机器学习项目二:帕金森病检测
目录
下载数据
一、导入相关包
二、数据加载
三、特征工程
四、构建模型
五、评估与可视化
六、程序流程
七、完整代码
一、导入相关包
# 导入库部分
import numpy as np # 数值计算基础库
import pandas as pd # 数据处理库
from sklearn.preprocessing import MinMaxScaler # 数据标准化
from xgboost import XGBClassifier # XGBoost分类器
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold # 数据分割和超参数优化
from sklearn.metrics import (accuracy_score, classification_report, confusion_matrix, roc_auc_score) # 评估指标
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # 高级可视化
import joblib # 模型持久化
from datetime import datetime # 时间戳生成二、数据加载
def load_data(path):"""加载并预处理数据"""df = pd.read_csv(path) # 读取CSV文件# 数据质量断言检查assert 'status' in df.columns, "数据必须包含status列"# 打印关键统计信息(调试用)print(f"数据分布:\n{df['status'].value_counts()}")print(f"\n缺失值统计:\n{df.isnull().sum()}")# 用中位数填充缺失值(比均值更抗异常值)df = df.fillna(df.median())return df三、特征工程
def feature_engineering(df):"""特征处理"""# 移除标签列和无关列(患者姓名)features = df.drop(['status', 'name'], axis=1) labels = df['status'].values# MinMax标准化到[-1,1]范围scaler = MinMaxScaler(feature_range=(-1, 1))features_scaled = scaler.fit_transform(features)return features_scaled, labels, scaler # 返回scaler对象用于后续推理四、构建模型
def optimize_model(X_train, y_train):"""使用网格搜索优化XGBoost"""# 扩展的参数网格(基于文献和实验)param_grid = {'learning_rate': [0.01, 0.05, 0.1], # 更精细的学习率设置'max_depth': [3, 5, 7], # 树深度范围'min_child_weight': [1, 3], # 子节点最小权重'gamma': [0, 0.1], # 分裂最小损失下降'subsample': [0.7, 0.9], # 样本采样比例'colsample_bytree': [0.7, 0.9], # 特征采样比例'reg_alpha': [0, 0.1], # L1正则化'reg_lambda': [0.1, 1], # L2正则化'n_estimators': [100, 200] # 树的数量}# 分层K折交叉验证(保持类别分布)cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 配置基准模型(带早停机制)base_model = XGBClassifier(objective='binary:logistic',eval_metric='logloss', # 使用对数损失early_stopping_rounds=10, # 早停轮数random_state=39)# 网格搜索配置grid_search = GridSearchCV(estimator=base_model,param_grid=param_grid,cv=cv,scoring='roc_auc', # 使用AUC作为优化目标n_jobs=-1, # 使用所有CPU核心verbose=1 # 打印进度)grid_search.fit(X_train, y_train)return grid_search.best_estimator_, grid_search.best_params_五、评估与可视化
def evaluate_model(model, X_test, y_test):"""模型评估与结果可视化"""# 生成预测结果y_pred = model.predict(X_test)y_proba = model.predict_proba(X_test)[:, 1] # 获取正类概率# 打印分类报告print("\n分类报告:")print(classification_report(y_test, y_pred))# 输出AUC分数print(f"\nAUC分数: {roc_auc_score(y_test, y_proba):.4f}")# 混淆矩阵热力图plt.figure(figsize=(6,4))cm = confusion_matrix(y_test, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=['健康', '患病'],yticklabels=['健康', '患病'])plt.title('混淆矩阵')plt.show()# 特征重要性可视化plt.figure(figsize=(10, 6))feat_imp = pd.Series(model.feature_importances_, index=df.drop(['status', 'name'], axis=1).columns)feat_imp.nlargest(15).plot(kind='barh')plt.title('Top 15特征重要性')plt.tight_layout()plt.show()六、程序流程
# 主程序流程
if __name__ == "__main__":# 数据加载df = load_data('./data/parkinsons.data')# 特征工程X, y, scaler = feature_engineering(df)# 数据分割(分层抽样)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, # 保持类别比例random_state=39)# 模型优化print("\n开始参数优化...")best_model, best_params = optimize_model(X_train, y_train)print(f"\n最佳参数: {best_params}")# 模型评估evaluate_model(best_model, X_test, y_test)# 模型保存(带时间戳)timestamp = datetime.now().strftime("%Y%m%d_%H%M")model_path = f"parkinson_model_v{timestamp}.pkl"joblib.dump({'model': best_model, 'scaler': scaler}, model_path)print(f"\n模型已保存到: {model_path}")七、完整代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split, GridSearchCV, StratifiedKFold
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, roc_auc_score
import matplotlib.pyplot as plt
import seaborn as sns
import joblib
from datetime import datetime# 1. 数据加载与预处理
def load_data(path):"""加载并预处理数据"""df = pd.read_csv(path)# 数据质量检查assert 'status' in df.columns, "数据必须包含status列"print(f"数据分布:\n{df['status'].value_counts()}")print(f"\n缺失值统计:\n{df.isnull().sum()}")# 识别数值列和非数值列numeric_cols = df.select_dtypes(include=[np.number]).columnsnon_numeric_cols = df.select_dtypes(exclude=[np.number]).columnsprint(f"\n数值列: {list(numeric_cols)}")print(f"非数值列: {list(non_numeric_cols)}")# 仅对数值列填充中位数df[numeric_cols] = df[numeric_cols].fillna(df[numeric_cols].median())return df# 2. 特征工程
def feature_engineering(df):"""特征处理"""# 分离特征和标签features = df.drop(['status', 'name'], axis=1) # 移除无关列labels = df['status'].values# 数据标准化scaler = MinMaxScaler(feature_range=(-1, 1))features_scaled = scaler.fit_transform(features)return features_scaled, labels, scaler# 3. 模型优化
def optimize_model(X_train, y_train):"""使用网格搜索优化XGBoost"""# 改进的参数网格(基于文献和实验)param_grid = {'learning_rate': [0.01, 0.05, 0.1], # 更精细的学习率'max_depth': [3, 5, 7],'min_child_weight': [1, 3],'gamma': [0, 0.1], # 添加gamma参数控制分裂'subsample': [0.7, 0.9],'colsample_bytree': [0.7, 0.9],'reg_alpha': [0, 0.1],'reg_lambda': [0.1, 1],'n_estimators': [100, 200]}# 改进的交叉验证策略(分层K折)cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)# 使用早停的基准模型base_model = XGBClassifier(objective='binary:logistic',eval_metric='logloss',early_stopping_rounds=10,random_state=39)# 网格搜索配置grid_search = GridSearchCV(estimator=base_model,param_grid=param_grid,cv=cv,scoring='roc_auc', # 使用AUC作为评估指标n_jobs=-1,verbose=1)grid_search.fit(X_train, y_train)return grid_search.best_estimator_, grid_search.best_params_# 4. 评估与可视化
def evaluate_model(model, X_test, y_test):"""模型评估与结果可视化"""y_pred = model.predict(X_test)y_proba = model.predict_proba(X_test)[:, 1]print("\n分类报告:")print(classification_report(y_test, y_pred))print(f"\nAUC分数: {roc_auc_score(y_test, y_proba):.4f}")# 混淆矩阵可视化cm = confusion_matrix(y_test, y_pred)sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')plt.title('混淆矩阵')plt.show()# 特征重要性plt.figure(figsize=(10, 6))feat_imp = pd.Series(model.feature_importances_,index=df.drop(['status', 'name'], axis=1).columns)feat_imp.nlargest(15).plot(kind='barh')plt.title('Top 15特征重要性')plt.show()# 主流程
if __name__ == "__main__":# 数据加载df = load_data('data/parkinsons.csv')# 特征工程X, y, scaler = feature_engineering(df)# 数据分割(分层抽样)X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2,stratify=y,random_state=39)# 模型优化print("\n开始参数优化...")best_model, best_params = optimize_model(X_train, y_train)print(f"\n最佳参数: {best_params}")# 模型评估evaluate_model(best_model, X_test, y_test)# 模型保存(带时间戳)timestamp = datetime.now().strftime("%Y%m%d_%H%M")model_path = f"parkinson_model_v{timestamp}.pkl"joblib.dump({'model': best_model, 'scaler': scaler}, model_path)print(f"\n模型已保存到: {model_path}")相关文章:

机器学习项目二:帕金森病检测
目录 下载数据 一、导入相关包 二、数据加载 三、特征工程 四、构建模型 五、评估与可视化 六、程序流程 七、完整代码 一、导入相关包 # 导入库部分 import numpy as np # 数值计算基础库 import pandas as pd # 数据处理库 from sklearn.preprocessing import MinMaxS…...

LDAP渗透测试
LDAP渗透测试 1.LDAP协议概述2.LDAP写公钥3.暴力破解LDAP4.LDAP信息收集ldapdomaindumpwindapsearch工具ldapsearch 1.LDAP协议概述 LDAP(Lightweight Directory Access Protocol,轻量目录访问协议)是一种访问和管理目录服务的应用层协议&am…...

五笔输入法学习的抉择:86版 or 98版?(一场关于效率与传承的思辨)
新开直接98,纯粹高开;老版过渡艰辛自知😋。 笔记模板由python脚本于2025-04-14 19:22:22创建,本篇笔记适合喜好汉字衷情母语的coder翻阅。 【学习的细节是欢悦的历程】 博客的核心价值:在于输出思考与经验,…...
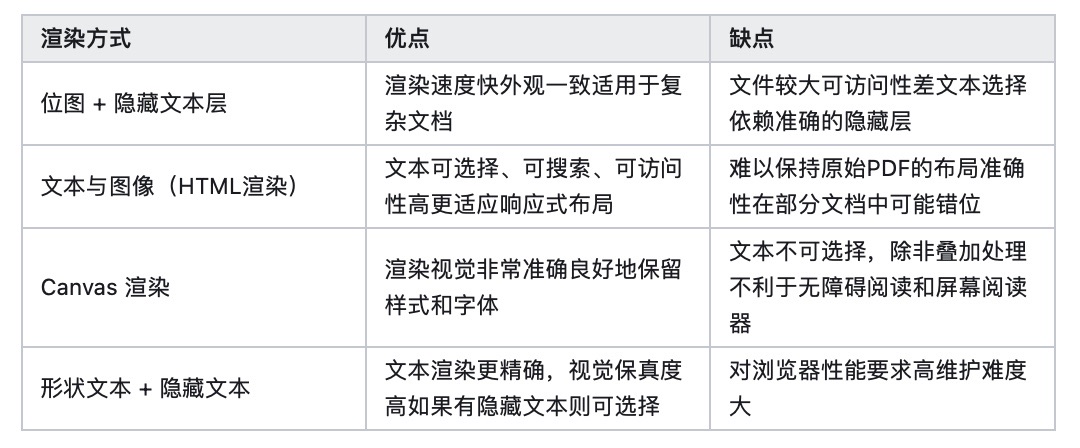
为您的 Web 应用选择最佳文档阅读器
为显示选择合适的文档查看器是开发 Web 应用过程中至关重要的一步。文档查看器应能在提供功能性的同时,确保用户体验的流畅性。 开发人员必须评估多种因素,以确保效率、性能和兼容性。本文将帮助您了解影响用户文档浏览体验成功与否的关键指标。 渲染质…...

微服务之protobuf:下载、语法和使用一站式教程
基本介绍 Protobuf全称 Protocol Buffer,是 Google 公司于2008年开源的一种语言无关、平台无关、可扩展的用于序列化结构化数据——类似于XML,但比XML更小、更快、更简单,它可用于(数据)通信协议、数据存储等。你只需…...

国产海光 DCU 资源监控脚本 + Promethues+grafana 深度解析
在当今数字化时代,对于服务器资源的高效监控与管理愈发重要。特别是在使用国产海光 DCU 的场景下,如何精准掌握其资源使用情况,成为了众多技术人员关注的焦点。本文将详细介绍一款国产海光 DCU 资源监控脚本,以及它与 Prometheus 和 Grafana 的结合使用,助力大家实现对 DC…...
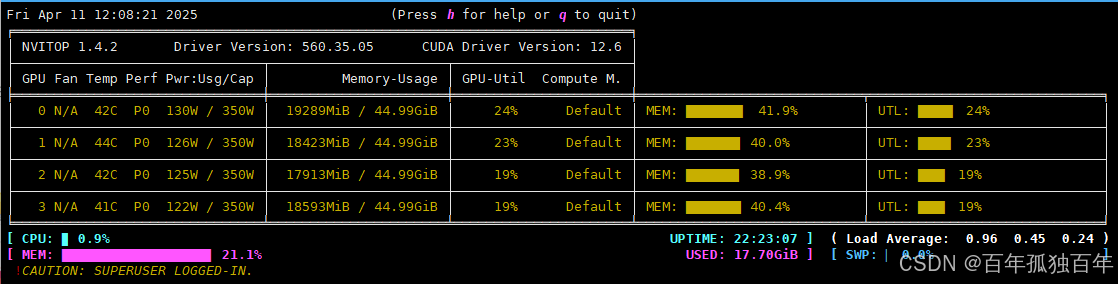
Ollama调用多GPU实现负载均衡
文章目录 📊 背景说明🛠️ 修改 systemd 服务配置1. 配置文件路径2. 编辑服务文件2. 重新加载配置并重启服务3. 验证配置是否成功 📈 应用效果示例1. 调用单个70b模型2. 调用多个模型(70b和32b模型) 总结📌…...
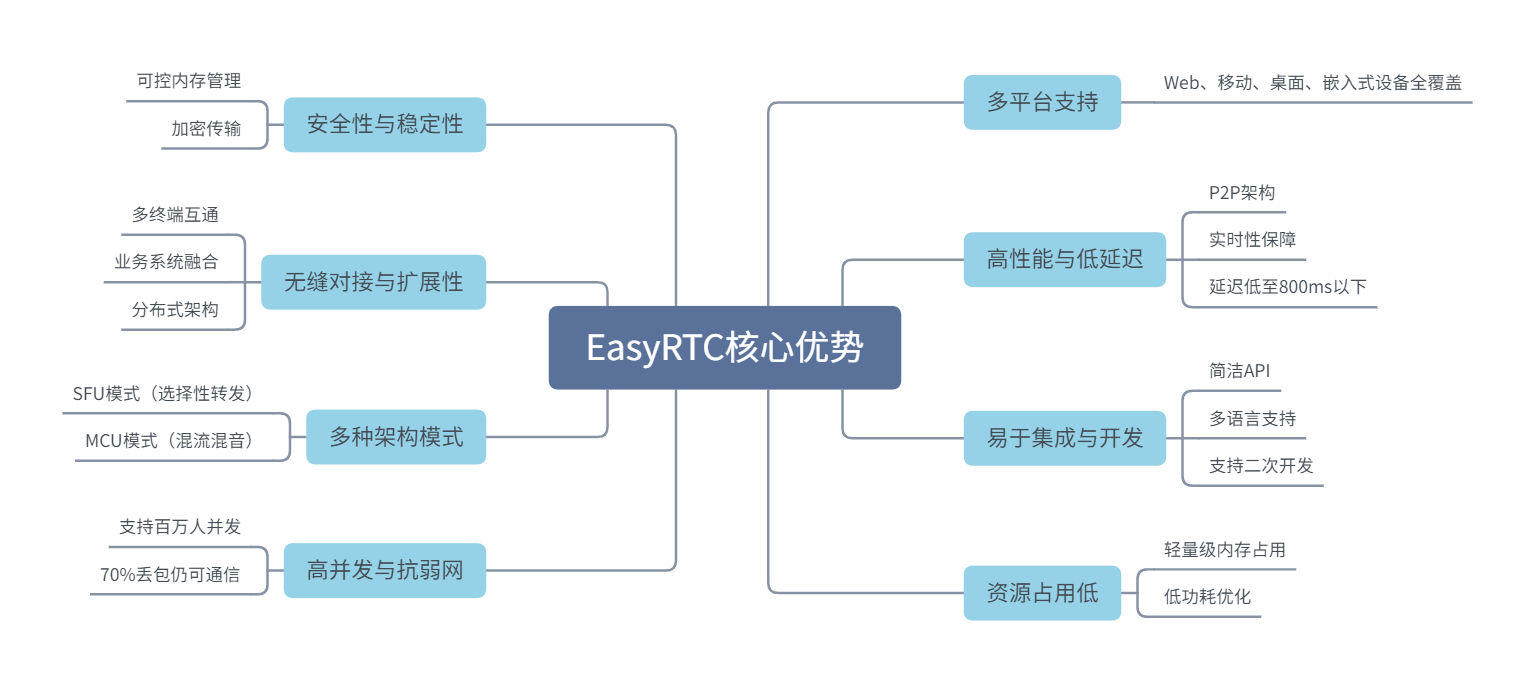
WebRTC实时通话EasyRTC嵌入式音视频通信SDK,构建智慧医疗远程会诊高效方案
一、方案背景 当前医疗领域,医疗资源分布不均问题尤为突出,大城市和发达地区优质医疗资源集中,偏远地区医疗设施陈旧、人才稀缺,患者难以获得高质量的医疗服务,制约医疗事业均衡发展。 EasyRTC技术基于WebRTC等先进技…...

深入理解计算机系统记录
在 C 语言中,struct(结构体)和 union(联合体)都是用来存储多个不同类型的数据成员,但它们在内存分配和数据存储方式上有显著区别。下面详细说明它们的主要区别: 1. 内存分配 结构体(…...

【笔记】对抗训练-GAN
对抗训练-GAN 深度学习中 GAN 的对抗目标函数详解与最优解推导一、GAN 的基本对抗目标函数二、判别器与生成器的博弈目标三、判别器的最优解推导四、最优判别器的含义五、总结六、WGAN 的动机(为后续铺垫) 深度学习中 GAN 的对抗目标函数详解与最优解推导…...
安卓开发中数据存储之Room详解)
(二十三)安卓开发中数据存储之Room详解
在安卓开发中,Room 是一个强大的本地数据库解决方案,它是 Android Jetpack 的一部分,基于 SQLite 构建,提供了更高层次的抽象。Room 简化了数据库操作,减少了样板代码,同时支持与 LiveData 和 ViewModel 的…...

AIoT 智变浪潮演讲实录 | 刘浩然:让硬件会思考:边缘大模型网关助力硬件智能革新
4 月 2 日,由火山引擎与英特尔联合主办的 AIoT “智变浪潮”技术沙龙在深圳成功举行,活动聚焦 AI 硬件产业的技术落地与生态协同,吸引了芯片厂商、技术方案商、品牌方及投资机构代表等 700 多位嘉宾参会。 会上,火山引擎边缘智能高…...
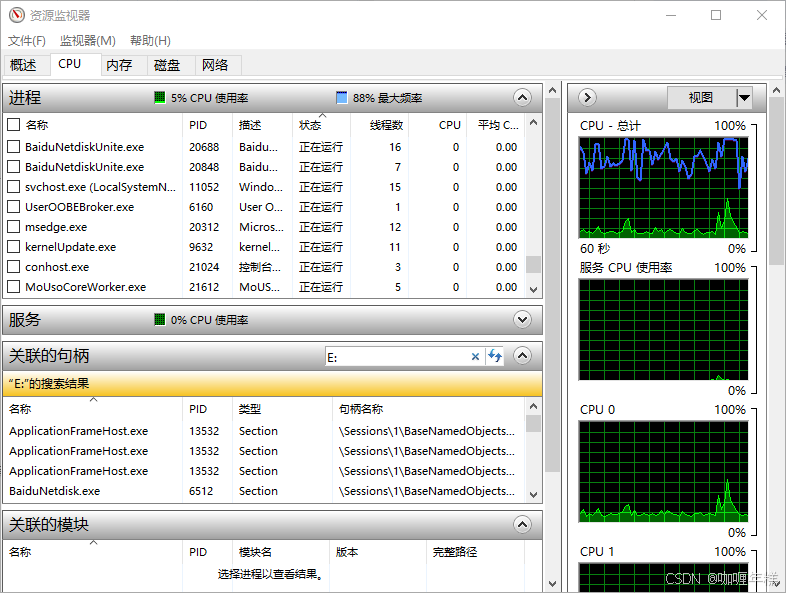
【Windows】系统安全移除移动存储设备指南:告别「设备被占用」弹窗
Windows系统安全移除移动存储设备指南:告别「设备被占用」弹窗 解决移动硬盘和U盘正在被占用无法弹出 一、问题背景 使用Windows系统时,经常遇到移动硬盘/U盘弹出失败提示「设备正在使用中」,即使已关闭所有可见程序。本文将系统梳理已验证…...

C++运算符重载全面总结
C运算符重载全面总结 运算符重载是C中一项强大的特性,它允许程序员为自定义类型定义运算符的行为。以下是关于C运算符重载的详细总结: 一、基本概念 1. 什么是运算符重载 运算符重载是指为自定义类型(类或结构体)重新定义或重…...
ArmSoM Sige5 CM5:RK3576 上 Ultralytics YOLOv11 边缘计算新标杆
在计算机视觉技术加速落地的今天,ArmSoM 正式宣布其基于 Rockchip RK3576 的旗舰产品 Sige5 开发板 和 CM5 核心板 全面支持 Ultralytics YOLOv11 模型的 RKNN 部署。这一突破标志着边缘计算领域迎来新一代高性能、低功耗的 AI 解决方案&am…...

【计算机网络】什么是路由?核心概念与实战详解
📌 引言 路由(Routing)是互联网的“导航系统”,负责将数据包从源设备精准送达目标设备。无论是浏览网页、发送消息还是视频通话,背后都依赖路由技术。本文将用通俗类比技术深度的方式,解析路由的核心机制。…...
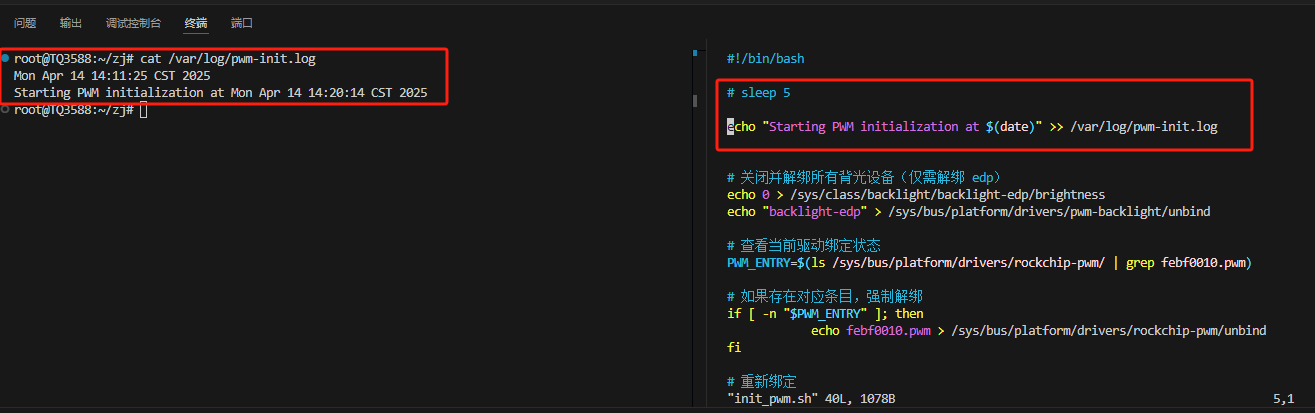
【ubuntu】linux开机自启动
目录 开机自启动: /etc/rc.loacl system V 使用/etc/rc*.d/系统运行优先级 遇到的问题: 1. Linux 系统启动阶段概述 方法1:/etc/rc5.d/ 脚本延时日志 方法二:使用 udev 规则来触发脚本执行 开机自启动: /etc/…...

dnf install openssl失败的原因和解决办法
网上有很多编译OpenSSL源码(3.x版本)为RPM包的文章,这些文章在安装RPM包时都是执行rpm -ivh openssl-xxx.rpm --nodeps --force 这个命令能在缺少依赖包的情况下能强行执行安装 其实根据Centos的文档,安装RPM包一般是执行yum install或dnf install。后者…...

Java 在人工智能领域的突围:从企业级架构到边缘计算的技术革新
一、Java AI 的底层逻辑:从语言特性到生态重构 在 Python 占据 AI 开发主导地位的当下,Java 正通过技术重构实现突围。作为拥有 30 年企业级开发经验的编程语言,Java 的核心优势在于强类型安全、内存管理能力和分布式系统支持,这…...

操作系统导论——第19章 分页:快速地址转换(TLB)
使用分页作为核心机制来实现虚拟内存,可能会带来较高的性能开销。使用分页,就要将内存地址空间切分成大量固定大小的单元(页),并且需要记录这些单元的地址映射信息。因为这些映射信息一般存储在物理内存中,…...

计算机网络:流量控制与可靠传输机制
目录 基本概念 流量控制:别噎着啦! 可靠传输:快递必达服务 传输差错:现实中的意外 滑动窗口 基本概念 换句话说:批量发货排队验收 停止-等待协议 SW(发1份等1份) 超时重传:…...

SaaS、Paas、IaaS、MaaS、BaaS五大云计算服务模式
科普版:通俗理解五大云计算服务模式 1. SaaS(软件即服务) 一句话解释:像“租用公寓”,直接使用现成的软件,无需操心维护。 案例:使用钉钉办公、在网页版WPS编辑文档。服务提供商负责软件更新和…...

计算机网络 - 三次握手相关问题
通过一些问题来讨论 TCP 协议中的三次握手机制 说一下三次握手的大致过程?为什么需要三次握手?2 次不可以吗?第三次握手,可以携带数据吗?第二次呢?三次握手连接阶段,最后一次ACK包丢失…...

通过使用 include 语句加载并执行一个CMake脚本来引入第三方库
通过使用 include 语句加载并执行一个CMake脚本来引入第三方库 当项目中使用到第三方库时,可以通过使用 include 语句来加载并执行一个CMake脚本,在引入的CMake脚本中进行第三方库的下载、构建和库查找路径的设置等操作,以这种方式简化项目中…...

架构生命周期(高软57)
系列文章目录 架构生命周期 文章目录 系列文章目录前言一、软件架构是什么?二、软件架构的内容三、软件设计阶段四、构件总结 前言 本节讲明架构设计的架构生命周期概念。 一、软件架构是什么? 二、软件架构的内容 三、软件设计阶段 四、构件 总结 就…...
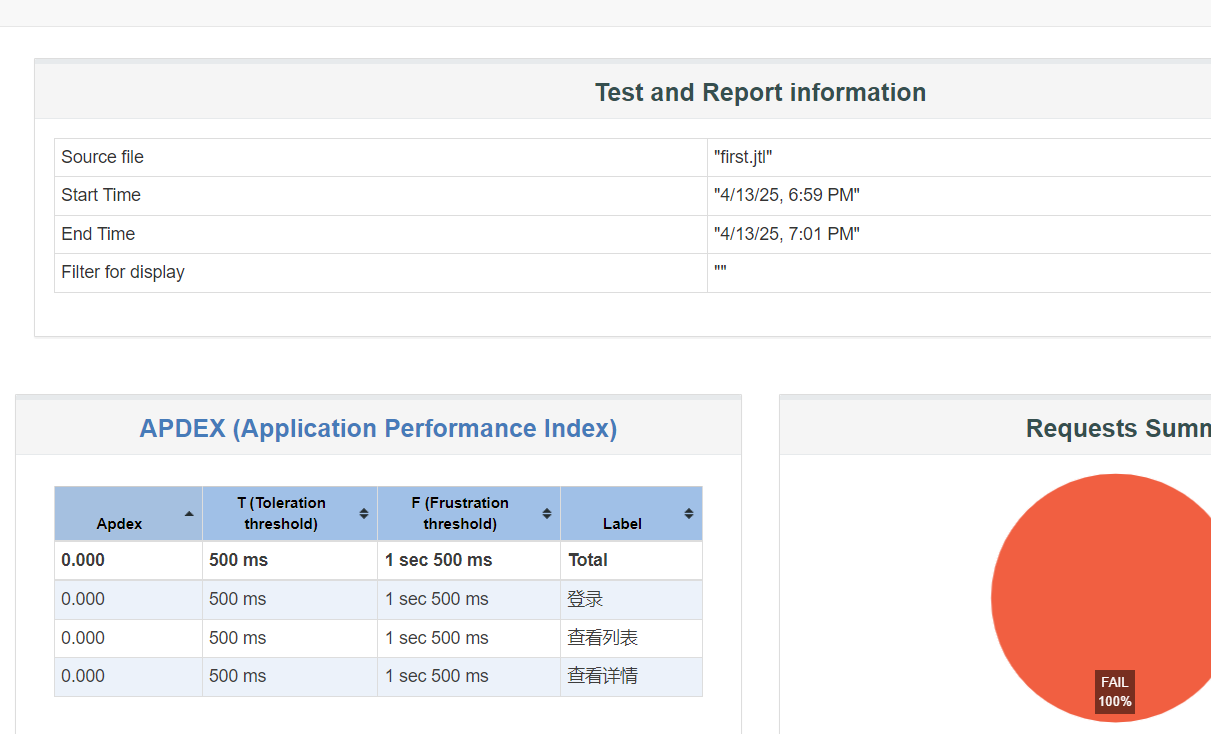
JMeter使用
1.简介 1.1 打开方式 ①点击bat,打开 ②添加JMeter系统环境变量,输⼊命令jmeter即可启动JMeter⼯具 1.2 配置 简体中文 放大字体 1.3 使用 ①添加线程组 ②创建http请求 2. 组件 2.1 线程组 控制JMeter将⽤于执⾏测试的线程数,也可以把⼀个线程理解为⼀个测…...

Ant Design Vue 表格复杂数据合并单元格
Ant Design Vue 表格复杂数据合并单元格 官方合并效果 官方示例 表头只支持列合并,使用 column 里的 colSpan 进行设置。 表格支持行/列合并,使用 render 里的单元格属性 colSpan 或者 rowSpan 设值为 0 时,设置的表格不会渲染。 <temp…...

Fiddler为什么可以看到一次HTTP请求数据?
1、作为代理服务器 Fiddler作为代理服务器,拦截了设备与互联网服务器之间的所有HTTP和HTTPS流量。当客户端(如浏览器)发送请求时,请求先到达Fiddler,然后由Fiddler转发到目标服务器;服务器的响应也会返回给…...

第十九讲 | XGBoost 与集成学习:精准高效的地学建模新范式
🟨 一、为什么要学习集成学习? 集成学习(Ensemble Learning) 是一种将多个弱学习器(如决策树)组合成一个强学习器的策略。它在地理学、生态学、遥感分类等领域表现尤为突出。 📌 应用优势&#…...

基于 GoFrame 框架的电子邮件发送实践:优势、特色与经验分享
1. 引言 如果你是一位有1-2年Go开发经验的后端开发者,可能已经熟悉了Go语言在性能和并发上的天然优势,也曾在项目中遇到过邮件发送的需求——无论是用户注册时的激活邮件、系统异常时的通知,还是营销活动中的批量促销邮件,邮件功…...