【MySQL】索引分类、聚簇与非聚簇索引,索引优化,常见explain分析索引案例,type字段
索引基本概念
索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录。它通过建立额外的数据结构来存储部分数据,从而加快查询速度。
索引的优缺点
| 优点 | 缺点 |
|---|---|
| 加快数据检索速度 | 占用额外存储空间 |
| 保证数据唯一性(唯一索引) | 插入、更新、删除时需要维护索引,增加性能开销 |
| 加速表与表之间的连接操作 | |
| 减少分组和排序的时间 |
MySQL索引类型分类
按存储结构划分:
- B+Tree索引:最常用的索引类型,支持范围查找。
- Hash索引:仅支持等值匹配,不支持范围查找。
- FULLTEXT全文索引:用于全文搜索(如搜索文章内容)。
- R-Tree索引:主要用于GIS空间数据。
R-Tree 是一种用于索引空间对象(如矩形、坐标点、多边形)的数据结构,能高效支持“交叉”“包含”等复杂空间查询。典型应用如:查找一个区域内的所有地理坐标点。
按应用层次划分:
- 普通索引:最基本的索引类型,无唯一性要求。
- 唯一索引:值必须唯一,允许NULL。
- 联合索引:组合多个列建立的索引。
- 聚簇索引(Clustered Index):索引和数据存储在一起(InnoDB主键)。
- 非聚簇索引:索引与数据分离,需回表。
索引底层实现
MySQL主要使用 B+树,原因如下:
| 比较对象 | 特点 | 缺点 |
|---|---|---|
| B+Tree | 非叶子节点仅存储键值,叶子节点通过链表连接,支持范围查询,I/O次数少 | 无法快速退化成链结构(对磁盘友好) |
| B树 | 所有节点存储数据,内存利用率低 | 树高更高,磁盘访问次数更多 |
| AVL/红黑树/BST | 平衡性好,适合内存结构 | 数据量大时树高过大,不适合磁盘访问 |
聚簇索引 vs 非聚簇索引
| 类型 | 数据与索引关系 | 特点 |
|---|---|---|
| 聚簇索引 | 索引与数据在一起 | InnoDB的主键索引;查询快,但插入顺序影响性能 |
| 非聚簇索引 | 索引存储的是主键指针 | 查询需要回表(通过非聚簇查到主键,再通过主键再查一次) |
一个表只能有一个聚簇索引,一般是主键。
联合索引与最左前缀原则
联合索引:多个列组成的索引。
最左前缀原则:只有从最左开始连续使用索引字段时,索引才生效。
示例:索引为 (a, b, c)
| 查询条件 | 是否使用索引 |
|---|---|
| WHERE a=1 AND b=2 AND c=3 | ✅ |
| WHERE a=1 AND b=2 | ✅ |
| WHERE a=1 | ✅ |
| WHERE b=2 | ❌ |
| WHERE a=1 AND c=3 | ✅(但只使用a列) |
索引优化相关概念
- 覆盖索引:查询的字段都包含在索引中,无需回表。
- 索引下推(ICP):MySQL 5.6 起支持,把过滤条件尽量交给存储引擎执行,减少回表。
- 前缀索引:只对字符串列的前 N 个字符建索引。
索引使用建议
- 为WHERE、JOIN、ORDER BY中的字段建立索引:这些操作频繁,索引能极大提升性能。
- 使用自增主键减少页分裂
页分裂是指新数据插入B+树中间节点导致节点分裂,影响性能;自增主键是顺序插入,避免频繁分裂,提升插入性能。
- 索引字段应尽量 NOT NULL
NULL值不能参与部分索引运算,且对查询优化器判断不利。
- 选择区分度高的列建索引(索引选择性)
索引选择性 =
count(distinct col)/count(*),越接近1越好。
索引选择性使用详细可看我的另一篇文章【MySQL】前缀索引、索引下推、访问方法,自适应哈希索引 - 尽量扩展已有索引,而不是新建多个冗余索引
减少索引数量,降低维护成本。
- 索引列不能参与计算、函数、类型转换
否则索引会失效,变成全表扫描。
索引失效场景
| 场景 | 示例 | 说明 |
|---|---|---|
使用 != 或 <> | WHERE a != 1 | 不走索引 |
| 类型不一致 | 字符串列和数字比 | 索引失效(隐式转换) |
| 索引列上使用函数 | WHERE DATE(dt) = ‘2023-01-01’ | 不走索引 |
| 索引列上使用运算 | WHERE a + 1 = 5 | 不走索引 |
OR连接不同字段 | WHERE a=1 OR b=2 | 若a、b无联合索引则失效 |
模糊查询 %开头 | WHERE name LIKE ‘%abc’ | 无法利用索引(违背最左前缀原则) |
| NOT IN、NOT EXISTS | WHERE a NOT IN (…) | 不走索引 |
| 违反最左前缀原则 | WHERE b=1 (索引a,b) | 无法命中索引 |
演示如何使用 EXPLAIN 分析索引使用情况:
1. 准备测试表
-- 创建测试表
CREATE TABLE user (id INT PRIMARY KEY AUTO_INCREMENT,username VARCHAR(50) NOT NULL,email VARCHAR(100) NOT NULL,age INT,created_at DATETIME,INDEX idx_username (username),UNIQUE INDEX uniq_email (email),INDEX idx_age_created (age, created_at)
);-- 插入测试数据
INSERT INTO user (username, email, age, created_at) VALUES
('user1', 'user1@example.com', 25, '2023-01-01'),
('user2', 'user2@example.com', 30, '2023-02-15'),
('user3', 'user3@example.com', 28, '2023-03-20');
2. 基础使用示例
示例1:索引生效的查询
EXPLAIN SELECT * FROM user WHERE username = 'user1';
输出结果:
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | user | NULL | ref | idx_username | idx_username| 202 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
关键字段解析:
possible_keys: 显示可能使用的索引(idx_username)key: 实际使用的索引(idx_username)type:ref表示使用了非唯一索引rows: 扫描行数(1行)
示例2:索引失效的查询
EXPLAIN SELECT * FROM user WHERE LOWER(username) = 'user1';
输出结果:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
关键字段解析:
possible_keys:NULL表示没有可用索引key:NULL表示未使用索引type:ALL表示全表扫描Extra:Using where表示在存储引擎层后过滤数据
3. 联合索引示例
示例3:符合最左前缀原则
EXPLAIN SELECT * FROM user WHERE age = 25 AND created_at > '2023-01-01';
输出结果:
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | user | NULL | range | idx_age_created | idx_age_created | 9 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+-----------------+---------+------+------+----------+-----------------------+
关键字段解析:
key_len: 9(4字节int + 5字节datetime)type:range表示范围扫描
示例4:违反最左前缀原则
EXPLAIN SELECT * FROM user WHERE created_at > '2023-01-01';
输出结果:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
关键解析:
- 联合索引
idx_age_created未生效 - 因为查询条件没有包含最左列
age
4. 冗余索引检测
示例5:查看可能使用的索引
EXPLAIN SELECT * FROM user
WHERE username = 'user1' AND email = 'user1@example.com';
输出结果:
+----+-------------+-------+------------+-------------+-------------------------+---------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+-------------------------+---------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | const | idx_username,uniq_email | uniq_email | 402 | const | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------------+-------------------------+---------+---------+-------+------+----------+-------------+
优化建议:
possible_keys显示两个索引都可用- 实际使用
uniq_email(唯一索引效率更高) - 如果
username索引很少单独使用,可以考虑删除idx_username避免冗余
5. 索引失效的经典场景
示例6:使用OR导致失效
EXPLAIN SELECT * FROM user WHERE username = 'user1' OR age = 25;
输出结果:
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user | NULL | ALL | idx_username,idx_age_created | NULL | NULL | NULL | 3 | 55.55 | Using where |
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
优化建议:
- 使用
UNION改写SQL:SELECT * FROM user WHERE username = 'user1' UNION SELECT * FROM user WHERE age = 25;
执行计划分析要点总结
| 字段 | 重要值说明 | 优化关注点 |
|---|---|---|
| type | ALL(全表扫描)、index(全索引扫描) | 出现ALL需重点关注 |
| possible_keys | 可能使用的索引 | 检查是否存在冗余索引 |
| key | 实际使用的索引 | 确认是否使用最优索引 |
| rows | 预估扫描行数 | 数值越大查询效率越低 |
| Extra | Using filesort/Using temporary | 出现这些值说明需要优化 |
通过定期分析 EXPLAIN 结果,可以:
- 验证索引是否按预期工作
- 发现全表扫描等高成本操作
- 识别冗余索引优化存储空间
- 检查联合索引的有效性
type 字段详解(访问类型)
type 是判断 SQL 性能非常重要的一列,它表示 MySQL 查询在表上的访问方式。访问方式越精确,效率越高。
下面是 MySQL 官方对访问方式的性能由好到差的排序:
| 排名 | 访问方式(type) | 说明 |
|---|---|---|
| 1️⃣ | system | 表只有一行,属于常量表(极快) |
| 2️⃣ | const | 表中最多只有一条匹配行(通过主键或唯一索引等值查询) |
| 3️⃣ | eq_ref | 联接时通过主键或唯一索引等值匹配,最多一条匹配(性能非常高) |
| 4️⃣ | ref | 通过普通索引等值匹配,返回多行结果(常见但高效) |
| 5️⃣ | range | 使用索引范围查询(例如 BETWEEN, <, >, LIKE 'xxx%') |
| 6️⃣ | index | 全索引扫描,但不回表(比全表扫描略快) |
| 7️⃣ | ALL | 全表扫描(最慢) |
类型示例及使用场景
| type | 示例 SQL | 说明 |
|---|---|---|
system | SELECT * FROM config LIMIT 1;(只有一行) | 极少见,性能最好 |
const | SELECT * FROM users WHERE id = 5;(主键等值) | 主键或唯一索引等值查询 |
eq_ref | 多表联接:SELECT * FROM a JOIN b ON a.id = b.a_id;(a_id 为唯一键) | 每次 join 只返回一条记录 |
ref | SELECT * FROM users WHERE name = 'Tom';(name 上有索引) | 索引等值匹配多行结果 |
range | SELECT * FROM users WHERE age BETWEEN 20 AND 30; | 范围匹配,适用范围查询 |
index | SELECT name FROM users;(走索引覆盖,不回表) | 只使用索引中的字段,无需回表 |
ALL | SELECT * FROM users;(没有条件) | 全表扫描,性能最差 |
实战建议
- 目标:尽量让
type处于ref或更优(即:ref、eq_ref、const、system)。 - 如果看到
ALL,要警惕是否没有加合适的索引,或 SQL 写法不当。
https://github.com/0voice
相关文章:

【MySQL】索引分类、聚簇与非聚簇索引,索引优化,常见explain分析索引案例,type字段
索引基本概念 索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录。它通过建立额外的数据结构来存储部分数据,从而加快查询速度。 索引的优缺点 优点缺点加快数据检索速度占用额外存储空间保证数据唯一性(唯一索引)插…...

MySQL Binlog 数据恢复总结
🌲 总入口:你想恢复什么? 恢复类型 ├── 表结构 表数据(整张表被 DROP) │ ├── Binlog 中包含 CREATE TABLE │ │ └── ✅ 直接用 mysqlbinlog 提取建表 数据语句,回放即可 │ └── B…...

STM32 HAL库内部 Flash 读写实现
一、STM32F407 内部 Flash 概述 1.1 Flash 存储器的基本概念 Flash 存储器是一种非易失性存储器,它可以在掉电的情况下保持数据。STM32F407 系列微控制器内部集成了一定容量的 Flash 存储器,用于存储程序代码和数据。Flash 存储器具有擦除和编程次数的…...

2.3 Spark运行架构与流程
Spark运行架构与流程包括几个核心概念:Driver负责提交应用并初始化作业,Executor在工作节点上执行任务,作业是一系列计算任务,任务是作业的基本执行单元,阶段是一组并行任务。Spark支持多种运行模式,包括单…...

Redisson分布式锁全攻略:用法、场景与要点
目录 1. 普通可重入锁(RLock) 2. 公平锁(RFairLock) 3. 读写锁(RReadWriteLock) 4. 多重锁(RedissonMultiLock) 1. 普通可重入锁(RLock) import org.redisson.Redisson; import org.redisson.api.RLoc…...
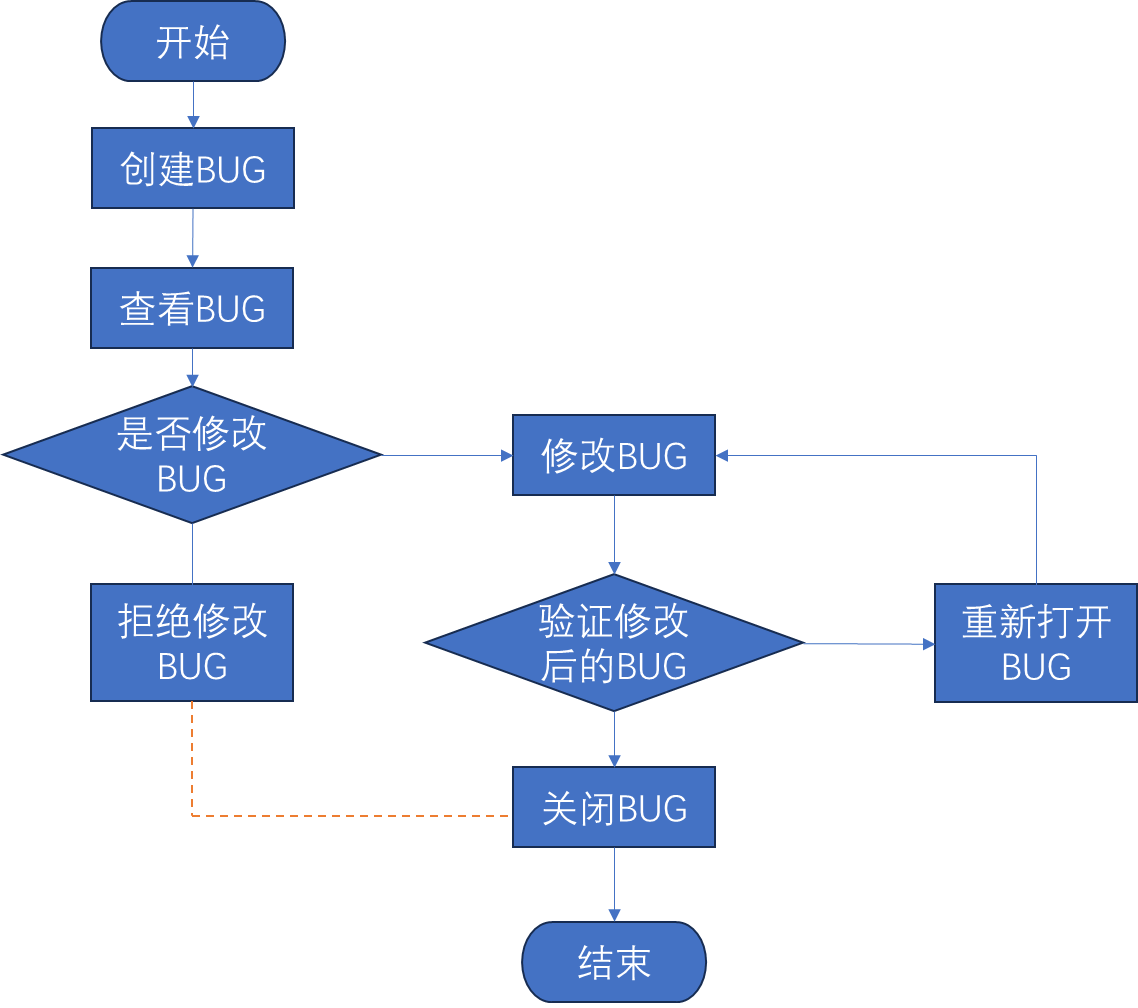
软件测试——BUG概念
目录 一、软件测试生命周期 二、BUG 2.1BUG概念 2.2BUG要素 2.3BUG级别 2.4 BUG的生命周期 2.5测试人员与开发人员因为BUG发生争执 2.6BUG评审 一、软件测试生命周期 软件测试贯穿于软件的整个生命周期 软件测试的生命周期指测试流程,每个阶段有不同的目标…...

二、Android Studio环境安装
一、下载安装 下载 Android Studio 和应用工具 - Android 开发者 | Android DevelopersAndroid Studio 提供了一些应用构建器以及一个已针对 Android 应用进行优化的集成式开发环境 (IDE)。立即下载 Android Studio。https://developer.android.google.cn/studio?hlzh-c…...

Hyperlane:重新定义Rust Web开发的未来 [特殊字符][特殊字符]
Hyperlane:重新定义Rust Web开发的未来 🚀🔥 大家好!👋 今天我要向各位技术爱好者介绍一个令人兴奋的Rust HTTP服务器库——Hyperlane 🌟。作为一个轻量级、高性能的框架,Hyperlane正在悄然改变…...
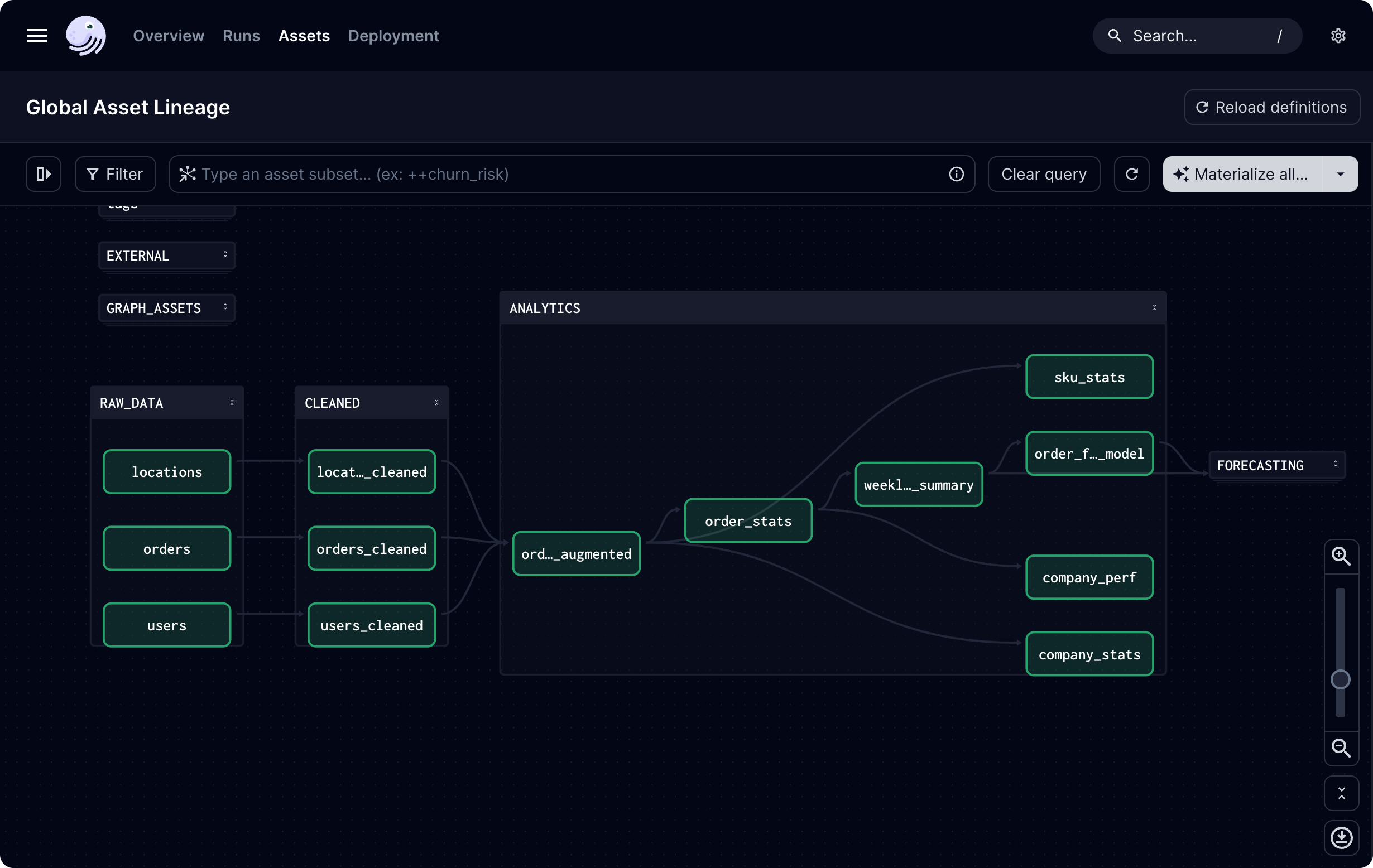
从零构建机器学习流水线:Dagster+PyTorch实战指南
本文将系统讲解机器学习流水线的核心原理,并通过Dagster编排框架与PyTorch深度学习库的实战结合,手把手演示从数据预处理到生产部署的全流程。文中包含可运行的代码示例、最佳实践和性能对比分析,帮助开发者快速构建可扩展、易维护的机器学习…...

RabbitMQ架构原理及消息分发机制
RabbitMQ架构原理及消息分发机制 在现代分布式系统中,消息队列是不可或缺的组件之一。它不仅能够解耦系统模块,还能实现异步通信和削峰填谷。在众多消息队列中,RabbitMQ 因其高并发、高可靠性和丰富的功能而备受青睐。本文将从 RabbitMQ 的基…...
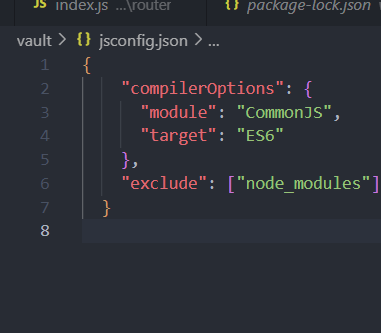
React 项目src文件结构
SCSS 组件库 SCSS为预处理器 支持除原生CSS外的其他语句 别名路径 在项目下的第一级目录就加入craco.config.js文件并且修改packpage.js 中的部分 // 扩展webpage的配置const path require(path)module.exports {// exports配置webpack:{// 配置别名alias:{:path.resolve(__d…...
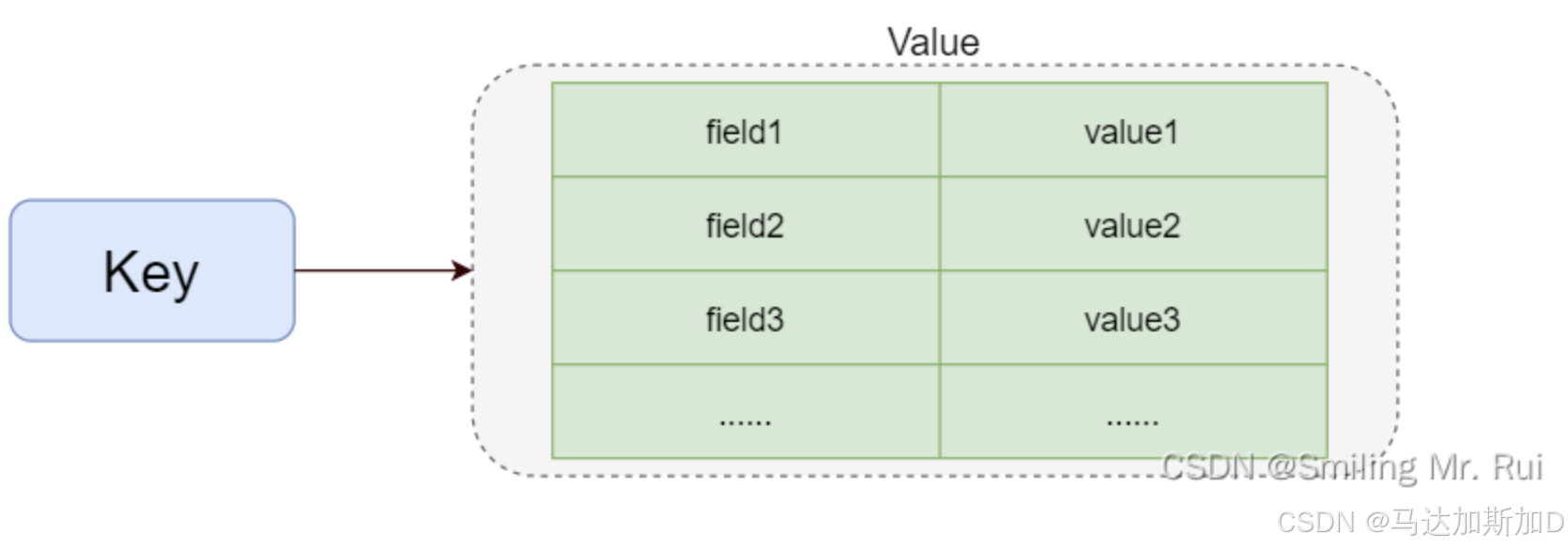
Redis --- 基本数据类型
Redis --- 基本数据类型 Redis Intro5种基础数据类型 Redis Intro Redis(Remote Dictionary Server)是一款开源的高性能键值存储系统,常用于缓存、消息中间件和实时数据处理场景。以下是其核心特点、数据类型及典型使用场景: 核心…...

React 高级特性与最佳实践
在掌握了 React 的基础知识后,我们可以进一步探索 React 的高级特性和最佳实践。这些特性将帮助你构建更高效、可维护和可扩展的 React 应用。本文重点介绍 Hooks、Context、Refs 和高阶组件等核心高级特性。 1. Hooks:函数组件的强大工具 Hooks 是 Rea…...

一个由通义千问以及FFmpeg的AVFrame、buffer引起的bug:前面几帧影响后面帧数据
目录 1 问题描述 2 我最开始的代码----错误代码 3 正确的代码 4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分 5 以后不要用通义千问写代码 1 问题描述 某个项目中,需要做人脸马赛克,然后这个是君正的某款芯片…...

12.第二阶段x64游戏实战-远程调试
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:11.第二阶段x64游戏实战-框架代码细节优化 本次写的内容是关于调试、排错相关的…...

Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标
以下是 Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标: 一、Coze 详细介绍 1. 基础信息 类型:低代码自动化平台(SaaS)。开源性:闭源(企业版需付费&…...

咋用fliki的AI生成各类视频?AI生成视频教程
最近想制作视频,多方考查了决定用fliki,于是订阅了一年试试,这个AI生成的视频效果来看真是不错,感兴趣的自己官网注册个账号体验一下就知道了。 fliki官网 Fliki生成视频教程 创建账户并登录 首先,访问fliki官网并注…...

【NLP】 20. Attention 和 self-attention
1. 背景与基本概念 1.1 编码器-解码器模型的瓶颈问题 传统的序列到序列(Seq2Seq)模型主要依靠编码器生成单一固定长度的上下文向量,然后由解码器逐步生成输出。这个过程存在两个主要问题: 瓶颈问题:固定…...

vue3+element-plus实现省市区三级地址多选
目录 背景实现功能点遗留问题完整代码参考 背景 需要实现:选择省级地址时,回传节点为 [ 省级地址 id], 选择市级地址时,回传节点为 [ 省级地址 id,市级地址 id], 选择区县地址时,回传节点为 [ …...

centos部署的openstack发布windows虚拟机
CentOS上部署的OpenStack可以发布Windows虚拟机。在CentOS上部署OpenStack后,可以通过OpenStack平台创建和管理Windows虚拟机。以下是具体的步骤和注意事项: 安装和配置OpenStack: 首先,确保系统满足OpenStack的最低硬件…...

Linux : 进程等待以及进程终止
进程控制之进程等待 (一)fork函数1*fork函数返回值2.父子进程的写时拷贝 (二)进程终止1.进程退出码2.进程常见退出方法(1)_exit(2)exit(3)return 3.进程的异常…...
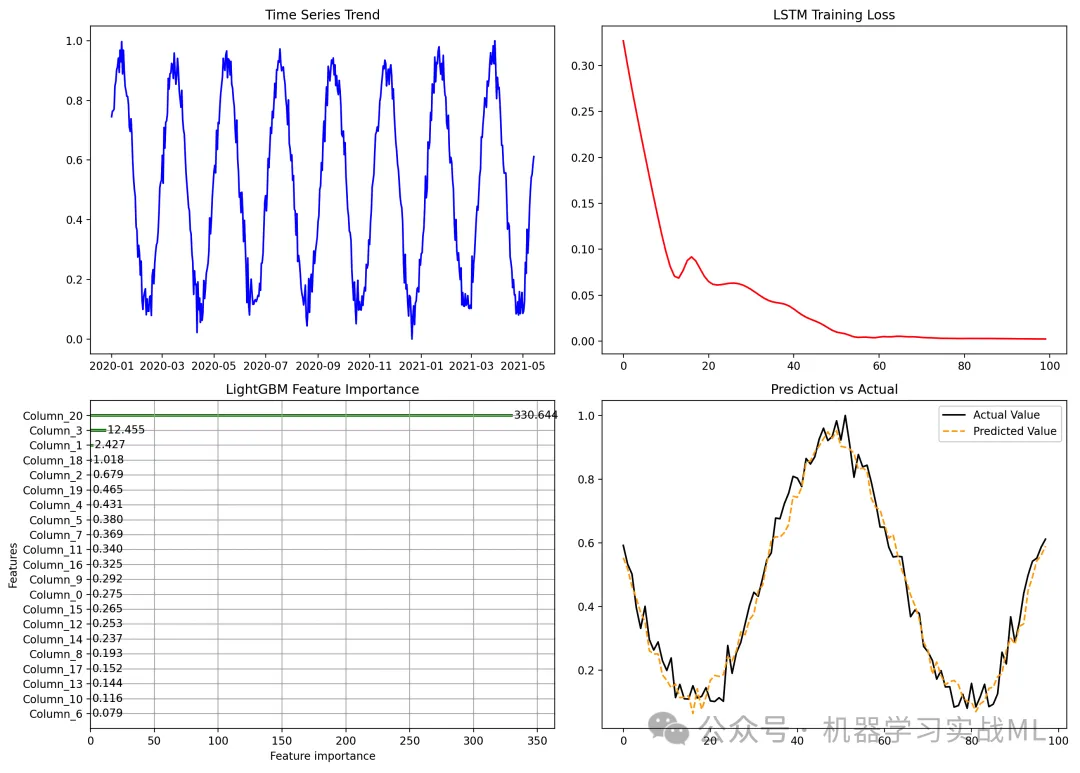
LSTM结合LightGBM高纬时序预测
1. LSTM 时间序列预测 LSTM 是 RNN(Recurrent Neural Network)的一种变体,它解决了普通 RNN 训练时的梯度消失和梯度爆炸问题,适用于长期依赖的时间序列建模。 LSTM 结构 LSTM 由 输入门(Input Gate)、遗…...

详细解释MCP项目中安装命令 bunx 和 npx区别
详细解释 bunx 和 npx 1. bunx bunx 是 Bun 的一个命令行工具,用于自动安装和运行来自 npm 的包。它是 Bun 生态系统中类似于 npx 或 yarn dlx 的工具。以下是 bunx 的主要特点和使用方法: 自动安装和运行: bunx 会自动从 npm 安装所需的包…...
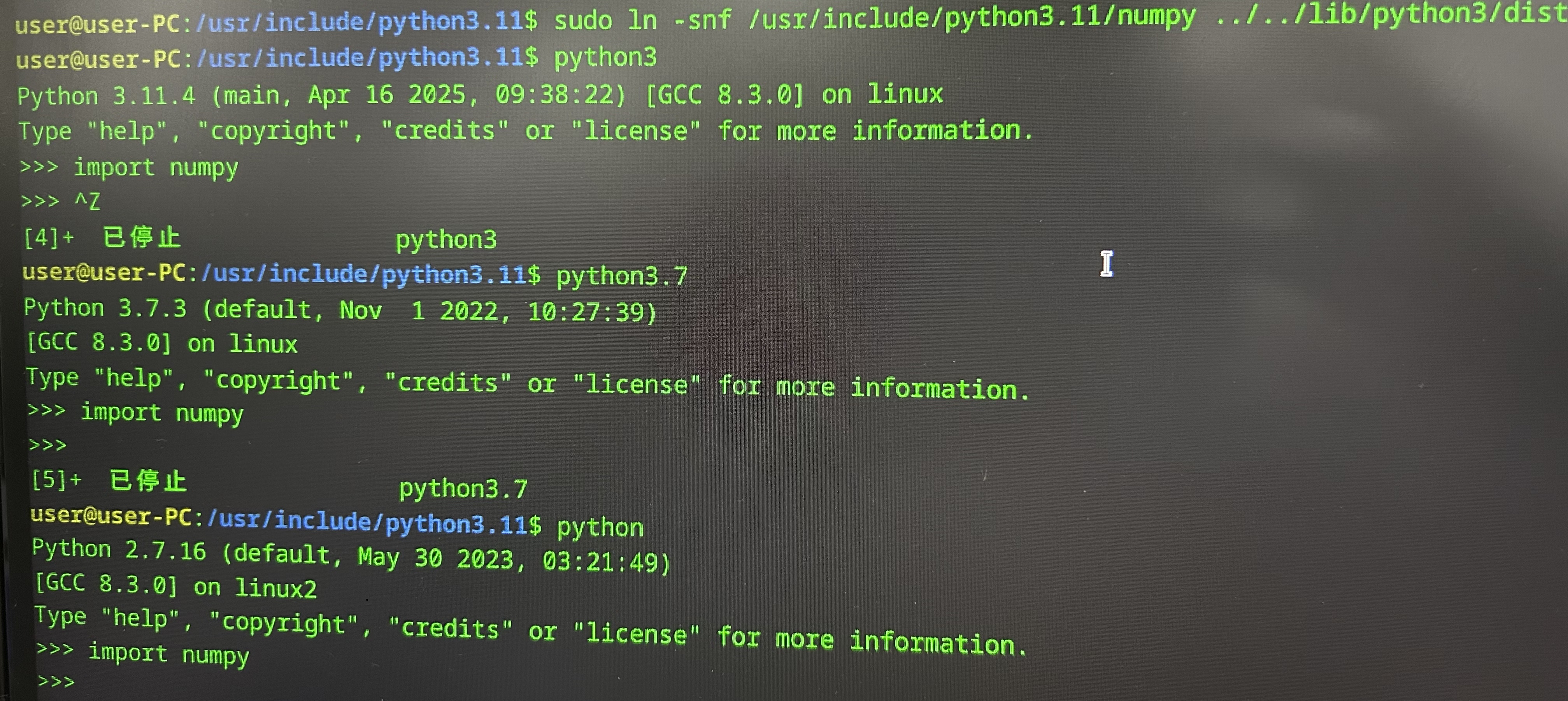
【统信UOS操作系统】python3.11安装numpy库及导入问题解决
一、安装Python3.11.4 首先来安装Python3.11.4。所用操作系统:统信UOS 前提是准备好Python3.11.4的安装包(可从官网下载(链接)),并解压到本地: 右键,选择“在终端中打开”ÿ…...

【中间件】nginx反向代理实操
一、说明 nginx用于做反向代理,其目标是将浏览器中的请求进行转发,应用场景如下: 说明: 1、用户在浏览器中发送请求 2、nginx监听到浏览器中的请求时,将该请求转发到网关 3、网关再将请求转发至对应服务 二、具体操作…...

嵌入式硬件篇---加法减法积分微分器
文章目录 前言1. 加法器(Summing Amplifier)结构反相加法器同相加法器 特点反相输出虚地特性 应用 2. 减法器(差分放大器)结构特点差分放大共模抑制比 应用 3. 积分器结构特点直流漂移问题应用 4. 微分器结构特点应用关键注意事项…...

Spring Cloud Gateway 的执行链路详解
Spring Cloud Gateway 的执行链路详解 🎯 核心目标 明确 Spring Cloud Gateway 的请求处理全过程(从接收到请求 → 到转发 → 到返回响应),方便你在合适的生命周期节点插入你的逻辑。 🧱 核心执行链路图(执…...
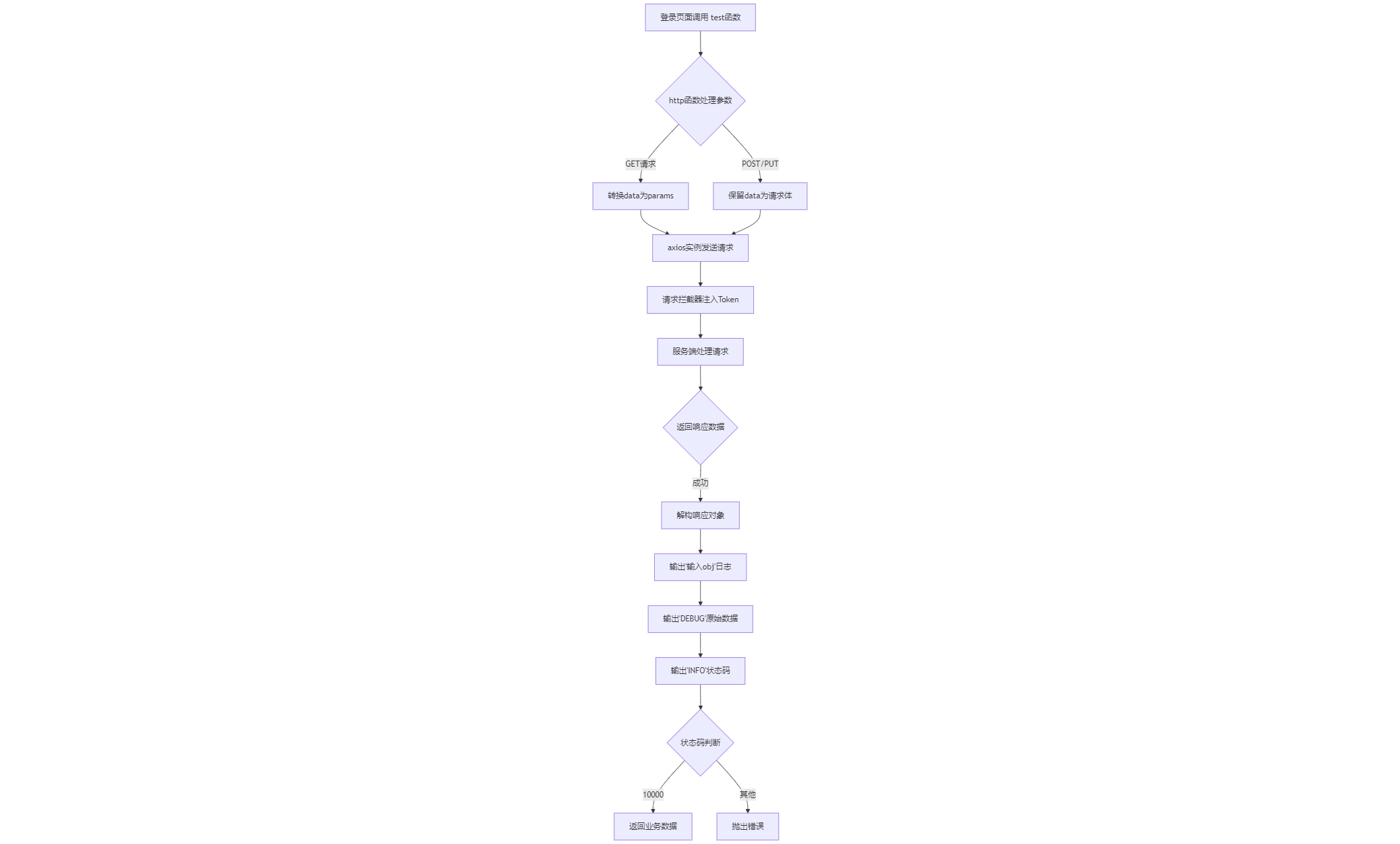
鸿蒙应用(医院诊疗系统)开发篇2·Axios网络请求封装全流程解析
一、项目初始化与环境准备 1. 创建鸿蒙工程 src/main/ets/ ├── api/ │ ├── api.ets # 接口聚合入口 │ ├── login.ets # 登录模块接口 │ └── request.ets # 网络请求核心封装 └── pages/ └── login.ets # 登录页面逻辑…...
突发重磅消息!!!CVE项目将被取消?
突发重磅消息!!!CVE项目将被取消?突发!来自可靠消息来源。MITRE 对 CVE 项目的支持将于明天到期。附件信件已发送给 CVE 董事会成员。https://mp.weixin.qq.com/s/N3qkiHaDfzDuBMK3JbBCjw...
详解与FTP服务器相关操作
目录 什么是FTP服务器 搭建FTP服务器相关 编辑 Unity中与FTP相关的类 上传文件到FTP服务器 使用FTP服务器上传文件的关键点 开始上传 从FTP服务器下载文件到客户端 使用FTP下载文件的关键点 开始下载 关于FTP服务器的其他操作 将文件的上传,下载&…...