分词与倒排索引的原理:深入解析与 Java 实践
在信息检索领域,如搜索引擎和全文检索系统,分词(Tokenization)和倒排索引(Inverted Index)是核心技术。分词将文本拆分为语义单元,为索引构建提供基础;倒排索引则高效映射词项到文档,实现快速查询。Java 开发者在构建搜索功能时,理解这两者的原理不仅有助于优化性能,还能指导系统设计。本文将深入剖析分词与倒排索引的原理,探讨其实现机制,并结合 Java 代码展示一个简易的搜索系统。
一、分词的基本概念
1. 什么是分词?
分词是将连续的文本分割为离散的词项(Token)的过程。词项通常是具有语义的单词、短语或其他单元。例如:
- 文本:“我爱学习编程”
- 分词结果:
["我", "爱", "学习", "编程"]
分词是自然语言处理(NLP)和信息检索的起点,直接影响索引质量和查询精度。
2. 分词的挑战
- 语言差异:
- 英文:单词以空格分隔,分词较简单(e.g., “I love coding” →
["I", "love", "coding"])。 - 中文:无明显分隔符,需语义分析(e.g., “我爱学习”可能分词为
["我", "爱", "学习"]或["我爱", "学习"])。
- 英文:单词以空格分隔,分词较简单(e.g., “I love coding” →
- 歧义:如“乒乓球拍”可分为
["乒乓球", "拍"]或["乒乓", "球拍"]。 - 停用词:如“的”、“是”,需过滤以减少索引噪声。
3. 分词算法
- 基于词典:
- 正向最大匹配(FMM):从左到右匹配最长词。
- 逆向最大匹配(BMM):从右到左匹配。
- 基于统计:
- HMM、CRF:根据语料库概率分词。
- 机器学习:如基于神经网络的序列标注。
- 混合方法:结合词典和统计,如 HanLP、jieba。
二、倒排索引的基本概念
1. 什么是倒排索引?
倒排索引是一种数据结构,用于映射词项到包含该词项的文档列表。它是搜索引擎的核心,结构如下:
- 词项(Term):分词后的单词或短语。
- 倒排表(Posting List):包含词项的文档 ID 列表,可能附带位置、频率等元数据。
示例:
- 文档集合:
- Doc1: “我爱学习”
- Doc2: “学习编程很有趣”
- Doc3: “我爱编程”
- 分词后倒排索引:
(格式:我: [(Doc1, 1), (Doc3, 1)] 爱: [(Doc1, 1), (Doc3, 1)] 学习: [(Doc1, 1), (Doc2, 1)] 编程: [(Doc2, 1), (Doc3, 1)] 有趣: [(Doc2, 1)]词项: [(文档ID, 词频)])
2. 倒排索引的优点
- 高效查询:通过词项直接定位文档,时间复杂度接近 O(1)。
- 灵活性:支持布尔查询(如 AND、OR)、短语查询等。
- 扩展性:可存储词频、位置等,优化排序和相关性。
3. 构建与查询流程
- 构建:
- 分词:将文档拆分为词项。
- 索引:为每个词项记录文档 ID 和元数据。
- 存储:倒排表通常存储在内存或磁盘。
- 查询:
- 分词:将查询文本拆分为词项。
- 查找:根据词项检索倒排表。
- 合并:对多词查询合并结果(如交集、并集)。
三、分词与倒排索引的实现原理
1. 分词实现
以正向最大匹配(FMM)为例:
- 输入:文本、词典(如
["我", "爱", "学习", "编程", "我爱"])。 - 流程:
- 从左到右扫描文本。
- 尝试匹配最长词。
- 记录词并移动指针。
- 示例:
- 文本:“我爱学习编程”
- 匹配:
- “我” → 匹配,指针+1。
- “爱” → 匹配,指针+1。
- “学习” → 匹配,指针+2。
- “编程” → 匹配,结束。
- 结果:
["我", "爱", "学习", "编程"]
伪代码:
List<String> segment(String text, Set<String> dict) {List<String> result = new ArrayList<>();int i = 0;while (i < text.length()) {String longest = "";for (int j = i + 1; j <= text.length(); j++) {String word = text.substring(i, j);if (dict.contains(word) && word.length() > longest.length()) {longest = word;}}if (longest.isEmpty()) {longest = text.charAt(i) + "";}result.add(longest);i += longest.length();}return result;
}
2. 倒排索引实现
- 数据结构:
Map<String, List<Posting>>:词项映射到倒排表。Posting:包含文档 ID、词频等。
- 构建:
- 分词每篇文档。
- 为每个词项添加文档 ID。
- 按词项排序存储。
- 查询:
- 单词查询:直接返回倒排表。
- 多词查询:合并倒排表(如交集)。
伪代码:
class InvertedIndex {Map<String, List<Posting>> index = new HashMap<>();void addDocument(int docId, String text) {List<String> tokens = segment(text);Map<String, Integer> freq = new HashMap<>();for (String token : tokens) {freq.put(token, freq.getOrDefault(token, 0) + 1);}for (Map.Entry<String, Integer> entry : freq.entrySet()) {index.computeIfAbsent(entry.getKey(), k -> new ArrayList<>()).add(new Posting(docId, entry.getValue()));}}List<Integer> search(String query) {List<String> tokens = segment(query);List<List<Integer>> results = new ArrayList<>();for (String token : tokens) {List<Integer> docIds = index.getOrDefault(token, Collections.emptyList()).stream().map(p -> p.docId).collect(Collectors.toList());results.add(docIds);}return intersect(results); // 交集}
}
四、Java 实践:简易搜索系统
以下通过 Spring Boot 实现一个简易搜索引擎,展示分词与倒排索引的应用。
1. 环境准备
- 依赖(
pom.xml):
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency>
</dependencies>
2. 分词实现
@Component
public class SimpleTokenizer {private final Set<String> dictionary;public SimpleTokenizer() {// 模拟词典dictionary = new HashSet<>(Arrays.asList("我", "爱", "学习", "编程", "很有趣", "代码", "开发"));}public List<String> tokenize(String text) {List<String> tokens = new ArrayList<>();int i = 0;while (i < text.length()) {String longest = "";for (int j = i + 1; j <= text.length() && j <= i + 5; j++) {String word = text.substring(i, j);if (dictionary.contains(word) && word.length() > longest.length()) {longest = word;}}if (longest.isEmpty()) {longest = text.charAt(i) + "";}tokens.add(longest);i += longest.length();}return tokens;}
}
3. 倒排索引实现
@Component
public class InvertedIndex {private final Map<String, List<Posting>> index = new HashMap<>();private final SimpleTokenizer tokenizer;@Autowiredpublic InvertedIndex(SimpleTokenizer tokenizer) {this.tokenizer = tokenizer;}public void addDocument(int docId, String content) {List<String> tokens = tokenizer.tokenize(content);Map<String, Integer> freq = new HashMap<>();for (String token : tokens) {freq.put(token, freq.getOrDefault(token, 0) + 1);}synchronized (index) {for (Map.Entry<String, Integer> entry : freq.entrySet()) {index.computeIfAbsent(entry.getKey(), k -> new ArrayList<>()).add(new Posting(docId, entry.getValue()));}}}public List<Integer> search(String query) {List<String> tokens = tokenizer.tokenize(query);List<List<Integer>> docLists = new ArrayList<>();for (String token : tokens) {List<Integer> docIds = index.getOrDefault(token, Collections.emptyList()).stream().map(p -> p.docId).collect(Collectors.toList());docLists.add(docIds);}return intersect(docLists);}private List<Integer> intersect(List<List<Integer>> lists) {if (lists.isEmpty()) return Collections.emptyList();List<Integer> result = new ArrayList<>(lists.get(0));for (int i = 1; i < lists.size(); i++) {List<Integer> next = lists.get(i);result.retainAll(next);}return result;}
}class Posting {int docId;int freq;Posting(int docId, int freq) {this.docId = docId;this.freq = freq;}
}
4. 服务类
@Service
public class SearchService {private final InvertedIndex index;private final Map<Integer, String> documents = new HashMap<>();private int docIdCounter = 1;@Autowiredpublic SearchService(InvertedIndex index) {this.index = index;}public void addDocument(String content) {int docId;synchronized (this) {docId = docIdCounter++;}documents.put(docId, content);index.addDocument(docId, content);}public List<String> search(String query) {List<Integer> docIds = index.search(query);List<String> results = new ArrayList<>();for (int docId : docIds) {results.add("Doc" + docId + ": " + documents.get(docId));}return results;}
}
5. 控制器
@RestController
@RequestMapping("/search")
public class SearchController {@Autowiredprivate SearchService searchService;@PostMapping("/add")public String addDocument(@RequestBody String content) {searchService.addDocument(content);return "Document added";}@GetMapping("/query")public List<String> search(@RequestParam String query) {return searchService.search(query);}
}
6. 主应用类
@SpringBootApplication
public class SearchDemoApplication {public static void main(String[] args) {SpringApplication.run(SearchDemoApplication.class, args);}
}
7. 测试
测试 1:添加文档
- 请求:
POST http://localhost:8080/search/add- Body:
"我爱学习编程" - Body:
"学习编程很有趣" - Body:
"我爱代码开发"
- Body:
- 响应:
"Document added"
测试 2:查询
- 请求:
GET http://localhost:8080/search/query?query=我爱 - 响应:
["Doc1: 我爱学习编程","Doc3: 我爱代码开发" ] - 分析:查询分词为
["我", "爱"],取倒排表交集,返回包含“我”和“爱”的文档。
测试 3:性能测试
- 代码:
public class SearchPerformanceTest {public static void main(String[] args) {SimpleTokenizer tokenizer = new SimpleTokenizer();InvertedIndex index = new InvertedIndex(tokenizer);// 添加 1000 篇文档for (int i = 1; i <= 1000; i++) {index.addDocument(i, "我爱学习编程代码开发很有趣" + i);}// 查询性能long start = System.currentTimeMillis();List<Integer> results = index.search("学习编程");long end = System.currentTimeMillis();System.out.println("Search time: " + (end - start) + "ms, Results: " + results.size());} } - 结果:
Search time: 2ms, Results: 1000 - 分析:倒排索引高效定位文档。
五、优化与实践经验
1. 分词优化
- 词典扩展:引入更大词库(如 THULAC)。
- 停用词:
Set<String> stopWords = Set.of("的", "是"); tokens.removeIf(stopWords::contains);
2. 倒排索引优化
- 压缩:存储差值编码的文档 ID。
- 缓存:热点词项缓存到内存。
- 并行查询:
CompletableFuture.supplyAsync(() -> index.search(token));
3. 注意事项
- 分词精度:中文需平衡粒度和语义。
- 索引更新:动态更新需加锁。
- 内存管理:大索引需分片存储。
六、总结
分词与倒排索引是信息检索的基石。分词通过算法(如 FMM)将文本分解为词项,为索引提供输入;倒排索引通过词项到文档的映射,实现高效查询。本文从原理到实现,结合源码和 Spring Boot 实践展示了二者的应用。
相关文章:

分词与倒排索引的原理:深入解析与 Java 实践
在信息检索领域,如搜索引擎和全文检索系统,分词(Tokenization)和倒排索引(Inverted Index)是核心技术。分词将文本拆分为语义单元,为索引构建提供基础;倒排索引则高效映射词项到文档…...
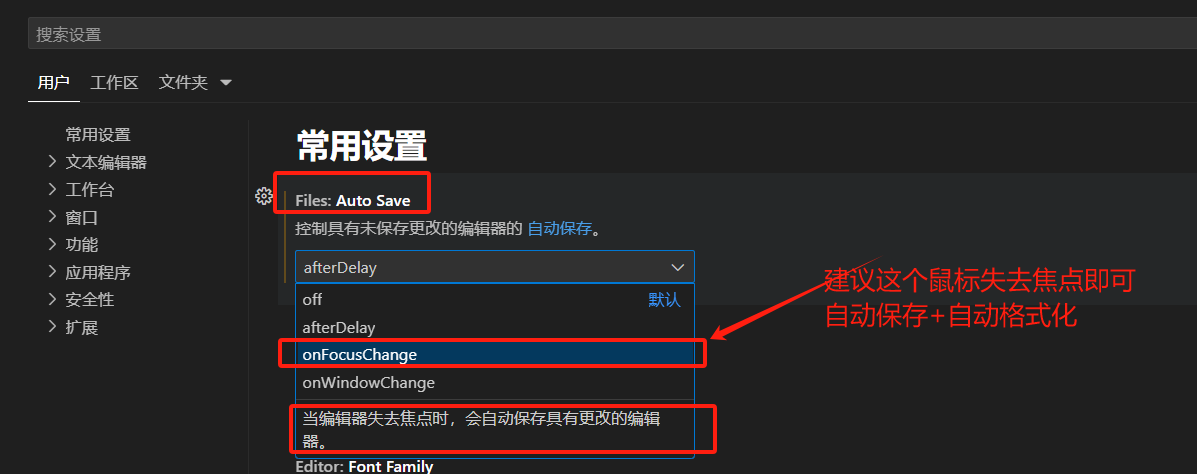
vscode格式化为什么失效?自动保存和格式化(Prettier - Code formatter,vue-format)
vscode自动格式化保存最终配置 博主找了好多的插件,也跟着教程配置了很多,结果还是没有办法格式化,最终发现了一个隐藏的小齿轮,配置完后就生效了 关键步骤 关键配置 一定要点小齿轮!!! 这个小…...
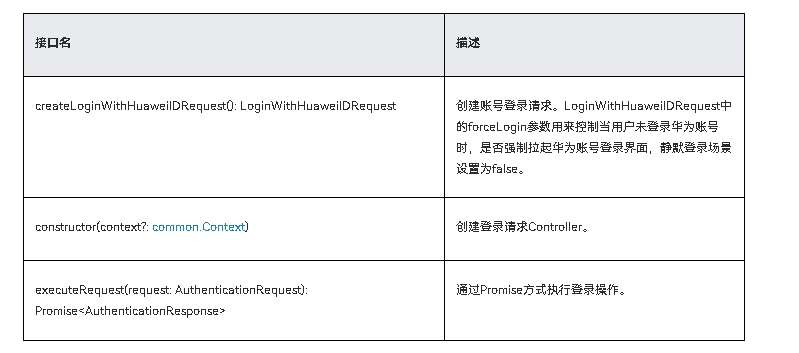
鸿蒙应用元服务开发-Account Kit配置登录权限
一、场景介绍 华为账号登录是基于OAuth 2.0协议标准和OpenID Connect协议标准构建的OAuth2.0 授权登录系统,元服务可以方便地获取华为账号用户的身份标识,快速建立元服务内的用户体系。 用户打开元服务时,不需要用户点击登录/注册按钮&#…...

如何提高webrtc操作跟手时间,降低延迟
第一次做webrtc项目,操作延迟,一直是个问题,多次调试都不能达到理想效果。偶尔发现提高jitterBuffer时间可以解决此问题。关键代码 const _setJitter (values: number) > { const receives peerConnection.getReceivers();receives.f…...

Promise链式调用、async和await
目录 回调函数地狱与Promise链式调用 一、回调函数地狱 1. 典型场景示例 2. 回调地狱的问题 二、Promise链式调用 1. 链式调用解决回调地狱 2. 链式调用的核心规则 三、链式调用深度解析 1. 链式调用本质 2. 错误处理机制 四、回调地狱 vs 链式调用 五、高级链式技…...

React ROUTER之嵌套路由
第一张是需要修改router文件createBrowserRouterd参数数组中的路由关系 第二张是需要在一级路由的index.js中选择二级路由的位置 第一步是在全局的router.js文件中加入新的children属性,如图 第二步是在一级路由的index.js文件中声明outLet组件 默认二级路由 在…...
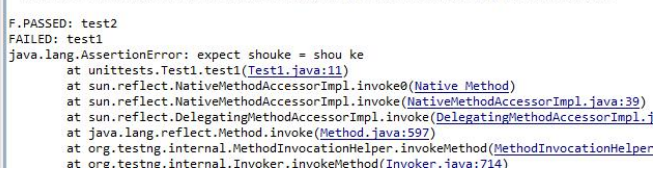
TestNG 单元测试详解
1、测试环境 jdk1.8.0 121 myeclipse-10.0-offline-installer-windows.exe TestNG 插件 org.testng.eclipse 6.8.6.20130607 0745 2、介绍 套件(suite):由一个 XML 文件表示,通过<suite>标签定义,包含一个或更多测试(test)。测试(test):由<test>定义…...

测试100问:http和https的区别是什么?
哈喽,大家好,我是十二,今天给大家分享的问题是:http和https的区别是什么? 首先我们要知道 HTTP 协议传播的数据都是未加密的,也就是明文的,因此呢使用 http协议传输一些隐私信息也就非常不安全&…...
通过python实现bilibili缓存视频转为mp4格式
需要提前下好ffmpeg import os import fnmatch import subprocess Bilibili缓存的视频,*280.m4s结尾的是音频文件,*050.m4s结尾的是视频,删除16进制下前9个0,即为正常音/视频 使用os.walk模块,遍历每一个目录…...
)
高效爬虫:一文掌握 Crawlee 的详细使用(web高效抓取和浏览器自动化库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Crawlee概述1.1 Crawlee介绍1.2 为什么 Crawlee 是网页抓取和爬取的首选?1.3 为什么使用 Crawlee 而不是 Scrapy1.4 Crawlee的安装二、Crawlee的基本使用2.1 BeautifulSoupCrawler的使用方式2.2 ParselCrawler的使…...
)
React中 点击事件写法 的注意(this、箭头函数)
目录 1、错误写法:onClick{this.acceptAlls()} 2、正确写法:onClick{this.acceptAlls}(不带括号) 总结 方案1:构造函数绑定 方案2:箭头函数包装方法(更简洁) 方案3&am…...

【分享】Ftrans文件摆渡系统:既保障传输安全,又提供强集成支持
【分享】Ftrans文件摆渡系统:既保障传输安全,又提供强集成支持! 在数字化浪潮中,企业对数据安全愈发重视,网络隔离成为保护核心数据的关键防线,比如隔离成研发网-办公网、生产网-测试网、内网-外网等。网络…...

Day31笔记-进程和线程
一、进程和线程简介 1.概念 1.1多任务 程序的运行是CPU和内存协同工作的结果 操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统 问题1:什么是多任务? 就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边…...

python每日一练
题目一 输入10个整数,输出其中不同的数,即如果一个数出现了多次,只输出一次(要求按照每一个不同的数第一次出现的顺序输出)。 解题 错误题解 a list(map(int,input().split())) b [] b.append(a[i]) for i in range(2,11):if a[i] not in b:b.append(a[i]) print(b)但是会…...

深入理解 RxSwift 中的 Driver:用法与实践
目录 前言 一、什么是Driver 1.不会发出错误 2.主线程保证 3.可重放 4.易于绑定 二、Driver vs Observable 三、使用场景 1.绑定数据到UI控件 2.响应用户交互 3.需要线程安全的逻辑 4.如何使用Driver? 1.绑定文本输入到Label 2.处理按钮点击事件 3.从网络请求…...
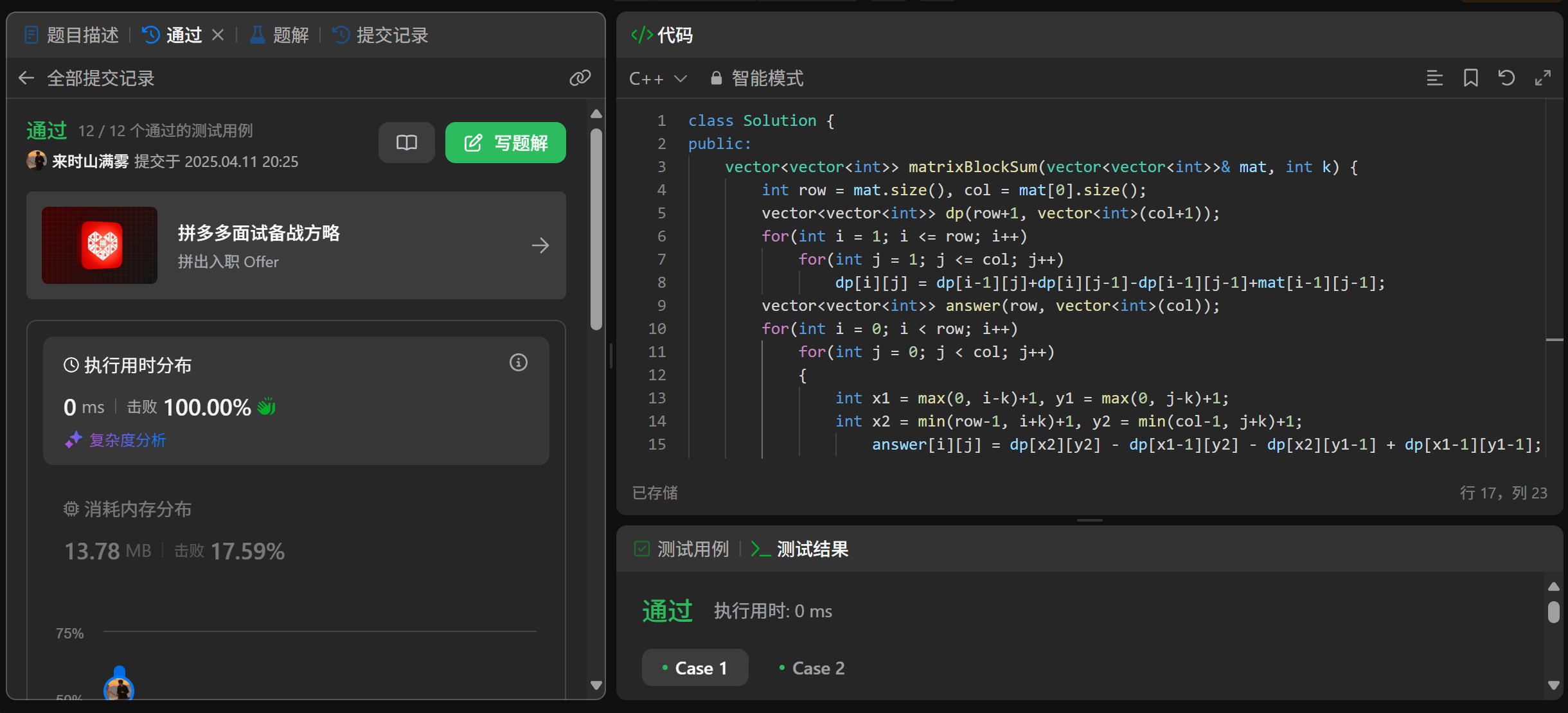
算法思想之前缀和(二)
欢迎拜访:雾里看山-CSDN博客 本篇主题:算法思想之前缀和(二) 发布时间:2025.4.11 隶属专栏:算法 目录 算法介绍核心思想大致步骤 例题和为 K 的子数组题目链接题目描述算法思路代码实现 和可被 K 整除的子数组题目链接题目描述算法…...
)
C++ - 数据容器之 unordered_map(声明与初始化、插入元素、访问元素、遍历元素、删除元素、查找元素)
一、unordered_map unordered_map 是 C STL 中的一个关联容器,它有如下特点 unordered_map 存储键值对,使用哈希表实现 unordered_map 的每个键在容器中只能出现一次 unordered_map 的存储的键值对是无序的 平均情况下,查找、插入、删除都…...

六、分布式嵌入
六、分布式嵌入 文章目录 六、分布式嵌入前言一、先要配置torch.distributed环境二、Distributed Embeddings2.1 EmbeddingBagCollectionSharder2.2 ShardedEmbeddingBagCollection 三、Planner总结 前言 我们已经使用了TorchRec的主模块:EmbeddedBagCollection。我…...
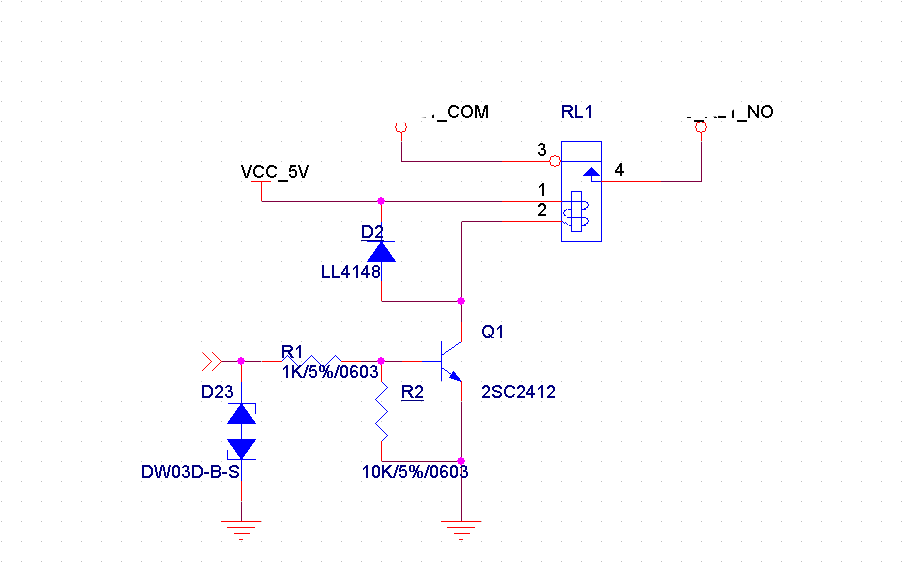
硬件知识积累 单片机+ 光耦 + 继电器需要注意的地方
1. 电路图 与其数值描述 1.1 单片机引脚信号为 OPtoCoupler_control_4 PC817SB 为 光耦 继电器 SRD-05VDC-SL-A 的线圈电压为 67Ω。 2. 需注意的地方 1. 单片机的推挽输出的电流最大为 25mA 2. 注意光耦的 CTR 参数 3. 注意继电器线圈的 内阻 4. 继电器的开启电压。 因为光耦…...
Dockerfile 学习指南和简单实战
引言 Dockerfile 是一种用于定义 Docker 镜像构建步骤的文本文件。它通过一系列指令描述了如何一步步构建一个镜像,包括安装依赖、设置环境变量、复制文件等。在现实生活中,Dockerfile 的主要用途是帮助开发者快速、一致地构建和部署应用。它确保了应用…...

MCU屏和RGB屏
一、MCU屏 MCU屏:全称为单片机控制屏(Microcontroller Unit Screen),在显示屏背后集成了单片机控制器,因此,MCU屏里面有专用的驱动芯片。驱动芯片如:ILI9488、ILI9341、SSD1963等。驱动芯片里…...

Elasticsearch 向量数据库,原生支持 Google Cloud Vertex AI 平台
作者:来自 Elastic Valerio Arvizzigno Elasticsearch 将作为第一个第三方原生语义对齐引擎,支持 Google Cloud 的 Vertex AI 平台和 Google 的 Gemini 模型。这使得联合用户能够基于企业数据构建完全可定制的生成式 AI 体验,并借助 Elastics…...
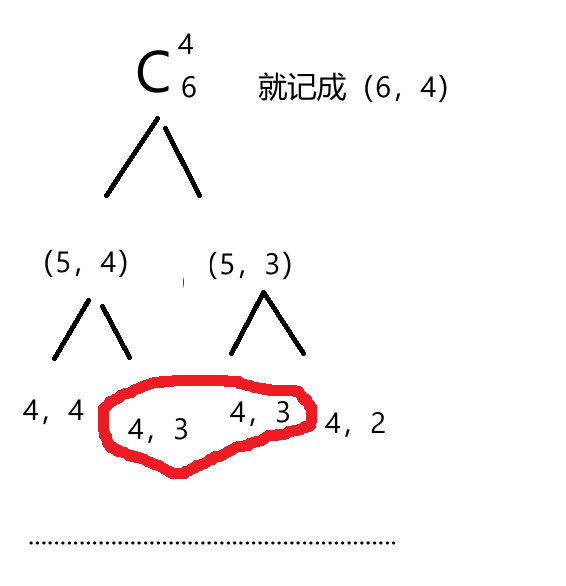
蓝桥杯基础数论入门
一.试除法 首先我们要了解,所有大于1的自然数都能进行质因数分解。试除法作用如下: 质数判断 试除法通过验证一个数是否能被小于它的数(一般是用2到用根号x)整除来判断其是否为质数。根据定义,质数只能被1和自身整除…...

Spring 事件机制与观察者模式的深度解析
一、引言 在软件设计中,观察者模式(Observer Pattern)是一种非常经典且实用的设计模式。它允许一个对象(Subject)在状态发生改变时通知所有依赖它的对象(Observers),从而实现对象之…...

【软考系统架构设计师】信息安全技术基础知识点
1、 信息安全包括5个基本要素:机密性、完整性、可用性、可控性与可审查性。 机密性:确保信息不暴露给未授权的实体或进程。(采取加密措施) 完整性:只有得到允许的人才能修改数据,并且能够判断出数据是否已…...

Python编程快速上手 让繁琐工作自动化笔记
编程基础 字符串使用单引号...

2025年第十六届蓝桥杯省赛真题解析 Java B组(简单经验分享)
之前一年拿了国二后,基本就没刷过题了,实力掉了好多,这次参赛只是为了学校的加分水水而已,希望能拿个省三吧 >_< 目录 1. 逃离高塔思路代码 2. 消失的蓝宝思路代码 3. 电池分组思路代码 4. 魔法科考试思路代码 5. 爆破思路…...

Java 设计模式:策略模式详解
Java 设计模式:策略模式详解 策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,将每个算法封装起来,并使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户端,从…...

什么是TensorFlow?
TensorFlow 是由 Google Brain 团队开发的开源机器学习框架,被广泛应用于深度学习和人工智能领域。它的基本概念包括: 1. 张量(Tensor):在 TensorFlow 中,数据以张量的形式进行处理。张量是多维数组的泛化…...

【3GPP核心网】【5G】精讲5G网络语音业务系统架构
1. 欢迎大家订阅和关注,精讲3GPP通信协议(2G/3G/4G/5G/IMS)知识点,专栏会持续更新中.....敬请期待! 目录 1. 音视频业务 2. 消息类业务 SMS over IMS SMS over NAS 3. 互联互通架构 3.1 音视频业务互通场景 3.2 5G 用户与 5G 用户互通 3.3 5G 用户与 4G 用户的互通…...