【愚公系列】《Python网络爬虫从入门到精通》052-Scrapy 编写 Item Pipeline
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟
📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主!
👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"挖山不止"的毅力为开发者们搬开知识道路上的重重阻碍!
💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node…
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
每日更新硬核教程+实战案例,助你打通技术任督二脉!
💌【特别邀请】
正在构建技术人脉圈的你:
👍 如果这篇推文让你收获满满,点击"在看"传递技术火炬
💬 在评论区留下你最想学习的技术方向
⭐ 点击"收藏"建立你的私人知识库
🔔 关注公众号获取独家技术内参
✨与其仰望大神,不如成为大神!关注"愚公搬代码",让坚持的力量带你穿越技术迷雾,见证从量变到质变的奇迹!✨ |
文章目录
- 🚀前言
- 🚀一、编写 Item Pipeline
- 🔎1.项目管道的核心方法
- 🔎2.将信息存储至数据库
🚀前言
在前几篇文章中,我们已经学习了如何搭建 Scrapy 爬虫框架,并掌握了 Scrapy 的基本应用。本篇文章中,我们将深入探讨 Scrapy 中的一个重要组件——Item Pipeline。
Item Pipeline 是 Scrapy 框架中用于处理抓取到的数据的关键部分。通过 Item Pipeline,我们可以对抓取到的数据进行清洗、验证、存储等一系列处理操作,实现数据从网页到最终存储的全流程管理。理解并正确使用 Item Pipeline,将极大提升我们爬虫项目的数据处理效率和质量。
在本篇文章中,我们将会学习到:
- Item Pipeline 的基本概念和作用:了解 Item Pipeline 在 Scrapy 项目中的地位和功能。
- 如何编写和配置 Item Pipeline:从定义和编写 Pipeline 到在项目中进行配置与使用。
- 数据清洗与验证:如何在 Pipeline 中进行数据清洗和验证,以确保数据的准确性和一致性。
- 数据存储:将抓取到的数据存储到各种存储后端,如文件、数据库等。
- 多个 Pipeline 的使用:如何在项目中配置和使用多个 Pipeline,灵活处理不同的数据处理需求。
通过本篇文章的学习,你将全面掌握 Scrapy Item Pipeline 的使用技巧,能够实现对抓取数据的高效处理和存储,使你的爬虫项目更加完整和可靠。
🚀一、编写 Item Pipeline
当爬取的数据被存储在 Item 对象后,Spider(爬虫)解析完 Response(响应结果)后,Item 会传递到 Item Pipeline(项目管道)中。通过自定义的管道类可实现数据清洗、验证、去重及存储到数据库等操作。
🔎1.项目管道的核心方法
Item Pipeline 的主要用途:
- 清理 HTML 数据
- 验证数据(检查字段完整性)
- 去重处理
- 存储数据至数据库
自定义 Pipeline 需实现的方法:
| 方法 | 说明 |
|---|---|
process_item() | 必须实现。处理 Item 对象,参数为 item(Item对象)和 spider(爬虫对象)。 |
open_spider() | 爬虫启动时调用,用于初始化操作(如连接数据库)。 |
close_spider() | 爬虫关闭时调用,用于收尾工作(如关闭数据库连接)。 |
from_crawler() | 类方法(需 @classmethod 装饰),返回实例对象并获取全局配置信息。 |
示例代码框架:
import pymysqlclass CustomPipeline:def __init__(self, host, database, user, password, port):# 初始化数据库参数self.host = hostself.database = databaseself.user = userself.password = passwordself.port = port@classmethoddef from_crawler(cls, crawler):# 从配置中读取数据库参数return cls(host=crawler.settings.get('SQL_HOST'),database=crawler.settings.get('SQL_DATABASE'),user=crawler.settings.get('SQL_USER'),password=crawler.settings.get('SQL_PASSWORD'),port=crawler.settings.get('SQL_PORT'))def open_spider(self, spider):# 连接数据库self.db = pymysql.connect(host=self.host,user=self.user,password=self.password,database=self.database,port=self.port,charset='utf8')self.cursor = self.db.cursor()def close_spider(self, spider):# 关闭数据库连接self.db.close()def process_item(self, item, spider):# 处理数据并插入数据库data = dict(item)sql = 'INSERT INTO table_name (col1, col2) VALUES (%s, %s)'self.cursor.execute(sql, (data['field1'], data['field2']))self.db.commit()return item
🔎2.将信息存储至数据库
实现步骤:
-
数据库准备
- 安装 MySQL,创建数据库
jd_data和数据表ranking(包含book_name,author,press字段)。
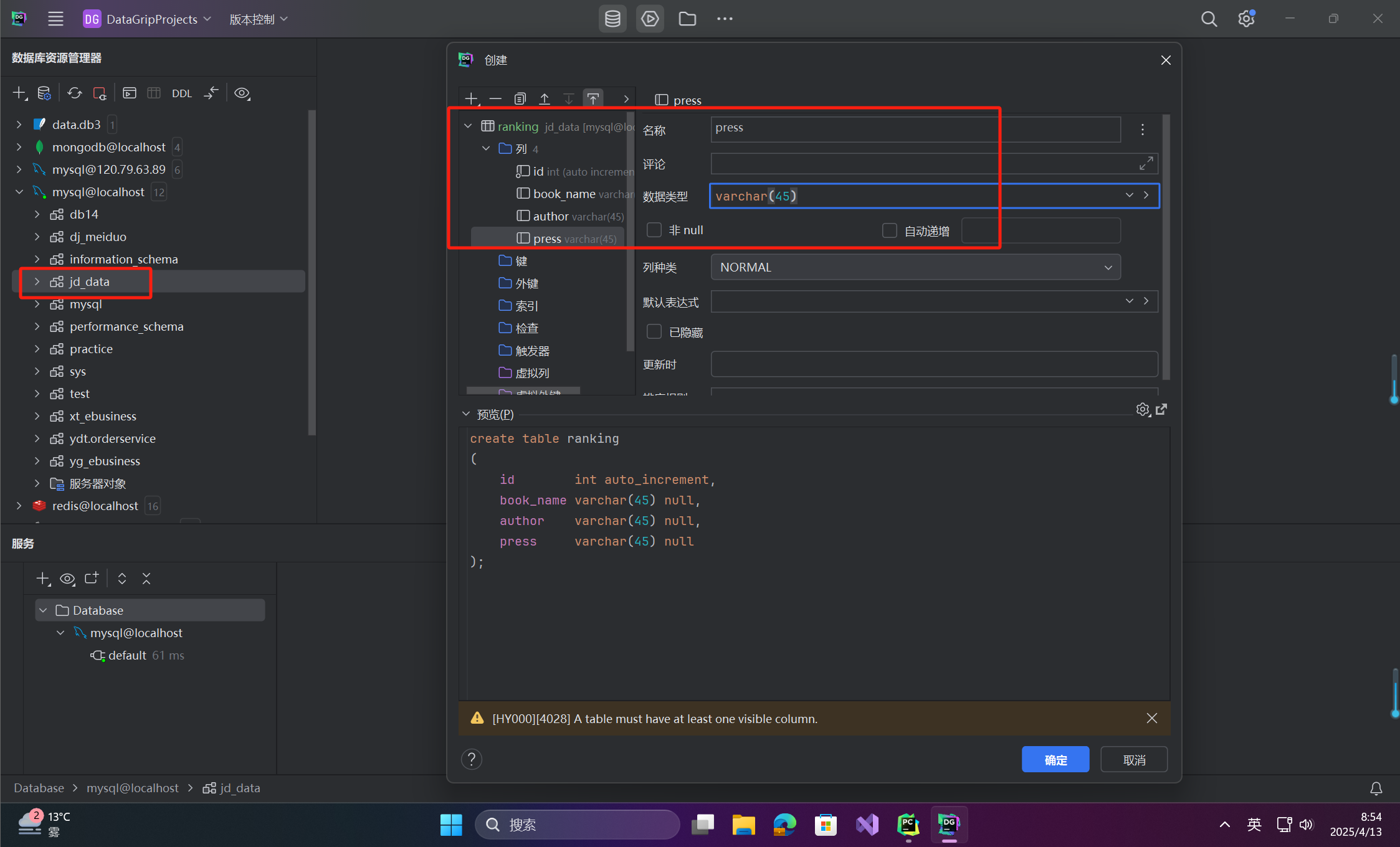
- 安装 MySQL,创建数据库
-
创建 Scrapy 项目
scrapy startproject jd cd jd scrapy genspider jdSpider book.jd.com -
定义 Item(items.py)
import scrapyclass JdItem(scrapy.Item):book_name = scrapy.Field() # 图书名称author = scrapy.Field() # 作者press = scrapy.Field() # 出版社 -
编写爬虫(jdSpider.py)
# -*- coding: utf-8 -*- import scrapy from jd.items import JdItem # 导入JdItem类class JdspiderSpider(scrapy.Spider):name = 'jdSpider' # 默认生成的爬虫名称allowed_domains = ['book.jd.com']start_urls = ['http://book.jd.com/']def start_requests(self):# 需要访问的地址url = 'https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-1'yield scrapy.Request(url=url, callback=self.parse) # 发送网络请求def parse(self, response):all=response.xpath(".//*[@class='p-detail']") # 获取所有信息book_name = all.xpath("./a[@class='p-name']/text()").extract() # 获取所有图书名称author = all.xpath("./dl[1]/dd/a[1]/text()").extract() # 获取所有作者名称press = all.xpath("./dl[2]/dd/a/text()").extract() # 获取所有出版社名称item = JdItem() # 创建Item对象# 将数据添加至Item对象item['book_name'] = book_nameitem['author'] = authoritem['press'] = pressyield item # 打印item信息pass# 导入CrawlerProcess类 from scrapy.crawler import CrawlerProcess # 导入获取项目设置信息 from scrapy.utils.project import get_project_settings# 程序入口 if __name__=='__main__':# 创建CrawlerProcess类对象并传入项目设置信息参数process = CrawlerProcess(get_project_settings())# 设置需要启动的爬虫名称process.crawl('jdSpider')# 启动爬虫process.start() -
配置管道(pipelines.py)
# -*- coding: utf-8 -*-# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport pymysql # 导入数据库连接pymysql模块class JdPipeline(object):# 初始化数据库参数def __init__(self,host,database,user,password,port):self.host = hostself.database = databaseself.user = userself.password = passwordself.port = port@classmethoddef from_crawler(cls,crawler):# 返回cls()实例对象,其中包含通过crawler获取配置文件中的数据库参数return cls(host=crawler.settings.get('SQL_HOST'),user=crawler.settings.get('SQL_USER'),password=crawler.settings.get('SQL_PASSWORD'),database = crawler.settings.get('SQL_DATABASE'),port = crawler.settings.get('SQL_PORT'))# 打开爬虫时调用def open_spider(self, spider):# 数据库连接self.db = pymysql.connect(self.host,self.user,self.password,self.database,self.port,charset='utf8')self.cursor = self.db.cursor() #床架游标# 关闭爬虫时调用def close_spider(self, spider):self.db.close()def process_item(self, item, spider):data = dict(item) # 将item转换成字典类型# sql语句sql = 'insert into ranking (book_name,press,author) values(%s,%s,%s)'# 执行插入多条数据self.cursor.executemany(sql, list(zip(data['book_name'], data['press'], data['author'])))self.db.commit() # 提交return item # 返回item -
激活管道(settings.py)
ITEM_PIPELINES = {'jd.pipelines.JdPipeline': 300, }SQL_HOST = 'localhost' SQL_USER = 'root' SQL_PASSWORD = 'root' SQL_DATABASE = 'jd_data' SQL_PORT = 3306 -
运行爬虫
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settingsif __name__ == '__main__':process = CrawlerProcess(get_project_settings())process.crawl('jdSpider')process.start()
注意事项
- 确保已安装
pymysql:pip install pymysql - 若出现编码问题,可在 MySQL 连接参数中添加
charset='utf8mb4'。 - 数据库表字段需与
Item中定义的字段一致。
相关文章:
【愚公系列】《Python网络爬虫从入门到精通》052-Scrapy 编写 Item Pipeline
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...
【AI News | 20250416】每日AI进展
AI Repos 1、Tutorial-Codebase-Knowledge 自动分析 GitHub 仓库并生成适合初学者的通俗易懂教程,清晰解释代码如何运行,还能生成可视化内容来展示核心功能。爬取 GitHub 仓库并从代码中构建知识库;分析整个代码库以识别核心抽象概念及其交互…...

GIS开发笔记(6)结合osg及osgEarth实现半球形区域绘制
一、实现效果 输入中心点坐标及半径,绘制半球形区域,地下部分不显示。 二、实现原理 根据中心点及半径绘制半球形区域,将其挂接到地球节点。 三、参考代码 void GlobeWidget::drawSphericalRegion(osg::Vec3d point,double radius) {// 使…...

Ant Design Vue 的表格数据,第一列项目区域,项目区域相同的行数据,第一列项目区域合并
在 Ant Design Vue 的表格中,如果需要根据第一列(如“项目区域”)的值进行动态合并,可以通过 customCell 方法实现。以下是完整的代码示例,展示如何根据“项目区域”相同的行数据,合并第一列单元格。 代码示…...
介绍)
SFOS2:常用容器(布局)介绍
一、前言 最近在进行sailfish os的开发,由于在此之前并没有从事过QT开发的工作,所以对这一套颇为生疏,以此记录一下。以下内容不一定完全准确,开发所使用的是Qt Quick 2.6与Sailfish.Silica 1.0两个库。 二、布局 1.Qt Quick 2.…...

C++ 核心进阶
模块九:进一步学习 (指引方向) 目录 标准模板库 (STL) 深入 1.1. std::map (进阶) 1.1.1. 迭代器的更多用法 1.1.2. 自定义比较函数 1.1.3. std::multimap 1.2. std::set (进阶) 1.2.1. 迭代器的更多用法 1.2.2. 自定义比较函数 1.2.3. std::multiset 和 std::un…...

守护进程编程
守护进程编程 1. 守护进程的含义 守护进程的含义: 守护进程(Daemon)是指一种在后台运行的进程,通常不与用户交互,用于执行一些常驻任务,如系统监控、日志管理、定时任务等。它通常在操作系统启动时就被启…...

[特殊字符] MySQL MCP 开发实战:打造智能数据库操作助手
💡 简介:本文详细介绍如何利用MCP(Model-Control-Panel)框架开发MySQL数据库操作工具,使AI助手能够直接执行数据库操作。 📚 目录 引言MCP框架简介项目架构设计开发环境搭建核心代码实现错误处理策略运行和…...
element-ui自定义主题
此处的element-ui为基于vue2.x的 由于https://element.eleme.cn/#/zh-CN/theme/preview(element的主题)报错503, 所以使用https://element.eleme.cn/#/zh-CN/component/custom-theme 自定义主题文档中,在项目中改变scss变量的方…...
windows下使用nginx + waitress 部署django
架构介绍 linux一般采用nginx uwsgi部署django,在Windows下,可以取代uwsgi的选项包括Waitressa、Daphnea、Hypercoma和Gunicorna(通过WSLa 运行)。windows服务器一般采用nginx waitress 部署django,,他们的关系如下 django是WEB应用…...
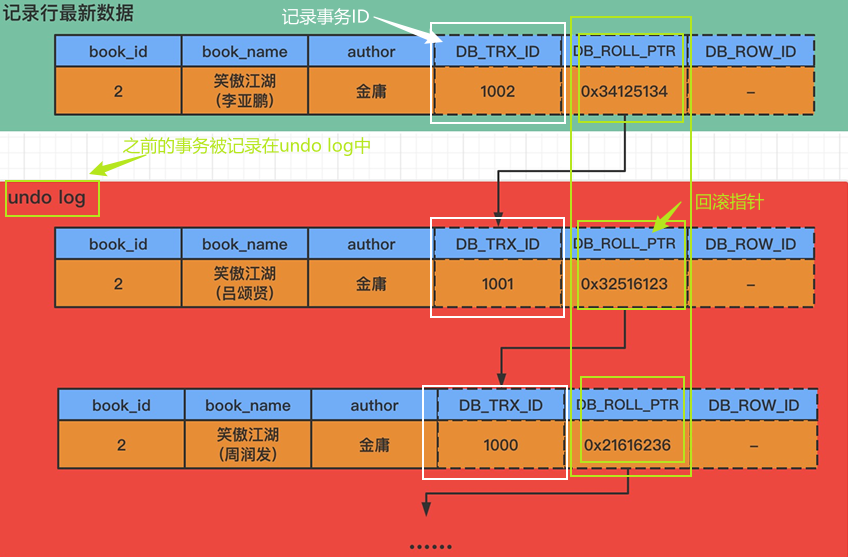
MySQL-多版本并发控制MVCC
文章目录 一、多版本并发控制MVCC二、undo log(回滚日志)二、已提交读三、可重复读总结 一、多版本并发控制MVCC MVCC是多版本并发控制(Multi-Version Concurrency Control),是MySQL中基于乐观锁理论实现隔离级别的方…...

Sherpa简介
Sherpa 是一个由 K2-FSA 团队 开发的 开源语音处理框架,旨在解决传统语音识别工具(如 Kaldi)在模型部署和跨平台适配中的复杂性问题。它通过整合现代深度学习技术和高效推理引擎,提供了从语音识别、合成到说话人识别的一站式解决方…...

4.15redis点评项目下
--->接redis点评项目上 Redis优化秒杀方案 下单流程为:用户请求nginx--->访问tomcat--->查询优惠券--->判断秒杀库存是否足够--->查询订单--->校验是否是一人一单--->扣减库存--->创建订单 以上流程如果要串行执行耗时会很多,…...

目标检测与分割:深度学习在视觉中的应用
🔍 PART 1:目标检测(Object Detection) 1️⃣ 什么是目标检测? 目标检测是计算机视觉中的一个任务,目标是让模型“在图像中找到物体”,并且判断: 它是什么类别(classif…...

SpringBoot 与 Vue3 实现前后端互联全解析
在当前的互联网时代,前后端分离架构已经成为构建高效、可维护且易于扩展应用系统的主流方式。本文将详细介绍如何利用 SpringBoot 与 Vue3 构建一个前后端分离的项目,展示两者如何通过 RESTful API 实现无缝通信,让读者了解从环境搭建、代码实…...

HEIF、HEIC、JPG 和 PNG是什么?
1. HEIF (High Efficiency Image Format) 定义:HEIF 是一种用于存储单张图像和图像序列(如连拍照片)的图像文件格式。优势:相比传统的图像格式,HEIF 提供了更高的压缩效率和更好的图像质量。压缩算法:HEI…...

第一层、第二层与第三层隧道协议
(本文由deepseek生成,特此声明) 隧道协议是网络通信中用于在不同网络间安全传输数据的关键技术,其工作层次决定了封装方式、功能特性及应用场景。本文将详细介绍物理层(第一层)、数据链路层(第…...

部署qwen2.5-VL-7B
简单串行执行 from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor from qwen_vl_utils import process_vision_info import torch, time, threadingdef llm(model_path,promptNone,imageNone,videoNone,imagesNone,videosNone,max_new_tokens2048,t…...

记录jdk8->jdk17 遇到的坑和解决方案
最近项目在升级jdk8->jdk17 springboot2->springboot3 顺序先升级业务服务,后升级组件服务。跟随迭代开发一起验证功能。 1. 使用parent pom 版本管理 spring相关组件的版本。 组件依赖低版本parent不变。 业务服务依赖高版本parent。 2. 修改maven jdk…...

vue3 uniapp vite 配置之定义指令
动态引入指令 // src/directives/index.js import trim from ./trim;const directives {trim, };export default {install(app) {console.log([✔] 自定义指令插件 install 触发了!);Object.entries(directives).forEach(([key, directive]) > {app.directive(…...

杰弗里·辛顿:深度学习教父
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 杰弗里辛顿:当坚持遇见突破,AI迎来新纪元 一、人物简介 杰弗…...
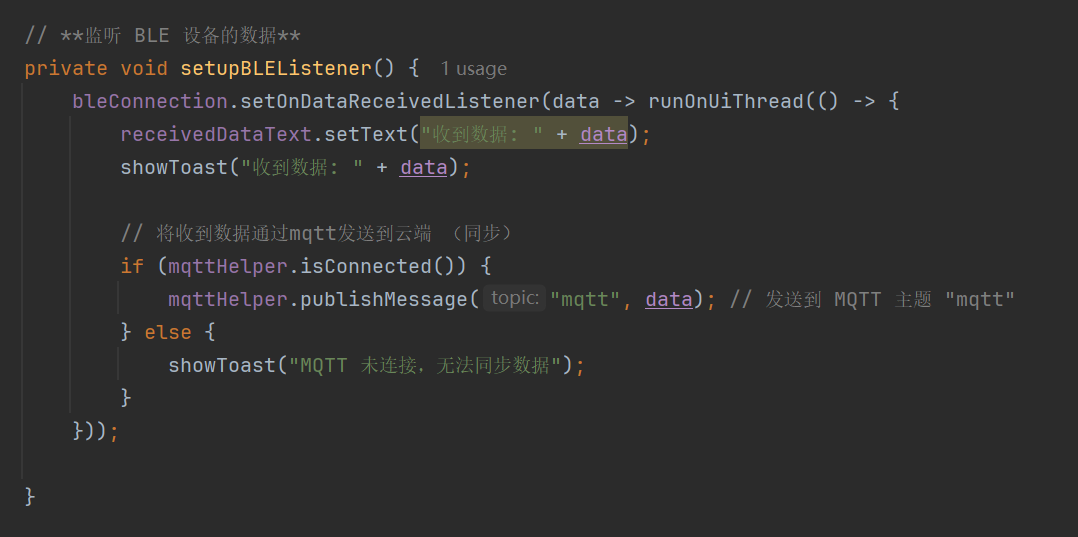
STM32蓝牙连接Android实现云端数据通信(电机控制-开源)
引言 基于 STM32F103C8T6 最小系统板完成电机控制。这个小项目采用 HAL 库方法实现,通过 CubeMAX 配置相关引脚,步进电机使用 28BYJ-48 (四相五线式步进电机),程序通过蓝牙连接手机 APP 端进行数据收发, OL…...

第一个Qt开发的OpenCV程序
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 下载安装Qt:https://download.qt.io/archive/qt/5.14/5.14.2/qt-opensource-windows-x86-5.14.2.exe 下载安装OpenCV:https://opencv.org/releases/ 下载安装CMake:Downl…...

如何编写爬取网络上的视频文件
网络爬虫程序,可以爬取某些网站上的视频,音频,图片或其它文件,然后保存到本地电脑上; 有时在工作中非常有用,那在技术上如何进行爬取文件和保存到本地呢?下面以python语言为例,讲解p…...
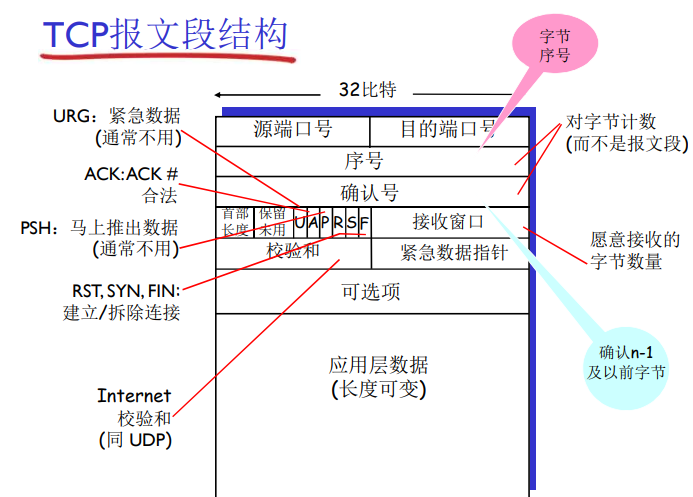
TCP 如何在网络 “江湖” 立威建交?
一、特点: (一)面向连接 在进行数据传输之前,TCP 需要在发送方和接收方之间建立一条逻辑连接。这一过程类似于打电话,双方在通话前需要先拨号建立连接。建立连接的过程通过三次握手来完成,确保通信双方都…...
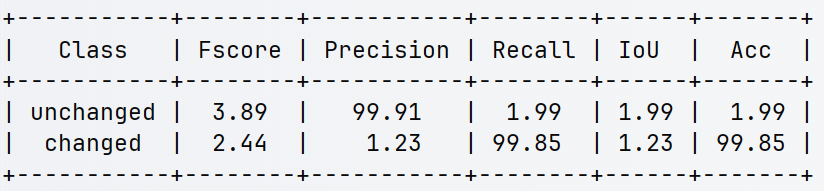
【小白训练日记——2025/4/15】
变化检测常用的性能指标 变化检测(Change Detection)的性能评估依赖于多种指标,每种指标从不同角度衡量模型的准确性。以下是常用的性能指标及其含义: 1. 混淆矩阵(Confusion Matrix) 定义:统…...

交叉熵在机器学习中的应用解析
文章目录 核心概念香农信息量(自信息)熵(Entropy)KL散度(Kullback-Leibler Divergence)交叉熵 在机器学习中的应用作为损失函数对于二分类(Binary Classification):对于多…...

ARM Cortex汇编指令
在ARM架构的MCU开发中,汇编指令集是底层编程的核心。以下是针对Cortex-M系列(如M0/M3/M4/M7/M85)的指令集体系、分类及查询方法的详细说明: 一、指令集体系与核心差异 1. 架构版本与指令集特性 处理器架构指令集特点典型应用场…...
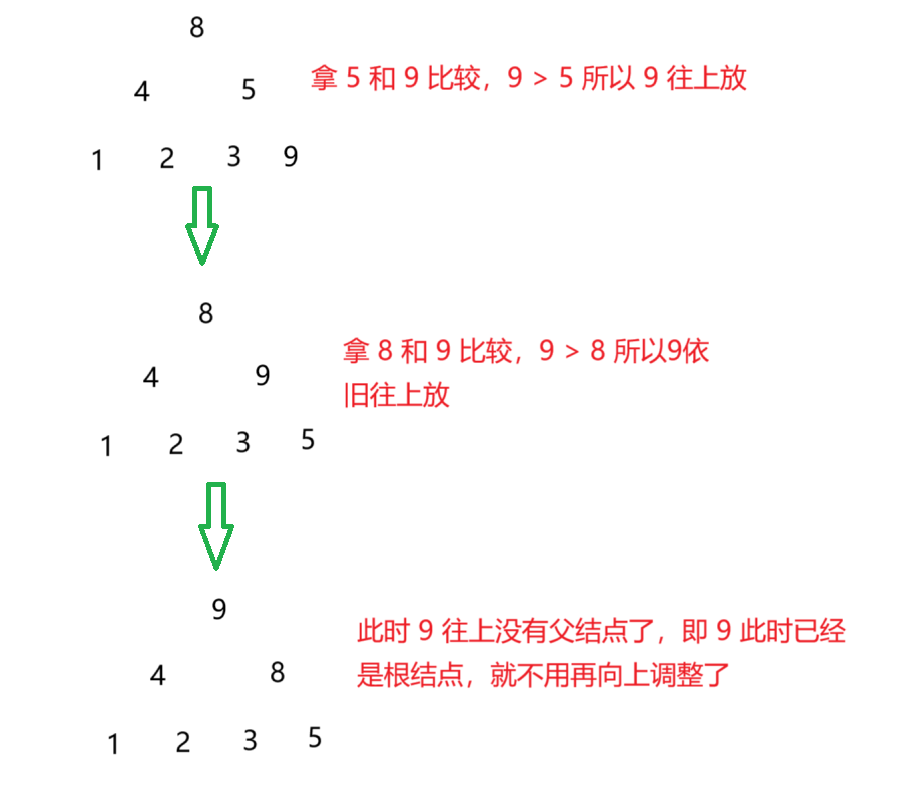
数据结构——二叉树(中)
接上一篇,上一篇主要讲解了关于二叉树的基本知识,也是为了接下来讲解关于堆结构和链式二叉树结构打基础,其实无论是堆结构还是链式二叉树结构,都是二叉树的存储结构,那么今天这一篇主要讲解关于堆结构的实现与应用 堆…...

InnoDB的MVCC实现原理?MVCC如何实现不同事务隔离级别?MVCC优缺点?
概念 InnoDB的MVCC(Multi-Version Concurrency Control)即多版本并发控制,是一种用于处理并发事务的机制。它通过保存数据在不同时间点的多个版本,让不同事务在同一时刻可以看到不同版本的数据,以此来减少锁竞争&…...