冒泡排序、插入排序、快速排序、堆排序、希尔排序、归并排序
目录
- 冒泡排序
- 插入排序
- 快速排序(未优化版本)
- 快速排序(优化版本)
- 堆排序
- 希尔排序
- 归并排序
- 各排序时间消耗对比
冒泡排序
冒泡排序核心逻辑就是对数组从第一个位置开始进行遍历,如果发现该元素比下一个元素大,则交换位置,如果不大,就拿着下一个比该元素大的元素向下继续比较,以此类推一直比较到最后,每一轮下来就会把当前最大的元素放到最后所以每一轮会确定一个最大元素。
public void bubbleSort(int[] array) {for (int i = 0; i < array.length; i++) {int flag = 0;for (int j = 1; j < array.length-i; j++) {if (array[j - 1] > array[j]) {swap(array,j-1,j);flag = 1;}}if (flag == 0) {break;}}}
这里做了一个优化,当某一轮发现一个元素都没有移动的时候,就表示这个数组已经是有序的了,不理解的可以举一个已经有序的例子推敲一下,所以定义一个flag如果为0就表示一整伦下来都没有发生过移动直接跳出循环,排序完成。
时间复杂度:O(N^2)
稳定性:稳定
空间复杂度:O(1)
插入排序
public void insertSort(int[] array) {for (int i = 1; i < array.length; i++) {int j = i - 1;int tmp = array[i];for (; j >= 0; j--) {if (array[j] >= tmp) {array[j+1] = array[j];} else {break;}}array[j+1] = tmp;}}
时间复杂度:O(N^2)
稳定性:稳定
空间复杂度:O(1)
快速排序(未优化版本)
public void quickSort (int[] array) {quick(array,0,array.length-1);}private void quick(int[] array, int start, int end) {if (start >= end) {return;}// 一个是霍尔法一个是挖坑法,两个都可int part = partition1(array,start,end); // 霍尔法//int part = partition2(array,start,end); // 挖坑法quick(array,start,part-1);quick(array,part+1,end);}private int partition1(int[] array, int left, int right) {int tmp = array[left];int tmpIndex = left;while (left < right) {while (left < right && array[right] >= tmp) {right--;}while (left < right && array[left] <= tmp) {left++;}swap(array,left,right);}swap(array,tmpIndex,left);return left;}private int partition2(int[] array, int left ,int right) {int tmp = array[left];while (left < right) {while (left < right && array[right] >= tmp) {right--;}array[left] = array[right];while (left < right && array[left] <= tmp) {left++;}array[right] = array[left];}array[left] = tmp;return left;}
最好时间复杂度:O(N*logN)
最坏时间复杂度:O(N^2)
空间复杂度:O(logN)
稳定性:不稳定
快速排序(优化版本)
public void quickSort (int[] array) {quick(array,0,array.length-1);}private void quick(int[] array, int start, int end) {if (start >= end) {return;}// 优化1(如果是少量的数据,直接插入排序速度是很快的,所以我们用直接插入排序处理数量小于等于15个的情况,不要小看这个优化,因为quickSort是树形的递归模式,在最后一层会有大量的数据存在,这个时候我们直接不进行递归直接进行插入排序可以节省大量的开销)if (end - start + 1 <= 15) {insertWithQuick(array,start,end);return;}// 优化2(三数取中优化,如果当一个数组比较趋于有序的情况下,那么构造出来的二叉树就是变成了一个链表,所以才会有时间复杂度区域O(N^2),我们只要打破这个顺序就好,我们直接去一个较为中间的值作为基准值就能均分了)int midIndex = findMidIndex(array,start,end);swap(array,start,midIndex);// 一个是霍尔法一个是挖坑法,两个都可int part = partition1(array,start,end); // 霍尔法//int part = partition2(array,start,end); // 挖坑法quick(array,start,part-1);quick(array,part+1,end);}private int partition1(int[] array, int left, int right) {int tmp = array[left];int tmpIndex = left;while (left < right) {while (left < right && array[right] >= tmp) {right--;}while (left < right && array[left] <= tmp) {left++;}swap(array,left,right);}swap(array,tmpIndex,left);return left;}private int partition2(int[] array, int left ,int right) {int tmp = array[left];while (left < right) {while (left < right && array[right] >= tmp) {right--;}array[left] = array[right];while (left < right && array[left] <= tmp) {left++;}array[right] = array[left];}array[left] = tmp;return left;}// 使用插入排序进行优化private void insertWithQuick(int[] array, int start, int end) {for (int i = start; i <= end; i++) {int j = i - 1;int tmp = array[i];for (; j >= start; j--) {if (array[j] >= tmp) {array[j+1] = array[j];} else {break;}}array[j+1] = tmp;}}// 使用三数取中找到中值下标private int findMidIndex(int[] array, int start, int end) {int midIndex = start + (end - start) / 2;if (array[start] > array[end]) {// end startif (array[midIndex] < array[end]) {return end;} else if (array[midIndex] > array[start]) {return start;} else {return midIndex;}} else {// start endif (array[midIndex] < array[start]) {return start;} else if (array[midIndex] > array[end]) {return end;} else {return midIndex;}}}
优化后的时间复杂度将会无限趋近于O(N*logN),空间复杂度不变
堆排序
public void heapSort (int[] array) {createBigHeap(array);int end = array.length-1;while (end >= 0) {swap(array,0,end);end--;siftDown(array,0,end);}}private void createBigHeap(int[] array) {for (int parent = (array.length-2); parent >= 0; parent--) {siftDown(array,parent,array.length-1);}}private void siftDown(int[] array, int parent, int end) {int child = parent * 2 + 1;while (child <= end) {if (child + 1 <= end && array[child+1] > array[child]) {child++;}if (array[child] > array[parent]) {swap(array,child,parent);parent = child;child = child * 2 + 1;} else {break;}}}
时间复杂度:O(N*logN)
空间复杂度:O(logN)
稳定性:不稳定
希尔排序
public void shallSort (int[] array) {int gap = array.length / 2;while (gap > 0) {shall(array,gap);gap /= 2;}}private void shall(int[] array, int gap) {for (int i = gap; i < array.length; i++) {int tmp = array[i];int j = i - gap;for (; j >= 0; j -= gap) {if (array[j] >= tmp) {array[j + gap] = array[j];} else {break;}}array[j+gap] = tmp;}}
希尔排序就是直接插入排序的升级版本
时间复杂度:不好计算业界公认的大概是O(N^1.3)
空间复杂度:O(1)
稳定性:不稳定
归并排序
public void mergeSort(int[] array) {mergeFun(array,0,array.length-1);}private void mergeFun(int[] array, int start, int end) {if (start >= end) {return;}int midIndex = start + (end - start) / 2;mergeFun(array,start,midIndex);mergeFun(array,midIndex+1,end);// mergemerge(array, start, end, midIndex);}private void merge(int[] array, int start, int end, int midIndex) {int rs = midIndex + 1 , k = 0, tmpIndex = start;int[] tmpArray = new int[end - start +1];while (start <= midIndex && rs <= end) {if (array[start] < array[rs]) {tmpArray[k++] = array[start++];} else {tmpArray[k++] = array[rs++];}}while (start <= midIndex) {tmpArray[k++] = array[start++];}while (rs <= end) {tmpArray[k++] = array[rs++];}for (int j = tmpIndex; j <= end; j++) {array[j] = tmpArray[j - tmpIndex];}}
时间复杂度:O(N*logN)
空间复杂度:O(N)
稳定性:稳定
各排序时间消耗对比
为了更直观的观察每个排序有时间效率,我将这几个排序进行了一个对比,先随机生成要给数组大小为100000的随机数,随机数范围是0-10000,之后分别计算各个排序所消耗的时间单位是毫秒
public static void main(String[] args) {Sort sort = new Sort();// 原数组int[] array = createRandomNumber(100_000,10_000);// copy数组int[] array1 = Arrays.copyOf(array, array.length);long start1 = System.currentTimeMillis();sort.quickSort(array1);System.out.println("quickSort : " + (System.currentTimeMillis()-start1) );int[] array2 = Arrays.copyOf(array, array.length);long start2 = System.currentTimeMillis();sort.shallSort(array2);System.out.println("shallSort : " + (System.currentTimeMillis()-start2) );int[] array3 = Arrays.copyOf(array, array.length);long start3 = System.currentTimeMillis();sort.heapSort(array3);System.out.println("heapSort : " + (System.currentTimeMillis()-start3) );int[] array4 = Arrays.copyOf(array, array.length);long start4 = System.currentTimeMillis();sort.mergeSort(array4);System.out.println("mergeSort : " + (System.currentTimeMillis()-start4) );int[] array5 = Arrays.copyOf(array, array.length);long start5 = System.currentTimeMillis();sort.insertSort(array5);System.out.println("insertSort : " + (System.currentTimeMillis()-start5) );int[] array6 = Arrays.copyOf(array, array.length);long start6 = System.currentTimeMillis();sort.bubbleSort(array6);System.out.println("bubbleSort : " + (System.currentTimeMillis()-start6) );}private static int[] createRandomNumber (int size, int range) {int[] array = new int[size];for (int i = 0; i < size; i++) {array[i] = new Random().nextInt(range);}return array;}
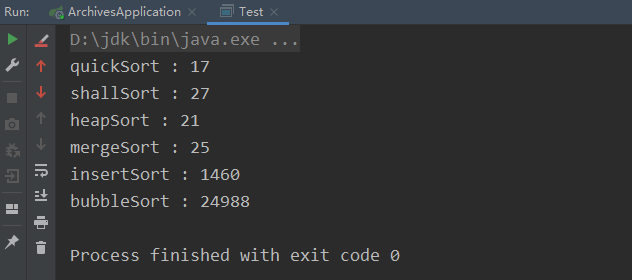
所以大家还是少用冒泡吧,虽然简单但是效率感人~ 快排还是牛掰
相关文章:
冒泡排序、插入排序、快速排序、堆排序、希尔排序、归并排序
目录 冒泡排序插入排序快速排序(未优化版本)快速排序(优化版本)堆排序希尔排序归并排序各排序时间消耗对比 冒泡排序 冒泡排序核心逻辑就是对数组从第一个位置开始进行遍历,如果发现该元素比下一个元素大,则交换位置,如果不大,就…...

Docker Compose 中配置 Host 网络模式
在 Docker Compose 中配置 Host 网络模式时,需通过 network_mode 参数直接指定容器使用宿主机的网络栈。以下是具体配置方法及注意事项: 1. 基础配置示例 在 docker-compose.yml 文件中,为需要启用 Host 模式的服务添加 network_mode: "…...

HTML、CSS 和 JavaScript 常见用法及使用规范
一、HTML 深度剖析 1. 文档类型声明 HTML 文档开头的 <!DOCTYPE html> 声明告知浏览器当前文档使用的是 HTML5 标准。它是文档的重要元信息,能确保浏览器以标准模式渲染页面,避免怪异模式下的兼容性问题。 2. 元数据标签 <meta> 标签&am…...

Elasticsearch 索引数据量激增的应对与优化:从原理到部署实践
Elasticsearch(ES)作为一款强大的分布式搜索和分析引擎,广泛应用于日志分析、全文搜索和实时数据处理等场景。然而,随着数据量激增,索引可能面临性能瓶颈,如写入变慢、查询延迟高或存储成本上升。如何有效应…...

CD27.【C++ Dev】类和对象 (18)友元和内部类
目录 1.友元 友元函数 几个特点 友元类 格式 代码示例 2.内部类(了解即可) 计算有内部类的类的大小 分析 注意:内部类不能直接定义 内部类是外部类的友元类 3.练习 承接CD21.【C Dev】类和对象(12) 流插入运算符的重载文章 1.友元 友元函数 在CD21.【C Dev】类和…...
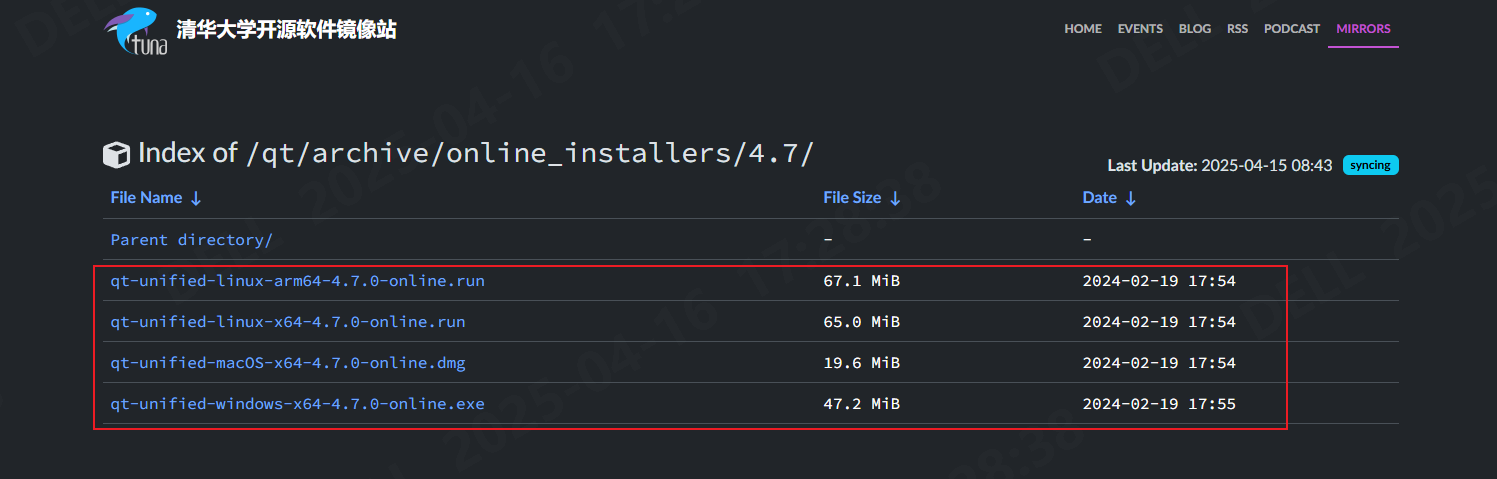
QT安装详细步骤
下载 清华源 : 清华源 1. 2. 3. 4....

Unity游戏多语言工具包
由于一开始的代码没有考虑多语言场景,导致代码中提示框和UI显示直接用了中文,最近开始提取代码的中文,提取起来太麻烦,所以拓展了之前的多语言包,降低了操作复杂度。最后把工具代码提取出来到单独项目里面,…...
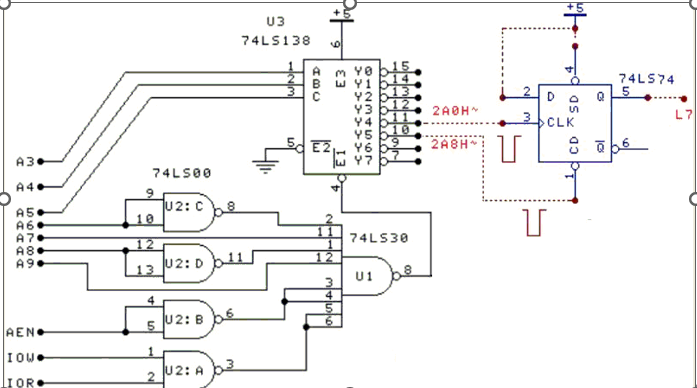
实验三 I/O地址译码
一、实验目的 掌握I/O地址译码电路的工作原理。 二、实验电路 实验电路如图1所示,其中74LS74为D触发器,可直接使用实验台上数字电路实验区的D触发器,74LS138为地址译码器, Y0:280H~287H&…...
视觉语言导航(VLN):连接语言、视觉与行动的桥梁
文章目录 1. 引言:什么是VLN及其重要性?2. VLN问题定义3. 核心挑战4. 基石:关键数据集与模拟器5. 评估指标6. 主要方法与技术演进6.1 前CLIP时代:奠定基础6.2 后CLIP时代:视觉与语言的统一 7. 最新进展与前沿趋势 (202…...

计算机网络中科大 - 第7章 网络安全(详细解析)-以及案例
目录 🛡️ 第8章:网络安全(Network Security)优化整合笔记📌 本章学习目标 一、网络安全概念二、加密技术(Encryption)1. 对称加密(Symmetric Key)2. 公钥加密࿰…...
)
2026《数据结构》考研复习笔记一(C++基础知识)
C基础知识复习 一、数据类型二、修饰符和运算符三、Lambda函数和表达式四、数学函数五、字符串六、结构体 一、数据类型 1.1基本类型 基本类型 描述 字节(位数) 范围 char 字符类型,存储ASCLL字符 1(8位) -128…...
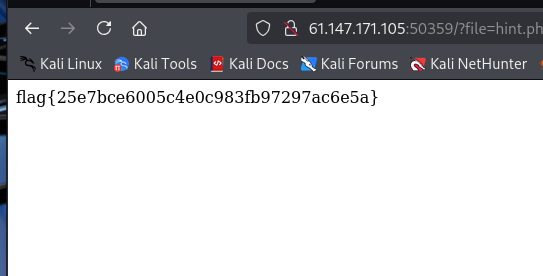
XCTF-web(四)
unserialize3 需要反序列化一下:O:4:“xctf”:2:{s:4:“flag”;s:3:“111”;} php_rce 题目提示rce漏洞,测试一下:?s/Index/\think\app/invokefunction&functioncall_user_func_array&vars[0]phpinfo&vars[1][]1 flag࿱…...
在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具
以下是 在Vue项目中查询所有版本号为 1.1.9 的依赖包名 的具体方法,支持 npm/yarn/pnpm 等主流工具: 一、使用 npm 1. 直接过滤依赖树 npm ls --depth0 | grep "1.1.9"说明: npm ls --depth0:仅显示直接依赖…...
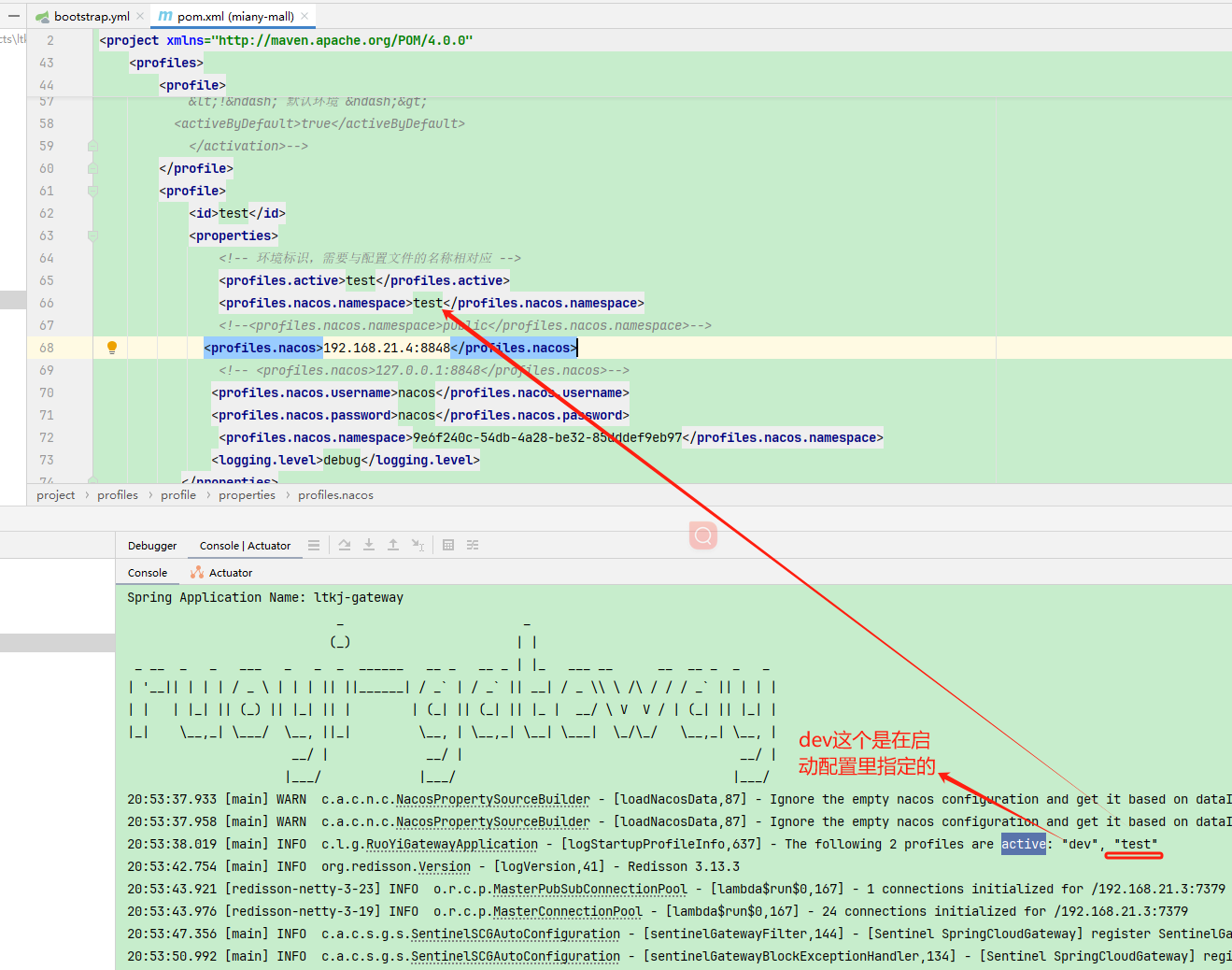
若依微服务版启动小程序后端
目录标题 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件 本地启动,dev对应 nacos里的 xxx-xxx-dev配置文件...

莒县第六实验小学:举行“阅读世界 丰盈自我”淘书会
4月16日,莒县第六实验小学校园内书香四溢、笑语盈盈,以“阅读世界 丰盈自我”为主题的第二十四届读书节之“淘书会”活动火热开启。全校师生齐聚一堂,以书会友、共享阅读之乐,为春日校园增添了一抹浓厚的文化气息。 活动在悠扬的诵…...

国产数据库与Oracle数据库事务差异分析
数据库中的ACID是事务的基本特性,而在Oracle等数据库迁移到国产数据库国产中,可能因为不同数据库事务处理机制的不同,在迁移后的业务逻辑处理上存在差异。本文简要介绍了事务的ACID属性、事务的隔离级别、回滚机制和超时机制,并总…...

C++学习记录:
今天我们来学习一门新的语言,也是C语言最著名的一个分支语言:C。 在C的学习中,我们主要学习的三大组成部分:语法、STL、数据结构。 C的介绍 C的历史可追溯至1979年,当时贝尔实验室的本贾尼斯特劳斯特卢普博士在面对复杂…...
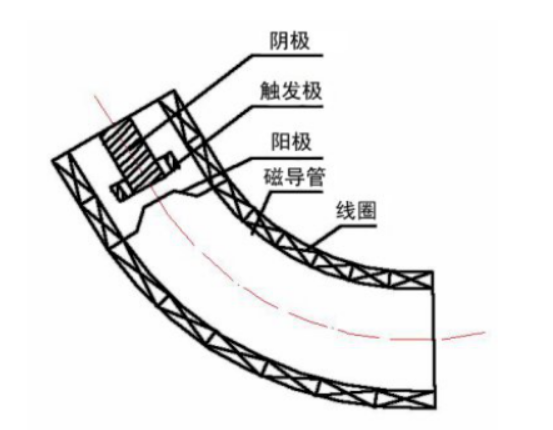
等离子体浸没离子注入(PIII)
一、PIII 是什么?基本原理和工艺 想象一下,你有一块金属或者硅片(就是做芯片的那种材料),你想给它的表面“升级”,让它变得更硬、更耐磨,或者有其他特殊功能。怎么做呢?PIII 就像是用…...

LeetCode-16.最接近的三数之和 C++实现
一 题目描述 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解 示例 1: 输入:nums [-1,2,1,-4], target 1 输出&…...

【机器学习】每日一讲-朴素贝叶斯公式
文章目录 **一、朴素贝叶斯公式详解****1. 贝叶斯定理基础****2. 从贝叶斯定理到分类任务****3. 特征独立性假设****4. 条件概率的估计** **二、在AI领域的作用****1. 文本分类与自然语言处理(NLP)****2. 推荐系统****3. 医疗与生物信息学****4. 实时监控…...

C 语言中的 volatile 关键字
1、概念 volatile 是 C/C 语言中的一个类型修饰符,用于告知编译器:该变量的值可能会在程序控制流之外被意外修改(如硬件寄存器、多线程共享变量或信号处理函数等),因此编译器不应对其进行激进的优化(如缓存…...

Python自学第1天:变量,打印,类型转化
突然想学Python了。经过Deepseek的推荐,下载了一个Python3.12安装。安装过程请自行搜索。 乖乖从最基础的学起来,废话不说了,上链接,呃,打错了,上知识点。 变量的定义 # 定义一个整数类型的变量 age 10#…...

探索鸿蒙应用开发:ArkTS应用执行入口揭秘
# 探索鸿蒙应用开发:ArkTS应用执行入口揭秘 在鸿蒙应用开发的领域中,ArkTS作为声明式开发语言,为开发者们带来了便捷与高效。对于刚接触鸿蒙开发的小伙伴来说,搞清楚ArkTS应用程序的执行入口是迈向成功开发的关键一步。今天&…...
idea中提高编译速度研究
探索过程: 有三种情况: 第一种: idea中用eclipse编译器编译springboot项目,然后debug启动Application报错找不到类。 有待继续研究。 第二种: idea中用javac编译器编译springboot项目,重新构建用时&a…...
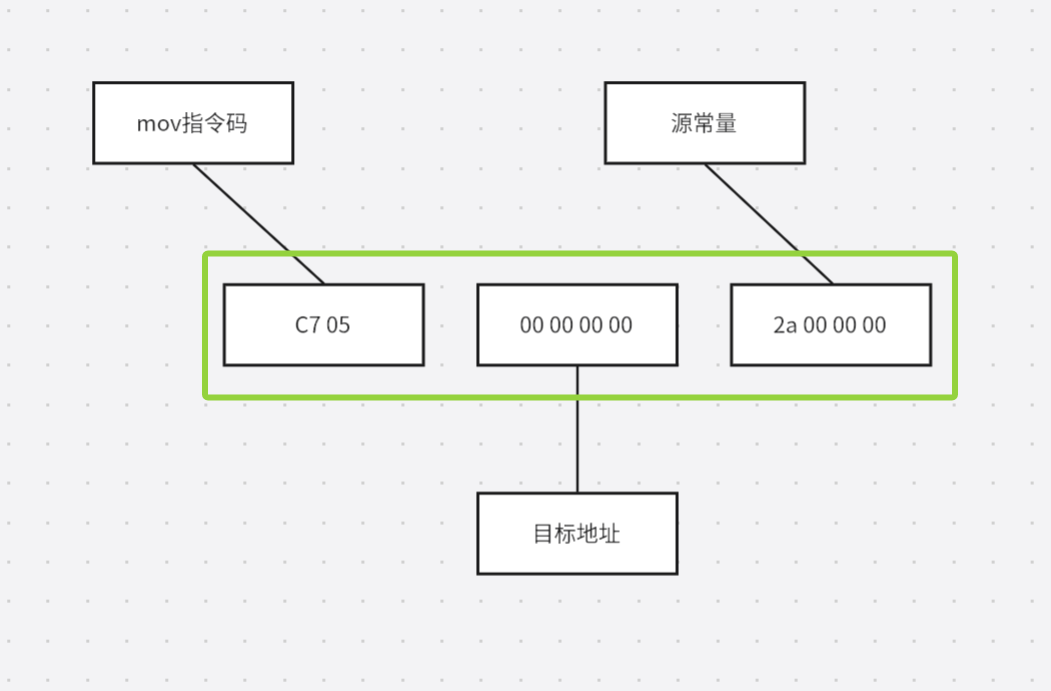
静态链接part2
编译 语义分析 由语义分析器完成,这个步骤只是完成了对表达式的语法层面的分析,它并不了解这个语句是否真的有意义(例如在C语言中两个指针做乘法运算,这个语句在语法上是合法的,但是没有什么意义;还有同样…...

Vue3+Vite+TypeScript+Element Plus开发-17.Tags-组件构建
系列文档目录 Vue3ViteTypeScript安装 Element Plus安装与配置 主页设计与router配置 静态菜单设计 Pinia引入 Header响应式菜单缩展 Mockjs引用与Axios封装 登录设计 登录成功跳转主页 多用户动态加载菜单 Pinia持久化 动态路由 -动态增加路由 动态路由-动态删除…...

MATLAB R2023b如何切换到UTF-8编码,解决乱码问题
网上都是抄来抄去,很少有动脑子的,里面说的方法都差不多,但是在R2023b上怎么试都不管用,所以静下心来分析了下,我的 ...\MATLAB\R2016b\bin\lcdata.xml 里面除了注释几乎是空的,如果这样就能用为什么要加…...

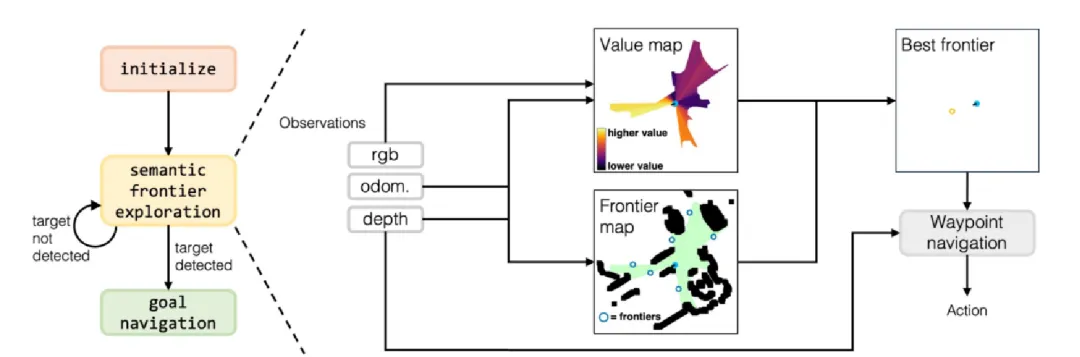
3D语义地图中的全局路径规划!iPPD:基于3D语义地图的指令引导路径规划视觉语言导航
作者: Zehao Wang, Mingxiao Li, Minye Wu, Marie-Francine Moens, Tinne Tuytelaars 单位:鲁汶大学电气工程系,鲁汶大学计算机科学系 论文标题: Instruction-guided path planning with 3D semantic maps for vision-language …...
ShellScript脚本编程
语法基础 脚本结构 我们先从这个小demo程序来窥探一下我们shell脚本的程序结构 #!/bin/bash# 注释信息echo_str"hello world"test(){echo $echo_str }test echo_str 首先我们可以通过文本编辑器(在这里我们使用linux自带文本编辑神器vim),新建一个文件…...

【HarmonyOS 5】敏感信息本地存储详解
【HarmonyOS 5】敏感信息本地存储详解 前言 鸿蒙其实自身已经通过多层次的安全机制,确保用户敏感信息本地存储安全。不过再此基础上,用户敏感信息一般三方应用还需要再进行加密存储。 本文章会从鸿蒙自身的安全机制进行展开,最后再说明本地…...