基于CNN+ViT的蔬果图像分类实验
本文只是做一个简单融合的实验,没有任何新颖,大家看看就行了。
1.数据集
本文所采用的数据集为Fruit-360 果蔬图像数据集,该数据集由 Horea Mureșan 等人整理并发布于 GitHub(项目地址:Horea94/Fruit-Images-Dataset),广泛应用于图像分类和目标识别等计算机视觉任务。该数据集共包含141 类水果和蔬菜图像,总计 94,110 张图像,每张图像的尺寸统一为 100×100 像素,且背景已统一处理为白色背景,以减少背景噪声对模型训练的影响。
数据集中涵盖了大量常见和不常见的果蔬品类,主要包括:
- 苹果(多个品种:如深雪、金苹果、金红、青奶奶、粉红女士、红苹果、红美味等)
- 香蕉(黄色、红色、淑女手指等)
- 葡萄(蓝色、粉红色、白色多个品种)
- 柑橘类(橙子、柠檬、酸橙、葡萄柚、柑橘等)
- 热带水果(芒果、木瓜、红毛丹、百香果、番石榴、荔枝、菠萝、火龙果等)
- 浆果类(蓝莓、覆盆子、草莓、黑加仑、红醋栗、桑葚等)
- 核果类与坚果类(桃子、李子、杏、椰子、榛子、核桃、栗子、山核桃等)
- 蔬菜类(黄瓜、茄子、胡椒、番茄、洋葱、花椰菜、甜菜根、玉米、土豆等)
- 其他类如:仙人掌果实、杨布拉、姜根、格兰纳迪拉、Physalis(灯笼果)、油桃、佩皮诺、罗望子、大头菜等。
在数据划分方面,本研究按照如下比例进行数据集划分:
(1)训练集:70,491 张图像
其中按照 8:2 的比例划分出验证集,得到最终:
训练子集:56,432 张
验证集:14,059 张
(2)测试集:23,619 张图像

2.模型简述
在图像分类任务中,深度学习方法已经取得了显著的进展,如残差神经网络(ResNet),Vision Transformer展现了较强的性能。ResNet作为CNN下的网络架构,在局部特征提取方面具有优势,能够有效地捕捉图像中的空间结构信息。而Vision Transformer作为Transformer的变种,在捕捉全局依赖关系和建模长程依赖性方面的具有更好的优势。
由于CNN的卷积操作本质上能够生成具有空间局部关联性的特征图,实际上可以视为一种变相的patch操作。因此,在将CNN与Transformer相结合时,可以避免传统ViT中对输入图像进行切分patch的操作,只需对图像进行位置编码,从而使得Transformer能够有效处理这些具有空间结构的特征图。这种设计不仅减少了计算开销,还使得整个模型在处理图像时更具效率与准确性。
同时,与原始ViT框架中描述的技术不同,原始框架通常会将一个可学习的位置嵌入向量预先添加到编码后的patch序列中,作为图像的位置信息进行表示。然而,为了简化模型的实现并提高计算效率,本文在架构设计上有所调整,省略了额外的位置编码步骤。具体来说,本文的模型通过直接输入编码后的patch序列到Transformer块中,跳过了对每个patch进行独立位置编码的操作。
基于这一思路,结合了残差神经网络(ResNet)和Vision Transformer(ViT)两种网络架构,将它们以串行连接的方式进行融合。具体模型架构图如下图所示
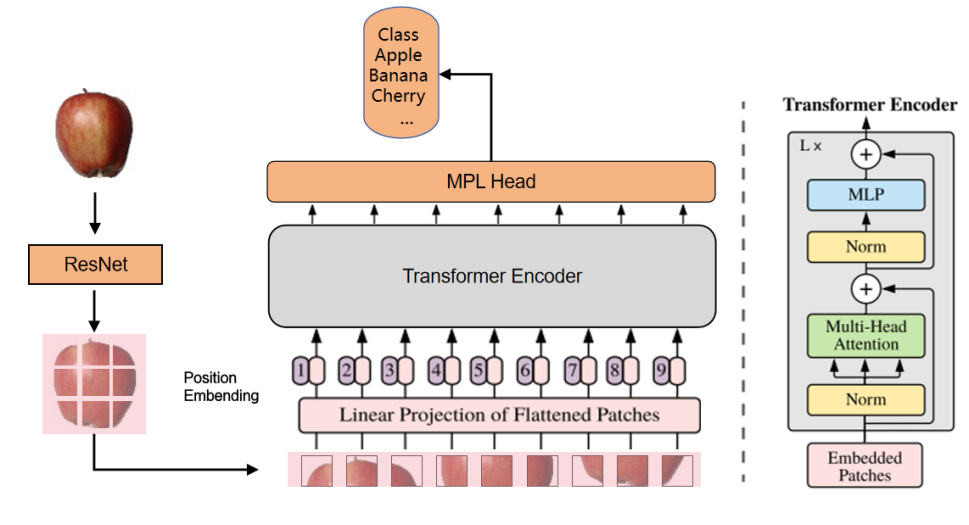
3.实验
模型代码(基于tensorflow2.X)
import glob
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers,models
import warnings
warnings.filterwarnings('ignore')
import osTrain = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Training"
Test = r"D:\archive (1)\fruits-360_dataset_100x100\fruits-360\Test"IMAGE_SIZE = 100
NUM_CLASSES = 141
BATCH_SIZE = 32imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0, validation_split=0.2, rotation_range=10, horizontal_flip=True)# Training and validation data generators
Train_Data = imagegenerator.flow_from_directory(Train,target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',subset='training'
)
Validation_Data = imagegenerator.flow_from_directory(Train,target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',subset='validation'
)# Test data generator (no augmentation)
test_imagegenerator = ImageDataGenerator(rescale=1.0 / 255.0)
Test_Data = test_imagegenerator.flow_from_directory(Test,target_size=(IMAGE_SIZE,IMAGE_SIZE),batch_size=BATCH_SIZE,class_mode='categorical',# subset='test'
)
class ResidualBlock(layers.Layer):def __init__(self, filters, kernel_size=(3, 3), strides=1):super(ResidualBlock, self).__init__()self.conv1 = layers.Conv2D(filters, kernel_size, strides=strides, padding="same", activation='relu')self.conv2 = layers.Conv2D(filters, kernel_size, strides=1, padding='same', activation='relu')self.shortcut = layers.Conv2D(filters, (1, 1), strides=strides, padding='same', activation='relu')self.bn1 = layers.BatchNormalization()self.bn2 = layers.BatchNormalization()self.relu = layers.ReLU()def call(self, inputs):x = self.conv1(inputs)x = self.bn1(x)x = self.relu(x)x = self.conv2(x)x = self.bn2(x)shortcut = self.shortcut(inputs)x = layers.add([x, shortcut])x = self.relu(x)return x# ResNet Model definition
class ResNetModel(layers.Layer):def __init__(self):super(ResNetModel, self).__init__()self.conv1 = layers.Conv2D(32, (5, 5), activation='relu', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),padding='same')self.maxpool1 = layers.MaxPooling2D((2, 2))# Residual Blocksself.resblock1 = ResidualBlock(32,strides=1)self.resblock2 = ResidualBlock(64,strides=2)self.resblock3 = ResidualBlock(128,strides=2)self.resblock4 = ResidualBlock(256, strides=2)# self.global_avg_pool = layers.GlobalAveragePooling2D()def call(self, inputs):print(inputs.shape)x = self.conv1(inputs)print(x.shape)x = self.maxpool1(x)print(x.shape)# Apply Residual Blocksx = self.resblock1(x)print(x.shape)x = self.resblock2(x)print(x.shape)# x = self.resblock3(x)# print(x.shape)# x = self.resblock4(x)# x = self.global_avg_pool(x)# print(x.shape)return x
class TransformerEncoder(layers.Layer):def __init__(self, num_heads=8, key_dim=64, ff_dim=256, dropout_rate=0.1):super(TransformerEncoder, self).__init__()self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=key_dim)self.dropout1 = layers.Dropout(dropout_rate)self.norm1 = layers.LayerNormalization()self.ff = layers.Dense(ff_dim, activation='relu')self.ff_output = layers.Dense(key_dim*num_heads)self.dropout2 = layers.Dropout(dropout_rate)self.norm2 = layers.LayerNormalization()def call(self, x):# Multi-head self-attentionattention_output = self.attention(x, x)attention_output = self.dropout1(attention_output)x = self.norm1(attention_output + x) # Residual connection# Feed Forward Networkff_output = self.ff(x)ff_output = self.ff_output(ff_output)ff_output = self.dropout2(ff_output)x = self.norm2(ff_output + x) # Residual connectionreturn x# Vision Transformer (ViT) 模型
class VisionTransformer(models.Model):def __init__(self, input_shape=(100, 100, 3), num_classes=141, num_encoders=3, patch_size=8, num_heads=16,key_dim=4, ff_dim=256, dropout_rate=0.2):super(VisionTransformer, self).__init__()self.patch_size = patch_size#Resnetself.resnet=ResNetModel()# Patch Embeddingself.conv = layers.Conv2D(64, (patch_size, patch_size), strides=(patch_size, patch_size), padding='valid')self.reshape = layers.Reshape((-1, 64))self.norm = layers.LayerNormalization()# 位置编码层self.position_encoding = self.add_weight("position_encoding", shape=(1, 625, 64))# Stack multiple Transformer Encoder layersself.encoders = [TransformerEncoder(num_heads=num_heads, key_dim=key_dim, ff_dim=ff_dim, dropout_rate=dropout_rate) for _ inrange(num_encoders)]# Global Average Poolingself.global_avg_pooling = layers.GlobalAveragePooling1D()# Fully connected layerself.fc1 = layers.Dense(256, activation='relu')self.dropout = layers.Dropout(0.2)self.fc2 = layers.Dense(num_classes, activation='softmax')def call(self, inputs):#resnetx = self.resnet(inputs)# print("===========================")# print(x.shape)# Patch Embeddingx = self.reshape(x)# 添加位置编码x = x + self.position_encoding # 将位置编码加到Patch嵌入向量中# print(x.shape)# x = self.norm(x)# Apply multiple Transformer encodersfor encoder in self.encoders:x = encoder(x)# Global Average Poolingx = self.global_avg_pooling(x)# Fully connected layersx = self.fc1(x)x = self.dropout(x)x = self.fc2(x)return x
# 构建 Vision Transformer 模型vit_model = VisionTransformer(input_shape=(100, 100, 3), num_classes=141, num_encoders=3)
vit_model.build(input_shape=(None, IMAGE_SIZE, IMAGE_SIZE, 3)) # 手动构建模型
# 打印模型摘要
vit_model.summary()
# 编译模型
vit_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss='categorical_crossentropy',metrics=['accuracy']
)
checkpoint_path = "training_checkpoints_1/vit_model_checkpoint_epoch_{epoch:02d}.h5"# 创建ModelCheckpoint回调
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,monitor='val_accuracy', # 你可以选择监控验证集的损失或准确度save_best_only=True, # 只保存验证集损失最小的模型save_weights_only=True, # 只保存权重(而不是整个模型)verbose=1 # 打印日志
)
# 检查是否有保存的模型权重文件
checkpoint_dir = "training_checkpoints_1/"
# 查找所有的 .h5 文件
checkpoint_files = glob.glob(os.path.join(checkpoint_dir, "vit_model_checkpoint_epoch_*.h5"))
# print(latest_checkpoint)
if checkpoint_files:# 使用 os.path.getctime() 获取文件创建时间(或者使用 getmtime() 获取修改时间)latest_checkpoint = max(checkpoint_files, key=os.path.getctime)print(f"Loading model from checkpoint: {latest_checkpoint}")# 加载模型权重vit_model.load_weights(latest_checkpoint)
else:print("No checkpoint found, starting from scratch.")# 训练模型
history = vit_model.fit(Train_Data,epochs=20,validation_data=Validation_Data,shuffle=True,callbacks=[checkpoint_callback]
)# 评估模型
test_loss, test_acc = vit_model.evaluate(Test_Data)
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_acc}")
# 训练和验证的准确率和损失历史记录
def plot_training_history(history):# 创建子图plt.figure(figsize=(14, 6))# 准备训练准确率和验证准确率的图plt.subplot(1, 2, 1)plt.title('Accuracy History')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.plot(history.history['accuracy'], label='Training Accuracy', marker='o')plt.plot(history.history['val_accuracy'], label='Validation Accuracy', color='green', marker='o')plt.legend()# 准备训练损失和验证损失的图plt.subplot(1, 2, 2)plt.title('Loss History')plt.xlabel('Epochs')plt.ylabel('Loss')plt.plot(history.history['loss'], label='Training Loss', marker='o')plt.plot(history.history['val_loss'], label='Validation Loss', color='green', marker='o')plt.legend()# 显示图形plt.tight_layout()plt.show()# 绘制训练过程
plot_training_history(history)
for i in range(16):# 获取测试数据的下一个批次img_batch, labels_batch = Test_Data.next()img = img_batch[0] # 获取当前批次的第一张图像true_label_idx = np.argmax(labels_batch[0]) # 获取真实标签的索引# 获取真实标签的名称true_label = [key for key, value in Train_Data.class_indices.items() if value == true_label_idx]# 扩展维度以匹配模型输入EachImage = np.expand_dims(img, axis=0)# 进行预测prediction = vit_model.predict(EachImage)# 获取预测标签predicted_label = [key for key, value in Train_Data.class_indices.items() ifvalue == np.argmax(prediction, axis=1)[0]]# 获取预测的概率predicted_prob = np.max(prediction, axis=1)[0]# 绘制图像plt.subplot(4, 4, i + 1)plt.imshow(img)plt.title(f"True: {true_label[0]} \nPred: {predicted_label[0]} \nProb: {predicted_prob:.2f}")plt.axis('off')plt.tight_layout()
plt.show()做了如下参数实验
| ResNet层数 | Encoder层数 | num_heads | test_accuracy |
| 2(32,64) | 3 | 4 | 92.14% |
| 3(32,64,128) | 3 | 4 | 94.53% |
| 2(32,64) | 3 | 8 | 96.19% |
| 3(32,64,128) | 3 | 8 | 97.46% |
| 2(32,64) | 3 | 16 | 93.32% |
| 3(32,64,128) | 3 | 16 | 93.17% |
分类效果图

相关文章:
基于CNN+ViT的蔬果图像分类实验
本文只是做一个简单融合的实验,没有任何新颖,大家看看就行了。 1.数据集 本文所采用的数据集为Fruit-360 果蔬图像数据集,该数据集由 Horea Mureșan 等人整理并发布于 GitHub(项目地址:Horea94/Fruit-Images-Datase…...
结构体(3)-arkts)
高级语言调用C接口(五)结构体(3)-arkts
上一篇文章提到了,arkts和C接口之前还有一个Napi层,这层代码最大的优势就是C/C编码,这样,我们只需要把数据通过Json格式传递到Napi层,Napi层再定义一个结构体并赋值即可。arkts层是TypeScript代码,想定义成…...
【虚幻C++笔记】接口
目录 概述创建接口 概述 简单的说,接口提供一组公共的方法,不同的对象中继承这些方法后可以有不同的具体实现。任何使用接口的类都必须实现这些接口。实现解耦解决多继承的问题 创建接口 // Fill out your copyright notice in the Description page o…...
【MCP】第一篇:MCP协议深度解析——大模型时代的“神经连接层“架构揭秘
【MCP】第一篇:MCP协议深度解析——大模型时代的"神经连接层"架构揭秘 一、什么是MCP?二、为什么需要MCP?三、MCP的架构四、MCP与AI交互的原理4.1 ReAct(Reasoning Acting)模式4.2 Function Calling 模式 五…...
实时模式下 libaom 与 x264 编码对比实验
前沿 理论基础:在相同视频质量下,AV1的压缩率比H.264高约30%-50%。实时模式:视频编码中的实时模式,其核心目标是平衡编码效率与延迟要求,尤其在视频会议、直播、实时通信等场景中至关重要。 低延迟要求:编…...
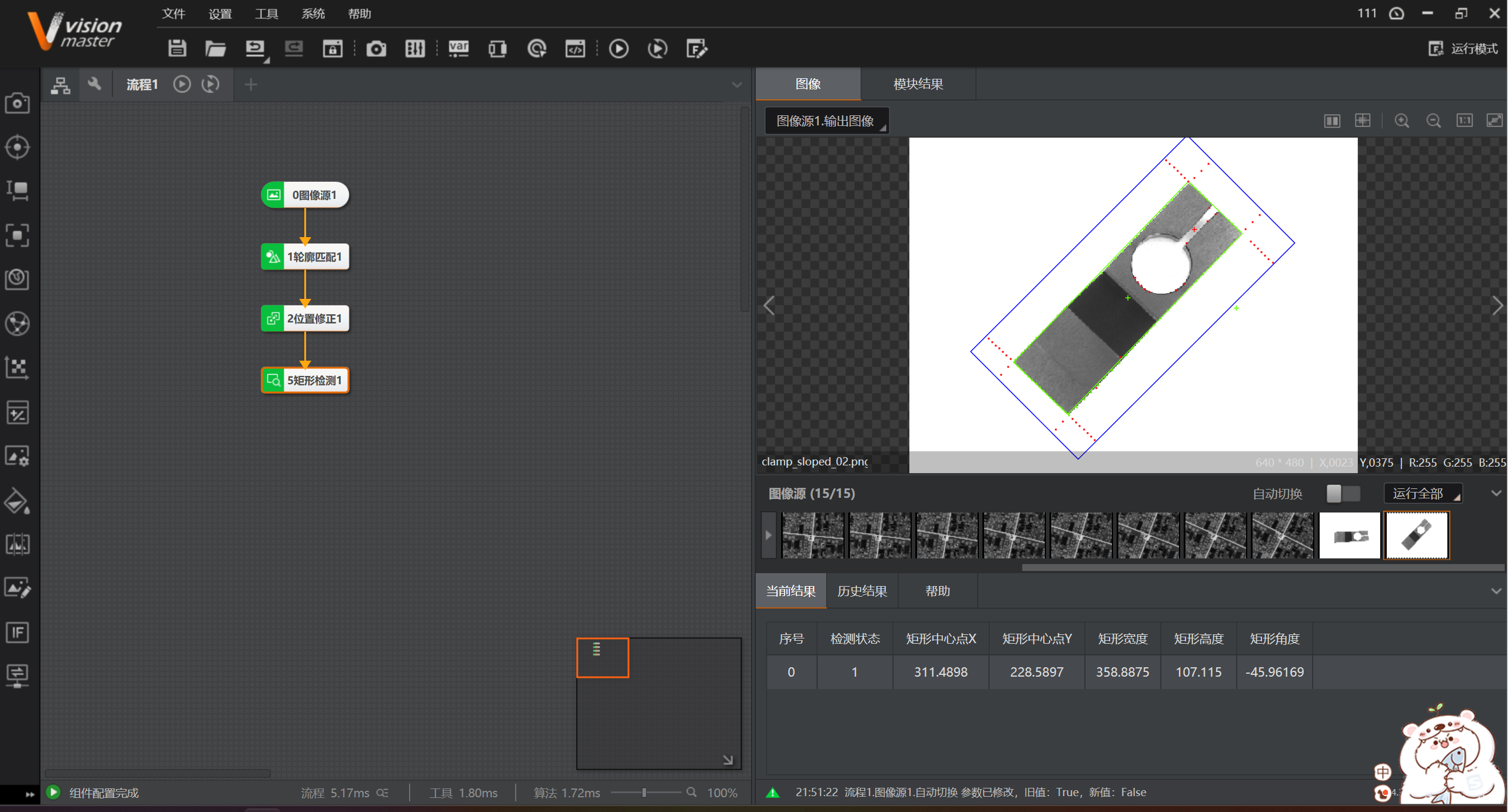
学习海康VisionMaster之矩形检测
这几天太忙了,好几天没有学习了,今天终于空下来了,继续学习之路吧。 一:进一步学习了 今天学习下VisionMaster中的矩形检测,这个一开始我以为是形态学方面的检测,实际操作下来其实还是边缘直线的衍生应用&…...

解决前端vue项目在linux上,npm install,node-sass 安装失败的问题
Unable to save binary /var/lib/jenkins/workspace/xxx/node_modules/node-sass/vendor/linux-x64-72 : Error: EACCES: permission denied, mkdir ‘/var/lib/jenkins/workspace/x/node_modules/node-sass/vendor’ 这个是node-sass安装失败导致的。 #将npm的默认仓库更改为…...
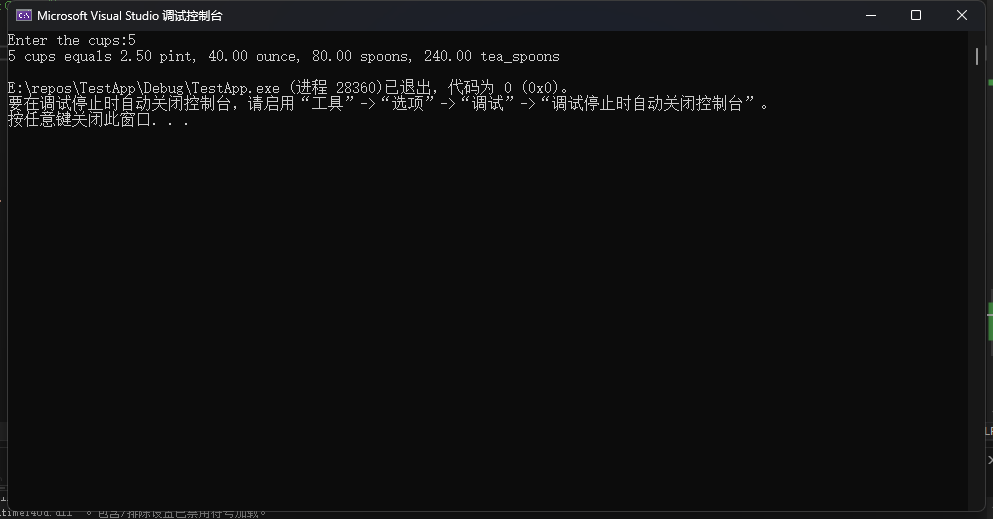
C Primer Plus 第6版 编程练习——第3章
1、通过试验(即编写带有此类问题的程序)观察系统如何处理整数上道、浮占数上溢和浮点数下溢的 int main(int argc, char** argv) {int intMax 2147483647;float floatMax 3.402823466e38f;float floatMin -3.402823466e38f;printf("intMax:%d, …...
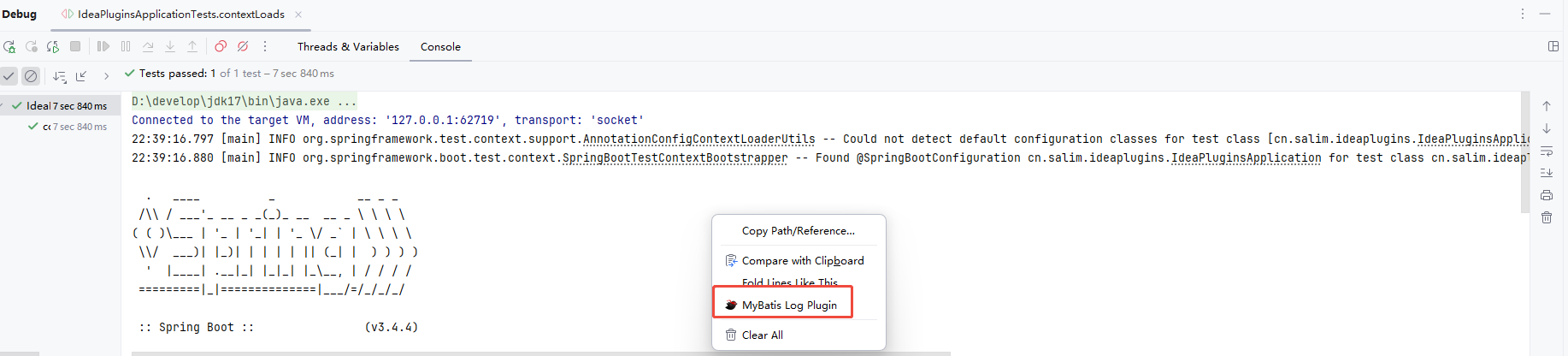
十倍开发效率 - IDEA插件之 Mybatis Log Free
提高效率不是为了完成更多任务,而是为了有充足的时间摸鱼 快速体验 MyBatis Log Free 支持打印执行的 SQL(完整的SQL,没有占位符的)。 没有使用 MyBatis Log Free 的开启日志打印是这样的: 用了 MyBatis Log Free 后…...
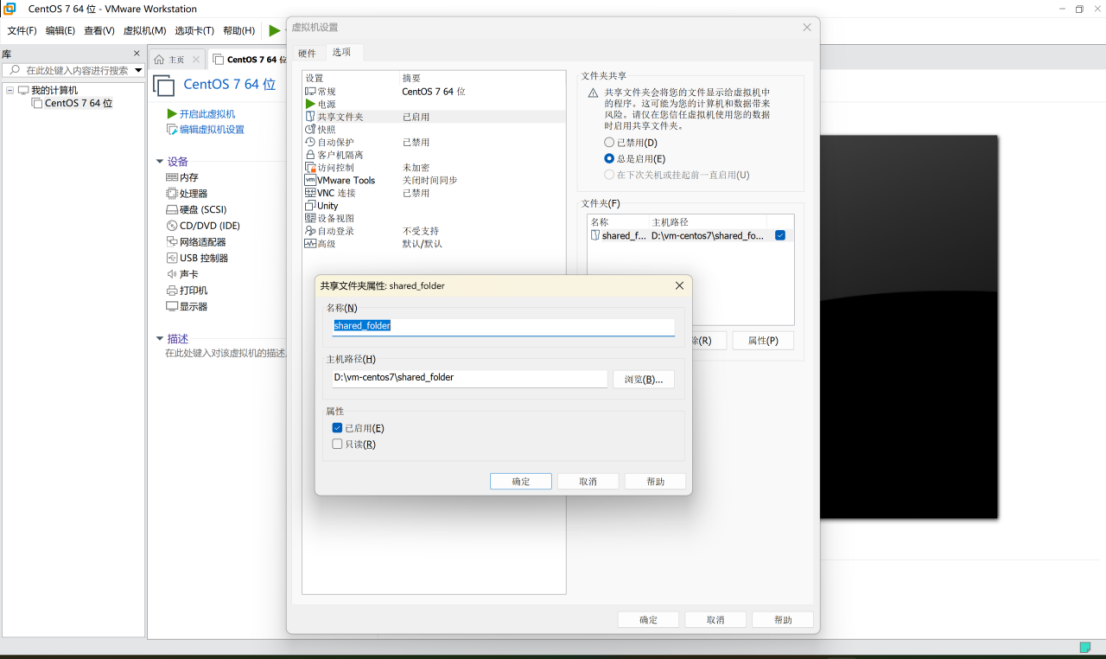
手动安装 VMware Tools 并设置虚拟机共享 Windows 文件夹
前言:在当今数字化的工作环境中,虚拟机技术为我们提供了强大的灵活性和便利性。VMware 作为虚拟化领域的佼佼者,其虚拟机软件被广泛应用于开发、测试和日常工作中。然而,许多用户在使用 VMware 虚拟机时,会遇到一个常见…...
(免费)flask调用讯飞星火AI,实现websocket
本文章可借鉴学习,不可直接盗用 接入ai要获取ID,Secret,Key,和接口地址,由于我们服务接口类型是websocket,所以要获取相应的接口地址。(千万不要复制粘贴到http的了) 还要获取doma…...

ARINC818协议-持续
一、帧头帧尾 SOF 和 EOF 分别代表视频帧传输的开始与结束,它们在封装过程有多种状态,SOF 分为 SOFi 和 SOFn,EOF 分为 EOFt 和 EOFn。传输系统中的视频信息包括像素数据信 息和辅助数据信息,分别存储在有效数据中的对象 0 和对象…...
)
分布式笔记(一)
分布式系统问题 并发性 没有全局时钟 故障独立性 分布式系统概念 分布式优势 资源共享、开放性、并发性、可扩展性、容错性 问题挑战 分布式系统总部特性很难了解 分布式系统响应不可预知 不能自顶向下 设计原则 透明性 开放性:按照普遍标准 可扩展性…...

linux常用基础命令_最新版
echo off setlocal enabledelayedexpansion :: Copyright © 2025 xianwen.deng :: All rights reserved. :: 591278546qq.com :: Version: 1.0 for /f “tokens2 delims:” %%a in (‘chcp’) do set “codepage%%a” set codepage!codepage: ! echo Codepage: !codepag…...
2021-11-09 C++三位数平方含有该数
缘由求解,运算函数,哪位大神教一下-编程语言-CSDN问答 void 三位数平方含有该数() {//缘由https://ask.csdn.net/questions/7560152?spm1005.2025.3001.5141int a 100, aa 1000, f 0;while (a < aa){f a*a;while (f > a)if ((f - a) % aa)f …...

MATLAB 程序实现了一个层次化光网络的数据传输模拟系统
% 主程序 num_pods = 4; % Pod 数量 num_racks_per_pod = 4; % 每个 Pod 的 Rack 数量 num_nodes_per_rack = 4; % 每个 Rack 的 Node 数量 max_wavelength = 50; % 可用波长数(根据冲突图动态调整) num_packets = 1000; % 模拟的…...

解锁 MCP 协议:AI 与数据交互的新桥梁
在人工智能(AI)蓬勃发展的当下,大型语言模型(LLM)展现出了令人惊叹的生成与推理能力。然而,它们在数据访问方面却面临着严峻的 “数据孤岛” 挑战。传统模式下,每个数据源都需要专门的连接器&am…...
StarRocks Community Monthly Newsletter (Mar)
版本动态 3.4.1 版本更新 核心功能升级 数据安全与权限管控 支持「安全视图」功能,严格管控视图查询权限 MySQL协议连接支持SSL认证,保障数据传输安全 存算分离架构增强 支持自动创建Snapshot(集群恢复更便捷) Storage Volu…...
Github 2FA(Two-Factor Authentication/两因素认证)
Github 2FA认证 多因素用户认证(Multi-Factor Authentication),基本上各个大互联网平台,尤其是云平台厂商(如:阿里云的MFA、华为云、腾讯云/QQ安全中心等)都有启用了,Github算是搞得比较晚些了。 双因素身…...

动态规划 -- 简单多状态dp,打家劫舍问题
1 按摩师 面试题 17.16. 按摩师 - 力扣(LeetCode) 本题的意思简单理解就是,如果我们接受了第 i 个预约,那么第 i -1 个预约和第 i1 个预约我们都是无法接受的,只能至少间隔一个选择。 按照以前的经验,我们…...

list的模拟实现和反向迭代器的底层
1:list的模拟实现 1:链表的节点 对于list的模拟实现,我们需要先定义一个节点的类可以使用(class也可以使用struct) // List的节点类 template<class T> struct ListNode {ListNode(const T& val T()){_p…...
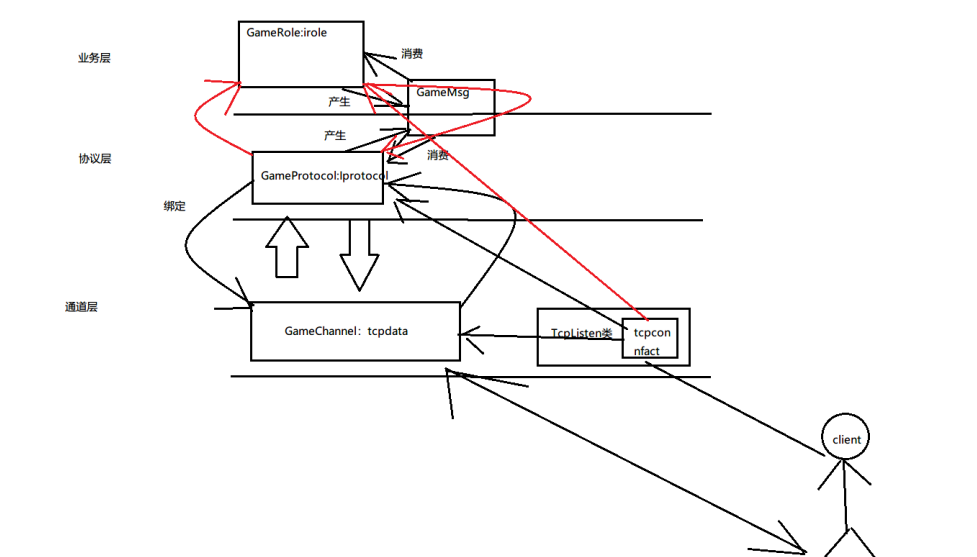
C++学习之游戏服务器开发⑤AOI业务逻辑
目录 1.项目进度回顾 2.完善整体架构 3.AOI网格思路 4.网络AOI数据结构 5.游戏世界类添加,删除和构造 6.AOI查找实现 7.GAMEROLE类结合AOI 8.登陆时发送ID和姓名 9.登陆时发送周围玩家位置 10.玩家上线完成 11.玩家下线处理 1.项目进度回顾 时间轮调度处理…...

C/C++语言常见问题-智能指针、多态原理
文章目录 智能指针实现原理智能指针,里面的计数器何时会改变std::shared_ptr的引用计数器:std::weak_ptr的弱引用计数器:std::unique_ptr的控制块:总结: 智能指针和管理的对象分别在哪个区面向对象的特性:多…...

Python 实现日志备份守护进程
实训背景 假设你是一名运维工程师,需要为公司的监控系统开发一个简单的日志备份守护进程。该进程需满足以下需求: 后台运行:脱离终端,长期监控指定目录(如 /var/log/app/)中的日志文件。自动备份…...
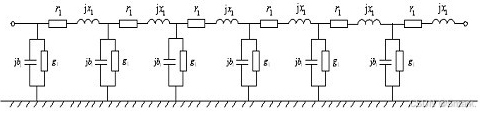
Electricity Market Optimization 探索系列(VII)- 直流潮流方程的推导及例题
本文参考书籍:电力经济与电力市场,甘德强,杨莉,冯冬涵 著 link \hspace{1.6em} 文章的结构如下:围绕电力传输系统中短线路的等值等效模型,从节点注入功率的角度和线路功率的角度分析电网中的潮流࿰…...

DataOutputStream 终极解析与记忆指南
DataOutputStream 终极解析与记忆指南 一、核心本质 DataOutputStream 是 Java 提供的数据字节输出流,继承自 FilterOutputStream,用于写入基本数据类型和字符串的二进制数据。 作用:1.将java程序中的数据直接写入到文件,写到文…...

Spring AI与通义千问的完美结合:构建智能对话应用
Spring AI是Spring生态系统中的新成员,它为开发人员提供了一套简单而强大的工具,用于集成各种AI大模型。本文将介绍如何使用Spring AI与阿里云通义千问大模型进行集成,构建智能对话应用,帮助你快速掌握AI应用开发的核心技能。 引言 随着人工智能技术的快速发展,越来越多的…...
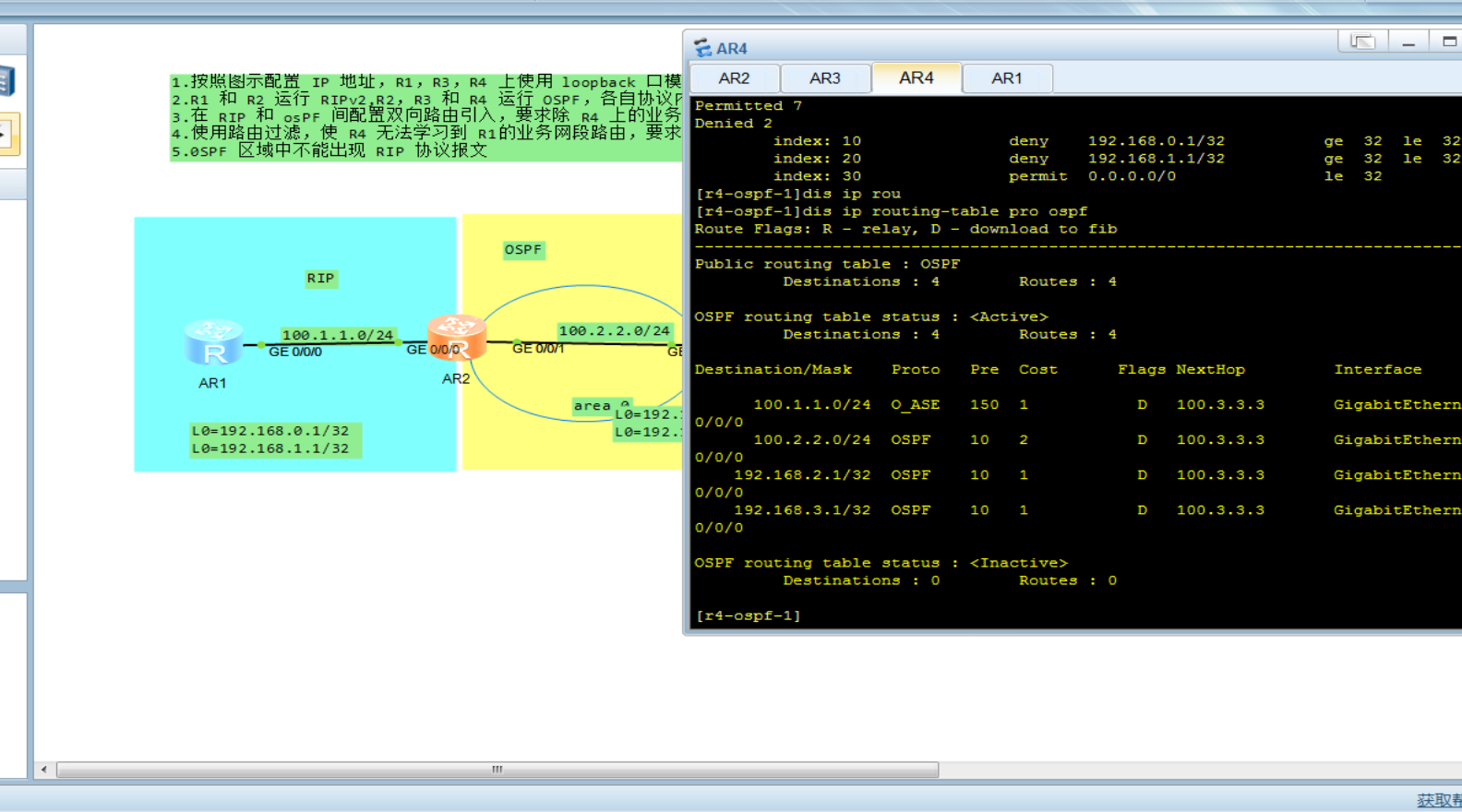
路由过滤实验
实验拓扑以及要求 此实验总结 1.ip-prefix 拒绝192.168.4.1 32,这样写的话并不会匹配192.168.4.1 32,需要加上范围less-eq 32,也就是说,192.168.4.1 32只是规则的范围,匹配还是得写范围 2.router-policy适合用在边界路由器引入 filter-policy都可以用 配置IP 配置ospf,rip …...
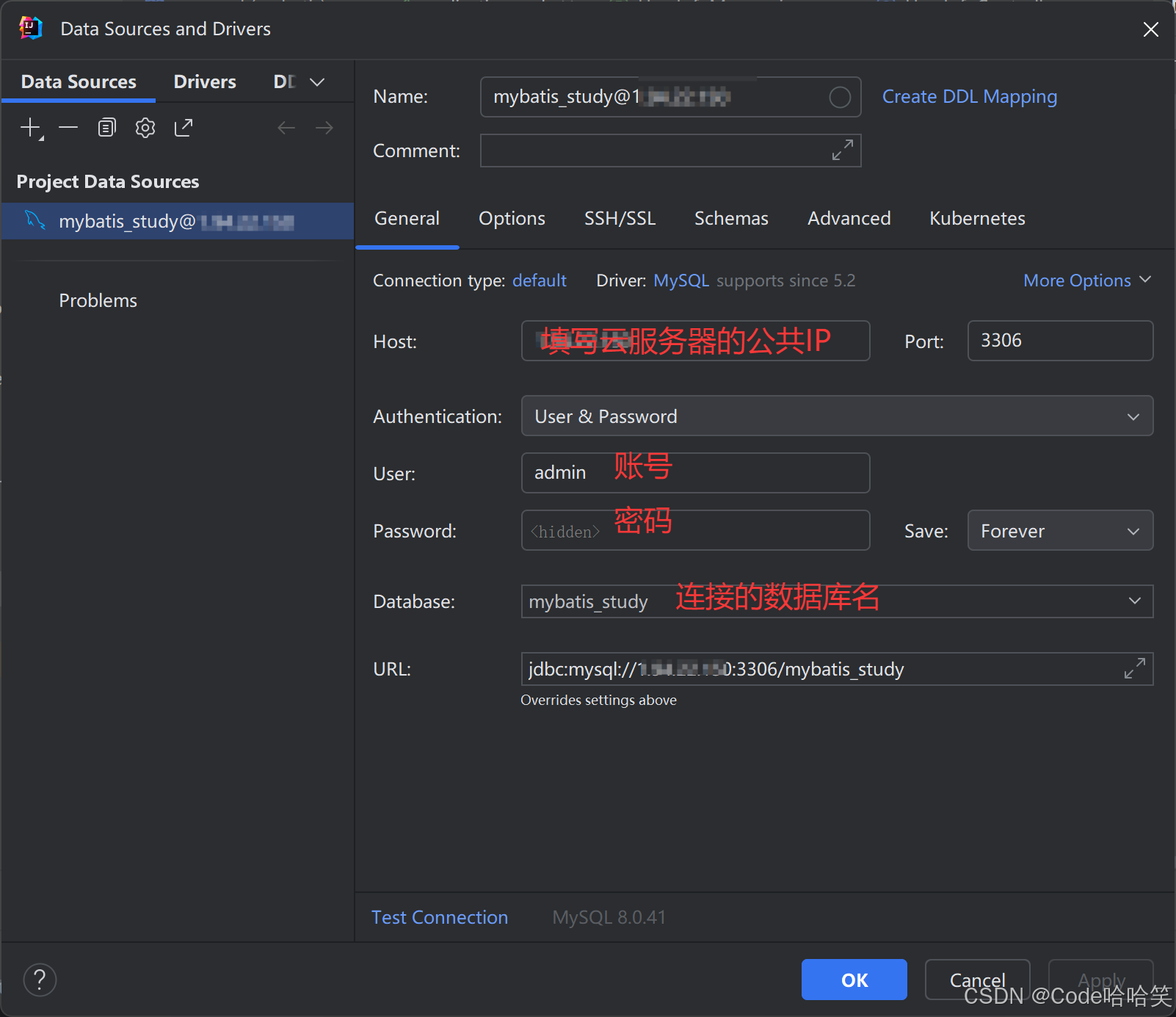
Idea连接远程云服务器上的MySQL,开放云服务器端口
1.开放云服务器的3306端口 (1)进入到云服务器的控制台 (2)点击使用的云服务器 (3)点击 配置安全组规则 (4)添加规则 (5)开放端口 2.创建可以远程访问…...

Oracle查询大表的全部数据
2000w的大表 表结构如下,其中id是索引 查询处理慢的写法 List<String> queryLoidForPage(Integer startNum,Integer endNum){try {Connection oracleConnection initBean.oracleConnection;Statement stmt oracleConnection.createStatement();// 4.执行查…...