2025年推荐使用的开源大语言模型top20:核心特性、选择指标和开源优势
李升伟 编译
随着人工智能技术的持续发展,开源大型语言模型(LLMs)正变得愈发强大,使最先进的AI能力得以普及。到2025年,开源生态系统中涌现出多个关键模型,它们在各类应用场景中展现出独特优势。
大型语言模型(LLMs)处于生成式AI革命的前沿。这些基于Transformer的AI系统依托数亿至数十亿的预训练参数,能够分析海量文本并生成高度拟人化的响应。尽管像ChatGPT、Claude、谷歌巴德(Gemini)、LLaMA和Mixtral等专有模型仍占据主流地位,但开源社区已迅速崛起,创造出兼具竞争力与可访问性的替代方案。
以下是预计将在2025年塑造AI未来的前20个开源大型语言模型(LLMs):
1. Llama 3.3(Meta)
Meta推出的Llama系列最新版本,基于前代模型改进了效率、推理能力和多轮对话理解。适用于聊天机器人、文档摘要和企业级AI解决方案。
核心特性:
✅ 支持更强大的微调能力
✅ 多语言支持
✅ 提升事实准确性与推理能力
✅ 优化小规模部署的效率
2. Mistral-Large-Instruct-2407(Mistral AI)
Mistral AI推出的指令调优模型,擅长自然语言处理(NLP)任务,如摘要、翻译和问答。
核心特性:
✅ 在文本生成和指令遵循方面表现优异
✅ 低延迟的高效分词处理
✅ 支持多轮对话处理
3. Llama-3.1-70B-Instruct(Meta)
Meta的另一款模型,针对复杂问题解决、编程和交互式AI任务进行了微调优化。
核心特性:
✅ 700亿参数量,提升上下文理解能力
✅ 优化指令调优以提升任务表现
✅ 强大的多语言支持
4. Gemma-2-9b-it(Google)
谷歌开源的Gemma系列改进版,专为指令遵循、编程辅助和数据分析优化。
核心特性:
✅ 紧凑的90亿参数模型,推理效率高
✅ 以负责任的AI原则训练
✅ 提升结构化输出的推理能力
5. DeepSeek R1
快速崛起的开源替代方案,专为高性能AI应用设计,支持多语言和强大的上下文感知能力。架构优化速度与效率,适合实际部署。
核心特性:
✅ 面向科研与工程任务的开源LLM模型
✅ 优化数学与逻辑问题解决
✅ 低计算成本的高效内存管理
6. Claude 3.5 Sonnet(Anthropic)
Anthropic虽多数模型为闭源,但Claude 3.5 Sonnet的开源版本聚焦安全与伦理AI开发。其推理与创造力的提升使其成为内容生成和决策任务的热门选择。
核心特性:
✅ 强大的推理与上下文理解
✅ 对话中更拟人化的回应
✅ 安全与隐私优先的AI开发
7. GPT-4 Turbo(OpenAI)
OpenAI的GPT-4 Turbo凭借速度与精度的平衡,仍是开发者首选的高质量AI响应模型。GPT-4.5作为其改进版,旨在弥合GPT-4与未来GPT-5的差距,提升效率、速度和准确性,并扩展多模态功能。
核心特性:
✅ 较前代更快、成本更低
✅ 支持复杂多步骤推理
✅ 优化代码生成与文本问题解决
8. Qwen2.5-72B-Instruct(阿里巴巴)
阿里巴巴的Qwen2.5-72B-Instruct在推理和多语言任务中表现卓越,可与西方模型竞争,适合科研和企业应用。
核心特性:
✅ 720亿参数模型,适用于企业与通用AI场景
✅ 支持复杂逻辑与指令驱动的响应
✅ 高效分词处理,实现实时AI响应
9. Grok 3(xAI)
埃隆·马斯克的xAI团队开发的Grok系列最新版,旨在与OpenAI的GPT模型竞争。通过深度集成X平台(原推特),Grok提供实时、上下文感知的响应,并带有鲜明的幽默与讽刺风格。
核心特性:
✅ 增强实时学习能力——通过实时网络数据获取最新见解
✅ 多模态支持——兼容文本、图像,未来或扩展视频
✅ 优化对话AI——自然流畅的对话,融入幽默与个性
✅ 深度集成X/推特——基于用户互动的个性化响应
典型应用场景:
📢 社交媒体互动
📊 实时数据分析
🤖 AI驱动的聊天机器人
10. Phi-4(微软)
Phi-4 是一款轻量级但功能强大的模型,专为边缘AI(Edge AI)和嵌入式应用设计,在更小的资源占用下实现高效性能。
核心特性:
✅ 针对个人AI助手优化的轻量级、高效率LLM
✅ 经过推理、数学和语言理解训练
✅ 在低计算资源需求下仍保持强劲性能
11. BLOOM(BigScience Project)
作为最早的大型开源LLM之一,BLOOM在多语言和研究型应用中仍具有实用性。其开源特性和伦理设计使其成为全球应用的热门选择。
核心特性:
✅ 全球最大的开源多语言模型之一
✅ 支持超过40种语言
✅ 开发透明且由社区驱动
12. Gemma 2.0 Flash(谷歌)
谷歌Gemma 2.0 Flash系列的改进版,专为实时交互和高速AI应用优化,适用于聊天机器人等场景。
核心特性:
✅ 低延迟响应,优化速度
✅ 实时AI应用表现优异
✅ 高效内存利用,适配AI工具
13. Doubao-1.5-Pro(字节跳动)
字节跳动的开源模型Doubao-1.5-Pro专为生成式AI任务设计,如内容创作、故事叙述和营销自动化。
核心特性:
✅ 专长于对话式AI和聊天机器人应用
✅ 优化内容审核与摘要生成
✅ 支持多语言
14. Janus-Pro-7B
开源领域的新晋模型,Janus-Pro-7B针对AI研究和通用用途设计,推理速度优化显著。其模块化架构支持灵活定制,深受开发者喜爱。
核心特性:
✅ 70亿参数模型,适配通用AI任务
✅ 高速推理,适用于聊天机器人和虚拟助手
✅ 可微调以满足特定业务需求
15. Imagen 3(谷歌)
虽以文本到图像生成为主,但Imagen 3具备强大的多模态能力,可集成到更广泛的AI系统中。
核心特性:
✅ 先进的文本到图像生成能力
✅ 更逼真的照片级图像合成
✅ 增强创意AI应用
16. CodeGen
专为AI辅助编程和自动化代码生成设计的强效工具,是开发者的首选。
核心特性:
✅ 优化AI辅助代码生成
✅ 支持多种编程语言
✅ 针对软件工程任务微调
17. Falcon 180B(阿联酋技术创新研究所)
Falcon 180B是开源领域领先的大型LLM,凭借其庞大的参数量和先进架构,成为研究和企业应用的首选。
核心特性:
✅ 1800亿参数,开源模型中性能最强之一
✅ 先进推理与文本补全能力
✅ 高适应性,适配多种AI应用
18. OPT-175B(Meta)
Meta的OPT-175B是完全开源的LLM,旨在与专有模型竞争。其透明性和可扩展性使其成为学术研究和大规模部署的热门选择。
核心特性:
✅ 专有LLM的开源替代方案
✅ 针对研究优化的大规模模型
✅ 强大的多语言支持
19. XGen-7B
开发者青睐的新兴模型,XGen-7B针对实时AI应用和对话代理优化。
核心特性:
✅ 70亿参数模型,专注企业级AI应用
✅ 支持法律和财务文档分析
✅ 优化快速响应时间
20. GPT-NeoX 和 GPT-J(EleutherAI)
EleutherAI开发的GPT-NeoX和GPT-J系列持续作为专有AI系统的开源替代方案,支持高质量NLP应用。
核心特性:
✅ GPT模型的开源替代方案
✅ 优化聊天机器人和通用AI应用
✅ 支持自定义微调
21. Vicuna 13B
基于LLaMA微调的Vicuna 13B专为聊天机器人交互、客户服务和社区驱动的AI项目设计。
核心特性:
✅ 基于微调的LLaMA架构
✅ 优化对话式AI
✅ 成本效益高且轻量级
22. Amazon Nova Pro(AWS)
AWS的Nova Pro是面向企业级应用的最新AI模型,旨在与OpenAI和谷歌的AI模型竞争,聚焦可扩展性、安全性和与AWS云服务的深度集成。
核心特性:
✅ 优化云计算——深度集成AWS服务
✅ 企业级安全——高级合规与数据保护
✅ 行业定制——为金融、医疗和电商等领域提供定制AI解决方案
✅ 高性能代码生成——适合使用AWS Lambda和SageMaker的开发者
使用场景:
🏢 企业级AI解决方案
📈 数据分析与预测建模
🤖 基于AI的客户服务自动化
选择适合您需求的开源大语言模型(LLM)🧠
随着开源大语言模型(LLMs)的兴起,选择适合特定需求的模型可能颇具挑战。无论是用于聊天机器人、内容生成、代码补全还是研究,选择最佳模型需考虑模型规模、速度、准确性和硬件要求等因素。以下是一份指南,助您做出明智选择。
1️⃣ 明确您的使用场景🎯
选择LLM的第一步是明确主要目标。不同模型在不同领域表现优异:
对话式AI与聊天机器人:LLaMA 3、Claude 3.5 Sonnet、Vicuna 13B
代码生成:CodeGen、GPT-NeoX、GPT-J、Mistral-Large
多模态AI(文本+图像+视频):Gemma 2.0 Flash、Imagen 3、Qwen2.5-72B
研究与通用知识:DeepSeek R1、Falcon 180B、BLOOM
企业级AI应用:GPT-4 Turbo、Janus-Pro-7B、OPT-175B
若需处理高度专业化的数据(如法律、医疗或金融领域),建议通过微调模型以提升领域特异性性能。
2️⃣ 考虑模型规模与性能
模型规模影响其准确度、计算需求及部署可行性:
小型轻量级模型(适合边缘AI与本地部署):
Phi-4(优化效率)
Llama-3.1-70B-Instruct(性能与速度的平衡)
Janus-Pro-7B(适合消费级GPU运行)
中型模型(适合通用AI应用):
Mistral-Large-Instruct-2407(性能均衡)
Qwen2.5-72B-Instruct(优化多语言支持)
DeepSeek R1(适合通用AI研究)
大型模型(适合企业AI与研究实验室):
GPT-4 Turbo(顶级性能,但需高性能计算)
Falcon 1和180B(功能强大的开源模型)
BLOOM & OPT-175B(高度可扩展,但运行成本高)
若计算资源有限,可考虑使用小型模型或量化版本(降低内存和处理需求)。
3️⃣ 开源许可与灵活性📜
不同开源LLM的许可协议差异显著:
完全开放且宽松:LLaMA 3、Falcon、Vicuna、GPT-NeoX
限制商业用途:部分DeepSeek R1、Gemma-2版本
企业级且允许商业用途:Mistral、Claude、Qwen
若开发商业AI产品,请确保模型许可允许无限制商业使用。
4️⃣ 多模态能力📸🎤
若需处理文本、图像或视频,可考虑:
Gemma 2.0 Flash(Google)——优化文本与图像
Imagen 3——高级图像生成模型
Claude 3.5 Sonnet——支持文本与图像的多模态能力
语音AI应用可选择OpenAI的Whisper或ElevenLabs模型。
5️⃣ 社区与生态支持🌍
强大的开发者社区和生态系统至关重要:
活跃社区:LLaMA、Mistral、Falcon、GPT-J
研究与论文支持:DeepSeek、Claude、Janus
企业支持模型:Qwen(阿里巴巴)、Gemma(谷歌)、OPT(Meta)
选择支持良好的模型,可获得预训练权重、微调指南和部署资源。
6️⃣ 计算与硬件需求💻
运行LLM需强大计算资源:
消费级GPU(低端,如RTX 3060,16GB内存) → Phi-4、Janus-Pro-7B、GPT-NeoX
中端GPU(如RTX 4090、A100,32GB+内存) → Mistral-Large、LLaMA 3、DeepSeek R1
企业级服务器(H100 GPU、云端计算) → GPT-4 Turbo、Falcon 180B、Claude 3.5 Sonnet
本地部署时,优先选择量化版本以减少显存消耗。
7️⃣ 微调与定制化🔧
部分模型支持对专有数据集的微调:
适合微调:LLaMA 3、Mistral、Qwen2.5、Janus-Pro-7B
微调支持有限:GPT-4 Turbo、Claude 3.5 Sonnet
若需训练自有数据,选择支持LoRA或全量微调的模型。
快速推荐✅
全能型最佳:LLaMA 3.3
多模态AI最佳:Claude 3.5 Sonnet、Gemma 2.0 Flash
企业级AI最佳:GPT-4 Turbo、Falcon 180B
代码生成最佳:CodeGen、GPT-NeoX、GPT-J
轻量级应用最佳:Phi-4、Janus-Pro-7B
开源LLM的优势🚀
开源大语言模型正成为开发者、企业和研究人员的变革工具。与专有模型相比,它们提供透明性、灵活性和成本效益。以下是主要优势:
1️⃣ 成本效益💰
开源LLM无需支付许可费,是初创公司、研究者和企业的经济之选。企业可部署自有模型,避免依赖闭源模型的API付费。
2️⃣ 完全定制与微调🎛️
开发者可对模型进行微调,优化特定领域应用(如医疗、金融或客服)。
3️⃣ 透明性与安全性🔍🔐
开源模型允许代码审查,确保无隐藏偏见或安全漏洞,这对需严格遵守隐私和安全法规的行业至关重要。
4️⃣ 减少对科技巨头的依赖🏢🚀
降低对OpenAI、谷歌或Anthropic等大公司的依赖,企业可自主部署模型,掌控数据与运营成本。
5️⃣ 快速创新与社区支持🌍🤝
开源模型依赖社区贡献,推动快速技术进步、性能提升和广泛采用。
6️⃣ 本地与边缘AI能力🏠📶
企业可本地运行模型,减少延迟并保障数据隐私,尤其适用于医疗等敏感数据领域。
7️⃣ 多语言与多模态支持🌍🖼️🔊
许多开源模型支持多语言和多模态输入(文本、图像、音频),适合全球应用和创意工具。
8️⃣ 伦理AI与开放研究📜⚖️
开源AI促进伦理发展,允许研究者分析偏见、提升公平性并确保负责任的AI实践。
9️⃣ 可扩展性与企业级性能🚀📈
开源模型兼具可扩展性和企业级性能,满足从边缘设备到云端的多样化需求。
10️⃣ 无API调用限制与内容审查🚫🔄
与施加严格API调用限制和内容约束的闭源模型不同,开源LLM提供无限制的使用权限。这对于需要大规模处理且不受限的企业而言是理想选择。
开源LLM的未来前景🚀
开源LLM通过提供高成本效益、可定制化且注重隐私的解决方案,正在重塑AI的未来。无论是开发AI驱动的应用程序、开展研究,还是优化业务流程,利用开源模型都能带来无与伦比的灵活性和创新性。
总结与展望
随着这些开源LLM在2025年引领AI发展,开发者和企业已拥有一系列强大的工具。无论是用于代码编写、研究、自动化,还是对话式AI,这些模型正在塑造下一代AI应用,同时让创新成果惠及所有人。
您今年使用或计划探索哪些开源LLM?欢迎在评论区分享!
原文链接:https://bigdataanalyticsnews.com/top-open-source-llm-models/
相关文章:

2025年推荐使用的开源大语言模型top20:核心特性、选择指标和开源优势
李升伟 编译 随着人工智能技术的持续发展,开源大型语言模型(LLMs)正变得愈发强大,使最先进的AI能力得以普及。到2025年,开源生态系统中涌现出多个关键模型,它们在各类应用场景中展现出独特优势。 大型语言…...
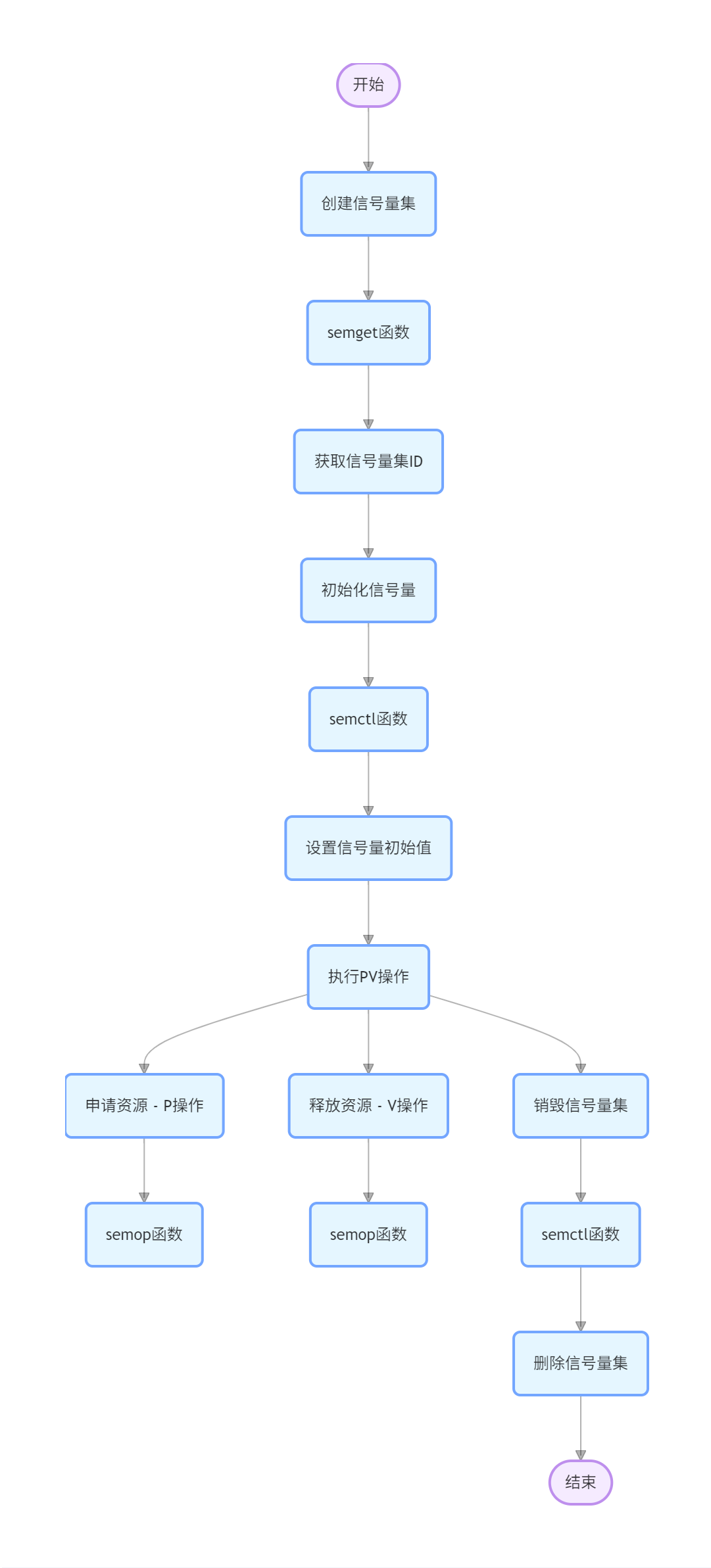
Linux 入门九:Linux 进程间通信
概述 进程间通信(IPC,Inter-Process Communication)是指在不同进程之间传递数据和信息的机制。Linux 提供了多种 IPC 方式,包括管道、信号、信号量、消息队列、共享内存和套接字等。 方式 一、管道(Pipe)…...

Spark-SQL核心编程实战:自定义函数与聚合函数详解
在大数据处理领域,Spark-SQL是极为重要的工具。今天和大家分享一下在Spark-SQL开发中的自定义函数和聚合函数的使用,这些都是基于实际项目开发经验的总结。 在Spark-SQL开发时,第一步是搭建开发环境。在IDEA中创建Spark-SQL子模块,…...

[Mysql][Mybatis][Spring]配置文件未能正确给驱动赋值,.properties文件username值被替换
这是最初的.properties配置文件: drivercom.mysql.cj.jdbc.Driver urljdbc:mysql://localhost:3306/qykf usernameroot password123456 在Mybatis中引入后进行赋值: <environments default"development"><environment id"deve…...

go 指针接收者和值接收者的区别
go 指针接收者和值接收者的区别 指针接收者和值接收者的区别主要有两点: Go 中函数传参是传值,因此指针接收者传递的是接收者的指针拷贝,值接收者传递的是接收者的拷贝---在方法中指针接收者的变量会被修改,而值接收者的成员变量…...

Redis之缓存更新策略
缓存更新策略 文章目录 缓存更新策略一、策略对比二、常见的缓存更新策略三、如何选择策略四、实际应用示例五、使用 Cache-Aside TTL 的方式,实现缓存商铺信息详情1.引入StringRedisTemplate2.将查询商铺信息加入缓存3.更新商铺信息时移除缓存总结 六、注意事项 一…...
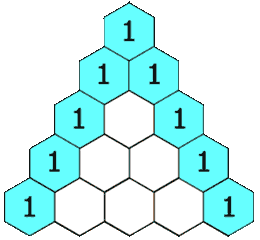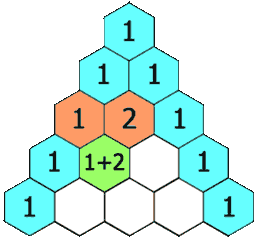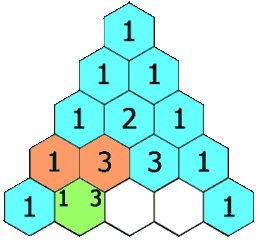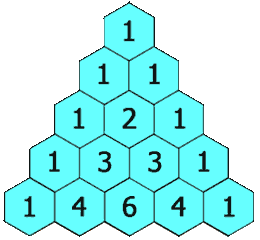
【leetcode100】杨辉三角
1、题目描述 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2: 输入: numRows 1 输出: [[1]…...

git reset详解
一、git reset 的核心作用 用于 移动当前分支的 HEAD 指针 到指定的提交,并可选择是否修改工作区和暂存区。 ⚠️ 注意:若提交已被推送到远程仓库,强制重置(--hard)后需谨慎操作,避免影响协作。 二、三种模…...

Selenium2+Python自动化:利用JS解决click失效问题
文章目录 前言一、遇到的问题二、点击父元素问题分析解决办法实现思路 三、使用JS直接点击四、参考代码 前言 在使用Selenium2和Python进行自动化测试时,我们有时会遇到这样的情况:元素明明已经被成功定位,代码运行也没有报错,但…...
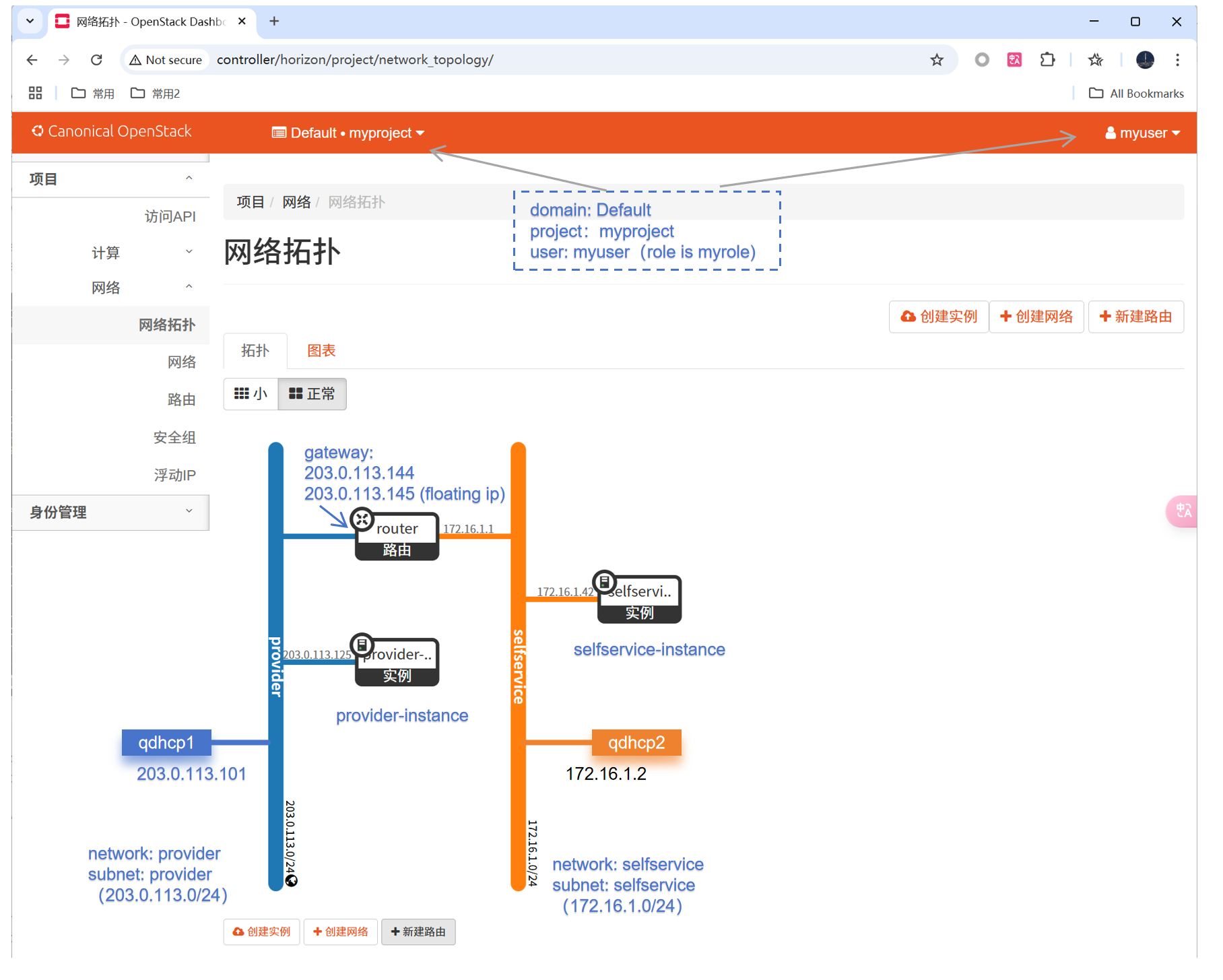
OpenStack Yoga版安装笔记(十九)启动一个实例(Self-service networks)
1、概述 1.1 官方文档 Launch an instancehttps://docs.openstack.org/install-guide/launch-instance.html 《OpenStack Yoga版安装笔记(十四)启动一个实例》文档中,已经按照Option1: Provider networks创建网络。 本文按照Option2&#…...
栈与队列)
数据结构(java)栈与队列
栈:(先进后出) 入栈: 1.普通栈一定要放、最小栈放的原则是: *如果最小栈是空的,那么放 *如果最小栈的栈顶元素没有当前的元素小,则放 2.如果要放的的元素小于等于最小栈栈顶元素可以放吗?放 出栈: 需要…...

Flask+Plotly结合动态加载图形页面实践
1. DeepSeek帮我实践 1.1. 我的提问既设计方案 原有如下主页:dashboard.html,现增加“预测模型学习”,对感知机神经网络描述如下: 1、输入与输出为固定值,例如输入层215,输出层48; 2、模型为回归神经网络; 3、中层是可动态调整的,例如定义如下:第二层,200,第三层…...

数学教学通讯杂志数学教学通讯杂志社数学教学通讯编辑部2025年第6期目录
课程教材教法 “课程思政”视域下的高中数学教学探索与实践——以“函数概念的发展历程”为例 赵文博; 3-617 PBL教学模式下高中统计教学的探索与实践——以“随机抽样(第一课时)”为例 陈沛余; 7-10 “三新”背景下的高中数学教学困境与应对…...

整活 kotlin + springboot3 + sqlite 配置一个 SQLiteCache
要实现一个 SQLiteCache 也是很简单的只需要创建一个 cacheManager Bean 即可 // 如果配置文件中 spring.cache.sqlite.enable false 则不启用 Bean("cacheManager") ConditionalOnProperty(name ["spring.cache.sqlite.enable"], havingValue "t…...
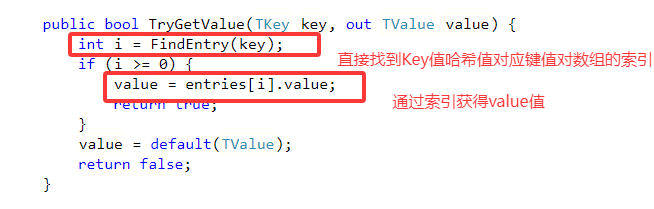
C#容器源码分析 --- Dictionary<TKey,TValue>
Dictionary<TKey, TValue> 是 System.Collections.Generic 命名空间下的高性能键值对集合,其核心实现基于哈希表和链地址法(Separate Chaining)。 .Net4.8 Dictionary<TKey,TValue>源码地址: dictionary…...
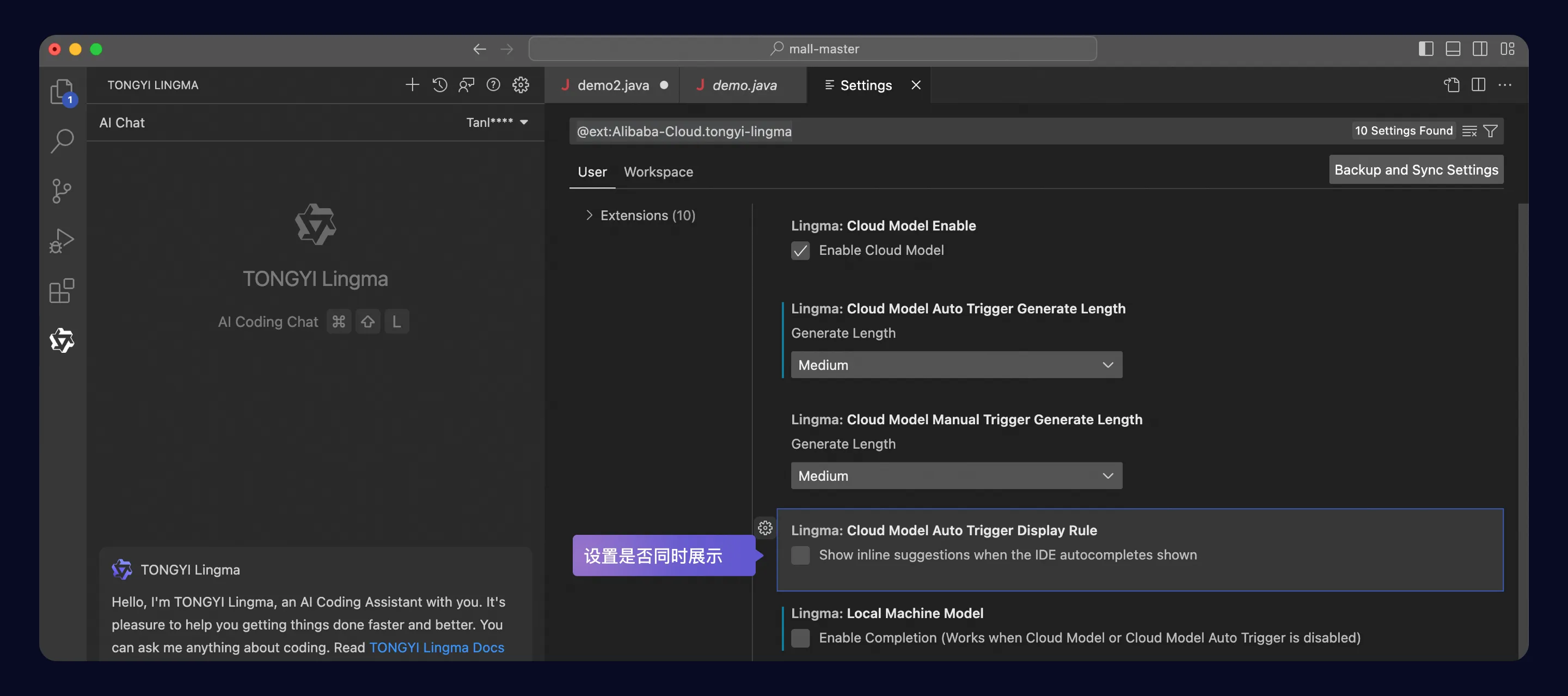
在 Visual Studio Code 中安装通义灵码 - 智能编码助手
高效的编码工具对于提升开发效率和代码质量至关重要。 通义灵码作为一款智能编码助手,为开发者提供了全方位的支持。 本文将详细介绍如何在 Visual Studio Code(简称 VSCode)中安装通义灵码,以及如何进行相关配置以开启智能编码…...
)
【AutoTest】自动化测试工具大全(Java)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…...
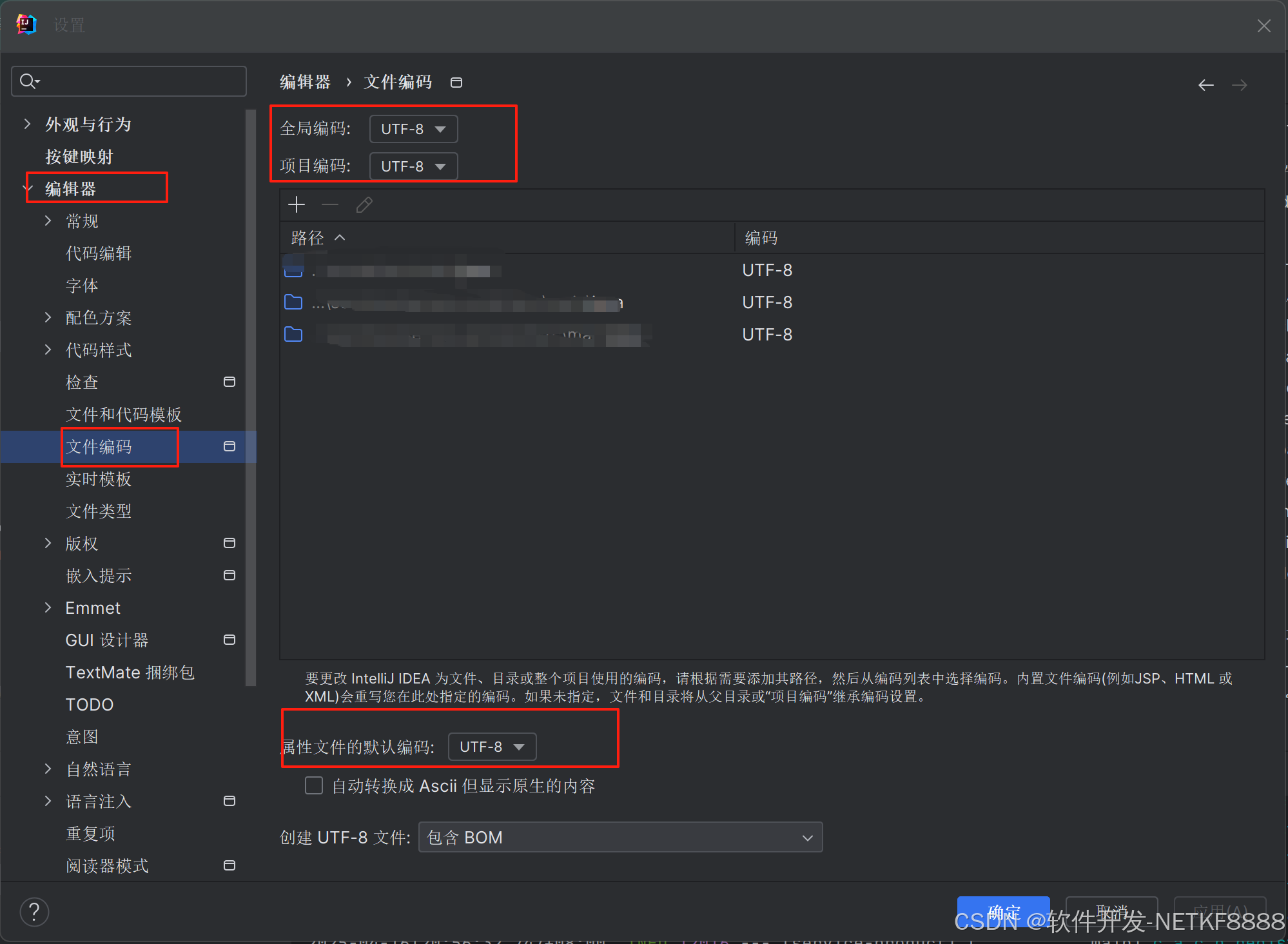
idea报错java: 非法字符: ‘\ufeff‘解决方案
解决方案步骤以及说明 BOM是什么?1. BOM的作用2. 为什么会出现 \ufeff 错误?3. 如何解决 \ufeff 问题? 最后重新编译,即可运行!!! BOM是什么? \ufeff 是 Unicode 中的 BOM࿰…...

PHY芯片与网络变压器接线设计指南——不同速率与接口的硬件设计原则
一、PHY与网络变压器的核心作用 • PHY芯片(物理层芯片) • 功能:实现数据编码(如Manchester、PAM4)、时钟恢复、链路协商(Auto-Negotiation)。 • 接口类型:MII/RMII/GMII/RGMII/…...
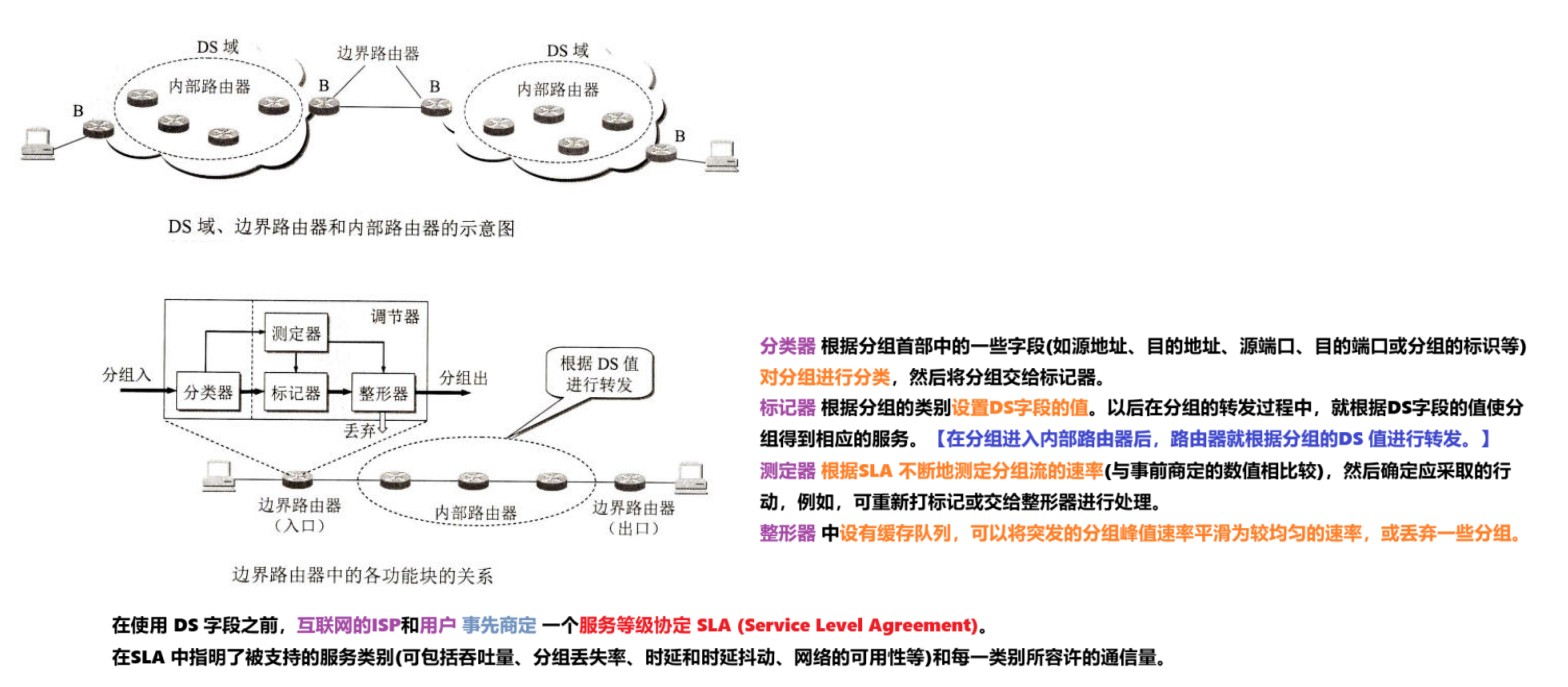
【学习笔记】计算机网络(八)—— 音频/视频服务
第8章 互联网上的音频/视频服务 文章目录 第8章 互联网上的音频/视频服务8.1概述8.2 流式存储音频/视频8.2.1 具有元文件的万维网服务器8.2.2 媒体服务器8.2.3 实时流式协议 RTSP 8.3 交互式音频/视频8.3.1 IP 电话概述8.3.2 IP电话所需要的几种应用协议8.3.3 实时运输协议 RTP…...

linux: 文件描述符fd
目录 1.C语言文件操作复习 2.底层的系统调用接口 3.文件描述符的分配规则 4.重定向 1.C语言文件操作复习 文件 内容 属性。所有对文件的操作有两部分:a.对内容的操作;b.对属性的操作。内容是数据,属性其实也是数据-存储文件,…...
记录一次后台项目的打包优化
文章目录 前言分析问题寻找切入点根据切入点逐一尝试cdn引入node包遇到的一些问题记录最终结果 前言 优化,所有开发者到一定的程度上,都绕不开的问题之一 例如: 首页加载优化白屏优化列表无限加载滚动优化,图片加载优化逻辑耦合…...

问题记录(四)——拦截器“失效”?null 还是“null“?
拦截器“失效”?null 还是"null"? 问题描述 这个问题本身并不复杂,但是却是一个容易被忽略的问题。 相信大家在项目中一定实现过强制登录的逻辑吧,巧了,所要介绍的问题就出现在测试强制登录接口的过程中&am…...

前端面试-HTML5与CSS3
HTML5/CSS3 1. HTML5语义化标签的作用是什么?请举例说明5个常用语义化标签及其适用场景 解答: 语义化标签通过标签名称直观表达内容结构,有利于: 提升可访问性(屏幕阅读器识别)改善SEO(搜索引…...

blender 导出衣服mesh为fbx,随后导入UE5,坐标轴如何保存一致
When exporting a clothing mesh from Blender to UE5 as an FBX file, maintaining consistent coordinate axes is crucial for proper positioning and orientation. Heres how to ensure coordinate consistency throughout the workflow: 当从 Blender 导出衣服 mesh 为 U…...
)
前端开发中的问题排查与定位:HTML、CSS、JavaScript(报错的解决方式)
目录 1.html 1. 结构错误调试:标签未正确嵌套 2. 语法问题调试:缺失引号 3. 断点调试:动态生成内容时的 JavaScript 错误 4. 网络调试:资源加载错误 5. 性能调试:页面加载性能 总结: 2.CSS 1. 定位…...

图论整理复习
回溯: 模板: void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯ÿ…...

MIMO预编码与检测算法的对比
在MIMO系统中,预编码(发送端处理)和检测算法(接收端处理)的核心公式及其作用对比如下: 1. 预编码算法(发送端) 预编码的目标是通过对发送信号进行预处理,优化空间复用或…...
C++修炼:vector模拟实现
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...
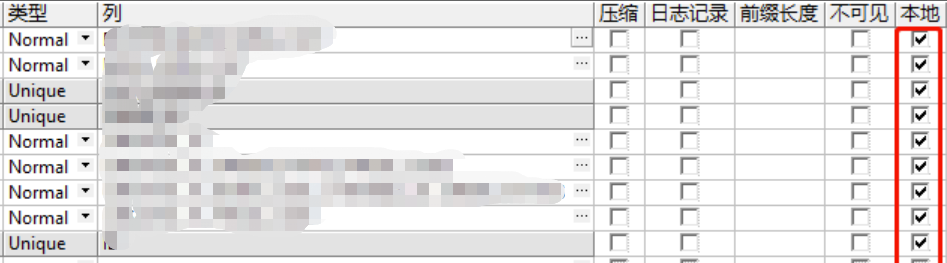
案例-索引对于并发Insert性能优化测试
前言 最近因业务并发量上升,开发反馈对订单表Insert性能降低。应开发要求对涉及Insert的表进行分析并提供优化方案。 一般对Insert 影响基本都在索引,涉及表已按创建日期做了分区表,索引全部为普通索引未做分区索引。 优化建议: 1、将UNIQUE改为HASH(64) GLOBAL IND…...