微服务即时通信系统---(四)框架学习
目录
ElasticSearch
介绍
安装
安装kibana
ES客户端安装
头文件包含和编译时链接库
ES核心概念
索引(Index)
类型(Type)
字段(Field)
映射(mapping)
文档(document)
ES对比MySQL
Kibana访问ES测试
创建索引库
新增数据
查看并搜索数据
删除索引
ES客户端接口介绍
ES二次封装(elasticSearch.hpp)
Json序列化
Json反序列化
创建索引(库)
插入数据
删除数据
数据搜索(查询)
二次封装测试
ES客户端操作句柄获取封装
cpp-httplib
介绍
安装
头文件和链接库
类于接口介绍
HTTP请求类
HTTP应答类
HTTP服务器类
HTTP客户端类
使用样例
websocketpp
Websocket协议介绍
Websocketpp介绍
WebSocketpp安装
类与接口
日志等级
状态码
数据帧类型
消息缓冲区
HTTP请求解析
connect连接后的相关操作(对请求进行响应)
服务器
endpoint(服务端/客户端的管理)
redis
介绍
安装
头文件包含和编译时链接库
接口介绍
Redis++客户端操作句柄获取封装
本章主要是学习和使用本项目中所需使用到的一些框架。
ElasticSearch
介绍
ElasticSearch,简称ES,是一个开源分布式搜索引擎。
它的特点有:分布式、零配置、自动发现、索引自动分片、索引副本机制、restful风格接口、多数据源、自动搜索负载等。
ES是面向文档的,意味着它可以存储整个对象或文档。
它不仅仅是存储,还会索引每个文档的内容,使之可以被搜索。
在ES中,可以对文档进行索引、搜索、排序、过滤。
安装
# 添加仓库秘钥
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -# 添加镜像源仓库
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elasticsearch.list # 更新软件包列表
sudo apt update # 安装es
sudo apt-get install elasticsearch=7.17.21 # 启动es
sudo systemctl start elasticsearch # 安装ik分词器插件
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install
https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21启动ES报错:
![]()
解决办法:
调整ES虚拟内存,虚拟内存默认最大映射数为65530,无法满足ES系统要求, 需要调整为262144以上。
sudo sysctl -w vm.max_map_count=262144在 /etc/elasticsearch/jvm.options中新增:
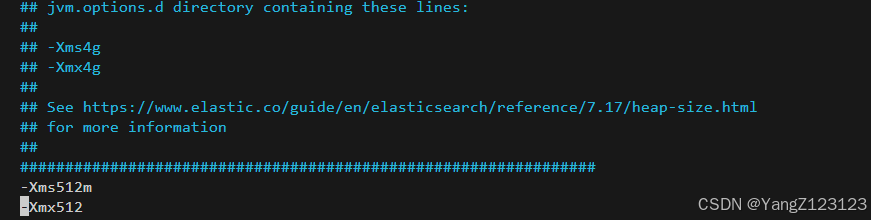
再次启动ES:成功。
但是我自己重新弄的时候,一直启动失败,后续查看日志发现:
sudo vim /var/log/elasticsearch/elasticsearch.log
前面下载的分词器,和当前版本不兼容(我的ES升级了,所以不兼容),于是寻找解决方案:删除旧版本分词器,下载与当前elasticsearch匹配的分词器:
sudo rm -rf /usr/share/elasticsearch/plugins/analysis-iksudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.25/elasticsearch-analysis-ik-7.17.25.zipsudo systemctl restart elasticsearch.service此时才完美解决。
验证ES是否安装启动成功:
curl -X GET "http://localhost:9200/"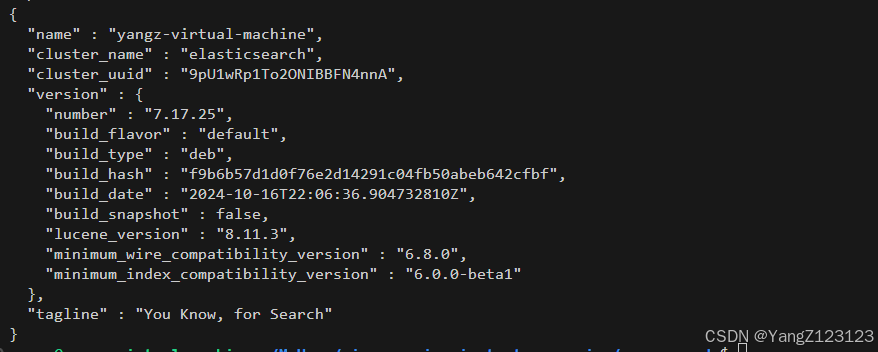
设置外网访问,如果新配置完成的话,默认只能在本机进行访问:
sudo vim /etc/elasticsearch/elasticsearch.yml![]()
![]()
此时用浏览器访问 "localhost:9200":
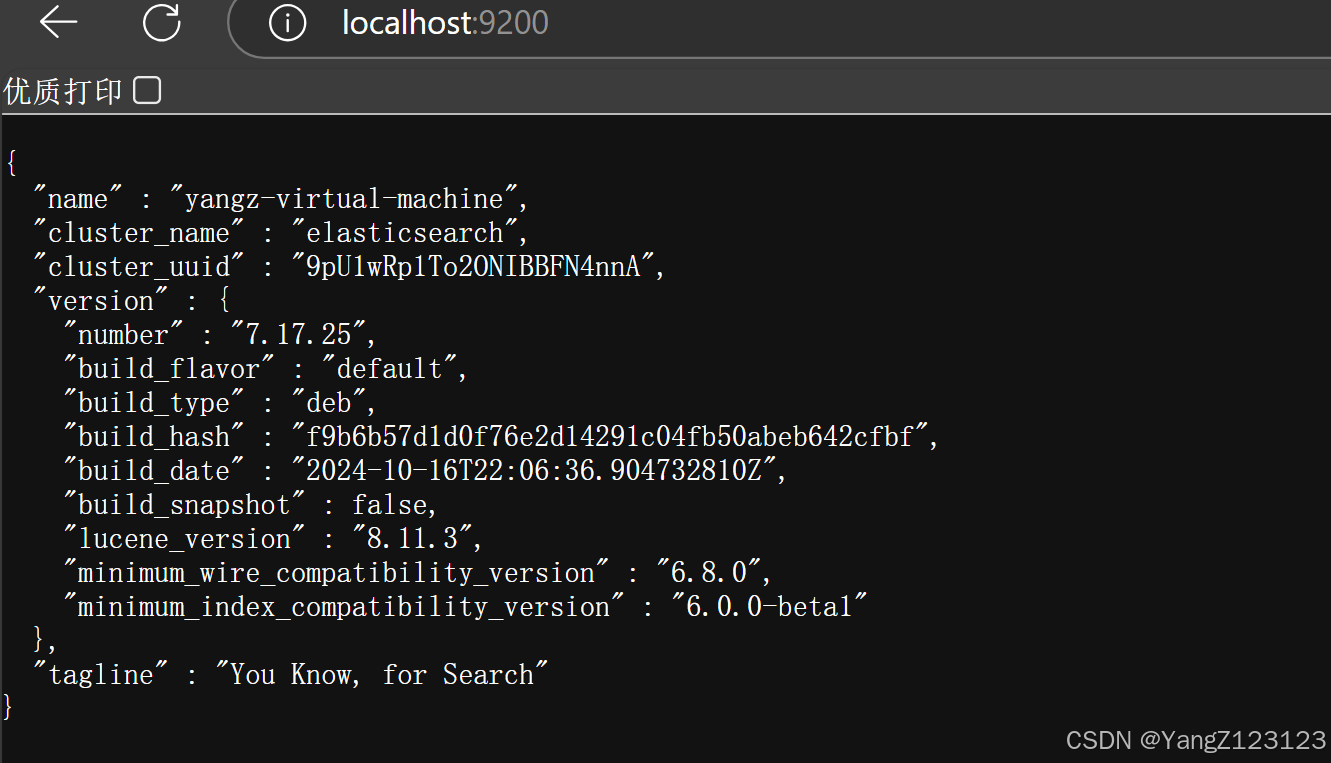
安装kibana
Kibana 是一个开源的数据可视化工具,专门为 Elasticsearch 设计。它提供了一个用户友好的界面,用于搜索、查看和分析存储在 Elasticsearch 中的数据。Kibana 通常与 Elasticsearch 一起使用,是 Elastic Stack(以前称为 ELK Stack,包括 Elasticsearch、Logstash 和 Kibana)的核心组件之一。
在浏览器上访问:"localhost:5601"。
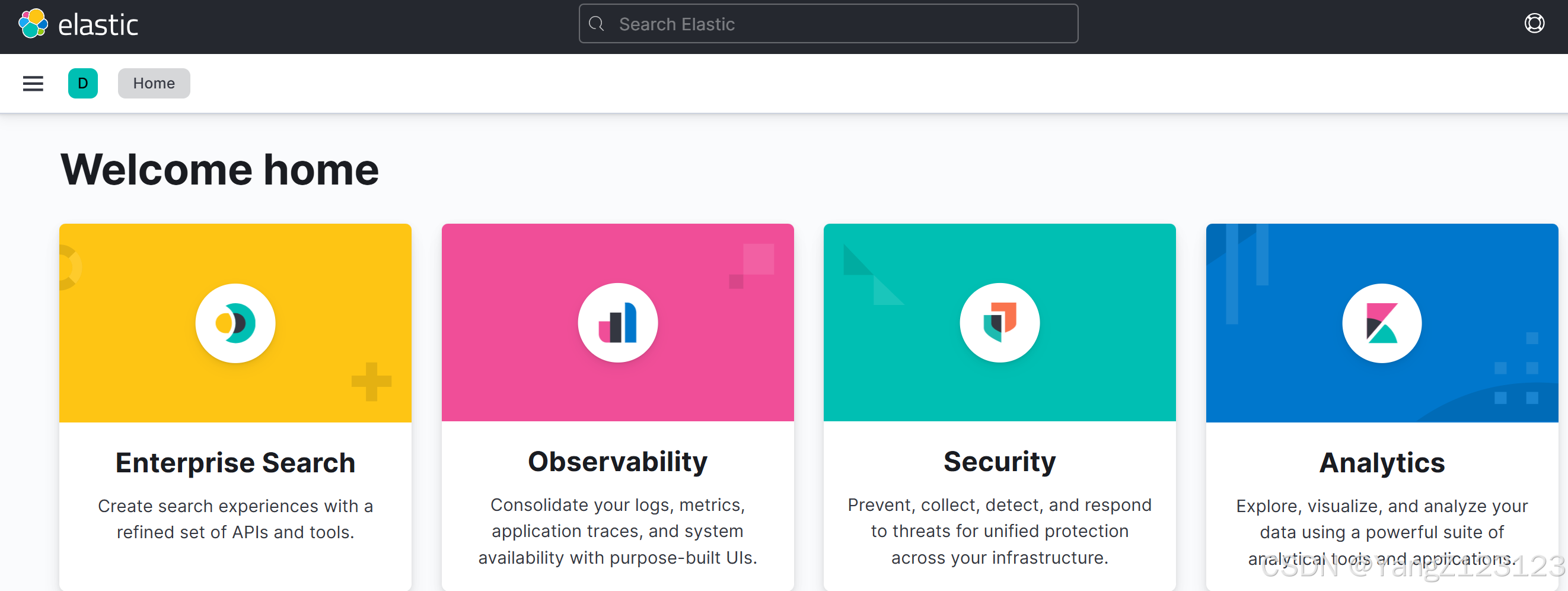
命令安装:
sudo apt install kibana配置 Kibana(可选):
根据需要配置 Kibana。配置文件通常位于 /etc/kibana/kibana.yml。可能需要
设置如服务器地址、端口、Elasticsearch URL 等。
sudo vim /etc/kibana/kibana.yml
例如,你可能需要设置 Elasticsearch 服务的 URL: 大概32行左右
elasticsearch.host: "http://localhost:9200"ES客户端安装
sudo apt-get install libmicrohttpd-dev # 克隆代码
git clone https://github.com/seznam/elasticlient # 切换目录
cd elasticlient # 更新子模块
git submodule update --init --recursive # 编译代码
mkdir build
cd build
cmake ..
make # 安装
make install # make的时候编译出错,这是子模块googletest没有编译安装
# 解决: 手动安装子模块
cd ../external/googletest/
mkdir cmake && cd cmake/
cmake -DCMAKE_INSTALL_PREFIX=/usr ..
make && sudo make install # 安装好了 再次 cmake即可头文件包含和编译时链接库
头文件
#include <cpr/response.h>
#include <elasticlient/client.h>库:
-lcpr -lelasticlientES核心概念
索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。
比如说,你可以有一个客户数据 的索引,一个产品目录的索引,还有一个订单数据的索引。
一个索引由一个名字来标 识(必须全部是小写字母的),并且当我们要对应于这个索引中的文档进行索引、搜索、 更新和删除的时候,都要使用到这个名字。
类型(Type)
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分 类/分区,其语义完全由你来定。
通常,会为具有一组共同字段的文档定义一个类型。
比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这 个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,为评论数 据定义另一个类型......
字段(Field)
| 分类 | 类型 | 备注 |
| 字符串 | text、keyword | text会被分词生成索引。 keyword不会被分词生成索引,只能精确搜索。 |
| 整形 | integer、long、short、byte | |
| 浮点 | double、float | |
| 逻辑 | boolean | true 或者 false |
| 日期 | date、date_nanos | “2018-01-13” 或 “2018-01-13 12:10:30” 或者时间戳,即1970到现在的秒数/毫秒数 |
| 二进制 | binary | 二进制通常只存储,不索引。 |
| 范围 | range |
映射(mapping)
映射是在处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、 分析器、是否被索引等等。
其它就是处理es里面数据 的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
| 名称 | 数值 | 备注 |
| enabled | true(默认)、false | 是否仅作存储,不做搜索和分析。 |
| index | true(默认)、false | 是否构建倒排锁芯(决定了是否分词,是否被索引)。 |
| index_option | ||
| dynamic | true(默认)、false | 控制mapping的自动更新。 |
| doc_value | true(默认)、false | 是否开启doc_value,用户聚合和排序分析,分词字段不能使用。 |
| fielddata | "fielddata" : {"format" : "disabled"} | 是否为text类型启动fielddata,实现排序和 聚合分析。 针对分词字段,参与排序或聚合时能提高性 能。 不分词字段统一建议使用doc_value。 |
| store | true、false(默认) | 是否单独设置此字段的是否存储,储而从 _source 字段中分离。 只能搜索,不能获取值。 |
| coerce | true(默认)、false | 是否开启自动数据类型转换功能。 比如:字符串转数字,浮点转整型 |
| analyzer | "analyzer" : "ik" | 指定分词器,默认分词器是standard analyzer |
| boost | "boost" : 1.23 | 字段级别的分数加权,默认值是1.0 |
| fields | "fields" : { "raw" : { "type": "text", "index": "not_analyzed", } } | 对一个字段提供多种索引模式。 同一个字段的值,一个分词,一个不分词。 |
| data_detection | true(默认)、false | 是否自动识别日期类型 |
文档(document)
一个文档是一个可被索引的基础信息单元。
比如,你可以拥有某一个客户的文档,某 一个产品的一个文档或者某个订单的一个文档。
文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个 index/type 里面,你可以存储任意多的文档。
一个文档必须被索引或者赋予一个索引 的type。
ES对比MySQL
| MySQL | ES | 说明 |
| Database | Index | 最顶层的逻辑容器。 |
| Table | Type (ES 7.x之后) | 存储结构化数据的单元。 |
| Row | Document | 一条记录。 |
| Column | Field | 数据字段。 |
| Schema | Mapping | 定义数据结构。 |
| Index(索引) | Inverted Index | 加速查询的数据结构。 |
| SQL | Query DSL | 查询语言。 |
| Primary Key | _id | 唯一标识符。 |
| 分库分表 | Shard | 数据分片。 |
| 主从复制 | Replica Shard | 数据复制和高可用性。 |
| 事务 | 版本控制 | 数据一致性机制。 |
| 全文搜索 | 核心功能 | ES 专为全文搜索设计,功能更强大。 |
Kibana访问ES测试
创建索引库
POST /user/_doc
{ "settings" : { "analysis" : { "analyzer" : { "ik" : { "tokenizer" : "ik_max_word" } } } }, "mappings" : { "dynamic" : true, "properties" : { "nickname" : { "type" : "text","analyzer" : "ik_max_word" }, "user_id" : { "type" : "keyword", "analyzer" : "standard" }, "phone" : { "type" : "keyword", "analyzer" : "standard" }, "description" : { "type" : "text", "enabled" : false }, "avatar_id" : { "type" : "keyword" ,"enabled" : false } } }
}新增数据
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id" : "USER4b862aaa-2df8654a-7eb4bb65e3507f66","nickname" : "昵称1","phone" : "手机号1","description" : "签名1","avatar_id" : "头像1"}
{"index":{"_id":"2"}}
{"user_id" : "USER14eeeaa5-442771b9-0262e455e4663d1d","nickname" : "昵称2","phone" : "手机号2","description" : "签名2","avatar_id" : "头像2"}
{"index":{"_id":"3"}}
{"user_id" : "USER484a6734-03a124f0-996c169dd05c1869","nickname" : "昵称3","phone" : "手机号3","description" : "签名3","avatar_id" : "头像3"}
{"index":{"_id":"4"}}
{"user_id" : "USER186ade83-4460d4a6-8c08068f83127b5d","nickname" : "昵称4","phone" : "手机号4","des相关文章:
微服务即时通信系统---(四)框架学习
目录 ElasticSearch 介绍 安装 安装kibana ES客户端安装 头文件包含和编译时链接库 ES核心概念 索引(Index) 类型(Type) 字段(Field) 映射(mapping) 文档(document) ES对比MySQL Kibana访问ES测试 创建索引库 新增数据 查看并搜索数据 删除索引 ES…...
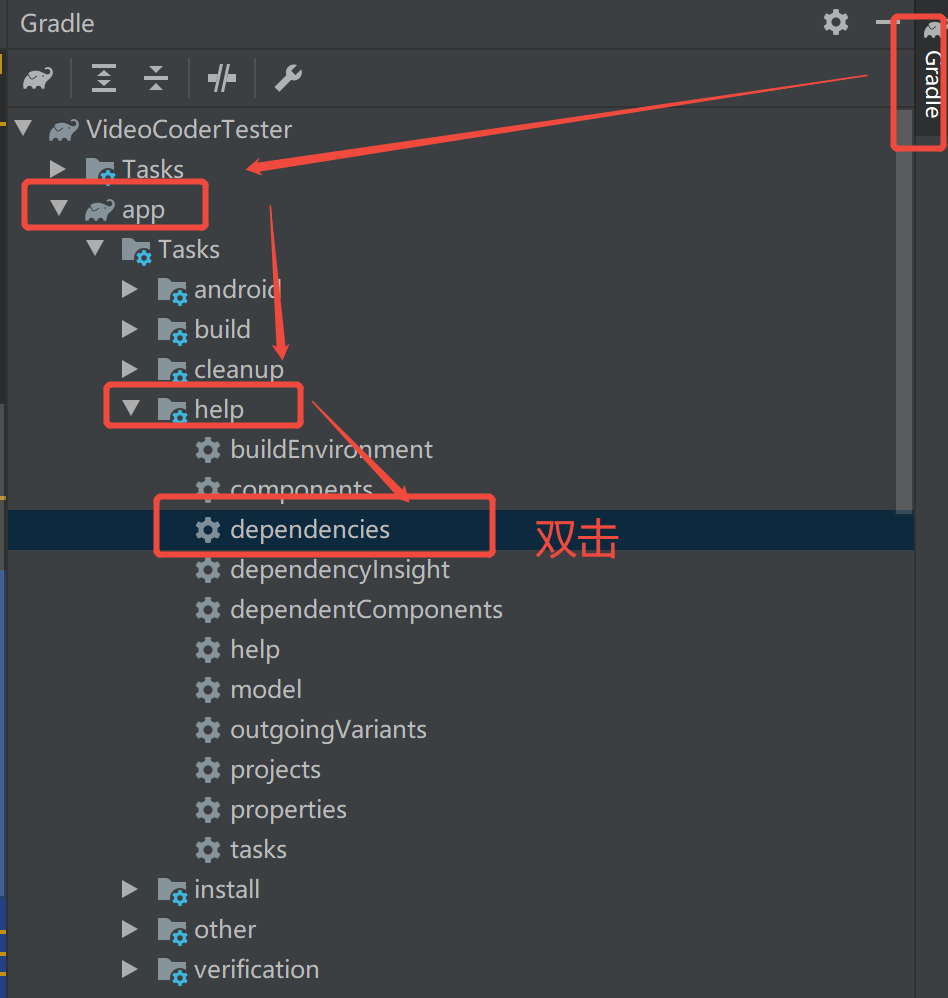
Android查看依赖树的方法,简单有效
一、使用命令打印 在工具栏“Terminal”中输入以下命令,即可打印依赖树信息 gradlew xxxx:dependencies (“xxxx”为module名称)二、工具栏双击打印 右侧“Gradle”工具栏打开按下图顺序依次查找到“dependencies”,双击后依赖树就会在控制台中打印出…...

自动化测试工具playwright中文文档-------14.Chrome 插件
介绍 注意 插件仅在以持久化上下文启动的 Chrome/Chromium 浏览器中工作。请谨慎使用自定义浏览器参数,因为其中一些可能会破坏 Playwright 的功能。 以下是获取位于 ./my-extension 的 Manifest v2 插件背景页面句柄的代码示例。 from playwright.sync_api imp…...
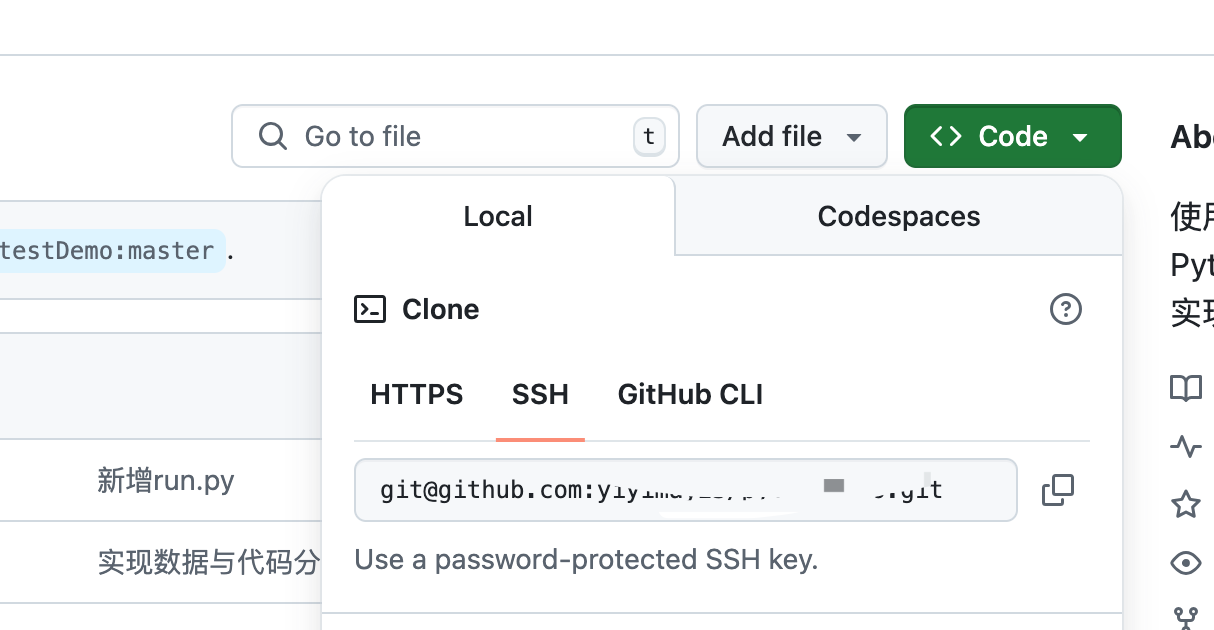
GitHub配置密钥
1.生成SSH密钥 1)检查 SSH 密钥是否存在 首先,确认是否已经在本地系统中生成了 SSH 密钥对。可以通过以下命令检查: ls -al ~/.ssh 在命令输出中,应该能看到类似 id_rsa 和 id_rsa.pub 这样一对文件。如果这些文件不存在&#…...
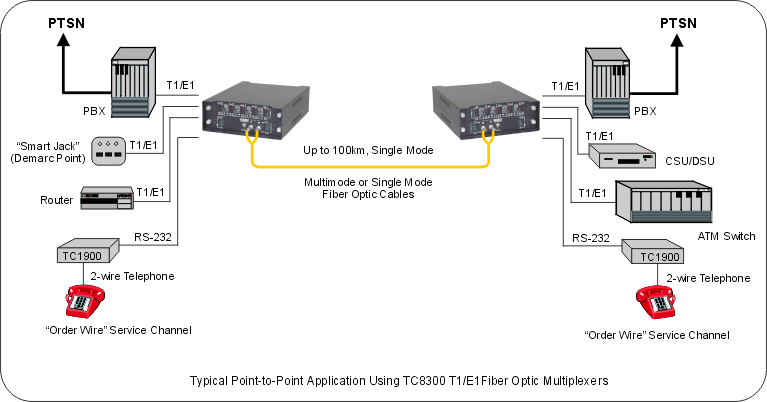
【2-10】E1与T1
前言 之前我们简单介绍了人类从电话线思维到如今的数据报分组交换思维过渡时期的各种技术产物,今天我们重点介绍 E1/T1技术。 文章目录 前言1. 产生背景2. T13. E14. SONET4.1 OC-14.2 OC-3 及其它 5. SDH5.1. STM-1 6. SONET VS SDH后记修改记录 1. 产生背景 E1/…...
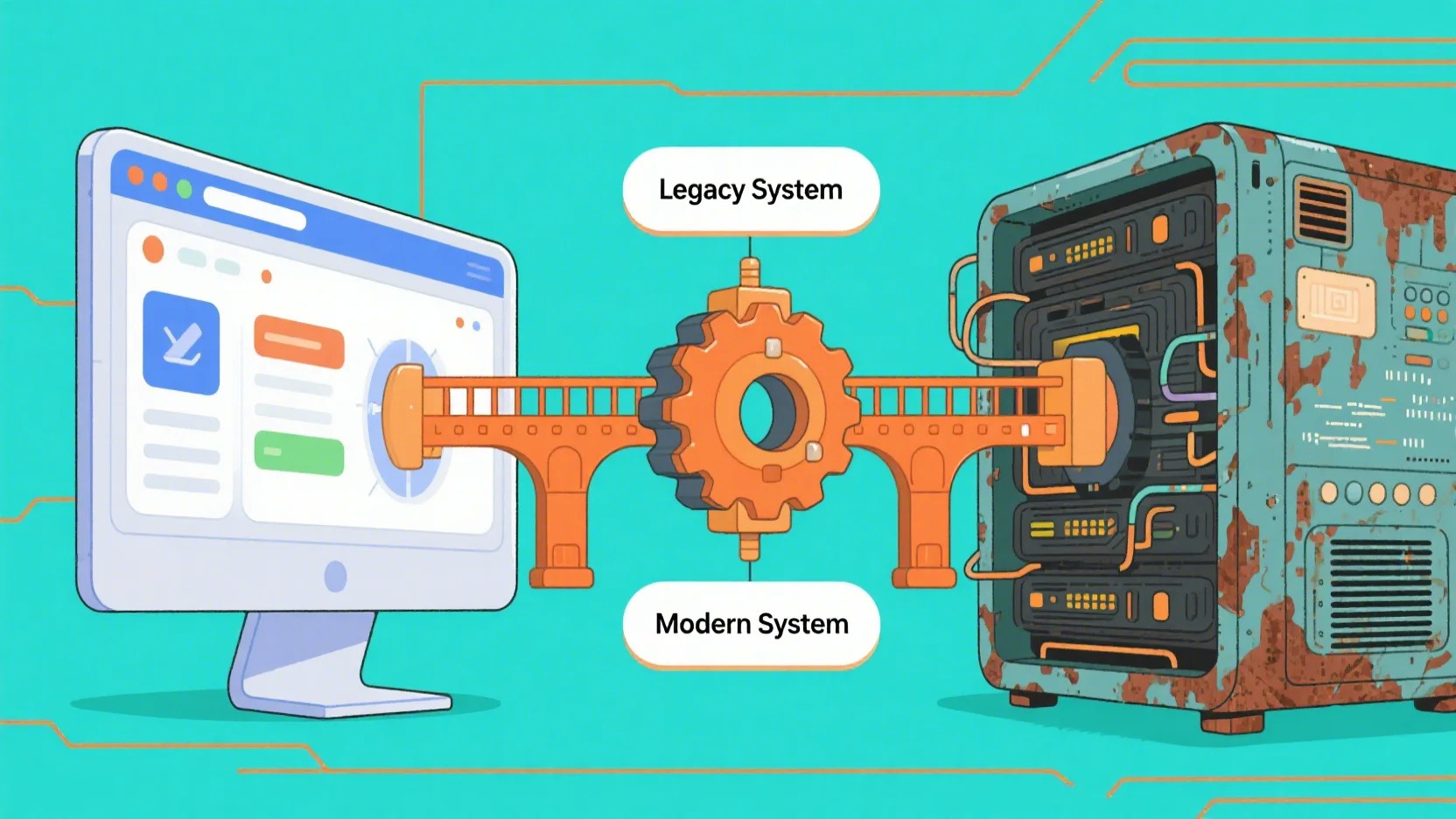
【设计模式】适配器模式:让不兼容的接口和谐共处
引言 在软件开发中,我们经常会遇到这样的情况:两个已经存在的接口无法直接协同工作,但我们又希望它们能够无缝对接。这时,适配器模式就派上用场了。适配器模式(Adapter Pattern)是一种结构型设计模式&…...

Servlet、HTTP与Spring Boot Web全面解析与整合指南
目录 第一部分:HTTP协议与Servlet基础 1. HTTP协议核心知识 2. Servlet核心机制 第二部分:Spring Boot Web深度整合 1. Spring Boot Web架构 2. 创建Spring Boot Web应用 3. 控制器开发实践 4. 请求与响应处理 第三部分:高级特性与最…...

PTA:古风排版
中国的古人写文字,是从右向左竖向排版的。本题就请你编写程序,把一段文字按古风排版。 输入格式: 输入在第一行给出一个正整数N(<100),是每一列的字符数。第二行给出一个长度不超过1000的非空字符串&a…...
)
Android LiveData学习总结(源码级理解)
LiveData 工作原理 数据持有与观察者管理:LiveData 内部维护着一个数据对象和一个观察者列表。当调用 observe 方法注册观察者时,会将 LifecycleOwner 和 Observer 包装成 LifecycleBoundObserver 对象并添加到观察者列表中。生命周期感知:L…...

Pandas进行数据预处理(标准化数据)③
数据标准化处理代码解析 数据标准化处理代码解析课前预习1. 离差标准化(Min - Max Scaling)结果2. 标准差标准化(Standard Scaling)结果3. 小数定标标准化(Decimal Scaling)结果 代码整体概述代码详细解析1…...

vue里provide作用:将一组全局方法注入到 Vue 应用的所有子组件中
在 Vue.js 中, provide(mainFunc, {...}) 是依赖注入(Dependency Injection)的提供者(provider)部分,它的作用是: 功能说明 : 将一组全局方法注入到 Vue 应用的所有子组件中子组件可以通过 inject 接收这些方法 import { provi…...

基于uniapp 实现画板签字
直接上效果图 代码 <template><view class"container"><!-- 签名画布 --><view class"canvas-container"><canvas canvas-id"signCanvas" class"sign-canvas"touchstart"handleTouchStart"touc…...
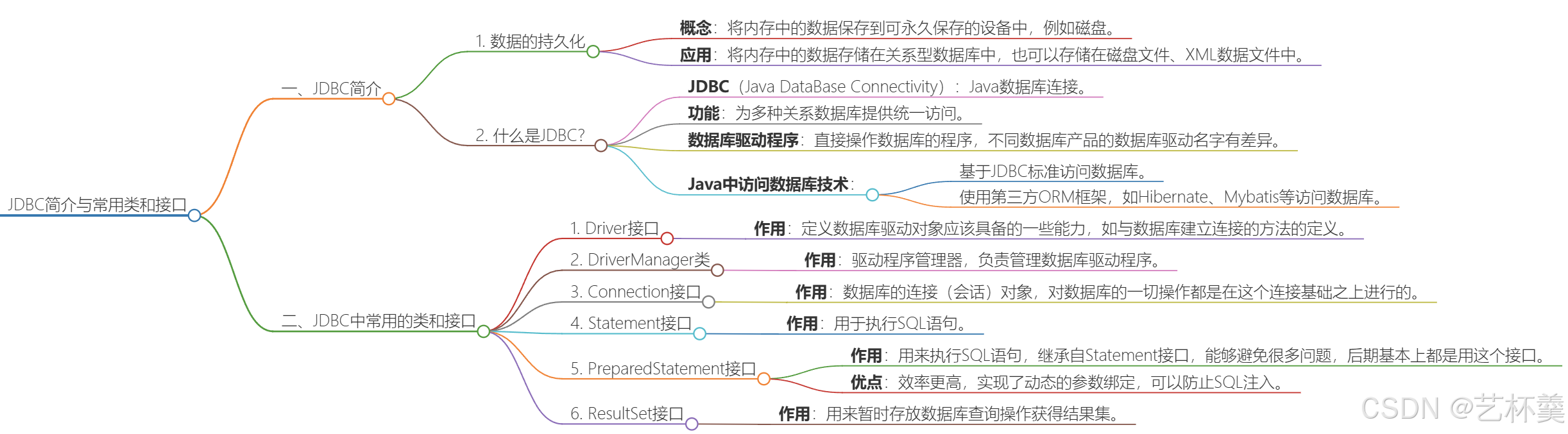
JDBC 初认识、速了解
目录 一. JDBC的简介 1. 数据的持久化 2. 什么是JDBC 二. JDBC中常用的类和接口 1. Driver 接口 2. DriverManager 类 3. Connection 接口 4. Statement 接口 5. PreparedStatement接口 6. ResultSet 接口 三. 总结 前言 从现在开始就来讲解JDBC的相关知识了 本文的…...
(2025亲测可用)Chatbox多端一键配置Claude/GPT/DeepSeek-网页端配置
1. 资源准备 API Key:此项配置填写在一步API官网创建API令牌,一键直达API令牌创建页面创建API令牌步骤请参考API Key的获取和使用API Host:此项配置填写https://yibuapi.com/v1查看支持的模型请参考这篇教程模型在线查询 2. ChatBox网页版配…...
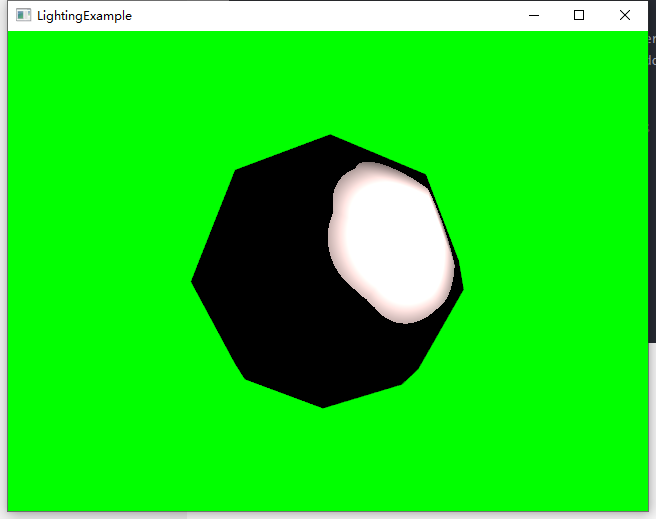
4.vtk光照vtkLight
文章目录 VTK中的光照1. vtkLight 的两种类型:位置光照和方向光照2. vtkLight 的常用方法3. 方法命名风格4. vtkProp 的可见性与 vtkLight 的开关 示例 VTK中的光照 vtkLight: 用于定义一个或多个光源。每个光源可以有其颜色、位置、焦点等属性。 vtkActor: 每个vtk…...
)
【速写】formatting_func与target_modules的细节(peft)
文章目录 SFTTrainer的构造参数版本差异怎么写formatting_func?关于lora_config中的target_modules能否在target_modules中指定特定某个模块? 以下面的示例pipeline为案: # -*- coding: utf8 -*- # author: caoyang # email: caoyangstu.sufe.edu.cnfr…...
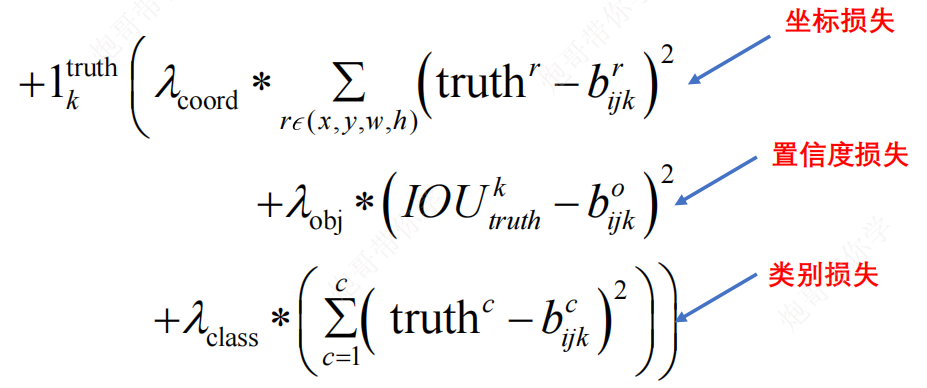
YOLOv2学习笔记
YOLOv2 背景 YOLOv2是YOLO的第二个版本,其目标是显著提高准确性,同时使其更快 相关改进: 添加了BN层——Batch Norm采用更高分辨率的网络进行分类主干网络的训练 Hi-res classifier去除了全连接层,采用卷积层进行模型的输出&a…...

第十五届蓝桥杯----数字串个数\Python
目录 问题: 思想: 代码: 问题: Q:小蓝想要构造出一个长度为 10000 的数字字符串,有以下要求: 1) 小蓝不喜欢数字 0 ,所以数字字符串中不可以出现 0 ; 2) 小蓝喜欢数字 3 和 7 ,所以数字字符串中必须…...

【YOLOv8改进 - 卷积Conv】PConv(Pinwheel-shaped Conv): 风车状卷积用于红外小目标检测, 复现!
YOLOv8目标检测创新改进与实战案例专栏 专栏目录: YOLOv8有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例 专栏链接: YOLOv8基础解析+创新改进+实战案例 文章目录 YOLOv8目标检测创新改进与实战案例专栏介绍摘要文章链…...

LeetCode:链表
160. 相交链表 /*** 单链表的定义* Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val x;* next null;* }* }*/ public class Solution {public ListNode getIntersectionN…...
Dockerfile项目实战-单阶段构建Vue2项目
单阶段构建镜像-Vue2项目 1 项目层级目录 以下是项目的基本目录结构: 2 Node版本 博主的Windows电脑安装了v14.18.3的node.js版本,所以直接使用本机电脑生成项目,然后拷到了 Centos 7 里面 # 查看本机node版本 node -v3 创建Vue2项目 …...

音视频小白系统入门笔记-0
本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅 音视频小白系统入门课 音视频基础ffmpeg原理 绪论 ffmpeg推流 ffplay/vlc拉流 使用rtmp协议 ffmpeg -i <source_path> -f flv rtmp://<rtmp_server_path> 为什么会推流失败? 默认…...
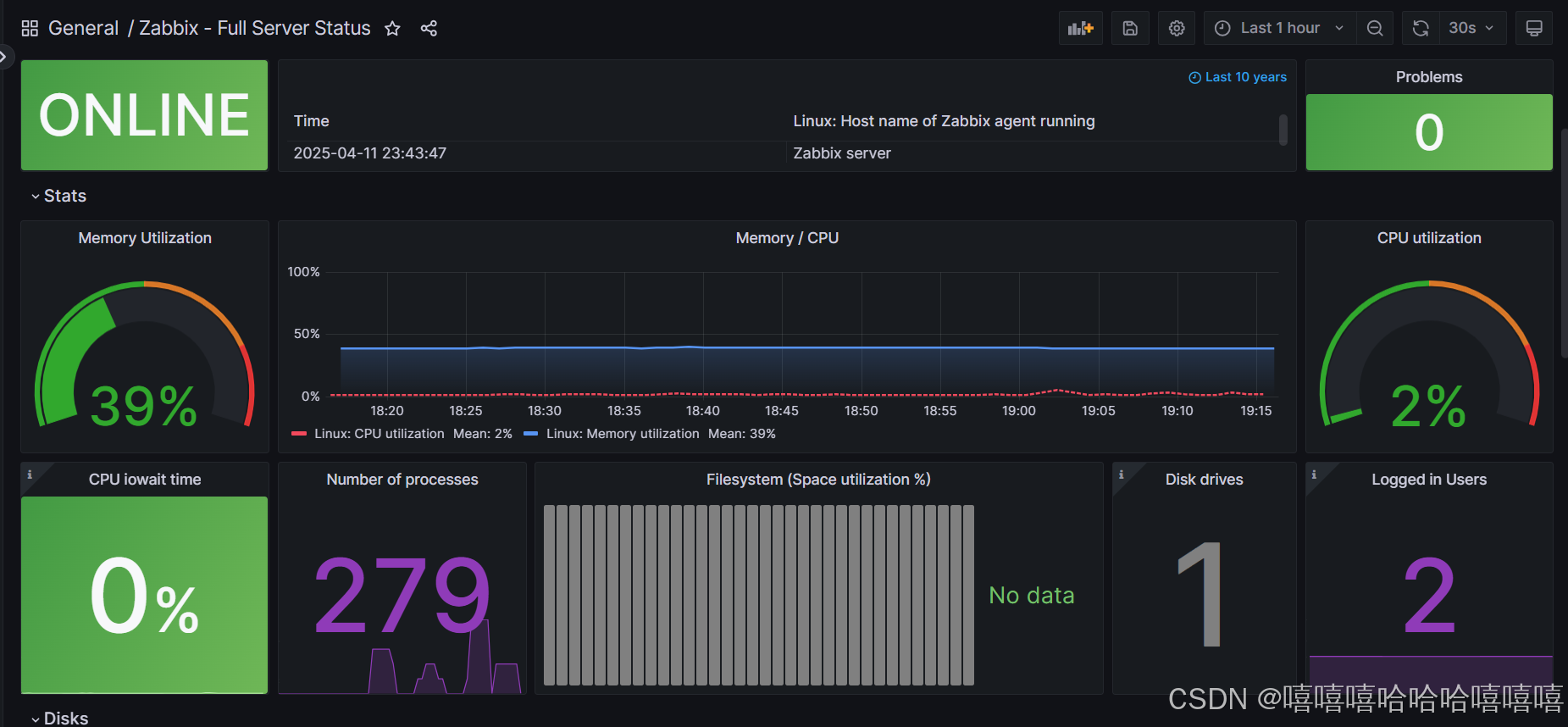
Zabbix 简介+部署+对接Grafana(详细部署!!)
目录 一.Zabbix简介 1.Zabbix是什么 2.Zabbix工作原理(重点) 3.Zabbix 的架构(重点) 1.服务端 2.客户端: 4.Zabbix和Prometheus区别 二.Zabbix 部署 1.前期准备 2.安装zabbix软件源和组件 3.安装数据库…...

C++: Initialization and References to const 初始化和常引用
cpp primer 5e, P97. 理解 这是一段很容易被忽略、 但是又非常重要的内容。 In 2.3.1 (p. 51) we noted that there are two exceptions to the rule that the type of a reference must match the type of the object to which it refers. The first exception is that we …...
Ubuntu2404装机指南
因为原来的2204升级到2404后直接嘎了,于是要重新装一下Ubuntu2404 Ubuntu系统下载 | Ubuntuhttps://cn.ubuntu.com/download我使用的是balenaEtcher将iso文件烧录进U盘后,使用u盘安装,默认选的英文版本, 安装后,安装…...

职坐标:智慧城市未来发展的核心驱动力
内容概要 智慧城市的演进正以颠覆性创新重构人类生存空间,其发展脉络由物联网、人工智能与云计算三大技术支柱交织而成。这些技术不仅推动城市治理从经验决策转向数据驱动模式,更通过实时感知与智能分析,实现交通、能源等领域的精准调控。以…...

DAY 45 leetcode 28的kmp算法实现
KMP算法的思路 例: 文本串:a a b a a b a a f 模式串:a a b a a f 两个指针分别指向上下两串,当出现分歧时,并不将上下的都重新回退,而是利用“next数组”获取已经比较过的信息,上面的指针不…...

从代码学习深度学习 - 自注意力和位置编码 PyTorch 版
这里写自定义目录标题 前言一、自注意力:Transformer 的核心1.1 多头注意力机制的实现1.2 缩放点积注意力1.3 掩码和序列处理1.4 自注意力示例二、位置编码:为序列添加位置信息2.1 位置编码的实现2.2 可视化位置编码总结前言 深度学习近年来在自然语言处理、计算机视觉等领域…...
 的波形发生器)
设计和实现一个基于 DDS(直接数字频率合成) 的波形发生器
设计和实现一个基于 DDS(直接数字频率合成) 的波形发生器 1. 学习和理解IP软核和DDS 关于 IP 核的使用方法 IP 核:在 FPGA 设计中,IP 核(Intellectual Property Core)是由硬件描述语言(HDL&a…...

AWS IAM权限详解:10个关键权限及其安全影响
1. 引言 在AWS (Amazon Web Services) 环境中,Identity and Access Management (IAM) 是确保云资源安全的核心组件。本文将详细解析10个关键的IAM权限,这些权限对AWS的权限管理至关重要,同时也可能被用于权限提升攻击。深入理解这些权限对于加强AWS环境的安全性至关重要。 2.…...