KWDB(Knowledge Worker Database)基础概念与原理完整指南
KWDB(Knowledge Worker Database)基础概念与原理完整指南—目录
- 前言
- 一、背景
- 1.1 知识工作者的痛点
- 1.2 技术演进推动
- 二、定义与定位
- 2.1 什么是KWDB?
- 2.2 KWDB与传统数据库的对比
- 与传统关系型数据库(如MySQL)的对比
- 与分布式数据库(如Cassandra)的对比
- 2.3 KWDB的优势与劣势
- 三、核心功能与技术
- 3.1 核心功能
- (1)多模态数据融合
- (2)知识图谱集成
- (3)智能查询与推理
- (4)协作与版本控制
- 3.2 关键技术组件
- 3.3 技术架构
- 四、应用场景实例
- 4.1 基础使用场景实例
- 实例1:企业知识库
- 实例2:医疗研究协作
- 4.2 进阶使用场景实例
- 实例1:金融风控中的跨领域分析
- 实例2:元宇宙数据管理
- 五、新增案例
- 案例3:教育领域的个性化学习平台
- 案例4:制造业的设备预测性维护
- 案例5:零售行业的供应链优化
- 六、挑战与机遇
- 6.1 挑战实例
- 实例1:医疗数据隐私合规
- 实例2:硬件资源限制
- 6.2 机遇实例
- 实例1:AI驱动的自动化决策
- 实例2:边缘计算与工业物联网
- 七、未来发展方向实例
- 八、总结
- 九、学习资源推荐
- 学习网站
- 研究文献
前言
在数字化与智能化浪潮中,知识工作者(如研究人员、金融分析师、医疗专家)面临的核心挑战是如何高效处理海量、多源、异构的数据,并从中提取有价值的知识以支持决策。传统数据库(如MySQL、分布式数据库)虽然在事务处理和简单分析中表现出色,但难以满足复杂语义关联、多模态数据融合和智能推理的需求。KWDB(Knowledge Worker Database) 应运而生,它结合了知识图谱、自然语言处理(NLP)和人工智能(AI)技术,为知识密集型场景提供全新的数据管理范式。本文将从背景、定义、技术架构到应用场景,全面解析KWDB的核心原理与实践价值,帮助读者理解其与传统数据库的差异、优势与挑战,并展望未来发展方向。
一、背景
1.1 知识工作者的痛点
知识工作者依赖数据驱动决策,但传统工具存在以下问题:
• 数据孤岛:跨部门、跨系统的数据格式不兼容,整合成本高。例如,医疗领域的研究人员需要整合患者电子健康记录(EHR)、基因组数据和学术论文,但这些数据通常存储在不同的系统中,格式差异巨大。
• 语义鸿沟:非结构化文本、图像等数据缺乏统一语义表达,难以被机器理解。例如,一份法律合同中的条款可能包含隐含的逻辑关系,但传统数据库无法自动提取这些关系。
• 推理能力缺失:无法自动发现数据中的隐含关联或趋势。例如,金融分析师需要从新闻舆情、交易数据和宏观经济指标中预测市场波动,但传统工具仅能提供静态统计结果。
• 协作效率低:版本控制与权限管理复杂,多人协同困难。例如,科研团队在协作编辑实验记录时,可能因版本冲突导致数据丢失。
1.2 技术演进推动
• 知识图谱:通过图结构建模实体关系,支持语义推理。例如,谷歌的知识图谱已能关联数十亿实体,支持智能问答。
• 大语言模型(LLM):实现自然语言交互与自动化洞察。例如,GPT-4可通过对话生成代码、解释复杂概念。
• 多模态存储:支持文本、图像、时序数据的统一管理。例如,特斯拉的自动驾驶系统需同时处理摄像头图像、雷达信号和车辆状态数据。
二、定义与定位
2.1 什么是KWDB?
KWDB(Knowledge Worker Database)是一种面向知识工作者设计的智能数据库系统,核心目标是通过整合结构化与非结构化数据、嵌入语义推理能力,提升知识发现与决策效率。其核心特征包括:
• 多模态数据融合:统一存储文本、表格、图像、音视频等数据,并通过嵌入技术(Embedding)将非结构化数据转化为向量表示。
• 知识图谱驱动:自动抽取实体与关系,构建动态知识图谱,支持语义推理与链接预测。
• AI原生架构:内置机器学习模块,支持假设验证、自动化洞察与动态优化。
2.2 KWDB与传统数据库的对比
与传统关系型数据库(如MySQL)的对比
| 维度 | MySQL | KWDB |
|---|---|---|
| 数据类型 | 仅支持结构化数据 | 支持多模态(结构化、非结构化、图数据) |
| 查询能力 | 基于SQL的静态查询 | 自然语言查询(NLQ)、图推理、假设验证 |
| 语义理解 | 无 | 内置知识图谱与语义解析 |
| 扩展性 | 垂直扩展为主 | 分布式架构,支持弹性扩展 |
| 适用场景 | 事务处理、简单分析 | 知识发现、复杂推理、跨领域协作 |
与分布式数据库(如Cassandra)的对比
| 维度 | Cassandra | KWDB |
|---|---|---|
| 数据模型 | 面向时序数据的宽表模型 | 知识图谱模型 + 多模态存储 |
| 查询灵活性 | 仅支持预定义查询 | 动态查询与推理 |
| 语义能力 | 无 | 基于图谱的语义关联与推理 |
| 协作支持 | 有限 | 实时协同编辑、版本控制 |
2.3 KWDB的优势与劣势
• 优势:
• 复杂语义关联与推理:通过知识图谱和图神经网络(GNN),支持隐含关系挖掘。例如,在医疗领域,系统可自动推断“基因突变→蛋白质功能异常→疾病”的逻辑链。
• 多源异构数据整合:统一管理结构化数据(如销售报表)、非结构化文档(如客户邮件)和图数据(如社交网络关系)。
• AI增强决策:结合LLM生成自然语言报告,降低人工分析成本。例如,金融分析师输入“生成2024年投资趋势报告”,KWDB自动整合数据并输出结论。
• 劣势:
• 技术复杂性:需集成知识图谱、分布式存储和AI模型,部署和维护成本高。
• 硬件资源需求:大规模图计算和实时推理对GPU/存储要求极高。
• 数据隐私与安全:跨机构协作时需解决数据合规性问题(如GDPR、HIPAA)。
三、核心功能与技术
3.1 核心功能
(1)多模态数据融合
• 统一存储:支持文本(PDF、Word)、表格(CSV、Excel)、图像(JPEG、PNG)、音视频(MP3、MP4)等格式。
• 嵌入技术(Embedding):将非结构化数据转化为向量表示。例如,使用BERT模型将文本转化为768维向量,图像使用ResNet提取特征向量。
• 数据对齐:通过元数据标签或语义相似度算法(如余弦相似度)关联多模态数据。例如,将某产品的用户评论与其销售数据关联。
(2)知识图谱集成
• 实体与关系抽取:利用NLP技术从文本中提取实体(如“苹果公司”)和关系(如“收购→ARM公司”)。工具包括Stanford NER、spaCy。
• 动态图更新:实时增量更新知识图谱。例如,当新论文发表时,自动提取作者、机构、关键词并添加到图谱中。
• 图神经网络(GNN):支持链接预测(预测缺失的关系)和社区发现(识别紧密关联的子群)。例如,在社交网络中识别潜在的影响者群体。
(3)智能查询与推理
• 自然语言查询(NLQ):用户输入“列出2020年后关于气候变化的经济影响论文”,KWDB自动生成结构化查询(如Cypher或SQL)。
• 假设验证:输入“药物A可能抑制疾病B”,系统通过知识图谱验证逻辑链(如药物靶点→基因表达→疾病通路)。
• 自动化洞察:利用ML模型发现异常模式。例如,检测到某地区用电量突增时,触发“电力设备故障”预警。
(4)协作与版本控制
• 实时协同编辑:允许多人同时修改同一知识库,冲突解决策略包括最后写入优先(LWW)或操作转换(OT)。
• 版本追溯:记录数据与知识图谱的历史变更,支持回滚与对比。例如,查看某论文引用次数随时间的变化。
• 权限管理:细粒度控制用户对数据、知识模块的访问与操作权限。例如,限制实习生仅能查看非敏感数据。
3.2 关键技术组件
• 语义解析引擎:将自然语言转换为结构化查询。例如,使用BERT或GPT-3模型解析用户意图。
• 图计算引擎:支持大规模图遍历与子图匹配。例如,Neo4j的Cypher查询引擎或Apache Giraph的分布式图计算框架。
• 机器学习模块:用于实体分类、异常检测与预测建模。例如,使用TensorFlow训练疾病预测模型。
• 分布式存储:混合使用列式存储(ClickHouse)、文档存储(MongoDB)和对象存储(MinIO)。
3.3 技术架构
KWDB采用分层架构设计:
- 存储层:
• 结构化数据:PostgreSQL(事务处理)、ClickHouse(分析型查询)。
• 图数据:Neo4j(高性能图查询)、Amazon Neptune(托管式图数据库)。
• 非结构化数据:Elasticsearch(全文搜索)、MinIO(分布式文件存储)。 - 计算层:
• 查询引擎:基于Apache Calcite优化查询计划,支持SQL和图查询的混合执行。
• 推理引擎:集成知识图谱与LLM(如GPT-4),实现逻辑推理与自然语言生成。 - 服务层:
• API网关:提供RESTful API和GraphQL接口,支持多语言客户端调用。
• 可视化工具:如Kibana(数据仪表盘)、Gephi(图谱可视化)。 - 应用层:
• 行业定制化应用:例如,医疗领域的基因组分析平台、金融领域的反欺诈系统。
四、应用场景实例
4.1 基础使用场景实例
实例1:企业知识库
• 场景:某咨询公司需要整合内部文档、行业报告与客户数据。
• KWDB功能:
• 自动分类与标签:使用NLP模型(如FastText)对文档进行主题分类,并添加关键词标签。
• 智能检索:用户输入“2023年亚洲市场增长最快的行业”,系统返回可视化图表(如柱状图)及关联文档链接。
• 协作编辑:团队成员实时更新报告,版本历史可追溯至具体修改时间与作者。
实例2:医疗研究协作
• 场景:研究团队管理实验数据与论文。
• KWDB功能:
• 数据关联:自动将论文中的实验数据与基因组图谱关联,生成交互式网络图。
• 假设验证:输入“基因X突变可能导致疾病Y”,系统遍历知识图谱中的相关文献与实验数据,返回支持或反驳该假设的证据。
4.2 进阶使用场景实例
实例1:金融风控中的跨领域分析
• 场景:银行需分析客户交易记录、新闻舆情与外部黑名单。
• KWDB功能:
• 实时风险评分:结合交易金额、地点、客户历史行为和新闻事件(如某国经济制裁),动态生成风险评分。
• 知识图谱推理:若某客户与多个高风险账户存在转账关系,系统触发反洗钱警报。
实例2:元宇宙数据管理
• 场景:虚拟世界中管理3D模型、用户交互日志与虚拟身份。
• KWDB功能:
• 多模态查询:用户输入“查找所有包含红色元素的3D模型”,系统返回匹配的模型列表及设计文档。
• 行为分析:通过图谱分析用户交互路径,推荐个性化内容(如相似风格的艺术品)。
五、新增案例
案例3:教育领域的个性化学习平台
• 场景:某在线教育平台需要为不同学生生成个性化学习路径。
• KWDB功能:
• 知识图谱构建:将课程知识点关联为图谱(如“微积分→导数→物理应用”)。
• 学习行为分析:通过学生答题记录构建个人知识图谱,识别薄弱环节。
• 动态推荐:输入“学生A需要加强代数基础”,系统推荐相关课程与习题。
案例4:制造业的设备预测性维护
• 场景:工厂需实时监控设备传感器数据并预测故障。
• KWDB功能:
• 多模态数据融合:整合振动传感器数据(时序)、设备手册(文本)、维修记录(表格)。
• 异常检测:通过图神经网络分析设备运行参数,识别异常模式(如轴承过热)。
• 知识推理:结合历史维修记录与设备结构图谱,生成维修建议(如“更换电机轴承”)。
案例5:零售行业的供应链优化
• 场景:零售商需优化全球供应链以应对突发需求波动。
• KWDB功能:
• 实时数据整合:聚合销售数据、物流信息、社交媒体舆情。
• 图谱驱动决策:分析供应商关系图谱(如交货延迟率、质量评分),动态调整采购策略。
• 需求预测:结合历史销售数据和外部事件(如天气、新闻),生成区域库存补货建议。
六、挑战与机遇
6.1 挑战实例
实例1:医疗数据隐私合规
• 问题:跨机构共享患者数据时需符合HIPAA等法规。
• 解决方案:
• 联邦学习:在本地医院训练模型,仅共享推理结果而非原始数据。
• 差分隐私:在数据中添加噪声,防止个体信息泄露。
实例2:硬件资源限制
• 问题:大规模图计算对GPU内存需求高。
• 解决方案:
• 分布式图计算框架:使用Apache Giraph或DGL(Deep Graph Library)分割任务到多台机器。
• 模型压缩:通过量化(Quantization)或剪枝(Pruning)减少模型参数量。
6.2 机遇实例
实例1:AI驱动的自动化决策
• 机会:结合LLM生成自然语言报告,降低人工分析成本。
• 案例:某零售企业输入“生成2024年节日促销策略”,KWDB自动分析销售数据、社交媒体趋势,输出包含预算分配、商品推荐的完整报告。
实例2:边缘计算与工业物联网
• 机会:在工厂边缘节点部署轻量级KWDB,实时分析设备传感器数据。
• 案例:预测设备故障并触发维护工单,减少停机时间。例如,通过振动传感器数据训练异常检测模型,提前72小时预警电机故障。
七、未来发展方向实例
-
AI原生架构:
• 实例:直接通过自然语言定义数据模型与查询逻辑。例如,用户输入“创建一个包含客户姓名、订单金额和产品类别的知识图谱”,系统自动生成图模式并导入数据。 -
联邦学习支持:
• 实例:跨医院联合训练疾病预测模型,保护患者隐私。例如,A医院的匿名化数据和B医院的匿名化数据共同训练模型,但原始数据不离开本地。 -
低代码/无代码平台:
• 实例:业务人员通过拖拽界面构建知识图谱。例如,市场营销人员无需编程即可定义“客户-产品-购买行为”关系,并生成推荐规则。 -
量子计算融合:
• 实例:用量子算法加速大规模图谱的链接预测任务。例如,使用量子退火算法解决NP-hard的图分割问题,提升社区发现效率。
八、总结
KWDB通过融合知识图谱、多模态存储与AI技术,重新定义了知识工作者的数据管理范式。尽管面临技术复杂性与成本挑战,但其在提升决策效率、加速跨领域协作方面的潜力不可忽视。随着AI与大模型技术的成熟,KWDB将成为企业智能化转型的核心基础设施之一。未来,随着联邦学习、边缘计算和量子计算的深度融合,KWDB将在隐私保护、实时推理和复杂问题求解中发挥更大作用。
九、学习资源推荐
学习网站
- Neo4j Graph Database
• 官网:https://neo4j.com/
• 内容:图数据库入门指南、Cypher查询语言教程。 - Apache Calcite
• 官网:https://calcite.apache.org/
• 内容:SQL优化与分布式查询引擎技术文档。 - Elasticsearch
• 官网:https://www.elastic.co/guide/index.html
• 内容:全文搜索与数据分析实战案例。
研究文献
- 《Knowledge Graphs in Enterprise Applications》 (ACM, 2022)
• 摘要:探讨知识图谱在企业级应用中的设计模式与挑战,附案例研究(如IBM Watson)。 - 《Multi-modal Data Integration: Challenges and Solutions》 (IEEE, 2023)
• 摘要:分析多模态数据对齐的技术难点,提出基于嵌入技术的解决方案。 - 《LLM-powered Autonomous Databases》 (arXiv, 2023)
• 摘要:研究如何利用大语言模型实现数据库的自动化管理与优化。
相关文章:
基础概念与原理完整指南)
KWDB(Knowledge Worker Database)基础概念与原理完整指南
KWDB(Knowledge Worker Database)基础概念与原理完整指南—目录 前言一、背景1.1 知识工作者的痛点1.2 技术演进推动 二、定义与定位2.1 什么是KWDB?2.2 KWDB与传统数据库的对比与传统关系型数据库(如MySQL)的对比与分…...
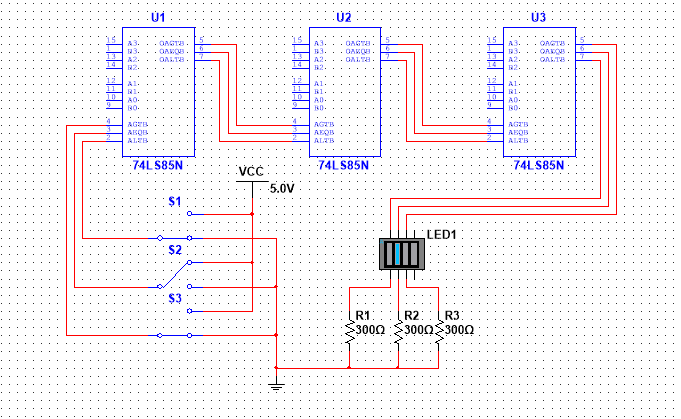
数字电子技术基础(四十七)——使用Mutlisim软件来模拟74LS85芯片
目录 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 1.2 器件选择 1.3 运行电路 2 使用74LS85N完成更多位的二进制比较 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 对于74LS85 是一款 4 位数值比较器集成电路,用于比较两个 4 位二进制数&…...
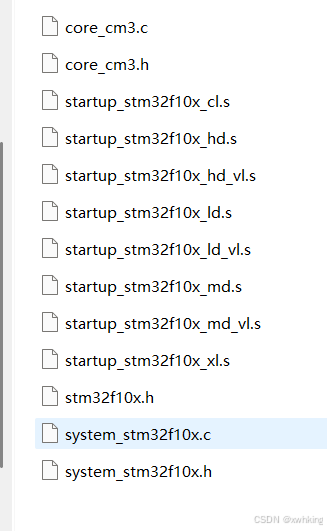
关于STM32创建工程文件启动文件选择
注意启动文件只要选择这几个 而不是要把所有都选上...
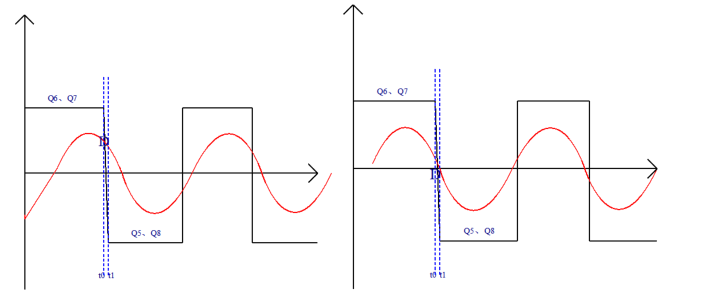
LLC电路工作在容性区的风险
在t0时刻之前,Q6Q7导通,回路如下所示,此时A点电压是低压,B点电压是高压 在t0时刻时,谐振电流相位发生变换,在t1时刻,Q5,Q8导通,对于Q8MOS管来说,B点电压在Q6Q…...
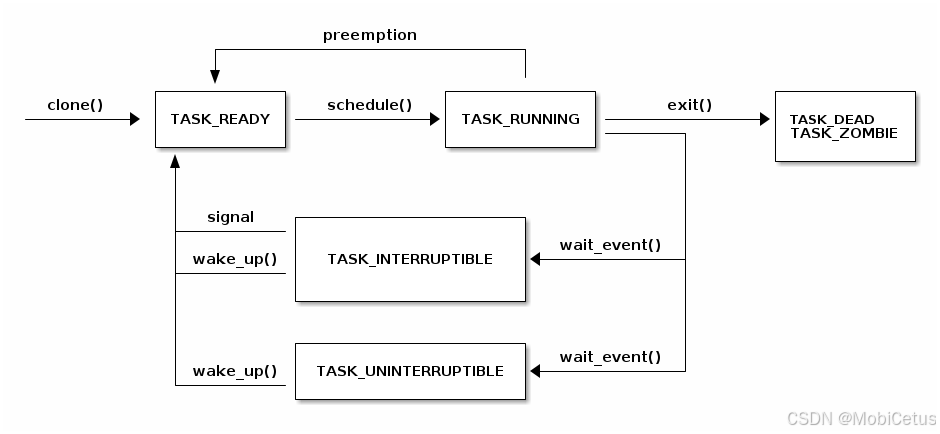
Linux Kernel 6
clone 系统调用(The clone system call) 在 Linux 中,使用 clone() 系统调用来创建新的线程或进程。fork() 系统调用和 pthread_create() 函数都基于 clone() 的实现。 clone() 系统调用允许调用者决定哪些资源应该与父进程共享,…...
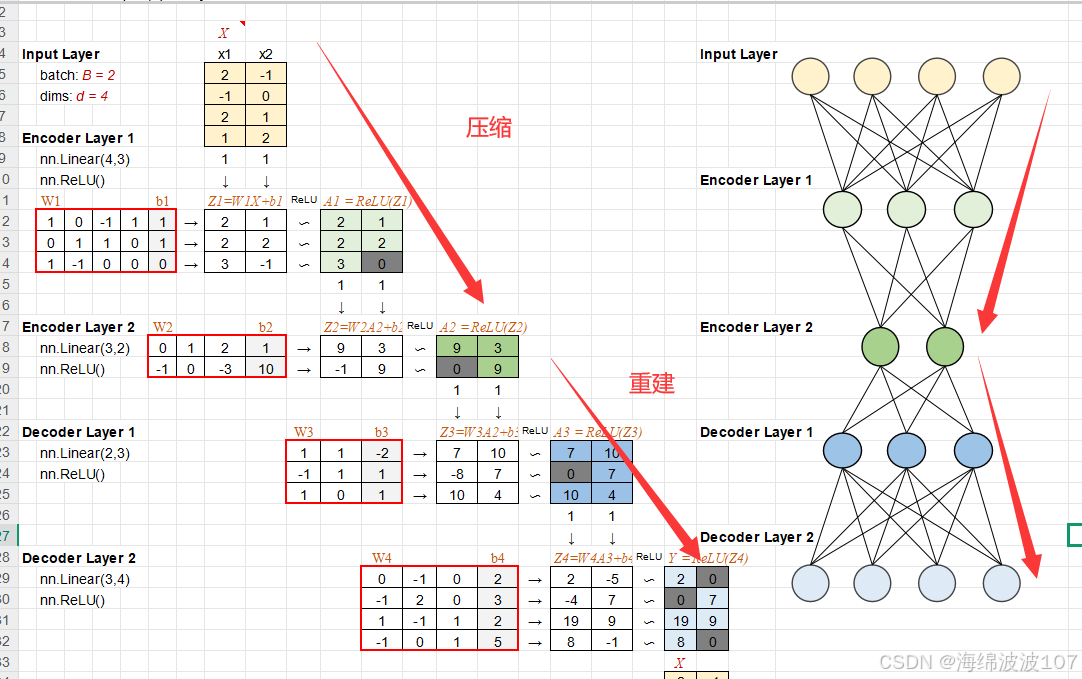
【开源项目】Excel手撕AI算法深入理解(四):AlphaFold、Autoencoder
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git 一、AlphaFold AlphaFold 是 DeepMind 开发的突破性 AI 算法,用于预测蛋白质的三维结构。它的出现解决了生物学领域长达 50 年的“蛋白质折叠问题”,被《科学》杂志评为…...
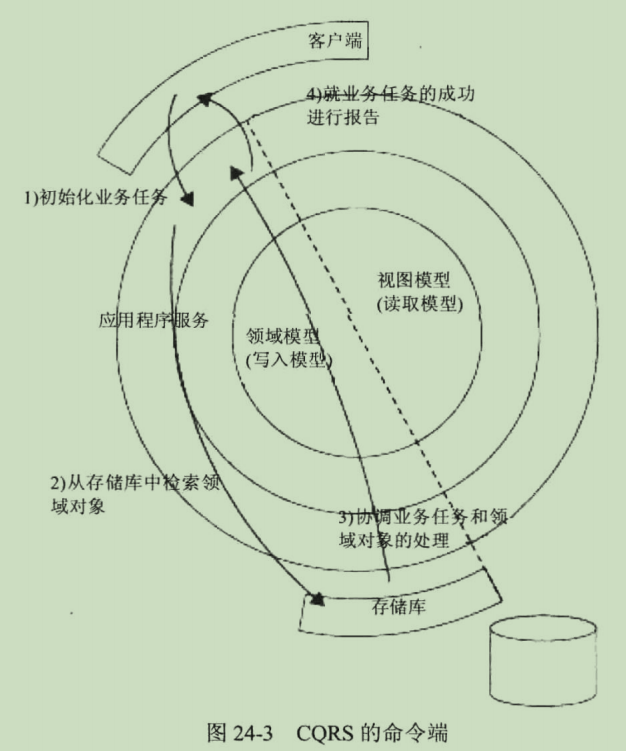
第IV部分有效应用程序的设计模式
第IV部分有效应用程序的设计模式 第IV部分有效应用程序的设计模式第23章:应用程序用户界面的架构设计23.1设计考量23.2示例1:用于非分布式有界上下文的一个基于HTMLAF的、服务器端的UI23.3示例2:用于分布式有界上下文的一个基于数据API的客户端UI23.4要点第24章:CQRS:一种…...

如何编制实施项目管理章程
本文档概述了一个项目管理系统的实施计划,旨在通过统一的业务规范和技术架构,加强集团公司的业务管控,并规范业务管理。系统建设将遵循集团统一模板,确保各单位项目系统建设的标准化和一致性。 实施范围涵盖投资管理、立项管理、设计管理、进度管理等多个方面,支持项目全生…...
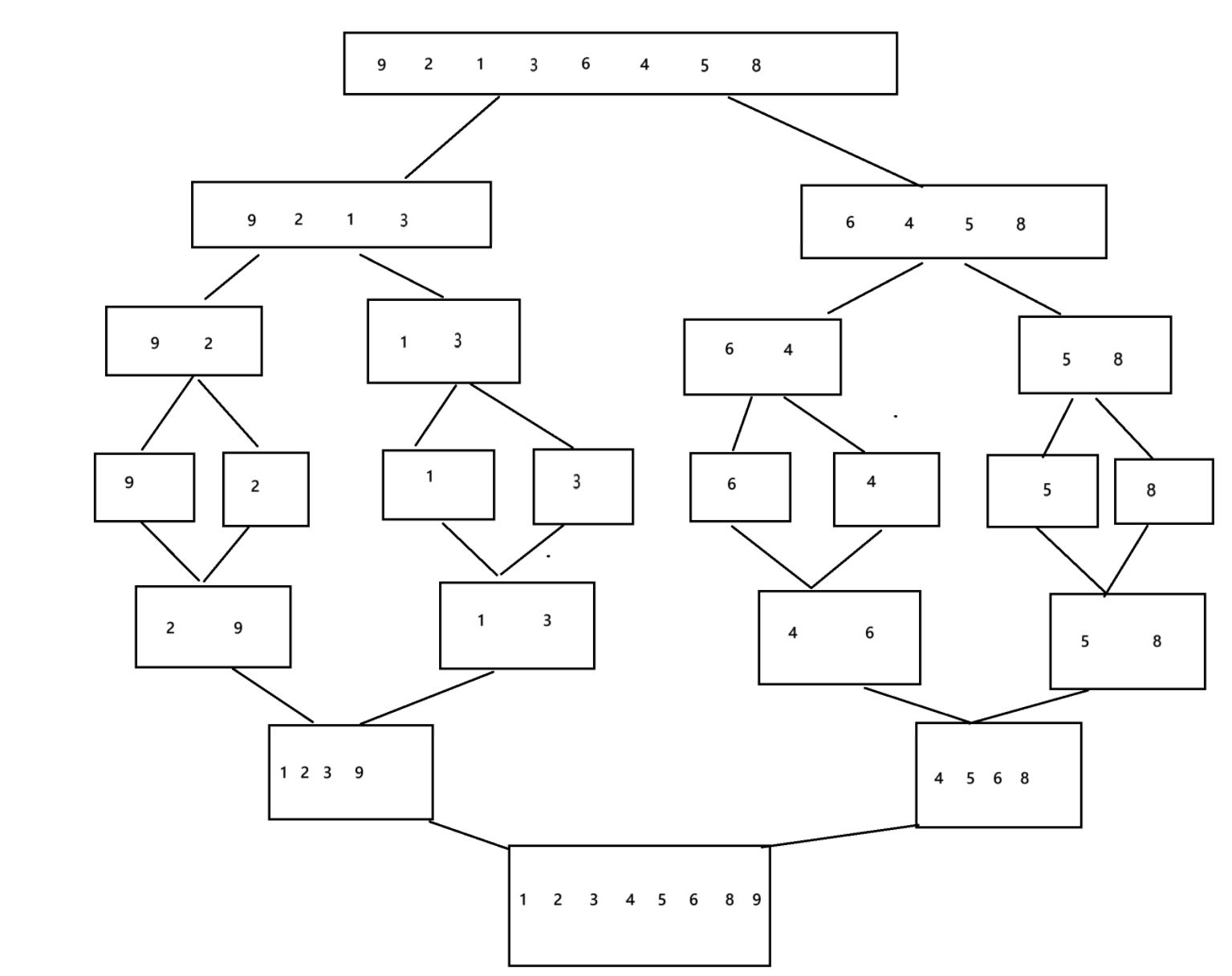
排序(java)
一.概念 排序:对一组数据进行从小到大/从大到小的排序 稳定性:即使进行排序相对位置也不受影响如: 如果再排序后 L 在 i 的前面则稳定性差,像图中这样就是稳定性好。 二.常见的排序 三.常见算法的实现 1.插入排序 1.1 直…...
内存管理补充版)
嵌入式C语言进阶(二+)内存管理补充版
C语言内存管理:从小白到大神的完全指南 前言:为什么需要理解内存管理 C语言以其高效性和灵活性著称,但这也意味着程序员需要手动管理内存。与Java、Python等高级语言不同,C语言没有自动垃圾回收机制,内存管理的重担完全落在开发者肩上。理解C语言的内存管理机制不仅能帮…...
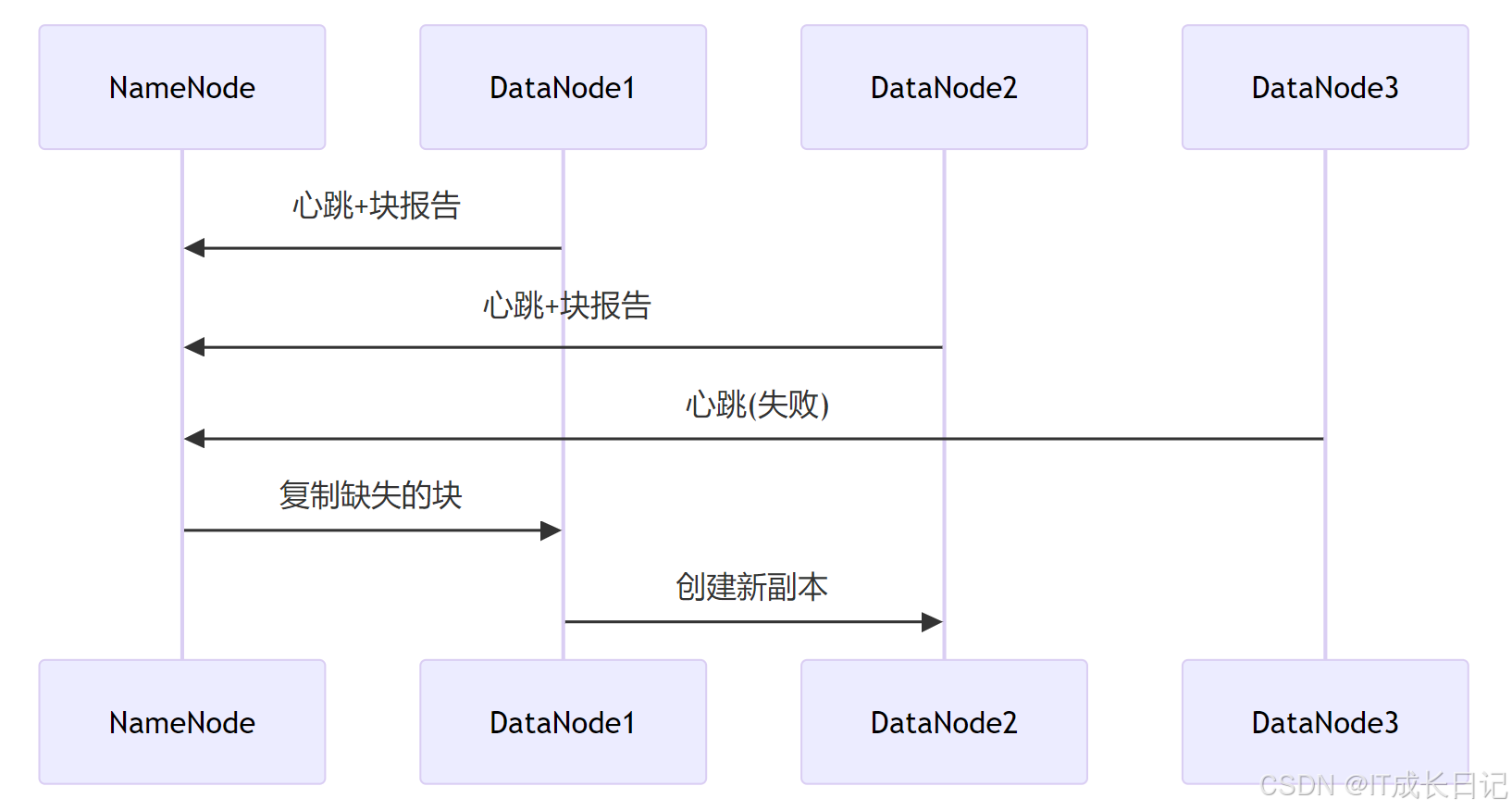
【HDFS入门】HDFS副本策略:深入浅出副本机制
目录 1 HDFS副本机制概述 2 HDFS副本放置策略 3 副本策略的优势 4 副本因子配置 5 副本管理流程 6 最佳实践与调优 7 总结 1 HDFS副本机制概述 Hadoop分布式文件系统(HDFS)的核心设计原则之一就是通过数据冗余来保证可靠性,而这一功能正是通过副本策略实现的…...

Excel自定义函数取拼音首字母
1.启动Excel 2003(其它版本请仿照操作),打开相应的工作表; 2.执行“工具 > 宏 > Visual Basic编辑器”命令(或者直接按“AltF11”组合键),进入Visual Basic编辑状态; 3.执行“…...
智能 GitHub Copilot 副驾驶® 更新升级!
智能 GitHub Copilot 副驾驶 迎来重大升级!现在,所有 VS Code 用户都能体验支持 Multi-Context Protocol(MCP)的全新 Agent Mode。此外,微软还推出了智能 GitHub Copilot 副驾驶 Pro 订阅计划,提供更强大的…...

Android ViewPager使用预加载机制导致出现页面穿透问题
缘由 在应用中使用ViewPager,并且设置预加载页面。结果出现了一些异常的现象。 我们有4个页面,分别是4个Fragment,暂且称为FragmentA、FragmentB、FragmentC、FragmentD,ViewPager在MainActivity中,切换时&#x…...

【今日三题】添加字符(暴力枚举) / 数组变换(位运算) / 装箱问题(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 添加字符(暴力枚举)数组变换(位运算)装箱问题(01背包) 添加字符(暴力枚举) 添加字符 当在A的开头或结尾添加字符直到和B长度…...
)
【AIoT】智能硬件GPIO通信详解(二)
前言 上一篇我们深入解析了智能硬件GPIO通信原理(传送门:【AIoT】智能硬件GPIO通信详解(一))。接下来,我们将结合无人售货机控制场景,通过具体案例进一步剖析物联网底层通信机制的实际应用。 在智能零售领域,无人售货机通过AI技术升级为智能柜,其设备控制的底层通信…...
Python中JSON的妙用:详解序列化与反序列化原理及实战案例)
Python(18)Python中JSON的妙用:详解序列化与反序列化原理及实战案例
目录 一、背景:为什么Python需要JSON?二、核心技术解析:序列化与反序列化2.1 核心概念2.2 类型映射对照表 三、Python操作JSON的四大核心方法3.1 基础方法库3.2 方法详解1. json.dumps()2. json.loads()3. json.dump()4. json.load() 四、实战…...

【Python进阶】字典:高效键值存储的十大核心应用
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:基础操作案例2:字典推导式…...
的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹)
MATLAB脚本实现了一个三自由度的通用航空运载器(CAV-H)的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹
%升力体:通用航空运载器CAV-H %读取数据1 升力系数 alpha = [10 15 20]; Ma = [3.5 5 8 10 15 20 23]; alpha1 = 10:0.1:20; Ma1 = 3.5:0.1:23; [Ma1, alpha1] = meshgrid(Ma1, alpha1); CL = readmatrix(simulation.xlsx, Sheet, Sheet1, Range, B2:H4); CL1 = interp2(…...
 函数)
多角度分析Vue3 nextTick() 函数
nextTick() 是 Vue 3 中的一个核心函数,它的作用是延迟执行某些操作,直到下一次 DOM 更新循环结束之后再执行。这个函数常用于在 Vue 更新 DOM 后立即获取更新后的 DOM 状态,或者在组件渲染完成后执行某些操作。 官方的解释是,当…...

Linux——消息队列
目录 一、消息队列的定义 二、相关函数 2.1 msgget 函数 2.2 msgsnd 函数 2.3 msgrcv 函数 2.4 msgctl 函数 三、消息队列的操作 3.1 创建消息队列 3.2 获取消息队列并发送消息 3.3 从消息队列接收消息recv 四、 删除消息队列 4.1 ipcrm 4.2 msgctl函数 一、消息…...
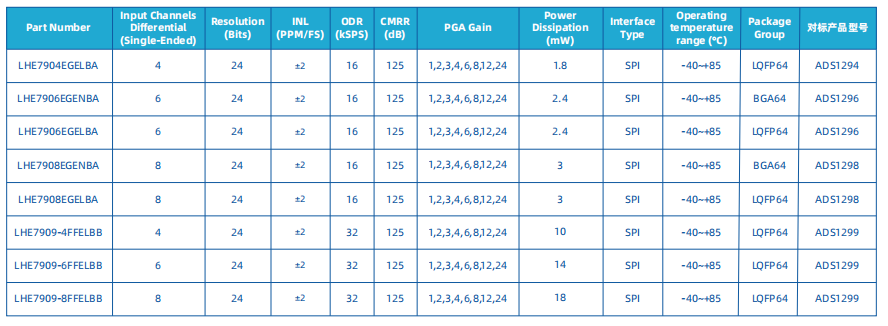
领慧立芯LHE7909可兼容替代TI的ADS1299
LHE7909是一款由领慧立芯(Legendsemi)推出的24位高精度Δ-Σ模数转换器(ADC),主要面向医疗电子和生物电势测量应用,如脑电图(EEG)、心电图(ECG)等设备。以下是…...

在PyTorch中,使用不同模型的参数进行模型预热
在PyTorch中,使用不同模型的参数进行模型预热(Warmstarting)是一种常见的迁移学习和加速训练的策略。以下是结合多个参考资料总结的实现方法和注意事项: 1. 核心机制:load_state_dict()与strict参数 • 部分参数加载&…...

conda 创建、激活、退出、删除环境命令
参考博客:Anaconda创建环境、删除环境、激活环境、退出环境 使用起来觉得有些不方便可以改进,故写此文。 1. 创建环境 使用 -y 跳过确认 conda create -n 你的环境名 -y 也可以直接选择特定版本 python 安装,以 3.10 为例: co…...

Redis核心数据类型在实际项目中的典型应用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Redis作为高性能的键值存储系统,在现代软件开发中扮演着重要角色。其多样化的数据结构为开发者提供了灵活的解决方案,本文将通过真实项…...
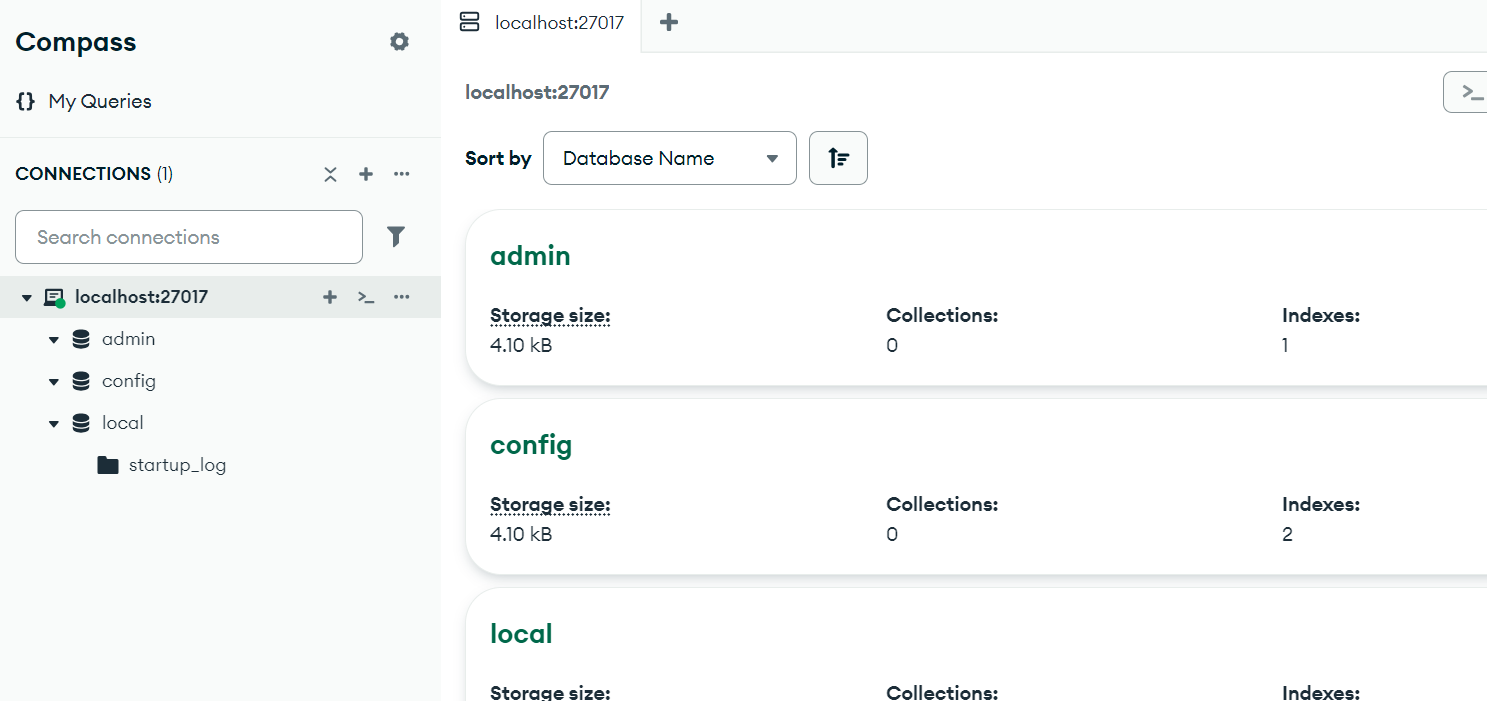
MongoDB简单用法
图片中 MongoDB Compass 中显示了默认的三个数据库: adminconfiglocal 如果在 .env 文件中配置的是: MONGODB_URImongodb://admin:passwordlocalhost:27017/ MONGODB_NAMERAGSAAS💡 一、为什么 Compass 里没有 RAGSAAS 数据库?…...

如何学习嵌入式
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 请各位前辈能否给我提点建议,或者学习路线指导一下 STM32单片机学习总…...

【AI】IDEA 集成 AI 工具的背景与意义
一、IDEA 集成 AI 工具的背景与意义 随着人工智能技术的迅猛发展,尤其是大语言模型的不断演进,软件开发行业也迎来了智能化变革的浪潮。对于开发者而言,日常工作中面临着诸多挑战,如代码编写的重复性劳动、复杂逻辑的实现、代码质…...
uniapp-商城-26-vuex 使用流程
为了能在所有的页面都实现状态管理,我们按照前面讲的页面进行状态获取,然后再进行页面设置和布局,那就是重复工作,vuex 就会解决这样的问题,如同类、高度提炼的接口来帮助我们实现这些重复工作的管理。避免一直在造一样的轮子。 https://vuex.vuejs.org/zh/#%E4%BB%80%E4…...
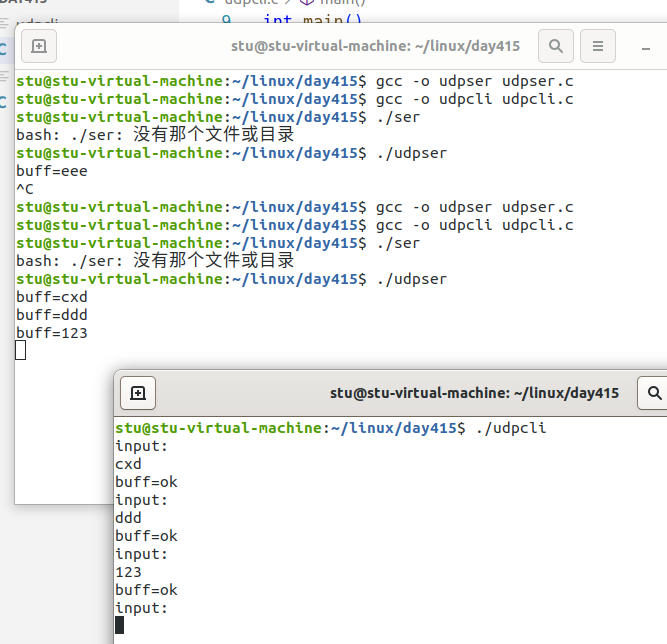
UDP概念特点+编程流程
UDP概念编程流程 目录 一、UDP基本概念 1.1 概念 1.2 特点 1.2.1 无连接性: 1.2.2 不可靠性 1.2.3 面向报文 二、UDP编程流程 2.1 客户端 cli.c 2.2 服务端ser.c 一、UDP基本概念 1.1 概念 UDP 即用户数据报协议(User Datagram Protocol &…...