自然语言处理Hugging Face Transformers
Hugging Face Transformers 是一个基于 PyTorch 和 TensorFlow 的开源库,专注于 最先进的自然语言处理(NLP)模型,如 BERT、GPT、RoBERTa、T5 等。它提供了 预训练模型、微调工具和推理 API,广泛应用于文本分类、机器翻译、问答系统等任务。
1. Hugging Face Transformers 的特点
✅ 丰富的预训练模型:支持 500+ 种模型(如 BERT、GPT-3、Llama 2)。
✅ 跨框架支持:兼容 PyTorch、TensorFlow、JAX。
✅ 易用 API:提供 pipeline,几行代码即可实现 NLP 任务。
✅ 社区支持:Hugging Face Hub 提供 数千个公开模型和数据集。
✅ 支持自定义训练:可微调(Fine-tune)模型以适应特定任务。
2. 主要功能
(1) 开箱即用的 NLP 任务
-
文本分类(情感分析、垃圾邮件检测)
-
命名实体识别(NER)
-
问答系统(QA)
-
文本生成(如 GPT-3、Llama 2)
-
机器翻译
-
摘要生成
(2) 核心组件
-
pipeline:快速调用预训练模型进行推理。 -
AutoModel/AutoTokenizer:自动加载模型和分词器。 -
Trainer:简化模型训练和微调流程。 -
Datasets:高效加载和处理数据集。
3. 安装与基本使用
(1) 安装
pip install transformers(可选)安装 PyTorch / TensorFlow:
pip install torch # PyTorch
pip install tensorflow # TensorFlow注:此处我尝试了安装gpu版本的,因为我电脑安装的cuda版本较低,所以试了几个版本的tensorflow-gpu版本都和transformer版本不匹配。
(2) 使用 pipeline 快速体验
from transformers import pipeline
# 情感分析 将下载的模型存于multilingual-sentiment-analysis路径下
classifier=pipeline("text-classification",model="./multilingual-sentiment-analysis")
print(classifier("我很骄傲"))
# 文本生成
# 指定本地路径加载模型,将下载的模型存于gpt2路径下
generator = pipeline("text-generation",model="./gpt2")# 本地模型路径
result=generator("AI will change",max_length=50)
print(result[0]['generated_text'])因为模型在线下载会比较麻烦,建议离线下载好,放到指定的文件夹下,方便调用
通过网盘分享的文件:gpt2
链接: https://pan.baidu.com/s/1Z9MZQKyOQrLlvn_jh3bGOg 提取码: 8ihe
通过网盘分享的文件:multilingual-sentiment-analysis
链接: https://pan.baidu.com/s/16e6Jvo44vetMmTxrQcZZqQ 提取码: tv4e
(3) 加载自定义模型
from transformers import AutoTokenizer, AutoModelForSequenceClassification# 加载模型和分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 处理输入
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
print(outputs)4. 常用预训练模型
| 模型 | 用途 | 示例模型 ID |
|---|---|---|
| BERT | 文本分类、NER、问答 | bert-base-uncased |
| GPT-2 | 文本生成 | gpt2 |
| T5 | 文本摘要、翻译 | t5-small |
| RoBERTa | 更强大的 BERT 变体 | roberta-base |
| Llama 2 | Meta 开源的大语言模型 | meta-llama/Llama-2-7b |
5. 与 spaCy 的比较
| 特性 | Hugging Face Transformers | spaCy |
|---|---|---|
| 模型类型 | 深度学习(BERT、GPT) | 传统统计模型 + 部分 DL |
| 速度 | 较慢(依赖 GPU 加速) | ⚡ 极快(CPU 友好) |
| 适用任务 | 复杂 NLP(翻译、生成) | 基础 NLP(分词、NER) |
| 自定义训练 | ✅ 支持(微调 LLM) | ✅ 支持(但规模较小) |
| 易用性 | 中等(需了解深度学习) | 👍 非常简单 |
👉 推荐选择:
-
如果需要 最先进的 NLP(如 ChatGPT 类应用) → Hugging Face。
-
如果需要 快速处理结构化文本(如实体提取) → spaCy。
6. 实战案例
(1) 聊天机器人(使用 GPT-2)
from transformers import pipeline
chatbot = pipeline("text-generation", model="./gpt2")
response = chatbot("What is the future of AI?", max_length=50)
print(response[0]['generated_text'])(2) 自定义微调(Fine-tuning)
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=8,num_train_epochs=3,
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)
trainer.train()(3)情感分析
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "./multilingual-sentiment-analysis"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)def predict_sentiment(texts):inputs = tokenizer(texts, return_tensors="pt", truncation=True, padding=True, max_length=512)with torch.no_grad():outputs = model(**inputs)probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)sentiment_map = {0: "Very Negative", 1: "Negative", 2: "Neutral", 3: "Positive", 4: "Very Positive"}return [sentiment_map[p] for p in torch.argmax(probabilities, dim=-1).tolist()]texts = [# English"I absolutely love the new design of this app!", "The customer service was disappointing.", "The weather is fine, nothing special.",# Chinese"这家餐厅的菜味道非常棒!", "我对他的回答很失望。", "天气今天一般。",# Spanish"¡Me encanta cómo quedó la decoración!", "El servicio fue terrible y muy lento.", "El libro estuvo más o menos.",# Arabic"الخدمة في هذا الفندق رائعة جدًا!", "لم يعجبني الطعام في هذا المطعم.", "كانت الرحلة عادية。",# Ukrainian"Мені дуже сподобалася ця вистава!", "Обслуговування було жахливим.", "Книга була посередньою。",# Hindi"यह जगह सच में अद्भुत है!", "यह अनुभव बहुत खराब था।", "फिल्म ठीक-ठाक थी।",# Bengali"এখানকার পরিবেশ অসাধারণ!", "সেবার মান একেবারেই খারাপ।", "খাবারটা মোটামুটি ছিল।",# Portuguese"Este livro é fantástico! Eu aprendi muitas coisas novas e inspiradoras.","Não gostei do produto, veio quebrado.", "O filme foi ok, nada de especial.",# Japanese"このレストランの料理は本当に美味しいです!", "このホテルのサービスはがっかりしました。", "天気はまあまあです。",# Russian"Я в восторге от этого нового гаджета!", "Этот сервис оставил у меня только разочарование.", "Встреча была обычной, ничего особенного.",# French"J'adore ce restaurant, c'est excellent !", "L'attente était trop longue et frustrante.", "Le film était moyen, sans plus.",# Turkish"Bu otelin manzarasına bayıldım!", "Ürün tam bir hayal kırıklığıydı.", "Konser fena değildi, ortalamaydı.",# Italian"Adoro questo posto, è fantastico!", "Il servizio clienti è stato pessimo.", "La cena era nella media.",# Polish"Uwielbiam tę restaurację, jedzenie jest świetne!", "Obsługa klienta była rozczarowująca.", "Pogoda jest w porządku, nic szczególnego.",# Tagalog"Ang ganda ng lugar na ito, sobrang aliwalas!", "Hindi maganda ang serbisyo nila dito.", "Maayos lang ang palabas, walang espesyal.",# Dutch"Ik ben echt blij met mijn nieuwe aankoop!", "De klantenservice was echt slecht.", "De presentatie was gewoon oké, niet bijzonder.",# Malay"Saya suka makanan di sini, sangat sedap!", "Pengalaman ini sangat mengecewakan.", "Hari ini cuacanya biasa sahaja.",# Korean"이 가게의 케이크는 정말 맛있어요!", "서비스가 너무 별로였어요.", "날씨가 그저 그렇네요.",# Swiss German"Ich find dä Service i de Beiz mega guet!", "Däs Esä het mir nöd gfalle.", "D Wätter hüt isch so naja."
]for text, sentiment in zip(texts, predict_sentiment(texts)):print(f"Text: {text}\nSentiment: {sentiment}\n")7. 学习资源
-
官方文档: huggingface.co/docs/transformers
-
Hugging Face 课程: huggingface.co/course(免费 NLP 课程)
-
模型库: huggingface.co/models
总结
Hugging Face Transformers 是 当今最强大的 NLP 库之一,适用于:
-
前沿 AI 研究(如 LLM、ChatGPT 类应用)
-
企业级 NLP 解决方案(如智能客服、自动摘要)
-
快速实验 SOTA 模型
🚀 推荐下一步:
-
尝试
pipeline()运行不同任务(如"text-generation")。 -
在 Hugging Face Hub 上探索开源模型(如
bert-base-uncased)。 -
学习 微调(Fine-tuning) 以适应自定义数据集。
相关文章:
自然语言处理Hugging Face Transformers
Hugging Face Transformers 是一个基于 PyTorch 和 TensorFlow 的开源库,专注于 最先进的自然语言处理(NLP)模型,如 BERT、GPT、RoBERTa、T5 等。它提供了 预训练模型、微调工具和推理 API,广泛应用于文本分类、机器翻…...

vue3+vite+ts使用daisyui/tailwindcss
vite创建vue3脚手架 npm init vitelatest myVue3 – --template vue cd .\myVue3\ npm i npm run dev 安装tailwindcss/daisyui 依赖安装 npm install -D tailwindcss postcss autoprefixer daisyui npx tailwindcss init -p 这条命令将生成postcss.config.js(因为加了…...

Android常见界面控件、程序活动单元Activity练习
第3章 Android常见界面控件、第4章程序活动单元Activity 一. 填空题 1. (填空题)Activity的启动模式包括standard、singleTop、singleTask和_________。 正确答案: (1) singleInstance 2. (填空题)启动一个新的Activity并且获取这个Activity的返回数据ÿ…...

大模型在直肠癌诊疗全流程预测及应用研究报告
目录 一、引言 1.1 研究背景与目的 1.2 国内外研究现状 1.3 研究方法与创新点 二、大模型预测直肠癌的原理与技术基础 2.1 大模型技术概述 2.2 用于直肠癌预测的数据来源 2.3 模型构建与训练过程 三、术前预测 3.1 肿瘤分期预测 3.1.1 基于影像组学的 T 分期预测模型…...
大联盟(特别版)双端互动平台完整套件分享:含多模块源码+本地部署环境
这是一套结构清晰、功能完整的互动平台组件,适合有开发经验的技术人员进行模块参考、结构研究或本地部署实验使用。 该平台覆盖前端展示、后端服务、移动端资源以及完整数据库,采用模块化架构,整体部署流程简单清晰,适合自研团队参…...

设计模式:迪米特法则 - 最少依赖,实现高内聚低耦合
一、迪米特法则简介 迪米特法则(Law of Demeter,简称 LoD),也称为“最少知识法则”,核心思想是:一个对象应当对其他对象有最少的了解,仅与直接相关的对象交互。通过减少对象之间的耦合度&#…...
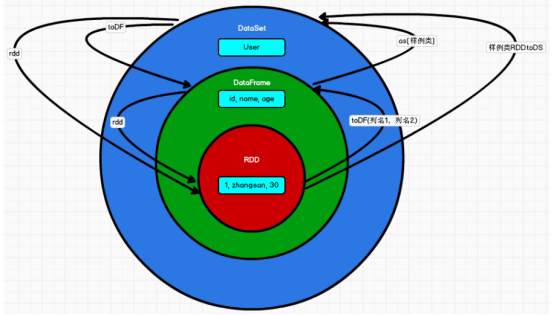
Spark-SQL
Spark-SQL 概述 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块 Shark 是伯克利实验室 Spark 生态环境的组件之一,是基于 Hive 所开发的工具,它修改了内存管理、物理计划、执行三个模块,并使之能运行在 Spark 引擎上…...
)
多任务响应2(Qt)
多任务响应2 扩展方案1. 设计思路2. 示例代码3. 说明 在多任务响应1的基础上,当任务响应比较复杂时,需要整合多个模块的信息。 扩展方案 利用【中介者模式】或【系统上下文】来整合多个模块的信息,并在命令对象中通过依赖注入(D…...

【MySQL】MVCC工作原理、事务隔离机制、undo log回滚日志、间隙锁
一、什么是MVCC? MVCC,即 Multiversion Concurrency Control(多版本并发控制),它是数据库实现并发控制的一种方式。 MVCC 的核心思想是: 为每个事务提供数据的“快照”版本,从而避免加锁&…...

无人机气动-结构耦合技术要点与难点
一、技术要点 1. 多学科耦合建模 气动载荷与结构响应的双向耦合:气动力(如升力、阻力、力矩)导致结构变形,而变形改变气动外形,进一步影响气流分布,形成闭环反馈。 建模方法: 高精度C…...

七大数据库全面对比:ClickHouse、ES、MySQL等特性、优缺点及使用场景
七大数据库全面对比:ClickHouse、ES、MySQL等特性、优缺点及使用场景 引言 在数字化时代,数据库的选择对于业务的成功至关重要。本文将通过表格形式,对ClickHouse、Elasticsearch(ES)、MySQL、SQL Server、MongoDB、HBase、Cassandra这七大数据库进行特性、优缺点及使用…...

element-ui plus 中 filter-method 函数多次触发问题解决
前情提要 点进这个文章的小伙伴,应该都是为了解决一个需求,把原本的前端过滤改为后端过滤,但是将filter-method修改为后端取数据后,发现其触发了很多次。博主也是在修改表格过滤时用到了这个坑,本篇文章为大家解决一下…...
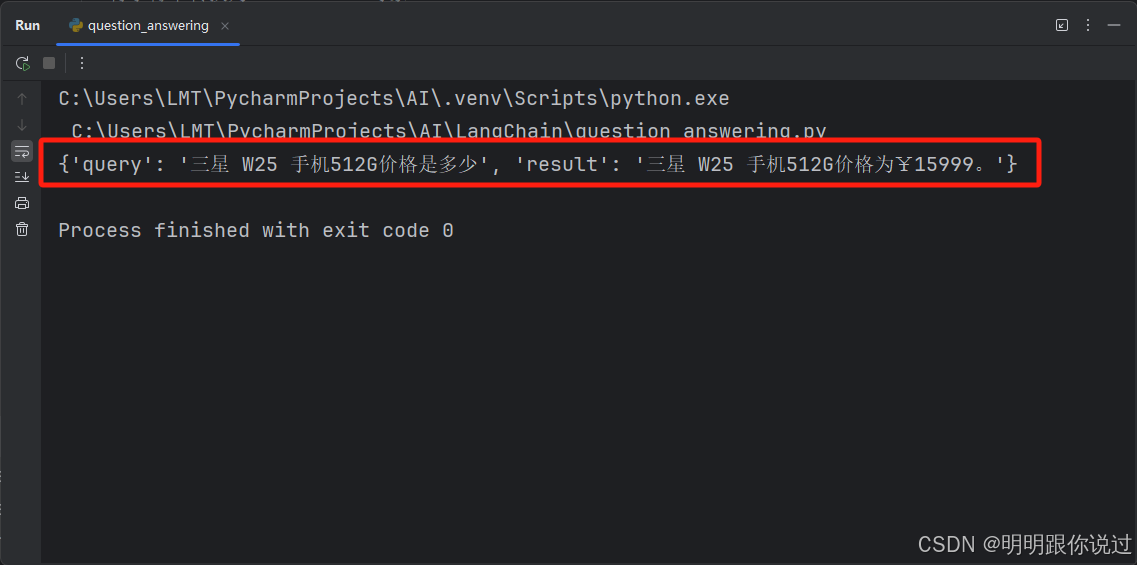
基于【Lang Chain】构建智能问答系统的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、LangChain在问答系统中的核心优…...

idea的快捷键使用以及相关设置
文章目录 快捷键常用设置 快捷键 快捷键作用ctrlshift/注释选中内容Ctrl /注释一行/** Enter文档注释ALT SHIFT ↑, ALT SHIFT ↓上下移动当前代码Ctrl ALT L格式化代码Ctrl X删除所在行并复制该行Ctrl D复制当前行数据到下一行main/psvm快速生成入口程序soutSystem.o…...
TestHubo安装及入门指南
TestHubo是一款开源免费的测试管理工具,提供一站式测试解决方案,涵盖功能测试、接口测试、性能测试以及 Web 和 App 测试等多个维度。TestHubo 整合了全面的测试能力,使团队可以在一个平台内完成所有测试需求。本文将介绍如何快速安装配置及入…...
react tailwindcss最简单的开始
参考教程: Install Tailwind CSS with Vite - TailwindCSS中文文档 | TailwindCSS中文网https://www.tailwindcss.cn/docs/guides/vite操作过程: Microsoft Windows [版本 10.0.26100.3476] (c) Microsoft Corporation。保留所有权利。D:\gitee\tailwi…...

openGauss新特性 | 自动参数化执行计划缓存
目录 自动化参数执行计划缓存简介 SQL参数化及约束条件 一般常量参数化示例 总结 自动化参数执行计划缓存简介 执行计划缓存用于减少执行计划的生成次数。openGauss数据库会缓存之前生成的执行计划,以便在下次执行该SQL时直接使用,可…...
3、组件:魔法傀儡的诞生——React 19 组件化开发全解析
一、开篇:魔法傀儡的觉醒 "每个React组件都像一具魔法傀儡,"邓布利多校长挥动魔杖,空中浮现出闪烁的代码字符,"它们能自主思考、协同工作,甚至能跨越时空(服务器与客户端)执行任…...

使用Python实现矢量路径的压缩、解压与可视化
引言 在图形设计和Web开发中,矢量路径数据的高效存储与传输至关重要。本文将通过一个Python示例,展示如何将复杂的矢量路径命令序列压缩为JSON格式,再将其解压还原,并通过matplotlib进行可视化。这一过程可应用于字体设计、矢量图…...
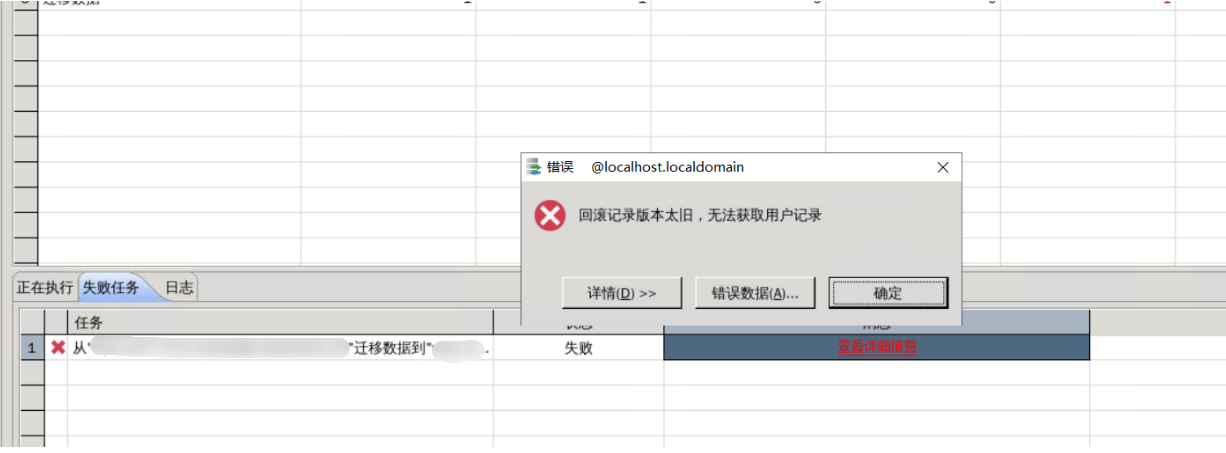
达梦数据库迁移问题总结
更多技术博客,请关注微信公众号:运维之美 问题一、DTS工具运行乱码 开启图形化 [rootlocalhost ~]# xhost #如果命令不存在执行sudo yum install xorg-x11-server-utils xhost: unable to open display "" [rootlocalhost ~]# su - dmd…...

OpenHarmony荷兰研习会回顾 | 仓颉语言赋能原生应用开发实践
近日,由全球顶级学术峰会EuroSys/ASPLOS和OpenHarmony社区在荷兰鹿特丹合办的操作系统深度研习会圆满收官,本次研习会以"架构探秘-开发实践-创新实验"三位一体的进阶模式,为全球开发者构建了沉浸式技术探索平台。其中,由…...

【远程工具】0 std::process::Command 介绍
std::process::Command 是 Rust 标准库中用于创建和配置子进程的主要类型。它允许你启动新的进程、设置其参数和环境变量、重定向输入/输出等。 基本用法 use std::process::Command;let output Command::new("echo").arg("Hello, world!").output().ex…...

【JAVA】JVM 堆内存“缓冲空间”的压缩机制及调整方法
1. 缓冲空间是否可压缩? 是的,JVM 会在满足条件时自动收缩堆内存,将未使用的缓冲空间释放回操作系统。但需满足以下条件: GC 触发堆收缩:某些垃圾回收器(如 G1、Serial、Parallel)在 Full GC …...

RV1126 人脸识别门禁系统解决方案
1. 方案简介 本方案为类人脸门禁机的产品级解决方案,已为用户构建一个带调度框架的UI应用工程;准备好我司的easyeai-api链接调用;准备好UI的开发环境。具备低模块耦合度的特点。其目的在于方便用户快速拓展自定义的业务功能模块,以及快速更换UI皮肤。 2. 快速上手 2.1 开…...
matlab内置的git软件版本管理功能
1、matlab多人协作开发比普通的嵌入式软件开发困难很多 用过matlab的人都知道,版本管理对于matlab来说真的很费劲,今天介绍的这个工具也不是说它就解决了这个痛点,只是让它变得简单一点。版本管理肯定是不可或缺的,干就完了 2、操作说明 如图所示,源代码管理,选项罗列的…...

【问题排查】SQLite安装失败
启动 Django 自带的开发服务器 python manage.py runserver出现如下报错: [rootiZ2zedudtf2cwzi9argky2Z myproject]# python manage.py runserver Watching for file changes with StatReloader Performing system checks...System check identified no issues (…...
详解:从零开始掌握(2))
Express中间件(Middleware)详解:从零开始掌握(2)
1. 请求耗时中间件的增强版 问题:原版只能记录到控制台,如何记录到文件? 改进点: 使用process.hrtime()是什么?获取更高精度的时间支持将日志写入文件记录更多信息(IP地址、状态码)工厂函数模式使中间件可配置 con…...

《前端面试题之 CSS篇(第一集)》
目录 1、CSS的盒模型2、CSS选择器及其优先级3、隐藏元素的方法有那些4、px、em、rem的区别及使用场景5、重排、重绘有什么区别6、水平垂直居中的实现7、CSS中可继承与不可继承属性有哪些8、Sass、Less 是什么?为什么要使用他们?9、CSS预处理器/后处理器是…...

MySQL部分总结
mysql学习笔记,如有不足还请指出,谢谢。 外连接,内连接,全连接 外连接:左外、右外 内连接:自己和自己连接 全连接:左外连接右外链接 mysql unique字段 unique可以在数据库层面避免插入相同…...

2025第十六届蓝桥杯PythonB组部分题解
一、攻击次数 题目描述 小蓝操控三个英雄攻击敌人,敌人初始血量2025: 第一个英雄每回合固定攻击5点第二个英雄奇数回合攻击15点,偶数回合攻击2点第三个英雄根据回合数除以3的余数攻击:余1攻2点,余2攻10点࿰…...