【AI模型学习】MAE——CV界的无监督预训练
文章目录
- 一、诞生背景
- 1.1 自监督学习的趋势
- 2.2 ViT 的出现
- 二、模型
- 2.1 模型架构
- 2.1.1 数据shape变化
- 2.1.2 模型架构流程图
- 2.1.3 PyTorch 代码示例(核心部分)
- 2.2 位置信息
- 2.3 非对称的编码器-解码器结构
- 2.4图片重构
- 三、实验
- 3.1 主实验
- 3.2 消融实验
- 3.3 总结
- 四、总结
论文 📝 MAE:Masked Autoencoders Are Scalable Vision Learners
Masked Autoencoders Are Scalable Vision Learners (He et al., 2021)。
一、诞生背景
1.1 自监督学习的趋势
在自然语言处理(NLP)中,BERT 使用了“掩码语言建模(MLM)”策略,通过掩盖输入序列的一部分并预测它们,从海量文本中学习通用语言表示。这种方法不依赖人工标注,大幅推动了 NLP 的发展。
而在视觉领域:
- 早期主流是 对比学习(如 MoCo, SimCLR),强调“相似-不相似”之间的对比。
- 但对比学习存在:
- 对 batch size 敏感;
- 训练难度高;
- 依赖复杂的负样本设计。
Yann LeCun(图灵奖得主、Meta 首席 AI 科学家)的一个非常经典的演讲或访谈中:
“如果机器学习是一块蛋糕,那么:
- 无监督学习是这块蛋糕的主体;
- 监督学习只是蛋糕上的奶油;
- 强化学习也许只是蛋糕上的樱桃;
- 而像 GAN 这样花哨的生成模型,是那几颗漂亮的水果装饰。”
—— Yann LeCun
蛋糕体 = 无监督学习(Unsupervised/Self-supervised)
- 最大份量:海量的数据(图像、文本、视频等)是未标注的,无监督学习能利用它们;
- 最核心:掌握“世界的结构”是智能的关键,不靠标签,仅靠模式本身;
- 未来趋势:LeCun 强调世界模型(world model)的学习是实现通用智能的基础,而这必须靠无监督/自监督。
奶油 = 有监督学习(Supervised)
- 很有效但需要人工标签;
- 数据依赖重:每个任务都要手工标数据,很昂贵;
- 不是 scalable 的方向:尤其在医学、遥感、视频等领域,标签严重不足。
樱桃 = 强化学习(RL)
- 在很多 AI 系统中是点缀;
- 很难训练,需求结构明确的环境;
- 在实际任务中用得不多,但“显得很酷”。
水果 = GAN 等生成模型
- GAN、Diffusion 之类生成模型非常吸睛;
- 能做图像生成、艺术创作、深度伪造等;
- 但更像是展示能力而非“认知核心”。
2.2 ViT 的出现
Vision Transformer (ViT) 将图像表示为 patch tokens,借助全局自注意力学习图像上下文,为图像应用 NLP 的技术打开了大门。
因此,自然的想法是:是否可以像 BERT 一样在图像领域做掩码建模?
二、模型
2.1 模型架构
2.1.1 数据shape变化
如同ViT一样做patch:
(B, 196, 768)
Mask 操作(通常 mask 掉 75%)
→ 随机选择 25% 的 patch 作为输入→ kept_patches.shape = (B, 49, 768) # 196 × 0.25 = 49
编码器输出
encoder_out.shape = (B, 49, D) # D 是维度,通常仍是 768
解码器输入(插入 learnable mask tokens)
→ 加入 147 个 mask token,拼接回去变成:decoder_in.shape = (B, 196, D)
解码器输出:重建所有 patch
decoder_out.shape = (B, 196, patch_dim) # patch_dim = 768
然后计算 MSE loss,仅在被 mask 的 75% 上:
loss = MSE(decoder_out[masked], original_patch[masked])
2.1.2 模型架构流程图
┌────────────────┐│ Input: x ││(B, 3, 224,224) │└─────┬──────────┘↓┌────────────────────┐│ Split into patches ││→ (B, 196, 768) │└─────┬──────────────┘↓┌────────────────────────────┐│ Random Masking (75%) ││ → keep 25%: (B, 49, 768) │└───────┬────────────────────┘↓┌───────────────────────────┐│ Encoder: Transformer ││ Input: (B, 49, 768) ││ Output: (B, 49, 768) │└───────┬───────────────────┘↓
┌────────────────────────────────────┐
│ Decoder Input = Encoder output │
│ + learnable mask tokens (147 个) │
│ → (B, 196, 768) │
└──────┬─────────────────────────────┘↓
┌────────────────────────────┐
│ Decoder: Transformer │
│ Output: (B, 196, 768) │
└──────┬─────────────────────┘↓
┌─────────────────────────────────────────────┐
│ Prediction = reconstruct patch pixel values │
│ 仅在被 mask 的 patch 上计算 MSE loss │
└─────────────────────────────────────────────┘

2.1.3 PyTorch 代码示例(核心部分)
class MAE(nn.Module):def __init__(self, encoder, decoder, mask_ratio=0.75):super().__init__()self.encoder = encoderself.decoder = decoderself.mask_ratio = mask_ratioself.patch_embed = nn.Linear(16*16*3, 768)self.mask_token = nn.Parameter(torch.zeros(1, 1, 768))def forward(self, x):B, C, H, W = x.shapex = self.patchify(x) # (B, 196, 768)# === masking ===x, mask, ids_restore = self.random_masking(x, self.mask_ratio)latent = self.encoder(x) # (B, 49, 768)# === decode ===full_tokens = self.restore_with_mask(latent, ids_restore) # (B, 196, 768)x_rec = self.decoder(full_tokens) # reconstruct pixelsreturn x_rec, maskdef patchify(self, imgs):# divide into patches and flattenp = 16B, C, H, W = imgs.shapepatches = imgs.reshape(B, C, H//p, p, W//p, p)patches = patches.permute(0,2,4,3,5,1).reshape(B, -1, p*p*C)return self.patch_embed(patches)def random_masking(self, x, mask_ratio):B, L, D = x.shapelen_keep = int(L * (1 - mask_ratio))noise = torch.rand(B, L)ids_shuffle = torch.argsort(noise, dim=1)ids_keep = ids_shuffle[:, :len_keep]x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).expand(-1, -1, D))# 返回还原顺序 index,mask 向量等return x_masked, ..., ...def restore_with_mask(self, latent, ids_restore):B, N, D = latent.shapemask_tokens = self.mask_token.repeat(B, ids_restore.shape[1] - N, 1)x_ = torch.cat([latent, mask_tokens], dim=1)x_full = torch.gather(x_, 1, ids_restore.unsqueeze(-1).expand(-1, -1, D))return x_full
2.2 位置信息
Transformer 是 序列模型,本身不具备位置感知能力。而图像是二维的,有强烈的空间结构。如果 Transformer 不知道某个 patch 来自图像的哪一块,它根本没法理解图像结构。
MAE 如何保留位置信息?
Patch embedding 之前或之后(但一定是在mask之前),加入位置编码
- 对每个 patch 位置 i ∈ [ 0 , N ) i \in [0, N) i∈[0,N)
生成一个 learnable 向量 pos i ∈ R D \text{pos}_i \in \mathbb{R}^D posi∈RD
将它加到 patch embedding 上:
x i ′ = patch i + pos i x_i' = \text{patch}_i + \text{pos}_i xi′=patchi+posi - 编码器(Encoder)只看部分 patch,但这些patch 带着它们的位置信息进入 encoder,所以 encoder 能知道“我正在看的是图的哪一部分”
注意:虽然 patch 是被乱序选择的,但位置编码是 绝对位置编码(absolute positional embedding),可以标记每个 token 的二维坐标(如 第 5 行第 2 列)
解码器如何知道 token 顺序?
MAE 中的设计:ids_restore 机制
- Mask 之前:每个 patch 是有顺序的,从 0 到 195
- Mask 后:encoder 只接收其中一部分,例如 patch 7, 31, 80…
- decoder 需要恢复原来的顺序,包括被遮挡的 patch,所以用一个 index 向量
ids_restore:
x_ = torch.cat([visible_tokens, mask_tokens], dim=1)
x_full = torch.gather(x_, dim=1, index=ids_restore)
这样 decoder 的输入顺序就和原图一致了,可以:
- 按照顺序进行解码
- 正确叠加位置编码(decoder 通常也有自己的 pos embedding)
2.3 非对称的编码器-解码器结构
在 MAE 中,所谓“不对称”,主要体现在两个方面:
| 组件 | Encoder | Decoder |
|---|---|---|
| 输入 | 仅可见 patch(25%) | 全部 patch(含 mask token) |
| 计算量 | 少得多(仅处理 49/196) | 多,但结构浅(轻量) |
| 网络结构 | 深 + 大(ViT-B/L) | 浅 + 小(3~4 层小 ViT) |
| 输出 | 表征(用于下游任务) | 重建像素 |
Encoder 要小输入 + 大容量
-
输入小(只看 25% patch)
- 节省计算:ViT 的注意力复杂度是 O(N^2),patch 多了算力爆炸;
- 只处理可见 patch(~49 个 token),减少 75% 的负担。
-
模型大(ViT-B、ViT-L、ViT-H)
- 虽然只看了图的一角,但模型有足够的 capacity 来理解上下文;
- 学到的是高质量的图像表征,能迁移到分类、检测、分割等任务。
Decoder 要大输入 + 小容量
-
输入大(加上了 mask token,还原全图)
- decoder 要 reconstruct 被遮挡的 patch,因此需要“填补回全部 196 个位置”。
-
模型小(浅层 Transformer)
- 目标是像素级重建,不是深层语义理解;
- decoder 只是帮 encoder 完成训练目标(像素恢复),不是核心;
- 如果 decoder 太强,反而容易“帮 encoder 猜答案”,encoder 就没学到好的表征(信息泄露问题);
优点如下:
| 优点 | 原因 |
|---|---|
| 高效 | encoder 只处理 1/4 的 patch,计算量 ↓3~4 倍 |
| 表征纯净 | encoder 没被迫 reconstruct,focus on语义学习 |
| 分工明确 | encoder 学表征,decoder 做辅助重建 |
| 易扩展 | 可以用 ViT-B/L/H 做 encoder,decoder 保持轻量 |
2.4图片重构
MAE在这一点上做的十分简单
Decoder Output:
(B, 196, 768)↓ reshape
(B, 14, 14, 16, 16, 3)↓ 合并 patch
(B, 224, 224, 3)↓ permute
(B, 3, 224, 224) ← final reconstructed image
MAE 的 decoder 输出每个 patch 的像素值(flatten 后),通过 unpatchify 把它 reshape 回图像结构,最终拼成整张图,用于训练中的重建误差计算。
三、实验
3.1 主实验
| 实验任务 | 模型设置 | 数据集 | 结果指标 | 性能 | 结论 |
|---|---|---|---|---|---|
| 图像分类 | ViT-B / ViT-L / ViT-H + MAE | ImageNet-1K | Top-1 Accuracy | 83.6% / 85.9% / 86.9% | MAE 可训练出大规模 ViT,性能超 ResNet |
| 目标检测 | ViT-L + MAE + Mask R-CNN | COCO | box mAP | 50.9 | MAE 预训练可迁移至目标检测 |
| 语义分割 | ViT-L + MAE + UPerNet | ADE20K | mIoU | 55.4 | MAE 表征对分割也有提升 |
3.2 消融实验
| 问题 | 对比设置 | 最佳设置 | 结论 |
|---|---|---|---|
| 最佳 mask 比例? | 0%、50%、75%、90% | 75% | 足够稀疏才能激发全局建模,太多则信息不足 |
| Decoder 深度影响? | 1、4、8 层 | 4 层 | 太浅重建不准,太深信息泄露 |
| Decoder 宽度(dim)? | 512、768、1024 | 768 | 与 encoder 一致效果最佳,decoder 无需变大 |
| 预训练时长? | 400、800、1600 epoch | 1600 epoch | 长训练时间带来稳定性能增益 |
| loss 应该计算哪里? | 仅 masked、全部 patch | 仅 masked | 避免 decoder 影响 visible 部分,提升表征纯度 |
| 目标类型(预测什么)? | 原始像素、CNN 中间特征、视觉 token | RGB 像素 | 最简单的重建目标效果最佳 |
| Decoder 架构复杂度? | 不同 decoder 宽度 / 层数 | 轻量、浅层 | decoder 太强会抢 encoder 的任务 |
| Patch 尺寸(未系统化,但有提及) | 16×16 vs 其他 | 16×16 | 平衡了细粒度与序列长度,训练稳定 |
3.3 总结
| 原则 | 解释 |
|---|---|
| 轻 decoder,重 encoder | encoder 专注学语义,decoder 只是辅助拼图 |
| 高 mask 比例是关键 | 掩码越多,模型越要“理解图”而不是“记忆图” |
| 不要复杂预测目标 | 原始像素 MSE 最简单,效果也最稳定 |
| 长训练周期 + 大模型 | 大 ViT + 足够训练时间是成功前提 |
| 仅 mask 区域监督 | 避免 visible 部分 loss 污染 encoder 学习 |
四、总结
总的来说,MAE 是一个特别“干净利落”的自监督学习方法。它的核心思路就是:把图像拆成小块(patch),随机遮掉大部分,然后让模型用剩下的一点点信息去“脑补”整张图。整个过程不依赖任何标签,完全靠模型自己学。
MAE 之所以成功,是因为它做到了三个字:简单、有用、高效。它把 encoder 和 decoder 分工明确——encoder 专注提取语义特征,decoder 只是个工具人,帮忙还原像素。这样不仅训练快、计算省,而且学出来的表示还能很好地迁移到下游任务,比如分类、检测、分割等等。
论文里也做了很多消融实验,验证了比如“75% 掩码比例最合适”、“decoder 不要太深”、“loss 只在被遮挡的地方算”等等这些设计选择确实有用。可以说,这些细节上的坚持,才成就了 MAE 的整体效果。
更重要的是,MAE 的成功也带动了后续一大批基于遮挡重建的视觉自监督方法,像 SimMIM、CAE、MaskFeat 等都受到了它的启发。
所以如果用一句话总结 MAE,那就是:
它用最简单的方式,把图像看懂了。
相关文章:
【AI模型学习】MAE——CV界的无监督预训练
文章目录 一、诞生背景1.1 自监督学习的趋势2.2 ViT 的出现 二、模型2.1 模型架构2.1.1 数据shape变化2.1.2 模型架构流程图2.1.3 PyTorch 代码示例(核心部分) 2.2 位置信息2.3 非对称的编码器-解码器结构2.4图片重构 三、实验3.1 主实验3.2 消融实验3.3…...
远方游子的归家记:模仿美食网页的制作与实现
前言 2023年的夏天,闲得无聊学了一个礼拜前端知识点。并根据所学知识点模仿制作了一篇网络上公开发布的关于家乡美食的文章。今天才想到有这个不错的案例可以分享出来,以供大家学习参考。 知识点简介 运用的知识点比较简单,常规的div盒子&…...

【消息队列kafka_中间件】三、Kafka 打造极致高效的消息处理系统
在当今数字化时代,数据量呈爆炸式增长,实时数据处理的需求变得愈发迫切。Kafka 作为一款高性能、分布式的消息队列系统,在众多企业级应用中得到了广泛应用。然而,要充分发挥 Kafka 的潜力,实现极致高效的消息处理&…...
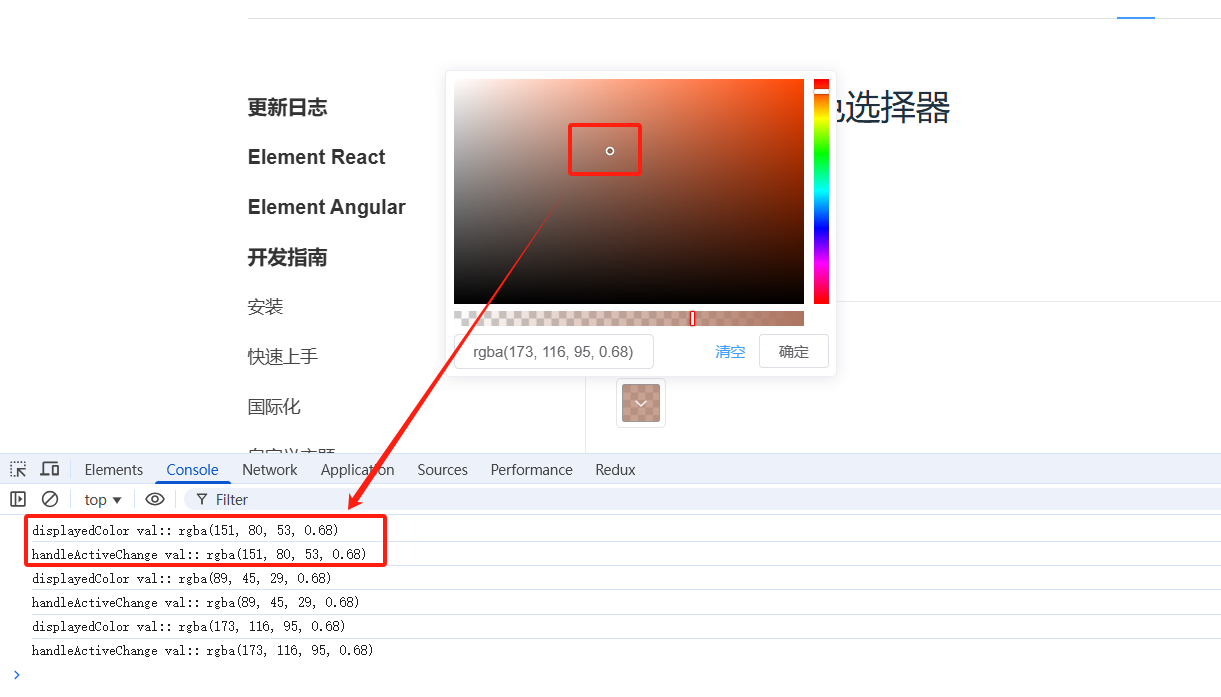
element-ui colorPicker 组件源码分享
简单分享 colorPicker 颜色选择器组件源码,主要从以下三个方面: 1、colorPicker 组件页面结构。 2、colorPicker 组件属性。 3、colorPicker 组件事件。 一、组件页面结构。 二、组件属性。 2.1 value/v-model 绑定值属性,类型为 string…...

Git 学习笔记
这篇笔记记录了我在git学习中常常用到的指令,方便在未来进行查阅。此篇文章也会根据笔者的学习进度持续更新。 网站分享 Git 常用命令大全 Learn Git Branching 基础 $ git init //在当前位置配置一个git版本库 $ git add <file> //将文件添加至…...
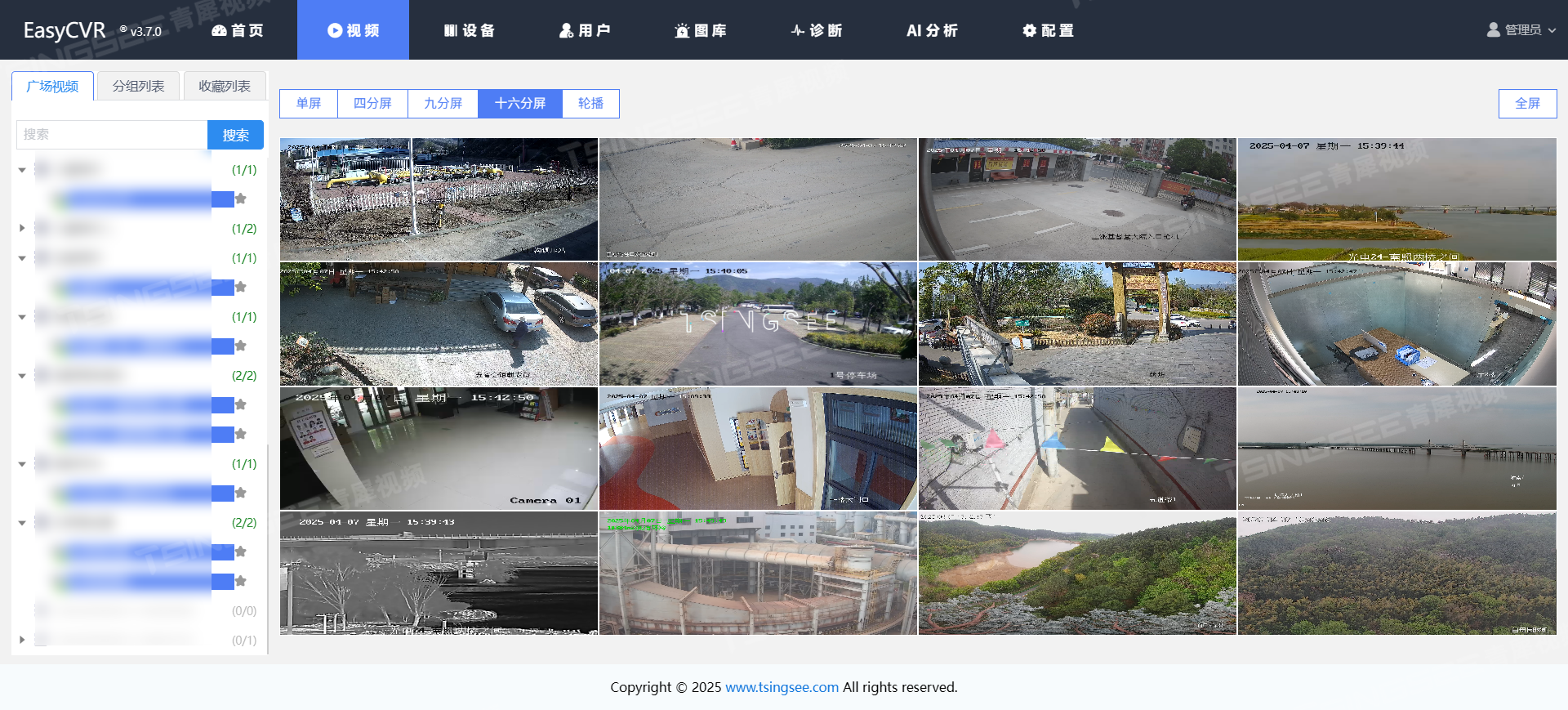
安防监控视频管理平台EasyCVR助力建筑工地施工4G/5G远程视频监管方案
一、项目背景 随着城市建设的快速发展,房地产建筑工地的数量、规模与施工复杂性都在增加,高空作业、机械操作频繁,人员流动大,交叉作业多,安全风险剧增。施工企业和政府管理部门在施工现场管理上都面临难题。政府部门…...
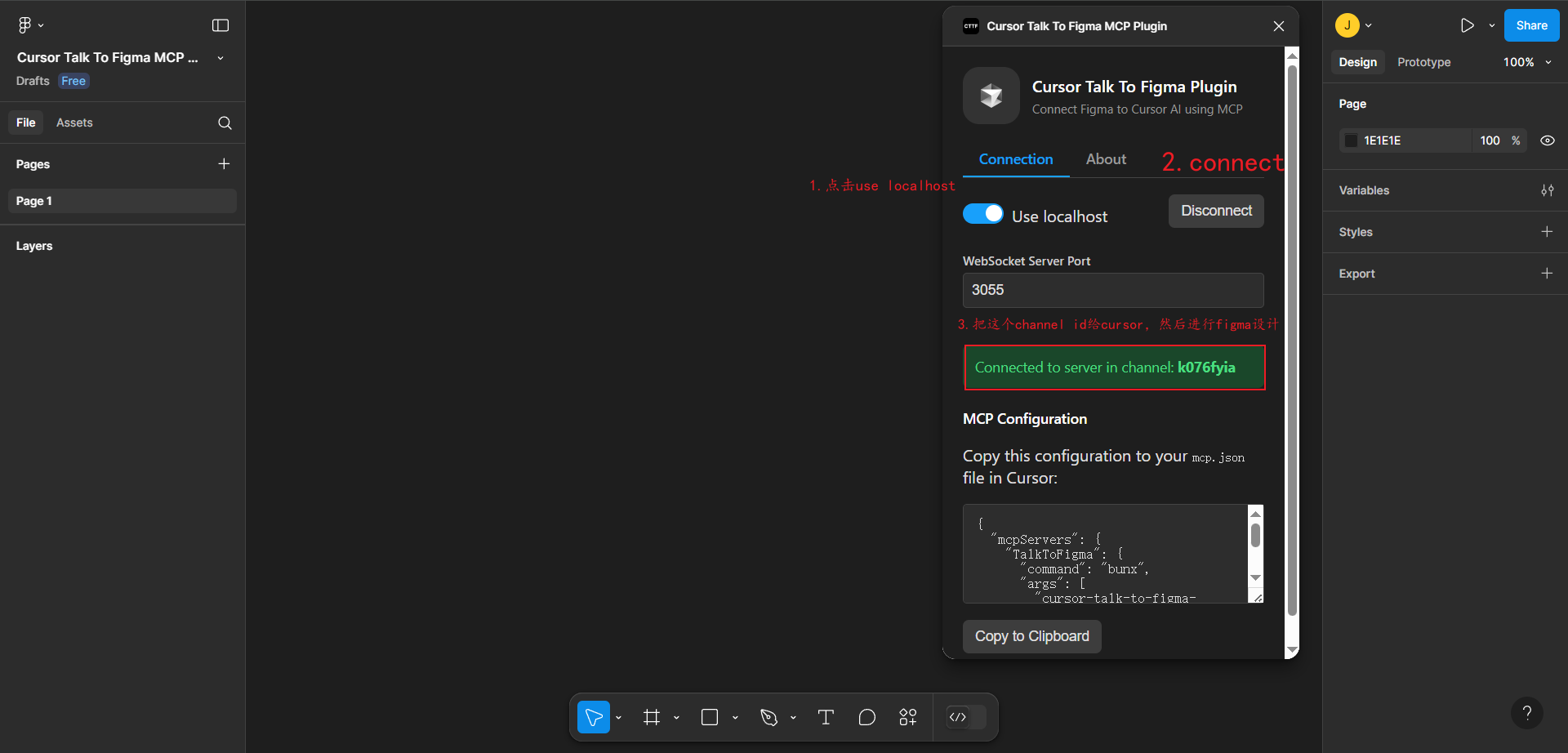
Cursor Talk To Figma MCP 安装与配置指南
Cursor Talk To Figma MCP 安装与配置指南 1.项目基础介绍 Cursor Talk To Figma MCP 是一个开源项目,它实现了 Cursor AI 与 Figma 之间的 Model Context Protocol(MCP)集成。通过这个集成,Cursor 能够与 Figma 进行通信&#…...

设计模式之状态模式:优雅管理对象行为变化
引言 状态模式(State Pattern)是一种行为型设计模式,它允许对象在其内部状态改变时改变它的行为,使对象看起来似乎修改了它的类。状态模式将状态转移逻辑和状态相关行为封装在独立的状态类中,完美解决了复杂条件判断问…...
高性能内存kv数据库Redis
目录 引言 一.Redis相关命令详解及其原理 1.redis是什么? 2.redis中存储数据的数据结构都有哪些? 3.redis的存储结构(KV) 4.reidis中value编码 5.string的基本原理和相关命令 5.1基本原理 5.2基础命令 5.3string存储结构 …...

C 语言宏定义的新用法
// power on/off #define SPK_POWER_ON() {GPIO_SET_OUT(PT_SPK_EN, PB_SPK_EN);GPIO_SET_HIGH(PT_SPK_EN, PB_SPK_EN);} #define SPK_POWER_OFF() {GPIO_SET_OUT(PT_SPK_EN, PB_SPK_EN);GPIO_SET_LOW(PT_SPK_EN, PB_SPK_EN);}在 C 语言中,宏定义可以…...

性能优化实践
4.1 大规模量子态处理的性能优化 背景与问题分析 量子计算中的大规模量子态处理(如量子模拟、量子态可视化)需要高效计算和实时渲染能力。传统图形API(如WebGL)在处理高维度量子态时可能面临性能瓶颈,甚至崩溃(如表格中14量子比特时WebGL的崩溃)。而现代API(如WebGPU…...
使用wpa_cli和wpa_supplicant配置Liunx开发板的wlan0无线网
目录 1 简单介绍下wpa_cli和wpa_supplicant 1.1 wpa_supplicant 简介 1.2 wpa_cli 简介 1.3 它们之间的关系 2 启动wpa_supplicant 3 使用rz工具把wpa_cli命令上传到开发板 4 用wpa_cli配置网络 参考文献: 1 简单介绍下wpa_cli和wpa_supplicant 1.1 wpa_su…...
C++Cherno 学习笔记day19 [76]-[80] std::optional、variant、any、如何让C++及字符串运行得更快
b站Cherno的课[76]-[80] 一、如何处理OPTIONAL数据 std::optional二、单一变量存放多类型的数据 std::variant三、如何存储任意类型的数据 std::any四、如何让C运行得更快五、如何让C字符串更快 一、如何处理OPTIONAL数据 std::optional std::optional C17 数据是否存在是可选…...
)
【信息系统项目管理师】高分论文:论信息系统项目的整合管理(旅游景区导游管理平台)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文一、制定项目章程二、制订项目管理计划三、指导和管理项目工作四、管理项目知识五、监控项目工作六、实施整体变更控制七、结束项目或阶段论文 在国家《中国旅游“十三五”发展规划信息化专项规划的背景下…...
【项目日记(一)】-仿mudou库one thread oneloop式并发服务器实现
1、模型框架 客户端处理思想:事件驱动模式 事件驱动处理模式:谁触发了我就去处理谁。 ( 如何知道触发了)技术支撑点:I/O的多路复用 (多路转接技术) 1、单Reactor单线程:在单个线程…...

[特殊字符] LoRA微调大模型实践:从MAC到Web的全流程指南
🚀 实践步骤概览 今天我们要在MAC上完成一个完整的AI项目闭环: 微调一个大模型 → 2. 导出模型并部署 → 3. 暴露API给web后端 → 4. 前端展示 🛠️ 微调模型准备 核心配置 框架:LLama-Factory 🏭 算法:…...

关于 Spring Boot 监控方式的详细对比说明及总结表格
以下是关于 Spring Boot 监控方式的详细对比说明及总结表格: 1. 监控方式概述 1.1 Actuator(内置核心监控) 功能: Spring Boot 内置的监控模块,提供健康检查、指标收集、环境信息、HTTP 追踪等端点。 适用场景&#…...

OpenCV 图形API(35)图像滤波-----中值模糊函数medianBlur()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 使用中值滤波器模糊图像。 该函数使用带有 ksizeksize 开口的中值滤波器来平滑图像。多通道图像的每个通道都是独立处理的。输出图像必须与输入…...

【嵌入式八股5】C++:多线程相关
1. 线程创建与管理 1.1 pthread_create 功能: 创建一个新的线程,并指定该线程的执行函数。参数: pthread_t *thread: 指向线程标识符的指针。const pthread_attr_t *attr: 线程属性,通常为 NULL。void *(*start_routine)(void *): 线程执行的函数指针。…...

视觉slam框架从理论到实践-第一节绪论
从opencv的基础实现学习完毕后,接下来依照视觉slam框架从理论到实践(第二版)的路线进行学习,主要以学习笔记的形式进行要点记录。 目录 1.数据里程计 2.后端优化 3.回环检测 4.建图 在视觉SLAM 中整体作业流程可分为࿱…...
图论--DFS搜索图/树
目录 一、图的存储结构 二、题目练习 846. 树的重心 - AcWing题 dfs,之前学习的回溯算法好多都是用dfs实现搜索的(把题目抽象成树形结构来搜索),其实 回溯算法就是 深搜,只不过针对某一搜索场景 我们给他一个更细分…...

Visual Studio + OpenCV C++ 安装与配置教程
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,广泛用于图像处理、视频分析、模式识别和机器学习等领域。它由Intel公司于1999年发起,并在2000年由Willow Garage(一个机器人研究机构)进一步开发和维护。OpenCV支持多种编程语言,包括C++、Python…...
)
Java核心知识点的系统整理(一)
目录 一、数据类型与运算符秘籍 1. 四类八种数据类型 2. 自增运算符的暗战 3. 位运算与逻辑运算对决 二、流程控制三剑客 1. 分支结构抉择 2. 循环控制四骑士 三、面向对象核心机制 1. final的三重封印 2. 静态成员生存法则 四、进阶特性解密 1. 多态的三重境界 2…...

在Android Studio中,`Settings`里的Gradle路径、环境变量以及`gradle - wrapper.properties`文件关联
在Android Studio中,Settings里的Gradle路径、环境变量以及gradle - wrapper.properties文件关联 Android Studio中Settings里的Gradle路径 在Android Studio的Settings(Preferences ) -> Build, Execution, Deployment -> Build Tools -> Gradle 中: Use defau…...

算法复习(二分+离散化+快速排序+归并排序+树状数组)
一、二分算法 二分算法,堪称算法世界中的高效查找利器,其核心思想在于利用数据的有序性,通过不断将查找区间减半,快速定位目标元素或满足特定条件的位置。 1. 普通二分 普通二分适用于在有序数组中查找特定元素的位置。我们可以…...

VSCode写java时常用的快捷键
首先得先安好java插件 1、获取返回值 这里是和idea一样的快捷键的,都是xxxx.var 比如现在我new一个对象 就输入 new MbDo().var // 点击回车即可变成下面的// MbDo mbDo new MbDo()//以此类推get方法也可获取 mbDo.getMc().var // 点击回车即可变成下面的 // St…...

【Code】《代码整洁之道》笔记-Chapter16-重构SerialDate
第16章 重构SerialDate 如果你找到JCommon类库,深入该类库,其中有个名为org.jfree.date的程序包。在该程序包中,有个名为SerialDate的类,我们即将剖析这个类。 SerialDate的作者是David Gilbert。David显然是一位经验丰富、能力…...

使用 Node.js、Express 和 React 构建强大的 API
了解如何使用 Node.js、Express 和 React 创建一个强大且动态的 API。这个综合指南将引导你从设置开发环境开始,到集成 React 前端,并利用 APIPost 进行高效的 API 测试。无论你是初学者还是经验丰富的开发者,这篇文章都适合你。 今天&#…...

深度学习入门:神经网络的学习
目录 1 从数据中学习1.1 数据驱动1.2 训练数据和测试数据 2损失函数2.1 均方误差2.2 交叉熵误差2.3 mini-batch学习2.4 mini-batch版交叉熵误差的实现2.5 为何要设定损失函数 3 数值微分3.1 数值微分3.3 偏导数 4 梯度4.1 梯度法4.2 神经网络的梯度 5 学习算法的实现5.1 2层神经…...

OSI参考模型和TCP/IP模型
1.OSI参考模型 OSI模型: OSI参考模型有7层,自下而上依次为物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。(记忆口诀:物联网叔会用)。低…...