LangGraph——Agent AI的持久化状态
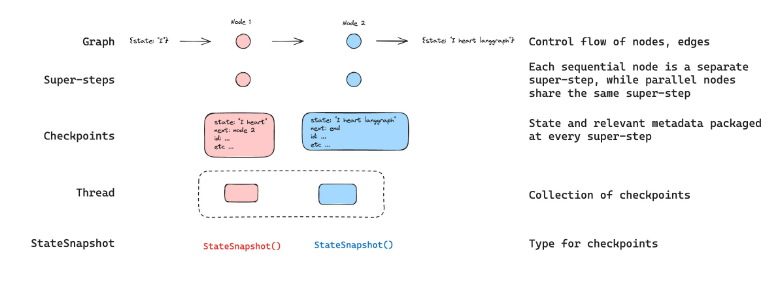
LangGraph 内置了一个持久化层,通过检查点(checkpointer)机制实现。当你使用检查点器编译图时,它会在每个超级步骤(super-step)自动保存图状态的检查点。这些检查点被存储在一个线程(thread)中,可在图执行后随时访问。由于线程允许在执行后访问图的状态,因此实现了人工介入(human-in-the-loop)、记忆(memory)、时间回溯(time travel)和容错(fault-tolerance)等强大功能。具体操作指南提供了端到端示例,说明如何为图添加并使用检查点器。下文我们将分别的详细讨论这些概念。
什么是内存(memory)?
记忆是一种认知功能,允许人们存储、检索和使用信息来理解他们的现在和未来。想象一下,与一个总是忘记你告诉他们事情的同事合作是多么令人沮丧,这需要不断地重复!随着人工智能代理承担涉及众多用户交互的更复杂任务,为它们配备记忆功能对于提高效率和用户满意度同样至关重要。通过记忆功能,代理可以从反馈中学习,并适应用户的偏好。
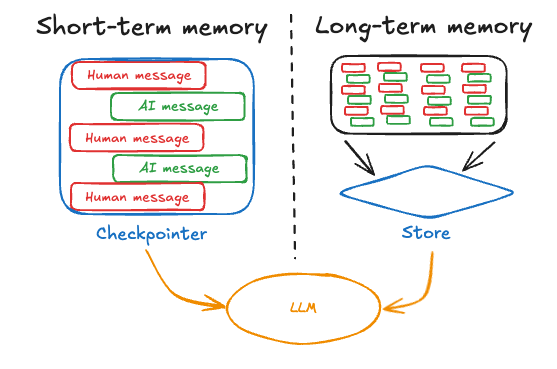
短期记忆(Short-term memory,),或称为线程范围内的记忆,可以在与用户的单个对话线程中的任何时间被回忆起来。LangGraph将短期记忆管理为代理状态的一部分。状态会被使用检查点机制保存到数据库中,以便对话线程可以在任何时间恢复。当图谱被调用或者一个步骤完成时,短期记忆会更新,并且在每个步骤开始时读取状态。
这种记忆类型使得AI能够在与用户的持续对话中保持上下文和连贯性,确保了交互的流畅性和效率。例如,在一系列的询问、回答或命令执行过程中,用户无需重复之前已经提供的信息,因为AI能够记住这些细节并根据需要利用这些信息进行响应或进一步的操作。这对于提升用户体验,尤其是复杂任务处理过程中的体验至关重要。
长期记忆(Long-term memory)是在多个对话线程之间共享的。它可以在任何时间、任何线程中被回忆起来。记忆的范围可以限定在任何自定义命名空间内,而不仅仅局限于单个线程ID。LangGraph提供了存储机制,允许您保存和回忆长期记忆。
这种记忆类型使得AI能够在不同对话或用户交互中保留和利用信息。例如,用户的偏好、历史记录或特定的上下文信息可以跨会话保存下来,并在未来的任何交互中被调用。这种方式为用户提供了一种无缝体验,无论他们何时或以何种方式与AI交互,AI都能根据过去的信息做出更个性化、更智能的响应。这对于构建深度用户关系和增强系统适应性至关重要。
持久化
许多AI应用需要记忆功能来在多次交互中共享上下文。在LangGraph中,这种类型的记忆可以通过线程级别的持久化添加到任何StateGraph中。
通过使用线程级别的持久化,LangGraph允许AI在与用户的连续对话或交互过程中保持信息的连贯性和一致性。这意味着,在一个交互中获得的信息可以被保存并在后续的交互中使用,极大地提升了用户体验。例如,用户在一个会话中表达的偏好可以在下一个会话中被记住和引用,使得交互更加个性化和高效。这种方法对于需要处理复杂或多步骤任务的应用特别有用,因为它确保了用户无需重复提供相同的信息,同时也让AI能够更好地理解和响应用户的需求。
LangGraph中使用 Memory
在创建任何LangGraph图时,您可以通过在编译图时添加一个检查点来设置其状态的持久化。这样做可以确保图的状态(包括短期和长期记忆中的信息)能够被保存下来,以便在未来的时间点恢复和继续执行。
如下面例子
from langgraph.checkpoint.memory import MemorySavercheckpointer = MemorySaver()
graph.compile(checkpointer=checkpointer)
我们先尝试一下定义普通图,不使用memory,那么对话的上下文将不会在交互之间持续存在。
import os
os.environ["OPENAI_API_KEY"] = 'sk-XXXXXXXXXXXXX'
os.environ["OPENAI_API_BASE"] = 'https://openkey.cloud/v1'
os.environ["SERPAPI_API_KEY"] = 'XXXXXXXXX'
os.environ["TAVILY_API_KEY"] = 'tvly-XXXXXX'from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)from typing import Annotated
from typing_extensions import TypedDictfrom langgraph.graph import StateGraph, MessagesState, STARTdef call_model(state: MessagesState):response = llm.invoke(state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile()input_message = {"role": "user", "content": "hi! I'm bob"}
for chunk in graph.stream({"messages": [input_message]}, stream_mode="values"):chunk["messages"][-1].pretty_print()input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]}, stream_mode="values"):chunk["messages"][-1].pretty_print()得到下面结果,大模型交互的时候并没有记忆力
================================ Human Message =================================hi! I'm bob
================================== Ai Message ==================================Hi Bob! How can I assist you today?
================================ Human Message =================================what's my name?
================================== Ai Message ==================================I'm sorry, but I don't have access to personal information about you unless you share it with me. How can I assist you today?
为了添加持久性,我们需要在编译图表时传递检查台。这个时候当我们给Graph添加上面MemorySaver_的时候,我们就可以与代理商进行互动,并看到它记住以前的消息!
config = {"configurable": {"thread_id": "1"}}
input_message = {"role": "user", "content": "hi! I'm bob"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================hi! I'm bob
================================== Ai Message ==================================Hi Bob! How can I assist you today?
这个时候我们再问一下大模型我们的名字
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
================================ Human Message =================================what's my name?
================================== Ai Message ==================================Your name is Bob! How can I help you today?
如果我们想开始一个新的对话,可以通过传递不同的会话标识符或配置来实现。这意味着为新的交互创建一个独立的上下文,确保新对话不会受到之前对话状态的影响,从而保持数据和记忆的隔离。
input_message = {"role": "user", "content": "what's my name?"}
for chunk in graph.stream({"messages": [input_message]},{"configurable": {"thread_id": "2"}},stream_mode="values",
):chunk["messages"][-1].pretty_print()
================================ Human Message =================================what's my name?
================================== Ai Message ==================================I'm sorry, but I don't have access to personal information about users unless it has been shared with me in the course of our conversation. How can I assist you today?
这样子所有的回忆都消失了。
LangGraph中使用 InMemoryStore
InMemoryStore是一个基于内存的存储系统,用于在程序运行时临时保存数据。它通常用于快速访问和存储短期记忆或会话数据。我们可以使用使用 langgraph 和 langchain_openai 库来创建一个基于内存的存储系统(InMemoryStore),并结合 OpenAI 的嵌入模型 (OpenAIEmbeddings) 来处理嵌入向量。
大家可能有疑惑,我们不是用了MemorySaver持久化消息吗,为啥还要用InMemoryStore,他们的主要区别在于数据的持久性和应用场景。InMemoryStore主要用于短期、临时的数据存储,强调快速访问;而MemorySaver则侧重于将数据从临时存储转移到持久存储,确保数据可以在多次程序执行间保持不变。在我们设计系统时,可以根据具体需求选择合适的存储策略。对于只需要在会话内保持的数据,可以选择InMemoryStore;而对于需要长期保存并能够在不同会话间共享的数据,则应考虑使用MemorySaver或其他形式的持久化存储解决方案。
下面给大家展示一个结合两种方式的例子,我们实现了一个对话模型的调用逻辑,通过从存储系统中检索与用户相关的记忆信息并将其作为上下文传递给模型,同时支持根据用户指令存储新记忆,确保每个用户的记忆数据独立且自包含,从而提升对话的个性化和连贯性。
from langgraph.store.memory import InMemoryStore
from langchain_openai import OpenAIEmbeddingsin_memory_store = InMemoryStore(index={"embed": OpenAIEmbeddings(model="text-embedding-3-small"),"dims": 1536,}
)import uuid
from typing import Annotated
from typing_extensions import TypedDictfrom langchain_anthropic import ChatAnthropic
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.base import BaseStoremodel = ChatAnthropic(model="claude-3-5-sonnet-20240620")def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):user_id = config["configurable"]["user_id"]namespace = ("memories", user_id)memories = store.search(namespace, query=str(state["messages"][-1].content))info = "\n".join([d.value["data"] for d in memories])system_msg = f"You are a helpful assistant talking to the user. User info: {info}"# Store new memories if the user asks the model to rememberlast_message = state["messages"][-1]if "remember" in last_message.content.lower():memory = "User name is Bob"store.put(namespace, str(uuid.uuid4()), {"data": memory})response = model.invoke([{"role": "system", "content": system_msg}] + state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_edge(START, "call_model")
graph = builder.compile(checkpointer=MemorySaver(), store=in_memory_store)
然后运行图
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
input_message = {"role": "user", "content": "Hi! Remember: my name is Bob"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
得到下面结果
================================ Human Message =================================Hi! Remember: my name is Bob
================================== Ai Message==================================Hello Bob! It's nice to meet you. I'll remember that your name is Bob. How can I assist you today?
我们先改变一下config
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
得到下面结果
================================ Human Message =================================what is my name?
================================== Ai Message ==================================Your name is Bob.
现在,我们可以检查我们的store,并验证我们实际上已经为用户保存了记忆:
for memory in in_memory_store.search(("memories", "1")):print(memory.value)
得到结果
{'data': 'User name is Bob'}
现在,让我们为另一个用户运行这个图,以验证关于第一个用户记忆是独立且自包含的。
config = {"configurable": {"thread_id": "3", "user_id": "2"}}
input_message = {"role": "user", "content": "what is my name?"}
for chunk in graph.stream({"messages": [input_message]}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
可以看到,我们之前存储的名字,换了用户id之后大模型已经忘了。
================================ Human Message =================================what is my name?================================== Ai Message ==================================I apologize, but I don't have any information about your name. As an AI assistant, I don't have access to personal information about users unless it has been specifically shared in our conversation. If you'd like, you can tell me your name and I'll be happy to use it in our discussion.
相关文章:
LangGraph——Agent AI的持久化状态
LangGraph 内置了一个持久化层,通过检查点(checkpointer)机制实现。当你使用检查点器编译图时,它会在每个超级步骤(super-step)自动保存图状态的检查点。这些检查点被存储在一个线程(thread)中,可在图执行后随时访问。由于线程允许在执行后访…...
【双指针】专题:LeetCode 1089题解——复写零
复写零 一、题目链接二、题目三、算法原理1、先找到最后一个要复写的数——双指针算法1.5、处理一下边界情况2、“从后向前”完成复写操作 四、编写代码五、时间复杂度和空间复杂度 一、题目链接 复写零 二、题目 三、算法原理 解法:双指针算法 先根据“异地”操…...
)
HTTP 1.1 比 HTTP1.0 多了什么?(详尽版)
相较于HTTP 1.0,1.1 版本增加了以上特性: 1. 新增了连接管理即 keepalive,允许持久连接。 定义: Keepalive允许客户端和服务器在完成一次请求-响应后,保持连接处于打开状态,以便后续请求复用同一连接&am…...
【C++初学】C++核心编程(一):内存管理和引用
前言 在C的世界里,面向对象编程(OOP)是核心中的核心。它不仅是一种编程范式,更是一种思考问题的方式。本文将带你从C的内存分区模型出发,深入探讨引用、函数、类和对象、继承、多态以及文件操作等核心概念。通过丰富的…...
)
深度学习(对抗)
数据预处理:像素标记与归一化 在 GAN 里,图像的确会被分解成一个个像素点来处理。在你的代码里,transform transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) 这部分对图像进行了预处理: tra…...

(PC+WAP)大气滚屏网站模板 电气电力设备网站源码下载
源码介绍 (PCWAP)大气滚屏网站模板 电气电力设备网站源码下载。PbootCMS内核开发的网站模板,该模板适用于滚屏网站模板、电气电力设备网站源码等企业,当然其他行业也可以做,只需要把文字图片换成其他行业的即可;PCWAP,…...

笔试专题(九)
文章目录 十字爆破(暴力)题解代码 比那名居的桃子(滑动窗口/前缀和)题解代码 分组(暴力枚举 优化二分)题解代码 十字爆破(暴力) 题目链接 题解 1. 暴力 预处理 2. 如果单纯的暴…...
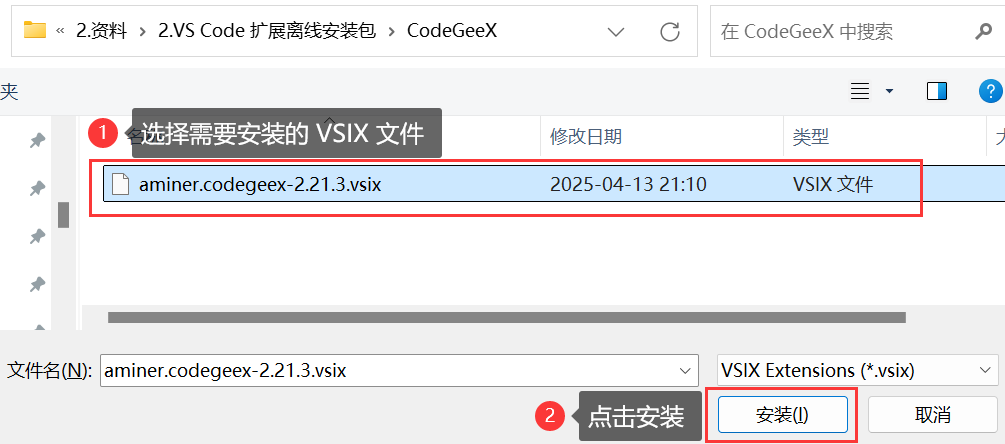
3 VS Code 配置优化与实用插件推荐:settings.json 详解、CodeGeeX 智能编程助手及插件离线安装方法
1 优化 settings.json 文件 1.1 settings.json 简介 settings.json 是 VS Code 的核心配置文件,用于存储用户的个性化设置和偏好。通过该文件,用户可以自定义和覆盖 VS Code 的默认行为,包括但不限于以下方面: 编辑器外观&#…...
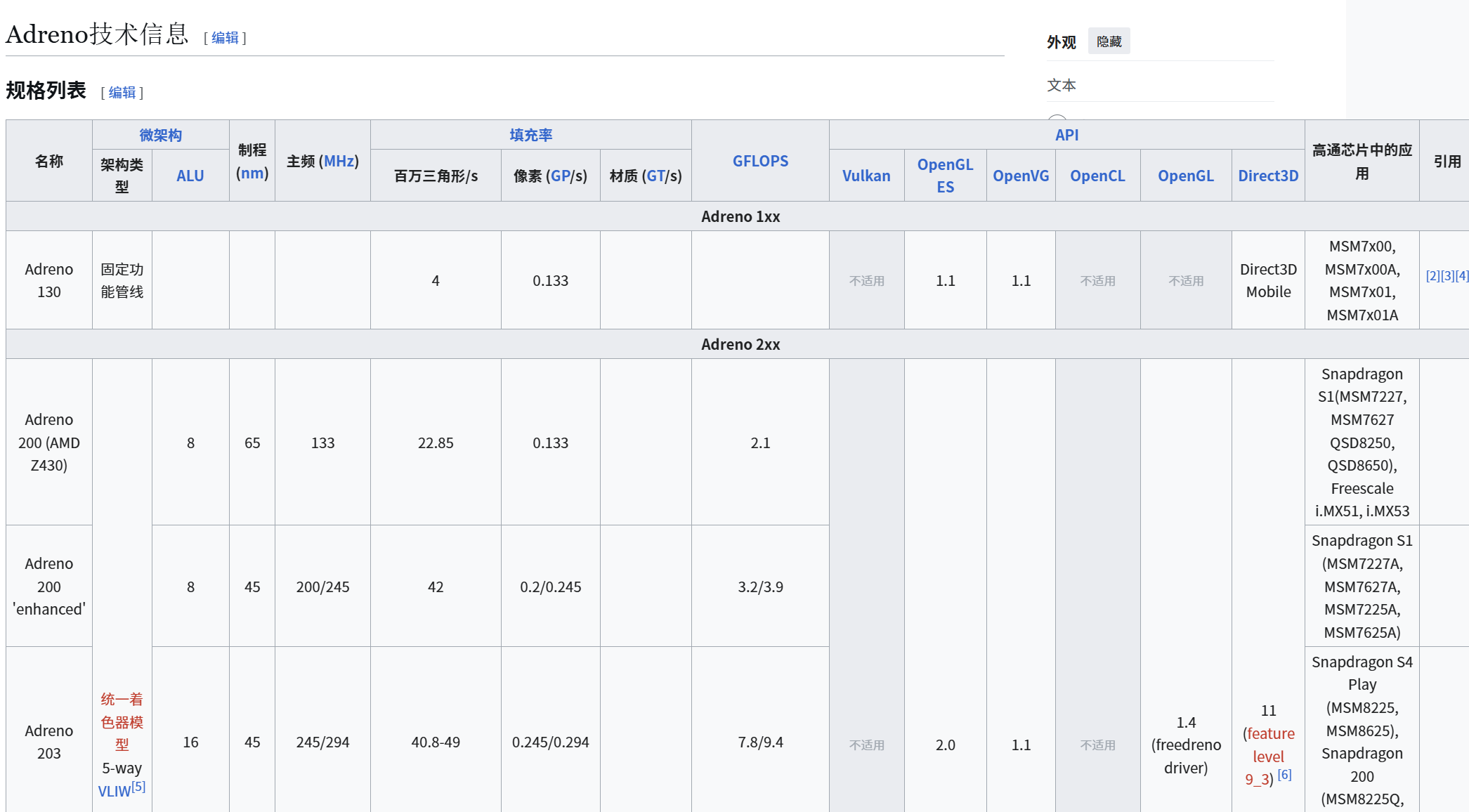
TA学习之路——1.6 PC手机图形API介绍
1前言 电脑的工作原理:电脑是由各种不同的硬件组成,由驱动软件驱使硬件进行工作。所有的软件工程师都会直接或者间接的使用到驱动。 定义:是一个图形库,用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序接口(API)。…...
【android bluetooth 框架分析 02】【Module详解 2】【gd_shim_module 模块介绍】
1. 背景 上一章节 我们介绍了 module_t 的 大体框架 ,本节内容我们就选择 我们的 gd_shim_module 模块为例子,具体剖析一下,它里面的逻辑。 static const char GD_SHIM_MODULE[] "gd_shim_module";// system/main/shim/shim.cc …...
”,并保存到新文件中)
从一堆新闻正文中,提取出“事实型句子(fact)”,并保存到新文件中
示例代码: import os import re import json import nltk from tqdm import tqdm from transformers import pipeline nltk.download(punkt) from nltk.tokenize import sent_tokenize ## Check If Fact or Opinion #lighteternal/fact-or-opinion-xlmr-elfact_opi…...
Matlab 调制信号和fft变换
1、内容简介 Matlab 194-调制信号和fft变换 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

Git 常用命令集与实际使用 Demo
Git 常用命令集与实际使用 Demo 一、初始化 & 配置 命令说明Demogit init在当前目录初始化本地 Git 仓库,生成 .git/ 文件夹mkdir newProject && cd newProject git initgit config --global user.name “xxx”设置全局用户名git config --global use…...

KaiwuDB:面向AIoT场景的多模融合数据库,赋能企业数字化转型
引言 在万物互联的AIoT时代,企业面临着海量时序数据处理、多模数据融合和实时分析等挑战。KaiwuDB应运而生,作为一款面向AIoT场景的分布式、多模融合、支持原生AI的数据库产品,为企业提供了一站式数据管理解决方案。 产品概述 KaiwuDB是一…...

STM32 vs ESP32:如何选择最适合你的单片机?
引言 在嵌入式开发中,STM32 和 ESP32 是两种最热门的微控制器方案。但许多开发者面对项目选型时仍会感到困惑:到底是选择功能强大的 STM32,还是集成无线的 ESP32? 本文将通过 硬件资源、开发场景、成本分析 等多维度对比…...

100M/1000M 以太网静电浪涌防护方案
方案简介 以太网是一种生产较早且广泛应用的局域网通讯方式,同时也是一种协议,其核 心在于实现区域内(如办公室、学校等)的网络互联。根据数据传输速度的不同,以 太网大致可以划分为几个等级:标准以太网…...

使用ADB工具分析Android应用崩溃原因:以闪动校园为例
使用adb工具分析模拟器或手机里app出错原因以闪动校园为例 使用ADB工具分析Android应用崩溃原因:以闪动校园为例 前言 应用崩溃是移动开发中常见的问题,尤其在复杂的Android生态系统中,找出崩溃原因可能十分棘手。本文将以流行的校园应用&q…...
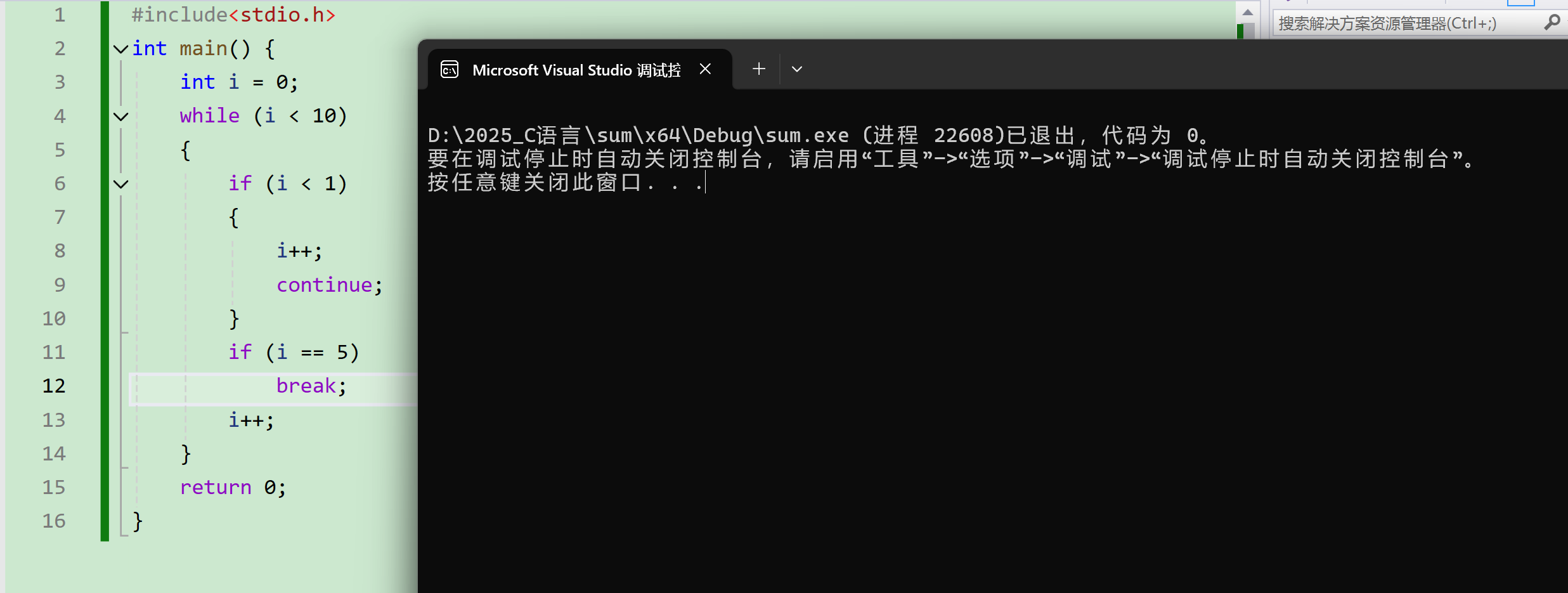
C语言中while的相关题目
一、题目引入 以下程序中,while循环的循环次数是多少次? 二、代码分析 首先要明确的一点 while循环是当循环条件为真 就会一直循环 不会停止 while中i是小于10的 说明i可以取到0 1 2 3 4 5 6 7 8 9 进入第一个if判断i小于1为真时执行continue i0是为真的 执行continue 后…...

关于使用 nuitka进行构建python应用的一些配置,以及github action自动构建;
1. 通用配置 # 设置输出目录和文件名output_dir "dist"app_name "CursorAutoFree"# 基础命令行选项base_options ["--follow-imports", # 跟踪导入"--enable-plugintk-inter", # 启用 Tkinter 支持"--include-packagecusto…...

[Dify] 基于明道云实现金融业务中的Confirmation生成功能
在金融业务的日常流程中,交易记录的处理不仅涉及数据录入、流程审批,更重要的是其最终输出形式——交易确认函(Confirmation)。本文将介绍如何通过明道云的打印模板功能,快速、准确地生成符合业务需求的交易Confirmation,提升工作效率与合规性。 为什么需要Confirmation?…...
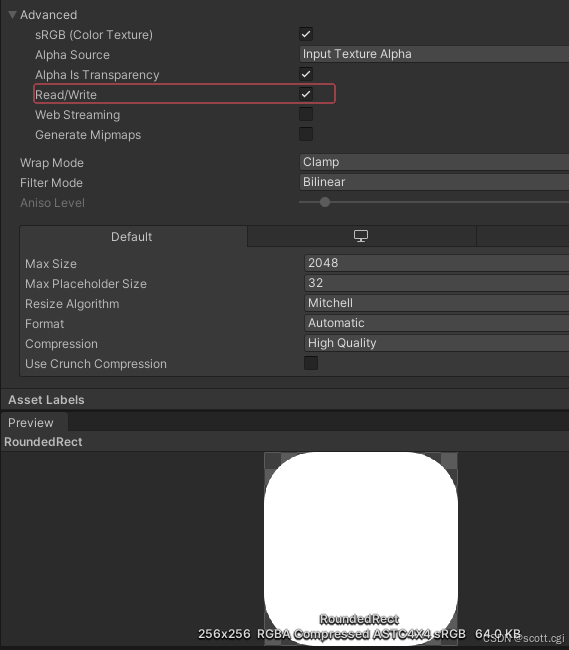
「Unity3D」图片导入选项取消Read/Write,就无法正确显示导入大小,以及Addressable打包无法正确显示的问题
如果在Edit -> Project Settings -> Editor中的“Load texture data on demand”勾选,就会让图片导入设置中,不勾选Read/Write,就无法正确显示纹理的大小数字。 更进一步的问题是,使用Addressable打包的时候, 如…...

使用Java截取MP4文件图片的技术指南
在多媒体处理中,从视频文件中截取图片是一个常见的需求。本文将详细介绍如何使用Java结合FFmpeg实现从MP4文件中截取图片的功能。我们将通过几种不同的方法来实现这一目标,包括直接调用FFmpeg命令行工具、使用JavaCV库以及使用JAVE库。 环境准备 在开始…...

在C盘新建文本文档
设定 C: 的 NTFS 文件夹权限为 Users 或 Domain Users 具有写入权限; 1. 选中C盘 2. 点右键选中属性(properties) 3. 选“安全”(Security) Tab 4. Users 5. “编辑”(Edit) 6. Full Control …...

Xcode为不同环境配置不同的环境变量
一般有三种方式: 一、通过多Target 二、通过scheme,也就是多configurations 三、通过.xcconfig文件 先来看第二种方式:通过scheme,也就是多configurations,包括自定义User-settings 第一步:增加configurations,Xcode默认为我们生成了…...
阿里通义实验室发布图片数字人项目LAM,实现高保真重建
简介 LAM项目结合了3D Gaussian Splatting(高斯点云渲染)和大规模预训练模型的优势,解决了传统头部重建方法效率低、依赖多数据的痛点。其背景源于AI生成内容(AIGC)领域对实时、高保真3D头像生成的需求,尤其…...

面试算法高频05-bfs-dfs
dfs bfs 深度优先搜索(DFS)和广度优先搜索(BFS)是图和树遍历中的重要算法,二者在实现方式和应用场景上存在明显差异。 定义与概念:DFS在遍历树或图时,以深度优先,从起始节点出发,尽可能深入地探索分支,直至无法继续,再回溯;BFS则按层次逐层遍历,从起始节点开始,…...
镜像端口及观察端口的配置
配好路由器的各个接口的IP PC1ping PC3的IP,在路由器中抓2/0/0端口的包,可观察到无结果 输入observe-port interface g 2/0/0 命令配置观察端口 输入mirror to observe-port both命令 (其中both表示接收来去的数据包,inboun…...
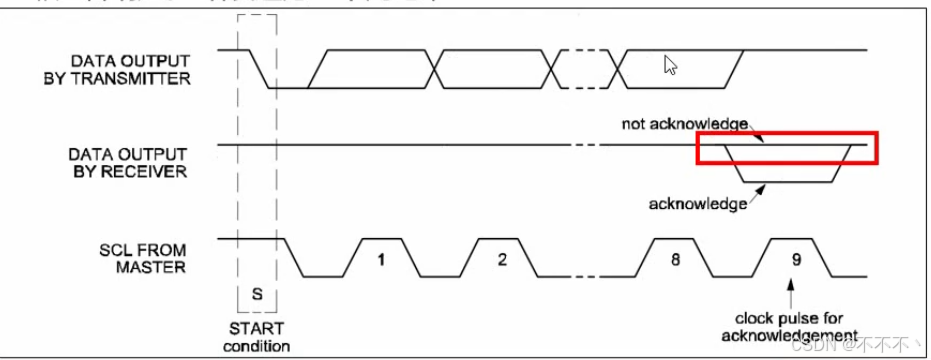
STM32——I2C通讯(软件模拟)
I2C概念 I2C:Inter-Integrated Circuit(内部集成电路) Philps公司80年代初期开发的,引脚少,硬件实现简单,可扩展性广泛地使用在系统内多个集成电路(IC)间的低速通讯 简单的双向两线制总线协议…...

JetBrains Terminal 又发布新架构,Android Studio 将再次迎来新终端
不到一年的时间,JetBrains 又要对 Terminal 「大刀阔斧」,本次发布的新终端是重构后的全新的架构,而上一次终端大调整还是去年 8 月的 v2024.2 版本,并且在「Android Studio Ladybug | 2024.2.1」也被引入。 不知道你们用不用内置…...

论文:Generalized Category Discovery with Large Language Models in the Loop
论文下载地址:Generalized Category Discovery with Large Language Models in the Loop - ACL Anthology 1、研究背景 尽管现代机器学习系统在许多任务上取得了优异的性能,绝大多数都遵循封闭世界的设置,假设训练和测试数据来自同一组预定义…...