python抓取HTML页面数据+可视化数据分析(投资者数量趋势)
本文所展示的代码是一个完整的数据采集、处理与可视化工具,主要用于从指定网站下载Excel文件,解析其中的数据,并生成投资者数量的趋势图表。以下是代码的主要功能模块及其作用:
1.网页数据获取
- 使用fetch_html_page函数从目标网站抓取HTML页面内容。
- 通过parse_html_for_excel_links解析HTML内容,提取所有Excel文件链接。
- 利用parse_html_for_max_page解析最大分页数,确保能够遍历所有页面。
2.文件下载与存储
- download_excel_file负责根据Excel文件的URL下载文件并保存到本地指定路径。
- download_excel_data实现批量下载功能,支持多页数据的完整采集。
3.数据读取与处理
- read_excel_file使用pandas库读取Excel文件内容。
- process_excel_data将Excel数据转换为字典格式,便于后续处理。
- process_downloaded_files批量处理下载的Excel文件,提取关键数据并存储为列表。
4.数据可视化
- plot_investor_trends利用matplotlib绘制双Y轴折线图,展示个人投资者和机构投资者的数量变化趋势。
- 图表包含日期、个人投资者数量(万名)和机构投资者数量(家),并通过不同颜色区分数据系列。
整体流程
- 代码从指定网站抓取数据,自动下载相关Excel文件。
- 解析Excel文件中的投资者数据,并生成趋势图表以直观展示数据变化。
import warningsimport requests
from bs4 import BeautifulSoup
import pandas as pd
import os
import re
import matplotlib# 设置matplotlib的字体配置,以支持中文显示
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 或者 ['Microsoft YaHei']
matplotlib.rcParams['axes.unicode_minus'] = False
matplotlib.use('TkAgg')
from matplotlib import pyplot as pltdef fetch_html_page(url):"""获取HTML页面内容。参数:url (str): 目标网页的URL。返回:str: 页面的HTML内容,如果请求失败则返回None。"""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}response = requests.get(url, headers=headers)if response.status_code == 200:print(f"成功获取页面: {url}")return response.textelse:print(f"Error: {response.status_code}, {response.text}")return Nonedef parse_html_for_excel_links(html_content):"""解析HTML内容中的Excel链接。参数:html_content (str): HTML页面内容。返回:list: 包含所有找到的Excel文件链接的列表。"""soup = BeautifulSoup(html_content, 'html.parser')excel_links = []for a_tag in soup.find_all('a', href=True):href = a_tag.get('href')if href and href.endswith('.xlsx'):excel_links.append(href)return excel_linksdef parse_html_for_max_page(html_content):"""解析HTML内容以找到最大页面数。参数:html_content (str): HTML页面内容。返回:int: 最大页面数。"""soup = BeautifulSoup(html_content, 'html.parser')max_page = 1for a_tag in soup.find_all('a', class_='pagingNormal'):onclick = a_tag.get('onclick')if onclick:match = re.search(r"'(/test/j/[^']+)'", onclick)if match:page_number = match.group(1).split('-')[-1].split('.')[0]max_page = max(max_page, int(page_number))return max_pagedef download_excel_file(url, save_path):"""下载Excel文件并保存到指定路径。参数:url (str): Excel文件的URL。save_path (str): 文件的保存路径。"""headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}response = requests.get(url, headers=headers)if response.status_code == 200:with open(save_path, 'wb') as f:f.write(response.content)print(f"下载完成: {save_path}")else:print(f"Error: {response.status_code}, {response.text}")def download_excel_data():"""下载所有Excel数据文件。"""base_url = 'https://test/index.html' # 替换为实际网页地址current_url = base_urlpage_number = 1html_content = fetch_html_page(current_url)if not html_content:returnmax_page = parse_html_for_max_page(html_content)print(f"最大页面数: {max_page}")while page_number <= max_page:print(f"正在处理第 {page_number} 页: {current_url}")html_content = fetch_html_page(current_url)if not html_content:breakexcel_links = parse_html_for_excel_links(html_content)if not excel_links:print("未找到Excel链接。")breakfor link in excel_links:full_url = f"https://www.test.cn{link}"# 提取日期和文件名部分file_path_parts = link.split('/')file_name = ('/'.join(file_path_parts[-3:-1]) + '/' + file_path_parts[-1]).replace('/', '-')save_path = os.path.join('downloads', file_name)os.makedirs(os.path.dirname(save_path), exist_ok=True)download_excel_file(full_url, save_path)if page_number < max_page:next_page_link = f"/test/d2bb5c19-{page_number + 1}.html"current_url = f"https://www.test.cn{next_page_link}"page_number += 1else:print("没有更多页面。")breakdef read_excel_file(file_path):"""读取Excel文件内容。参数:file_path (str): Excel文件的路径。返回:DataFrame: 读取到的Excel文件内容,如果读取失败则返回None。"""try:with warnings.catch_warnings():warnings.simplefilter("ignore", UserWarning)df = pd.read_excel(file_path, engine='openpyxl', header=None)return dfexcept Exception as e:print(f"读取Excel文件时出错: {e}")return Nonedef process_excel_data(df):"""处理Excel数据,将其转换为字典格式。参数:df (DataFrame): Excel文件内容。返回:dict: 转换后的字典数据。"""if df is None:return {}# 处理合并单元格# df = df.fillna(method='ffill').fillna(method='bfill')# 将数据转换为字典data_dict = {}current_section = Nonefor index, row in df.iterrows():if index == 1: # 第二行key = row[1]if pd.isnull(key):key = df.iloc[1, 0]value = row[2] if pd.notnull(row[2]) else Nonedata_dict[key] = valueelif index > 1:if pd.notnull(row[0]):current_section = row[0]data_dict[current_section] = {}if pd.notnull(row[1]):key = row[1]value = row[2] if pd.notnull(row[2]) else Nonedata_dict[current_section][key] = valuereturn data_dictdef process_downloaded_files(directory):"""处理下载的Excel文件,提取数据。参数:directory (str): 存放下载文件的目录路径。返回:list: 包含所有处理后的数据字典的列表。"""data_list = []for filename in os.listdir(directory):if filename.endswith('.xlsx'):file_path = os.path.join(directory, filename)df = read_excel_file(file_path)if df is not None:print(f"处理文件: {filename}")data_dict = process_excel_data(df)print(data_dict) # 打印处理后的字典data_list.append(data_dict)return data_listdef plot_investor_trends(data_list):"""绘制投资者数量趋势图。参数:data_list (list): 包含投资者数据的列表。"""# 提取时间值和投资者数量dates = []individual_investors = []institutional_investors = []for data_dict in data_list:date_str = data_dict['统计指标']date = pd.to_datetime(date_str)dates.append(date)individual_investors.append(data_dict['证券公司开展业务情况']['个人投资者数量(万名)'])institutional_investors.append(data_dict['证券公司开展业务情况']['机构投资者数量(家)'])# 创建折线图fig, ax1 = plt.subplots(figsize=(10, 6))# 绘制个人投资者数量color = 'tab:red'ax1.set_xlabel('日期')ax1.set_ylabel('个人投资者数量(万名)', color=color)ax1.plot(dates, individual_investors, color=color, label='个人投资者数量(万名)', marker='o')ax1.tick_params(axis='y', labelcolor=color)# 创建第二个 Y 轴ax2 = ax1.twinx() # 共享 X 轴# 绘制机构投资者数量color = 'tab:blue'ax2.set_ylabel('机构投资者数量(家)', color=color)ax2.plot(dates, institutional_investors, color=color, label='机构投资者数量(家)', marker='o')ax2.tick_params(axis='y', labelcolor=color)# 设置标题和图例fig.tight_layout() # 调整子图参数,防止标签重叠plt.title('投资者数量趋势')fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9))# 显示图形plt.show()# 调用函数绘制投资者趋势图
plot_investor_trends(process_downloaded_files('downloads'))

相关文章:
python抓取HTML页面数据+可视化数据分析(投资者数量趋势)
本文所展示的代码是一个完整的数据采集、处理与可视化工具,主要用于从指定网站下载Excel文件,解析其中的数据,并生成投资者数量的趋势图表。以下是代码的主要功能模块及其作用: 1.网页数据获取 使用fetch_html_page函数从目标网…...

C++ std::function的含义、意义和用法,与std::bind的区别
在 C 中,std::function 是一个通用的多态函数包装器,它是 C 标准库 <functional> 头文件中的一部分。下面从含义、意义和用法三个方面详细介绍 std::function。 含义 std::function 是一个类模板,它可以存储、复制和调用任何可调用对…...
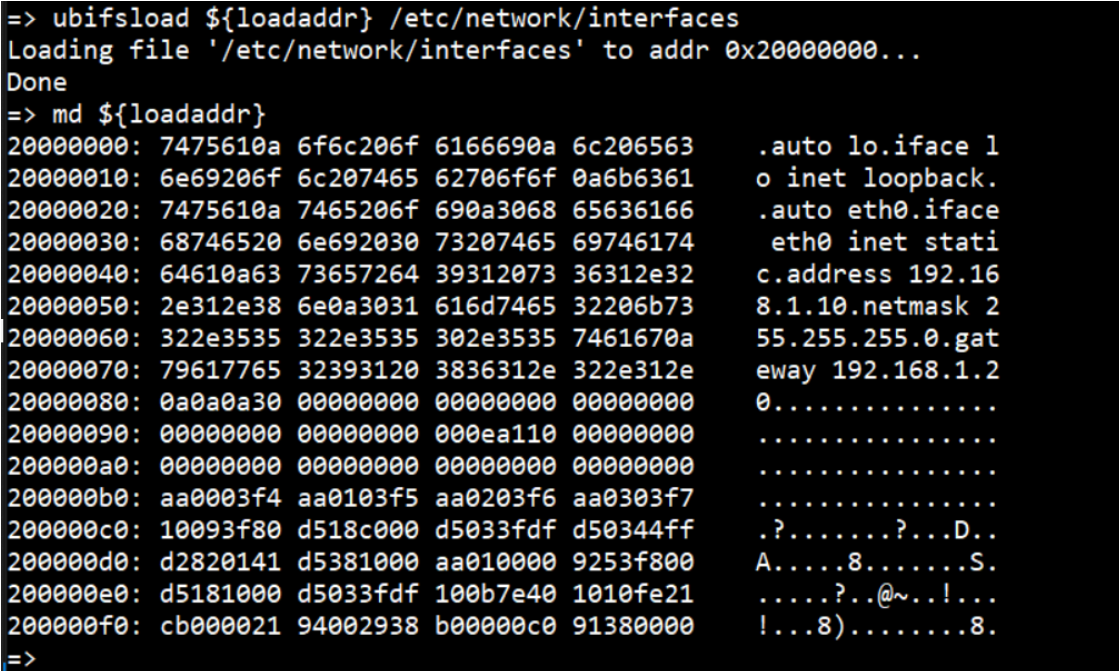
uboot下读取ubifs分区的方法
在uboot 的defconfig中增加以下内容: CONFIG_MTDIDS_DEFAULT"nand0nand0" CONFIG_MTDPARTS_DEFAULT"mtdpartsnand0:1M(boot1),1M(boot2),1M(hwinfo),6M(kernel1),6M(kernel2),56M(rootfs1),56M(rootfs2),-(ubi2)" CONFIG_CMD_UBIy 其中&#x…...

HAL详解
一、直通式HAL 这里使用一个案例来介绍直通式HAL,选择MTK的NFC HIDL 1.0为例,因为比较简单,代码量也比较小,其源码路径:vendor/hardware/interfaces/nfc/1.0/ 1、NFC HAL的定义 1)NFC HAL数据类型 通常定…...
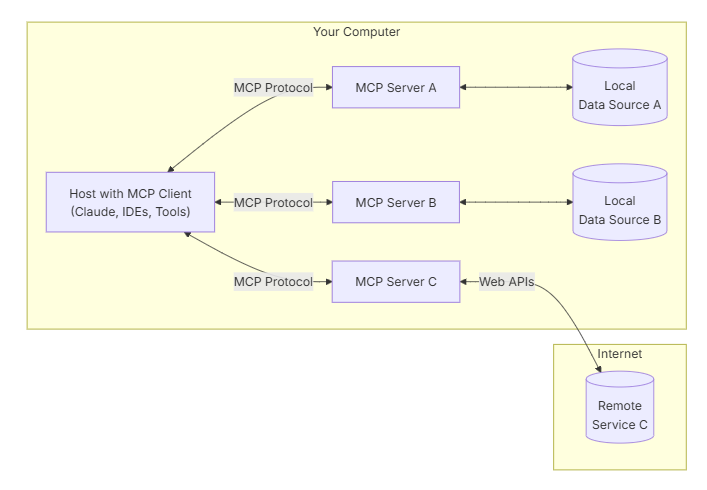
MCP(模型上下文协议)说明
背景 MCP(Model Context Protocol,模型上下文协议)旨在解决大型语言模型(LLM)与外部数据源及工具集成的问题。由Anthropic公司于2024年11月提出并开源,目标是实现AI模型与现有系统的无缝集成。 解决的问题…...

AI当前状态:有哪些新技术
一、到目前为址AI领域出现的新技术 到目前为止,AI领域涌现了许多令人兴奋的新技术。以下是一些关键的进展,涵盖了从基础模型到实际应用的多个方面: 1. 更强大的大型语言模型 (LLMs): 性能提升: 新一代LLM,例如OpenAI的GPT-4o和…...

如何校验一个字符串是否是可以正确序列化的JSON字符串呢?
方法1:先给一个比较暴力的方法 try {JSONObject o new JSONObject(yourString); } catch (JSONException e) {LOGGER.error("No valid json"); } 方法2: Object json new cn.hutool.json.JSONTokener("[{\"name\":\"t…...
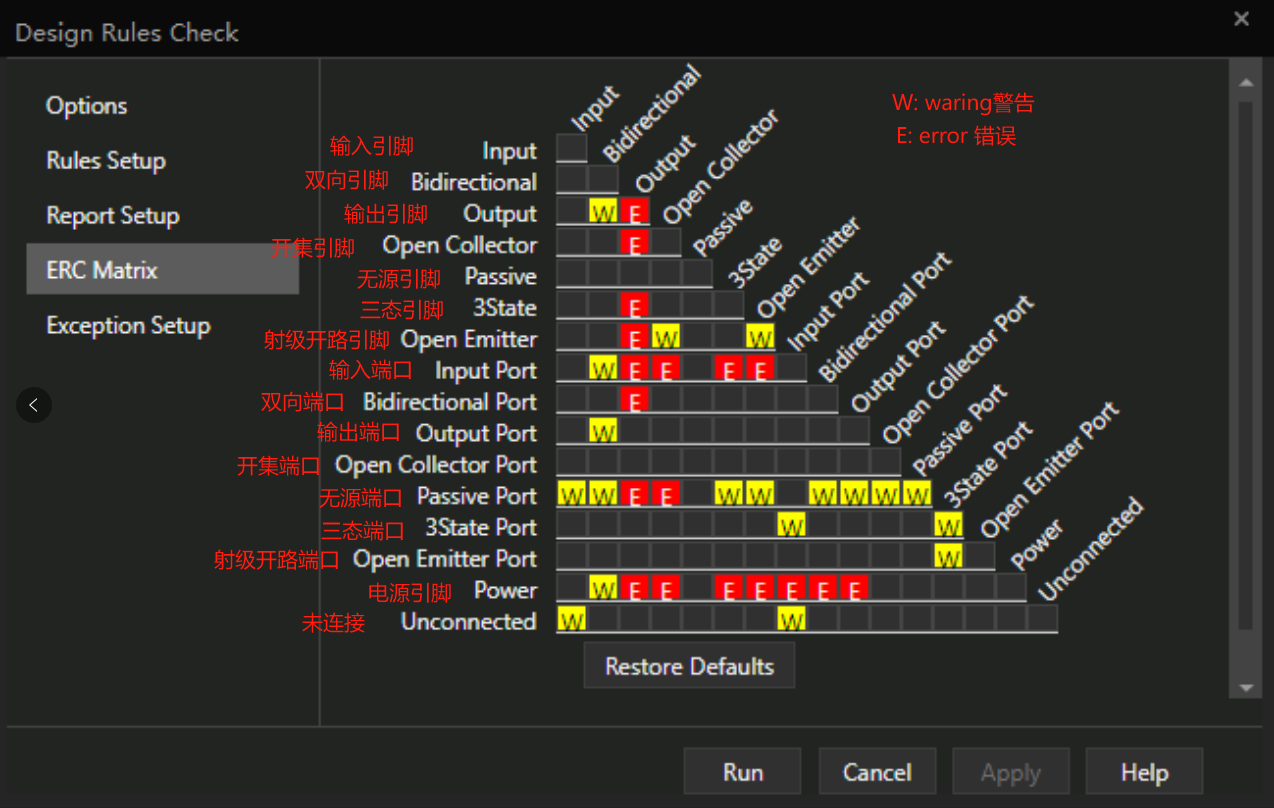
orcad csi 17.4 DRC规则设置及检查
rCAD绘制完原理图之后总是需要开启DRC检测,但是DRC一般都是英文版的,下面基于Cadence17.4 的orCAD16.6 对DRC的界面做简单的介绍 首先,鼠标点击原理图,然后再点击右上方的小勾图标 desine rules check option选项的界面 电气规…...

k8s教程3:Kubernetes应用的部署和管理
学习目标 理解Kubernetes中应用部署的基本概念和方法掌握Deployment、ReplicaSet、StatefulSet、DaemonSet、Job与CronJob等控制器的使用了解Helm作为Kubernetes的包管理工具的基本使用通过实际示例学习应用的部署、更新与管理 Kubernetes提供了一套强大而灵活的机制ÿ…...

微信小程序获得当前城市,获得当前天气
// // 获取用户当前所在城市 // wx.getLocation({// type: wgs84, // 默认为 wgs84 返回 gps 坐标,gcj02 返回可用于 wx.openLocation 的坐标 // success: function(res) {// console.log(获取位置成功, res); // // 使用腾讯地图API进行逆地址解析 // wx…...

磁流变式汽车减振器创新设计与关键技术研究
摘要 本文针对智能悬架系统的发展需求,深入探讨磁流变减振器(MR Damper)的核心设计原理与工程实现路径。通过建立磁场-流场耦合模型,优化磁路结构与控制策略,提出具有快速响应特性的新型磁流变减振器设计方案…...

Python3.14都有什么重要新特性
目录 1、语法糖新宠:模式匹配再进化 1.1 结构化数据克星 1.2 类型守卫(Type Guard) 2、性能黑科技:尾递归与异步双杀 2.1 尾调用优化(TCO) 2.2 异步任务重构 3、注释系统重构:annotationlib深度解析 3.1 延迟评估机制 3.2 类型推导增…...

前端资源加载失败后重试加载(CSS,JS等引用资源)
前端资源加载失败后的重试 .前端引用资源时出现了资源加载失败(这里针对的是路径引用异常或者url解析错误时) 解决这个问题首先要明确一下几个步骤 1.什么情况或者什么时候重试 2.如何重试 3.重试过程中的边界处理 这里引入里三个测试脚本,分别加载里三个不同的脚…...
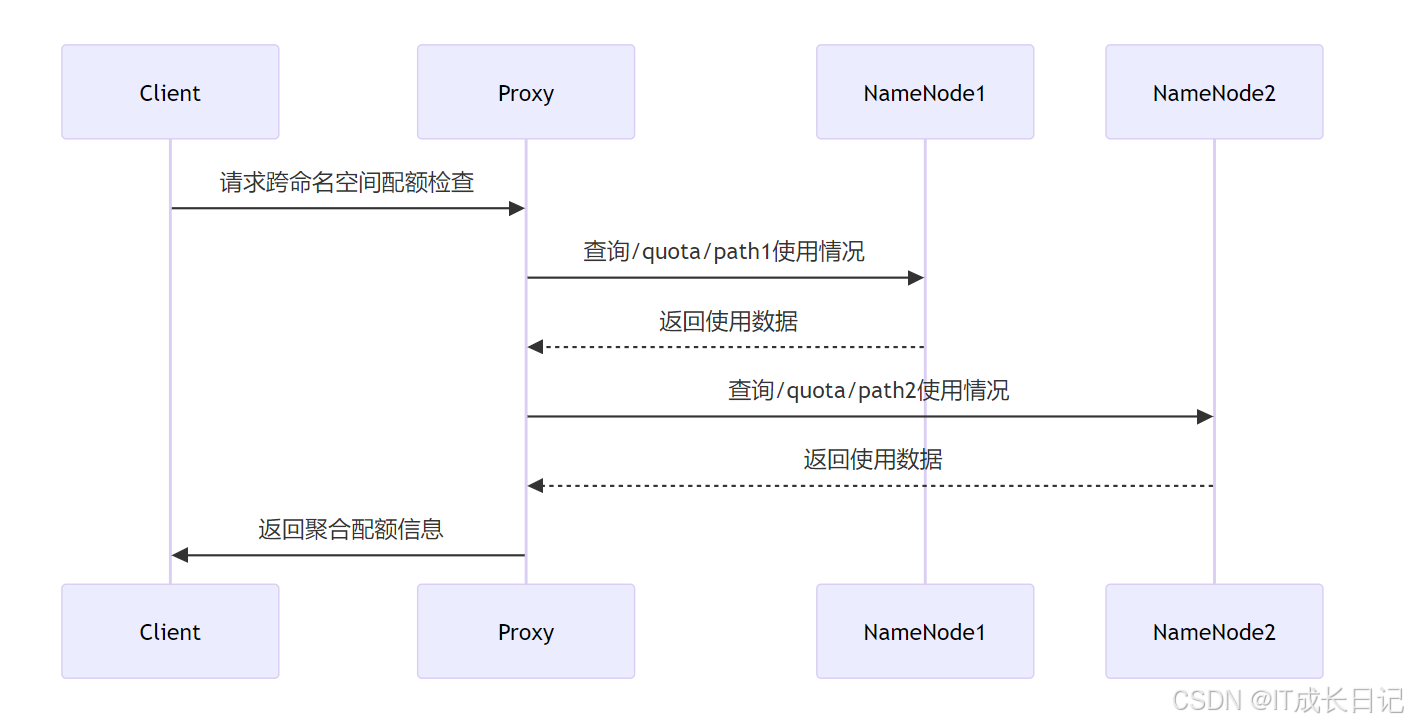
【HDFS入门】联邦机制(Federation)与扩展性:HDFS NameNode水平扩展深度解析
目录 引言 1 NameNode水平扩展原理 1.1 传统HDFS架构的局限性 1.2 联邦机制的基本原理 1.3 联邦架构的关键组件 2 多个Namespace的路由规则配置 2.1 客户端挂载表概念 2.2 挂载表配置示例 2.3 挂载表匹配规则 2.4 配置示例 3 BlockPool与Namespace的映射关系 3.1 B…...

C#学习第16天:聊聊反射
什么是反射? 定义:反射是一种机制,允许程序在运行时获取关于自身的信息,并且可以动态调用方法、访问属性或创建实例。用途:常用于框架设计、工具开发、序列化、代码分析和测试等场景 反射的核心概念 1. 获取类型信息…...

论文阅读:2024 arxiv AI Safety in Generative AI Large Language Models: A Survey
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 AI Safety in Generative AI Large Language Models: A Survey https://arxiv.org/pdf/2407.18369 https://www.doubao.com/chat/3262156521106434 速览 研究动机&#x…...
AI推荐系统的详细解析 +推荐系统中滤泡效应(Filter Bubble)的详细解析+ 基于Java构建电商推荐系统的分步实现方案,结合机器学习与工程实践
以下是AI推荐系统的详细解析: 一、核心概念 定义 推荐系统是通过分析用户行为、物品特征或用户画像,向用户推荐个性化内容的技术,广泛应用于电商、视频、社交等领域。 目标 提升用户留存与转化率增强用户体验实现精准营销 二、技术原理 1…...

CSS 美化页面(五)
一、position属性 属性值描述应用场景static默认定位方式,元素遵循文档流正常排列,top/right/bottom/left 属性无效。普通文档流布局,默认布局,无需特殊定位。relative相对定位,相对于元素原本位置进行偏…...

java 设计模式之模板方法模式
简介 模板方法模式:定义一个算法的基本流程,将一些步骤延迟到子类中实现。模板方法模式可以提高代码的复用性, 模板方法中包含的角色: 抽象类:负责给出一个算法的基本流程,它由一个模板方法和若干个基本…...

基于大模型的腹股沟疝诊疗全流程风险预测与方案制定研究报告
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目的与创新点 二、大模型技术概述 2.1 大模型基本原理 2.2 常用大模型类型及特点 2.3 大模型在医疗领域的应用潜力 三、腹股沟疝诊疗流程分析 3.1 腹股沟疝的发病机制与分类 3.2 传统术前评估方法与局…...
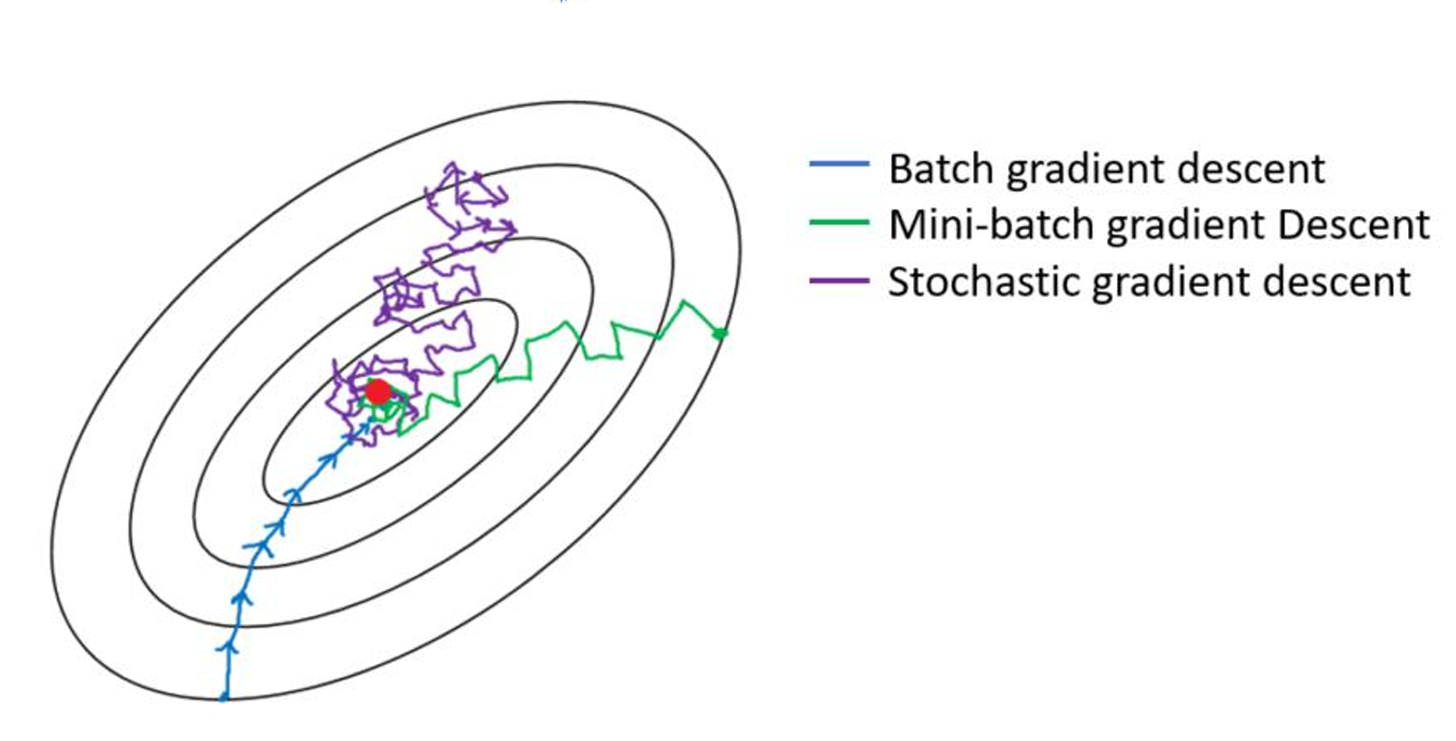
无约束最优化问题的求解算法--梯度下降法(Gradient Descent)
文章目录 梯度下降法梯度下降法原理(通俗版)梯度下降法公式学习率的设置**如何选择学习率?** 全局最优解梯度下降法流程损失函数的导函数三种梯度下降法**梯度下降法核心步骤回顾****优缺点详解****1. 全量梯度下降 (Batch Gradient Descent,…...
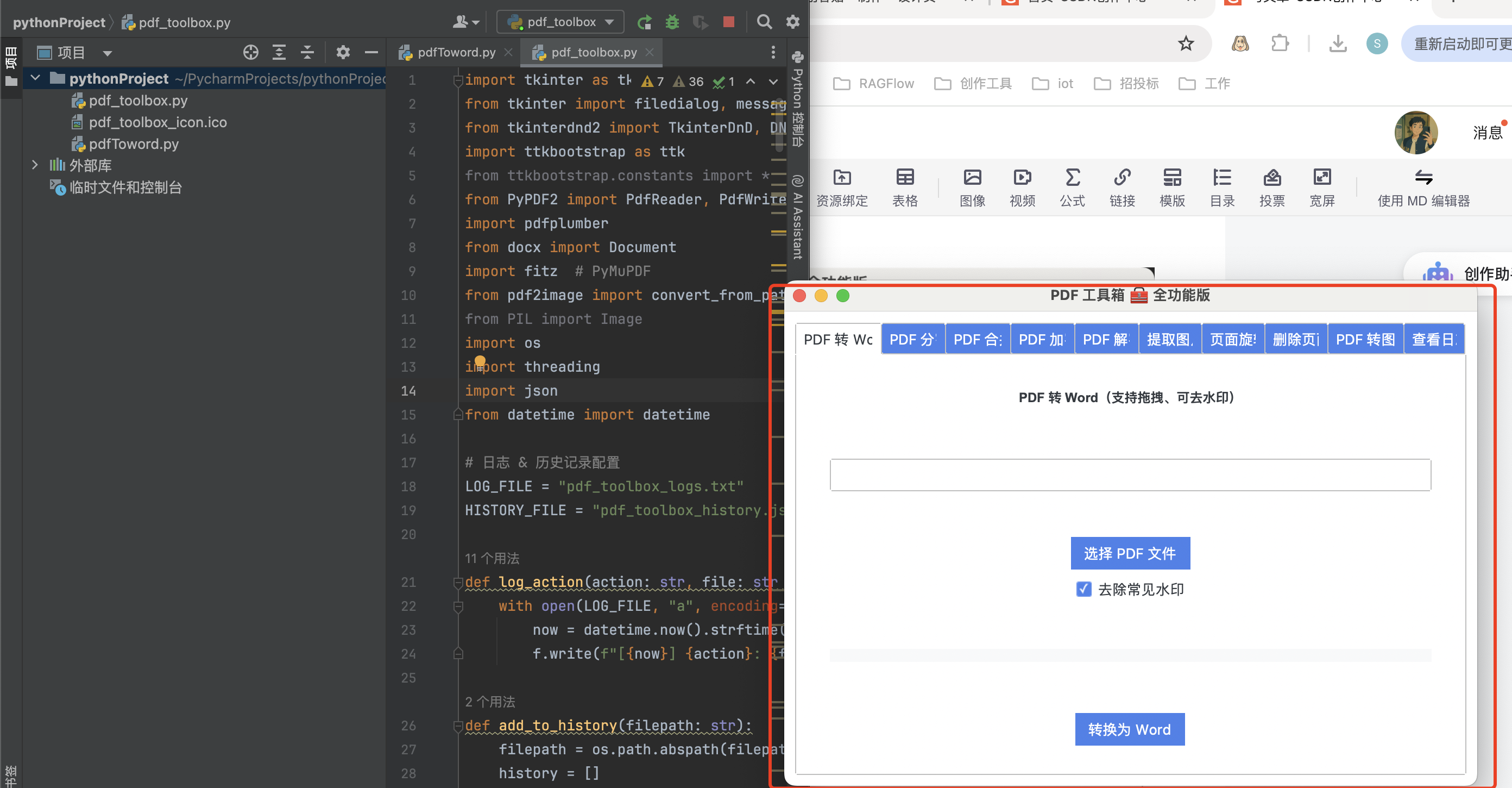
Python全功能PDF工具箱GUI:支持转换、加密、旋转、图片提取、日志记录等多功能操作
使用Python打造一款集成 PDF转换、编辑、加密、解密、图片提取、日志追踪 等多个功能于一体的桌面工具应用(Tkinter ttkbootstrap PyPDF2 等库)。 ✨项目背景与开发动机 在日常办公或学习中,我们经常会遇到各种关于PDF文件的操作需求&#…...

[密码学实战]国密算法面试题解析及应用
以下是密码学领域常见的面试题及其详细解析,涵盖基础理论、算法实现与应用场景,帮助系统化备战技术面试 一、基础概念类 1. 密码学的主要目标是什么? 答案: 确保数据的机密性(加密防止窃听)、完整性(哈希校验防篡改)、认证性(数字签名验证身份)和不可否认性(签名防…...

React 受控表单绑定基础
React 中最常见的几个需求是: 渲染一组列表绑定点击事件表单数据与组件状态之间的绑定 受控表单绑定是理解表单交互的关键之一。 📍什么是受控组件? 在 React 中,所谓“受控组件”,指的是表单元素(如 &l…...
计算机视觉---相机标定
相机标定在机器人系统中的作用 1.确定相机的内部参数 相机的内部参数包括焦距、主点坐标、像素尺寸等。这些参数决定了相机成像的几何关系。通过标定,可以精确获取这些参数,从而将图像中的像素坐标与实际的物理坐标建立联系。例如,已知相机…...

LeetCode 443 压缩字符串
字符数组压缩算法详解:实现与分析 一、引言 在处理字符数组时,我们常常遇到需要对连续重复字符进行压缩的场景。这不仅可以节省存储空间,还能提升数据传输效率。本文将深入解析一个经典的字符数组压缩算法,通过详细的实现步骤和…...

datasheet数据手册-阅读方法
DataSheet Datasheet(数据手册):电子元器件或者芯片的数据手册,一般由厂家编写,格式一般为PDF,内容为电子分立元器件或者芯片的各项参数,电性参数,物理参数,甚至制造材料…...

AI绘制流程图,方法概述
1 deepseek 生成图片的mermaid格式代码,在kimi中进行绘图或在jupter notebook中绘制: 或在draw.io中进行绘制(mermaid代码) 2 svg是矢量图,可以插入到word """mermaid graph TDA[基线解算] --> B[北…...

ObjectOutputStream 深度解析
ObjectOutputStream 深度解析 ObjectOutputStream 是 Java IO 体系中的一个关键类,用于序列化(将对象转换为字节流),通常与 ObjectInputStream 配合使用,实现对象的持久化存储或网络传输。 1.作用:完成对象的序列化过程 2.它可以将JVM当中的Java对象序列化到文件中/网…...

git回滚指定版本并操作
你可以通过以下步骤切换到第三个版本。根据你的需求,有两种主要方法: 方法 1:临时查看第三个版本(不修改当前分支) 适用于仅查看或测试旧版本,不保留后续修改: 找到第三个版本的提交哈希&#…...