Transformer模型解析与实例:搭建一个自己的预测语言模型
目录
1. 前言
2. Transformer 的核心结构
2.1 编码器(Encoder)
2.2 解码器(Decoder)
2.3 位置编码(Positional Encoding)
3. 使用 PyTorch 构建 Transformer
3.1 导入所需的模块:
3.2 定义位置编码
3.3 构建 Transformer 模型
3.4 训练模型
3.5 完整代码
4. 总结
1. 前言
Transformer 是一种革命性的深度学习架构,最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。它通过引入自注意力机制(Self-Attention),解决了传统 RNN 和 LSTM 在处理长序列时的效率和性能问题。Transformer 的核心思想是让模型能够同时关注序列中所有位置的信息,而不是像 RNN 那样逐个处理序列元素。
本文将深入剖析 Transformer 的核心结构,并通过 PyTorch 实现一个完整的 Transformer 模型,帮助读者全面理解这一架构的原理和应用,同时也作为LLM学习的第一章。
2. Transformer 的核心结构
首先的首先,文章中每个单词都会被映射为一个高维的向量,称其为embedding层,该映射后的向量则称为嵌入向量。
2.1 编码器(Encoder)
Transformer 的编码器由多个相同的层堆叠而成,每一层包含两个主要子模块:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈神经网络(Feed-Forward Network)
多头自注意力机制
多头自注意力机制是 Transformer 的核心组件之一。它的作用是让模型能够同时关注序列中不同位置的元素,并捕捉它们之间的关系。
自注意力机制(Self-Attention)
自注意力机制通过计算查询向量(Query)、键向量(Key)和值向量(Value)之间的点积,得到一个注意力分数,用于加权求和得到输出向量。
-
输入表示:输入是一个序列,每个元素是一个向量 xi。
-
线性变换:将输入向量分别映射到查询向量 Q、键向量 K 和值向量 V:
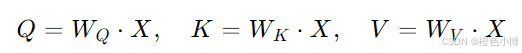
其中 WQ,WK,WV 是可学习的权重矩阵。
-
计算注意力分数:通过点积计算查询向量和键向量之间的相似度:
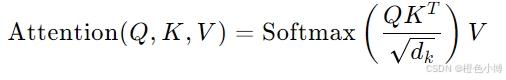
其中 dk 是键向量的维度,用于缩放点积以稳定训练。
多头注意力(Multi-Head Attention)
多头注意力通过将输入向量映射到多个不同的注意力头,每个头独立计算注意力分数,最后将所有头的输出拼接在一起。这种方法可以捕捉不同粒度的特征。
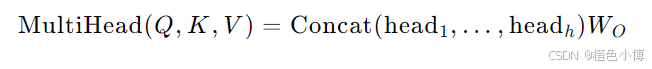
通过 WO 矩阵将拼接后的输出投影到模型所需的维度。
其中:
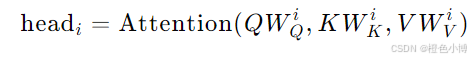
前馈神经网络
每个编码器层的第二个子模块是一个前馈神经网络,用于进一步处理注意力机制的输出。这个网络对每个位置的元素独立应用相同的变换:
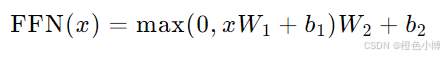
前馈神经网络对每个位置的词向量独立进行处理,这意味着它可以在所有位置上并行计算。这种设计充分利用了现代硬件(如 GPU)的并行计算能力,显著提高了模型的效率。
残差连接与层归一化
为了稳定训练,编码器的每个子模块都使用了残差连接(Residual Connection)和层归一化(Layer Normalization):
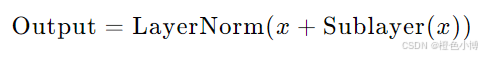
2.2 解码器(Decoder)
解码器的结构与编码器类似,但多了一个额外的子模块:
-
掩码多头自注意力机制(Masked Multi-Head Self-Attention)
-
编码器-解码器注意力(Encoder-Decoder Attention)
-
前馈神经网络
掩码多头自注意力机制
掩码多头自注意力机制的作用是防止解码器在生成目标序列时看到未来的位置信息。通过在注意力分数中应用掩码(将未来位置的分数设为负无穷),确保每个位置只能关注当前位置及之前的位置。
-
编码器的多头自注意力:查询(Q)、键(K)和值(V)都来自同一个输入序列。
-
解码器的多头自注意力:查询(Q)、键(K)和值(V)都来自解码器的上一层输出,但受到掩码的限制。
编码器-解码器注意力
编码器-解码器注意力用于将解码器的输出与编码器的输出结合起来。查询向量来自解码器,而键和值向量来自编码器,这样解码器可以利用编码器生成的上下文信息。
2.3 位置编码(Positional Encoding)
由于 Transformer 没有像 RNN 那样的隐状态来捕捉序列顺序,因此需要引入位置编码。位置编码通过将序列的位置信息嵌入到词向量中,使模型能够感知序列的顺序。
词嵌入与位置编码相加,而不是拼接,他们的效率差不多,但是拼接的话维度会变大,所以不考虑。
位置编码通常通过正弦和余弦函数实现:

其中 pos 是位置,i 是维度(某个位置向量中的第 i 个维度)。
3. 使用 PyTorch 构建 Transformer
3.1 导入所需的模块:
import torch
import torch.nn as nn
import torch.optim as optim
import math3.2 定义位置编码
位置编码通过正弦和余弦函数实现:
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:x.size(0), :]return self.dropout(x)-
torch.arange:生成一个从 0 到max_len-1的一维张量,步长为 1。 -
unsqueeze(1):在张量的第 1 个维度(索引从 0 开始)增加一个维度。这将一维张量(max_len,)转换为二维张量(max_len, 1)。
-
position:表示位置信息,形状为(max_len, 1)。 -
div_term:用于计算 100002i/dmodel,形状为(d_model//2,)。
-
(-math.log(10000.0) / d_model):计算一个负的对数值,除以d_model。这个值用于调整正弦和余弦波的频率。 -
0::2:表示从索引 0 开始,每隔两列取一个元素(即偶数列)。
-
pe.unsqueeze(0):在pe的第 0 维增加一个维度,将形状从(max_len, d_model)转换为(1, max_len, d_model)。 -
pe.transpose(0, 1):交换第 0 维和第 1 维,得到形状为(max_len, 1, d_model)。 -
pe = pe.unsqueeze(0).transpose(0, 1)用于调整位置编码的形状,使其能够与输入词向量相加。
缓冲区用于存储模型中需要保存但不需要被优化器更新的张量。例如:
-
位置编码(Positional Encoding):位置编码是模型的一部分,但不需要在训练过程中更新。
-
词向量(Embedding):如果词向量是预训练的且不需要更新,也可以将其注册为缓冲区。
通过 self.register_buffer('pe', pe),将 pe 注册为模型的缓冲区,这样:
-
pe会成为模型的一部分,并在保存和加载模型时被自动保存和加载。 -
pe不会被优化器更新,因为它不是可学习的参数。
3.3 构建 Transformer 模型
class TransformerModel(nn.Module):def __init__(self, vocab_size, d_model, nhead, nhid, nlayers, dropout=0.5):super(TransformerModel, self).__init__()self.model_type = 'Transformer'self.pos_encoder = PositionalEncoding(d_model, dropout)self.embedding = nn.Embedding(vocab_size, d_model)self.transformer = nn.Transformer(d_model, nhead, nlayers, nlayers, nhid, dropout)self.fc_out = nn.Linear(d_model, vocab_size)self.init_weights()def init_weights(self):initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.fc_out.weight.data.uniform_(-initrange, initrange)self.fc_out.bias.data.zero_()def forward(self, src, tgt, src_mask=None, tgt_mask=None):src = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)src = self.pos_encoder(src)tgt = self.embedding(tgt) * math.sqrt(self.embedding.embedding_dim)tgt = self.pos_encoder(tgt)output = self.transformer(src, tgt, src_mask, tgt_mask)output = self.fc_out(output)return output-
vocab_size:词汇表的大小,即词典中不同单词的数量。 -
d_model:词向量的维度,也是 Transformer 中每个层的输入和输出维度。 -
nhead:多头注意力机制中的头数。 -
nhid:前馈神经网络的隐藏层维度。 -
nlayers:编码器和解码器的层数。 -
dropout:Dropout 的概率,默认为 0.5。
设置模型类型为 'Transformer',用于标识模型的架构。
self.fc_out = nn.Linear(d_model, vocab_size)初始化输出层,将 Transformer 的输出映射回词汇表的大小,用于预测下一个单词。
initrange = 0.1
-
作用:定义了一个初始化范围,用于设置权重的初始值范围。
-
值:
0.1表示权重将被初始化为在-0.1到0.1之间的均匀分布。
self.embedding.weight.data.uniform_(-initrange, initrange)
-
作用:将词嵌入层的权重初始化为均匀分布。
-
uniform_:PyTorch 中的函数,用于将张量的值填充为指定范围内的均匀分布。 -
self.embedding.weight.data:访问词嵌入层的权重张量。 -
-initrange, initrange:指定均匀分布的范围。
self.fc_out.bias.data.zero_()
-
作用:将输出层的偏置初始化为零。
对于forward函数:
-
self.embedding:词嵌入层,将单词索引映射到词向量。 -
src和tgt:分别是输入序列和目标序列。 -
math.sqrt(self.embedding.embedding_dim):对嵌入向量进行缩放,确保其具有合适的尺度,防止梯度消失或爆炸。 -
src_mask和tgt_mask:分别是输入序列和目标序列的掩码,用于处理填充部分或防止信息泄露。
其中
src = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)-
输入:
src的形状为(seq_len, batch_size),其中seq_len是序列长度,batch_size是批量大小。 -
输出:
src的形状为(seq_len, batch_size, d_model),其中d_model是词向量的维度。 -
嵌入向量的方差:嵌入向量的初始化通常具有方差
1/d_model,乘以sqrt(d_model)后方差变为 1。
nn.Linear 是 PyTorch 中的全连接层,它接受任意维度的输入,只要最后一个维度是输入特征的维度即可。在这种情况下,输入张量的形状是 (tgt_seq_len, batch_size, d_model),其中 d_model 是输入特征的维度。
3.4 训练模型
# 定义超参数
vocab_size = 10000 # 假设词汇表大小为 10000
d_model = 512 # 词向量维度
nhead = 8 # 多头注意力的头数
nhid = 2048 # 前馈网络的隐藏层维度
nlayers = 6 # 编码器和解码器的层数
dropout = 0.5 # Dropout 概率# 创建模型
model = TransformerModel(vocab_size, d_model, nhead, nhid, nlayers, dropout)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train()total_loss = 0for batch in train_loader:src, tgt = batch # 假设 src 和 tgt 是训练数据optimizer.zero_grad()output = model(src, tgt[:, :-1]) # 输入解码器时去掉最后一个词loss = criterion(output.view(-1, vocab_size), tgt[:, 1:].reshape(-1)) # 预测下一个词loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader)}")3.5 完整代码
完整代码(数据集需要自己定义)如下方便调试:
import torch
import torch.nn as nn
import torch.optim as optim
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:x.size(0), :]return self.dropout(x)class TransformerModel(nn.Module):def __init__(self, vocab_size, d_model, nhead, nhid, nlayers, dropout=0.5):super(TransformerModel, self).__init__()self.model_type = 'Transformer'self.pos_encoder = PositionalEncoding(d_model, dropout)self.embedding = nn.Embedding(vocab_size, d_model)self.transformer = nn.Transformer(d_model, nhead, nlayers, nlayers, nhid, dropout)self.fc_out = nn.Linear(d_model, vocab_size)self.init_weights()def init_weights(self):initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.fc_out.weight.data.uniform_(-initrange, initrange)self.fc_out.bias.data.zero_()def forward(self, src, tgt, src_mask=None, tgt_mask=None):src = self.embedding(src) * math.sqrt(self.embedding.embedding_dim)src = self.pos_encoder(src)tgt = self.embedding(tgt) * math.sqrt(self.embedding.embedding_dim)tgt = self.pos_encoder(tgt)output = self.transformer(src, tgt, src_mask, tgt_mask)output = self.fc_out(output)return outputvocab_size = 10000 # 假设词汇表大小为 10000
d_model = 512 # 词向量维度
nhead = 8 # 多头注意力的头数
nhid = 2048 # 前馈网络的隐藏层维度
nlayers = 6 # 编码器和解码器的层数
dropout = 0.5 # Dropout 概率# 创建模型
model = TransformerModel(vocab_size, d_model, nhead, nhid, nlayers, dropout)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train()total_loss = 0for batch in train_loader:src, tgt = batch # 假设 src 和 tgt 是训练数据optimizer.zero_grad()output = model(src, tgt[:, :-1]) # 输入解码器时去掉最后一个词loss = criterion(output.view(-1, vocab_size), tgt[:, 1:].reshape(-1)) # 预测下一个词loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader)}")4. 总结
Transformer 架构通过自注意力机制和位置编码,解决了传统 RNN 和 LSTM 在处理长序列时的效率问题。它的核心在于多头自注意力机制,能够同时关注序列中所有位置的信息。本文通过 PyTorch 实现了一个完整的 Transformer 模型,并详细讲解了其核心机制和代码实现。
Transformer 的应用非常广泛,包括机器翻译、文本生成、问答系统等。希望大家能够通过本文深入理解 Transformer 的原理,并在实际项目中灵活应用这一强大的架构。我是橙色小博,关注我,一起在人工智能领域学习进步!
相关文章:
Transformer模型解析与实例:搭建一个自己的预测语言模型
目录 1. 前言 2. Transformer 的核心结构 2.1 编码器(Encoder) 2.2 解码器(Decoder) 2.3 位置编码(Positional Encoding) 3. 使用 PyTorch 构建 Transformer 3.1 导入所需的模块: 3.2 定…...

Java常用安全编码的规范整理及工具
对Java安全编码的主要规范及要求的一些整理: 一、输入验证与数据校验 外部输入校验 对所有外部输入(如用户输入、文件、网络数据)进行合法性校验,采用白名单机制限制输入内容范围 。校验前对输入数据做归一化处理ÿ…...

重返JAVA之路——面向对象
目录 面向对象 1.什么是面向对象? 2.面向对象的特点有哪些? 3.什么是对象? 4.什么是类? 5.什么是构造方法? 6.构造方法的特性有哪些? 封装 1.什么是封装? 2.封装有哪些特点? 数据隐…...
)
Java设计模式全解析(共 23 种)
一、设计模式全解: Java 中的设计模式是为了解决在软件开发中常见问题的一些“最佳实践”总结。设计模式分为三大类,共 23 种经典模式: 1. 创建型模式(5 种) 用于对象的创建,解决对象实例化过程中的问题。…...

Python10天突击--Day 2: 实现观察者模式
以下是 Python 实现观察者模式的完整方案,包含同步/异步支持、类型注解、线程安全等特性: 1. 经典观察者模式实现 from abc import ABC, abstractmethod from typing import List, Anyclass Observer(ABC):"""观察者抽象基类""…...

springboot框架集成websocket依赖实现物联网设备、前端网页实时通信!
需求: 最近在对接一个物联网里设备,他的通信方式是 websocket 。所以我需要在 springboot框架中集成websocket 依赖,从而实现与设备实时通信! 框架:springboot2.7 java版本:java8 好了,还是直接…...
ubuntu18.04 升级python3.6到python3.7,安装pip3)
【玩泰山派】5、点灯,驱动led-(2)ubuntu18.04 升级python3.6到python3.7,安装pip3
文章目录 前言升级python3.71、安装 software-properties-common 包2、添加 deadsnakes PPA 源3、安装 Python 3.71. 安装 Python 3.72. 安装 Python 3.7 的开发包和虚拟环境支持(可选但推荐)3. 设置 Python 3.7 为默认版本4. 验证 Python 版本注意事项 …...

ES6学习03-字符串扩展(unicode、for...of、字符串模板)和新方法()
一、字符串扩展 1. eg: 2.for...of eg: 3. eg: 二。字符串新增方法 1. 2. 3. 4. 5....

c++中的this
在 C 中,this 是一个指向当前对象实例的指针,它隐式地存在于类的非静态成员函数中。以下是 this 的详细用法和常见场景: 1. 常见场景 明确成员归属:当成员变量与局部变量同名时,用 this-> 显式访问成员。当成员变量…...

目前状况下,计算机和人工智能是什么关系?
目录 一、计算机和人工智能的关系 (一)从学科发展角度看 计算机是基础 人工智能是计算机的延伸和拓展 (二)从技术应用角度看 二、计算机系学生对人工智能的了解程度 (一)基础层面的了解 必备知识 …...
Flutter 2025 Roadmap
2025 这个路线图是有抱负的。它主要代表了我们这些在谷歌工作的人收集的内容。到目前为止,非Google贡献者的数量超过了谷歌雇佣的贡献者,所以这并不是一个详尽的列表,列出了我们希望今年Flutter能够出现的所有令人兴奋的新事物!在…...

[数据结构]排序 --2
目录 8、快速排序 8.1、Hoare版 8.2、挖坑法 8.3、前后指针法 9、快速排序优化 9.1、三数取中法 9.2、采用插入排序 10、快速排序非递归 11、归并排序 12、归并排序非递归 13、排序类算法总结 14、计数排序 15、其他排序 15.1、基数排序 15.2、桶排序 8、快速排…...
第16届蓝桥杯c++省赛c组个人题解
偷偷吐槽: c组没人写题解吗,找不到题解啊 P12162 [蓝桥杯 2025 省 C/研究生组] 数位倍数 题目背景 本站蓝桥杯 2025 省赛测试数据均为洛谷自造,与官方数据可能存在差异,仅供学习参考。 题目描述 请问在 1 至 202504ÿ…...
记一次InternVL3- 2B 8B的部署测验日志
1、模型下载魔搭社区 2、运行环境: 1、硬件 RTX 3090*1 云主机[普通性能] 8核15G 200G 免费 32 Mbps付费68Mbps ubuntu22.04 cuda12.4 2、软件: flash_attn(好像不用装 忘记了) numpy Pillow10.3.0 Requests2.31.0 transfo…...

Android PowerManager功能接口详解
PowerManager 是 Android 系统中用于管理设备电源状态的核心服务,开发者可以通过它控制设备的唤醒、休眠、屏幕亮灭等行为。以下是对 PowerManager 核心功能接口的详细说明,包含使用场景、注意事项和代码示例。 1. 获取 PowerManager 实例 通过 Context…...

使用SSH解决在IDEA中Push出现403的问题
错误截图: 控制台日志: 12:15:34.649: [xxx] git -c core.quotepathfalse -c log.showSignaturefalse push --progress --porcelain master refs/heads/master:master fatal: unable to access https://github.com/xxx.git/: The requested URL return…...

Tauri 2.3.1+Leptos 0.7.8开发桌面应用--Sqlite数据库的写入、展示和选择删除
在前期工作的基础上(Tauri2Leptos开发桌面应用--Sqlite数据库操作_tauri sqlite-CSDN博客),尝试制作产品化学成分录入界面,并展示数据库内容,删除选中的数据。具体效果如下: 一、前端Leptos程序 前端程序主…...
技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比)
关于 Java 预先编译(AOT)技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比
以下是关于 Java 预先编译(AOT)技术的详细说明,涵盖 GraalVM 的配置、Spring Boot 3.x 的集成、使用示例及优缺点对比: 1. 预先编译(AOT)技术详解 1.1 核心概念 AOT(Ahead-of-Time)…...

《车辆人机工程-》实验报告
汽车驾驶操纵实验 汽车操纵装置有哪几种,各有什么特点 汽车操纵装置是驾驶员直接控制车辆行驶状态的关键部件,主要包括以下几种,其特点如下: 一、方向盘(转向操纵装置) 作用:控制车辆行驶方向…...

使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构
使用多进程和 Socket 接收解析数据并推送到 Kafka 的高性能架构 在现代应用程序中,实时数据处理和高并发性能是至关重要的。本文将介绍如何使用 Python 的多进程和 Socket 技术来接收和解析数据,并将处理后的数据推送到 Kafka,从而实现高效的…...
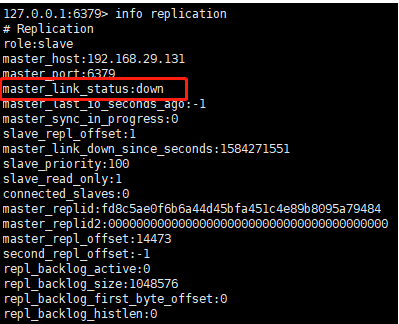
Redis 哨兵模式 搭建
1 . 哨兵模式拓扑 与 简介 本文介绍如何搭建 单主双从 多哨兵模式的搭建 哨兵有12个作用 。通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。 当哨兵监测到master宕机,会自动将slave切换成master,然后通过…...

【网络安全 | 项目开发】Web 安全响应头扫描器(提升网站安全性)
原创项目,未经许可,不得转载。 文章目录 项目简介工作流程示例输出技术栈项目代码使用说明项目简介 安全响应头是防止常见 Web 攻击(如点击劫持、跨站脚本攻击等)的有效防线,因此合理的配置这些头部信息对任何网站的安全至关重要。 Web 安全响应头扫描器(Security Head…...

构建灵活的接口抽象层:支持多种后端数据存取的实战指南
构建灵活的接口抽象层:支持多种后端数据存取的实战指南 引言 在现代软件开发中,数据存取成为业务逻辑的核心组成部分。然而,由于后端数据存储方式的多样性(如关系型数据库、NoSQL数据库和文件存储),如何设计一套能够适配多种后端数据存取的接口抽象层,成为技术团队关注…...

计算机的发展及应用
一、计算机的发展历程 计算机的发展经历了从机械计算到电子计算的跨越,其核心驱动力是 硬件技术革新 和 体系结构演进,大致可分为以下阶段: 1. 前电子计算机时代(19世纪-20世纪40年代) 机械计算装置: 16…...

深入理解linux操作系统---第4讲 用户、组和密码管理
4.1 UNIX系统的用户和组 4.1.1 用户与UID UID定义:用户身份唯一标识符,16位或32位整数,范围0-65535。系统用户UID为0(root)、1-999(系统服务),普通用户从1000开始分配特殊UID&…...

【NLP】18. Encoder 和 Decoder
1. Encoder 和 Decoder 概述 在序列到序列(sequence-to-sequence,简称 seq2seq)的模型中,整个系统通常分为两大部分:Encoder(编码器)和 Decoder(解码器)。 Encoder&…...

Npfs!NpFsdCreate函数分析之从NpCreateClientEnd函数分析到Npfs!NpSetConnectedPipeState
第一部分: 1: kd> g Breakpoint 5 hit Npfs!NpFsdCreate: baaecba6 55 push ebp 1: kd> kc # 00 Npfs!NpFsdCreate 01 nt!IofCallDriver 02 nt!IopParseDevice 03 nt!ObpLookupObjectName 04 nt!ObOpenObjectByName 05 nt!IopCreateFile 06…...
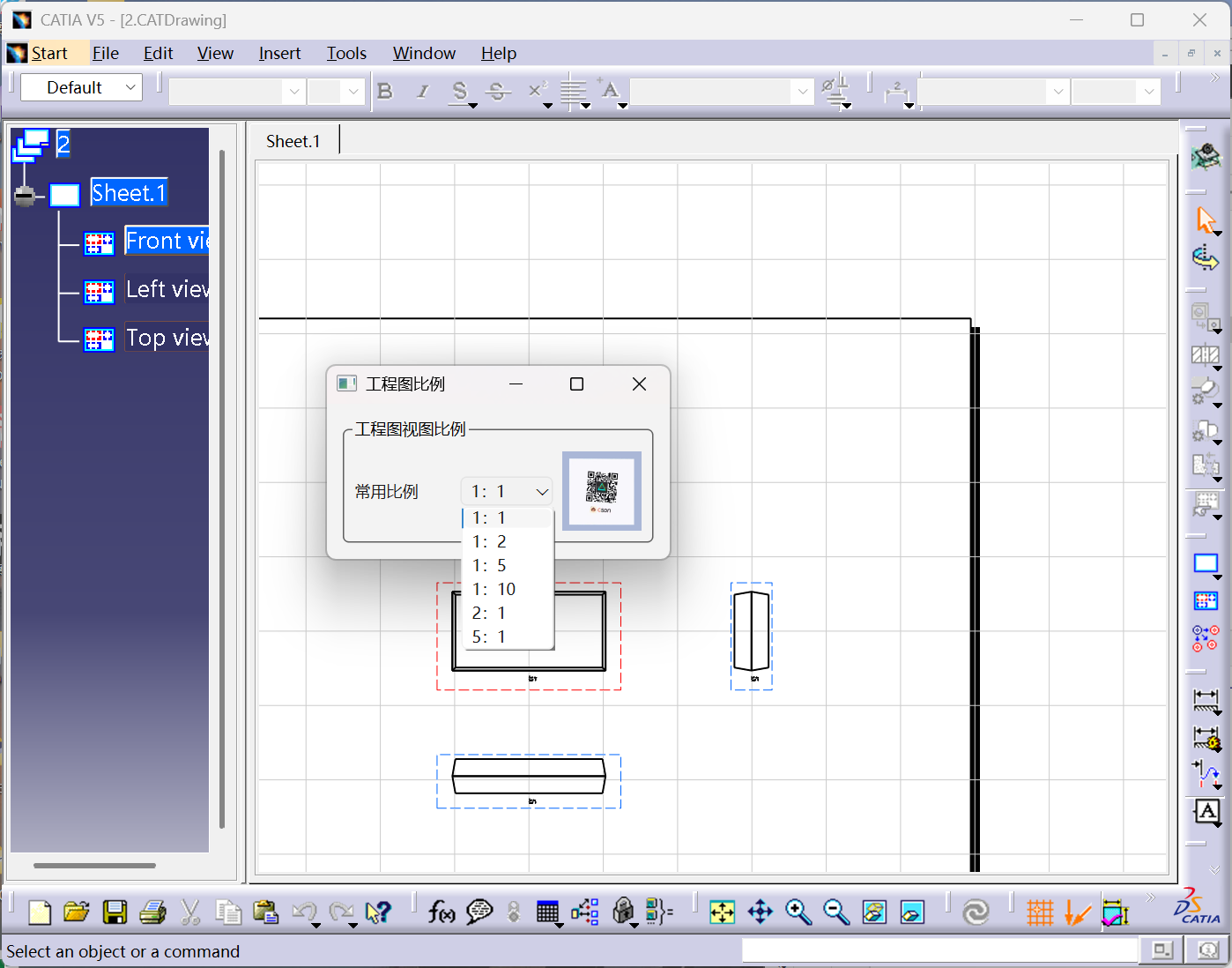
基于PySide6与pycatia的CATIA绘图比例智能调节工具开发全解析
引言:工程图纸自动化处理的技术革新 在机械设计领域,CATIA图纸的比例调整是高频且重复性极强的操作。传统手动调整方式效率低下且易出错。本文基于PySide6+pycatia技术栈,提出一种支持智能比例匹配、实时视图控制、异常自处理的图纸批处理方案,其核心突破体现在: 操作效…...

STM32硬件IIC+DMA驱动OLED显示——释放CPU资源,提升实时性
目录 前言 一、软件IIC与硬件IIC 1、软件IIC 2、硬件IIC 二、STM32CubeMX配置KEIL配置 三、OLED驱动示例 1、0.96寸OLED 2、OLED驱动程序 3、运用示例 4、效果展示 总结 前言 0.96寸OLED屏是一个很常见的显示模块,其驱动方式在用采IIC通讯时,常用软件IIC…...

Spring Bean的创建过程与三级缓存的关系详解
以下以 Bean A 和 Bean B 互相依赖为例,结合源码和流程图,详细说明 Bean 的创建过程与三级缓存的交互。 1. Bean 的完整生命周期(简化版) #mermaid-svg-uwqaB5dgOFDQ97Yd {font-family:"trebuchet ms",verdana,arial,sa…...