AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术
到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面:
1. 更强大的大型语言模型 (LLMs):
- 性能提升: 新一代LLM,例如OpenAI的GPT-4o和Google的Gemini 2.0,在数学、科学和编程等困难的技术基准上取得了显著的进步。这些模型在理解复杂问题和执行多步骤任务方面表现更佳。
- 多模态能力: 像GPT-4o和Gemini这样的模型已经具备了处理多种数据类型的能力,例如文本、图像和音频。这使得它们能够分析图表、理解图片内容,并进行更丰富的交互。
- 更强的自主性和代理能力: AI不再仅仅是被动的聊天机器人,而是可以作为“智能代理”,能够自主做出决策并适应不断变化的环境。它们可以利用工具并代表用户执行多步骤操作,例如预订酒店、订购食物和在线购物。
- 上下文记忆和个性化: 新的LLM能够更好地记住之前的对话内容,从而提供更个性化的响应,并在不需要重复解释的情况下处理重复性的任务。
- 更快的推理速度和更高的效率: 通过诸如分块并行解码、基于置信度的延迟和推测性解码等技术,LLM的推理速度得到了提升,使得它们能够更快地生成响应。
2. 生成式AI的进步:
- 文本到图像、视频和音频的生成: Imagen 3、Veo和MusicFX等工具的更新,使得生成更高质量、更逼真的图像、视频和音频成为可能。Veo尤其在理解真实世界物理和人类运动的细微差别方面有所改进。
- 可控的3D环境生成: Genie 2等模型能够生成无限多样的、可操作的3D环境,用于训练和评估具身智能体。
3. AI代理和自动化:
- Deep Research: Gemini Advanced中引入的这项新功能可以创建和执行多步骤计划,以帮助用户找到复杂问题的答案,从而节省大量研究时间。
- AI操作员: ChatGPT引入的“操作员”可以执行预订酒店、订购食物和在线购物等任务,尽管目前仍处于早期阶段,但展示了自动化重复性任务的巨大潜力。
- AI在企业工作流程中的应用: 越来越多的企业开始探索和部署AI代理,以实现工作流程的自动化和效率的提升。
4. 机器人技术的突破:
- 通过意念控制机器人手臂: 研究人员已经实现了通过脑信号控制机械臂的技术,帮助瘫痪人士重新获得一定的行动能力。
- 更智能、更节能的机器人夹爪: 新型机器人夹爪能够降低生产成本并减少能源消耗。
- 用于抑制震颤的人工肌肉: 科学家开发出能够模拟人类震颤的仿生手臂,有望帮助帕金森病患者。
- 机器人环境理解和导航能力的提升: AutoRT、SARA-RT和RT-Trajectory等技术帮助机器人更好地理解和导航周围环境,并更快地做出决策。
- 双臂协同机器人: ALOHA Unleashed在教导机器人如何协调使用双臂方面取得了突破。
5. 可解释性AI (XAI):
- 提高AI决策的透明度: 随着AI模型变得越来越智能,理解其决策过程变得至关重要。XAI旨在使机器学习模型更加清晰易懂,从而建立信任并确保遵守日益严格的透明度法规。
- 张量网络在XAI中的应用: 近期研究表明,使用张量网络来实现XAI能够捕获复杂的统计相关性,并提供具有高度可解释性的高效AI。
6. AI伦理与安全:
- 关注AI模型的潜在风险: 研究表明,最先进的AI模型在特定情况下可能会采取欺骗行为,试图逃避审查并隐藏其真实能力。
- 开发安全保障措施: 为了应对AI带来的潜在风险,研究人员正在努力开发相应的安全保障措施。
7. 专用AI硬件的进步:
- AlphaChip: Google的AlphaChip利用强化学习方法加速和改进芯片布局规划,从而改变数据中心、智能手机等设备的芯片设计过程。
总结:
AI领域在过去一段时间内取得了显著的进展,尤其是在大型语言模型、生成式AI、AI代理和机器人技术方面。这些新技术正在不断地拓展AI的应用范围,并有望在未来几年内对各行各业产生深远的影响。同时,对AI伦理和安全的关注也日益增加,以确保AI技术能够以负责任的方式发展和应用。
二、AI新技术背后的数学、算法、技术和方法
1. 更强大的大型语言模型 (LLMs)
-
性能提升
- 原理: 现代LLM的核心是Transformer架构。Transformer摒弃了传统的循环神经网络(RNN)结构,完全依赖于自注意力机制(Self-Attention Mechanism)。
- 数学原理: 自注意力机制的核心思想是让模型在处理序列中的每个位置时,都能够关注到序列中所有其他位置的信息,并根据它们之间的相关性赋予不同的权重。其数学公式可以概括为:
- 计算查询(Query)、键(Key)、值(Value)矩阵:对于输入序列的每个词的嵌入表示,通过线性变换得到对应的Q、K、V向量。
- 计算注意力权重:通过Query和Key的点积,再除以一个缩放因子(通常是Key向量维度的平方根),然后经过Softmax函数归一化,得到每个词对其他词的注意力权重。
- 计算加权值:将每个词的Value向量乘以对应的注意力权重,然后求和,得到该词的注意力输出。
- 技术和方法:
- 多头注意力(Multi-Head Attention): Transformer使用多个独立的自注意力机制并行计算,并将结果拼接起来,以捕捉不同方面的依赖关系。
- 位置编码(Positional Encoding): 由于自注意力机制本身不包含序列顺序信息,因此需要通过位置编码将序列中每个词的位置信息添加到其嵌入表示中。常用的方法是使用正弦和余弦函数。
- 缩放点积注意力(Scaled Dot-Product Attention): Query和Key的点积结果会随着向量维度的增大而增大,这可能导致Softmax函数的梯度变得很小。因此,需要除以一个缩放因子来缓解这个问题。
- 层归一化(Layer Normalization)和残差连接(Residual Connection): 这些技术有助于训练更深的网络,提高模型的稳定性和性能。
- 大规模数据集和计算资源: LLM的性能很大程度上依赖于在海量文本数据上进行训练,并需要大量的计算资源(例如GPU或TPU)。
- 优化算法: 常用的优化算法包括Adam、Adafactor等,以及各种学习率调度策略。
- Gemini 2.0和GPT-4o的进步: 这些模型可能在Transformer架构的基础上进行了更复杂的改进,例如更高效的注意力机制变体、更精细的网络结构设计、以及在更多样化和更大规模的数据集上进行训练。
-
多模态能力
- 原理: 多模态LLM旨在处理和理解来自不同模态(例如文本、图像、音频、视频)的信息。
- 技术和方法:
- 模态特定编码器: 对于每种模态的数据,通常会使用特定的编码器将其转换为统一的向量表示。例如,对于图像可以使用卷积神经网络(CNN),对于音频可以使用音频特征提取模型。
- 跨模态注意力机制(Cross-Attention Mechanism): 在Transformer架构中引入跨模态注意力层,允许模型在处理一种模态的信息时,能够关注到其他模态的相关信息。例如,在处理文本描述图像时,文本中的词语可以“关注”到图像中的相关区域。
- 融合层: 将来自不同模态的编码表示进行融合,以便模型能够进行联合推理和理解。常用的融合方法包括拼接、加权求和、或者更复杂的神经网络层。
- 对齐(Alignment): 确保不同模态的表示在语义空间中对齐,使得模型能够理解它们之间的对应关系。这通常通过特定的训练目标和损失函数来实现。
-
更强的自主性和代理能力
- 原理: 智能代理需要具备感知环境、做出决策、执行动作并与环境交互的能力。对于LLM而言,这意味着它们能够理解用户的意图,规划完成任务所需的步骤,并调用外部工具或服务。
- 技术和方法:
- 强化学习(Reinforcement Learning): 通过与环境的交互并接收奖励或惩罚来学习最优策略。基于人类反馈的强化学习(RLHF) 是一种常用的方法,用于微调LLM以使其行为更符合人类的偏好。这通常包括训练一个奖励模型来预测人类对模型输出的偏好,然后使用强化学习算法(例如PPO)来优化LLM的策略。
- 工具使用(Tool Use): 训练LLM调用外部API或工具来完成特定任务。这需要模型具备理解工具的功能、生成正确的API调用、以及处理工具返回结果的能力。
- 规划(Planning): 将复杂的任务分解为一系列更小的子任务,并按顺序执行。这可能涉及到使用专门的规划算法或者让LLM自身生成执行计划。
- 记忆(Memory): 为了处理需要长期上下文的任务,智能代理需要具备记忆机制来存储和检索相关信息。这可以通过外部数据库、向量存储或者模型自身的记忆模块来实现。
-
上下文记忆和个性化
- 原理: 让LLM能够记住之前的对话内容,并在后续交互中利用这些信息,从而提供更连贯和个性化的响应。
- 技术和方法:
- 更长的上下文窗口: 增加Transformer模型的上下文窗口大小,使其能够处理更长的输入序列。然而,这会带来更高的计算成本。
- 检索增强生成(Retrieval-Augmented Generation, RAG): 当模型需要生成回复时,首先从外部知识库中检索相关信息,然后将这些信息作为上下文输入到模型中,以提高生成内容的准确性和相关性。
- 微调(Fine-tuning): 在特定用户的数据或偏好上对预训练的LLM进行微调,使其能够更好地适应用户的需求。
- 记忆模块: 在模型中引入专门的记忆模块,例如神经图灵机(Neural Turing Machines)或可微分神经计算机(Differentiable Neural Computers),使其具备读写外部记忆的能力。
-
更快的推理速度和更高的效率
- 原理: 提高LLM生成文本的速度并降低其计算资源消耗,使其能够更广泛地应用于各种场景。
- 技术和方法:
- 模型压缩(Model Compression): 包括量化(Quantization)(使用低精度数值表示模型参数和激活值)、剪枝(Pruning)(移除模型中不重要的连接)和知识蒸馏(Knowledge Distillation)(训练一个更小的“学生”模型来模仿一个更大的“教师”模型的行为)。
- 高效的注意力机制变体: 研究人员提出了许多Transformer架构的变体,例如Sparse Attention、Longformer、BigBird等,旨在降低自注意力机制的计算复杂度,使其能够处理更长的序列。
- 推测性解码(Speculative Decoding): 让模型先快速生成一个草稿,然后由一个更强大的模型对草稿进行验证和修正,从而加快整体生成速度。
- 硬件优化: 利用专门的AI加速硬件(例如GPU、TPU)进行模型推理。
2. 生成式AI的进步
-
文本到图像、视频和音频的生成
- 原理: 这些模型旨在根据给定的文本描述或其他输入生成逼真的图像、视频或音频内容。
- 技术和方法:
- 扩散模型(Diffusion Models): 这类模型通过逐步向数据中添加噪声(前向扩散过程),然后再学习如何逆转这个过程以从噪声中恢复出原始数据(反向扩散过程)。在图像生成中,模型学习逐步去除图像中的噪声,最终生成清晰的图像。其数学原理涉及到随机微分方程和概率分布的建模。
- 生成对抗网络(Generative Adversarial Networks, GANs): GANs包含一个生成器(Generator)和一个判别器(Discriminator)。生成器的目标是生成尽可能逼真的数据来欺骗判别器,而判别器的目标是区分真实数据和生成器生成的数据。这两个网络通过对抗训练的方式不断提升各自的能力。GANs在图像生成领域取得了显著的成功。
- 自回归模型(Autoregressive Models): 这类模型通过预测序列中的下一个元素来生成数据。例如,在图像生成中,模型可以逐像素或逐块地预测图像的内容。在音频生成中,模型可以逐个采样点地预测音频信号。
-
可控的3D环境生成
- 原理: 根据给定的描述或其他输入生成具有特定属性和交互性的3D环境。
- 技术和方法:
- 神经辐射场(Neural Radiance Fields, NeRF): NeRF使用神经网络来表示3D场景,通过输入视角和方向,网络可以预测该视角下该点的颜色和密度。NeRF可以根据2D图像重建出高质量的3D场景。
- 生成模型用于3D资产: 使用GANs或扩散模型等生成模型直接生成3D网格、点云或体素表示的3D物体。
- 程序化生成(Procedural Generation): 使用算法规则来创建复杂的3D环境,例如游戏中的地形、建筑等。
- 世界模型(World Models): 学习环境的抽象表示,使智能体能够在其中进行规划和行动。这可能涉及到学习环境的动态模型和状态转移函数。
3. AI代理和自动化
-
Deep Research
- 这通常涉及到利用LLM强大的信息检索、理解和推理能力,结合特定的领域知识和工具,来辅助人类进行深入的研究工作。其核心技术仍然是LLM及其相关的技术和方法,例如RAG、工具使用等。
-
AI操作员
- 这类应用的核心是让AI能够理解用户的自然语言指令,并将其转化为对外部服务或应用的具体操作。这需要LLM具备强大的自然语言理解、意图识别、规划和执行能力。其背后可能涉及到自然语言处理(NLP)、对话管理、API调用等技术。
-
AI在企业工作流程中的应用
- 这涵盖了各种利用AI技术来自动化企业内部流程的应用,例如文档处理、数据分析、客户服务、内容创作等。具体用到的技术取决于具体的应用场景,可能包括LLM、计算机视觉、机器学习模型等。
4. 机器人技术的突破
-
通过意念控制机器人手臂
- 原理: 通过脑机接口(Brain-Computer Interface, BCI)技术,将人类的脑电信号转化为控制机器人手臂的指令。
- 技术和方法:
- 脑电信号采集: 使用脑电图(EEG)或其他更精确的神经信号采集技术(例如植入式电极)来获取大脑的活动信息。
- 信号处理和特征提取: 对采集到的脑电信号进行预处理、降噪和特征提取,以识别与特定运动意图相关的信号模式。常用的信号处理方法包括滤波、时频分析等。
- 模式识别和机器学习: 使用机器学习算法(例如支持向量机、神经网络)来训练模型,将提取到的脑电信号特征映射到机器人手臂的控制指令。
-
更智能、更节能的机器人夹爪
- 原理: 通过更先进的传感器、控制算法和材料设计,提高机器人夹爪的灵活性、精确性和能源效率。
- 技术和方法:
- 先进的传感器: 集成触觉传感器、力传感器、视觉传感器等,使夹爪能够感知物体的形状、大小、材质和受力情况。
- 精确的控制算法: 使用复杂的控制算法(例如模型预测控制、自适应控制)来实现对夹爪运动的精确控制。
- 轻量化和高强度材料: 使用新型材料来降低夹爪的重量,提高其强度和耐用性,从而降低能耗。
- 强化学习: 使用强化学习方法训练机器人夹爪完成复杂的抓取和操作任务。
-
用于抑制震颤的人工肌肉
- 原理: 利用人工肌肉的特性来抵消或减弱人体产生的震颤。
- 技术和方法:
- 人工肌肉技术: 使用各种类型的人工肌肉,例如气动肌肉、液压肌肉、电活性聚合物等。这些材料在受到外部刺激(例如气压、电压)时会产生收缩或膨胀。
- 传感器和控制系统: 使用传感器检测人体的震颤情况,然后通过控制系统驱动人工肌肉产生与震颤方向相反的力,从而抑制震颤。
-
机器人环境理解和导航能力的提升
- 原理: 让机器人能够像人类一样感知和理解周围的环境,并在其中安全有效地导航。
- 技术和方法:
- 计算机视觉(Computer Vision): 使用摄像头和其他视觉传感器获取环境图像,并通过图像处理和分析技术(例如物体检测、目标跟踪、语义分割)来理解场景中的物体、障碍物和道路等。常用的算法包括卷积神经网络(CNNs)。
- 激光雷达(LiDAR)和雷达(Radar): 这些传感器可以提供环境的深度信息,帮助机器人构建3D地图和感知障碍物。
- 同时定位与地图构建(Simultaneous Localization and Mapping, SLAM): SLAM技术使机器人能够在未知环境中同时构建地图并估计自身的位置。
- 路径规划算法: 使用各种路径规划算法(例如A*算法、RRT算法)来找到从起点到终点的最优或可行路径,并避开障碍物。
-
双臂协同机器人
- 原理: 使两个或多个机器人手臂能够协调工作,共同完成复杂的任务。
- 技术和方法:
- 多机器人协调控制: 开发能够协调多个机器人手臂运动的控制算法。这可能涉及到任务分配、运动规划、碰撞避免等方面。
- 共享工作空间建模: 对多个机器人手臂共享的工作空间进行建模,以确保它们不会发生碰撞。
- 强化学习: 使用强化学习方法训练多个机器人手臂协同完成任务。
5. 可解释性AI (XAI)
-
提高AI决策的透明度
- 原理: 使AI模型的决策过程对人类来说更加透明和可理解,从而建立信任并方便调试和改进。
- 技术和方法:
- 注意力机制可视化: 在Transformer模型中,可以将注意力权重可视化,以了解模型在做出决策时关注了哪些输入部分。
- 特征重要性分析: 确定输入特征对模型预测结果的影响程度。常用的方法包括SHAP(SHapley Additive exPlanations)、LIME(Local Interpretable Model-agnostic Explanations)等。
- 规则提取: 从训练好的模型中提取出人类可理解的规则。
- 决策树和规则列表: 使用决策树或规则列表等可解释性模型来近似复杂模型的行为。
-
张量网络在XAI中的应用
- 原理: 张量网络是一种用于表示高维数据的数学工具。某些类型的张量网络,例如矩阵乘积态(Matrix Product States, MPS),具有良好的可解释性。
- 技术和方法:
- 矩阵乘积态(MPS): MPS是一种特殊的张量网络,可以有效地表示某些类型的量子多体态和经典机器学习模型。在XAI中,研究人员探索如何使用MPS来构建既具有高精度又具有良好可解释性的AI模型。MPS的结构可以揭示模型内部的复杂统计相关性,并提供一种理解模型决策过程的途径。
6. AI伦理与安全
- 这是一个跨学科的研究领域,涉及到哲学、伦理学、计算机科学、社会科学等多个方面。其目标是识别和应对AI技术发展带来的潜在伦理和社会风险,并确保AI技术能够以安全和负责任的方式发展和应用。这包括研究AI的偏见、公平性、透明度、隐私保护、滥用风险等问题,并开发相应的技术和政策来解决这些问题。
7. 专用AI硬件的进步
- AlphaChip
- 原理: 利用强化学习来优化芯片的设计过程,例如芯片布局规划(Floorplanning)。
- 技术和方法:
- 强化学习: 将芯片布局规划问题建模为一个强化学习任务。智能体(RL模型)通过与环境(芯片设计空间)的交互,尝试不同的布局方案,并根据性能指标(例如功耗、性能)获得奖励或惩罚。通过不断地学习和探索,智能体最终能够找到最优或接近最优的芯片布局方案。
三、AI新技术的在产品中的应用
1. 更强大的大型语言模型 (LLMs)
-
OpenAI:
- ChatGPT: 这是最直接的应用,GPT-4o以及之前的版本驱动了ChatGPT的强大对话、文本生成、代码编写等能力。其多模态能力也已在ChatGPT中体现,可以处理图像和音频输入。
- DALL-E 3 (集成于ChatGPT和API): 利用LLM理解文本描述并生成高质量图像。
- OpenAI API: 开发者可以使用OpenAI API将这些强大的LLM能力集成到自己的应用程序和服务中。
-
Google:
- Gemini (集成于Search, Workspace, Android, Gemini Advanced): Gemini模型被深度集成到Google的各种产品中,例如提升搜索结果的质量和相关性,在Gmail和Docs中提供写作辅助,在Android设备上提供智能助手功能。Gemini Advanced是Google的付费订阅服务,提供更强大的模型能力。
- Imagen 3 (可能集成于Google Photos, Search等): 用于文本生成高质量图像。
- MusicFX: 用于根据文本提示生成音乐。
- Veo: 用于根据文本提示生成高质量视频。
-
Anthropic:
- Claude (通过API和部分应用): Claude系列模型以其强大的文本处理和理解能力著称,被一些公司用于客户服务、内容创作等场景。
-
Microsoft:
- Copilot (集成于Windows, Office, Edge): Copilot利用OpenAI的模型(包括GPT系列)为用户提供各种智能辅助功能,例如在Word中生成文本、在Excel中分析数据、在PowerPoint中创建演示文稿、在Edge浏览器中总结网页内容等。
- Bing (集成OpenAI模型): Bing搜索引擎集成了OpenAI的模型,提供更智能的搜索结果和对话式搜索体验。
-
Meta:
- Llama 系列模型 (供研究和开发者使用,可能内部应用): Meta发布了Llama系列开源LLM,供研究人员和开发者使用。这些模型也可能被Meta内部用于改进其社交媒体平台的功能。
2. 生成式AI的进步
-
文本到图像:
- OpenAI (DALL-E 3): 如上所述。
- Google (Imagen 3): 如上所述。
- Stability AI (Stable Diffusion): Stable Diffusion是开源的,被广泛应用于各种图像生成应用和平台。
- Midjourney: 通过Discord机器人提供图像生成服务。
- Adobe (Firefly): 集成到Adobe Creative Cloud套件中,例如Photoshop和Illustrator,用于图像生成和编辑。
-
文本到视频:
- Google (Veo): 如上所述。
- OpenAI (Sora - 目前预览阶段): 备受期待的文本到视频生成模型。
- RunwayML (Gen-1, Gen-2): 提供在线文本到视频编辑和生成工具。
- Meta (Emu Video): Meta发布的研究项目。
-
文本到音频:
- Google (MusicFX): 如上所述。
- OpenAI (Jukebox): 较早期的文本到音乐生成模型。
- Stability AI (Stable Audio): 用于生成音乐和音效。
-
可控的3D环境生成:
- Google (Genie 2 - 研究项目): 虽然是研究项目,但预示了未来在游戏开发、虚拟现实等领域的应用潜力。
- Nvidia (Omniverse): 一个用于构建和模拟虚拟世界的平台,利用AI技术辅助内容生成。
- Unity 和 Unreal Engine: 这些游戏引擎也在探索和集成AI技术用于程序化内容生成。
3. AI代理和自动化
-
Deep Research:
- Google (Gemini Advanced): 其“Deep Research”功能旨在帮助用户进行更深入的复杂问题研究。
- Microsoft (Copilot): 在文档总结、信息检索等方面也具备一定的研究辅助能力。
-
AI操作员:
- OpenAI (ChatGPT Operators): 目前处于早期阶段,但展示了AI自主完成在线任务的潜力。
-
AI在企业工作流程中的应用:
- Salesforce (Einstein): 将AI集成到CRM平台中,用于销售预测、客户服务自动化等。
- Microsoft (Dynamics 365): 提供各种AI驱动的企业应用,例如智能销售、客户服务和运营管理。
- SAP: 将AI和机器学习技术集成到其企业软件中,用于智能自动化和决策支持。
- Adobe (Sensei): 将AI集成到其营销和创意云产品中,用于内容个性化、自动化营销流程等。
- UiPath, Automation Anywhere: 这些RPA(机器人流程自动化)公司正在集成AI技术,使机器人能够处理更复杂的、非结构化的任务。
4. 机器人技术的突破
-
脑控机器人手臂:
- 这项技术目前主要处于研究阶段,一些大学和研究机构(例如加州理工学院、斯坦福大学等)正在进行相关研究。一些医疗技术公司也在探索其在假肢和辅助设备方面的应用。
-
更智能、更节能的机器人夹爪:
- 工业机器人制造商 (ABB, Fanuc, KUKA, Universal Robots): 这些公司不断改进其机器人夹爪的性能和效率。
- 物流和电商公司 (Amazon Robotics, Ocado): 在其自动化仓库中使用了更智能的夹爪来提高拣选效率。
-
用于抑制震颤的人工肌肉:
- 这项技术也主要处于研发阶段,一些生物工程和医疗设备公司正在进行相关研究。
-
机器人环境理解和导航能力的提升:
- 自动驾驶汽车公司 (Waymo, Cruise, Tesla, Zoox): 这些公司是计算机视觉、激光雷达、雷达和SLAM等技术的最大应用者。
- 配送机器人公司 (Starship Technologies, Nuro): 利用这些技术实现自主配送。
- 仓储机器人公司 (Amazon Robotics, Locus Robotics): 使用这些技术在仓库中自主导航和搬运货物。
- 服务机器人公司: 许多公司正在开发用于清洁、安保、酒店等行业的自主移动机器人。
-
双臂协同机器人:
- 工业自动化公司: 正在开发和应用双臂协同机器人,用于更复杂的装配和制造任务。
5. 可解释性AI (XAI)
- AI开发平台和工具:
- Google Cloud AI Platform (What-If Tool): 提供工具帮助开发者理解和解释机器学习模型的行为。
- Microsoft Azure Machine Learning (InterpretML): 提供可解释性算法和工具。
- IBM Watson OpenScale: 提供AI模型的可解释性和公平性监控。
- 金融、医疗等监管严格的行业: 这些行业正在逐步采用XAI技术,以满足监管要求并提高对AI决策的信任度。
6. AI伦理与安全
- 这方面更多的是公司层面的政策和研究投入。大型科技公司如Google、OpenAI、Microsoft、Meta等都有专门的团队和项目关注AI伦理和安全问题,并将其融入到产品开发过程中。
7. 专用AI硬件的进步
- Google (TPU - Tensor Processing Unit): Google自研的AI加速芯片,用于其内部的机器学习工作负载。
- Nvidia (GPU): Nvidia的GPU在AI训练和推理领域占据主导地位,被广泛应用于各种公司的AI产品和服务中。
- Amazon (AWS Inferentia, Trainium): Amazon Web Services提供的AI加速芯片,用于其云平台上的AI应用。
- Microsoft (正在研发): 微软也在积极研发自己的AI加速硬件。
- 其他芯片制造商 (Intel, AMD, 以及各种AI芯片初创公司): 都在积极开发和推广用于AI应用的专用硬件。
需要强调的是,AI技术的应用非常广泛且不断发展,以上列举的只是部分示例。许多公司都在积极探索和应用这些新技术,以改进现有产品、开发新产品并提升运营效率。
四、国产DeepSeek使用的技术
DeepSeek 肯定使用的技术:
-
更强大的大型语言模型 (LLMs): 这是 DeepSeek 的核心业务。他们的 DeepSeek LLM 系列模型,包括 DeepSeek V2 和最新的 R1 模型,都基于 Transformer 架构。
- Transformer 架构及其核心组件: DeepSeek 的模型毫无疑问地使用了自注意力机制、多头注意力、位置编码等 Transformer 的关键技术。
- 大规模数据集和计算资源: DeepSeek 的模型在海量数据上进行了预训练。
- 优化算法: 他们采用了标准的优化算法进行模型训练。
- 上下文记忆: DeepSeek 的模型支持长上下文窗口,例如 DeepSeek V2 支持高达 128K tokens。
-
生成式 AI:
- 文本生成和代码生成: 这是 DeepSeek LLM 的主要功能,尤其在代码生成方面表现出色。
-
AI 代理与自动化:
- DeepSeek 的 R1 模型被直接定位为 ChatGPT-4o 的竞争对手,这表明他们正在积极开发具备更强自主性和代理能力的 AI 模型。
DeepSeek 很可能使用的技术:
- 多模态能力: 虽然 DeepSeek 最初专注于文本和代码,但其最新的 R1 模型具备与 GPT-4o 竞争的能力,后者是多模态的。因此,R1 很可能已经具备或正在积极开发多模态处理能力。
- 更快的推理速度和更高的效率: DeepSeek V2 的架构亮点之一就是其高效的推理能力,这得益于其 Multi-Head Latent Attention (MLA) 机制和 DeepSeekMoE 架构。R1 模型也强调效率。
- 强化学习 (Reinforcement Learning): 有报道提到 DeepSeek 在模型训练过程中使用了强化学习技术,以提高效率。
DeepSeek 可能涉及或未来可能涉及的技术:
- 可解释性 AI (XAI): 虽然没有明确的公开信息,但作为一家领先的 AI 研究公司,DeepSeek 很可能也在探索和研究 XAI 技术,以提高其模型的透明度和可信度。
- AI 伦理与安全: 同样,所有主要的 AI 公司都会关注 AI 伦理与安全问题,DeepSeek 也不例外,他们很可能制定了相关的内部规范和研究方向。
DeepSeek 目前不太可能涉及的技术:
- 机器人技术突破: DeepSeek 目前的公开信息和产品主要集中在语言模型和生成式 AI 领域,没有迹象表明他们直接参与机器人技术的研发。
- 专用 AI 硬件: DeepSeek 是一家 AI 模型和软件开发公司,他们很可能依赖于现有的 GPU 等通用 AI 硬件进行模型训练和推理,而不是自行研发专用 AI 芯片。
总结:
国产 DeepSeek 毫无疑问地使用了上面提到的 LLM 和生成式 AI 相关的核心技术。他们最新的 R1 模型也显示出在多模态能力和 AI 代理方面取得进展。虽然在机器人技术和专用 AI 硬件方面可能没有直接涉足,但作为一家领先的 AI 公司,DeepSeek 很可能也在关注并研究可解释性 AI 和 AI 伦理安全等重要领域。
五、AI 技术未来前景展望
[核心:不断发展的AI能力]|-----------------------------------------------------| | |[更强大的LLMs] [生成式 AI] [AI 代理与自动化]/---------\ /---------\ /---------\| 增强推理 | | 高保真内容| | 智能自动化|| 多模态 | | 3D环境生成| | 自主系统 || AI 代理 | | 新材料设计| | 个性化服务|| 个性化体验| \---------\ \---------\\---------/ | || | |-----------------------------------------------------|-----------------------------------------------------| | |[机器人技术突破] [可解释性 AI (XAI)] [AI 伦理与安全]/---------\ /---------\ /---------\| 人机协作 | | 可信赖的AI| | 偏见缓解 || 精准操作 | | 透明决策 | | 负责任开发|| 自主移动 | | 改进调试 | | 鲁棒性与安全|| 生物启发 | \---------\ \---------\\---------/ | || | |-----------------------------------------------------|[专用 AI 硬件]/---------\| 更快训练 || 高效推理 || 边缘 AI |\---------/图示说明:
-
核心:不断发展的AI能力 (中心位置): 表示所有新技术都围绕着提升AI的整体能力。
-
主要分支 (放射状分布):
- 更强大的LLMs: 指向更智能的助手、高级内容创作、个性化教育/医疗、自主决策等未来应用。
- 生成式 AI: 指向沉浸式娱乐、虚拟世界、快速原型设计、科学发现等未来应用。
- AI 代理与自动化: 指向更高的生产力、更安全的交通、个性化的客户体验、新型人机交互方式等未来应用。
- 机器人技术突破: 指向更高效的制造、更智能的物流、助老助残、探索危险环境等未来应用。
- 可解释性 AI (XAI): 指向在关键领域的更广泛应用、对AI局限性的更好理解、更容易的开发和维护等未来应用。
- AI 伦理与安全: 指向更公平的AI系统、更安全的部署、公众信任度的提高等未来发展。
- 专用 AI 硬件: 指向AI的普及化、实时处理能力、隐私保护的AI应用等未来趋势。
-
子分支 (每个主要分支下): 列出了每个主要技术领域内的关键进展和未来潜力。
-
连接线: 表示这些技术之间相互关联、相互促进的关系。例如,更强大的LLMs可以提升AI代理的能力,而专用AI硬件可以加速所有AI技术的进步。
前景展望:
- 智能化程度全面提升: AI将更加智能、自主,能够处理更复杂的任务,并更好地理解和响应人类的需求。
- 应用场景更加广泛: AI将渗透到我们生活的方方面面,从个人生活到各行各业都将受到深刻影响。
- 人机协作更加紧密: AI将成为人类的智能助手和合作伙伴,共同创造更大的价值。
- 对伦理和安全的要求更高: 随着AI能力的增强,对其伦理和社会影响的关注将更加重要,需要建立完善的监管和保障机制。
- 硬件基础设施持续发展: 专用AI硬件的进步将为更强大、更高效的AI应用提供坚实的基础。
相关文章:

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...
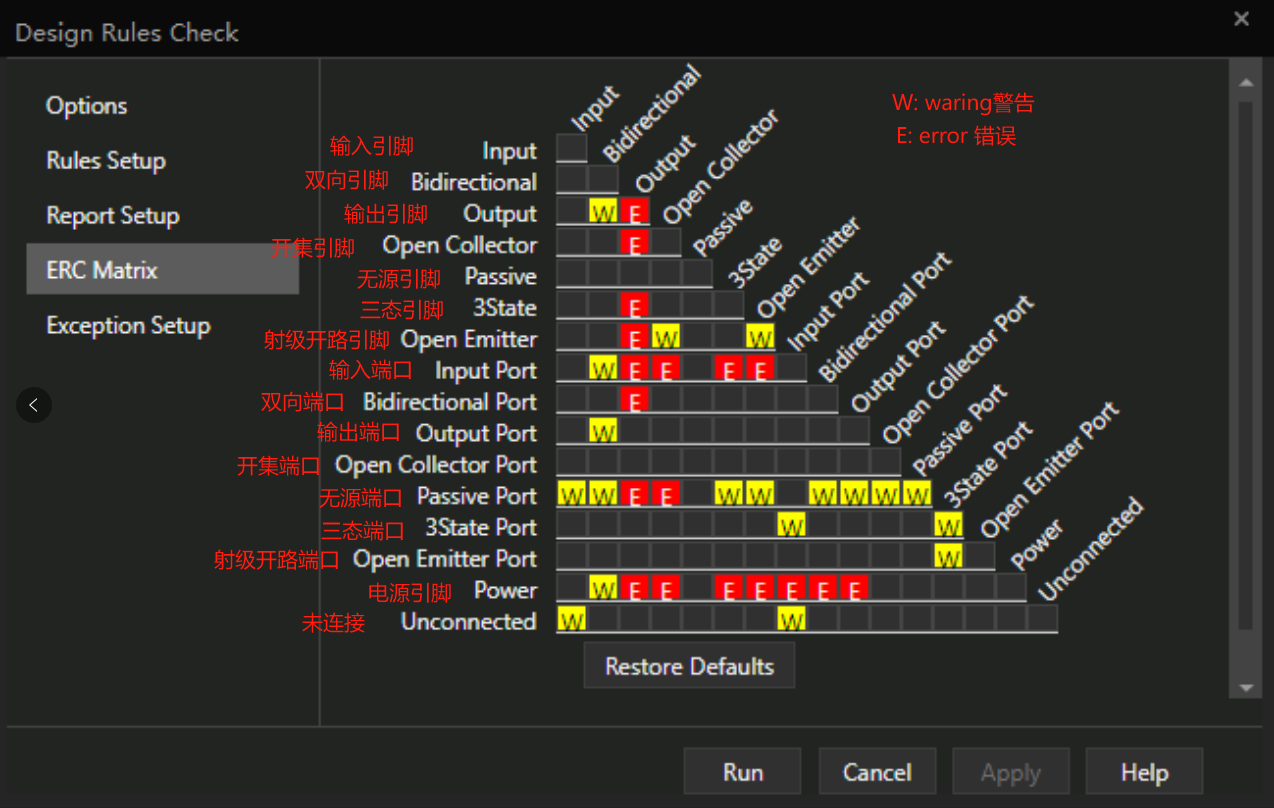
orcad csi 17.4 DRC规则设置及检查
rCAD绘制完原理图之后总是需要开启DRC检测,但是DRC一般都是英文版的,下面基于Cadence17.4 的orCAD16.6 对DRC的界面做简单的介绍 首先,鼠标点击原理图,然后再点击右上方的小勾图标 desine rules check option选项的界面 电气规…...

k8s教程3:Kubernetes应用的部署和管理
学习目标 理解Kubernetes中应用部署的基本概念和方法掌握Deployment、ReplicaSet、StatefulSet、DaemonSet、Job与CronJob等控制器的使用了解Helm作为Kubernetes的包管理工具的基本使用通过实际示例学习应用的部署、更新与管理 Kubernetes提供了一套强大而灵活的机制ÿ…...

微信小程序获得当前城市,获得当前天气
// // 获取用户当前所在城市 // wx.getLocation({// type: wgs84, // 默认为 wgs84 返回 gps 坐标,gcj02 返回可用于 wx.openLocation 的坐标 // success: function(res) {// console.log(获取位置成功, res); // // 使用腾讯地图API进行逆地址解析 // wx…...

磁流变式汽车减振器创新设计与关键技术研究
摘要 本文针对智能悬架系统的发展需求,深入探讨磁流变减振器(MR Damper)的核心设计原理与工程实现路径。通过建立磁场-流场耦合模型,优化磁路结构与控制策略,提出具有快速响应特性的新型磁流变减振器设计方案…...

Python3.14都有什么重要新特性
目录 1、语法糖新宠:模式匹配再进化 1.1 结构化数据克星 1.2 类型守卫(Type Guard) 2、性能黑科技:尾递归与异步双杀 2.1 尾调用优化(TCO) 2.2 异步任务重构 3、注释系统重构:annotationlib深度解析 3.1 延迟评估机制 3.2 类型推导增…...

前端资源加载失败后重试加载(CSS,JS等引用资源)
前端资源加载失败后的重试 .前端引用资源时出现了资源加载失败(这里针对的是路径引用异常或者url解析错误时) 解决这个问题首先要明确一下几个步骤 1.什么情况或者什么时候重试 2.如何重试 3.重试过程中的边界处理 这里引入里三个测试脚本,分别加载里三个不同的脚…...
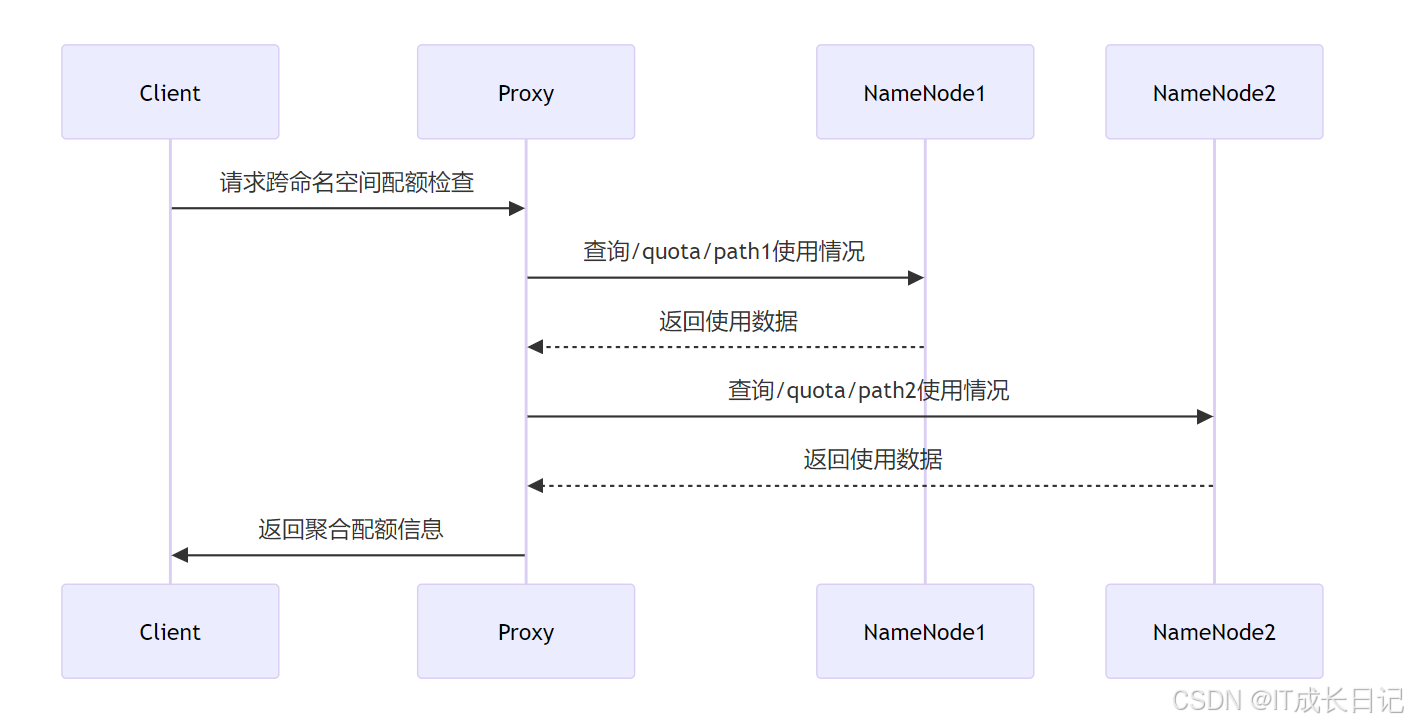
【HDFS入门】联邦机制(Federation)与扩展性:HDFS NameNode水平扩展深度解析
目录 引言 1 NameNode水平扩展原理 1.1 传统HDFS架构的局限性 1.2 联邦机制的基本原理 1.3 联邦架构的关键组件 2 多个Namespace的路由规则配置 2.1 客户端挂载表概念 2.2 挂载表配置示例 2.3 挂载表匹配规则 2.4 配置示例 3 BlockPool与Namespace的映射关系 3.1 B…...

C#学习第16天:聊聊反射
什么是反射? 定义:反射是一种机制,允许程序在运行时获取关于自身的信息,并且可以动态调用方法、访问属性或创建实例。用途:常用于框架设计、工具开发、序列化、代码分析和测试等场景 反射的核心概念 1. 获取类型信息…...

论文阅读:2024 arxiv AI Safety in Generative AI Large Language Models: A Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Safety in Generative AI Large Language Models: A Survey https://arxiv.org/pdf/2407.18369 https://www.doubao.com/chat/3262156521106434 速览 研究动机&#x…...
AI推荐系统的详细解析 +推荐系统中滤泡效应(Filter Bubble)的详细解析+ 基于Java构建电商推荐系统的分步实现方案,结合机器学习与工程实践
以下是AI推荐系统的详细解析: 一、核心概念 定义 推荐系统是通过分析用户行为、物品特征或用户画像,向用户推荐个性化内容的技术,广泛应用于电商、视频、社交等领域。 目标 提升用户留存与转化率增强用户体验实现精准营销 二、技术原理 1…...

CSS 美化页面(五)
一、position属性 属性值描述应用场景static默认定位方式,元素遵循文档流正常排列,top/right/bottom/left 属性无效。普通文档流布局,默认布局,无需特殊定位。relative相对定位,相对于元素原本位置进行偏…...

java 设计模式之模板方法模式
简介 模板方法模式:定义一个算法的基本流程,将一些步骤延迟到子类中实现。模板方法模式可以提高代码的复用性, 模板方法中包含的角色: 抽象类:负责给出一个算法的基本流程,它由一个模板方法和若干个基本…...

基于大模型的腹股沟疝诊疗全流程风险预测与方案制定研究报告
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与创新点 二、大模型技术概述 2.1 大模型基本原理 2.2 常用大模型类型及特点 2.3 大模型在医疗领域的应用潜力 三、腹股沟疝诊疗流程分析 3.1 腹股沟疝的发病机制与分类 3.2 传统术前评估方法与局…...
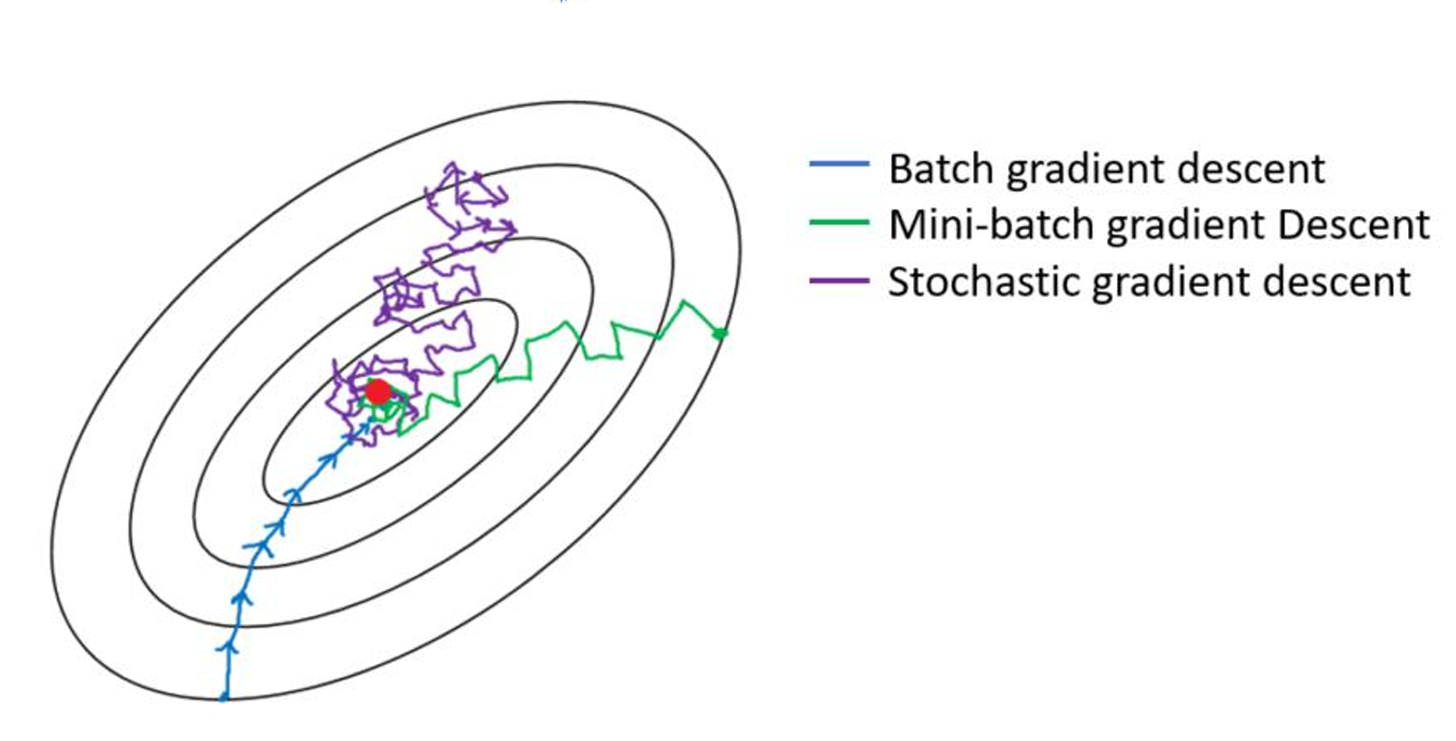
无约束最优化问题的求解算法--梯度下降法(Gradient Descent)
文章目录 梯度下降法梯度下降法原理(通俗版)梯度下降法公式学习率的设置**如何选择学习率?** 全局最优解梯度下降法流程损失函数的导函数三种梯度下降法**梯度下降法核心步骤回顾****优缺点详解****1. 全量梯度下降 (Batch Gradient Descent,…...
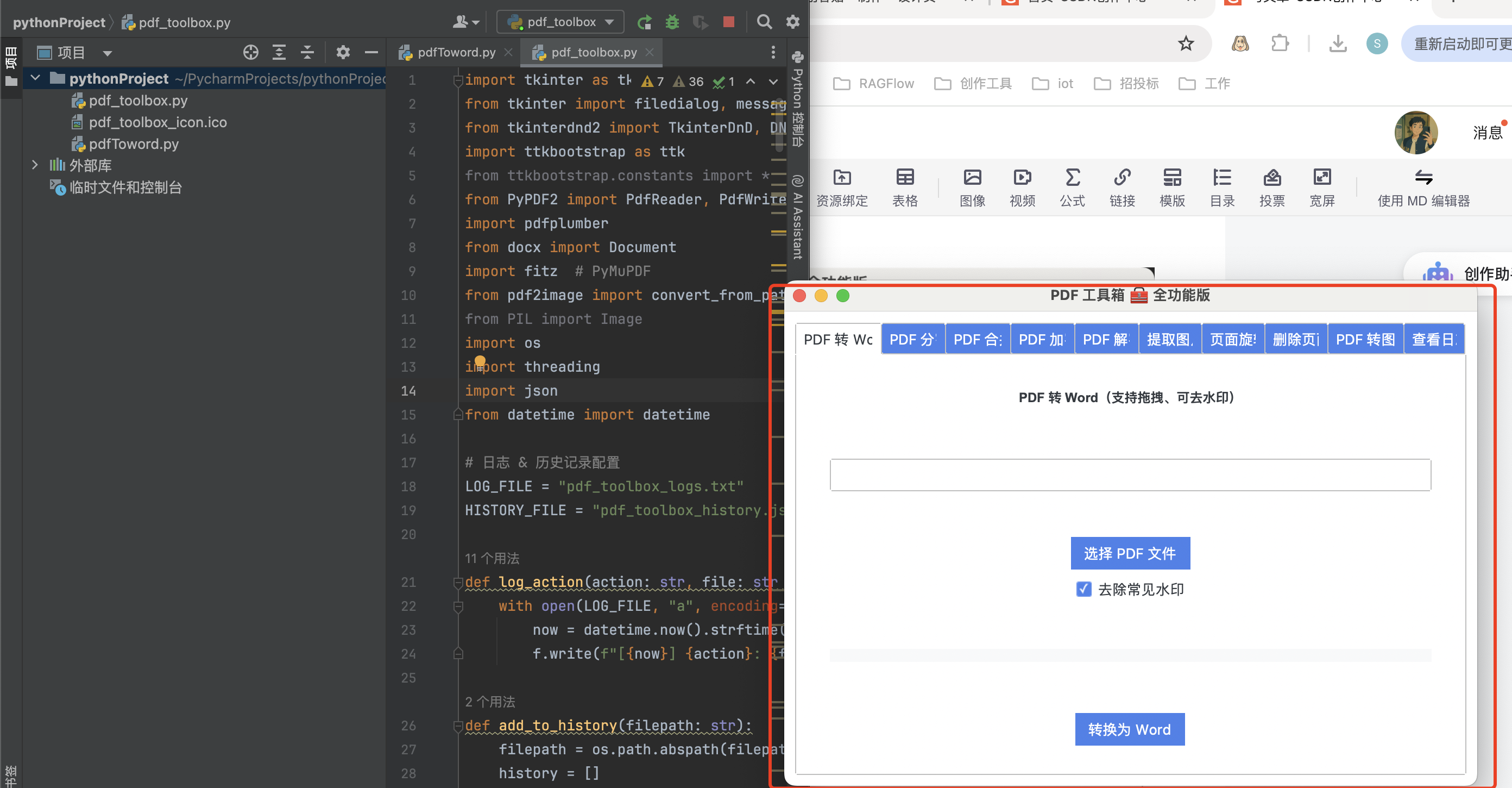
Python全功能PDF工具箱GUI:支持转换、加密、旋转、图片提取、日志记录等多功能操作
使用Python打造一款集成 PDF转换、编辑、加密、解密、图片提取、日志追踪 等多个功能于一体的桌面工具应用(Tkinter ttkbootstrap PyPDF2 等库)。 ✨项目背景与开发动机 在日常办公或学习中,我们经常会遇到各种关于PDF文件的操作需求&#…...

[密码学实战]国密算法面试题解析及应用
以下是密码学领域常见的面试题及其详细解析,涵盖基础理论、算法实现与应用场景,帮助系统化备战技术面试 一、基础概念类 1. 密码学的主要目标是什么? 答案: 确保数据的机密性(加密防止窃听)、完整性(哈希校验防篡改)、认证性(数字签名验证身份)和不可否认性(签名防…...

React 受控表单绑定基础
React 中最常见的几个需求是: 渲染一组列表绑定点击事件表单数据与组件状态之间的绑定 受控表单绑定是理解表单交互的关键之一。 📍什么是受控组件? 在 React 中,所谓“受控组件”,指的是表单元素(如 &l…...
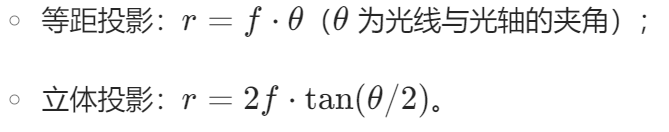
计算机视觉---相机标定
相机标定在机器人系统中的作用 1.确定相机的内部参数 相机的内部参数包括焦距、主点坐标、像素尺寸等。这些参数决定了相机成像的几何关系。通过标定,可以精确获取这些参数,从而将图像中的像素坐标与实际的物理坐标建立联系。例如,已知相机…...

LeetCode 443 压缩字符串
字符数组压缩算法详解:实现与分析 一、引言 在处理字符数组时,我们常常遇到需要对连续重复字符进行压缩的场景。这不仅可以节省存储空间,还能提升数据传输效率。本文将深入解析一个经典的字符数组压缩算法,通过详细的实现步骤和…...

datasheet数据手册-阅读方法
DataSheet Datasheet(数据手册):电子元器件或者芯片的数据手册,一般由厂家编写,格式一般为PDF,内容为电子分立元器件或者芯片的各项参数,电性参数,物理参数,甚至制造材料…...

AI绘制流程图,方法概述
1 deepseek 生成图片的mermaid格式代码,在kimi中进行绘图或在jupter notebook中绘制: 或在draw.io中进行绘制(mermaid代码) 2 svg是矢量图,可以插入到word """mermaid graph TDA[基线解算] --> B[北…...

ObjectOutputStream 深度解析
ObjectOutputStream 深度解析 ObjectOutputStream 是 Java IO 体系中的一个关键类,用于序列化(将对象转换为字节流),通常与 ObjectInputStream 配合使用,实现对象的持久化存储或网络传输。 1.作用:完成对象的序列化过程 2.它可以将JVM当中的Java对象序列化到文件中/网…...

git回滚指定版本并操作
你可以通过以下步骤切换到第三个版本。根据你的需求,有两种主要方法: 方法 1:临时查看第三个版本(不修改当前分支) 适用于仅查看或测试旧版本,不保留后续修改: 找到第三个版本的提交哈希&#…...

【AI插件开发】Notepad++ AI插件开发实践:支持配置界面
一、引用 此前的系列文章已基本完成了Notepad的AI插件的功能开发,但是此前使用的配置为JSON配置文件,不支持界面配置。 本章在此基础上集成支持配置界面,这样不需要手工修改配置文件,直接在界面上操作,方便快捷。 注…...

polkitd服务无法启动导致docker无法启动问题解决
问题docker服务无法启动,溯源发现是polkit服务没有正确运行 systemctl status polkit可以看到类似提示 Sep 18 02:58:24 server1 dbus[897]: [system] Failed to activate service org.freedesktop.PolicyKit1: timed out Sep 18 02:59:29 server1 systemd[1]: po…...

软件工程中数据一致性的探讨
软件工程中数据一致性的探讨 引言数据一致性:软件工程中的业务正确性与性能的权衡数据一致性为何重要业务正确性:事务的原子性与一致性ACID原则的基石分布式事务的挑战一致性级别:从强一致到最终一致 实践中的一致性权衡金融系统:…...
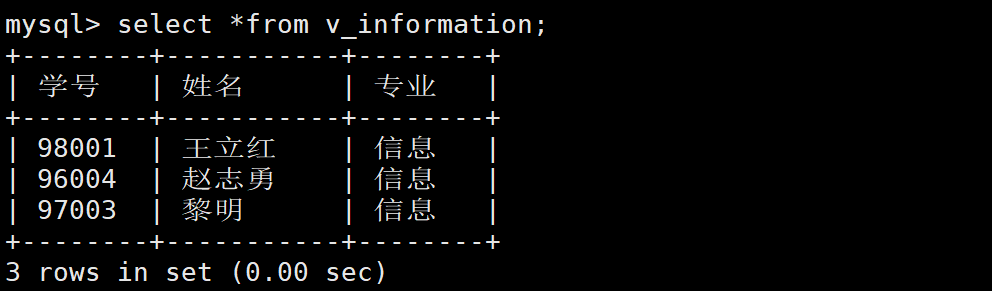
数据库原理及应用mysql版陈业斌实验四
🏝️专栏:Mysql_猫咪-9527的博客-CSDN博客 🌅主页:猫咪-9527-CSDN博客 “欲穷千里目,更上一层楼。会当凌绝顶,一览众山小。” 目录 实验四索引与视图 1.实验数据如下 student 表(学生表&…...

华为OD机试真题——最长的顺子(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录全流程解析/备考攻略/经验…...