【Nodebb系列】Nodebb笔记写入方案
NodeBB写入方案
前言
最近在整理以前记录的碎片笔记,想把它们汇总到NodeBB中,方便管理和浏览。但是笔记内容有点多,并且用发帖的形式写到NodeBB中会丢失时间信息,因此整理了一套NodeBB写入方案,大致流程如下:
- 建立标准笔记格式
- 导出原始笔记,并编写脚本将笔记内容转换为标准格式
- 本地搭建NodeBB,修改时间戳相关字段,使得可以进行时间戳写入
- 在本地NodeBB写入标准笔记内容
- 将本地笔记内容导出,并在云端进行恢复
注:本帖仅适用于纯文本的笔记带时间写入NodeBB
1、标准笔记格式
关键API字段(NodeBB开发文档)
create a new topic/post:https://try.nodebb.org/api/v3/topics/{tid}
get a topic/get:https://try.nodebb.org/api/v3/topics/{tid}
reply to a topic/post:https://try.nodebb.org/api/v3/topics/{tid}
get a post/get:https://try.nodebb.org/api/v3/posts/{pid}
edit a post/put:https://try.nodebb.org/api/v3/posts/{pid}
关键字段及生成规则
标题(title):帖子标题,可为空
正文(content):帖子正文内容,笔记的核心部分,不可为空
时间(time):帖子的创建时间,格式为2025-04-08 15:32:00,拼接已知时间和当前时间,为空时默认当前时间,避免时间戳重复
时间戳(timestamp):帖子创建时间的时间戳,格式为1744097860750毫秒级时间戳,根据time字段自动生成
标签(tags):帖子标签,格式为标签1,标签2,...,中间使用英文逗号分隔,可为空
话题(topic):帖子所属话题,自定义生成,可为空
分类(category):话题所属类别,自定义生成,可为空
{
"title": "...",
"content": "...",
"raw_content": "...",
"time": "2021-07-13 04:27:59",
"timestamp": 1626121679512,
"tags": "..., ..., ...",
"topic": "...",
"category": "..."
}
2、笔记导出及格式标准化
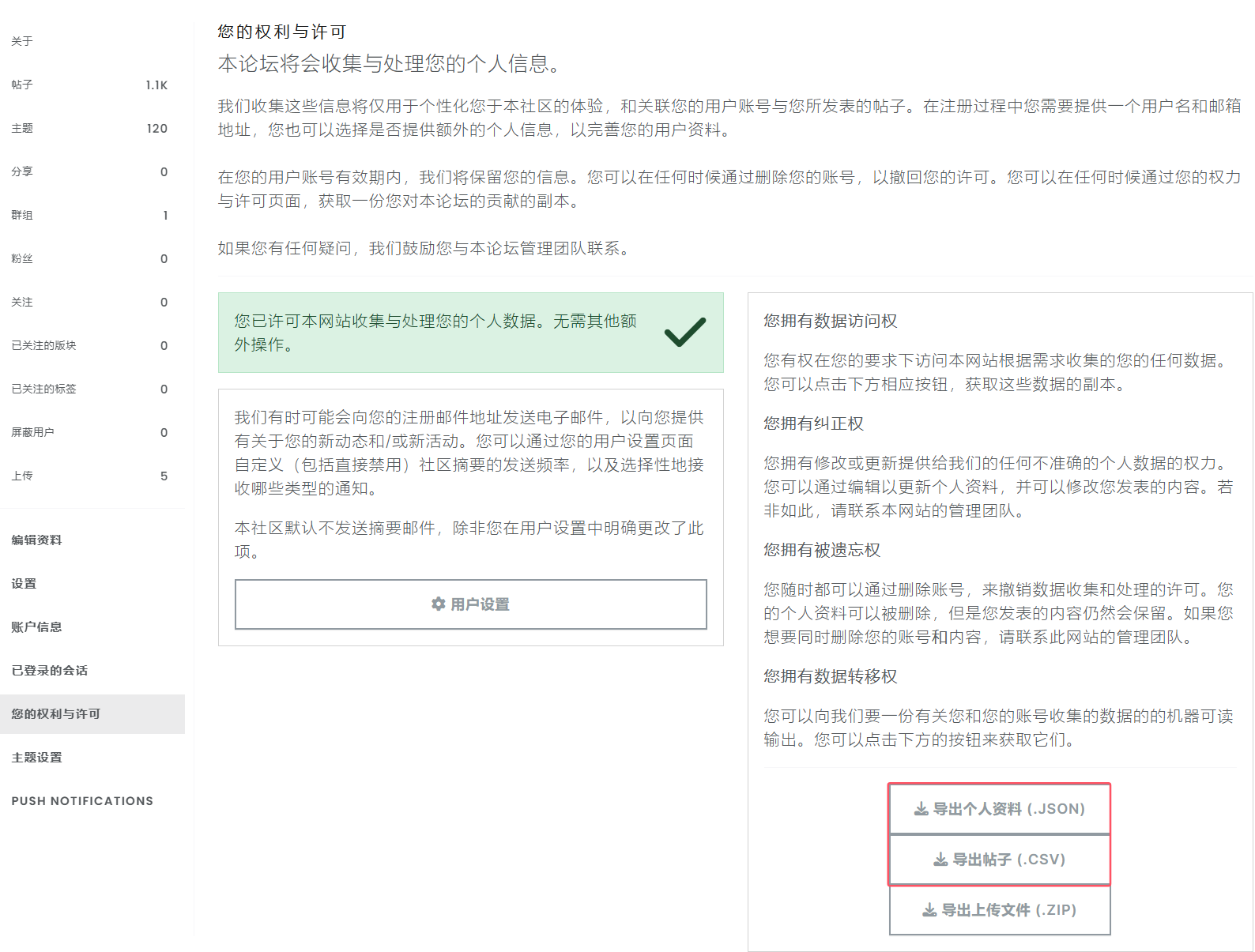
在NodeBB中的权利与许可界面,导出个人资料(包含tid和title),帖子(包含帖子正文)
编写脚本将碎片笔记转换为标准格式
在原始笔记内容中,大部分只有正文内容(content)、话题(topic)、时间(time)字段,其他字段都是缺失的,自己一条条添加比较费劲,这里就直接调用本地部署的Deepseek生成一下了,完整的脚本如下。
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@FileName: transmat.py
@Author: zhifeix
@Email: kforum@163.com
@Description: Stream processing and saving with resume capability
@Date: 2025/4/8 16:28
"""
import csv
import json
import requests
import re
from datetime import datetime
import os# 日志文件,用于记录处理的序号
LOG_FILE = "processing_log.txt"def parse_timestamp(timestamp_str):now = datetime.now()# 如果传入空字符串,直接返回当前时间if not timestamp_str or not isinstance(timestamp_str, str):return now.strftime("%Y-%m-%d %H:%M:%S"), int(now.timestamp() * 1000)# 清理时间字符串time_str = timestamp_str.replace("T", " ").replace("Z", "").strip()# 定义支持的格式及其解析方式formats = [(r"\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}", "%Y-%m-%d %H:%M:%S"), # 年月日时分秒(r"\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}", "%Y-%m-%d %H:%M"), # 年月日时分(r"\d{4}-\d{2}-\d{2}", "%Y-%m-%d"), # 年月日(r"\d{4}-\d{2}", "%Y-%m"), # 年月(r"\d{4}", "%Y"), # 年(r"\d{4}/\d{2}/\d{2}\s+\d{2}:\d{2}:\d{2}", "%Y/%m/%d %H:%M:%S"), # 年/月/日 时:分:秒(r"\d{4}/\d{2}/\d{2}\s+\d{2}:\d{2}", "%Y/%m/%d %H:%M"), # 年/月/日 时:分(r"\d{4}/\d{2}/\d{2}", "%Y/%m/%d"), # 年/月/日(r"\d{6}", lambda s: datetime.strptime(f"20{s[:2]}-{s[2:4]}-{s[4:]}", "%Y-%m-%d")), # YYMMDD(r"\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}\.\d+", "%Y-%m-%d %H:%M:%S.%f"), # ISO 带微秒]# 尝试每种格式for pattern, fmt in formats:try:match = re.search(pattern, time_str)if match:matched_str = match.group(0)# 如果是特殊格式(例如 YYMMDD),使用 lambda 函数处理if callable(fmt):dt = fmt(matched_str)else:dt = datetime.strptime(matched_str, fmt)# 补全缺失的字段if "%H" not in fmt:dt = dt.replace(hour=now.hour, minute=now.minute, second=now.second)elif "%M" not in fmt:dt = dt.replace(minute=now.minute, second=now.second)elif "%S" not in fmt:dt = dt.replace(second=now.second)return dt.strftime("%Y-%m-%d %H:%M:%S"), int(dt.timestamp() * 1000)except ValueError:continue # 当前格式解析失败,继续尝试下一种# 如果所有格式都无法解析,使用当前时间return now.strftime("%Y-%m-%d %H:%M:%S"), int(now.timestamp() * 1000)def generate_fields_with_model(content):data = {"model": "deepseek-r1:14b","prompt": f'根据以下内容生成笔记的标题、标签、分类和清理后的正文内容'f'(请注意,尽可能保持原文所有内容,不要做任何修改,包括正文、格式等,换行符之类的都不要修改)。'f'请严格遵循以下规则:\n'f'输入内容:\n'f'{content}\n'f'规则:\n'f'1. **优先提取**:\n'f' - **标题 (title)**:\n'f' - 智能判断内容中可能的标题(通常是第一行或显著的短语),若无明确标题则生成。\n'f' - 示例:若第一行是“【例子】”,可提取“【例子】写作历程反思”;若无明显标题,则根据正文生成。\n'f' - **时间 (time)**:\n'f' - 从正文或元数据中提取任何形似时间的信息,优先级如下:\n'f' 1. 显式标注的时间字段(如“创建时间:2023/9/2 21:21”、“更新时间:2023/9/2 22:15”),优先取最早的“创建时间”,若无则取最新的更新时间。 \n'f' 2. 正文中形似时间的字符串(如“241026”、“2023年7月6日”、“2022-01-01”)。\n'f' 3. 若无明确时间,则不输出该字段(注意:若提取不到时间,则留空,不要使用当前时间)。\n'f' - 支持的时间格式示例:\n'f' - "YYYY-MM-DD HH:MM:SS"(如 "2023-09-02 21:21")\n'f' - "YYYY/MM/DD HH:MM"(如 "2023/9/2 21:21")\n'f' - "YYYY-MM-DD"(如 "2023-09-02")\n'f' - "YYYYMMDD"(如 "241026",应解析为 "2024-10-26")\n'f' - "YYYY年MM月DD日"(如 "2023年7月6日")\n'f' - 输出时,将提取的时间转换为 "YYYY-MM-DD HH:MM:SS" 格式,缺少的部分直接空出来不写,后面我会手动进行解析。\n'f' - **标签 (tags)**:\n'f' - 从正文中提取 2-5 个关键词(如“【例子】”、“【例子】”),根据语义判断。\n'f' - 若无法提取,生成 3 个相关标签。\n'f' - 每个标签不超过 10 个字符,用逗号分隔。\n'f' - **分类 (category)**:\n'f' - 根据内容语义推导通用分类(如“【例子】”、“【例子】”),若无明确分类则生成。\n'f' - 若提取到上述字段,移除这些元数据后输出清理后的正文 (cleaned_content)。(注意,提取到才移除,假如是生成的则不移除)\n\n'f'2. **生成**:\n'f' - 若无法提取以下字段,则根据正文内容生成:\n'f' - **标题 (title)**:生成一个简洁且符合主题的标题,长度不超过 20 个字符。\n'f' - **标签 (tags)**:生成 3 个相关标签,最多不超过 5 个,每个不超过 10 个字符,用逗号分隔。\n'f' - **分类 (category)**:生成一个通用分类名称,长度不超过 15 个字符。\n'f' - 若生成字段,则正文保持不变,作为 cleaned_content 输出。\n\n'f' - 注意:若无法提取时间,则 time 字段留空,不生成默认时间。\n\n'f'3. **输出格式**:\n'f' - 以 JSON 格式返回,包含字段:title、time(若提取到)、tags、category、cleaned_content。\n'f' - 示例(提取成功):\n'f' ```json\n'f' {{\n'f' "title": "...",\n'f' "time": "2023/7/6 10:21",\n'f' "tags": ".., .., ..",\n'f' "category": "....",\n'f' "cleaned_content": "..."\n'f' }}\n'f' ```\n'f'请根据以上规则处理输入内容并返回结果。',"max_tokens": 500,"temperature": 0.7,"top_p": 0.9,"top_k": 40}response = requests.post("http://localhost:11434/api/generate", json=data, stream=True)if response.status_code == 200:full_response = ""for line in response.iter_lines():if line:json_line = json.loads(line.decode("utf-8"))if "response" in json_line:full_response += json_line["response"]json_start = full_response.find("```json")json_end = full_response.rfind("```")try:if json_start != -1 and json_end != -1:json_str = full_response[json_start + 7:json_end].strip()return json.loads(json_str)except:print("未找到有效的 JSON 部分")return {"title": "未命名", "tags": "", "category": "未分类", "cleaned_content": content}else:print(f"模型请求失败,状态码:{response.status_code}")return {"title": "未命名", "tags": "", "category": "未分类", "cleaned_content": content}def read_last_processed_index():"""读取上次处理的最后序号"""if os.path.exists(LOG_FILE):with open(LOG_FILE, 'r', encoding='utf-8') as f:return int(f.read().strip())return 0def save_last_processed_index(index):"""保存当前处理的序号"""with open(LOG_FILE, 'w', encoding='utf-8') as f:f.write(str(index))def append_to_json(data, output_file):"""追加数据到 JSON 文件"""if not os.path.exists(output_file):with open(output_file, 'w', encoding='utf-8') as f:json.dump([], f) # 初始化为空列表with open(output_file, 'r+', encoding='utf-8') as f:existing_data = json.load(f)existing_data.append(data)f.seek(0)json.dump(existing_data, f, ensure_ascii=False, indent=4)def json_to_csv(json_file, csv_file):"""将 JSON 文件转换为 CSV 文件。"""# 检查 JSON 文件是否存在if not os.path.exists(json_file):print(f"错误:输入文件 {json_file} 不存在")return# 读取 JSON 数据with open(json_file, 'r', encoding='utf-8') as f:data = json.load(f)# 如果 JSON 数据为空或不是列表,直接返回if not data or not isinstance(data, list):print(f"警告:{json_file} 为空或格式不正确,无法转换为 CSV")return# 获取所有可能的字段名(从第一个记录开始,动态扩展)fieldnames = set()for item in data:fieldnames.update(item.keys())fieldnames = list(fieldnames) # 转换为列表以固定顺序# 写入 CSV 文件with open(csv_file, 'w', encoding='utf-8', newline='') as f:writer = csv.DictWriter(f, fieldnames=fieldnames)writer.writeheader() # 写入表头for item in data:writer.writerow(item)print(f"转换完成,结果已保存至 {csv_file}")
def process_and_save_stream(csv_file, json_file, output_json, output_csv):last_index = read_last_processed_index()print(f"从序号 {last_index} 开始处理")with open(csv_file, 'r', encoding='utf-8') as f:reader = csv.DictReader(f)rows = list(reader) # 将 CSV 转为列表以支持索引json_data = json.load(open(json_file, 'r', encoding='utf-8')) if json_file and os.path.exists(json_file) else Nonefor i, row in enumerate(rows):if i < last_index:continue # 跳过已处理的行content = row["content"].strip('"""')timestamp_iso = row.get("timestampISO", "")tid = row.get("tid", "")# 从 JSON 提取 topictopic = ""if json_data and tid:watched_topics = json_data.get("watchedTopics", [])for t in watched_topics:if str(t["tid"]) == str(tid):topic = t["title"]break# 使用模型生成字段和清理后的内容model_result = generate_fields_with_model(content)title = model_result["title"]tags = model_result["tags"]category = model_result["category"]cleaned_content = model_result["cleaned_content"]extracted_time = model_result.get("time", None)# 处理时间time_str, timestamp = parse_timestamp(extracted_time) if extracted_time else parse_timestamp(timestamp_iso)note = {"title": title,"content": cleaned_content,"raw_content": content,"time": time_str,"timestamp": timestamp,"tags": tags,"topic": topic if topic else "","category": category}# 立即保存当前记录# append_to_csv(note, output_csv)append_to_json(note, output_json)save_last_processed_index(i)print(f"已处理并保存序号 {i}")# 将最终的json文件转换为csv文件json_to_csv(output_json, output_csv)def main():# 输入文件路径csv_file = "2_posts.csv"json_file = "2_profile.json"output_json = "standard_notes.json"output_csv = "standard_notes.csv"# 检查文件是否存在if not os.path.exists(csv_file):print(f"错误:输入文件 {csv_file} 不存在")returnif not os.path.exists(json_file):print(f"错误:输入文件 {json_file} 不存在")return# 流式处理并保存process_and_save_stream(csv_file, json_file, output_json, output_csv)print(f"处理完成,结果已保存至 {output_json} 和 {output_csv}")if __name__ == "__main__":main()
3、NodeBB本地搭建
在Github下载NodeBB项目源码
NodeBB项目地址:NodeBB/NodeBB: Node.js based forum software built for the modern web
下载并部署MongoDB数据库
MongoDB Sever下载地址:Download MongoDB Community Server | MongoDB
MongoDB Shell下载地址:MongoDB Shell Download | MongoDB
下载完成后直接安装就行,安装过程可参考下面这篇帖子:
Win10下新版MongoDB的安装部署(保姆级)_win10安装mongodb-CSDN博客
启动项目并进行相关配置
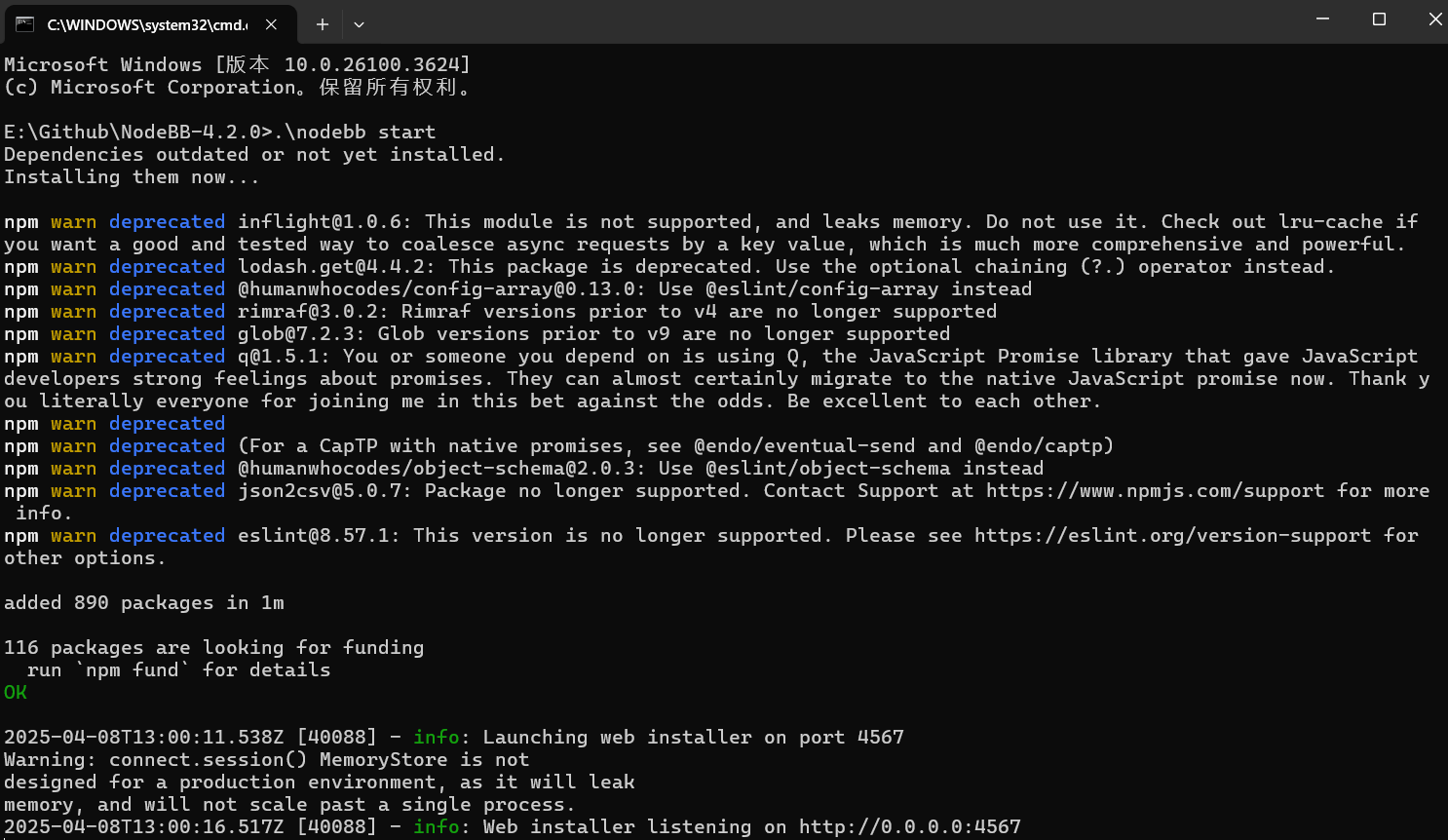
- 解压NodeBB压缩包,并进入项目目录,打开cmd命令行启动项目。
.\nodebb start
- 进入http://localhost:4567/,配置基础信息
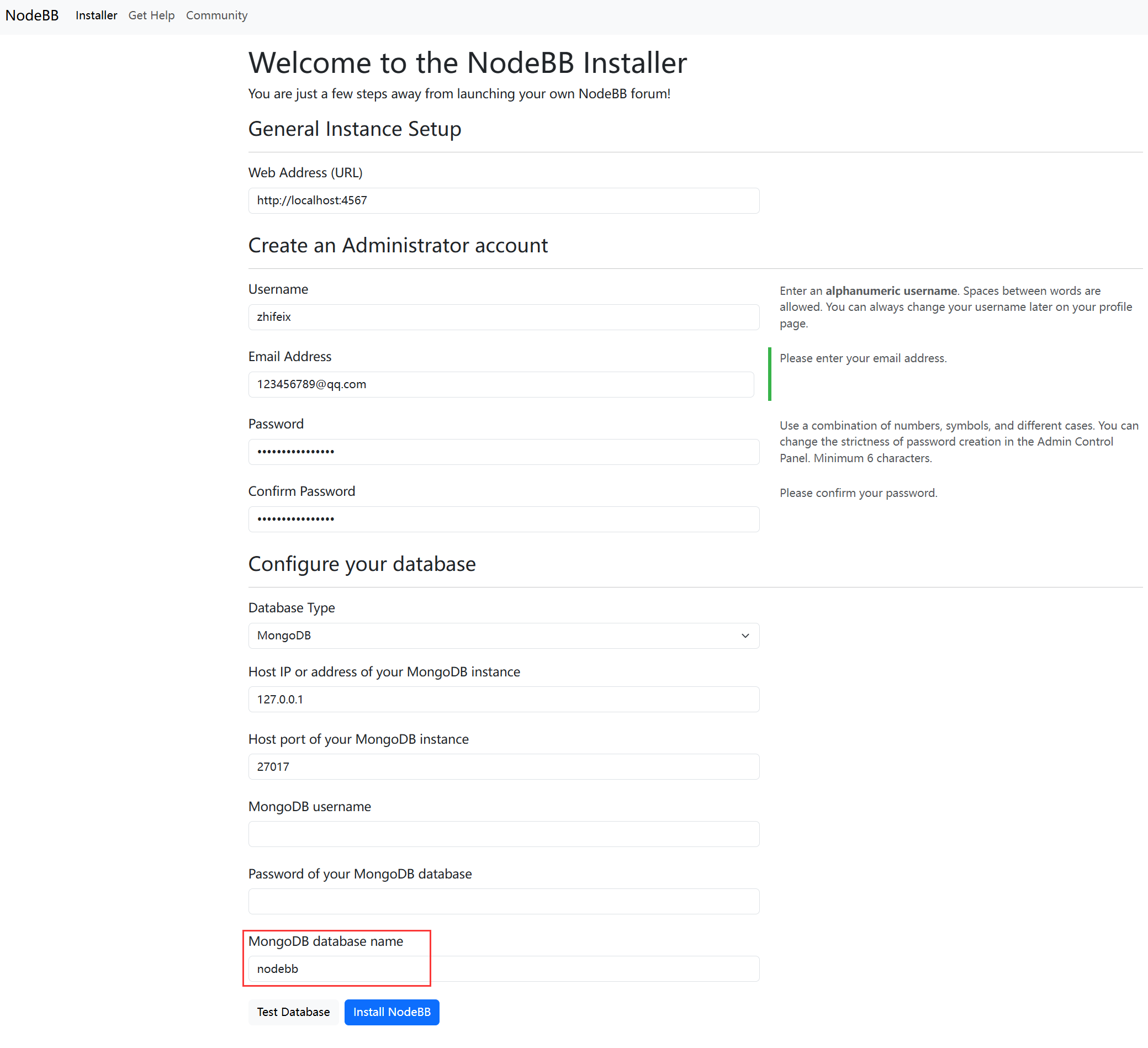
配置完成后,点击Install NodeBB进行安装,安装完成后会自动跳转到登录界面,点击登录即可
4、源码修改及笔记写入
Nodebb提供了一些API接口,可以满足建帖和发帖的需求,但是这些接口不支持修改帖子的时间戳,因此要修改一下相应的源码,使得笔记的创建时间得以保存,(参考:Hooks · NodeBB/NodeBB Wiki (github.com))。
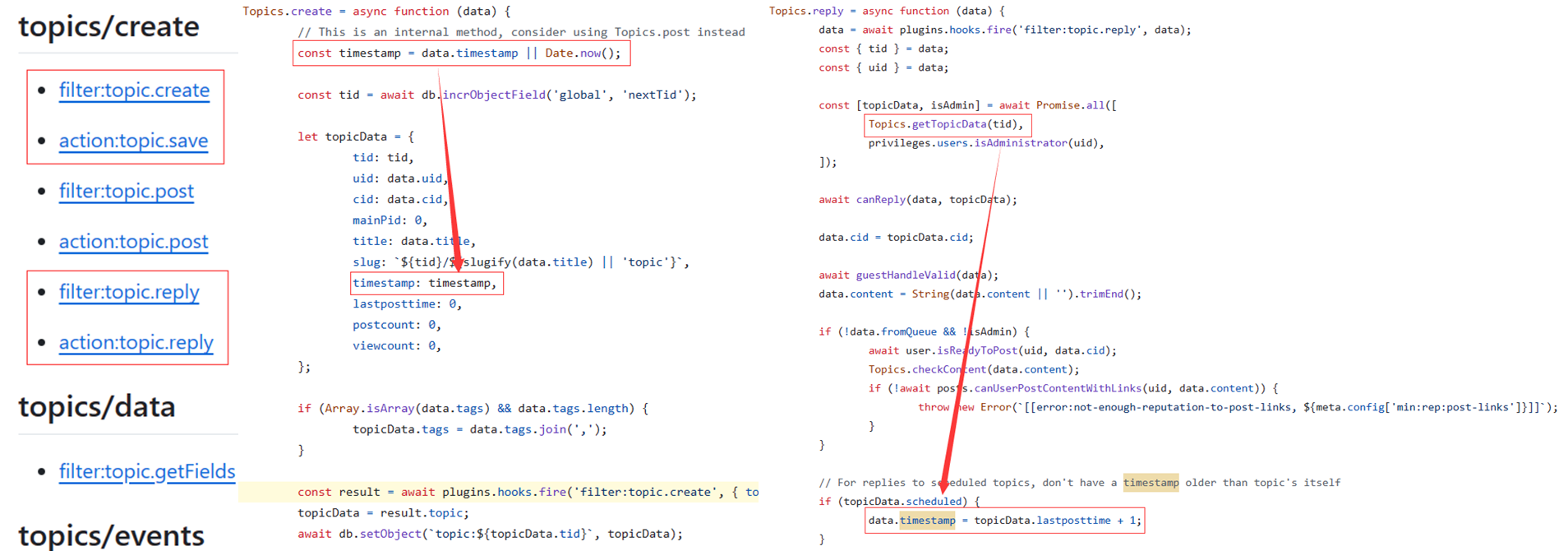
发帖接口测试
要将标准笔记内容写入到NodeBB,首先要分析一下发帖的接口是如何调用的,然后找到对应代码进行修改。在主界面发送一条测试帖子,然后捕获相应的请求信息。
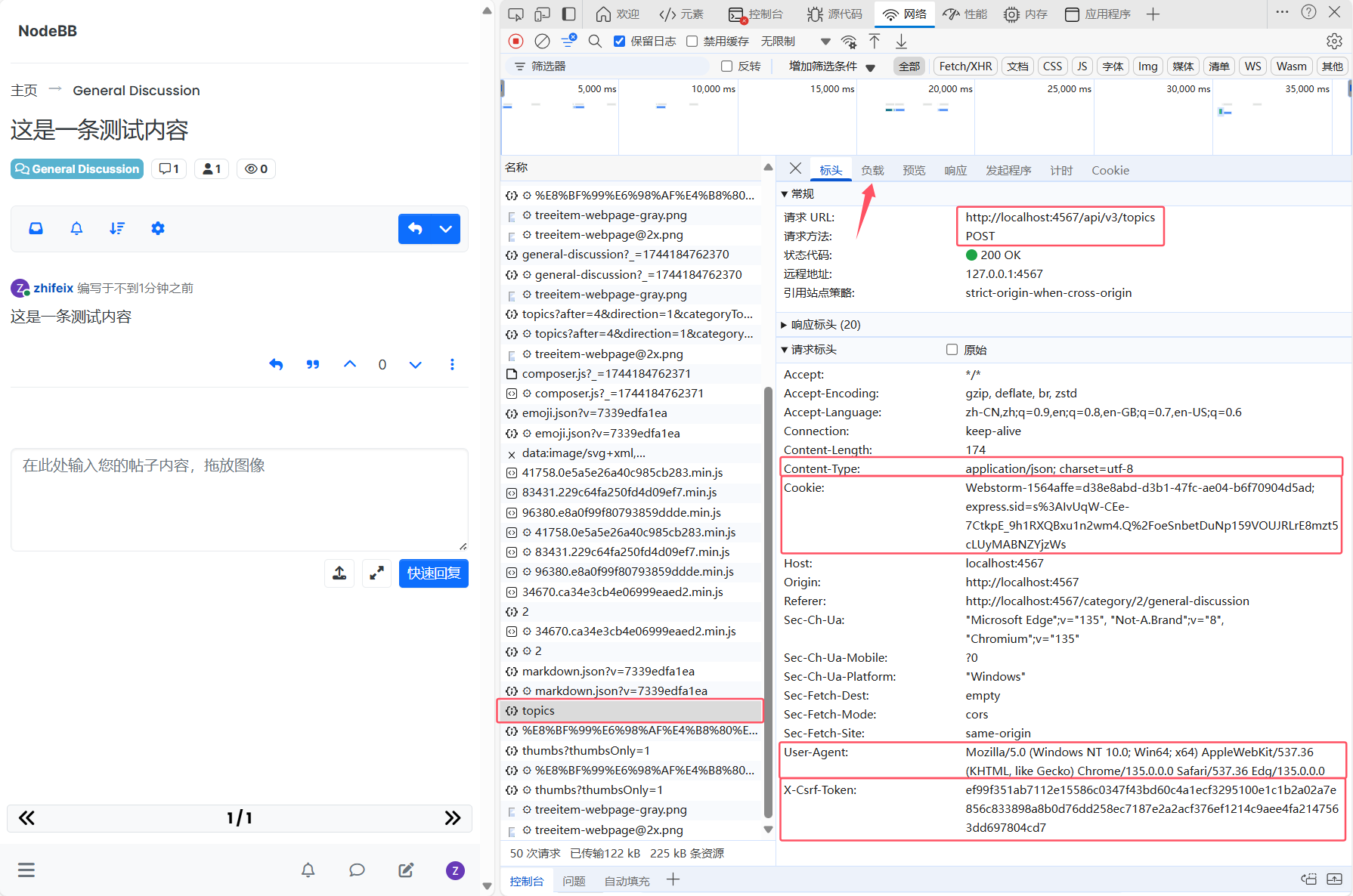
(注:除了图上的信息外,还需要在负载里面获取一下uuid)
修改时间戳生成代码
经过仔细且严密的分析,只需要修改下面的代码就可以了(具体分析过程参考这篇帖子【Nodebb系列】Nodebb搭建笔记系统-CSDN博客)
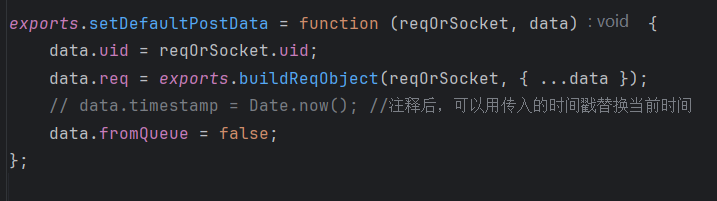
笔记写入脚本
接下来编写脚本,将笔记写入到本地NodeBB数据库中,这里只关注正文内容content和时间戳timestamp,其他内容仅作存档。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@FileName: uploads.py
@Author: zhifeix
@Email: kforum@163.com
@Description:
@Date: 2025/4/9 15:14
"""
import json
import requests
from datetime import datetime# 创建新主题
def createtopic(headers, data):# 从传入的时间戳生成 datetime 对象dt = datetime.fromtimestamp(data['timestamp'] / 1000)# 将日期设置为当月第一天,时间清零dt = dt.replace(day=1, hour=0, minute=0, second=0, microsecond=0)# 将 dt 转换回毫秒级时间戳adjusted_timestamp = int(dt.timestamp() * 1000)payload = {"uuid": data['uuid'],"title": data['title'],"content": "此处记录{}期间的内容".format(data['title']),"cid": data['cid'],"tags": [],"timestamp": adjusted_timestamp, # 使用调整后的时间戳}response = session.post(f"{url}", headers=headers, json=payload)if response.status_code == 200:tid = json.loads(response.text)['response']['tid']tid_dic[data['title']] = tidprint(f"创建主题成功:{data['title']},tid={tid}")return tidelse:print(f"创建主题失败:{response.status_code} - {response.text}")return None# 回复主题
def replytopic(headers, data):payload = {"uuid": data['uuid'],"tid": data['tid'],"handle": "","content": data['content'],"timestamp": data['timestamp']}response = session.post(f"{url}/{data['tid']}", headers=headers,json=payload)if response.status_code == 200:print(f"回复主题成功:tid={data['tid']}")else:print(f"回复主题失败:tid={data['tid']},状态码={response.status_code} - {response.text}")# 上传笔记
def uploadnotes(note):# 从笔记中提取时间戳和内容timestamp = note['timestamp']content = note['content']# 将毫秒级时间戳转换为 datetime 对象datetime_obj = datetime.fromtimestamp(timestamp / 1000)# 提取年份和月份year = datetime_obj.yearmonth = datetime_obj.monthtitle = "【{}年{}月】".format(year, str(month).zfill(2))# 构造上传数据data = {'uuid': uuid,'title': title,'content': content,'cid': cid,'timestamp': timestamp}# 检查是否需要创建新主题if title not in tid_dic:tid = createtopic(headers, data)if tid is None:return # 创建失败,直接返回else:data['tid'] = tid_dic[title]# 回复主题data['tid'] = tid_dic[title]replytopic(headers, data)# 全局参数设置
url = "http://localhost:4567/api/v3/topics"
headers = {'Content-Type': 'application/json; charset=utf-8','Cookie': 'Webstorm-1564affe=d38e8abd-d3b1-47fc-ae04-b6f70904d5ad; express.sid=s%3AIvUqW-CEe-7CtkpE_9h1RXQBxu1n2wm4.Q%2FoeSnbetDuNp159VOUJRLrE8mzt5cLUyMABNZYjzWs','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0','X-Csrf-Token': 'ef99f351ab7112e15586c0347f43bd60c4a1ecf3295100e1c1b2a02a7e856c833898a8b0d76dd258ec7187e2a2acf376ef1214c9aee4fa2147563dd697804cd7'
}cid = 2 # 目录id
uuid = "d0bc48a6-4170-4362-a3e9-1ef696c27d0a"
tid_dic = {} # 创建tid全局索引
session = requests.Session()def main():# 读取 standard_notes.json 文件json_file = "standard_notes.json"try:with open(json_file, 'r', encoding='utf-8') as f:notes = json.load(f)except FileNotFoundError:print(f"错误:文件 {json_file} 不存在")returnexcept json.JSONDecodeError:print(f"错误:文件 {json_file} 格式不正确")returnif not notes:print("警告:笔记数据为空")return# 遍历并上传每条笔记for note in notes:uploadnotes(note)print("所有笔记上传完成")if __name__ == '__main__':main()
5、数据导出及云端恢复
下载并部署MongoDB工具
MongoDB Tools下载地址:Download MongoDB Command Line Database Tools | MongoDB
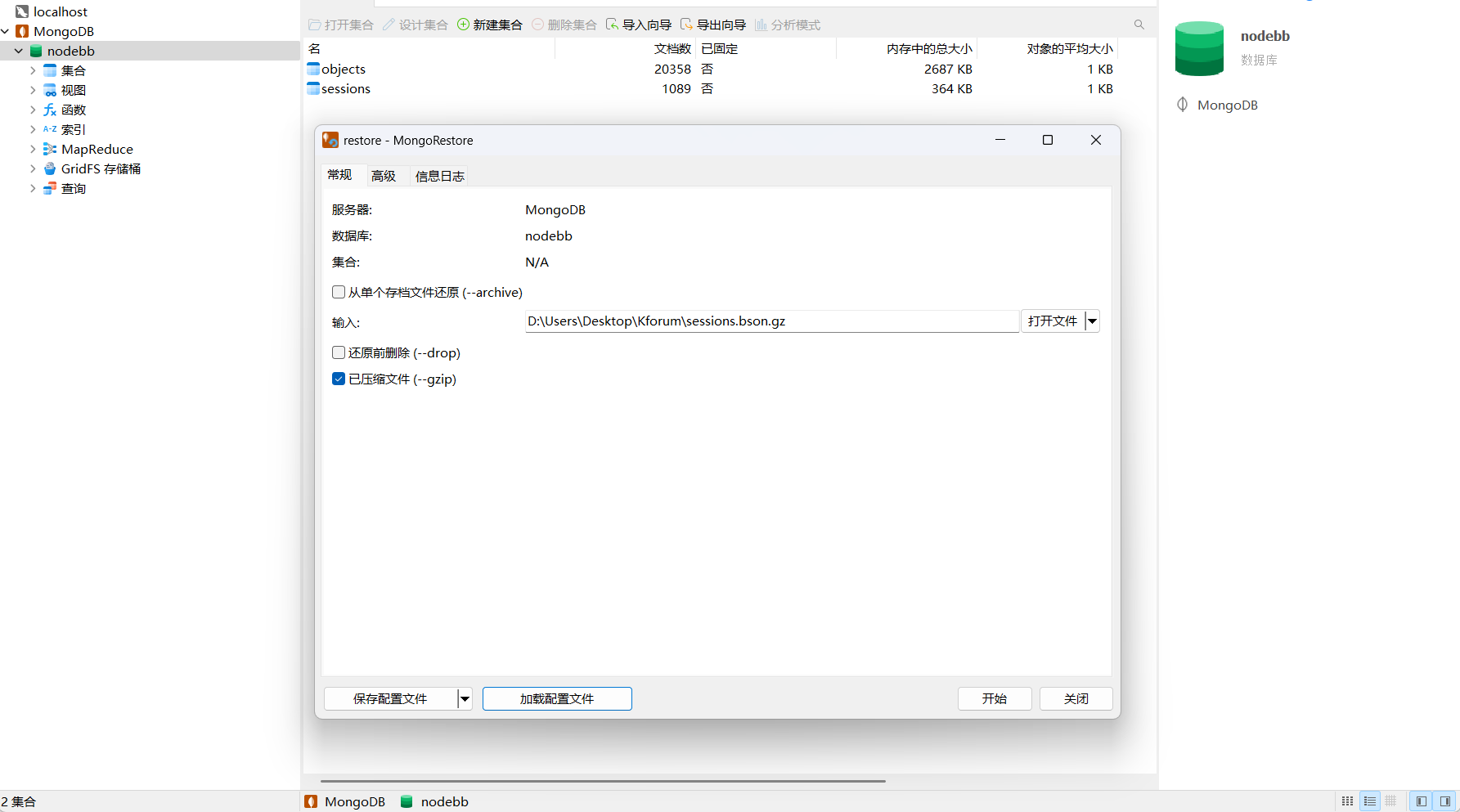
在Navicat中连接云端MongoDB数据库,并将处理好的数据restore到云端数据库,这样就可以把写入的笔记同步到云端了。
6、另一种方法
除了通过数据库进行迁移外,还可以修改云端系统的源码,然后直接调用脚本将笔记内容通过发帖形式上传到线上的NodeBB即可。
进入nodebb的bash命令行
docker exec -it nodebb bash
修改helpers.js相应代码
vim src/api/helpers.js
修改的部分参考第4部分的内容。接着配置好写入脚本,就可以将笔记带时间戳传到线上NodeBB了。
小结
经过漫长的折腾,终于整理出一套比较完整的笔记转移方案,主要是借助NodeBB发帖的形式,统一管理自己记的碎片笔记,中间使用了Deepseek帮助整理碎片笔记中缺失的一些字段,最核心的还是保留笔记时间戳信息,以便梳理思路的变化。笔记整理就先告一段落了,有类似需求的小伙伴可以参考一下上面的内容,希望会有所帮助。
相关文章:
【Nodebb系列】Nodebb笔记写入方案
NodeBB写入方案 前言 最近在整理以前记录的碎片笔记,想把它们汇总到NodeBB中,方便管理和浏览。但是笔记内容有点多,并且用发帖的形式写到NodeBB中会丢失时间信息,因此整理了一套NodeBB写入方案,大致流程如下…...

计算机视觉——基于YOLOV8 的人体姿态估计训练与推理
概述 自 Ultralytics 发布 YOLOV5 之后,YOLO 的应用方向和使用方式变得更加多样化且简单易用。从图像分类、目标检测、图像分割、目标跟踪到关键点检测,YOLO 几乎涵盖了计算机视觉的各个领域,似乎已经成为计算机视觉领域的“万能工具”。 Y…...

鸿蒙小案例---心情日记
效果演示 代码实现 import { router, window } from kit.ArkUIEntry Component struct Index {async aboutToAppear(): Promise<void> {let w await window.getLastWindow(getContext())w.setWindowSystemBarProperties({statusBarColor: #00C6C3,statusBarContentColo…...

力扣第206场周赛
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台 1. 二进制矩阵中的特殊位置 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中…...

从 SYN Flood 到 XSS:常见网络攻击类型、区别及防御要点
常见的网络攻击类型 SYN Flood、DoS(Denial of Service) 和 DDoS(Distributed Denial of Service) 是常见的网络攻击类型,它们的目标都是使目标系统无法正常提供服务。以下是它们的详细说明: 1. SYN Flood…...

el-tree 实现树形菜单子级取消选中后父级选中效果不变
背景 在复杂的企业级管理系统中,树形菜单是一种常见的数据展示和交互组件。传统的树形菜单通常存在以下交互局限: 子节点取消选中时,父节点会自动取消选中无法满足复杂的权限分配和数据筛选场景实际应用场景: 组织架构权限管理多层级资源分配复杂的数据筛选与展示实现需求…...

Java虚拟机——JVM(Java Virtual Machine)解析一
1.JVM是什么? 1.1 JVM概念 Java Virtual Machine (JVM) 是JDK的核心组件之一,它使得 Java 程序能够在任何支持 JVM 的设备或操作系统上运行,而无需修改源代码 JDK是什么,JDK和JVM是什么关系?1.Java IDE(Integrated …...

开源的PMPI库实现及示例代码
开源的PMPI库实现及示例代码 PMPI (Profiling MPI) 是MPI标准中定义的接口,允许开发者通过拦截MPI调用进行性能测量和调试。以下是几个常用的开源PMPI库实现: 1. MPICH的PMPI接口 MPICH本身提供了PMPI接口,可以直接使用。 2. OpenMPI的PM…...
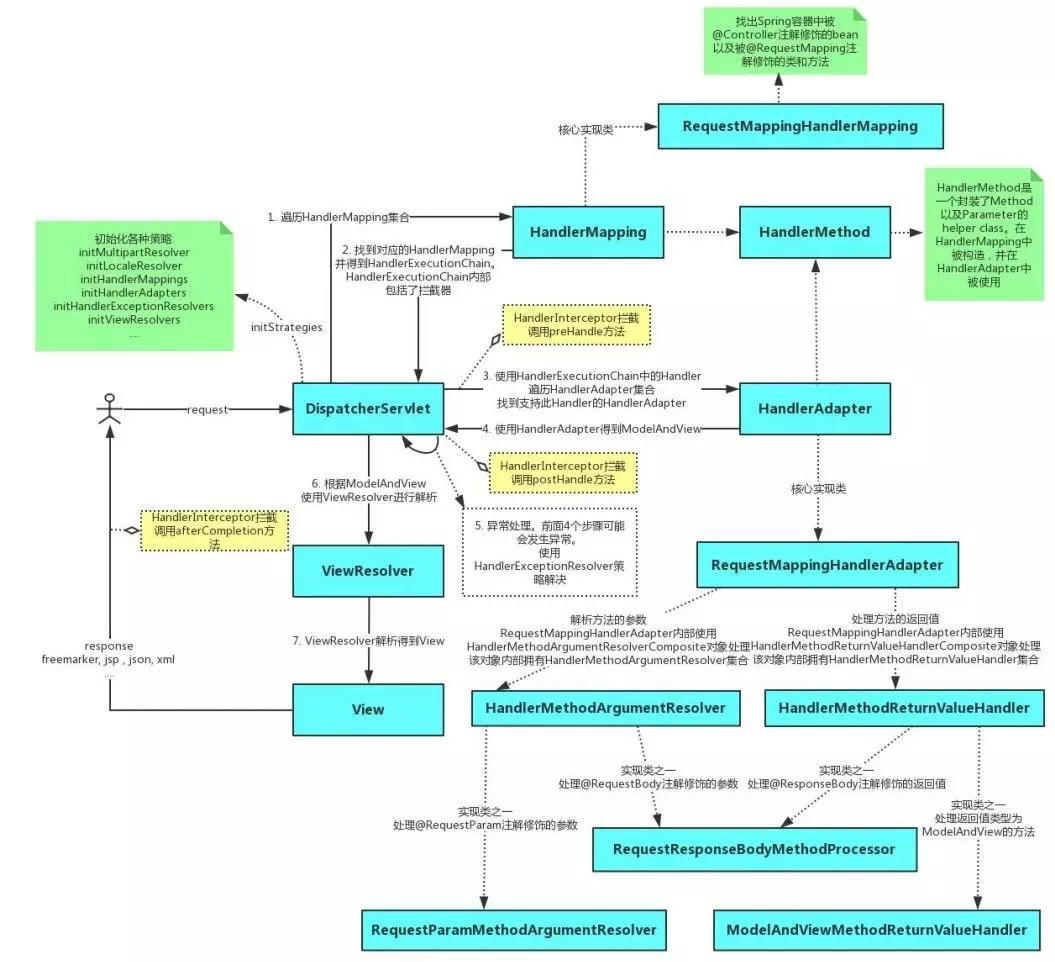
【源码】SpringMvc源码分析
文章目录 SpringMVC 基础回顾核心组件源码分析DispatcherServletHandlerMappingHandlerAdapterViewResolver 请求处理流程源码解析 在当今的 Java Web 开发领域,SpringMVC 无疑是最为广泛应用的 Web 框架之一。它以其强大的功能、灵活的配置以及高度的…...

tcp特点+TCP的状态转换图+time_wait详解
tcp特点TCP的状态转换图time wait详解 目录 一、tcp特点解释 1.1 面向连接 1.1.1 连接建立——三次握手 1.1.2 连接释放——四次挥手 1.2 可靠的 1.2.1 应答确认 1.2.2 超时重传 1.2.3 乱序重排 1.2.4 去重 1.2.5 滑动窗口进行流量控制 1.3 流失服务(字节…...
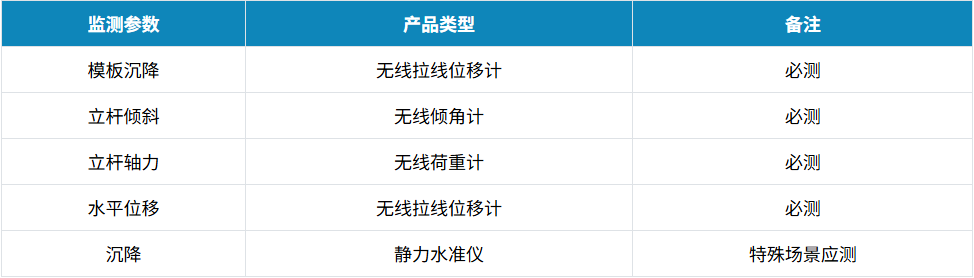
高支模自动化监测解决方案
1.行业现状 高大模板支撑系统在浇筑施工过程中,诸多重大安全风险点进行实时自动化安全监测的解决方案主要监测由于顶杆失稳、扣件失效、承压过大等引起的支撑轴力、模板沉降、相对位移、支撑体系倾斜等参数变化。系统采用无线自动组网、高频连续采样,实时…...

Node.js EventEmitter 深入解析
Node.js EventEmitter 深入解析 概述 Node.js 作为一种强大的 JavaScript 运行环境,以其异步、事件驱动特性在服务器端编程中占据了重要地位。EventEmitter 是 Node.js 中处理事件的一种机制,它允许对象(称为“发射器”)发出事件…...
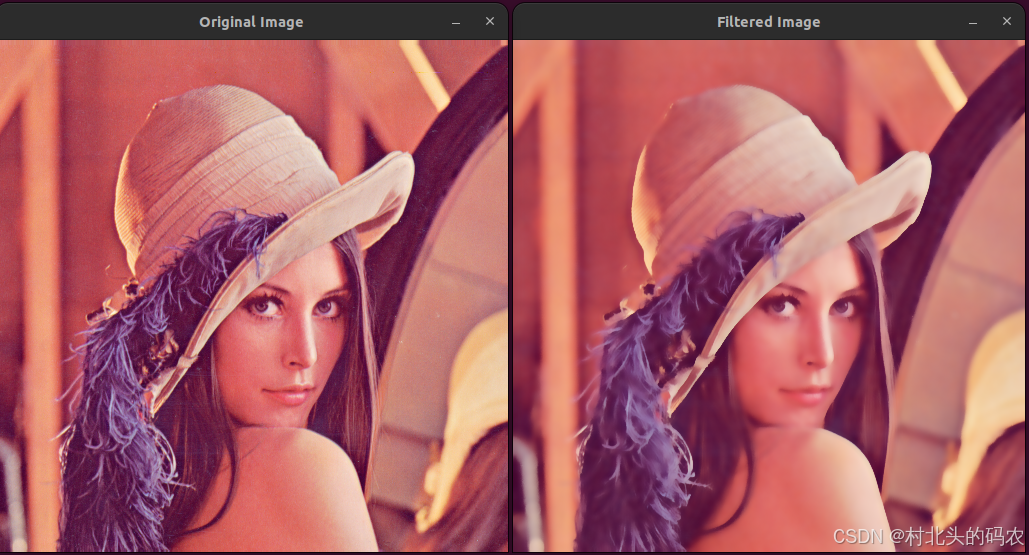
OpenCV 图形API(24)图像滤波-----双边滤波函数bilateralFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 应用双边滤波到图像。 该函数对输入图像应用双边滤波,如 http://www.dai.ed.ac.uk/CVonline/LOCAL_COPIES/MANDUCHI1/Bilateral_Fil…...

单双线程的理解 和 lua基础语法
1.什么是单进程 ,什么是多进程 当一个程序开始运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源。而一个进程又是由单个或多个线程所组成的。 1.1 像apache nginx 这类 服务器中间件就是多进程的软件 ࿰…...
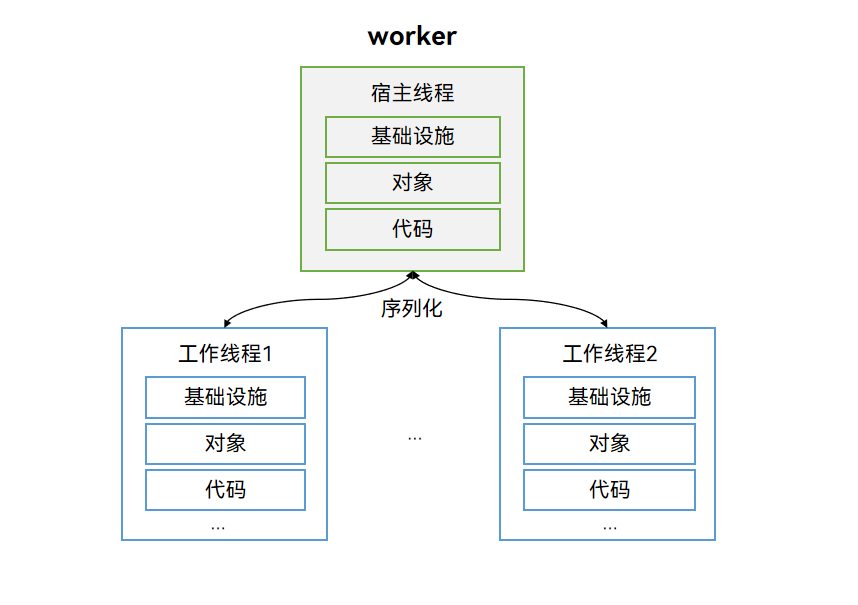
HarmonyOS中的多线程并发机制
目录 多线程并发1. 多线程并发概述2 多线程并发模型3 TaskPool简介4 Worker简介4.1 Woker注意事项4.2 Woker基本用法示例 5. TaskPool和Worker的对比5.1 实现特点对比5.2 适用场景对比 多线程并发 1. 多线程并发概述 并发模型是用来实现不同应用场景中并发任务的编程模型&…...

机器学习 | 强化学习方法分类汇总 | 概念向
文章目录 📚Model-Free RL vs Model-Based RL🐇核心定义🐇核心区别📚Policy-Based RL vs Value-Based RL🐇核心定义🐇 核心区别📚Monte-Carlo update vs Temporal-Difference update🐇核心定义🐇核心区别📚On-Policy vs Off-Policy🐇核心定义🐇核心区别…...

构件与中间件技术:概念、复用、分类及标准全解析
以下是对构件与中间件技术相关内容更详细的介绍: 一、构件与中间件技术的概念 1.构件技术 定义:构件是具有特定功能、可独立部署和替换的软件模块,它遵循一定的规范和接口标准,能够在不同的软件系统中被复用。构件技术就是以构…...
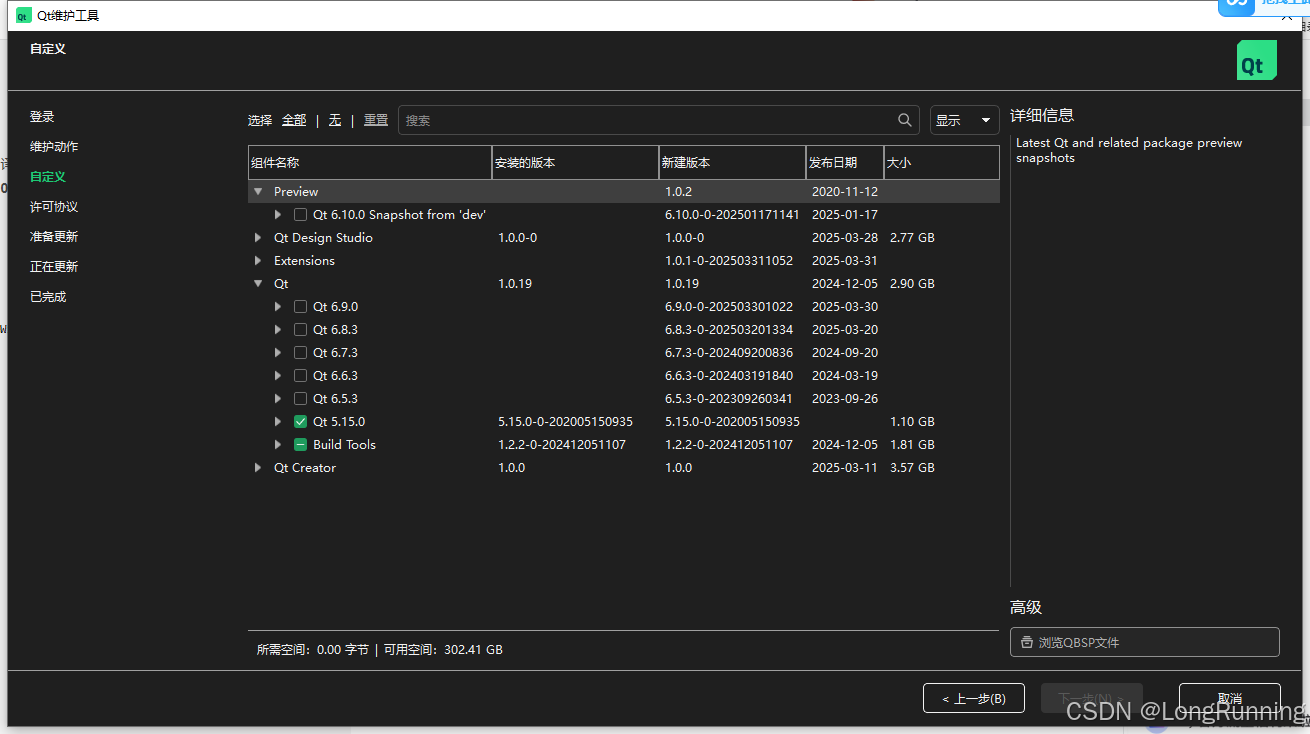
【随手笔记】QT避坑一(串口readyRead信号不产生)
问题描述: 使用QT5.15.2版本 测试串口readyRead绑定槽函数,接收到数据后 不能触发 试了很多网友的程序,他们的发布版本可以,但是源码我编译后就不能触发,判断不是代码的问题 看到有人提到QT版本的问题,于…...

基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案
基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案 一、架构设计 分层架构: 订阅管理层(Spring Boot)消息分发层(RabbitMQ Cluster)推送执行层(Spring Cloud Stream)数据存储层(Redis + MySQL)核心组件: +-------------------+ +-------------------+ …...

5.11 GitHub API调试五大高频坑:从JSON异常到异步阻塞的实战避坑指南
GitHub API调试五大高频坑:从JSON异常到异步阻塞的实战避坑指南 关键词:GitHub API 调试、JSON 解析异常、提示工程优化、异步任务阻塞、数据清洗策略 5.5 测试与调试:调试常见问题 问题1:GitHub API 调用异常 现象: requests.exceptions.HTTPError: 403 Client Error…...

反序列化漏洞介绍与挖掘指南
目录 反序列化漏洞介绍与挖掘指南 一、漏洞核心原理与危害 二、漏洞成因与常见场景 1. 漏洞根源 2. 高危场景 三、漏洞挖掘方法论 1. 静态分析 2. 动态测试 3. 利用链构造 四、防御与修复策略 1. 代码层防护 2. 架构优化 3. 运维实践 五、工具与资源推荐 总结 反…...
【产品】ToB产品需求分析
需求分析流程 合格产品经理 帮助用户、引导用户、分析需求、判断需求、设计方案 不能苛求用户提出合理、严谨的需求,这不是用户的责任和义务,而应该通过自己的专业能力来完成需求的采集工作 #mermaid-svg-ASu8vocank48X6FI {font-family:"trebuche…...
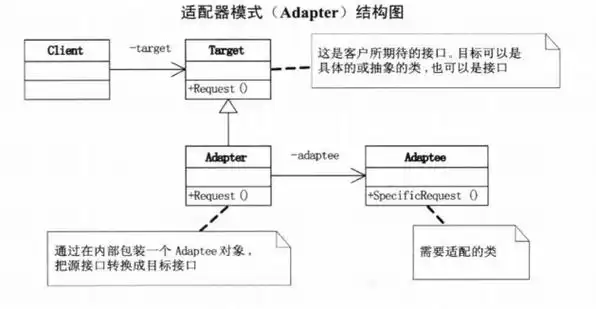
驱动开发硬核特训 · Day 10 (理论上篇):设备模型 ≈ 运行时的适配器机制
🔍 B站相应的视屏教程: 📌 内核:博文视频 - 总线驱动模型实战全解析 敬请关注,记得标为原始粉丝。 在 Linux 驱动开发中,设备模型(Device Model)是理解驱动架构的核心。而从软件工程…...

AWS服务器 磁盘空间升级到100G后,怎么使其生效?
在AWS(Amazon Web Services)上扩展EBS(Elastic Block Store)卷的大小后,服务器操作系统并不会自动识别新增的空间。要使操作系统识别并使用新增的磁盘空间,您需要进行一些额外的步骤。以下是详细的指导和说…...
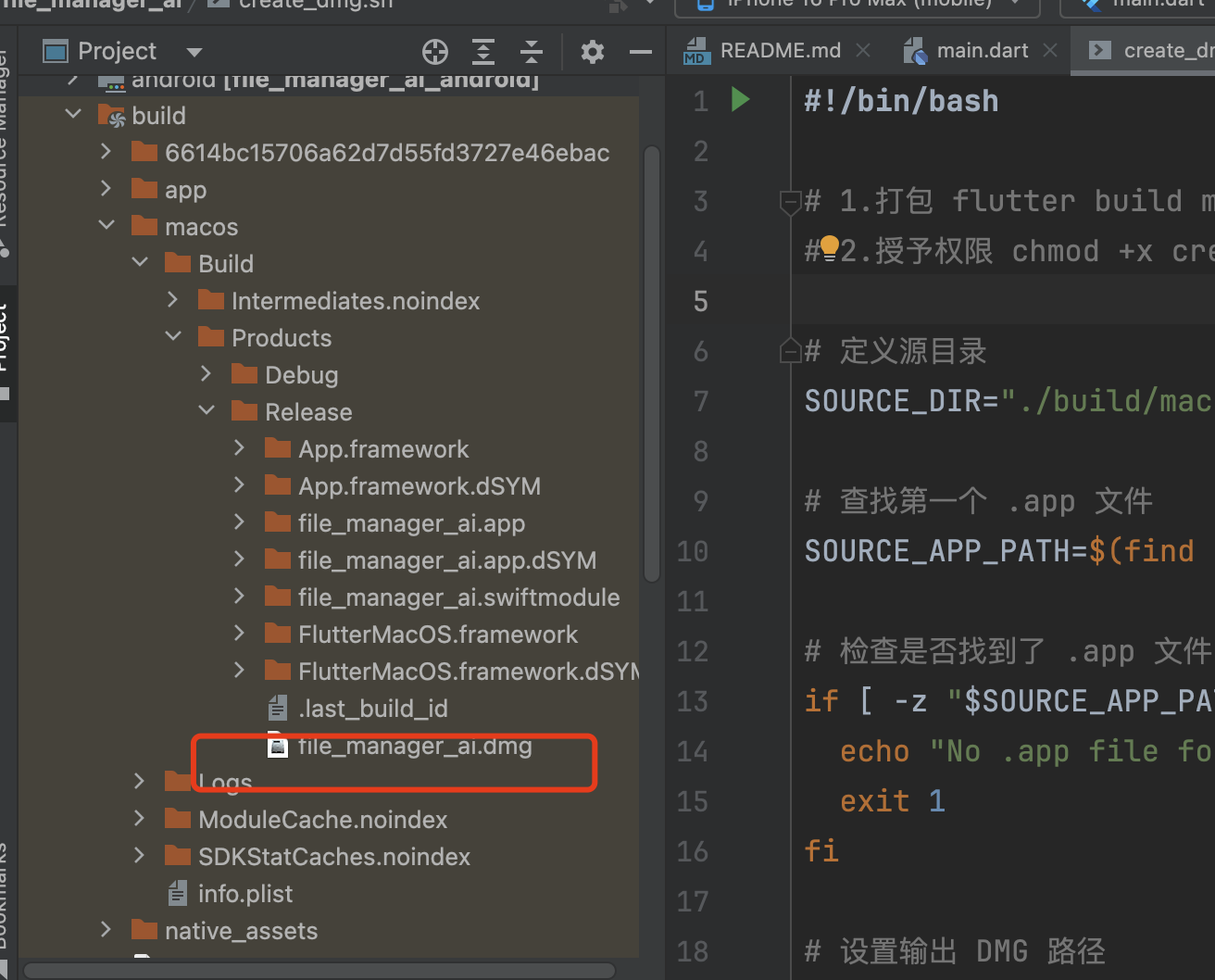
flutter 打包mac程序 dmg教程
✅ 前提条件 ✅ 你已经在 macOS 上安装了 Android Studio Flutter SDK。 ✅ Flutter 支持 macOS 构建。 运行下面命令确认是否支持: Plain Text bash 复制编辑 flutter doctor ---## 🧱 第一步:启用 macOS 支持如果是新项目,…...
【数据结构与算法】——堆(补充)
前言 上一篇文章讲解了堆的概念和堆排序,本文是对堆的内容补充 主要包括:堆排序的时间复杂度、TOP 这里写目录标题 前言正文堆排序的时间复杂度TOP-K 正文 堆排序的时间复杂度 前文提到,利用堆的思想完成的堆排序的代码如下(包…...
atypica.AI:用「语言模型」为「主观世界」建模
人们不是在处理概率,而是在处理故事。 —— 丹尼尔卡尼曼 People dont choose between things, they choose between descriptions of things. —— Daniel Kahneman 商业研究是一门理解人类决策的学问。人并不只是根据纯粹理性做决策,而是受到叙事、情…...
LLaMA-Factory双卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域
unsloth单卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域后,跑通一下多卡微调。 1,准备2卡RTX 4090 2,准备数据集 医学领域 pip install -U huggingface_hub export HF_ENDPOINThttps://hf-mirror.com huggingface-cli download --resum…...

【WPF】自定义控件:ShellEditControl-同列单元格编辑支持文本框、下拉框和弹窗
需要实现表格同一列,单元格可以使用文本框直接输入编辑、下拉框选择和弹窗,文本框只能输入数字,弹窗中的数据是若干位的二进制值。 本文提供了两种实现单元格编辑状态下,不同编辑控件的方法: 1、DataTrigger控制控件的…...
)
21天Python计划:零障碍学语法(更新完毕)
目录 序号标题链接day1Python下载和开发工具介绍https://blog.csdn.net/XiaoRungen/article/details/146583769?spm1001.2014.3001.5501day2数据类型、字符编码、文件处理https://blog.csdn.net/XiaoRungen/article/details/146603325?spm1011.2415.3001.5331day3基础语法与…...