ScholarCopilot:“学术副驾驶“
这里写目录标题
- 引言:学术写作的痛点与 AI 的曙光
- ScholarCopilot 的核心武器库:智能生成与精准引用
- 智能文本生成:不止于“下一句”
- 智能引用管理:让引用恰到好处
- 揭秘背后机制:检索与生成的动态协同
- 快速上手:部署与使用你的 ScholarCopilot
- 部署本地 Demo
- 保持语料库更新
- (可选) 训练专属模型
- 应用前景
- 结论
在学术研究的征途中,论文写作无疑是关键一环,而准确、规范的引用更是衡量学术严谨性的重要标尺。然而,繁琐的文献检索、格式调整以及在写作过程中实时插入恰当引用的需求,常常让研究者们倍感压力。今天,我们将深入探讨一个旨在革新这一流程的开源项目——ScholarCopilot,一个由 TIGER-Lab 倾力打造的智能学术写作助手。它不仅仅是一个简单的文本生成工具,更是一位懂得何时、何地、如何精准引用的“学术副驾驶”。

引言:学术写作的痛点与 AI 的曙光
撰写高质量的学术论文,不仅需要清晰的逻辑、深入的见解,还需要对相关文献的广泛涉猎和精确引用。传统的写作流程中,研究者往往需要在不同的工具和数据库之间切换,手动查找、筛选、整理文献,并按照特定的格式插入文中,这一过程耗时耗力且容易出错。近年来,大型语言模型(LLM)在文本生成方面取得了显著进展,但将其直接应用于需要高度精确性和严谨性的学术写作,尤其是在处理引文方面,仍然面临巨大挑战。通用 LLM 往往难以保证引用的真实性和准确性,甚至可能产生“幻觉”引用。
正是在这样的背景下,ScholarCopilot 应运而生。它并非简单地替换写作者,而是作为一个强大的“Copilot”,在写作过程中提供智能化的辅助,特别是在文本补全和引用管理这两个核心环节上,展现出了令人瞩目的能力。
ScholarCopilot 的核心武器库:智能生成与精准引用
ScholarCopilot 的核心价值在于其两大关键特性:智能化的文本生成和精准的引用管理。这不仅仅是功能的堆砌,而是基于对学术写作流程深刻理解的精心设计。
智能文本生成:不止于“下一句”
许多写作助手都能提供文本建议,但 ScholarCopilot 的目标是提供更贴合学术语境的、结构化的内容生成。
- 上下文感知的句子建议: 它不仅仅是预测下一个词,而是能根据你已经写下的内容,提供接下来三句高度相关的、符合学术表达习惯的句子建议。这有助于打破写作障碍,保持思路流畅。
- 完整章节的自动补全: 对于论文中的标准章节(如引言、相关工作、方法等),ScholarCopilot 能够根据上下文和用户的初步输入,生成结构完整、逻辑连贯的章节草稿。这极大地提高了初稿的撰写效率。
- 保持连贯性: 所有的文本生成都基于对现有文本的理解,确保新生成的内容与前文在风格、术语和逻辑上保持一致,避免了通用模型可能产生的突兀感。
智能引用管理:让引用恰到好处
这是 ScholarCopilot 最具特色的功能,也是其区别于许多通用写作工具的关键所在。
- 实时上下文引用建议: 在你写作时,ScholarCopilot 会实时分析文本内容,并在它认为需要引用支撑的地方,主动推荐相关的参考文献。这就像有一位经验丰富的导师在旁边提醒你:“这里需要一个引用来支持你的观点。”
- 一键式引用插入: 对于推荐的文献,用户只需简单点击,即可将其按照规范的学术格式(如 [1], (Author, Year) 等,具体格式可能需配置)插入到当前光标位置。
- BibTeX 条目自动生成与导出: 更为便捷的是,所有插入的引用,ScholarCopilot 都能自动生成对应的 BibTeX 条目,方便用户在论文末尾整理参考文献列表,并导出使用。
揭秘背后机制:检索与生成的动态协同
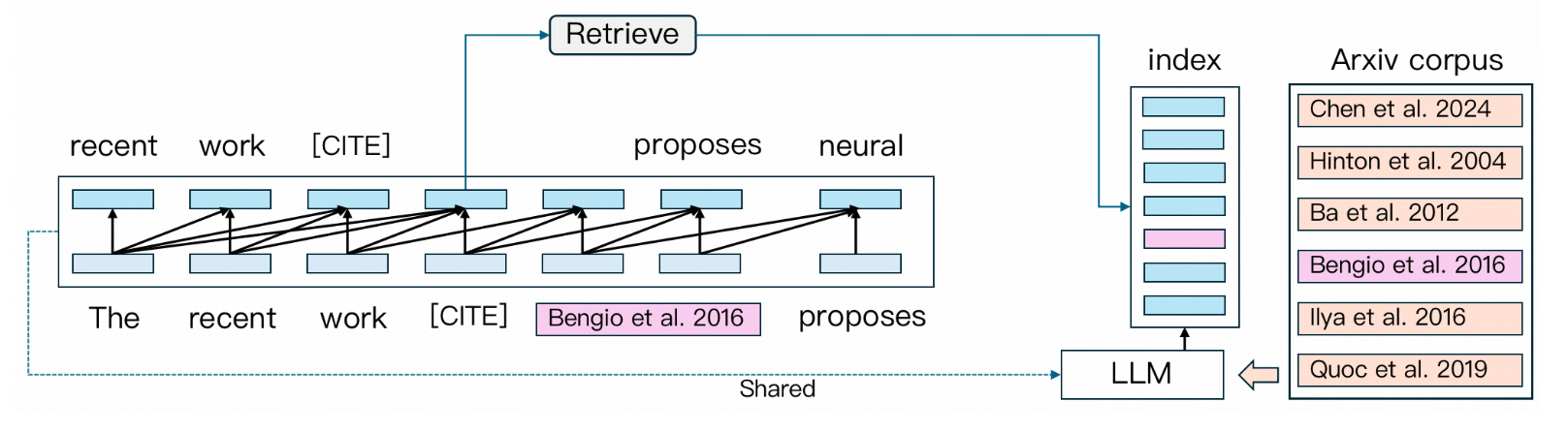
如此智能的功能是如何实现的?ScholarCopilot 的 README 文件揭示了其核心的推理流程:一个巧妙融合了检索(Retrieval)与生成(Generation)的统一模型架构。
(图片来源: ScholarCopilot GitHub Repository)
这个流程的关键在于一种动态切换机制。模型在生成文本的过程中,并非一味地向前输出,而是会利用其学习到的“引用模式”(learned citation patterns)来判断当前位置是否适合插入引用。
当模型判定需要引用时,它会暂停文本生成任务,并利用生成到“引用标记”(citation token)时的隐藏状态(hidden states)。这些隐藏状态编码了当前上下文的语义信息,可以被视为一个高效的查询向量。模型使用这个向量在其内部或外部的论文语料库(Corpus)中进行检索,找到最相关的几篇论文。
一旦用户确认或模型选择了合适的参考文献,系统会将其格式化并插入文本。随后,模型会无缝地切换回生成模式,基于更新后的上下文继续撰写连贯的文本。这种“生成-判断-检索-插入-继续生成”的闭环,使得 ScholarCopilot 能够将精准的引用有机地融入流畅的写作过程中,这相较于传统的“先写后补”或依赖外部插件的引用方式,无疑是巨大的进步。
快速上手:部署与使用你的 ScholarCopilot
TIGER-Lab 不仅发布了研究成果,还提供了代码和 Demo,让开发者和研究者能够快速体验和部署。
部署本地 Demo
1、克隆仓库:
git clone git@github.com:TIGER-AI-Lab/ScholarCopilot.git
cd ScholarCopilot/run_demo
2、设置环境:
pip install -r requirements.txt
3、下载模型与数据: 项目提供了便捷的脚本来下载所需资源。
bash download.sh
4、启动 Demo:
bash run_demo.sh
执行完毕后,根据提示即可在本地访问 ScholarCopilot 的演示界面。
保持语料库更新
学术研究日新月异,保持引用语料库的更新至关重要。ScholarCopilot 也考虑到了这一点,提供了更新 arXiv 语料库的流程:
1、从 Kaggle 等渠道下载最新的 arXiv 元数据。
2、使用提供的 Python 脚本处理元数据:
cd utils/
python process_arxiv_meta_data.py ARXIV_META_DATA_PATH ../data/corpus_data_arxiv_1215.jsonl
3、为新的语料库生成嵌入(Embedding),这是后续高效检索的基础:
bash encode_corpus.sh
4、构建 HNSW(Hierarchical Navigable Small World)索引,以实现快速相似性搜索:
python build_hnsw_index.py --input_dir <embedding dir> --output_dir <hnsw index dir>
通过这些步骤,你可以将最新的研究成果纳入 ScholarCopilot 的“视野”。
(可选) 训练专属模型
对于有更高定制化需求或希望在特定领域语料上进行优化的用户,项目还提供了训练指南:
1、下载训练数据:cd train/ && bash download.sh
2、配置并运行训练脚本:cd src/ && bash start_train.sh
- 注意:根据文档,复现论文结果需要相当大的计算资源(例如 4 台机器,每台 8 个 GPU,共 32 个 GPU)。
应用前景
ScholarCopilot 的出现,为广大学生、教师和科研工作者带来了福音。
- 效率提升: 大幅缩短文献检索、引用格式调整和文本撰写的时间,让研究者能更专注于思考和创新。
- 质量保障: 智能推荐和一键插入有助于减少引用错误和遗漏,提高论文的规范性和严谨性。
- 降低门槛: 对于初涉科研的学生,它能作为一个很好的辅助工具,帮助他们更快地掌握学术写作规范。
相较于市面上其他写作工具或通用大模型,ScholarCopilot 的核心优势在于其深度整合的、上下文感知的、以精准引用为目标的设计理念。它不是简单地做文本生成或文献管理,而是将两者无缝结合,真正服务于学术写作的特殊需求。
当然,作为一项新兴技术,它也可能存在一些局限性,例如对特定领域、非英语文献的覆盖程度,对复杂引用格式的适应性,以及对计算资源的需求等。但其展现出的潜力已足够令人兴奋。
结论
ScholarCopilot 以其创新的思路和实用的功能,为我们描绘了 AI 赋能学术写作的美好图景。它通过智能化的文本生成和精准的引用管理,有望将研究者从繁琐的事务性工作中解放出来,显著提升科研产出的效率和质量。虽然项目仍在发展中,但其开源的模式、清晰的架构和详尽的指南,无疑为社区的进一步贡献和完善奠定了良好基础。
如果你也为学术写作中的引用问题所困扰,不妨关注并尝试一下 ScholarCopilot。它或许就是你一直在寻找的那个“学术副驾驶”。
资源链接:
- 项目主页: https://tiger-ai-lab.github.io/ScholarCopilot/
- 论文: https://arxiv.org/abs/2504.00824
- 数据: https://huggingface.co/datasets/TIGER-Lab/ScholarCopilot-Data-v1/
- 模型: https://huggingface.co/TIGER-Lab/ScholarCopilot-v1
- Demo: https://huggingface.co/spaces/TIGER-Lab/ScholarCopilot
- GitHub: https://github.com/TIGER-AI-Lab/ScholarCopilot
相关文章:
ScholarCopilot:“学术副驾驶“
这里写目录标题 引言:学术写作的痛点与 AI 的曙光ScholarCopilot 的核心武器库:智能生成与精准引用智能文本生成:不止于“下一句”智能引用管理:让引用恰到好处 揭秘背后机制:检索与生成的动态协同快速上手:…...

MATLAB仿真多相滤波抽取与插值的频谱变化(可视化混叠和镜像)
MATLAB画图仿真多相滤波抽取与插值的频谱变化 可视化多速率信号处理抽取与插值的频谱变化 实信号/复信号 可视化混叠和镜像 目录 前言 一、抽取的基本原理 二、MATLAB仿真抽取运算 三、内插的基本原理 四、MATLAB仿真内插运算 总结 前言 在多速率系统中增加信号采样率的运…...

mongodb 远程访问
mongodb 远程访问 MongoDB 数据库的远程访问通常需要一些配置步骤,以确保安全性并正确设置网络访问权限。以下是一些基本步骤来允许远程访问 MongoDB 数据库: 修改 MongoDB 配置文件 首先,你需要编辑 MongoDB 的配置文件(通常是 …...
)
DAY 44 leetcode 28--字符串.实现strStr()
题号28 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 我的解法 双指针,slow定位&…...
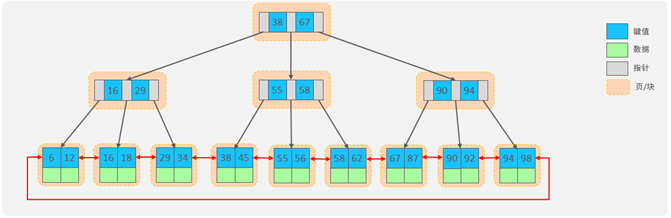
MySQL-存储引擎索引
存储引擎 MySQL体系结构 1). 连接层 最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程 池的概念,为通过认证安…...

图像处理有哪些核心技术?技术发展现状如何?
在数字化信息爆炸的时代,文档图像预处理技术正悄然改变着我们处理文字信息的方式。无论是手持拍摄的收据、扫描仪中的身份证,还是工业机器人采集的复杂文档,预处理技术都在背后默默提升着OCR(光学字符识别)系统的性能。…...

【小沐学GIS】基于C++绘制三维数字地球Earth(QT5、OpenGL、GIS、卫星)第五期
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第二期3【小沐学GIS】…...

KEGG注释脚本kofam2kegg.py--脚本010
采用kofam结合kegg官网htxt进行注释 用法: python kofam2kegg.py kofam.out ath00001.keg my_kegg_output code: import sys from collections import defaultdictdef parse_kofam_file(kofam_file):ko_to_genes defaultdict(list)with open(kofam_file) as f:…...
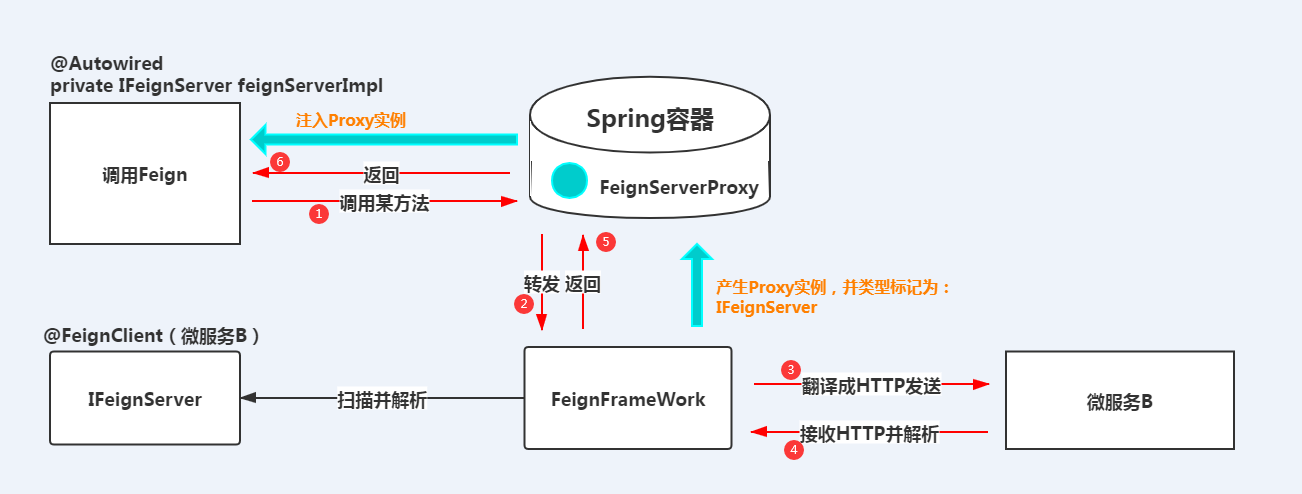
spring cloud OpenFeign 详解:安装配置、客户端负载均衡、声明式调用原理及代码示例
OpenFeign 详解:安装配置、客户端负载均衡、声明式调用原理及代码示例 1. OpenFeign 安装与配置 (1) 依赖管理 <!-- pom.xml 添加以下依赖 --> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud…...

【Java八股】
JVM JVM中有哪些引用 在Java中,引用(Reference)是指向对象的一个变量。Java中的引用不仅仅有常规的直接引用,还有不同类型的引用,用于控制垃圾回收(GC)的行为和优化性能。JVM中有四种引用类型…...

用 Deepseek 写的uniapp血型遗传查询工具
引言 在现代社会中,了解血型遗传规律对于优生优育、医疗健康等方面都有重要意义。本文将介绍如何使用Uniapp开发一个跨平台的血型遗传查询工具,帮助用户预测孩子可能的血型。 一、血型遗传基础知识 人类的ABO血型系统由三个等位基因决定:I…...
:4A广告代理公司与行业资质解读)
程序化广告行业(84/89):4A广告代理公司与行业资质解读
程序化广告行业(84/89):4A广告代理公司与行业资质解读 大家好!在探索程序化广告行业的道路上,每一次知识的分享都是我们共同进步的阶梯。一直以来,我都希望能和大家携手前行,深入了解这个充满机…...

go语言gRPC使用流程
1. 安装工具和依赖 安装 Protocol Buffers 编译器 (protoc) 下载地址:https://github.com/protocolbuffers/protobuf/releases 使用说明:https://protobuf.dev/ 【centos环境】yum方式安装:protoc[rootlocalhost demo-first]# yum install …...
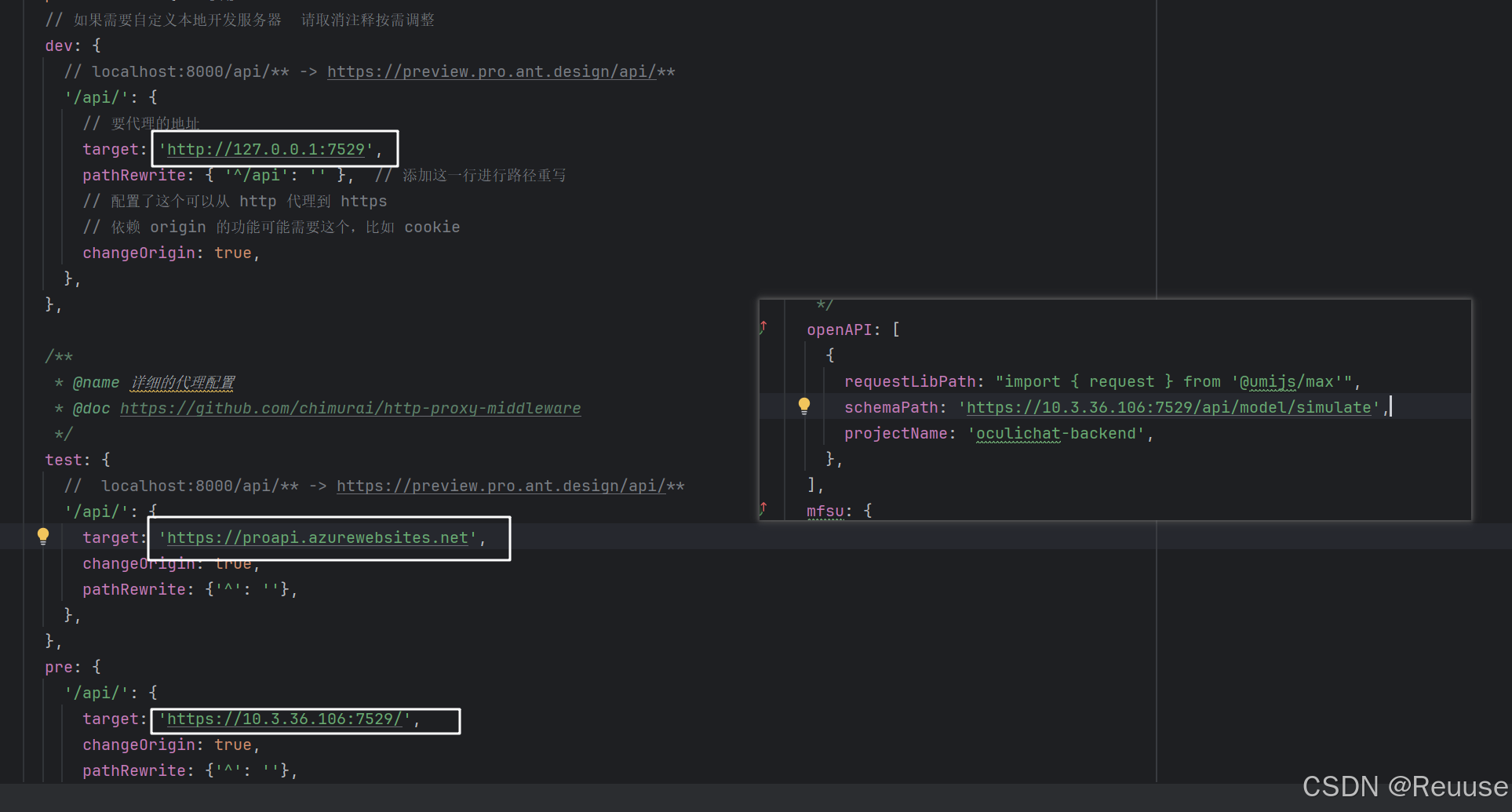
【眼底辅助诊断开放平台】项目笔记
这是一个标题 任务一前端页面开发:后端接口配置: 任务二自行部署接入服务 日志修改样式和解析MD文档接入服务 Note前端登陆不进去/更改后端api接口304 Not Modifiedlogin.cache.jsonERR_CONNECTION_TIMED_OUT跨域一般提交格式proxy.ts src/coponents 目录…...

Java笔记5——面向对象(下)
目录 一、抽象类和接口 1-1、抽象类(包含抽象方法的类) 1-2、接口 编辑编辑 二、多态 编辑 1. 自动类型转换(向上转型) 示例: 注意: 2. 强制类型转换(向下转型) 示…...
NI的LABVIEW工具安装及卸载步骤说明
一.介绍 最近接到个转交的项目,项目主要作为上位机工具开发,在对接下位机时,有用到NI的labview工具。labview软件是由美国国家仪器(NI)公司研制开发的一种程序开发环境,主要用于汽车测试、数据采集、芯片测…...
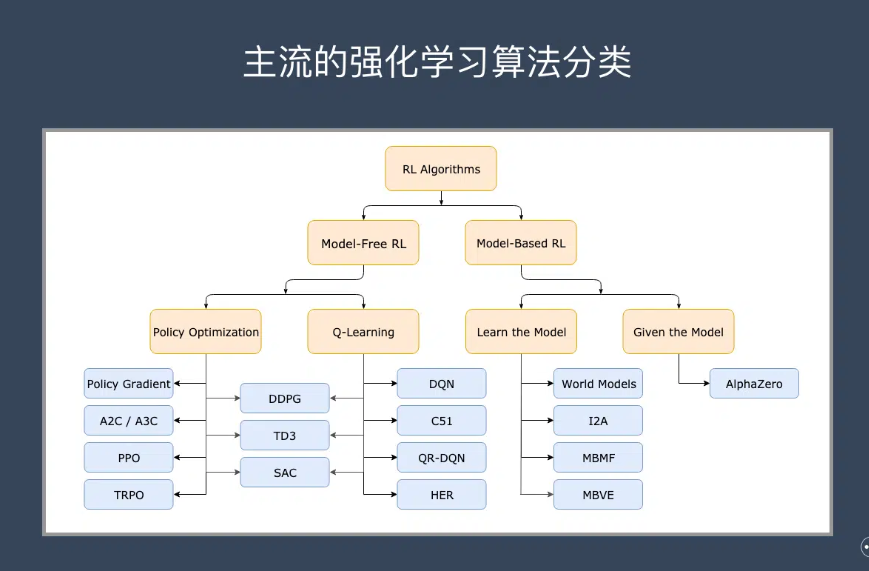
[reinforcement learning] 是什么 | 应用场景 | Andrew Barto and Richard Sutton
目录 什么是强化学习? 强化学习的应用场景 广告和推荐 对话系统 强化学习的主流算法 纽约时报:Turing Award Goes to 2 Pioneers of Artificial Intelligence wiki 资料混合:youtube, wiki, github 今天下午上课刷到了不少࿰…...

css一些注意事项
css一些注意事项 .bg_ {background-image: url(/static/photo/activity_bg.png);background-size: 100% auto;background-repeat: no-repeat;background: linear-gradient(to bottom, #CADCEA, #E8F3F6);min-height: 100vh; } 背景图片路径正确但是并没有显示 // 方案1&…...

[从零开始学数据库] 基本SQL
注意我们的主机就是我们的Mysql数据库服务器 这里我们可以用多个库 SQL分类(核心是字段的CRUD) 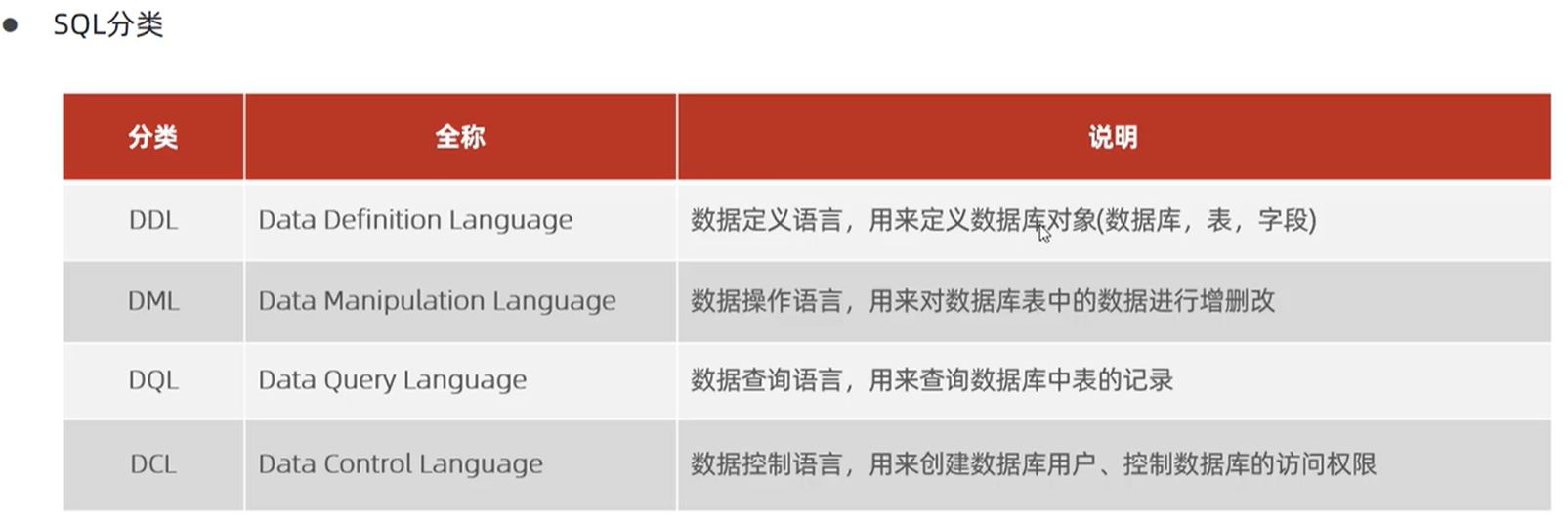 重点是我…...

react/vue中前端多图片展示页面优化图片加载速度的五种方案
需求背景 在多项目中 例如官网项目中 会出现很多大图片显示的情况 这个时候就会出现图片过大 公司带宽不够之类导致页面加载速度过慢及页面出现后图片仍然占位但并未加载出来 或者因为网络问题导致图片区域黑块等等场景 这个时候我们就要对图片和当前场景进行优化 方案定…...

qt中的正则表达式
问题: 1.在文本中把dog替换成cat,但可能会把dog1替换成cat1,如果原本不想替换dog1,就会出现问题 2文本中想获取某种以.txt为结尾的多有文本,普通的不能使用 3如果需要找到在不同的系统中寻找换行符,可以…...

AT_abc400_e [ABC400E] Ringo‘s Favorite Numbers 3 题解
题目传送门 题目大意 题目描述 对于正整数 N N N,当且仅当满足以下两个条件时, N N N 被称为 400 number: N N N 恰好有 2 2 2 种不同的素因数。对于 N N N 的每个素因数 p p p, N N N 被 p p p 整除的次数为偶数次。更严…...

git 提交标签
Git 提交标签 提交消息格式: <type>: <description> (示例:git commit -m "feat: add user login API") 标签适用场景feat新增功能(Feature)。fix修复 Bug(Bug fix&…...
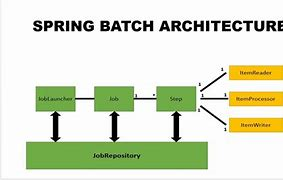
关于 Spring Batch 的详细解析及其同类框架的对比分析,以及如何自己设计一个java批处理框架(类似spring batch)的步骤
以下是关于 Spring Batch 的详细解析及其同类框架的对比分析: 一、Spring Batch 核心详解 1. 核心概念 作业(Job):批处理任务的顶层容器,由多个步骤(Step)组成。 步骤(Step&#…...

【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识
【Java面试系列】Spring Cloud微服务架构中的分布式事务实现与性能优化详解 - 3-5年Java开发必备知识 引言 在微服务架构中,分布式事务是一个不可避免的挑战。随着业务复杂度的提升,如何保证跨服务的数据一致性成为面试中的高频问题。本文将从基础到进…...

【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇+改进】A题解题全流程(持续更新)
【第十三届“泰迪杯”数据挖掘挑战赛】【2025泰迪杯】【论文篇改进】A题解题全流程(持续更新) 写在前面: 我是一个人,没有团队,所以出的比较慢,每年只做一次赛题,泰迪杯,我会认真对…...
)
Linux系统常见磁盘扩容操作(Common Disk Expansion Operations in Linux Systems)
Linux系统常见磁盘扩容操作 目录说明 一、准备工作:获取目标磁盘信息 (1)确认分区表格式和文件系统 二、扩容已有MBR分区 (1)分区后扩容 ext为例 xfs为例 三、扩容已有GPT分区 (1)分区…...

数据结构——哈希详解
数据结构——哈希详解 目录 一、哈希的定义 二、六种哈希函数的构造方法 2.1 除留取余法 2.2 平方取中法 2.3 随机数法 2.4 折叠法 2.5 数字分析法 2.6 直接定值法 三、四种解决哈希冲突的方法 3.1 开放地址法 3.1.1 线性探测法 3.1.2 二次探测法 3.2 链地址法 3…...
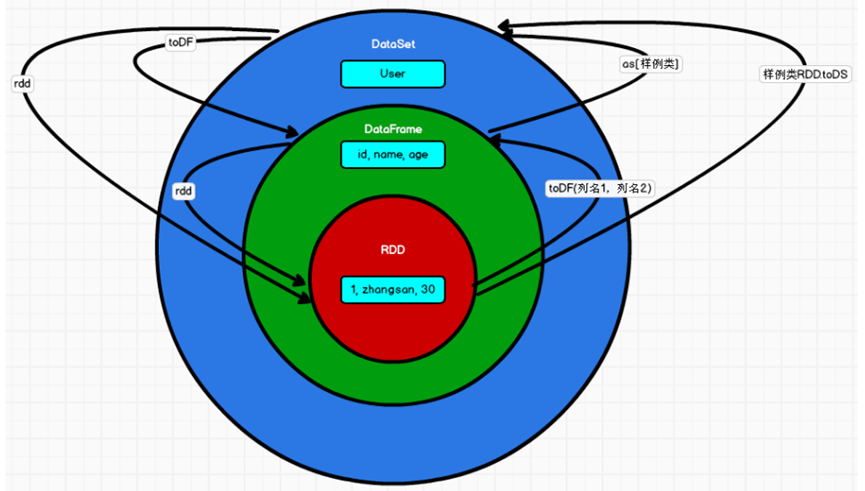
Spark-SQL核心编程
简介 Hadoop与Spark-SQL的对比 Hadoop在处理结构化数据方面存在局限性,无法有效处理某些类型的数据。 Spark应运而生,特别设计了处理结构化数据的模块,称为Spark SQL(原称Shark)。 SparkSQL的发展历程: Sp…...

pywebview 常用问题分享
文章目录 前言问题描述与方案(待补充)1、动态设置本地调试目录和打包目录2、构建后运行程序白屏 前言 最近做一个pywebview项目,遇到了一些问题,记录一下,分享给大家,希望能帮助有遇到相似问题的人事。 问题描述与方案(待补充) …...