Day09【基于jieba分词和RNN实现的简单中文分词】
基于jieba分词和RNN实现的中文分词
- 目标
- 数据准备
- 主程序
- 预测效果
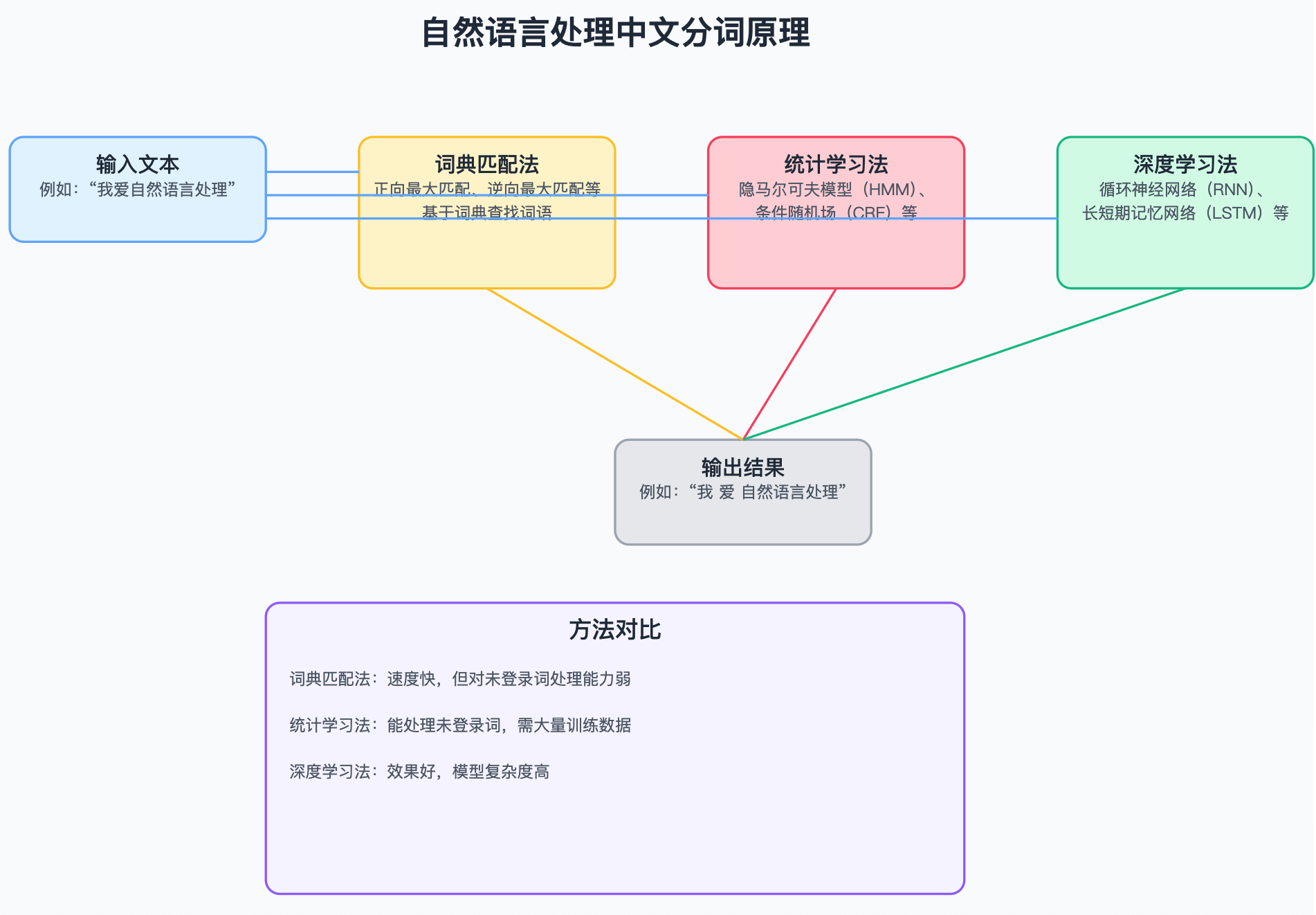
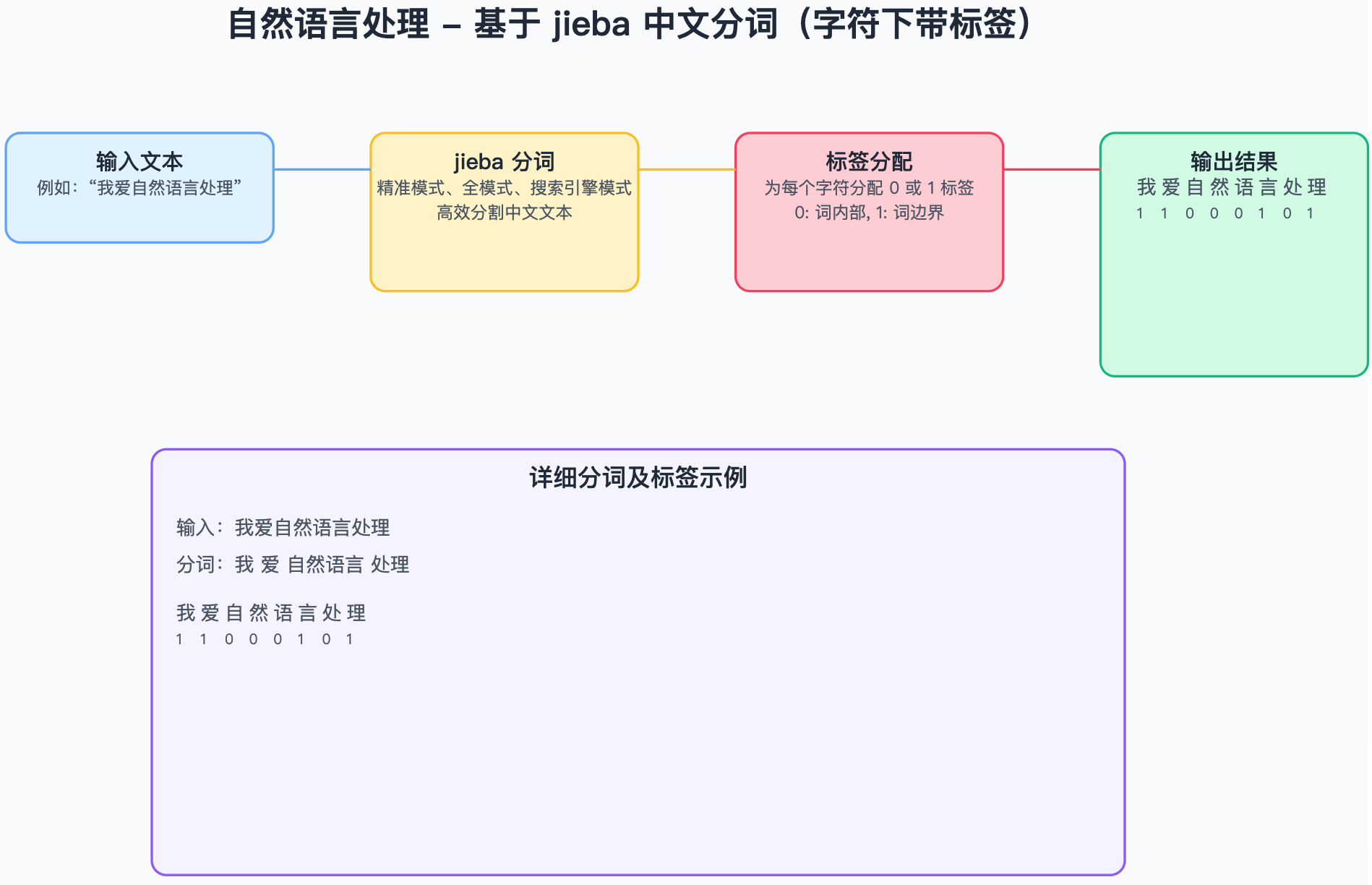
目标
本文基于给定的中文词表,将输入的文本基于jieba分词分割为若干个词,词的末尾对应的标签为1,中间部分对应的标签为0,同时将分词后的单词基于中文词表做初步序列化,之后经过embedding和 RNN循环神经网络等网络结构层,最后输出在两类别(词内部和词边界)标签上的概率分布,从而实现一个简单中文分词任务。
数据准备
词表文件chars.txt
中文语料文件corpus.txt中文语料文件
主程序
#coding:utf8import torch
import torch.nn as nn
import jieba
import numpy as np
import random
import json
from torch.utils.data import DataLoader"""
基于pytorch的网络编写一个分词模型
我们使用jieba分词的结果作为训练数据
看看是否可以得到一个效果接近的神经网络模型
"""class TorchModel(nn.Module):def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):super(TorchModel, self).__init__()self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)self.rnn_layer = nn.RNN(input_size=input_dim,hidden_size=hidden_size,batch_first=True,bidirectional=False,num_layers=num_rnn_layers,nonlinearity="relu",dropout=0.1)self.classify = nn.Linear(hidden_size, 2)self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)#当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)y_pred = self.classify(x) #input shape:(batch_size, sen_len, class_num)if y is not None:#(batch_size * sen_len, class_num), (batch_size * sen_len, 1)return self.loss_func(y_pred.view(-1, 2), y.view(-1))else:return y_predclass Dataset:def __init__(self, corpus_path, vocab, max_length):self.vocab = vocabself.corpus_path = corpus_pathself.max_length = max_lengthself.load()def load(self):self.data = []with open(self.corpus_path, encoding="utf8") as f:for line in f:sequence = sentence_to_sequence(line, self.vocab)label = sequence_to_label(line)sequence, label = self.padding(sequence, label)sequence = torch.LongTensor(sequence)label = torch.LongTensor(label)self.data.append([sequence, label])if len(self.data) > 10000:breakdef padding(self, sequence, label):sequence = sequence[:self.max_length]sequence += [0] * (self.max_length - len(sequence))label = label[:self.max_length]label += [-100] * (self.max_length - len(label))return sequence, labeldef __len__(self):return len(self.data)def __getitem__(self, item):return self.data[item]#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):sequence = [vocab.get(char, vocab['unk']) for char in sentence]return sequence#基于结巴生成分级结果的标注
def sequence_to_label(sentence):words = jieba.lcut(sentence)label = [0] * len(sentence)pointer = 0for word in words:pointer += len(word)label[pointer - 1] = 1return label#加载字表
def build_vocab(vocab_path):vocab = {}with open(vocab_path, "r", encoding="utf8") as f:for index, line in enumerate(f):char = line.strip()vocab[char] = index + 1 #每个字对应一个序号vocab['unk'] = len(vocab) + 1return vocab#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torchreturn data_loaderdef main():epoch_num = 10 #训练轮数batch_size = 20 #每次训练样本个数char_dim = 50 #每个字的维度hidden_size = 100 #隐含层维度num_rnn_layers = 3 #rnn层数max_length = 20 #样本最大长度learning_rate = 1e-3 #学习率vocab_path = "chars.txt" #字表文件路径corpus_path = "corpus.txt" #语料文件路径vocab = build_vocab(vocab_path) #建立字表data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器#训练开始for epoch in range(epoch_num):model.train()watch_loss = []for x, y in data_loader:optim.zero_grad() #梯度归零loss = model(x, y) #计算lossloss.backward() #计算梯度optim.step() #更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))#保存模型torch.save(model.state_dict(), "model.pth")#保存词表writer = open("vocab.json", "w", encoding="utf8")writer.write(json.dumps(vocab, ensure_ascii=False, indent=2))writer.close()return#最终预测
def predict(model_path, vocab_path, input_strings):#配置保持和训练时一致char_dim = 50 # 每个字的维度hidden_size = 100 # 隐含层维度num_rnn_layers = 3 # rnn层数vocab = build_vocab(vocab_path) #建立字表model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重model.eval()for input_string in input_strings:#逐条预测x = sentence_to_sequence(input_string, vocab)# print(x)with torch.no_grad():result = model.forward(torch.LongTensor([x]))[0]result = torch.argmax(result, dim=-1) #预测出的01序列print(result)#在预测为1的地方切分,将切分后文本打印出来for index, p in enumerate(result):if p == 1:print(input_string[index], end=" ")else:print(input_string[index], end="")print()if __name__ == "__main__":print(torch.backends.mps.is_available())main()input_strings = ["同时国内有望出台新汽车刺激方案","沪胶后市有望延续强势","经过两个交易日的强势调整后","昨日上海天然橡胶期货价格再度大幅上扬"]predict("model.pth", "chars.txt", input_strings)主要实现了一个基于jieba分词的中文分词模型,模型采用 RNN(循环神经网络)来处理中文文本,通过对句子进行分词,预测每个字是否为词的结尾。具体内容如下:
-
模型结构(
TorchModel):- 使用
nn.Embedding层将每个字符映射到一个高维空间。 - 通过
nn.RNN层处理字符序列,提取上下文信息,使用单向RNN(bidirectional=False)。 - 最后通过
nn.Linear层将 RNN 输出转化为每个字符的分类结果,分类为0(非词结尾)或1(词结尾)。 - 损失函数为
CrossEntropyLoss,计算预测与真实标签的差异。
- 使用
-
数据处理(
Dataset):- 使用
jieba分词工具将文本切分为词,并为每个字符标注一个标签。标签为1表示该字符是词的结尾,0表示不是词结尾。 - 将文本转换为数字序列,并根据最大句子长度进行填充,使得输入数据的形状一致。
- 使用
-
训练过程:
- 数据通过
DataLoader按批加载,使用Adam优化器进行训练。 - 在每一轮训练中,计算损失并通过反向传播优化模型权重,训练 10 轮。
- 数据通过
-
预测功能(
predict):- 加载训练好的模型,使用
torch.no_grad()禁用梯度计算,提高推理速度。 - 对每个输入字符串进行分词预测,输出每个字是否为词的结尾。若为词结尾,则切分该词并打印。
- 加载训练好的模型,使用
-
核心流程:
sentence_to_sequence将文本转换为字符序列,sequence_to_label生成对应的标签序列。- 训练完成后,保存模型和词表,以便后续加载和预测。
代码实现了一个简单的中文分词模型,通过标注每个字符是否为词的结尾,结合 RNN 提取上下文信息,从而实现文本分词功能。
预测效果
输入语句:
“同时国内有望出台新汽车刺激方案”,
“沪胶后市有望延续强势”,
“经过两个交易日的强势调整后”,
“昨日上海天然橡胶期货价格再度大幅上扬”
中文分词后结果:
tensor([0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1])
同时 国内 有 望 出台 新 汽车 刺激 方案
tensor([1, 1, 0, 1, 1, 1, 0, 1, 0, 1])
沪 胶 后市 有 望 延续 强势
tensor([0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1])
经过 两个 交易 日 的 强势 调整 后
tensor([0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1])
昨日 上海 天然 橡胶 期货 价格 再度 大幅 上扬
相关文章:
Day09【基于jieba分词和RNN实现的简单中文分词】
基于jieba分词和RNN实现的中文分词 目标数据准备主程序预测效果 目标 本文基于给定的中文词表,将输入的文本基于jieba分词分割为若干个词,词的末尾对应的标签为1,中间部分对应的标签为0,同时将分词后的单词基于中文词表做初步序列…...
自动化测试——selenium
简介 Selenium 是一个广泛使用的自动化测试工具,主要用于 Web 应用程序的自动化测试。它能实现的功能是网页的自动化操作,例如自动抢票刷课等。同时你应该也见到过有些网站在打开之后并没有直接加载出网站的所有内容,比如一些图片等等&#x…...

java和python实现mqtt
说明: MQTT 异步通信系统功能文档 系统概述 本系统基于 MQTT 协议实现异步通信,包含三个核心组件: Broker(消息代理):负责消息的路由和转发。 Client(主客户端):定时发…...

5.9 《GPT-4调试+测试金字塔:构建高可靠系统的5大实战策略》
5.4 测试与调试:构建企业级质量的保障体系 关键词:测试金字塔模型、GPT-4调试助手、LangChain调试模式、异步任务验证 测试策略设计(测试金字塔实践) #mermaid-svg-RblGbJVMnCIShiCW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill…...

Linux——进程通信
我们知道,进程具有独立性,各进程之间互不干扰,但我们为什么还要让其联系,建立通信呢?比如:数据传输,资源共享,通知某个事件,或控制某个进程。因此,让进程间建…...

学习笔记十三—— 理解 Rust 闭包:从语法到 impl Fn vs Box<dyn Fn>
🧠 理解 Rust 闭包:从语法到 impl Fn vs Box 📚 目录 闭包是什么?和普通函数有什么不同?闭包的语法长什么样?闭包“捕获变量”是什么意思?闭包和所有权的关系Fn、FnMut、FnOnce 三种闭包类型的…...

【免费参会合集】2025年生物制药行业展会会议表格整理
全文精心整理, 建议今年参会前都好好收藏着,记得点赞! 医药人非常吃资源,资源从何而来?作为一名从事医药行业的工作者,可以很负责任的告诉诸位,其中非常重要的一个渠道就是会议会展! 建议所有医…...
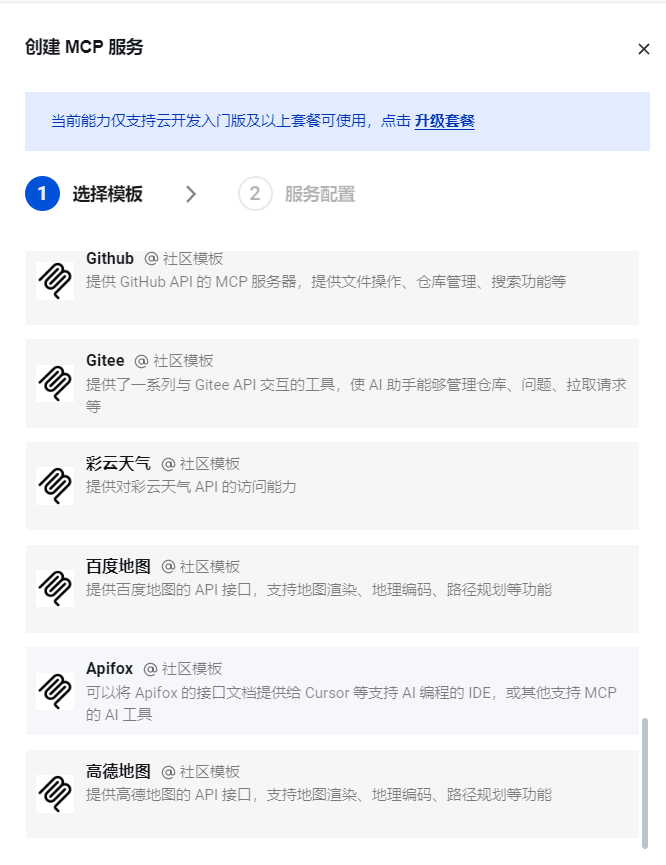
腾讯云开发+MCP:旅游规划攻略
1.登录注册好之后进入腾讯云开发 2.创建环境 4.创建好环境之后点击去开发 5.进入控制台后,选择AI,找到MCP 6.点击创建MCP Server 使用腾讯云开发创建MCP目前需要云开发入门版99/月,我没开通,所以没办法往下进行。...

银河麒麟系统 达梦8 安装 dlask 框架后端环境
适配的一套环境为 dmPython2.5.8 dmSQLAlchemy1.4.39 Flask2.0.3 Flask-Cors3.0.10 Flask-SQLAlchemy2.5.1 SQLAlchemy1.4.54 Werkzeug2.2.2其中 # sqlalchemy-dm1.4.39 通过dmdbms目录内文件进行源码安装 (MindSpore) [ma-user python]$pwd /home/syl/dmdbms/drivers/python…...
 vpc-flow 数据抽样)
Cribl (实验) vpc-flow 数据抽样
先看文档: Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. | Cribl Docs Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. Recipe for Sampling Firewall Logs Firewall logs are another source of important operational (and security) data. Typical examples include Ama…...

Sklearn入门之数据预处理preprocessing
、 Sklearn全称:Scipy-toolkit Learn是 一个基于scipy实现的的开源机器学习库。它提供了大量的算法和工具,用于数据挖掘和数据分析,包括分类、回归、聚类等多种任务。本文我将带你了解并入门Sklearn下的preprocessing在机器学习中的基本用法。 获取方式…...

我想自己组装一台服务器,微调大模型通义千问2.5 Omni 72B,但是我是个人购买,资金非常有限,最省的方案
目录 🧠 首先我们要搞清楚几个核心点: 🎯 目标:微调 Qwen2.5-Omni-72B 🚨 现实问题:作为个人用户,72B 模型几乎无法负担全量微调 💸 全量微调硬件需求: ✅ 最省的个人方案:不组 72B,只训练 Qwen2.5-Omni-7B 或 14B 💡 推荐方案 A:个人桌面级多卡训练服…...

家用打印机性价比排名及推荐
文章目录 品牌性价比一、核心参数对比与场景适配二、技术类型深度解析三、不同场景选择 相关文章 品牌 性价比 一、核心参数对比与场景适配 兄弟T436W 优势: 微压电技术,打印头寿命长,堵头率低。 支持A4无边距和5G WiFi,适合照片…...
基础概念与原理完整指南)
KWDB(Knowledge Worker Database)基础概念与原理完整指南
KWDB(Knowledge Worker Database)基础概念与原理完整指南—目录 前言一、背景1.1 知识工作者的痛点1.2 技术演进推动 二、定义与定位2.1 什么是KWDB?2.2 KWDB与传统数据库的对比与传统关系型数据库(如MySQL)的对比与分…...
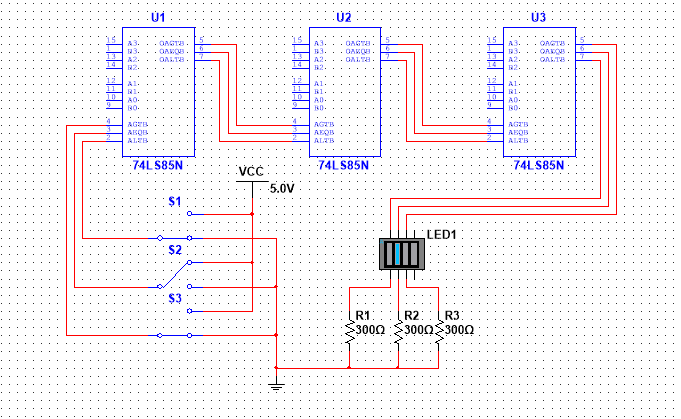
数字电子技术基础(四十七)——使用Mutlisim软件来模拟74LS85芯片
目录 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 1.2 器件选择 1.3 运行电路 2 使用74LS85N完成更多位的二进制比较 1 使用74LS85N芯片完成四位二进制数的比较 1.1原理介绍 对于74LS85 是一款 4 位数值比较器集成电路,用于比较两个 4 位二进制数&…...
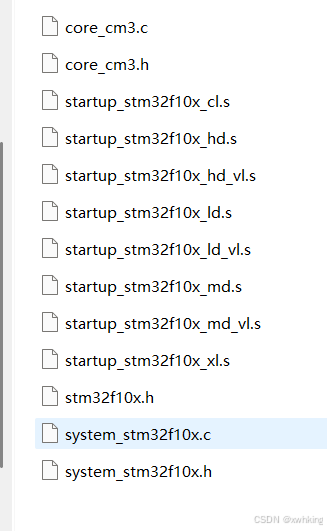
关于STM32创建工程文件启动文件选择
注意启动文件只要选择这几个 而不是要把所有都选上...
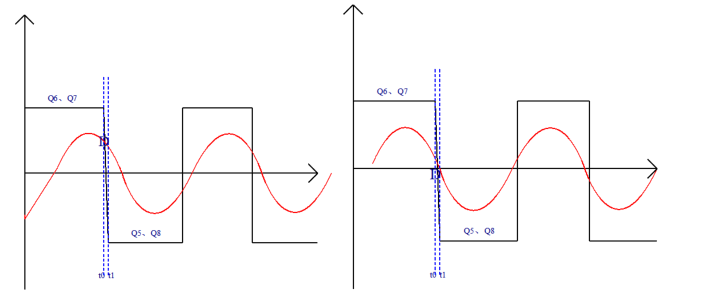
LLC电路工作在容性区的风险
在t0时刻之前,Q6Q7导通,回路如下所示,此时A点电压是低压,B点电压是高压 在t0时刻时,谐振电流相位发生变换,在t1时刻,Q5,Q8导通,对于Q8MOS管来说,B点电压在Q6Q…...
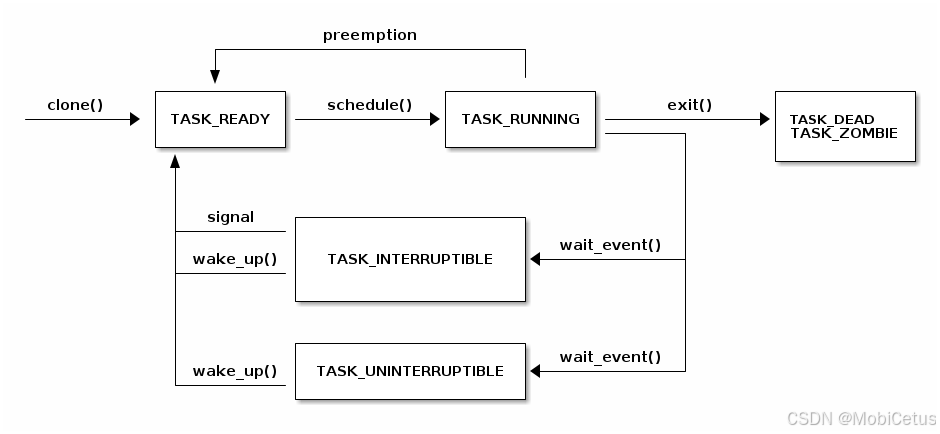
Linux Kernel 6
clone 系统调用(The clone system call) 在 Linux 中,使用 clone() 系统调用来创建新的线程或进程。fork() 系统调用和 pthread_create() 函数都基于 clone() 的实现。 clone() 系统调用允许调用者决定哪些资源应该与父进程共享,…...
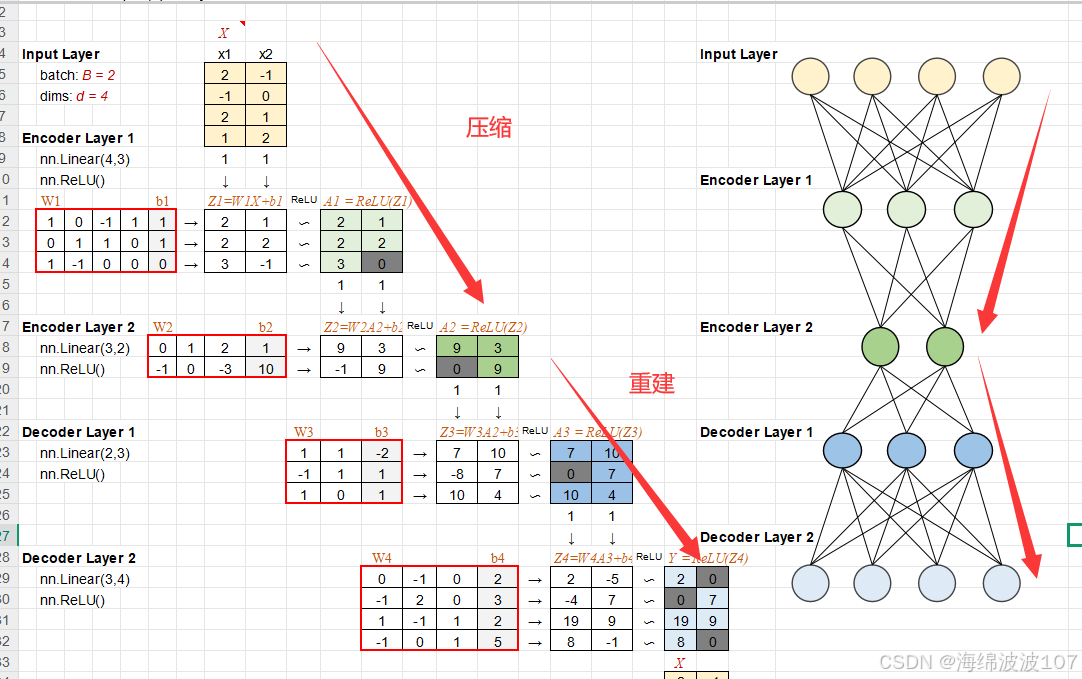
【开源项目】Excel手撕AI算法深入理解(四):AlphaFold、Autoencoder
项目源码地址:https://github.com/ImagineAILab/ai-by-hand-excel.git 一、AlphaFold AlphaFold 是 DeepMind 开发的突破性 AI 算法,用于预测蛋白质的三维结构。它的出现解决了生物学领域长达 50 年的“蛋白质折叠问题”,被《科学》杂志评为…...
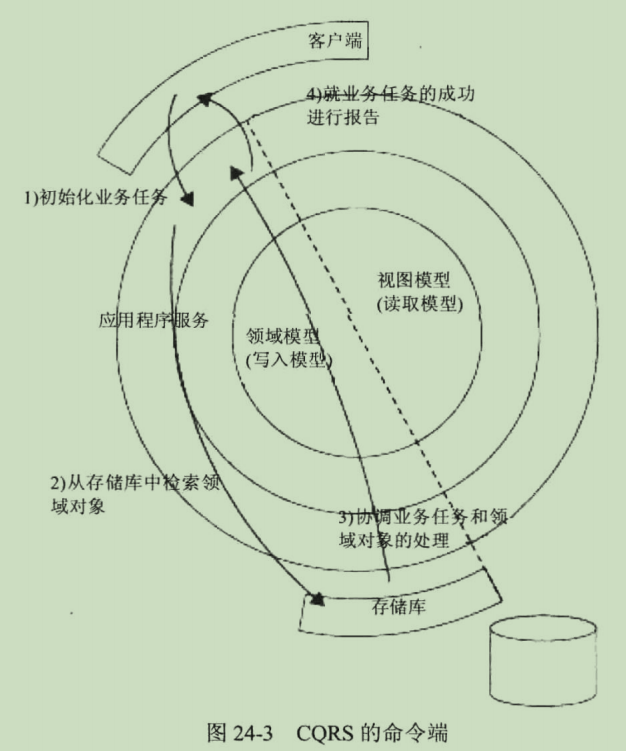
第IV部分有效应用程序的设计模式
第IV部分有效应用程序的设计模式 第IV部分有效应用程序的设计模式第23章:应用程序用户界面的架构设计23.1设计考量23.2示例1:用于非分布式有界上下文的一个基于HTMLAF的、服务器端的UI23.3示例2:用于分布式有界上下文的一个基于数据API的客户端UI23.4要点第24章:CQRS:一种…...

如何编制实施项目管理章程
本文档概述了一个项目管理系统的实施计划,旨在通过统一的业务规范和技术架构,加强集团公司的业务管控,并规范业务管理。系统建设将遵循集团统一模板,确保各单位项目系统建设的标准化和一致性。 实施范围涵盖投资管理、立项管理、设计管理、进度管理等多个方面,支持项目全生…...
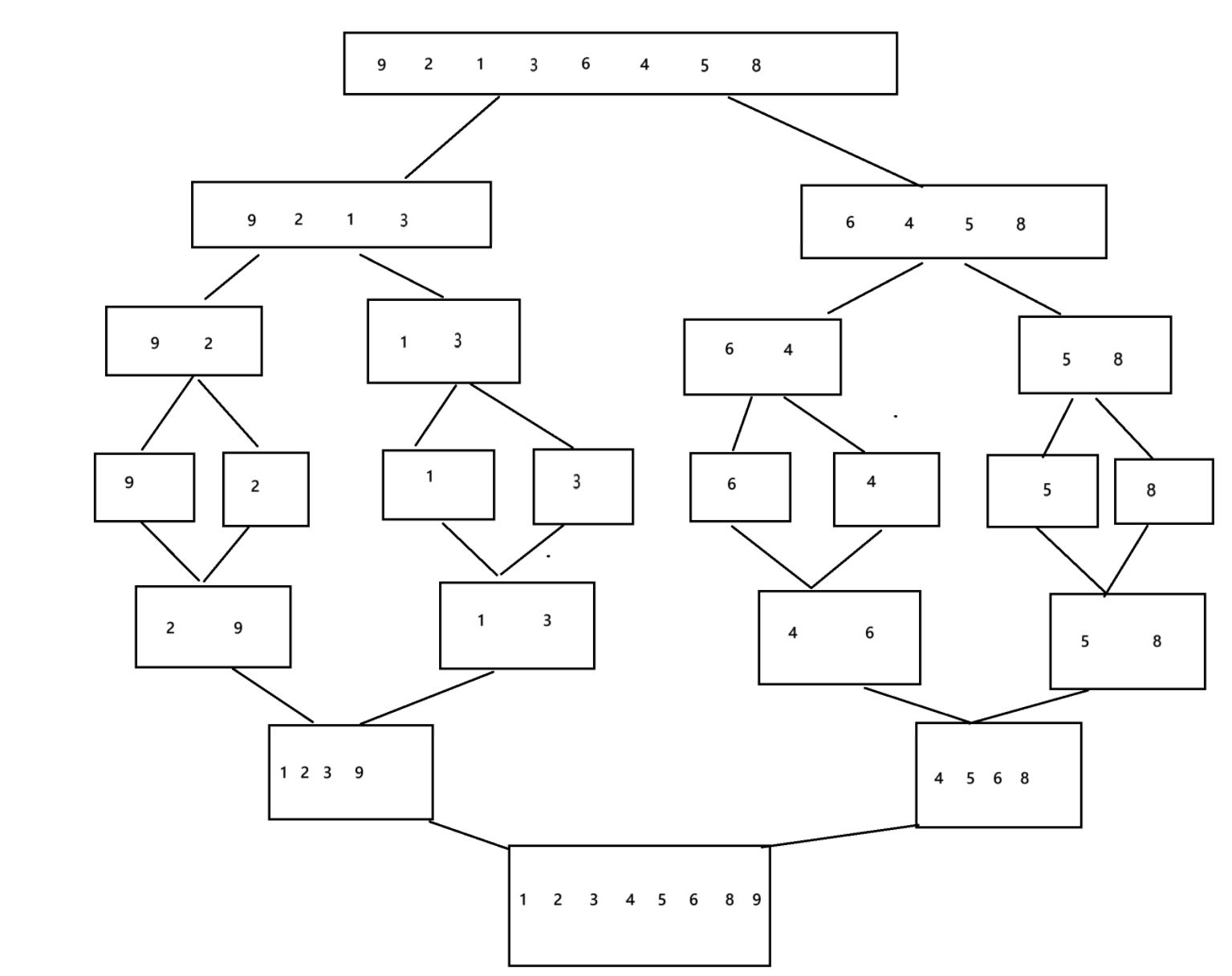
排序(java)
一.概念 排序:对一组数据进行从小到大/从大到小的排序 稳定性:即使进行排序相对位置也不受影响如: 如果再排序后 L 在 i 的前面则稳定性差,像图中这样就是稳定性好。 二.常见的排序 三.常见算法的实现 1.插入排序 1.1 直…...
内存管理补充版)
嵌入式C语言进阶(二+)内存管理补充版
C语言内存管理:从小白到大神的完全指南 前言:为什么需要理解内存管理 C语言以其高效性和灵活性著称,但这也意味着程序员需要手动管理内存。与Java、Python等高级语言不同,C语言没有自动垃圾回收机制,内存管理的重担完全落在开发者肩上。理解C语言的内存管理机制不仅能帮…...
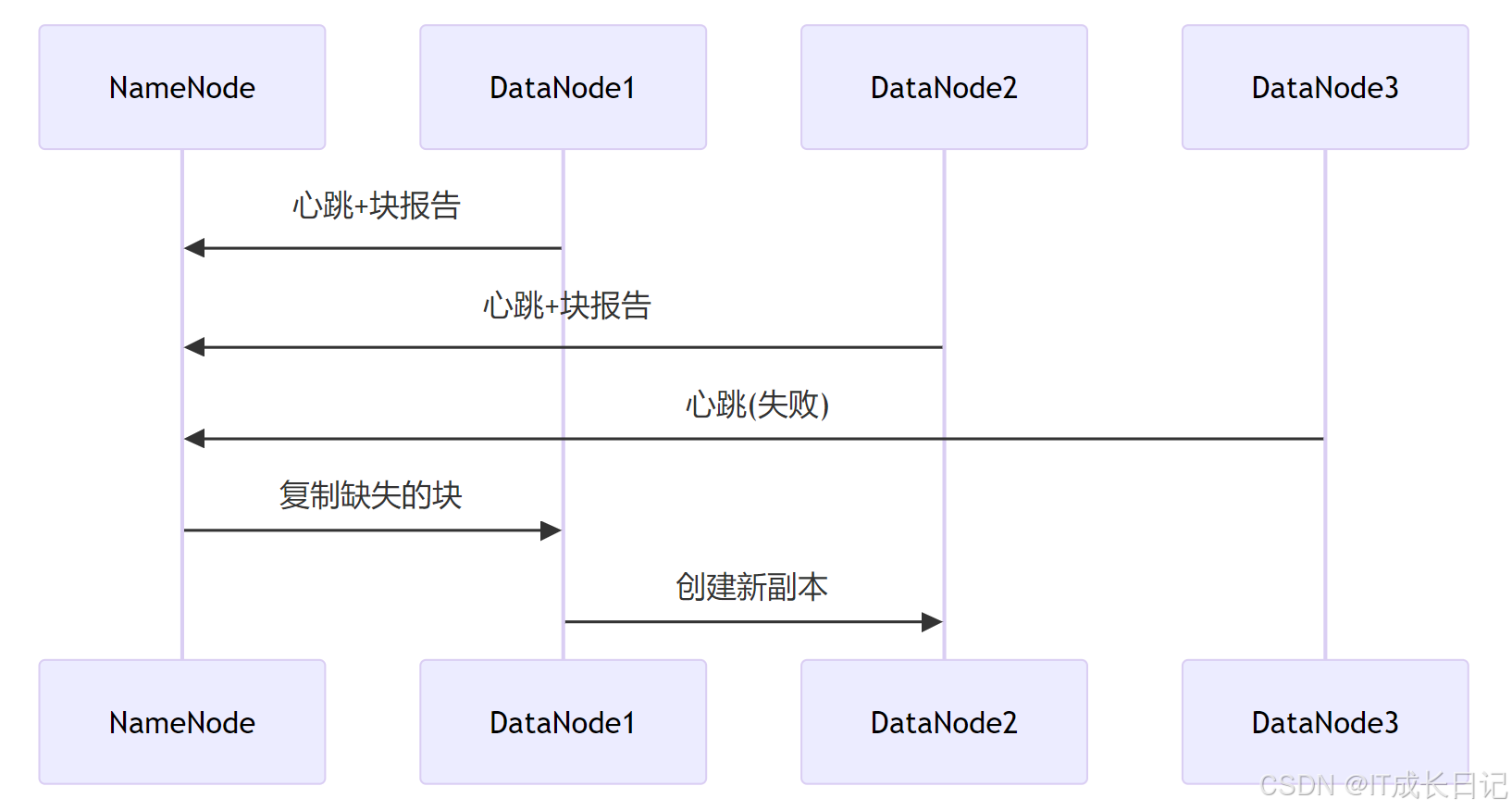
【HDFS入门】HDFS副本策略:深入浅出副本机制
目录 1 HDFS副本机制概述 2 HDFS副本放置策略 3 副本策略的优势 4 副本因子配置 5 副本管理流程 6 最佳实践与调优 7 总结 1 HDFS副本机制概述 Hadoop分布式文件系统(HDFS)的核心设计原则之一就是通过数据冗余来保证可靠性,而这一功能正是通过副本策略实现的…...

Excel自定义函数取拼音首字母
1.启动Excel 2003(其它版本请仿照操作),打开相应的工作表; 2.执行“工具 > 宏 > Visual Basic编辑器”命令(或者直接按“AltF11”组合键),进入Visual Basic编辑状态; 3.执行“…...
智能 GitHub Copilot 副驾驶® 更新升级!
智能 GitHub Copilot 副驾驶 迎来重大升级!现在,所有 VS Code 用户都能体验支持 Multi-Context Protocol(MCP)的全新 Agent Mode。此外,微软还推出了智能 GitHub Copilot 副驾驶 Pro 订阅计划,提供更强大的…...

Android ViewPager使用预加载机制导致出现页面穿透问题
缘由 在应用中使用ViewPager,并且设置预加载页面。结果出现了一些异常的现象。 我们有4个页面,分别是4个Fragment,暂且称为FragmentA、FragmentB、FragmentC、FragmentD,ViewPager在MainActivity中,切换时&#x…...

【今日三题】添加字符(暴力枚举) / 数组变换(位运算) / 装箱问题(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 添加字符(暴力枚举)数组变换(位运算)装箱问题(01背包) 添加字符(暴力枚举) 添加字符 当在A的开头或结尾添加字符直到和B长度…...
)
【AIoT】智能硬件GPIO通信详解(二)
前言 上一篇我们深入解析了智能硬件GPIO通信原理(传送门:【AIoT】智能硬件GPIO通信详解(一))。接下来,我们将结合无人售货机控制场景,通过具体案例进一步剖析物联网底层通信机制的实际应用。 在智能零售领域,无人售货机通过AI技术升级为智能柜,其设备控制的底层通信…...
Python中JSON的妙用:详解序列化与反序列化原理及实战案例)
Python(18)Python中JSON的妙用:详解序列化与反序列化原理及实战案例
目录 一、背景:为什么Python需要JSON?二、核心技术解析:序列化与反序列化2.1 核心概念2.2 类型映射对照表 三、Python操作JSON的四大核心方法3.1 基础方法库3.2 方法详解1. json.dumps()2. json.loads()3. json.dump()4. json.load() 四、实战…...