从一堆新闻正文中,提取出“事实型句子(fact)”,并保存到新文件中
示例代码:
import os
import re
import json
import nltk
from tqdm import tqdm
from transformers import pipeline
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
## Check If Fact or Opinion
#lighteternal/fact-or-opinion-xlmr-elfact_opinion_classifier = pipeline("text-classification", model="lighteternal/fact-or-opinion-xlmr-el")def wr_dict(filename,dic):if not os.path.isfile(filename):data = []data.append(dic)with open(filename, 'w') as f:json.dump(data, f)else: with open(filename, 'r') as f:data = json.load(f)data.append(dic)with open(filename, 'w') as f:json.dump(data, f)def rm_file(file_path):if os.path.exists(file_path):os.remove(file_path)with open('datasource/news_filter_dup.json', 'r') as file:data = json.load(file)save_path = 'datasource/news_filter_fact.json'
print(len(data))
print(data[0].keys())
rm_file(save_path)for d in tqdm(data):fact_list = []body = d['body']paragraphs = re.split(r'\n{2,}', body)for text in paragraphs:sentences = sent_tokenize(text)for sentence in sentences:try:sentence_result = fact_opinion_classifier(sentence)[0]# If Factif sentence_result["label"] == "LABEL_1":fact_list.append(sentence)except:print(sentence)d['fact_list'] = fact_listwr_dict(save_path,d)
💡 代码功能:
把新闻正文拆成句子,每句用模型
lighteternal/fact-or-opinion-xlmr-el判断是否为“Fact”,如果是,就保留下来,最终写入新的 JSON 文件中。
🔍 分段详细解析
📦 1. 导入依赖 & 初始化模型
import os, re, json, nltk
from tqdm import tqdm
from transformers import pipeline
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
nltk.download('punkt'): 下载英文句子分割工具(句子分割器)pipeline("text-classification", model=...):加载判断“Fact/Opinion”的模型
fact_opinion_classifier = pipeline("text-classification", model="lighteternal/fact-or-opinion-xlmr-el")
🧱 2. 工具函数
def wr_dict(filename,dic):...
- 把每个处理好的新闻写入 JSON 文件,逐条追加写入
def rm_file(file_path):...
- 如果输出文件已存在,先删除,避免旧内容混入
📂 3. 加载输入数据(新闻正文)
with open('datasource/news_filter_dup.json', 'r') as file:data = json.load(file)
- 加载去重后的新闻文件
🧹 4. 主处理逻辑(提取事实句子)
for d in tqdm(data): # 遍历每条新闻fact_list = []body = d['body'] # 新闻正文
- 先用
\n\n把正文分成段落 - 然后再用
sent_tokenize分成句子
paragraphs = re.split(r'\n{2,}', body)for text in paragraphs:sentences = sent_tokenize(text)
- 对每句话调用模型分类(模型返回一个 label)
for sentence in sentences:try:sentence_result = fact_opinion_classifier(sentence)[0]if sentence_result["label"] == "LABEL_1":fact_list.append(sentence)
🔵 LABEL_1 就是 Fact(事实)
📝 5. 保存结果
d['fact_list'] = fact_listwr_dict(save_path,d)
- 把提取出来的事实句子加到原来的数据结构中
- 写入保存路径:
datasource/news_filter_fact.json
✅ 示例说明
输入 JSON 文件(news_filter_dup.json)的一条数据:
{"title": "NASA discovers new exoplanet","body": "NASA announced a new discovery today.\n\nThey found a planet that is 1.3 times the size of Earth. It orbits a star 300 light-years away.\n\nScientists say it might have liquid water."
}
模型判断过程:
分出来的句子:
NASA announced a new discovery today.⟶ OpinionThey found a planet that is 1.3 times the size of Earth.⟶ ✅ FactIt orbits a star 300 light-years away.⟶ ✅ FactScientists say it might have liquid water.⟶ Opinion
输出 JSON 文件(news_filter_fact.json)的一条数据:
{"title": "NASA discovers new exoplanet","body": "NASA announced a new discovery today.\n\nThey found a planet that is 1.3 times the size of Earth. It orbits a star 300 light-years away.\n\nScientists say it might have liquid water.","fact_list": ["They found a planet that is 1.3 times the size of Earth.","It orbits a star 300 light-years away."]
}
🧠 小结
| 模块 | 作用 |
|---|---|
re + sent_tokenize | 切段落、切句子 |
pipeline(...xlmr-el) | 判断句子是 Fact 还是 Opinion |
LABEL_1 | 是 Fact,才保留 |
fact_list | 存放所有 fact 句子 |
wr_dict | 把每条带 fact 的新闻写入文件 |
相关文章:
”,并保存到新文件中)
从一堆新闻正文中,提取出“事实型句子(fact)”,并保存到新文件中
示例代码: import os import re import json import nltk from tqdm import tqdm from transformers import pipeline nltk.download(punkt) from nltk.tokenize import sent_tokenize ## Check If Fact or Opinion #lighteternal/fact-or-opinion-xlmr-elfact_opi…...
Matlab 调制信号和fft变换
1、内容简介 Matlab 194-调制信号和fft变换 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

Git 常用命令集与实际使用 Demo
Git 常用命令集与实际使用 Demo 一、初始化 & 配置 命令说明Demogit init在当前目录初始化本地 Git 仓库,生成 .git/ 文件夹mkdir newProject && cd newProject git initgit config --global user.name “xxx”设置全局用户名git config --global use…...

KaiwuDB:面向AIoT场景的多模融合数据库,赋能企业数字化转型
引言 在万物互联的AIoT时代,企业面临着海量时序数据处理、多模数据融合和实时分析等挑战。KaiwuDB应运而生,作为一款面向AIoT场景的分布式、多模融合、支持原生AI的数据库产品,为企业提供了一站式数据管理解决方案。 产品概述 KaiwuDB是一…...

STM32 vs ESP32:如何选择最适合你的单片机?
引言 在嵌入式开发中,STM32 和 ESP32 是两种最热门的微控制器方案。但许多开发者面对项目选型时仍会感到困惑:到底是选择功能强大的 STM32,还是集成无线的 ESP32? 本文将通过 硬件资源、开发场景、成本分析 等多维度对比…...

100M/1000M 以太网静电浪涌防护方案
方案简介 以太网是一种生产较早且广泛应用的局域网通讯方式,同时也是一种协议,其核 心在于实现区域内(如办公室、学校等)的网络互联。根据数据传输速度的不同,以 太网大致可以划分为几个等级:标准以太网…...

使用ADB工具分析Android应用崩溃原因:以闪动校园为例
使用adb工具分析模拟器或手机里app出错原因以闪动校园为例 使用ADB工具分析Android应用崩溃原因:以闪动校园为例 前言 应用崩溃是移动开发中常见的问题,尤其在复杂的Android生态系统中,找出崩溃原因可能十分棘手。本文将以流行的校园应用&q…...
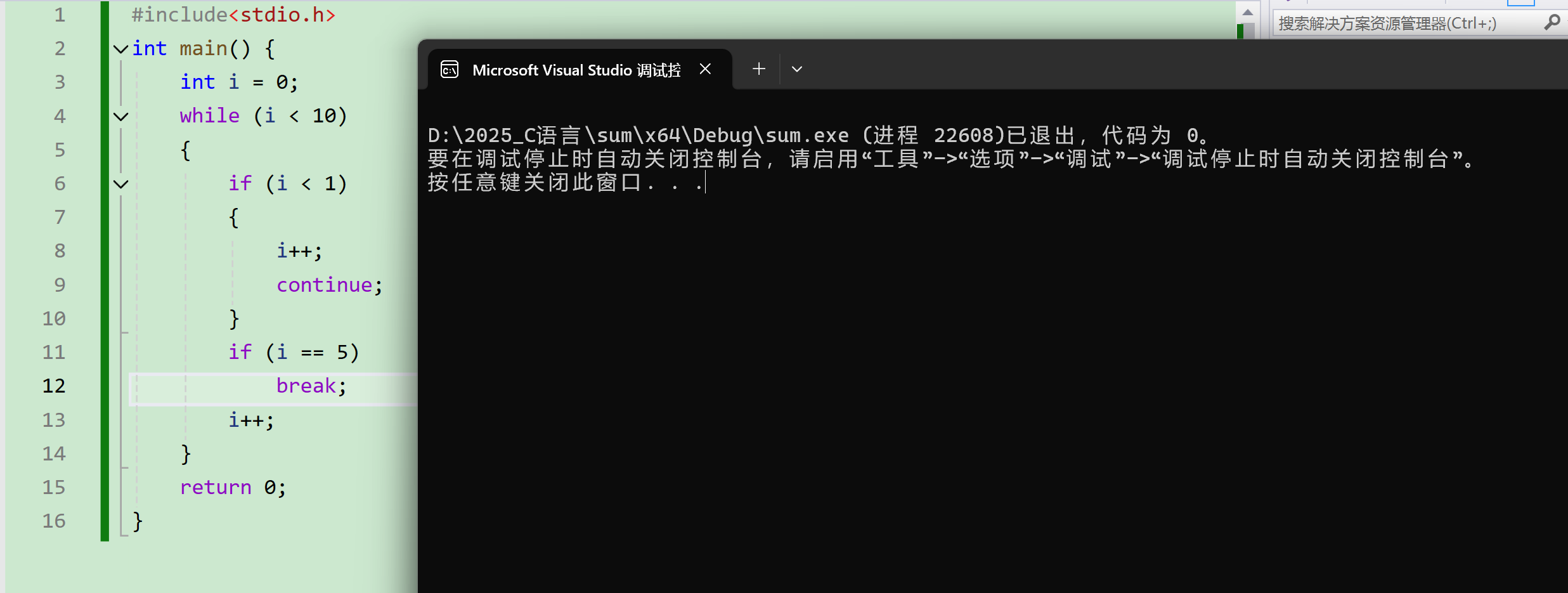
C语言中while的相关题目
一、题目引入 以下程序中,while循环的循环次数是多少次? 二、代码分析 首先要明确的一点 while循环是当循环条件为真 就会一直循环 不会停止 while中i是小于10的 说明i可以取到0 1 2 3 4 5 6 7 8 9 进入第一个if判断i小于1为真时执行continue i0是为真的 执行continue 后…...

关于使用 nuitka进行构建python应用的一些配置,以及github action自动构建;
1. 通用配置 # 设置输出目录和文件名output_dir "dist"app_name "CursorAutoFree"# 基础命令行选项base_options ["--follow-imports", # 跟踪导入"--enable-plugintk-inter", # 启用 Tkinter 支持"--include-packagecusto…...

[Dify] 基于明道云实现金融业务中的Confirmation生成功能
在金融业务的日常流程中,交易记录的处理不仅涉及数据录入、流程审批,更重要的是其最终输出形式——交易确认函(Confirmation)。本文将介绍如何通过明道云的打印模板功能,快速、准确地生成符合业务需求的交易Confirmation,提升工作效率与合规性。 为什么需要Confirmation?…...
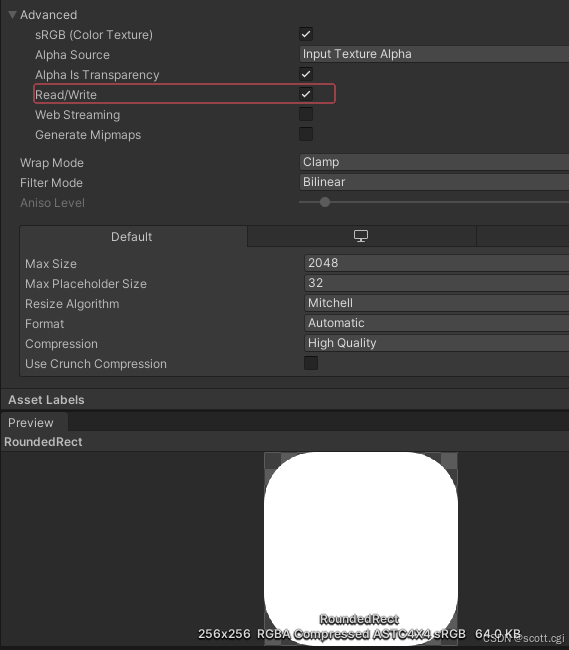
「Unity3D」图片导入选项取消Read/Write,就无法正确显示导入大小,以及Addressable打包无法正确显示的问题
如果在Edit -> Project Settings -> Editor中的“Load texture data on demand”勾选,就会让图片导入设置中,不勾选Read/Write,就无法正确显示纹理的大小数字。 更进一步的问题是,使用Addressable打包的时候, 如…...

使用Java截取MP4文件图片的技术指南
在多媒体处理中,从视频文件中截取图片是一个常见的需求。本文将详细介绍如何使用Java结合FFmpeg实现从MP4文件中截取图片的功能。我们将通过几种不同的方法来实现这一目标,包括直接调用FFmpeg命令行工具、使用JavaCV库以及使用JAVE库。 环境准备 在开始…...

在C盘新建文本文档
设定 C: 的 NTFS 文件夹权限为 Users 或 Domain Users 具有写入权限; 1. 选中C盘 2. 点右键选中属性(properties) 3. 选“安全”(Security) Tab 4. Users 5. “编辑”(Edit) 6. Full Control …...

Xcode为不同环境配置不同的环境变量
一般有三种方式: 一、通过多Target 二、通过scheme,也就是多configurations 三、通过.xcconfig文件 先来看第二种方式:通过scheme,也就是多configurations,包括自定义User-settings 第一步:增加configurations,Xcode默认为我们生成了…...
阿里通义实验室发布图片数字人项目LAM,实现高保真重建
简介 LAM项目结合了3D Gaussian Splatting(高斯点云渲染)和大规模预训练模型的优势,解决了传统头部重建方法效率低、依赖多数据的痛点。其背景源于AI生成内容(AIGC)领域对实时、高保真3D头像生成的需求,尤其…...

面试算法高频05-bfs-dfs
dfs bfs 深度优先搜索(DFS)和广度优先搜索(BFS)是图和树遍历中的重要算法,二者在实现方式和应用场景上存在明显差异。 定义与概念:DFS在遍历树或图时,以深度优先,从起始节点出发,尽可能深入地探索分支,直至无法继续,再回溯;BFS则按层次逐层遍历,从起始节点开始,…...
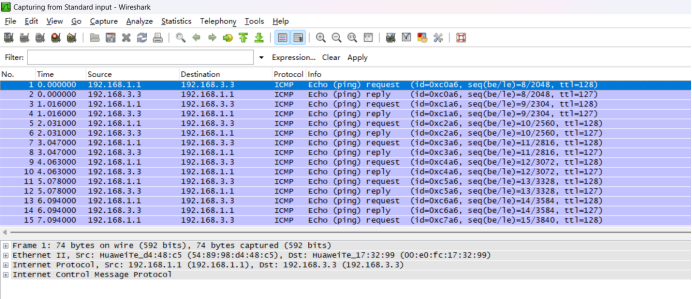
镜像端口及观察端口的配置
配好路由器的各个接口的IP PC1ping PC3的IP,在路由器中抓2/0/0端口的包,可观察到无结果 输入observe-port interface g 2/0/0 命令配置观察端口 输入mirror to observe-port both命令 (其中both表示接收来去的数据包,inboun…...
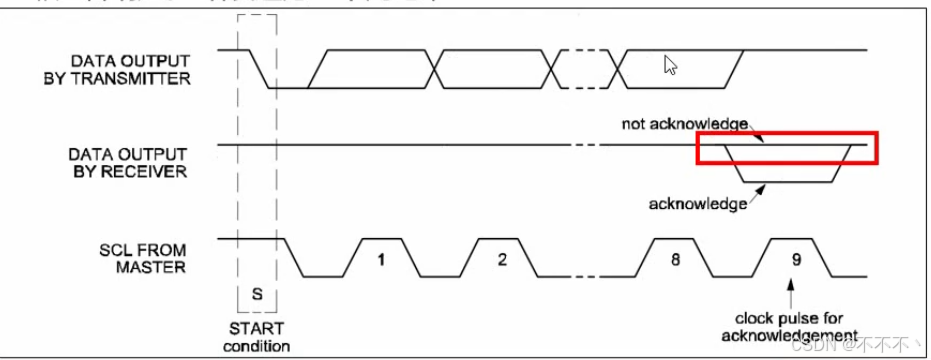
STM32——I2C通讯(软件模拟)
I2C概念 I2C:Inter-Integrated Circuit(内部集成电路) Philps公司80年代初期开发的,引脚少,硬件实现简单,可扩展性广泛地使用在系统内多个集成电路(IC)间的低速通讯 简单的双向两线制总线协议…...

JetBrains Terminal 又发布新架构,Android Studio 将再次迎来新终端
不到一年的时间,JetBrains 又要对 Terminal 「大刀阔斧」,本次发布的新终端是重构后的全新的架构,而上一次终端大调整还是去年 8 月的 v2024.2 版本,并且在「Android Studio Ladybug | 2024.2.1」也被引入。 不知道你们用不用内置…...

论文:Generalized Category Discovery with Large Language Models in the Loop
论文下载地址:Generalized Category Discovery with Large Language Models in the Loop - ACL Anthology 1、研究背景 尽管现代机器学习系统在许多任务上取得了优异的性能,绝大多数都遵循封闭世界的设置,假设训练和测试数据来自同一组预定义…...
第十六届蓝桥杯 省赛C/C++ 大学B组
编程题目现在在洛谷上都可以提交了。 未完待续,写不动了。 C11 编译命令 g A.cpp -o A -Wall -lm -stdc11A. 移动距离 本题总分:5 分 问题描述 小明初始在二维平面的原点,他想前往坐标 ( 233 , 666 ) (233, 666) (233,666)。在移动过程…...

从输入URL到页面渲染:浏览器请求的完整旅程解析
🌐 从输入URL到页面渲染:浏览器请求的完整旅程解析 #网络协议 #浏览器原理 #性能优化 #Web开发 一、概览:一次请求的9大关键阶段 1. 用户输入URL → 2. DNS解析 → 3. 建立TCP连接 → 4. 发送HTTP请求 5. 服务器处理 → 6. 接收响应 → 7…...
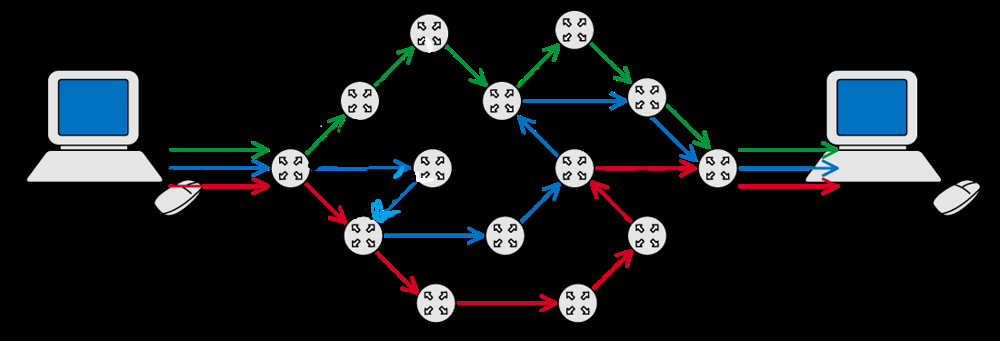
【计网】网络交换技术之分组交换(复习自用,重要1)
复习自用的,处理得比较草率,复习的同学或者想看基础的同学可以看看,大佬的话可以不用浪费时间在我的水文上了 另外两种交换技术可以直接点击链接访问相关笔记: 电路交换 报文交换 一、分组交换的定义 1.定义 分组交换&#x…...

6.2 GitHub API接口设计实战:突破限流+智能缓存实现10K+仓库同步
GitHub Sentinel 定期更新 API 接口设计 关键词:GitHub API 集成、异步爬虫开发、RESTful 接口设计、请求限流策略、数据增量更新 1. 接口架构设计原则 采用 分层隔离架构 实现数据采集与业务逻辑解耦: #mermaid-svg-WihvC78J0F5oGDbs {font-family:"trebuchet ms&quo…...

考研单词笔记 2025.04.13
alleviate v减轻,缓解 alleviation n减轻,缓解 blunt a钝的,不锋利的,坦率的,直截了当的v使减弱,使变钝 dampen v抑制,减弱,使潮湿 dim v减弱,淡化,变昏暗…...

解密CHASE-SQL和XiYan-SQL多智能体AI如何最终实现TEXT2SQL的突破
想象一个世界,无论技术背景如何,任何人都能轻松查询海量数据库、挖掘深层洞察。比如:“我想知道安徽地区最畅销电子产品的第三季度销售额?”——只需一句话。“去年营销支出与客户获取成本之间的相关性如何?”——像聊天一样输入问题。这就是Text-to-SQL的承诺:将人类语言…...

思考力提升的黄金标准:广度、深度与速度的深度剖析
文章目录 引言一、广度的拓展:构建多元知识网络1.1 定义与重要性1.2 IT技术实例与提升策略小结:构建多元知识网络,提升IT领域思考力广度 二、深度的挖掘:追求知识的精髓2.1 定义与重要性2.2 IT技术实例与提升策略小结:…...
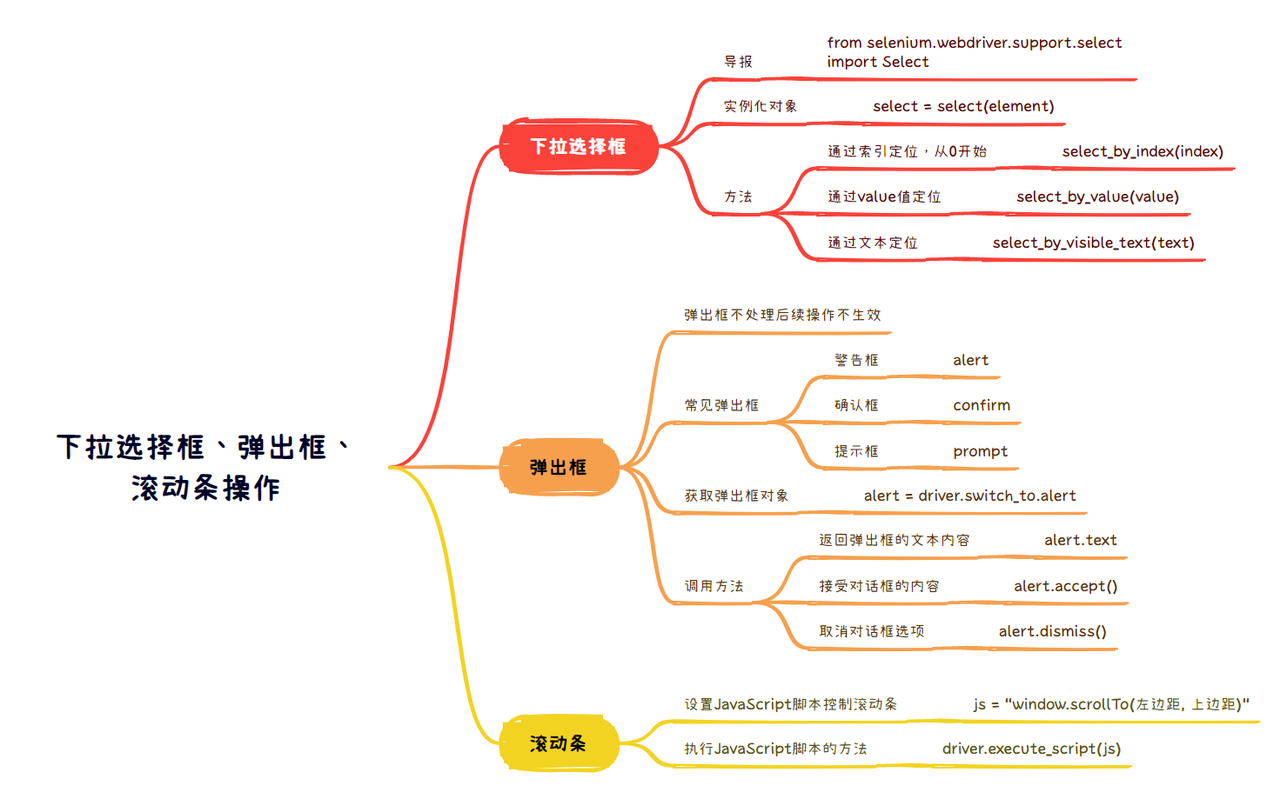
web自动化:下拉选择框、弹出框、滚动条的操作
web自动化:下拉选择框、弹出框、滚动条的操作 一、下拉选择框 1、导包 from selenium.webdriver.support.select inport Select 2、实例化对象 Select(element) 3、常用方法 通过option索引来定位,从0开始:select_by_index(index)通过…...

数字人:打破次元壁,从娱乐舞台迈向教育新课堂(4/10)
摘要:数字人正从娱乐领域的璀璨明星跨界到教育领域的智慧导师,展现出无限潜力。从虚拟偶像、影视游戏到直播短视频,数字人在娱乐产业中大放异彩,创造巨大商业价值。在教育领域,数字人助力个性化学习、互动课堂和虚拟实…...

互联网三高-数据库高并发之分库分表ShardingJDBC
1 ShardingJDBC介绍 1.1 常见概念术语 ① 数据节点Node:数据分片的最小单元,由数据源名称和数据表组成 如:ds0.product_order_0 ② 真实表:再分片的数据库中真实存在的物理表 如:product_order_0 ③ 逻辑表:…...