图论整理复习
回溯:
模板:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}77.组合:
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4], ]
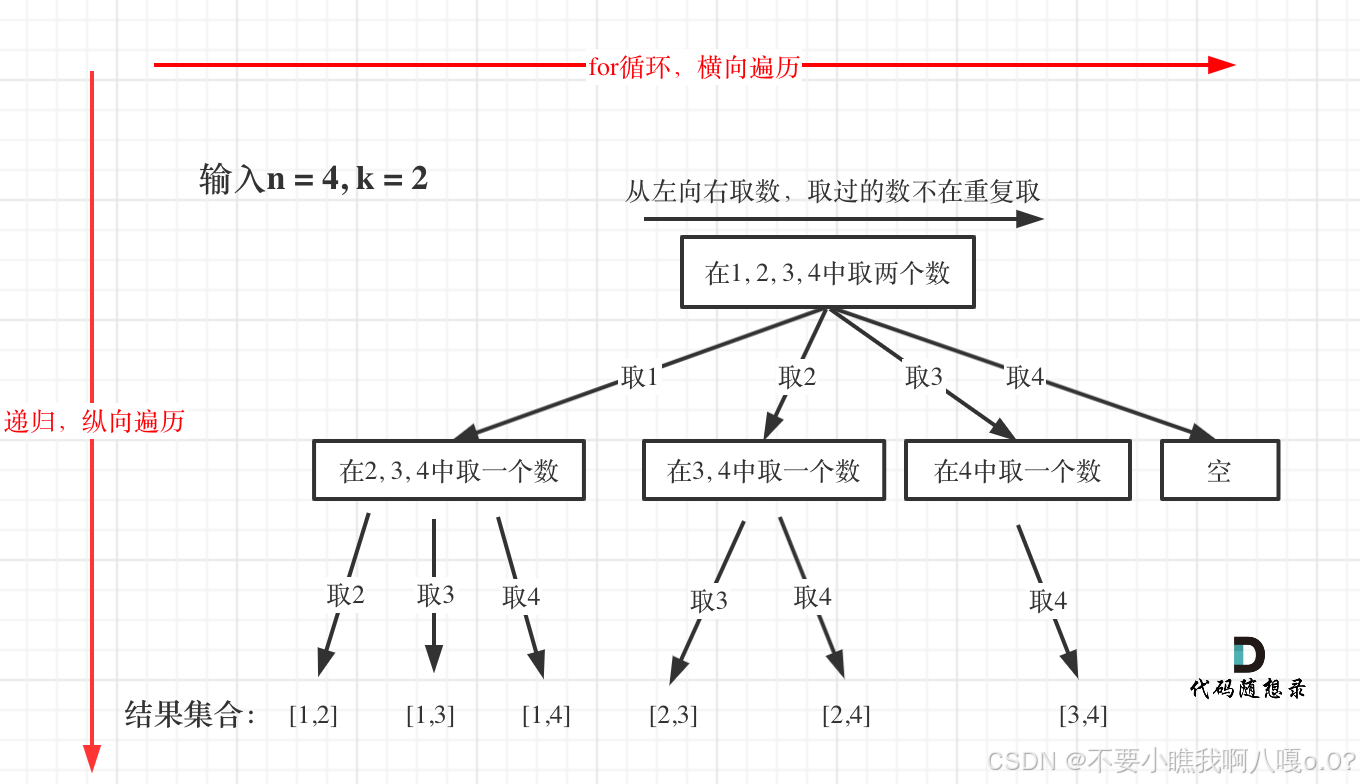
主要记忆:横向为for循环控制,纵向遍历为递归控制,在每次递归操作之后要加上回溯的操作,也就是绘图递归前的那一步操作。
class Solution {
public:vector<int> path;vector<vector<int>> res;void backtrack(int n, int k, int sindex){if(path.size() == k){res.push_back(path);return;}for(int i = sindex; i <= n; i++){path.push_back(i);backtrack(n, k, i + 1);path.pop_back();}}vector<vector<int>> combine(int n, int k) {backtrack(n, k, 1);return res;}
};216:组合总和
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例 1:
输入: k = 3, n = 7 输出: [[1,2,4]] 解释: 1 + 2 + 4 = 7 没有其他符合的组合了。
class Solution {
public:vector<int> path;vector<vector<int>> res;int sum = 0;void backtrack(int n, int k, int sindex){if(sum == n && path.size() == k){res.push_back(path);return;}for(int i = sindex; i <= 9; i++){path.push_back(i);sum += i;backtrack(n, k, i + 1);sum -= i;path.pop_back();}}vector<vector<int>> combinationSum3(int k, int n) {backtrack(n, k, 1);return res;}
};DFS:
模板:
记录每一个符合的区域,需要用到回溯的思想,在每一次进入递归回溯后需要进行复位操作:
#include <iostream>
#include <vector>
using namespace std;vector<vector<int> > result; // 收集符合条件的路径
vector<int> path; // 1节点到终点的路径
vector<bool> visited; // 标记节点是否被访问过void dfs(const vector<vector<int> >& graph, int x, int n) {// 停止搜索的条件:// 1. 搜索到了已经搜索过的节点(在path中的节点)// 2. 搜索到了不符合需求的节点(这里不需要特别判断,因为for循环会自动处理无出边的情况)if (x == n) { // 找到符合条件的一条路径result.push_back(path);return;}for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点if (graph[x][i] == 1 && !visited[i]) { // 找到x链接的且未访问过的节点visited[i] = true; // 标记为已访问path.push_back(i); // 遍历到的节点加入到路径中来dfs(graph, i, n); // 进入下一层递归path.pop_back(); // 回溯,撤销本节点visited[i] = false; // 回溯,取消访问标记}}
}int main() {int n, m, s, t;cin >> n >> m;// 节点编号从1到n,所以申请 n+1 这么大的数组vector<vector<int> > graph(n + 1, vector<int>(n + 1, 0));visited.resize(n + 1, false); // 初始化visited数组while (m--) {cin >> s >> t;// 使用邻接矩阵 表示无向图,1 表示 s 与 t 是相连的graph[s][t] = 1;}visited[1] = true; // 起点标记为已访问path.push_back(1); // 无论什么路径已经是从1节点出发dfs(graph, 1, n); // 开始遍历// 输出结果if (result.size() == 0) {cout << -1 << endl;}for (size_t i = 0; i < result.size(); i++) {for (size_t j = 0; j < result[i].size() - 1; j++) {cout << result[i][j] << " ";}cout << result[i][result[i].size() - 1] << endl;}return 0;
}547:省份数量
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例 1:

输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2
class Solution {
public:// 需要额外添加一个visited矩阵来确定当前遍历到的点是否已经走过,进行剪枝,提前终止递归,作为递归停止的条件void dfs(vector<vector<int>>& isConnected, int x, vector<bool>& visited){if(visited[x]){return;}visited[x] = true;for(int i = 0; i < isConnected.size(); i++){if(isConnected[x][i] == 1 && !visited[i]){dfs(isConnected, i, visited);}}}int findCircleNum(vector<vector<int>>& isConnected) {vector<bool> visited(isConnected.size(), false);int res = 0;for(int i = 0; i < isConnected.size(); i++){if(!visited[i]){dfs(isConnected, i, visited);res++;}}return res;}
};200:岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [["1","1","1","1","0"],["1","1","0","1","0"],["1","1","0","0","0"],["0","0","0","0","0"] ] 输出:1
class Solution {
public:// 定义四个方向的偏移量:下、右、上、左int opt[4][2] = {{1, 0}, {0, 1}, {-1, 0}, {0, -1}};// DFS函数:深度优先搜索标记相连的陆地// 参数:grid-网格,visited-访问标记,i,j-当前坐标void dfs(const vector<vector<char>>& grid, vector<vector<bool>>& visited, int i, int j){// 终止条件:越界、已访问过、或遇到水域('0')if(i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == '0'){return;}visited[i][j] = true; // 标记当前陆地为已访问for(int a = 0; a < 4; a++){ // 遍历四个方向int x = i + opt[a][0]; // 计算新坐标xint y = j + opt[a][1]; // 计算新坐标ydfs(grid, visited, x, y); // 递归探索相邻位置}}// 主函数:计算岛屿数量// 参数:grid-二维字符网格// 返回值:岛屿总数int numIslands(vector<vector<char>>& grid) {// 处理空输入情况if (grid.empty() || grid[0].empty()) return 0;int n = grid.size(), m = grid[0].size(); // n:行数, m:列数int res = 0; // 岛屿计数器// 创建访问标记数组,初始化为falsevector<vector<bool>> visited(n, vector<bool>(m, false));// 遍历整个网格for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){// 发现未访问的陆地if(!visited[i][j] && grid[i][j] == '1'){res++; // 岛屿数量加1dfs(grid, visited, i, j); // DFS标记整个岛屿}}}return res; // 返回总岛屿数}
};695:岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:

输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 解释:答案不应该是11,因为岛屿只能包含水平或垂直这四个方向上的1。
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算岛屿面积// 参数:// grid - 输入的二维网格(只读)// visited - 访问标记数组// i, j - 当前探索的坐标// s - 当前岛屿面积(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& s) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前位置已访问过// 3. 当前位置是水域(值为0)if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == 0) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前位置为已访问s++; // 当前岛屿面积增加1// 遍历四个方向(下、上、右、左)for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算新坐标的行号int y = j + opt[a][1]; // 计算新坐标的列号dfs(grid, visited, x, y, s); // 递归探索相邻位置}}// 主函数:计算网格中最大岛屿的面积// 参数:// grid - 二维整数网格,1表示陆地,0表示水域// 返回值:最大岛屿的面积(相连的1的总数)int maxAreaOfIsland(vector<vector<int>>& grid) {// 检查输入是否为空,若为空则返回0if (grid.empty() || grid[0].empty()) return 0;int rows = grid.size(); // 获取网格的行数int cols = grid[0].size(); // 获取网格的列数int res = 0; // 记录最大岛屿面积// 创建访问标记数组,初始化所有位置为未访问(false)vector<vector<bool>> visited(rows, vector<bool>(cols, false));// 遍历网格的每一个位置for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {// 如果当前位置是未访问的陆地if (grid[i][j] == 1 && !visited[i][j]) {int s = 0; // 初始化当前岛屿面积为0dfs(grid, visited, i, j, s); // 通过DFS计算当前岛屿的面积res = max(res, s); // 更新最大岛屿面积}}}return res; // 返回最大岛屿面积}
};463:岛屿的周长
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 1:
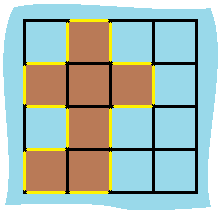
输入:grid = [[0,1,0,0],[1,1,1,0],[0,1,0,0],[1,1,0,0]] 输出:16 解释:它的周长是上面图片中的 16 个黄色的边
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算岛屿周长// 参数:// grid - 输入的二维网格(只读),1表示陆地,0表示水域// visited - 访问标记数组,用于避免重复访问// i, j - 当前探索的坐标// c - 周长计数器(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& c) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前位置已访问过// 3. 当前位置是水域(值为0)if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == 0) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前位置为已访问// 遍历四个方向,检查每个相邻位置for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算相邻位置的行号int y = j + opt[a][1]; // 计算相邻位置的列号// 检查相邻位置是否是边界或水域if (x < 0 || y < 0 || x >= grid.size() || y >= grid[0].size() || grid[x][y] == 0) {c++; // 如果是边界或水域,周长加1}// 递归探索相邻位置(即使是边界或水域也会被上面的if拦截)dfs(grid, visited, x, y, c);}}// 主函数:计算岛屿的总周长// 参数:// grid - 二维整数网格,1表示陆地,0表示水域// 返回值:所有岛屿的总周长int islandPerimeter(vector<vector<int>>& grid) {int res = 0; // 初始化周长结果int m = grid.size(); // 获取网格的行数int n = grid[0].size(); // 获取网格的列数// 创建访问标记数组,初始化所有位置为未访问(false)vector<vector<bool>> visited(m, vector<bool>(n, false));// 遍历网格的每一个位置for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {// 如果当前位置是未访问的陆地if (grid[i][j] == 1 && !visited[i][j]) {dfs(grid, visited, i, j, res); // 通过DFS计算当前岛屿的周长// 注意:这里假设只有一个岛屿,若有多个岛屿,res会累加所有周长}}}return res; // 返回总周长}
};2658:网格图中鱼的最大数目
给你一个下标从 0 开始大小为 m x n 的二维整数数组 grid ,其中下标在 (r, c) 处的整数表示:
- 如果
grid[r][c] = 0,那么它是一块 陆地 。 - 如果
grid[r][c] > 0,那么它是一块 水域 ,且包含grid[r][c]条鱼。
一位渔夫可以从任意 水域 格子 (r, c) 出发,然后执行以下操作任意次:
- 捕捞格子
(r, c)处所有的鱼,或者 - 移动到相邻的 水域 格子。
请你返回渔夫最优策略下, 最多 可以捕捞多少条鱼。如果没有水域格子,请你返回 0 。
格子 (r, c) 相邻 的格子为 (r, c + 1) ,(r, c - 1) ,(r + 1, c) 和 (r - 1, c) ,前提是相邻格子在网格图内。
示例 1:
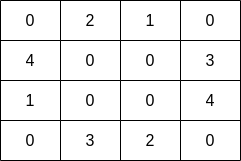
输入:grid = [[0,2,1,0],[4,0,0,3],[1,0,0,4],[0,3,2,0]] 输出:7 解释:渔夫可以从格子(1,3)出发,捕捞 3 条鱼,然后移动到格子(2,3),捕捞 4 条鱼。
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左,用于探索相邻格子int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算单一连通区域的鱼数// 参数:// grid - 输入的二维网格(只读),0表示水域,大于0表示鱼的数量// visited - 访问标记数组,用于记录已访问的格子// i, j - 当前探索的网格坐标// fishes - 当前连通区域的鱼数总和(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& fishes) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前格子是水域(grid[i][j] == 0)// 3. 当前格子已访问过if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || grid[i][j] == 0 || visited[i][j]) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前格子为已访问fishes += grid[i][j]; // 将当前格子的鱼数累加到fishes中// 遍历四个方向(下、上、右、左)for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算相邻格子的行号int y = j + opt[a][1]; // 计算相邻格子的列号dfs(grid, visited, x, y, fishes); // 递归探索相邻格子}}// 主函数:找到网格中单一连通区域的最大鱼数// 参数:// grid - 二维整数网格,0表示水域,大于0表示鱼的数量// 返回值:最大连通区域的鱼数总和int findMaxFish(vector<vector<int>>& grid) {int res = 0; // 记录最大鱼数,初始化为0int fishes = 0; // 记录当前连通区域的鱼数int m = grid.size(); // 获取网格的行数int n = grid[0].size(); // 获取网格的列数// 创建访问标记数组,初始化所有格子为未访问(false)vector<vector<bool>> visited(m, vector<bool>(n, false));// 遍历网格的每一个格子for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {// 如果当前格子有鱼(>=0)且未访问// 注意:这里应改为 > 0,因为0表示水域,但保留原逻辑以匹配代码if (grid[i][j] >= 0 && !visited[i][j]) {fishes = 0; // 重置当前区域鱼数为0,准备计算新区域dfs(grid, visited, i, j, fishes); // 通过DFS计算当前连通区域的鱼数res = max(res, fishes); // 更新最大鱼数}}}return res; // 返回最大鱼数}
};1034:边界着色
给你一个大小为 m x n 的整数矩阵 grid ,表示一个网格。另给你三个整数 row、col 和 color 。网格中的每个值表示该位置处的网格块的颜色。
如果两个方块在任意 4 个方向上相邻,则称它们 相邻 。
如果两个方块具有相同的颜色且相邻,它们则属于同一个 连通分量 。
连通分量的边界 是指连通分量中满足下述条件之一的所有网格块:
- 在上、下、左、右任意一个方向上与不属于同一连通分量的网格块相邻
- 在网格的边界上(第一行/列或最后一行/列)
请你使用指定颜色 color 为所有包含网格块 grid[row][col] 的 连通分量的边界 进行着色。
并返回最终的网格 grid 。
示例 1:
输入:grid = [[1,1],[1,2]], row = 0, col = 0, color = 3 输出:[[3,3],[3,2]]
示例 2:
输入:grid = [[1,2,2],[2,3,2]], row = 0, col = 1, color = 3 输出:[[1,3,3],[2,3,3]]
class Solution {
public:// DFS 函数:标记连通区域的边界void dfs(vector<vector<int>>& grid, int m, int n, int i, int j, const int cur, vector<vector<bool>>& visited, vector<vector<bool>>& is_border) {// 终止条件:越界、颜色不同或已访问if (i < 0 || j < 0 || i >= m || j >= n || grid[i][j] != cur || visited[i][j]) {return;}visited[i][j] = true; // 标记当前格子为已访问bool isBorder = false; // 使用局部变量判断是否为边界// 检查四个方向是否为边界if (i == 0 || i == m-1 || j == 0 || j == n-1) { // 网格边缘isBorder = true;} else { // 内部格子,检查相邻颜色if (grid[i+1][j] != cur || grid[i-1][j] != cur || grid[i][j+1] != cur || grid[i][j-1] != cur) {isBorder = true;}}if (isBorder) {is_border[i][j] = true; // 标记为边界}// 显式递归调用四个方向,避免数组索引dfs(grid, m, n, i+1, j, cur, visited, is_border);dfs(grid, m, n, i-1, j, cur, visited, is_border);dfs(grid, m, n, i, j+1, cur, visited, is_border);dfs(grid, m, n, i, j-1, cur, visited, is_border);}// 主函数:给指定连通区域的边界染色vector<vector<int>> colorBorder(vector<vector<int>>& grid, int row, int col, int color) {// 检查空输入或无效坐标if (grid.empty() || grid[0].empty() || row < 0 || row >= grid.size() || col < 0 || col >= grid[0].size()) {return grid;}int m = grid.size(); // 行数int n = grid[0].size(); // 列数vector<vector<bool>> visited(m, vector<bool>(n, false)); // 访问标记vector<vector<bool>> is_border(m, vector<bool>(n, false)); // 边界标记int cur = grid[row][col]; // 起始格子的颜色dfs(grid, m, n, row, col, cur, visited, is_border); // 执行DFS// 染色边界格子for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (is_border[i][j]) { // 简化为直接判断布尔值grid[i][j] = color;}}}return grid;}
};BFS:
借助queue队列实现对当前节点的扩散式搜索:
模板:
邻接表存储图:
// 图的邻接表表示
class Graph {
private:int V; // 顶点数vector<vector<int> > adj; // 邻接表public:Graph(int vertices) : V(vertices) {adj.resize(V);}// 添加边(无向图)void addEdge(int u, int v) {adj[u].push_back(v);adj[v].push_back(u); // 如果是有向图,注释掉这一行}// BFS实现void bfs(int start) {// 标记访问数组vector<bool> visited(V, false);// 记录距离的数组vector<int> distance(V, -1);// 创建队列queue<int> q;// 从起点开始visited[start] = true;distance[start] = 0;q.push(start);while (!q.empty()) {// 取出队首节点int current = q.front();q.pop();// 输出当前节点(可以根据需求修改)cout << "Visiting node " << current << " at distance " << distance[current] << endl;// 遍历当前节点的所有邻接节点for (vector<int>::iterator it = adj[current].begin(); it != adj[current].end(); ++it) {int neighbor = *it;if (!visited[neighbor]) {visited[neighbor] = true;distance[neighbor] = distance[current] + 1;q.push(neighbor);}}}}
};邻接矩阵存储图:
#include <iostream>
#include <vector>
#include <queue>
#include <utility> // for std::pairusing namespace std; // 如果不用这个,需要在pair前加std::int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向void bfs(vector<vector<char> >& grid, vector<vector<bool> >& visited, int x, int y) {queue<pair<int, int> > que; // 定义队列que.push(pair<int, int>(x, y)); // 起始节点加入队列visited[x][y] = true; // 标记为已访问while (!que.empty()) { // 开始遍历队列里的元素pair<int, int> cur = que.front(); que.pop(); // 从队列取元素int curx = cur.first;int cury = cur.second; // 当前节点坐标for (int i = 0; i < 4; i++) { // 遍历四个方向int nextx = curx + dir[i][0];int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界,跳过if (!visited[nextx][nexty]) { // 如果节点没被访问过que.push(pair<int, int>(nextx, nexty)); // 队列添加该节点visited[nextx][nexty] = true; // 标记为已访问}}}
}// 测试代码
int main() {int rows = 3, cols = 3;vector<vector<char> > grid(rows, vector<char>(cols, '1'));vector<vector<bool> > visited(rows, vector<bool>(cols, false));cout << "Starting BFS from (0, 0)" << endl;bfs(grid, visited, 0, 0);return 0;
}3243:新增道路后的查询后的最短距离I
给你一个整数 n 和一个二维整数数组 queries。
有 n 个城市,编号从 0 到 n - 1。初始时,每个城市 i 都有一条单向道路通往城市 i + 1( 0 <= i < n - 1)。
queries[i] = [ui, vi] 表示新建一条从城市 ui 到城市 vi 的单向道路。每次查询后,你需要找到从城市 0 到城市 n - 1 的最短路径的长度。
返回一个数组 answer,对于范围 [0, queries.length - 1] 中的每个 i,answer[i] 是处理完前 i + 1 个查询后,从城市 0 到城市 n - 1 的最短路径的长度。
示例 1:
输入: n = 5, queries = [[2, 4], [0, 2], [0, 4]]
输出: [3, 2, 1]
解释:

新增一条从 2 到 4 的道路后,从 0 到 4 的最短路径长度为 3。

新增一条从 0 到 2 的道路后,从 0 到 4 的最短路径长度为 2。

新增一条从 0 到 4 的道路后,从 0 到 4 的最短路径长度为 1。
思路:采用邻接表存储图,套用bfs模板,在每次遍历queries时要重置visited和dis数组:
class Solution {
public:void bfs(const vector<vector<int>>& graph, vector<bool>& visited, vector<int>& dis, int x){queue<int> que;que.push(x);visited[x] = true;while(!que.empty()){int cur = que.front(); que.pop();for(int i = 0; i < graph[cur].size(); i++){int next = graph[cur][i];if(!visited[next]){dis[next] = dis[cur] + 1;visited[next] = true;que.push(next);}else{continue;}}}}vector<int> shortestDistanceAfterQueries(int n, vector<vector<int>>& queries) {vector<int> res(queries.size(), 0);vector<vector<int>> graph(n);vector<int> dis(n, 0);vector<bool> visited(n, false);for(int i = 0; i < n - 1; i++){graph[i].push_back(i + 1);}for(int i = 0; i < queries.size(); i++){int x = queries[i][0];int y = queries[i][1];graph[x].push_back(y);for(int i = 0; i < n; i++){visited[i] = false;dis[i] = 0;}bfs(graph, visited, dis, 0);res[i] = dis[n - 1];}return res;}
};无向图中判断是否存在环路:
方法:
(1)DFS遍历整张图
(2)对于每一个符合要求的节点记录其父节点
(3)在遍历终于到符合要求节点但已经访问过,检查是否为当前递归下的父节点
相关文章:
图论整理复习
回溯: 模板: void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯ÿ…...

MIMO预编码与检测算法的对比
在MIMO系统中,预编码(发送端处理)和检测算法(接收端处理)的核心公式及其作用对比如下: 1. 预编码算法(发送端) 预编码的目标是通过对发送信号进行预处理,优化空间复用或…...
C++修炼:vector模拟实现
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...
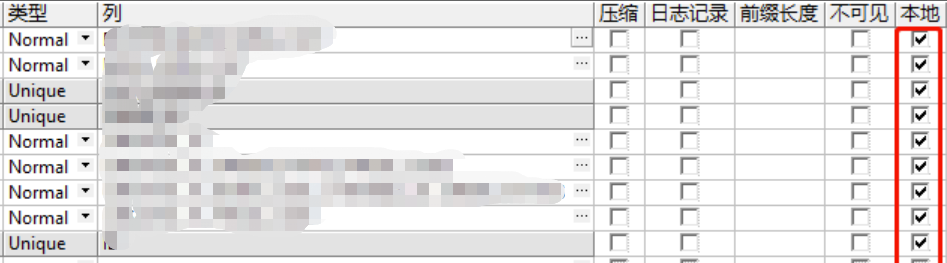
案例-索引对于并发Insert性能优化测试
前言 最近因业务并发量上升,开发反馈对订单表Insert性能降低。应开发要求对涉及Insert的表进行分析并提供优化方案。 一般对Insert 影响基本都在索引,涉及表已按创建日期做了分区表,索引全部为普通索引未做分区索引。 优化建议: 1、将UNIQUE改为HASH(64) GLOBAL IND…...
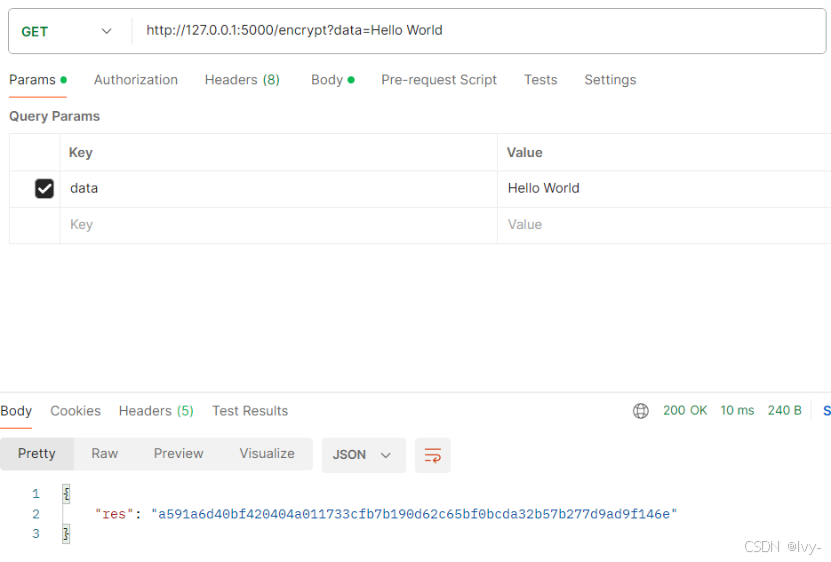
[区块链lab2] 构建具备加密功能的Web服务端
实验目标: 掌握区块链中密码技术的工作原理。在基于Flask框架的服务端中实现哈希算法的加密功能。 实验内容: 构建Flash Web服务器,实现哈希算法、非对称加密算法的加密功能。 实验步骤: 哈希算法的应用:创建hash…...
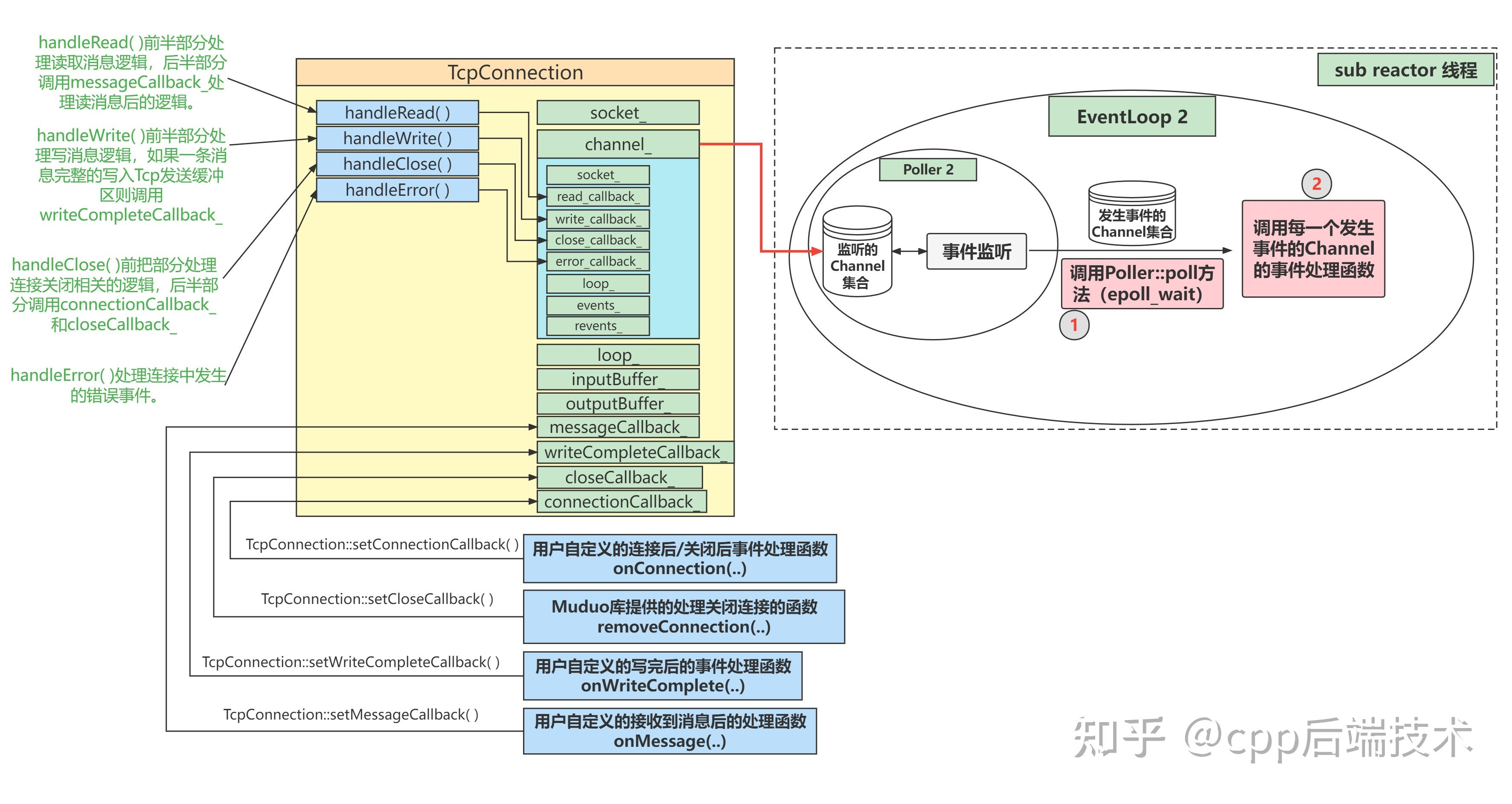
muduo库源码分析: TcpConnection
一. 主要成员: socket_:用于保存已连接套接字文件描述符。channel_:封装了上面的socket_及其各类事件的处理函数(读、写、错误、关闭等事件处理函数)。这个Channel中保存的各类事件的处理函数是在TcpConnection对象构造函数中注册…...

RuoYi-Vue升级为https访问-后端安装SSL证书(单台Linux服务器部署)
一、前言 当Nginx已经作为反向代理并成功配置了SSL证书时,前端客户端与Nginx的通信已经是加密的。但Nginx和后端服务之间的连接可能仍然存在明文传输的风险。 如果Nginx和后端服务位于同一台物理机器或者通过安全的内部网络(如私有VLAN或防火墙保护的内网)进行通信,则可以…...

EasyExcel系列:读取空数据行的问题
定义Excel模板时,会生产空行问问题,可以自定义监听器过滤空行。以PageReadListener为例。 /*** 自定义读取监听器,解决无法空行问题**/ Slf4j public class MyPageReadListener<T> extends PageReadListener<T> {Overridepublic …...

博客文章文件名该怎么取?
文章目录 🧾 1. 博客文章文件名该怎么取?📌 2. 为什么文件名重要?✅ 3. 推荐命名规范✅ 3.1 使用 **小写英文 中划线(kebab-case)**✅ 3.2 简短但具备语义✅ 3.3 如果是系列文章,可加前缀序号或…...

【GIT】放弃”本地更改,恢复到远程仓库的状态git fetch origin git reset --hard origin/分支名
如果你想完全放弃本地更改,恢复到远程仓库的状态,可以按照以下步骤操作: 获取远程最新版本 首先执行: git fetch origin这条命令会把远程仓库的最新提交拉取到你的本地,但不会自动合并到你的当前分支。 硬重置你的当前…...

有哪些哲学流派适合创业二
好的,让我们更深入地探讨如何将哲学与数学深度融合,构建一套可落地的创业操作系统。以下从认知框架、决策引擎、执行算法三个维度展开,包含具体工具和黑箱拆解: 一、认知框架:用哲学重构商业本质 1. 本体…...

【Web API系列】Web Shared Storage API之WorkletSharedStorage深度解析与实践指南
前言 在现代Web开发领域,数据存储与隐私保护的矛盾始终存在。传统存储方案如LocalStorage和Cookies面临着日益严格的安全限制,而跨域数据共享的需求却在持续增长。正是在这样的背景下,Web Shared Storage API应运而生,其核心组件…...

UE5 制作方块边缘渐变边框效果
该效果基于之前做的(https://blog.csdn.net/grayrail/article/details/144546427)进行修改得到,思路也很简单: 1.打开实时预览 1.为了制作时每个细节调整方便,勾选Live Update中的三个选项,开启实时预览。…...

MyBatis 如何使用
1. 环境准备 添加依赖(Maven) 在 pom.xml 中添加 MyBatis 和数据库驱动依赖: <dependencies><!-- MyBatis 核心库 --><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId&g…...

【MySQL】索引分类、聚簇与非聚簇索引,索引优化,常见explain分析索引案例,type字段
索引基本概念 索引是数据库中用于加速数据检索的数据结构,类似于书籍的目录。它通过建立额外的数据结构来存储部分数据,从而加快查询速度。 索引的优缺点 优点缺点加快数据检索速度占用额外存储空间保证数据唯一性(唯一索引)插…...

MySQL Binlog 数据恢复总结
🌲 总入口:你想恢复什么? 恢复类型 ├── 表结构 表数据(整张表被 DROP) │ ├── Binlog 中包含 CREATE TABLE │ │ └── ✅ 直接用 mysqlbinlog 提取建表 数据语句,回放即可 │ └── B…...

STM32 HAL库内部 Flash 读写实现
一、STM32F407 内部 Flash 概述 1.1 Flash 存储器的基本概念 Flash 存储器是一种非易失性存储器,它可以在掉电的情况下保持数据。STM32F407 系列微控制器内部集成了一定容量的 Flash 存储器,用于存储程序代码和数据。Flash 存储器具有擦除和编程次数的…...

2.3 Spark运行架构与流程
Spark运行架构与流程包括几个核心概念:Driver负责提交应用并初始化作业,Executor在工作节点上执行任务,作业是一系列计算任务,任务是作业的基本执行单元,阶段是一组并行任务。Spark支持多种运行模式,包括单…...

Redisson分布式锁全攻略:用法、场景与要点
目录 1. 普通可重入锁(RLock) 2. 公平锁(RFairLock) 3. 读写锁(RReadWriteLock) 4. 多重锁(RedissonMultiLock) 1. 普通可重入锁(RLock) import org.redisson.Redisson; import org.redisson.api.RLoc…...
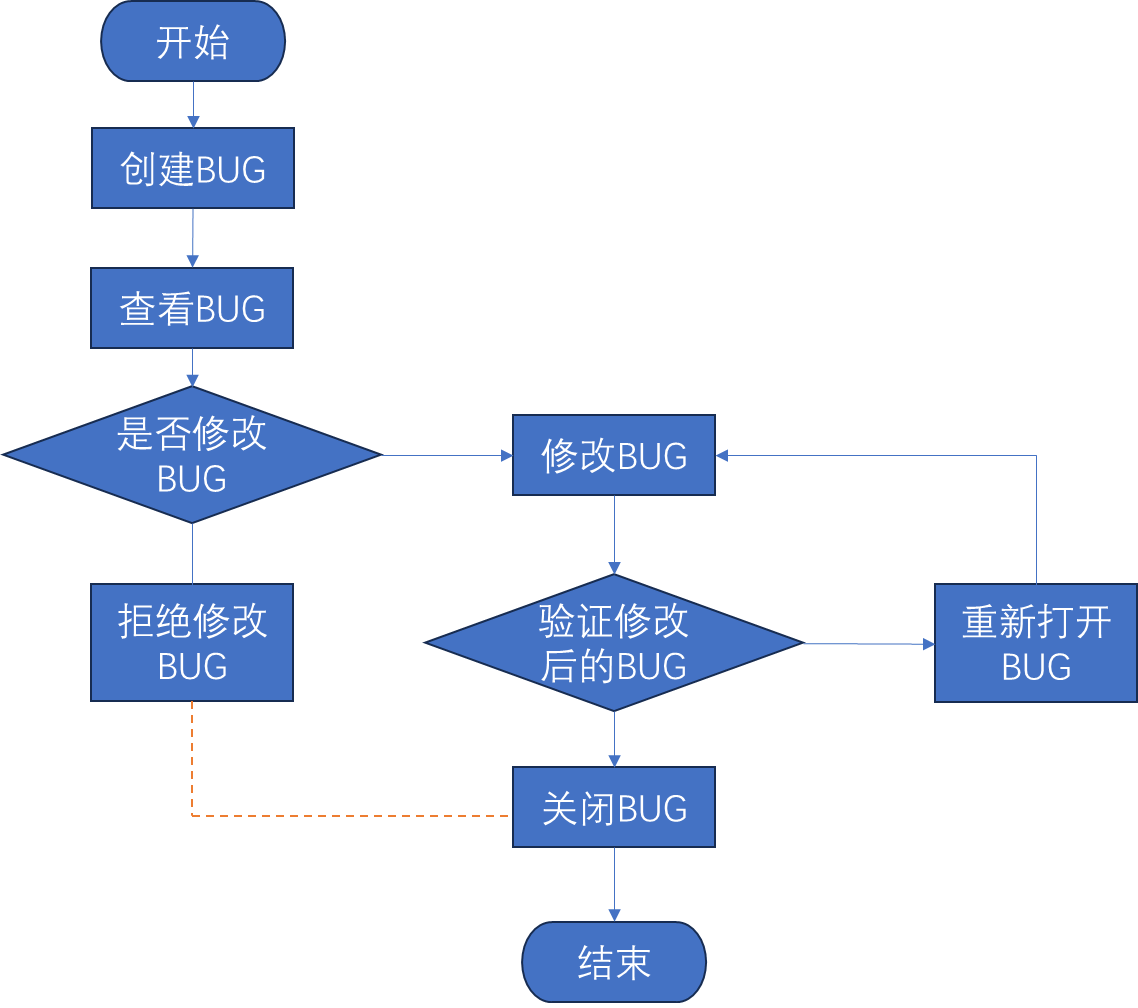
软件测试——BUG概念
目录 一、软件测试生命周期 二、BUG 2.1BUG概念 2.2BUG要素 2.3BUG级别 2.4 BUG的生命周期 2.5测试人员与开发人员因为BUG发生争执 2.6BUG评审 一、软件测试生命周期 软件测试贯穿于软件的整个生命周期 软件测试的生命周期指测试流程,每个阶段有不同的目标…...

二、Android Studio环境安装
一、下载安装 下载 Android Studio 和应用工具 - Android 开发者 | Android DevelopersAndroid Studio 提供了一些应用构建器以及一个已针对 Android 应用进行优化的集成式开发环境 (IDE)。立即下载 Android Studio。https://developer.android.google.cn/studio?hlzh-c…...

Hyperlane:重新定义Rust Web开发的未来 [特殊字符][特殊字符]
Hyperlane:重新定义Rust Web开发的未来 🚀🔥 大家好!👋 今天我要向各位技术爱好者介绍一个令人兴奋的Rust HTTP服务器库——Hyperlane 🌟。作为一个轻量级、高性能的框架,Hyperlane正在悄然改变…...
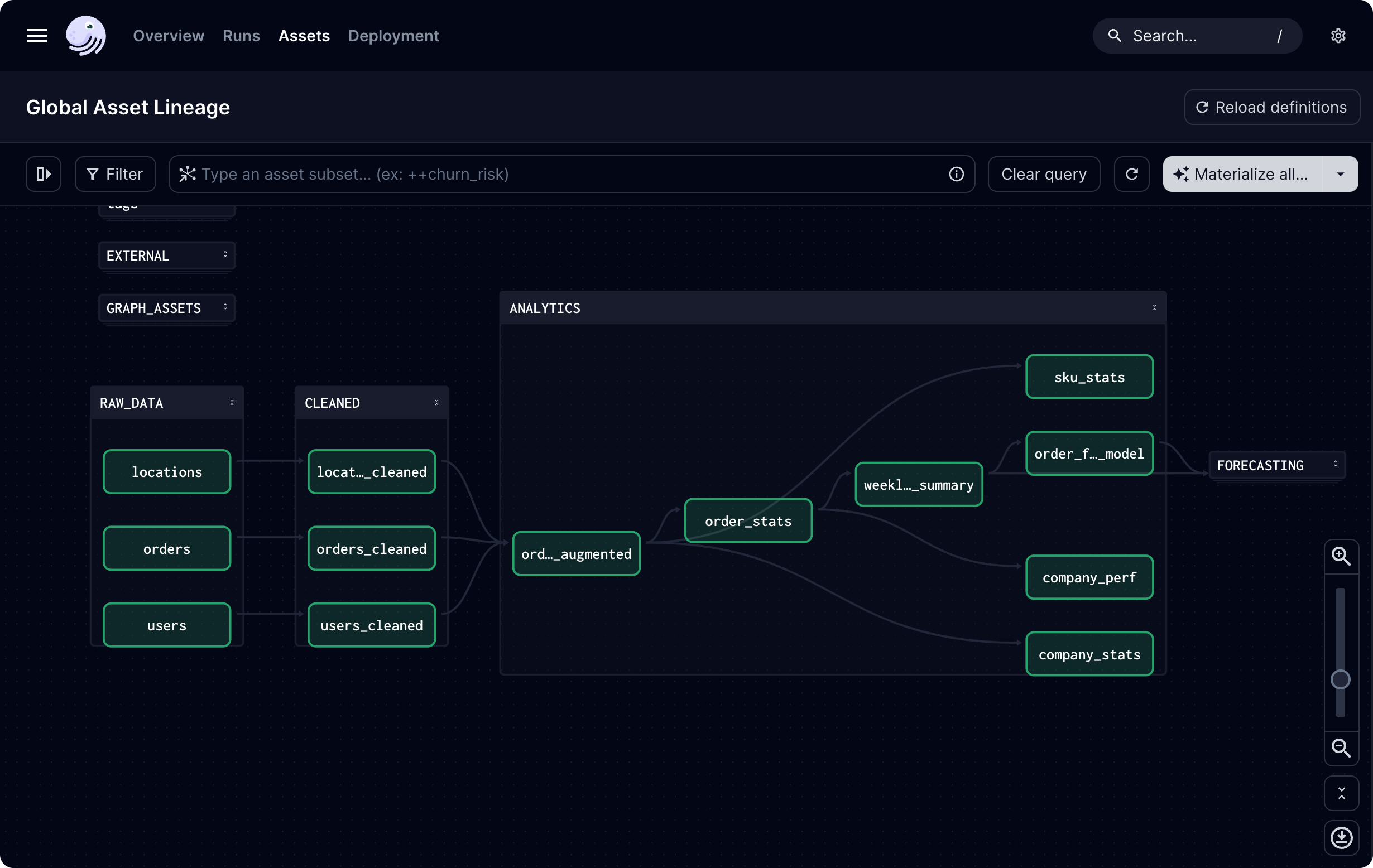
从零构建机器学习流水线:Dagster+PyTorch实战指南
本文将系统讲解机器学习流水线的核心原理,并通过Dagster编排框架与PyTorch深度学习库的实战结合,手把手演示从数据预处理到生产部署的全流程。文中包含可运行的代码示例、最佳实践和性能对比分析,帮助开发者快速构建可扩展、易维护的机器学习…...

RabbitMQ架构原理及消息分发机制
RabbitMQ架构原理及消息分发机制 在现代分布式系统中,消息队列是不可或缺的组件之一。它不仅能够解耦系统模块,还能实现异步通信和削峰填谷。在众多消息队列中,RabbitMQ 因其高并发、高可靠性和丰富的功能而备受青睐。本文将从 RabbitMQ 的基…...
React 项目src文件结构
SCSS 组件库 SCSS为预处理器 支持除原生CSS外的其他语句 别名路径 在项目下的第一级目录就加入craco.config.js文件并且修改packpage.js 中的部分 // 扩展webpage的配置const path require(path)module.exports {// exports配置webpack:{// 配置别名alias:{:path.resolve(__d…...
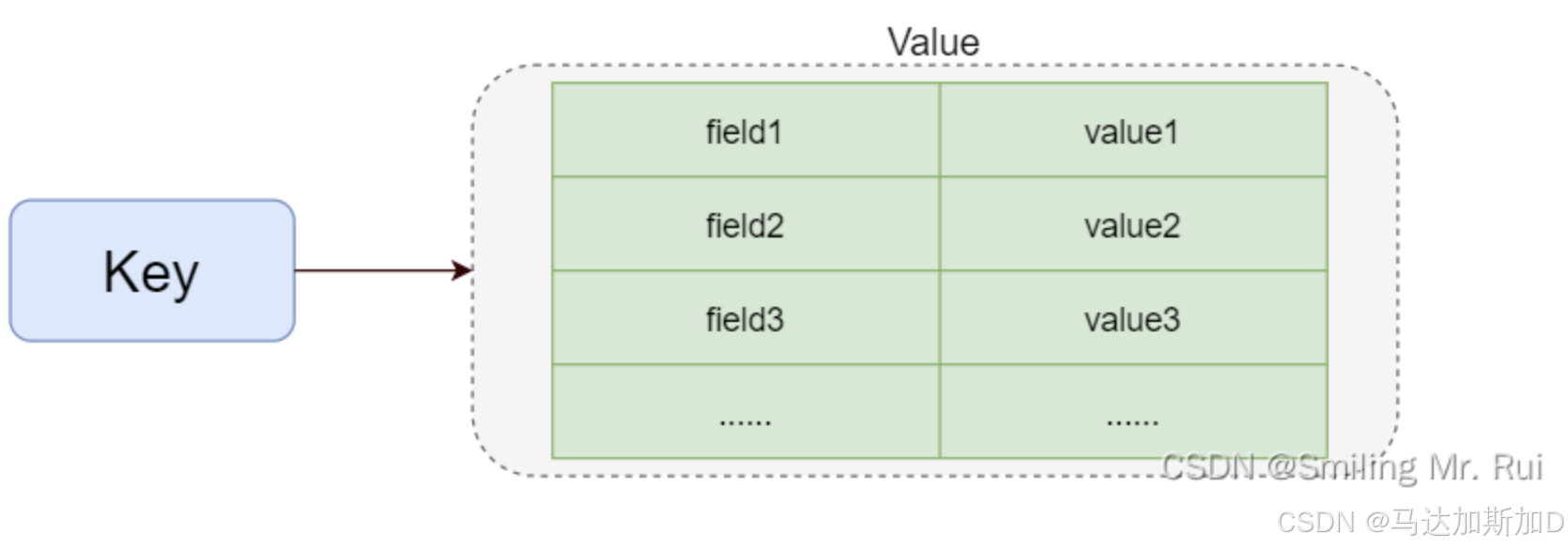
Redis --- 基本数据类型
Redis --- 基本数据类型 Redis Intro5种基础数据类型 Redis Intro Redis(Remote Dictionary Server)是一款开源的高性能键值存储系统,常用于缓存、消息中间件和实时数据处理场景。以下是其核心特点、数据类型及典型使用场景: 核心…...

React 高级特性与最佳实践
在掌握了 React 的基础知识后,我们可以进一步探索 React 的高级特性和最佳实践。这些特性将帮助你构建更高效、可维护和可扩展的 React 应用。本文重点介绍 Hooks、Context、Refs 和高阶组件等核心高级特性。 1. Hooks:函数组件的强大工具 Hooks 是 Rea…...

一个由通义千问以及FFmpeg的AVFrame、buffer引起的bug:前面几帧影响后面帧数据
目录 1 问题描述 2 我最开始的代码----错误代码 3 正确的代码 4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分 5 以后不要用通义千问写代码 1 问题描述 某个项目中,需要做人脸马赛克,然后这个是君正的某款芯片…...

12.第二阶段x64游戏实战-远程调试
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:11.第二阶段x64游戏实战-框架代码细节优化 本次写的内容是关于调试、排错相关的…...

Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标
以下是 Coze 和 n8n 的详细介绍及多维度对比分析,涵盖功能、架构、适用场景、成本等关键指标: 一、Coze 详细介绍 1. 基础信息 类型:低代码自动化平台(SaaS)。开源性:闭源(企业版需付费&…...