar.gz 链接: 百度网盘 请输入提取码 提取码: 1234 1.安装…...

使用 TFIDF+分类器 范式进行企业级文本分类(二)
1.开场白 上一期讲了 TF-IDF 的底层原理,简单讲了一下它可以将文本转为向量形式,并搭配相应分类器做文本分类,且即便如今的企业实践中也十分常见。详情请见我的上一篇文章 从One-Hot到TF-IDF(点我跳转) 光说不练假把…...

《车辆人机工程-汽车驾驶操纵实验》
汽车操纵装置有哪几种,各有什么特点 汽车操纵装置是驾驶员直接控制车辆行驶状态的关键部件,主要包括以下几种,其特点如下: 一、方向盘(转向操纵装置) 作用:控制车辆行驶方向,通过转…...

[ABC400F] Happy Birthday! 3 题解
考虑正难则反。问题转化为: 一个环上有 n n n 个物品,颜色分别为 c o l i col_i coli,每次操作选择两个数 i , j i, j i,j 使得 ∀ k ∈ [ i , j ] , c o l k c o l i ∨ c o l k 0 \forall k \in [i, j], col_k col_i \lor col_k …...

python高级编程一(生成器与高级编程)
@TOC 生成器 生成器使用 通过列表⽣成式,我们可以直接创建⼀个列表。但是,受到内存限制,列表容量肯定是有限的。⽽且,创建⼀个包含100万个元素的列表,不仅占⽤很⼤的存储空间,如果我们仅仅需要访问前⾯⼏个元素,那后⾯绝⼤多数元素占 ⽤的空间都⽩⽩浪费了。所以,如果…...

Go 字符串四种拼接方式的性能对比
简介 使用完整的基准测试代码文件,可以直接运行来比较四种字符串拼接方法的性能。 for 索引 的方式 for range 的方式 strings.Join 的方式 strings.Builder 的方式 写一个基准测试文件 echo_bench_test.go package mainimport ("os""stri…...

windows安装fastbev环境时,安装mmdetection3d出现的问题总结
出现的问题如下: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\include\crt/host_config.h(160): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions between 2017 and 2019 (inclusive) are supporte…...

单片机Day05---动态数码管显示01234567
一、原理图 数组索引段码值二进制显示内容00x3f0011 1111010x060000 0110120x5b0101 1011230x4f0100 1111340x660110 0110450x6d0110 1101560x7d0111 1101670x070000 0111780x7f0111 1111890x6f0110 11119100x770111 0111A110x7c0111 1100B120x390011 1001C130x5e0101 1110D140…...

【Python3教程】Python3基础篇之数据结构
博主介绍:✌全网粉丝22W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...

muduo库源码分析: One Loop Per Thread
One Loop Per Thread的含义就是,一个EventLoop和一个线程唯一绑定,和这个EventLoop有关的,被这个EventLoop管辖的一切操作都必须在这个EventLoop绑定线程中执行 1.在MainEventLoop中,负责新连接建立的操作都要在MainEventLoop线程…...

使用Python解决Logistic方程
引言 在数学和计算机科学中,Logistic 方程是描述人口增长、传播过程等现象的一种常见模型。它通常用于表示一种有限资源下的增长过程,比如动物种群、疾病传播等。本文将带领大家通过 Python 实现 Logistic 方程的求解,帮助你更好地理解这一经典数学模型。 1.什么是 Logist…...
——【多Agent】MetaGPT)
AI Agent工程师认证-学习笔记(3)——【多Agent】MetaGPT
学习链接:【多Agent】MetaGPT学习教程 源代码链接(觉得很好,star一下):GitHub - 基于MetaGPT的多智能体入门与开发教程 MetaGPT链接:GitHub - MetaGPT 前期准备 1、获取MetaGPT (1)使用pip获取MetaGPT pip install metagpt==0.6.6#或者在国内加速安装镜像 #pip in…...

MCP结合高德地图完成配置
文章目录 1.MCP到底是什么2.cursor配置2.1配置之后的效果2.2如何进行正确的配置2.3高德地图获取key2.4选择匹配的模型 1.MCP到底是什么 作为学生,我们应该如何认识MCP?最近看到了好多跟MCP相关的文章,我觉得我们不应该盲目的追求热点的技术&…...
重读《人件》Peopleware -(5)Ⅰ管理人力资源Ⅳ-质量—若时间允许
20世纪的心理学理论认为,人类的性格主要由少数几个基本本能所主导:生存、自尊、繁衍、领地等。这些本能直接嵌入大脑的“固件”中。我们可以在没有强烈情感的情况下理智地考虑这些本能(就像你现在正在做的那样),但当我…...
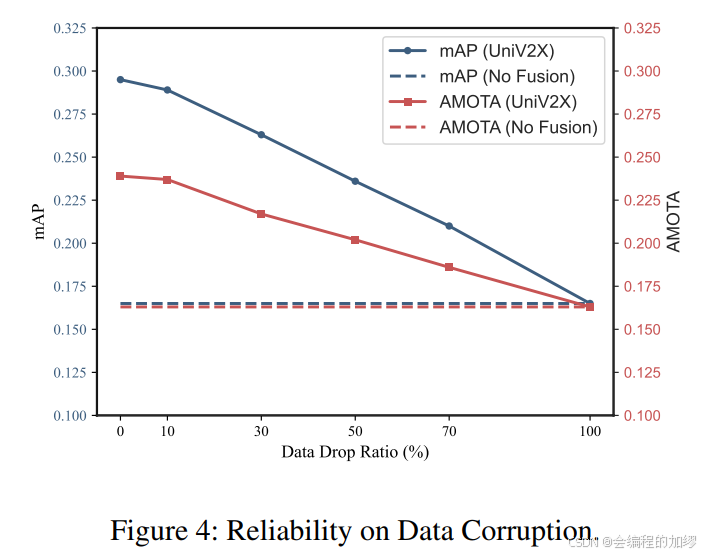
文献总结:AAAI2025-UniV2X-End-to-end autonomous driving through V2X cooperation
UniV2X 一、文章基本信息二、文章背景三、UniV2X框架1. 车路协同自动驾驶问题定义2. 稀疏-密集混合形态数据3. 交叉视图数据融合(智能体融合)4. 交叉视图数据融合(车道融合)5. 交叉视图数据融合(占用融合)6…...

制造一只电子喵 (qwen2.5:0.5b 微调 LoRA 使用 llama-factory)
AI (神经网络模型) 可以认为是计算机的一种新的 “编程” 方式. 为了充分利用计算机, 只学习传统的编程 (编程语言/代码) 是不够的, 我们还要掌握 AI. 本文以 qwen2.5 和 llama-factory 举栗, 介绍语言模型 (LLM) 的微调 (LoRA SFT). 为了方便上手, 此处选择使用小模型 (qwen2…...

如何查询node inode上限是多少?
在 Linux 系统中,inode 上限由文件系统的类型和格式化时的参数决定。不同文件系统(如 ext4、XFS)有不同的查询方法。以下是详细操作步骤: 1. 确认文件系统类型 首先确定目标磁盘分区的文件系统类型(如 ext4、XFS&…...
Redis核心功能实现
前言 学习是个输入的过程,在进行输入之后再进行一些输出,比如写写文章,笔记,或者做一些技术串讲,虽然需要花费不少时间,但是好处很多,首先是能通过输出给自己的输入带来一些动力,然…...