互联网三高-数据库高并发之分库分表ShardingJDBC
1 ShardingJDBC介绍
1.1 常见概念术语
① 数据节点Node:数据分片的最小单元,由数据源名称和数据表组成
如:ds0.product_order_0
② 真实表:再分片的数据库中真实存在的物理表
如:product_order_0
③ 逻辑表:相同逻辑和数据结构表的总称
如:product_order
④ 绑定规则:指分片规则一致的主表和子表
如:order表和order_item表,都是按照order_id分片
绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率提升
1.2 常见分片算法
分片键:用于分片的数据库字段,是将数据库(表)水平拆分的关键字段
ShardingJDBC既支持单分片键,也支持多个字段进行分片
分片策略
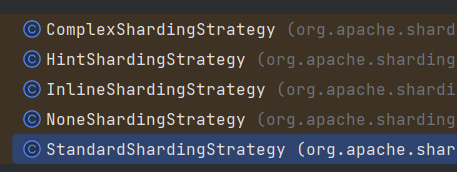
① 行表达式分片:InlineShardingStrategy
只支持单分片键
使用groovy表达式,提供对SQL语言的 = 和 IN 的分片操作支持
如:product_order_$->{user_id % 2} => product_order_0 和 product_order_1
② 标准分片:StandardShardingStrategy
只支持单分片键
PreciseShardingAlgorithm:精准分片,处理 = 和 IN 的分片操作
RangeShardingAlgorithm:范围分片,处理 BETWEEN AND 的分片操作
③ 复合分片:ComplexShardingStrategy
支持多分片键
提供 = 、 IN 和 BETWEEN AND 的分片操作
④ Hint分片:HintShardingStrategy
无需配置分片键,外部手动指定分片键
⑤ 不分片:NoneShardingStrategy
2 快速入门
SpringBoot整合ShardingJDBC
(1)导入依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.5.5</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.5.5</version></dependency> </dependencies>(2)编写启动类
@SpringBootApplication @EnableTransactionManagement @MapperScan("com.pandy.mapper") public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);} }(3)创建数据库、表(2个库,4个表)
CREATE TABLE `product_order_0` (`id` bigint NOT NULL AUTO_INCREMENT,`out_trade_no` varchar(64) DEFAULT NULL COMMENT '订单唯一标识',`state` varchar(11) DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',`nickname` varchar(64) DEFAULT NULL COMMENT '昵称',`user_id` bigint DEFAULT NULL COMMENT '用户id',PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
(4)编写实体类
@Data @TableName("product_order") @EqualsAndHashCode(callSuper = false) public class ProductOrderDO {@TableId(value = "id",type = IdType.AUTO)private Long id;private String outTradeNo;private String state;private Date createTime;private Double payAmount;private String nickname;private Long userId; }(5)编写配置信息-分库分表(这里以分表为例,以user_id为分片键)
# 打印执行的数据库以及语句 spring.shardingsphere.props.sql.show=true# 数据源 db0 spring.shardingsphere.datasource.names=ds0,ds1# 第一个数据库 spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://192.168.5.135:3306/sharding_db_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds0.username=root spring.shardingsphere.datasource.ds0.password=root# 第二个数据库 spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://192.168.5.135:3306/sharding_db_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true spring.shardingsphere.datasource.ds1.username=root spring.shardingsphere.datasource.ds1.password=root# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...}, # 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...} spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】 spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}(6)单元测试
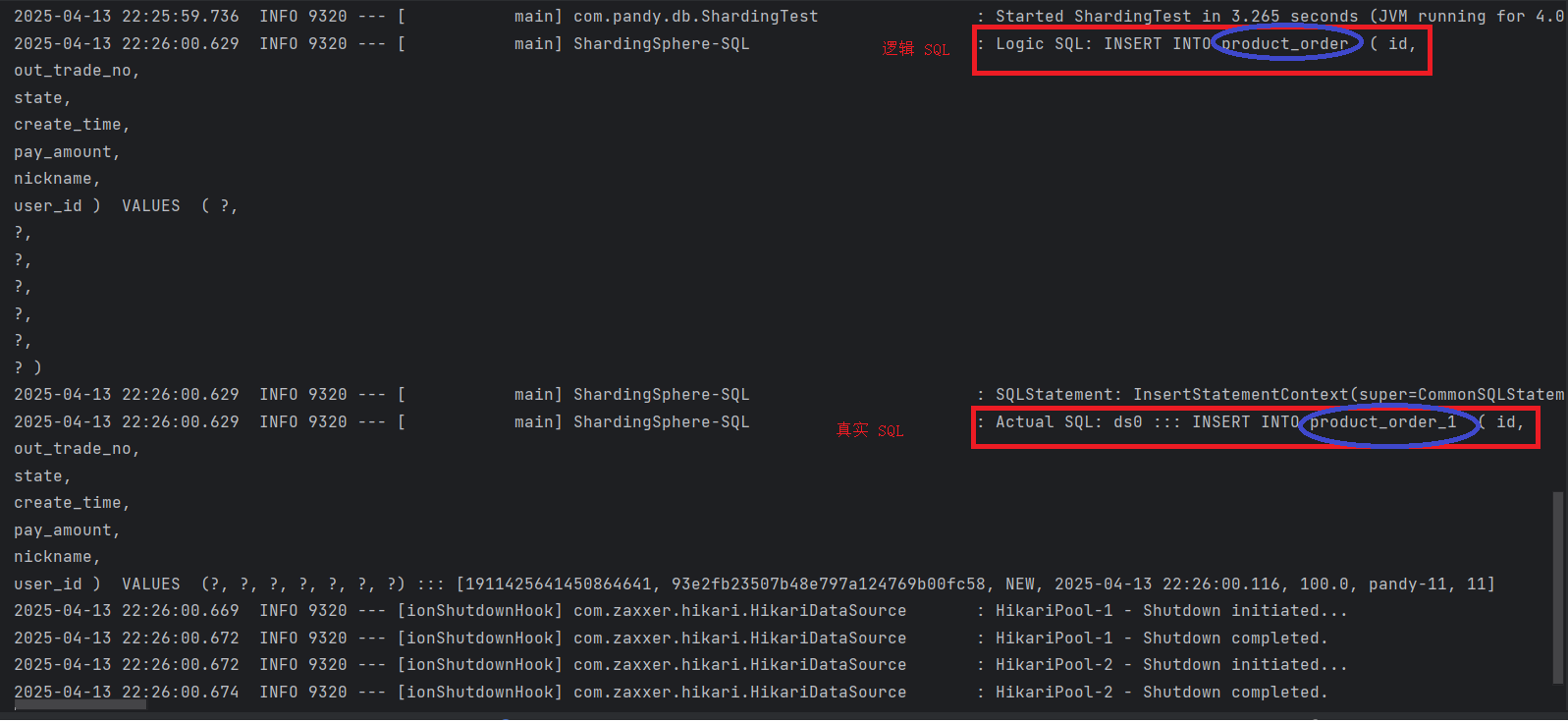
@Test public void testInsertProductOrder() {for(int i=0; i<10; i++) {ProductOrderDO orderDO = new ProductOrderDO();orderDO.setOutTradeNo(UUID.randomUUID().toString().replaceAll("-",""));orderDO.setCreateTime(new Date());orderDO.setPayAmount(100d);orderDO.setState("NEW");orderDO.setNickname("pandy-" + i);orderDO.setUserId(Long.parseLong(i + ""));productOrderMapper.insert(orderDO);} }分库分表执行逻辑
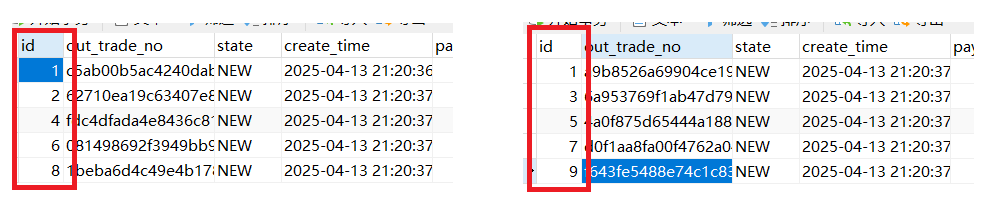
(7)主键重复问题
使用自增主键,出现主键ID重复问题
3 分库分表常见主键ID生成策略
需求:
① 性能强劲
② 全局唯一
③ 防止恶意用户根据ID规则来猜测和获取数据
3.1 业界常见解决方案
(1)自增ID,设置不同的自增步长
缺点:① 未来扩容比较麻烦
② 主从切换时不一致可能会导致重复ID
③ 性能瓶颈
(2)UUID
UUID.randomUUID().toString().replaceAll("-","");优点:性能非常高,没有网络消耗
缺点:① 无序的字符串,不具备趋势自增特性
② UUID太长,不易于存储,浪费存储空间
(3)Redis发号器
利用Redis的incr 或incrby 来实现,原子操作,线程安全
缺点:① 需要占用网络资源,增加系统复杂性
(4)snowflake雪花算法
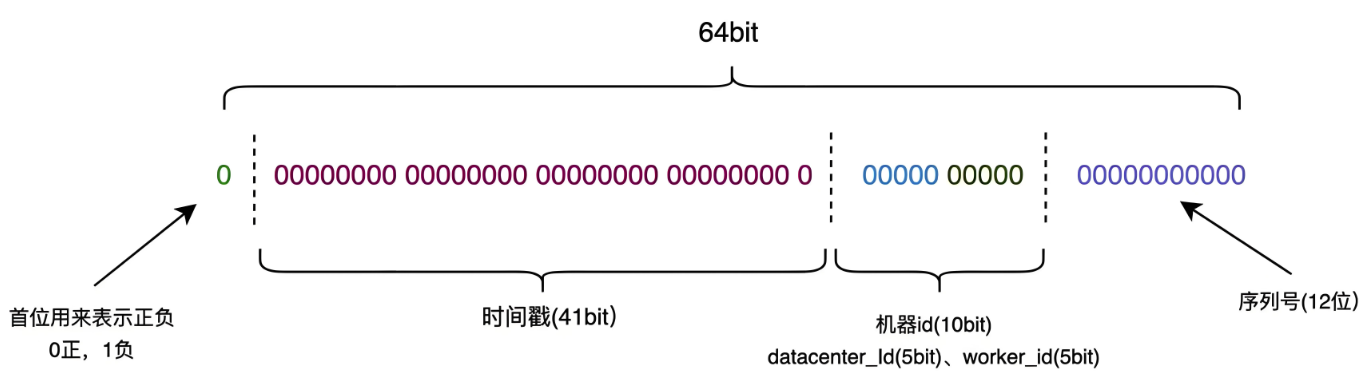
twitter开源的分布式ID生成算法
生成的ID中包含时间戳,所以生成的ID按照时间递增
部署多台服务器,需要保证系统时间一样,机器编号不一样
缺点:依赖系统时间(时钟回拨问题)
配置使用shardingjdbc的雪花算法
# 配置ID使用雪花算法
spring.shardingsphere.sharding.key-generator.column=id
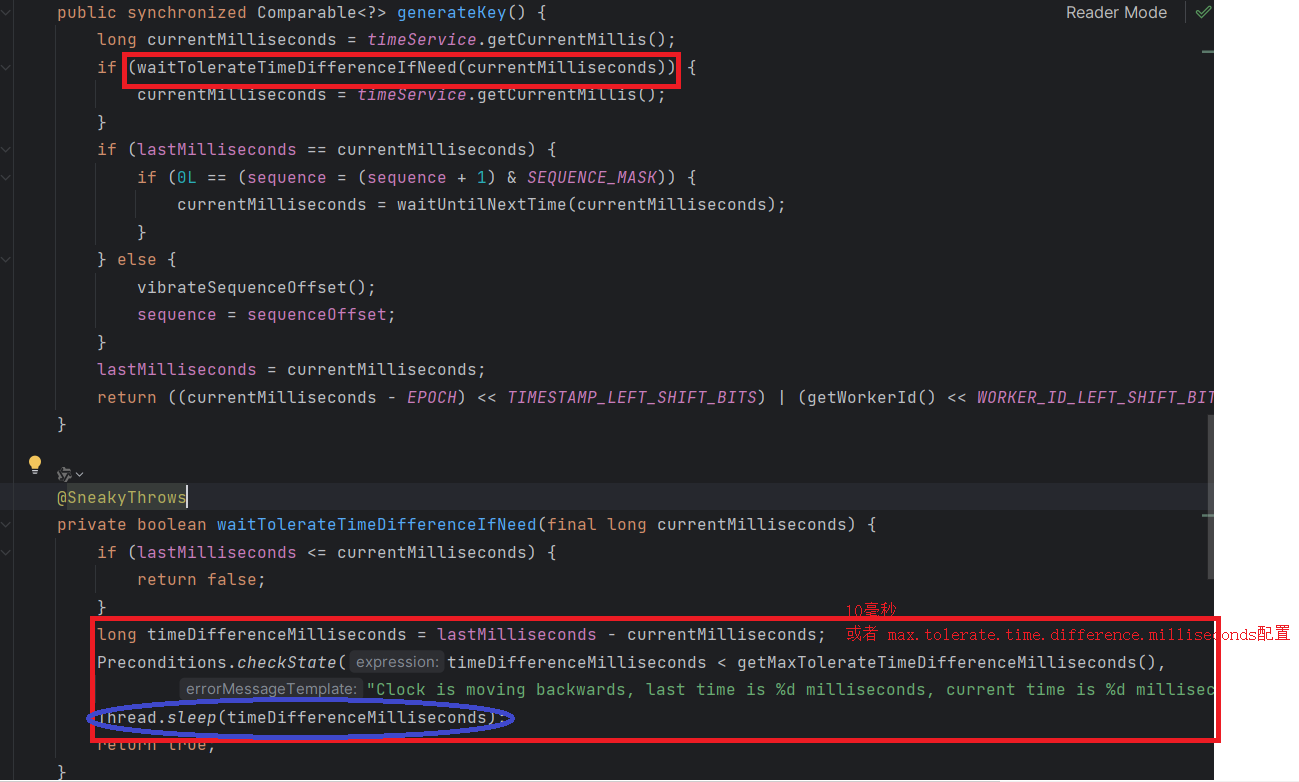
spring.shardingsphere.sharding.key-generator.type=SNOWFLAKE看一下源码, shardingjdbc的雪花算法是怎么解决时钟回拨问题的?
4 广播表和绑定表配置
广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
如:字典表,配置表等
(1)创建一个配置表
CREATE TABLE `config` (`id` bigint unsigned NOT NULL COMMENT '主键id',`config_key` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',`config_value` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',`type` varchar(128) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;(3)创建实体类
@Data @TableName("config") @EqualsAndHashCode(callSuper = false) public class ConfigDO {@TableId(value = "id")private Long id;private String configKey;private String configValue;private String type; }(3)添加广播表配置
#配置广播表 spring.shardingsphere.sharding.broadcast-tables=config(4)测试代码
@Test public void insertConfig() {ConfigDO configDO = new ConfigDO();configDO.setConfigKey("iphone");configDO.setConfigValue("iphone16秒杀广告");configDO.setType("AD");configMapper.insert(configDO); }
5 分库分表核心流程
解析 --> 路由 --> 改写 --> 执行 --> 结果归并
(1)解析
词法解析
语法解析
(2)路由
分片路由(带分片键):直接路由,标准路由,笛卡尔积路由
广播路由(不带分片键):全库表路由,全库路由,全实例路由
(3)改写
将逻辑SQL改写为可以正确执行的真实SQL
(4)执行
采用自动化的执行引擎
内存限制模式:适用于OLAP(连接数量不做限制,多线程并发执行)
连接限制模式:适用于OLAP(1库1线程,多库多线程,保证数据库资源足够多使用)
(5)结果归并
从各个数据节点获取多数据结果集,组合成为一个结果集
流式归并:每一次从结果集中获取到数据
内存归并:分片结果集的数据存储在内存中
相关文章:

互联网三高-数据库高并发之分库分表ShardingJDBC
1 ShardingJDBC介绍 1.1 常见概念术语 ① 数据节点Node:数据分片的最小单元,由数据源名称和数据表组成 如:ds0.product_order_0 ② 真实表:再分片的数据库中真实存在的物理表 如:product_order_0 ③ 逻辑表:…...

【NLP】 18. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法 在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法: 1.1 人工评价 人工评价主要关注以下几点: 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。充分性…...

Android游戏逆向工程全面指南
文章目录 第一部分:基础概念与环境搭建1.1 游戏逆向工程概述1.2 法律与道德考量1.3 开发环境准备基础工具集:环境配置示例: 第二部分:静态分析技术2.1 APK反编译与资源提取使用Apktool解包:关键文件分析: 2…...

ip route show 命令详解
《Linux 中 ip route show 输出结果解析及关键概念》 以下是对 ip route show 输出结果的详细解析,帮助你理解每条路由的含义及作用: 一、路由表整体结构 Linux 路由表中的每条条目包含 目标网络 / 主机、下一跳网关、出接口、路由协议、作用域、源地…...

antv x6使用(支持节点排序、新增节点、编辑节点、删除节点、选中节点)
项目需要实现如下效果流程图,功能包括节点排序、新增节点、编辑节点、删除节点、选中节点等 html部分如下: <template><div class"MindMapContent"><el-button size"small" click"addNode">新增节点&…...

DP主站如何华丽变身Modbus TCP网关!
DP主站如何华丽变身Modbus TCP网关! 在工业自动化领域,Profibus DP和Modbus TCP是两种常用的通信协议。Profibus DP通常应用于制造业自动化场景,而Modbus TCP则广泛使用于工业自动化和楼宇自动化等领域。为了实现这两种协议之间的互联互通&a…...

榕壹云在线商城系统:基于THinkPHP+ Mysql+UniApp全端适配、高效部署的电商解决方案
项目背景:解决多端电商开发的痛点 随着移动互联网的普及和用户购物习惯的碎片化,传统电商系统面临以下挑战: 1. 多平台适配成本高:需要同时开发App、小程序、H5等多端应用,重复开发导致资源浪费。 2. 技术依赖第三方…...

Pinia最基本用法
1. 定义 Store 首先,定义一个 Pinia Store,使用组合式 API 风格和 ref 来管理状态。 示例:stores/ids.js import { defineStore } from pinia; import { ref } from vue;export const useIdsStore defineStore(ids, () > {const ids …...

Android studio打包uniapp插件
一.参考资料与环境准备 原生工程配置需要使用到Android studio和HbuilderX 当前测试的as版本-20240301,下载地址:HbuilderX版本:4.36 二.插件创建流程 1.导入下载的UniPlugin-Hello-AS工程(下载地址见参考资料) 2.生成jks证书…...
App Cleaner Pro for Mac 中 Mac软件卸载工具
App Cleaner Pro for Mac 中 Mac软件卸载工具 一、介绍 App Cleaner & Uninstaller Pro Mac破解,是一款Mac软件卸载工具,残余垃圾清除工具!可以卸载应用程序或只删除不需要的服务文件,甚至可以删除以前删除的应用程序中的文…...

多线程与Tkinter界面交互
在现代图形用户界面(GUI)应用程序中,可能会遇到需要长时间运行的任务,例如网络请求、数据处理或文件读取等。如果这些任务直接在主线程中运行,会导致GUI界面“卡顿”或“不响应”。为了保持界面流畅和响应用户操作,我们可以通过使用多线程来将这些任务移到后台运行。然而…...
开发规范——Restful风格
目录 Restful Apifox 介绍 端口号8080怎么来的? 为什么要使用Apifox? Restful 如果请求方式是Post,那我就知道了要执行新增操作,要新增一个用户 如果请求方式是Put,那就代表我要修改用户 具体要对这些资源进行什么样的操…...

大模型——Llama Stack快速入门 部署构建AI大模型指南
Llama Stack快速入门 部署构建AI大模型指南 介绍 Llama Stack 是一组标准化和有主见的接口,用于如何构建规范的工具链组件(微调、合成数据生成)和代理应用程序。我们希望这些接口能够在整个生态系统中得到采用,这将有助于更轻松地实现互操作性。 Llama Stack 定义并标准化…...

符号右移“ >>= “ 与 无符号右移“ >>>= “ 的区别
符号右移" >> " 与 无符号右移" >>> " 的区别 一、符号右移" >> " 与 无符号右移" >>> " 的区别1. 符号右移(>>)与无符号右移(>>>)的区别…...

利用阿里云企业邮箱服务实现Python群发邮件
目录 一、阿里云企业邮箱群发邮件全流程实现 1. 准备工作与环境配置 2. 收件人列表管理 3. 邮件内容构建 4. 附件添加实现 5. 邮件发送核心逻辑 二、开发过程中遇到的问题与解决方案 1. 附件发送失败问题 2. 中文文件名乱码问题 3. 企业邮箱认证失败 三、完整工作流…...

探秘 Ruby 与 JavaScript:动态语言的多面风采
1 语法特性对比:简洁与灵活 1.1 Ruby 的语法优雅 Ruby 的语法设计旨在让代码读起来像自然语言一样流畅。它拥有简洁而富有表现力的语法结构,例如代码块、符号等。 以下是一个使用 Ruby 进行数组操作的简单示例: # 定义一个数组 numbers [1…...
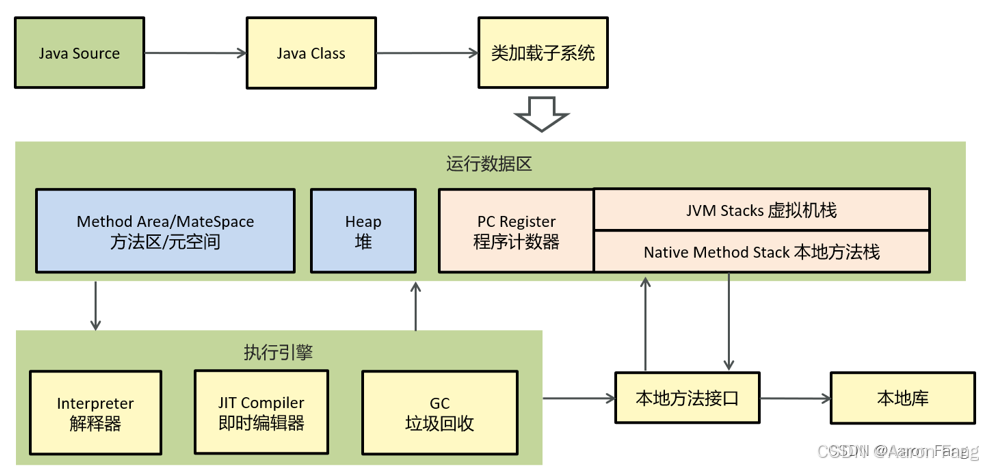
08-JVM 面试题-mk
文章目录 1.JVM 的各部分组成2.运行时数据区2.1.什么是程序计数器?2.2.你能给我详细的介绍Java堆吗?2.3.能不能解释一下方法区?2.3.1常量池2.3.2.运行时常量池2.4.什么是虚拟机栈?2.4.1.垃圾回收是否涉及栈内存?2.4.2.栈内存分配越大越好吗?2.4.3.方法内的局部变量是否线…...

PostgreSQL技术大讲堂 - 第86讲:数据安全之--data_checksums天使与魔鬼
PostgreSQL技术大讲堂 - 第86讲,主题:数据安全之--data_checksums天使与魔鬼 1、data_checksums特性 2、避开DML规则,嫁接非法数据并合法化 3、避开约束规则,嫁接非法数据到表中 4、避开数据检查,读取坏块中的数据…...

DOM解析XML:Java程序员的“乐高积木式“数据搭建
各位代码建筑师们!今天我们要玩一个把XML变成内存乐高城堡的游戏——DOM解析!和SAX那种"边看监控边破案"的刺激不同,DOM就像把整个乐高说明书一次性倒进大脑,然后慢慢拼装(内存:你不要过来啊&…...

C++ 入门六:多态 —— 同一接口的多种实现之道
在面向对象编程中,多态是最具魅力的特性之一。它允许我们通过统一的接口处理不同类型的对象,实现 “一个接口,多种实现”。本章将从基础概念到实战案例,逐步解析多态的核心原理与应用场景,帮助新手掌握这一关键技术。 …...

关于获取文件大小的方法总结
编程开发中,获取文件大小是一项常见的需求,无论是进行文件管理、数据传输还是资源监控等操作,都可能需要知道文件的具体大小。下面将介绍几种常见的获取文件大小的方式,并进行对比分析。 几种可行的文件大小获取方式 1. 使用 fs…...

从宇树摇操avp_teleoperate到unitree_IL_lerobot:如何基于宇树人形进行二次开发(含Open-TeleVision源码解析)
前言 如之前的文章所述,我司「七月在线」正在并行开发多个订单,目前正在全力做好每一个订单,因为保密协议的原因,暂时没法拿出太多细节出来分享 但可以持续解读我们所创新改造或二次开发的对象,即解读paper和开源库…...

告别 ifconfig:为什么现代 Linux 系统推荐使用 ip 命令
告别 ifconfig:为什么现代 Linux 系统推荐使用 ip 命令 ifconfig 指令已经被视为过时的工具,不再是查看和配置网络接口的推荐方式。 与 netstat 被 ss 替代类似。 本文简要介绍 ip addr 命令的使用 简介ip ifconfig 属于 net-tools 包,这个…...
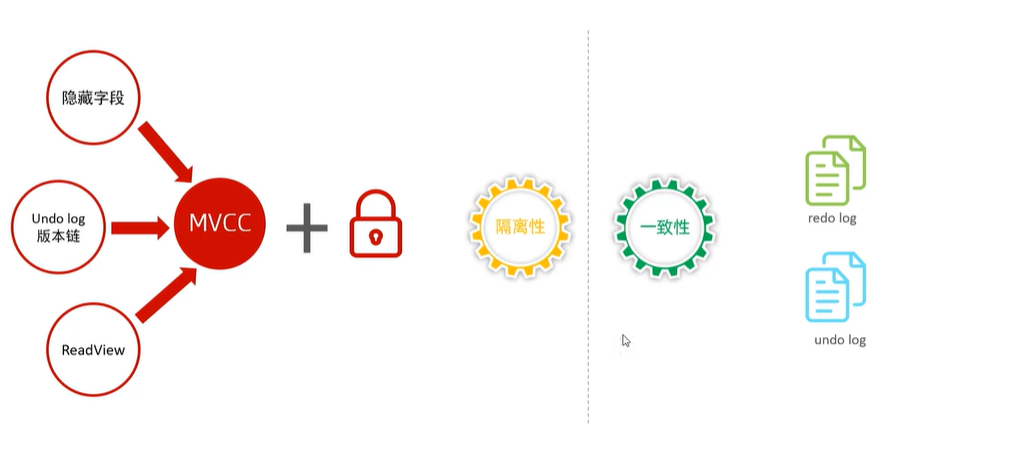
MySQL——MVCC(多版本并发控制)
目录 1.MVCC多版本并发控制的一些基本概念 MVCC实现原理 记录中的隐藏字段 undo log undo log 版本链 ReadView 数据访问规则 具体实现逻辑 总结 1.MVCC多版本并发控制的一些基本概念 当前读:该取的是记录的最新版本,读取时还要保证其他并发事务…...

Gateway-网关-分布式服务部署
前言 什么是API⽹关 API⽹关(简称⽹关)也是⼀个服务, 通常是后端服务的唯⼀⼊⼝. 它的定义类似设计模式中的Facade模式(⻔⾯模式, 也称外观模式). 它就类似整个微服务架构的⻔⾯, 所有的外部客⼾端访问, 都需要经过它来进⾏调度和过滤. 常⻅⽹关实现 Spring Cloud Gateway&a…...

火影 遇上 python Baby_Brother_GGY
上视频先~ 66666 import pygame import random import sys import math from pygame.locals import *# 初始化pygame pygame.init() pygame.mixer.init()# 屏幕设置 WIDTH, HEIGHT 1480, 750 screen pygame.display.set_mode((WIDTH, HEIGHT)) py…...
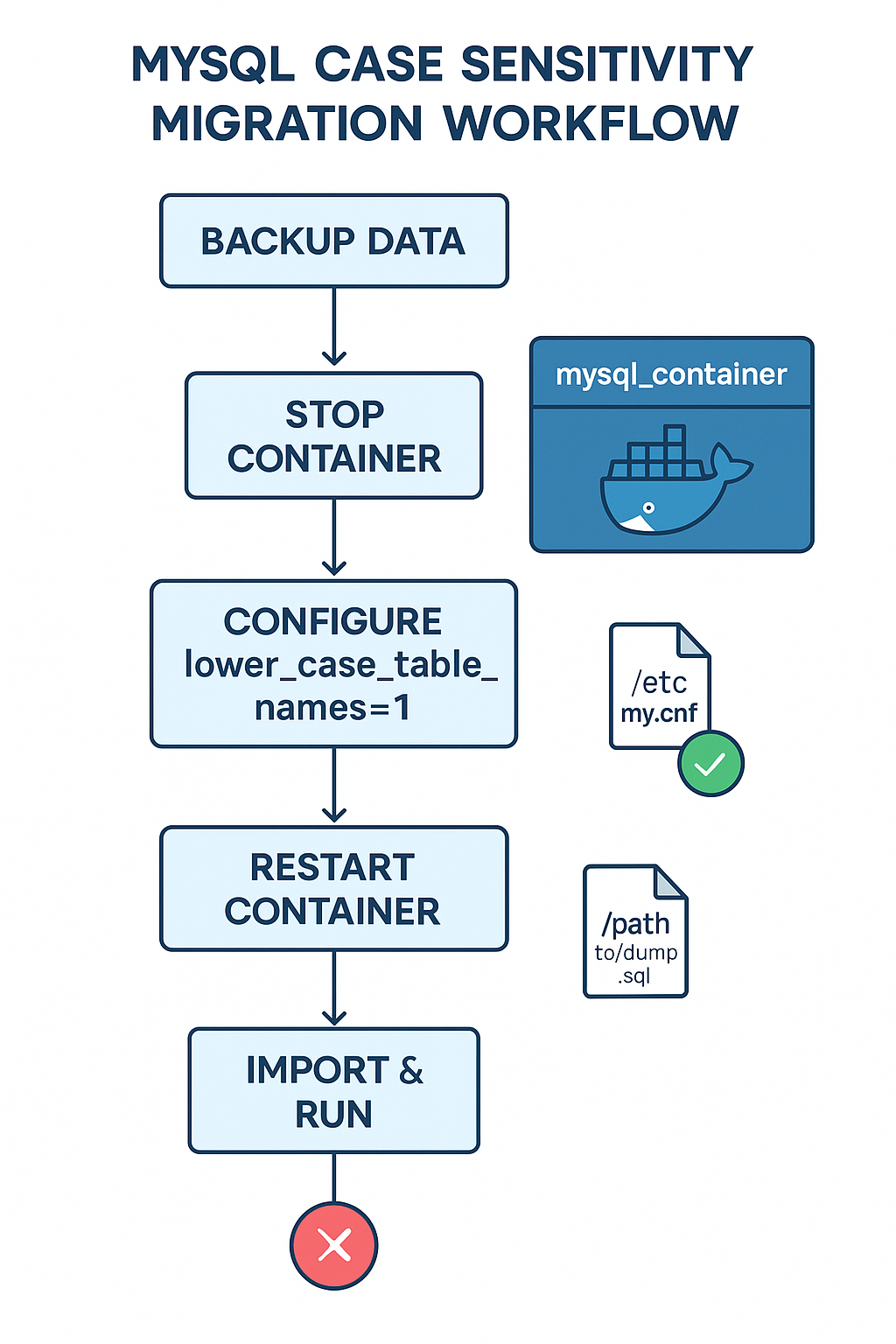
Docker部署MySQL大小写不敏感配置与数据迁移实战20250409
Docker部署MySQL大小写不敏感配置与数据迁移实战 🧭 引言 在企业实际应用中,尤其是使用Java、Hibernate等框架开发的系统,MySQL默认的大小写敏感特性容易引发各种兼容性问题。特别是在Linux系统中部署Docker版MySQL时,默认行为可…...

面试题之网络相关
最近开始面试了,410面试了一家公司 问了我几个网络相关的问题,我都不会!!现在来恶补一下,整理到博客中,好难记啊,虽然整理下来了。在这里先祝愿大家在现有公司好好沉淀,定位好自己的…...

使用MPI-IO并行读写HDF5文件
使用MPI-IO并行读写HDF5文件 HDF5支持通过MPI-IO进行并行读写,这对于大规模科学计算应用非常重要。下面我将提供C和Fortran的示例程序,展示如何使用MPI-IO并行读写HDF5文件。 准备工作 在使用MPI-IO的HDF5之前,需要确保: HDF5库编译时启用…...
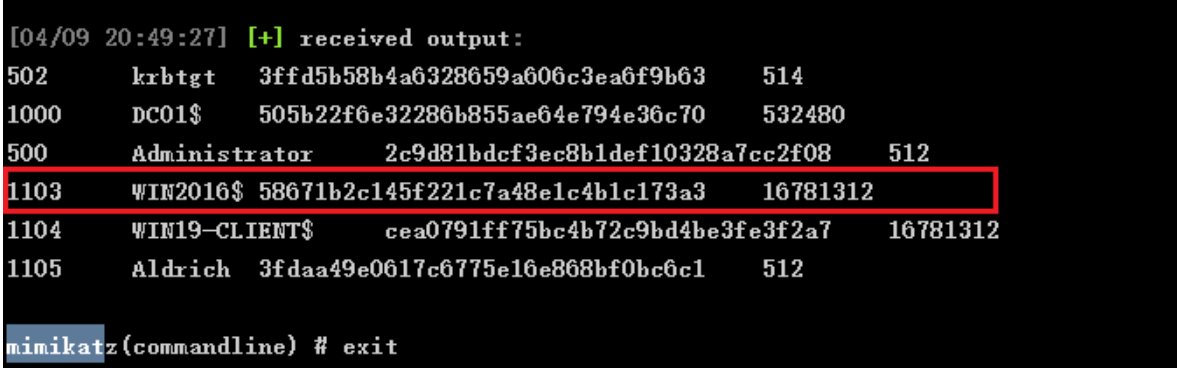
[春秋云镜] Tsclient仿真场景
文章目录 靶标介绍:外网mssql弱口令SweetPotato提权上线CSCS注入在线用户进程上线 内网chisel搭建代理密码喷洒攻击映像劫持 -- 放大镜提权krbrelayup提权Dcsync 参考文章 考点: mssql弱口令SweetPotato提权CS注入在线用户进程上线共享文件CS不出网转发上线密码喷洒…...