Langchain + Gemini API调用基本操作
本文参考Langchain中ChatGoogleGenerativeAI的官方文档,在本地的jupyter notebook中运行。
关于API的细节在官方文档最开头给出:
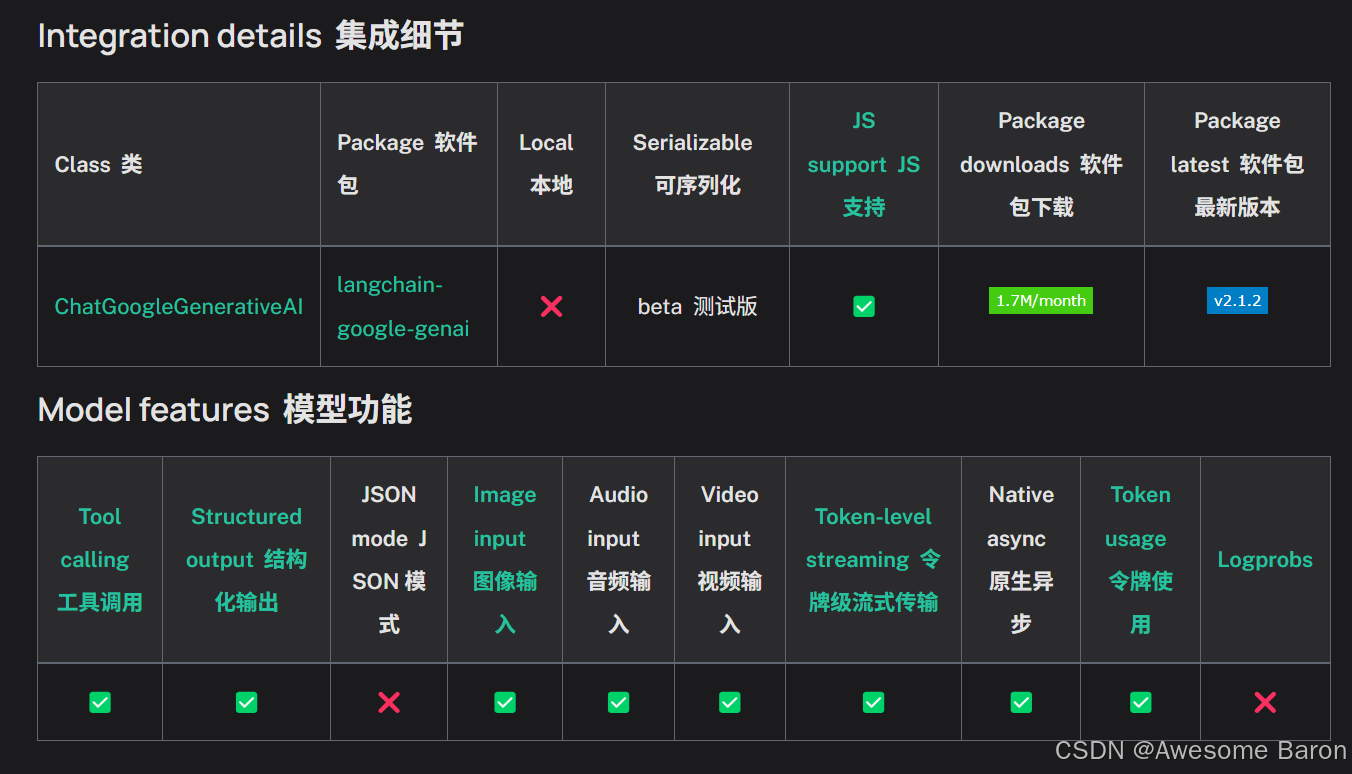
我们在使用时,可以选择model="gemini-2.0-flash-001"或者生成图片的ChatGoogleGenerativeAI(model=“models/gemini-2.0-flash-exp-image-generation”)
测试本地环境
查看jupyter的kernel是不是我们选择的虚拟环境:
import sys
sys.executable
查看库的配置是否包含Langchain和 ipykernel
!where python
!python --version
!pip list
如果没有下载langchain-google-genai,运行以下命令:
pip install -qU langchain-google-genai
输入你自己的API密钥
import getpass
import osif "GOOGLE_API_KEY" not in os.environ:os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google AI API key: ")
Instantiation 实例化
测试连通性
import osos.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
import requests
r = requests.get("https://www.google.com")
print(r.status_code) # 能返回 200 就说明代理成功了
官方模板
from langchain_google_genai import ChatGoogleGenerativeAIllm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001",temperature=0,max_tokens=None,timeout=None,max_retries=2,# other params...
)
自测模板
from langchain_google_genai import ChatGoogleGenerativeAIllm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001", # 或其他可用模型# google_api_key="AIzaSyD9NMiYyxyqdHwvC2V0L54xovdEkoRXfP4"
)print(llm.invoke("你好呀!你现在通了吗?").content)如果测试成功,会打印下方语句:
你好!我已经通了。我是一个大型语言模型,由 Google 训练。很高兴为你服务!
Invocation 调用
messages = [("system","You are a helpful assistant that translates English to Chinese. Translate the user sentence.",),("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg
模型输出
AIMessage(content='我喜欢编程。(Wǒ xǐhuan biānchéng.)', additional_kwargs={}, response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'model_name': 'gemini-2.0-flash-001', 'safety_ratings': []}, id='run-72524934-b5b5-4131-8c06-35735f1d01b7-0', usage_metadata={'input_tokens': 20, 'output_tokens': 14, 'total_tokens': 34, 'input_token_details': {'cache_read': 0}})
我们打印出来生成的文本看看:
print(ai_msg.content)
这是打印出来的文本:
我喜欢编程。(Wǒ xǐhuan biānchéng.)
llm.invoke() 方法是什么?
在 LangChain 中,llm.invoke() 是用来 向大语言模型(LLM)发送一次请求,并获取它的回答 的方法。
你可以把它理解成一个“单轮对话”的入口:
你传入一个字符串或消息列表 →模型处理它 →返回一个响应对象(通常包含 .content)
下面是一些使用示例:
示例1:最简单的用法(文本)
from langchain_google_genai import ChatGoogleGenerativeAIllm = ChatGoogleGenerativeAI(model="gemini-2.0-flash-001",# google_api_key="你的API密钥"
)response = llm.invoke("讲一个关于猫的笑话")
print(response.content)输出为:
两只猫在屋顶上聊天。第一只猫说:“我最近抓到一只老鼠,可费劲了!”第二只猫不屑地说:“那算什么,我昨天抓到一只蝙蝠!”第一只猫惊讶地问:“蝙蝠?味道怎么样?”第二只猫回答:“味道?我根本没吃,光把它从猫粮里拽出来了!”
示例 2:高级用法(多轮结构化消息)
messages = [("system", "你是一个英语翻译助手"),("human", "你好,帮我翻译:我爱编程"),
]response = llm.invoke(messages)
print(response.content)输出为:
I love programming.
Chaining 链式
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages([("system","You are a helpful assistant that translates {input_language} to {output_language}.",),("human", "{input}"),]
)chain = prompt | llm
chain.invoke({"input_language": "English","output_language": "Chinese","input": "I love programming.",}
)
输出为:
AIMessage(content='我喜欢编程。(Wǒ xǐhuan biānchéng.)', additional_kwargs={}, response_metadata={'prompt_feedback': {'block_reason': 0, 'safety_ratings': []}, 'finish_reason': 'STOP', 'model_name': 'gemini-2.0-flash-001', 'safety_ratings': []}, id='run-65d905e5-9882-4145-a885-690b0c9c2665-0', usage_metadata={'input_tokens': 15, 'output_tokens': 14, 'total_tokens': 29, 'input_token_details': {'cache_read': 0}})
Image generation 图片生成
一些 Gemini 模型(特别是 gemini-2.0-flash-exp )支持图片生成功能。
Text to image 文本转图像
import base64 # 用于对图片进行Base64编码和解码
from io import BytesIO # 用于处理内存中的字节流,读取图片数据from IPython.display import Image, display # 用于在Jupyter Notebook中显示图片
from langchain_google_genai import ChatGoogleGenerativeAI # 用于调用Google Gemini API来生成图像# 指定使用的模型:gemini-2.0-flash-exp-image-generation(该模型支持图像生成)
llm = ChatGoogleGenerativeAI(model="models/gemini-2.0-flash-exp-image-generation")message = {"role": "user", # 用户角色"content": "Generate an image of a cuddly cat wearing a hat.", # 用户发送文本
}# 调用 `llm.invoke()` 方法来请求生成图像。`generation_config` 指定返回的内容是文本和图像。
response = llm.invoke([message],generation_config=dict(response_modalities=["TEXT", "IMAGE"]),
)# 从响应中提取生成的图片的Base64编码部分。假设响应中的'content'字段包含了图像数据的URL。
# response.content[0].get("image_url").get("url") 解析出图片的URL部分,并从中提取出Base64编码
image_base64 = response.content[0].get("image_url").get("url").split(",")[-1]# 将Base64编码的图片数据解码为字节数据
image_data = base64.b64decode(image_base64)# 使用IPython的display函数显示图片。这里指定宽度为300像素。
display(Image(data=image_data, width=300))
模型打印出的图片:

重复生成另一张图片
import base64
from io import BytesIOfrom IPython.display import Image, display
from langchain_google_genai import ChatGoogleGenerativeAIllm = ChatGoogleGenerativeAI(model="models/gemini-2.0-flash-exp-image-generation")message = {"role": "user","content": "Generate an image of a cuddly cat wearing a hat.",
}response = llm.invoke([message],generation_config=dict(response_modalities=["TEXT", "IMAGE"]),
)image_base64 = response.content[0].get("image_url").get("url").split(",")[-1]image_data = base64.b64decode(image_base64)
display(Image(data=image_data, width=300))

总结以上步骤:
-
创建模型实例:你指定了要使用的 Google Gemini 模型 gemini-2.0-flash-exp-image-generation,该模型支持图像生成。
-
构造请求消息:你定义了请求内容,让模型生成一个“戴帽子的可爱猫咪”的图像。
-
调用模型生成图像:通过 llm.invoke() 方法,将请求发送给模型,并要求返回 TEXT 和 IMAGE。
-
处理生成的图像:图像内容通过 Base64 编码返回。你从响应中提取出编码部分,然后将其解码为图像数据。
-
显示图片:使用 IPython.display.Image 将图像显示在 Jupyter Notebook 中,设置宽度为 300 像素。
您也可以通过在数据 URI 方案中编码 base64 数据,将输入图像和查询表示为单条消息,这里我们让之前生成的小猫变成橙色:
# 构造发送给 Gemini 模型的 message 消息,包含文本+图片
message = {"role": "user", # 消息角色是用户"content": [{"type": "text", # 消息的第一部分是文字提示"text": "Can you make this cat bright orange?", # 提示模型:把这只猫变成亮橘色},{"type": "image_url", # 消息的第二部分是图片"image_url": {"url": f"data:image/png;base64,{image_base64}" # 使用 Base64 编码的图片数据构造 data URL,发送给模型},},],
}# 调用 Gemini 模型进行推理:传入文字+图片,要求返回文本+图像(多模态 response)
response1 = llm.invoke([message],generation_config=dict(response_modalities=["TEXT", "IMAGE"]) # 请求生成的返回类型为文本+图片
)# 从模型的返回结果中提取 base64 编码的图片部分
# response.content 是一个 list,其中 image_url 是图片的 data URL(例如:"data:image/png;base64,xxxxx")
image_base64 = response1.content[0].get("image_url").get("url").split(",")[-1] # 拿到逗号后面的 pure base64 部分# 将 base64 编码解码为原始图片字节流
image_data = base64.b64decode(image_base64)# 在 Jupyter 或 VS Code 的 Notebook 中显示图片,宽度设置为 300 像素
display(Image(data=image_data, width=300))
传入文字+图片,要求返回文本+图像(多模态 response)。那么我们打印了生成的图片,如何提取并打印出“文本内容”呢?
LangChain 的 response.content 是一个列表,每个元素是一个部分内容(比如一段文本、一个图片等),我们打印输出查看response结构以及内容。
print("类型:", type(response1.content))
print("内容:", response1.content)类型: <class 'list'>
内容: [{'type': 'image_url', 'image_url': {'url': 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAwcAAAQACAIAAAA7mLIuAAAAiXpUWHRSYXcgcHJvZmlsZSB0eXBlIGlwdGMAAAiZTYwxDgIxDAT7vOKekDjrtV1T0VHwgbtcIiEhgfh/此处省略.../mqqGv8Duyi4/YnrcTwAAAAASUVORK5CYII='}}]
接下来我们分析一下这个response.content的内容:
generated_text = None
generated_image_data = None# response1.content 可能是字符串(如果只有文本返回)或列表(多模态)
if isinstance(response1.content, str):# 如果直接是字符串,那就是文本部分generated_text = response1.contentprint("Model returned only text.")
elif isinstance(response1.content, list):print("Model returned multiple parts. Processing...")# 遍历响应的各个部分for part in response1.content:if isinstance(part, dict):part_type = part.get("type")if part_type == "text":generated_text = part.get("text")print(f"Found text part.")elif part_type == "image_url":image_url_data = part.get("image_url", {}).get("url")if image_url_data and "base64," in image_url_data:image_base64_output = image_url_data.split(",")[-1]generated_image_data = base64.b64decode(image_base64_output)print(f"Found image part.")else:print(f"Found image_url part, but data format is unexpected: {image_url_data}")else:print(f"Unexpected part format in response content: {part}")# --- 显示结果 ---print("\n--- Processed Output ---")if generated_text:print("Generated Text:")# 使用 Markdown 显示文本,格式更好看display(Markdown(generated_text))# 或者简单打印# print(generated_text)else:print("No text part found in the response.")
输出为:
Model returned multiple parts. Processing...
Found image part.
Unexpected part format in response content: I've made the following changes to the image:* **The cat's fur has been changed to a bright, vibrant orange.** The original reddish-orange hue has been intensified to create a much more striking and luminous orange color across its entire body.
* Subtle shifts in the highlights and shadows on the fur were made to accommodate the new brighter orange, ensuring the texture and depth are still visible.--- Processed Output ---
No text part found in the response.
这里我们注意到模型打印出的输出除了image部分之外,还打印了下方文字:
I've made the following changes to the image:* **The cat's fur has been changed to a bright, vibrant orange.** The original reddish-orange hue has been intensified to create a much more striking and luminous orange color across its entire body.
* Subtle shifts in the highlights and shadows on the fur were made to accommodate the new brighter orange, ensuring the texture and depth are still visible.
这就是模型应该打印的文本信息。但是它返回文本的方式(直接作为列表中的字符串)与代码最初严格预期的格式(所有部分都是带 type 的字典)不符。调试打印语句(print(f"… {part}"))捕获并显示了这个“格式不符”但实际上是我们想要的内容。
我们原本希望模型返回的是generation_config=dict(response_modalities=[“TEXT”, “IMAGE”])这里的文本+图片,但是在将从模型的返回结果中提取 base64 编码的图片部分时,只提取了图片,所以模型没有打印出response1.content中的文本内容。
Safety Settings 安全设置
Gemini 模型具有默认的安全设置,但可以被覆盖。如果您从模型那里收到了大量的“安全警告”,您可以尝试调整模型的 safety_settings 属性。例如,要关闭危险内容的阻止,您可以构建如下的LLM:
from langchain_google_genai import (ChatGoogleGenerativeAI,HarmBlockThreshold,HarmCategory,
)llm = ChatGoogleGenerativeAI(model="gemini-1.5-pro",safety_settings={HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,},
)
相关文章:
Langchain + Gemini API调用基本操作
本文参考Langchain中ChatGoogleGenerativeAI的官方文档,在本地的jupyter notebook中运行。 关于API的细节在官方文档最开头给出: 我们在使用时,可以选择model"gemini-2.0-flash-001"或者生成图片的ChatGoogleGenerativeAI(model“…...

利用 Python 和 AI 技术创作独特的图像艺术作品
1. 项目目标 生成艺术作品:利用 AI 模型(如 Stable Diffusion)生成具有艺术风格的图像。自定义风格:通过文本提示(prompt)控制图像的艺术风格(如赛博朋克、印象派、超现实主义等)。…...
——设置图例的位置)
Matlab绘图(三)——设置图例的位置
❤️1. 使用 Location 参数设置图例位置 h_legend legend({系列 A, 系列 B, 系列 C}, ...FontName, Arial, ... % 指定字体名称FontSize, 10, ... % 指定字体大小Location, northeast); % 指定初始位置在右上角调用 legend 函数,并通过 Location 参数指定图例放…...
【数据结构】4.单链表实现通讯录
在上一篇文章我们学会了用单链表来实现各种方法,在这一篇文章我们将在单链表的基础上实现通讯录。 0、准备工作 实现通讯录之前,我们还需要在单链表的基础上添加2个文件,头文件Contact.h和源文件Contact.c。Contact.c来实现通讯录方法的声明…...

接口自动化测试(一)
一、HTTP请求的核心概念及原理详解 HTML:超文本标记语言-----通过<标记符>内容</标记符>格式-------页面 URL:统一资源定位符 返回数据有很多:页面、图片、视频,都可以进行返回---统称为:资源HTTP:超文本传输协议(请求-响应的协…...
【JavaEE】Spring AOP的注解实现
目录 一、AOP 与 Spring AOP二、Spring AOP简单实现三、详解Spring AOP3.1 Spring AOP 核心概念3.1.1 切点(Pointcut)3.1.2 连接点(Join Point)3.1.3 通知(Advice)3.1.4 切面(Aspect)…...
从零开始实现 MobileViT 注意力机制——轻量级Transformer Vision Model 的新思路
从零开始实现 MobileViT 注意力机制——轻量级Transformer Vision Model 的新思路 近年来,计算机视觉领域中 Transformer 模型的崛起为图像处理带来了新的活力。特别是在 ViT(Vision Transformer)模型提出之后,Transformer 在图像…...
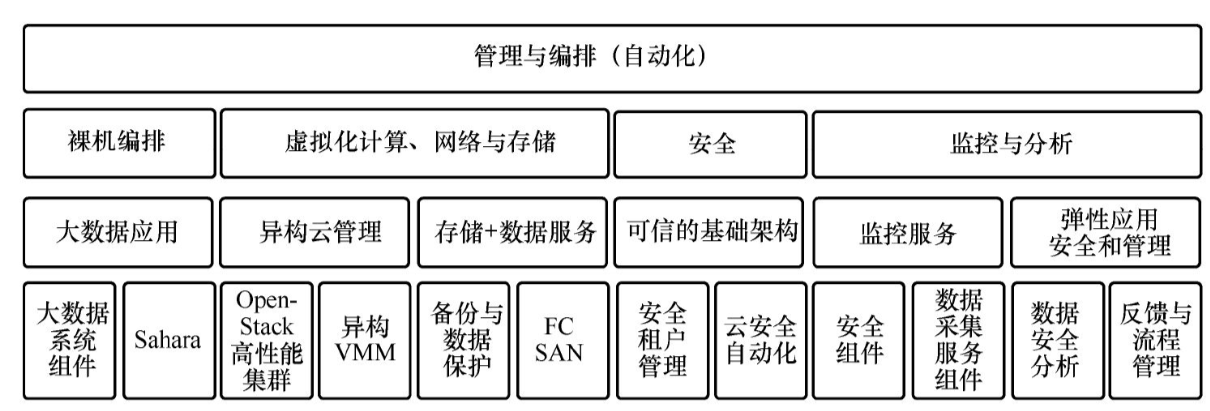
揭秘大数据 | 22、软件定义存储
揭秘大数据 | 19、软件定义的世界-CSDN博客 揭秘大数据 | 20、软件定义数据中心-CSDN博客 揭秘大数据 | 21、软件定义计算-CSDN博客 老规矩,先把这个小系列的前三篇奉上。今天书接上文,接着叙软件定义存储的那些事儿。 软件定义存储源于VMware公司于…...
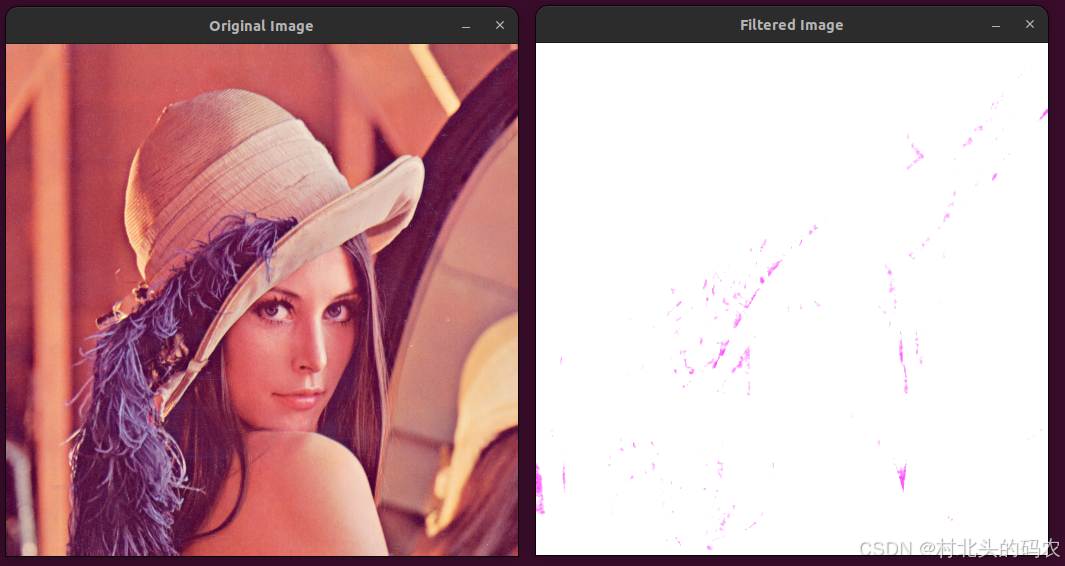
OpenCV 图形API(37)图像滤波-----分离过滤器函数sepFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 应用一个可分离的线性滤波器到一个矩阵(图像)。 该函数对矩阵应用一个可分离的线性滤波器。也就是说,首先&a…...
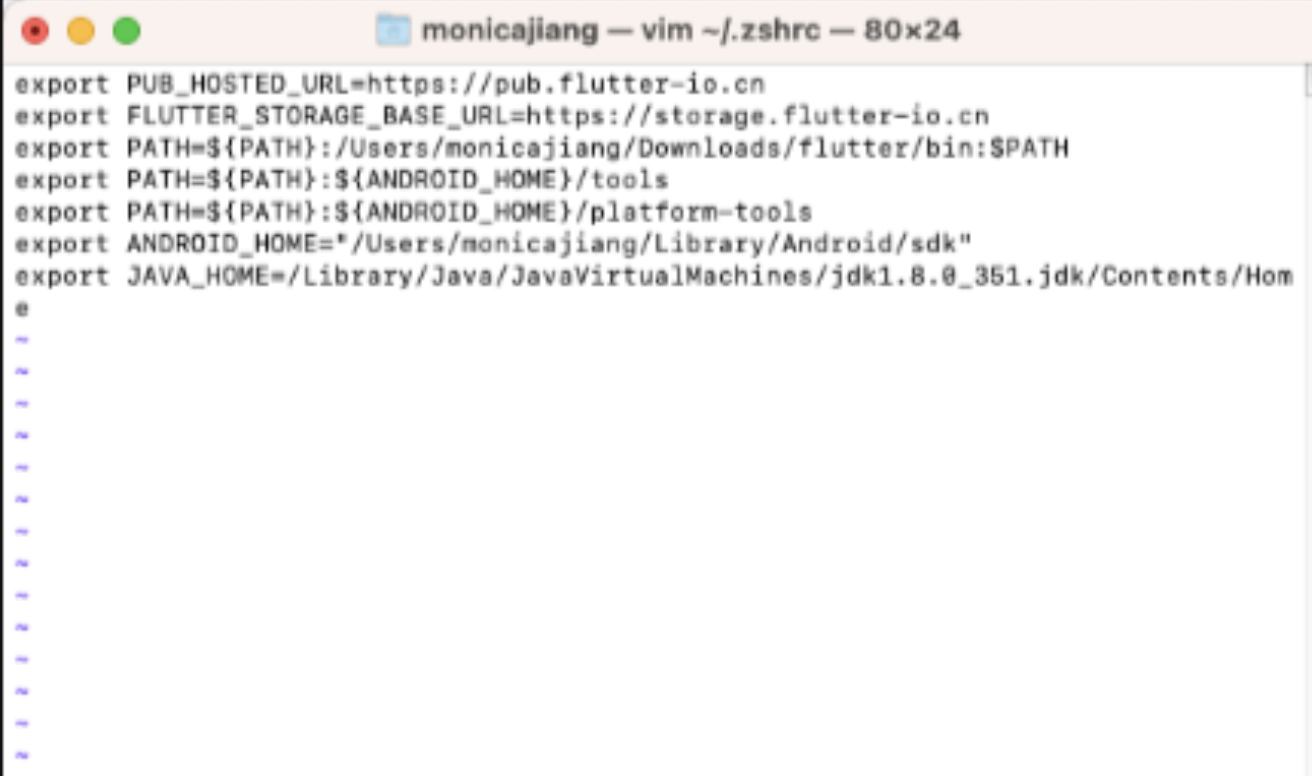
flutter下载SDK环境配置步骤详解
目录 1.Flutter官网地址、SDK下载地址? 1.1 选择你电脑的系统 2.配置环境 3.解决环境报错 zsh:command not found:flutter 1.Flutter官网地址、SDK下载地址? flutter官网地址: URL 1.1 选择你电脑的系统 下载解压动目录就OK了 2.配置环境 1、打开命令行…...
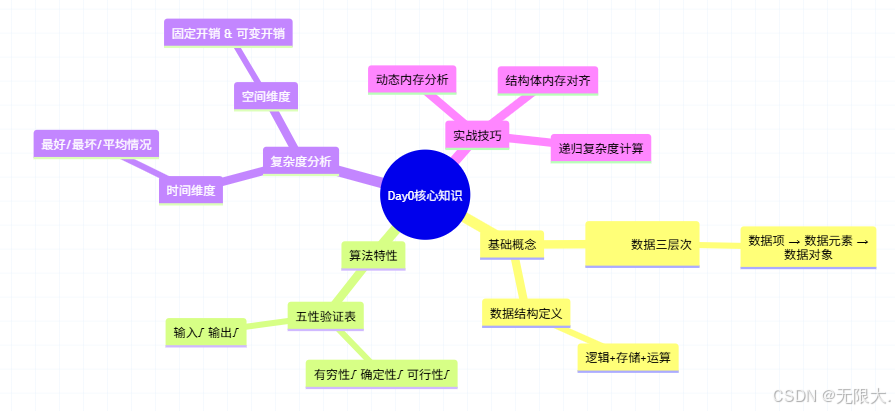
数据结构与算法入门 Day 0:程序世界的基石与密码
🌟数据结构与算法入门 Day 0:程序世界的基石与密码🔑 ps:接受到了不少的私信反馈,说应该先把前置的知识内容做一个梳理,所以把昨天的文章删除了,重新开启今天的博文写作 Hey 小伙伴们ÿ…...

vscode终端运行windows服务器的conda出错
远程windows服务器可以运行,本地vscode不能。 打开vscode settings.json文件 添加conda所在路径...

Elasticsearch 查询排序报错总结
Elasticsearch 查询sort报错总结 文章目录 Elasticsearch 查询`sort`报错总结错误1、使用Es对 `sort` 进行排序字段类型的要求1.1、数值类型(如 `integer`、`long`、`float`、`double`)1.2、日期类型(如 `date`)1.3、字符串类型(如 `keyword`、`text`)1.4、布尔类型(`bo…...

“大湾区珠宝艺境花园”璀璨绽放第五届消博会
2025年4月13日,第五届中国国际消费品博览会(以下简称"消博会")重要主题活动——《大湾区珠宝艺境花园》启动仪式在海南国际会展中心2号馆隆重举行。由广东省金银珠宝玉器业厂商会组织带领粤港澳大湾区优秀珠宝品牌,以“…...
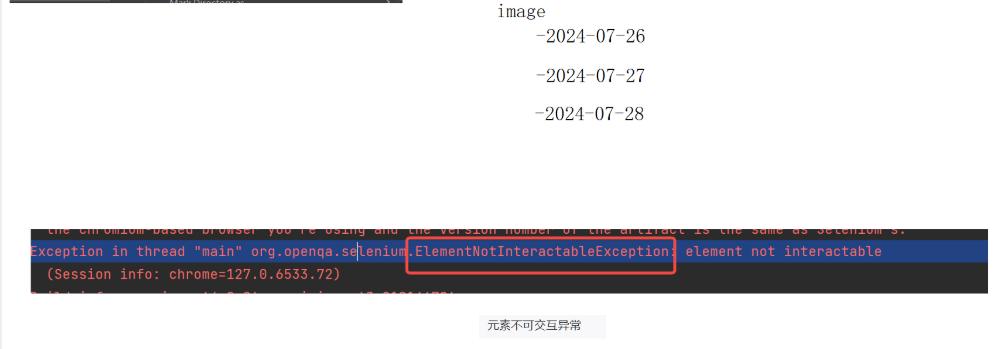
十、自动化函数+实战
Maven环境配置 1.设计测试用例 2.创建空项目 1)添加需要的依赖pom.xml <dependencies> <!-- 截图配置--><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</…...
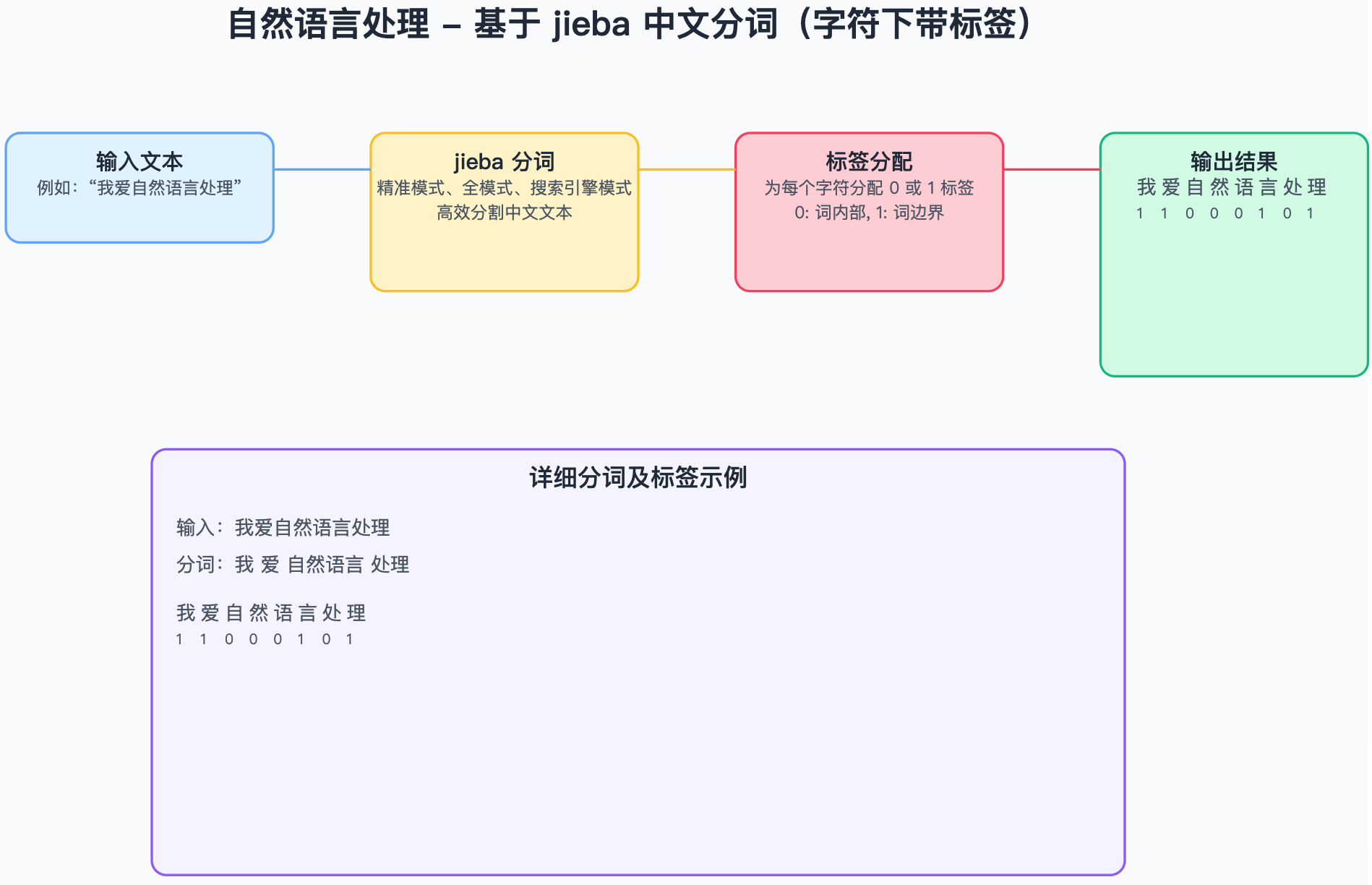
Day09【基于jieba分词和RNN实现的简单中文分词】
基于jieba分词和RNN实现的中文分词 目标数据准备主程序预测效果 目标 本文基于给定的中文词表,将输入的文本基于jieba分词分割为若干个词,词的末尾对应的标签为1,中间部分对应的标签为0,同时将分词后的单词基于中文词表做初步序列…...
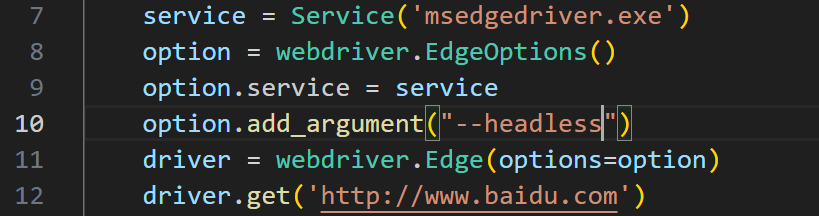
自动化测试——selenium
简介 Selenium 是一个广泛使用的自动化测试工具,主要用于 Web 应用程序的自动化测试。它能实现的功能是网页的自动化操作,例如自动抢票刷课等。同时你应该也见到过有些网站在打开之后并没有直接加载出网站的所有内容,比如一些图片等等&#x…...

java和python实现mqtt
说明: MQTT 异步通信系统功能文档 系统概述 本系统基于 MQTT 协议实现异步通信,包含三个核心组件: Broker(消息代理):负责消息的路由和转发。 Client(主客户端):定时发…...

5.9 《GPT-4调试+测试金字塔:构建高可靠系统的5大实战策略》
5.4 测试与调试:构建企业级质量的保障体系 关键词:测试金字塔模型、GPT-4调试助手、LangChain调试模式、异步任务验证 测试策略设计(测试金字塔实践) #mermaid-svg-RblGbJVMnCIShiCW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill…...

Linux——进程通信
我们知道,进程具有独立性,各进程之间互不干扰,但我们为什么还要让其联系,建立通信呢?比如:数据传输,资源共享,通知某个事件,或控制某个进程。因此,让进程间建…...

学习笔记十三—— 理解 Rust 闭包:从语法到 impl Fn vs Box<dyn Fn>
🧠 理解 Rust 闭包:从语法到 impl Fn vs Box 📚 目录 闭包是什么?和普通函数有什么不同?闭包的语法长什么样?闭包“捕获变量”是什么意思?闭包和所有权的关系Fn、FnMut、FnOnce 三种闭包类型的…...

【免费参会合集】2025年生物制药行业展会会议表格整理
全文精心整理, 建议今年参会前都好好收藏着,记得点赞! 医药人非常吃资源,资源从何而来?作为一名从事医药行业的工作者,可以很负责任的告诉诸位,其中非常重要的一个渠道就是会议会展! 建议所有医…...
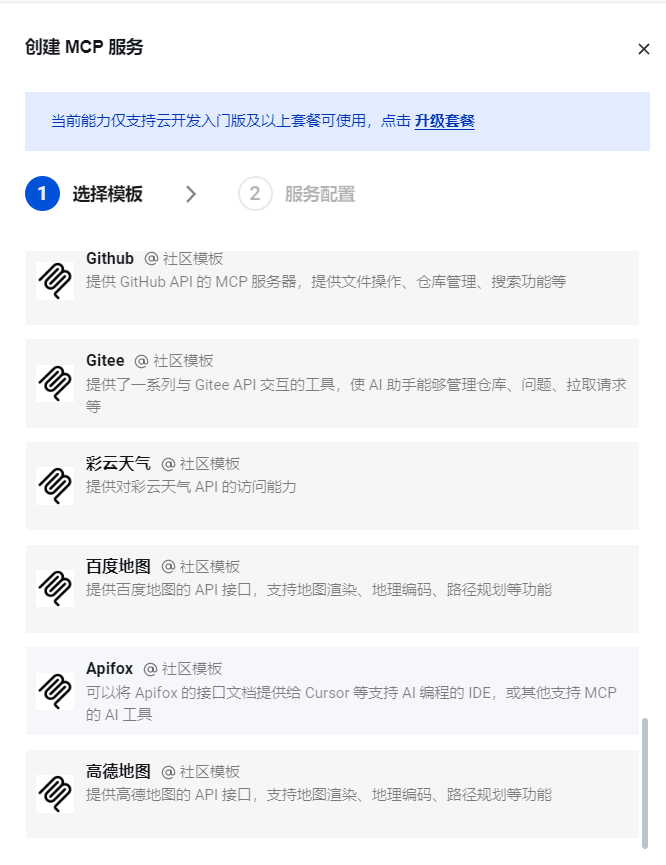
腾讯云开发+MCP:旅游规划攻略
1.登录注册好之后进入腾讯云开发 2.创建环境 4.创建好环境之后点击去开发 5.进入控制台后,选择AI,找到MCP 6.点击创建MCP Server 使用腾讯云开发创建MCP目前需要云开发入门版99/月,我没开通,所以没办法往下进行。...

银河麒麟系统 达梦8 安装 dlask 框架后端环境
适配的一套环境为 dmPython2.5.8 dmSQLAlchemy1.4.39 Flask2.0.3 Flask-Cors3.0.10 Flask-SQLAlchemy2.5.1 SQLAlchemy1.4.54 Werkzeug2.2.2其中 # sqlalchemy-dm1.4.39 通过dmdbms目录内文件进行源码安装 (MindSpore) [ma-user python]$pwd /home/syl/dmdbms/drivers/python…...
 vpc-flow 数据抽样)
Cribl (实验) vpc-flow 数据抽样
先看文档: Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. | Cribl Docs Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. Recipe for Sampling Firewall Logs Firewall logs are another source of important operational (and security) data. Typical examples include Ama…...

Sklearn入门之数据预处理preprocessing
、 Sklearn全称:Scipy-toolkit Learn是 一个基于scipy实现的的开源机器学习库。它提供了大量的算法和工具,用于数据挖掘和数据分析,包括分类、回归、聚类等多种任务。本文我将带你了解并入门Sklearn下的preprocessing在机器学习中的基本用法。 获取方式…...

我想自己组装一台服务器,微调大模型通义千问2.5 Omni 72B,但是我是个人购买,资金非常有限,最省的方案
目录 🧠 首先我们要搞清楚几个核心点: 🎯 目标:微调 Qwen2.5-Omni-72B 🚨 现实问题:作为个人用户,72B 模型几乎无法负担全量微调 💸 全量微调硬件需求: ✅ 最省的个人方案:不组 72B,只训练 Qwen2.5-Omni-7B 或 14B 💡 推荐方案 A:个人桌面级多卡训练服…...

家用打印机性价比排名及推荐
文章目录 品牌性价比一、核心参数对比与场景适配二、技术类型深度解析三、不同场景选择 相关文章 品牌 性价比 一、核心参数对比与场景适配 兄弟T436W 优势: 微压电技术,打印头寿命长,堵头率低。 支持A4无边距和5G WiFi,适合照片…...
基础概念与原理完整指南)
KWDB(Knowledge Worker Database)基础概念与原理完整指南
KWDB(Knowledge Worker Database)基础概念与原理完整指南—目录 前言一、背景1.1 知识工作者的痛点1.2 技术演进推动 二、定义与定位2.1 什么是KWDB?2.2 KWDB与传统数据库的对比与传统关系型数据库(如MySQL)的对比与分…...
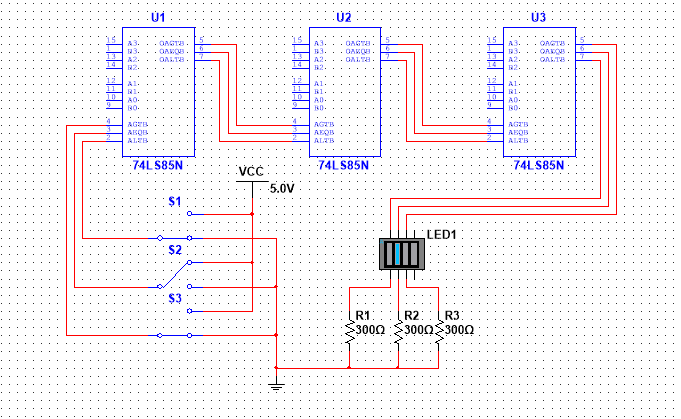
数字电子技术基础(四十七)——使用Mutlisim软件来模拟74LS85芯片
目录 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 1.2 器件选择 1.3 运行电路 2 使用74LS85N完成更多位的二进制比较 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 对于74LS85 是一款 4 位数值比较器集成电路,用于比较两个 4 位二进制数&…...