Pandas进行数据预处理(标准化数据)③
数据标准化处理代码解析
- 数据标准化处理代码解析
- 课前预习
- 1. 离差标准化(Min - Max Scaling)
- 结果
- 2. 标准差标准化(Standard Scaling)
- 结果
- 3. 小数定标标准化(Decimal Scaling)
- 结果
- 代码整体概述
- 代码详细解析
- 1. 导入必要的库
- 2. 读取数据并进行预处理
- 3. 离差标准化
- 4. 标准差标准化
- 5. 小数定标标准化
- 结果
- 总结
数据标准化处理代码解析
在数据分析和机器学习领域,数据标准化是一个重要的预处理步骤,它可以使不同特征的数据具有可比性,提高模型的性能。本文将详细解析一段Python代码,该代码实现了对用户每月支出数据的三种标准化方法:离差标准化、标准差标准化和小数定标标准化。
课前预习
当然可以!下面为你详细解释离差标准化、标准差标准化和小数定标标准化,并给出简单的例子。
1. 离差标准化(Min - Max Scaling)

离差标准化是将数据缩放到[0, 1]区间的一种方法。其公式为:
[
X_{scaled} = \frac{X - X_{min}}{X_{max} - X_{min}}
]
示例:
假设有一组数据:[10, 20, 30, 40, 50]。
- 首先,找出最小值 X m i n = 10 X_{min}=10 Xmin=10和最大值 X m a x = 50 X_{max}=50 Xmax=50。
- 对于数据点
10,标准化后的值为: 10 − 10 50 − 10 = 0 \frac{10 - 10}{50 - 10} = 0 50−1010−10=0 - 对于数据点
20,标准化后的值为: 20 − 10 50 − 10 = 0.25 \frac{20 - 10}{50 - 10} = 0.25 50−1020−10=0.25 - 对于数据点
30,标准化后的值为: 30 − 10 50 − 10 = 0.5 \frac{30 - 10}{50 - 10} = 0.5 50−1030−10=0.5 - 对于数据点
40,标准化后的值为: 40 − 10 50 − 10 = 0.75 \frac{40 - 10}{50 - 10} = 0.75 50−1040−10=0.75 - 对于数据点
50,标准化后的值为: 50 − 10 50 − 10 = 1 \frac{50 - 10}{50 - 10} = 1 50−1050−10=1
以下是使用Python实现的代码:
import numpy as npdata = np.array([10, 20, 30, 40, 50])
min_val = data.min()
max_val = data.max()
scaled_data = (data - min_val) / (max_val - min_val)
print("离差标准化后的数据:", scaled_data)
结果
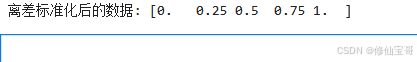
2. 标准差标准化(Standard Scaling)

标准差标准化是将数据转换为均值为0,标准差为1的标准正态分布。其公式为:
[
X_{scaled} = \frac{X - \mu}{\sigma}
]
其中, μ \mu μ是数据的均值, σ \sigma σ是数据的标准差。
示例:
假设有一组数据:[10, 20, 30, 40, 50]。
- 首先,计算均值 μ = 10 + 20 + 30 + 40 + 50 5 = 30 \mu = \frac{10 + 20 + 30 + 40 + 50}{5} = 30 μ=510+20+30+40+50=30
- 然后,计算标准差 σ = ( 10 − 30 ) 2 + ( 20 − 30 ) 2 + ( 30 − 30 ) 2 + ( 40 − 30 ) 2 + ( 50 − 30 ) 2 5 ≈ 14.14 \sigma=\sqrt{\frac{(10 - 30)^2+(20 - 30)^2+(30 - 30)^2+(40 - 30)^2+(50 - 30)^2}{5}}\approx14.14 σ=5(10−30)2+(20−30)2+(30−30)2+(40−30)2+(50−30)2≈14.14
- 对于数据点
10,标准化后的值为: 10 − 30 14.14 ≈ − 1.41 \frac{10 - 30}{14.14}\approx - 1.41 14.1410−30≈−1.41 - 对于数据点
20,标准化后的值为: 20 − 30 14.14 ≈ − 0.71 \frac{20 - 30}{14.14}\approx - 0.71 14.1420−30≈−0.71 - 对于数据点
30,标准化后的值为: 30 − 30 14.14 = 0 \frac{30 - 30}{14.14}=0 14.1430−30=0 - 对于数据点
40,标准化后的值为: 40 − 30 14.14 ≈ 0.71 \frac{40 - 30}{14.14}\approx0.71 14.1440−30≈0.71 - 对于数据点
50,标准化后的值为: 50 − 30 14.14 ≈ 1.41 \frac{50 - 30}{14.14}\approx1.41 14.1450−30≈1.41
以下是使用Python实现的代码:
import numpy as npdata = np.array([10, 20, 30, 40, 50])
mean_val = data.mean()
std_val = data.std()
scaled_data = (data - mean_val) / std_val
print("标准差标准化后的数据:", scaled_data)
结果
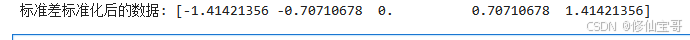
3. 小数定标标准化(Decimal Scaling)

小数定标标准化通过移动小数点的位置来进行数据缩放。其公式为:
[
X_{scaled} = \frac{X}{10^j}
]
其中, j j j是满足 1 0 j ≥ max ( ∣ X ∣ ) 10^j\geq\max(|X|) 10j≥max(∣X∣)的最小整数。
示例:
假设有一组数据:[10, 20, 30, 40, 50]。
- 首先,找出数据的绝对值的最大值 max ( ∣ X ∣ ) = 50 \max(|X|)=50 max(∣X∣)=50。
- 因为 1 0 2 = 100 ≥ 50 10^2 = 100\geq50 102=100≥50,所以 j = 2 j = 2 j=2。
- 对于数据点
10,标准化后的值为: 10 1 0 2 = 0.1 \frac{10}{10^2}=0.1 10210=0.1 - 对于数据点
20,标准化后的值为: 20 1 0 2 = 0.2 \frac{20}{10^2}=0.2 10220=0.2 - 对于数据点
30,标准化后的值为: 30 1 0 2 = 0.3 \frac{30}{10^2}=0.3 10230=0.3 - 对于数据点
40,标准化后的值为: 40 1 0 2 = 0.4 \frac{40}{10^2}=0.4 10240=0.4 - 对于数据点
50,标准化后的值为: 50 1 0 2 = 0.5 \frac{50}{10^2}=0.5 10250=0.5
以下是使用Python实现的代码:
import numpy as npdata = np.array([10, 20, 30, 40, 50])
j = np.ceil(np.log10(np.abs(data).max()))
scaled_data = data / (10 ** j)
print("小数定标标准化后的数据:", scaled_data)
结果

这些标准化方法在数据预处理中非常有用,可以帮助提高机器学习模型的性能。
代码整体概述
代码主要使用了pandas和numpy库,从CSV文件中读取用户每月支出信息,对数据进行清洗和预处理,然后分别使用自定义的函数对每月支出数据进行三种标准化处理,并打印出标准化前后的数据。
代码详细解析
1. 导入必要的库
import pandas as pd
import numpy as np
- 代码解释:
import pandas as pd:导入pandas库并将其重命名为pd,pandas是一个强大的数据处理和分析库,用于读取、处理和分析表格数据。import numpy as np:导入numpy库并将其重命名为np,numpy是Python的一个科学计算库,提供了高效的数组操作和数学函数。
2. 读取数据并进行预处理
try:pay = pd.read_csv('./data/user_pay_info.csv', index_col=0)# 确保每月支出列是数值类型pay['每月支出'] = pd.to_numeric(pay['每月支出'], errors='coerce')pay = pay.dropna(subset=['每月支出'])
- 代码解释:
pd.read_csv('./data/user_pay_info.csv', index_col=0):使用pandas的read_csv函数从CSV文件中读取数据,并将第一列作为索引列。pd.to_numeric(pay['每月支出'], errors='coerce'):将每月支出列的数据转换为数值类型,errors='coerce'表示如果遇到无法转换的值,将其转换为NaN。pay.dropna(subset=['每月支出']):删除每月支出列中包含NaN值的行。
3. 离差标准化
# 自定义离差标准化函数def min_max_scale(data):data = (data - data.min()) / (data.max() - data.min())return data# 对用户每月支出信息表的每月支出数据做离差标准化pay_min_max = min_max_scale(pay['每月支出'])print('离差标准化之前每月支出数据为:\n', pay['每月支出'].head())print('离差标准化之后每月支出数据为\n', pay_min_max.head())
- 代码解释:
min_max_scale函数:自定义的离差标准化函数,公式为 x s c a l e d = x − x m i n x m a x − x m i n x_{scaled}=\frac{x - x_{min}}{x_{max}-x_{min}} xscaled=xmax−xminx−xmin,将数据缩放到[0, 1]区间。min_max_scale(pay['每月支出']):调用min_max_scale函数对每月支出列的数据进行离差标准化。print语句:打印离差标准化前后的每月支出数据的前几行。
4. 标准差标准化
# 自定义标准差标准化函数def standard_scaler(data):std = data.std()if std == 0:return pd.Series([0] * len(data), index=data.index)data = (data - data.mean()) / stdreturn data# 对用户每月支出信息表的每月支出数据做标准差标准化pay_standard = standard_scaler(pay['每月支出'])print('标准差标准化之前每月支出数据为:\n', pay['每月支出'].head())print('标准差标准化之后每月支出数据为:\n', pay_standard.head())
- 代码解释:
standard_scaler函数:自定义的标准差标准化函数,公式为 x s c a l e d = x − μ σ x_{scaled}=\frac{x - \mu}{\sigma} xscaled=σx−μ,其中 μ \mu μ 是数据的均值, σ \sigma σ 是数据的标准差。如果标准差为0,则将所有数据置为0。standard_scaler(pay['每月支出']):调用standard_scaler函数对每月支出列的数据进行标准差标准化。print语句:打印标准差标准化前后的每月支出数据的前几行。
5. 小数定标标准化
# 自定义小数定标标准化函数def decimal_scaler(data):data = data / 10 ** np.ceil(np.log10(data.abs().max()))return data# 对用户每月支出信息表的每月支出数据做小数定标标准化pay_decimal = decimal_scaler(pay['每月支出'])print('小数定标标准化之前的每月支出数据:\n', pay['每月支出'].head())print('小数定标标准化之后的每月支出数据:\n', pay_decimal.head())except FileNotFoundError:print("错误:未找到文件,请检查文件路径。")
except Exception as e:print(f"发生未知错误:{e}")
- 代码解释:
decimal_scaler函数:自定义的小数定标标准化函数,公式为 x s c a l e d = x 1 0 j x_{scaled}=\frac{x}{10^j} xscaled=10jx,其中 j j j 是满足 1 0 j ≥ max ( ∣ x ∣ ) 10^j \geq \max(|x|) 10j≥max(∣x∣) 的最小整数。decimal_scaler(pay['每月支出']):调用decimal_scaler函数对每月支出列的数据进行小数定标标准化。print语句:打印小数定标标准化前后的每月支出数据的前几行。except语句:捕获文件未找到错误和其他未知错误,并打印相应的错误信息。
结果

总结
通过本文的代码解析,我们学习了如何使用Python对数据进行三种常见的标准化处理:离差标准化、标准差标准化和小数定标标准化。读者在学习后能够掌握以下知识和技能:
- 学会使用
pandas和numpy库进行数据读取、处理和分析。 - 理解离差标准化、标准差标准化和小数定标标准化的原理和实现方法。
- 掌握自定义函数的编写和调用,以及异常处理的方法。
相关文章:
Pandas进行数据预处理(标准化数据)③
数据标准化处理代码解析 数据标准化处理代码解析课前预习1. 离差标准化(Min - Max Scaling)结果2. 标准差标准化(Standard Scaling)结果3. 小数定标标准化(Decimal Scaling)结果 代码整体概述代码详细解析1…...

vue里provide作用:将一组全局方法注入到 Vue 应用的所有子组件中
在 Vue.js 中, provide(mainFunc, {...}) 是依赖注入(Dependency Injection)的提供者(provider)部分,它的作用是: 功能说明 : 将一组全局方法注入到 Vue 应用的所有子组件中子组件可以通过 inject 接收这些方法 import { provi…...

基于uniapp 实现画板签字
直接上效果图 代码 <template><view class"container"><!-- 签名画布 --><view class"canvas-container"><canvas canvas-id"signCanvas" class"sign-canvas"touchstart"handleTouchStart"touc…...
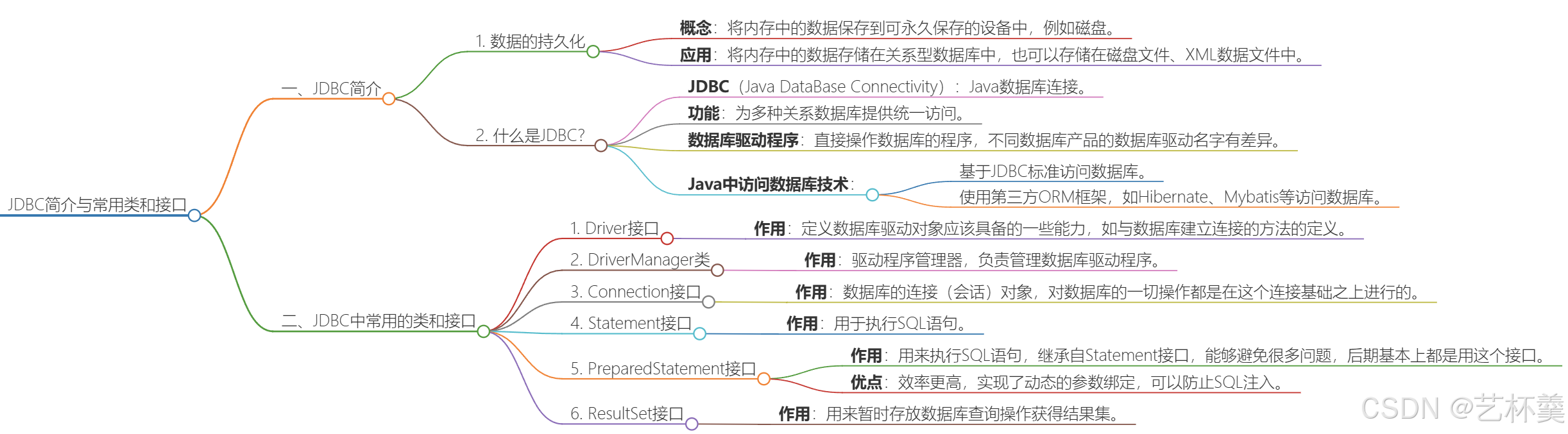
JDBC 初认识、速了解
目录 一. JDBC的简介 1. 数据的持久化 2. 什么是JDBC 二. JDBC中常用的类和接口 1. Driver 接口 2. DriverManager 类 3. Connection 接口 4. Statement 接口 5. PreparedStatement接口 6. ResultSet 接口 三. 总结 前言 从现在开始就来讲解JDBC的相关知识了 本文的…...
(2025亲测可用)Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置
1. 资源准备 API Key:此项配置填写在一步API官网创建API令牌,一键直达API令牌创建页面创建API令牌步骤请参考API Key的获取和使用API Host:此项配置填写https://yibuapi.com/v1查看支持的模型请参考这篇教程模型在线查询 2. ChatBox网页版配…...
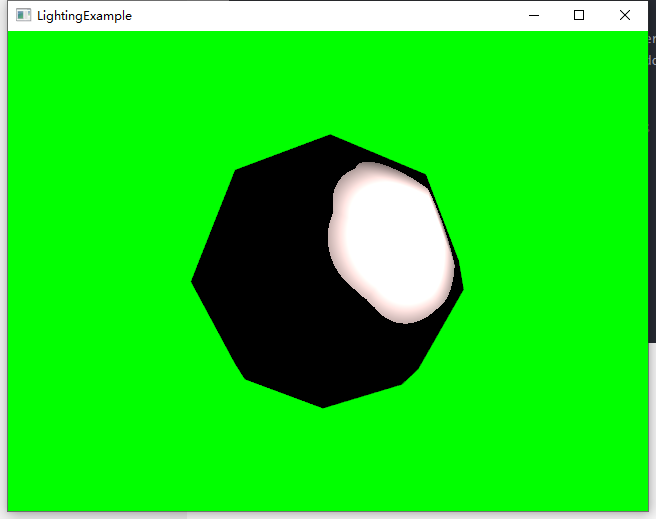
4.vtk光照vtkLight
文章目录 VTK中的光照1. vtkLight 的两种类型:位置光照和方向光照2. vtkLight 的常用方法3. 方法命名风格4. vtkProp 的可见性与 vtkLight 的开关 示例 VTK中的光照 vtkLight: 用于定义一个或多个光源。每个光源可以有其颜色、位置、焦点等属性。 vtkActor: 每个vtk…...
)
【速写】formatting_func与target_modules的细节(peft)
文章目录 SFTTrainer的构造参数版本差异怎么写formatting_func?关于lora_config中的target_modules能否在target_modules中指定特定某个模块? 以下面的示例pipeline为案: # -*- coding: utf8 -*- # author: caoyang # email: caoyangstu.sufe.edu.cnfr…...
YOLOv2学习笔记
YOLOv2 背景 YOLOv2是YOLO的第二个版本,其目标是显著提高准确性,同时使其更快 相关改进: 添加了BN层——Batch Norm采用更高分辨率的网络进行分类主干网络的训练 Hi-res classifier去除了全连接层,采用卷积层进行模型的输出&a…...

第十五届蓝桥杯----数字串个数\Python
目录 问题: 思想: 代码: 问题: Q:小蓝想要构造出一个长度为 10000 的数字字符串,有以下要求: 1) 小蓝不喜欢数字 0 ,所以数字字符串中不可以出现 0 ; 2) 小蓝喜欢数字 3 和 7 ,所以数字字符串中必须…...

【YOLOv8改进 - 卷积Conv】PConv(Pinwheel-shaped Conv): 风车状卷积用于红外小目标检测, 复现!
YOLOv8目标检测创新改进与实战案例专栏 专栏目录: YOLOv8有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例 专栏链接: YOLOv8基础解析+创新改进+实战案例 文章目录 YOLOv8目标检测创新改进与实战案例专栏介绍摘要文章链…...

LeetCode:链表
160. 相交链表 /*** 单链表的定义* Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public class Solution {public ListNode getIntersectionN…...
Dockerfile项目实战-单阶段构建Vue2项目
单阶段构建镜像-Vue2项目 1 项目层级目录 以下是项目的基本目录结构: 2 Node版本 博主的Windows电脑安装了v14.18.3的node.js版本,所以直接使用本机电脑生成项目,然后拷到了 Centos 7 里面 # 查看本机node版本 node -v3 创建Vue2项目 …...

音视频小白系统入门笔记-0
本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅 音视频小白系统入门课 音视频基础ffmpeg原理 绪论 ffmpeg推流 ffplay/vlc拉流 使用rtmp协议 ffmpeg -i <source_path> -f flv rtmp://<rtmp_server_path> 为什么会推流失败? 默认…...
Zabbix 简介+部署+对接Grafana(详细部署!!)
目录 一.Zabbix简介 1.Zabbix是什么 2.Zabbix工作原理(重点) 3.Zabbix 的架构(重点) 1.服务端 2.客户端: 4.Zabbix和Prometheus区别 二.Zabbix 部署 1.前期准备 2.安装zabbix软件源和组件 3.安装数据库…...

C++: Initialization and References to const 初始化和常引用
cpp primer 5e, P97. 理解 这是一段很容易被忽略、 但是又非常重要的内容。 In 2.3.1 (p. 51) we noted that there are two exceptions to the rule that the type of a reference must match the type of the object to which it refers. The first exception is that we …...
Ubuntu2404装机指南
因为原来的2204升级到2404后直接嘎了,于是要重新装一下Ubuntu2404 Ubuntu系统下载 | Ubuntuhttps://cn.ubuntu.com/download我使用的是balenaEtcher将iso文件烧录进U盘后,使用u盘安装,默认选的英文版本, 安装后,安装…...

职坐标:智慧城市未来发展的核心驱动力
内容概要 智慧城市的演进正以颠覆性创新重构人类生存空间,其发展脉络由物联网、人工智能与云计算三大技术支柱交织而成。这些技术不仅推动城市治理从经验决策转向数据驱动模式,更通过实时感知与智能分析,实现交通、能源等领域的精准调控。以…...

DAY 45 leetcode 28的kmp算法实现
KMP算法的思路 例: 文本串:a a b a a b a a f 模式串:a a b a a f 两个指针分别指向上下两串,当出现分歧时,并不将上下的都重新回退,而是利用“next数组”获取已经比较过的信息,上面的指针不…...

从代码学习深度学习 - 自注意力和位置编码 PyTorch 版
这里写自定义目录标题 前言一、自注意力:Transformer 的核心1.1 多头注意力机制的实现1.2 缩放点积注意力1.3 掩码和序列处理1.4 自注意力示例二、位置编码:为序列添加位置信息2.1 位置编码的实现2.2 可视化位置编码总结前言 深度学习近年来在自然语言处理、计算机视觉等领域…...
 的波形发生器)
设计和实现一个基于 DDS(直接数字频率合成) 的波形发生器
设计和实现一个基于 DDS(直接数字频率合成) 的波形发生器 1. 学习和理解IP软核和DDS 关于 IP 核的使用方法 IP 核:在 FPGA 设计中,IP 核(Intellectual Property Core)是由硬件描述语言(HDL&a…...

AWS IAM权限详解:10个关键权限及其安全影响
1. 引言 在AWS (Amazon Web Services) 环境中,Identity and Access Management (IAM) 是确保云资源安全的核心组件。本文将详细解析10个关键的IAM权限,这些权限对AWS的权限管理至关重要,同时也可能被用于权限提升攻击。深入理解这些权限对于加强AWS环境的安全性至关重要。 2.…...

UniRig ,清华联合 VAST 开源的通用自动骨骼绑定框架
UniRig是清华大学计算机系与VAST联合开发的前沿自动骨骼绑定框架,专为处理复杂且多样化的3D模型而设计。基于强大的自回归模型和骨骼点交叉注意力机制,UniRig能够生成高质量的骨骼结构和精确的蒙皮权重,大幅提升动画制作的效率和质量。 UniR…...

DELL电脑开机进入自检界面
疑难解答 - 如何解决开机直接进入BIOS画面 添加链接描述 一、DELL电脑开机自检提示please run setup program 未设置一天中的时间-请运行安装程序(Time-of-day not set - please run SETUP program) 配置信息无效-请运行安装程序(Invalid configuration information - ple…...

分库分表-除了hash分片还有别的吗?
在分库分表的设计中,除了常见的 Hash 分片,还有多种策略根据业务场景灵活选择。以下是几种主流的分库分表策略及其应用场景、技术实现和优缺点分析,结合项目经验(如标易行投标服务平台的高并发场景)进行说明: 一、常见分库分表策略 1. 范围分片(Range Sharding) 原理:…...

Spring Cloud初探之使用load balance包做负载均衡(三)
一、背景说明 基于前一篇文章《Spring Cloud初探之nacos服务注册管理(二)》,我们已经将服务注册到nacos。接下来继续分析如何用Spring cloud的load balance做负载均衡。 load balance是客户端负载均衡组件。本质是调用方拿到所有注册的服务实例列表,然…...

MySQL 数据库备份和恢复全指南
MySQL 是一款常用的开源数据库系统,在日常运维中,数据备份和恢复是系统管理的重要一环。本文将细致介绍 MySQL 两大备份方案—— mysqldump 和 XtraBackup,包括备份方式、恢复步骤、定时脚本、远程备份和常见问题处理方案。 一、mysqldump 备…...

Linux 命令全解析:从零开始掌握 Linux 命令行
Linux 作为一款强大的开源操作系统,广泛应用于服务器、嵌入式系统以及超级计算机领域。掌握 Linux 命令行技能,是每一位开发者和系统管理员的必备能力。本文将从基础开始,为你详细介绍常用的 Linux 命令,以及它们的使用场景和示例…...

vector常用的接口和底层
一.vector的构造函数 我们都是只讲常用的。 这四个都是比较常用的。 第一个简单来看就是无参构造,是通过一个无参的对象来对我们的对象进行初始化的,第一个我们常用来当无参构造来使用。 第二个我们常用的就是通过多个相同的数字来初始化一个vector。 像…...

VMware安装Ubuntu实战分享
1.前期准备 1. 硬件要求 确保您的计算机满足以下基本硬件要求,以便顺利运行 VMware 和 Ubuntu: 处理器: 至少支持虚拟化技术(如 Intel VT-x 或 AMD-V)。可以在 BIOS 设置中启用此功能。 内存: 至少 4GB …...

解锁Grok-3的极致潜能:高阶应用与创新实践
引言 Grok-3,作为xAI公司推出的第三代人工智能模型,以其强大的推理能力和多模态处理能力在全球AI领域掀起了热潮。不仅在数学、科学和编程等基准测试中超越了众多主流模型,其独特的DeepSearch和Big Brain模式更赋予了它处理复杂任务的卓越性…...