高并发内存池(三):PageCache(页缓存)的实现
前言:
在前两期内容中,我们深入探讨了内存管理机制中在 ThreadCache 和 CentralCache两个层级进行内存申请的具体实现。这两层缓存作为高效的内存分配策略,能够快速响应线程的内存需求,减少锁竞争,提升程序性能。
本期文章将继续沿着这一脉络,聚焦于PageCache层级的内存申请逻辑。作为内存分配体系的更高层级,PageCache承担着从操作系统获取大块内存,并对其进行管理和再分配的重要职责。通过对PageCache内存申请流程的剖析,我们将完整地勾勒出整个内存分配体系的工作流程。这不仅有助于我们理解内存分配的底层机制,也为后续深入探讨内存释放策略奠定了基础。
接下来,让我们一同走进PageCache的内存世界。
目录
一、PageCache的概述
二、PageCache结构
三、内存申请的核心流程
四、PageCache类的设计
五、代码实现
1.GetOneSpan的实现
2.NewSpan的实现
3.加锁保护
六、源码
一、PageCache的概述
⻚缓存是在central cache缓存上⾯的⼀层缓存,存储的内存是以⻚为单位存储及分配的。当central cache没有内存对象时,从page cache分配出⼀定数量的page,并切割成定⻓⼤⼩的⼩块内存,分配给central cache。当⼀个span的⼏个跨度⻚的对象都回收以后,page cache会回收central cache满⾜条件的span对象,并且合并相邻的⻚,组成更⼤的⻚,缓解内存碎⽚的问题。
二、PageCache结构
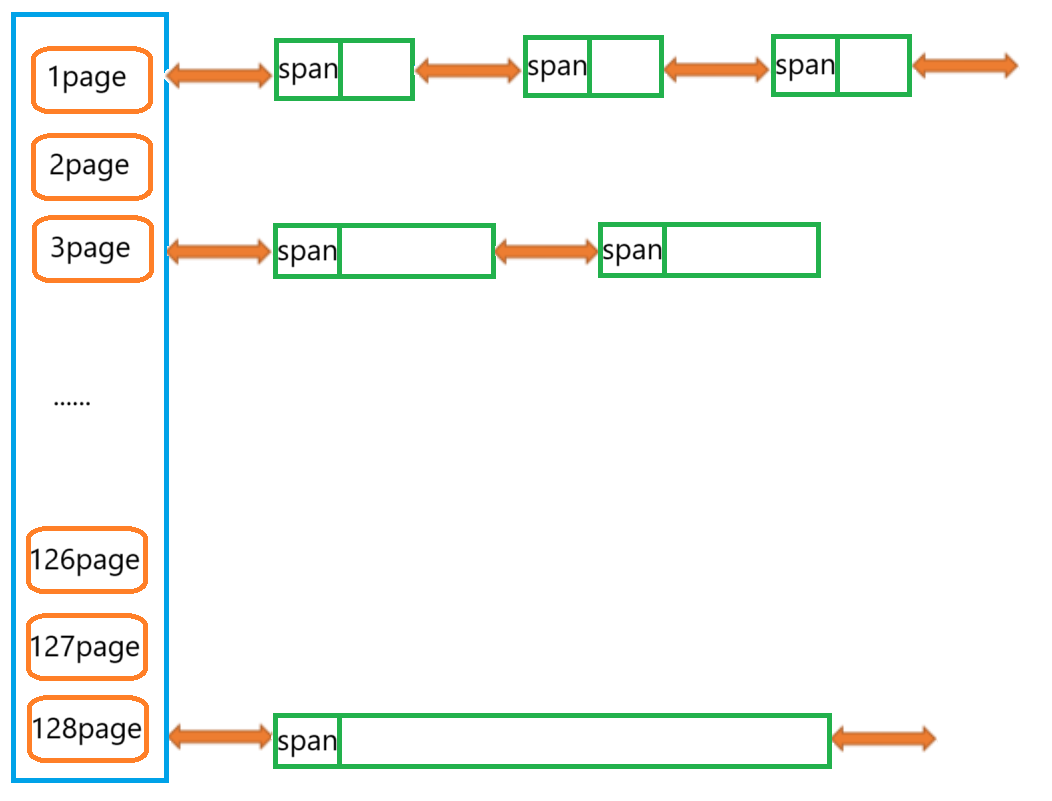
PageCache的结构是一个哈希表,如上图所示,也就是一个储存span双链表的数组,这一点和CentralCache的结构完全类似,区别在于这里的Span是大块的页(1页~128页)没有进行分割,而CentralCache中的Span是分割好的小块内存(自由链表),这样做的好处是方便页与页之间的分割与合并,有效的缓解内存外碎片,在下文会详细讲解。
PageCache结构的哈希映射方法是直接定址法,下标为n的位置储存的Span双链表中每个节点有n个页。
这个哈希表也是所有线程共用一个,属于临界资源需要加锁,但不是桶锁,而是一整个大锁,为什么呢?同样在下文细讲。
注:通常以4KB或8KB为一页,这里我们以8KB为一页。
三、内存申请的核心流程
- ThreadCache
CentralCache
当ThreadCache的自由链表内没有内存时,会向CentralCache中的一个Span申请,如果没有可用的Span,就向PageCache申请一个Span大块页,如果没有Span大块页了,最后才会向系统申请。
那么CentralCache具体是如何向PageCache申请内存的呢?
同样的PageCache一次只给一个Span,然后把这个Span切割成小块连接到CentralCache的哈希桶中,要给几页的Span呢?,这需要根据要将它切割成多大为单位的小块内存来进行具体分配,如果要切较小的内存块,页数就给小一些,如果要切大内存块,页数就给多一些。这里我们就先记为n页的Span。
因为PageCache中的哈希映射是直接定址法,所以直接找到n下标位置的Span链,如果有Span则取出并切成小块连接到CentralCache的哈希桶中。
如果没有n页的Span并不是直接去系统申请,而是到更大的页单位去找Span。比如找到有(n+k)页的Span,k>0,n+k<=128,那么把(n+k)拆开为n页与k页,并连接到相应位置。这样就有了n页的Span,把它切割和连接就行。
如果直到找到128页也没有找到可用的Span那么就向系统申请128页的内存,即128*8*1024字节,然后再执行上面逻辑。这就是整个在PageCache申请内存的逻辑。
处理临界资源互斥问题
如上,PageCache的哈希桶中各个桶是互相联动的,主要体现在这三方面:
- 当前桶没Span要往后找。
- 后面的桶切割Span后要连接到前面的桶。
- 在内存回收时又需要前面桶的Span合并成大页的Span连接到后面的桶。
所以这里不像CentralCache结构的桶相互独立,如果用桶锁会造成频繁的锁申请和释放,效率反而变得很低。用一个大锁来管理整个哈希桶更为合理。
四、PageCache类的设计
把这个类的设计放在头文件PageCache.h里,它核心就两个成员变量:锁和哈希桶,然后再声明一个用来申请Span的成员函数,如下:
class PageCache
{
public:Span* NewSpan(size_t k);std::mutex _pageMtx;
private:SpanList _spanLists[NPAGES];
};- Span* NewSpan(size_t k):申请一个k页的Span
- mutex _pageMtx:锁,因为它要在外部使用,所以设为public。
- SpanList _spanLists[NPAGES]:哈希桶,其中NPAGES是一个静态全局变量为129,在Common.h中定义。设为129是因为哈希表中存1页~128页的Span,要通过页数直接定址的方式找到Span链表,就需要开辟129大小的数组。
PageCache类和CentralCache类一样所有线程共用一份,所以把它创建为单例模式,它分为以下几步:
- 把构造函数设为私有。
- 把拷贝构造禁用。
- 声明静态的PageCache对象,并在PageCache.cpp中定义。
- 提供一个获取PageCache对象的静态成员函数,并设为public。
代码示例:
class PageCache
{
public:static PageCache* GetInstance(){return &_sInst;}Span* NewSpan(size_t k);std::mutex _pageMtx;
private:PageCache() {}PageCache(const PageCache&) = delete;SpanList _spanLists[NPAGES];static PageCache _sInst;
};五、代码实现
1.GetOneSpan的实现
回顾上一期我们只是假设通过GetOneSpan从CentralCache中取到了Span,然后继续做后面的处理。接下来我们一起来实现GetOneSpan函数。
因为要在Span链表中取一个有用的Span节点,所以需要遍历Span链表,那么可以模拟一个迭代器。我们在SpanList类中封装这两个函数:
Span* Begin()
{return _head->_next;
}
Span* End()
{return _head;
}注:SpanList是一个带头双向环形链表。
接下来遍历链表找到可用的Span并返回,如果没有则到PageCache中申请。
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//走到这里说明没有可用的Span了,向PageCache中申请。//......
}- SpanList& list:指定的一个哈希桶,即一个Span链表的头结点。
- size_t size:进行内存对齐后实际需要申请的字节大小。
注意在PageCache中申请的是大块的Span页,还需要把它切割,然后连接到CentralCache的桶中并返回。
在PageCache类中我们准备实现的函数NewSpan就是用来实现这个功能,现在需要考虑的是要传入的参数是多少,即要申请多少页的Span。
这里我们是以8KB为一页,即 1页=8*1024字节(2^13字节)为方便后面做位运算,我们在Common.h文件定义一个这样一个变量:
static int const PAGE_SHIFT = 13;
当然了这里也可以做成宏定义。
接下来在SizeClass类里封装一个函数NumMovePage用来计算一个size需要申请几页的Span,如下:
//用来计算ThreadCache向CentralCache申请几个小内存块
static inline size_t NumMoveSize(size_t size)
{int ret = MAX_BYTES / size;if (ret < 2) ret = 2;if (ret > 512) ret = 512;return ret;
}
//用来计算CentralCache向PageCache申请几个页的Span
static inline size_t NumMovePage(size_t size)
{int num = NumMoveSize(size);int npage = num * size;npage >>= PAGE_SHIFT; //除以8KBif (npage < 1) npage = 1;return npage;
}在此,大家无需过度纠结于该设计背后的原理。这或许是相关领域的资深专家在历经大量测试与实践后,所总结提炼出的有效策略,我们继续走下面的逻辑。
//申请Span
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
//切割Span
//......NewSpan函数我们待会再设计,现在假设已经申请到一个Span的大块页,接下来就是进行切割。
首先我们需要得到的是这个页的起始地址与终止地址,在这个范围内以size的跨度切割。
用char*的指针变量start,end分别来储存起始地址和终止地址,用char*类型是因为char*类型指针变量加多少,就移动多少字节,方便后面做切割运算。
起始页地址的获取:
取到Span的页号,用页号乘以8KB(2^13字节)就能得到页的起始地址,即:
char* start = (char*)(span->_pageId << PAGE_SHIFT);
终止页地址的获取:
取到Span的页数,用页数乘以8KB再加上起始页地址就能得到终止页地址,即:
int bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
注:页号是通过申请到的内存的虚拟地址除以8KB得到的。
接下来把start连接到Span的自由链表中,然后使用循环把[start,end]这块内存以size为跨度进行切割,如下:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{Span* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}it = it->_next;}//申请SpanSpan* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//切割Spanchar* start = (char*)(span->_pageId << PAGE_SHIFT);int bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;span->_freeList = start;while (start < end){Nextobj(start) = start + size;start = (char*)Nextobj(start);}Nextobj(end) = nullptr;//连接到CentralCache中list.PushFront(span);return span;
}这里直接以尾插的方式切,好处在于用户在使用内存时是连在一块的,相关的数据会被一并载入寄存器中,可以增加高速缓存命中率,提高效率。
最后实现一个类方法PushFront,用来把Span连接到哈希桶里。
void PushFront(Span* node)
{//在Begin()前插入node,即头插Insert(Begin(), node);
}2.NewSpan的实现
NewSpan我们放在源文件PageCache.cpp中实现。
查找当前桶
首先可以用assert断言页数的有效性,然后直接定址找到Span链,如果不为空返回一个Span节点,如果为空到后面的大页去找,如下:
Span* PageCache::NewSpan(size_t k)
{//判断页数的有效性assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//到后面更大块的Span页切割//......//向系统申请内存//......
}到大页切割
当k号桶没有Span后,从k+1号桶开始往后找,比如找到i号桶不为空,则把Span节点取出来,记为nSpan,然后切割为k页和i-k页,切割的本质就是改变页数_n和页号_pageId。
new一个Span空间,用kSpan变量指向,然后把nSpan头k个页切出来储存到一个kSpan中,即:
- kSpan->_pageId = nSpan->_pageId:更新kSpan的页号。
- kSpan->_n = k:更新kSpan的页数。
- nSpan->_pageId += k:原nSpan的页起始页号后移k位。
- nSpan->_n -= k:原nSpan的页数减少k。
这样就相当于把原来大块的nSpan切割成了两块,最后把割剩下的nSpan插入到对应的哈希桶中,把kSpan返回。
for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}向系统申请
当k号桶往后的桶都是空的,那么我们就需要向系统申请内存了,直接申请一个128的页,放在128号桶,再执行上面的逻辑。
对于内存申请,在windows下我们使用VirtualAlloc函数,与malloc相比VirtualAlloc直接与操作系统交互,无额外开销,效率高,通常用来申请超大块内存。
VirtualAlloc的声明
LPVOID VirtualAlloc(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect );
- LPVOID lpAddress:期望的起始地址(通常设为0由系统决定)
- SIZE_T dwSize:分配的内存大小(字节)
- DWORD flAllocationType: 分配的类型(如保留或提交)
- DWORD flProtect:内存保护选项(如读写权限)
返回值:LPVOID ,本质是void*,需强制类型转换后使用。
flAllocationType
MEM_COMMIT:提交内存,使其可用。
MEM_RESERVE:保留地址空间,暂不分配物理内存。二者可组合使用(
MEM_RESERVE | MEM_COMMIT),同时保留并提交。flProtect
控制内存访问权限,常用选项:
PAGE_READWRITE:可读/写。
PAGE_NOACCESS:禁止访问(触发访问违规)。
PAGE_EXECUTE_READ:可执行/读。
因为还要考虑其他系统的需求,我们在Common.h内封装一个向系统申请内存的函数,并使用条件编译来选择不同的函数调用,如下:
#ifdef _WIN32#include <windows.h>
#else//Linux...
#endifinline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();//抛异常return ptr;
}接下来继续NewSpan的执行逻辑,向系统申请内存后,new一个Span储存相关的页信息,即计算页号(地址/8KB),填写页数,然后把Span连接到128号哈希桶,最后需要做的就是把它切割为k页的Span和(128-k)页的Span和前面的逻辑一模一样,为提高代码复用率以递归的方式返回。如下:
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}for (int i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//向系统申请内存Span* span = new Span;void* ptr = SystemAlloc(NPAGES - 1);span->_pageId = (PANGE_ID)ptr>>PAGE_SHIFT;span->_n = NPAGES - 1;_spanLists[span->_n].PushFront(span);return NewSpan(k);
}3.加锁保护
PageCache哈希桶是临界资源,需要对它进行加锁保护。上文已经讲过只用加一个大锁,而不是用桶锁。
因为NewSpan函数涉及递归,需要使用递归锁,这样比较高效。但这里也可以把锁加到NewSpan外面,也就是GetOneSpan函数里,如下:

其次有一个优化的点:线程进入PageCache这一层之前是先进入了CentralCache的,并在这一层加了桶锁,那么此时CentralCache的哈希桶它暂时不用,但可能其他线程要用,可以先把锁释放掉,等从PageCache申请完内存后再去申请锁。
虽然说线程走到PageCache这一层说明CentralCache的哈希桶已经没有内存了,其他线程来了也申请不到内存,但别忘了还有内存的释放呢。把桶锁释放了,其他线程释放内存对象回来,就不会阻塞。如下:

六、源码
代码量比较大,就不放在这里了,需要的小伙伴到我的gitee上取:
PageCache/PageCache · 敲上瘾/ConcurrentMemoryPool - 码云 - 开源中国
相关文章:
高并发内存池(三):PageCache(页缓存)的实现
前言: 在前两期内容中,我们深入探讨了内存管理机制中在 ThreadCache 和 CentralCache两个层级进行内存申请的具体实现。这两层缓存作为高效的内存分配策略,能够快速响应线程的内存需求,减少锁竞争,提升程序性能。 本期…...

pycharm已有python3.7,如何新增Run Configurations中的Python interpreter为python 3.9
在 PyCharm 中,如果你已经安装了 Python 3.9,并且希望在 Run Configurations 中新增一个 Python 3.9 的解释器,可以按照以下步骤操作: 步骤 1:打开 PyCharm 设置 点击 PyCharm 左上角的 File 菜单。选择 Settings&am…...

Linux驱动开发-网络设备驱动
Linux驱动开发-网络设备驱动 一,网络设备总体结构1.1 总体架构1.2 NAPI数据处理机制 二,RMII和MDIO2.1 RMII接口2.2 MDIO接口 三,MAC和PHY模块3.1 MAC模块3.2 PHY模块 四,网络模型4.1 网络的OSI和TCP/IP分层模型4.1.1 传输层&…...

学习笔记083——Java Stream API
文章目录 1、过滤数据 filter()2、转换元素 map()3、排序 sorted()3.1、自定义排序规则 4、去重 distinct()5、限制元素数量 limit()6、收集结果 collect()6.1、收集为List6.2、收集为Set6.3、转为Map6.4、基本用法(注意键冲突会抛异常)6.5、处理键冲突&…...
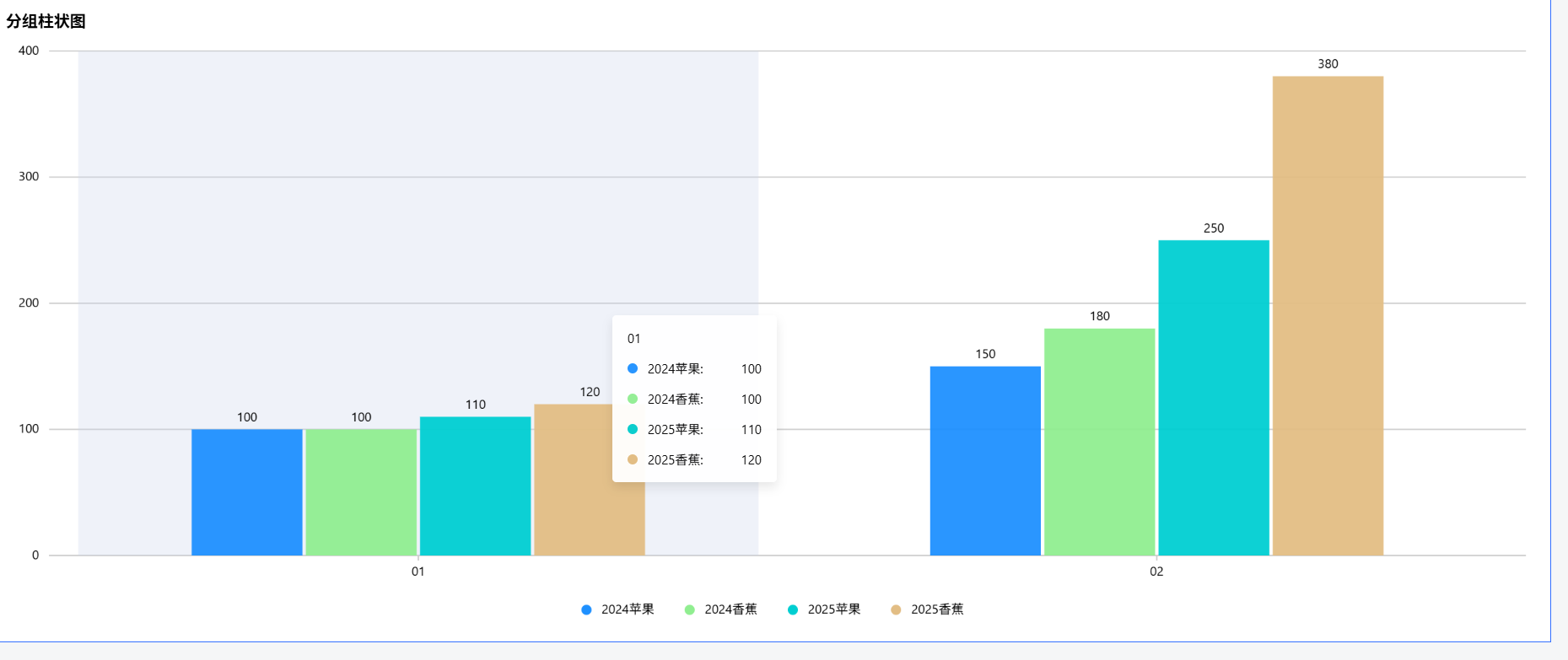
DataEase同比环比
DataEase同比环比 前言术语实现表结构设计DataEase设计创建数据集创建仪表盘最后前言 某大数据项目,需要比较展示今年跟去年的数据,如下图: 说明:比较24,25的产品销量,相同月份做一组,并排放一块 还有更进一步: 说明:比较24,25相同月份,相同产品的销量 直接用DataE…...
RAG 工程基础
RAG 概念 RAG(Retrieval - Augmented Generation)技术是一种将检索与生成相结合的人工智能技术,旨在利用外部知识源来增强语言模型的生成能力,提高生成内容的质量、准确性和相关性。 具体来说,RAG 技术在处理用户输入的…...

基础算法:滑动窗口_python版本
能使用滑动窗口的题,基本都需要数字为正整数,这样才能保证滑入一个数字总和是增加的(单调性) 一、209. 长度最小的子数组 思路: 已每个位置为右端点,依次加大左端点,最短不满足 sum(num[left,right]) < target的。…...
Qt 之opengl shader language
着色器示例代码 实际运行效果...
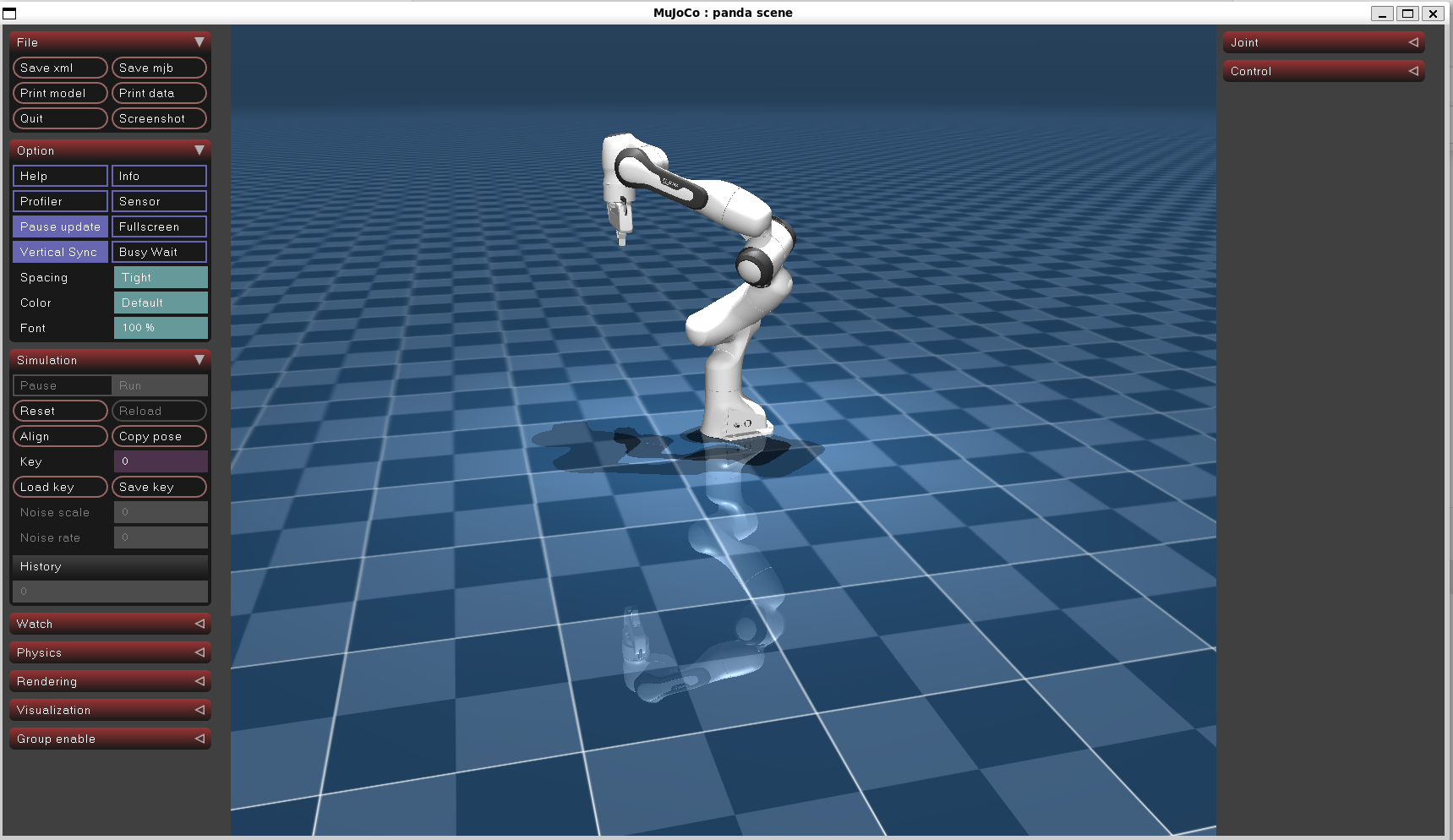
PyRoboPlan 库,给 panda 机械臂微分 IK 上大分,关节限位、碰撞全不怕
视频讲解: PyRoboPlan 库,给 panda 机械臂微分 IK 上大分,关节限位、碰撞全不怕 代码仓库:https://github.com/LitchiCheng/mujoco-learning 今天分享PyRoboPlan库,比之前的方式优点在于,这个库考虑了机械…...
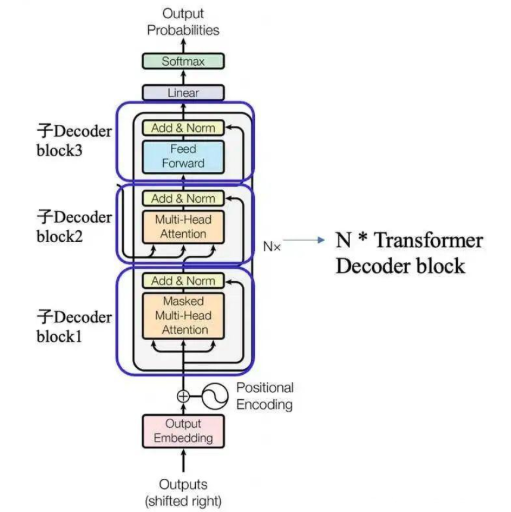
GPT - TransformerDecoderBlock
本节代码定义了一个 TransformerDecoderBlock 类,它是 Transformer 架构中解码器的一个基本模块。这个模块包含了多头自注意力(Multi-Head Attention)、前馈网络(Feed-Forward Network, FFN)和层归一化(Lay…...

LabVIEW 控制电机需注意的关键问题
在自动化控制系统中,LabVIEW 作为图形化编程平台,因其高度可视化、易于集成硬件等优势,被广泛应用于电机控制场景。然而,要实现稳定、精确、高效的电机控制,仅有软件并不足够,还需结合硬件选型、控制逻辑设…...

CSS 定位属性的生动比喻:以排队为例理解 relative 与 absolute
目录 一、理解标准流与队伍的类比 二、relative 定位:队伍中 “小范围活动” 的人 三、absolute 定位:队伍中 “彻底离队” 的人 在学习 CSS 的过程中,定位属性relative和absolute常常让初学者感到困惑。它们的行为方式和对页面布局的影响较为抽象,不过,我们可以通过一个…...
Jenkins 发送钉钉消息
这里不介绍 Jenkins 的安装,可以网上找到很多安装教程,重点介绍如何集成钉钉消息。 需要提前准备钉钉机器人的 webhook 地址。(网上找下,很多教程) 下面开始配置钉钉机器人,登录 Jenkins,下载 …...

nt!KeRemoveQueue 函数分析之加入队列后进入等待状态
第一部分: 参考例子:应用程序调用kernel32!GetQueuedCompletionStatus后会调用nt!KeRemoveQueue函数进入进入等待状态 0: kd> g Breakpoint 8 hit nt!KiDeliverApc: 80a3c776 55 push ebp 0: kd> kc # 00 nt!KiDeliverApc 01 nt…...

OpenCV 风格迁移
一、引言 在计算机视觉和图像处理领域,风格迁移是一项令人着迷的技术。它能够将一幅图像(风格图像)的艺术风格,如梵高画作的笔触风格、莫奈的色彩风格等,迁移到另一幅图像(内容图像)上&#x…...

35.Java线程池(线程池概述、线程池的架构、线程池的种类与创建、线程池的底层原理、线程池的工作流程、线程池的拒绝策略、自定义线程池)
一、线程池概述 1、线程池的优势 线程池是一种线程使用模式,线程过多会带来调度开销,进而影响缓存局部性和整体性能,而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务,这避免了在处理短时间任务时创建与…...
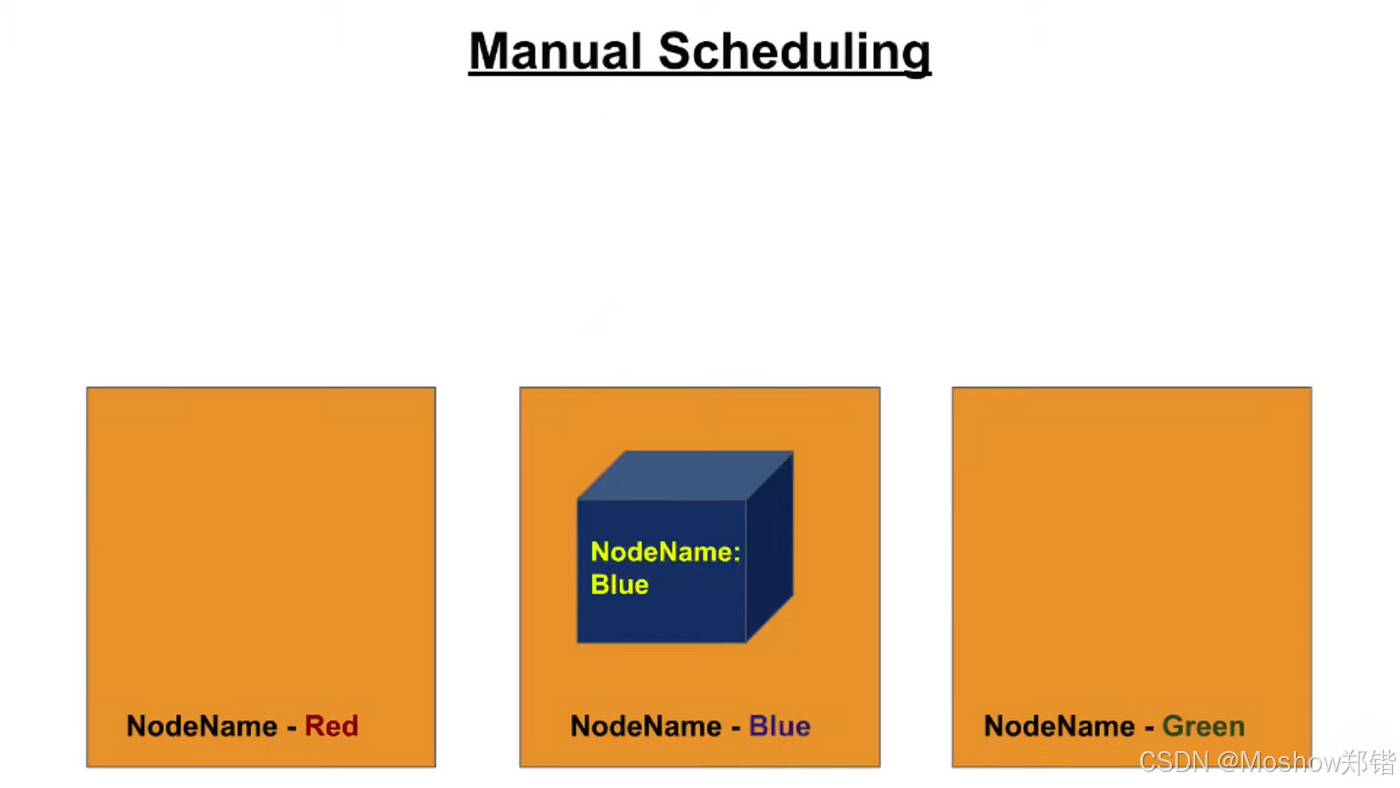
Kubernetes nodeName Manual Scheduling practice (K8S节点名称绑定以及手工调度)
Manual Scheduling 在 Kubernetes 中,手动调度框架允许您将 Pod 分配到特定节点,而无需依赖默认调度器。这对于测试、调试或处理特定工作负载非常有用。您可以通过在 Pod 的规范中设置 nodeName 字段来实现手动调度。以下是一个示例: apiVe…...

QML中访问c++数据,并实现类似C#中mvvm模式详细方法
1. 背景需求2. 实现步骤 2.1. 定义 Model(数据模型) 2.1.1. DataModel.h2.1.2. DataModel.cpp 2.2. 定义 ViewModel(视图模型) 2.2.1. PersonViewModel.h2.2.2. PersonViewModel.cpp 2.3. 在 QML 中使用 ViewModel 2.3.1. main.cp…...

React 获得dom节点和组件通信
通过REF 实例对象的.current属性获得绑定的DOM节点 组件通信 组件通信 1 父传子 父组件传递数据 子组件接受数据 通过pros对象接受 子组件的形参列表props只读 props中数据不可修改 特殊情况 在子传父的过程中没有直接给子组件添加属性,而是向父组件中添加其他…...
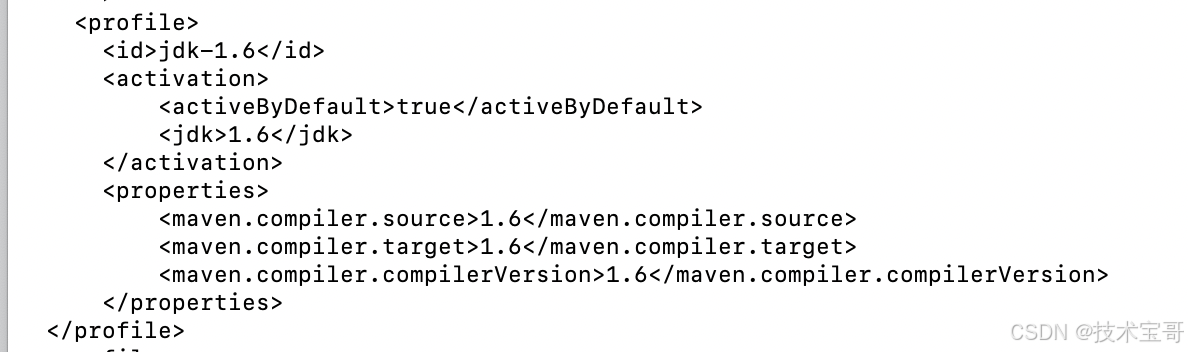
代码,Java Maven项目打包遇到的环境问题
这几天在写一些Java版本的Langchain4J的 AI 测试case,有一段时间不运行的Java环境,反复出现环境问题,记录下 1、Java编译版本的问题 修改编译版本: 2、在IDE中运行遇到Maven中JDK版本问题 在ide中执行maven命令,遇到下…...

fisco-bcos 关于服务bash status.sh启动runing 中但是5002端口监听不到,出错的问题
bash status.sh Server com.webank.webase.front.Application Port 5002 is running PID(4587) yjmyjm-VMware-Virtual-Platform:~/webase-front$ sudo netstat -anlp | grep 5002 没有端口信息输出 此时可以查看log文件夹下的WeBASE-front.log,找到报错信息如下…...

C++ 数据结构之图:从理论到实践
一、图的基本概念 1.1 图的定义与组成 图(Graph)由顶点(Vertex)和边(Edge)组成,形式化定义为: G (V, E) 顶点集合 V:表示实体(如城市、用户) …...

linux多线(进)程编程——(5)虚拟内存与内存映射
前言(前情回顾) 进程君开发了管道这门技术后,修真界的各种沟通越来越频繁,这天进程君正与自己的孩子沟通,进程君的孩子说道: “爸爸,昨天我看他们斗法,小明一拳打到了小刚的肚子上&…...

SpringBoot 动态路由菜单 权限系统开发 菜单权限 数据库设计 不同角色对应不同权限
介绍 系统中的路由配置可以根据用户的身份、角色或其他权限信息动态生成,而不是固定在系统中。不同的用户根据其权限会看到不同的路由,访问不同的页面。对应各部门不同的权限。 效果 [{"id": 1,"menuName": "用户管理"…...
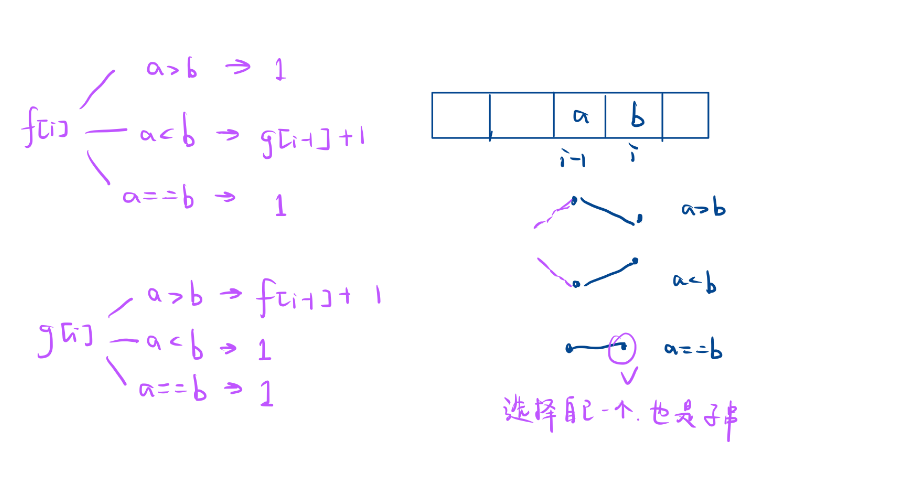
[dp8_子数组] 乘积为正数的最长子数组长度 | 等差数列划分 | 最长湍流子数组
目录 1.乘积为正数的最长子数组长度 2.等差数列划分 3.最长湍流子数组 写代码做到,只用维护好自己的一小步 1.乘积为正数的最长子数组长度 链接:1567. 乘积为正数的最长子数组长度 给你一个整数数组 nums ,请你求出乘积为正数的最长子数…...

资深词源学家提示词
Role: 资深词源学家 Profile: Language: 中文Description: 作为在词源学领域的卓越专家,具备深厚且多元的学术背景。精通拉丁语、古希腊语、梵语等一众古老语言,能够精准解析这些语言的古代文献,为探寻词汇起源挖掘第一手资料。在汉语研究方…...

深入探讨MySQL存储引擎:选择最适合你的数据库解决方案
前言 大家好,今天我们将详细探讨MySQL中几种主要的存储引擎,了解它们的工作机制、适用场景以及各自的优缺点。通过这篇文章,希望能帮助你根据具体需求选择最合适的存储引擎,优化数据库性能。 1. InnoDB - 默认且强大的事务性存储…...

【图像处理基石】什么是通透感?
一、画面的通透感定义 画面的通透感指图像在色彩鲜明度、空间层次感、物体轮廓清晰度三方面的综合表现,具体表现为: 色彩鲜明:颜色纯净且饱和度适中,无灰暗或浑浊感;层次分明:明暗过渡自然,光…...

无锡无人机超视距驾驶证怎么考?
无锡无人机超视距驾驶证怎么考?在近年来,无人机技术的迅猛发展使得无人机的应用场景变得愈发广泛,其不仅在环境监测、农业喷洒、快递配送等领域展现出真金白银的价值,同时也推动了无人机驾驶证的需求。尤其是在无锡,随…...

213、【图论】有向图的完全联通(Python)
题目描述 原题链接:105. 有向图的完全联通 代码实现 import collectionsn, k list(map(int, input().split())) adjacency collections.defaultdict(list) for _ in range(k):head, tail list(map(int, input().split()))adjacency[head].append(tail)visited_…...