ViT 模型讲解
文章目录
- 一、模型的诞生背景
- 1.1 背景
- 1.2 ViT 的提出(2020年)
- 二、模型架构
- 2.1 patch
- 2.2 模型结构
- 2.2.1 数据 shape 变化
- 2.2.2 代码示例
- 2.2.3 模型结构图
- 2.3 关于空间信息
- 三、实验
- 3.1 主要实验
- 3.2 消融实验
- 四、先验问题
- 4.1 归纳偏置
- 4.2 先验or大数据???
- 五、补充
- 5.1 二维的位置编码
- 5.2 挖坑
Vision Transformer(ViT)是一个开创性的计算机视觉模型,它首次成功地将Transformer架构引入到视觉领域,打破了长期以来以卷积神经网络(CNN)为主导的局面。
一、模型的诞生背景
1.1 背景
-
Transformer 在 NLP 的成功
Transformer 架构由 Vaswani 等人在 2017 年提出(论文《Attention is All You Need》),它在 NLP 中(比如 BERT、GPT)表现非常出色。 -
CV 领域的主流仍是 CNN
视觉领域长期由 CNN 主导(如 ResNet、EfficientNet 等),这些模型通过局部卷积提取空间信息。 -
挑战:Transformer 在图像上的应用
图像不像文本那样是离散的序列,Transformer 需要序列化输入,因此直接用 Transformer 处理图像并不直观。
1.2 ViT 的提出(2020年)
论文:“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”
作者:Google Research
意义:首次证明了,在足够的数据和算力支持下,Transformer 可以在图像分类任务中超过最好的 CNN。
二、模型架构
2.1 patch
假设输入是一批图像,维度为:
(B, H, W, C)
- B = batch size
- H = 高(比如 224)
- W = 宽(比如 224)
- C = 通道数(比如 RGB → 3)
我们想让 Transformer 接收这个图像,但问题:Transformer 要求输入是序列: 每个 token 有一个 embedding,形状应该是:
(B, N, D)
- N = 序列长度(token 数)
- D = 每个 token 的 embedding 维度
那我们能不能把图像 reshape 成这种形状呢?
尝试直接 reshape:把每个像素当作一个 token?
(B, H, W, C) → reshape → (B, H*W, C)
比如说:
B = 32
H = W = 224
C = 3→ (32, 224*224, 3) = (32, 50176, 3)
问题:序列长度 N = 50,176,太长了!
- Transformer 的注意力是 O(N²),即
O(50176²) ≈ 2.5 billion,显存、计算量巨大! - 实际上,BERT 这样的 NLP 模型一般处理的序列长度才 512 左右。
这就是 ViT 的关键创新:
把图像划分为 Patch,每个 Patch 当成一个 token。
我们将图像划分为大小为 P x P 的 patch,比如 16 x 16。
-
则每个 patch 的像素数为:
P*P*C = 16*16*3 = 768 -
每张图像总共包含 patch 数:
N = (H / P) * (W / P) = (224 / 16)^2 = 14 * 14 = 196 -
所以 reshape 后的数据维度是:
(B, 14, 14, 16, 16, 3) -> (B, 14*14, 16*16*3)
2.2 模型结构
设定一个典型 ViT 的输入参数如下:
- 图像大小:
224 x 224 x 3(高×宽×通道)- Patch 大小:
16 x 16- 输出维度(embedding dim):
768- Patch 数量:
(224 / 16)^2 = 14 x 14 = 196- Transformer 层数:
12- Head 数:
12- MLP Head 输出类别数:
1000(如 ImageNet)
2.2.1 数据 shape 变化
数据 shape 流程(标准 ViT)
Input Image: (3, 224, 224)↓
1. Split into Patches (16x16) → 每个 patch 展平成向量:得到 (196, 3*16*16) = (196, 768)↓
2. Linear Projection of Patches → Embedding:每个 patch 向量映射为 (196, 768)↓
3. 加入 CLS token:+ 1 个 token,shape 变为 (197, 768)↓
4. 加入 Position Embedding:shape 仍是 (197, 768)↓
5. 输入 Transformer Encoder(L 层):每层输出:仍是 (197, 768)Attention → FFN → Add & Norm↓
6. 取 CLS token 表示:(1, 768)↓
7. 分类头(MLP Head):Linear(768 → 1000)得到 (1, 1000)↓
8. softmax 输出:1000 类别概率
架构图(图示)
┌─────────────────────┐Image │ Input Image │(3, 224, 224) │ (3 x 224 x 224) │└────────┬────────────┘↓┌────────────────────────┐│ Split into Patches ││ 16x16 patches ││ 196 patches total │└────────┬───────────────┘↓┌─────────────────────────────┐│ Flatten + Linear Projection ││ Each patch → (1 x 768) ││ → (196 x 768) │└────────┬────────────────────┘↓┌──────────────────────────┐│ Add CLS Token (1 x 768) ││ → (197 x 768) │└────────┬─────────────────┘↓┌───────────────────────────────┐│ Add Positional Embedding ││ → (197 x 768) │└────────┬──────────────────────┘↓┌────────────────────────────┐│ L x Transformer Encoder ││ (Self-Attn + FFN) ││ Output: (197 x 768) │└────────┬───────────────────┘↓┌──────────────────────────────┐│ Take [CLS] token (1 x 768) │└────────┬─────────────────────┘↓┌─────────────────────────────┐│ MLP Head → Class logits ││ Linear: 768 → 1000 │└────────┬────────────────────┘↓Output: (1 x 1000)
2.2.2 代码示例
PyTorch 实现的示例
# 假设输入图像 batch 为 (B, 3, 224, 224)
B = 32
patch_size = 16
embed_dim = 768
num_patches = (224 // patch_size) ** 2 # 14 * 14 = 196# 1. Patch embedding
x = torch.randn(B, 3, 224, 224)
patches = x.unfold(2, patch_size, patch_size).unfold(3, patch_size, patch_size)
patches = patches.contiguous().view(B, 3, -1, patch_size, patch_size)
patches = patches.permute(0, 2, 1, 3, 4).contiguous().view(B, num_patches, -1) # (B, 196, 768)# 2. Linear projection + Add cls + pos embedding → (B, 197, 768)
# 3. Transformer blocks → 输出 shape 不变 (B, 197, 768)
# 4. MLP Head → (B, 1000)
2.2.3 模型结构图

2.3 关于空间信息
ViT 把每个 patch flatten 后再当作 token 输入,是否会丢失空间信息?模型还能理解图像的空间结构吗?
我们来逐步拆解这个问题。
原图 → (B, 224, 224, 3)
patch → 划成 (B, 14, 14, 16, 16, 3)
flatten → (B, 196, 768) ← 每个 patch 被完全拉平
也就是说:
- 每个
16x16patch 被视为一个 768 维向量,送进 Transformer。 - 在 patch 内部,像素之间的 2D 空间关系已经丢失了(被 flatten)。
这其实是一个 trade-off:局部 vs 全局
CNN 是局部建模:
- 用卷积核滑动 → 保留局部空间结构
- 多层堆叠 → 扩展感受野
ViT 是全局建模:
- 每个 patch 被视作一个整体 token,不知道 patch 内部的位置信息
- 但可以通过 self-attention 在patch 之间建模全局关系
ViT 是如何弥补空间结构缺失的?
-
位置编码(Positional Embedding)
虽然 patch 本身是被 flatten 的,但 ViT 给每个 patch 加了一个位置向量:
patch_embeddings + positional_embeddings- 这些 positional embeddings 是可学习参数,形状为
(num_patches, embed_dim),比如(196, 768) - 它告诉模型:第几个 patch 是图像的哪一部分(左上、右下、中间…)
- 这些 positional embeddings 是可学习参数,形状为
-
Self-Attention 建模 patch 间的关系
虽然每个 patch 内部的空间结构被 flatten 掉了,但 ViT 有全局的 self-attention:
- 每个 patch 可以“看到”所有其他 patch
- 自注意力机制可以自动学习到:哪些 patch 是连续的、有相似内容的、有上下文关系的
patch之间有位置编码,那patch内部的空间信息就真的没了吗?
基本上……是的,ViT 在标准设计中:
完全忽略了 patch 内部像素的空间结构(除了间接靠大量数据让模型学到某些模式)
这就是为什么后续很多改进型 ViT 试图引入更精细的空间建模,比如:
-
CNN + ViT 结合
比如CvT,ConViT:在 embedding 之前加一层卷积提取局部特征。 -
局部注意力 / 层次结构
比如Swin Transformer:只在局部窗口内做注意力,保留 patch 内空间结构。 -
使用 Patch Token Hierarchy
把图像分层次进行划分,像 CNN 的 downsampling 一样逐层抽象。 -
位置编码增强
有些 ViT 用坐标编码(x, y)拼进去,或者使用相对位置编码(像 NLP 中那样)。
| 问题 | 是否存在 | 弥补方式 |
|---|---|---|
| Patch 内部 flatten 导致空间信息丢失 | 存在 | 无法恢复(在标准 ViT 中) |
| Patch 之间的空间结构 | 被建模 | 位置编码 + attention |
| 模型理解图像结构的能力 | 部分靠 attention 建模 | 更依赖大规模预训练数据 |
三、实验
3.1 主要实验
| 实验 | 变量 | 设置 | 结果/结论 |
|---|---|---|---|
| ViT vs ResNet | 模型结构 | ViT-B/16 vs ResNet152x4 | 在 ImageNet-21k 上 ViT > ResNet,参数更少,性能更高 |
| 不同预训练数据 | 数据规模 | ImageNet (1M) vs IN-21k (14M) vs JFT-300M (300M) | ViT 在大数据集上才训练得好,小数据集会过拟合 |
| 小样本迁移能力 | Fine-tune 到小数据集 | CIFAR, Flowers, VTAB | ViT 表现良好,迁移性强 |
| 与其他模型迁移对比 | 方法对比 | ResNet vs ViT | ViT 表现更好,但需要预训练支持 |
3.2 消融实验
- Patch Size 影响
- Patch size: 8x8、16x16、32x32
- 越小越好(序列变长,表达力强)
- 但计算量 ↑,内存占用 ↑
- 16x16 是最佳平衡
结论:小 patch 能提升性能,但要付出代价。
- 位置编码
- 加 vs 不加
- 绝对位置 vs 相对位置
- 插值位置编码支持不同分辨率
结论:必须加位置编码,且可插值适配不同输入大小。
- MLP Head 设计
- Linear head vs 多层 MLP
- 结果几乎一样
结论:简单的 linear classifier 足以。
- LayerNorm 放置位置
- Pre-LN(LN 在 Attention 前) vs Post-LN
- Pre-LN 更稳定,训练更好收敛
结论:Pre-LN 更适合 ViT。
- Class Token 的作用
- 类似 BERT 的 [CLS]
- 每层 attention 都能访问,用于最终分类
结论:必须有,模型依赖它来提取全局特征。
- 是否需要强数据增强 / 自监督
- 加了 CutMix、RandAug 等 → 效果提升小
- ViT 不如 CNN 那么依赖数据增强
结论:数据增强对 ViT 不敏感,但对 CNN 很关键。
- 是否使用卷积替代 patch embedding
- 用卷积提 patch embedding 没有显著提升
结论:线性投影就可以,无需 CNN 特征提取头。
关键有效设计
| 组件 | 作用 | 是否关键 |
|---|---|---|
| Patch embedding | 降低序列长度 | 1 |
| Positional Encoding | 建模空间顺序 | 1 |
| Class Token | 输出图像全局表征 | 1 |
| Self-Attention | 全局建模 | 1 |
| Pre-LN 架构 | 稳定训练 | 1 |
| 大规模数据预训练 | 避免过拟合 | 111 |
可有可无的点
| 组件 | 作用 | 结论 |
|---|---|---|
| 强数据增强 | 抗扰动、泛化 | 提升小,可有可无 |
| MLP Head | 增加判别能力 | 线性 head 足够 |
| 卷积前置层 | 提取局部特征 | 变化不大 |
四、先验问题
4.1 归纳偏置
“先验(prior)”在深度学习里,其实就是“归纳偏置(inductive bias)”的一个通俗说法。
归纳偏置(Inductive Bias):指的是一个学习算法在数据不足时,如何做出合理泛化的偏好或假设。
简化理解:
当我看不到所有数据的时候,我默认事情是这样的 —— 这就是我的归纳偏置。
举几个通俗例子:
| 模型 | 归纳偏置 / 先验 |
|---|---|
| CNN | 局部连接、权重共享、平移不变性(空间先验) |
| RNN/LSTM | 时间顺序相关性 |
| GNN | 图结构邻居影响中心点 |
| Transformer | 无特别强的归纳偏置(完全数据驱动) |
先验 = 归纳偏置 = 模型对现实世界的一种结构性假设
4.2 先验or大数据???
ViT 完全基于 Transformer,没有 CNN 的结构先验:
- 不知道局部区域重要;
- 不知道平移后的图还是同一个图;
- 所以 ViT 必须通过大量数据自己“悟出这些结构”;
- 而 CNN 天生就有这些“归纳偏置”植入其中。
ViT 证明了一件事:在足够大、足够多样的数据下,模型可以学出先验,从而超越“手工嵌入先验”的模型。
在 ViT 的实验中:
| 数据集 | 模型表现 |
|---|---|
| ImageNet-1k | ViT 差于 CNN |
| ImageNet-21k | ViT ≈ CNN |
| JFT-300M | ViT > CNN(显著) |
这清楚地说明了:
- 在小数据(ImageNet-1k)下,CNN 的归纳偏置(如局部性、平移不变)提供了巨大优势;
- 在大数据(JFT-300M)下,ViT 能通过学习自动获得这些归纳偏置(甚至更多),从而反超 CNN;
- 也就是说:数据能“弥补”先验的缺失,甚至最终超越它。
所以,ViT 是一个“用海量数据和大模型学到归纳偏置”的典范。
但这并不是说“先验没用了”!
ViT 不是在否定先验的价值,而是在提出一个新的平衡:
归纳偏置(先验)和数据之间,是可以相互替代的,但各有代价。
| 有强归纳偏置(CNN) | 少数据、高效训练、泛化强,但灵活性差 |
| 无归纳偏置(ViT) | 灵活、能力上限高,但数据、算力需求大 |
所以:
- CNN 很适合“小数据集、低资源”的任务;
- ViT 更适合“数据丰富、资源充足”的大规模学习;
- ViT 的出现是因为 Google 拥有海量数据和TPU,大部分人是玩不起纯 ViT 的。
ViT 后续的发展说明了:先验和数据,是可以结合的
很多 ViT 变体其实都在 “加回先验”:
- Swin Transformer:加入了局部窗口(locality),有点像滑动卷积核;
- CvT、LeViT:在前几层用卷积替代patch embedding;
- DeiT + distillation:用CNN当teacher,把先验“蒸馏”给ViT;
- Token2Token ViT:加了局部token聚合结构;
- ConvNeXt:是个有Transformer设计灵感的CNN,重新思考CNN架构;
这些模型的核心目标:
找到“结构先验”和“灵活模型”之间最优的折中点。
五、补充
5.1 二维的位置编码
论文中虽然使用的是一维的位置编码(形状是 ( N \times D )),但其内部其实是用 二维网格的位置(行、列)来生成的。这种方式可以分两种做法:
方法一:直接学习一个二维位置编码表
- 假设有一个 ( h \times w ) 的patch grid,例如 ( 14 \times 14 );
- 可以学习一个形状为 ( h \times w \times D ) 的可训练tensor;
- 然后 reshape 为 ( N \times D )(即 ( 196 \times 768 ));
- 加到 patch embedding 上。
方法二:分离式编码(Horizontal + Vertical)
这是某些 ViT 变种(比如 Axial Attention、Swin Transformer、BEiT 等)采用的方式。
- 学两个 embedding:行方向的位置编码
h × D/2和列方向的位置编码w × D/2; - 对于每个位置 (i,j),位置编码是两个向量之和或拼接:
PE i , j = RowPE i ∣ ∣ ColPE j \text{PE}_{i,j} = \text{RowPE}_i || \text{ColPE}_j PEi,j=RowPEi∣∣ColPEj - 再 reshape 成一维序列。
这种方式的好处是更结构化、可扩展、可插值(这在fine-tuning时很有用)。
5.2 挖坑
众所周知,ViT挖了很多坑。
众所周知,CV界是出了名的卷。坑多,填坑的也多。
略微总结:
| 坑号 | 挖坑主题 | 被谁填了? |
|---|---|---|
| 1 | 去CNN化 | Swin、PVT、CvT、LeViT、ConvNeXt |
| 2 | 位置编码不泛化 | 相对PE、Swin移动窗口、Focal、Twins |
| 3 | 局部性完全缺失 | T2T、DeiT distill、RegionViT、MobileViT |
| 4 | 训练资源极高 | DeiT、MAE、DINO、BEiT、自监督系列 |
| 5 | 没有多尺度层次 | PVT、Swin、SegFormer、Pix2Seq |
| 6 | 归纳偏置之争 | 整个 community 都在参与 |
| 7 | 图像语言统一建模范式 | CLIP、BLIP、GPT-4V、Flamingo |
相关文章:
ViT 模型讲解
文章目录 一、模型的诞生背景1.1 背景1.2 ViT 的提出(2020年) 二、模型架构2.1 patch2.2 模型结构2.2.1 数据 shape 变化2.2.2 代码示例2.2.3 模型结构图 2.3 关于空间信息 三、实验3.1 主要实验3.2 消融实验 四、先验问题4.1 归纳偏置4.2 先验or大数据&…...
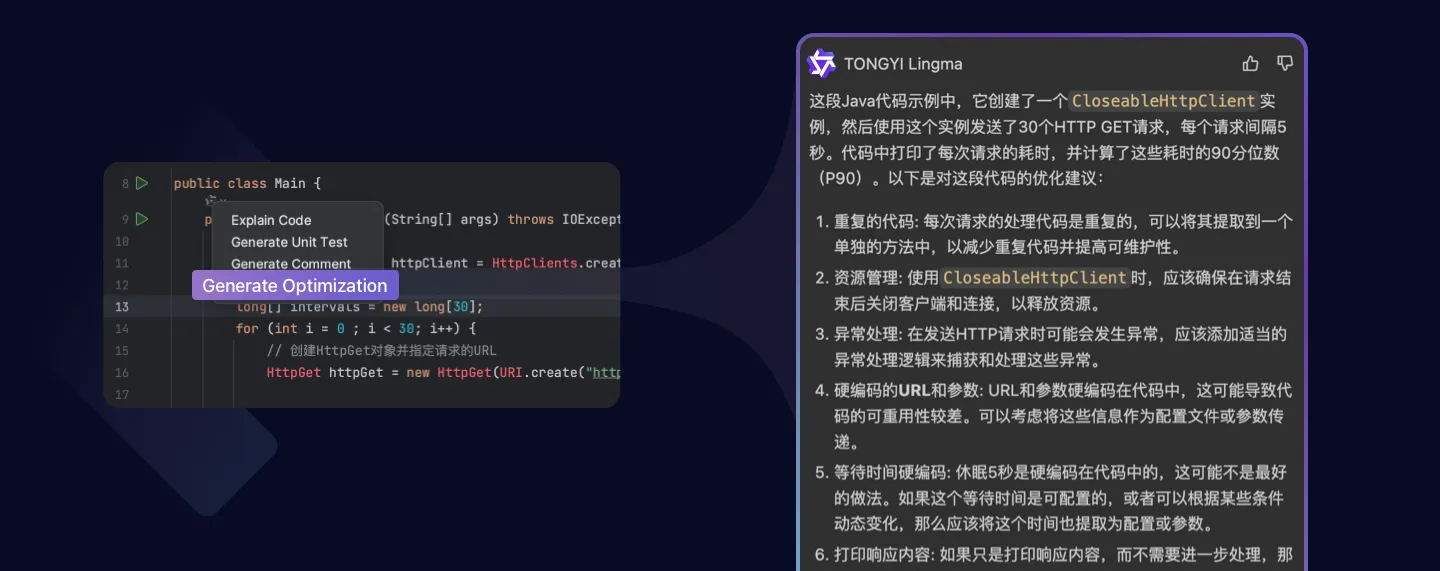
IntelliJ IDEA 中安装和使用通义灵码 AI 编程助手教程
随着人工智能技术的发展,AI 编程助手逐渐成为提升开发效率的强大工具。通义灵码是阿里云推出的一款 AI 编程助手,它能够帮助开发者实现智能代码补全、代码解释、生成单元测试等功能,极大地提升了编程效率和代码质量。 IntelliJ IDEA 是一款广…...

面向HPC平台应用的HBM电源完整性/信号完整性分析与设计方法
近年来,人工智能技术的爆发式增长推动大数据处理领域发生根本性变革,促使工业界转向基于大数据的工作模型。为应对海量数据处理的复杂问题,基于多边交互服务的数据中心不断涌现。此类应用被称为高性能计算(HPC)&#x…...

FreeRTOS入门与工程实践-基于STM32F103(一)(单片机程序设计模式,FreeRTOS源码概述,内存管理,任务管理,同步互斥与通信,队列,信号量)
裸机程序设计模式 裸机程序的设计模式可以分为:轮询、前后台、定时器驱动、基于状态机。前面三种方法都无法解决一个问题:假设有A、B两个都很耗时的函数,无法降低它们相互之间的影响。第4种方法可以解决这个问题,但是实践起来有难…...
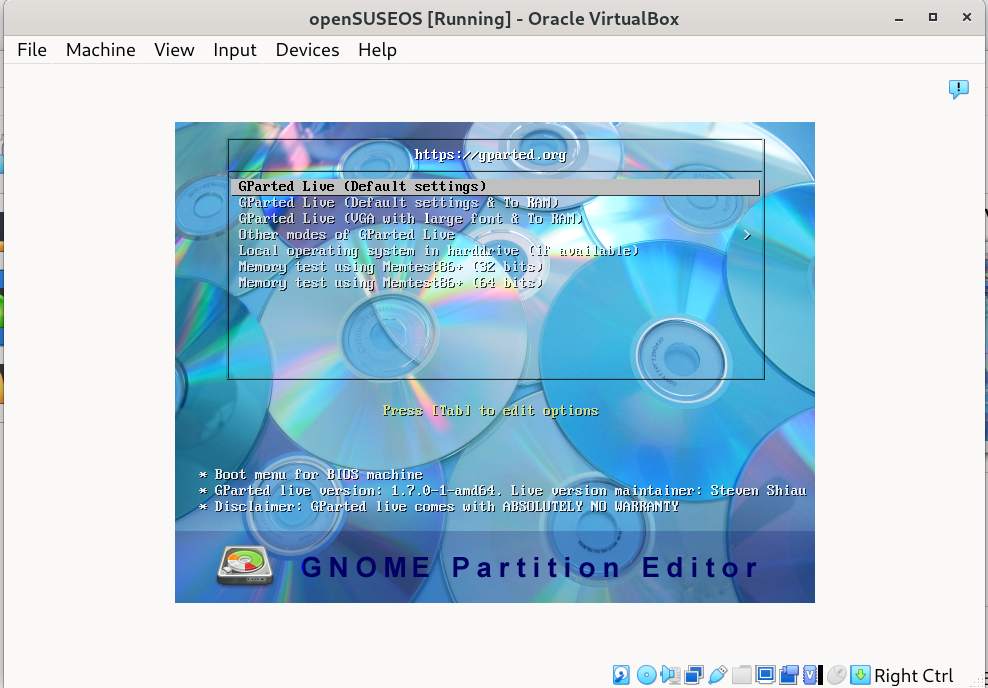
can‘t set boot order in virtualbox
Boot order setting is ignored if UEFI is enabled https://forums.virtualbox.org/viewtopic.php?t99121 如果勾选EFI boot order就是灰色的 传统BIOS就是可选的 然后选中任意介质,通过右边的上下箭头调节顺序,最上面的应该是优先级最高的 然后就…...

2025年第十六届蓝桥杯省赛C++ A组真题
2025年第十六届蓝桥杯省赛C A组真题 1.说明2.题目A:寻找质数(5分)3.题目B:黑白棋(5分)4. 题目C:抽奖(10分)5. 题目D:红黑树(10分)6. 题…...

asp.net Kestrel 和iis区别
Kestrel 和 IIS 都是用于托管 Web 应用程序的服务器,不过它们在多个方面存在显著差异,下面为你详细分析: 1. 所属平台与跨平台能力 Kestrel:是.NET Core 及后续版本的一部分,具备跨平台特性,可在 Windows…...

《植物大战僵尸融合版v2.4.1》,塔防与创新融合的完美碰撞
《植物大战僵尸融合版》是基于经典塔防游戏《植物大战僵尸》的创意同人改版,由“蓝飘飘fly”等开发者主导制作。它在保留原版核心玩法的基础上,引入了独特的植物融合机制,玩家可以将不同的植物进行组合,创造出全新的植物种类&…...

SGP4 基于C、C++安装指南
简介:SGP4 是一个用于简化轨道摄动模型的开源项目。 依赖:GCC/CLang, CMake 下载:GitCode - 全球开发者的开源社区,开源代码托管平台 (https://gitcode.com/gh_mirrors/sg/sgp4)或者从我的资源下载 https…...

SBTI认证的意义,什么是SBTI认证,sbti科学碳目标的好处
SBTI认证的意义与科学碳目标(SBT)的好处 1. 什么是SBTI认证? SBTI(Science Based Targets initiative,科学碳目标倡议)是由全球环境信息研究中心(CDP)、联合国全球契约(…...

[LeetCode 1696] 跳跃游戏 6(Ⅵ)
题面: LeetCode 1696 数据范围: 1 ≤ n u m s . l e n g t h , k ≤ 1 0 5 1 \le nums.length, \ k \le 10^5 1≤nums.length, k≤105 − 1 0 4 ≤ n u m s [ i ] ≤ 1 0 4 -10^4 \le nums[i] \le 10^4 −104≤nums[i]≤104 思路 & Code 重点&…...

在思科模拟器show IP route 发现Gateway of last resort is not set没有设置最后的通道
如果在show ip route的时候出现没有设置最后的通道Gateway of last resort is not set Switch#show ip route Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA exte…...

Redis 常问知识
1.Redis 缓存穿透问题 缓存穿透:当请求的数据在缓存和数据库中不存在时,该请求就跳出我们使用缓存的架构(先从缓存找,再从数据库查找、这样就导致了一直去数据库中找),因为这个数据缓存中永远也不会存在。…...
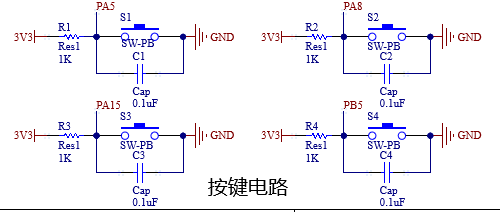
履带小车+六轴机械臂(2)
本次介绍原理图部分 开发板部分,电源供电部分,六路舵机,PS2手柄接收器,HC-05蓝牙模块,蜂鸣器,串口,TB6612电机驱动模块,LDO线性稳压电路,按键部分 1、开发板部分 需要注…...
多卡集群 - Docker命令来启动一个容器的实例
一、Docker下载安装及相关配置 桌面版:Docker Desktop: The #1 Containerization Tool for Developers | Docker 服务器版:Install | Docker Docs 我们先以windows桌面版为例进行安装,一般在公司里会使用服务器版本,后期也会出一…...

测试第三课-------自动化测试相关
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

【C++教程】进制转换的实现方法
在C中进行进制转换可以通过标准库函数或自定义算法实现。以下是两种常见场景的转换方法及示例代码: 一、使用C标准库函数 任意进制转十进制 #include <string> #include <iostream>int main() {std::string num "1A3F"; // 十六进制数int…...

科普:如何通过ROC曲线,确定二分类的“理论阈值”
在二分类问题中,已知预测概率(如逻辑回归、神经网络输出的概率值)时,阈值的选择直接影响分类结果(正/负样本判定)。 一、实践中的阈值选择方法 1. 基于业务目标的调整 最大化准确率:适用于样…...

ebpf: CO-RE, BTF, and Libbpf(二)
本文内容主要来源于Learning eBPF,可阅读原文了解更全面的内容。 本文涉及源码也来自于书中对应的github:https://github.com/lizrice/learning-ebpf/ 概述 上篇文章主要讲了CO-RE最关键的一环:BTF,了解其如何记录内核中的数据结…...
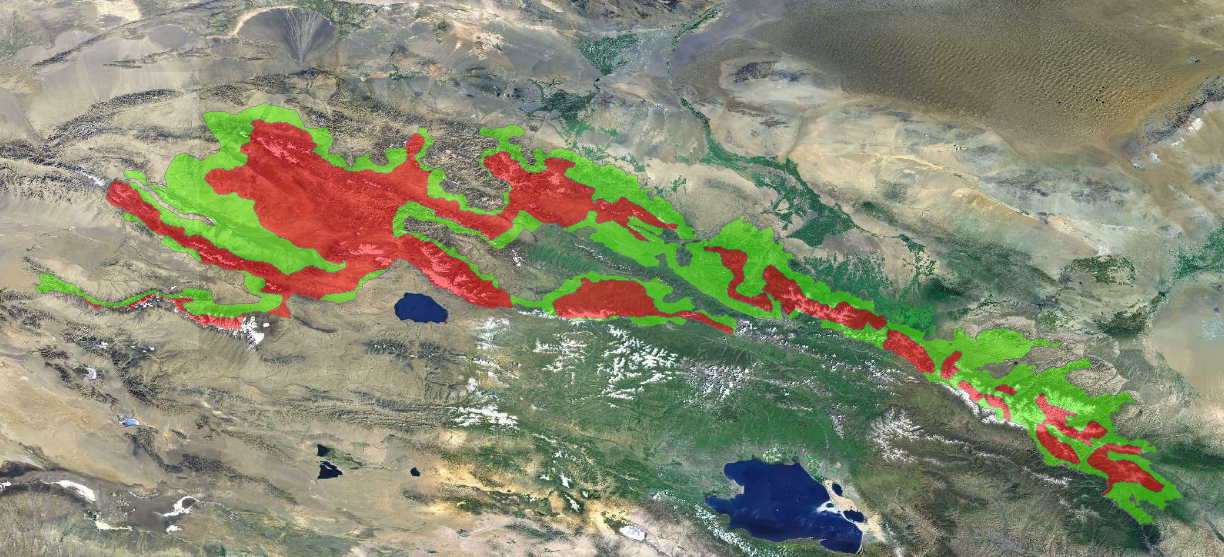
祁连山国家公园shp格式数据
地理位置 祁连山国家公园位于中国西北部,横跨甘肃省与青海省交界处,主体处于青藏高原东北边缘。总面积约5.02万平方公里,是中国首批设立的10个国家公园之一。 设立背景 保护措施 文化与历史 旅游与教育 意义与挑战 祁连山国家公园的设立标志…...

《AI大模型应知应会100篇》 第16篇:AI安全与对齐:大模型的灵魂工程
第16篇:AI安全与对齐:大模型的灵魂工程 摘要 在人工智能技术飞速发展的今天,大型语言模型(LLM)已经成为推动社会进步的重要工具。然而,随着这些模型能力的增强,如何确保它们的行为符合人类的期…...

探索QEMU-KVM虚拟化:麒麟系统下传统与云镜像创建虚拟机的最佳实践
随着云计算和虚拟化技术的不断进步,虚拟化在管理服务器、隔离资源以及提升性能方面的好处越来越明显。麒麟操作系统Kylin OS是我们国家自己开发的操作系统,在政府机构和企业中用得很多。这篇文章会教你如何在麒麟操作系统上设置QEMU-KVM虚拟化环境&#…...

[ComfyUI] 最新控制模型EasyControl,吉卜力风格一键转绘
一、EasyControl介绍 玩ComfyUI的都知道Controlnet的重要性,可以根据约束来引导图片的生成,这也是ComfyUI商业化里面很重要的一环。 不过之前我们用的Controlnet都是基于Unet技术框架下的。 最近出的这个EasyControl有点不一样,是基于DiT&a…...

项目执行中的目标管理:从战略到落地的闭环实践
——如何让目标不“跑偏”、团队不“掉队”? 引言:为什么目标管理决定项目成败? 根据PMI研究,47%的项目失败源于目标模糊或频繁变更。在复杂多变的项目环境中,目标管理不仅是制定KPI,更是构建“方向感-执行…...

《计算机视觉度量:从特征描述到深度学习》—深度学习工业检测方案评估
谢谢各位粉丝的支持,过去了一年多才再次更新技术博客。原因是个人家庭和技术发展在这短短一年多,发生了很大变化。本人身为技术博主,也在不断的探索和研究新技术在工业检测领域的技术方案。 并在这期间已经完成了基础的工业检测大模型的设计…...

网页防篡改与盗链防护:实时监控与自动化修复实践
摘要:针对网页内容篡改与盗链问题,本文基于群联AI云防护系统,详解如何通过哈希校验、实时监控与CDN联动实现秒级修复,并提供Python与AWS S3集成代码。 一、网页安全的核心需求 防篡改:保障页面内容完整性,…...
LR(0)
LR0就是当我处在自动机为红色这些结束状态的时候,这些红色状态就代表我们识别到了一个句柄,那现在的问题就是识别到了句柄,那要不要对他进行归约?LR0就是我不管当前指针指向的终结符是什么,我都拿它做规约 这里的二号状…...

鸿蒙开发-页面跳转
1.路由使用 //1.引入路由 import router from ohos.router//2.使用跳转router.pushUrl({url: "pages/Show"})2.页面跳转 import { router } from kit.ArkUI;Entry Component struct LoginPage {State message: string 登陆页;build() {Row() {Column() {Text(this…...

#MES系统中的一些相关的名词
📌MES系统 部分 术语表 缩写英文全称中文名称详细解释MESManufacturing Execution System制造执行系统用于连接计划系统与生产现场,实时管理和控制整个生产过程,覆盖物料、人员、设备、质量、指令等。ERPEnterprise Resource Planning企业资…...
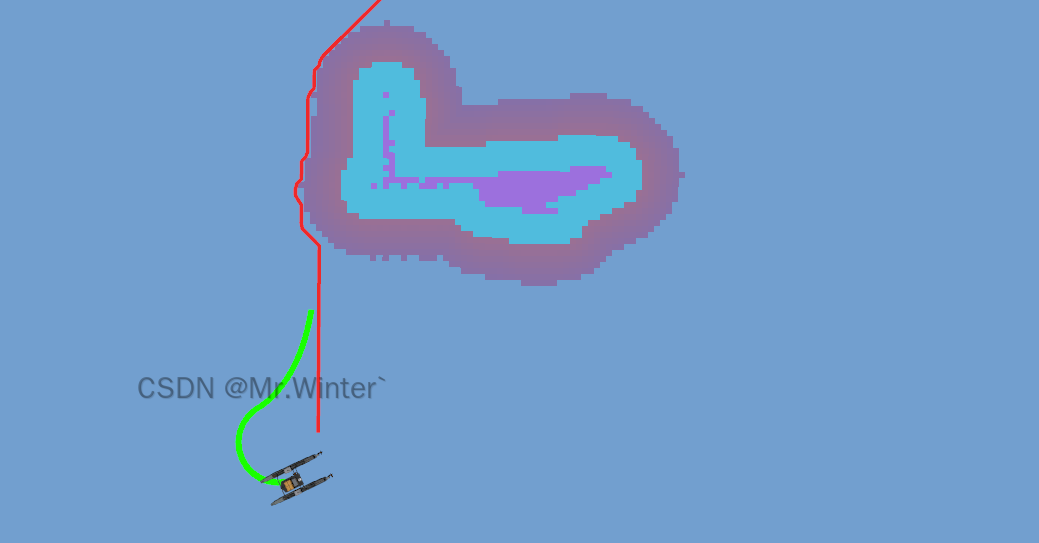
无人船 | 图解基于视线引导(LOS)的无人艇制导算法
目录 1 视线引导法介绍2 LOS制导原理推导3 Lyapunov稳定性分析4 LOS制导效果 1 视线引导法介绍 视线引导法(Line of Sight, LOS)作为无人水面艇(USV)自主导航领域的核心技术,通过几何制导与动态控制深度融合的机制&am…...