PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装
PyTorch是一个很强大的深度学习库,在学术中使用占比很大。
我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。
第二章 基础知识
这里划重点!
- 张量的创建/随机初始化
a = torch.tensor(1.0, dtype=torch.float)
d = torch.FloatTensor(2,3)
f = torch.IntTensor([1,2,3,4])
k = torch.rand(2, 3)
l = torch.ones(2, 3)
m = torch.zeros(2, 3)
n = torch.arange(0, 10, 2) #arrange用于创造等差数列 interval is 2
-
查看/修改维度
.shape or .size()
.view(row,column)
.unsqeeze(1)#加一维度
.squeeze(1) -
tensor&numpy.array
1.array->tensor
h = torch.tensor(g) #g = np.array([[1,2,3],[4,5,6]])
i = torch.from_numpy(g)2.tensor->array
j = h.numpy()
共享内存的情况
torch.from_numpy()和torch.as_tensor()从numpy array创建得到的张量和原数据是共享内存的,张量对应的变量不是独立变量,修改numpy array会导致对应tensor的改变。
如代码例中所示,修改g改变i
- tensor运算
o = torch.add(k,l)#o=k+l
#broadcast is two different size of tensors adding.
print(p + q)
- 灵活运用索引 [:]
- 自动求导
x1 = torch.tensor(1.0, requires_grad=True)
x1.grad.data是在有requires_grad=True即要求求导数的该数字的结果。
y.backward()反向传播于梯度,不清0会累积。
x1.grad #可尝试查看导数
第三章 组成模块
-
设计及解决学习任务
步骤如下:
1.数据预处理(格式统一、数据变换、划分训练集/测试集的)
2.选择模型,损失函数,优化函数,超参(常用:batch_size,learning rate ,max_epochs,configuration of gpu)
3.训练并计算得到表现-深度学习&机器学习 1.深度学习样本多,有批batch训练。 2.层多,需要按顺序逐层搭建。 3.损失函数,优化器使得其更灵活 -
gpu配置:略
-
数据读入:Dataset+DataLoader
Dataset定义数据格式和变换形式,DataLoader用iterative的方式不断读入批次数据
自定义Dataset类需要继承PyTorch自身的Dataset类。- 主要包含三个函数:
init: 用于向类中传入外部参数,同时定义样本集
getitem: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
len: 用于返回数据集的样本数 - 涉及到的API
1.PyTorch自带的ImageFolder类的用于读取按一定结构存储的图片数据(path对应图片存放的目录,目录下包含若干子目录,每个子目录对应属于同一个类的图片),其中“data_transform”可以对图像进行一定的变换,如翻转、裁剪等操作,可自己定义。
- 主要包含三个函数:
-
用cifar10数据集(识别普适物体的小型数据集)构建Dataset类实例:图片存放在一个文件夹,另外有一个csv文件给出了图片名称对应的标签。这种情况下需要自己来定义Dataset类
利用ImageFolder,
train_data = datasets.ImageFolder(root, transform=None, target_transform=None, loader=default_loader)- 关于ImageFolder,展开如下:(细节部分转自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改动)
root:在root指定的路径下寻找图片
transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象
target_transform:对label的转换
loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象 - label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。

- 关于ImageFolder,展开如下:(细节部分转自https://blog.csdn.net/weixin_40123108/article/details/85099449,有改动)
from torchvision import transforms as T
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
# cat文件夹的图片对应label 0,dog对应1
print(dataset.class_to_idx)
# 所有图片的路径和对应的label
print(dataset.imgs)
print(dataset[0][1])# 第一维是第几张图,第二维为1返回label
print(dataset[0][0]) # 为0返回图片数据
#transform配置
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([T.RandomResizedCrop(224),#即先随机采集,然后对裁剪得到的图像缩放为同一大小T.RandomHorizontalFlip(),#水平翻转T.ToTensor(),normalize,
])
dataset = ImageFolder('data1/dogcat_2/', transform=transform)
# 深度学习中图片数据一般保存成CxHxW,即通道数x图片高x图片宽
#print(dataset[0][0].size())
to_img = T.ToPILImage()
- 另一种读入方式,自定义构建数据集
class MyDataset(Dataset):#to build dataset we needdef __init__(self, data_dir, info_csv, image_list, transform=None):"""Args:data_dir: path to image directory.info_csv: path to the csv file containing image indexeswith corresponding labels.image_list: path to the txt file contains image names to training/validation settransform: optional transform to be applied on a sample."""label_info = pd.read_csv(info_csv)image_file = open(image_list).readlines()#distinguish among read()/readline()/readlines()#link:https://zhuanlan.zhihu.com/p/26573496self.data_dir = data_dirself.image_file = image_file #custom/user-definedself.label_info = label_infoself.transform = transformdef __getitem__(self, index):#return image and label."""Args:index: the index of itemReturns:image and its labels"""image_name = self.image_file[index].strip('\n')#只要头尾包含有指定字符序列中的字符就删除,中间的删不掉,若'12'则字符串中的'21'也能删掉 raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]#显示索引:.loc,第一个参数为 index切片,第二个为 columns列名label = raw_label.iloc[:,0]#隐式索引:.iloc(integer_location), 只能传入整数。image_name = os.path.join(self.data_dir, image_name)#path.join拼接规则https://www.jianshu.com/p/3090f7875f9bimage = Image.open(image_name).convert('RGB')if self.transform is not None:image = self.transform(image)return image, labeldef __len__(self):return len(self.image_file)
#Finishing dataset,we can use DataLoader to load batch data.
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
#batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
#num_workers:有多少个进程用于读取数据
#shuffle:是否将读入的数据打乱
#drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
#PyTorch中的DataLoader的读取可以使用next和iter来完成,next(iterable[, default])
#next() 返回迭代器的下一个项目。next() 函数要和生成迭代器的iter() 函数一起使用。
#iter()函数获取这些可迭代对象的迭代器。对获取到的迭代器不断使⽤next()函数来获取下⼀条数据,调⽤了可迭代对象的 iter ⽅法.
#iterable – 可迭代对象,default – 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。images, labels = next(iter(val_loader))
print(images.shape)
plt.imshow(images[0].transpose(1,2,0))
plt.show()
- 模型构建
基于 Module 类的模型来完成,Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。 Module 类它的子类既可以是⼀个层(如PyTorch提供的 Linear 类),⼜可以是一个模型(如这里定义的 MLP 类),或者是模型的⼀个部分。- 继承 Module 类构造多层感知机。代码中定义的 MLP (Multilayer Perceptron)类重载了 Module 类的 init 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。

- 继承 Module 类构造多层感知机。代码中定义的 MLP (Multilayer Perceptron)类重载了 Module 类的 init 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。
import torch
from torch import nnclass MLP(nn.Module):# 声明带有模型参数的层,这里声明了两个全连接层def __init__(self, **kwargs):# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数super(MLP, self).__init__(**kwargs)self.hidden = nn.Linear(784, 256)#set fully connected layer#[in_features,out_features]#从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。self.act = nn.ReLU()self.output = nn.Linear(256,10)# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出def forward(self, x):o = self.act(self.hidden(x))return self.output(o) #实例化
X = torch.rand(2,784)
net = MLP()
print(net)
net(X)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
我们可以实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传入输⼊数据 X 做一次前向计算。其中, net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算。
#Parameter 类其实是 Tensor 的子类,如果一 个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter ,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典。#torch.mul()对应位相乘
#torch.mm()矩阵乘法
class MyListDense(nn.Module):def __init__(self):super(MyListDense, self).__init__()self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for i in range(len(self.params)):x = torch.mm(x, self.params[i])return x
net = MyListDense()
print(net)class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice])net = MyDictDense()
print(net)
- 卷积层

#卷积运算(二维互相关)
def corr2d(X, K): h, w = K.shapeX, K = X.float(), K.float()Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i: i + h, j: j + w] * K).sum()return Y
#Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
# 二维卷积层
class Conv2D(nn.Module):def __init__(self, kernel_size):super(Conv2D, self).__init__()self.weight = nn.Parameter(torch.randn(kernel_size))self.bias = nn.Parameter(torch.randn(1))def forward(self, x):return corr2d(x, self.weight) + self.bias #corr2d 上面的二维卷积运算
#padding
X = X.view((1, 1) + X.shape)#原shape前加两个维度
# 在⾼和宽两侧的填充数分别为2和1,将每次滑动的行数和列数称为步幅(stride)
conv2d = nn.Conv2d(..., padding=(2, 1), stride=(3, 4))
#pooling最大池化或平均池化if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max()elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
#一个nn.Module包含各个层和一个forward(input)方法,该方法返回output
#instance:
#前馈神经网络 (feed-forward network)(LeNet)
#步骤:
#定义包含一些可学习参数(或者叫权重)的神经网络
#在输入数据集上迭代
#通过网络处理输入
#计算 loss (输出和正确答案的距离)
#将梯度反向传播给网络的参数
#更新网络的权重,一般使用一个简单的规则:weight = weight - learning_rate * gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
#n包则依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。
#backward函数会在使用autograd时自动定义,backward函数用来计算导数。def __init__(self):super(Net, self).__init__()#Net找其父类,将父类init东西给self# 输入图像channel:1;输出channel:6;5x5卷积核self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# 2x2 Max poolingx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# 如果是方阵,则可以只使用一个数字进行定义x = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, self.num_flat_features(x))#把特征拍扁x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):#计算特征数用于拍扁size = x.size()[1:] # 除去批处理维度的其他所有维度num_features = 1for s in size:num_features *= sreturn num_features
net = Net()
print(net)#print the net's structure.#返回可学习参数
print(net.parameters())
params = list(net.parameters())
#print(params)
print(len(params))
print(params[0].size()) # conv1的权重#to use my model
#注意:这个网络 (LeNet)的期待输入是 32x32 的张量。如果使用 MNIST 数据集来训练这个网络,要把图片大小重新调整到 32x32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
net.zero_grad()#梯度清零
out.backward(torch.randn(1, 10))#随机梯度的反向传播
#torch.nn supports mini-batches rather than only one sample.
#nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width,如果是一个单独的样本,只需要使用input.unsqueeze(0) 来添加一个“假的”批大小维度。
-
涉及到的模块总结
- torch.Tensor - 一个多维数组,支持诸如backward()等的自动求导操作,同时也保存了张量的梯度。
- nn.Module- 神经网络模块。是一种方便封装参数的方式,具有将参数移动到GPU、导出、加载等功能。
- nn.Parameter- 张量的一种,当它作为一个属性分配给一个Module时,它会被自动注册为一个参数。
- autograd.Function - 实现了自动求导前向和反向传播的定义,每个Tensor至少创建一个Function节点,该节点连接到创建Tensor的函数并对其历史进行编码。
-
AlexNet

5个卷积层和3个全连接层组成的,深度总共8层。
class AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()self.conv = nn.Sequential(#convolution layersnn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, paddingnn.ReLU(),nn.MaxPool2d(3, 2), # kernel_size, stride# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(3, 2),# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。# 前两个卷积层后不使用池化层来减小输入的高和宽nn.Conv2d(256, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 384, 3, 1, 1),nn.ReLU(),nn.Conv2d(384, 256, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(3, 2))# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合self.fc = nn.Sequential(#fully connected layersnn.Linear(256*5*5, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10),)def forward(self, img):feature = self.conv(img)output = self.fc(feature.view(img.shape[0], -1))return output

- 损失函数
#二分类交叉熵损失函数Cross Entropy
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
#在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
#size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
#reduce:数据类型为bool,为True时,loss的返回是标量。
#(2) 默认情况下 nn.BCELoss(),reduce = True,size_average = True。
#(3) 如果reduce为False,size_average不起作用,返回向量形式的loss。
#(4) 如果reduce为True,size_average为True,返回loss的均值,即loss.mean()。
#(5) 如果reduce为True,size_average为False,返回loss的和,即loss.sum()。m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
output.backward()#交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
#ignore_index:忽略某个类的损失函数。
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()#L1损失函数:计算输出y和真实标签target之间的差值的绝对值。
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
#reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。 sum:所有元素求和,返回标量。 mean:加权平均,返回标量。 如果选择none,那么返回的结果是和输入元素相同尺寸的。默认计算方式是求平均。
loss = nn.L1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#MSE损失函数:计算输出y和真实标签target之差的平方。
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()#平滑L1 (Smooth L1)损失函数:L1的平滑输出,其功能是减轻离群点带来的影响
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
#过程同理,略#可视化:平滑l1与l1对比
import matplotlib.pyplot as plt
inputs = torch.linspace(-10, 10, steps=5000)
target = torch.zeros_like(inputs)loss_f_smooth = nn.SmoothL1Loss(reduction='none')
loss_smooth = loss_f_smooth(inputs, target)
loss_f_l1 = nn.L1Loss(reduction='none')
loss_l1 = loss_f_l1(inputs,target)plt.plot(inputs.numpy(), loss_smooth.numpy(), label='Smooth L1 Loss')#画图
plt.plot(inputs.numpy(), loss_l1, label='L1 loss')
plt.xlabel('x_i - y_i')
plt.ylabel('loss value')
plt.legend()#图例
plt.grid()#网格线
plt.show()#目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
#log_input:输入是否为对数形式,决定计算公式。如果log_input=False:输入数据还不是对数形式,计算中还需要对input取对数,取对数时有可能遇到input=0,这样就无法正常进行取对数运算,因此在input后加入修正项eps。其中修正项很小,它的加入并不会影响到对input对数数值的,即便有影响也可忽略不计。
#full:计算所有 loss,默认为 False。
#eps:修正项,避免 input 为 0 时,log(input) 为 nan 的情况。
Smooth L1:
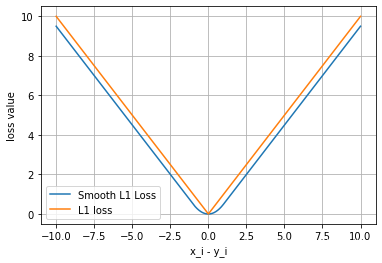
由图可见,smoothL1处x=0尖端更平滑
PoissonNLLLoss:
当参数log_input=True: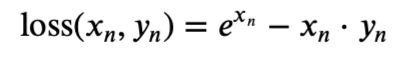
当参数log_input=False:
KLDivLoss

#kl散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
#功能:计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
#reduction:计算模式,可为 none/sum/mean/batchmean。
inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]])
target = torch.tensor([[0.9, 0.05, 0.05], [0.1, 0.7, 0.2]], dtype=torch.float)
loss = nn.KLDivLoss()
output = loss(inputs,target)#排序损失函数MarginRankingLoss
#计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
#margin:边界值,x1 and x2之间的差异值
loss = nn.MarginRankingLoss()
input1 = torch.randn(3, requires_grad=True)
input2 = torch.randn(3, requires_grad=True)
target = torch.randn(3).sign()
output = loss(input1, input2, target)
output.backward()
MarginRankingLoss:

相关文章:
PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...
proteus8.17 环境配置
Proteus介绍 Proteus 8.17 是一款功能强大的电子设计自动化(EDA)软件,广泛应用于电子电路设计、仿真和分析。以下是其主要特点和新功能: ### 主要功能 - **电路仿真**:支持数字和模拟电路的仿真,包括静态…...

Microsoft SQL Server Management 一键删除数据库所有外键
DECLARE ESQL VARCHAR(1000); DECLARE FCursor CURSOR --定义游标 FOR (SELECT ALTER TABLE O.name DROP CONSTRAINT F.name; AS CommandSQL from SYS.FOREIGN_KEYS F JOIN SYS.ALL_OBJECTS O ON F.PARENT_OBJECT_ID O.OBJECT_ID WHERE O.TYPE U AND F.TYPE …...

【JAVAFX】自定义FXML 文件存放的位置以及使用
情况 1:FXML 文件与调用类在同一个包中(推荐) 假设类 MainApp 的包是 com.example,且 FXML 文件放在 resources/com/example 下: 项目根目录 ├── src │ └── sample │ └── Main.java ├── src/s…...

Oracle 如何停止正在运行的 Job
Oracle 如何停止正在运行的 Job 先了解是dbms_job 还是 dbms_scheduler,再确定操作命令。 一 使用 DBMS_JOB 包停止作业(适用于旧版 Job) 1.1 查看正在运行的 Job SELECT job, what, this_date, this_sec, failures, broken FROM user_j…...
结构体(2)-Python)
高级语言调用C接口(四)结构体(2)-Python
这个专栏好久没有更新了,主要是坑开的有点大,也不知道怎么填,涉及到的开发语言比较多,写起来比较累,需要看的人其实并不多,只能说,慢慢填吧,中间肯定还会插很多别的东西,…...
Java对接Dify API接口完整指南
Java对接Dify API接口完整指南 一、Dify API简介 Dify是一款AI应用开发平台,提供多种自然语言处理能力。通过调用Dify开放API,开发者可以快速集成智能对话、文本生成等功能到自己的Java应用中。 二、准备工作 获取API密钥 登录Dify平台控制台在「API密…...

极狐GitLab GEO 功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Geo (PREMIUM SELF) Geo 是广泛分布的开发团队的解决方案,可作为灾难恢复策略的一部分提供热备份。Geo 不是 开箱…...

Nginx-前言
nginx是什么? 轻量级,开源免费的web服务器软件,服务器安装nginx,服务器则成为web服务器 nginx的稳定版版本号: 偶数版本 nginx的相关目录: /etc/nginx/nginx.conf nginx的主配置文件 /etc/nginx/ngi…...

LFI to RCE
LFI不止可以来读取文件,还能用来RCE 在多道CTF题目中都有LFItoRCE的非预期解,下面总结一下LFI的利用姿势 1. /proc/self/environ 利用 条件:目标能读取 /proc/self/environ,并且网页中存在LFI点 利用方式: 修改请…...
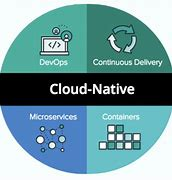
云原生(Cloud Native)的详解、开发流程及同类软件对比
以下是云原生(Cloud Native)的详解、开发流程及同类软件对比: 一、云原生核心概念 定义: 云原生(Cloud Native)是基于云环境设计和运行应用程序的方法论,强调利用云平台的弹性、分布式和自动化…...
生成策略)
全局唯一标识符(UID)生成策略
目录 一、UUID 二、雪花算法 三、时间戳 随机数 四、利用数据库的自增字段 五、 基于 Redis 的原子操作 总结 在信息系统中,生成唯一ID是非常常见的需求,尤其是在分布式系统或高并发场景下。以下是几种常见的生成唯一ID的算法或方式: …...

学习笔记:减速机工作原理
学习笔记:减速机工作原理 一、减速机图片二、减速比概念三、减速机的速比与扭矩之间的关系四、题外内容--电机扭矩 一、减速机图片 二、减速比概念 即减速装置的传动比,是传动比的一种,是指减速机构中,驱动轴与被驱动轴瞬时输入速…...

《UE5_C++多人TPS完整教程》学习笔记36 ——《P37 拾取组件(Pickup Widget)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P37 拾取组件(Pickup Widget)》 的学习笔记,该系列教学视频为计算机工程师、程序员、游戏开发者、作家(Engineer, Programmer, Game Developer, Author) Steph…...

《空间复杂度(C语言)》
文章目录 前言一、什么是空间复杂度?通俗理解: 二、空间复杂度的数学定义三、常见空间复杂度举例(含C语言代码)🔹 O(1):常数空间🔹 O(n):线性空间🔹 O(n^2):平…...
)
Kaggle-Store Sales-(回归+多表合并+xgboost模型)
Store Sales 题意: 给出很多商店,给出商店的类型,某时某刻卖了多少销售额。 给出了油价表,假期表,进货表。 让你求出测试集合中每个商店的销售额是多少。 数据处理: 1.由于是多表,所以要先把其他表与tr…...

在 Tailwind CSS 中优雅地隐藏滚动条
在开发中,我们经常需要隐藏滚动条但保持滚动功能,这在构建现代化的用户界面时很常见。 本文将介绍两种在 Tailwind CSS 项目中实现这一目标的方法,方便同学们记录和查阅。 方法一:使用 tailwind-scrollbar-hide 插件 这是一种更…...
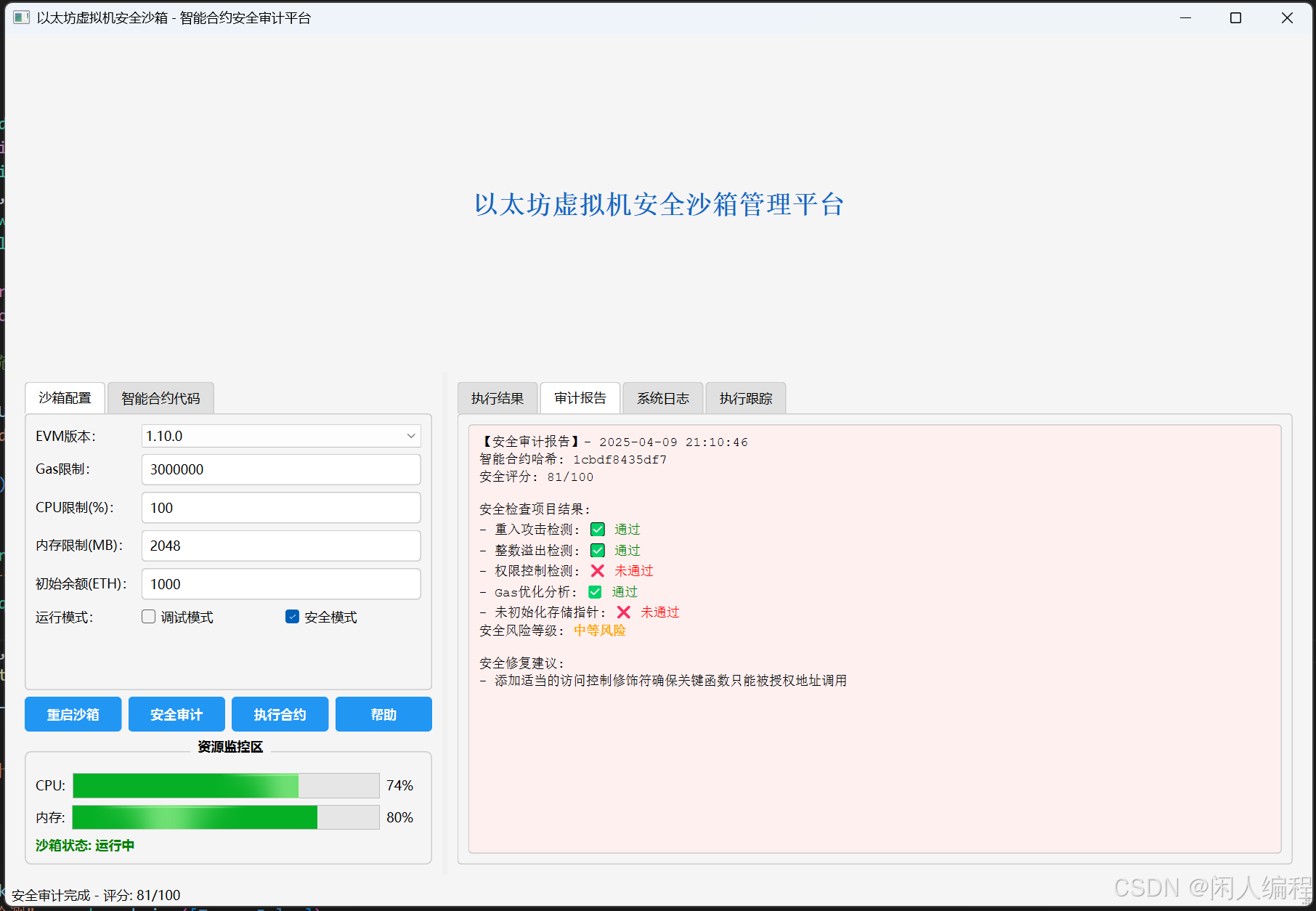
智能合约安全审计平台——以太坊虚拟机安全沙箱
目录 以太坊虚拟机安全沙箱 —— 理论、设计与实战1. 引言2. 理论背景与安全原理2.1 以太坊虚拟机(EVM)概述2.2 安全沙箱的基本概念2.3 安全证明与形式化验证3. 系统架构与模块设计3.1 模块功能说明3.2 模块之间的数据流与安全性4. 安全性与密码学考量4.1 密码学保障在沙箱中…...
)
std::unordered_map(C++)
std::unordered_map 1. 概述2. 内部实现3. 性能特征4. 常用 API5. 使用示例6. 自定义哈希与相等比较7. 注意事项与优化8. 使用建议9. emplace和insert异同相同点不同点例子对比何时优先使用哪种? 1. 概述 定义:std::unordered_map<Key, T, Hash, KeyE…...

【MCP教程】Claude Desktop 如何连接部署在远程的remote mcp server服务器(remote host)
前言 最近MCP特别火热,笔者自己也根据官方文档尝试了下。 官方文档给的Demo是在本地部署一个weather.py,然后用本地的Claude Desktop去访问该mcp服务器,从而完成工具的调用: 但是,问题来了,Claude Deskto…...
)
Android Input——输入事件回调完成(十四)
前面几篇文章介绍了事件回调的相关流程,以及回调事件处理函数的相关内容,最后我们再来看一下事件处理完后,如何通知 InputDispatcher 去回调 Callback。 一、客户端回调 在 Android 的事件分发机制中,当客户端(即应用层)完成事件处理后,最终会调用 ViewRootImpl 的 fin…...

数据通信学习笔记之OSPF配置命令
华为 [huawei]ospf 10 router-id 1.1.1.1 //创建ospf进程,本地有效area 1 // 进入区域1network 192.168.1.0 0.0.0.255 // 宣告网段,使用反掩码stub // 配置为stub区域stub no-summary // 配置为Totally Stub 完全末节区域。在ABR上配置࿰…...

Python -yield 在python 中什么意思
在 Python 中,yield 是一个关键字,用于定义生成器函数(generator function)。它的作用是将一个普通函数转变为可迭代的生成器,具有惰性计算的特性。以下是关键要点: 核心概念 生成器函数: 当函数…...
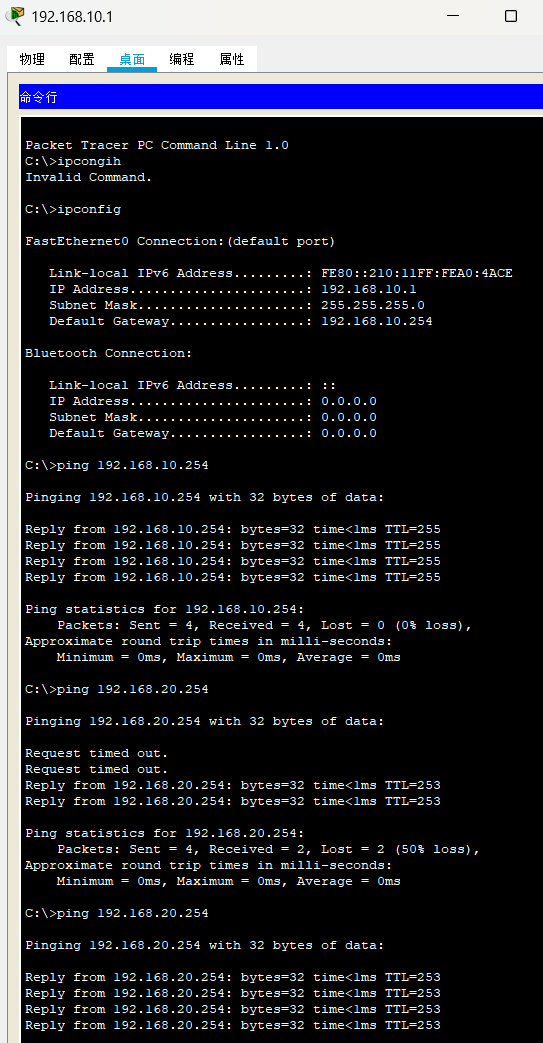
多个路由器互通(静态路由)无单臂路由(简单版)
多个路由器互通(静态路由)无单臂路由(简单版) 开启端口并配ip地址 维护1 Router>en Router#conf t Router(config)#int g0/0 Router(config-if)#no shutdown Router(config-if)#ip address 192.168.10.254 255.255.255.0 Ro…...
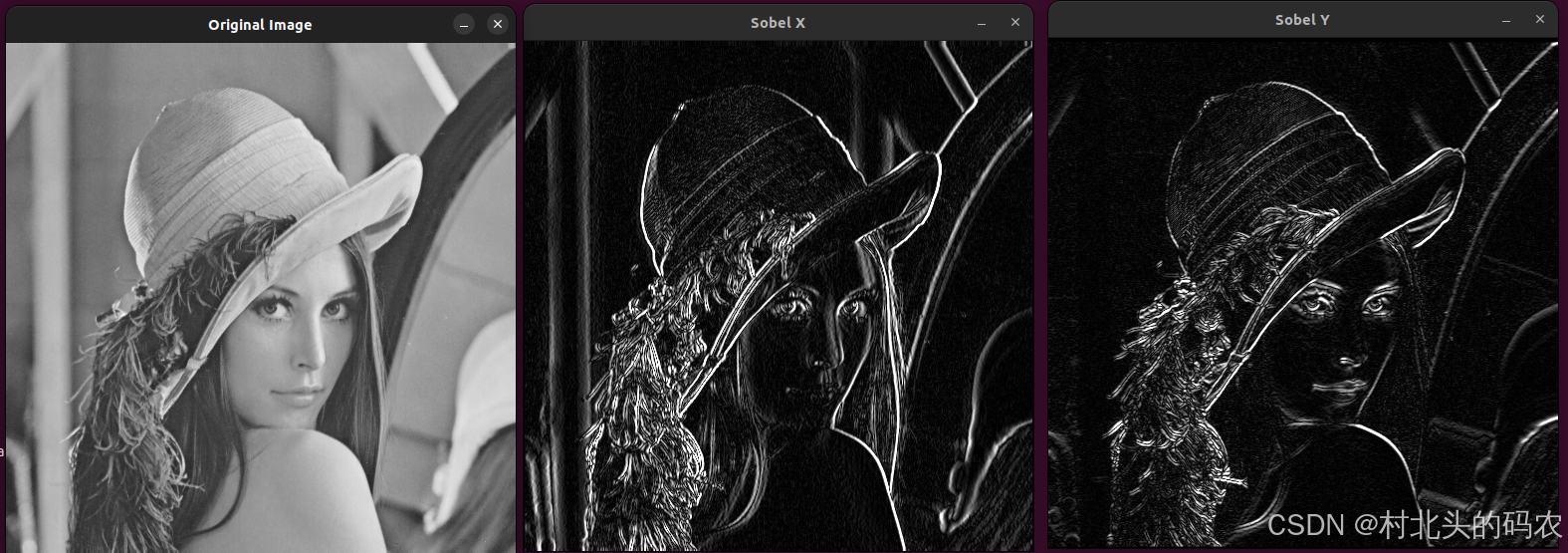
OpenCV 图形API(38)图像滤波-----Sobel 算子操作函数Sobel()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::gapi::Sobel 函数是 OpenCV 的 G-API 模块中用于执行 Sobel 算子操作的一个函数,主要用于图像的边缘检测。Sobel 算子通过计算图…...

3DS 转 STL 全攻略:传统工具与迪威模型网在线转换深度解析
在 3D 建模与 3D 打印的技术领域中,常常会遇到需要将不同格式的文件进行转换的情况。其中,把 3DS 文件转换为 STL 格式是较为常见的操作。3DS 文件作为一种旧版 Autodesk 3D Studio 使用的 3D 图像格式,存储着丰富的信息,包括网格…...
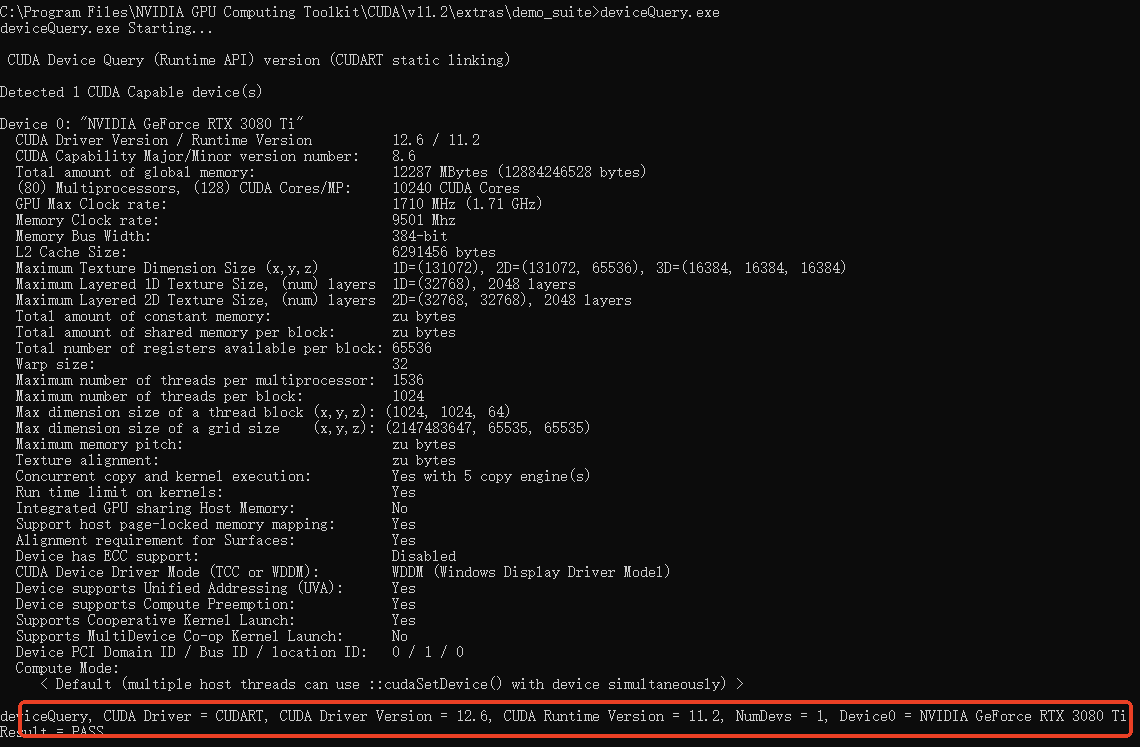
windows系统安装驱动、cuda和cudnn
一、首先在自己的电脑里安装了nvidia的独立显卡 显卡的查找方式: CtrlShiftEsc打开任务管理器,点击性能,点击GPU 0查看显卡型号,如下图所示: 只要电脑中有nvidia的独立显卡,就可以暗转显卡驱动、cuda和cu…...
嵌入式开发--STM32软件和硬件CRC的使用--续篇
本文是《嵌入式开发–STM32软件和硬件CRC的使用》的续篇,又踩到一个坑,发出来让大家避一下坑。 按照G0系列的设置,得出错误的结果 前文对应的是STM32G0系列,今天在用STM32G4系列时,按照前文的设置,用硬件…...

2.深入剖析 Rust+Axum 类型安全路由系统
摘要 详细解读 RustAxum 路由系统的关键设计原理,涵盖基于 Rust 类型系统的路由匹配机制、动态路径参数与正则表达式验证以及嵌套路由与模块化组织等多种特性。 一、引言 在现代 Web 开发中,路由系统是构建 Web 应用的核心组件之一,它负责…...

c# 委托和事件的区别及联系,Action<T1,T2>与Func<T1,T2>的区别
定义与本质 委托: 委托是一种类型,用于存储对方法的引用。它允许将方法作为参数传递、存储和调用。委托可以绑定一个或多个方法,并通过和-操作符动态添加或移除方法。 事件: 事件是基于委托的封装,提供了一种发布/订阅机制。事件…...