机器学习(5)——支持向量机
1. 支持向量机(SVM)是什么?
支持向量机(SVM,Support Vector Machine)是一种监督学习算法,广泛应用于分类和回归问题,尤其适用于高维数据的分类。其核心思想是寻找最优分类超平面,使得不同类别的样本间隔(Margin)最大化,从而提高模型的泛化能力。
2. SVM的基本原理
2.1. 核心思想
- 目标: 在特征空间中找到一个超平面(决策边界),使得两类样本的间隔最大化。
- 关键概念:
- 支持向量(Support Vectors): 距离超平面最近的样本点,决定超平面的位置。这些点在定义分类边界时起着至关重要的作用,因此称为“支持向量”
- 间隔(Margin): 支持向量到超平面的距离,越大表示分类器鲁棒性越强。SVM通过最大化这个间隔来选择最佳超平面。
3. 线性可分和非线性可分
-
线性可分: 如果数据可以通过一个直线(二维空间)或超平面(高维空间)分开,则称数据是线性可分的。在这种情况下,SVM能够找到一个线性决策边界。
-
非线性可分: 当数据不是线性可分时,我们可以通过核函数将数据映射到更高维的空间,使得在这个高维空间中数据变得线性可分。这个过程称为核技巧。
4. SVM的数学基础
4.1. 线性可分情况(硬间隔 SVM)
4.1.1. 间隔最大化
-
在二维空间中,我们用一个线性决策边界(直线)来将数据分开。假设数据点可以被线性分开,则可以表示为:
w ⋅ x + b = 0 w⋅x+b=0 w⋅x+b=0 -
其中:
- w w w 是法向量,决定超平面的方向。
- b b b 是偏置项,控制超平面与原点的距离。
- x x x 是数据点。
-
目标是找到一个决策边界,使得不同类别的数据点到该边界的距离尽量远。最大化间隔可以转化为如下的优化问题:
m a x i m i z e 2 ∥ w ∥ maximize \frac{2}{\|w\|} maximize∥w∥2
- 其中, ∥ w ∥ \|w\| ∥w∥是法向量的范数,优化的目标是使这个范数最小化,从而间隔最大化。
4.1.2. SVM 的优化目标
-
假设数据线性可分,SVM 的优化目标是:
最大化间隔 等价于 最小化 1 2 ∥ w ∥ 2 最大化间隔 \ 等价于 \ 最小化 \frac {1}{2}\|w\|^2 最大化间隔 等价于 最小化21∥w∥2 -
约束条件: y i ( w T x i + b ) ≥ 1 , ∀ i y_i(w^T x_i + b) \geq 1, \quad \forall i yi(wTxi+b)≥1,∀i
-
其中
- w w w:是法向量。
- b b b :是偏置项。
- y i ∈ − 1 , + 1 y_i∈{−1,+1} yi∈−1,+1:样本标签。
-
几何解释:
-
超平面方程: w T x + b = 0 w^Tx+b=0 wTx+b=0。
-
支持向量满足 y i ( w T x i + b ) = 1 y_i(w ^Tx_i +b)=1 yi(wTxi+b)=1。
-
3. 线性不可分情况(软间隔 SVM)
当数据存在噪声或轻微重叠时,引入松弛变量(Slack Variables) ξ i ≥ 0 \xi_i≥0 ξi≥0,允许部分样本违反约束:
最大化间隔 等价于 min 1 2 ∥ w ∥ 2 + C ∑ i = 1 N ξ i 最大化间隔 \ 等价于 \min \frac{1}{2} \|w\|^2 + C \sum_{i=1}^{N} \xi_i 最大化间隔 等价于min21∥w∥2+Ci=1∑Nξi
- ξ i \xi_i ξi是松弛变量,表示第 i i i个样本点与分类边界的偏差。
约束条件:
y i ( w T x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 y_i(w^T x_i + b) \geq 1 - \xi_i, \xi_i≥0 yi(wTxi+b)≥1−ξi,ξi≥0
-
参数 C C C:控制分类严格性:
-
C C C 大 → 更严格(可能过拟合)。
-
C C C 小 → 允许更多错误(提高泛化性)。
-
4. 非线性 SVM(核方法)
当数据非线性可分时,通过核函数(Kernel)将数据映射到高维空间,使其线性可分。
常用核函数
- 线性核(无映射):
K ( x i , x j ) = x i T x j K(x_i, x_j) = x_i^T x_j K(xi,xj)=xiTxj - 线性核(无映射):
K ( x i , x j ) = ( x i T x j + c ) d K(x_i, x_j) = (x_i^T x_j + c)^d K(xi,xj)=(xiTxj+c)d - 高斯核(RBF)(最常用):
K ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) K(x_i, x_j) = \exp \left( -\frac{\|x_i - x_j\|^2}{2\sigma^2} \right) K(xi,xj)=exp(−2σ2∥xi−xj∥2)- σ 控制样本间影响范围(小 → 过拟合,大 → 欠拟合)。
- Sigmoid 核:
K ( x i , x j ) = tanh ( α x i T x j + c ) K(x_i, x_j) = \tanh(\alpha x_i^T x_j + c) K(xi,xj)=tanh(αxiTxj+c)
核技巧(Kernel Trick)
- 无需显式计算高维映射 ϕ ( x ) ϕ(x) ϕ(x),直接通过核函数计算内积:
ϕ ( x i ) T ϕ ( x j ) = K ( x i , x j ) \phi(x_i)^T \phi(x_j) = K(x_i, x_j) ϕ(xi)Tϕ(xj)=K(xi,xj)
5. 优化方法(对偶问题)
原始问题转化为拉格朗日对偶问题,通过求解:
max α ∑ i = 1 n α i − 1 2 ∑ i , j α i α j y i y j K ( x i , x j ) \max_{\alpha} \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i,j} \alpha_i \alpha_j y_i y_j K(x_i, x_j) αmaxi=1∑nαi−21i,j∑αiαjyiyjK(xi,xj)
约束:
∑ i = 1 n α i y i = 0 , 0 ≤ α i ≤ C \sum_{i=1}^{n} \alpha_i y_i = 0, \quad 0 \leq \alpha_i \leq C i=1∑nαiyi=0,0≤αi≤C
α i α_i αi:拉格朗日乘子,非零 α i α_i αi 对应支持向量。
最终决策函数:
f ( x ) = sign ( ∑ i ∈ S V α i y i K ( x i , x ) + b ) f(x) = \text{sign} \left( \sum_{i \in SV} \alpha_i y_i K(x_i, x) + b \right) f(x)=sign(i∈SV∑αiyiK(xi,x)+b)
6. 优缺点
-
✅ 优点
-
高维数据有效(尤其适合文本、图像)。
-
核方法处理非线性问题。
-
泛化能力强(最大化间隔)。
-
对过拟合有一定鲁棒性(通过 C C C 控制)。
-
-
❌ 缺点
-
计算复杂度高(训练时间随样本数增长)。
-
对参数( C C C、核参数)敏感。
-
不直接提供概率输出(需额外校准)。
-
7. Python 示例(Scikit-learn)
7.1. 线性 SVM
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 训练线性SVM(C=1.0)
model = SVC(kernel='linear', C=1.0)
model.fit(X_train, y_train)# 评估
print("Accuracy:", model.score(X_test, y_test))
7.2. 非线性 SVM(RBF 核)
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 训练RBF核SVM(C=1.0, gamma='scale')
model = SVC(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train_scaled, y_train)# 预测
print("Accuracy:", model.score(X_test_scaled, y_test))
7.3. 支持向量可视化
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay# 仅用前两特征简化可视化
X_2d = X[:, :2]
model = SVC(kernel='linear').fit(X_2d, y)disp = DecisionBoundaryDisplay.from_estimator(model, X_2d, response_method="predict",plot_method="pcolormesh", alpha=0.3,
)
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y, edgecolor='k')
plt.title("SVM Decision Boundary")
plt.show()
8. 关键参数调优
-
C C C:平衡分类严格性与泛化能力。
- 网格搜索:GridSearchCV(param_grid={‘C’: [0.1, 1, 10]})
-
核函数选择:
-
线性:kernel=‘linear’
-
RBF:kernel=‘rbf’(需调 gamma)
-
-
γ γ γ(RBF核):
- 小 → 决策边界平滑,大 → 复杂(过拟合风险)。
9. 总结
-
SVM 核心:最大化间隔的超平面,支持核方法处理非线性。
-
关键参数:
-
正则化参数 C C C。
-
核函数类型(RBF/线性/多项式)。
-
RBF 核的 γ γ γ。
-
-
适用场景:
-
中小规模高维数据(如文本分类、图像识别)。
-
需强泛化能力的分类任务。
-
相关文章:
——支持向量机)
机器学习(5)——支持向量机
1. 支持向量机(SVM)是什么? 支持向量机(SVM,Support Vector Machine)是一种监督学习算法,广泛应用于分类和回归问题,尤其适用于高维数据的分类。其核心思想是寻找最优分类超平面&am…...

访问不到服务器上启动的llamafactory-cli webui
采用SSH端口转发有效,在Windows上面进行访问 在服务器上启动 llamafactory-cli webui 后,访问方式需根据服务器类型和网络环境选择以下方案: 一、本地服务器(物理机/虚拟机) 1. 直接访问 若服务器与操作设备处于同一…...
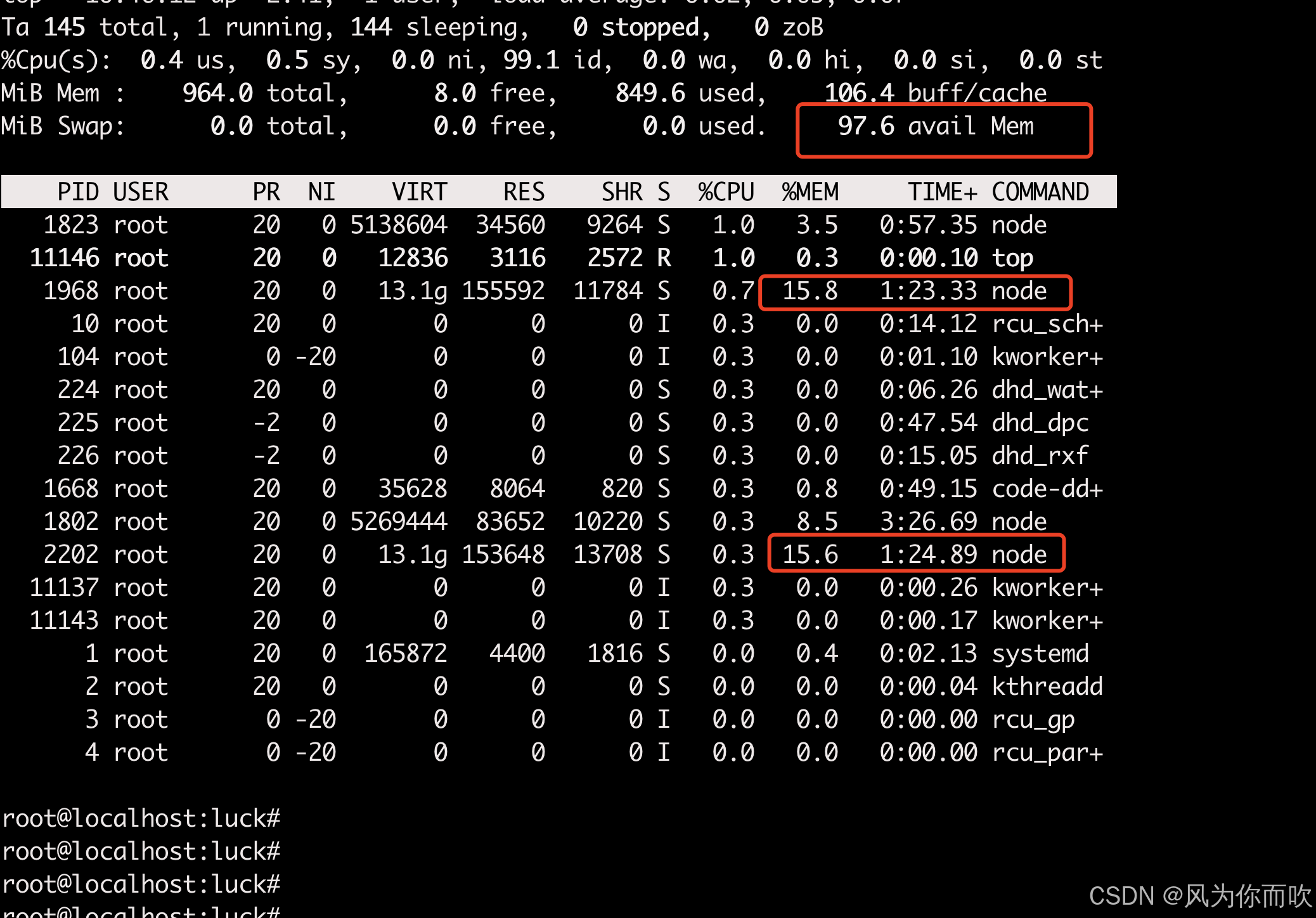
【玩泰山派】MISC(杂项)- 使用vscode远程连接泰山派进行开发
文章目录 前言流程1、安装、启动sshd2、配置一下允许root登录3、vscode中配置1、安装remote插件2、登录 **注意** 前言 有时候要在开发板中写一写代码,直接在终端中使用vim这种工具有时候也不是很方便。这里准备使用vscode去通过ssh远程连接泰山派去操作࿰…...

量子纠缠物理本质、技术实现、应用场景及前沿研究
以下是关于 量子纠缠(Quantum Entanglement) 的深度解析,涵盖物理本质、技术实现、应用场景及前沿研究,以技术视角展开: 一、量子纠缠的物理本质 1. 核心定义 量子纠缠是多个量子系统(如粒子)间的一种关联状态,表现为: 非局域性:纠缠态粒子无论相距多远,测量其中一…...

Spring Boot中接入DeepSeek的流式输出
第一步,添加依赖: <!-- WebFlux 响应式支持 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId> </dependency> 第二步,配置We…...

同步/异步日志系统
同步/异步日志系统 项目演示基础测试性能测试测试环境:同步日志器单线程同步日志器多线程异步日志器单线程异步日志器多线程 工具类(util.hpp)日志等级level.hpp 日志消息message.hpp 日志消息格式化formatter.hpp 日志消息落地sink.hpp 日志…...
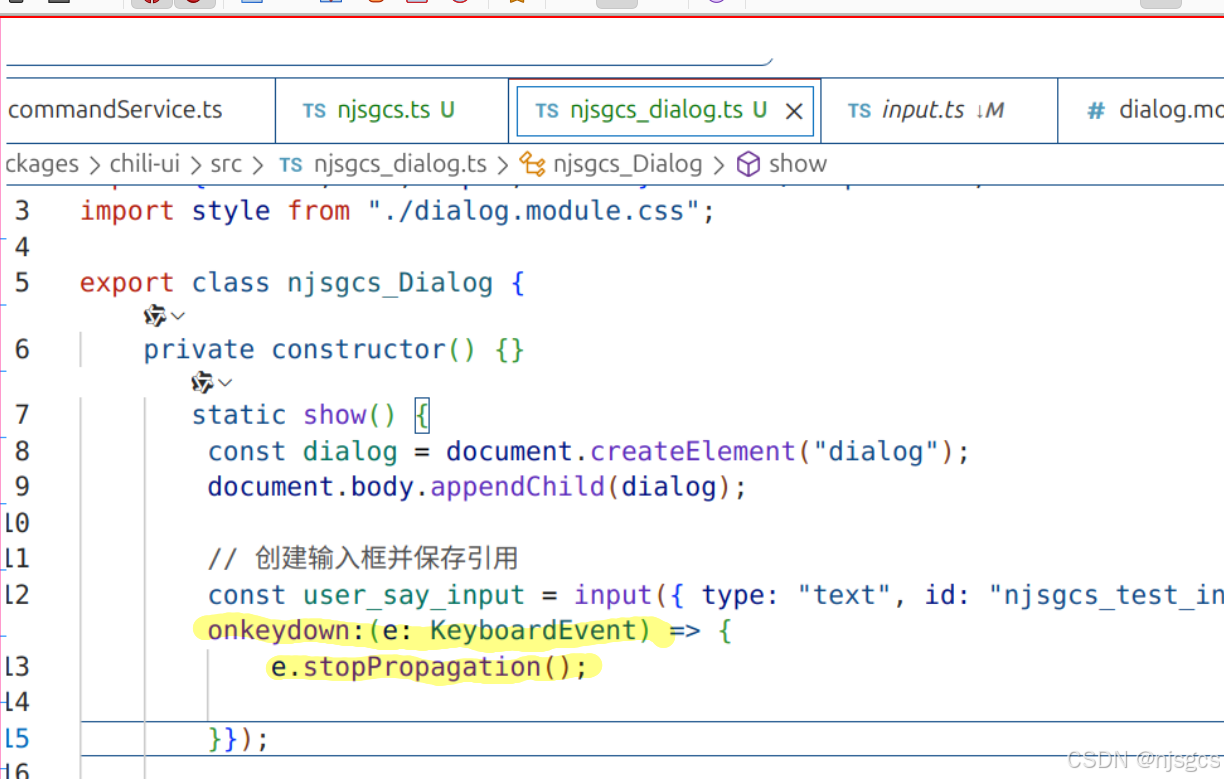
typescript html input无法输入解决办法
input里加上这个: onkeydown:(e: KeyboardEvent) > {e.stopPropagation();...

游戏引擎学习第224天
回顾游戏运行并指出一个明显的图像问题。 回顾一下之前那个算法 我们今天要做一点预加载的处理。上周刚完成了游戏序章部分的所有剪辑内容。在运行这一部分时,如果观察得足够仔细,就会注意到一个问题。虽然因为视频流压缩质量较低,很难清楚…...

SAP-ABAP:SAP HANA高可用与灾备——存储镜像与系统复制的核心技术
SAP HANA作为企业关键业务的核心数据库,其高可用性(High Availability, HA)与灾备(Disaster Recovery, DR)能力直接影响业务连续性。HANA通过存储镜像、系统复制及集群集成三大核心技术,实现秒级故障切换与…...

工厂能耗系统智能化解决方案 —— 安科瑞企业能源管控平台
安科瑞顾强 政策背景与“双碳”战略驱动 2025年《政府工作报告》明确提出“单位国内生产总值能耗降低3%左右”的目标,要求通过产业结构升级(如高耗能行业技术革新或转型)、能源结构优化(提高非化石能源占比)及数字化…...

【pytorch图像视觉】lesson17深度视觉应用(上)构建自己的深度视觉项目
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、 数据1、认识经典数据1.1入门数据:MNIST、其他数字与字母识别(1)数据下载(2)查看数据的特征和标…...

java中的Future的设计模式 手写一个简易的Future
案例 例如:今天是小妹的生日,需要一个蛋糕有点仪式感,于是去蛋糕店预定,预定完之后,店老板说蛋糕做好了,到时电话通知你,不可能在这傻傻的等着吧,还有其他事情要做啊,于…...
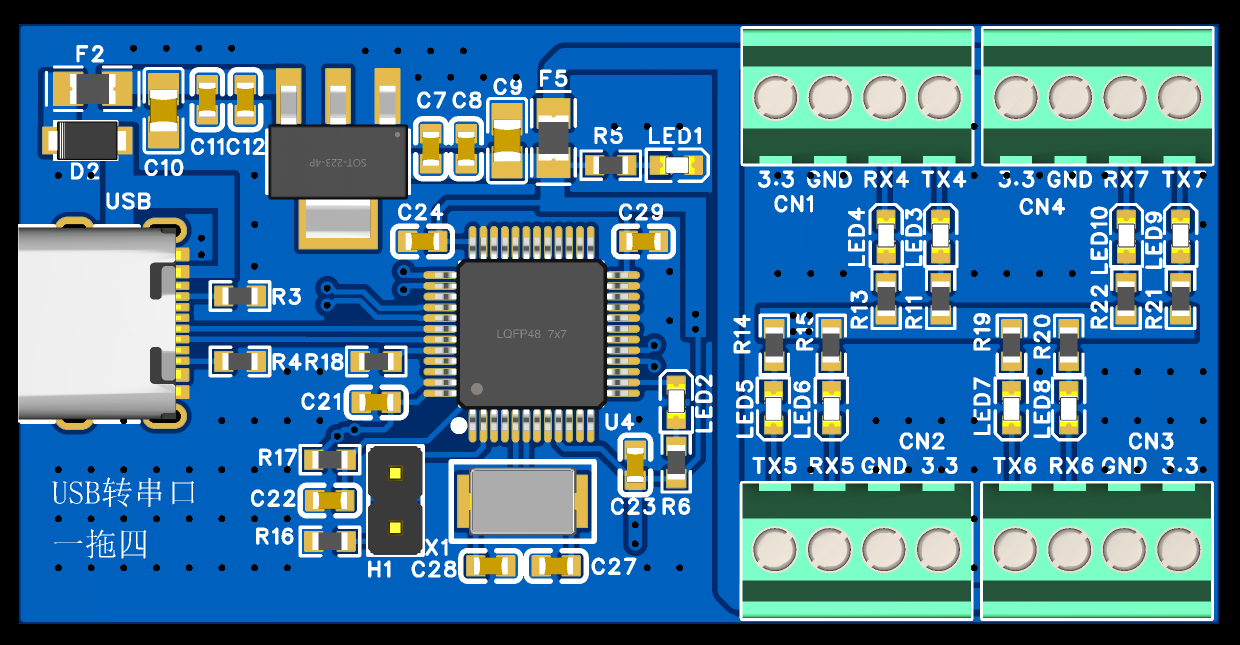
USB(TYPE-C)转串口(TTL)模块设计讲解
目录 一 、引言 二、方案设计 三、USB TYPE-C介绍 1、TYPE-C接口定义 1、24P全引脚描述 2、Type C 接口 VBUS/GND 作用 3、Type C 接口 D/D- 作用 1、数据传输: 2、设备识别: 3、充电协议协商: 4、Type C 接口 CC1/CC2 作用 1、主从设备区…...

JavaScript | ajax实现原理
在早期,web应用,更多采用mvc框架,通过后端输出整个页面的内容,然后再用浏览器进行渲染,这样效率不高,对于事件绑定来说比较麻烦,于是提出了ajax,其最大的特点就是能实现局部更新。通…...

PyTorch张量操作指南:cat、stack、split与chunk的实战拆解
本文深入探讨PyTorch中用于调整张量结构的四个核心函数——torch.cat、torch.stack、torch.split和torch.chunk。通过实际应用场景分析和代码演示,帮助读者掌握它们的功能差异及适用条件,提升模型开发的灵活性与效率。 在深度学习实践中,张量…...

YOLO涨点技巧之分层扩展路径聚合网络 (HEPAN)
一、应用场景与问题背景 1.1 无人机图像检测挑战 https://ai-studio-static-online.cdn.bcebos.com/3d4f7e8c4d8d4d2d8a4c8e4b4e8c4d8d 场景特点:无人机航拍视角下的小目标检测(如行人、车辆、农作物病害等)核心难点: 目标尺寸小(<3232像素)复杂背景干扰(如城市…...

SQLite、MySQL、SQL Server、Oracle 和 PostgreSQL 五种数据库的区别
以下是 SQLite、MySQL、SQL Server、Oracle 和 PostgreSQL 五种主流关系型数据库管理系统(RDBMS)的区别,从多个维度进行对比: 1. 架构与部署 SQLite(Structured Query Language Lite): 嵌入式数据库,无服务器架构。数据库存储在一个单一的磁盘文件中。部署简单,适合轻量…...

git在分支上会退到某个指定的commit
1、在idea上先备份好分支(基于现有分支new branch) 2、在gitlab管理端删除现有分支 3、在idea中大卡terminal,执行 git log 查看commit log ,找到要会退到的commit唯一码,然后执行git reset 唯一码 4、查看本地代码状态 git st…...

玩机进阶教程----MTK芯片设备刷机导致的死砖修复实例解析 连电脑毫无反应 非硬件问题
在高通芯片机型中,我们可以通过短接主板测试点来激活高通芯片特有的9008底层端口来刷写救砖固件。但通常MTK芯片类的设备联机电脑即可触发深刷模式。但有些例外的情况会导致链接电脑毫无反应。遇到类似故障的友友可以参阅此博文尝试解决。 通过博文了解 1💝💝💝-----实…...
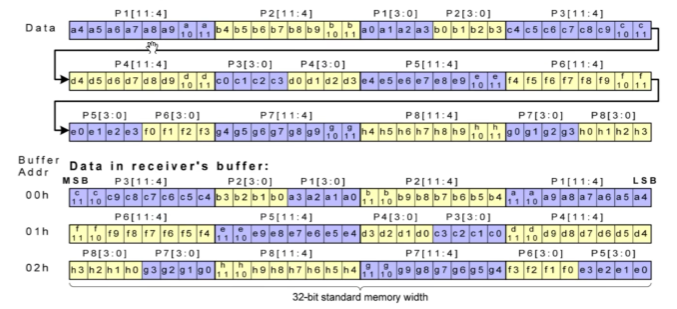
MIPI协议介绍
MIPI协议介绍 mipi 协议分为 CSI 和DSI,两者的区别在于 CSI用于接收sensor数据流 DSI用于连接显示屏 csi分类 csi 分为 csi2 和 csi3 csi2根据物理层分为 c-phy 和 d-phy, csi-3采用的是m-phy 一般采用csi2 c-phy 和 d-phy的区别 d-phy的时钟线和数据线是分开的,2根线一对…...

MySQL 中 `${}` 和 `#{}` 占位符详解及面试高频考点
文章目录 一、概述二、#{} 和 ${} 的核心区别1. 底层机制代码示例 2. 核心区别总结 三、为什么表名只能用 ${}?1. 预编译机制的限制2. 动态表名的实现 四、安全性注意事项1. ${} 的风险场景2. 安全实践 五、面试高频考点1. 基础原理类问题**问题 1**:**问…...

AI应用开发平台 和 通用自动化工作流工具 的详细对比,涵盖定义、核心功能、典型工具、适用场景及优缺点分析
以下是 AI应用开发平台 和 通用自动化工作流工具 的详细对比,涵盖定义、核心功能、典型工具、适用场景及优缺点分析: 1. AI应用开发平台 vs 通用自动化工作流工具 (1) 定义与目标 类型AI应用开发平台通用自动化工作流工具定义用于快速构建、训练、部署…...
)
GitHub 趋势日报 (2025年04月12日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1yeongpin/cursor-free-vip[Support 0.48.x](Reset Cursor AI MachineID & Auto Sign Up / In & Bypass Higher…...

asm汇编源代码之-字库转换程序
将标准的16x16点阵汉字库(下载16x16汉字库)转换成适合VGA文本模式下显示的点阵汉字库 本程序需要调用file.asm中的子程序,所以连接时需要把file连接进来,如下 C:\> tlink chghzk file 调用参数描述如下 C:\> chghzk ; 无调用参数,转换标准库文件(SRC16.FNT)为适合VGA…...

VMware Ubuntu挂载Windows机器的共享文件
https://www.dong-blog.fun/post/2029 在VMware Ubuntu中访问Windows共享文件夹:完整指南 在使用VMware运行Ubuntu虚拟机时,访问Windows主机上的文件是常见需求。本文将详细介绍如何通过网络共享方式,让Ubuntu虚拟机直接访问Windows主机的文…...
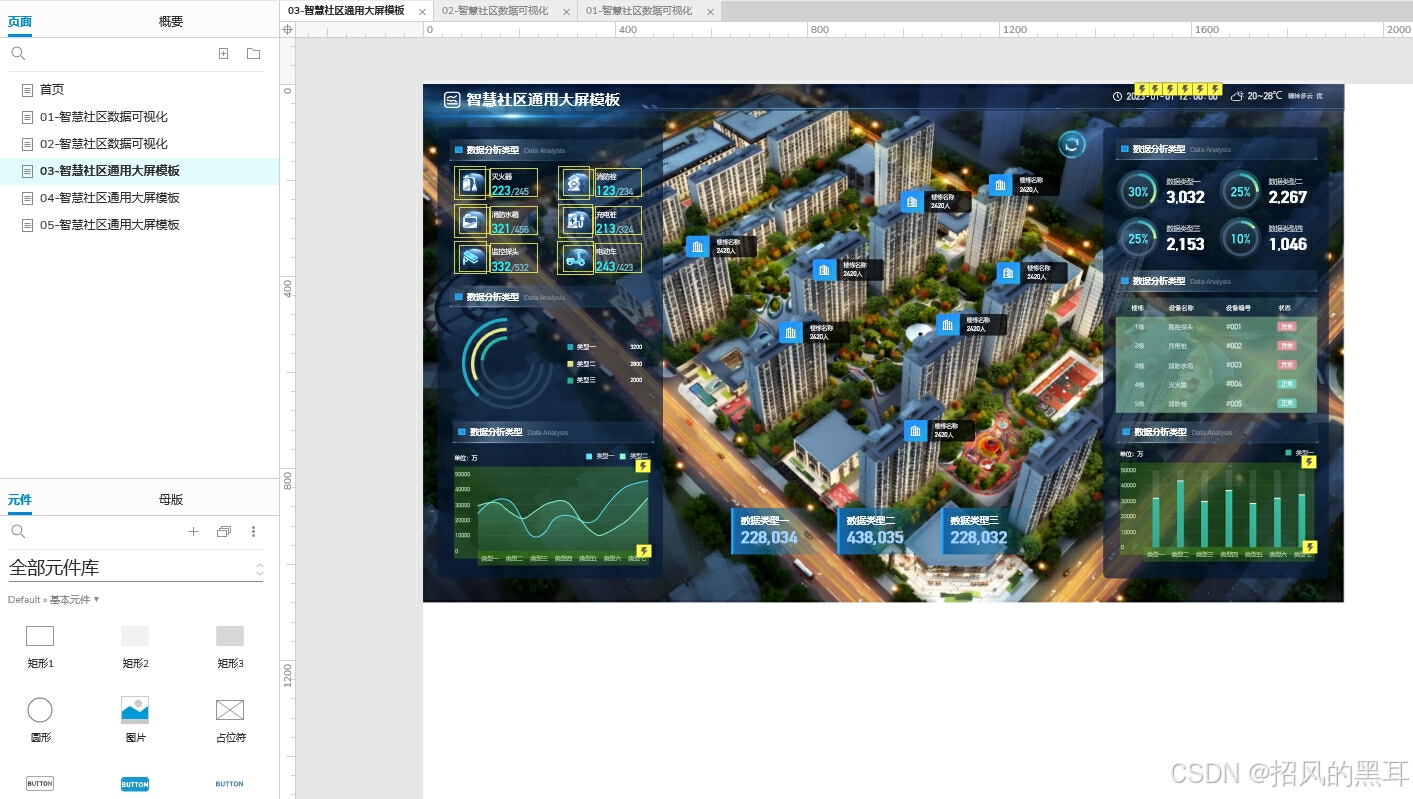
智慧社区数据可视化中枢平台——Axure全场景交互式大屏解决方案
在数字化治理的时代浪潮中,社区管理正面临数据碎片化、响应滞后、决策盲区等核心挑战。如何将分散的安防、环境、能源、民生服务等数据整合为可操作的智慧洞察?如何让冰冷的数字转化为社区管理者手中的决策利器?Axure智慧社区可视化大屏原型模…...
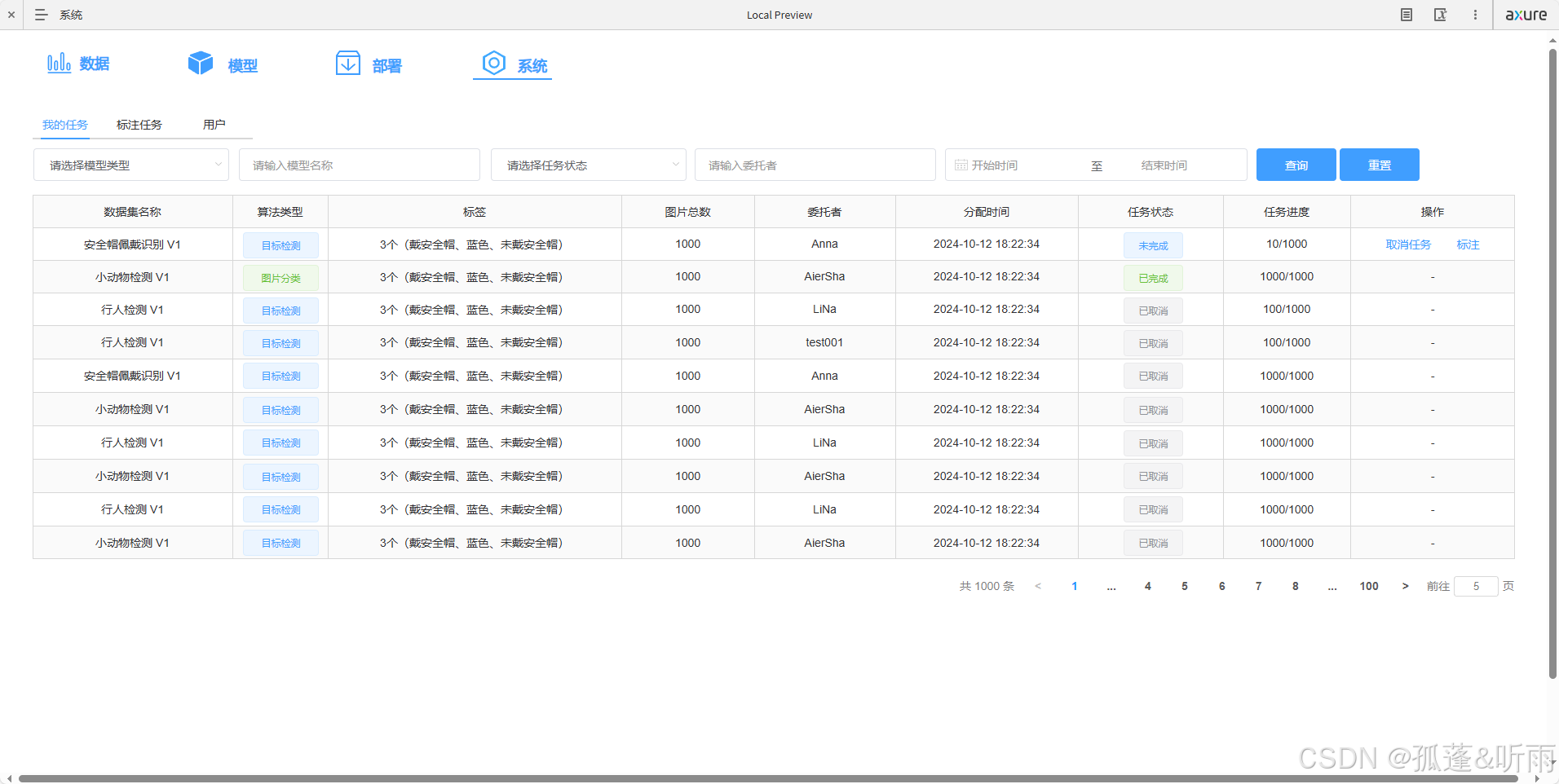
Axure高保真AI算法训练平台
点击下载《Axure高保真AI算法训练平台(.rp) 》 原型效果:https://axhub.im/ax9/69fdf8f2b10b59c3/#g1 摘要 本文介绍了一款功能全面且高效的AI算法训练平台,旨在为数据科学家、研究人员和工程师提供从数据准备到模型部署的一站式解决方案。该平台由四大…...
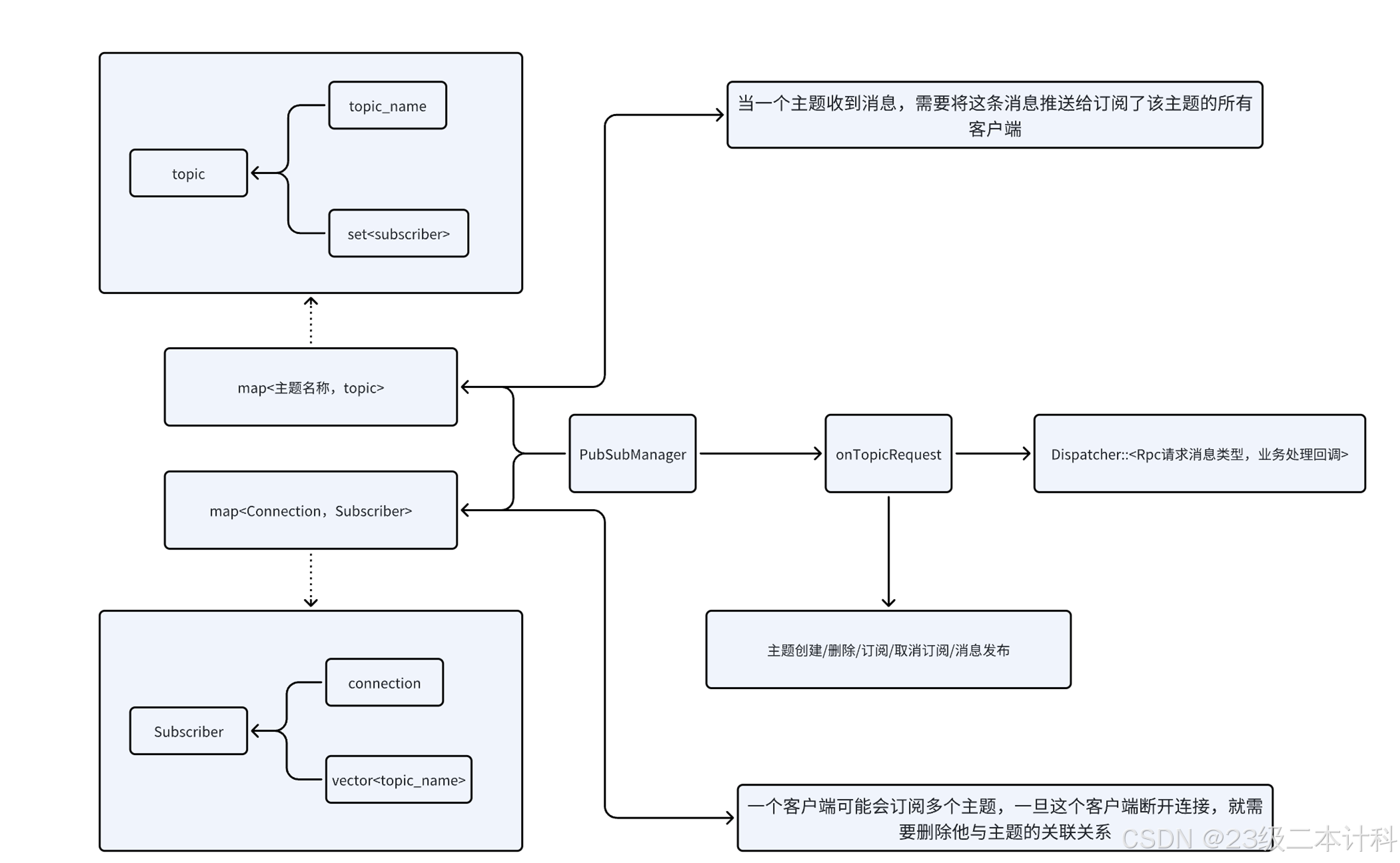
C++ Json-Rpc框架-3项目实现(2)
一.消息分发Dispatcher实现 Dispatcher 就是“消息分发中枢”:根据消息类型 MType,把消息派发给对应的处理函数(Handler)执行。 初版: #pragma once #include "net.hpp" #include "message.hpp"n…...

youtube视频和telegram视频加载原理差异分析
1. 客户侧缓存与流式播放机制 流式视频应用(如 Netflix、YouTube)通过边下载边播放实现流畅体验,其核心依赖以下技术: 缓存预加载:客户端在后台持续下载视频片段(如 DASH/HLS 协议的…...

LLM小白自学笔记:1.两种指令微调
一、LoRA 简单来说,LoRA不直接调整个大模型的全部参数(那样太费资源),而是在模型的某些层(通常是注意力层)加个“旁路”——两个小的矩阵(低秩矩阵)。训练时只更新这俩小矩阵&#x…...