快速认识:数据库、数仓(数据仓库)、数据湖与数据运河
数据技术核心概念对比表
| 概念 | 核心定义 | 核心功能 | 数据特征 | 典型技术/工具 | 核心应用场景 |
|---|---|---|---|---|---|
| 数据库 | 结构化数据的「电子档案柜」,按固定 schema 存储和管理数据,支持高效读写和事务处理。 | 实时事务处理(增删改查),确保数据一致性(ACID 特性),支持单表/关联查询。 | 结构化数据(表格式),Schema 固定,数据高度清洗。 | 关系型:Oracle、MySQL、PostgreSQL、TiDB 非关系型:MongoDB、Redis 向量型:Milvus、Pinecone | 核心业务系统(订单管理、用户登录)、实时交易(如支付、库存扣减)。 |
| 数据仓库 | 面向分析的「数据实验室」,存储历史结构化数据,按主题组织,支持复杂查询和指标计算。 | 离线/准实时分析(OLAP),通过 ETL 清洗整合多源数据,构建分析模型并输出报表/指标。 | 结构化数据(表格式),Schema 稳定,数据经清洗、整合、维度建模。 | 云原生:Snowflake、BigQuery、StarRocks 传统:Hive、Teradata 湖仓一体:Delta Lake、Iceberg | 企业级报表(如销售日报)、历史趋势分析(用户留存率)、KPI 计算(ROI 分析)。 |
| 数据湖 | 原始数据的「大熔炉」,存储多格式(结构化/半结构化/非结构化)的原始数据,保留数据原始形态。 | 存储海量多模数据,支持数据探索、大数据分析和 AI 训练,按需处理(ELT)。 | 多格式数据(表/JSON/日志/图片),Schema 灵活(读时定义),数据原始未清洗。 | 存储:S3、ADLS、OSS 管理:Delta Lake、Hudi 分析:Presto、Spark SQL | 机器学习训练(用户行为建模)、日志挖掘、非结构化数据归档(图片/视频存储)。 |
| 数据运河 | 数据流动的「管道系统」,负责在不同数据系统间实时/批量传输数据,实现数据集成与同步。 | 数据抽取(CDC)、转换(ETL/ELT)、加载,保障跨系统数据流动的实时性和可靠性。 | 不存储数据,仅传输,支持结构化/非结构化数据的流式或批量迁移。 | 实时:Kafka、Debezium、Flink 批量:Sqoop、Flume 可视化:NiFi、Fivetran | 数据同步(跨机房备份)、实时流处理(金融风控)、多系统集成(电商订单同步至分析平台)。 |
一、数据库:精准的「数据档案柜」
🧑💼 技术画像
穿定制西装的档案管理员,手持索引卡精准定位每一份数据,遵循「借阅必登记,修改必留痕」的铁律,确保数据操作的绝对可靠。
⚙️ 核心能力
| 技术流派 | 代表工具 | 数据管理模式 | 典型场景 | 技术亮点 |
|---|---|---|---|---|
| 关系型 | Oracle/MySQL | 二维表格(SQL语言) | 银行转账、订单交易 | B+树索引秒级检索,ACID事务保障数据强一致性 |
| 文档型 | MongoDB | JSON文档(BSON格式) | 电商商品详情、日志存储 | 灵活嵌套数据结构,支持动态schema演进 |
| 向量型 | Cloudera Vector(技术展望) | 高维向量空间 | 推荐系统、图像识别 | GPU加速十亿级向量检索,余弦相似度计算延迟<1ms |
🏭 典型场景
- 银行核心系统使用Oracle确保每笔转账的原子性(要么全部成功,要么全部回滚)
- 抖音用户行为日志通过MongoDB存储,支持快速迭代的JSON格式变更
二、数据仓库:智能的「数据分析师」
👓 技术画像
戴圆框眼镜的逻辑大师,擅长用星型/雪花模型构建数据立方体,口头禅是「让数据在SQL中跳舞」,专注从历史数据中提炼业务洞察。
🛠️ 核心技术
-
云原生架构
- Snowflake:存储计算分离(S3存储层+弹性计算集群),按需扩展成本降低40%,支持PB级数据秒级查询
- Apache Doris(StarRocks):MPP架构实时数仓,小米千万级日订单分析延迟<500ms,实时大屏秒级刷新
-
数据版本控制
- Apache Iceberg:时间旅行功能(支持按时间戳回溯数据),Z-Order索引优化多维查询,TPC-DS性能提升40%
- 技术优势:解决传统数仓「更新难」问题,支持数据的增删改查(ACID for Data Warehouse)
📊 典型场景
- 某零售企业用Snowflake分析10年销售数据,动态计算各季度促销活动ROI
- 美团外卖用Doris实时计算骑手接单量,高峰期资源自动扩容保障服务稳定性
三、数据湖:开放的「数据生态湿地」
🌿 技术画像
穿登山靴的自然主义者,主张「数据先存储后定义」,将原始数据(结构化/半结构化/非结构化)像保护湿地一样统一收纳,支持无限可能的数据分析。
🌊 核心特性
-
低成本存储
- AWS S3:对象存储「诺亚方舟」,支持Parquet/ORC列式存储(压缩比10:1),存储成本仅为传统HDFS的40%
- 典型应用:特斯拉存储海量车载传感器数据(CSV/日志/图像混合格式)
-
数据治理升级
- Delta Lake:为数据湖加装「ACID事务引擎」,解决多用户并发写入冲突,支持数据版本管理(类似Git的数据提交记录)
- Netflix实践:通过Presto联邦查询跨13个数据湖,30秒内完成用户观影习惯分析
🔬 技术对比(湖vs仓)
| 特性 | 数据湖 | 数据仓库 |
|---|---|---|
| 数据格式 | 支持全类型(CSV/JSON/图片) | 严格结构化(SQL表) |
| Schema定义 | 读取时定义(Schema-on-Read) | 写入时定义(Schema-on-Write) |
| 核心场景 | AI训练数据准备、多源数据整合 | 历史指标分析、固定报表生成 |
四、数据运河:高效的「数据传输管道」
👷 技术画像
穿工装的管道工程师,专注构建数据流通的「高速公路」,确保数据在不同系统间实时、可靠流转,口头禅是「数据不落地,流动即价值」。
🚀 核心组件
-
实时数据采集
- Debezium+Kafka:捕获MySQL Binlog日志(增量数据采集),支持百万级TPS传输,延迟<200ms(典型案例:支付宝交易流水实时同步)
- 技术优势:非侵入式采集,不影响源数据库性能
-
流处理引擎
- Apache Flink:毫秒级延迟的流处理王者,金融场景下反欺诈规则计算延迟<10ms,日均处理万亿级事件
- 网易实践:NDC系统跨机房数据同步延迟<1秒,支撑日均TB级订单流水实时计算
📐 典型架构(实时分析黄金三角)
graph LR A[业务数据库] -->|Debezium捕获增量| B(Kafka消息队列) B -->|Flink实时计算| C(Iceberg数据仓库) C -->|Presto联邦查询| D[BI可视化大屏] 说明:从数据变更到可视化呈现全链路延迟<3秒,某快消品企业用此架构实现用户画像实时更新
五、技术联盟:数据平台的「复仇者联盟」
1. 湖仓一体(Lakehouse)—— 数据湖与数据仓的融合进化
- 技术价值:统一存储层(S3/ADLS)支持原始数据存储+结构化分析,兼具数据湖的灵活性与数据仓的分析效率
- 典型组合:
- Delta Lake(事务管理)+ Databricks(分析平台):查询性能比纯数据湖提升40%
- 国产方案:柏睿数据Rapids引擎,内置10+AI算法库,流处理吞吐量超越Spark 30%
2. 云原生架构—— 数据平台的容器化革命
- Snowflake on Kubernetes:计算节点按需弹性伸缩,资源利用率提升50%,成本降低60%
- Cloudera CDP:AI驱动的自动化管家,支持存储策略自动优化(如冷热数据分层),TPC-DS性能提升30%
六、最佳实践:企业数据平台建设指南
📌 小米数据仓库建设三原则
- 高内聚低耦合:按业务域划分数据模块(如订单域、用户域),国际部与中国区模块可独立扩展
- 公共逻辑下沉:统一数据清洗规则(如无效订单过滤)至公共层(DWM),避免重复开发
- 成本性能平衡:维度表采用四级冗余策略(明细层→轻度聚合→高度聚合→应用层),查询速度提升50%而存储成本仅增10%
🛒 沃尔玛数据运河优化方案
- 传输压缩:采用Zstandard算法(压缩比3:1),网络带宽占用减少70%,CPU消耗降低50%
- 高可用性:基于Raft协议实现三副本强一致,故障切换时间<500ms,数据零丢失
七、未来展望:2025数据技术趋势
1. 边缘计算前置处理—— 数据的「本地预处理站」
- 工厂场景:Hadoop Edge Server在车间端过滤90%无效传感器数据,仅回传关键指标,5G流量成本降低80%
- 技术价值:解决物联网数据爆炸问题,实现「数据本地清洗,价值远程传输」
2. 隐私计算—— 数据的「匿名化装舞会」
- 差分隐私:在金融统计中添加可控噪声,信息泄露风险降低90%(如计算「某小区平均工资」时保护个人隐私)
- 区块链存证:HDFS集成Hyperledger Fabric,数据操作全链路上链,篡改检测准确率99.99%
3. 自治数据库—— DBA的「智能助手」
- TiDB v7:内置AI调优引擎,通过强化学习动态调整索引(如夜间自动优化慢查询),运维效率提升70%
- 技术愿景:让数据库具备「自我诊断、自我优化」能力,DBA从日常运维中解放
八、技术选型决策树
def 数据平台选型(业务场景): if 场景 == "实时交易": return "数据库(Oracle/MySQL)+ 数据运河(Kafka+Flink)" elif 场景 == "历史分析": return "数据仓库(Snowflake)+ 湖仓一体(Iceberg)" elif 场景 == "AI训练": return "数据湖(S3)+ 向量数据库(Cloudera Vector)" else: return "企业级数据平台(Cloudera CDP/华为云DWS)"
关键原则:根据数据处理时效(实时vs离线)、数据格式(结构化vs非结构化)、分析目标(报表vsAI)选择合适工具组合
结语:数据技术的本质是「让数据流动产生价值」
从严谨的数据库到开放的数据湖,从静态的报表分析到实时的数据流转,四大技术体系共同构建了数据世界的基础设施。企业无需纠结「非此即彼」的选择,而是应像搭建城市交通网一样,让数据在合适的「管道」中高效流动——让交易数据走「高速公路」(实时数据库+运河),让历史数据进「图书馆」(数仓),让原始数据住「生态湿地」(数据湖)。
当技术回归本质,我们最终追求的,是让数据像自来水一样,随时可用、安全可靠、按需流转。这,就是数据技术的终极浪漫。
相关文章:
、数据湖与数据运河)
快速认识:数据库、数仓(数据仓库)、数据湖与数据运河
数据技术核心概念对比表 概念核心定义核心功能数据特征典型技术/工具核心应用场景数据库结构化数据的「电子档案柜」,按固定 schema 存储和管理数据,支持高效读写和事务处理。实时事务处理(增删改查),确保数据一致性&…...
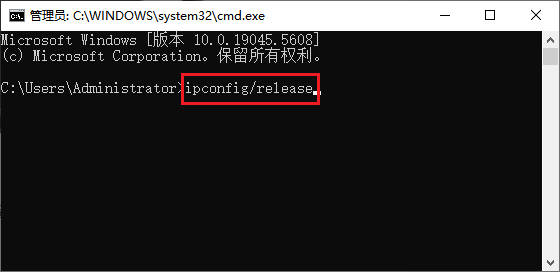
不关“猫”如何改变外网IP?3种免重启切换IP方案
每次更换外网IP都要重启路由器?太麻烦了!那么,不关猫怎么改变外网IP?无论是为了网络调试、爬虫需求,还是解决IP限制问题,频繁重启设备既耗时又影响效率。其实,更换外网IP并不一定要依赖“重启大…...
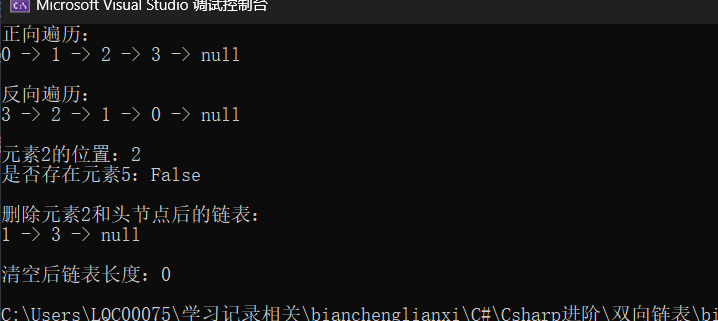
C#进阶学习(五)单向链表和双向链表,循环链表(中)双向链表
目录 一、双向链表的声明 1. 节点类声明 2. 链表类框架声明 3、实现其中的每一个函数 增删操作(核心方法组) 删除操作(核心方法组) 查询操作(辅助方法) 维护方法(内部逻辑) …...

case客户续保预测中用到的特征工程、回归分析和决策树分析的总结
文章目录 [toc]1. 回归分析概述1.1 基本概念1.2 与分类的区别 2. 常见回归算法2.1 线性回归2.2 决策树回归2.3 逻辑回归(Logistic Regression)2.3 其他算法补充:通俗版:决策树 vs 随机森林🌳 决策树:像玩「…...

Android系统通知机制深度解析:Framework至SystemUI全链路剖析
1. 前言 在Android 13的ROM定制化开发中,系统通知机制作为用户交互的核心组件,其实现涉及Framework层到SystemUI的复杂协作。本文将深入剖析从Notification发送到呈现的全链路流程,重点解析关键类的作用机制及系统服务间的交互逻辑ÿ…...

重学Redis:Redis常用数据类型+存储结构(源码篇)
一、SDS 1,SDS源码解读 sds (Simple Dynamic String),Simple的意思是简单,Dynamic即动态,意味着其具有动态增加空间的能力,扩容不需要使用者关心。String是字符串的意思。说白了就是用C语言自己封装了一个字符串类型&a…...

Elasticsearch的Java客户端库QueryBuilders查询方法大全
matchAllQuery 使用方法:创建一个查询,匹配所有文档。 示例:QueryBuilders.matchAllQuery() 注意事项:这种查询不加任何条件,会返回索引中的所有文档,可能会影响性能,特别是文档数量很多时。 ma…...
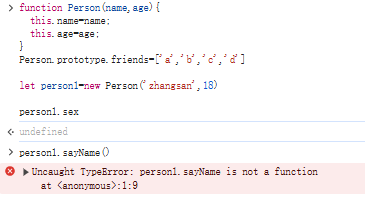
js原型和原型链
js原型: 1、原型诞生的目的是什么呢? js原型的产生是为了解决在js对象实例之间共享属性和方法,并把他们很好聚集在一起(原型对象上)。每个函数都会创建一个prototype属性,这个属性指向的就是原型对象。 …...

usb重定向qemu前端处理
1、qemu添加spicevmc前端时会创建vmc通道。 -chardev spicevmc,idusbredirchardev0,nameusbredir red::shared_ptr<RedCharDevice> spicevmc_device_connect(RedsState *reds, SpiceCharDeviceInstance *sin, uint8_t channel_type) {auto channel(red_vmc_channel_new(r…...
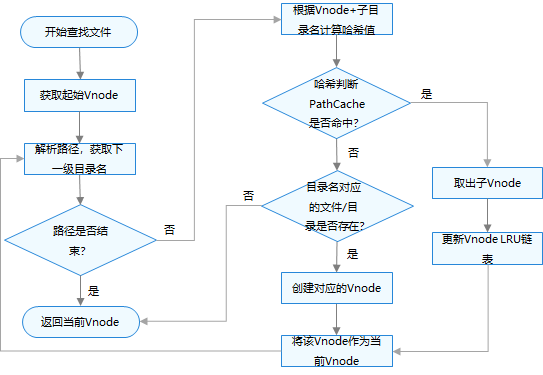
OpenHarmony - 小型系统内核(LiteOS-A)(五)
OpenHarmony - 小型系统内核(LiteOS-A)(五) 六、文件系统 虚拟文件系统 基本概念 VFS(Virtual File System)是文件系统的虚拟层,它不是一个实际的文件系统,而是一个异构文件系统之…...

PyTorch进阶学习笔记[长期更新]
第一章 PyTorch简介和安装 PyTorch是一个很强大的深度学习库,在学术中使用占比很大。 我这里是Mac系统的安装,相比起教程中的win/linux安装感觉还是简单不少(之前就已经安好啦),有需要指导的小伙伴可以评论。 第二章…...
proteus8.17 环境配置
Proteus介绍 Proteus 8.17 是一款功能强大的电子设计自动化(EDA)软件,广泛应用于电子电路设计、仿真和分析。以下是其主要特点和新功能: ### 主要功能 - **电路仿真**:支持数字和模拟电路的仿真,包括静态…...

Microsoft SQL Server Management 一键删除数据库所有外键
DECLARE ESQL VARCHAR(1000); DECLARE FCursor CURSOR --定义游标 FOR (SELECT ALTER TABLE O.name DROP CONSTRAINT F.name; AS CommandSQL from SYS.FOREIGN_KEYS F JOIN SYS.ALL_OBJECTS O ON F.PARENT_OBJECT_ID O.OBJECT_ID WHERE O.TYPE U AND F.TYPE …...

【JAVAFX】自定义FXML 文件存放的位置以及使用
情况 1:FXML 文件与调用类在同一个包中(推荐) 假设类 MainApp 的包是 com.example,且 FXML 文件放在 resources/com/example 下: 项目根目录 ├── src │ └── sample │ └── Main.java ├── src/s…...

Oracle 如何停止正在运行的 Job
Oracle 如何停止正在运行的 Job 先了解是dbms_job 还是 dbms_scheduler,再确定操作命令。 一 使用 DBMS_JOB 包停止作业(适用于旧版 Job) 1.1 查看正在运行的 Job SELECT job, what, this_date, this_sec, failures, broken FROM user_j…...
结构体(2)-Python)
高级语言调用C接口(四)结构体(2)-Python
这个专栏好久没有更新了,主要是坑开的有点大,也不知道怎么填,涉及到的开发语言比较多,写起来比较累,需要看的人其实并不多,只能说,慢慢填吧,中间肯定还会插很多别的东西,…...
Java对接Dify API接口完整指南
Java对接Dify API接口完整指南 一、Dify API简介 Dify是一款AI应用开发平台,提供多种自然语言处理能力。通过调用Dify开放API,开发者可以快速集成智能对话、文本生成等功能到自己的Java应用中。 二、准备工作 获取API密钥 登录Dify平台控制台在「API密…...

极狐GitLab GEO 功能介绍
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Geo (PREMIUM SELF) Geo 是广泛分布的开发团队的解决方案,可作为灾难恢复策略的一部分提供热备份。Geo 不是 开箱…...

Nginx-前言
nginx是什么? 轻量级,开源免费的web服务器软件,服务器安装nginx,服务器则成为web服务器 nginx的稳定版版本号: 偶数版本 nginx的相关目录: /etc/nginx/nginx.conf nginx的主配置文件 /etc/nginx/ngi…...

LFI to RCE
LFI不止可以来读取文件,还能用来RCE 在多道CTF题目中都有LFItoRCE的非预期解,下面总结一下LFI的利用姿势 1. /proc/self/environ 利用 条件:目标能读取 /proc/self/environ,并且网页中存在LFI点 利用方式: 修改请…...
云原生(Cloud Native)的详解、开发流程及同类软件对比
以下是云原生(Cloud Native)的详解、开发流程及同类软件对比: 一、云原生核心概念 定义: 云原生(Cloud Native)是基于云环境设计和运行应用程序的方法论,强调利用云平台的弹性、分布式和自动化…...
生成策略)
全局唯一标识符(UID)生成策略
目录 一、UUID 二、雪花算法 三、时间戳 随机数 四、利用数据库的自增字段 五、 基于 Redis 的原子操作 总结 在信息系统中,生成唯一ID是非常常见的需求,尤其是在分布式系统或高并发场景下。以下是几种常见的生成唯一ID的算法或方式: …...

学习笔记:减速机工作原理
学习笔记:减速机工作原理 一、减速机图片二、减速比概念三、减速机的速比与扭矩之间的关系四、题外内容--电机扭矩 一、减速机图片 二、减速比概念 即减速装置的传动比,是传动比的一种,是指减速机构中,驱动轴与被驱动轴瞬时输入速…...

《UE5_C++多人TPS完整教程》学习笔记36 ——《P37 拾取组件(Pickup Widget)》
本文为B站系列教学视频 《UE5_C多人TPS完整教程》 —— 《P37 拾取组件(Pickup Widget)》 的学习笔记,该系列教学视频为计算机工程师、程序员、游戏开发者、作家(Engineer, Programmer, Game Developer, Author) Steph…...

《空间复杂度(C语言)》
文章目录 前言一、什么是空间复杂度?通俗理解: 二、空间复杂度的数学定义三、常见空间复杂度举例(含C语言代码)🔹 O(1):常数空间🔹 O(n):线性空间🔹 O(n^2):平…...
)
Kaggle-Store Sales-(回归+多表合并+xgboost模型)
Store Sales 题意: 给出很多商店,给出商店的类型,某时某刻卖了多少销售额。 给出了油价表,假期表,进货表。 让你求出测试集合中每个商店的销售额是多少。 数据处理: 1.由于是多表,所以要先把其他表与tr…...

在 Tailwind CSS 中优雅地隐藏滚动条
在开发中,我们经常需要隐藏滚动条但保持滚动功能,这在构建现代化的用户界面时很常见。 本文将介绍两种在 Tailwind CSS 项目中实现这一目标的方法,方便同学们记录和查阅。 方法一:使用 tailwind-scrollbar-hide 插件 这是一种更…...
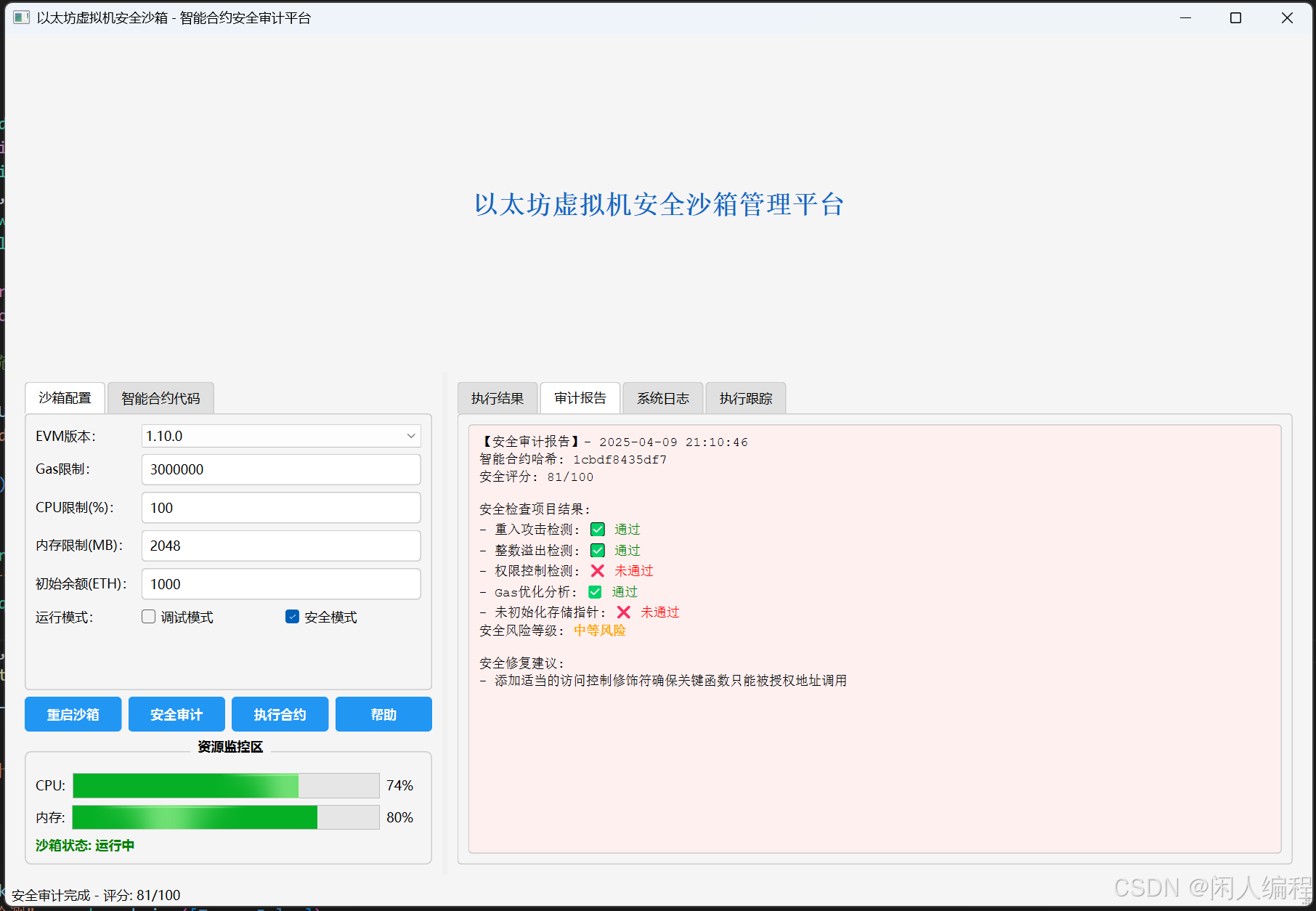
智能合约安全审计平台——以太坊虚拟机安全沙箱
目录 以太坊虚拟机安全沙箱 —— 理论、设计与实战1. 引言2. 理论背景与安全原理2.1 以太坊虚拟机(EVM)概述2.2 安全沙箱的基本概念2.3 安全证明与形式化验证3. 系统架构与模块设计3.1 模块功能说明3.2 模块之间的数据流与安全性4. 安全性与密码学考量4.1 密码学保障在沙箱中…...
)
std::unordered_map(C++)
std::unordered_map 1. 概述2. 内部实现3. 性能特征4. 常用 API5. 使用示例6. 自定义哈希与相等比较7. 注意事项与优化8. 使用建议9. emplace和insert异同相同点不同点例子对比何时优先使用哪种? 1. 概述 定义:std::unordered_map<Key, T, Hash, KeyE…...

【MCP教程】Claude Desktop 如何连接部署在远程的remote mcp server服务器(remote host)
前言 最近MCP特别火热,笔者自己也根据官方文档尝试了下。 官方文档给的Demo是在本地部署一个weather.py,然后用本地的Claude Desktop去访问该mcp服务器,从而完成工具的调用: 但是,问题来了,Claude Deskto…...