大数据(7.1)Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优
目录
- 一、实时数据洪流下的技术突围
- 1.1 行业需求演进曲线
- 1.2 传统方案的技术瓶颈
- 二、Kafka实时架构设计精要
- 2.1 生产者核心参数矩阵
- 2.1.1 分区策略选择指南
- 2.2 消费者组智能负载均衡
- 三、实时数据管道实战案例
- 3.1 电商大促实时看板
- 3.2 工业物联网预测性维护
- 四、生产环境性能调优
- 4.1 集群部署黄金法则
- 4.2 JVM参数优化模板
- 4.3 监控指标体系
- 五、容灾与安全加固
- 5.1 跨地域数据同步
- 六、演进趋势与展望
- 大数据相关文章(推荐)
一、实时数据洪流下的技术突围
1.1 行业需求演进曲线
2023年全球实时数据处理市场规模突破$58.6亿(数据来源:Gartner),各行业对实时数据的需求呈现指数级增长:
- 金融交易:高频交易系统要求<5ms端到端延迟
- 智能物联:车联网场景每秒处理10万+传感器事件
- 直播电商:实时推荐系统需要秒级更新用户画像
1.2 传统方案的技术瓶颈
二、Kafka实时架构设计精要
2.1 生产者核心参数矩阵
// 高性能生产者配置模板
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
props.put("acks", "all"); // 确保所有副本确认
props.put("compression.type", "lz4"); // 压缩效率比Snappy高20%
props.put("linger.ms", 5); // 微批次优化
props.put("batch.size", 16384); // 16KB批处理
props.put("max.in.flight.requests.per.connection", 5); // 并行吞吐优化2.1.1 分区策略选择指南
| 策略类型 | 适用场景 | 吞吐量 |
|---|---|---|
| 哈希分区 | 金融交易订单 | 150k msg/s |
| 轮询分区 | IoT传感器数据 | 300k msg/s |
| 自定义分区 | 地理位置敏感型数据 | 200k msg/s |
2.2 消费者组智能负载均衡
# 消费端容错处理示例(confluent-kafka)
consumer = Consumer({'bootstrap.servers': 'kafka-cluster:9092','group.id': 'real-time-group','auto.offset.reset': 'earliest','enable.auto.commit': False,'isolation.level': 'read_committed'
})try:while True:msg = consumer.poll(1.0)if msg is None: continueif msg.error():handle_error(msg.error())continueprocess_message(msg.value())consumer.commit(msg)
except Exception as e:send_alert(f"Consumer failure: {str(e)}")
finally:consumer.close()三、实时数据管道实战案例
3.1 电商大促实时看板
业务需求:双11期间实时追踪:
- 每秒订单量波动
- 地域销量分布
- 爆款商品TOP10
技术方案:
// 使用Kafka Streams处理
KStream<String, Order> stream = builder.stream("orders");
stream.mapValues(order -> {order.setGeoHash(GeoUtils.encode(order.getLat(), order.getLng()));return order;
}).groupBy((k, v) -> v.getGeoHash()).windowedBy(TimeWindows.of(Duration.ofSeconds(5))).count().toStream().to("geo-sales", Produced.with(WindowedSerdes.geoWindowedSerde(), Serdes.Long()));// Flink实时计算TopN
DataStream<Order> orders = env.addSource(new FlinkKafkaConsumer<>("orders", ...));
orders.keyBy("itemId").timeWindow(Time.seconds(10)).aggregate(new CountAggregator(), new WindowResultFunction()).keyBy("windowEnd").process(new TopNHotItems(5)).addSink(new KafkaSink<>("hot-items"));3.2 工业物联网预测性维护
设备规模:5万台机床,每秒产生200万条振动数据
架构优化:
- 数据压缩:使用AVRO二进制格式(比JSON节省65%空间)
- 分区策略:按工厂编号进行哈希分区(保证同工厂数据局部性)
- 流处理优化:
# 调整Kafka Streams配置
streamsConfig.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 16);
streamsConfig.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024L);四、生产环境性能调优
4.1 集群部署黄金法则
| 资源类型 | 配置标准 | 示例规格 |
|---|---|---|
| 磁盘 | 4×HDD RAID10 + 1×NVMe | 10TB×4 + 2TB |
| 网络 | 25Gbps RDMA网卡 | Mellanox CX-6 |
| CPU | 物理核心数≥16 | Intel Xeon 8358 |
4.2 JVM参数优化模板
-Xmx64g
-Xms64g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:InitiatingHeapOccupancyPercent=45
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=1024m4.3 监控指标体系
关键Dashboard配置:
- 生产者吞吐量:records-sent-rate > 100k/s
- 消费者延迟:consumer-lag > 1000触发自动扩容
- Broker负载:network-io > 80%持续10分钟报警
五、容灾与安全加固
5.1 跨地域数据同步
# 使用MirrorMaker2配置
bin/connect-mirror-maker.sh connect-mirror-maker.properties \
--clusters primary secondary \
--topics ".*" \
--groups ".*" \
--emit.checkpoints.interval.seconds 305.2 安全防护体系
- 传输加密:SSL/TLS + SASL/SCRAM认证
- 权限控制:
bin/kafka-acls.sh --add \
--allow-principal User:flink \
--operation READ \
--topic realtime-orders- 审计日志:启用kafka-request.log记录所有操作
六、演进趋势与展望
- Serverless架构:基于Knative实现自动弹性伸缩
- 智能数据路由:集成AI模型预测最佳分区策略
- 边缘计算集成:Kafka Edge支持5G环境下的低延迟处理
大数据相关文章(推荐)
-
架构搭建:
中小型企业大数据平台全栈搭建:Hive+HDFS+YARN+Hue+ZooKeeper+MySQL+Sqoop+Azkaban 保姆级配置指南 -
大数据入门:大数据(1)大数据入门万字指南:从核心概念到实战案例解析
-
Yarn资源调度文章参考:大数据(3)YARN资源调度全解:从核心原理到万亿级集群的实战调优
-
Hive函数汇总:Hive函数大全:从核心内置函数到自定义UDF实战指南(附详细案例与总结)
-
Hive函数高阶:累积求和和滑动求和:Hive(15)中使用sum() over()实现累积求和和滑动求和
-
Hive面向主题性、集成性、非易失性:大数据(4)Hive数仓三大核心特性解剖:面向主题性、集成性、非易失性如何重塑企业数据价值?
-
Hive核心操作:大数据(4.2)Hive核心操作实战指南:表创建、数据加载与分区/分桶设计深度解析
-
Hive基础查询:大数据(4.3)Hive基础查询完全指南:从SELECT到复杂查询的10大核心技巧
-
Hive多表JOIN:大数据(4.4)Hive多表JOIN终极指南:7大关联类型与性能优化实战解析
-
Hive数据仓库分层架构实战:Hive数据仓库分层架构实战:4层黄金模型×6大业务场景×万亿级数据优化方案
-
Hive执行引擎选型:大数据(4.6)Hive执行引擎选型终极指南:MapReduce/Tez/Spark性能实测×万亿级数据资源配置公式
-
Hive查询优化:大数据(4.7)Hive查询优化四大黑科技:分区裁剪×谓词下推×列式存储×慢查询分析,性能提升600%实战手册
-
Spark安装部署:大数据(5)Spark部署核弹级避坑指南:从高并发集群调优到源码级安全加固(附万亿级日志分析实战+智能运维巡检系统)
-
Spark RDD编程:大数据(5.1)Spark RDD编程核弹级指南:从血泪踩坑到性能碾压(附万亿级数据处理优化策略+容错机制源码解析)
-
Spark SQL:大数据(5.2)Spark SQL核弹级优化实战:从执行计划血案到万亿级秒级响应(附企业级Hive迁移方案+Catalyst源码级调优手册)
-
Spark Streaming:大数据(5.3)Spark Streaming核弹级调优:从数据丢失血案到万亿级实时处理(附毫秒级延迟调优手册+容灾演练全流程)
-
Kafka核心原理揭秘:大数据(7)Kafka核心原理揭秘:从入门到企业级实战应用
相关文章:
Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优)
大数据(7.1)Kafka实时数据采集与分发的企业级实践:从架构设计到性能调优
目录 一、实时数据洪流下的技术突围1.1 行业需求演进曲线1.2 传统方案的技术瓶颈 二、Kafka实时架构设计精要2.1 生产者核心参数矩阵2.1.1 分区策略选择指南 2.2 消费者组智能负载均衡 三、实时数据管道实战案例3.1 电商大促实时看板3.2 工业物联网预测性维护 四、生产环境性能…...

UniApp 实现兼容 H5 和小程序的拖拽排序组件
如何使用 UniApp 实现一个兼容 H5 和小程序的 九宫格拖拽排序组件,实现思路和关键步骤。 一、完整效果图示例 H5端 小程序端 git地址 二、实现目标 支持拖动菜单项改变顺序拖拽过程实时预览移动位置拖拽松开后自动吸附回网格兼容 H5 和小程序平台 三、功能…...

C,C++,C#
C、C 和 C# 是三种不同的编程语言,虽然它们名称相似,但在设计目标、语法特性、运行环境和应用场景上有显著区别。以下是它们的核心区别: 1. 设计目标和历史 语言诞生时间设计目标特点C1972(贝尔实验室)面向过程&#…...

MySQL | 三大日志文件
Undo Log(回滚日志) 实现原理与分类 原理:Undo Log 记录的是数据修改前的旧值,通过这些旧值可以将数据恢复到修改之前的状态。它采用的是逻辑日志,即记录的是如何撤销操作,而不是物理数据的实际值。 分类…...
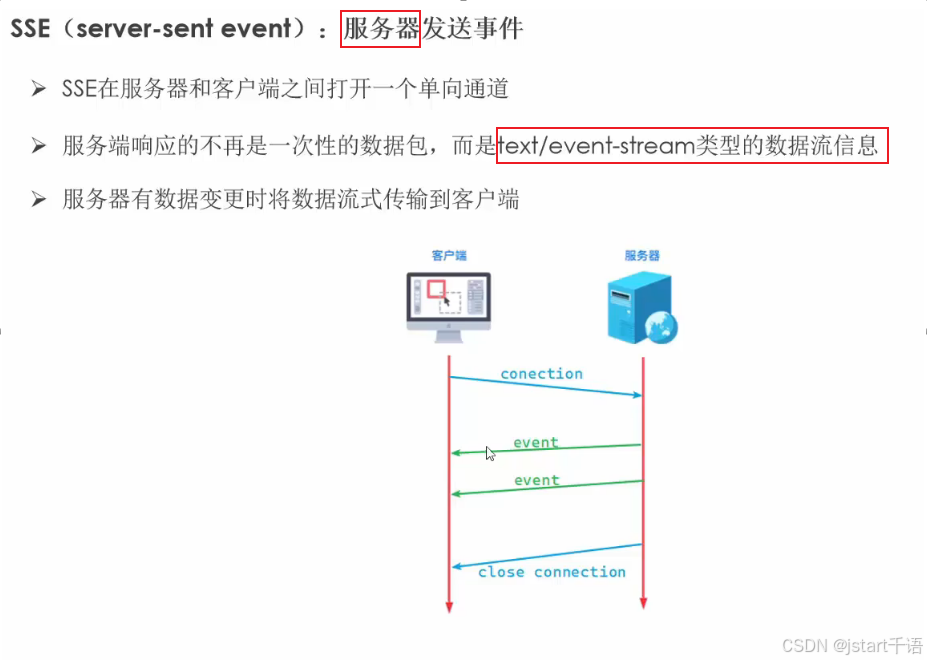
【网络协议】WebSocket讲解
目录 webSocket简介 连接原理解析: 客户端API 服务端API(java) 实战案例 (1)引入依赖 (2)编写服务端逻辑 (3)注册配置类 (4)前端连接 WebSocket 示例…...
啥是Spring,有什么用,既然收费,如何免费创建SpringBoot项目,依赖下载不下来的解决方法,解决99%问题!
一、啥是Spring,为啥选择它 我们平常说的Spring指的是Spring全家桶,我们为什么要选择Spring,看看官方的话: 意思就是:用这个东西,又快又好又安全,反正就是好处全占了,所以我们选择它…...

一天时间,我用AI(deepseek)做了一个配色网站
前言 最近在开发颜色搭配主题的相关H5和小程序,想到需要补充一个web网站,因此有了这篇文章。 一、确定需求 向AI要答案之前,一定要清楚自己想要做什么。如果你没有100%了解自己的需求,可以先让AI帮你理清逻辑和思路,…...

Day14:关于MySQL的索引——创、查、删
前言:先创建一个练习的数据库和数据 1.创建数据库并创建数据表的基本结构 -- 创建练习数据库 CREATE DATABASE index_practice; USE index_practice;-- 创建基础表(包含CREATE TABLE时创建索引) CREATE TABLE products (id INT PRIMARY KEY…...
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(二) 7. 实现条件WGAN-GP # 训练条件WGAN-GP def train_conditional_wgan_gp():# 用于记录损失d_losses []g_losses []# 用于记录生成样本的多样性(通过类别分…...

Spring - 13 ( 11000 字 Spring 入门级教程 )
一: Spring AOP 备注:之前学习 Spring 学到 AOP 就去梳理之前学习的知识点了,后面因为各种原因导致 Spring AOP 的博客一直搁置。。。。。。下面开始正式的讲解。 学习完 Spring 的统一功能后,我们就进入了 Spring AOP 的学习。…...
Spring Cloud Alibaba微服务治理实战:Nacos+Sentinel深度解析
一、引言 在微服务架构中,服务发现、配置管理、流量控制是保障系统稳定性的核心问题。Spring Cloud Netflix 生态曾主导微服务解决方案,但其部分组件(如 Eureka、Hystrix)已进入维护模式。 Spring Cloud Alibaba 凭借 高性能、轻…...

设计模式之迭代器模式:遍历的艺术与实现
引言 迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供了一种顺序访问聚合对象中各个元素的方法,而又不暴露其底层实现。迭代器模式将遍历逻辑与聚合对象解耦,使得我们可以用统一的方式处理不同的集合结构。…...

红宝书第三十六讲:持续集成(CI)配置入门指南
红宝书第三十六讲:持续集成(CI)配置入门指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、什么是持续集成? 持续集成(CI)就像咖啡厅的…...

Java—HTML:3D形变
今天我要介绍的是在Java HTML中CSS的相关知识点内容之一:3D形变(3D变换)。该内容包含透视(属性:perspective),3D变换,3D变换函数以及案例演示, 接下来我将逐一介绍&…...

什么是音频预加重与去加重,预加重与去加重的原理是什么,在什么条件下会使用预加重与去加重?
音频预加重与去加重是音频处理中的两个重要概念,以下是对其原理及应用条件的详细介绍: 1、音频预加重与去加重的定义 预加重:在音频信号的发送端,对音频信号的高频部分进行提升,增加高频信号的幅度,使其在…...

免费下载 | 2025清华五道口:“十五五”金融规划研究白皮书
《2025清华五道口:“十五五”金融规划研究白皮书》的核心内容主要包括以下几个方面: 一、五年金融规划的重要功能与作用 凝聚共识:五年金融规划是国家金融发展的前瞻性谋划和战略性安排,通过广泛听取社会各界意见,凝…...

微信小程序实战案例 - 餐馆点餐系统 阶段 4 - 订单列表 状态
✅ 阶段 4 – 订单列表 & 状态 目标 展示用户「我的订单」列表支持状态筛选(全部 / 待处理 / 已完成)支持分页加载和实时刷新使用原生组件编写 ✅ 1. 页面结构:文件结构 pages/orders/├─ index.json├─ index.wxml├─ index.js└─…...

如何为C++实习做准备?
博主介绍:程序喵大人 35- 资深C/C/Rust/Android/iOS客户端开发10年大厂工作经验嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手《C20高级编程》《C23高级编程》等多本书籍著译者更多原创精品文章,首发gzh,见文末👇…...

【docker】--部署--安装docker教程
文章目录 环境方法一:脚本安装方法二:手动安装**步骤 1:卸载旧版本(如有)****步骤 2:更新系统并安装依赖****步骤 3:添加 Docker 官方 GPG 密钥****步骤 4:设置 Docker 仓库****步骤…...

【开发记录】服务外包大赛记录
参加服务外包大赛的A07赛道中,最近因为频繁的DEBUG,心态爆炸 记录错误 以防止再次出现错误浪费时间。。。 2025.4.13 项目在上传图片之后 会自动刷新 没有等待后端返回 Network中的fetch /upload显示canceled. 然而这是使用了VS的live Server插件才这样&…...
Cesium.js(6):Cesium相机系统
Camera表示观察场景的视角。通过操作摄像机,可以控制视图的位置、方向和角度。 帮助文档:Camera - Cesium Documentation 1 setView setView 方法允许你指定相机的目标位置和姿态。你可以通过 Cartesian3 对象来指定目标位置,并通过 orien…...
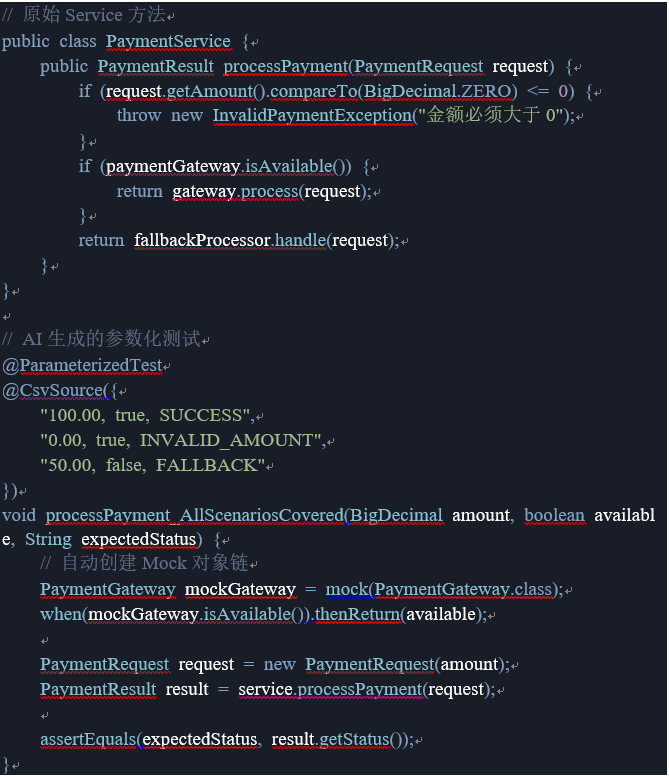
AI 代码生成工具如何突破 Java 单元测试效能天花板?
一、传统单元测试的四大痛点 时间黑洞:根据 JetBrains 调研,Java 开发者平均花费 35% 时间编写测试代码覆盖盲区:手工测试覆盖率普遍低于 60%(Jacoco 全球统计数据)维护困境:业务代码变更导致 38% 的测试用…...

AF3 ProteinDataset类的_patch方法解读
AlphaFold3 protein_dataset模块 ProteinDataset 类 _patch 方法的主要目的是围绕锚点残基(anchor residues)裁剪蛋白质数据,提取一个局部补丁(patch)作为模型输入。 源代码: def _patch(self, data):"""Cut the data around the anchor residues."…...

客户端负载均衡与服务器端负载均衡详解
客户端负载均衡与服务器端负载均衡详解 1. 客户端负载均衡(Client-Side Load Balancing) 核心概念 定义:负载均衡逻辑在客户端实现,客户端主动选择目标服务实例。典型场景:微服务内部调用(如Spring Cloud…...

vue-element-plus-admin的安装
文档链接:开始 | vue-element-plus-admin 之前尝试按照官方文档来安装,运行npm run dev命令却不能正常打开访问浏览器,换一个方式 首先在目录下打开命令窗口 1、克隆项目 从 GitHub 获取代码 # clone 代码 git clone https://github.com…...
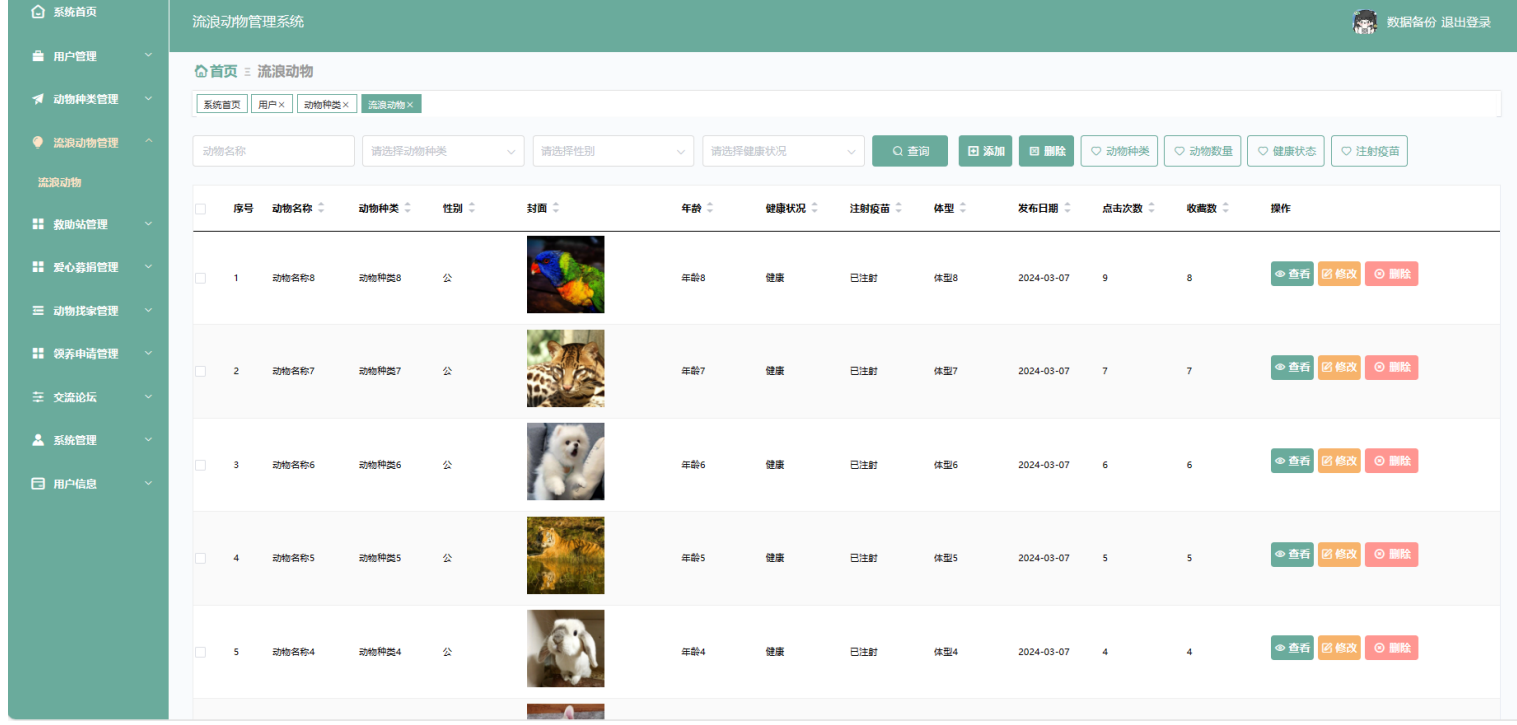
基于springboot的“流浪动物管理系统”的设计与实现(源码+数据库+文档+PPT)
基于springboot的“流浪动物管理系统”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:springboot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 局部E-R图 系统首页界面 系统…...

爬虫解决debbugger之替换文件
鼠鼠上次做一个网站的时候,遇到的debbugger问题,是通过打断点然后编辑断点解决的,现在鼠鼠又学会了一个新的技能 首先需要大家下载一个reres的插件,这里最好用谷歌浏览器 先请大家看看案例国家水质自动综合监管平台 这里我们只…...
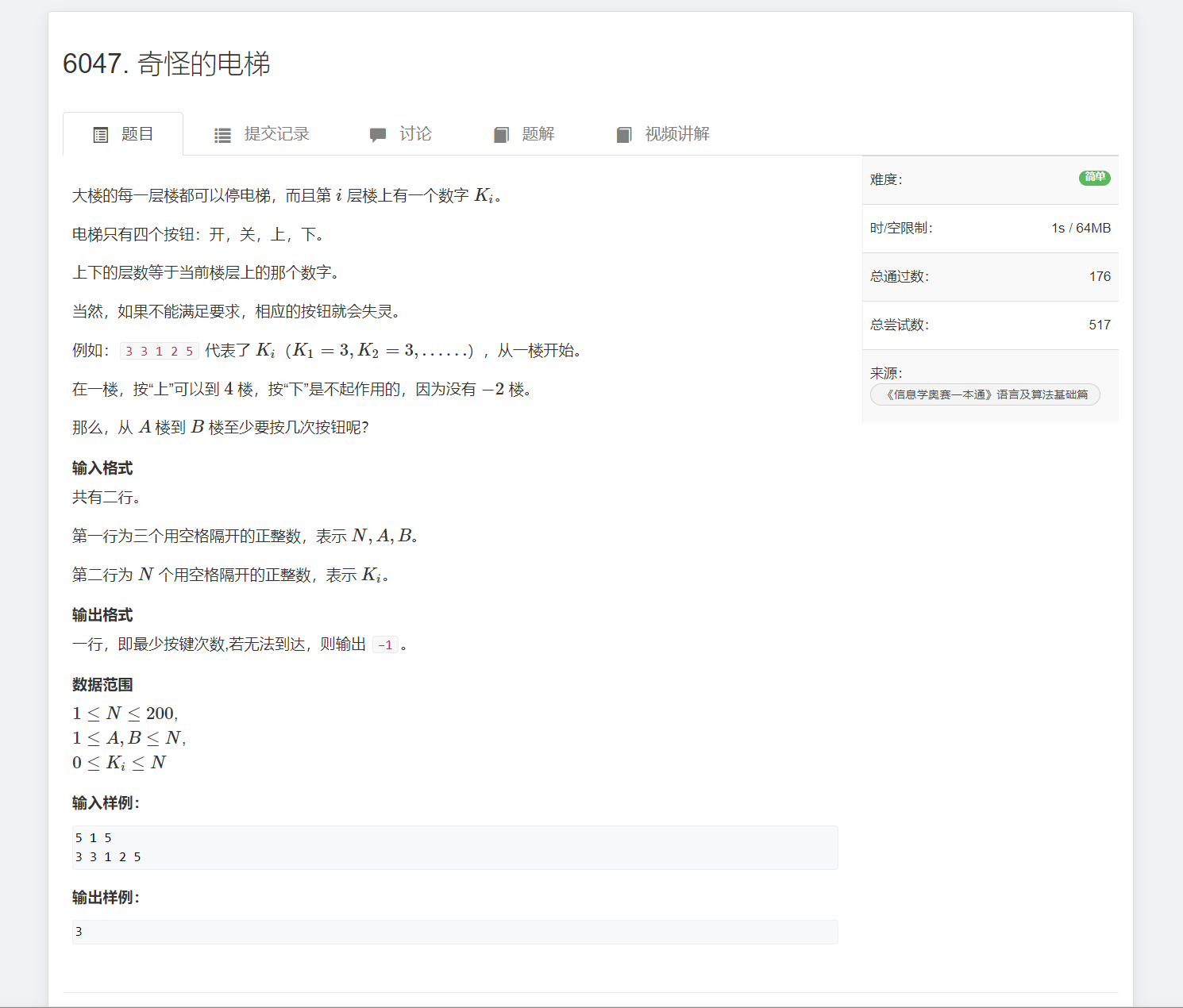
奇怪的电梯——DFS算法
题目 题解 每到一层楼都面临了两种选择:上还是下?因此我们可以定义一个布尔数组用来记录选择。 终止条件其实也明显,要么到了B层,要么没有找到楼层。 如果找到了,选择一个步骤少的方式。又怎么表示没有找到楼层&…...

Open GL ES-> 工厂设计模式包装 SurfaceView + 自定义EGL的OpenGL ES 渲染框架
XML文件 <?xml version"1.0" encoding"utf-8"?> <com.example.myapplication.EGLSurfaceView xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"…...

2.4goweb加解密和jwt
MD5的基本实现 1. 标准库调用 Go语言通过crypto/md5包提供MD5算法的实现。核心步骤包括: 创建哈希对象:使用md5.New()生成一个实现了hash.Hash接口的实例。写入数据:通过Write()方法或io.WriteString()将数据写入…...