PyTorch张量操作指南:cat、stack、split与chunk的实战拆解
本文深入探讨PyTorch中用于调整张量结构的四个核心函数——
torch.cat、torch.stack、torch.split和torch.chunk。通过实际应用场景分析和代码演示,帮助读者掌握它们的功能差异及适用条件,提升模型开发的灵活性与效率。
在深度学习实践中,张量的维度变换是数据处理和模型构建的基础技能。无论是多模态数据的融合(如图像与文本),还是批处理数据的拆分重组,合理运用张量操作函数可显著优化计算流程。PyTorch提供的cat、stack、split和chunk正是解决此类问题的利器。以下将逐一解析其原理与应用。
一、torch.cat: 沿指定维度拼接张量
功能描述
torch.cat(concatenate)沿已有的某一维度连接多个形状兼容的张量,生成更高维度的单一张量。要求除拼接维度外,其余维度的大小必须完全一致。
示例代码
import torcha = torch.tensor([[1, 2], [3, 4]]) # 形状 (2, 2)
b = torch.tensor([[5, 6], [7, 8]])# 在第0维拼接(垂直方向)
c = torch.cat([a, b], dim=0)
print(c)
# 输出:
# tensor([[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]])# 在第1维拼接(水平方向)
d = torch.cat([a, b], dim=1)
print(d)
# 输出:
# tensor([[1, 2, 5, 6],
# [3, 4, 7, 8]])
二、torch.stack: 创建新维度堆叠张量
功能描述
torch.stack会将输入张量沿新创建的维度进行堆叠,所有参与堆叠的张量必须具有完全相同的形状。输出张量的维度比原张量多一维。
示例代码
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])# 沿第0维堆叠,生成二维张量
c = torch.stack([a, b], dim=0)
print(c.shape) # torch.Size([2, 3])
print(c)
# 输出:
# tensor([[1, 2, 3],
# [4, 5, 6]])# 沿第1维堆叠,生成二维张量
d = torch.stack([a, b], dim=1)
print(d.shape) # torch.Size([3, 2])
print(d)
# 输出:
# tensor([[1, 4],
# [2, 5],
# [3, 6]])
三、torch.split: 按尺寸分割张量
功能描述
torch.split根据指定的尺寸将输入张量分割为多个子张量。支持两种参数形式:
- 整数列表:每个元素表示对应分片的长度
- 整数N:等分为N个子张量(需总长度可被整除)
示例代码
a = torch.arange(9) # tensor([0, 1, 2, 3, 4, 5, 6, 7, 8])# 按列表尺寸分割 [2,3,4]
parts = torch.split(a, [2, 3, 4], dim=0)
for part in parts:print(part)'''
输出:
tensor([0, 1])
tensor([2, 3, 4])
tensor([5, 6, 7, 8])
'''# 平均分割为3份
chunks = torch.split(a, 3, dim=0)
print([c.shape for c in chunks]) # [torch.Size([3]), torch.Size([3]), torch.Size([3])]
四、torch.chunk: 按数量均分张量
功能描述
torch.chunk将输入张量沿指定维度均匀划分为N份。若无法整除,剩余元素分配到前面的分片中。
示例代码
a = torch.arange(10) # tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])# 分成3份,默认在第0维操作
chunks = torch.chunk(a, chunks=3, dim=0)
for i, chunk in enumerate(chunks):print(f"Chunk {i}: {chunk}")'''
输出:
Chunk 0: tensor([0, 1, 2, 3])
Chunk 1: tensor([4, 5, 6])
Chunk 2: tensor([7, 8, 9])
'''# 在第1维分割二维张量
b = a.reshape(2,5)
chunks = torch.chunk(b, chunks=2, dim=1)
print(chunks[0].shape) # torch.Size([2, 2])
print(chunks[1].shape) # torch.Size([2, 3])
综合示例
以下是结合图像数据的完整操作示例,模拟图像预处理流程中的张量操作场景:
综合示例:图像数据的分割与合并处理
场景设定
假设我们有一批RGB图像数据(尺寸为 3×256×256),需要完成以下操作:
- 将图像拆分为RGB三个通道
- 对每个通道进行独立归一化
- 合并处理后的通道
- 将多张图像堆叠成批次
- 分割批次为训练/验证集
代码实现
import torch
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt# 1. 加载示例图像 (H, W, C) -> 转换为 (C, H, W)
image = Image.open('cat.jpg').convert('RGB')
image = transforms.ToTensor()(image) # shape: torch.Size([3, 256, 256])# 2. 使用split分离RGB通道
r_channel, g_channel, b_channel = torch.split(image, split_size_or_sections=1, dim=0)''' 可视化原始通道
plt.figure(figsize=(12,4))
plt.subplot(131), plt.imshow(r_channel.squeeze().numpy(), cmap='Reds'), plt.title('Red')
plt.subplot(132), plt.imshow(g_channel.squeeze().numpy(), cmap='Greens'), plt.title('Green')
plt.subplot(133), plt.imshow(b_channel.squeeze().numpy(), cmap='Blues'), plt.title('Blue')
plt.show()
'''# 3. 对每个通道进行归一化(示例操作)
def normalize(tensor):return (tensor - tensor.mean()) / tensor.std()r_norm = normalize(r_channel)
g_norm = normalize(g_channel)
b_norm = normalize(b_channel)# 4. 使用cat合并处理后的通道
normalized_img = torch.cat([r_norm, g_norm, b_norm], dim=0)
'''观察归一化效果
plt.imshow(normalized_img.permute(1,2,0))
plt.title('Normalized Image')
plt.show()
'''# 5. 创建模拟图像批次 (假设有4张相同图像)
batch_images = torch.stack([image]*4, dim=0) # shape: (4, 3, 256, 256)# 6. 使用chunk分割批次为训练集/验证集
train_set, val_set = torch.chunk(batch_images, chunks=2, dim=0)
print(f"Train set size: {train_set.shape}") # torch.Size([2, 3, 256, 256])
print(f"Val set size: {val_set.shape}") # torch.Size([2, 3, 256, 256])
关键操作解析
| 步骤 | 函数 | 作用 | 维度变化 |
|---|---|---|---|
| 通道分离 | torch.split | 提取单独颜色通道 | (3,256,256)→3个(1,256,256) |
| 数据合并 | torch.cat | 合并处理后的通道数据 | 3个(1,256,256)→(3,256,256) |
| 批次构建 | torch.stack | 将单张图像复制为4张图像的批次 | (3,256,256)→(4,3,256,256) |
| 批次划分 | torch.chunk | 将批次按比例划分为训练/验证集 | (4,3,256,256)→2×(2,3,256,256) |
扩展应用建议
- 数据增强:对split后的通道进行不同变换(如仅对R通道做对比度调整)
- 模型输入:stack后的批次可直接输入CNN网络
- 分布式训练:利用chunk将数据分布到多个GPU处理
- 特征可视化:通过split提取中间层特征图的单个通道进行分析
通过这个完整的图像处理流程示例,可以清晰看到:
split+cat组合常用于特征处理管道stack+chunk组合是构建批处理系统的关键工具- 这些操作在保持计算效率的同时提供了灵活的数据控制能力
总结与对比
| 函数 | 核心作用 | 维度变化 | 输入要求 |
|---|---|---|---|
torch.cat | 沿现有维度拼接 | 不变 | 各张量形状需匹配 |
torch.stack | 新建维度堆叠 | +1维 | 所有张量形状完全相同 |
torch.split | 按尺寸分割 | 不变 | 需指定分割尺寸或份数 |
torch.chunk | 按数量均分 | 不变 | 总长度需可分配 |
应用建议:
- 当需要合并同类数据且保留原始维度时用
cat; - 若需扩展维度以表示批次或通道时用
stack; - 对序列数据分段处理优先考虑
split; - 均匀划分特征图或张量时选择
chunk。
掌握这些工具后,您将能更灵活地操控张量维度,适应复杂模型的构建需求!
相关文章:

PyTorch张量操作指南:cat、stack、split与chunk的实战拆解
本文深入探讨PyTorch中用于调整张量结构的四个核心函数——torch.cat、torch.stack、torch.split和torch.chunk。通过实际应用场景分析和代码演示,帮助读者掌握它们的功能差异及适用条件,提升模型开发的灵活性与效率。 在深度学习实践中,张量…...

YOLO涨点技巧之分层扩展路径聚合网络 (HEPAN)
一、应用场景与问题背景 1.1 无人机图像检测挑战 https://ai-studio-static-online.cdn.bcebos.com/3d4f7e8c4d8d4d2d8a4c8e4b4e8c4d8d 场景特点:无人机航拍视角下的小目标检测(如行人、车辆、农作物病害等)核心难点: 目标尺寸小(<3232像素)复杂背景干扰(如城市…...

SQLite、MySQL、SQL Server、Oracle 和 PostgreSQL 五种数据库的区别
以下是 SQLite、MySQL、SQL Server、Oracle 和 PostgreSQL 五种主流关系型数据库管理系统(RDBMS)的区别,从多个维度进行对比: 1. 架构与部署 SQLite(Structured Query Language Lite): 嵌入式数据库,无服务器架构。数据库存储在一个单一的磁盘文件中。部署简单,适合轻量…...

git在分支上会退到某个指定的commit
1、在idea上先备份好分支(基于现有分支new branch) 2、在gitlab管理端删除现有分支 3、在idea中大卡terminal,执行 git log 查看commit log ,找到要会退到的commit唯一码,然后执行git reset 唯一码 4、查看本地代码状态 git st…...

玩机进阶教程----MTK芯片设备刷机导致的死砖修复实例解析 连电脑毫无反应 非硬件问题
在高通芯片机型中,我们可以通过短接主板测试点来激活高通芯片特有的9008底层端口来刷写救砖固件。但通常MTK芯片类的设备联机电脑即可触发深刷模式。但有些例外的情况会导致链接电脑毫无反应。遇到类似故障的友友可以参阅此博文尝试解决。 通过博文了解 1💝💝💝-----实…...
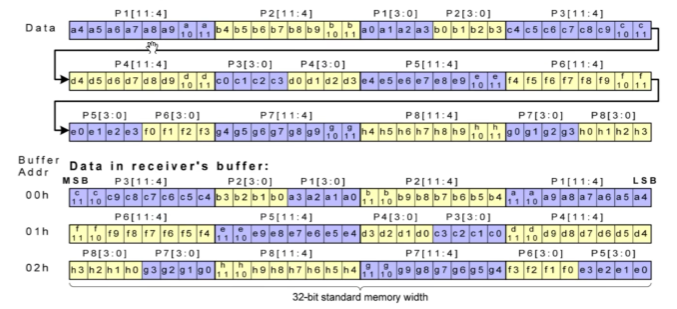
MIPI协议介绍
MIPI协议介绍 mipi 协议分为 CSI 和DSI,两者的区别在于 CSI用于接收sensor数据流 DSI用于连接显示屏 csi分类 csi 分为 csi2 和 csi3 csi2根据物理层分为 c-phy 和 d-phy, csi-3采用的是m-phy 一般采用csi2 c-phy 和 d-phy的区别 d-phy的时钟线和数据线是分开的,2根线一对…...

MySQL 中 `${}` 和 `#{}` 占位符详解及面试高频考点
文章目录 一、概述二、#{} 和 ${} 的核心区别1. 底层机制代码示例 2. 核心区别总结 三、为什么表名只能用 ${}?1. 预编译机制的限制2. 动态表名的实现 四、安全性注意事项1. ${} 的风险场景2. 安全实践 五、面试高频考点1. 基础原理类问题**问题 1**:**问…...

AI应用开发平台 和 通用自动化工作流工具 的详细对比,涵盖定义、核心功能、典型工具、适用场景及优缺点分析
以下是 AI应用开发平台 和 通用自动化工作流工具 的详细对比,涵盖定义、核心功能、典型工具、适用场景及优缺点分析: 1. AI应用开发平台 vs 通用自动化工作流工具 (1) 定义与目标 类型AI应用开发平台通用自动化工作流工具定义用于快速构建、训练、部署…...
)
GitHub 趋势日报 (2025年04月12日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1yeongpin/cursor-free-vip[Support 0.48.x](Reset Cursor AI MachineID & Auto Sign Up / In & Bypass Higher…...

asm汇编源代码之-字库转换程序
将标准的16x16点阵汉字库(下载16x16汉字库)转换成适合VGA文本模式下显示的点阵汉字库 本程序需要调用file.asm中的子程序,所以连接时需要把file连接进来,如下 C:\> tlink chghzk file 调用参数描述如下 C:\> chghzk ; 无调用参数,转换标准库文件(SRC16.FNT)为适合VGA…...

VMware Ubuntu挂载Windows机器的共享文件
https://www.dong-blog.fun/post/2029 在VMware Ubuntu中访问Windows共享文件夹:完整指南 在使用VMware运行Ubuntu虚拟机时,访问Windows主机上的文件是常见需求。本文将详细介绍如何通过网络共享方式,让Ubuntu虚拟机直接访问Windows主机的文…...
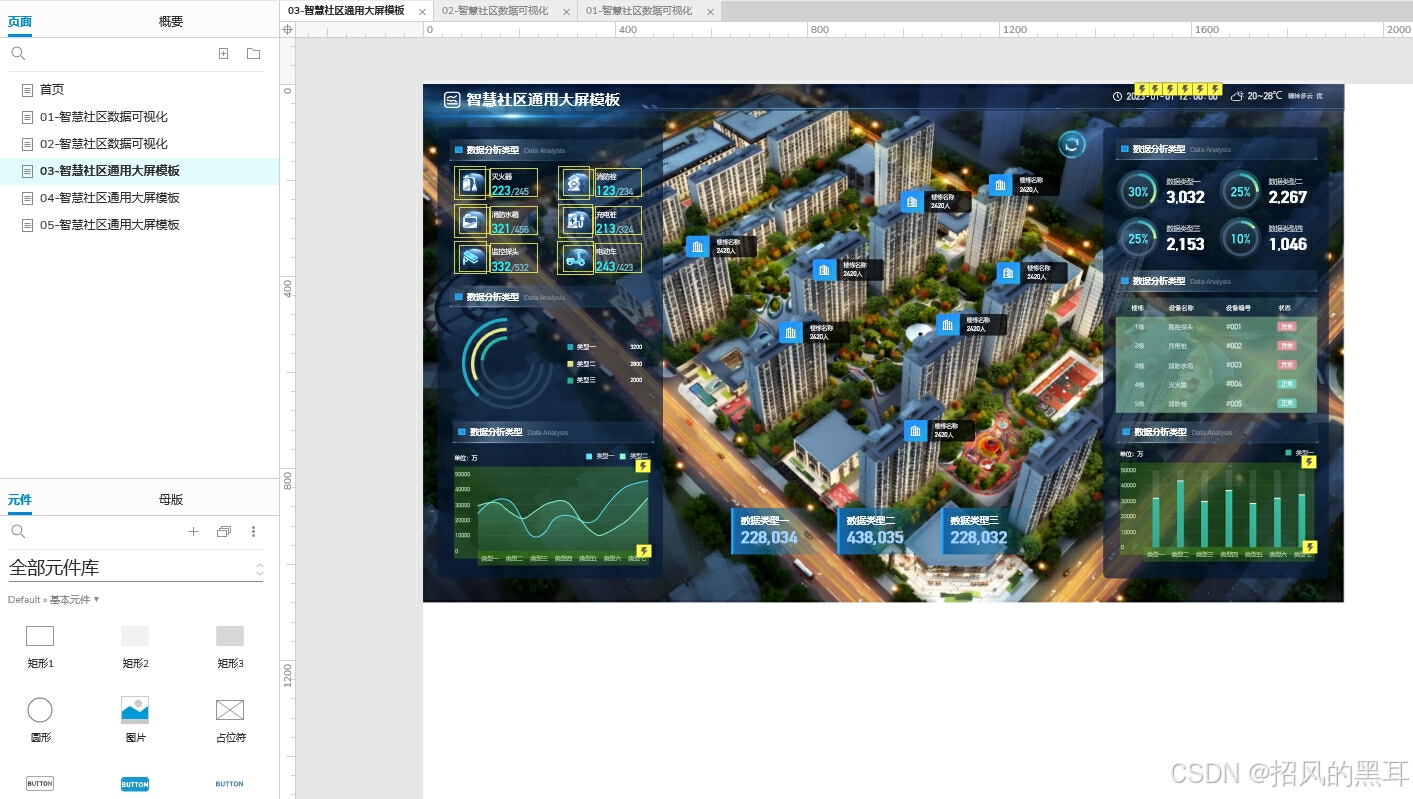
智慧社区数据可视化中枢平台——Axure全场景交互式大屏解决方案
在数字化治理的时代浪潮中,社区管理正面临数据碎片化、响应滞后、决策盲区等核心挑战。如何将分散的安防、环境、能源、民生服务等数据整合为可操作的智慧洞察?如何让冰冷的数字转化为社区管理者手中的决策利器?Axure智慧社区可视化大屏原型模…...
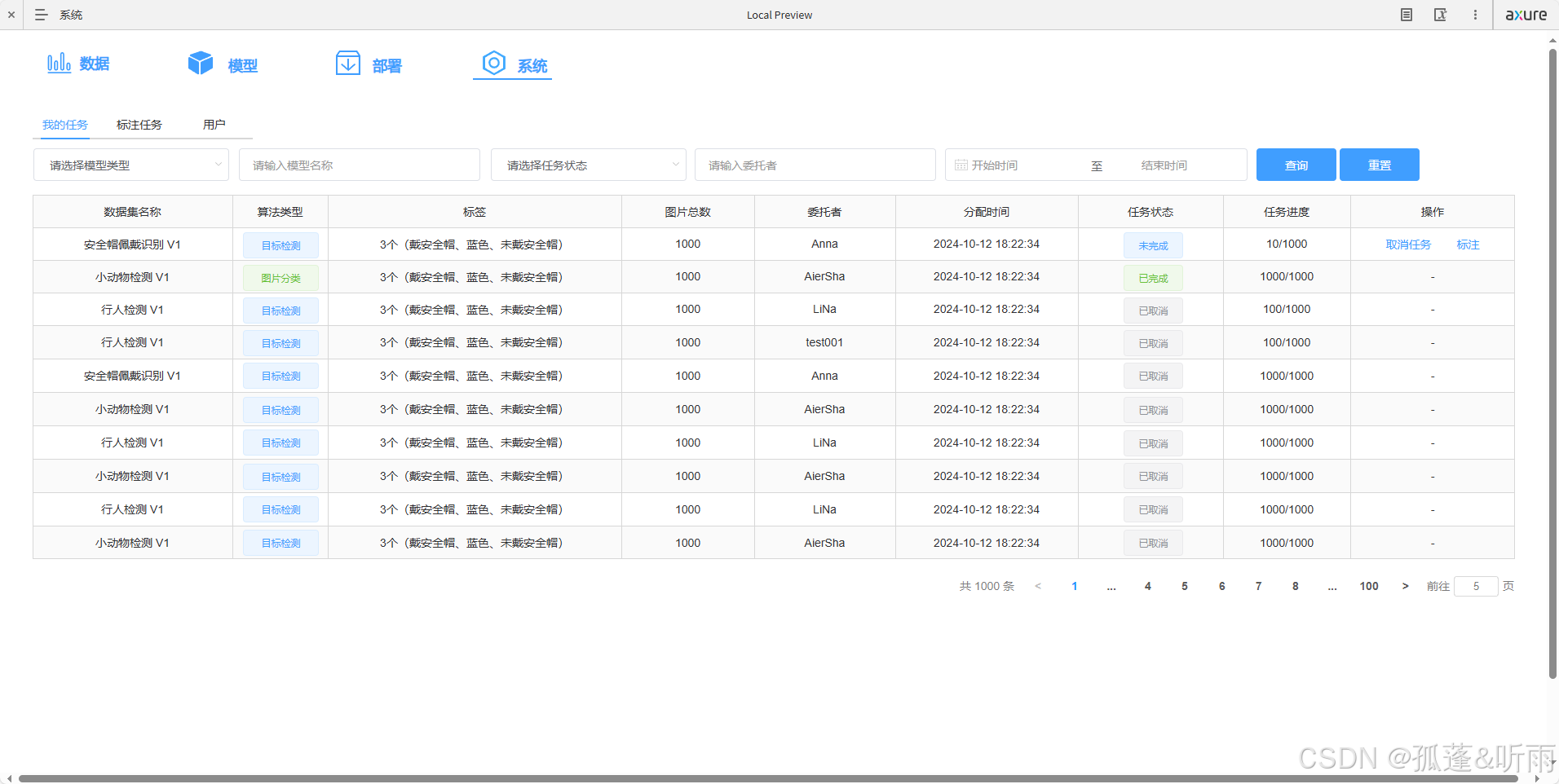
Axure高保真AI算法训练平台
点击下载《Axure高保真AI算法训练平台(.rp) 》 原型效果:https://axhub.im/ax9/69fdf8f2b10b59c3/#g1 摘要 本文介绍了一款功能全面且高效的AI算法训练平台,旨在为数据科学家、研究人员和工程师提供从数据准备到模型部署的一站式解决方案。该平台由四大…...
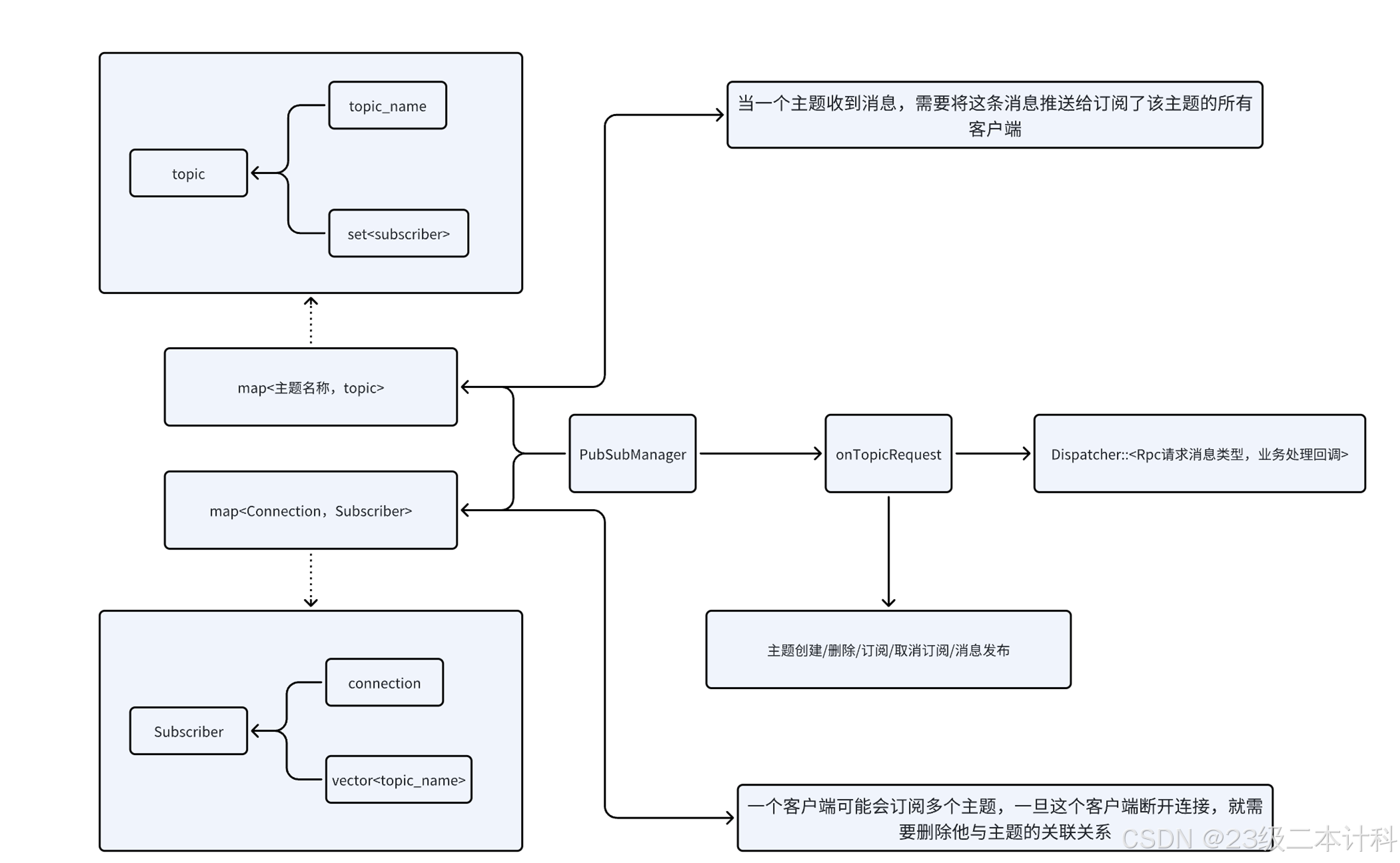
C++ Json-Rpc框架-3项目实现(2)
一.消息分发Dispatcher实现 Dispatcher 就是“消息分发中枢”:根据消息类型 MType,把消息派发给对应的处理函数(Handler)执行。 初版: #pragma once #include "net.hpp" #include "message.hpp"n…...

youtube视频和telegram视频加载原理差异分析
1. 客户侧缓存与流式播放机制 流式视频应用(如 Netflix、YouTube)通过边下载边播放实现流畅体验,其核心依赖以下技术: 缓存预加载:客户端在后台持续下载视频片段(如 DASH/HLS 协议的…...

LLM小白自学笔记:1.两种指令微调
一、LoRA 简单来说,LoRA不直接调整个大模型的全部参数(那样太费资源),而是在模型的某些层(通常是注意力层)加个“旁路”——两个小的矩阵(低秩矩阵)。训练时只更新这俩小矩阵&#x…...

【NLP】 19. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法 在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法: 1.1 人工评价 人工评价主要关注以下几点: 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。充分性…...
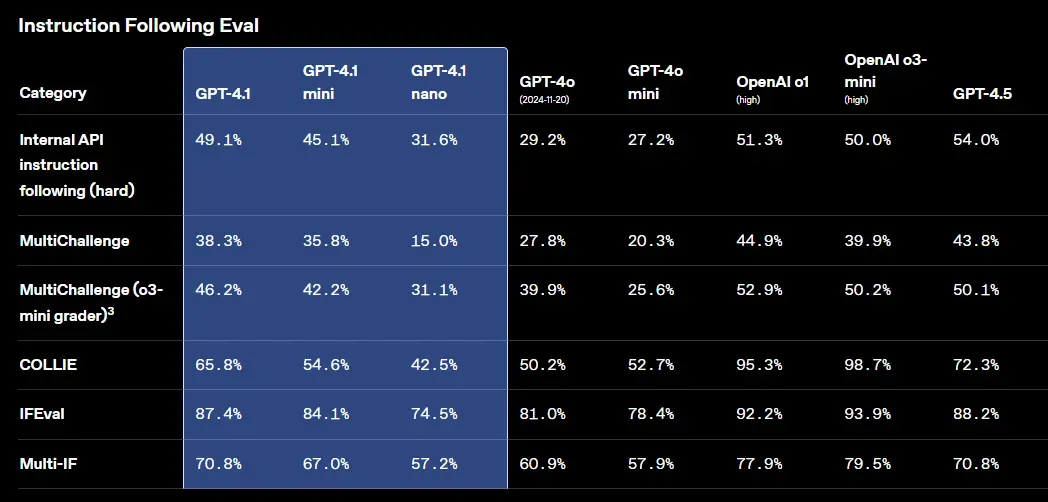
OpenAI发布GPT-4.1系列模型——开发者可免费使用
OpenAI刚刚推出GPT-4.1模型家族,包含GPT-4.1、GPT-4.1 Mini和GPT-4.1 Nano三款模型。重点是——现在全部免费开放! 虽然技术升级值得关注,但真正具有变革意义的是开发者能通过Cursor、Windsurf和GitHub Copilot等平台立即免费调用这些模型。…...
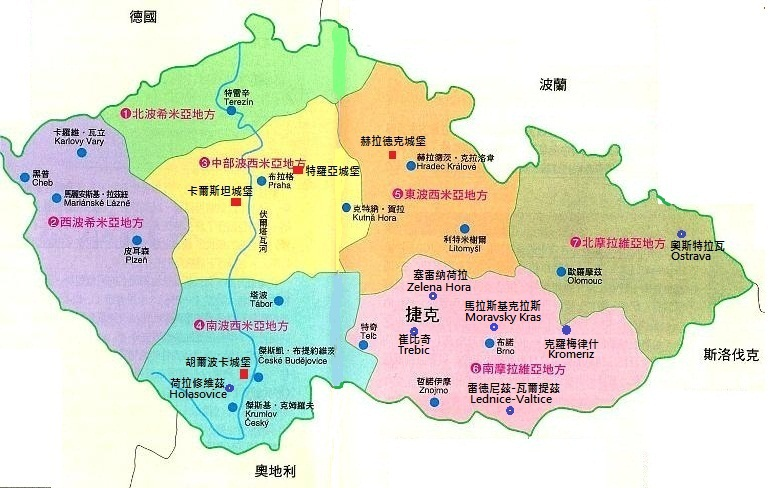
各地物价和生活成本 东欧篇
东欧地区的物价差异相对较大,一些国家的物价较高,而另一些国家则相对便宜。这些差异主要受当地经济发展水平、工资水平、旅游业发展以及国际关系等因素影响。以下是一些典型的东欧国家,按物价高低进行分类: 🌍 物价较高…...

Vue —— 实用的工具函数
目录 响应式数据管理1. toRef 和 torefs2. shallowRef 和 shallowReactive3. markRaw 依赖追踪与副作用1. computed2. watch 和 watchEffect 类型判断与优化1. unref2. isRef 、isReactive 和 isProxy 组件通信与生命周期1. provide 和 inject2. nextTick 高级工具1. useAttrs …...
flex布局(笔记)
弹性布局(Flex布局)是一种现代的CSS布局方式,通过使用display: flex属性来创建一个弹性容器,并在其中使用灵活的盒子模型来进行元素的排列和定位。 主轴与交叉轴:弹性容器具有主轴(main axis)和…...

第二阶段:数据结构与函数
模块4:常用数据结构 (Organizing Lots of Data) 在前面的模块中,我们学习了如何使用变量来存储单个数据,比如一个数字、一个名字或一个布尔值。但很多时候,我们需要处理一组相关的数据,比如班级里所有学生的名字、一本…...

云函数采集架构:Serverless模式下的动态IP与冷启动优化
在 Serverless 架构中使用云函数进行网页数据采集,不仅能大幅降低运维成本,还能根据任务负载动态扩展。然而,由于云函数的无状态特性及冷启动问题,加上目标网站对采集行为的反制措施(如 IP 限制、Cookie 校验等&#x…...
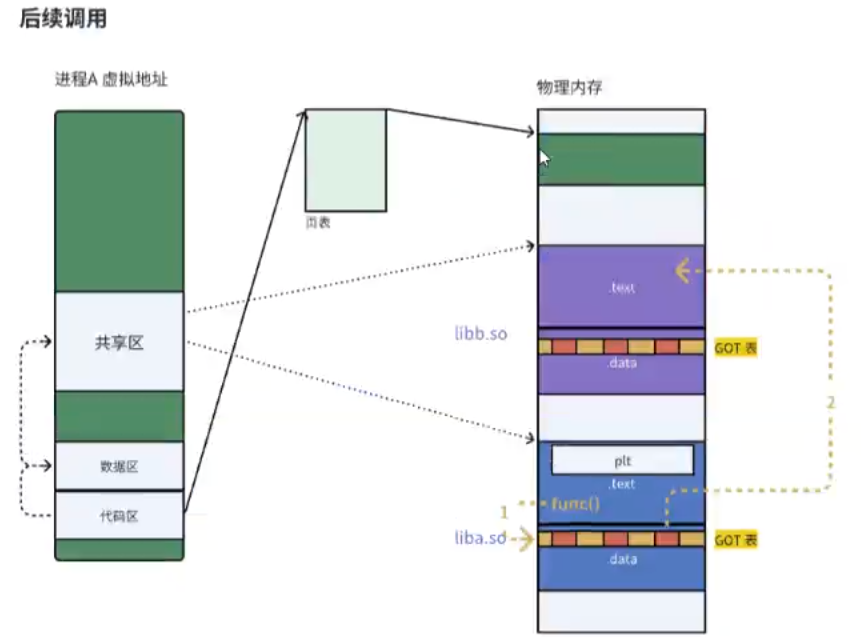
Linux笔记---动静态库(原理篇)
1. ELF文件格式 动静态库文件的构成是什么样的呢?或者说二者的内容是什么? 实际上,可执行文件,目标文件,静态库文件,动态库文件都是使用ELF文件格式进行组织的。 ELF(Executable and Linkable…...

string的模拟实现 (6)
目录 1.string.h 2.string.cpp 3.test.cpp 4.一些注意点 本篇博客就学习下如何模拟实现简易版的string类,学好string类后面学习其他容器也会更轻松些。 代码实现如下: 1.string.h #define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include <…...
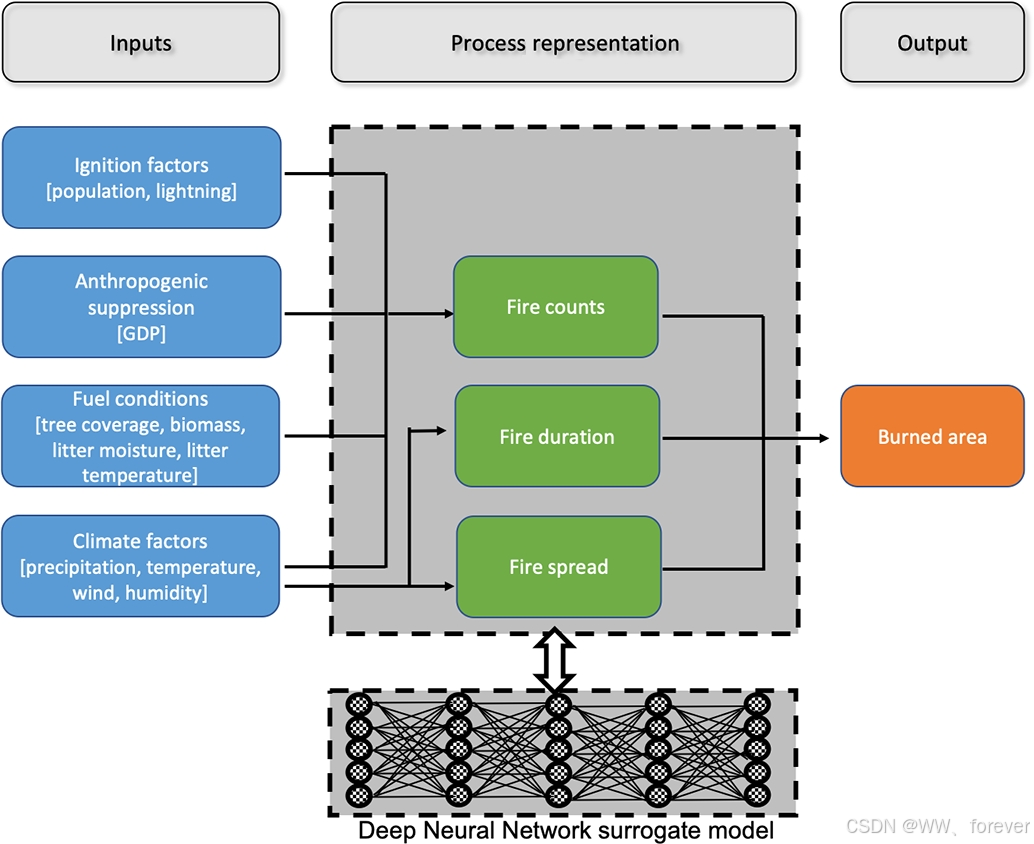
【野火模型】利用深度神经网络替代 ELMv1 野火参数化:机制、实现与性能评估
目录 一、ELMv1 野火过程表示法(BASE-Fire)关键机制野火模拟的核心过程 二、采用神经网络模拟野火过程三、总结参考 一、ELMv1 野火过程表示法(BASE-Fire) ELMv1 中的野火模型(称为 BASE-Fire)源自 Commun…...

红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南
红宝书第四十七讲:Node.js服务器框架解析:Express vs Koa 完全指南 资料取自《JavaScript高级程序设计(第5版)》。 查看总目录:红宝书学习大纲 一、框架定位:HTTP服务器的工具箱 共同功能: 快…...
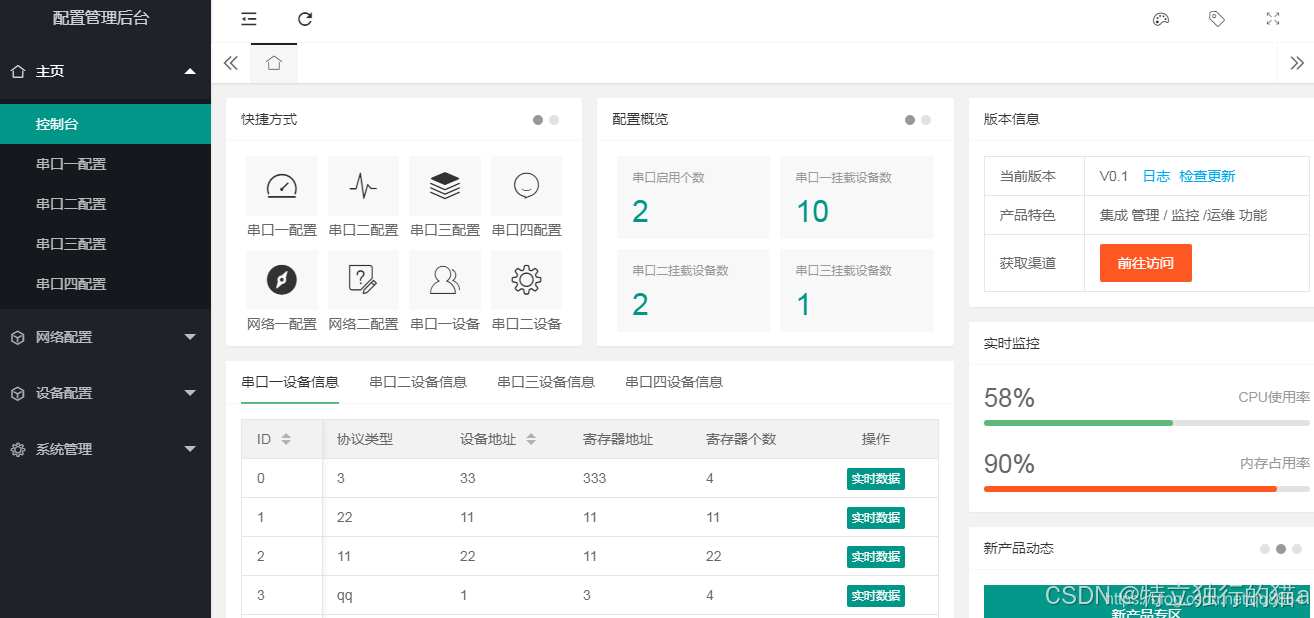
嵌入式Linux设备使用Go语言快速构建Web服务,实现设备参数配置管理方案探究
本文探讨,利用Go语言及gin框架在嵌入式Linux设备上高效搭建Web服务器,以实现设备参数的网页配置。通过gin框架,我们可以在几分钟内创建一个功能完善的管理界面,方便对诸如集中器,集线器等没有界面的嵌入式设备的管理。…...

【NLP 59、大模型应用 —— 字节对编码 bpe 算法】
目录 一、词表的构造问题 二、bpe(byte pair encoding) 压缩算法 算法步骤 示例: 步骤 1:初始化符号表和频率统计 步骤 2:统计相邻符号对的频率 步骤 3:合并最高频的符号对 步骤 4:重复合并直至终止条件 三、bpe在NLP中…...
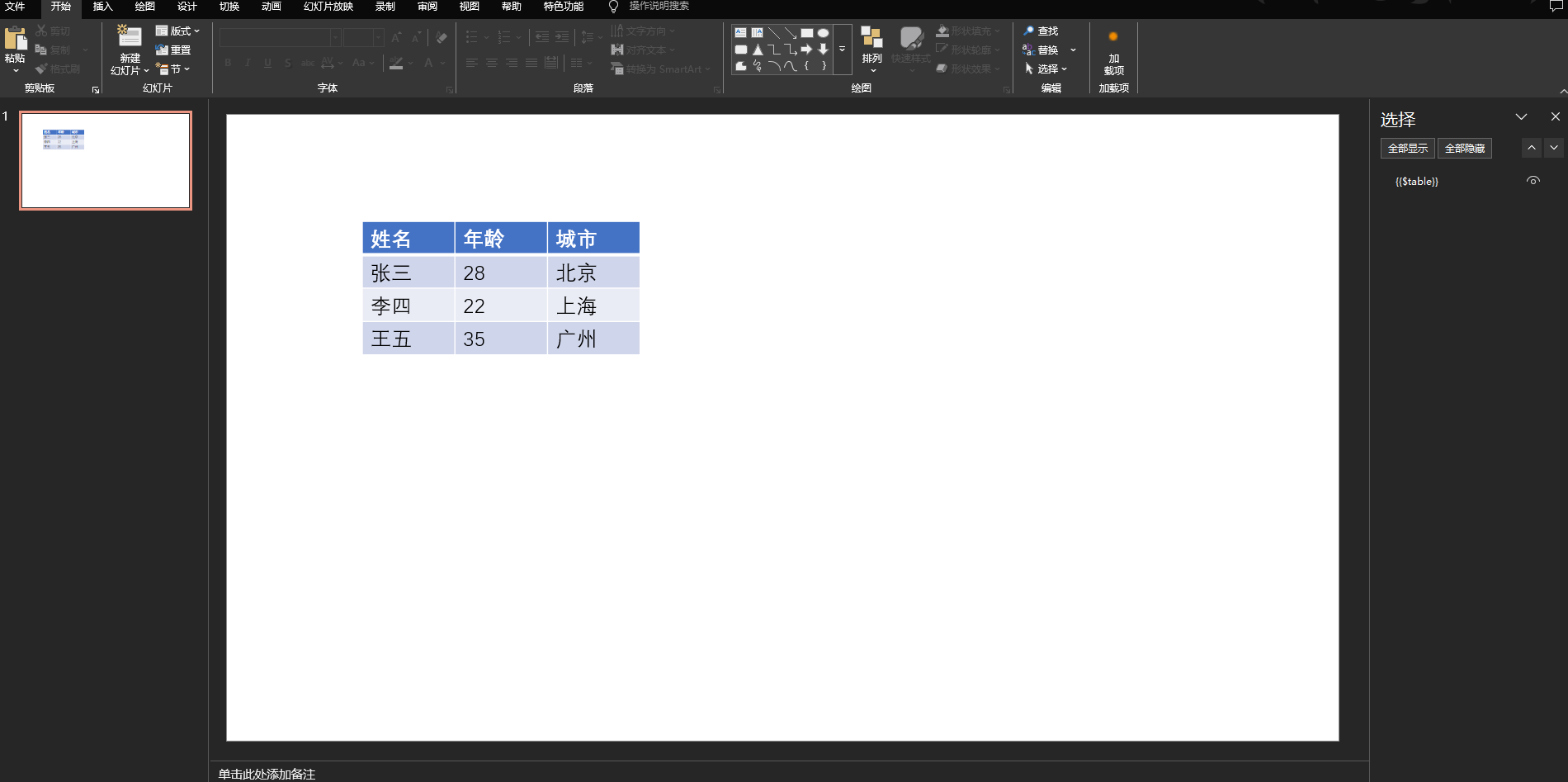
Python对ppt进行文本替换、插入图片、生成表格
目录 1. 安装pptx2. 文本替换和插入图片3. 生成表格 1. 安装pptx pip install python-pptx2. 文本替换和插入图片 文本通过占位符例如{{$xxx}}进行标记,然后进行替换;图片通过ppt中的图形和图片中的占位符进行标记ppt如下 具体实现 from pptx import …...