C++STL——容器-list(含模拟实现,即底层原理)(含迭代器失效问题)(所有你不理解的问题,这里都有解答,最详细)
目录
1.迭代器的分类
2.list的使用
2.1 list的构造
2.2 list iterator
2.3 list capacity
2.4 list element access
编辑
2.5 list modifiers
编辑2.5.1 list插入和删除
2.5.2 insert /erase
2.5.3 resize/swap/clear
编辑
2.6 list的一些其他接口
2.6.1 splice
2.6.2 remove
2.6.3 sort
3.list的模拟实现
4.最后一个问题
1.迭代器的分类


这里需要说明一些东西:
1.就是下面的是上面的子类:比如双向迭代器是单向迭代器的子类(这个父子类的判断,跟迭代器的功能可没关系,不要说双向迭代器的功能比单向多,就说单向是双向的子类,不是这么来判断的)。
2.还有就是看上面的第二张图,越往后,迭代器的功能就越多,而且,都是对上一个迭代器的功能进行了继承并拓展。比如:双向迭代器的功能有++/--,而单向迭代器有++,双向迭代器是不是继承了单向迭代器的功能,并实现了拓展?是的!
2.list的使用
2.1 list的构造

list<int> l1; // 构造空的l1
list<int> l2(4, 100); // l2中放4个值为100的元素
list<int> l3(l2.begin(), l2.end()); // 用l2的[begin(), end())左闭右开的区间构造l3
list<int> l4(l3); // 用l3拷贝构造l4
list<int> l6={ 1,2,3,4,5 };//初始化列表初始化l6
2.2 list iterator
其实,对于lterator,也就跟前面的那几个一样使用就行,只不过,这里需要注意的是,vector是原生态指针,而list是对原生态指针(节点指针)进行封装,(模板),后面的模拟实现会讲。
注意:遍历链表只能用迭代器和范围for
2.3 list capacity

2.4 list element access

2.5 list modifiers
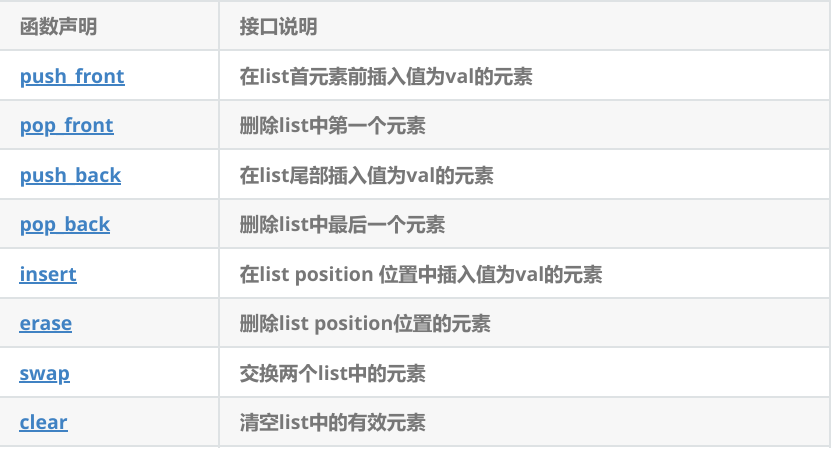 2.5.1 list插入和删除
2.5.1 list插入和删除
push_back/pop_back/push_front/pop_front

2.5.2 insert /erase
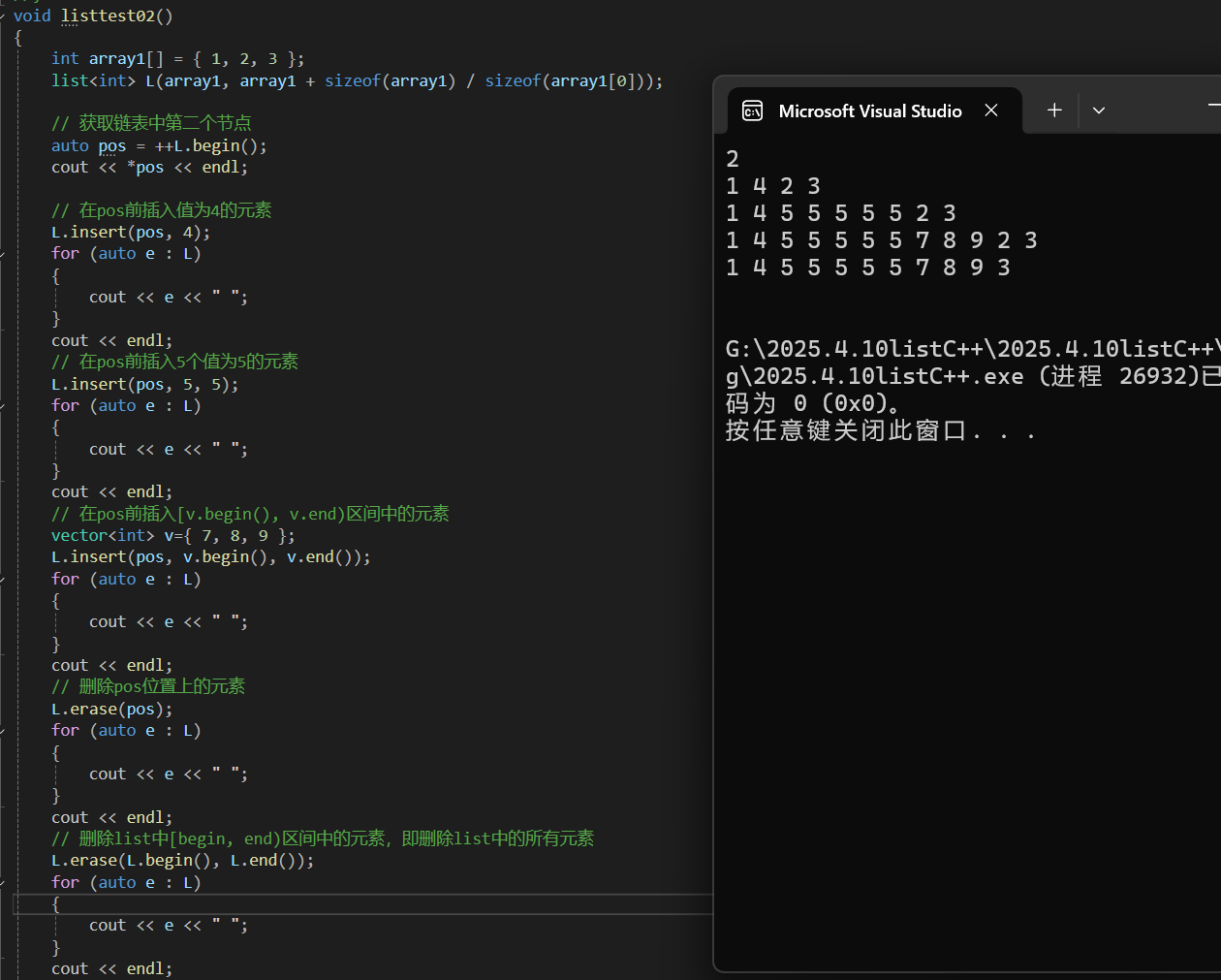
2.5.3 resize/swap/clear
2.6 list的一些其他接口
2.6.1 splice
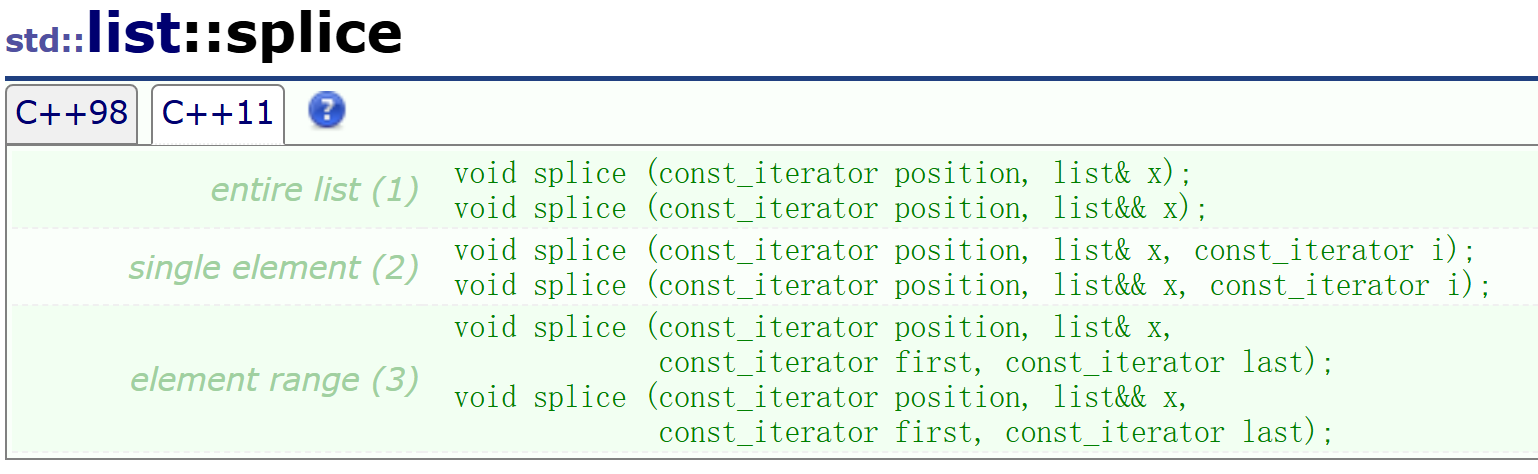
C++11相对于C++98来说增加了一个"模板特化",这个东西咱们后面会出一期模板专题,专门来讲这个模板。那么接下来先不看模板特化,先看引用。
这个接口的作用是将一个链表中的数据裁剪(裁剪后,原链表中的数据将消失),到另一个链表中。接下来看官方库中的代码例子来理解:
std::list<int> mylist1, mylist2;std::list<int>::iterator it;// set some initial values:for (int i=1; i<=4; ++i)mylist1.push_back(i); // mylist1: 1 2 3 4for (int i=1; i<=3; ++i)mylist2.push_back(i*10); // mylist2: 10 20 30it = mylist1.begin();++it; // points to 2mylist1.splice (it, mylist2); // mylist1: 1 10 20 30 2 3 4// mylist2 (empty)// "it" still points to 2 (the 5th element)mylist2.splice (mylist2.begin(),mylist1, it);// mylist1: 1 10 20 30 3 4// mylist2: 2// "it" is now invalid.it = mylist1.begin();std::advance(it,3); // "it" points now to 30mylist1.splice ( mylist1.begin(), mylist1, it, mylist1.end());// mylist1: 30 3 4 1 10 20
直接来看mylist1.splice ,这个的意思是将mylist2中的数据剪裁到 it指向的那个数据之前的位置,并将原mylist2中的数据清零。
第二个:将mylist1中的原it指向的数据(2),剪裁到mylist2的begin()指向的位置。
第三个:将mylist1中的从it位置开始,end()结束的数据(30,3,4)剪裁到begin()的位置。
2.6.2 remove
void remove (const value_type& val);
删除链表中值为val的数据。
2.6.3 sort
 其实list中的sort无法使用算法库中的sort,因为算法库中的sort实现是靠+/-来实现,但是list迭代器不支持+/-,而且,相对于vector来说,list的sort排序,特别对于一些特别大的数据来说,效率 会很低。
其实list中的sort无法使用算法库中的sort,因为算法库中的sort实现是靠+/-来实现,但是list迭代器不支持+/-,而且,相对于vector来说,list的sort排序,特别对于一些特别大的数据来说,效率 会很低。
3.list的模拟实现
其实,list的模拟实现还是比较难的,咱们以前模拟实现的vector,string难在它的实现上面,而list的模拟实现难在它的实现框架上面,那么下面让博主来帮助你们理解吧。

这个分为三个重要的模板。
1.一个是对于链表中的节点的模板(因为数据T可能有不同的类型)
2.一个是对于迭代器实现的模板,那这时候就要有人问了:以前的vector不是没有迭代器实现模板吗?这不一样,list的迭代器是对原生态指针的封装,就是一个模板。而且,在这里的iterator相当于是类了,就是好像不再是指针,但还是具有指针的效果。
3.最后一个就是整个的list链表它也是一个模板。
那么接下来让咱们来看看模板吧,等会我会把为什么这么写的目的,以及细节全部讲透。
//这是第一个类模板
template<class T>
struct list_node
{
list_node* _next;
list_node* _prev;
T _data;//注意,这里的_data是模板数据,后面会用到这个知识点。
list_node(const T& x = T())//初始化
:_next(nullptr)
,_prev(nullptr)
,_data(x)
{}
};
//这是第二个类模板// typedef list_iterator<T, T&, T*> iterator;
// typedef list_iterator<T, const T&, const T*> const_iterator;
template<class T, class Ref, class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
Node* _node;
list_iterator(Node* node)//初始化
:_node(node)
{}
};
//这是第三个类模板
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
//typedef list_const_iterator<T> const_iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
List() //初始化
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}private:
Node* _head;
size_t _size;
};
每一个类或者类模板写出来后,一定要记得初始化,这里需要注意一点,也是我写代码的时候发现的:当你写一个类的时候,一定要注意,这个类的构造尤其重要,就比如我这个,我如果说不写这个构造的话,那么编译器会默认构造,那么_head就是空,你是在end()位置插入,也就是_head位置,你的_head还是空,当你的pos._node获得节点的时候,这个还是空呢,是访问不了任何成员的。因为下面要用到cur去访问,所以记住,空节点访问不了任何成员 。
这个注意事项涉及到insert的模拟实现的,所以在这里咱们先把insert的模拟实现写了。
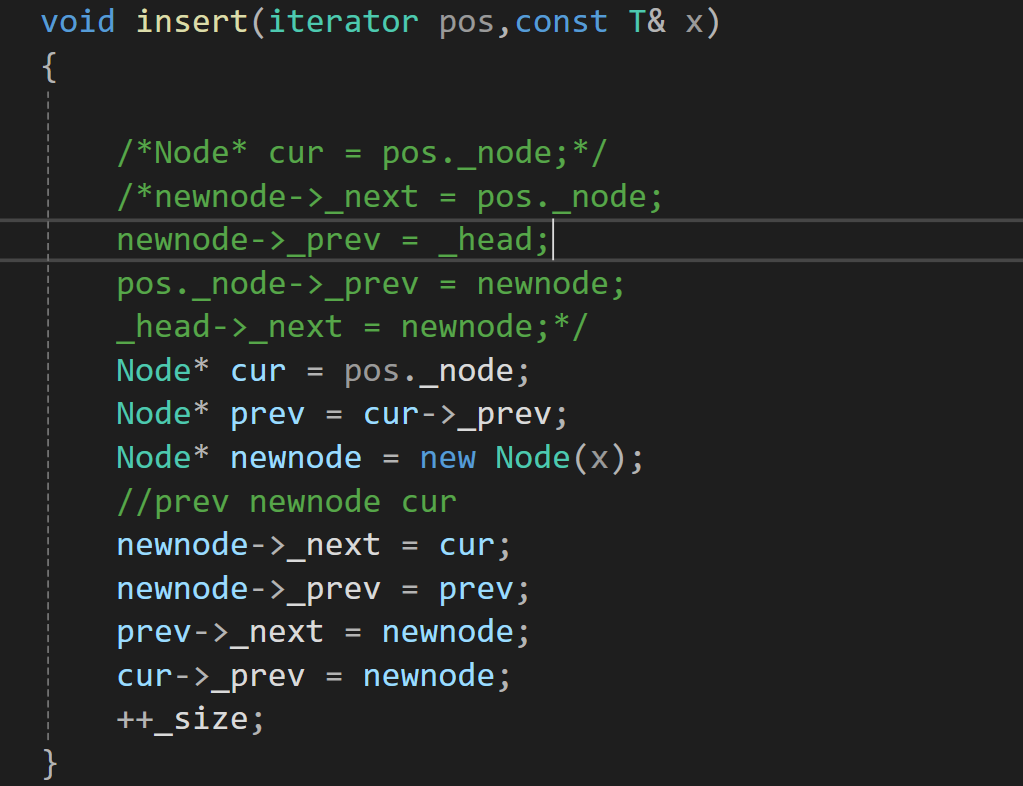
这里涉及到几个老生常谈的问题:
1.连接链表的时候的顺序问题,一般先将新插入的链表连接好,(当然,你要是说先将各个要用到的节点重新定义一下,那就不要管顺序的问题了),顺序的问题就是为了避免有找不到节点的情况出现。
2.这里的pos是迭代器类型,不是说迭代器是指针嘛?怎么访问它的成员变量不应该用->嘛?怎么用"."呢?这个问题,咱们后面跟另外一个问题一起将。 (标题:最后一个问题处)
好,那么咱们接下来接着往后看模拟实现:
第一个类模板已经实现完了,接下来看第二个类模板的实现:
// typedef list_iterator<T, T&, T*> iterator;
// typedef list_iterator<T, const T&, const T*> const_iterator;
template<class T,class Ref,class Ptr>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T, Ref, Ptr> Self;
Node* _node;//定义一个节点list_iterator(Node* node)
:_node(node)//初始化那个节点
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
//前置++
Self& operator++()
{
_node = _node->_next;
return *this;
}
//后置++
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}
//前置--
Self& operator--()
{
_node = _node->_prev;
return *this;
}
//后置--
Self operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const Self &s) const//lt.end()这是个迭代器类型啊,肯定是Self&,怎么能是List<T>呢?
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}};
这里由于放图片,代码太长,影响观看,所以直接用块引用。
1.这个T,Ref,Ptr 都是指代的什么东西呀?首先,这是一个类模板,所以说,这三个肯定都是指代的一类东西。根据上面的两行代码可知,T就是_data的类型,而Ref是T&或const T&,所以知道为什么要写成模板了吧,你要是不写模板,就要实现两次关于T&以及const T&的代码,造成代码冗余。Ptr同理。
2.对于list这样对原生态指针进行封装(类模板)的,都是不可以直接使用*以及->的,都需要自己去自定义实现。这里的typedef也是为了避免代码的冗余。
3.*是对一个指针的解引用,拿到的是数据,所以说,用的是Ref(即T&或const T&),->跟*一样,都是访问元素的操作。只不过在标准迭代器设计中,->应该返回容器中元素的地址(指针)。
一个是元素的地址,一个是元素的引用,返回的都跟元素有关,所以说,是跟T(数据)有关。
4.而++,--,这个是返回的是迭代器本身,因为`operator++`的作用是移动迭代器到下一个位置。
就是移动倒了下一个节点。所以返回`Self`或`Self&`确保了迭代器类型的正确性。如果返回`Ref`或`Ptr`,则会导致类型不匹配。
可以这么理解,就是从小到大,小就是节点中的数据的访问就是返回的是Ref以及Ptr,而大就是整个节点的移动。
5.判断两个节点是否相等,传参用的是self,因为判断节点时候相等,本来就是判断连那两个迭代器是否相等(节点中的元素),因为对元素的访问用的就是迭代器。
好了,这个类模板中的问题我已经说清楚了,接下来看最后一个类模板。
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<const T, const T&, const T*> const_iterator;
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);//注意是_head,不是_head->_prev
}
const_iterator begin() const //后面的这个const 不能忘了
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);//注意是_head,不是_head->_prev
}
/*~list()
{
_data = nullptr;
_head->_next = _head->_prev = _head;
}*/
//你这个写的不是析构,顶多算是初始化,只有一个哨兵位。
~list()
{
clear();
delete _head;
_head = nullptr;//别忘了置为空
}
//拷贝构造
list(List<T>& s)
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;_size = 0;
for (auto& e : s)
{
push_back(e);
}
}
//lt2=lt3
list<T>& operator=(List<T> ta)
{
swap(ta);
return *this;
}
void swap(List<int>& ta)
{
std::swap(_head, ta._head);
std::swap(_size, ta._size);
}
list(initializer_list<T> il)//列表初始化的模拟实现
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;_size = 0;
for (auto& e : il)
{
push_back(e);
}
}
void clear()//clear的模拟实现
{
List<int>::iterator it = begin();
while (it != end())
{
it=erase(it);
it++;
}
}//当你写一个类的时候,一定要注意,这个类的构造尤其重要
//就比如我这个,我如果说不写这个构造的话,那么编译器会默认构造,那么_head就是空
//你是在end()位置插入,也就是_head位置,你的_head还是空,
//当你的pos._node获得节点的时候,这个还是空呢,是访问不了任何成员的。
list() //因为下面要用到cur去访问,所以记住,空节点访问不了任何成员
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}void insert(iterator pos,const T& x)
{
/*Node* cur = pos._node;*/
/*newnode->_next = pos._node;
newnode->_prev = _head;
pos._node->_prev = newnode;
_head->_next = newnode;*/
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
//prev newnode cur
newnode->_next = cur;
newnode->_prev = prev;
prev->_next = newnode;
cur->_prev = newnode;
++_size;
}
iterator erase(iterator pos)
{
assert(pos != end());
Node* cur = pos._node;
Node* next = cur->_next;//这儿有错
Node* prev = cur->_prev;
next->_prev = prev;
prev->_next = next;
delete cur;
cur = nullptr;
--_size;
return next;
//return iterator(next)
//这样写也可以,第二种写法,这个类型也是iterator的,正好
//第一种写法也可以,只不过单参数返回支持隐式类型转换,所以说也不要担心他的类型问题。
}
void push_back(const T& x)
{
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
private:
Node* _head;
size_t _size;
};
1.为什么这里的erase返回的是next(下一个位置)?而vector中返回的是原位置?这里都涉及到迭代器失效的问题,不过呢,vector的底层是数组啊,底层是连续的,而且它的erase后,后面的元素都得往前移动一个,所以说vector的erase返回的还是下一个元素位置,只不过下一个元素的位置现在是被删除元素的位置。而list的erase后,所有的元素的位置并不发生任何变化,所以说这个返回的是真真正正的下一个元素的位置。
2.list迭代器失效:
前面说过,此处大家可将迭代器暂时理解成类似于指针,迭代器失效即迭代器所指向的节点的无 效,即该节点被删除了。因为list的底层结构为带头结点的双向循环链表,因此在list中进行插入 时是不会导致list的迭代器失效的,只有在删除时才会失效,并且失效的只是指向被删除节点的迭 代器,其他迭代器不会受到影响。
3.这里有些博友可能会有些疑问:iterator begin()不是迭代器嘛?不是应该定义在iterator那个模板中嘛?为什么会出现在list这个大模板中?
首先,begin()和end()是容器的成员函数,属于容器的接口,用于获取容器的起始和结束迭代器。迭代器类本身不负责管理容器的元素范围,它只负责遍历和访问元素。因此,begin()的位置应该在容器类中,而不是迭代器类里。
其次:迭代器的作用是提供一种访问容器元素的方法,但它并不了解容器的内部结构,比如链表的头节点_head的位置。只有容器自己知道如何获取起始和结束的位置,所以容器必须提供这些方法。如果让迭代器自己生成begin(),它需要访问容器的私有成员(如_head),这会破坏封装性,或者需要将迭代器设为容器的友元,增加耦合。
总结下来就是list中实现的是整个迭代器,而iterator中实现的是迭代器对元素的访问,并不关心整个迭代器是怎么运行的,搭建的,它只关心怎么访问数据。其实这种设计符合面向对象的原则,容器管理数据,迭代器提供访问方式,各司其职。
好,还剩下几个问题,把他们说清楚:
1.为什么前两个模板都是使用struct?使用class不可以吗?
首先看list_node结构体,它有三个成员变量:_next、_prev和_data,构造函数也是public的。如果用class的话,默认是private,需要显式声明public才能让外部访问这些成员。而用struct的话,构造函数和成员变量默认都是public的,这样在list类中可以直接访问这些成员,比如在list的insert或erase函数里,可以直接操作节点的_next和_prev指针。为了更方便的访问成员变量,且要频繁的访问成员变量,就将那个类置为struct。
struct用于那些需要所有成员公开的情况,比如节点和迭代器,而class用于需要封装的情况,比如容器本身。这样的选择主要是基于默认访问权限的不同,简化代码的同时保持必要的封装性。
2.这三个模板写一块不可以吗?为什么要分开写?
首先,我需要确认这三个模板各自的职责:
1. **list_node**:通常是一个结构体,包含数据和指向前后节点的指针,作为链表的节点。
2. **list_iterator**:迭代器类,用于遍历链表,提供操作符重载如++、--、*、->等。
3. **list**:链表类本身,管理节点的创建、删除,提供插入、删除等接口。
而之所以不把他们设置为一个类,是因为你的class中的成员变量不想被别人访问,但是你的其他的类中的成员变量确实被频繁访问,要是都放到一个类中,那肯定就混乱了。
其实就是每个模板负责不同的职责,分离关注点,符合良好的面向对象设计原则。
4.最后一个问题
先来看一段代码:
struct AA
{
int _a1;
int _a2;
AA(int a1 = 1, int a2 = 1)
:_a1(a1)
,_a2(a2)
{}
};
list<AA> lt1;
lt1.push_back({ 1,1 });
lt1.push_back({ 2,2 });
lt1.push_back({ 3,3 });
list<AA>::iterator lit1 = lt1.begin();
while (lit1 != lt1.end())
{
//cout << (*lit1)._a1 <<":"<< (*lit1)._a2 << endl;
// 特殊处理,省略了一个->,为了可读性
cout << lit1->_a1 << ":" << lit1->_a2 << endl;
cout << lit1.operator->()->_a1 << ":" << lit1.operator->()->_a2 << endl;
++lit1;
}
cout << endl;
1.好,咱们先来处理那个遗留下来的问题: 为什么pos后要用"."来访问成员变量,首先:这个地方iterator是一个类,不是指针,所以,pos是这个类实例化出的对象,所以现在知道这里为什么用“."来访问成员变量了吧。
2.这里,原先咱们说T是一个数据类型对吧,那么这里的AA就是_data,所以,_data中还有数据:_a1,_a2。所以,这里_data就是一个struct类。
2.1先来看注释掉的那个代码,其实是调用了operator*,返回的是AA&,而AA又是一个类,所以访问其中的元素就是用到了"."。
2.2
-> 用于指针:当变量是指向结构体/类类型的指针时,用 -> 访问成员(等价于 (*lit1)._a1)。
lit1.operator->()->_a1是类实例化出的lit1对象,先调用operator->()重载,返回的是AA*,而AA(_data)是个类,所以再次访问AA类中的成员变量需要用到_>。
其实这个等价于lit1._node->_data._a1。
且 lit1.operator->()->_a1简写就是lit1->_a1。
lit1->_a1:调用 list_iterator::operator->(),返回指向当前节点数据(AA 对象)的指针(AA*)。等价代码:AA* ptr = &(lit1._node->_data); // operator-> 返回 &_data cout << ptr->_a1 << ":" << ptr->_a2 << endl;
ok,那么关于这个模块的所有问题我已经讲清楚了,各位如果能看到最后,那么经过我的讲解,一定可以理解这些问题。
本篇完...................
相关文章:
C++STL——容器-list(含模拟实现,即底层原理)(含迭代器失效问题)(所有你不理解的问题,这里都有解答,最详细)
目录 1.迭代器的分类 2.list的使用 2.1 list的构造 2.2 list iterator 2.3 list capacity 2.4 list element access 编辑 2.5 list modifiers 编辑2.5.1 list插入和删除 2.5.2 insert /erase 2.5.3 resize/swap/clear 编辑 2.6 list的一些其他接口…...

计算机组成原理笔记(十五)——3.5指令系统的发展
不同类型的计算机有各具特色的指令系统,由于计算机的性能、机器结构和使用环境不同,指令系统的差异也是很大的。 3.5.1 x86架构的扩展指令集 x86架构的扩展指令集是为了增强处理器在多媒体、三维图形、并行计算等领域的性能而设计的。这些扩展指令集通…...
基于时间序列分解与XGBoost的交通通行时间预测方法解析
一、问题背景与数据概览 在城市交通管理系统中,准确预测道路通行时间对于智能交通调度和路径规划具有重要意义。本文基于真实道路传感器数据,构建了一个结合时间序列分解与机器学习模型的预测框架。数据源包含三个核心部分: 道路通行数据(new_gy_contest_traveltime_train…...
基于XGBoost的异烟酸生产收率预测:冠军解决方案解析
1. 引言 在化工生产领域,准确预测产品收率对优化工艺流程、降低生产成本具有重要意义。本文以异烟酸生产为研究对象,通过机器学习方法构建预测模型,在包含10个生产步骤、42个工艺参数的数据集上实现高精度收率预测。该方案在工业竞赛中斩获冠军,本文将深度解析其技术实现细…...

计算机视觉算法实现——电梯禁止电瓶车进入检测:原理、实现与行业应用(主页有源码)
✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连 ✨ ✨个人主页欢迎您的访问 ✨期待您的三连✨ 1. 电梯安全检测领域概述 近年来,随着电动自行车(以下简称"电瓶车"&…...

智能制造方案精读:117页MES制造执行系统解决方案【附全文阅读】
本方案围绕制造执行系统(MES)展开,阐述了智能制造相关概念及发展趋势,指出 MES 是连接 ERP 与生产现场的关键系统。介绍其在加工、装配及其他场景的应用,通过实例展示各场景下的功能、特点和实施效果,如实现生产信息可视化、产品追溯、设备监控等。还提及实施 MES 面临的…...

【操作系统】【内存分配过程】
内存分配的过程 过程 程序向内存请求空间(如new,malloc)程序检查虚拟内存是否有剩余分配虚拟内存调用程序时,CPU 会查页表,若发现该虚拟页未映射,则触发缺页中断分配物理页,并建立页表映射继续…...

MOM成功实施分享(八)汽车活塞生产制造MOM建设方案(第二部分)
在制造业数字化转型的浪潮中,方案对活塞积极探索,通过实施一系列数字化举措,在生产管理、供应链协同、质量控制等多个方面取得显著成效,为行业提供了优秀范例。 1.转型背景与目标:活塞在数字化转型前面临诸多挑战&…...
)
Swift的学习笔记(一)
Swift的学习笔记(一) 文章目录 Swift的学习笔记(一)元组基本语法1. **创建元组**2. **访问元组的值**3. **命名的元组**4. **解构元组**5. **忽略某些值** 可选值类型定义 OptionalOptional 的基本使用1. **给 Optional 赋值和取值…...

Azure AI Foundry 正在构建一个技术无障碍的未来世界
我们习以为常的街道和数字世界,往往隐藏着被忽视的障碍——凹凸不平的路面、不兼容的网站、延迟的字幕或无法识别多样化声音的AI模型。这些细节对某些群体而言,却是日常的挑战。正如盲道不仅帮助视障者,也优化了整体城市体验,信息…...

中厂算法岗面试总结
时间:2025.4.10 地点:上市的电子有限公司 面试流程: 1.由负责人讲解公司文化 2,由技术人员讲解公司的技术岗位,还有成果 3.带领参观各个工作位置,还有场所 4.中午吃饭 5.面试题,闭卷考试…...

地毯填充luogu
P1228 地毯填补问题 题目描述 相传在一个古老的阿拉伯国家里,有一座宫殿。宫殿里有个四四方方的格子迷宫,国王选择驸马的方法非常特殊,也非常简单:公主就站在其中一个方格子上,只要谁能用地毯将除公主站立的地方外的所有地方盖上,美丽漂亮聪慧的公主就是他的人了。公主…...

哈喽打车 小程序 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 这一次遇到这种风控感觉挺有…...
基于 Vue 3 + Express 的网盘资源搜索与转存工具,支持响应式布局,移动端与PC完美适配
一个基于 Vue 3 Express 的网盘资源搜索与转存工具,支持响应式布局,移动端与PC完美适配,可通过 Docker 一键部署。 功能特性 🔍 多源资源搜索 支持多个资源订阅源搜索支持关键词搜索与资源链接解析支持豆瓣热门榜单展示 &#…...

OL9设置oracle23ai数据库开机自启动
1、设置oracle用户的环境变量信息 [oracleOracleLinuxR9U5 ~]$vim ~/.bash_profile # Set Oracle environment variables for Oracle 23c AI export ORACLE_HOME/opt/oracle/product/23ai/dbhomeFree export ORACLE_SIDFREE export PATH$ORACLE_HOME/bin:$PATH export LD_LIB…...

【操作系统学习篇-Linux】进程
1. 什么是进程 课本概念:程序的一个执行实例,正在执行的程序等 内核观点:担当分配系统资源(CPU时间,内存)的实体。 如果你就看这个来理解进程,那么恭喜你,作为初学者,你…...

CF985G Team Players
我敢赌,就算你知道怎么做,也必然得调试半天才能 AC。 [Problem Discription] \color{blue}{\texttt{[Problem Discription]}} [Problem Discription] 图片来自洛谷。 [Analysis] \color{blue}{\texttt{[Analysis]}} [Analysis] 显然不可能正面计算。所以…...

企业经营决策风险
在企业的经营过程中,领导者每天都在面对大量的决策——该扩大生产还是收缩业务?该增设销售渠道还是提升产品质量?但你知道吗,企业最大的成本,不是生产成本,也不是人工成本,而是决策错误的成本&a…...
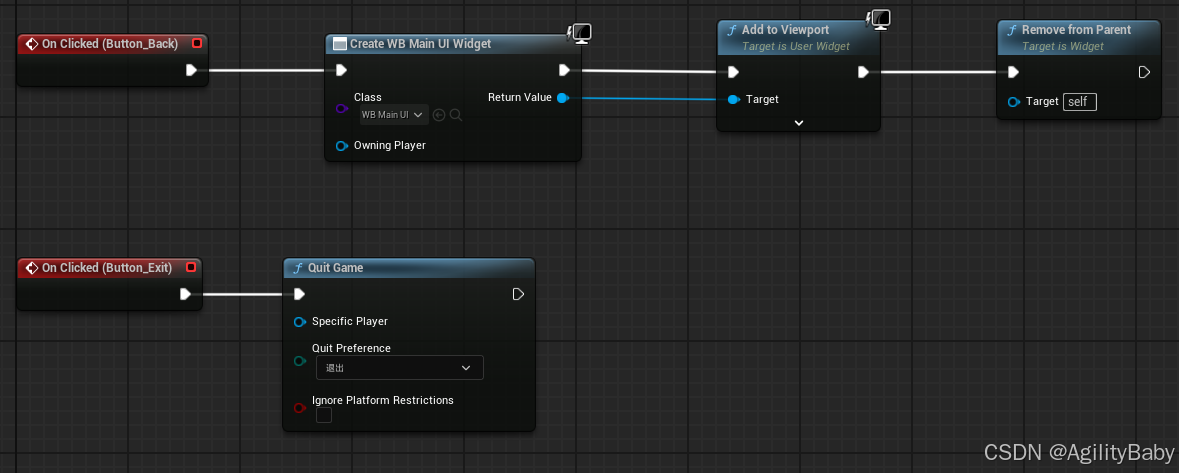
UE5蓝图实现打开和关闭界面、退出
Button_Back 和Button_Exit是创建的两个按钮事件。 1.Create Widget 创建界面(打开界面) 2.Add to Viewport 添加到视图 3.remove form Parent,Target:self 从父节点移除当前界面(关闭界面) 4.Quit Game 退…...

【Linux C】简单bash设计
主要功能 循环提示用户输入命令(minibash$)。创建子进程(fork())执行命令(execlp)。父进程等待子进程结束(waitpid)。关键问题 参数处理缺失:scanf("%s", buf)…...

安全是基石
“安全是基石”这句话强调了安全在个人、企业、社会等各个层面中的基础性和不可替代的重要性。无论是物理安全、网络安全、数据安全,还是生产安全、公共安全,都是保障稳定发展的前提。以下是不同领域中“安全”作为基石的体现: 1. 个人安全 基…...
JavaWeb 课堂笔记 —— 09 MySQL 概述 + DDL
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...
echarts 图表
echart快速上手 快速上手 - 使用手册 - Apache EChartshttps://echarts.apache.org/handbook/zh/get-started/...
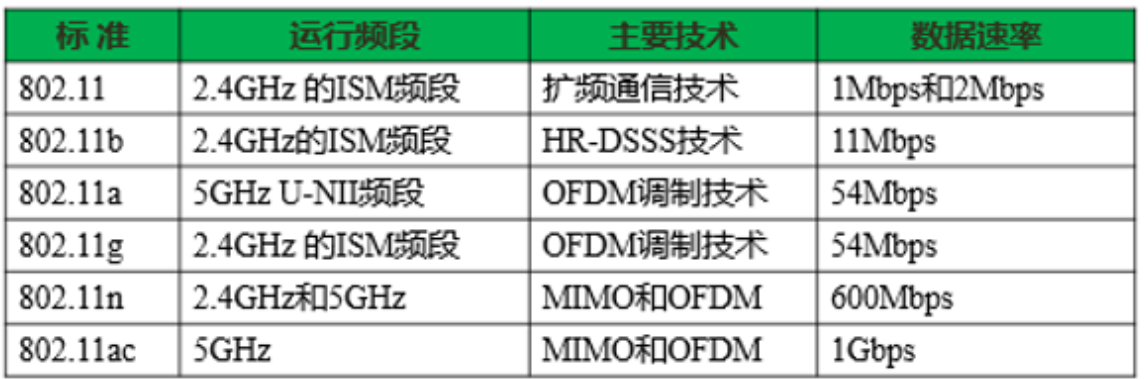
无线通信网
1.2.4G相邻信道间有干扰,5G相邻信道几乎无干扰 2.2.4G频段的优点是信号强,衰减小,穿墙强,覆盖距离远;缺点是带宽较窄,速度较慢,干扰较大。 5G频段的优点是带宽较宽,速度较快&#…...

数据结构:哈希表 | C++中的set与map
上回说到,红黑树是提升了动态数据集中频繁插入或删除操作的性能。而哈希表(Hash Table),则是解决了传统数组或链表查找数据必须要遍历的缺点。 哈希表 哈希表的特点就是能够让数据通过哈希函数存到表中,哈希函数能够将数据处理为表中位置的索…...

随笔 20250413 Elasticsearch 的 term 查询
你这个问题非常经典,来自于 Elasticsearch 的 term 查询是 ✅精确匹配(case-sensitive,大小写敏感)! 🧨 为什么查不到 "World"? 你的查询语句是: GET /movie/_search {&…...
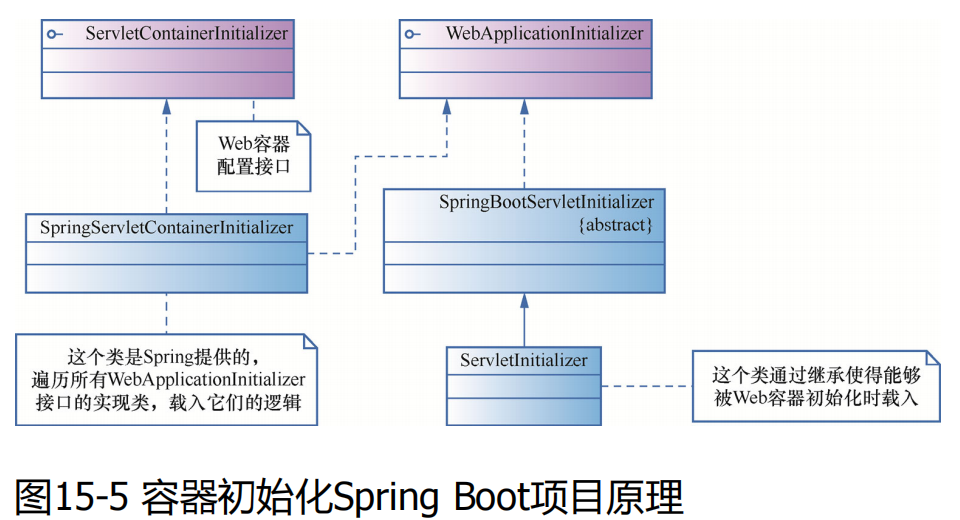
容器初始化Spring Boot项目原理,即web项目(war)包涉及相关类对比详解
以下是关于 SpringBootServletInitializer、ServletContainerInitializer、SpringServletContainerInitializer、WebApplicationInitializer 和 ServletInitializer 的对比详解及总结表格: 1. 核心对比详解 (1) SpringBootServletInitializer 作用: S…...

Python创意:AI图像生成
1. 基本概念 AI 图像生成通常基于以下几种方法: 一.生成对抗网络 (GAN) 生成对抗网络(GAN,Generative Adversarial Network)是一种深度学习框架,主要用于生成新的、类似于训练数据的样本。自2014年由Ian Goodfellow及…...
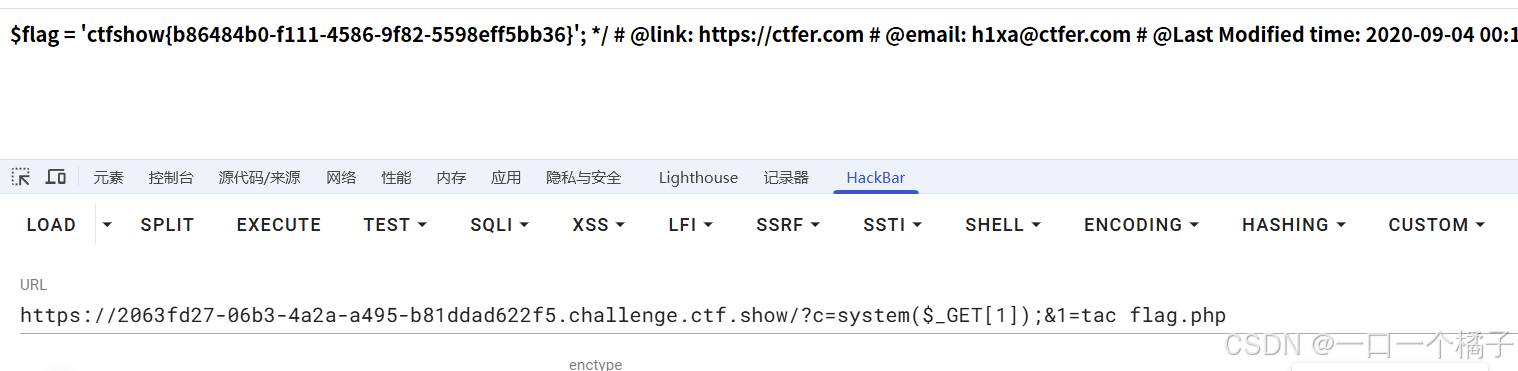
[ctfshow web入门] web29
前置知识 eval: 把字符串按照 PHP 代码来执行,例如eval(“echo 1;”);这个函数拥有回显 system:使php程序执行系统命令,例如,system(“ls”);就是查看当前目录,这个拥有回显 preg_match:查找字符串是否匹配…...

5.JVM-G1垃圾回收器
一、什么是G1 二、G1的三种垃圾回收方式 region默认2048 三、YGC的过程(Step1) 3.1相关代码 public class YGC1 {/*-Xmx128M -XX:UseG1GC -XX:PrintGCTimeStamps -XX:PrintGCDetails -XX:UnlockExperimentalVMOptions -XX:G1LogLevelfinest128m5% 60%6.4M 75M*/private stati…...